【DRL-7】Distributional DQN: Quantile Regression-DQN


论文
这篇文章在上一篇的基础之上做了扩展,作者还是同一拨人。
提要:QR-DQN是对DQN的扩展,是model-free,off-policy,value-based,discrete的方法。
听说点赞的人逢投必中。
在这之前你需要了解一些分位数和分位数回归的知识,建议先读
同时还有一些Bellman算子的知识,建议先读

首先我们来介绍一个数学概念,Wasserstein距离。
Wasserstein距离度量两个概率分布之间的距离,(狭义的)定义如下:
直接看这个式子可能过于抽象了,因为它和我们熟悉的度量不一样,它好像不是确定性的,而是带有一个 。
这里的Wasserstein距离又叫推土机距离,看下面的图,你就能很形象的理解Wasserstein距离。
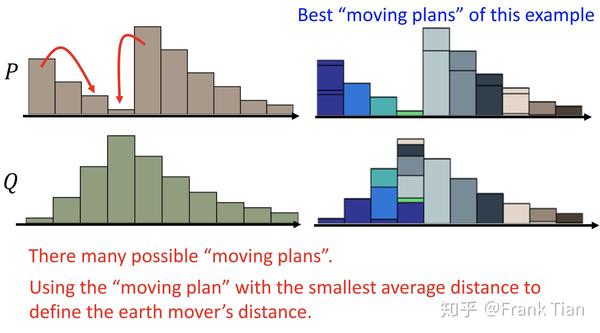
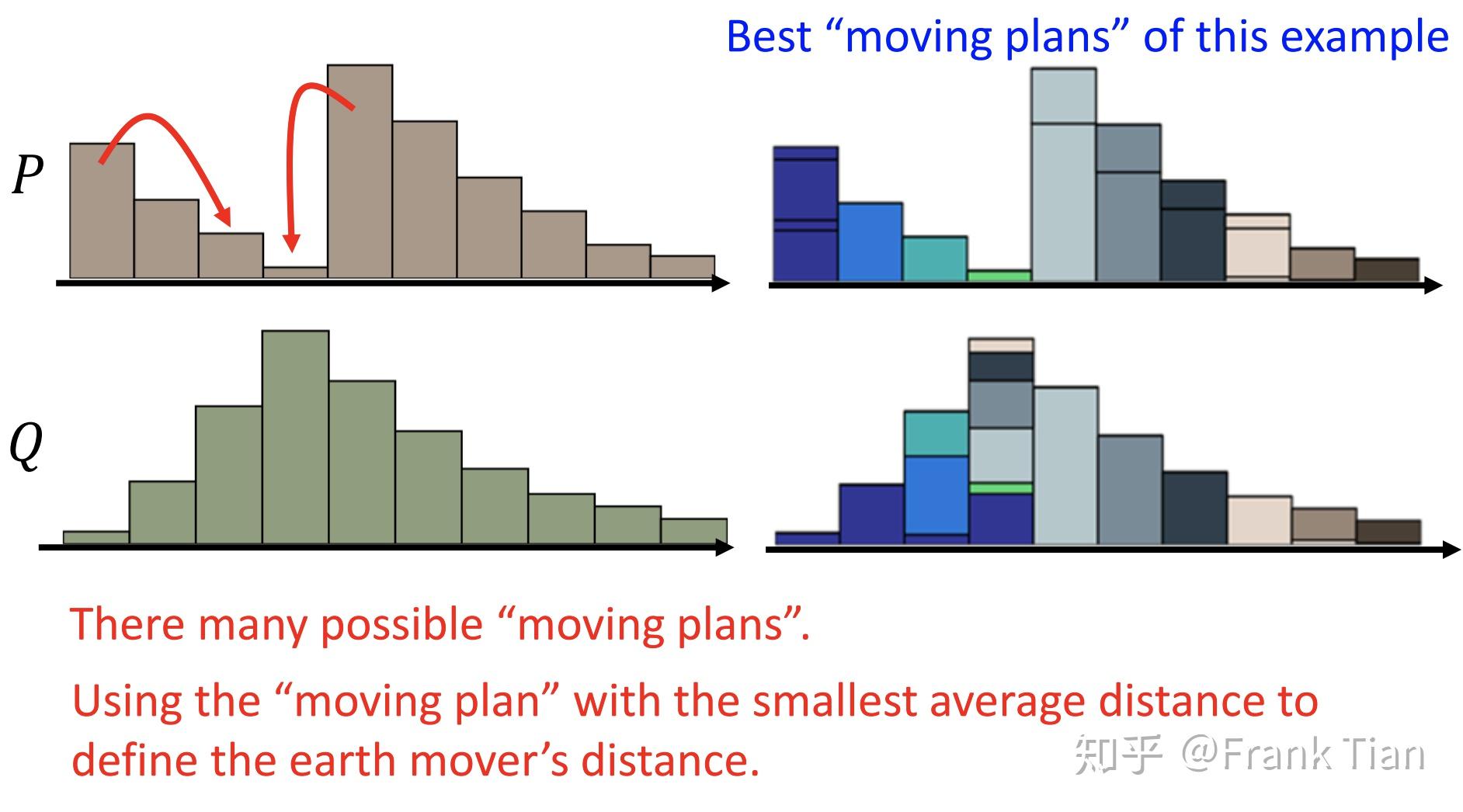
它的意思是,将一个分布转变为另一个分布,所需要移动的最少的“土”的量。
注意,因为是分布,概率的和为1,也就是说“土”的总量是相同的。同时,这个移动的量是指“土”的“距离*数量”。
可以看到,又很多种移动的方案,而Wasserstein距离指的是最少的那种,当然可能有多个方案都是最少,但是这不重要,重要的是移动的值。
我们把每一种移动方案叫做一个moving plan,用下面的矩阵表示:
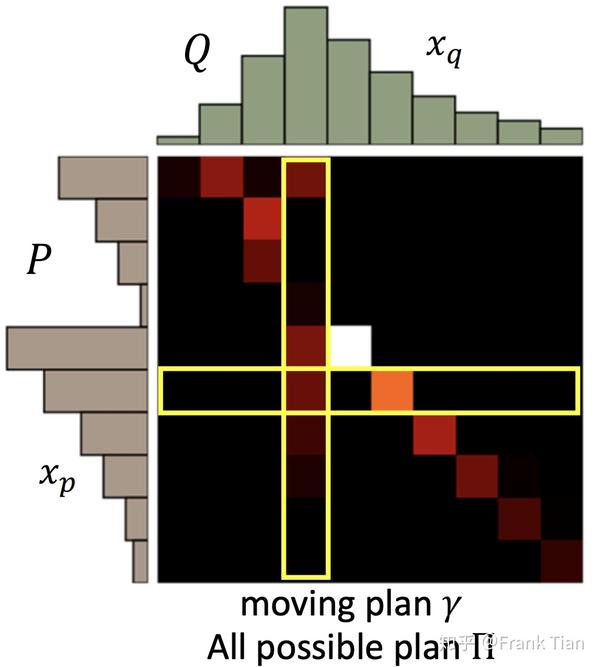
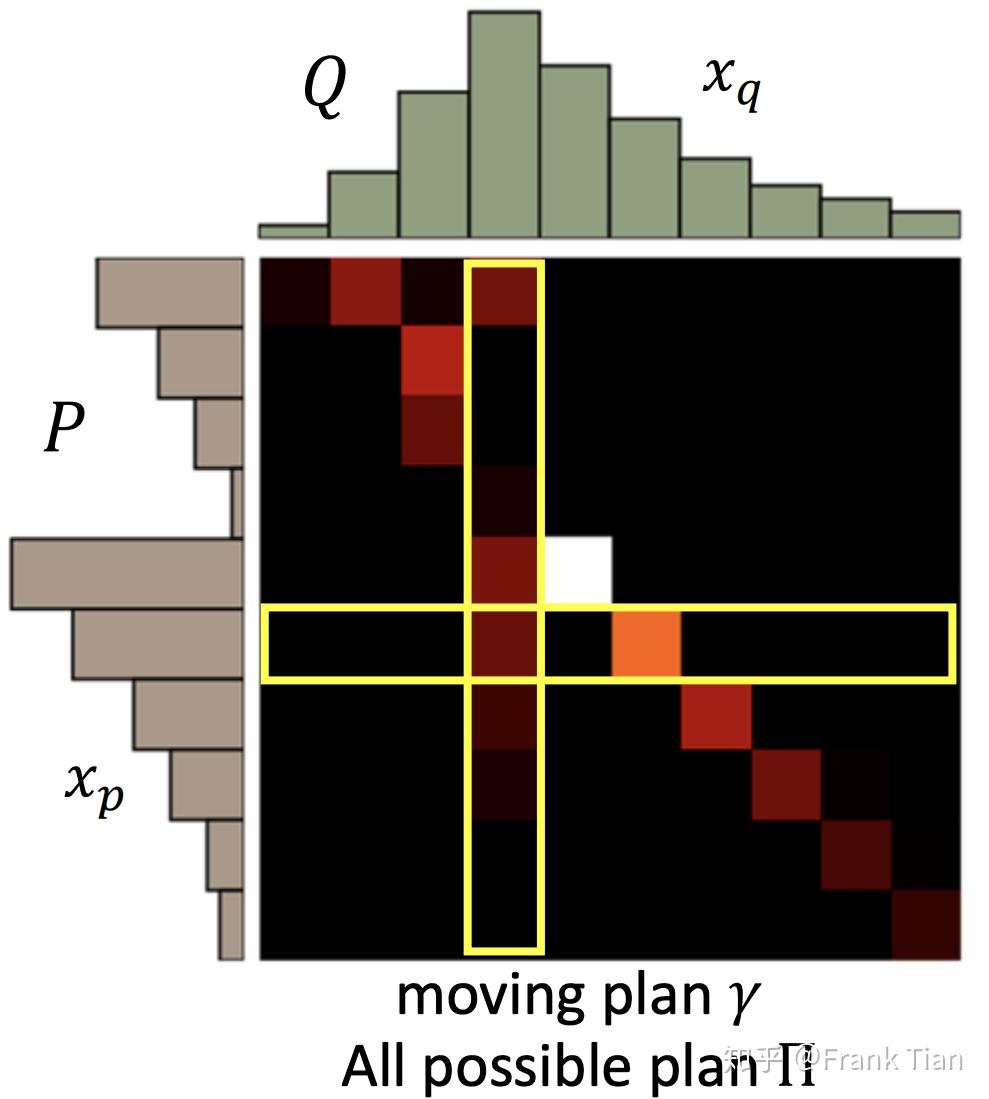
上面的矩阵代表了将P移动到Q的moving plan,明暗程度代表大小。
用 代表一个moving plan, 代表moving plans的全集。
的意思就是,从 中挑选出那个能让“移动土的量”最少的方案。
然而上述的定义只算是一个特例,标准的Wasserstein Metric的定义更为复杂,如果我有两个分布 ,那么它们的p-Wasserstein Metric为
其中
当 的时候,上面的公式就退化成为我们最开始看到的推土机距离。
当 的时候这个式子还是容易理解的,这里的 就是 的CDF函数,而 可以理解为计算 的 分位数。
而 的表达式,则是将这个代表分位数的 从 到 积分。
下图形象的描述了 情况下的Wasserstein Metric,这不过这个定义是连续的,刚才的那个是离散的。
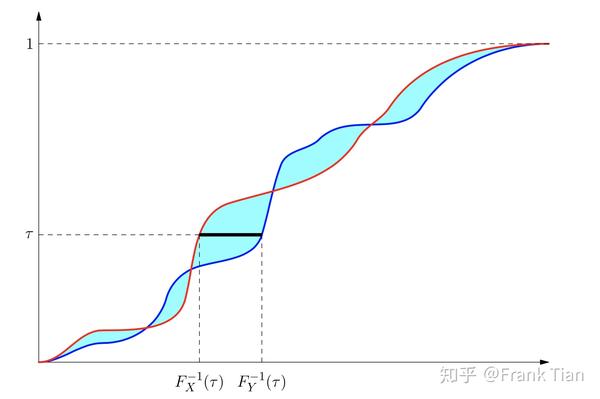
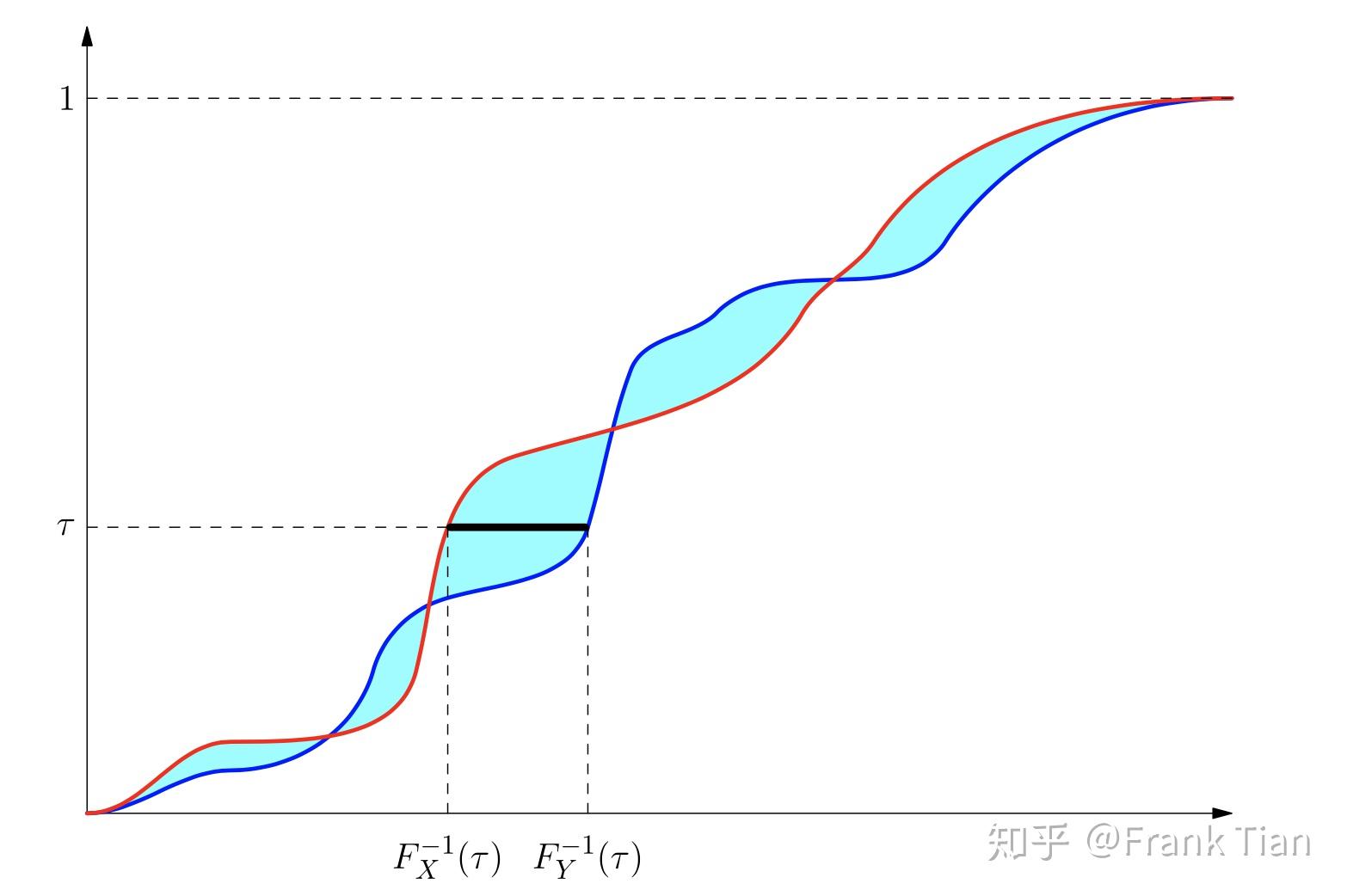
上图中红色和蓝色的线分别是 和 的CDF函数,对于某一个分位数 ,我们可以计算得到两个值,分别是 和 。
它们的差值的绝对值就是上图中黑线的长度,把这个长度积分就是青色部分的面积,这就代表了两个分布的差异。
接下来我们步入正题,在上一篇文章

中,我们说到,可以用 表示值分布,准确的说,它可以表示成下面的形式
接下来我们定义 这个函数所在的空间
在Bellman算子的那篇文章中,我们说我们如果想要证明某个方法能否收敛,需要证明它对应的算子有唯一的不动点,也就是要证明这个算子是的。
在 的例子中,我们证明bellman operator是的,即证明
这里的 表示直径,也就是这两个函数 和 的最远距离。
在值函数的例子中,这个 的定义很简单,就是 ,也就是它们差值的无穷范数。
注意,这里我们其实用到了两个度量,一个是“差值”,一个是“无穷范数”。第一个度量取决于你的实际用途,而第二个度量是不可避免的,因为它定义了“直径”。
在值分布的例子中,我们也要证明bellman operator是的,那么我们需要找到合适的度量。
这里的度量就是Wasserstein Metric。
于是,在这个例子中, 就变成了
其中的 发挥了无穷级数的作用,而 发挥了第一个度量,也就是差值的作用。
那么,要证明值分布的情况下算法依旧收敛,只需要证明对于任意的 ,有
这里我们就不做证明了,具体证明在论文的附录中有。
上面的说明给值分布的算法提供了理论保证,但是一开始作者们并没有想到合适的方法模拟Wasserstein Metric这个过程,于是提出了使用KL散度做近似的想法。
实际上,基于这个想法提出的C51算法确实效果不错。
然而,紧接着作者们又提出了更“正统”的算法QR-DQN,它继承了最开始的理论想法。
首先,我们要做的是改变“分布”的表现形式。
是 的函数,它的输出是一个分布 。
我们一开始是用 个atoms 作为基准,再用 个离散的分布 来描述这个分布。
这种形式用来计算KL散度是极好的,但是不适合计算W度量,现在我们介绍另外一种,是用分位数描述的方法。
其实也很直觉,就是按照这个分布的CDF的 轴,把它均等的分成 分,例如下面的是分布的PDF的 轴,我们把它分成10等分


那么自然就会得到10个 ,这10个 就定义了10个分位数
分位数是下图的小红点
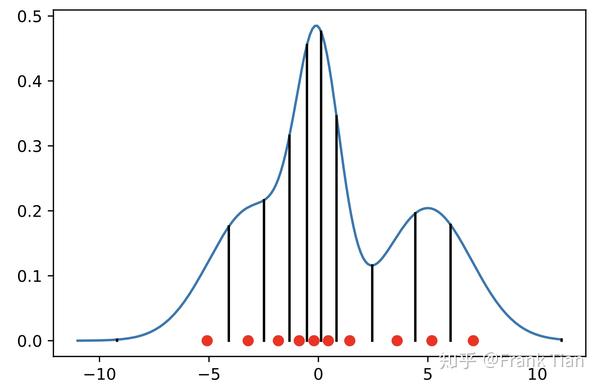
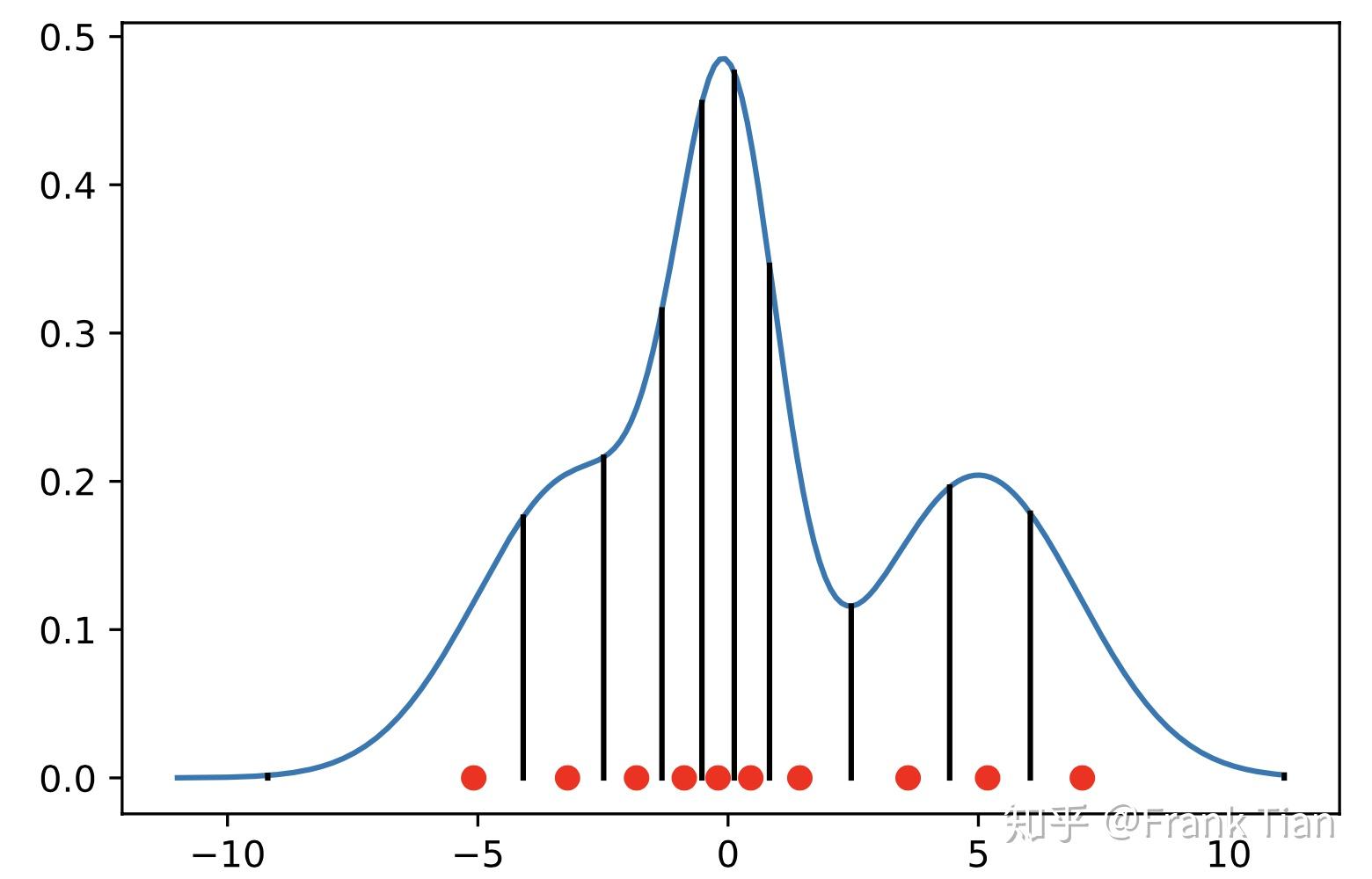
于是,我们现在只需要记录 个分位数的位置,就可以描述整个分布了。
接下来,我们如何去学习出这 个分位数呢?
还记得在C中,我们设计了一个神经网络 ,它的输入是状态 ,输出是一个矩阵,矩阵的每一行代表一个动作的 个概率,分别是 。
而学习出分位数,就需要分位数回归的知识了。
我在这里再简单叙述一下。
在传统的回归中,我们想要的是,对于一个自变量 ,条件概率 的期望,因此我们的损失函数是
其中 就代表了模型的参数。这是很显然的,因为让MSE最小的点正好是期望。
如果我们想求 的中位数呢?那就不能再用MSE了,而是应该用MAE
上面的式子也可以表示为
这个式子的来历很简单,就是分类讨论了一下。
在训练的时候,也很容易求梯度
其中
可以把梯度理解为将 往中间推的力量。
实际上,我们说中位数就是 的分位数,求其他任意的分位数也很容易扩展了
这可以看作推的力量有了一个“加权“,使之不再正好往中间推,而是推向了某一个位置,这个位置正是由 决定的。
梯度表示为
其中
我们还可以换一种形式表示 ,令 表示
于是
所以
其中
因为 在 出不可导,我们可以把它换成其他函数,论文中使用的是
这个 可以看作另一个超参数,但是其实没有调节它的必要啦。
当 时
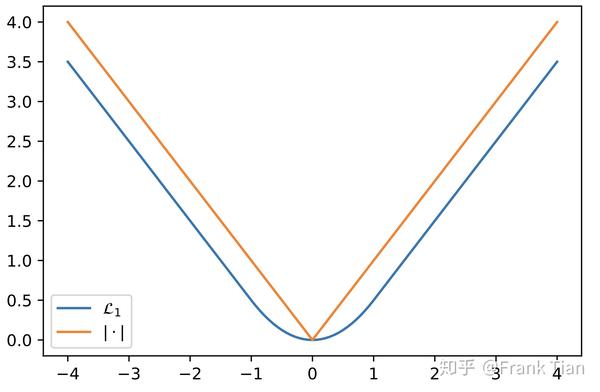
那么现在我们有
对比一下 和
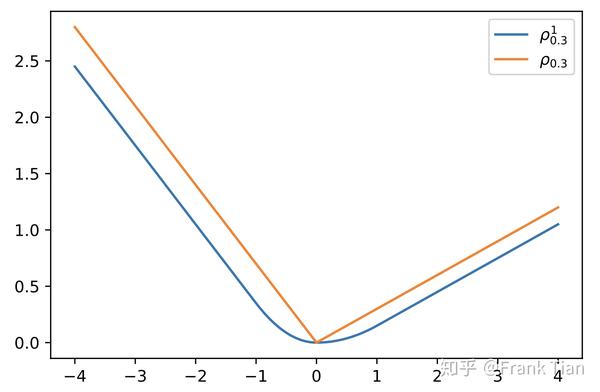
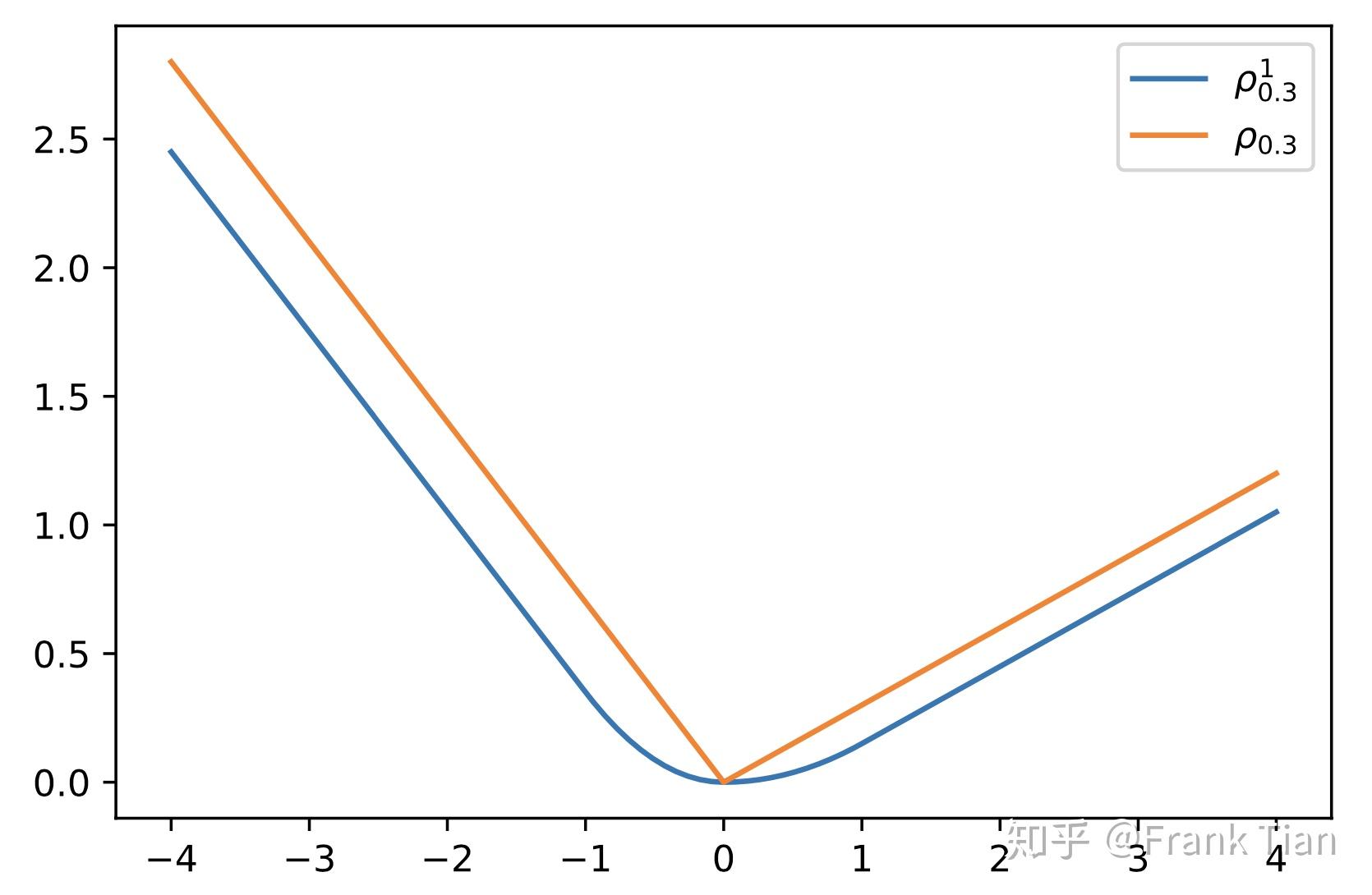
最终我们把损失函数定义为
在QR-DQN中,神经网络是怎么定义的呢?
其实和C51的很像,也是输出一个矩阵,只不过每列不再是atoms对应的 了,而是atoms的位置,也就是 ,因为在QR-DQN中atoms的概率是确定的,都是 。
现在让我们看一下训练的过程。
首先我们从Buffer中采样出 ,接下来我们需要计算出 ,和C51的想法一样,我们依旧用 来计算。
先算
挑出最大的作为
根据这个 计算出分布 ,我们设这个分布的atoms的位置表示为
那么目标分布表示为
这里的好处是不用再对齐了,因为我们的atoms的位置是可以改变的,而正是用这个变量来描述整个分布,自然没有对齐之说。
最关键的是,我们要让分布 和目标分布 尽可能相似。
我们假设用 来描述分布 ,这其实就是 个分位数。
那么描述目标分布的 就可以当作ground truth,也就是把他们看作 中不同的 。
此外,我们并不是只有一个 ,我们有 个 ,我们需要计算它们的损失函数的和,也就是
其中
而 就是用来决定 个分位数的值
最后算法如下


我们来直观的感受一下QR-DQN做了什么。
假设我们现在可以画出 ,它就是下图的红线
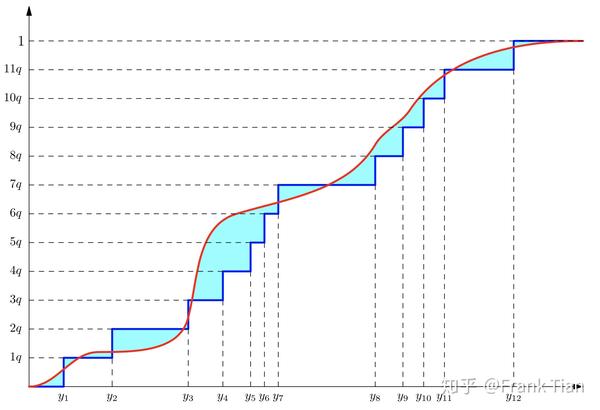
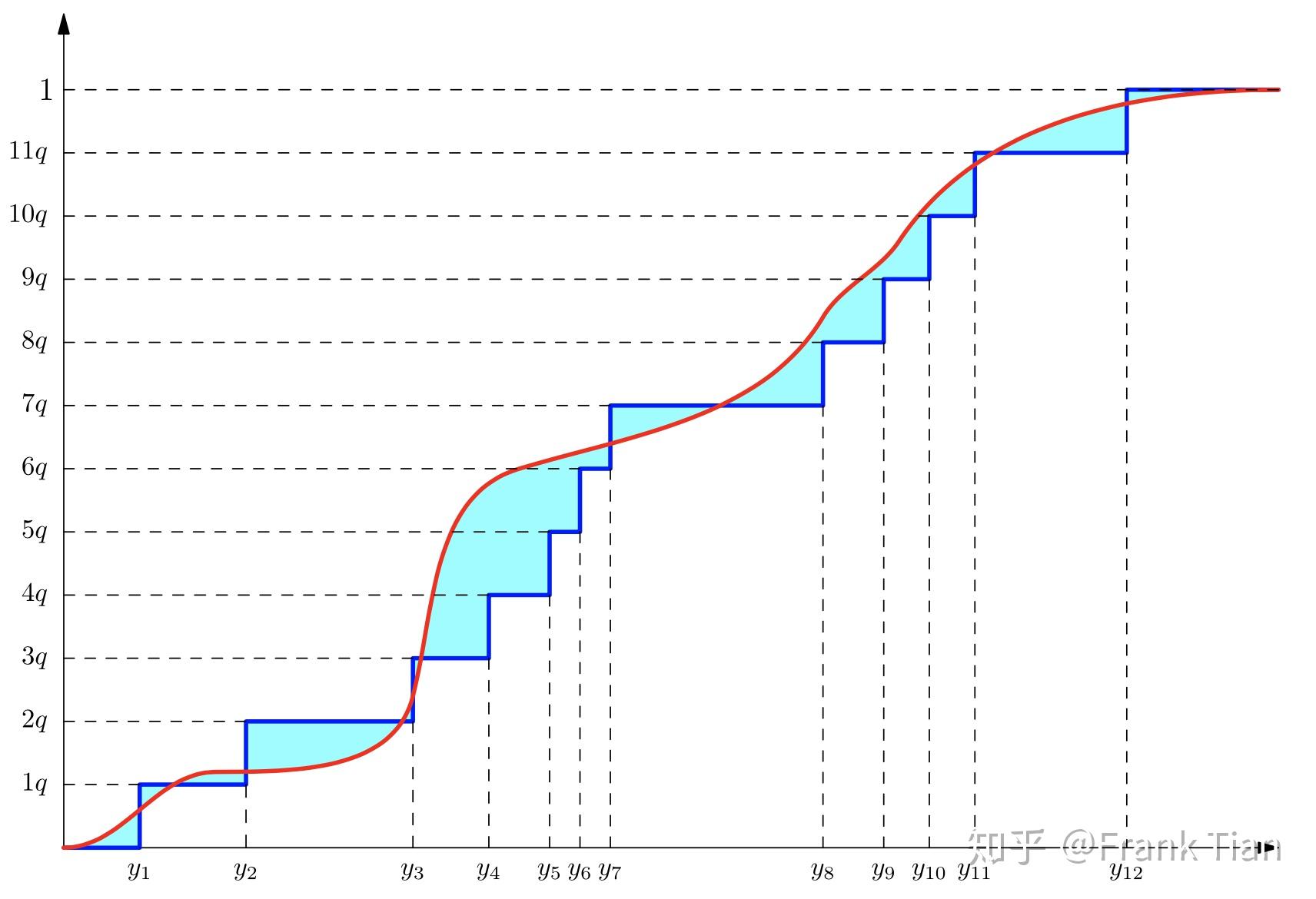
那么蓝色的线就是初始状态的 。
从Distributional DQN定义的角度,我们希望什么呢?我们希望青色的面积更小。
那么QR-DQN希望什么呢?
它希望 可以可以作为 对应的分位数, 可以可以作为 对应的分位数,以此类推。
如果做到了这一点,图像就会变成
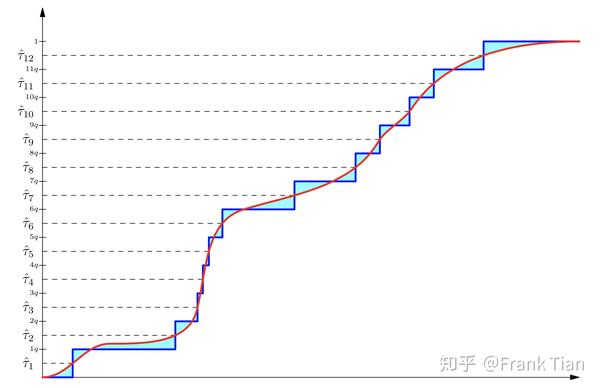
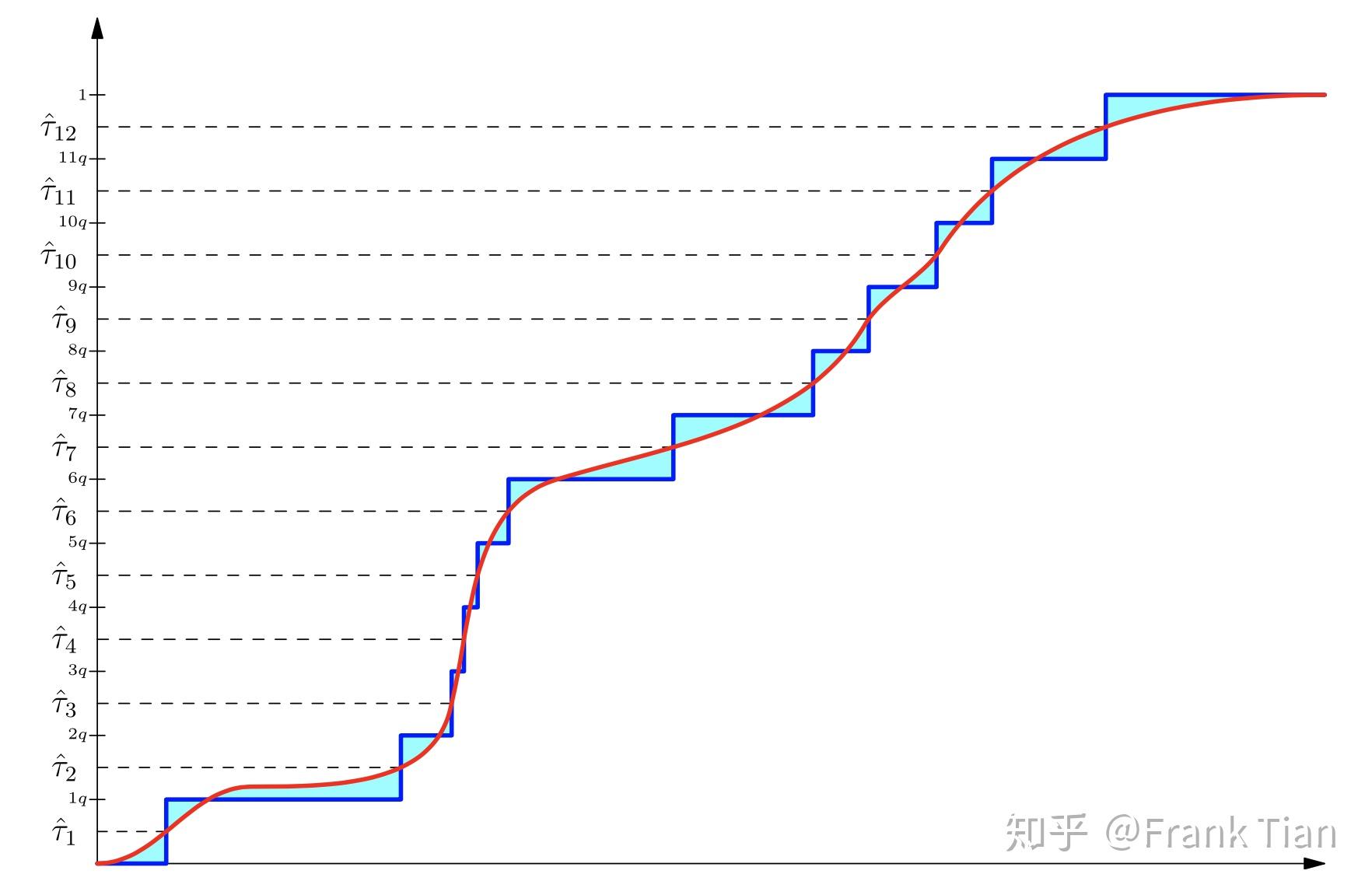
Amazing啊,青色这不就变少了。
如果我们调节超参数 ,让QR-DQN的分布描述的更细致,会变成
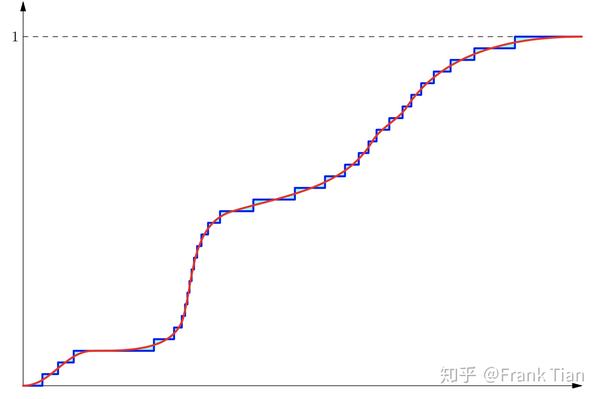
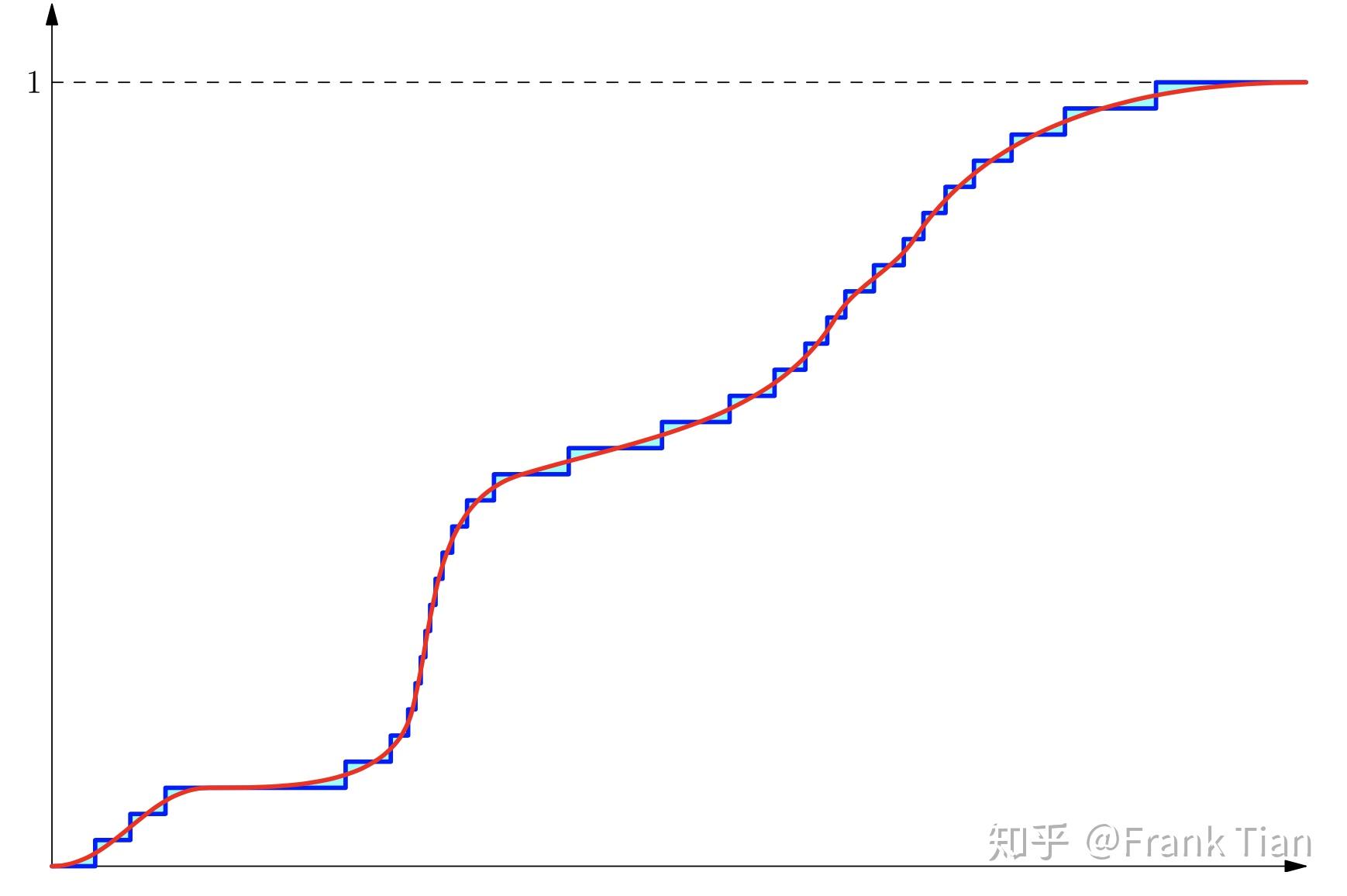
青色更少了。
本文参考自