還看不懂Wasserstein Distance嗎?看看這篇。
前言
之前聽學生介紹Wasserstein Distance實在聽不懂他們在說什麼,(希望他們知道自己在講什麼),但我只知道這個距離,但沒實際去研究過這個在幹嘛,只知道WGAN用這個解掉一些問題(這個很多文章都有寫,有空再補一篇)。我從網路查了一堆文章,終於讓我整理出Wasserstein Distance在一維要怎麼手算了。以下內容皆為個人理解,也許非原著要提的物理概念。
在機器/深度學習上採用了很多種loss function目的都是希望結果更好,但在採用這些loss的時候,往往忘記了去思考為什麼要用這個loss,用了這個loss好處是什麼?
部分內容節錄至小弟的書「機器學習的統計基礎:深度學習背後的核心技術」
本篇文章主要講述
1. KL Divergence(Kullback-Leibler Divergence)
2. JS Divergence(Jensen-Shannon Divergence)
3. KL與MLE(最大概似估計)的關係
4. Wasserstein Distance
1. KL Divergence (Kullback-Leibler Divergence)
Reference: 機器學習的統計基礎:深度學習背後的核心技術
KL Divergence又稱為相對熵(relative entropy),通常是用來度量兩個機率分布(P和Q)之間的距離,基於Q分布下,P分布的KL Divergence的定義為:
見下圖,可以想像KL是在評估兩個分布在取log後over所有x下的差異,所以實際度量出來的值並非一般認知的距離,而是兩個分布之間的差異度(重疊率)。所以當兩個分布越重疊,兩個分布的差值越小,則KLDivergence越小(例子2);反之評估差值越大,KLDivergence越大(例子1)。
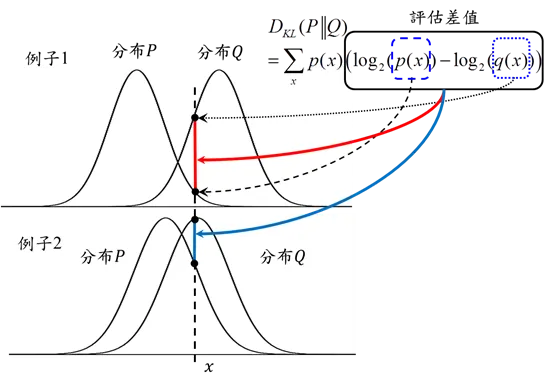
當P=Q,KL=0,
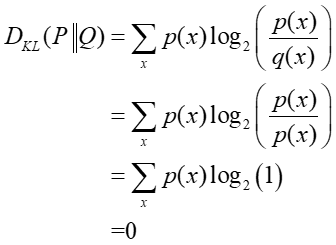
KL Divergence有個很重要的特性就是非對稱性,因為KL Divergence是條件機率的概念,所以從分布P到Q分布之間的差異度通常並不等於從Q到P分布之間的差異度,也就是
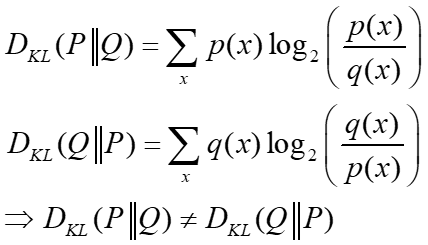
這也意味著選擇 還是 對於演算法來說會有影響。例如說在生成對抗網路(Generative Adversarial Network,GAN)則是希望找到生成網路參數 讓生成資料經由區別網路編碼後的分布可以逼近真實資料經由區別神經網路編碼後的分布。(小弟的書有比較多的講述)
2. JS Divergence(Jensen-Shannon Divergence)
KL Divergence不具有對稱性,因此JS Divergence就是提出來用來避免這個非對稱性的問題,簡單說就是在KL的非對稱性是因為”基於Q分布下來計算P分布的KL Divergence”或是”基於P分布下來計算Q分布的KL Divergence”,那什麼時候會滿足對稱性,直接將兩個分布的距離計算平均就好了,因此JS Divergence的定義為
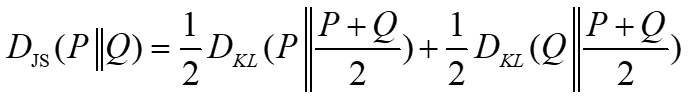
因此這樣JS Divergence具有對稱特性,且結果會更平滑。
3. KL與MLE(最大概似估計)的關係
Reference: 機器學習的統計基礎:深度學習背後的核心技術
我們來看一下KL Divergence的公式,可以發現cross-entropy和KL Divergence是有相關的,
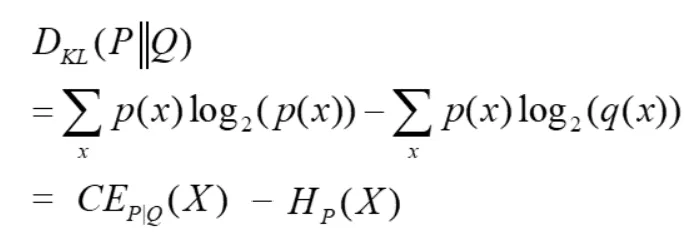
同樣的概念也等價於統計學的最大概似估計(MLE),假設 分布為Ground Truth的分布(人工標註資料的分布),所以AI模型(f~Q,f服從Q分布)就是希望學到的結果 分布會近似 分布,這樣也就是模型學得很好。AI模型(f)內的參數為 ,所以簡單說目標是最小化KL Divergence(從上式來看,等價於最小化cross-entropy)
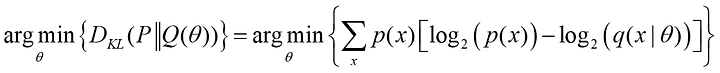
如果我們希望最小化KL Divergence,等同於希望上式的-log項越大越好,也就是希望最大化Q分布的訊息量,
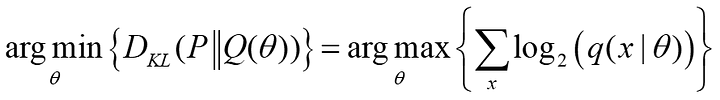
所以最小化KL Divergence等價於最大化Q分布的概似函數。
4. Wasserstein Distance
Wasserstein Distance也稱為推土機/動土距離(Earth Mover’s distance, EMD),Wasserstein Distance的定義是評估由P分布轉換成Q分布所需要代價(移动的平均距離的最小值)→和挖東牆補西牆很類似(把一個形狀轉換成另一個形狀所需要做的最小工),所以很神奇的很常查到Wasserstein Distance稱為推土機距離。
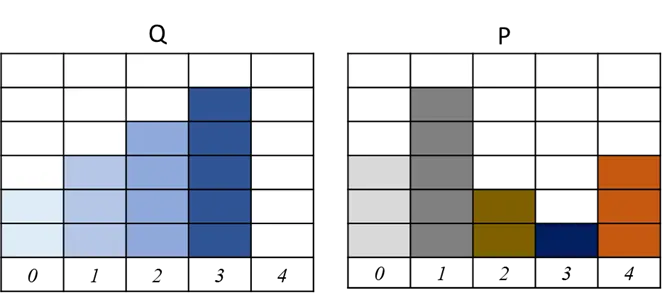
Wasserstein Distance範例1:
假設有兩個分布P分布和Q分布,這邊用離散的分布比較好介紹,(假設x1→x2、x2→x3、x3→x4、x4→x5距離都是1)
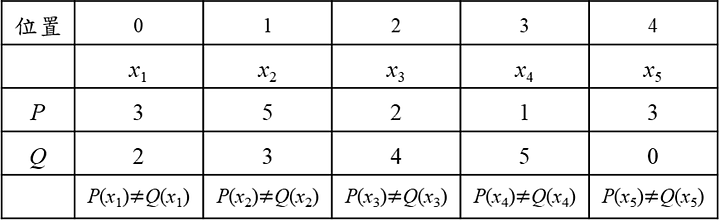
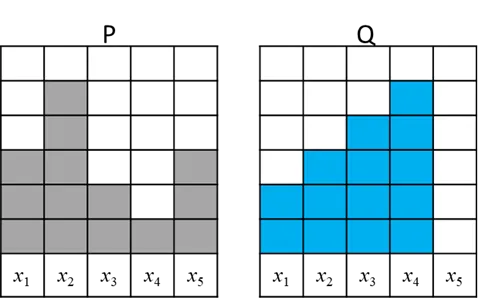
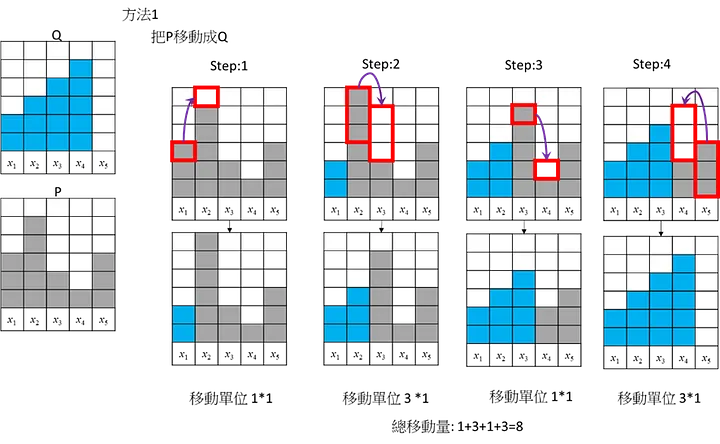
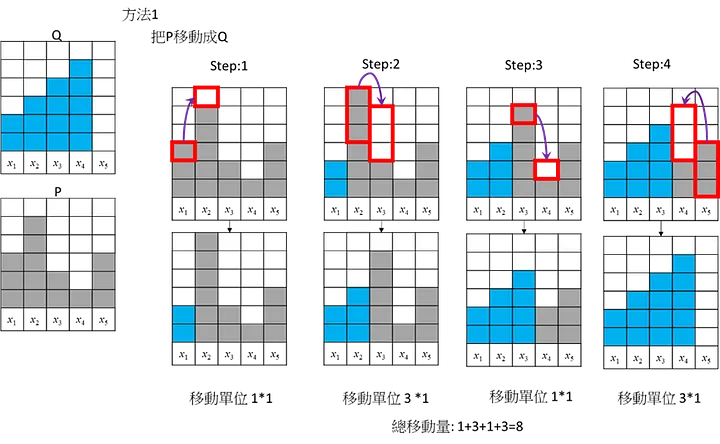
這邊舉3個不同移動的方式,將P移動成Q
方式1:
方式2:
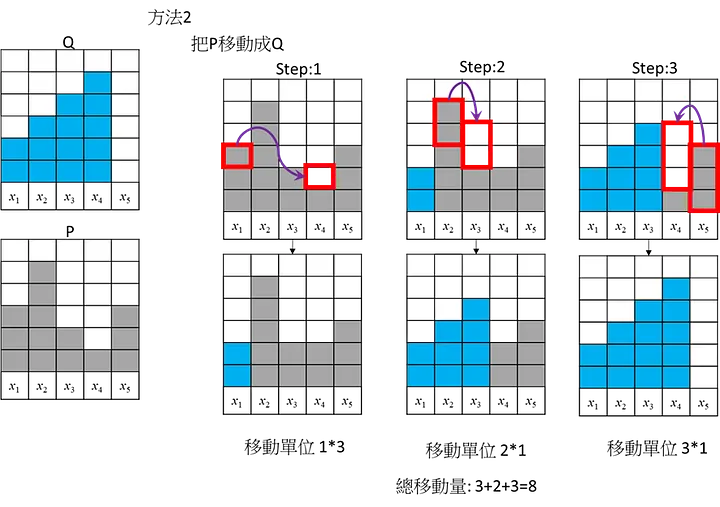
方式3:
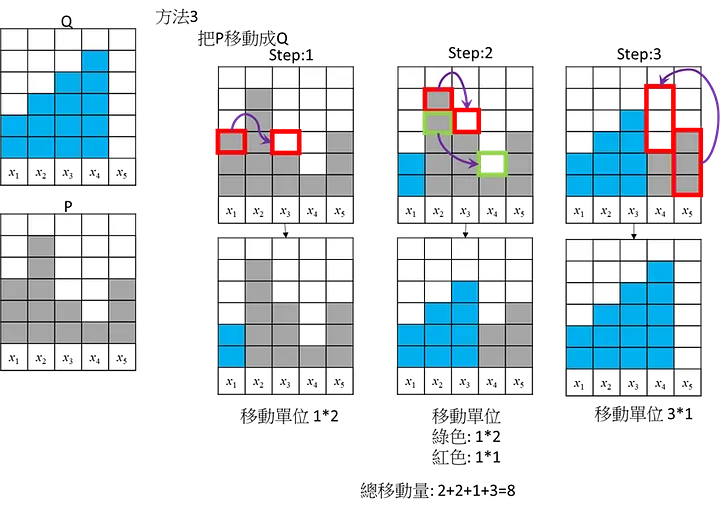
三個方法的總移動量都是8。這是個簡單的範例應該沒有更短的移動方式,所以此範例地的Wasserstein Distance/EMD = 8,但實際上Wasserstein Distance/ EMD計算要進行正規化去移動(考慮總數14個): 所以Wasserstein Distance = 8/14=4/7= 0.5714
python程式(利用scipy函數)計算
import scipy.statsimport numpy as npP = np.array([3,5,2,1,3])Q = np.array([2,3,4,5,0])dists=[i for i in range(len(A))]D=scipy.stats.wasserstein_distance(dists,dists,P,Q)print(D)
ANS: 0.5714285714285714
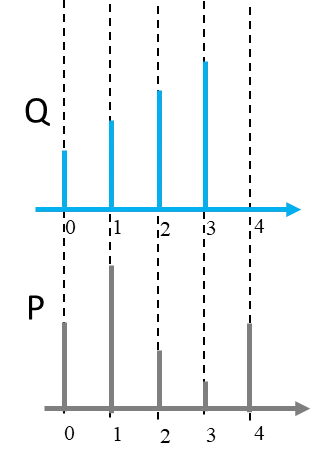
實際上P和Q的分布是長得像下圖,所以在用scipy計算Wasserstein Distance輸入項,前兩項是在看在X軸的位置,所以我用[0,1,2,3,4]作為前兩項輸入,來計算Wasserstein Distance。
Wasserstein Distance範例2:
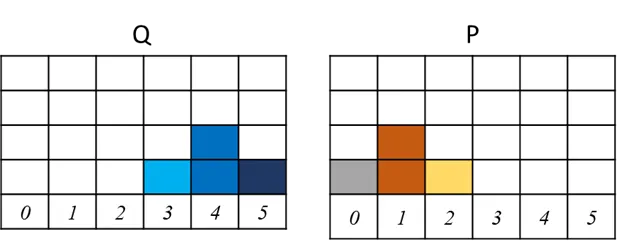
假設有兩個分布P分布和Q分布,這邊用離散的分布比較好介紹,(假設x1→x2、x2→x3、x3→x4、x4→x5、x5→x6距離都是1)
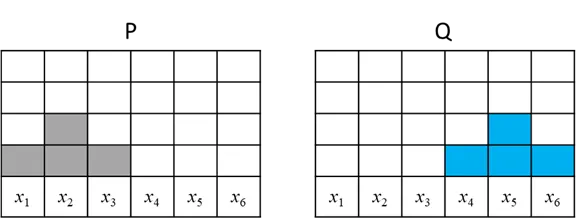
這邊舉1個不同移動的方式,將P移動成Q
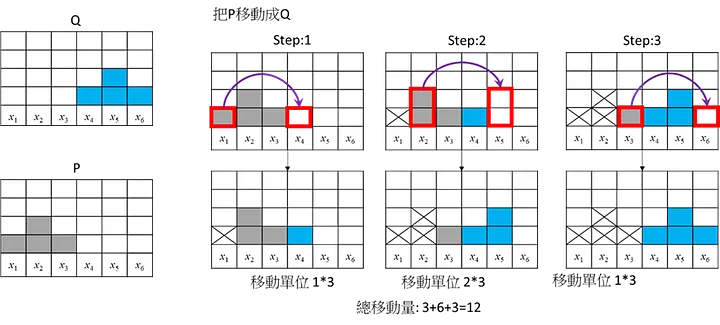
總移動量都是12。這是個簡單的範例應該沒有更短的移動方式,此範例計算要正規化去移動(考慮總數4個): 所以Wasserstein Distance = 12/4=3
python程式計算
import scipy.statsimport numpy as npP = np.array([1,2,1])Q = np.array([1,2,1])dists _P=[0,1,2]dists _Q=[3,4,5]D1=scipy.stats.wasserstein_distance(dists_P, dists_Q, P, Q)print(D1)
ANS: 3.0
實際上P和Q的分布是長得像下圖,所以在用scipy計算Wasserstein Distance輸入項,前兩項是在看在X軸的位置,所以在P分布用[0,1,2],Q分布是用[4, 5, 6]作為前兩項輸入,來計算Wasserstein Distance。
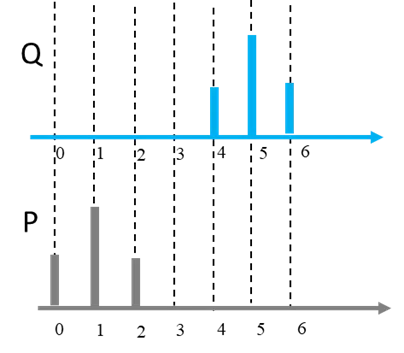
聰明的你應該有發現兩件事情:
第一件: Wasserstein Distance應該有公式
第二件: 動土法的移動我在範例一中可以找到3種不同移動方式(範例二其實也可以我懶了),所以沒有固定的移動方式都可以找到最小的移動量,前面兩個範例都提到”這是個簡單的範例應該沒有更短的移動方式”,那是因為範例簡單,如果實際的分布超級複雜我們怎麼這樣慢慢移動用肉眼找到最小解。
第一件: Wasserstein Distance應該有公式
我們看一下網路文章最常看到的Earth Mover’s Distance公式:
從P移動到Q,假設P有M堆土(在P第i堆土有多少量的土pi),Q有N堆土(在Q第j堆土有多少量的土qj)。
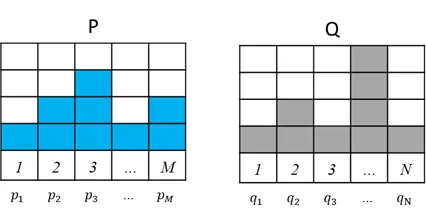

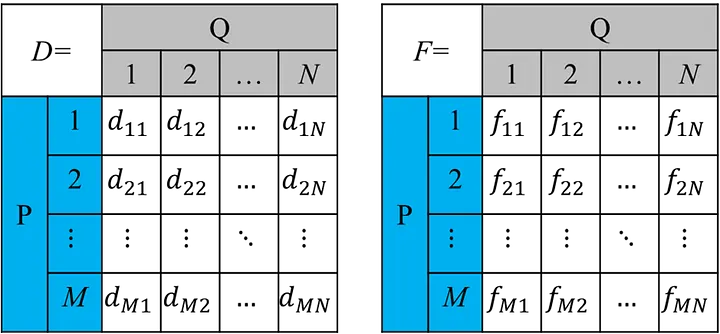
所以從P移動到Q所花費的移動次數和量為
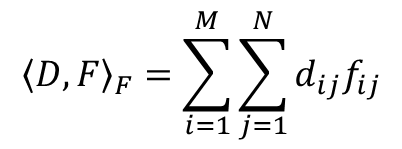
<D,F>_F為計算D和F的弗羅貝尼烏斯範數(Frobenius norm)。
EMD就是希望最小化(P移動到Q所花費的移動次數和量)
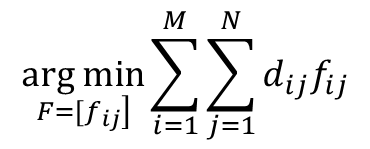
當然會有一些限制條件

所以在目標函數與限制式都滿足的狀態下,找到的最佳F* (最小化P移動到Q所花費的移動次數和量)就是我們要求的EMD,
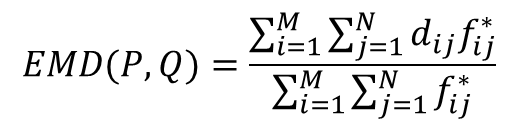
我們看一下前面範例一的方法1寫成方程式會長怎樣,

假設方法這個解(F*)最好:
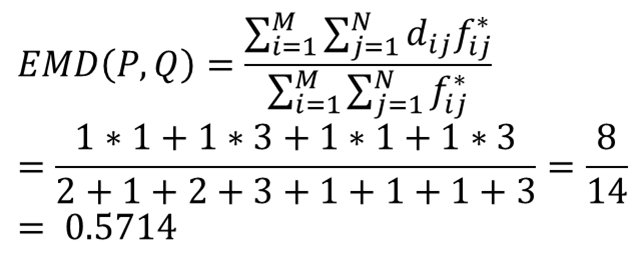
當然有些文章會用下面兩種方式定義Wasserstein distance
1. 假設有兩分布P和Q

所以在某聯合分布下,此分布下求的所有x和y的距離期望值,而這個期望值的下界(infimum,也就是方程式內的inf)就是的Wasserstein distance。
2. Scipy定義的1D分布的Wasserstein distance :
The first Wasserstein distance between distribution u and v:
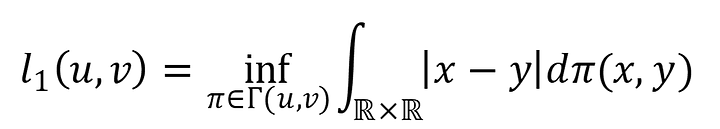
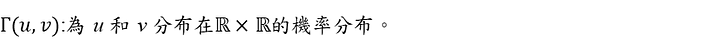
在scipy定義的1D的Wasserstein distance,其實為(1)方程式利用期望值式子展開後的結果。
結果我們從上面兩個方程式的定義還是不知道Wasserstein distance怎麼計算,這個其實也困擾我很久,但在認真看Scipy的解說和深入去看scipy source code (code裡面真的沒有寫的很難),其實Wasserstein distance可以從累積分布函數(英語:Cumulative Distribution Function、CDF)來計算。

我們用CDFs的方式來計算前兩個範例的Wasserstein distance給大家看,這邊假設大家都知道什麼是CDF,不知道可以看一下WIKI。
範例1:
CDF
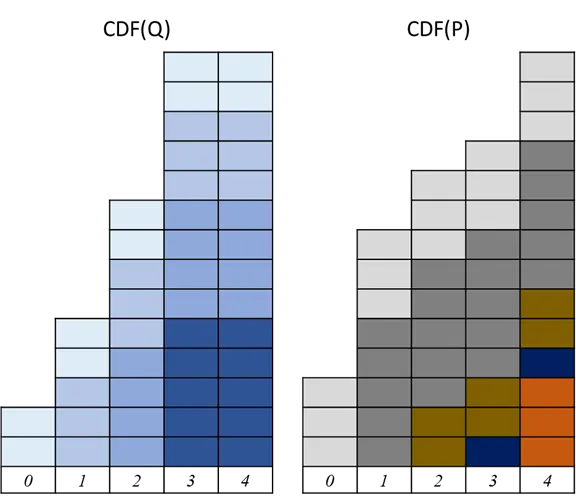
所以此範例基於CDF計算的Wasserstein distance (其實CDF是累積分布函數,所以裡面的element應該是機率,但換成機率計算很麻煩,所以我們算完再除上總數14個)
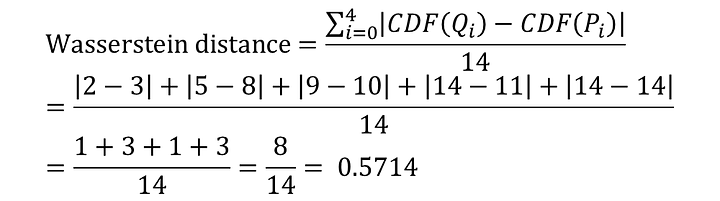
範例2:
CDF
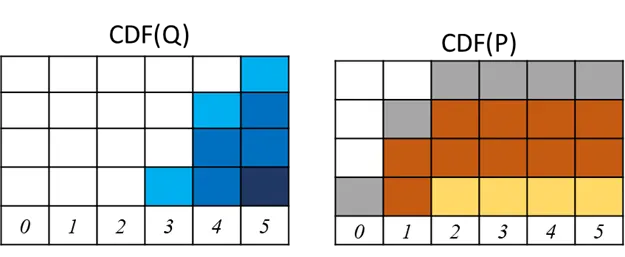
所以此範例基於CDF計算的Wasserstein distance (其實CDF是累積分布函數,所以裡面的element應該是機率,但換成機率計算很麻煩,所以我們算完再除上總數4個)
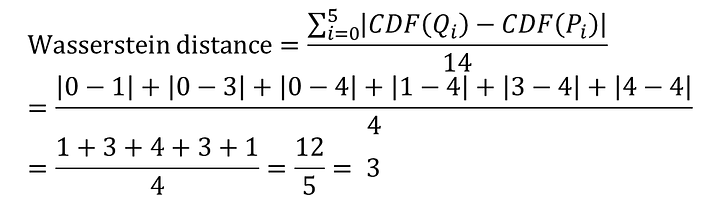
看到這邊如果還看不懂Wasserstein distance,我也愛莫能助,下一篇來寫為什麼在GAN要用Wasserstein distance