【推荐系统】笔记 — Bandit 算法
本文并非原创,而是参考以下文章写就,涉及到论文的部分则是去原始论文中来替换,确保原汁原味且没有错误。如有错误,还望批评指正。
【参考文章】:
Bandit算法,A/B测试,孰优孰劣? - 云+社区 - 腾讯云
科学网-Bandit:一种简单而强大的在线学习算法 - 范深的博文
推荐系统遇上深度学习(十二)--推荐系统中的EE问题及基本Bandit算法 - 简书
【总结】Bandit算法与推荐系统 - 一寒惊鸿 - CSDN博客
[1] - Bandit算法的起源
Bandit算法来源于历史悠久的赌博学,它要解决的问题是这样的[1]:一个赌徒,要去摇老虎机,走进赌场一看,一排老虎机,外表一模一样,但是每个老虎机吐钱的概率可不一样,他不知道每个老虎机吐钱的概率分布是什么,那么每次该选择哪个老虎机可以做到最大化收益呢?这就是多臂赌博机问题 ( Multi-armed bandit problem, K-armed bandit problem, MAB )。
解决这个问题最好的办法是去试,但不是盲目地试,而是有策略地快速试一试,这些策略就是Bandit算法。
假设我们已经经过一些试验,得到了当前每个老虎机的吐钱的概率,如果想要获得最大的收益,我们会一直摇那个吐钱概率最高的老虎机,这就是 Exploitation 。但是,当前获得的信息并不是老虎机吐钱的真实概率,可能还有更好的老虎机吐钱概率更高,因此还需要进一步探索,这就是 Exploration 问题。
这个多臂问题,推荐系统里很多问题都与它类似:
- 假设一个用户对不同类别的内容感兴趣程度不同,那么我们的推荐系统初次见到这个用户时,怎么快速地知道他对每类内容的感兴趣程度?这就是推荐系统的冷启动。
- 假设我们有若干广告库存,怎么知道该给每个用户展示哪个广告,从而获得最大的点击收益?是每次都挑效果最好那个么?那么新广告如何才有出头之日?
- 我们的算法工程师又想出了新的模型,有没有比A/B test更快的方法知道它和旧模型相比谁更靠谱?
- 如果只是推荐已知的用户感兴趣的物品,如何才能科学地冒险给他推荐一些新鲜的物品?
[2] - Bandit 算法和推荐系统
Exploration and Exploitation(EE问题,探索与开发) 是计算广告和推荐系统里常见的一个问题。其中,Exploitation就是:对用户比较确定的兴趣,当然要利用开采迎合,好比说已经挣到的钱,当然要花;而Exploration就是:光对着用户已知的兴趣使用,用户很快会腻,所以要不断探索用户新的兴趣才行,这就好比虽然有一点钱可以花了,但是还得继续搬砖挣钱,不然花完了就得喝西北风。
用户冷启动问题,也就是面对新用户时,如何能够通过若干次实验,猜出用户的大致兴趣。
用 Bandit 算法解决冷启动的大致思路如下:用分类或者 Topic 来表示每个用户兴趣,也就是 MAB 问题中的臂 ( Arm ) ,我们可以通过几次试验,来刻画出新用户心目中对每个Topic的感兴趣概率。这里,如果用户对某个 Topic 感兴趣(提供了显式反馈或隐式反馈),就表示我们得到了收益,如果推给了它不感兴趣的 Topic ,推荐系统就表示很遗憾 ( regret ) 了。如此经历“选择-观察-更新-选择”的循环,理论上是越来越逼近用户真正感兴趣的 Topic 的。
[3] - 相关概念
通常使用累积遗憾[2] (regret) 来衡量不同 Bandit 算法在解决多臂问题上的效果。
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQ1LjYxOGV4IiBoZWlnaHQ9IjcuMzQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4wMDVleDsiIHZpZXdCb3g9IjAgLTE4NjcuNyAxOTY0MC45IDMxNjEuNCIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MiIgZD0iTTIzMCA2MzdRMjAzIDYzNyAxOTggNjM4VDE5MyA2NDlRMTkzIDY3NiAyMDQgNjgyUTIwNiA2ODMgMzc4IDY4M1E1NTAgNjgyIDU2NCA2ODBRNjIwIDY3MiA2NTggNjUyVDcxMiA2MDZUNzMzIDU2M1Q3MzkgNTI5UTczOSA0ODQgNzEwIDQ0NVQ2NDMgMzg1VDU3NiAzNTFUNTM4IDMzOEw1NDUgMzMzUTYxMiAyOTUgNjEyIDIyM1E2MTIgMjEyIDYwNyAxNjJUNjAyIDgwVjcxUTYwMiA1MyA2MDMgNDNUNjE0IDI1VDY0MCAxNlE2NjggMTYgNjg2IDM4VDcxMiA4NVE3MTcgOTkgNzIwIDEwMlQ3MzUgMTA1UTc1NSAxMDUgNzU1IDkzUTc1NSA3NSA3MzEgMzZRNjkzIC0yMSA2NDEgLTIxSDYzMlE1NzEgLTIxIDUzMSA0VDQ4NyA4MlE0ODcgMTA5IDUwMiAxNjZUNTE3IDIzOVE1MTcgMjkwIDQ3NCAzMTNRNDU5IDMyMCA0NDkgMzIxVDM3OCAzMjNIMzA5TDI3NyAxOTNRMjQ0IDYxIDI0NCA1OVEyNDQgNTUgMjQ1IDU0VDI1MiA1MFQyNjkgNDhUMzAyIDQ2SDMzM1EzMzkgMzggMzM5IDM3VDMzNiAxOVEzMzIgNiAzMjYgMEgzMTFRMjc1IDIgMTgwIDJRMTQ2IDIgMTE3IDJUNzEgMlQ1MCAxUTMzIDEgMzMgMTBRMzMgMTIgMzYgMjRRNDEgNDMgNDYgNDVRNTAgNDYgNjEgNDZINjdROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFEyODcgNjM1IDIzMCA2MzdaTTYzMCA1NTRRNjMwIDU4NiA2MDkgNjA4VDUyMyA2MzZRNTIxIDYzNiA1MDAgNjM2VDQ2MiA2MzdINDQwUTM5MyA2MzcgMzg2IDYyN1EzODUgNjI0IDM1MiA0OTRUMzE5IDM2MVEzMTkgMzYwIDM4OCAzNjBRNDY2IDM2MSA0OTIgMzY3UTU1NiAzNzcgNTkyIDQyNlE2MDggNDQ5IDYxOSA0ODZUNjMwIDU1NFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oyLTIyMTEiIGQ9Ik02MCA5NDhRNjMgOTUwIDY2NSA5NTBIMTI2N0wxMzI1IDgxNVExMzg0IDY3NyAxMzg4IDY2OUgxMzQ4TDEzNDEgNjgzUTEzMjAgNzI0IDEyODUgNzYxUTEyMzUgODA5IDExNzQgODM4VDEwMzMgODgxVDg4MiA4OThUNjk5IDkwMkg1NzRINTQzSDI1MUwyNTkgODkxUTcyMiAyNTggNzI0IDI1MlE3MjUgMjUwIDcyNCAyNDZRNzIxIDI0MyA0NjAgLTU2TDE5NiAtMzU2UTE5NiAtMzU3IDQwNyAtMzU3UTQ1OSAtMzU3IDU0OCAtMzU3VDY3NiAtMzU4UTgxMiAtMzU4IDg5NiAtMzUzVDEwNjMgLTMzMlQxMjA0IC0yODNUMTMwNyAtMTk2UTEzMjggLTE3MCAxMzQ4IC0xMjRIMTM4OFExMzg4IC0xMjUgMTM4MSAtMTQ1VDEzNTYgLTIxMFQxMzI1IC0yOTRMMTI2NyAtNDQ5TDY2NiAtNDUwUTY0IC00NTAgNjEgLTQ0OFE1NSAtNDQ2IDU1IC00MzlRNTUgLTQzNyA1NyAtNDMzTDU5MCAxNzdRNTkwIDE3OCA1NTcgMjIyVDQ1MiAzNjZUMzIyIDU0NEw1NiA5MDlMNTUgOTI0UTU1IDk0NSA2MCA5NDhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNjkiIGQ9Ik0xODQgNjAwUTE4NCA2MjQgMjAzIDY0MlQyNDcgNjYxUTI2NSA2NjEgMjc3IDY0OVQyOTAgNjE5UTI5MCA1OTYgMjcwIDU3N1QyMjYgNTU3UTIxMSA1NTcgMTk4IDU2N1QxODQgNjAwWk0yMSAyODdRMjEgMjk1IDMwIDMxOFQ1NCAzNjlUOTggNDIwVDE1OCA0NDJRMTk3IDQ0MiAyMjMgNDE5VDI1MCAzNTdRMjUwIDM0MCAyMzYgMzAxVDE5NiAxOTZUMTU0IDgzUTE0OSA2MSAxNDkgNTFRMTQ5IDI2IDE2NiAyNlExNzUgMjYgMTg1IDI5VDIwOCA0M1QyMzUgNzhUMjYwIDEzN1EyNjMgMTQ5IDI2NSAxNTFUMjgyIDE1M1EzMDIgMTUzIDMwMiAxNDNRMzAyIDEzNSAyOTMgMTEyVDI2OCA2MVQyMjMgMTFUMTYxIC0xMVExMjkgLTExIDEwMiAxMFQ3NCA3NFE3NCA5MSA3OSAxMDZUMTIyIDIyMFExNjAgMzIxIDE2NiAzNDFUMTczIDM4MFExNzMgNDA0IDE1NiA0MDRIMTU0UTEyNCA0MDQgOTkgMzcxVDYxIDI4N1E2MCAyODYgNTkgMjg0VDU4IDI4MVQ1NiAyNzlUNTMgMjc4VDQ5IDI3OFQ0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzciIGQ9Ik01ODAgMzg1UTU4MCA0MDYgNTk5IDQyNFQ2NDEgNDQzUTY1OSA0NDMgNjc0IDQyNVQ2OTAgMzY4UTY5MCAzMzkgNjcxIDI1M1E2NTYgMTk3IDY0NCAxNjFUNjA5IDgwVDU1NCAxMlQ0ODIgLTExUTQzOCAtMTEgNDA0IDVUMzU1IDQ4UTM1NCA0NyAzNTIgNDRRMzExIC0xMSAyNTIgLTExUTIyNiAtMTEgMjAyIC01VDE1NSAxNFQxMTggNTNUMTA0IDExNlExMDQgMTcwIDEzOCAyNjJUMTczIDM3OVExNzMgMzgwIDE3MyAzODFRMTczIDM5MCAxNzMgMzkzVDE2OSA0MDBUMTU4IDQwNEgxNTRRMTMxIDQwNCAxMTIgMzg1VDgyIDM0NFQ2NSAzMDJUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1EyMSAyOTMgMjkgMzE1VDUyIDM2NlQ5NiA0MThUMTYxIDQ0MVEyMDQgNDQxIDIyNyA0MTZUMjUwIDM1OFEyNTAgMzQwIDIxNyAyNTBUMTg0IDExMVExODQgNjUgMjA1IDQ2VDI1OCAyNlEzMDEgMjYgMzM0IDg3TDMzOSA5NlYxMTlRMzM5IDEyMiAzMzkgMTI4VDM0MCAxMzZUMzQxIDE0M1QzNDIgMTUyVDM0NSAxNjVUMzQ4IDE4MlQzNTQgMjA2VDM2MiAyMzhUMzczIDI4MVE0MDIgMzk1IDQwNiA0MDRRNDE5IDQzMSA0NDkgNDMxUTQ2OCA0MzEgNDc1IDQyMVQ0ODMgNDAyUTQ4MyAzODkgNDU0IDI3NFQ0MjIgMTQyUTQyMCAxMzEgNDIwIDEwN1YxMDBRNDIwIDg1IDQyMyA3MVQ0NDIgNDJUNDg3IDI2UTU1OCAyNiA2MDAgMTQ4UTYwOSAxNzEgNjIwIDIxM1Q2MzIgMjczUTYzMiAzMDYgNjE5IDMyNVQ1OTMgMzU3VDU4MCAzODVaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkYiIGQ9Ik0yMDEgLTExUTEyNiAtMTEgODAgMzhUMzQgMTU2UTM0IDIyMSA2NCAyNzlUMTQ2IDM4MFEyMjIgNDQxIDMwMSA0NDFRMzMzIDQ0MSAzNDEgNDQwUTM1NCA0MzcgMzY3IDQzM1Q0MDIgNDE3VDQzOCAzODdUNDY0IDMzOFQ0NzYgMjY4UTQ3NiAxNjEgMzkwIDc1VDIwMSAtMTFaTTEyMSAxMjBRMTIxIDcwIDE0NyA0OFQyMDYgMjZRMjUwIDI2IDI4OSA1OFQzNTEgMTQyUTM2MCAxNjMgMzc0IDIxNlQzODggMzA4UTM4OCAzNTIgMzcwIDM3NVEzNDYgNDA1IDMwNiA0MDVRMjQzIDQwNSAxOTUgMzQ3UTE1OCAzMDMgMTQwIDIzMFQxMjEgMTIwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTcwIiBkPSJNMjMgMjg3UTI0IDI5MCAyNSAyOTVUMzAgMzE3VDQwIDM0OFQ1NSAzODFUNzUgNDExVDEwMSA0MzNUMTM0IDQ0MlEyMDkgNDQyIDIzMCAzNzhMMjQwIDM4N1EzMDIgNDQyIDM1OCA0NDJRNDIzIDQ0MiA0NjAgMzk1VDQ5NyAyODFRNDk3IDE3MyA0MjEgODJUMjQ5IC0xMFEyMjcgLTEwIDIxMCAtNFExOTkgMSAxODcgMTFUMTY4IDI4TDE2MSAzNlExNjAgMzUgMTM5IC01MVQxMTggLTEzOFExMTggLTE0NCAxMjYgLTE0NVQxNjMgLTE0OEgxODhRMTk0IC0xNTUgMTk0IC0xNTdUMTkxIC0xNzVRMTg4IC0xODcgMTg1IC0xOTBUMTcyIC0xOTRRMTcwIC0xOTQgMTYxIC0xOTRUMTI3IC0xOTNUNjUgLTE5MlEtNSAtMTkyIC0yNCAtMTk0SC0zMlEtMzkgLTE4NyAtMzkgLTE4M1EtMzcgLTE1NiAtMjYgLTE0OEgtNlEyOCAtMTQ3IDMzIC0xMzZRMzYgLTEzMCA5NCAxMDNUMTU1IDM1MFExNTYgMzU1IDE1NiAzNjRRMTU2IDQwNSAxMzEgNDA1UTEwOSA0MDUgOTQgMzc3VDcxIDMxNlQ1OSAyODBRNTcgMjc4IDQzIDI3OEgyOVEyMyAyODQgMjMgMjg3Wk0xNzggMTAyUTIwMCAyNiAyNTIgMjZRMjgyIDI2IDMxMCA0OVQzNTYgMTA3UTM3NCAxNDEgMzkyIDIxNVQ0MTEgMzI1VjMzMVE0MTEgNDA1IDM1MCA0MDVRMzM5IDQwNSAzMjggNDAyVDMwNiAzOTNUMjg2IDM4MFQyNjkgMzY1VDI1NCAzNTBUMjQzIDMzNlQyMzUgMzI2TDIzMiAzMjJRMjMyIDMyMSAyMjkgMzA4VDIxOCAyNjRUMjA0IDIxMlExNzggMTA2IDE3OCAxMDJaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzQiIGQ9Ik0yNiAzODVRMTkgMzkyIDE5IDM5NVExOSAzOTkgMjIgNDExVDI3IDQyNVEyOSA0MzAgMzYgNDMwVDg3IDQzMUgxNDBMMTU5IDUxMVExNjIgNTIyIDE2NiA1NDBUMTczIDU2NlQxNzkgNTg2VDE4NyA2MDNUMTk3IDYxNVQyMTEgNjI0VDIyOSA2MjZRMjQ3IDYyNSAyNTQgNjE1VDI2MSA1OTZRMjYxIDU4OSAyNTIgNTQ5VDIzMiA0NzBMMjIyIDQzM1EyMjIgNDMxIDI3MiA0MzFIMzIzUTMzMCA0MjQgMzMwIDQyMFEzMzAgMzk4IDMxNyAzODVIMjEwTDE3NCAyNDBRMTM1IDgwIDEzNSA2OFExMzUgMjYgMTYyIDI2UTE5NyAyNiAyMzAgNjBUMjgzIDE0NFEyODUgMTUwIDI4OCAxNTFUMzAzIDE1M0gzMDdRMzIyIDE1MyAzMjIgMTQ1UTMyMiAxNDIgMzE5IDEzM1EzMTQgMTE3IDMwMSA5NVQyNjcgNDhUMjE2IDZUMTU1IC0xMVExMjUgLTExIDk4IDRUNTkgNTZRNTcgNjQgNTcgODNWMTAxTDkyIDI0MVExMjcgMzgyIDEyOCAzODNRMTI4IDM4NSA3NyAzODVIMjZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjEyIiBkPSJNODQgMjM3VDg0IDI1MFQ5OCAyNzBINjc5UTY5NCAyNjIgNjk0IDI1MFQ2NzkgMjMwSDk4UTg0IDIzNyA4NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDIiIGQ9Ik0yMzEgNjM3UTIwNCA2MzcgMTk5IDYzOFQxOTQgNjQ5UTE5NCA2NzYgMjA1IDY4MlEyMDYgNjgzIDMzNSA2ODNRNTk0IDY4MyA2MDggNjgxUTY3MSA2NzEgNzEzIDYzNlQ3NTYgNTQ0UTc1NiA0ODAgNjk4IDQyOVQ1NjUgMzYwTDU1NSAzNTdRNjE5IDM0OCA2NjAgMzExVDcwMiAyMTlRNzAyIDE0NiA2MzAgNzhUNDUzIDFRNDQ2IDAgMjQyIDBRNDIgMCAzOSAyUTM1IDUgMzUgMTBRMzUgMTcgMzcgMjRRNDIgNDMgNDcgNDVRNTEgNDYgNjIgNDZINjhROTUgNDYgMTI4IDQ5UTE0MiA1MiAxNDcgNjFRMTUwIDY1IDIxOSAzMzlUMjg4IDYyOFEyODggNjM1IDIzMSA2MzdaTTY0OSA1NDRRNjQ5IDU3NCA2MzQgNjAwVDU4NSA2MzRRNTc4IDYzNiA0OTMgNjM3UTQ3MyA2MzcgNDUxIDYzN1Q0MTYgNjM2SDQwM1EzODggNjM1IDM4NCA2MjZRMzgyIDYyMiAzNTIgNTA2UTM1MiA1MDMgMzUxIDUwMEwzMjAgMzc0SDQwMVE0ODIgMzc0IDQ5NCAzNzZRNTU0IDM4NiA2MDEgNDM0VDY0OSA1NDRaTTU5NSAyMjlRNTk1IDI3MyA1NzIgMzAyVDUxMiAzMzZRNTA2IDMzNyA0MjkgMzM3UTMxMSAzMzcgMzEwIDMzNlEzMTAgMzM0IDI5MyAyNjNUMjU4IDEyMkwyNDAgNTJRMjQwIDQ4IDI1MiA0OFQzMzMgNDZRNDIyIDQ2IDQyOSA0N1E0OTEgNTQgNTQzIDEwNVQ1OTUgMjI5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oxLTI4IiBkPSJNMTUyIDI1MVExNTIgNjQ2IDM4OCA4NTBINDE2UTQyMiA4NDQgNDIyIDg0MVE0MjIgODM3IDQwMyA4MTZUMzU3IDc1M1QzMDIgNjQ5VDI1NSA0ODJUMjM2IDI1MFEyMzYgMTI0IDI1NSAxOVQzMDEgLTE0N1QzNTYgLTI1MVQ0MDMgLTMxNVQ0MjIgLTM0MFE0MjIgLTM0MyA0MTYgLTM0OUgzODhRMzU5IC0zMjUgMzMyIC0yOTZUMjcxIC0yMTNUMjEyIC05N1QxNzAgNTZUMTUyIDI1MVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjEtMjkiIGQ9Ik0zMDUgMjUxUTMwNSAtMTQ1IDY5IC0zNDlINTZRNDMgLTM0OSAzOSAtMzQ3VDM1IC0zMzhRMzcgLTMzMyA2MCAtMzA3VDEwOCAtMjM5VDE2MCAtMTM2VDIwNCAyN1QyMjEgMjUwVDIwNCA0NzNUMTYwIDYzNlQxMDggNzQwVDYwIDgwN1QzNSA4MzlRMzUgODUwIDUwIDg1MEg1Nkg2OVExOTcgNzQzIDI1NiA1NjZRMzA1IDQyNSAzMDUgMjUxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjJDNSIgZD0iTTc4IDI1MFE3OCAyNzQgOTUgMjkyVDEzOCAzMTBRMTYyIDMxMCAxODAgMjk0VDE5OSAyNTFRMTk5IDIyNiAxODIgMjA4VDEzOSAxOTBUOTYgMjA3VDc4IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NyIgZD0iTTQzNiA2ODNRNDUwIDY4MyA0ODYgNjgyVDU1MyA2ODBRNjA0IDY4MCA2MzggNjgxVDY3NyA2ODJRNjk1IDY4MiA2OTUgNjc0UTY5NSA2NzAgNjkyIDY1OVE2ODcgNjQxIDY4MyA2MzlUNjYxIDYzN1E2MzYgNjM2IDYyMSA2MzJUNjAwIDYyNFQ1OTcgNjE1UTU5NyA2MDMgNjEzIDM3N1Q2MjkgMTM4TDYzMSAxNDFRNjMzIDE0NCA2MzcgMTUxVDY0OSAxNzBUNjY2IDIwMFQ2OTAgMjQxVDcyMCAyOTVUNzU5IDM2MlE4NjMgNTQ2IDg3NyA1NzJUODkyIDYwNFE4OTIgNjE5IDg3MyA2MjhUODMxIDYzN1E4MTcgNjM3IDgxNyA2NDdRODE3IDY1MCA4MTkgNjYwUTgyMyA2NzYgODI1IDY3OVQ4MzkgNjgyUTg0MiA2ODIgODU2IDY4MlQ4OTUgNjgyVDk0OSA2ODFRMTAxNSA2ODEgMTAzNCA2ODNRMTA0OCA2ODMgMTA0OCA2NzJRMTA0OCA2NjYgMTA0NSA2NTVUMTAzOCA2NDBUMTAyOCA2MzdRMTAwNiA2MzcgOTg4IDYzMVQ5NTggNjE3VDkzOSA2MDBUOTI3IDU4NEw5MjMgNTc4TDc1NCAyODJRNTg2IC0xNCA1ODUgLTE1UTU3OSAtMjIgNTYxIC0yMlE1NDYgLTIyIDU0MiAtMTdRNTM5IC0xNCA1MjMgMjI5VDUwNiA0ODBMNDk0IDQ2MlE0NzIgNDI1IDM2NiAyMzlRMjIyIC0xMyAyMjAgLTE1VDIxNSAtMTlRMjEwIC0yMiAxOTcgLTIyUTE3OCAtMjIgMTc2IC0xNVExNzYgLTEyIDE1NCAzMDRUMTMxIDYyMlExMjkgNjMxIDEyMSA2MzNUODIgNjM3SDU4UTUxIDY0NCA1MSA2NDhRNTIgNjcxIDY0IDY4M0g3NlExMTggNjgwIDE3NiA2ODBRMzAxIDY4MCAzMTMgNjgzSDMyM1EzMjkgNjc3IDMyOSA2NzRUMzI3IDY1NlEzMjIgNjQxIDMxOCA2MzdIMjk3UTIzNiA2MzQgMjMyIDYyMFEyNjIgMTYwIDI2NiAxMzZMNTAxIDU1MEw0OTkgNTg3UTQ5NiA2MjkgNDg5IDYzMlE0ODMgNjM2IDQ0NyA2MzdRNDI4IDYzNyA0MjIgNjM5VDQxNiA2NDhRNDE2IDY1MCA0MTggNjYwUTQxOSA2NjQgNDIwIDY2OVQ0MjEgNjc2VDQyNCA2ODBUNDI4IDY4MlQ0MzYgNjgzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjIxNyIgZD0iTTIyOSAyODZRMjE2IDQyMCAyMTYgNDM2UTIxNiA0NTQgMjQwIDQ2NFEyNDEgNDY0IDI0NSA0NjRUMjUxIDQ2NVEyNjMgNDY0IDI3MyA0NTZUMjgzIDQzNlEyODMgNDE5IDI3NyAzNTZUMjcwIDI4NkwzMjggMzI4UTM4NCAzNjkgMzg5IDM3MlQzOTkgMzc1UTQxMiAzNzUgNDIzIDM2NVQ0MzUgMzM4UTQzNSAzMjUgNDI1IDMxNVE0MjAgMzEyIDM1NyAyODJUMjg5IDI1MEwzNTUgMjE5TDQyNSAxODRRNDM0IDE3NSA0MzQgMTYxUTQzNCAxNDYgNDI1IDEzNlQ0MDEgMTI1UTM5MyAxMjUgMzgzIDEzMVQzMjggMTcxTDI3MCAyMTNRMjgzIDc5IDI4MyA2M1EyODMgNTMgMjc2IDQ0VDI1MCAzNVEyMzEgMzUgMjI0IDQ0VDIxNiA2M1EyMTYgODAgMjIyIDE0M1QyMjkgMjEzTDE3MSAxNzFRMTE1IDEzMCAxMTAgMTI3UTEwNiAxMjQgMTAwIDEyNFE4NyAxMjQgNzYgMTM0VDY0IDE2MVE2NCAxNjYgNjQgMTY5VDY3IDE3NVQ3MiAxODFUODEgMTg4VDk0IDE5NVQxMTMgMjA0VDEzOCAyMTVUMTcwIDIzMFQyMTAgMjUwTDc0IDMxNVE2NSAzMjQgNjUgMzM4UTY1IDM1MyA3NCAzNjNUOTggMzc0UTEwNiAzNzQgMTE2IDM2OFQxNzEgMzI4TDIyOSAyODZaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIxNjM1IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjY5MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQ3LC0xMDkwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIzNDUiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTEyNCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI2NjkiIHk9IjE2MjciPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQzMDIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjEtMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NTgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NyIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDcxNiwtMTUwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MCIgeD0iNDg1IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc0IiB4PSI5ODkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMTk5MyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI5OTQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NyIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDcxNiwtMTg3KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS00MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSI3NTkiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjExNDkiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTQ5NCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMS0yOSIgeD0iNTYwMSIgeT0iLTEiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjEwNjQwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjExNjk3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMkM1IiB4PSIxMjYyMyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzMTI0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTciIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjE3IiB4PSIxNTI2IiB5PSI1ODMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMTQ4ODAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNTg4MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQ3LC0xMDkwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIzNDUiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTEyNCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI2NjkiIHk9IjE2MjciPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE3NDkyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzciIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MTYsLTE4NykiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iNzU5IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSIxMTQ5IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjE0OTQiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L3N2Zz4=)
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQuOTkxZXgiIGhlaWdodD0iMi41MDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0xLjE3MWV4OyIgdmlld0JveD0iMCAtNTc2LjEgMjE0OC43IDEwODAuNCIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03NyIgZD0iTTU4MCAzODVRNTgwIDQwNiA1OTkgNDI0VDY0MSA0NDNRNjU5IDQ0MyA2NzQgNDI1VDY5MCAzNjhRNjkwIDMzOSA2NzEgMjUzUTY1NiAxOTcgNjQ0IDE2MVQ2MDkgODBUNTU0IDEyVDQ4MiAtMTFRNDM4IC0xMSA0MDQgNVQzNTUgNDhRMzU0IDQ3IDM1MiA0NFEzMTEgLTExIDI1MiAtMTFRMjI2IC0xMSAyMDIgLTVUMTU1IDE0VDExOCA1M1QxMDQgMTE2UTEwNCAxNzAgMTM4IDI2MlQxNzMgMzc5UTE3MyAzODAgMTczIDM4MVExNzMgMzkwIDE3MyAzOTNUMTY5IDQwMFQxNTggNDA0SDE1NFExMzEgNDA0IDExMiAzODVUODIgMzQ0VDY1IDMwMlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3UTIxIDI5MyAyOSAzMTVUNTIgMzY2VDk2IDQxOFQxNjEgNDQxUTIwNCA0NDEgMjI3IDQxNlQyNTAgMzU4UTI1MCAzNDAgMjE3IDI1MFQxODQgMTExUTE4NCA2NSAyMDUgNDZUMjU4IDI2UTMwMSAyNiAzMzQgODdMMzM5IDk2VjExOVEzMzkgMTIyIDMzOSAxMjhUMzQwIDEzNlQzNDEgMTQzVDM0MiAxNTJUMzQ1IDE2NVQzNDggMTgyVDM1NCAyMDZUMzYyIDIzOFQzNzMgMjgxUTQwMiAzOTUgNDA2IDQwNFE0MTkgNDMxIDQ0OSA0MzFRNDY4IDQzMSA0NzUgNDIxVDQ4MyA0MDJRNDgzIDM4OSA0NTQgMjc0VDQyMiAxNDJRNDIwIDEzMSA0MjAgMTA3VjEwMFE0MjAgODUgNDIzIDcxVDQ0MiA0MlQ0ODcgMjZRNTU4IDI2IDYwMCAxNDhRNjA5IDE3MSA2MjAgMjEzVDYzMiAyNzNRNjMyIDMwNiA2MTkgMzI1VDU5MyAzNTdUNTgwIDM4NVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00MiIgZD0iTTIzMSA2MzdRMjA0IDYzNyAxOTkgNjM4VDE5NCA2NDlRMTk0IDY3NiAyMDUgNjgyUTIwNiA2ODMgMzM1IDY4M1E1OTQgNjgzIDYwOCA2ODFRNjcxIDY3MSA3MTMgNjM2VDc1NiA1NDRRNzU2IDQ4MCA2OTggNDI5VDU2NSAzNjBMNTU1IDM1N1E2MTkgMzQ4IDY2MCAzMTFUNzAyIDIxOVE3MDIgMTQ2IDYzMCA3OFQ0NTMgMVE0NDYgMCAyNDIgMFE0MiAwIDM5IDJRMzUgNSAzNSAxMFEzNSAxNyAzNyAyNFE0MiA0MyA0NyA0NVE1MSA0NiA2MiA0Nkg2OFE5NSA0NiAxMjggNDlRMTQyIDUyIDE0NyA2MVExNTAgNjUgMjE5IDMzOVQyODggNjI4UTI4OCA2MzUgMjMxIDYzN1pNNjQ5IDU0NFE2NDkgNTc0IDYzNCA2MDBUNTg1IDYzNFE1NzggNjM2IDQ5MyA2MzdRNDczIDYzNyA0NTEgNjM3VDQxNiA2MzZINDAzUTM4OCA2MzUgMzg0IDYyNlEzODIgNjIyIDM1MiA1MDZRMzUyIDUwMyAzNTEgNTAwTDMyMCAzNzRINDAxUTQ4MiAzNzQgNDk0IDM3NlE1NTQgMzg2IDYwMSA0MzRUNjQ5IDU0NFpNNTk1IDIyOVE1OTUgMjczIDU3MiAzMDJUNTEyIDMzNlE1MDYgMzM3IDQyOSAzMzdRMzExIDMzNyAzMTAgMzM2UTMxMCAzMzQgMjkzIDI2M1QyNTggMTIyTDI0MCA1MlEyNDAgNDggMjUyIDQ4VDMzMyA0NlE0MjIgNDYgNDI5IDQ3UTQ5MSA1NCA1NDMgMTA1VDU5NSAyMjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY5IiBkPSJNMTg0IDYwMFExODQgNjI0IDIwMyA2NDJUMjQ3IDY2MVEyNjUgNjYxIDI3NyA2NDlUMjkwIDYxOVEyOTAgNTk2IDI3MCA1NzdUMjI2IDU1N1EyMTEgNTU3IDE5OCA1NjdUMTg0IDYwMFpNMjEgMjg3UTIxIDI5NSAzMCAzMThUNTQgMzY5VDk4IDQyMFQxNTggNDQyUTE5NyA0NDIgMjIzIDQxOVQyNTAgMzU3UTI1MCAzNDAgMjM2IDMwMVQxOTYgMTk2VDE1NCA4M1ExNDkgNjEgMTQ5IDUxUTE0OSAyNiAxNjYgMjZRMTc1IDI2IDE4NSAyOVQyMDggNDNUMjM1IDc4VDI2MCAxMzdRMjYzIDE0OSAyNjUgMTUxVDI4MiAxNTNRMzAyIDE1MyAzMDIgMTQzUTMwMiAxMzUgMjkzIDExMlQyNjggNjFUMjIzIDExVDE2MSAtMTFRMTI5IC0xMSAxMDIgMTBUNzQgNzRRNzQgOTEgNzkgMTA2VDEyMiAyMjBRMTYwIDMyMSAxNjYgMzQxVDE3MyAzODBRMTczIDQwNCAxNTYgNDA0SDE1NFExMjQgNDA0IDk5IDM3MVQ2MSAyODdRNjAgMjg2IDU5IDI4NFQ1OCAyODFUNTYgMjc5VDUzIDI3OFQ0OSAyNzhUNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NyIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDcxNiwtMTg3KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS00MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSI3NTkiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjExNDkiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTQ5NCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=) 是第
是第 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjAuODAyZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgMzQ1LjUgOTM2LjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNjkiIGQ9Ik0xODQgNjAwUTE4NCA2MjQgMjAzIDY0MlQyNDcgNjYxUTI2NSA2NjEgMjc3IDY0OVQyOTAgNjE5UTI5MCA1OTYgMjcwIDU3N1QyMjYgNTU3UTIxMSA1NTcgMTk4IDU2N1QxODQgNjAwWk0yMSAyODdRMjEgMjk1IDMwIDMxOFQ1NCAzNjlUOTggNDIwVDE1OCA0NDJRMTk3IDQ0MiAyMjMgNDE5VDI1MCAzNTdRMjUwIDM0MCAyMzYgMzAxVDE5NiAxOTZUMTU0IDgzUTE0OSA2MSAxNDkgNTFRMTQ5IDI2IDE2NiAyNlExNzUgMjYgMTg1IDI5VDIwOCA0M1QyMzUgNzhUMjYwIDEzN1EyNjMgMTQ5IDI2NSAxNTFUMjgyIDE1M1EzMDIgMTUzIDMwMiAxNDNRMzAyIDEzNSAyOTMgMTEyVDI2OCA2MVQyMjMgMTFUMTYxIC0xMVExMjkgLTExIDEwMiAxMFQ3NCA3NFE3NCA5MSA3OSAxMDZUMTIyIDIyMFExNjAgMzIxIDE2NiAzNDFUMTczIDM4MFExNzMgNDA0IDE1NiA0MDRIMTU0UTEyNCA0MDQgOTkgMzcxVDYxIDI4N1E2MCAyODYgNTkgMjg0VDU4IDI4MVQ1NiAyNzlUNTMgMjc4VDQ5IDI3OFQ0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 次试验时被选中臂的期望收益,
次试验时被选中臂的期望收益, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIuNzE4ZXgiIGhlaWdodD0iMi4zNDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtODYzLjEgMTE3MC40IDEwMDguNiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03NyIgZD0iTTU4MCAzODVRNTgwIDQwNiA1OTkgNDI0VDY0MSA0NDNRNjU5IDQ0MyA2NzQgNDI1VDY5MCAzNjhRNjkwIDMzOSA2NzEgMjUzUTY1NiAxOTcgNjQ0IDE2MVQ2MDkgODBUNTU0IDEyVDQ4MiAtMTFRNDM4IC0xMSA0MDQgNVQzNTUgNDhRMzU0IDQ3IDM1MiA0NFEzMTEgLTExIDI1MiAtMTFRMjI2IC0xMSAyMDIgLTVUMTU1IDE0VDExOCA1M1QxMDQgMTE2UTEwNCAxNzAgMTM4IDI2MlQxNzMgMzc5UTE3MyAzODAgMTczIDM4MVExNzMgMzkwIDE3MyAzOTNUMTY5IDQwMFQxNTggNDA0SDE1NFExMzEgNDA0IDExMiAzODVUODIgMzQ0VDY1IDMwMlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3UTIxIDI5MyAyOSAzMTVUNTIgMzY2VDk2IDQxOFQxNjEgNDQxUTIwNCA0NDEgMjI3IDQxNlQyNTAgMzU4UTI1MCAzNDAgMjE3IDI1MFQxODQgMTExUTE4NCA2NSAyMDUgNDZUMjU4IDI2UTMwMSAyNiAzMzQgODdMMzM5IDk2VjExOVEzMzkgMTIyIDMzOSAxMjhUMzQwIDEzNlQzNDEgMTQzVDM0MiAxNTJUMzQ1IDE2NVQzNDggMTgyVDM1NCAyMDZUMzYyIDIzOFQzNzMgMjgxUTQwMiAzOTUgNDA2IDQwNFE0MTkgNDMxIDQ0OSA0MzFRNDY4IDQzMSA0NzUgNDIxVDQ4MyA0MDJRNDgzIDM4OSA0NTQgMjc0VDQyMiAxNDJRNDIwIDEzMSA0MjAgMTA3VjEwMFE0MjAgODUgNDIzIDcxVDQ0MiA0MlQ0ODcgMjZRNTU4IDI2IDYwMCAxNDhRNjA5IDE3MSA2MjAgMjEzVDYzMiAyNzNRNjMyIDMwNiA2MTkgMzI1VDU5MyAzNTdUNTgwIDM4NVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMTciIGQ9Ik0yMjkgMjg2UTIxNiA0MjAgMjE2IDQzNlEyMTYgNDU0IDI0MCA0NjRRMjQxIDQ2NCAyNDUgNDY0VDI1MSA0NjVRMjYzIDQ2NCAyNzMgNDU2VDI4MyA0MzZRMjgzIDQxOSAyNzcgMzU2VDI3MCAyODZMMzI4IDMyOFEzODQgMzY5IDM4OSAzNzJUMzk5IDM3NVE0MTIgMzc1IDQyMyAzNjVUNDM1IDMzOFE0MzUgMzI1IDQyNSAzMTVRNDIwIDMxMiAzNTcgMjgyVDI4OSAyNTBMMzU1IDIxOUw0MjUgMTg0UTQzNCAxNzUgNDM0IDE2MVE0MzQgMTQ2IDQyNSAxMzZUNDAxIDEyNVEzOTMgMTI1IDM4MyAxMzFUMzI4IDE3MUwyNzAgMjEzUTI4MyA3OSAyODMgNjNRMjgzIDUzIDI3NiA0NFQyNTAgMzVRMjMxIDM1IDIyNCA0NFQyMTYgNjNRMjE2IDgwIDIyMiAxNDNUMjI5IDIxM0wxNzEgMTcxUTExNSAxMzAgMTEwIDEyN1ExMDYgMTI0IDEwMCAxMjRRODcgMTI0IDc2IDEzNFQ2NCAxNjFRNjQgMTY2IDY0IDE2OVQ2NyAxNzVUNzIgMTgxVDgxIDE4OFQ5NCAxOTVUMTEzIDIwNFQxMzggMjE1VDE3MCAyMzBUMjEwIDI1MEw3NCAzMTVRNjUgMzI0IDY1IDMzOFE2NSAzNTMgNzQgMzYzVDk4IDM3NFExMDYgMzc0IDExNiAzNjhUMTcxIDMyOEwyMjkgMjg2WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc3IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxNyIgeD0iMTAxMyIgeT0iNTgzIj48L3VzZT4KPC9nPgo8L3N2Zz4=) 是所有臂中最优的那个,如果上帝提前告诉我们,我们当然每次试验都选它,问题是上帝不告诉我们。这个公式可以用来对比不同 Bandit 算法的效果:对同样的多臂问题,用不同的 Bandit 算法试验相同次数,看看谁的 regret 增长得慢。
是所有臂中最优的那个,如果上帝提前告诉我们,我们当然每次试验都选它,问题是上帝不告诉我们。这个公式可以用来对比不同 Bandit 算法的效果:对同样的多臂问题,用不同的 Bandit 算法试验相同次数,看看谁的 regret 增长得慢。
[4] - 经典 Bandit 算法
朴素 Bandit 算法
先随机试若干次,计算每个臂的平均收益,一直选均值最大那个臂。这个算法是人类在实际中最常采用的,不可否认,它还是比随机乱猜要好。
Epsilon-Greedy 算法
这个算法有点类似模拟退火的思想。选一个 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjUuMTY4ZXgiIGhlaWdodD0iMi44NDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjgzOGV4OyIgdmlld0JveD0iMCAtODYzLjEgMjIyNS4yIDEyMjMuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMCIgZD0iTTk2IDU4NVExNTIgNjY2IDI0OSA2NjZRMjk3IDY2NiAzNDUgNjQwVDQyMyA1NDhRNDYwIDQ2NSA0NjAgMzIwUTQ2MCAxNjUgNDE3IDgzUTM5NyA0MSAzNjIgMTZUMzAxIC0xNVQyNTAgLTIyUTIyNCAtMjIgMTk4IC0xNlQxMzcgMTZUODIgODNRMzkgMTY1IDM5IDMyMFEzOSA0OTQgOTYgNTg1Wk0zMjEgNTk3UTI5MSA2MjkgMjUwIDYyOVEyMDggNjI5IDE3OCA1OTdRMTUzIDU3MSAxNDUgNTI1VDEzNyAzMzNRMTM3IDE3NSAxNDUgMTI1VDE4MSA0NlEyMDkgMTYgMjUwIDE2UTI5MCAxNiAzMTggNDZRMzQ3IDc2IDM1NCAxMzBUMzYyIDMzM1EzNjIgNDc4IDM1NCA1MjRUMzIxIDU5N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJDIiBkPSJNNzggMzVUNzggNjBUOTQgMTAzVDEzNyAxMjFRMTY1IDEyMSAxODcgOTZUMjEwIDhRMjEwIC0yNyAyMDEgLTYwVDE4MCAtMTE3VDE1NCAtMTU4VDEzMCAtMTg1VDExNyAtMTk0UTExMyAtMTk0IDEwNCAtMTg1VDk1IC0xNzJROTUgLTE2OCAxMDYgLTE1NlQxMzEgLTEyNlQxNTcgLTc2VDE3MyAtM1Y5TDE3MiA4UTE3MCA3IDE2NyA2VDE2MSAzVDE1MiAxVDE0MCAwUTExMyAwIDk2IDE3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzAiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9Ijg5MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjEzMzUiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxODM1IiB5PSIwIj48L3VzZT4KPC9nPgo8L3N2Zz4=) 之间较小的数
之间较小的数 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjAuOTQ0ZXgiIGhlaWdodD0iMS42NzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNTc2LjEgNDA2LjUgNzIxLjYiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktM0Y1IiBkPSJNMjI3IC0xMVExNDkgLTExIDk1IDQxVDQwIDE3NFE0MCAyNjIgODcgMzIyUTEyMSAzNjcgMTczIDM5NlQyODcgNDMwUTI4OSA0MzEgMzI5IDQzMUgzNjdRMzgyIDQyNiAzODIgNDExUTM4MiAzODUgMzQxIDM4NUgzMjVIMzEyUTE5MSAzODUgMTU0IDI3N0wxNTAgMjY1SDMyN1EzNDAgMjU2IDM0MCAyNDZRMzQwIDIyOCAzMjAgMjE5SDEzOFYyMTdRMTI4IDE4NyAxMjggMTQzUTEyOCA3NyAxNjAgNTJUMjMxIDI2UTI1OCAyNiAyODQgMzZUMzI2IDU3VDM0MyA2OFEzNTAgNjggMzU0IDU4VDM1OCAzOVEzNTggMzYgMzU3IDM1UTM1NCAzMSAzMzcgMjFUMjg5IDBUMjI3IC0xMVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS0zRjUiIHg9IjAiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) ,每次以 的概率在所有臂中随机选一个。以
,每次以 的概率在所有臂中随机选一个。以 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQuOTQ3ZXgiIGhlaWdodD0iMi4zNDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjUwNWV4OyIgdmlld0JveD0iMCAtNzkxLjMgMjEyOS45IDEwMDguNiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMTIiIGQ9Ik04NCAyMzdUODQgMjUwVDk4IDI3MEg2NzlRNjk0IDI2MiA2OTQgMjUwVDY3OSAyMzBIOThRODQgMjM3IDg0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS0zRjUiIGQ9Ik0yMjcgLTExUTE0OSAtMTEgOTUgNDFUNDAgMTc0UTQwIDI2MiA4NyAzMjJRMTIxIDM2NyAxNzMgMzk2VDI4NyA0MzBRMjg5IDQzMSAzMjkgNDMxSDM2N1EzODIgNDI2IDM4MiA0MTFRMzgyIDM4NSAzNDEgMzg1SDMyNUgzMTJRMTkxIDM4NSAxNTQgMjc3TDE1MCAyNjVIMzI3UTM0MCAyNTYgMzQwIDI0NlEzNDAgMjI4IDMyMCAyMTlIMTM4VjIxN1ExMjggMTg3IDEyOCAxNDNRMTI4IDc3IDE2MCA1MlQyMzEgMjZRMjU4IDI2IDI4NCAzNlQzMjYgNTdUMzQzIDY4UTM1MCA2OCAzNTQgNThUMzU4IDM5UTM1OCAzNiAzNTcgMzVRMzU0IDMxIDMzNyAyMVQyODkgMFQyMjcgLTExWiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjcyMiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTNGNSIgeD0iMTcyMyIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 的概率选择截止当前,平均收益最大的那个臂。根据选择臂的回报值来对回报期望进行更新。
的概率选择截止当前,平均收益最大的那个臂。根据选择臂的回报值来对回报期望进行更新。
这里 的值可以控制对 exploit 和 explore 的偏好程度,每次决策以概率 去 Exploration , 的概率来 Exploitation 。
Thompson sampling 算法
Thompson sampling[3] 算法用到了 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQuOTE3ZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgMjExNyA5MzYuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00MiIgZD0iTTIzMSA2MzdRMjA0IDYzNyAxOTkgNjM4VDE5NCA2NDlRMTk0IDY3NiAyMDUgNjgyUTIwNiA2ODMgMzM1IDY4M1E1OTQgNjgzIDYwOCA2ODFRNjcxIDY3MSA3MTMgNjM2VDc1NiA1NDRRNzU2IDQ4MCA2OTggNDI5VDU2NSAzNjBMNTU1IDM1N1E2MTkgMzQ4IDY2MCAzMTFUNzAyIDIxOVE3MDIgMTQ2IDYzMCA3OFQ0NTMgMVE0NDYgMCAyNDIgMFE0MiAwIDM5IDJRMzUgNSAzNSAxMFEzNSAxNyAzNyAyNFE0MiA0MyA0NyA0NVE1MSA0NiA2MiA0Nkg2OFE5NSA0NiAxMjggNDlRMTQyIDUyIDE0NyA2MVExNTAgNjUgMjE5IDMzOVQyODggNjI4UTI4OCA2MzUgMjMxIDYzN1pNNjQ5IDU0NFE2NDkgNTc0IDYzNCA2MDBUNTg1IDYzNFE1NzggNjM2IDQ5MyA2MzdRNDczIDYzNyA0NTEgNjM3VDQxNiA2MzZINDAzUTM4OCA2MzUgMzg0IDYyNlEzODIgNjIyIDM1MiA1MDZRMzUyIDUwMyAzNTEgNTAwTDMyMCAzNzRINDAxUTQ4MiAzNzQgNDk0IDM3NlE1NTQgMzg2IDYwMSA0MzRUNjQ5IDU0NFpNNTk1IDIyOVE1OTUgMjczIDU3MiAzMDJUNTEyIDMzNlE1MDYgMzM3IDQyOSAzMzdRMzExIDMzNyAzMTAgMzM2UTMxMCAzMzQgMjkzIDI2M1QyNTggMTIyTDI0MCA1MlEyNDAgNDggMjUyIDQ4VDMzMyA0NlE0MjIgNDYgNDI5IDQ3UTQ5MSA1NCA1NDMgMTA1VDU5NSAyMjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNjUiIGQ9Ik0zOSAxNjhRMzkgMjI1IDU4IDI3MlQxMDcgMzUwVDE3NCA0MDJUMjQ0IDQzM1QzMDcgNDQySDMxMFEzNTUgNDQyIDM4OCA0MjBUNDIxIDM1NVE0MjEgMjY1IDMxMCAyMzdRMjYxIDIyNCAxNzYgMjIzUTEzOSAyMjMgMTM4IDIyMVExMzggMjE5IDEzMiAxODZUMTI1IDEyOFExMjUgODEgMTQ2IDU0VDIwOSAyNlQzMDIgNDVUMzk0IDExMVE0MDMgMTIxIDQwNiAxMjFRNDEwIDEyMSA0MTkgMTEyVDQyOSA5OFQ0MjAgODJUMzkwIDU1VDM0NCAyNFQyODEgLTFUMjA1IC0xMVExMjYgLTExIDgzIDQyVDM5IDE2OFpNMzczIDM1M1EzNjcgNDA1IDMwNSA0MDVRMjcyIDQwNSAyNDQgMzkxVDE5OSAzNTdUMTcwIDMxNlQxNTQgMjgwVDE0OSAyNjFRMTQ5IDI2MCAxNjkgMjYwUTI4MiAyNjAgMzI3IDI4NFQzNzMgMzUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc0IiBkPSJNMjYgMzg1UTE5IDM5MiAxOSAzOTVRMTkgMzk5IDIyIDQxMVQyNyA0MjVRMjkgNDMwIDM2IDQzMFQ4NyA0MzFIMTQwTDE1OSA1MTFRMTYyIDUyMiAxNjYgNTQwVDE3MyA1NjZUMTc5IDU4NlQxODcgNjAzVDE5NyA2MTVUMjExIDYyNFQyMjkgNjI2UTI0NyA2MjUgMjU0IDYxNVQyNjEgNTk2UTI2MSA1ODkgMjUyIDU0OVQyMzIgNDcwTDIyMiA0MzNRMjIyIDQzMSAyNzIgNDMxSDMyM1EzMzAgNDI0IDMzMCA0MjBRMzMwIDM5OCAzMTcgMzg1SDIxMEwxNzQgMjQwUTEzNSA4MCAxMzUgNjhRMTM1IDI2IDE2MiAyNlExOTcgMjYgMjMwIDYwVDI4MyAxNDRRMjg1IDE1MCAyODggMTUxVDMwMyAxNTNIMzA3UTMyMiAxNTMgMzIyIDE0NVEzMjIgMTQyIDMxOSAxMzNRMzE0IDExNyAzMDEgOTVUMjY3IDQ4VDIxNiA2VDE1NSAtMTFRMTI1IC0xMSA5OCA0VDU5IDU2UTU3IDY0IDU3IDgzVjEwMUw5MiAyNDFRMTI3IDM4MiAxMjggMzgzUTEyOCAzODUgNzcgMzg1SDI2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTYxIiBkPSJNMzMgMTU3UTMzIDI1OCAxMDkgMzQ5VDI4MCA0NDFRMzMxIDQ0MSAzNzAgMzkyUTM4NiA0MjIgNDE2IDQyMlE0MjkgNDIyIDQzOSA0MTRUNDQ5IDM5NFE0NDkgMzgxIDQxMiAyMzRUMzc0IDY4UTM3NCA0MyAzODEgMzVUNDAyIDI2UTQxMSAyNyA0MjIgMzVRNDQzIDU1IDQ2MyAxMzFRNDY5IDE1MSA0NzMgMTUyUTQ3NSAxNTMgNDgzIDE1M0g0ODdRNTA2IDE1MyA1MDYgMTQ0UTUwNiAxMzggNTAxIDExN1Q0ODEgNjNUNDQ5IDEzUTQzNiAwIDQxNyAtOFE0MDkgLTEwIDM5MyAtMTBRMzU5IC0xMCAzMzYgNVQzMDYgMzZMMzAwIDUxUTI5OSA1MiAyOTYgNTBRMjk0IDQ4IDI5MiA0NlEyMzMgLTEwIDE3MiAtMTBRMTE3IC0xMCA3NSAzMFQzMyAxNTdaTTM1MSAzMjhRMzUxIDMzNCAzNDYgMzUwVDMyMyAzODVUMjc3IDQwNVEyNDIgNDA1IDIxMCAzNzRUMTYwIDI5M1ExMzEgMjE0IDExOSAxMjlRMTE5IDEyNiAxMTkgMTE4VDExOCAxMDZRMTE4IDYxIDEzNiA0NFQxNzkgMjZRMjE3IDI2IDI1NCA1OVQyOTggMTEwUTMwMCAxMTQgMzI1IDIxN1QzNTEgMzI4WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjUiIHg9Ijc1OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc0IiB4PSIxMjI2IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjEiIHg9IjE1ODciIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) [4]分布。假设每个臂是否产生收益,其背后有一个概率分布,产生收益的概率为
[4]分布。假设每个臂是否产生收益,其背后有一个概率分布,产生收益的概率为 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuMjU5ZXgiIGhlaWdodD0iMi4wMDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyBtYXJnaW4tbGVmdDogLTAuMDg5ZXg7IiB2aWV3Qm94PSItMzguNSAtNTc2LjEgNTQyIDg2NS4xIiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTcwIiBkPSJNMjMgMjg3UTI0IDI5MCAyNSAyOTVUMzAgMzE3VDQwIDM0OFQ1NSAzODFUNzUgNDExVDEwMSA0MzNUMTM0IDQ0MlEyMDkgNDQyIDIzMCAzNzhMMjQwIDM4N1EzMDIgNDQyIDM1OCA0NDJRNDIzIDQ0MiA0NjAgMzk1VDQ5NyAyODFRNDk3IDE3MyA0MjEgODJUMjQ5IC0xMFEyMjcgLTEwIDIxMCAtNFExOTkgMSAxODcgMTFUMTY4IDI4TDE2MSAzNlExNjAgMzUgMTM5IC01MVQxMTggLTEzOFExMTggLTE0NCAxMjYgLTE0NVQxNjMgLTE0OEgxODhRMTk0IC0xNTUgMTk0IC0xNTdUMTkxIC0xNzVRMTg4IC0xODcgMTg1IC0xOTBUMTcyIC0xOTRRMTcwIC0xOTQgMTYxIC0xOTRUMTI3IC0xOTNUNjUgLTE5MlEtNSAtMTkyIC0yNCAtMTk0SC0zMlEtMzkgLTE4NyAtMzkgLTE4M1EtMzcgLTE1NiAtMjYgLTE0OEgtNlEyOCAtMTQ3IDMzIC0xMzZRMzYgLTEzMCA5NCAxMDNUMTU1IDM1MFExNTYgMzU1IDE1NiAzNjRRMTU2IDQwNSAxMzEgNDA1UTEwOSA0MDUgOTQgMzc3VDcxIDMxNlQ1OSAyODBRNTcgMjc4IDQzIDI3OEgyOVEyMyAyODQgMjMgMjg3Wk0xNzggMTAyUTIwMCAyNiAyNTIgMjZRMjgyIDI2IDMxMCA0OVQzNTYgMTA3UTM3NCAxNDEgMzkyIDIxNVQ0MTEgMzI1VjMzMVE0MTEgNDA1IDM1MCA0MDVRMzM5IDQwNSAzMjggNDAyVDMwNiAzOTNUMjg2IDM4MFQyNjkgMzY1VDI1NCAzNTBUMjQzIDMzNlQyMzUgMzI2TDIzMiAzMjJRMjMyIDMyMSAyMjkgMzA4VDIxOCAyNjRUMjA0IDIxMlExNzggMTA2IDE3OCAxMDJaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzAiIHg9IjAiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) ,同时该概率 的概率分布符合
,同时该概率 的概率分布符合 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjE2LjcwN2V4IiBoZWlnaHQ9IjIuODQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMC44MzhleDsiIHZpZXdCb3g9IjAgLTg2My4xIDcxOTMuMiAxMjIzLjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDIiIGQ9Ik0yMzEgNjM3UTIwNCA2MzcgMTk5IDYzOFQxOTQgNjQ5UTE5NCA2NzYgMjA1IDY4MlEyMDYgNjgzIDMzNSA2ODNRNTk0IDY4MyA2MDggNjgxUTY3MSA2NzEgNzEzIDYzNlQ3NTYgNTQ0UTc1NiA0ODAgNjk4IDQyOVQ1NjUgMzYwTDU1NSAzNTdRNjE5IDM0OCA2NjAgMzExVDcwMiAyMTlRNzAyIDE0NiA2MzAgNzhUNDUzIDFRNDQ2IDAgMjQyIDBRNDIgMCAzOSAyUTM1IDUgMzUgMTBRMzUgMTcgMzcgMjRRNDIgNDMgNDcgNDVRNTEgNDYgNjIgNDZINjhROTUgNDYgMTI4IDQ5UTE0MiA1MiAxNDcgNjFRMTUwIDY1IDIxOSAzMzlUMjg4IDYyOFEyODggNjM1IDIzMSA2MzdaTTY0OSA1NDRRNjQ5IDU3NCA2MzQgNjAwVDU4NSA2MzRRNTc4IDYzNiA0OTMgNjM3UTQ3MyA2MzcgNDUxIDYzN1Q0MTYgNjM2SDQwM1EzODggNjM1IDM4NCA2MjZRMzgyIDYyMiAzNTIgNTA2UTM1MiA1MDMgMzUxIDUwMEwzMjAgMzc0SDQwMVE0ODIgMzc0IDQ5NCAzNzZRNTU0IDM4NiA2MDEgNDM0VDY0OSA1NDRaTTU5NSAyMjlRNTk1IDI3MyA1NzIgMzAyVDUxMiAzMzZRNTA2IDMzNyA0MjkgMzM3UTMxMSAzMzcgMzEwIDMzNlEzMTAgMzM0IDI5MyAyNjNUMjU4IDEyMkwyNDAgNTJRMjQwIDQ4IDI1MiA0OFQzMzMgNDZRNDIyIDQ2IDQyOSA0N1E0OTEgNTQgNTQzIDEwNVQ1OTUgMjI5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY1IiBkPSJNMzkgMTY4UTM5IDIyNSA1OCAyNzJUMTA3IDM1MFQxNzQgNDAyVDI0NCA0MzNUMzA3IDQ0MkgzMTBRMzU1IDQ0MiAzODggNDIwVDQyMSAzNTVRNDIxIDI2NSAzMTAgMjM3UTI2MSAyMjQgMTc2IDIyM1ExMzkgMjIzIDEzOCAyMjFRMTM4IDIxOSAxMzIgMTg2VDEyNSAxMjhRMTI1IDgxIDE0NiA1NFQyMDkgMjZUMzAyIDQ1VDM5NCAxMTFRNDAzIDEyMSA0MDYgMTIxUTQxMCAxMjEgNDE5IDExMlQ0MjkgOThUNDIwIDgyVDM5MCA1NVQzNDQgMjRUMjgxIC0xVDIwNSAtMTFRMTI2IC0xMSA4MyA0MlQzOSAxNjhaTTM3MyAzNTNRMzY3IDQwNSAzMDUgNDA1UTI3MiA0MDUgMjQ0IDM5MVQxOTkgMzU3VDE3MCAzMTZUMTU0IDI4MFQxNDkgMjYxUTE0OSAyNjAgMTY5IDI2MFEyODIgMjYwIDMyNyAyODRUMzczIDM1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03NCIgZD0iTTI2IDM4NVExOSAzOTIgMTkgMzk1UTE5IDM5OSAyMiA0MTFUMjcgNDI1UTI5IDQzMCAzNiA0MzBUODcgNDMxSDE0MEwxNTkgNTExUTE2MiA1MjIgMTY2IDU0MFQxNzMgNTY2VDE3OSA1ODZUMTg3IDYwM1QxOTcgNjE1VDIxMSA2MjRUMjI5IDYyNlEyNDcgNjI1IDI1NCA2MTVUMjYxIDU5NlEyNjEgNTg5IDI1MiA1NDlUMjMyIDQ3MEwyMjIgNDMzUTIyMiA0MzEgMjcyIDQzMUgzMjNRMzMwIDQyNCAzMzAgNDIwUTMzMCAzOTggMzE3IDM4NUgyMTBMMTc0IDI0MFExMzUgODAgMTM1IDY4UTEzNSAyNiAxNjIgMjZRMTk3IDI2IDIzMCA2MFQyODMgMTQ0UTI4NSAxNTAgMjg4IDE1MVQzMDMgMTUzSDMwN1EzMjIgMTUzIDMyMiAxNDVRMzIyIDE0MiAzMTkgMTMzUTMxNCAxMTcgMzAxIDk1VDI2NyA0OFQyMTYgNlQxNTUgLTExUTEyNSAtMTEgOTggNFQ1OSA1NlE1NyA2NCA1NyA4M1YxMDFMOTIgMjQxUTEyNyAzODIgMTI4IDM4M1ExMjggMzg1IDc3IDM4NUgyNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02MSIgZD0iTTMzIDE1N1EzMyAyNTggMTA5IDM0OVQyODAgNDQxUTMzMSA0NDEgMzcwIDM5MlEzODYgNDIyIDQxNiA0MjJRNDI5IDQyMiA0MzkgNDE0VDQ0OSAzOTRRNDQ5IDM4MSA0MTIgMjM0VDM3NCA2OFEzNzQgNDMgMzgxIDM1VDQwMiAyNlE0MTEgMjcgNDIyIDM1UTQ0MyA1NSA0NjMgMTMxUTQ2OSAxNTEgNDczIDE1MlE0NzUgMTUzIDQ4MyAxNTNINDg3UTUwNiAxNTMgNTA2IDE0NFE1MDYgMTM4IDUwMSAxMTdUNDgxIDYzVDQ0OSAxM1E0MzYgMCA0MTcgLThRNDA5IC0xMCAzOTMgLTEwUTM1OSAtMTAgMzM2IDVUMzA2IDM2TDMwMCA1MVEyOTkgNTIgMjk2IDUwUTI5NCA0OCAyOTIgNDZRMjMzIC0xMCAxNzIgLTEwUTExNyAtMTAgNzUgMzBUMzMgMTU3Wk0zNTEgMzI4UTM1MSAzMzQgMzQ2IDM1MFQzMjMgMzg1VDI3NyA0MDVRMjQyIDQwNSAyMTAgMzc0VDE2MCAyOTNRMTMxIDIxNCAxMTkgMTI5UTExOSAxMjYgMTE5IDExOFQxMTggMTA2UTExOCA2MSAxMzYgNDRUMTc5IDI2UTIxNyAyNiAyNTQgNTlUMjk4IDExMFEzMDAgMTE0IDMyNSAyMTdUMzUxIDMyOFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzciIGQ9Ik01ODAgMzg1UTU4MCA0MDYgNTk5IDQyNFQ2NDEgNDQzUTY1OSA0NDMgNjc0IDQyNVQ2OTAgMzY4UTY5MCAzMzkgNjcxIDI1M1E2NTYgMTk3IDY0NCAxNjFUNjA5IDgwVDU1NCAxMlQ0ODIgLTExUTQzOCAtMTEgNDA0IDVUMzU1IDQ4UTM1NCA0NyAzNTIgNDRRMzExIC0xMSAyNTIgLTExUTIyNiAtMTEgMjAyIC01VDE1NSAxNFQxMTggNTNUMTA0IDExNlExMDQgMTcwIDEzOCAyNjJUMTczIDM3OVExNzMgMzgwIDE3MyAzODFRMTczIDM5MCAxNzMgMzkzVDE2OSA0MDBUMTU4IDQwNEgxNTRRMTMxIDQwNCAxMTIgMzg1VDgyIDM0NFQ2NSAzMDJUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1EyMSAyOTMgMjkgMzE1VDUyIDM2NlQ5NiA0MThUMTYxIDQ0MVEyMDQgNDQxIDIyNyA0MTZUMjUwIDM1OFEyNTAgMzQwIDIxNyAyNTBUMTg0IDExMVExODQgNjUgMjA1IDQ2VDI1OCAyNlEzMDEgMjYgMzM0IDg3TDMzOSA5NlYxMTlRMzM5IDEyMiAzMzkgMTI4VDM0MCAxMzZUMzQxIDE0M1QzNDIgMTUyVDM0NSAxNjVUMzQ4IDE4MlQzNTQgMjA2VDM2MiAyMzhUMzczIDI4MVE0MDIgMzk1IDQwNiA0MDRRNDE5IDQzMSA0NDkgNDMxUTQ2OCA0MzEgNDc1IDQyMVQ0ODMgNDAyUTQ4MyAzODkgNDU0IDI3NFQ0MjIgMTQyUTQyMCAxMzEgNDIwIDEwN1YxMDBRNDIwIDg1IDQyMyA3MVQ0NDIgNDJUNDg3IDI2UTU1OCAyNiA2MDAgMTQ4UTYwOSAxNzEgNjIwIDIxM1Q2MzIgMjczUTYzMiAzMDYgNjE5IDMyNVQ1OTMgMzU3VDU4MCAzODVaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNjkiIGQ9Ik0xODQgNjAwUTE4NCA2MjQgMjAzIDY0MlQyNDcgNjYxUTI2NSA2NjEgMjc3IDY0OVQyOTAgNjE5UTI5MCA1OTYgMjcwIDU3N1QyMjYgNTU3UTIxMSA1NTcgMTk4IDU2N1QxODQgNjAwWk0yMSAyODdRMjEgMjk1IDMwIDMxOFQ1NCAzNjlUOTggNDIwVDE1OCA0NDJRMTk3IDQ0MiAyMjMgNDE5VDI1MCAzNTdRMjUwIDM0MCAyMzYgMzAxVDE5NiAxOTZUMTU0IDgzUTE0OSA2MSAxNDkgNTFRMTQ5IDI2IDE2NiAyNlExNzUgMjYgMTg1IDI5VDIwOCA0M1QyMzUgNzhUMjYwIDEzN1EyNjMgMTQ5IDI2NSAxNTFUMjgyIDE1M1EzMDIgMTUzIDMwMiAxNDNRMzAyIDEzNSAyOTMgMTEyVDI2OCA2MVQyMjMgMTFUMTYxIC0xMVExMjkgLTExIDEwMiAxMFQ3NCA3NFE3NCA5MSA3OSAxMDZUMTIyIDIyMFExNjAgMzIxIDE2NiAzNDFUMTczIDM4MFExNzMgNDA0IDE1NiA0MDRIMTU0UTEyNCA0MDQgOTkgMzcxVDYxIDI4N1E2MCAyODYgNTkgMjg0VDU4IDI4MVQ1NiAyNzlUNTMgMjc4VDQ5IDI3OFQ0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJDIiBkPSJNNzggMzVUNzggNjBUOTQgMTAzVDEzNyAxMjFRMTY1IDEyMSAxODcgOTZUMjEwIDhRMjEwIC0yNyAyMDEgLTYwVDE4MCAtMTE3VDE1NCAtMTU4VDEzMCAtMTg1VDExNyAtMTk0UTExMyAtMTk0IDEwNCAtMTg1VDk1IC0xNzJROTUgLTE2OCAxMDYgLTE1NlQxMzEgLTEyNlQxNTcgLTc2VDE3MyAtM1Y5TDE3MiA4UTE3MCA3IDE2NyA2VDE2MSAzVDE1MiAxVDE0MCAwUTExMyAwIDk2IDE3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZDIiBkPSJNMTE3IDU5UTExNyAyNiAxNDIgMjZRMTc5IDI2IDIwNSAxMzFRMjExIDE1MSAyMTUgMTUyUTIxNyAxNTMgMjI1IDE1M0gyMjlRMjM4IDE1MyAyNDEgMTUzVDI0NiAxNTFUMjQ4IDE0NFEyNDcgMTM4IDI0NSAxMjhUMjM0IDkwVDIxNCA0M1QxODMgNlQxMzcgLTExUTEwMSAtMTEgNzAgMTFUMzggODVRMzggOTcgMzkgMTAyTDEwNCAzNjBRMTY3IDYxNSAxNjcgNjIzUTE2NyA2MjYgMTY2IDYyOFQxNjIgNjMyVDE1NyA2MzRUMTQ5IDYzNVQxNDEgNjM2VDEzMiA2MzdUMTIyIDYzN1ExMTIgNjM3IDEwOSA2MzdUMTAxIDYzOFQ5NSA2NDFUOTQgNjQ3UTk0IDY0OSA5NiA2NjFRMTAxIDY4MCAxMDcgNjgyVDE3OSA2ODhRMTk0IDY4OSAyMTMgNjkwVDI0MyA2OTNUMjU0IDY5NFEyNjYgNjk0IDI2NiA2ODZRMjY2IDY3NSAxOTMgMzg2VDExOCA4M1ExMTggODEgMTE4IDc1VDExNyA2NVY1OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RiIgZD0iTTIwMSAtMTFRMTI2IC0xMSA4MCAzOFQzNCAxNTZRMzQgMjIxIDY0IDI3OVQxNDYgMzgwUTIyMiA0NDEgMzAxIDQ0MVEzMzMgNDQxIDM0MSA0NDBRMzU0IDQzNyAzNjcgNDMzVDQwMiA0MTdUNDM4IDM4N1Q0NjQgMzM4VDQ3NiAyNjhRNDc2IDE2MSAzOTAgNzVUMjAxIC0xMVpNMTIxIDEyMFExMjEgNzAgMTQ3IDQ4VDIwNiAyNlEyNTAgMjYgMjg5IDU4VDM1MSAxNDJRMzYwIDE2MyAzNzQgMjE2VDM4OCAzMDhRMzg4IDM1MiAzNzAgMzc1UTM0NiA0MDUgMzA2IDQwNVEyNDMgNDA1IDE5NSAzNDdRMTU4IDMwMyAxNDAgMjMwVDEyMSAxMjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY1IiB4PSI3NTkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NCIgeD0iMTIyNiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTYxIiB4PSIxNTg3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMjExNyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc3IiB4PSIyNTA2IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjMyMjMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMzU2OCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI0MTY5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iNDYzOCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZDIiB4PSI1MDgzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkYiIHg9IjUzODIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iNTg2NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY1IiB4PSI2MzM3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iNjgwMyIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 分布,每个臂都维护一个 分布的参数,即
分布,每个臂都维护一个 分布的参数,即 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjkuOTgxZXgiIGhlaWdodD0iMi41MDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyIgdmlld0JveD0iMCAtNzkxLjMgNDI5Ny4yIDEwODAuNCIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03NyIgZD0iTTU4MCAzODVRNTgwIDQwNiA1OTkgNDI0VDY0MSA0NDNRNjU5IDQ0MyA2NzQgNDI1VDY5MCAzNjhRNjkwIDMzOSA2NzEgMjUzUTY1NiAxOTcgNjQ0IDE2MVQ2MDkgODBUNTU0IDEyVDQ4MiAtMTFRNDM4IC0xMSA0MDQgNVQzNTUgNDhRMzU0IDQ3IDM1MiA0NFEzMTEgLTExIDI1MiAtMTFRMjI2IC0xMSAyMDIgLTVUMTU1IDE0VDExOCA1M1QxMDQgMTE2UTEwNCAxNzAgMTM4IDI2MlQxNzMgMzc5UTE3MyAzODAgMTczIDM4MVExNzMgMzkwIDE3MyAzOTNUMTY5IDQwMFQxNTggNDA0SDE1NFExMzEgNDA0IDExMiAzODVUODIgMzQ0VDY1IDMwMlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3UTIxIDI5MyAyOSAzMTVUNTIgMzY2VDk2IDQxOFQxNjEgNDQxUTIwNCA0NDEgMjI3IDQxNlQyNTAgMzU4UTI1MCAzNDAgMjE3IDI1MFQxODQgMTExUTE4NCA2NSAyMDUgNDZUMjU4IDI2UTMwMSAyNiAzMzQgODdMMzM5IDk2VjExOVEzMzkgMTIyIDMzOSAxMjhUMzQwIDEzNlQzNDEgMTQzVDM0MiAxNTJUMzQ1IDE2NVQzNDggMTgyVDM1NCAyMDZUMzYyIDIzOFQzNzMgMjgxUTQwMiAzOTUgNDA2IDQwNFE0MTkgNDMxIDQ0OSA0MzFRNDY4IDQzMSA0NzUgNDIxVDQ4MyA0MDJRNDgzIDM4OSA0NTQgMjc0VDQyMiAxNDJRNDIwIDEzMSA0MjAgMTA3VjEwMFE0MjAgODUgNDIzIDcxVDQ0MiA0MlQ0ODcgMjZRNTU4IDI2IDYwMCAxNDhRNjA5IDE3MSA2MjAgMjEzVDYzMiAyNzNRNjMyIDMwNiA2MTkgMzI1VDU5MyAzNTdUNTgwIDM4NVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02OSIgZD0iTTE4NCA2MDBRMTg0IDYyNCAyMDMgNjQyVDI0NyA2NjFRMjY1IDY2MSAyNzcgNjQ5VDI5MCA2MTlRMjkwIDU5NiAyNzAgNTc3VDIyNiA1NTdRMjExIDU1NyAxOTggNTY3VDE4NCA2MDBaTTIxIDI4N1EyMSAyOTUgMzAgMzE4VDU0IDM2OVQ5OCA0MjBUMTU4IDQ0MlExOTcgNDQyIDIyMyA0MTlUMjUwIDM1N1EyNTAgMzQwIDIzNiAzMDFUMTk2IDE5NlQxNTQgODNRMTQ5IDYxIDE0OSA1MVExNDkgMjYgMTY2IDI2UTE3NSAyNiAxODUgMjlUMjA4IDQzVDIzNSA3OFQyNjAgMTM3UTI2MyAxNDkgMjY1IDE1MVQyODIgMTUzUTMwMiAxNTMgMzAyIDE0M1EzMDIgMTM1IDI5MyAxMTJUMjY4IDYxVDIyMyAxMVQxNjEgLTExUTEyOSAtMTEgMTAyIDEwVDc0IDc0UTc0IDkxIDc5IDEwNlQxMjIgMjIwUTE2MCAzMjEgMTY2IDM0MVQxNzMgMzgwUTE3MyA0MDQgMTU2IDQwNEgxNTRRMTI0IDQwNCA5OSAzNzFUNjEgMjg3UTYwIDI4NiA1OSAyODRUNTggMjgxVDU2IDI3OVQ1MyAyNzhUNDkgMjc4VDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZFIiBkPSJNMjEgMjg3UTIyIDI5MyAyNCAzMDNUMzYgMzQxVDU2IDM4OFQ4OSA0MjVUMTM1IDQ0MlExNzEgNDQyIDE5NSA0MjRUMjI1IDM5MFQyMzEgMzY5UTIzMSAzNjcgMjMyIDM2N0wyNDMgMzc4UTMwNCA0NDIgMzgyIDQ0MlE0MzYgNDQyIDQ2OSA0MTVUNTAzIDMzNlQ0NjUgMTc5VDQyNyA1MlE0MjcgMjYgNDQ0IDI2UTQ1MCAyNiA0NTMgMjdRNDgyIDMyIDUwNSA2NVQ1NDAgMTQ1UTU0MiAxNTMgNTYwIDE1M1E1ODAgMTUzIDU4MCAxNDVRNTgwIDE0NCA1NzYgMTMwUTU2OCAxMDEgNTU0IDczVDUwOCAxN1Q0MzkgLTEwUTM5MiAtMTAgMzcxIDE3VDM1MCA3M1EzNTAgOTIgMzg2IDE5M1Q0MjMgMzQ1UTQyMyA0MDQgMzc5IDQwNEgzNzRRMjg4IDQwNCAyMjkgMzAzTDIyMiAyOTFMMTg5IDE1N1ExNTYgMjYgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTIgMTgwVDE1MiAzNDNRMTUzIDM0OCAxNTMgMzY2UTE1MyA0MDUgMTI5IDQwNVE5MSA0MDUgNjYgMzA1UTYwIDI4NSA2MCAyODRRNTggMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkMiIGQ9Ik03OCAzNVQ3OCA2MFQ5NCAxMDNUMTM3IDEyMVExNjUgMTIxIDE4NyA5NlQyMTAgOFEyMTAgLTI3IDIwMSAtNjBUMTgwIC0xMTdUMTU0IC0xNThUMTMwIC0xODVUMTE3IC0xOTRRMTEzIC0xOTQgMTA0IC0xODVUOTUgLTE3MlE5NSAtMTY4IDEwNiAtMTU2VDEzMSAtMTI2VDE1NyAtNzZUMTczIC0zVjlMMTcyIDhRMTcwIDcgMTY3IDZUMTYxIDNUMTUyIDFUMTQwIDBRMTEzIDAgOTYgMTdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkMiIGQ9Ik0xMTcgNTlRMTE3IDI2IDE0MiAyNlExNzkgMjYgMjA1IDEzMVEyMTEgMTUxIDIxNSAxNTJRMjE3IDE1MyAyMjUgMTUzSDIyOVEyMzggMTUzIDI0MSAxNTNUMjQ2IDE1MVQyNDggMTQ0UTI0NyAxMzggMjQ1IDEyOFQyMzQgOTBUMjE0IDQzVDE4MyA2VDEzNyAtMTFRMTAxIC0xMSA3MCAxMVQzOCA4NVEzOCA5NyAzOSAxMDJMMTA0IDM2MFExNjcgNjE1IDE2NyA2MjNRMTY3IDYyNiAxNjYgNjI4VDE2MiA2MzJUMTU3IDYzNFQxNDkgNjM1VDE0MSA2MzZUMTMyIDYzN1QxMjIgNjM3UTExMiA2MzcgMTA5IDYzN1QxMDEgNjM4VDk1IDY0MVQ5NCA2NDdROTQgNjQ5IDk2IDY2MVExMDEgNjgwIDEwNyA2ODJUMTc5IDY4OFExOTQgNjg5IDIxMyA2OTBUMjQzIDY5M1QyNTQgNjk0UTI2NiA2OTQgMjY2IDY4NlEyNjYgNjc1IDE5MyAzODZUMTE4IDgzUTExOCA4MSAxMTggNzVUMTE3IDY1VjU5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZGIiBkPSJNMjAxIC0xMVExMjYgLTExIDgwIDM4VDM0IDE1NlEzNCAyMjEgNjQgMjc5VDE0NiAzODBRMjIyIDQ0MSAzMDEgNDQxUTMzMyA0NDEgMzQxIDQ0MFEzNTQgNDM3IDM2NyA0MzNUNDAyIDQxN1Q0MzggMzg3VDQ2NCAzMzhUNDc2IDI2OFE0NzYgMTYxIDM5MCA3NVQyMDEgLTExWk0xMjEgMTIwUTEyMSA3MCAxNDcgNDhUMjA2IDI2UTI1MCAyNiAyODkgNThUMzUxIDE0MlEzNjAgMTYzIDM3NCAyMTZUMzg4IDMwOFEzODggMzUyIDM3MCAzNzVRMzQ2IDQwNSAzMDYgNDA1UTI0MyA0MDUgMTk1IDM0N1ExNTggMzAzIDE0MCAyMzBUMTIxIDEyMFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02NSIgZD0iTTM5IDE2OFEzOSAyMjUgNTggMjcyVDEwNyAzNTBUMTc0IDQwMlQyNDQgNDMzVDMwNyA0NDJIMzEwUTM1NSA0NDIgMzg4IDQyMFQ0MjEgMzU1UTQyMSAyNjUgMzEwIDIzN1EyNjEgMjI0IDE3NiAyMjNRMTM5IDIyMyAxMzggMjIxUTEzOCAyMTkgMTMyIDE4NlQxMjUgMTI4UTEyNSA4MSAxNDYgNTRUMjA5IDI2VDMwMiA0NVQzOTQgMTExUTQwMyAxMjEgNDA2IDEyMVE0MTAgMTIxIDQxOSAxMTJUNDI5IDk4VDQyMCA4MlQzOTAgNTVUMzQ0IDI0VDI4MSAtMVQyMDUgLTExUTEyNiAtMTEgODMgNDJUMzkgMTY4Wk0zNzMgMzUzUTM2NyA0MDUgMzA1IDQwNVEyNzIgNDA1IDI0NCAzOTFUMTk5IDM1N1QxNzAgMzE2VDE1NCAyODBUMTQ5IDI2MVExNDkgMjYwIDE2OSAyNjBRMjgyIDI2MCAzMjcgMjg0VDM3MyAzNTNaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzciIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iNzE2IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjEwNjIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTY2MiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9IjIxMzIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QyIgeD0iMjU3NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZGIiB4PSIyODc1IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjMzNjEiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02NSIgeD0iMzgzMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 。每次试验后,选中一个臂摇一下,有收益则该臂的
。每次试验后,选中一个臂摇一下,有收益则该臂的 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQuOTUyZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgMjEzMiA5MzYuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03NyIgZD0iTTU4MCAzODVRNTgwIDQwNiA1OTkgNDI0VDY0MSA0NDNRNjU5IDQ0MyA2NzQgNDI1VDY5MCAzNjhRNjkwIDMzOSA2NzEgMjUzUTY1NiAxOTcgNjQ0IDE2MVQ2MDkgODBUNTU0IDEyVDQ4MiAtMTFRNDM4IC0xMSA0MDQgNVQzNTUgNDhRMzU0IDQ3IDM1MiA0NFEzMTEgLTExIDI1MiAtMTFRMjI2IC0xMSAyMDIgLTVUMTU1IDE0VDExOCA1M1QxMDQgMTE2UTEwNCAxNzAgMTM4IDI2MlQxNzMgMzc5UTE3MyAzODAgMTczIDM4MVExNzMgMzkwIDE3MyAzOTNUMTY5IDQwMFQxNTggNDA0SDE1NFExMzEgNDA0IDExMiAzODVUODIgMzQ0VDY1IDMwMlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3UTIxIDI5MyAyOSAzMTVUNTIgMzY2VDk2IDQxOFQxNjEgNDQxUTIwNCA0NDEgMjI3IDQxNlQyNTAgMzU4UTI1MCAzNDAgMjE3IDI1MFQxODQgMTExUTE4NCA2NSAyMDUgNDZUMjU4IDI2UTMwMSAyNiAzMzQgODdMMzM5IDk2VjExOVEzMzkgMTIyIDMzOSAxMjhUMzQwIDEzNlQzNDEgMTQzVDM0MiAxNTJUMzQ1IDE2NVQzNDggMTgyVDM1NCAyMDZUMzYyIDIzOFQzNzMgMjgxUTQwMiAzOTUgNDA2IDQwNFE0MTkgNDMxIDQ0OSA0MzFRNDY4IDQzMSA0NzUgNDIxVDQ4MyA0MDJRNDgzIDM4OSA0NTQgMjc0VDQyMiAxNDJRNDIwIDEzMSA0MjAgMTA3VjEwMFE0MjAgODUgNDIzIDcxVDQ0MiA0MlQ0ODcgMjZRNTU4IDI2IDYwMCAxNDhRNjA5IDE3MSA2MjAgMjEzVDYzMiAyNzNRNjMyIDMwNiA2MTkgMzI1VDU5MyAzNTdUNTgwIDM4NVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02OSIgZD0iTTE4NCA2MDBRMTg0IDYyNCAyMDMgNjQyVDI0NyA2NjFRMjY1IDY2MSAyNzcgNjQ5VDI5MCA2MTlRMjkwIDU5NiAyNzAgNTc3VDIyNiA1NTdRMjExIDU1NyAxOTggNTY3VDE4NCA2MDBaTTIxIDI4N1EyMSAyOTUgMzAgMzE4VDU0IDM2OVQ5OCA0MjBUMTU4IDQ0MlExOTcgNDQyIDIyMyA0MTlUMjUwIDM1N1EyNTAgMzQwIDIzNiAzMDFUMTk2IDE5NlQxNTQgODNRMTQ5IDYxIDE0OSA1MVExNDkgMjYgMTY2IDI2UTE3NSAyNiAxODUgMjlUMjA4IDQzVDIzNSA3OFQyNjAgMTM3UTI2MyAxNDkgMjY1IDE1MVQyODIgMTUzUTMwMiAxNTMgMzAyIDE0M1EzMDIgMTM1IDI5MyAxMTJUMjY4IDYxVDIyMyAxMVQxNjEgLTExUTEyOSAtMTEgMTAyIDEwVDc0IDc0UTc0IDkxIDc5IDEwNlQxMjIgMjIwUTE2MCAzMjEgMTY2IDM0MVQxNzMgMzgwUTE3MyA0MDQgMTU2IDQwNEgxNTRRMTI0IDQwNCA5OSAzNzFUNjEgMjg3UTYwIDI4NiA1OSAyODRUNTggMjgxVDU2IDI3OVQ1MyAyNzhUNDkgMjc4VDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZFIiBkPSJNMjEgMjg3UTIyIDI5MyAyNCAzMDNUMzYgMzQxVDU2IDM4OFQ4OSA0MjVUMTM1IDQ0MlExNzEgNDQyIDE5NSA0MjRUMjI1IDM5MFQyMzEgMzY5UTIzMSAzNjcgMjMyIDM2N0wyNDMgMzc4UTMwNCA0NDIgMzgyIDQ0MlE0MzYgNDQyIDQ2OSA0MTVUNTAzIDMzNlQ0NjUgMTc5VDQyNyA1MlE0MjcgMjYgNDQ0IDI2UTQ1MCAyNiA0NTMgMjdRNDgyIDMyIDUwNSA2NVQ1NDAgMTQ1UTU0MiAxNTMgNTYwIDE1M1E1ODAgMTUzIDU4MCAxNDVRNTgwIDE0NCA1NzYgMTMwUTU2OCAxMDEgNTU0IDczVDUwOCAxN1Q0MzkgLTEwUTM5MiAtMTAgMzcxIDE3VDM1MCA3M1EzNTAgOTIgMzg2IDE5M1Q0MjMgMzQ1UTQyMyA0MDQgMzc5IDQwNEgzNzRRMjg4IDQwNCAyMjkgMzAzTDIyMiAyOTFMMTg5IDE1N1ExNTYgMjYgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTIgMTgwVDE1MiAzNDNRMTUzIDM0OCAxNTMgMzY2UTE1MyA0MDUgMTI5IDQwNVE5MSA0MDUgNjYgMzA1UTYwIDI4NSA2MCAyODRRNTggMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc3IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjcxNiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIxMDYyIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjE2NjIiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) 增加
增加 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuMTYyZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgNTAwLjUgOTM2LjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMSIgZD0iTTIxMyA1NzhMMjAwIDU3M1ExODYgNTY4IDE2MCA1NjNUMTAyIDU1Nkg4M1Y2MDJIMTAyUTE0OSA2MDQgMTg5IDYxN1QyNDUgNjQxVDI3MyA2NjNRMjc1IDY2NiAyODUgNjY2UTI5NCA2NjYgMzAyIDY2MFYzNjFMMzAzIDYxUTMxMCA1NCAzMTUgNTJUMzM5IDQ4VDQwMSA0Nkg0MjdWMEg0MTZRMzk1IDMgMjU3IDNRMTIxIDMgMTAwIDBIODhWNDZIMTE0UTEzNiA0NiAxNTIgNDZUMTc3IDQ3VDE5MyA1MFQyMDEgNTJUMjA3IDU3VDIxMyA2MVY1NzhaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) ,否则该臂的
,否则该臂的 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjMuOTk1ZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgMTcyMCA5MzYuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02QyIgZD0iTTExNyA1OVExMTcgMjYgMTQyIDI2UTE3OSAyNiAyMDUgMTMxUTIxMSAxNTEgMjE1IDE1MlEyMTcgMTUzIDIyNSAxNTNIMjI5UTIzOCAxNTMgMjQxIDE1M1QyNDYgMTUxVDI0OCAxNDRRMjQ3IDEzOCAyNDUgMTI4VDIzNCA5MFQyMTQgNDNUMTgzIDZUMTM3IC0xMVExMDEgLTExIDcwIDExVDM4IDg1UTM4IDk3IDM5IDEwMkwxMDQgMzYwUTE2NyA2MTUgMTY3IDYyM1ExNjcgNjI2IDE2NiA2MjhUMTYyIDYzMlQxNTcgNjM0VDE0OSA2MzVUMTQxIDYzNlQxMzIgNjM3VDEyMiA2MzdRMTEyIDYzNyAxMDkgNjM3VDEwMSA2MzhUOTUgNjQxVDk0IDY0N1E5NCA2NDkgOTYgNjYxUTEwMSA2ODAgMTA3IDY4MlQxNzkgNjg4UTE5NCA2ODkgMjEzIDY5MFQyNDMgNjkzVDI1NCA2OTRRMjY2IDY5NCAyNjYgNjg2UTI2NiA2NzUgMTkzIDM4NlQxMTggODNRMTE4IDgxIDExOCA3NVQxMTcgNjVWNTlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkYiIGQ9Ik0yMDEgLTExUTEyNiAtMTEgODAgMzhUMzQgMTU2UTM0IDIyMSA2NCAyNzlUMTQ2IDM4MFEyMjIgNDQxIDMwMSA0NDFRMzMzIDQ0MSAzNDEgNDQwUTM1NCA0MzcgMzY3IDQzM1Q0MDIgNDE3VDQzOCAzODdUNDY0IDMzOFQ0NzYgMjY4UTQ3NiAxNjEgMzkwIDc1VDIwMSAtMTFaTTEyMSAxMjBRMTIxIDcwIDE0NyA0OFQyMDYgMjZRMjUwIDI2IDI4OSA1OFQzNTEgMTQyUTM2MCAxNjMgMzc0IDIxNlQzODggMzA4UTM4OCAzNTIgMzcwIDM3NVEzNDYgNDA1IDMwNiA0MDVRMjQzIDQwNSAxOTUgMzQ3UTE1OCAzMDMgMTQwIDIzMFQxMjEgMTIwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY1IiBkPSJNMzkgMTY4UTM5IDIyNSA1OCAyNzJUMTA3IDM1MFQxNzQgNDAyVDI0NCA0MzNUMzA3IDQ0MkgzMTBRMzU1IDQ0MiAzODggNDIwVDQyMSAzNTVRNDIxIDI2NSAzMTAgMjM3UTI2MSAyMjQgMTc2IDIyM1ExMzkgMjIzIDEzOCAyMjFRMTM4IDIxOSAxMzIgMTg2VDEyNSAxMjhRMTI1IDgxIDE0NiA1NFQyMDkgMjZUMzAyIDQ1VDM5NCAxMTFRNDAzIDEyMSA0MDYgMTIxUTQxMCAxMjEgNDE5IDExMlQ0MjkgOThUNDIwIDgyVDM5MCA1NVQzNDQgMjRUMjgxIC0xVDIwNSAtMTFRMTI2IC0xMSA4MyA0MlQzOSAxNjhaTTM3MyAzNTNRMzY3IDQwNSAzMDUgNDA1UTI3MiA0MDUgMjQ0IDM5MVQxOTkgMzU3VDE3MCAzMTZUMTU0IDI4MFQxNDkgMjYxUTE0OSAyNjAgMTY5IDI2MFEyODIgMjYwIDMyNyAyODRUMzczIDM1M1oiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QyIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZGIiB4PSIyOTgiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iNzg0IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjUiIHg9IjEyNTMiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) 增加 。
增加 。
每次选择臂的方式是:用每个臂现有的 分布产生一个随机数,选择所有臂产生的随机数中最大的那个臂去摇。
UCB 算法
UCB 算法全称是 Upper Confidence Bound(置信区间上界)。算法步骤[5]:先对每一个臂都试一遍,之后在任意时刻 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjkuODE0ZXgiIGhlaWdodD0iMi44NDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjgzOGV4OyIgdmlld0JveD0iMCAtODYzLjEgNDIyNS42IDEyMjMuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03NCIgZD0iTTI2IDM4NVExOSAzOTIgMTkgMzk1UTE5IDM5OSAyMiA0MTFUMjcgNDI1UTI5IDQzMCAzNiA0MzBUODcgNDMxSDE0MEwxNTkgNTExUTE2MiA1MjIgMTY2IDU0MFQxNzMgNTY2VDE3OSA1ODZUMTg3IDYwM1QxOTcgNjE1VDIxMSA2MjRUMjI5IDYyNlEyNDcgNjI1IDI1NCA2MTVUMjYxIDU5NlEyNjEgNTg5IDI1MiA1NDlUMjMyIDQ3MEwyMjIgNDMzUTIyMiA0MzEgMjcyIDQzMUgzMjNRMzMwIDQyNCAzMzAgNDIwUTMzMCAzOTggMzE3IDM4NUgyMTBMMTc0IDI0MFExMzUgODAgMTM1IDY4UTEzNSAyNiAxNjIgMjZRMTk3IDI2IDIzMCA2MFQyODMgMTQ0UTI4NSAxNTAgMjg4IDE1MVQzMDMgMTUzSDMwN1EzMjIgMTUzIDMyMiAxNDVRMzIyIDE0MiAzMTkgMTMzUTMxNCAxMTcgMzAxIDk1VDI2NyA0OFQyMTYgNlQxNTUgLTExUTEyNSAtMTEgOTggNFQ1OSA1NlE1NyA2NCA1NyA4M1YxMDFMOTIgMjQxUTEyNyAzODIgMTI4IDM4M1ExMjggMzg1IDc3IDM4NUgyNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRSIgZD0iTTg0IDUyMFE4NCA1MjggODggNTMzVDk2IDUzOUw5OSA1NDBRMTA2IDU0MCAyNTMgNDcxVDU0NCAzMzRMNjg3IDI2NVE2OTQgMjYwIDY5NCAyNTBUNjg3IDIzNVE2ODUgMjMzIDM5NSA5NkwxMDcgLTQwSDEwMVE4MyAtMzggODMgLTIwUTgzIC0xOSA4MyAtMTdRODIgLTEwIDk4IC0xUTExNyA5IDI0OCA3MVEzMjYgMTA4IDM3OCAxMzJMNjI2IDI1MEwzNzggMzY4UTkwIDUwNCA4NiA1MDlRODQgNTEzIDg0IDUyMFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00QiIgZD0iTTI4NSA2MjhRMjg1IDYzNSAyMjggNjM3UTIwNSA2MzcgMTk4IDYzOFQxOTEgNjQ3UTE5MSA2NDkgMTkzIDY2MVExOTkgNjgxIDIwMyA2ODJRMjA1IDY4MyAyMTQgNjgzSDIxOVEyNjAgNjgxIDM1NSA2ODFRMzg5IDY4MSA0MTggNjgxVDQ2MyA2ODJUNDgzIDY4MlE1MDAgNjgyIDUwMCA2NzRRNTAwIDY2OSA0OTcgNjYwUTQ5NiA2NTggNDk2IDY1NFQ0OTUgNjQ4VDQ5MyA2NDRUNDkwIDY0MVQ0ODYgNjM5VDQ3OSA2MzhUNDcwIDYzN1Q0NTYgNjM3UTQxNiA2MzYgNDA1IDYzNFQzODcgNjIzTDMwNiAzMDVRMzA3IDMwNSA0OTAgNDQ5VDY3OCA1OTdRNjkyIDYxMSA2OTIgNjIwUTY5MiA2MzUgNjY3IDYzN1E2NTEgNjM3IDY1MSA2NDhRNjUxIDY1MCA2NTQgNjYyVDY1OSA2NzdRNjYyIDY4MiA2NzYgNjgyUTY4MCA2ODIgNzExIDY4MVQ3OTEgNjgwUTgxNCA2ODAgODM5IDY4MVQ4NjkgNjgyUTg4OSA2ODIgODg5IDY3MlE4ODkgNjUwIDg4MSA2NDJRODc4IDYzNyA4NjIgNjM3UTc4NyA2MzIgNzI2IDU4NlE3MTAgNTc2IDY1NiA1MzRUNTU2IDQ1NUw1MDkgNDE4TDUxOCAzOTZRNTI3IDM3NCA1NDYgMzI5VDU4MSAyNDRRNjU2IDY3IDY2MSA2MVE2NjMgNTkgNjY2IDU3UTY4MCA0NyA3MTcgNDZINzM4UTc0NCAzOCA3NDQgMzdUNzQxIDE5UTczNyA2IDczMSAwSDcyMFE2ODAgMyA2MjUgM1E1MDMgMyA0ODggMEg0NzhRNDcyIDYgNDcyIDlUNDc0IDI3UTQ3OCA0MCA0ODAgNDNUNDkxIDQ2SDQ5NFE1NDQgNDYgNTQ0IDcxUTU0NCA3NSA1MTcgMTQxVDQ4NSAyMTZMNDI3IDM1NEwzNTkgMzAxTDI5MSAyNDhMMjY4IDE1NVEyNDUgNjMgMjQ1IDU4UTI0NSA1MSAyNTMgNDlUMzAzIDQ2SDMzNFEzNDAgMzcgMzQwIDM1UTM0MCAxOSAzMzMgNVEzMjggMCAzMTcgMFEzMTQgMCAyODAgMVQxODAgMlExMTggMiA4NSAyVDQ5IDFRMzEgMSAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDcgNjUgMjE2IDMzOVQyODUgNjI4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzQiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSI4NjEiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NCIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0UiIHg9IjE4OTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00QiIgeD0iMjk0NiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjM4MzYiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) 按照如下公式计算每个臂的分数,然后选择分数最大的臂作为选择
按照如下公式计算每个臂的分数,然后选择分数最大的臂作为选择
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjE1Ljk5MWV4IiBoZWlnaHQ9IjcuNjc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4zMzhleDsiIHZpZXdCb3g9IjAgLTE4NjcuNyA2ODg1LjEgMzMwNC45IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc4IiBkPSJNNTIgMjg5UTU5IDMzMSAxMDYgMzg2VDIyMiA0NDJRMjU3IDQ0MiAyODYgNDI0VDMyOSAzNzlRMzcxIDQ0MiA0MzAgNDQyUTQ2NyA0NDIgNDk0IDQyMFQ1MjIgMzYxUTUyMiAzMzIgNTA4IDMxNFQ0ODEgMjkyVDQ1OCAyODhRNDM5IDI4OCA0MjcgMjk5VDQxNSAzMjhRNDE1IDM3NCA0NjUgMzkxUTQ1NCA0MDQgNDI1IDQwNFE0MTIgNDA0IDQwNiA0MDJRMzY4IDM4NiAzNTAgMzM2UTI5MCAxMTUgMjkwIDc4UTI5MCA1MCAzMDYgMzhUMzQxIDI2UTM3OCAyNiA0MTQgNTlUNDYzIDE0MFE0NjYgMTUwIDQ2OSAxNTFUNDg1IDE1M0g0ODlRNTA0IDE1MyA1MDQgMTQ1UTUwNCAxNDQgNTAyIDEzNFE0ODYgNzcgNDQwIDMzVDMzMyAtMTFRMjYzIC0xMSAyMjcgNTJRMTg2IC0xMCAxMzMgLTEwSDEyN1E3OCAtMTAgNTcgMTZUMzUgNzFRMzUgMTAzIDU0IDEyM1Q5OSAxNDNRMTQyIDE0MyAxNDIgMTAxUTE0MiA4MSAxMzAgNjZUMTA3IDQ2VDk0IDQxTDkxIDQwUTkxIDM5IDk3IDM2VDExMyAyOVQxMzIgMjZRMTY4IDI2IDE5NCA3MVEyMDMgODcgMjE3IDEzOVQyNDUgMjQ3VDI2MSAzMTNRMjY2IDM0MCAyNjYgMzUyUTI2NiAzODAgMjUxIDM5MlQyMTcgNDA0UTE3NyA0MDQgMTQyIDM3MlQ5MyAyOTBROTEgMjgxIDg4IDI4MFQ3MiAyNzhINThRNTIgMjg0IDUyIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLUFGIiBkPSJNNjkgNTQ0VjU5MEg0MzBWNTQ0SDY5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZBIiBkPSJNMjk3IDU5NlEyOTcgNjI3IDMxOCA2NDRUMzYxIDY2MVEzNzggNjYxIDM4OSA2NTFUNDAzIDYyM1E0MDMgNTk1IDM4NCA1NzZUMzQwIDU1N1EzMjIgNTU3IDMxMCA1NjdUMjk3IDU5NlpNMjg4IDM3NlEyODggNDA1IDI2MiA0MDVRMjQwIDQwNSAyMjAgMzkzVDE4NSAzNjJUMTYxIDMyNVQxNDQgMjkzTDEzNyAyNzlRMTM1IDI3OCAxMjEgMjc4SDEwN1ExMDEgMjg0IDEwMSAyODZUMTA1IDI5OVExMjYgMzQ4IDE2NCAzOTFUMjUyIDQ0MVEyNTMgNDQxIDI2MCA0NDFUMjcyIDQ0MlEyOTYgNDQxIDMxNiA0MzJRMzQxIDQxOCAzNTQgNDAxVDM2NyAzNDhWMzMyTDMxOCAxMzNRMjY3IC02NyAyNjQgLTc1UTI0NiAtMTI1IDE5NCAtMTY0VDc1IC0yMDRRMjUgLTIwNCA3IC0xODNULTEyIC0xMzdRLTEyIC0xMTAgNyAtOTFUNTMgLTcxUTcwIC03MSA4MiAtODFUOTUgLTExMlE5NSAtMTQ4IDYzIC0xNjdRNjkgLTE2OCA3NyAtMTY4UTExMSAtMTY4IDEzOSAtMTQwVDE4MiAtNzRMMTkzIC0zMlEyMDQgMTEgMjE5IDcyVDI1MSAxOTdUMjc4IDMwOFQyODkgMzY1UTI4OSAzNzIgMjg4IDM3NloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzQiIGQ9Ik0yNiAzODVRMTkgMzkyIDE5IDM5NVExOSAzOTkgMjIgNDExVDI3IDQyNVEyOSA0MzAgMzYgNDMwVDg3IDQzMUgxNDBMMTU5IDUxMVExNjIgNTIyIDE2NiA1NDBUMTczIDU2NlQxNzkgNTg2VDE4NyA2MDNUMTk3IDYxNVQyMTEgNjI0VDIyOSA2MjZRMjQ3IDYyNSAyNTQgNjE1VDI2MSA1OTZRMjYxIDU4OSAyNTIgNTQ5VDIzMiA0NzBMMjIyIDQzM1EyMjIgNDMxIDI3MiA0MzFIMzIzUTMzMCA0MjQgMzMwIDQyMFEzMzAgMzk4IDMxNyAzODVIMjEwTDE3NCAyNDBRMTM1IDgwIDEzNSA2OFExMzUgMjYgMTYyIDI2UTE5NyAyNiAyMzAgNjBUMjgzIDE0NFEyODUgMTUwIDI4OCAxNTFUMzAzIDE1M0gzMDdRMzIyIDE1MyAzMjIgMTQ1UTMyMiAxNDIgMzE5IDEzM1EzMTQgMTE3IDMwMSA5NVQyNjcgNDhUMjE2IDZUMTU1IC0xMVExMjUgLTExIDk4IDRUNTkgNTZRNTcgNjQgNTcgODNWMTAxTDkyIDI0MVExMjcgMzgyIDEyOCAzODNRMTI4IDM4NSA3NyAzODVIMjZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJCIiBkPSJNNTYgMjM3VDU2IDI1MFQ3MCAyNzBIMzY5VjQyMEwzNzAgNTcwUTM4MCA1ODMgMzg5IDU4M1E0MDIgNTgzIDQwOSA1NjhWMjcwSDcwN1E3MjIgMjYyIDcyMiAyNTBUNzA3IDIzMEg0MDlWLTY4UTQwMSAtODIgMzkxIC04MkgzODlIMzg3UTM3NSAtODIgMzY5IC02OFYyMzBINzBRNTYgMjM3IDU2IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi02QyIgZD0iTTQyIDQ2SDU2UTk1IDQ2IDEwMyA2MFY2OFExMDMgNzcgMTAzIDkxVDEwMyAxMjRUMTA0IDE2N1QxMDQgMjE3VDEwNCAyNzJUMTA0IDMyOVExMDQgMzY2IDEwNCA0MDdUMTA0IDQ4MlQxMDQgNTQyVDEwMyA1ODZUMTAzIDYwM1ExMDAgNjIyIDg5IDYyOFQ0NCA2MzdIMjZWNjYwUTI2IDY4MyAyOCA2ODNMMzggNjg0UTQ4IDY4NSA2NyA2ODZUMTA0IDY4OFExMjEgNjg5IDE0MSA2OTBUMTcxIDY5M1QxODIgNjk0SDE4NVYzNzlRMTg1IDYyIDE4NiA2MFExOTAgNTIgMTk4IDQ5UTIxOSA0NiAyNDcgNDZIMjYzVjBIMjU1TDIzMiAxUTIwOSAyIDE4MyAyVDE0NSAzVDEwNyAzVDU3IDFMMzQgMEgyNlY0Nkg0MloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTZFIiBkPSJNNDEgNDZINTVROTQgNDYgMTAyIDYwVjY4UTEwMiA3NyAxMDIgOTFUMTAyIDEyMlQxMDMgMTYxVDEwMyAyMDNRMTAzIDIzNCAxMDMgMjY5VDEwMiAzMjhWMzUxUTk5IDM3MCA4OCAzNzZUNDMgMzg1SDI1VjQwOFEyNSA0MzEgMjcgNDMxTDM3IDQzMlE0NyA0MzMgNjUgNDM0VDEwMiA0MzZRMTE5IDQzNyAxMzggNDM4VDE2NyA0NDFUMTc4IDQ0MkgxODFWNDAyUTE4MSAzNjQgMTgyIDM2NFQxODcgMzY5VDE5OSAzODRUMjE4IDQwMlQyNDcgNDIxVDI4NSA0MzdRMzA1IDQ0MiAzMzYgNDQyUTQ1MCA0MzggNDYzIDMyOVE0NjQgMzIyIDQ2NCAxOTBWMTA0UTQ2NCA2NiA0NjYgNTlUNDc3IDQ5UTQ5OCA0NiA1MjYgNDZINTQyVjBINTM0TDUxMCAxUTQ4NyAyIDQ2MCAyVDQyMiAzUTMxOSAzIDMxMCAwSDMwMlY0NkgzMThRMzc5IDQ2IDM3OSA2MlEzODAgNjQgMzgwIDIwMFEzNzkgMzM1IDM3OCAzNDNRMzcyIDM3MSAzNTggMzg1VDMzNCA0MDJUMzA4IDQwNFEyNjMgNDA0IDIyOSAzNzBRMjAyIDM0MyAxOTUgMzE1VDE4NyAyMzJWMTY4VjEwOFExODcgNzggMTg4IDY4VDE5MSA1NVQyMDAgNDlRMjIxIDQ2IDI0OSA0NkgyNjVWMEgyNTdMMjM0IDFRMjEwIDIgMTgzIDJUMTQ1IDNRNDIgMyAzMyAwSDI1VjQ2SDQxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU0IiBkPSJNNDAgNDM3UTIxIDQzNyAyMSA0NDVRMjEgNDUwIDM3IDUwMVQ3MSA2MDJMODggNjUxUTkzIDY2OSAxMDEgNjc3SDU2OUg2NTlRNjkxIDY3NyA2OTcgNjc2VDcwNCA2NjdRNzA0IDY2MSA2ODcgNTUzVDY2OCA0NDRRNjY4IDQzNyA2NDkgNDM3UTY0MCA0MzcgNjM3IDQzN1Q2MzEgNDQyTDYyOSA0NDVRNjI5IDQ1MSA2MzUgNDkwVDY0MSA1NTFRNjQxIDU4NiA2MjggNjA0VDU3MyA2MjlRNTY4IDYzMCA1MTUgNjMxUTQ2OSA2MzEgNDU3IDYzMFQ0MzkgNjIyUTQzOCA2MjEgMzY4IDM0M1QyOTggNjBRMjk4IDQ4IDM4NiA0NlE0MTggNDYgNDI3IDQ1VDQzNiAzNlE0MzYgMzEgNDMzIDIyUTQyOSA0IDQyNCAxTDQyMiAwUTQxOSAwIDQxNSAwUTQxMCAwIDM2MyAxVDIyOCAyUTk5IDIgNjQgMEg0OVE0MyA2IDQzIDlUNDUgMjdRNDkgNDAgNTUgNDZIODNIOTRRMTc0IDQ2IDE4OSA1NVExOTAgNTYgMTkxIDU2UTE5NiA1OSAyMDEgNzZUMjQxIDIzM1EyNTggMzAxIDI2OSAzNDRRMzM5IDYxOSAzMzkgNjI1UTMzOSA2MzAgMzEwIDYzMEgyNzlRMjEyIDYzMCAxOTEgNjI0UTE0NiA2MTQgMTIxIDU4M1Q2NyA0NjdRNjAgNDQ1IDU3IDQ0MVQ0MyA0MzdINDBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yQyIgZD0iTTc4IDM1VDc4IDYwVDk0IDEwM1QxMzcgMTIxUTE2NSAxMjEgMTg3IDk2VDIxMCA4UTIxMCAtMjcgMjAxIC02MFQxODAgLTExN1QxNTQgLTE1OFQxMzAgLTE4NVQxMTcgLTE5NFExMTMgLTE5NCAxMDQgLTE4NVQ5NSAtMTcyUTk1IC0xNjggMTA2IC0xNTZUMTMxIC0xMjZUMTU3IC03NlQxNzMgLTNWOUwxNzIgOFExNzAgNyAxNjcgNlQxNjEgM1QxNTIgMVQxNDAgMFExMTMgMCA5NiAxN1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjQtMjIxQSIgZD0iTTk4MyAxNzM5UTk4OCAxNzUwIDEwMDEgMTc1MFExMDA4IDE3NTAgMTAxMyAxNzQ1VDEwMjAgMTczM1ExMDIwIDE3MjYgNzQyIDI0NFQ0NjAgLTEyNDFRNDU4IC0xMjUwIDQzOSAtMTI1MEg0MzZRNDI0IC0xMjUwIDQyNCAtMTI0OEw0MTAgLTExNjZRMzk1IC0xMDgzIDM2NyAtOTIwVDMxMiAtNjAxTDIwMSA0NEwxMzcgLTgzTDExMSAtNTdMMTg3IDk2TDI2NCAyNDdRMjY1IDI0NiAzNjkgLTM1N1E0NzAgLTk1OCA0NzMgLTk2M0w3MjcgMzg0UTk3OSAxNzI5IDk4MyAxNzM5WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiIgeD0iNjMiIHk9IjciPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkEiIHg9IjgwOSIgeT0iLTIxMyI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDExMzAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzQiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijc1MSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMjQ5MyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0OTQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtMjIxQSIgeD0iMCIgeT0iLTg0Ij48L3VzZT4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMjM5MCIgaGVpZ2h0PSI2MCIgeD0iMTAwMCIgeT0iMTYwNyI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDAwLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMjE1MCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU5LDY3NikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjY3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02QyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNkUiIHg9IjI3OCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzQiIHg9IjE2NjgiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM2MCwtNjk4KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTg0LC0xNTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZBIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9IjQxMiIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NCIgeD0iNjkxIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9zdmc+)
观察选择结果,更新 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjAuODRleCIgaGVpZ2h0PSIyLjAwOWV4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTAuMzM4ZXg7IiB2aWV3Qm94PSIwIC03MTkuNiAzNjEuNSA4NjUuMSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03NCIgZD0iTTI2IDM4NVExOSAzOTIgMTkgMzk1UTE5IDM5OSAyMiA0MTFUMjcgNDI1UTI5IDQzMCAzNiA0MzBUODcgNDMxSDE0MEwxNTkgNTExUTE2MiA1MjIgMTY2IDU0MFQxNzMgNTY2VDE3OSA1ODZUMTg3IDYwM1QxOTcgNjE1VDIxMSA2MjRUMjI5IDYyNlEyNDcgNjI1IDI1NCA2MTVUMjYxIDU5NlEyNjEgNTg5IDI1MiA1NDlUMjMyIDQ3MEwyMjIgNDMzUTIyMiA0MzEgMjcyIDQzMUgzMjNRMzMwIDQyNCAzMzAgNDIwUTMzMCAzOTggMzE3IDM4NUgyMTBMMTc0IDI0MFExMzUgODAgMTM1IDY4UTEzNSAyNiAxNjIgMjZRMTk3IDI2IDIzMCA2MFQyODMgMTQ0UTI4NSAxNTAgMjg4IDE1MVQzMDMgMTUzSDMwN1EzMjIgMTUzIDMyMiAxNDVRMzIyIDE0MiAzMTkgMTMzUTMxNCAxMTcgMzAxIDk1VDI2NyA0OFQyMTYgNlQxNTUgLTExUTEyNSAtMTEgOTggNFQ1OSA1NlE1NyA2NCA1NyA4M1YxMDFMOTIgMjQxUTEyNyAzODIgMTI4IDM4M1ExMjggMzg1IDc3IDM4NUgyNloiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NCIgeD0iMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 和
和 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjMuMzE4ZXgiIGhlaWdodD0iMi44NDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0xLjAwNWV4OyIgdmlld0JveD0iMCAtNzkxLjMgMTQyOC43IDEyMjMuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZBIiBkPSJNMjk3IDU5NlEyOTcgNjI3IDMxOCA2NDRUMzYxIDY2MVEzNzggNjYxIDM4OSA2NTFUNDAzIDYyM1E0MDMgNTk1IDM4NCA1NzZUMzQwIDU1N1EzMjIgNTU3IDMxMCA1NjdUMjk3IDU5NlpNMjg4IDM3NlEyODggNDA1IDI2MiA0MDVRMjQwIDQwNSAyMjAgMzkzVDE4NSAzNjJUMTYxIDMyNVQxNDQgMjkzTDEzNyAyNzlRMTM1IDI3OCAxMjEgMjc4SDEwN1ExMDEgMjg0IDEwMSAyODZUMTA1IDI5OVExMjYgMzQ4IDE2NCAzOTFUMjUyIDQ0MVEyNTMgNDQxIDI2MCA0NDFUMjcyIDQ0MlEyOTYgNDQxIDMxNiA0MzJRMzQxIDQxOCAzNTQgNDAxVDM2NyAzNDhWMzMyTDMxOCAxMzNRMjY3IC02NyAyNjQgLTc1UTI0NiAtMTI1IDE5NCAtMTY0VDc1IC0yMDRRMjUgLTIwNCA3IC0xODNULTEyIC0xMzdRLTEyIC0xMTAgNyAtOTFUNTMgLTcxUTcwIC03MSA4MiAtODFUOTUgLTExMlE5NSAtMTQ4IDYzIC0xNjdRNjkgLTE2OCA3NyAtMTY4UTExMSAtMTY4IDEzOSAtMTQwVDE4MiAtNzRMMTkzIC0zMlEyMDQgMTEgMjE5IDcyVDI1MSAxOTdUMjc4IDMwOFQyODkgMzY1UTI4OSAzNzIgMjg4IDM3NloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJDIiBkPSJNNzggMzVUNzggNjBUOTQgMTAzVDEzNyAxMjFRMTY1IDEyMSAxODcgOTZUMjEwIDhRMjEwIC0yNyAyMDEgLTYwVDE4MCAtMTE3VDE1NCAtMTU4VDEzMCAtMTg1VDExNyAtMTk0UTExMyAtMTk0IDEwNCAtMTg1VDk1IC0xNzJROTUgLTE2OCAxMDYgLTE1NlQxMzEgLTEyNlQxNTcgLTc2VDE3MyAtM1Y5TDE3MiA4UTE3MCA3IDE2NyA2VDE2MSAzVDE1MiAxVDE0MCAwUTExMyAwIDk2IDE3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc0IiBkPSJNMjYgMzg1UTE5IDM5MiAxOSAzOTVRMTkgMzk5IDIyIDQxMVQyNyA0MjVRMjkgNDMwIDM2IDQzMFQ4NyA0MzFIMTQwTDE1OSA1MTFRMTYyIDUyMiAxNjYgNTQwVDE3MyA1NjZUMTc5IDU4NlQxODcgNjAzVDE5NyA2MTVUMjExIDYyNFQyMjkgNjI2UTI0NyA2MjUgMjU0IDYxNVQyNjEgNTk2UTI2MSA1ODkgMjUyIDU0OVQyMzIgNDcwTDIyMiA0MzNRMjIyIDQzMSAyNzIgNDMxSDMyM1EzMzAgNDI0IDMzMCA0MjBRMzMwIDM5OCAzMTcgMzg1SDIxMEwxNzQgMjQwUTEzNSA4MCAxMzUgNjhRMTM1IDI2IDE2MiAyNlExOTcgMjYgMjMwIDYwVDI4MyAxNDRRMjg1IDE1MCAyODggMTUxVDMwMyAxNTNIMzA3UTMyMiAxNTMgMzIyIDE0NVEzMjIgMTQyIDMxOSAxMzNRMzE0IDExNyAzMDEgOTVUMjY3IDQ4VDIxNiA2VDE1NSAtMTFRMTI1IC0xMSA5OCA0VDU5IDU2UTU3IDY0IDU3IDgzVjEwMUw5MiAyNDFRMTI3IDM4MiAxMjggMzgzUTEyOCAzODUgNzcgMzg1SDI2WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTg0LC0xNTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZBIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9IjQxMiIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NCIgeD0iNjkxIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==) 。其中
。其中 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjUuMjc1ZXgiIGhlaWdodD0iMy4wMDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0xLjAwNWV4OyIgdmlld0JveD0iMCAtODYzLjEgMjI3MS4zIDEyOTUuNyIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03OCIgZD0iTTUyIDI4OVE1OSAzMzEgMTA2IDM4NlQyMjIgNDQyUTI1NyA0NDIgMjg2IDQyNFQzMjkgMzc5UTM3MSA0NDIgNDMwIDQ0MlE0NjcgNDQyIDQ5NCA0MjBUNTIyIDM2MVE1MjIgMzMyIDUwOCAzMTRUNDgxIDI5MlQ0NTggMjg4UTQzOSAyODggNDI3IDI5OVQ0MTUgMzI4UTQxNSAzNzQgNDY1IDM5MVE0NTQgNDA0IDQyNSA0MDRRNDEyIDQwNCA0MDYgNDAyUTM2OCAzODYgMzUwIDMzNlEyOTAgMTE1IDI5MCA3OFEyOTAgNTAgMzA2IDM4VDM0MSAyNlEzNzggMjYgNDE0IDU5VDQ2MyAxNDBRNDY2IDE1MCA0NjkgMTUxVDQ4NSAxNTNINDg5UTUwNCAxNTMgNTA0IDE0NVE1MDQgMTQ0IDUwMiAxMzRRNDg2IDc3IDQ0MCAzM1QzMzMgLTExUTI2MyAtMTEgMjI3IDUyUTE4NiAtMTAgMTMzIC0xMEgxMjdRNzggLTEwIDU3IDE2VDM1IDcxUTM1IDEwMyA1NCAxMjNUOTkgMTQzUTE0MiAxNDMgMTQyIDEwMVExNDIgODEgMTMwIDY2VDEwNyA0NlQ5NCA0MUw5MSA0MFE5MSAzOSA5NyAzNlQxMTMgMjlUMTMyIDI2UTE2OCAyNiAxOTQgNzFRMjAzIDg3IDIxNyAxMzlUMjQ1IDI0N1QyNjEgMzEzUTI2NiAzNDAgMjY2IDM1MlEyNjYgMzgwIDI1MSAzOTJUMjE3IDQwNFExNzcgNDA0IDE0MiAzNzJUOTMgMjkwUTkxIDI4MSA4OCAyODBUNzIgMjc4SDU4UTUyIDI4NCA1MiAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi1BRiIgZD0iTTY5IDU0NFY1OTBINDMwVjU0NEg2OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02QSIgZD0iTTI5NyA1OTZRMjk3IDYyNyAzMTggNjQ0VDM2MSA2NjFRMzc4IDY2MSAzODkgNjUxVDQwMyA2MjNRNDAzIDU5NSAzODQgNTc2VDM0MCA1NTdRMzIyIDU1NyAzMTAgNTY3VDI5NyA1OTZaTTI4OCAzNzZRMjg4IDQwNSAyNjIgNDA1UTI0MCA0MDUgMjIwIDM5M1QxODUgMzYyVDE2MSAzMjVUMTQ0IDI5M0wxMzcgMjc5UTEzNSAyNzggMTIxIDI3OEgxMDdRMTAxIDI4NCAxMDEgMjg2VDEwNSAyOTlRMTI2IDM0OCAxNjQgMzkxVDI1MiA0NDFRMjUzIDQ0MSAyNjAgNDQxVDI3MiA0NDJRMjk2IDQ0MSAzMTYgNDMyUTM0MSA0MTggMzU0IDQwMVQzNjcgMzQ4VjMzMkwzMTggMTMzUTI2NyAtNjcgMjY0IC03NVEyNDYgLTEyNSAxOTQgLTE2NFQ3NSAtMjA0UTI1IC0yMDQgNyAtMTgzVC0xMiAtMTM3US0xMiAtMTEwIDcgLTkxVDUzIC03MVE3MCAtNzEgODIgLTgxVDk1IC0xMTJROTUgLTE0OCA2MyAtMTY3UTY5IC0xNjggNzcgLTE2OFExMTEgLTE2OCAxMzkgLTE0MFQxODIgLTc0TDE5MyAtMzJRMjA0IDExIDIxOSA3MlQyNTEgMTk3VDI3OCAzMDhUMjg5IDM2NVEyODkgMzcyIDI4OCAzNzZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc0IiBkPSJNMjYgMzg1UTE5IDM5MiAxOSAzOTVRMTkgMzk5IDIyIDQxMVQyNyA0MjVRMjkgNDMwIDM2IDQzMFQ4NyA0MzFIMTQwTDE1OSA1MTFRMTYyIDUyMiAxNjYgNTQwVDE3MyA1NjZUMTc5IDU4NlQxODcgNjAzVDE5NyA2MTVUMjExIDYyNFQyMjkgNjI2UTI0NyA2MjUgMjU0IDYxNVQyNjEgNTk2UTI2MSA1ODkgMjUyIDU0OVQyMzIgNDcwTDIyMiA0MzNRMjIyIDQzMSAyNzIgNDMxSDMyM1EzMzAgNDI0IDMzMCA0MjBRMzMwIDM5OCAzMTcgMzg1SDIxMEwxNzQgMjQwUTEzNSA4MCAxMzUgNjhRMTM1IDI2IDE2MiAyNlExOTcgMjYgMjMwIDYwVDI4MyAxNDRRMjg1IDE1MCAyODggMTUxVDMwMyAxNTNIMzA3UTMyMiAxNTMgMzIyIDE0NVEzMjIgMTQyIDMxOSAxMzNRMzE0IDExNyAzMDEgOTVUMjY3IDQ4VDIxNiA2VDE1NSAtMTFRMTI1IC0xMSA5OCA0VDU5IDU2UTU3IDY0IDU3IDgzVjEwMUw5MiAyNDFRMTI3IDM4MiAxMjggMzgzUTEyOCAzODUgNzcgMzg1SDI2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSI2MyIgeT0iNyI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QSIgeD0iODA5IiB5PSItMjEzIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTEzMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NCIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iNzUxIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==) 表示的是
表示的是the average reward obtained from machine j, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjE0LjU0OGV4IiBoZWlnaHQ9IjIuODQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMC44MzhleDsgbWFyZ2luLWxlZnQ6IC0wLjAyN2V4OyIgdmlld0JveD0iLTExLjUgLTg2My4xIDYyNjMuOSAxMjIzLjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkEiIGQ9Ik0yOTcgNTk2UTI5NyA2MjcgMzE4IDY0NFQzNjEgNjYxUTM3OCA2NjEgMzg5IDY1MVQ0MDMgNjIzUTQwMyA1OTUgMzg0IDU3NlQzNDAgNTU3UTMyMiA1NTcgMzEwIDU2N1QyOTcgNTk2Wk0yODggMzc2UTI4OCA0MDUgMjYyIDQwNVEyNDAgNDA1IDIyMCAzOTNUMTg1IDM2MlQxNjEgMzI1VDE0NCAyOTNMMTM3IDI3OVExMzUgMjc4IDEyMSAyNzhIMTA3UTEwMSAyODQgMTAxIDI4NlQxMDUgMjk5UTEyNiAzNDggMTY0IDM5MVQyNTIgNDQxUTI1MyA0NDEgMjYwIDQ0MVQyNzIgNDQyUTI5NiA0NDEgMzE2IDQzMlEzNDEgNDE4IDM1NCA0MDFUMzY3IDM0OFYzMzJMMzE4IDEzM1EyNjcgLTY3IDI2NCAtNzVRMjQ2IC0xMjUgMTk0IC0xNjRUNzUgLTIwNFEyNSAtMjA0IDcgLTE4M1QtMTIgLTEzN1EtMTIgLTExMCA3IC05MVQ1MyAtNzFRNzAgLTcxIDgyIC04MVQ5NSAtMTEyUTk1IC0xNDggNjMgLTE2N1E2OSAtMTY4IDc3IC0xNjhRMTExIC0xNjggMTM5IC0xNDBUMTgyIC03NEwxOTMgLTMyUTIwNCAxMSAyMTkgNzJUMjUxIDE5N1QyNzggMzA4VDI4OSAzNjVRMjg5IDM3MiAyODggMzc2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjIwOCIgZD0iTTg0IDI1MFE4NCAzNzIgMTY2IDQ1MFQzNjAgNTM5UTM2MSA1MzkgMzc3IDUzOVQ0MTkgNTQwVDQ2OSA1NDBINTY4UTU4MyA1MzIgNTgzIDUyMFE1ODMgNTExIDU3MCA1MDFMNDY2IDUwMFEzNTUgNDk5IDMyOSA0OTRRMjgwIDQ4MiAyNDIgNDU4VDE4MyA0MDlUMTQ3IDM1NFQxMjkgMzA2VDEyNCAyNzJWMjcwSDU2OFE1ODMgMjYyIDU4MyAyNTBUNTY4IDIzMEgxMjRWMjI4UTEyNCAyMDcgMTM0IDE3N1QxNjcgMTEyVDIzMSA0OFQzMjggN1EzNTUgMSA0NjYgMEg1NzBRNTgzIC0xMCA1ODMgLTIwUTU4MyAtMzIgNTY4IC00MEg0NzFRNDY0IC00MCA0NDYgLTQwVDQxNyAtNDFRMjYyIC00MSAxNzIgNDVRODQgMTI3IDg0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkMiIGQ9Ik03OCAzNVQ3OCA2MFQ5NCAxMDNUMTM3IDEyMVExNjUgMTIxIDE4NyA5NlQyMTAgOFEyMTAgLTI3IDIwMSAtNjBUMTgwIC0xMTdUMTU0IC0xNThUMTMwIC0xODVUMTE3IC0xOTRRMTEzIC0xOTQgMTA0IC0xODVUOTUgLTE3MlE5NSAtMTY4IDEwNiAtMTU2VDEzMSAtMTI2VDE1NyAtNzZUMTczIC0zVjlMMTcyIDhRMTcwIDcgMTY3IDZUMTYxIDNUMTUyIDFUMTQwIDBRMTEzIDAgOTYgMTdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yRSIgZD0iTTc4IDYwUTc4IDg0IDk1IDEwMlQxMzggMTIwUTE2MiAxMjAgMTgwIDEwNFQxOTkgNjFRMTk5IDM2IDE4MiAxOFQxMzkgMFQ5NiAxN1Q3OCA2MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00QiIgZD0iTTI4NSA2MjhRMjg1IDYzNSAyMjggNjM3UTIwNSA2MzcgMTk4IDYzOFQxOTEgNjQ3UTE5MSA2NDkgMTkzIDY2MVExOTkgNjgxIDIwMyA2ODJRMjA1IDY4MyAyMTQgNjgzSDIxOVEyNjAgNjgxIDM1NSA2ODFRMzg5IDY4MSA0MTggNjgxVDQ2MyA2ODJUNDgzIDY4MlE1MDAgNjgyIDUwMCA2NzRRNTAwIDY2OSA0OTcgNjYwUTQ5NiA2NTggNDk2IDY1NFQ0OTUgNjQ4VDQ5MyA2NDRUNDkwIDY0MVQ0ODYgNjM5VDQ3OSA2MzhUNDcwIDYzN1Q0NTYgNjM3UTQxNiA2MzYgNDA1IDYzNFQzODcgNjIzTDMwNiAzMDVRMzA3IDMwNSA0OTAgNDQ5VDY3OCA1OTdRNjkyIDYxMSA2OTIgNjIwUTY5MiA2MzUgNjY3IDYzN1E2NTEgNjM3IDY1MSA2NDhRNjUxIDY1MCA2NTQgNjYyVDY1OSA2NzdRNjYyIDY4MiA2NzYgNjgyUTY4MCA2ODIgNzExIDY4MVQ3OTEgNjgwUTgxNCA2ODAgODM5IDY4MVQ4NjkgNjgyUTg4OSA2ODIgODg5IDY3MlE4ODkgNjUwIDg4MSA2NDJRODc4IDYzNyA4NjIgNjM3UTc4NyA2MzIgNzI2IDU4NlE3MTAgNTc2IDY1NiA1MzRUNTU2IDQ1NUw1MDkgNDE4TDUxOCAzOTZRNTI3IDM3NCA1NDYgMzI5VDU4MSAyNDRRNjU2IDY3IDY2MSA2MVE2NjMgNTkgNjY2IDU3UTY4MCA0NyA3MTcgNDZINzM4UTc0NCAzOCA3NDQgMzdUNzQxIDE5UTczNyA2IDczMSAwSDcyMFE2ODAgMyA2MjUgM1E1MDMgMyA0ODggMEg0NzhRNDcyIDYgNDcyIDlUNDc0IDI3UTQ3OCA0MCA0ODAgNDNUNDkxIDQ2SDQ5NFE1NDQgNDYgNTQ0IDcxUTU0NCA3NSA1MTcgMTQxVDQ4NSAyMTZMNDI3IDM1NEwzNTkgMzAxTDI5MSAyNDhMMjY4IDE1NVEyNDUgNjMgMjQ1IDU4UTI0NSA1MSAyNTMgNDlUMzAzIDQ2SDMzNFEzNDAgMzcgMzQwIDM1UTM0MCAxOSAzMzMgNVEzMjggMCAzMTcgMFEzMTQgMCAyODAgMVQxODAgMlExMTggMiA4NSAyVDQ5IDFRMzEgMSAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDcgNjUgMjE2IDMzOVQyODUgNjI4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMDgiIHg9IjY5MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjE2MzUiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIyMTM2IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iMjYzNiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9IjMwODEiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSIzNTI2IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iMzk3MiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9IjQ0MTciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00QiIgeD0iNDg2MiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjU3NTEiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) ,后面的叫做
,后面的叫做bonus,本质上是均值的标准差, 是目前的试验次数, 是the number of times j has been played so far。
显然,以上四种算法中,UCB算法和Thompson采样算法更优秀一些 。这里[6]有以上四种代码的实现方式以及一个简单的效果评估实验。
[5] - LinUCB — 改造后的 UCB 算法
UCB 算法在做 EE ( Exploit-Explore ) 的时候表现不错,但它是上下文无关 (context free) 的 bandit 算法,它只管埋头干活,根本不观察一下面对的都是些什么特点的 arm,下次遇到相似特点但不一样的 arm 也帮不上什么忙。
UCB 解决 Multi-armed bandit 问题的思路是:用置信区间。置信区间可以简单地理解为不确定性的程度,区间越宽,越不确定。每个 item 的回报均值都有个置信区间,随着试验次数增加,置信区间会变窄(逐渐确定了到底回报丰厚还是可怜)。每次选择前,都根据已经试验的结果重新估计每个 item 的均值及置信区间,选择置信区间上限最大的那个 item。这句话反映了几个意思:
- 如果 item 置信区间很宽(被选次数很少,还不确定),那么它会倾向于被多次选择,这个是算法冒风险的部分;
- 如果 item 置信区间很窄(备选次数很多,比较确定其好坏了),那么均值大的倾向于被多次选择,这个是算法保守稳妥的部分;
- UCB 是一种乐观的算法,选择置信区间上界排序,如果是悲观保守的做法,是选择置信区间下界排序。
Yahoo! 的科学家们在 2010 年发表了一篇论文[7],给 UCB 引入了特征信息,同时还把改造后的 UCB 算法用在了 Yahoo! 的新闻推荐中,算法名叫 LinUCB ,刘鹏博士在《计算广告》[8]一书中也有介绍 LinUCB 在计算广告中的应用。
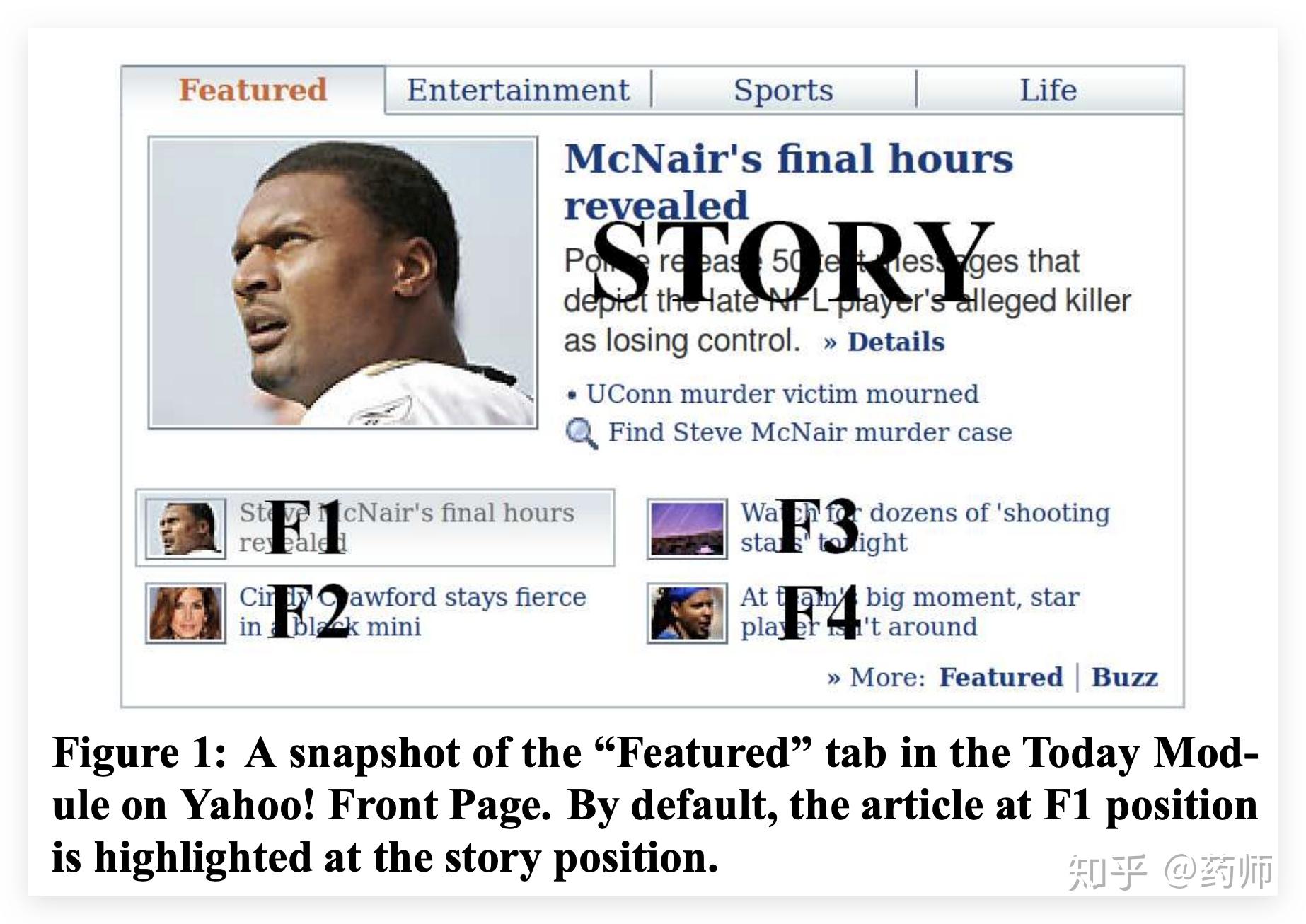
单纯的老虎机回报情况就是老虎机自己内部决定的,而在广告推荐领域,一个选择的回报,是由 User 和 Item 一起决定的,如果我们能用 feature 来刻画 User 和 Item 这一对 CP,在每次选择 item 之前,通过 feature 预估每一个 arm (item) 的期望回报及置信区间,选择的收益就可以通过 feature 泛化到不同的 item 上。为 UCB 算法插上了特征的翅膀,这就是 LinUCB 最大的特色。
LinUCB 算法做了一个假设:一个 Item 被选择后推送给一个 User,其回报和相关 Feature 成线性关系,这里的 “相关 feature” 就是 context,也是实际项目中发挥空间最大的部分。于是试验过程就变成:用 User 和 Item 的特征预估回报及其置信区间,选择置信区间上界最大的 item 推荐,观察回报后更新线性关系的参数,以此达到试验学习的目的。


上图是论文中给出的 LinUCB 算法,其中参数 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuNDg4ZXgiIGhlaWdodD0iMS42NzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNTc2LjEgNjQwLjUgNzIxLjYiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktM0IxIiBkPSJNMzQgMTU2UTM0IDI3MCAxMjAgMzU2VDMwOSA0NDJRMzc5IDQ0MiA0MjEgNDAyVDQ3OCAzMDRRNDg0IDI3NSA0ODUgMjM3VjIwOFE1MzQgMjgyIDU2MCAzNzRRNTY0IDM4OCA1NjYgMzkwVDU4MiAzOTNRNjAzIDM5MyA2MDMgMzg1UTYwMyAzNzYgNTk0IDM0NlQ1NTggMjYxVDQ5NyAxNjFMNDg2IDE0N0w0ODcgMTIzUTQ4OSA2NyA0OTUgNDdUNTE0IDI2UTUyOCAyOCA1NDAgMzdUNTU3IDYwUTU1OSA2NyA1NjIgNjhUNTc3IDcwUTU5NyA3MCA1OTcgNjJRNTk3IDU2IDU5MSA0M1E1NzkgMTkgNTU2IDVUNTEyIC0xMEg1MDVRNDM4IC0xMCA0MTQgNjJMNDExIDY5TDQwMCA2MVEzOTAgNTMgMzcwIDQxVDMyNSAxOFQyNjcgLTJUMjAzIC0xMVExMjQgLTExIDc5IDM5VDM0IDE1NlpNMjA4IDI2UTI1NyAyNiAzMDYgNDdUMzc5IDkwTDQwMyAxMTJRNDAxIDI1NSAzOTYgMjkwUTM4MiA0MDUgMzA0IDQwNVEyMzUgNDA1IDE4MyAzMzJRMTU2IDI5MiAxMzkgMjI0VDEyMSAxMjBRMTIxIDcxIDE0NiA0OVQyMDggMjZaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktM0IxIiB4PSIwIiB5PSIwIj48L3VzZT4KPC9nPgo8L3N2Zz4=) 决定了 Explore 的程度。如第二行所示,首先获取每一个 arm 的特征向量
决定了 Explore 的程度。如第二行所示,首先获取每一个 arm 的特征向量 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjMuNDgzZXgiIGhlaWdodD0iMi4zNDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0xLjAwNWV4OyIgdmlld0JveD0iMCAtNTc2LjEgMTQ5OS41IDEwMDguNiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03OCIgZD0iTTUyIDI4OVE1OSAzMzEgMTA2IDM4NlQyMjIgNDQyUTI1NyA0NDIgMjg2IDQyNFQzMjkgMzc5UTM3MSA0NDIgNDMwIDQ0MlE0NjcgNDQyIDQ5NCA0MjBUNTIyIDM2MVE1MjIgMzMyIDUwOCAzMTRUNDgxIDI5MlQ0NTggMjg4UTQzOSAyODggNDI3IDI5OVQ0MTUgMzI4UTQxNSAzNzQgNDY1IDM5MVE0NTQgNDA0IDQyNSA0MDRRNDEyIDQwNCA0MDYgNDAyUTM2OCAzODYgMzUwIDMzNlEyOTAgMTE1IDI5MCA3OFEyOTAgNTAgMzA2IDM4VDM0MSAyNlEzNzggMjYgNDE0IDU5VDQ2MyAxNDBRNDY2IDE1MCA0NjkgMTUxVDQ4NSAxNTNINDg5UTUwNCAxNTMgNTA0IDE0NVE1MDQgMTQ0IDUwMiAxMzRRNDg2IDc3IDQ0MCAzM1QzMzMgLTExUTI2MyAtMTEgMjI3IDUyUTE4NiAtMTAgMTMzIC0xMEgxMjdRNzggLTEwIDU3IDE2VDM1IDcxUTM1IDEwMyA1NCAxMjNUOTkgMTQzUTE0MiAxNDMgMTQyIDEwMVExNDIgODEgMTMwIDY2VDEwNyA0NlQ5NCA0MUw5MSA0MFE5MSAzOSA5NyAzNlQxMTMgMjlUMTMyIDI2UTE2OCAyNiAxOTQgNzFRMjAzIDg3IDIxNyAxMzlUMjQ1IDI0N1QyNjEgMzEzUTI2NiAzNDAgMjY2IDM1MlEyNjYgMzgwIDI1MSAzOTJUMjE3IDQwNFExNzcgNDA0IDE0MiAzNzJUOTMgMjkwUTkxIDI4MSA4OCAyODBUNzIgMjc4SDU4UTUyIDI4NCA1MiAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzQiIGQ9Ik0yNiAzODVRMTkgMzkyIDE5IDM5NVExOSAzOTkgMjIgNDExVDI3IDQyNVEyOSA0MzAgMzYgNDMwVDg3IDQzMUgxNDBMMTU5IDUxMVExNjIgNTIyIDE2NiA1NDBUMTczIDU2NlQxNzkgNTg2VDE4NyA2MDNUMTk3IDYxNVQyMTEgNjI0VDIyOSA2MjZRMjQ3IDYyNSAyNTQgNjE1VDI2MSA1OTZRMjYxIDU4OSAyNTIgNTQ5VDIzMiA0NzBMMjIyIDQzM1EyMjIgNDMxIDI3MiA0MzFIMzIzUTMzMCA0MjQgMzMwIDQyMFEzMzAgMzk4IDMxNyAzODVIMjEwTDE3NCAyNDBRMTM1IDgwIDEzNSA2OFExMzUgMjYgMTYyIDI2UTE5NyAyNiAyMzAgNjBUMjgzIDE0NFEyODUgMTUwIDI4OCAxNTFUMzAzIDE1M0gzMDdRMzIyIDE1MyAzMjIgMTQ1UTMyMiAxNDIgMzE5IDEzM1EzMTQgMTE3IDMwMSA5NVQyNjcgNDhUMjE2IDZUMTU1IC0xMVExMjUgLTExIDk4IDRUNTkgNTZRNTcgNjQgNTcgODNWMTAxTDkyIDI0MVExMjcgMzgyIDEyOCAzODNRMTI4IDM4NSA3NyAzODVIMjZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yQyIgZD0iTTc4IDM1VDc4IDYwVDk0IDEwM1QxMzcgMTIxUTE2NSAxMjEgMTg3IDk2VDIxMCA4UTIxMCAtMjcgMjAxIC02MFQxODAgLTExN1QxNTQgLTE1OFQxMzAgLTE4NVQxMTcgLTE5NFExMTMgLTE5NCAxMDQgLTE4NVQ5NSAtMTcyUTk1IC0xNjggMTA2IC0xNTZUMTMxIC0xMjZUMTU3IC03NlQxNzMgLTNWOUwxNzIgOFExNzAgNyAxNjcgNlQxNjEgM1QxNTIgMVQxNDAgMFExMTMgMCA5NiAxN1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02MSIgZD0iTTMzIDE1N1EzMyAyNTggMTA5IDM0OVQyODAgNDQxUTMzMSA0NDEgMzcwIDM5MlEzODYgNDIyIDQxNiA0MjJRNDI5IDQyMiA0MzkgNDE0VDQ0OSAzOTRRNDQ5IDM4MSA0MTIgMjM0VDM3NCA2OFEzNzQgNDMgMzgxIDM1VDQwMiAyNlE0MTEgMjcgNDIyIDM1UTQ0MyA1NSA0NjMgMTMxUTQ2OSAxNTEgNDczIDE1MlE0NzUgMTUzIDQ4MyAxNTNINDg3UTUwNiAxNTMgNTA2IDE0NFE1MDYgMTM4IDUwMSAxMTdUNDgxIDYzVDQ0OSAxM1E0MzYgMCA0MTcgLThRNDA5IC0xMCAzOTMgLTEwUTM1OSAtMTAgMzM2IDVUMzA2IDM2TDMwMCA1MVEyOTkgNTIgMjk2IDUwUTI5NCA0OCAyOTIgNDZRMjMzIC0xMCAxNzIgLTEwUTExNyAtMTAgNzUgMzBUMzMgMTU3Wk0zNTEgMzI4UTM1MSAzMzQgMzQ2IDM1MFQzMjMgMzg1VDI3NyA0MDVRMjQyIDQwNSAyMTAgMzc0VDE2MCAyOTNRMTMxIDIxNCAxMTkgMTI5UTExOSAxMjYgMTE5IDExOFQxMTggMTA2UTExOCA2MSAxMzYgNDRUMTc5IDI2UTIxNyAyNiAyNTQgNTlUMjk4IDExMFEzMDAgMTE0IDMyNSAyMTdUMzUxIDMyOFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03OCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU3MiwtMTUwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJDIiB4PSIzNjEiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjEiIHg9IjY0MCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=) 。接下来开始计算每一个 arm 的预估回报及其置信区间,如果 arm 还未被试验过,那么用单位矩阵初始化
。接下来开始计算每一个 arm 的预估回报及其置信区间,如果 arm 还未被试验过,那么用单位矩阵初始化 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIuODQ1ZXgiIGhlaWdodD0iMi41MDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyIgdmlld0JveD0iMCAtNzkxLjMgMTIyNC45IDEwODAuNCIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00MSIgZD0iTTIwOCA3NFEyMDggNTAgMjU0IDQ2UTI3MiA0NiAyNzIgMzVRMjcyIDM0IDI3MCAyMlEyNjcgOCAyNjQgNFQyNTEgMFEyNDkgMCAyMzkgMFQyMDUgMVQxNDEgMlE3MCAyIDUwIDBINDJRMzUgNyAzNSAxMVEzNyAzOCA0OCA0Nkg2MlExMzIgNDkgMTY0IDk2UTE3MCAxMDIgMzQ1IDQwMVQ1MjMgNzA0UTUzMCA3MTYgNTQ3IDcxNkg1NTVINTcyUTU3OCA3MDcgNTc4IDcwNkw2MDYgMzgzUTYzNCA2MCA2MzYgNTdRNjQxIDQ2IDcwMSA0NlE3MjYgNDYgNzI2IDM2UTcyNiAzNCA3MjMgMjJRNzIwIDcgNzE4IDRUNzA0IDBRNzAxIDAgNjkwIDBUNjUxIDFUNTc4IDJRNDg0IDIgNDU1IDBINDQzUTQzNyA2IDQzNyA5VDQzOSAyN1E0NDMgNDAgNDQ1IDQzTDQ0OSA0Nkg0NjlRNTIzIDQ5IDUzMyA2M0w1MjEgMjEzSDI4M0wyNDkgMTU1UTIwOCA4NiAyMDggNzRaTTUxNiAyNjBRNTE2IDI3MSA1MDQgNDE2VDQ5MCA1NjJMNDYzIDUxOVE0NDcgNDkyIDQwMCA0MTJMMzEwIDI2MEw0MTMgMjU5UTUxNiAyNTkgNTE2IDI2MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02MSIgZD0iTTMzIDE1N1EzMyAyNTggMTA5IDM0OVQyODAgNDQxUTMzMSA0NDEgMzcwIDM5MlEzODYgNDIyIDQxNiA0MjJRNDI5IDQyMiA0MzkgNDE0VDQ0OSAzOTRRNDQ5IDM4MSA0MTIgMjM0VDM3NCA2OFEzNzQgNDMgMzgxIDM1VDQwMiAyNlE0MTEgMjcgNDIyIDM1UTQ0MyA1NSA0NjMgMTMxUTQ2OSAxNTEgNDczIDE1MlE0NzUgMTUzIDQ4MyAxNTNINDg3UTUwNiAxNTMgNTA2IDE0NFE1MDYgMTM4IDUwMSAxMTdUNDgxIDYzVDQ0OSAxM1E0MzYgMCA0MTcgLThRNDA5IC0xMCAzOTMgLTEwUTM1OSAtMTAgMzM2IDVUMzA2IDM2TDMwMCA1MVEyOTkgNTIgMjk2IDUwUTI5NCA0OCAyOTIgNDZRMjMzIC0xMCAxNzIgLTEwUTExNyAtMTAgNzUgMzBUMzMgMTU3Wk0zNTEgMzI4UTM1MSAzMzQgMzQ2IDM1MFQzMjMgMzg1VDI3NyA0MDVRMjQyIDQwNSAyMTAgMzc0VDE2MCAyOTNRMTMxIDIxNCAxMTkgMTI5UTExOSAxMjYgMTE5IDExOFQxMTggMTA2UTExOCA2MSAxMzYgNDRUMTc5IDI2UTIxNyAyNiAyNTQgNTlUMjk4IDExMFEzMDAgMTE0IDMyNSAyMTdUMzUxIDMyOFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00MSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02MSIgeD0iMTA2MSIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9zdmc+) ,用
,用 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuMTYyZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgNTAwLjUgOTM2LjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMCIgZD0iTTk2IDU4NVExNTIgNjY2IDI0OSA2NjZRMjk3IDY2NiAzNDUgNjQwVDQyMyA1NDhRNDYwIDQ2NSA0NjAgMzIwUTQ2MCAxNjUgNDE3IDgzUTM5NyA0MSAzNjIgMTZUMzAxIC0xNVQyNTAgLTIyUTIyNCAtMjIgMTk4IC0xNlQxMzcgMTZUODIgODNRMzkgMTY1IDM5IDMyMFEzOSA0OTQgOTYgNTg1Wk0zMjEgNTk3UTI5MSA2MjkgMjUwIDYyOVEyMDggNjI5IDE3OCA1OTdRMTUzIDU3MSAxNDUgNTI1VDEzNyAzMzNRMTM3IDE3NSAxNDUgMTI1VDE4MSA0NlEyMDkgMTYgMjUwIDE2UTI5MCAxNiAzMTggNDZRMzQ3IDc2IDM1NCAxMzBUMzYyIDMzM1EzNjIgNDc4IDM1NCA1MjRUMzIxIDU5N1oiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMwIiB4PSIwIiB5PSIwIj48L3VzZT4KPC9nPgo8L3N2Zz4=) 向量初始化
向量初始化 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIuMDk5ZXgiIGhlaWdodD0iMi41MDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyIgdmlld0JveD0iMCAtNzkxLjMgOTAzLjkgMTA4MC40IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTYyIiBkPSJNNzMgNjQ3UTczIDY1NyA3NyA2NzBUODkgNjgzUTkwIDY4MyAxNjEgNjg4VDIzNCA2OTRRMjQ2IDY5NCAyNDYgNjg1VDIxMiA1NDJRMjA0IDUwOCAxOTUgNDcyVDE4MCA0MThMMTc2IDM5OVExNzYgMzk2IDE4MiA0MDJRMjMxIDQ0MiAyODMgNDQyUTM0NSA0NDIgMzgzIDM5NlQ0MjIgMjgwUTQyMiAxNjkgMzQzIDc5VDE3MyAtMTFRMTIzIC0xMSA4MiAyN1Q0MCAxNTBWMTU5UTQwIDE4MCA0OCAyMTdUOTcgNDE0UTE0NyA2MTEgMTQ3IDYyM1QxMDkgNjM3UTEwNCA2MzcgMTAxIDYzN0g5NlE4NiA2MzcgODMgNjM3VDc2IDY0MFQ3MyA2NDdaTTMzNiAzMjVWMzMxUTMzNiA0MDUgMjc1IDQwNVEyNTggNDA1IDI0MCAzOTdUMjA3IDM3NlQxODEgMzUyVDE2MyAzMzBMMTU3IDMyMkwxMzYgMjM2UTExNCAxNTAgMTE0IDExNFExMTQgNjYgMTM4IDQyUTE1NCAyNiAxNzggMjZRMjExIDI2IDI0NSA1OFEyNzAgODEgMjg1IDExNFQzMTggMjE5UTMzNiAyOTEgMzM2IDMyNVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02MSIgZD0iTTMzIDE1N1EzMyAyNTggMTA5IDM0OVQyODAgNDQxUTMzMSA0NDEgMzcwIDM5MlEzODYgNDIyIDQxNiA0MjJRNDI5IDQyMiA0MzkgNDE0VDQ0OSAzOTRRNDQ5IDM4MSA0MTIgMjM0VDM3NCA2OFEzNzQgNDMgMzgxIDM1VDQwMiAyNlE0MTEgMjcgNDIyIDM1UTQ0MyA1NSA0NjMgMTMxUTQ2OSAxNTEgNDczIDE1MlE0NzUgMTUzIDQ4MyAxNTNINDg3UTUwNiAxNTMgNTA2IDE0NFE1MDYgMTM4IDUwMSAxMTdUNDgxIDYzVDQ0OSAxM1E0MzYgMCA0MTcgLThRNDA5IC0xMCAzOTMgLTEwUTM1OSAtMTAgMzM2IDVUMzA2IDM2TDMwMCA1MVEyOTkgNTIgMjk2IDUwUTI5NCA0OCAyOTIgNDZRMjMzIC0xMCAxNzIgLTEwUTExNyAtMTAgNzUgMzBUMzMgMTU3Wk0zNTEgMzI4UTM1MSAzMzQgMzQ2IDM1MFQzMjMgMzg1VDI3NyA0MDVRMjQyIDQwNSAyMTAgMzc0VDE2MCAyOTNRMTMxIDIxNCAxMTkgMTI5UTExOSAxMjYgMTE5IDExOFQxMTggMTA2UTExOCA2MSAxMzYgNDRUMTc5IDI2UTIxNyAyNiAyNTQgNTlUMjk4IDExMFEzMDAgMTE0IDMyNSAyMTdUMzUxIDMyOFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02MSIgeD0iNjA3IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L3N2Zz4=) 。接着,计算线性参数
。接着,计算线性参数 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuMDlleCIgaGVpZ2h0PSIyLjE3NmV4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTAuMzM4ZXg7IiB2aWV3Qm94PSIwIC03OTEuMyA0NjkuNSA5MzYuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS0zQjgiIGQ9Ik0zNSAyMDBRMzUgMzAyIDc0IDQxNVQxODAgNjEwVDMxOSA3MDRRMzIwIDcwNCAzMjcgNzA0VDMzOSA3MDVRMzkzIDcwMSA0MjMgNjU2UTQ2MiA1OTYgNDYyIDQ5NVE0NjIgMzgwIDQxNyAyNjFUMzAyIDY2VDE2OCAtMTBIMTYxUTEyNSAtMTAgOTkgMTBUNjAgNjNUNDEgMTMwVDM1IDIwMFpNMzgzIDU2NlEzODMgNjY4IDMzMCA2NjhRMjk0IDY2OCAyNjAgNjIzVDIwNCA1MjFUMTcwIDQyMVQxNTcgMzcxUTIwNiAzNzAgMjU0IDM3MEwzNTEgMzcxUTM1MiAzNzIgMzU5IDQwNFQzNzUgNDg0VDM4MyA1NjZaTTExMyAxMzJRMTEzIDI2IDE2NiAyNlExODEgMjYgMTk4IDM2VDIzOSA3NFQyODcgMTYxVDMzNSAzMDdMMzQwIDMyNEgxNDVRMTQ1IDMyMSAxMzYgMjg2VDEyMCAyMDhUMTEzIDEzMloiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS0zQjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) ,用 和特征向量 计算预估回报,同时加上置信区间宽度。处理完每一个 arm 之后,选择计算出的最大值对应的 arm ,观察真实的回报
,用 和特征向量 计算预估回报,同时加上置信区间宽度。处理完每一个 arm 之后,选择计算出的最大值对应的 arm ,观察真实的回报 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuODc1ZXgiIGhlaWdodD0iMi4wMDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyIgdmlld0JveD0iMCAtNTc2LjEgODA3LjEgODY1LjEiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzIiIGQ9Ik0yMSAyODdRMjIgMjkwIDIzIDI5NVQyOCAzMTdUMzggMzQ4VDUzIDM4MVQ3MyA0MTFUOTkgNDMzVDEzMiA0NDJRMTYxIDQ0MiAxODMgNDMwVDIxNCA0MDhUMjI1IDM4OFEyMjcgMzgyIDIyOCAzODJUMjM2IDM4OVEyODQgNDQxIDM0NyA0NDFIMzUwUTM5OCA0NDEgNDIyIDQwMFE0MzAgMzgxIDQzMCAzNjNRNDMwIDMzMyA0MTcgMzE1VDM5MSAyOTJUMzY2IDI4OFEzNDYgMjg4IDMzNCAyOTlUMzIyIDMyOFEzMjIgMzc2IDM3OCAzOTJRMzU2IDQwNSAzNDIgNDA1UTI4NiA0MDUgMjM5IDMzMVEyMjkgMzE1IDIyNCAyOThUMTkwIDE2NVExNTYgMjUgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTQgMTg5VDE1NCAzNjZRMTU0IDQwNSAxMjggNDA1UTEwNyA0MDUgOTIgMzc3VDY4IDMxNlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc0IiBkPSJNMjYgMzg1UTE5IDM5MiAxOSAzOTVRMTkgMzk5IDIyIDQxMVQyNyA0MjVRMjkgNDMwIDM2IDQzMFQ4NyA0MzFIMTQwTDE1OSA1MTFRMTYyIDUyMiAxNjYgNTQwVDE3MyA1NjZUMTc5IDU4NlQxODcgNjAzVDE5NyA2MTVUMjExIDYyNFQyMjkgNjI2UTI0NyA2MjUgMjU0IDYxNVQyNjEgNTk2UTI2MSA1ODkgMjUyIDU0OVQyMzIgNDcwTDIyMiA0MzNRMjIyIDQzMSAyNzIgNDMxSDMyM1EzMzAgNDI0IDMzMCA0MjBRMzMwIDM5OCAzMTcgMzg1SDIxMEwxNzQgMjQwUTEzNSA4MCAxMzUgNjhRMTM1IDI2IDE2MiAyNlExOTcgMjYgMjMwIDYwVDI4MyAxNDRRMjg1IDE1MCAyODggMTUxVDMwMyAxNTNIMzA3UTMyMiAxNTMgMzIyIDE0NVEzMjIgMTQyIDMxOSAxMzNRMzE0IDExNyAzMDEgOTVUMjY3IDQ4VDIxNiA2VDE1NSAtMTFRMTI1IC0xMSA5OCA0VDU5IDU2UTU3IDY0IDU3IDgzVjEwMUw5MiAyNDFRMTI3IDM4MiAxMjggMzgzUTEyOCAzODUgNzcgMzg1SDI2WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc0IiB4PSI2MzgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) ,最后更新
,最后更新 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjMuNDkxZXgiIGhlaWdodD0iMi42NzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjgzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgMTUwMy4yIDExNTIuMSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00MSIgZD0iTTIwOCA3NFEyMDggNTAgMjU0IDQ2UTI3MiA0NiAyNzIgMzVRMjcyIDM0IDI3MCAyMlEyNjcgOCAyNjQgNFQyNTEgMFEyNDkgMCAyMzkgMFQyMDUgMVQxNDEgMlE3MCAyIDUwIDBINDJRMzUgNyAzNSAxMVEzNyAzOCA0OCA0Nkg2MlExMzIgNDkgMTY0IDk2UTE3MCAxMDIgMzQ1IDQwMVQ1MjMgNzA0UTUzMCA3MTYgNTQ3IDcxNkg1NTVINTcyUTU3OCA3MDcgNTc4IDcwNkw2MDYgMzgzUTYzNCA2MCA2MzYgNTdRNjQxIDQ2IDcwMSA0NlE3MjYgNDYgNzI2IDM2UTcyNiAzNCA3MjMgMjJRNzIwIDcgNzE4IDRUNzA0IDBRNzAxIDAgNjkwIDBUNjUxIDFUNTc4IDJRNDg0IDIgNDU1IDBINDQzUTQzNyA2IDQzNyA5VDQzOSAyN1E0NDMgNDAgNDQ1IDQzTDQ0OSA0Nkg0NjlRNTIzIDQ5IDUzMyA2M0w1MjEgMjEzSDI4M0wyNDkgMTU1UTIwOCA4NiAyMDggNzRaTTUxNiAyNjBRNTE2IDI3MSA1MDQgNDE2VDQ5MCA1NjJMNDYzIDUxOVE0NDcgNDkyIDQwMCA0MTJMMzEwIDI2MEw0MTMgMjU5UTUxNiAyNTkgNTE2IDI2MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02MSIgZD0iTTMzIDE1N1EzMyAyNTggMTA5IDM0OVQyODAgNDQxUTMzMSA0NDEgMzcwIDM5MlEzODYgNDIyIDQxNiA0MjJRNDI5IDQyMiA0MzkgNDE0VDQ0OSAzOTRRNDQ5IDM4MSA0MTIgMjM0VDM3NCA2OFEzNzQgNDMgMzgxIDM1VDQwMiAyNlE0MTEgMjcgNDIyIDM1UTQ0MyA1NSA0NjMgMTMxUTQ2OSAxNTEgNDczIDE1MlE0NzUgMTUzIDQ4MyAxNTNINDg3UTUwNiAxNTMgNTA2IDE0NFE1MDYgMTM4IDUwMSAxMTdUNDgxIDYzVDQ0OSAxM1E0MzYgMCA0MTcgLThRNDA5IC0xMCAzOTMgLTEwUTM1OSAtMTAgMzM2IDVUMzA2IDM2TDMwMCA1MVEyOTkgNTIgMjk2IDUwUTI5NCA0OCAyOTIgNDZRMjMzIC0xMCAxNzIgLTEwUTExNyAtMTAgNzUgMzBUMzMgMTU3Wk0zNTEgMzI4UTM1MSAzMzQgMzQ2IDM1MFQzMjMgMzg1VDI3NyA0MDVRMjQyIDQwNSAyMTAgMzc0VDE2MCAyOTNRMTMxIDIxNCAxMTkgMTI5UTExOSAxMjYgMTE5IDExOFQxMTggMTA2UTExOCA2MSAxMzYgNDRUMTc5IDI2UTIxNyAyNiAyNTQgNTlUMjk4IDExMFEzMDAgMTE0IDMyNSAyMTdUMzUxIDMyOFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03NCIgZD0iTTI2IDM4NVExOSAzOTIgMTkgMzk1UTE5IDM5OSAyMiA0MTFUMjcgNDI1UTI5IDQzMCAzNiA0MzBUODcgNDMxSDE0MEwxNTkgNTExUTE2MiA1MjIgMTY2IDU0MFQxNzMgNTY2VDE3OSA1ODZUMTg3IDYwM1QxOTcgNjE1VDIxMSA2MjRUMjI5IDYyNlEyNDcgNjI1IDI1NCA2MTVUMjYxIDU5NlEyNjEgNTg5IDI1MiA1NDlUMjMyIDQ3MEwyMjIgNDMzUTIyMiA0MzEgMjcyIDQzMUgzMjNRMzMwIDQyNCAzMzAgNDIwUTMzMCAzOTggMzE3IDM4NUgyMTBMMTc0IDI0MFExMzUgODAgMTM1IDY4UTEzNSAyNiAxNjIgMjZRMTk3IDI2IDIzMCA2MFQyODMgMTQ0UTI4NSAxNTAgMjg4IDE1MVQzMDMgMTUzSDMwN1EzMjIgMTUzIDMyMiAxNDVRMzIyIDE0MiAzMTkgMTMzUTMxNCAxMTcgMzAxIDk1VDI2NyA0OFQyMTYgNlQxNTUgLTExUTEyNSAtMTEgOTggNFQ1OSA1NlE1NyA2NCA1NyA4M1YxMDFMOTIgMjQxUTEyNyAzODIgMTI4IDM4M1ExMjggMzg1IDc3IDM4NUgyNloiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00MSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDc1MCwtMTUwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02MSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NCIgeD0iNjUyIiB5PSItMjAzIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==) 和
和 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIuNzQ2ZXgiIGhlaWdodD0iMi42NzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjgzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgMTE4Mi4yIDExNTIuMSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02MiIgZD0iTTczIDY0N1E3MyA2NTcgNzcgNjcwVDg5IDY4M1E5MCA2ODMgMTYxIDY4OFQyMzQgNjk0UTI0NiA2OTQgMjQ2IDY4NVQyMTIgNTQyUTIwNCA1MDggMTk1IDQ3MlQxODAgNDE4TDE3NiAzOTlRMTc2IDM5NiAxODIgNDAyUTIzMSA0NDIgMjgzIDQ0MlEzNDUgNDQyIDM4MyAzOTZUNDIyIDI4MFE0MjIgMTY5IDM0MyA3OVQxNzMgLTExUTEyMyAtMTEgODIgMjdUNDAgMTUwVjE1OVE0MCAxODAgNDggMjE3VDk3IDQxNFExNDcgNjExIDE0NyA2MjNUMTA5IDYzN1ExMDQgNjM3IDEwMSA2MzdIOTZRODYgNjM3IDgzIDYzN1Q3NiA2NDBUNzMgNjQ3Wk0zMzYgMzI1VjMzMVEzMzYgNDA1IDI3NSA0MDVRMjU4IDQwNSAyNDAgMzk3VDIwNyAzNzZUMTgxIDM1MlQxNjMgMzMwTDE1NyAzMjJMMTM2IDIzNlExMTQgMTUwIDExNCAxMTRRMTE0IDY2IDEzOCA0MlExNTQgMjYgMTc4IDI2UTIxMSAyNiAyNDUgNThRMjcwIDgxIDI4NSAxMTRUMzE4IDIxOVEzMzYgMjkxIDMzNiAzMjVaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNjEiIGQ9Ik0zMyAxNTdRMzMgMjU4IDEwOSAzNDlUMjgwIDQ0MVEzMzEgNDQxIDM3MCAzOTJRMzg2IDQyMiA0MTYgNDIyUTQyOSA0MjIgNDM5IDQxNFQ0NDkgMzk0UTQ0OSAzODEgNDEyIDIzNFQzNzQgNjhRMzc0IDQzIDM4MSAzNVQ0MDIgMjZRNDExIDI3IDQyMiAzNVE0NDMgNTUgNDYzIDEzMVE0NjkgMTUxIDQ3MyAxNTJRNDc1IDE1MyA0ODMgMTUzSDQ4N1E1MDYgMTUzIDUwNiAxNDRRNTA2IDEzOCA1MDEgMTE3VDQ4MSA2M1Q0NDkgMTNRNDM2IDAgNDE3IC04UTQwOSAtMTAgMzkzIC0xMFEzNTkgLTEwIDMzNiA1VDMwNiAzNkwzMDAgNTFRMjk5IDUyIDI5NiA1MFEyOTQgNDggMjkyIDQ2UTIzMyAtMTAgMTcyIC0xMFExMTcgLTEwIDc1IDMwVDMzIDE1N1pNMzUxIDMyOFEzNTEgMzM0IDM0NiAzNTBUMzIzIDM4NVQyNzcgNDA1UTI0MiA0MDUgMjEwIDM3NFQxNjAgMjkzUTEzMSAyMTQgMTE5IDEyOVExMTkgMTI2IDExOSAxMThUMTE4IDEwNlExMTggNjEgMTM2IDQ0VDE3OSAyNlEyMTcgMjYgMjU0IDU5VDI5OCAxMTBRMzAwIDExNCAzMjUgMjE3VDM1MSAzMjhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzQiIGQ9Ik0yNiAzODVRMTkgMzkyIDE5IDM5NVExOSAzOTkgMjIgNDExVDI3IDQyNVEyOSA0MzAgMzYgNDMwVDg3IDQzMUgxNDBMMTU5IDUxMVExNjIgNTIyIDE2NiA1NDBUMTczIDU2NlQxNzkgNTg2VDE4NyA2MDNUMTk3IDYxNVQyMTEgNjI0VDIyOSA2MjZRMjQ3IDYyNSAyNTQgNjE1VDI2MSA1OTZRMjYxIDU4OSAyNTIgNTQ5VDIzMiA0NzBMMjIyIDQzM1EyMjIgNDMxIDI3MiA0MzFIMzIzUTMzMCA0MjQgMzMwIDQyMFEzMzAgMzk4IDMxNyAzODVIMjEwTDE3NCAyNDBRMTM1IDgwIDEzNSA2OFExMzUgMjYgMTYyIDI2UTE5NyAyNiAyMzAgNjBUMjgzIDE0NFEyODUgMTUwIDI4OCAxNTFUMzAzIDE1M0gzMDdRMzIyIDE1MyAzMjIgMTQ1UTMyMiAxNDIgMzE5IDEzM1EzMTQgMTE3IDMwMSA5NVQyNjcgNDhUMjE2IDZUMTU1IC0xMVExMjUgLTExIDk4IDRUNTkgNTZRNTcgNjQgNTcgODNWMTAxTDkyIDI0MVExMjcgMzgyIDEyOCAzODNRMTI4IDM4NSA3NyAzODVIMjZaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0MjksLTE1MCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNTc0KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzQiIHg9IjY1MiIgeT0iLTIwMyI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=) 。
。
注意到上面算法中给特征矩阵加了一个单位矩阵,这就是岭回归[9] (ridge regression),岭回归主要用于当样本数小于特征数时,对回归参数进行修正。 对于加了特征的 bandit 问题,正符合这个特点:试验次数(样本)少于特征数。每一次观察真实回报之后,要更新的不止是岭回归参数,还有每个 arm 的回报向量 。
LinUCB 算法有一个很重要的步骤,就是给 User 和 Item 构建特征,也就是刻画 context。在原始论文里,Item 是文章,其中专门介绍了它们是怎么构建特征的。
【原始用户特征】有:人口统计学,性别特征(2 类),年龄特征(离散成 10 个区间);地域信息,遍布全球的大都市,美国各个州;行为类别,代表用户历史行为的 1000 个类别取值。
【原始文章特征】:URL 类别,根据文章来源分成了几十个类别;编辑打标签,编辑人工给内容从几十个话题标签中挑选出来的。


原始特征向量都要归一化成单位向量。还要对原始特征降维,以及模型要能刻画一些非线性的关系。 用 Logistic Regression 去拟合用户 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuMzNleCIgaGVpZ2h0PSIxLjY3NmV4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTAuMzM4ZXg7IiB2aWV3Qm94PSIwIC01NzYuMSA1NzIuNSA3MjEuNiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03NSIgZD0iTTIxIDI4N1EyMSAyOTUgMzAgMzE4VDU1IDM3MFQ5OSA0MjBUMTU4IDQ0MlEyMDQgNDQyIDIyNyA0MTdUMjUwIDM1OFEyNTAgMzQwIDIxNiAyNDZUMTgyIDEwNVExODIgNjIgMTk2IDQ1VDIzOCAyN1QyOTEgNDRUMzI4IDc4TDMzOSA5NVEzNDEgOTkgMzc3IDI0N1E0MDcgMzY3IDQxMyAzODdUNDI3IDQxNlE0NDQgNDMxIDQ2MyA0MzFRNDgwIDQzMSA0ODggNDIxVDQ5NiA0MDJMNDIwIDg0UTQxOSA3OSA0MTkgNjhRNDE5IDQzIDQyNiAzNVQ0NDcgMjZRNDY5IDI5IDQ4MiA1N1Q1MTIgMTQ1UTUxNCAxNTMgNTMyIDE1M1E1NTEgMTUzIDU1MSAxNDRRNTUwIDEzOSA1NDkgMTMwVDU0MCA5OFQ1MjMgNTVUNDk4IDE3VDQ2MiAtOFE0NTQgLTEwIDQzOCAtMTBRMzcyIC0xMCAzNDcgNDZRMzQ1IDQ1IDMzNiAzNlQzMTggMjFUMjk2IDZUMjY3IC02VDIzMyAtMTFRMTg5IC0xMSAxNTUgN1ExMDMgMzggMTAzIDExM1ExMDMgMTcwIDEzOCAyNjJUMTczIDM3OVExNzMgMzgwIDE3MyAzODFRMTczIDM5MCAxNzMgMzkzVDE2OSA0MDBUMTU4IDQwNEgxNTRRMTMxIDQwNCAxMTIgMzg1VDgyIDM0NFQ2NSAzMDJUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NSIgeD0iMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 对文章
对文章 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuMjNleCIgaGVpZ2h0PSIxLjY3NmV4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTAuMzM4ZXg7IiB2aWV3Qm94PSIwIC01NzYuMSA1MjkuNSA3MjEuNiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02MSIgZD0iTTMzIDE1N1EzMyAyNTggMTA5IDM0OVQyODAgNDQxUTMzMSA0NDEgMzcwIDM5MlEzODYgNDIyIDQxNiA0MjJRNDI5IDQyMiA0MzkgNDE0VDQ0OSAzOTRRNDQ5IDM4MSA0MTIgMjM0VDM3NCA2OFEzNzQgNDMgMzgxIDM1VDQwMiAyNlE0MTEgMjcgNDIyIDM1UTQ0MyA1NSA0NjMgMTMxUTQ2OSAxNTEgNDczIDE1MlE0NzUgMTUzIDQ4MyAxNTNINDg3UTUwNiAxNTMgNTA2IDE0NFE1MDYgMTM4IDUwMSAxMTdUNDgxIDYzVDQ0OSAxM1E0MzYgMCA0MTcgLThRNDA5IC0xMCAzOTMgLTEwUTM1OSAtMTAgMzM2IDVUMzA2IDM2TDMwMCA1MVEyOTkgNTIgMjk2IDUwUTI5NCA0OCAyOTIgNDZRMjMzIC0xMCAxNzIgLTEwUTExNyAtMTAgNzUgMzBUMzMgMTU3Wk0zNTEgMzI4UTM1MSAzMzQgMzQ2IDM1MFQzMjMgMzg1VDI3NyA0MDVRMjQyIDQwNSAyMTAgMzc0VDE2MCAyOTNRMTMxIDIxNCAxMTkgMTI5UTExOSAxMjYgMTE5IDExOFQxMTggMTA2UTExOCA2MSAxMzYgNDRUMTc5IDI2UTIxNyAyNiAyNTQgNTlUMjk4IDExMFEzMDAgMTE0IDMyNSAyMTdUMzUxIDMyOFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02MSIgeD0iMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 的点击历史,其中的线性回归部分为:
的点击历史,其中的线性回归部分为:
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjcuNjk3ZXgiIGhlaWdodD0iMi44NDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyIgdmlld0JveD0iMCAtOTM0LjkgMzMxNC4xIDEyMjMuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS0zRDUiIGQ9Ik00MDkgNjg4UTQxMyA2OTQgNDIxIDY5NEg0MjlINDQyUTQ0OCA2ODggNDQ4IDY4NlE0NDggNjc5IDQxOCA1NjNRNDExIDUzNSA0MDQgNTA0VDM5MiA0NThMMzg4IDQ0MlEzODggNDQxIDM5NyA0NDFUNDI5IDQzNVQ0NzcgNDE4UTUyMSAzOTcgNTUwIDM1N1Q1NzkgMjYwVDU0OCAxNTFUNDcxIDY1VDM3NCAxMVQyNzkgLTEwSDI3NUwyNTEgLTEwNVEyNDUgLTEyOCAyMzggLTE2MFEyMzAgLTE5MiAyMjcgLTE5OFQyMTUgLTIwNUgyMDlRMTg5IC0yMDUgMTg5IC0xOThRMTg5IC0xOTMgMjExIC0xMDNMMjM0IC0xMVEyMzQgLTEwIDIyNiAtMTBRMjIxIC0xMCAyMDYgLThUMTYxIDZUMTA3IDM2VDYyIDg5VDQzIDE3MVE0MyAyMzEgNzYgMjg0VDE1NyAzNzBUMjU0IDQyMlQzNDIgNDQxUTM0NyA0NDEgMzQ4IDQ0NUwzNzggNTY3UTQwOSA2ODYgNDA5IDY4OFpNMTIyIDE1MFExMjIgMTE2IDEzNCA5MVQxNjcgNTNUMjAzIDM1VDIzNyAyN0gyNDRMMzM3IDQwNFEzMzMgNDA0IDMyNiA0MDNUMjk3IDM5NVQyNTUgMzc5VDIxMSAzNTBUMTcwIDMwNFExNTIgMjc2IDEzNyAyMzdRMTIyIDE5MSAxMjIgMTUwWk01MDAgMjgyUTUwMCAzMjAgNDg0IDM0N1Q0NDQgMzg1VDQwNSA0MDBUMzgxIDQwNEgzNzhMMzMyIDIxN0wyODQgMjlRMjg0IDI3IDI4NSAyN1EyOTMgMjcgMzE3IDMzVDM1NyA0N1E0MDAgNjYgNDMxIDEwMFQ0NzUgMTcwVDQ5NCAyMzRUNTAwIDI4MloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc1IiBkPSJNMjEgMjg3UTIxIDI5NSAzMCAzMThUNTUgMzcwVDk5IDQyMFQxNTggNDQyUTIwNCA0NDIgMjI3IDQxN1QyNTAgMzU4UTI1MCAzNDAgMjE2IDI0NlQxODIgMTA1UTE4MiA2MiAxOTYgNDVUMjM4IDI3VDI5MSA0NFQzMjggNzhMMzM5IDk1UTM0MSA5OSAzNzcgMjQ3UTQwNyAzNjcgNDEzIDM4N1Q0MjcgNDE2UTQ0NCA0MzEgNDYzIDQzMVE0ODAgNDMxIDQ4OCA0MjFUNDk2IDQwMkw0MjAgODRRNDE5IDc5IDQxOSA2OFE0MTkgNDMgNDI2IDM1VDQ0NyAyNlE0NjkgMjkgNDgyIDU3VDUxMiAxNDVRNTE0IDE1MyA1MzIgMTUzUTU1MSAxNTMgNTUxIDE0NFE1NTAgMTM5IDU0OSAxMzBUNTQwIDk4VDUyMyA1NVQ0OTggMTdUNDYyIC04UTQ1NCAtMTAgNDM4IC0xMFEzNzIgLTEwIDM0NyA0NlEzNDUgNDUgMzM2IDM2VDMxOCAyMVQyOTYgNlQyNjcgLTZUMjMzIC0xMVExODkgLTExIDE1NSA3UTEwMyAzOCAxMDMgMTEzUTEwMyAxNzAgMTM4IDI2MlQxNzMgMzc5UTE3MyAzODAgMTczIDM4MVExNzMgMzkwIDE3MyAzOTNUMTY5IDQwMFQxNTggNDA0SDE1NFExMzEgNDA0IDExMiAzODVUODIgMzQ0VDY1IDMwMlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU3IiBkPSJNNDM2IDY4M1E0NTAgNjgzIDQ4NiA2ODJUNTUzIDY4MFE2MDQgNjgwIDYzOCA2ODFUNjc3IDY4MlE2OTUgNjgyIDY5NSA2NzRRNjk1IDY3MCA2OTIgNjU5UTY4NyA2NDEgNjgzIDYzOVQ2NjEgNjM3UTYzNiA2MzYgNjIxIDYzMlQ2MDAgNjI0VDU5NyA2MTVRNTk3IDYwMyA2MTMgMzc3VDYyOSAxMzhMNjMxIDE0MVE2MzMgMTQ0IDYzNyAxNTFUNjQ5IDE3MFQ2NjYgMjAwVDY5MCAyNDFUNzIwIDI5NVQ3NTkgMzYyUTg2MyA1NDYgODc3IDU3MlQ4OTIgNjA0UTg5MiA2MTkgODczIDYyOFQ4MzEgNjM3UTgxNyA2MzcgODE3IDY0N1E4MTcgNjUwIDgxOSA2NjBRODIzIDY3NiA4MjUgNjc5VDgzOSA2ODJRODQyIDY4MiA4NTYgNjgyVDg5NSA2ODJUOTQ5IDY4MVExMDE1IDY4MSAxMDM0IDY4M1ExMDQ4IDY4MyAxMDQ4IDY3MlExMDQ4IDY2NiAxMDQ1IDY1NVQxMDM4IDY0MFQxMDI4IDYzN1ExMDA2IDYzNyA5ODggNjMxVDk1OCA2MTdUOTM5IDYwMFQ5MjcgNTg0TDkyMyA1NzhMNzU0IDI4MlE1ODYgLTE0IDU4NSAtMTVRNTc5IC0yMiA1NjEgLTIyUTU0NiAtMjIgNTQyIC0xN1E1MzkgLTE0IDUyMyAyMjlUNTA2IDQ4MEw0OTQgNDYyUTQ3MiA0MjUgMzY2IDIzOVEyMjIgLTEzIDIyMCAtMTVUMjE1IC0xOVEyMTAgLTIyIDE5NyAtMjJRMTc4IC0yMiAxNzYgLTE1UTE3NiAtMTIgMTU0IDMwNFQxMzEgNjIyUTEyOSA2MzEgMTIxIDYzM1Q4MiA2MzdINThRNTEgNjQ0IDUxIDY0OFE1MiA2NzEgNjQgNjgzSDc2UTExOCA2ODAgMTc2IDY4MFEzMDEgNjgwIDMxMyA2ODNIMzIzUTMyOSA2NzcgMzI5IDY3NFQzMjcgNjU2UTMyMiA2NDEgMzE4IDYzN0gyOTdRMjM2IDYzNCAyMzIgNjIwUTI2MiAxNjAgMjY2IDEzNkw1MDEgNTUwTDQ5OSA1ODdRNDk2IDYyOSA0ODkgNjMyUTQ4MyA2MzYgNDQ3IDYzN1E0MjggNjM3IDQyMiA2MzlUNDE2IDY0OFE0MTYgNjUwIDQxOCA2NjBRNDE5IDY2NCA0MjAgNjY5VDQyMSA2NzZUNDI0IDY4MFQ0MjggNjgyVDQzNiA2ODNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNjEiIGQ9Ik0zMyAxNTdRMzMgMjU4IDEwOSAzNDlUMjgwIDQ0MVEzMzEgNDQxIDM3MCAzOTJRMzg2IDQyMiA0MTYgNDIyUTQyOSA0MjIgNDM5IDQxNFQ0NDkgMzk0UTQ0OSAzODEgNDEyIDIzNFQzNzQgNjhRMzc0IDQzIDM4MSAzNVQ0MDIgMjZRNDExIDI3IDQyMiAzNVE0NDMgNTUgNDYzIDEzMVE0NjkgMTUxIDQ3MyAxNTJRNDc1IDE1MyA0ODMgMTUzSDQ4N1E1MDYgMTUzIDUwNiAxNDRRNTA2IDEzOCA1MDEgMTE3VDQ4MSA2M1Q0NDkgMTNRNDM2IDAgNDE3IC04UTQwOSAtMTAgMzkzIC0xMFEzNTkgLTEwIDMzNiA1VDMwNiAzNkwzMDAgNTFRMjk5IDUyIDI5NiA1MFEyOTQgNDggMjkyIDQ2UTIzMyAtMTAgMTcyIC0xMFExMTcgLTEwIDc1IDMwVDMzIDE1N1pNMzUxIDMyOFEzNTEgMzM0IDM0NiAzNTBUMzIzIDM4NVQyNzcgNDA1UTI0MiA0MDUgMjEwIDM3NFQxNjAgMjkzUTEzMSAyMTQgMTE5IDEyOVExMTkgMTI2IDExOSAxMThUMTE4IDEwNlExMTggNjEgMTM2IDQ0VDE3OSAyNlEyMTcgMjYgMjU0IDU5VDI5OCAxMTBRMzAwIDExNCAzMjUgMjE3VDM1MSAzMjhaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktM0Q1IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI4NDMiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NSIgeD0iODQzIiB5PSItMjExIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTciIHg9IjExOTQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMjQzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktM0Q1IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTYxIiB4PSI4NDMiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9zdmc+)
拟合得到参数矩阵 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIuNDM1ZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgMTA0OC41IDkzNi45IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU3IiBkPSJNNDM2IDY4M1E0NTAgNjgzIDQ4NiA2ODJUNTUzIDY4MFE2MDQgNjgwIDYzOCA2ODFUNjc3IDY4MlE2OTUgNjgyIDY5NSA2NzRRNjk1IDY3MCA2OTIgNjU5UTY4NyA2NDEgNjgzIDYzOVQ2NjEgNjM3UTYzNiA2MzYgNjIxIDYzMlQ2MDAgNjI0VDU5NyA2MTVRNTk3IDYwMyA2MTMgMzc3VDYyOSAxMzhMNjMxIDE0MVE2MzMgMTQ0IDYzNyAxNTFUNjQ5IDE3MFQ2NjYgMjAwVDY5MCAyNDFUNzIwIDI5NVQ3NTkgMzYyUTg2MyA1NDYgODc3IDU3MlQ4OTIgNjA0UTg5MiA2MTkgODczIDYyOFQ4MzEgNjM3UTgxNyA2MzcgODE3IDY0N1E4MTcgNjUwIDgxOSA2NjBRODIzIDY3NiA4MjUgNjc5VDgzOSA2ODJRODQyIDY4MiA4NTYgNjgyVDg5NSA2ODJUOTQ5IDY4MVExMDE1IDY4MSAxMDM0IDY4M1ExMDQ4IDY4MyAxMDQ4IDY3MlExMDQ4IDY2NiAxMDQ1IDY1NVQxMDM4IDY0MFQxMDI4IDYzN1ExMDA2IDYzNyA5ODggNjMxVDk1OCA2MTdUOTM5IDYwMFQ5MjcgNTg0TDkyMyA1NzhMNzU0IDI4MlE1ODYgLTE0IDU4NSAtMTVRNTc5IC0yMiA1NjEgLTIyUTU0NiAtMjIgNTQyIC0xN1E1MzkgLTE0IDUyMyAyMjlUNTA2IDQ4MEw0OTQgNDYyUTQ3MiA0MjUgMzY2IDIzOVEyMjIgLTEzIDIyMCAtMTVUMjE1IC0xOVEyMTAgLTIyIDE5NyAtMjJRMTc4IC0yMiAxNzYgLTE1UTE3NiAtMTIgMTU0IDMwNFQxMzEgNjIyUTEyOSA2MzEgMTIxIDYzM1Q4MiA2MzdINThRNTEgNjQ0IDUxIDY0OFE1MiA2NzEgNjQgNjgzSDc2UTExOCA2ODAgMTc2IDY4MFEzMDEgNjgwIDMxMyA2ODNIMzIzUTMyOSA2NzcgMzI5IDY3NFQzMjcgNjU2UTMyMiA2NDEgMzE4IDYzN0gyOTdRMjM2IDYzNCAyMzIgNjIwUTI2MiAxNjAgMjY2IDEzNkw1MDEgNTUwTDQ5OSA1ODdRNDk2IDYyOSA0ODkgNjMyUTQ4MyA2MzYgNDQ3IDYzN1E0MjggNjM3IDQyMiA2MzlUNDE2IDY0OFE0MTYgNjUwIDQxOCA2NjBRNDE5IDY2NCA0MjAgNjY5VDQyMSA2NzZUNDI0IDY4MFQ0MjggNjgyVDQzNiA2ODNaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTciIHg9IjAiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) ,其中
,其中 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIuNTU4ZXgiIGhlaWdodD0iMi41MDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyIgdmlld0JveD0iMCAtNzkxLjMgMTEwMS4zIDEwODAuNCIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS0zRDUiIGQ9Ik00MDkgNjg4UTQxMyA2OTQgNDIxIDY5NEg0MjlINDQyUTQ0OCA2ODggNDQ4IDY4NlE0NDggNjc5IDQxOCA1NjNRNDExIDUzNSA0MDQgNTA0VDM5MiA0NThMMzg4IDQ0MlEzODggNDQxIDM5NyA0NDFUNDI5IDQzNVQ0NzcgNDE4UTUyMSAzOTcgNTUwIDM1N1Q1NzkgMjYwVDU0OCAxNTFUNDcxIDY1VDM3NCAxMVQyNzkgLTEwSDI3NUwyNTEgLTEwNVEyNDUgLTEyOCAyMzggLTE2MFEyMzAgLTE5MiAyMjcgLTE5OFQyMTUgLTIwNUgyMDlRMTg5IC0yMDUgMTg5IC0xOThRMTg5IC0xOTMgMjExIC0xMDNMMjM0IC0xMVEyMzQgLTEwIDIyNiAtMTBRMjIxIC0xMCAyMDYgLThUMTYxIDZUMTA3IDM2VDYyIDg5VDQzIDE3MVE0MyAyMzEgNzYgMjg0VDE1NyAzNzBUMjU0IDQyMlQzNDIgNDQxUTM0NyA0NDEgMzQ4IDQ0NUwzNzggNTY3UTQwOSA2ODYgNDA5IDY4OFpNMTIyIDE1MFExMjIgMTE2IDEzNCA5MVQxNjcgNTNUMjAzIDM1VDIzNyAyN0gyNDRMMzM3IDQwNFEzMzMgNDA0IDMyNiA0MDNUMjk3IDM5NVQyNTUgMzc5VDIxMSAzNTBUMTcwIDMwNFExNTIgMjc2IDEzNyAyMzdRMTIyIDE5MSAxMjIgMTUwWk01MDAgMjgyUTUwMCAzMjAgNDg0IDM0N1Q0NDQgMzg1VDQwNSA0MDBUMzgxIDQwNEgzNzhMMzMyIDIxN0wyODQgMjlRMjg0IDI3IDI4NSAyN1EyOTMgMjcgMzE3IDMzVDM1NyA0N1E0MDAgNjYgNDMxIDEwMFQ0NzUgMTcwVDQ5NCAyMzRUNTAwIDI4MloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03NSIgZD0iTTIxIDI4N1EyMSAyOTUgMzAgMzE4VDU1IDM3MFQ5OSA0MjBUMTU4IDQ0MlEyMDQgNDQyIDIyNyA0MTdUMjUwIDM1OFEyNTAgMzQwIDIxNiAyNDZUMTgyIDEwNVExODIgNjIgMTk2IDQ1VDIzOCAyN1QyOTEgNDRUMzI4IDc4TDMzOSA5NVEzNDEgOTkgMzc3IDI0N1E0MDcgMzY3IDQxMyAzODdUNDI3IDQxNlE0NDQgNDMxIDQ2MyA0MzFRNDgwIDQzMSA0ODggNDIxVDQ5NiA0MDJMNDIwIDg0UTQxOSA3OSA0MTkgNjhRNDE5IDQzIDQyNiAzNVQ0NDcgMjZRNDY5IDI5IDQ4MiA1N1Q1MTIgMTQ1UTUxNCAxNTMgNTMyIDE1M1E1NTEgMTUzIDU1MSAxNDRRNTUwIDEzOSA1NDkgMTMwVDU0MCA5OFQ1MjMgNTVUNDk4IDE3VDQ2MiAtOFE0NTQgLTEwIDQzOCAtMTBRMzcyIC0xMCAzNDcgNDZRMzQ1IDQ1IDMzNiAzNlQzMTggMjFUMjk2IDZUMjY3IC02VDIzMyAtMTFRMTg5IC0xMSAxNTUgN1ExMDMgMzggMTAzIDExM1ExMDMgMTcwIDEzOCAyNjJUMTczIDM3OVExNzMgMzgwIDE3MyAzODFRMTczIDM5MCAxNzMgMzkzVDE2OSA0MDBUMTU4IDQwNEgxNTRRMTMxIDQwNCAxMTIgMzg1VDgyIDM0NFQ2NSAzMDJUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS0zRDUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzUiIHg9Ijg0MyIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9zdmc+) 和
和 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIuNDg3ZXgiIGhlaWdodD0iMi41MDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyIgdmlld0JveD0iMCAtNzkxLjMgMTA3MC45IDEwODAuNCIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS0zRDUiIGQ9Ik00MDkgNjg4UTQxMyA2OTQgNDIxIDY5NEg0MjlINDQyUTQ0OCA2ODggNDQ4IDY4NlE0NDggNjc5IDQxOCA1NjNRNDExIDUzNSA0MDQgNTA0VDM5MiA0NThMMzg4IDQ0MlEzODggNDQxIDM5NyA0NDFUNDI5IDQzNVQ0NzcgNDE4UTUyMSAzOTcgNTUwIDM1N1Q1NzkgMjYwVDU0OCAxNTFUNDcxIDY1VDM3NCAxMVQyNzkgLTEwSDI3NUwyNTEgLTEwNVEyNDUgLTEyOCAyMzggLTE2MFEyMzAgLTE5MiAyMjcgLTE5OFQyMTUgLTIwNUgyMDlRMTg5IC0yMDUgMTg5IC0xOThRMTg5IC0xOTMgMjExIC0xMDNMMjM0IC0xMVEyMzQgLTEwIDIyNiAtMTBRMjIxIC0xMCAyMDYgLThUMTYxIDZUMTA3IDM2VDYyIDg5VDQzIDE3MVE0MyAyMzEgNzYgMjg0VDE1NyAzNzBUMjU0IDQyMlQzNDIgNDQxUTM0NyA0NDEgMzQ4IDQ0NUwzNzggNTY3UTQwOSA2ODYgNDA5IDY4OFpNMTIyIDE1MFExMjIgMTE2IDEzNCA5MVQxNjcgNTNUMjAzIDM1VDIzNyAyN0gyNDRMMzM3IDQwNFEzMzMgNDA0IDMyNiA0MDNUMjk3IDM5NVQyNTUgMzc5VDIxMSAzNTBUMTcwIDMwNFExNTIgMjc2IDEzNyAyMzdRMTIyIDE5MSAxMjIgMTUwWk01MDAgMjgyUTUwMCAzMjAgNDg0IDM0N1Q0NDQgMzg1VDQwNSA0MDBUMzgxIDQwNEgzNzhMMzMyIDIxN0wyODQgMjlRMjg0IDI3IDI4NSAyN1EyOTMgMjcgMzE3IDMzVDM1NyA0N1E0MDAgNjYgNDMxIDEwMFQ0NzUgMTcwVDQ5NCAyMzRUNTAwIDI4MloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02MSIgZD0iTTMzIDE1N1EzMyAyNTggMTA5IDM0OVQyODAgNDQxUTMzMSA0NDEgMzcwIDM5MlEzODYgNDIyIDQxNiA0MjJRNDI5IDQyMiA0MzkgNDE0VDQ0OSAzOTRRNDQ5IDM4MSA0MTIgMjM0VDM3NCA2OFEzNzQgNDMgMzgxIDM1VDQwMiAyNlE0MTEgMjcgNDIyIDM1UTQ0MyA1NSA0NjMgMTMxUTQ2OSAxNTEgNDczIDE1MlE0NzUgMTUzIDQ4MyAxNTNINDg3UTUwNiAxNTMgNTA2IDE0NFE1MDYgMTM4IDUwMSAxMTdUNDgxIDYzVDQ0OSAxM1E0MzYgMCA0MTcgLThRNDA5IC0xMCAzOTMgLTEwUTM1OSAtMTAgMzM2IDVUMzA2IDM2TDMwMCA1MVEyOTkgNTIgMjk2IDUwUTI5NCA0OCAyOTIgNDZRMjMzIC0xMCAxNzIgLTEwUTExNyAtMTAgNzUgMzBUMzMgMTU3Wk0zNTEgMzI4UTM1MSAzMzQgMzQ2IDM1MFQzMjMgMzg1VDI3NyA0MDVRMjQyIDQwNSAyMTAgMzc0VDE2MCAyOTNRMTMxIDIxNCAxMTkgMTI5UTExOSAxMjYgMTE5IDExOFQxMTggMTA2UTExOCA2MSAxMzYgNDRUMTc5IDI2UTIxNyAyNiAyNTQgNTlUMjk4IDExMFEzMDAgMTE0IDMyNSAyMTdUMzUxIDMyOFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS0zRDUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjEiIHg9Ijg0MyIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9zdmc+) 分别对应特征向量。之后,可以将原始用户特征(1000 多维)投射到文章的原始特征空间(80 多维),投射计算方式:
分别对应特征向量。之后,可以将原始用户特征(1000 多维)投射到文章的原始特征空间(80 多维),投射计算方式:
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjExLjMzM2V4IiBoZWlnaHQ9IjMuNjc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMC42NzFleDsiIHZpZXdCb3g9IjAgLTEyOTMuNyA0ODc5LjYgMTU4Mi43IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTNDOCIgZD0iTTE2MSA0NDFRMjAyIDQ0MSAyMjYgNDE3VDI1MCAzNThRMjUwIDMzOCAyMTggMjUyVDE4NyAxMjdRMTkwIDg1IDIxNCA2MVEyMzUgNDMgMjU3IDM3UTI3NSAyOSAyODggMjlIMjg5TDM3MSAzNjBRNDU1IDY5MSA0NTYgNjkyUTQ1OSA2OTQgNDcyIDY5NFE0OTIgNjk0IDQ5MiA2ODdRNDkyIDY3OCA0MTEgMzU2UTMyOSAyOCAzMjkgMjdUMzM1IDI2UTQyMSAyNiA0OTggMTE0VDU3NiAyNzhRNTc2IDMwMiA1NjggMzE5VDU1MCAzNDNUNTMyIDM2MVQ1MjQgMzg0UTUyNCA0MDUgNTQxIDQyNFQ1ODMgNDQzUTYwMiA0NDMgNjE4IDQyNVQ2MzQgMzY2UTYzNCAzMzcgNjIzIDI4OFQ2MDUgMjIwUTU3MyAxMjUgNDkyIDU3VDMyOSAtMTFIMzE5TDI5NiAtMTA0UTI3MiAtMTk4IDI3MiAtMTk5UTI3MCAtMjA1IDI1MiAtMjA1SDIzOVEyMzMgLTE5OSAyMzMgLTE5N1EyMzMgLTE5MiAyNTYgLTEwMlQyNzkgLTlRMjcyIC04IDI2NSAtOFExMDYgMTQgMTA2IDEzOVExMDYgMTc0IDEzOSAyNjRUMTczIDM3OVExNzMgMzgwIDE3MyAzODFRMTczIDM5MCAxNzMgMzkzVDE2OSA0MDBUMTU4IDQwNEgxNTRRMTMxIDQwNCAxMTIgMzg1VDgyIDM0NFQ2NSAzMDJUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1EyMSAyOTkgMzQgMzMzVDgyIDQwNFQxNjEgNDQxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc1IiBkPSJNMjEgMjg3UTIxIDI5NSAzMCAzMThUNTUgMzcwVDk5IDQyMFQxNTggNDQyUTIwNCA0NDIgMjI3IDQxN1QyNTAgMzU4UTI1MCAzNDAgMjE2IDI0NlQxODIgMTA1UTE4MiA2MiAxOTYgNDVUMjM4IDI3VDI5MSA0NFQzMjggNzhMMzM5IDk1UTM0MSA5OSAzNzcgMjQ3UTQwNyAzNjcgNDEzIDM4N1Q0MjcgNDE2UTQ0NCA0MzEgNDYzIDQzMVE0ODAgNDMxIDQ4OCA0MjFUNDk2IDQwMkw0MjAgODRRNDE5IDc5IDQxOSA2OFE0MTkgNDMgNDI2IDM1VDQ0NyAyNlE0NjkgMjkgNDgyIDU3VDUxMiAxNDVRNTE0IDE1MyA1MzIgMTUzUTU1MSAxNTMgNTUxIDE0NFE1NTAgMTM5IDU0OSAxMzBUNTQwIDk4VDUyMyA1NVQ0OTggMTdUNDYyIC04UTQ1NCAtMTAgNDM4IC0xMFEzNzIgLTEwIDM0NyA0NlEzNDUgNDUgMzM2IDM2VDMxOCAyMVQyOTYgNlQyNjcgLTZUMjMzIC0xMVExODkgLTExIDE1NSA3UTEwMyAzOCAxMDMgMTEzUTEwMyAxNzAgMTM4IDI2MlQxNzMgMzc5UTE3MyAzODAgMTczIDM4MVExNzMgMzkwIDE3MyAzOTNUMTY5IDQwMFQxNTggNDA0SDE1NFExMzEgNDA0IDExMiAzODVUODIgMzQ0VDY1IDMwMlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi02NCIgZD0iTTM3NiA0OTVRMzc2IDUxMSAzNzYgNTM1VDM3NyA1NjhRMzc3IDYxMyAzNjcgNjI0VDMxNiA2MzdIMjk4VjY2MFEyOTggNjgzIDMwMCA2ODNMMzEwIDY4NFEzMjAgNjg1IDMzOSA2ODZUMzc2IDY4OFEzOTMgNjg5IDQxMyA2OTBUNDQzIDY5M1Q0NTQgNjk0SDQ1N1YzOTBRNDU3IDg0IDQ1OCA4MVE0NjEgNjEgNDcyIDU1VDUxNyA0Nkg1MzVWMFE1MzMgMCA0NTkgLTVUMzgwIC0xMUgzNzNWNDRMMzY1IDM3UTMwNyAtMTEgMjM1IC0xMVExNTggLTExIDk2IDUwVDM0IDIxNVEzNCAzMTUgOTcgMzc4VDI0NCA0NDJRMzE5IDQ0MiAzNzYgMzkzVjQ5NVpNMzczIDM0MlEzMjggNDA1IDI2MCA0MDVRMjExIDQwNSAxNzMgMzY5UTE0NiAzNDEgMTM5IDMwNVQxMzEgMjExUTEzMSAxNTUgMTM4IDEyMFQxNzMgNTlRMjAzIDI2IDI1MSAyNlEzMjIgMjYgMzczIDEwM1YzNDJaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi02NSIgZD0iTTI4IDIxOFEyOCAyNzMgNDggMzE4VDk4IDM5MVQxNjMgNDMzVDIyOSA0NDhRMjgyIDQ0OCAzMjAgNDMwVDM3OCAzODBUNDA2IDMxNlQ0MTUgMjQ1UTQxNSAyMzggNDA4IDIzMUgxMjZWMjE2UTEyNiA2OCAyMjYgMzZRMjQ2IDMwIDI3MCAzMFEzMTIgMzAgMzQyIDYyUTM1OSA3OSAzNjkgMTA0TDM3OSAxMjhRMzgyIDEzMSAzOTUgMTMxSDM5OFE0MTUgMTMxIDQxNSAxMjFRNDE1IDExNyA0MTIgMTA4UTM5MyA1MyAzNDkgMjFUMjUwIC0xMVExNTUgLTExIDkyIDU4VDI4IDIxOFpNMzMzIDI3NVEzMjIgNDAzIDIzOCA0MTFIMjM2UTIyOCA0MTEgMjIwIDQxMFQxOTUgNDAyVDE2NiAzODFUMTQzIDM0MFQxMjcgMjc0VjI2N0gzMzNWMjc1WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNjYiIGQ9Ik0yNzMgMFEyNTUgMyAxNDYgM1E0MyAzIDM0IDBIMjZWNDZINDJRNzAgNDYgOTEgNDlROTkgNTIgMTAzIDYwUTEwNCA2MiAxMDQgMjI0VjM4NUgzM1Y0MzFIMTA0VjQ5N0wxMDUgNTY0TDEwNyA1NzRRMTI2IDYzOSAxNzEgNjY4VDI2NiA3MDRRMjY3IDcwNCAyNzUgNzA0VDI4OSA3MDVRMzMwIDcwMiAzNTEgNjc5VDM3MiA2MjdRMzcyIDYwNCAzNTggNTkwVDMyMSA1NzZUMjg0IDU5MFQyNzAgNjI3UTI3MCA2NDcgMjg4IDY2N0gyODRRMjgwIDY2OCAyNzMgNjY4UTI0NSA2NjggMjIzIDY0N1QxODkgNTkyUTE4MyA1NzIgMTgyIDQ5N1Y0MzFIMjkzVjM4NUgxODVWMjI1UTE4NSA2MyAxODYgNjFUMTg5IDU3VDE5NCA1NFQxOTkgNTFUMjA2IDQ5VDIxMyA0OFQyMjIgNDdUMjMxIDQ3VDI0MSA0NlQyNTEgNDZIMjgyVjBIMjczWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTNENSIgZD0iTTQwOSA2ODhRNDEzIDY5NCA0MjEgNjk0SDQyOUg0NDJRNDQ4IDY4OCA0NDggNjg2UTQ0OCA2NzkgNDE4IDU2M1E0MTEgNTM1IDQwNCA1MDRUMzkyIDQ1OEwzODggNDQyUTM4OCA0NDEgMzk3IDQ0MVQ0MjkgNDM1VDQ3NyA0MThRNTIxIDM5NyA1NTAgMzU3VDU3OSAyNjBUNTQ4IDE1MVQ0NzEgNjVUMzc0IDExVDI3OSAtMTBIMjc1TDI1MSAtMTA1UTI0NSAtMTI4IDIzOCAtMTYwUTIzMCAtMTkyIDIyNyAtMTk4VDIxNSAtMjA1SDIwOVExODkgLTIwNSAxODkgLTE5OFExODkgLTE5MyAyMTEgLTEwM0wyMzQgLTExUTIzNCAtMTAgMjI2IC0xMFEyMjEgLTEwIDIwNiAtOFQxNjEgNlQxMDcgMzZUNjIgODlUNDMgMTcxUTQzIDIzMSA3NiAyODRUMTU3IDM3MFQyNTQgNDIyVDM0MiA0NDFRMzQ3IDQ0MSAzNDggNDQ1TDM3OCA1NjdRNDA5IDY4NiA0MDkgNjg4Wk0xMjIgMTUwUTEyMiAxMTYgMTM0IDkxVDE2NyA1M1QyMDMgMzVUMjM3IDI3SDI0NEwzMzcgNDA0UTMzMyA0MDQgMzI2IDQwM1QyOTcgMzk1VDI1NSAzNzlUMjExIDM1MFQxNzAgMzA0UTE1MiAyNzYgMTM3IDIzN1ExMjIgMTkxIDEyMiAxNTBaTTUwMCAyODJRNTAwIDMyMCA0ODQgMzQ3VDQ0NCAzODVUNDA1IDQwMFQzODEgNDA0SDM3OEwzMzIgMjE3TDI4NCAyOVEyODQgMjcgMjg1IDI3UTI5MyAyNyAzMTcgMzNUMzU3IDQ3UTQwMCA2NiA0MzEgMTAwVDQ3NSAxNzBUNDk0IDIzNFQ1MDAgMjgyWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU0IiBkPSJNNDAgNDM3UTIxIDQzNyAyMSA0NDVRMjEgNDUwIDM3IDUwMVQ3MSA2MDJMODggNjUxUTkzIDY2OSAxMDEgNjc3SDU2OUg2NTlRNjkxIDY3NyA2OTcgNjc2VDcwNCA2NjdRNzA0IDY2MSA2ODcgNTUzVDY2OCA0NDRRNjY4IDQzNyA2NDkgNDM3UTY0MCA0MzcgNjM3IDQzN1Q2MzEgNDQyTDYyOSA0NDVRNjI5IDQ1MSA2MzUgNDkwVDY0MSA1NTFRNjQxIDU4NiA2MjggNjA0VDU3MyA2MjlRNTY4IDYzMCA1MTUgNjMxUTQ2OSA2MzEgNDU3IDYzMFQ0MzkgNjIyUTQzOCA2MjEgMzY4IDM0M1QyOTggNjBRMjk4IDQ4IDM4NiA0NlE0MTggNDYgNDI3IDQ1VDQzNiAzNlE0MzYgMzEgNDMzIDIyUTQyOSA0IDQyNCAxTDQyMiAwUTQxOSAwIDQxNSAwUTQxMCAwIDM2MyAxVDIyOCAyUTk5IDIgNjQgMEg0OVE0MyA2IDQzIDlUNDUgMjdRNDkgNDAgNTUgNDZIODNIOTRRMTc0IDQ2IDE4OSA1NVExOTAgNTYgMTkxIDU2UTE5NiA1OSAyMDEgNzZUMjQxIDIzM1EyNTggMzAxIDI2OSAzNDRRMzM5IDYxOSAzMzkgNjI1UTMzOSA2MzAgMzEwIDYzMEgyNzlRMjEyIDYzMCAxOTEgNjI0UTE0NiA2MTQgMTIxIDU4M1Q2NyA0NjdRNjAgNDQ1IDU3IDQ0MVQ0MyA0MzdINDBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTciIGQ9Ik00MzYgNjgzUTQ1MCA2ODMgNDg2IDY4MlQ1NTMgNjgwUTYwNCA2ODAgNjM4IDY4MVQ2NzcgNjgyUTY5NSA2ODIgNjk1IDY3NFE2OTUgNjcwIDY5MiA2NTlRNjg3IDY0MSA2ODMgNjM5VDY2MSA2MzdRNjM2IDYzNiA2MjEgNjMyVDYwMCA2MjRUNTk3IDYxNVE1OTcgNjAzIDYxMyAzNzdUNjI5IDEzOEw2MzEgMTQxUTYzMyAxNDQgNjM3IDE1MVQ2NDkgMTcwVDY2NiAyMDBUNjkwIDI0MVQ3MjAgMjk1VDc1OSAzNjJRODYzIDU0NiA4NzcgNTcyVDg5MiA2MDRRODkyIDYxOSA4NzMgNjI4VDgzMSA2MzdRODE3IDYzNyA4MTcgNjQ3UTgxNyA2NTAgODE5IDY2MFE4MjMgNjc2IDgyNSA2NzlUODM5IDY4MlE4NDIgNjgyIDg1NiA2ODJUODk1IDY4MlQ5NDkgNjgxUTEwMTUgNjgxIDEwMzQgNjgzUTEwNDggNjgzIDEwNDggNjcyUTEwNDggNjY2IDEwNDUgNjU1VDEwMzggNjQwVDEwMjggNjM3UTEwMDYgNjM3IDk4OCA2MzFUOTU4IDYxN1Q5MzkgNjAwVDkyNyA1ODRMOTIzIDU3OEw3NTQgMjgyUTU4NiAtMTQgNTg1IC0xNVE1NzkgLTIyIDU2MSAtMjJRNTQ2IC0yMiA1NDIgLTE3UTUzOSAtMTQgNTIzIDIyOVQ1MDYgNDgwTDQ5NCA0NjJRNDcyIDQyNSAzNjYgMjM5UTIyMiAtMTMgMjIwIC0xNVQyMTUgLTE5UTIxMCAtMjIgMTk3IC0yMlExNzggLTIyIDE3NiAtMTVRMTc2IC0xMiAxNTQgMzA0VDEzMSA2MjJRMTI5IDYzMSAxMjEgNjMzVDgyIDYzN0g1OFE1MSA2NDQgNTEgNjQ4UTUyIDY3MSA2NCA2ODNINzZRMTE4IDY4MCAxNzYgNjgwUTMwMSA2ODAgMzEzIDY4M0gzMjNRMzI5IDY3NyAzMjkgNjc0VDMyNyA2NTZRMzIyIDY0MSAzMTggNjM3SDI5N1EyMzYgNjM0IDIzMiA2MjBRMjYyIDE2MCAyNjYgMTM2TDUwMSA1NTBMNDk5IDU4N1E0OTYgNjI5IDQ4OSA2MzJRNDgzIDYzNiA0NDcgNjM3UTQyOCA2MzcgNDIyIDYzOVQ0MTYgNjQ4UTQxNiA2NTAgNDE4IDY2MFE0MTkgNjY0IDQyMCA2NjlUNDIxIDY3NlQ0MjQgNjgwVDQyOCA2ODJUNDM2IDY4M1oiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS0zQzgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzUiIHg9IjkyMSIgeT0iLTIxMyI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0MzQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI3MyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsNTY4KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTY0Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjUiIHg9IjU1NiIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTY2IiB4PSIxMDAxIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI2MzYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS0zRDUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9Ijg0MyIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc1IiB4PSI4NDMiIHk9Ii0yMTEiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU3IiB4PSIzODMxIiB5PSIwIj48L3VzZT4KPC9nPgo8L3N2Zz4=)
然后,用投射后的 80 多维特征对用户聚类(可以使用 K-means),得到 5 个类簇,文章页同样聚类成 5 个簇,再加上常数 1,用户和文章各自被表示成 6 维向量。Yahoo! 的科学家们之所以选定为 6 维,因为数据表明它的效果最好[10],并且这大大降低了计算复杂度和存储空间。
LinUCB 算法有以下优点:由于加入了特征,所以收敛比 UCB 更快(论文有证明);特征构建是效果的关键,也是工程上最麻烦和值的发挥的地方;由于参与计算的是特征,所以可以处理动态的推荐候选池,编辑可以增删文章;特征降维很有必要,关系到计算效率。
[6] - Bandit 算法与协同过滤
推荐系统里面,传统经典的算法肯定离不开协同过滤,协同过滤背后的思想简单深刻。协同过滤看上去是一种算法,不如说是一种方法论,不是机器在给你推荐,而是 “集体智慧” 在给你推荐。
它的基本假设就是 “物以类聚,人以群分”,你的圈子决定了你能见到的物品。这个假设很靠谱,却隐藏了一些重要的问题:作为用户的我们还可能看到新的东西吗?还可能有惊喜吗?还可能有圈子之间的更迭流动吗?这些问题的背后其实就是在前面提到过的 EE 问题(Exploit & Explore)。我们关注推荐的准确率,但是我们也应该关注推荐系统的演进发展,因为 “推荐系统不止眼前的 Exploit,还有远方的 Explore”。
做 Explore 的方法有很多,bandit 算法是其中的一种流派,前面也进行了许多介绍。那 bandit 算法,能不能和协同过滤这种算法结合起来呢?事实上已经有人做过了,叫做 COFIBA 算法,具体在题目为 《Collaborative Filtering Bandits》[11] 和《Online Clustering of Bandits》[12] 的两篇文章中有详细的描述,两篇文章的区别是后者只对用户聚类(即只考虑了 User-based 的协同过滤),而前者采用了协同聚类(co-clustering,可以理解为 item-based 和 user-based 两种协同方式在同时进行),后者是前者的一个特殊情况。
很多推荐场景中都有这两个规律:相似的用户对同一个物品的反馈可能是一样的。也就是对一个聚类用户群体推荐同一个 item,他们可能都喜欢,也可能都不喜欢,同样地,同一个用户会对相似的物品反馈相同,这是属于协同过滤可以解决的问题;在使用推荐系统过程中,用户的决策是动态进行的,尤其是新用户。这就导致无法提前为用户准备好推荐候选,只能 “走一步看一步”,是一个动态的推荐过程。
每一个推荐候选 item,都可以根据用户对其偏好不同(payoff 不同)将用户聚类成不同的群体,一个群体来集体预测这个 item 的可能的收益,这就有了协同的效果,然后再实时观察真实反馈回来更新用户的个人参数,这就有了 bandit 的思想在里面。
另外,如果要推荐的候选 item 较多,还需要对 item 进行聚类,这样就不用按照每一个 item 对 user 聚类,而是按照每一个 item 的类簇对 user 聚类,如此以来,item 的类簇数相对于 item 数要大大减少。
基于这些思想,有人提出了算法 COFIBA[13](读作 coffee bar)
在时刻 t,用户来访问推荐系统,推荐系统需要从已有的候选池子中挑一个最佳的物品推荐给他,然后观察他的反馈,用观察到的反馈来更新挑选策略。 这里的每个物品都有一个特征向量,所以这里的 bandit 算法是 context 相关的。 这里依然是用岭回归去拟合用户的权重向量,用于预测用户对每个物品的可能反馈 (payoff),这一点和 linUCB 算法是一样的。
对比 LinUCB 算法,COFIBA 算法的不同有两个:基于用户聚类挑选最佳的 item(相似用户集体决策的 bandit);基于用户的反馈情况调整 user 和 item 的聚类(协同过滤部分)。
算法针对某个用户 ,首先计算该用户的 bandit 参数 (和 LinUCB 相同),但是这个参数并不直接参与到 bandit 的选择决策中(和 LinUCB 不同),而是用来更新用户聚类的;接着遍历候选 item,每一个 item 表示成一个 context 向量;这样,每一个 item 都对应一套用户聚类结果,所以遍历到每一个 item 时判断当前用户在当前 item 下属于哪个类簇,然后把对应类簇中每个用户的 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIuNDQyZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgMTA1MS41IDkzNi45IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTREIiBkPSJNMjg5IDYyOVEyODkgNjM1IDIzMiA2MzdRMjA4IDYzNyAyMDEgNjM4VDE5NCA2NDhRMTk0IDY0OSAxOTYgNjU5UTE5NyA2NjIgMTk4IDY2NlQxOTkgNjcxVDIwMSA2NzZUMjAzIDY3OVQyMDcgNjgxVDIxMiA2ODNUMjIwIDY4M1QyMzIgNjg0UTIzOCA2ODQgMjYyIDY4NFQzMDcgNjgzUTM4NiA2ODMgMzk4IDY4M1Q0MTQgNjc4UTQxNSA2NzQgNDUxIDM5Nkw0ODcgMTE3TDUxMCAxNTRRNTM0IDE5MCA1NzQgMjU0VDY2MiAzOTRRODM3IDY3MyA4MzkgNjc1UTg0MCA2NzYgODQyIDY3OFQ4NDYgNjgxTDg1MiA2ODNIOTQ4UTk2NSA2ODMgOTg4IDY4M1QxMDE3IDY4NFExMDUxIDY4NCAxMDUxIDY3M1ExMDUxIDY2OCAxMDQ4IDY1NlQxMDQ1IDY0M1ExMDQxIDYzNyAxMDA4IDYzN1E5NjggNjM2IDk1NyA2MzRUOTM5IDYyM1E5MzYgNjE4IDg2NyAzNDBUNzk3IDU5UTc5NyA1NSA3OTggNTRUODA1IDUwVDgyMiA0OFQ4NTUgNDZIODg2UTg5MiAzNyA4OTIgMzVRODkyIDE5IDg4NSA1UTg4MCAwIDg2OSAwUTg2NCAwIDgyOCAxVDczNiAyUTY3NSAyIDY0NCAyVDYwOSAxUTU5MiAxIDU5MiAxMVE1OTIgMTMgNTk0IDI1UTU5OCA0MSA2MDIgNDNUNjI1IDQ2UTY1MiA0NiA2ODUgNDlRNjk5IDUyIDcwNCA2MVE3MDYgNjUgNzQyIDIwN1Q4MTMgNDkwVDg0OCA2MzFMNjU0IDMyMlE0NTggMTAgNDUzIDVRNDUxIDQgNDQ5IDNRNDQ0IDAgNDMzIDBRNDE4IDAgNDE1IDdRNDEzIDExIDM3NCAzMTdMMzM1IDYyNEwyNjcgMzU0UTIwMCA4OCAyMDAgNzlRMjA2IDQ2IDI3MiA0NkgyODJRMjg4IDQxIDI4OSAzN1QyODYgMTlRMjgyIDMgMjc4IDFRMjc0IDAgMjY3IDBRMjY1IDAgMjU1IDBUMjIxIDFUMTU3IDJRMTI3IDIgOTUgMVQ1OCAwUTQzIDAgMzkgMlQzNSAxMVEzNSAxMyAzOCAyNVQ0MyA0MFE0NSA0NiA2NSA0NlExMzUgNDYgMTU0IDg2UTE1OCA5MiAyMjMgMzU0VDI4OSA2MjlaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNEQiIHg9IjAiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) 矩阵 (对应 LinUCB 里面的 A 矩阵),
矩阵 (对应 LinUCB 里面的 A 矩阵), ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjAuOTk4ZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgNDI5LjUgOTM2LjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNjIiIGQ9Ik03MyA2NDdRNzMgNjU3IDc3IDY3MFQ4OSA2ODNROTAgNjgzIDE2MSA2ODhUMjM0IDY5NFEyNDYgNjk0IDI0NiA2ODVUMjEyIDU0MlEyMDQgNTA4IDE5NSA0NzJUMTgwIDQxOEwxNzYgMzk5UTE3NiAzOTYgMTgyIDQwMlEyMzEgNDQyIDI4MyA0NDJRMzQ1IDQ0MiAzODMgMzk2VDQyMiAyODBRNDIyIDE2OSAzNDMgNzlUMTczIC0xMVExMjMgLTExIDgyIDI3VDQwIDE1MFYxNTlRNDAgMTgwIDQ4IDIxN1Q5NyA0MTRRMTQ3IDYxMSAxNDcgNjIzVDEwOSA2MzdRMTA0IDYzNyAxMDEgNjM3SDk2UTg2IDYzNyA4MyA2MzdUNzYgNjQwVDczIDY0N1pNMzM2IDMyNVYzMzFRMzM2IDQwNSAyNzUgNDA1UTI1OCA0MDUgMjQwIDM5N1QyMDcgMzc2VDE4MSAzNTJUMTYzIDMzMEwxNTcgMzIyTDEzNiAyMzZRMTE0IDE1MCAxMTQgMTE0UTExNCA2NiAxMzggNDJRMTU0IDI2IDE3OCAyNlEyMTEgMjYgMjQ1IDU4UTI3MCA4MSAyODUgMTE0VDMxOCAyMTlRMzM2IDI5MSAzMzYgMzI1WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTYyIiB4PSIwIiB5PSIwIj48L3VzZT4KPC9nPgo8L3N2Zz4=) 向量(payoff 向量,对应 LinUCB 里面的 向量)聚合起来,从而针对这个类簇求解一个岭回归参数(类似 LinUCB 里面单独针对每个用户所做),同时计算其 payoff 预测值和置信上边界;然后,每个 item 都得到一个 payoff 预测值及置信区间上界,挑出那个上边界最大的 item 推出去(和 LinUCB 相同);观察用户的真实反馈,然后更新用户自己的 矩阵和 向量(更新个人的,对应类簇里其他的不更新)。
向量(payoff 向量,对应 LinUCB 里面的 向量)聚合起来,从而针对这个类簇求解一个岭回归参数(类似 LinUCB 里面单独针对每个用户所做),同时计算其 payoff 预测值和置信上边界;然后,每个 item 都得到一个 payoff 预测值及置信区间上界,挑出那个上边界最大的 item 推出去(和 LinUCB 相同);观察用户的真实反馈,然后更新用户自己的 矩阵和 向量(更新个人的,对应类簇里其他的不更新)。
以上是 COFIBA 算法的一次决策过程。在收到用户真实反馈之后,还有两个计算过程:更新 user 聚类和更新 item 聚类。论文中给出的更新 user 和 item 的聚类示意图如下所示。
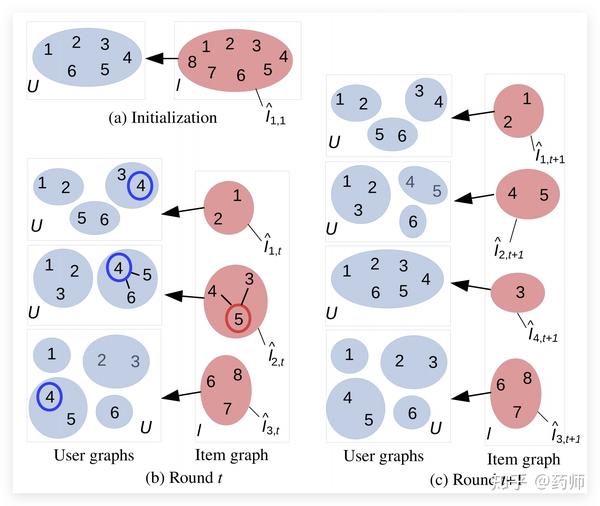

解释一下这个图。
(a)这里有个 user、
个 item,初始化时,user 和 item 的类簇个数都是
(b1)在某一轮试验时,推荐系统面对的用户是。推荐过程就是遍历 1~8 每个 item,然后看看对应每个 item 时,user
胜出,被推荐出去了。
(b2)在时刻个类簇,需要更新的用户聚类是 item
(c)更新完用户类簇后,item,都去构造一个 user 的近邻集合
,这个集合的用户对 item
简单来说就是:
- User-based 协同过滤来选择要推荐的 item,选择时用了 LinUCB 的思想
- 根据用户的反馈,调整 User-based 和 Item-based 的聚类结果
- Item-based 的聚类变化又改变了 User 的聚类
- 不断根据用户实时动态的反馈来划分 User-Item 矩阵
有兴趣可以直接去看原始论文。
[7] - 总结
Exploit-Explore 这一对矛盾一直客观存在,bandit 算法是公认的一种比较好的解决 EE 问题的方案。除了 bandit 算法之外,还有一些其他的 explore 的办法,比如:在推荐时,随机地去掉一些用户历史行为(特征)。解决 Explore,势必就是要冒险,势必要走向未知,而这显然就是会伤害用户体验的:明知道用户肯定喜欢 A,你还偏偏以某个小概率给推荐非 A。
实际上,很少有公司会采用这些理性的办法做 Explore,反而更愿意用一些盲目主观的方式。究其原因,可能是因为:
- 互联网产品生命周期短,而 Explore 又是为了提升长期利益的,所以没有动力做;
- 用户使用互联网产品时间越来越碎片化,Explore 的时间长,难以体现出 Explore 的价值;
- 同质化互联网产品多,用户选择多,稍有不慎,用户用脚投票,分分钟弃你于不顾。
- 已经成规模的平台,红利杠杠的,其实是没有动力做 Explore 的;
基于这些,我们如果想在自己的推荐系统中引入 Explore 机制,需要注意以下几点:
- 用于 Explore 的 item 要保证其本身质量,纵使用户不感兴趣,也不至于引起其反感;
- Explore 本身的产品需要精心设计,让用户有耐心陪你玩儿;
- 深度思考,这样才不会做出脑残的产品,产品不会早早夭折,才有可能让 Explore 机制有用武之地
参考
- ^https://en.wikipedia.org/wiki/Multi-armed_bandit
- ^https://nbviewer.jupyter.org/github/CamDavidsonPilon/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers/blob/master/Chapter6_Priorities/Ch6_Priors_PyMC3.ipynb#A-Measure-of-Good
- ^https://en.wikipedia.org/wiki/Thompson_sampling
- ^https://zh.wikipedia.org/wiki/%CE%92%E5%88%86%E5%B8%83
- ^http://hunch.net/~coms-4771/lecture20.pdf
- ^https://gist.github.com/anonymous/211b599b7bef958e50af
- ^https://arxiv.org/pdf/1003.0146.pdf
- ^《计算广告:互联网商业变现的市场与技术》P253,刘鹏、王超著
- ^https://en.wikipedia.org/wiki/Tikhonov_regularization
- ^http://www.gatsby.ucl.ac.uk/~chuwei/paper/isp781-chu.pdf
- ^https://arxiv.org/pdf/1502.03473.pdf
- ^https://arxiv.org/pdf/1401.8257.pdf
- ^https://github.com/qw2ky/CoLinUCB_Revised/blob/master/COFIBA.py
![[零基础入门推荐系统(1)]基于用户和基于物品的协同过滤方法(python代码实现)](https://pic3.zhimg.com/v2-278d6b0438e5eefcf9f844c07ee9adfe_250x0.jpg?source=172ae18b)
9 条评论
正好工作中接触到相关知识,文章深入浅出
您好~可不可以请教一下,LinUCB算法,对某一个用户的某一个arm来说,每一个t时刻的特征不是不变的吗?x不变的话,怎么训练参数呀?
这个应该是变化的吧,肯定有arm的实时特征,随着时间变化
ridge regression那步怎么看出来的,能解释一下么?