【DRL-8】Distributional DQN: Implicit Quantile Nets


论文
提要:IQN是对DQN的扩展,是model-free,off-policy,value-based,discrete的方法。
听说点赞的人逢投必中。
在介绍IQN之前我们现在说说Risk-Sensitive Reinforcement Learning。
Risk-Sensitive强化学习指的是我们在针对相同的 分布时,根据不同的偏好,应该做出不同的动作。
在以前的DQN中,这种事情是不肯呢个发生的,因为回想一下,我们是拿不到 的分布的,我们用来评价每一个 的信息只有 ,这只是一个实数。
还记得小学的数学题吗,两个打枪的运动员,一个均值很高但方差也很大,另一个均值没那么高但是实力稳定,在不同的情况下我们会选择不同的运动员。
比如如果你们国家的实力很菜,那就不如让第一个去,万一呢。
但是如果你们实力比较强,这时候讲究发挥稳定,这时候就应该派第二个去了。
这就是所谓的偏好,在不同任务,不同场景下,我们的偏好应该不同。
在DQN中,我们只能拿到一个 ,也就是 ,连方差都没有,自然没办法作出这种抉择。
我们把对待风险两种不同的态度成为risk-averse和risk-seeking,接下来,我们用一种正式的数学语言来描述它们。
描述这种偏好的公理被成为独立性,它有两个版本。
版本一
如果有两个随机变量 ,我们相比 更偏好 ,写作 ,那么这代表对任何随机变量 , 和 的混合都优于 和 的混合,这种“优于”表示为
在这种情况下,我们可以找到一个效用函数 来描述这种偏好,那么策略可以表示为
版本二
如果有两个随机变量 ,我们相比 更偏好 ,写作 ,那么这代表对任何随机变量 , 和 的混合都优于 和 的混合,这种“优于”表示为
在这种情况下,我们可以找到一个distortion risk measure 来描述这种偏好,那么策略可以表示为
可以证明,这两种表示是可逆的,也就是哪个方便按哪个来。
举个例子,在第一个版本中,如果 ,那么策略就会变成
在第二个版本中,如果 ,那么策略就会变成
这两者便等价了。
在IQN中,我们倾向于使用第二种表示,因为它可以推导出一种很容易计算的表示。
不难证明,
令
其中 是一个 ,被称为distortion risk measure,我们定义基于 的distorted expectation
其中 ,显然
这就把 和前面的风险偏好联系起来了。
最后,策略可以表示为
接下来再让我们看看不同的 就起到什么不同的效果。
整理而言,当 为凸函数时,偏好是risk-averse的,当 为凹函数时,偏好是risk-seeking的。
有一些现成的函数可以作为
CPW函数
Wang函数(其中 是标准正态分布的CDF函数)
Pow函数
conditional value-at-risk函数
这些函数的 都可以看作是超参数,而 则是自变量,例如
下面是有关这些函数的图像
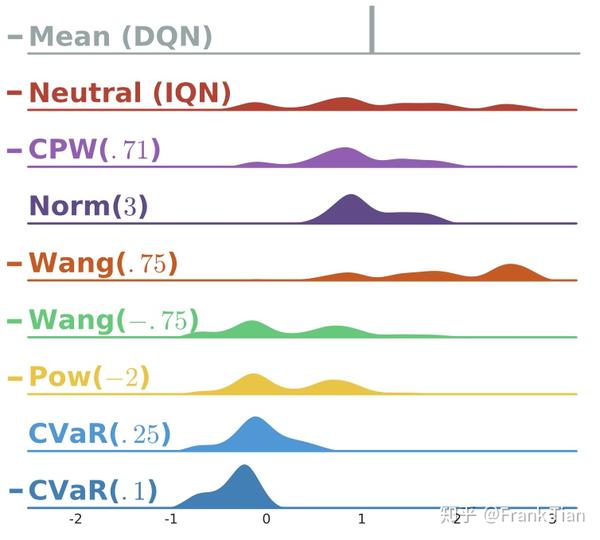
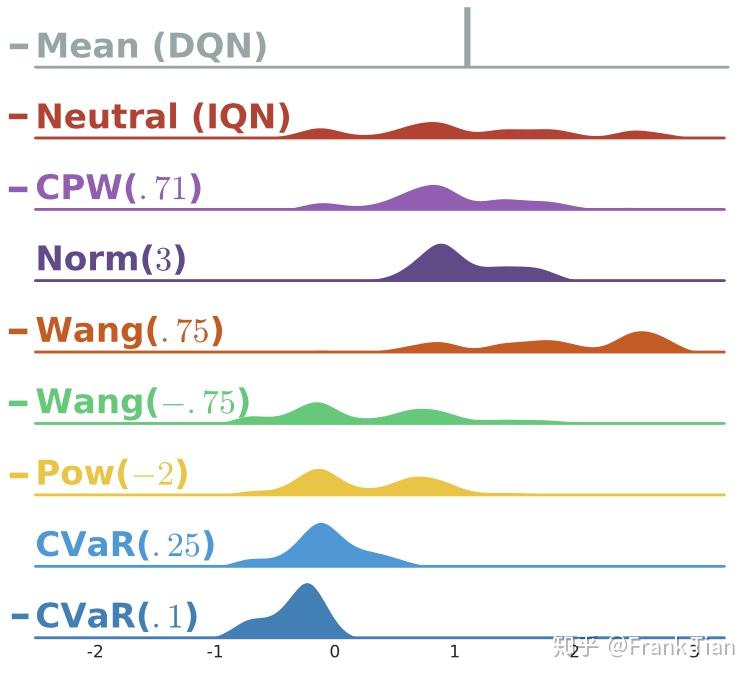
第二列的Neutral是原始的 的分布,而其他列的图像都是经过加工后的 的图像。
可以看到,这些不同的 有些对风险比较积极,例如 ,而有些则很保守,只集中在原分布中值比较大的部分,例如 。
最后,让我们步入正题,看看IQN是怎么训练的。
下面的图很好的描绘来DQN,C51,QR-DQN和IQN的区别。
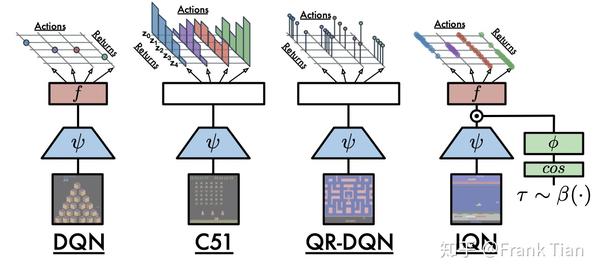
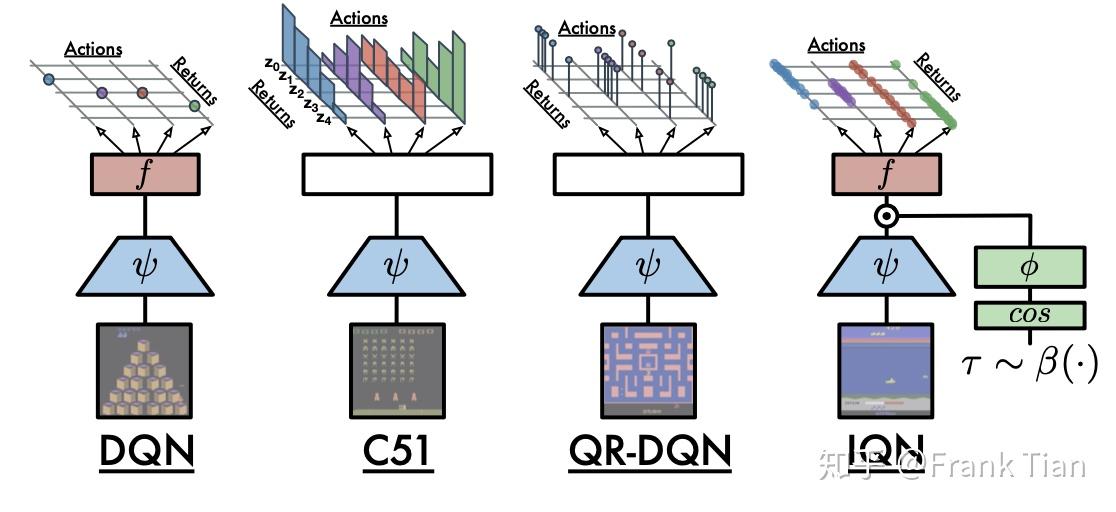
C51,QR-DQN和IQN都是想去学习一个分布,但是它们的方式并不一样。
C51和QR-DQN是去找到了一种间接的方式去表示这个分布,也就是用atoms的方式。
而IQN更像是直接的学出了这个分布。
IQN的输入和输出是什么呢?
它是输入是状态 ,和采样 ,而输出和DQN很像,是一个 维的向量。
区别在于,DQN只能输出每个动作的期望,而IQN可以根据输入的 ,输出每个动作的 分位数。
这样看来,IQN和C51,QR-DQN的不同之处在于,它不在想办法表示这个分布,它直接就是这个分布!
那这个前面提到的Risk-Sensitive强化学习有什么关系呢?
试想,如果我们可以学习出 ,那么不就可以计算出对于任何 的 了吗?这样我们就可以在作出决定的时候根据我们的偏好,而不是只能根据期望 去计算。
那么,最后的问题,这个网络怎么训练呢?
首先还是从Buffer中拿到采样 。
接下来我们要根据 选出最好的动作 。
但是,这里我们不再用 算出 选择了,而是应该加入偏好 ,当然,如果没有特殊的偏好,令 即可。
我们需要事先设定一个超参数 ,用来决定计算 的采样次数,于是
其中
于是
接下来我们要缩短 和 这两个分布之间的距离。
但是我们现在没有某种表示去表示这个分布了,我们的网络就是分布本身。
因此我们需要从网络中采样,来估计这两个分布。我们又引入两个超参数 ,分别代表估计这两个分布所需要的采样次数,于是有
对于两个单独的 ,它们之间的差表示为
那么总的差值就是
我们没有用 而是用 这是因为我们本质上还是在做分位数回归,而不是标准的回归。
最后, 表示的是绝对值函数的软化,我们在上一篇文章中提到过
最终的算法如下

