强化学习——每次访问MC方法和首次访问MC方法的相关理论证明
前言
本文主要给出每次访问MC方法和首次访问MC方法的相关理论证明,方便大家从根本上去理解这两种方法。
示例——首次访问MC方法和每次访问MC方法的区别
- 首次访问蒙特卡洛策略评估
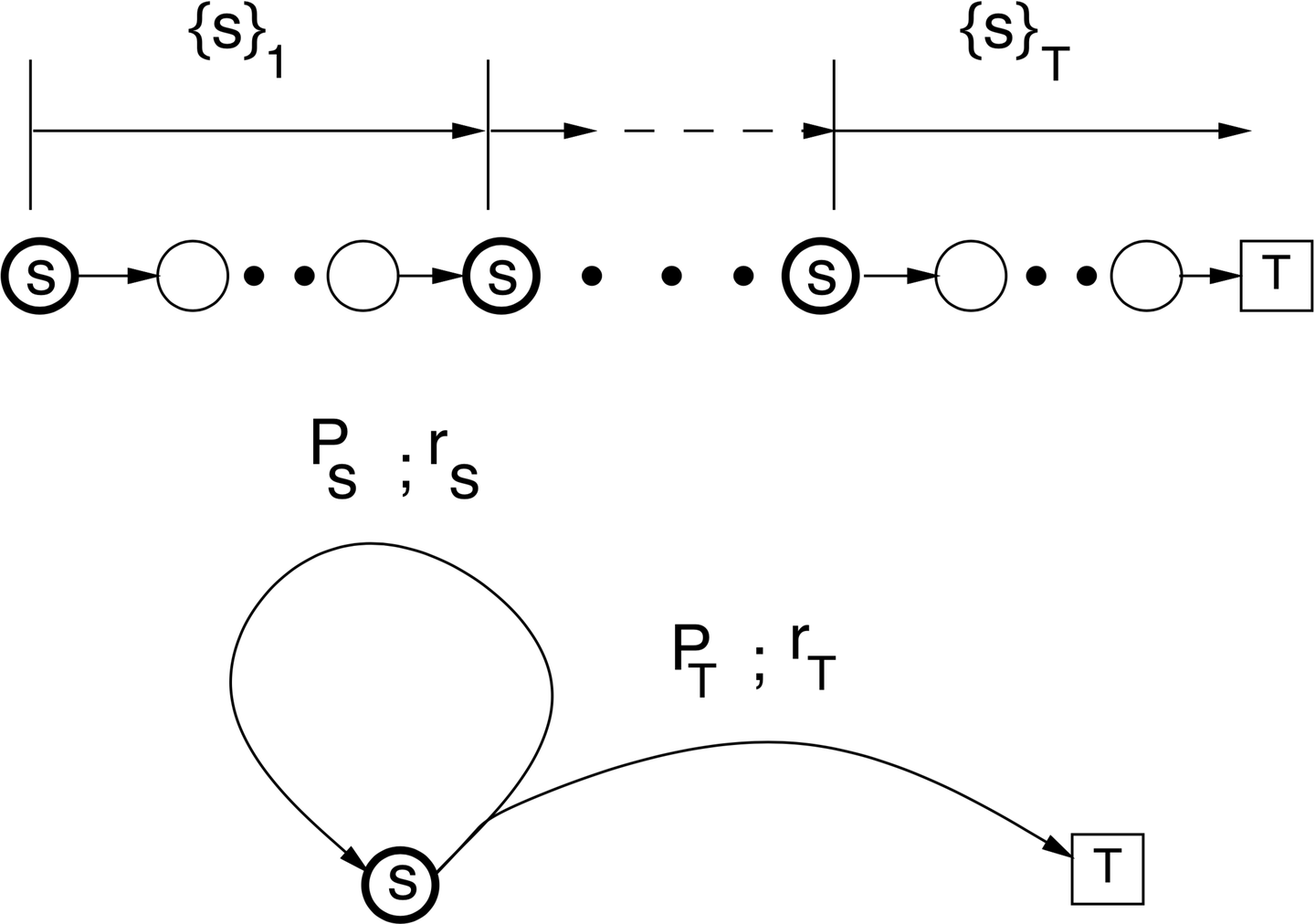
在给定一个策略,使用一系列完整episode评估某一个状态 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuMDlleCIgaGVpZ2h0PSIxLjY3NmV4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTAuMzM4ZXg7IiB2aWV3Qm94PSIwIC01NzYuMSA0NjkuNSA3MjEuNiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 时,对于每一个episode,仅当该状态 首次出现的时间
时,对于每一个episode,仅当该状态 首次出现的时间 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjAuODRleCIgaGVpZ2h0PSIyLjAwOWV4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTAuMzM4ZXg7IiB2aWV3Qm94PSIwIC03MTkuNiAzNjEuNSA4NjUuMSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03NCIgZD0iTTI2IDM4NVExOSAzOTIgMTkgMzk1UTE5IDM5OSAyMiA0MTFUMjcgNDI1UTI5IDQzMCAzNiA0MzBUODcgNDMxSDE0MEwxNTkgNTExUTE2MiA1MjIgMTY2IDU0MFQxNzMgNTY2VDE3OSA1ODZUMTg3IDYwM1QxOTcgNjE1VDIxMSA2MjRUMjI5IDYyNlEyNDcgNjI1IDI1NCA2MTVUMjYxIDU5NlEyNjEgNTg5IDI1MiA1NDlUMjMyIDQ3MEwyMjIgNDMzUTIyMiA0MzEgMjcyIDQzMUgzMjNRMzMwIDQyNCAzMzAgNDIwUTMzMCAzOTggMzE3IDM4NUgyMTBMMTc0IDI0MFExMzUgODAgMTM1IDY4UTEzNSAyNiAxNjIgMjZRMTk3IDI2IDIzMCA2MFQyODMgMTQ0UTI4NSAxNTAgMjg4IDE1MVQzMDMgMTUzSDMwN1EzMjIgMTUzIDMyMiAxNDVRMzIyIDE0MiAzMTkgMTMzUTMxNCAxMTcgMzAxIDk1VDI2NyA0OFQyMTYgNlQxNTUgLTExUTEyNSAtMTEgOTggNFQ1OSA1NlE1NyA2NCA1NyA4M1YxMDFMOTIgMjQxUTEyNyAzODIgMTI4IDM4M1ExMjggMzg1IDc3IDM4NUgyNloiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NCIgeD0iMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 列入计算:
列入计算:
状态出现的次数加1: ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjE3LjU0NGV4IiBoZWlnaHQ9IjIuODQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMC44MzhleDsiIHZpZXdCb3g9IjAgLTg2My4xIDc1NTMuNSAxMjIzLjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNEUiIGQ9Ik0yMzQgNjM3UTIzMSA2MzcgMjI2IDYzN1EyMDEgNjM3IDE5NiA2MzhUMTkxIDY0OVExOTEgNjc2IDIwMiA2ODJRMjA0IDY4MyAyOTkgNjgzUTM3NiA2ODMgMzg3IDY4M1Q0MDEgNjc3UTYxMiAxODEgNjE2IDE2OEw2NzAgMzgxUTcyMyA1OTIgNzIzIDYwNlE3MjMgNjMzIDY1OSA2MzdRNjM1IDYzNyA2MzUgNjQ4UTYzNSA2NTAgNjM3IDY2MFE2NDEgNjc2IDY0MyA2NzlUNjUzIDY4M1E2NTYgNjgzIDY4NCA2ODJUNzY3IDY4MFE4MTcgNjgwIDg0MyA2ODFUODczIDY4MlE4ODggNjgyIDg4OCA2NzJRODg4IDY1MCA4ODAgNjQyUTg3OCA2MzcgODU4IDYzN1E3ODcgNjMzIDc2OSA1OTdMNjIwIDdRNjE4IDAgNTk5IDBRNTg1IDAgNTgyIDJRNTc5IDUgNDUzIDMwNUwzMjYgNjA0TDI2MSAzNDRRMTk2IDg4IDE5NiA3OVEyMDEgNDYgMjY4IDQ2SDI3OFEyODQgNDEgMjg0IDM4VDI4MiAxOVEyNzggNiAyNzIgMEgyNTlRMjI4IDIgMTUxIDJRMTIzIDIgMTAwIDJUNjMgMlQ0NiAxUTMxIDEgMzEgMTBRMzEgMTQgMzQgMjZUMzkgNDBRNDEgNDYgNjIgNDZRMTMwIDQ5IDE1MCA4NVExNTQgOTEgMjIxIDM2MkwyODkgNjM0UTI4NyA2MzUgMjM0IDYzN1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIxOTAiIGQ9Ik05NDQgMjYxVDk0NCAyNTBUOTI5IDIzMEgxNjVRMTY3IDIyOCAxODIgMjE2VDIxMSAxODlUMjQ0IDE1MlQyNzcgOTZUMzAzIDI1UTMwOCA3IDMwOCAwUTMwOCAtMTEgMjg4IC0xMVEyODEgLTExIDI3OCAtMTFUMjcyIC03VDI2NyAyVDI2MyAyMVEyNDUgOTQgMTk1IDE1MVQ3MyAyMzZRNTggMjQyIDU1IDI0N1E1NSAyNTQgNTkgMjU3VDczIDI2NFExMjEgMjgzIDE1OCAzMTRUMjE1IDM3NVQyNDcgNDM0VDI2NCA0ODBMMjY3IDQ5N1EyNjkgNTAzIDI3MCA1MDVUMjc1IDUwOVQyODggNTExUTMwOCA1MTEgMzA4IDUwMFEzMDggNDkzIDMwMyA0NzVRMjkzIDQzOCAyNzggNDA2VDI0NiAzNTJUMjE1IDMxNVQxODUgMjg3VDE2NSAyNzBIOTI5UTk0NCAyNjEgOTQ0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJCIiBkPSJNNTYgMjM3VDU2IDI1MFQ3MCAyNzBIMzY5VjQyMEwzNzAgNTcwUTM4MCA1ODMgMzg5IDU4M1E0MDIgNTgzIDQwOSA1NjhWMjcwSDcwN1E3MjIgMjYyIDcyMiAyNTBUNzA3IDIzMEg0MDlWLTY4UTQwMSAtODIgMzkxIC04MkgzODlIMzg3UTM3NSAtODIgMzY5IC02OFYyMzBINzBRNTYgMjM3IDU2IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00RSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9Ijg4OCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMjc4IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTc0NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjE5MCIgeD0iMjQxNCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTRFIiB4PSIzNjkzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iNDU4MSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI0OTcxIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iNTQ0MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjYwNTIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSI3MDUzIiB5PSIwIj48L3VzZT4KPC9nPgo8L3N2Zz4=)
总的收获值更新: ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjE3LjkwNWV4IiBoZWlnaHQ9IjIuODQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMC44MzhleDsiIHZpZXdCb3g9IjAgLTg2My4xIDc3MDkuMSAxMjIzLjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTMiIGQ9Ik0zMDggMjRRMzY3IDI0IDQxNiA3NlQ0NjYgMTk3UTQ2NiAyNjAgNDE0IDI4NFEzMDggMzExIDI3OCAzMjFUMjM2IDM0MVExNzYgMzgzIDE3NiA0NjJRMTc2IDUyMyAyMDggNTczVDI3MyA2NDhRMzAyIDY3MyAzNDMgNjg4VDQwNyA3MDRINDE4SDQyNVE1MjEgNzA0IDU2NCA2NDBRNTY1IDY0MCA1NzcgNjUzVDYwMyA2ODJUNjIzIDcwNFE2MjQgNzA0IDYyNyA3MDRUNjMyIDcwNVE2NDUgNzA1IDY0NSA2OThUNjE3IDU3N1Q1ODUgNDU5VDU2OSA0NTZRNTQ5IDQ1NiA1NDkgNDY1UTU0OSA0NzEgNTUwIDQ3NVE1NTAgNDc4IDU1MSA0OTRUNTUzIDUyMFE1NTMgNTU0IDU0NCA1NzlUNTI2IDYxNlQ1MDEgNjQxUTQ2NSA2NjIgNDE5IDY2MlEzNjIgNjYyIDMxMyA2MTZUMjYzIDUxMFEyNjMgNDgwIDI3OCA0NThUMzE5IDQyN1EzMjMgNDI1IDM4OSA0MDhUNDU2IDM5MFE0OTAgMzc5IDUyMiAzNDJUNTU0IDI0MlE1NTQgMjE2IDU0NiAxODZRNTQxIDE2NCA1MjggMTM3VDQ5MiA3OFQ0MjYgMThUMzMyIC0yMFEzMjAgLTIyIDI5OCAtMjJRMTk5IC0yMiAxNDQgMzNMMTM0IDQ0TDEwNiAxM1E4MyAtMTQgNzggLTE4VDY1IC0yMlE1MiAtMjIgNTIgLTE0UTUyIC0xMSAxMTAgMjIxUTExMiAyMjcgMTMwIDIyN0gxNDNRMTQ5IDIyMSAxNDkgMjE2UTE0OSAyMTQgMTQ4IDIwN1QxNDQgMTg2VDE0MiAxNTNRMTQ0IDExNCAxNjAgODdUMjAzIDQ3VDI1NSAyOVQzMDggMjRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMTkwIiBkPSJNOTQ0IDI2MVQ5NDQgMjUwVDkyOSAyMzBIMTY1UTE2NyAyMjggMTgyIDIxNlQyMTEgMTg5VDI0NCAxNTJUMjc3IDk2VDMwMyAyNVEzMDggNyAzMDggMFEzMDggLTExIDI4OCAtMTFRMjgxIC0xMSAyNzggLTExVDI3MiAtN1QyNjcgMlQyNjMgMjFRMjQ1IDk0IDE5NSAxNTFUNzMgMjM2UTU4IDI0MiA1NSAyNDdRNTUgMjU0IDU5IDI1N1Q3MyAyNjRRMTIxIDI4MyAxNTggMzE0VDIxNSAzNzVUMjQ3IDQzNFQyNjQgNDgwTDI2NyA0OTdRMjY5IDUwMyAyNzAgNTA1VDI3NSA1MDlUMjg4IDUxMVEzMDggNTExIDMwOCA1MDBRMzA4IDQ5MyAzMDMgNDc1UTI5MyA0MzggMjc4IDQwNlQyNDYgMzUyVDIxNSAzMTVUMTg1IDI4N1QxNjUgMjcwSDkyOVE5NDQgMjYxIDk0NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yQiIgZD0iTTU2IDIzN1Q1NiAyNTBUNzAgMjcwSDM2OVY0MjBMMzcwIDU3MFEzODAgNTgzIDM4OSA1ODNRNDAyIDU4MyA0MDkgNTY4VjI3MEg3MDdRNzIyIDI2MiA3MjIgMjUwVDcwNyAyMzBINDA5Vi02OFE0MDEgLTgyIDM5MSAtODJIMzg5SDM4N1EzNzUgLTgyIDM2OSAtNjhWMjMwSDcwUTU2IDIzNyA1NiAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDciIGQ9Ik01MCAyNTJRNTAgMzY3IDExNyA0NzNUMjg2IDY0MVQ0OTAgNzA0UTU4MCA3MDQgNjMzIDY1M1E2NDIgNjQzIDY0OCA2MzZUNjU2IDYyNkw2NTcgNjIzUTY2MCA2MjMgNjg0IDY0OVE2OTEgNjU1IDY5OSA2NjNUNzE1IDY3OVQ3MjUgNjkwTDc0MCA3MDVINzQ2UTc2MCA3MDUgNzYwIDY5OFE3NjAgNjk0IDcyOCA1NjFRNjkyIDQyMiA2OTIgNDIxUTY5MCA0MTYgNjg3IDQxNVQ2NjkgNDEzSDY1M1E2NDcgNDE5IDY0NyA0MjJRNjQ3IDQyMyA2NDggNDI5VDY1MCA0NDlUNjUxIDQ4MVE2NTEgNTUyIDYxOSA2MDVUNTEwIDY1OVE0OTIgNjU5IDQ3MSA2NTZUNDE4IDY0M1QzNTcgNjE1VDI5NCA1NjdUMjM2IDQ5NlQxODkgMzk0VDE1OCAyNjBRMTU2IDI0MiAxNTYgMjIxUTE1NiAxNzMgMTcwIDEzNlQyMDYgNzlUMjU2IDQ1VDMwOCAyOFQzNTMgMjRRNDA3IDI0IDQ1MiA0N1Q1MTQgMTA2UTUxNyAxMTQgNTI5IDE2MVQ1NDEgMjE0UTU0MSAyMjIgNTI4IDIyNFQ0NjggMjI3SDQzMVE0MjUgMjMzIDQyNSAyMzVUNDI3IDI1NFE0MzEgMjY3IDQzNyAyNzNINDU0UTQ5NCAyNzEgNTk0IDI3MVE2MzQgMjcxIDY1OSAyNzFUNjk1IDI3MlQ3MDcgMjcyUTcyMSAyNzIgNzIxIDI2M1E3MjEgMjYxIDcxOSAyNDlRNzE0IDIzMCA3MDkgMjI4UTcwNiAyMjcgNjk0IDIyN1E2NzQgMjI3IDY1MyAyMjRRNjQ2IDIyMSA2NDMgMjE1VDYyOSAxNjRRNjIwIDEzMSA2MTQgMTA4UTU4OSA2IDU4NiAzUTU4NCAxIDU4MSAxUTU3MSAxIDU1MyAyMVQ1MzAgNTJRNTMwIDUzIDUyOCA1MlQ1MjIgNDdRNDQ4IC0yMiAzMjIgLTIyUTIwMSAtMjIgMTI2IDU1VDUwIDI1MloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03NCIgZD0iTTI2IDM4NVExOSAzOTIgMTkgMzk1UTE5IDM5OSAyMiA0MTFUMjcgNDI1UTI5IDQzMCAzNiA0MzBUODcgNDMxSDE0MEwxNTkgNTExUTE2MiA1MjIgMTY2IDU0MFQxNzMgNTY2VDE3OSA1ODZUMTg3IDYwM1QxOTcgNjE1VDIxMSA2MjRUMjI5IDYyNlEyNDcgNjI1IDI1NCA2MTVUMjYxIDU5NlEyNjEgNTg5IDI1MiA1NDlUMjMyIDQ3MEwyMjIgNDMzUTIyMiA0MzEgMjcyIDQzMUgzMjNRMzMwIDQyNCAzMzAgNDIwUTMzMCAzOTggMzE3IDM4NUgyMTBMMTc0IDI0MFExMzUgODAgMTM1IDY4UTEzNSAyNiAxNjIgMjZRMTk3IDI2IDIzMCA2MFQyODMgMTQ0UTI4NSAxNTAgMjg4IDE1MVQzMDMgMTUzSDMwN1EzMjIgMTUzIDMyMiAxNDVRMzIyIDE0MiAzMTkgMTMzUTMxNCAxMTcgMzAxIDk1VDI2NyA0OFQyMTYgNlQxNTUgLTExUTEyNSAtMTEgOTggNFQ1OSA1NlE1NyA2NCA1NyA4M1YxMDFMOTIgMjQxUTEyNyAzODIgMTI4IDM4M1ExMjggMzg1IDc3IDM4NUgyNloiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MyIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjY0NSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDM1IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTUwNCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjE5MCIgeD0iMjE3MSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUzIiB4PSIzNDUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iNDA5NSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI0NDg1IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iNDk1NCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjU1NjYiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2NTY3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDciIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzQiIHg9IjExMTIiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9zdmc+)
状态 的价值: ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjE4LjMxZXgiIGhlaWdodD0iMi44NDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjgzOGV4OyIgdmlld0JveD0iMCAtODYzLjEgNzg4My42IDEyMjMuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NiIgZD0iTTUyIDY0OFE1MiA2NzAgNjUgNjgzSDc2UTExOCA2ODAgMTgxIDY4MFEyOTkgNjgwIDMyMCA2ODNIMzMwUTMzNiA2NzcgMzM2IDY3NFQzMzQgNjU2UTMyOSA2NDEgMzI1IDYzN0gzMDRRMjgyIDYzNSAyNzQgNjM1UTI0NSA2MzAgMjQyIDYyMFEyNDIgNjE4IDI3MSAzNjlUMzAxIDExOEwzNzQgMjM1UTQ0NyAzNTIgNTIwIDQ3MVQ1OTUgNTk0UTU5OSA2MDEgNTk5IDYwOVE1OTkgNjMzIDU1NSA2MzdRNTM3IDYzNyA1MzcgNjQ4UTUzNyA2NDkgNTM5IDY2MVE1NDIgNjc1IDU0NSA2NzlUNTU4IDY4M1E1NjAgNjgzIDU3MCA2ODNUNjA0IDY4MlQ2NjggNjgxUTczNyA2ODEgNzU1IDY4M0g3NjJRNzY5IDY3NiA3NjkgNjcyUTc2OSA2NTUgNzYwIDY0MFE3NTcgNjM3IDc0MyA2MzdRNzMwIDYzNiA3MTkgNjM1VDY5OCA2MzBUNjgyIDYyM1Q2NzAgNjE1VDY2MCA2MDhUNjUyIDU5OVQ2NDUgNTkyTDQ1MiAyODJRMjcyIC05IDI2NiAtMTZRMjYzIC0xOCAyNTkgLTIxTDI0MSAtMjJIMjM0UTIxNiAtMjIgMjE2IC0xNVEyMTMgLTkgMTc3IDMwNVExMzkgNjIzIDEzOCA2MjZRMTMzIDYzNyA3NiA2MzdINTlRNTIgNjQyIDUyIDY0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUzIiBkPSJNMzA4IDI0UTM2NyAyNCA0MTYgNzZUNDY2IDE5N1E0NjYgMjYwIDQxNCAyODRRMzA4IDMxMSAyNzggMzIxVDIzNiAzNDFRMTc2IDM4MyAxNzYgNDYyUTE3NiA1MjMgMjA4IDU3M1QyNzMgNjQ4UTMwMiA2NzMgMzQzIDY4OFQ0MDcgNzA0SDQxOEg0MjVRNTIxIDcwNCA1NjQgNjQwUTU2NSA2NDAgNTc3IDY1M1Q2MDMgNjgyVDYyMyA3MDRRNjI0IDcwNCA2MjcgNzA0VDYzMiA3MDVRNjQ1IDcwNSA2NDUgNjk4VDYxNyA1NzdUNTg1IDQ1OVQ1NjkgNDU2UTU0OSA0NTYgNTQ5IDQ2NVE1NDkgNDcxIDU1MCA0NzVRNTUwIDQ3OCA1NTEgNDk0VDU1MyA1MjBRNTUzIDU1NCA1NDQgNTc5VDUyNiA2MTZUNTAxIDY0MVE0NjUgNjYyIDQxOSA2NjJRMzYyIDY2MiAzMTMgNjE2VDI2MyA1MTBRMjYzIDQ4MCAyNzggNDU4VDMxOSA0MjdRMzIzIDQyNSAzODkgNDA4VDQ1NiAzOTBRNDkwIDM3OSA1MjIgMzQyVDU1NCAyNDJRNTU0IDIxNiA1NDYgMTg2UTU0MSAxNjQgNTI4IDEzN1Q0OTIgNzhUNDI2IDE4VDMzMiAtMjBRMzIwIC0yMiAyOTggLTIyUTE5OSAtMjIgMTQ0IDMzTDEzNCA0NEwxMDYgMTNRODMgLTE0IDc4IC0xOFQ2NSAtMjJRNTIgLTIyIDUyIC0xNFE1MiAtMTEgMTEwIDIyMVExMTIgMjI3IDEzMCAyMjdIMTQzUTE0OSAyMjEgMTQ5IDIxNlExNDkgMjE0IDE0OCAyMDdUMTQ0IDE4NlQxNDIgMTUzUTE0NCAxMTQgMTYwIDg3VDIwMyA0N1QyNTUgMjlUMzA4IDI0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkYiIGQ9Ik00MjMgNzUwUTQzMiA3NTAgNDM4IDc0NFQ0NDQgNzMwUTQ0NCA3MjUgMjcxIDI0OFQ5MiAtMjQwUTg1IC0yNTAgNzUgLTI1MFE2OCAtMjUwIDYyIC0yNDVUNTYgLTIzMVE1NiAtMjIxIDIzMCAyNTdUNDA3IDc0MFE0MTEgNzUwIDQyMyA3NTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNEUiIGQ9Ik0yMzQgNjM3UTIzMSA2MzcgMjI2IDYzN1EyMDEgNjM3IDE5NiA2MzhUMTkxIDY0OVExOTEgNjc2IDIwMiA2ODJRMjA0IDY4MyAyOTkgNjgzUTM3NiA2ODMgMzg3IDY4M1Q0MDEgNjc3UTYxMiAxODEgNjE2IDE2OEw2NzAgMzgxUTcyMyA1OTIgNzIzIDYwNlE3MjMgNjMzIDY1OSA2MzdRNjM1IDYzNyA2MzUgNjQ4UTYzNSA2NTAgNjM3IDY2MFE2NDEgNjc2IDY0MyA2NzlUNjUzIDY4M1E2NTYgNjgzIDY4NCA2ODJUNzY3IDY4MFE4MTcgNjgwIDg0MyA2ODFUODczIDY4MlE4ODggNjgyIDg4OCA2NzJRODg4IDY1MCA4ODAgNjQyUTg3OCA2MzcgODU4IDYzN1E3ODcgNjMzIDc2OSA1OTdMNjIwIDdRNjE4IDAgNTk5IDBRNTg1IDAgNTgyIDJRNTc5IDUgNDUzIDMwNUwzMjYgNjA0TDI2MSAzNDRRMTk2IDg4IDE5NiA3OVEyMDEgNDYgMjY4IDQ2SDI3OFEyODQgNDEgMjg0IDM4VDI4MiAxOVEyNzggNiAyNzIgMEgyNTlRMjI4IDIgMTUxIDJRMTIzIDIgMTAwIDJUNjMgMlQ0NiAxUTMxIDEgMzEgMTBRMzEgMTQgMzQgMjZUMzkgNDBRNDEgNDYgNjIgNDZRMTMwIDQ5IDE1MCA4NVExNTQgOTEgMjIxIDM2MkwyODkgNjM0UTI4NyA2MzUgMjM0IDYzN1oiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9Ijc2OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMTU5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTYyOCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjIyOTUiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MyIgeD0iMzM1MiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjM5OTciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iNDM4NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjQ4NTYiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJGIiB4PSI1MjQ2IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNEUiIHg9IjU3NDYiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSI2NjM1IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjcwMjQiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI3NDk0IiB5PSIwIj48L3VzZT4KPC9nPgo8L3N2Zz4=)
当 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEwLjkwMWV4IiBoZWlnaHQ9IjIuODQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMC44MzhleDsiIHZpZXdCb3g9IjAgLTg2My4xIDQ2OTMuNiAxMjIzLjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNEUiIGQ9Ik0yMzQgNjM3UTIzMSA2MzcgMjI2IDYzN1EyMDEgNjM3IDE5NiA2MzhUMTkxIDY0OVExOTEgNjc2IDIwMiA2ODJRMjA0IDY4MyAyOTkgNjgzUTM3NiA2ODMgMzg3IDY4M1Q0MDEgNjc3UTYxMiAxODEgNjE2IDE2OEw2NzAgMzgxUTcyMyA1OTIgNzIzIDYwNlE3MjMgNjMzIDY1OSA2MzdRNjM1IDYzNyA2MzUgNjQ4UTYzNSA2NTAgNjM3IDY2MFE2NDEgNjc2IDY0MyA2NzlUNjUzIDY4M1E2NTYgNjgzIDY4NCA2ODJUNzY3IDY4MFE4MTcgNjgwIDg0MyA2ODFUODczIDY4MlE4ODggNjgyIDg4OCA2NzJRODg4IDY1MCA4ODAgNjQyUTg3OCA2MzcgODU4IDYzN1E3ODcgNjMzIDc2OSA1OTdMNjIwIDdRNjE4IDAgNTk5IDBRNTg1IDAgNTgyIDJRNTc5IDUgNDUzIDMwNUwzMjYgNjA0TDI2MSAzNDRRMTk2IDg4IDE5NiA3OVEyMDEgNDYgMjY4IDQ2SDI3OFEyODQgNDEgMjg0IDM4VDI4MiAxOVEyNzggNiAyNzIgMEgyNTlRMjI4IDIgMTUxIDJRMTIzIDIgMTAwIDJUNjMgMlQ0NiAxUTMxIDEgMzEgMTBRMzEgMTQgMzQgMjZUMzkgNDBRNDEgNDYgNjIgNDZRMTMwIDQ5IDE1MCA4NVExNTQgOTEgMjIxIDM2MkwyODkgNjM0UTI4NyA2MzUgMjM0IDYzN1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIxOTIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEg4MzVRNzE5IDM1NyA2OTIgNDkzUTY5MiA0OTQgNjkyIDQ5NlQ2OTEgNDk5UTY5MSA1MTEgNzA4IDUxMUg3MTFRNzIwIDUxMSA3MjMgNTEwVDcyOSA1MDZUNzMyIDQ5N1Q3MzUgNDgxVDc0MyA0NTZRNzY1IDM4OSA4MTYgMzM2VDkzNSAyNjFROTQ0IDI1OCA5NDQgMjUwUTk0NCAyNDQgOTM5IDI0MVQ5MTUgMjMxVDg3NyAyMTJRODM2IDE4NiA4MDYgMTUyVDc2MSA4NVQ3NDAgMzVUNzMyIDRRNzMwIC02IDcyNyAtOFQ3MTEgLTExUTY5MSAtMTEgNjkxIDBRNjkxIDcgNjk2IDI1UTcyOCAxNTEgODM1IDIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjIxRSIgZD0iTTU1IDIxN1E1NSAzMDUgMTExIDM3M1QyNTQgNDQyUTM0MiA0NDIgNDE5IDM4MVE0NTcgMzUwIDQ5MyAzMDNMNTA3IDI4NEw1MTQgMjk0UTYxOCA0NDIgNzQ3IDQ0MlE4MzMgNDQyIDg4OCAzNzRUOTQ0IDIxNFE5NDQgMTI4IDg4OSA1OVQ3NDMgLTExUTY1NyAtMTEgNTgwIDUwUTU0MiA4MSA1MDYgMTI4TDQ5MiAxNDdMNDg1IDEzN1EzODEgLTExIDI1MiAtMTFRMTY2IC0xMSAxMTEgNTdUNTUgMjE3Wk05MDcgMjE3UTkwNyAyODUgODY5IDM0MVQ3NjEgMzk3UTc0MCAzOTcgNzIwIDM5MlQ2ODIgMzc4VDY0OCAzNTlUNjE5IDMzNVQ1OTQgMzEwVDU3NCAyODVUNTU5IDI2M1Q1NDggMjQ2TDU0MyAyMzhMNTc0IDE5OFE2MDUgMTU4IDYyMiAxMzhUNjY0IDk0VDcxNCA2MVQ3NjUgNTFRODI3IDUxIDg2NyAxMDBUOTA3IDIxN1pNOTIgMjE0UTkyIDE0NSAxMzEgODlUMjM5IDMzUTM1NyAzMyA0NTYgMTkzTDQyNSAyMzNRMzY0IDMxMiAzMzQgMzM3UTI4NSAzODAgMjMzIDM4MFExNzEgMzgwIDEzMiAzMzFUOTIgMjE0WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTRFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iODg4IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEyNzgiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxNzQ3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMTkyIiB4PSIyNDE0IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjFFIiB4PSIzNjkzIiB5PSIwIj48L3VzZT4KPC9nPgo8L3N2Zz4=) 时,
时, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEzLjUwM2V4IiBoZWlnaHQ9IjIuODQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMC44MzhleDsiIHZpZXdCb3g9IjAgLTg2My4xIDU4MTMuNiAxMjIzLjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTYiIGQ9Ik01MiA2NDhRNTIgNjcwIDY1IDY4M0g3NlExMTggNjgwIDE4MSA2ODBRMjk5IDY4MCAzMjAgNjgzSDMzMFEzMzYgNjc3IDMzNiA2NzRUMzM0IDY1NlEzMjkgNjQxIDMyNSA2MzdIMzA0UTI4MiA2MzUgMjc0IDYzNVEyNDUgNjMwIDI0MiA2MjBRMjQyIDYxOCAyNzEgMzY5VDMwMSAxMThMMzc0IDIzNVE0NDcgMzUyIDUyMCA0NzFUNTk1IDU5NFE1OTkgNjAxIDU5OSA2MDlRNTk5IDYzMyA1NTUgNjM3UTUzNyA2MzcgNTM3IDY0OFE1MzcgNjQ5IDUzOSA2NjFRNTQyIDY3NSA1NDUgNjc5VDU1OCA2ODNRNTYwIDY4MyA1NzAgNjgzVDYwNCA2ODJUNjY4IDY4MVE3MzcgNjgxIDc1NSA2ODNINzYyUTc2OSA2NzYgNzY5IDY3MlE3NjkgNjU1IDc2MCA2NDBRNzU3IDYzNyA3NDMgNjM3UTczMCA2MzYgNzE5IDYzNVQ2OTggNjMwVDY4MiA2MjNUNjcwIDYxNVQ2NjAgNjA4VDY1MiA1OTlUNjQ1IDU5Mkw0NTIgMjgyUTI3MiAtOSAyNjYgLTE2UTI2MyAtMTggMjU5IC0yMUwyNDEgLTIySDIzNFEyMTYgLTIyIDIxNiAtMTVRMjEzIC05IDE3NyAzMDVRMTM5IDYyMyAxMzggNjI2UTEzMyA2MzcgNzYgNjM3SDU5UTUyIDY0MiA1MiA2NDhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMTkyIiBkPSJNNTYgMjM3VDU2IDI1MFQ3MCAyNzBIODM1UTcxOSAzNTcgNjkyIDQ5M1E2OTIgNDk0IDY5MiA0OTZUNjkxIDQ5OVE2OTEgNTExIDcwOCA1MTFINzExUTcyMCA1MTEgNzIzIDUxMFQ3MjkgNTA2VDczMiA0OTdUNzM1IDQ4MVQ3NDMgNDU2UTc2NSAzODkgODE2IDMzNlQ5MzUgMjYxUTk0NCAyNTggOTQ0IDI1MFE5NDQgMjQ0IDkzOSAyNDFUOTE1IDIzMVQ4NzcgMjEyUTgzNiAxODYgODA2IDE1MlQ3NjEgODVUNzQwIDM1VDczMiA0UTczMCAtNiA3MjcgLThUNzExIC0xMVE2OTEgLTExIDY5MSAwUTY5MSA3IDY5NiAyNVE3MjggMTUxIDgzNSAyMzBINzBRNTYgMjM3IDU2IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03NiIgZD0iTTE3MyAzODBRMTczIDQwNSAxNTQgNDA1UTEzMCA0MDUgMTA0IDM3NlQ2MSAyODdRNjAgMjg2IDU5IDI4NFQ1OCAyODFUNTYgMjc5VDUzIDI3OFQ0OSAyNzhUNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdRMjEgMjk0IDI5IDMxNlQ1MyAzNjhUOTcgNDE5VDE2MCA0NDFRMjAyIDQ0MSAyMjUgNDE3VDI0OSAzNjFRMjQ5IDM0NCAyNDYgMzM1UTI0NiAzMjkgMjMxIDI5MVQyMDAgMjAyVDE4MiAxMTNRMTgyIDg2IDE4NyA2OVEyMDAgMjYgMjUwIDI2UTI4NyAyNiAzMTkgNjBUMzY5IDEzOVQzOTggMjIyVDQwOSAyNzdRNDA5IDMwMCA0MDEgMzE3VDM4MyAzNDNUMzY1IDM2MVQzNTcgMzgzUTM1NyA0MDUgMzc2IDQyNFQ0MTcgNDQzUTQzNiA0NDMgNDUxIDQyNVQ0NjcgMzY3UTQ2NyAzNDAgNDU1IDI4NFQ0MTggMTU5VDM0NyA0MFQyNDEgLTExUTE3NyAtMTEgMTM5IDIyUTEwMiA1NCAxMDIgMTE3UTEwMiAxNDggMTEwIDE4MVQxNTEgMjk4UTE3MyAzNjIgMTczIDM4MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS0zQzAiIGQ9Ik0xMzIgLTExUTk4IC0xMSA5OCAyMlYzM0wxMTEgNjFRMTg2IDIxOSAyMjAgMzM0TDIyOCAzNThIMTk2UTE1OCAzNTggMTQyIDM1NVQxMDMgMzM2UTkyIDMyOSA4MSAzMThUNjIgMjk3VDUzIDI4NVE1MSAyODQgMzggMjg0UTE5IDI4NCAxOSAyOTRRMTkgMzAwIDM4IDMyOVQ5MyAzOTFUMTY0IDQyOVExNzEgNDMxIDM4OSA0MzFRNTQ5IDQzMSA1NTMgNDMwUTU3MyA0MjMgNTczIDQwMlE1NzMgMzcxIDU0MSAzNjBRNTM1IDM1OCA0NzIgMzU4SDQwOEw0MDUgMzQxUTM5MyAyNjkgMzkzIDIyMlEzOTMgMTcwIDQwMiAxMjlUNDIxIDY1VDQzMSAzN1E0MzEgMjAgNDE3IDVUMzgxIC0xMFEzNzAgLTEwIDM2MyAtN1QzNDcgMTdUMzMxIDc3UTMzMCA4NiAzMzAgMTIxUTMzMCAxNzAgMzM5IDIyNlQzNTcgMzE4VDM2NyAzNThIMjY5TDI2OCAzNTRRMjY4IDM1MSAyNDkgMjc1VDIwNiAxMTRUMTc1IDE3UTE2NCAtMTEgMTMyIC0xMVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9Ijc2OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMTU5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTYyOCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjE5MiIgeD0iMjI5NSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM1NzQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS0zQzAiIHg9IjY4NiIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iNDU2NSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI0OTU0IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iNTQyNCIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+)
- 每次访问蒙特卡洛策略评估
在给定一个策略,使用一系列完整的episode评估某一个状态 时,对于每一个episode,状态 每次出现在状态转移链时,例如,一次在时刻 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuODk0ZXgiIGhlaWdodD0iMi4zNDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyIgdmlld0JveD0iMCAtNzE5LjYgODE1LjQgMTAwOC42IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc0IiBkPSJNMjYgMzg1UTE5IDM5MiAxOSAzOTVRMTkgMzk5IDIyIDQxMVQyNyA0MjVRMjkgNDMwIDM2IDQzMFQ4NyA0MzFIMTQwTDE1OSA1MTFRMTYyIDUyMiAxNjYgNTQwVDE3MyA1NjZUMTc5IDU4NlQxODcgNjAzVDE5NyA2MTVUMjExIDYyNFQyMjkgNjI2UTI0NyA2MjUgMjU0IDYxNVQyNjEgNTk2UTI2MSA1ODkgMjUyIDU0OVQyMzIgNDcwTDIyMiA0MzNRMjIyIDQzMSAyNzIgNDMxSDMyM1EzMzAgNDI0IDMzMCA0MjBRMzMwIDM5OCAzMTcgMzg1SDIxMEwxNzQgMjQwUTEzNSA4MCAxMzUgNjhRMTM1IDI2IDE2MiAyNlExOTcgMjYgMjMwIDYwVDI4MyAxNDRRMjg1IDE1MCAyODggMTUxVDMwMyAxNTNIMzA3UTMyMiAxNTMgMzIyIDE0NVEzMjIgMTQyIDMxOSAxMzNRMzE0IDExNyAzMDEgOTVUMjY3IDQ4VDIxNiA2VDE1NSAtMTFRMTI1IC0xMSA5OCA0VDU5IDU2UTU3IDY0IDU3IDgzVjEwMUw5MiAyNDFRMTI3IDM4MiAxMjggMzgzUTEyOCAzODUgNzcgMzg1SDI2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc0IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjUxMSIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9zdmc+) ,一次在时刻
,一次在时刻 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuODk0ZXgiIGhlaWdodD0iMi4zNDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyIgdmlld0JveD0iMCAtNzE5LjYgODE1LjQgMTAwOC42IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc0IiBkPSJNMjYgMzg1UTE5IDM5MiAxOSAzOTVRMTkgMzk5IDIyIDQxMVQyNyA0MjVRMjkgNDMwIDM2IDQzMFQ4NyA0MzFIMTQwTDE1OSA1MTFRMTYyIDUyMiAxNjYgNTQwVDE3MyA1NjZUMTc5IDU4NlQxODcgNjAzVDE5NyA2MTVUMjExIDYyNFQyMjkgNjI2UTI0NyA2MjUgMjU0IDYxNVQyNjEgNTk2UTI2MSA1ODkgMjUyIDU0OVQyMzIgNDcwTDIyMiA0MzNRMjIyIDQzMSAyNzIgNDMxSDMyM1EzMzAgNDI0IDMzMCA0MjBRMzMwIDM5OCAzMTcgMzg1SDIxMEwxNzQgMjQwUTEzNSA4MCAxMzUgNjhRMTM1IDI2IDE2MiAyNlExOTcgMjYgMjMwIDYwVDI4MyAxNDRRMjg1IDE1MCAyODggMTUxVDMwMyAxNTNIMzA3UTMyMiAxNTMgMzIyIDE0NVEzMjIgMTQyIDMxOSAxMzNRMzE0IDExNyAzMDEgOTVUMjY3IDQ4VDIxNiA2VDE1NSAtMTFRMTI1IC0xMSA5OCA0VDU5IDU2UTU3IDY0IDU3IDgzVjEwMUw5MiAyNDFRMTI3IDM4MiAxMjggMzgzUTEyOCAzODUgNzcgMzg1SDI2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzIiIGQ9Ik0xMDkgNDI5UTgyIDQyOSA2NiA0NDdUNTAgNDkxUTUwIDU2MiAxMDMgNjE0VDIzNSA2NjZRMzI2IDY2NiAzODcgNjEwVDQ0OSA0NjVRNDQ5IDQyMiA0MjkgMzgzVDM4MSAzMTVUMzAxIDI0MVEyNjUgMjEwIDIwMSAxNDlMMTQyIDkzTDIxOCA5MlEzNzUgOTIgMzg1IDk3UTM5MiA5OSA0MDkgMTg2VjE4OUg0NDlWMTg2UTQ0OCAxODMgNDM2IDk1VDQyMSAzVjBINTBWMTlWMzFRNTAgMzggNTYgNDZUODYgODFRMTE1IDExMyAxMzYgMTM3UTE0NSAxNDcgMTcwIDE3NFQyMDQgMjExVDIzMyAyNDRUMjYxIDI3OFQyODQgMzA4VDMwNSAzNDBUMzIwIDM2OVQzMzMgNDAxVDM0MCA0MzFUMzQzIDQ2NFEzNDMgNTI3IDMwOSA1NzNUMjEyIDYxOVExNzkgNjE5IDE1NCA2MDJUMTE5IDU2OVQxMDkgNTUwUTEwOSA1NDkgMTE0IDU0OVExMzIgNTQ5IDE1MSA1MzVUMTcwIDQ4OVExNzAgNDY0IDE1NCA0NDdUMTA5IDQyOVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI1MTEiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) ,则两次对应的
,则两次对应的 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjMuNDg0ZXgiIGhlaWdodD0iMi44NDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0xLjAwNWV4OyIgdmlld0JveD0iMCAtNzkxLjMgMTUwMC4yIDEyMjMuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NyIgZD0iTTUwIDI1MlE1MCAzNjcgMTE3IDQ3M1QyODYgNjQxVDQ5MCA3MDRRNTgwIDcwNCA2MzMgNjUzUTY0MiA2NDMgNjQ4IDYzNlQ2NTYgNjI2TDY1NyA2MjNRNjYwIDYyMyA2ODQgNjQ5UTY5MSA2NTUgNjk5IDY2M1Q3MTUgNjc5VDcyNSA2OTBMNzQwIDcwNUg3NDZRNzYwIDcwNSA3NjAgNjk4UTc2MCA2OTQgNzI4IDU2MVE2OTIgNDIyIDY5MiA0MjFRNjkwIDQxNiA2ODcgNDE1VDY2OSA0MTNINjUzUTY0NyA0MTkgNjQ3IDQyMlE2NDcgNDIzIDY0OCA0MjlUNjUwIDQ0OVQ2NTEgNDgxUTY1MSA1NTIgNjE5IDYwNVQ1MTAgNjU5UTQ5MiA2NTkgNDcxIDY1NlQ0MTggNjQzVDM1NyA2MTVUMjk0IDU2N1QyMzYgNDk2VDE4OSAzOTRUMTU4IDI2MFExNTYgMjQyIDE1NiAyMjFRMTU2IDE3MyAxNzAgMTM2VDIwNiA3OVQyNTYgNDVUMzA4IDI4VDM1MyAyNFE0MDcgMjQgNDUyIDQ3VDUxNCAxMDZRNTE3IDExNCA1MjkgMTYxVDU0MSAyMTRRNTQxIDIyMiA1MjggMjI0VDQ2OCAyMjdINDMxUTQyNSAyMzMgNDI1IDIzNVQ0MjcgMjU0UTQzMSAyNjcgNDM3IDI3M0g0NTRRNDk0IDI3MSA1OTQgMjcxUTYzNCAyNzEgNjU5IDI3MVQ2OTUgMjcyVDcwNyAyNzJRNzIxIDI3MiA3MjEgMjYzUTcyMSAyNjEgNzE5IDI0OVE3MTQgMjMwIDcwOSAyMjhRNzA2IDIyNyA2OTQgMjI3UTY3NCAyMjcgNjUzIDIyNFE2NDYgMjIxIDY0MyAyMTVUNjI5IDE2NFE2MjAgMTMxIDYxNCAxMDhRNTg5IDYgNTg2IDNRNTg0IDEgNTgxIDFRNTcxIDEgNTUzIDIxVDUzMCA1MlE1MzAgNTMgNTI4IDUyVDUyMiA0N1E0NDggLTIyIDMyMiAtMjJRMjAxIC0yMiAxMjYgNTVUNTAgMjUyWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc0IiBkPSJNMjYgMzg1UTE5IDM5MiAxOSAzOTVRMTkgMzk5IDIyIDQxMVQyNyA0MjVRMjkgNDMwIDM2IDQzMFQ4NyA0MzFIMTQwTDE1OSA1MTFRMTYyIDUyMiAxNjYgNTQwVDE3MyA1NjZUMTc5IDU4NlQxODcgNjAzVDE5NyA2MTVUMjExIDYyNFQyMjkgNjI2UTI0NyA2MjUgMjU0IDYxNVQyNjEgNTk2UTI2MSA1ODkgMjUyIDU0OVQyMzIgNDcwTDIyMiA0MzNRMjIyIDQzMSAyNzIgNDMxSDMyM1EzMzAgNDI0IDMzMCA0MjBRMzMwIDM5OCAzMTcgMzg1SDIxMEwxNzQgMjQwUTEzNSA4MCAxMzUgNjhRMTM1IDI2IDE2MiAyNlExOTcgMjYgMjMwIDYwVDI4MyAxNDRRMjg1IDE1MCAyODggMTUxVDMwMyAxNTNIMzA3UTMyMiAxNTMgMzIyIDE0NVEzMjIgMTQyIDMxOSAxMzNRMzE0IDExNyAzMDEgOTVUMjY3IDQ4VDIxNiA2VDE1NSAtMTFRMTI1IC0xMSA5OCA0VDU5IDU2UTU3IDY0IDU3IDgzVjEwMUw5MiAyNDFRMTI3IDM4MiAxMjggMzgzUTEyOCAzODUgNzcgMzg1SDI2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ3IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzg2LC0xNTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc0IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjU3NCkiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjQ0NSIgeT0iLTI0MyI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=) ,
, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjMuNDg0ZXgiIGhlaWdodD0iMi44NDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0xLjAwNWV4OyIgdmlld0JveD0iMCAtNzkxLjMgMTUwMC4yIDEyMjMuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NyIgZD0iTTUwIDI1MlE1MCAzNjcgMTE3IDQ3M1QyODYgNjQxVDQ5MCA3MDRRNTgwIDcwNCA2MzMgNjUzUTY0MiA2NDMgNjQ4IDYzNlQ2NTYgNjI2TDY1NyA2MjNRNjYwIDYyMyA2ODQgNjQ5UTY5MSA2NTUgNjk5IDY2M1Q3MTUgNjc5VDcyNSA2OTBMNzQwIDcwNUg3NDZRNzYwIDcwNSA3NjAgNjk4UTc2MCA2OTQgNzI4IDU2MVE2OTIgNDIyIDY5MiA0MjFRNjkwIDQxNiA2ODcgNDE1VDY2OSA0MTNINjUzUTY0NyA0MTkgNjQ3IDQyMlE2NDcgNDIzIDY0OCA0MjlUNjUwIDQ0OVQ2NTEgNDgxUTY1MSA1NTIgNjE5IDYwNVQ1MTAgNjU5UTQ5MiA2NTkgNDcxIDY1NlQ0MTggNjQzVDM1NyA2MTVUMjk0IDU2N1QyMzYgNDk2VDE4OSAzOTRUMTU4IDI2MFExNTYgMjQyIDE1NiAyMjFRMTU2IDE3MyAxNzAgMTM2VDIwNiA3OVQyNTYgNDVUMzA4IDI4VDM1MyAyNFE0MDcgMjQgNDUyIDQ3VDUxNCAxMDZRNTE3IDExNCA1MjkgMTYxVDU0MSAyMTRRNTQxIDIyMiA1MjggMjI0VDQ2OCAyMjdINDMxUTQyNSAyMzMgNDI1IDIzNVQ0MjcgMjU0UTQzMSAyNjcgNDM3IDI3M0g0NTRRNDk0IDI3MSA1OTQgMjcxUTYzNCAyNzEgNjU5IDI3MVQ2OTUgMjcyVDcwNyAyNzJRNzIxIDI3MiA3MjEgMjYzUTcyMSAyNjEgNzE5IDI0OVE3MTQgMjMwIDcwOSAyMjhRNzA2IDIyNyA2OTQgMjI3UTY3NCAyMjcgNjUzIDIyNFE2NDYgMjIxIDY0MyAyMTVUNjI5IDE2NFE2MjAgMTMxIDYxNCAxMDhRNTg5IDYgNTg2IDNRNTg0IDEgNTgxIDFRNTcxIDEgNTUzIDIxVDUzMCA1MlE1MzAgNTMgNTI4IDUyVDUyMiA0N1E0NDggLTIyIDMyMiAtMjJRMjAxIC0yMiAxMjYgNTVUNTAgMjUyWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc0IiBkPSJNMjYgMzg1UTE5IDM5MiAxOSAzOTVRMTkgMzk5IDIyIDQxMVQyNyA0MjVRMjkgNDMwIDM2IDQzMFQ4NyA0MzFIMTQwTDE1OSA1MTFRMTYyIDUyMiAxNjYgNTQwVDE3MyA1NjZUMTc5IDU4NlQxODcgNjAzVDE5NyA2MTVUMjExIDYyNFQyMjkgNjI2UTI0NyA2MjUgMjU0IDYxNVQyNjEgNTk2UTI2MSA1ODkgMjUyIDU0OVQyMzIgNDcwTDIyMiA0MzNRMjIyIDQzMSAyNzIgNDMxSDMyM1EzMzAgNDI0IDMzMCA0MjBRMzMwIDM5OCAzMTcgMzg1SDIxMEwxNzQgMjQwUTEzNSA4MCAxMzUgNjhRMTM1IDI2IDE2MiAyNlExOTcgMjYgMjMwIDYwVDI4MyAxNDRRMjg1IDE1MCAyODggMTUxVDMwMyAxNTNIMzA3UTMyMiAxNTMgMzIyIDE0NVEzMjIgMTQyIDMxOSAxMzNRMzE0IDExNyAzMDEgOTVUMjY3IDQ4VDIxNiA2VDE1NSAtMTFRMTI1IC0xMSA5OCA0VDU5IDU2UTU3IDY0IDU3IDgzVjEwMUw5MiAyNDFRMTI3IDM4MiAxMjggMzgzUTEyOCAzODUgNzcgMzg1SDI2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzIiIGQ9Ik0xMDkgNDI5UTgyIDQyOSA2NiA0NDdUNTAgNDkxUTUwIDU2MiAxMDMgNjE0VDIzNSA2NjZRMzI2IDY2NiAzODcgNjEwVDQ0OSA0NjVRNDQ5IDQyMiA0MjkgMzgzVDM4MSAzMTVUMzAxIDI0MVEyNjUgMjEwIDIwMSAxNDlMMTQyIDkzTDIxOCA5MlEzNzUgOTIgMzg1IDk3UTM5MiA5OSA0MDkgMTg2VjE4OUg0NDlWMTg2UTQ0OCAxODMgNDM2IDk1VDQyMSAzVjBINTBWMTlWMzFRNTAgMzggNTYgNDZUODYgODFRMTE1IDExMyAxMzYgMTM3UTE0NSAxNDcgMTcwIDE3NFQyMDQgMjExVDIzMyAyNDRUMjYxIDI3OFQyODQgMzA4VDMwNSAzNDBUMzIwIDM2OVQzMzMgNDAxVDM0MCA0MzFUMzQzIDQ2NFEzNDMgNTI3IDMwOSA1NzNUMjEyIDYxOVExNzkgNjE5IDE1NCA2MDJUMTE5IDU2OVQxMDkgNTUwUTEwOSA1NDkgMTE0IDU0OVExMzIgNTQ5IDE1MSA1MzVUMTcwIDQ4OVExNzAgNDY0IDE1NCA0NDdUMTA5IDQyOVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NyIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDc4NiwtMTUwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI0NDUiIHk9Ii0yNDMiPjwvdXNlPgo8L2c+CjwvZz4KPC9zdmc+) 都要用于计算 对应的值。
都要用于计算 对应的值。
状态出现的次数加1:
总的收获值更新:
状态s的价值:
当 时,
详情请参考:
搬砖的旺财:David Silver 增强学习——Lecture 4 不基于模型的预测

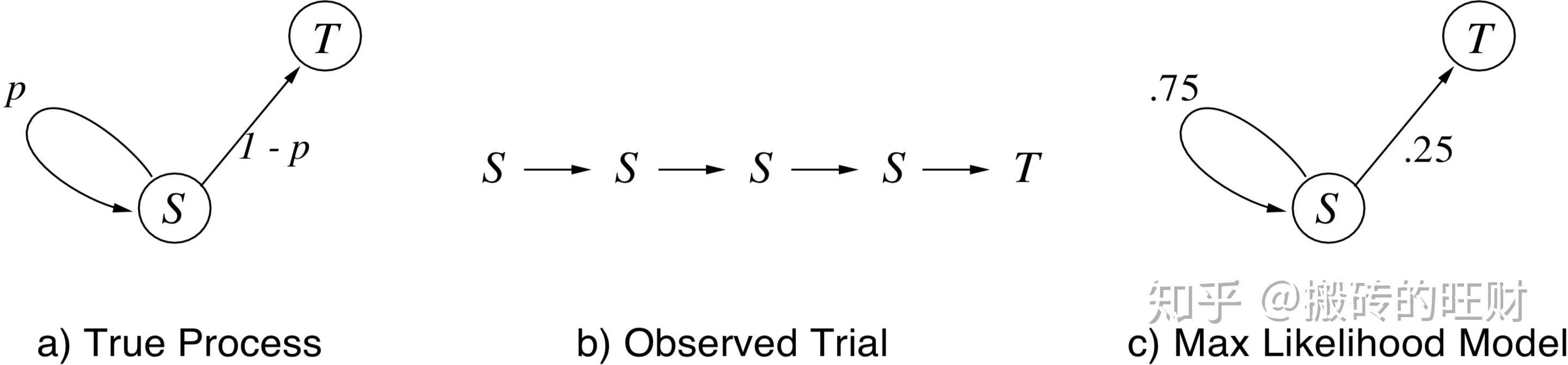
首先考虑图1 a)中所示的马尔可夫链,在每一步中,链或者以概率 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuMjU5ZXgiIGhlaWdodD0iMi4wMDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyBtYXJnaW4tbGVmdDogLTAuMDg5ZXg7IiB2aWV3Qm94PSItMzguNSAtNTc2LjEgNTQyIDg2NS4xIiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTcwIiBkPSJNMjMgMjg3UTI0IDI5MCAyNSAyOTVUMzAgMzE3VDQwIDM0OFQ1NSAzODFUNzUgNDExVDEwMSA0MzNUMTM0IDQ0MlEyMDkgNDQyIDIzMCAzNzhMMjQwIDM4N1EzMDIgNDQyIDM1OCA0NDJRNDIzIDQ0MiA0NjAgMzk1VDQ5NyAyODFRNDk3IDE3MyA0MjEgODJUMjQ5IC0xMFEyMjcgLTEwIDIxMCAtNFExOTkgMSAxODcgMTFUMTY4IDI4TDE2MSAzNlExNjAgMzUgMTM5IC01MVQxMTggLTEzOFExMTggLTE0NCAxMjYgLTE0NVQxNjMgLTE0OEgxODhRMTk0IC0xNTUgMTk0IC0xNTdUMTkxIC0xNzVRMTg4IC0xODcgMTg1IC0xOTBUMTcyIC0xOTRRMTcwIC0xOTQgMTYxIC0xOTRUMTI3IC0xOTNUNjUgLTE5MlEtNSAtMTkyIC0yNCAtMTk0SC0zMlEtMzkgLTE4NyAtMzkgLTE4M1EtMzcgLTE1NiAtMjYgLTE0OEgtNlEyOCAtMTQ3IDMzIC0xMzZRMzYgLTEzMCA5NCAxMDNUMTU1IDM1MFExNTYgMzU1IDE1NiAzNjRRMTU2IDQwNSAxMzEgNDA1UTEwOSA0MDUgOTQgMzc3VDcxIDMxNlQ1OSAyODBRNTcgMjc4IDQzIDI3OEgyOVEyMyAyODQgMjMgMjg3Wk0xNzggMTAyUTIwMCAyNiAyNTIgMjZRMjgyIDI2IDMxMCA0OVQzNTYgMTA3UTM3NCAxNDEgMzkyIDIxNVQ0MTEgMzI1VjMzMVE0MTEgNDA1IDM1MCA0MDVRMzM5IDQwNSAzMjggNDAyVDMwNiAzOTNUMjg2IDM4MFQyNjkgMzY1VDI1NCAzNTBUMjQzIDMzNlQyMzUgMzI2TDIzMiAzMjJRMjMyIDMyMSAyMjkgMzA4VDIxOCAyNjRUMjA0IDIxMlExNzggMTA2IDE3OCAxMDJaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzAiIHg9IjAiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) 保持在
保持在 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuNDk5ZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgNjQ1LjUgOTM2LjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTMiIGQ9Ik0zMDggMjRRMzY3IDI0IDQxNiA3NlQ0NjYgMTk3UTQ2NiAyNjAgNDE0IDI4NFEzMDggMzExIDI3OCAzMjFUMjM2IDM0MVExNzYgMzgzIDE3NiA0NjJRMTc2IDUyMyAyMDggNTczVDI3MyA2NDhRMzAyIDY3MyAzNDMgNjg4VDQwNyA3MDRINDE4SDQyNVE1MjEgNzA0IDU2NCA2NDBRNTY1IDY0MCA1NzcgNjUzVDYwMyA2ODJUNjIzIDcwNFE2MjQgNzA0IDYyNyA3MDRUNjMyIDcwNVE2NDUgNzA1IDY0NSA2OThUNjE3IDU3N1Q1ODUgNDU5VDU2OSA0NTZRNTQ5IDQ1NiA1NDkgNDY1UTU0OSA0NzEgNTUwIDQ3NVE1NTAgNDc4IDU1MSA0OTRUNTUzIDUyMFE1NTMgNTU0IDU0NCA1NzlUNTI2IDYxNlQ1MDEgNjQxUTQ2NSA2NjIgNDE5IDY2MlEzNjIgNjYyIDMxMyA2MTZUMjYzIDUxMFEyNjMgNDgwIDI3OCA0NThUMzE5IDQyN1EzMjMgNDI1IDM4OSA0MDhUNDU2IDM5MFE0OTAgMzc5IDUyMiAzNDJUNTU0IDI0MlE1NTQgMjE2IDU0NiAxODZRNTQxIDE2NCA1MjggMTM3VDQ5MiA3OFQ0MjYgMThUMzMyIC0yMFEzMjAgLTIyIDI5OCAtMjJRMTk5IC0yMiAxNDQgMzNMMTM0IDQ0TDEwNiAxM1E4MyAtMTQgNzggLTE4VDY1IC0yMlE1MiAtMjIgNTIgLTE0UTUyIC0xMSAxMTAgMjIxUTExMiAyMjcgMTMwIDIyN0gxNDNRMTQ5IDIyMSAxNDkgMjE2UTE0OSAyMTQgMTQ4IDIwN1QxNDQgMTg2VDE0MiAxNTNRMTQ0IDExNCAxNjAgODdUMjAzIDQ3VDI1NSAyOVQzMDggMjRaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTMiIHg9IjAiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) 中,或者以概率
中,或者以概率 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjUuMTcyZXgiIGhlaWdodD0iMi41MDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyIgdmlld0JveD0iMCAtNzkxLjMgMjIyNi45IDEwODAuNCIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMTIiIGQ9Ik04NCAyMzdUODQgMjUwVDk4IDI3MEg2NzlRNjk0IDI2MiA2OTQgMjUwVDY3OSAyMzBIOThRODQgMjM3IDg0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MCIgZD0iTTIzIDI4N1EyNCAyOTAgMjUgMjk1VDMwIDMxN1Q0MCAzNDhUNTUgMzgxVDc1IDQxMVQxMDEgNDMzVDEzNCA0NDJRMjA5IDQ0MiAyMzAgMzc4TDI0MCAzODdRMzAyIDQ0MiAzNTggNDQyUTQyMyA0NDIgNDYwIDM5NVQ0OTcgMjgxUTQ5NyAxNzMgNDIxIDgyVDI0OSAtMTBRMjI3IC0xMCAyMTAgLTRRMTk5IDEgMTg3IDExVDE2OCAyOEwxNjEgMzZRMTYwIDM1IDEzOSAtNTFUMTE4IC0xMzhRMTE4IC0xNDQgMTI2IC0xNDVUMTYzIC0xNDhIMTg4UTE5NCAtMTU1IDE5NCAtMTU3VDE5MSAtMTc1UTE4OCAtMTg3IDE4NSAtMTkwVDE3MiAtMTk0UTE3MCAtMTk0IDE2MSAtMTk0VDEyNyAtMTkzVDY1IC0xOTJRLTUgLTE5MiAtMjQgLTE5NEgtMzJRLTM5IC0xODcgLTM5IC0xODNRLTM3IC0xNTYgLTI2IC0xNDhILTZRMjggLTE0NyAzMyAtMTM2UTM2IC0xMzAgOTQgMTAzVDE1NSAzNTBRMTU2IDM1NSAxNTYgMzY0UTE1NiA0MDUgMTMxIDQwNVExMDkgNDA1IDk0IDM3N1Q3MSAzMTZUNTkgMjgwUTU3IDI3OCA0MyAyNzhIMjlRMjMgMjg0IDIzIDI4N1pNMTc4IDEwMlEyMDAgMjYgMjUyIDI2UTI4MiAyNiAzMTAgNDlUMzU2IDEwN1EzNzQgMTQxIDM5MiAyMTVUNDExIDMyNVYzMzFRNDExIDQwNSAzNTAgNDA1UTMzOSA0MDUgMzI4IDQwMlQzMDYgMzkzVDI4NiAzODBUMjY5IDM2NVQyNTQgMzUwVDI0MyAzMzZUMjM1IDMyNkwyMzIgMzIyUTIzMiAzMjEgMjI5IDMwOFQyMTggMjY0VDIwNCAyMTJRMTc4IDEwNiAxNzggMTAyWiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjcyMiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcwIiB4PSIxNzIzIiB5PSIwIj48L3VzZT4KPC9nPgo8L3N2Zz4=) 前往
前往 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuNjM2ZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgNzA0LjUgOTM2LjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTQiIGQ9Ik00MCA0MzdRMjEgNDM3IDIxIDQ0NVEyMSA0NTAgMzcgNTAxVDcxIDYwMkw4OCA2NTFROTMgNjY5IDEwMSA2NzdINTY5SDY1OVE2OTEgNjc3IDY5NyA2NzZUNzA0IDY2N1E3MDQgNjYxIDY4NyA1NTNUNjY4IDQ0NFE2NjggNDM3IDY0OSA0MzdRNjQwIDQzNyA2MzcgNDM3VDYzMSA0NDJMNjI5IDQ0NVE2MjkgNDUxIDYzNSA0OTBUNjQxIDU1MVE2NDEgNTg2IDYyOCA2MDRUNTczIDYyOVE1NjggNjMwIDUxNSA2MzFRNDY5IDYzMSA0NTcgNjMwVDQzOSA2MjJRNDM4IDYyMSAzNjggMzQzVDI5OCA2MFEyOTggNDggMzg2IDQ2UTQxOCA0NiA0MjcgNDVUNDM2IDM2UTQzNiAzMSA0MzMgMjJRNDI5IDQgNDI0IDFMNDIyIDBRNDE5IDAgNDE1IDBRNDEwIDAgMzYzIDFUMjI4IDJROTkgMiA2NCAwSDQ5UTQzIDYgNDMgOVQ0NSAyN1E0OSA0MCA1NSA0Nkg4M0g5NFExNzQgNDYgMTg5IDU1UTE5MCA1NiAxOTEgNTZRMTk2IDU5IDIwMSA3NlQyNDEgMjMzUTI1OCAzMDEgMjY5IDM0NFEzMzkgNjE5IDMzOSA2MjVRMzM5IDYzMCAzMTAgNjMwSDI3OVEyMTIgNjMwIDE5MSA2MjRRMTQ2IDYxNCAxMjEgNTgzVDY3IDQ2N1E2MCA0NDUgNTcgNDQxVDQzIDQzN0g0MFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 结束。假设我们想要估计从状态 开始到终止前的预期步数。考虑从估计值函数入手,那么假设每一步都会得到
结束。假设我们想要估计从状态 开始到终止前的预期步数。考虑从估计值函数入手,那么假设每一步都会得到 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIuOTcxZXgiIGhlaWdodD0iMi4zNDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjUwNWV4OyIgdmlld0JveD0iMCAtNzkxLjMgMTI3OSAxMDA4LjYiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yQiIgZD0iTTU2IDIzN1Q1NiAyNTBUNzAgMjcwSDM2OVY0MjBMMzcwIDU3MFEzODAgNTgzIDM4OSA1ODNRNDAyIDU4MyA0MDkgNTY4VjI3MEg3MDdRNzIyIDI2MiA3MjIgMjUwVDcwNyAyMzBINDA5Vi02OFE0MDEgLTgyIDM5MSAtODJIMzg5SDM4N1EzNzUgLTgyIDM2OSAtNjhWMjMwSDcwUTU2IDIzNyA1NiAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMSIgZD0iTTIxMyA1NzhMMjAwIDU3M1ExODYgNTY4IDE2MCA1NjNUMTAyIDU1Nkg4M1Y2MDJIMTAyUTE0OSA2MDQgMTg5IDYxN1QyNDUgNjQxVDI3MyA2NjNRMjc1IDY2NiAyODUgNjY2UTI5NCA2NjYgMzAyIDY2MFYzNjFMMzAzIDYxUTMxMCA1NCAzMTUgNTJUMzM5IDQ4VDQwMSA0Nkg0MjdWMEg0MTZRMzk1IDMgMjU3IDNRMTIxIDMgMTAwIDBIODhWNDZIMTE0UTEzNiA0NiAxNTIgNDZUMTc3IDQ3VDE5MyA1MFQyMDEgNTJUMjA3IDU3VDIxMyA2MVY1NzhaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9Ijc3OCIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 的奖励,在这种情况下
的奖励,在这种情况下 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjUuNDgzZXgiIGhlaWdodD0iMi44NDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjgzOGV4OyIgdmlld0JveD0iMCAtODYzLjEgMjM2MC43IDEyMjMuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NiIgZD0iTTUyIDY0OFE1MiA2NzAgNjUgNjgzSDc2UTExOCA2ODAgMTgxIDY4MFEyOTkgNjgwIDMyMCA2ODNIMzMwUTMzNiA2NzcgMzM2IDY3NFQzMzQgNjU2UTMyOSA2NDEgMzI1IDYzN0gzMDRRMjgyIDYzNSAyNzQgNjM1UTI0NSA2MzAgMjQyIDYyMFEyNDIgNjE4IDI3MSAzNjlUMzAxIDExOEwzNzQgMjM1UTQ0NyAzNTIgNTIwIDQ3MVQ1OTUgNTk0UTU5OSA2MDEgNTk5IDYwOVE1OTkgNjMzIDU1NSA2MzdRNTM3IDYzNyA1MzcgNjQ4UTUzNyA2NDkgNTM5IDY2MVE1NDIgNjc1IDU0NSA2NzlUNTU4IDY4M1E1NjAgNjgzIDU3MCA2ODNUNjA0IDY4MlQ2NjggNjgxUTczNyA2ODEgNzU1IDY4M0g3NjJRNzY5IDY3NiA3NjkgNjcyUTc2OSA2NTUgNzYwIDY0MFE3NTcgNjM3IDc0MyA2MzdRNzMwIDYzNiA3MTkgNjM1VDY5OCA2MzBUNjgyIDYyM1Q2NzAgNjE1VDY2MCA2MDhUNjUyIDU5OVQ2NDUgNTkyTDQ1MiAyODJRMjcyIC05IDI2NiAtMTZRMjYzIC0xOCAyNTkgLTIxTDI0MSAtMjJIMjM0UTIxNiAtMjIgMjE2IC0xNVEyMTMgLTkgMTc3IDMwNVExMzkgNjIzIDEzOCA2MjZRMTMzIDYzNyA3NiA2MzdINTlRNTIgNjQyIDUyIDY0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTMiIGQ9Ik0zMDggMjRRMzY3IDI0IDQxNiA3NlQ0NjYgMTk3UTQ2NiAyNjAgNDE0IDI4NFEzMDggMzExIDI3OCAzMjFUMjM2IDM0MVExNzYgMzgzIDE3NiA0NjJRMTc2IDUyMyAyMDggNTczVDI3MyA2NDhRMzAyIDY3MyAzNDMgNjg4VDQwNyA3MDRINDE4SDQyNVE1MjEgNzA0IDU2NCA2NDBRNTY1IDY0MCA1NzcgNjUzVDYwMyA2ODJUNjIzIDcwNFE2MjQgNzA0IDYyNyA3MDRUNjMyIDcwNVE2NDUgNzA1IDY0NSA2OThUNjE3IDU3N1Q1ODUgNDU5VDU2OSA0NTZRNTQ5IDQ1NiA1NDkgNDY1UTU0OSA0NzEgNTUwIDQ3NVE1NTAgNDc4IDU1MSA0OTRUNTUzIDUyMFE1NTMgNTU0IDU0NCA1NzlUNTI2IDYxNlQ1MDEgNjQxUTQ2NSA2NjIgNDE5IDY2MlEzNjIgNjYyIDMxMyA2MTZUMjYzIDUxMFEyNjMgNDgwIDI3OCA0NThUMzE5IDQyN1EzMjMgNDI1IDM4OSA0MDhUNDU2IDM5MFE0OTAgMzc5IDUyMiAzNDJUNTU0IDI0MlE1NTQgMjE2IDU0NiAxODZRNTQxIDE2NCA1MjggMTM3VDQ5MiA3OFQ0MjYgMThUMzMyIC0yMFEzMjAgLTIyIDI5OCAtMjJRMTk5IC0yMiAxNDQgMzNMMTM0IDQ0TDEwNiAxM1E4MyAtMTQgNzggLTE4VDY1IC0yMlE1MiAtMjIgNTIgLTE0UTUyIC0xMSAxMTAgMjIxUTExMiAyMjcgMTMwIDIyN0gxNDNRMTQ5IDIyMSAxNDkgMjE2UTE0OSAyMTQgMTQ4IDIwN1QxNDQgMTg2VDE0MiAxNTNRMTQ0IDExNCAxNjAgODdUMjAzIDQ3VDI1NSAyOVQzMDggMjRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkzNiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTAzNSIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=) 等于终止前的预期步数。假设已经观察到的唯一数据是由马尔可夫链产生的单个试验——该试验持续4个步骤,
等于终止前的预期步数。假设已经观察到的唯一数据是由马尔可夫链产生的单个试验——该试验持续4个步骤, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuMTYyZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgNTAwLjUgOTM2LjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMyIgZD0iTTEyNyA0NjNRMTAwIDQ2MyA4NSA0ODBUNjkgNTI0UTY5IDU3OSAxMTcgNjIyVDIzMyA2NjVRMjY4IDY2NSAyNzcgNjY0UTM1MSA2NTIgMzkwIDYxMVQ0MzAgNTIyUTQzMCA0NzAgMzk2IDQyMVQzMDIgMzUwTDI5OSAzNDhRMjk5IDM0NyAzMDggMzQ1VDMzNyAzMzZUMzc1IDMxNVE0NTcgMjYyIDQ1NyAxNzVRNDU3IDk2IDM5NSAzN1QyMzggLTIyUTE1OCAtMjIgMTAwIDIxVDQyIDEzMFE0MiAxNTggNjAgMTc1VDEwNSAxOTNRMTMzIDE5MyAxNTEgMTc1VDE2OSAxMzBRMTY5IDExOSAxNjYgMTEwVDE1OSA5NFQxNDggODJUMTM2IDc0VDEyNiA3MFQxMTggNjdMMTE0IDY2UTE2NSAyMSAyMzggMjFRMjkzIDIxIDMyMSA3NFEzMzggMTA3IDMzOCAxNzVWMTk1UTMzOCAyOTAgMjc0IDMyMlEyNTkgMzI4IDIxMyAzMjlMMTcxIDMzMEwxNjggMzMyUTE2NiAzMzUgMTY2IDM0OFExNjYgMzY2IDE3NCAzNjZRMjAyIDM2NiAyMzIgMzcxUTI2NiAzNzYgMjk0IDQxM1QzMjIgNTI1VjUzM1EzMjIgNTkwIDI4NyA2MTJRMjY1IDYyNiAyNDAgNjI2UTIwOCA2MjYgMTgxIDYxNVQxNDMgNTkyVDEzMiA1ODBIMTM1UTEzOCA1NzkgMTQzIDU3OFQxNTMgNTczVDE2NSA1NjZUMTc1IDU1NVQxODMgNTQwVDE4NiA1MjBRMTg2IDQ5OCAxNzIgNDgxVDEyNyA0NjNaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMyIgeD0iMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 个从 传递到 ,并且
个从 传递到 ,并且 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuMTYyZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgNTAwLjUgOTM2LjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMSIgZD0iTTIxMyA1NzhMMjAwIDU3M1ExODYgNTY4IDE2MCA1NjNUMTAyIDU1Nkg4M1Y2MDJIMTAyUTE0OSA2MDQgMTg5IDYxN1QyNDUgNjQxVDI3MyA2NjNRMjc1IDY2NiAyODUgNjY2UTI5NCA2NjYgMzAyIDY2MFYzNjFMMzAzIDYxUTMxMCA1NCAzMTUgNTJUMzM5IDQ4VDQwMSA0Nkg0MjdWMEg0MTZRMzk1IDMgMjU3IDNRMTIxIDMgMTAwIDBIODhWNDZIMTE0UTEzNiA0NiAxNTIgNDZUMTc3IDQ3VDE5MyA1MFQyMDEgNTJUMjA3IDU3VDIxMyA2MVY1NzhaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 个从 传递到 ,如图2 b)所示。那么两个MC方法从这个试验中将会得出什么结论?
个从 传递到 ,如图2 b)所示。那么两个MC方法从这个试验中将会得出什么结论?
我们假设这些方法不知道马尔可夫链的结构。它们所知道的只是图1 b)中所示的试验。
首次访问MC方法(first-visit MC)实际上观察到的是从第一次访问 到 的单次遍历(singel traversal)。该遍历持续 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuMTYyZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgNTAwLjUgOTM2LjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zNCIgZD0iTTQ2MiAwUTQ0NCAzIDMzMyAzUTIxNyAzIDE5OSAwSDE5MFY0NkgyMjFRMjQxIDQ2IDI0OCA0NlQyNjUgNDhUMjc5IDUzVDI4NiA2MVEyODcgNjMgMjg3IDExNVYxNjVIMjhWMjExTDE3OSA0NDJRMzMyIDY3NCAzMzQgNjc1UTMzNiA2NzcgMzU1IDY3N0gzNzNMMzc5IDY3MVYyMTFINDcxVjE2NUgzNzlWMTE0UTM3OSA3MyAzNzkgNjZUMzg1IDU0UTM5MyA0NyA0NDIgNDZINDcxVjBINDYyWk0yOTMgMjExVjU0NUw3NCAyMTJMMTgzIDIxMUgyOTNaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zNCIgeD0iMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 步,因此其对 的估计为 。
步,因此其对 的估计为 。
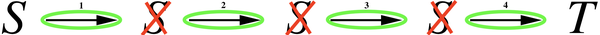

另一方面,每次访问MC方法(every-visit MC)实际上观察到的是从 到 的 个单独的遍历,一个有 个步骤,一个有 个步骤,一个有 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuMTYyZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgNTAwLjUgOTM2LjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMiIgZD0iTTEwOSA0MjlRODIgNDI5IDY2IDQ0N1Q1MCA0OTFRNTAgNTYyIDEwMyA2MTRUMjM1IDY2NlEzMjYgNjY2IDM4NyA2MTBUNDQ5IDQ2NVE0NDkgNDIyIDQyOSAzODNUMzgxIDMxNVQzMDEgMjQxUTI2NSAyMTAgMjAxIDE0OUwxNDIgOTNMMjE4IDkyUTM3NSA5MiAzODUgOTdRMzkyIDk5IDQwOSAxODZWMTg5SDQ0OVYxODZRNDQ4IDE4MyA0MzYgOTVUNDIxIDNWMEg1MFYxOVYzMVE1MCAzOCA1NiA0NlQ4NiA4MVExMTUgMTEzIDEzNiAxMzdRMTQ1IDE0NyAxNzAgMTc0VDIwNCAyMTFUMjMzIDI0NFQyNjEgMjc4VDI4NCAzMDhUMzA1IDM0MFQzMjAgMzY5VDMzMyA0MDFUMzQwIDQzMVQzNDMgNDY0UTM0MyA1MjcgMzA5IDU3M1QyMTIgNjE5UTE3OSA2MTkgMTU0IDYwMlQxMTkgNTY5VDEwOSA1NTBRMTA5IDU0OSAxMTQgNTQ5UTEzMiA1NDkgMTUxIDUzNVQxNzAgNDg5UTE3MCA0NjQgMTU0IDQ0N1QxMDkgNDI5WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) 个步骤,一个有 个步骤。对这四个有效试验进行平均,每次访问MC方法估计的 为
个步骤,一个有 个步骤。对这四个有效试验进行平均,每次访问MC方法估计的 为 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIwLjA3N2V4IiBoZWlnaHQ9IjUuMTc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMS44MzhleDsiIHZpZXdCb3g9IjAgLTE0MzcuMiA4NjQ0LjQgMjIyOC41IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzIiIGQ9Ik0xMDkgNDI5UTgyIDQyOSA2NiA0NDdUNTAgNDkxUTUwIDU2MiAxMDMgNjE0VDIzNSA2NjZRMzI2IDY2NiAzODcgNjEwVDQ0OSA0NjVRNDQ5IDQyMiA0MjkgMzgzVDM4MSAzMTVUMzAxIDI0MVEyNjUgMjEwIDIwMSAxNDlMMTQyIDkzTDIxOCA5MlEzNzUgOTIgMzg1IDk3UTM5MiA5OSA0MDkgMTg2VjE4OUg0NDlWMTg2UTQ0OCAxODMgNDM2IDk1VDQyMSAzVjBINTBWMTlWMzFRNTAgMzggNTYgNDZUODYgODFRMTE1IDExMyAxMzYgMTM3UTE0NSAxNDcgMTcwIDE3NFQyMDQgMjExVDIzMyAyNDRUMjYxIDI3OFQyODQgMzA4VDMwNSAzNDBUMzIwIDM2OVQzMzMgNDAxVDM0MCA0MzFUMzQzIDQ2NFEzNDMgNTI3IDMwOSA1NzNUMjEyIDYxOVExNzkgNjE5IDE1NCA2MDJUMTE5IDU2OVQxMDkgNTUwUTEwOSA1NDkgMTE0IDU0OVExMzIgNTQ5IDE1MSA1MzVUMTcwIDQ4OVExNzAgNDY0IDE1NCA0NDdUMTA5IDQyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMzIiBkPSJNMTI3IDQ2M1ExMDAgNDYzIDg1IDQ4MFQ2OSA1MjRRNjkgNTc5IDExNyA2MjJUMjMzIDY2NVEyNjggNjY1IDI3NyA2NjRRMzUxIDY1MiAzOTAgNjExVDQzMCA1MjJRNDMwIDQ3MCAzOTYgNDIxVDMwMiAzNTBMMjk5IDM0OFEyOTkgMzQ3IDMwOCAzNDVUMzM3IDMzNlQzNzUgMzE1UTQ1NyAyNjIgNDU3IDE3NVE0NTcgOTYgMzk1IDM3VDIzOCAtMjJRMTU4IC0yMiAxMDAgMjFUNDIgMTMwUTQyIDE1OCA2MCAxNzVUMTA1IDE5M1ExMzMgMTkzIDE1MSAxNzVUMTY5IDEzMFExNjkgMTE5IDE2NiAxMTBUMTU5IDk0VDE0OCA4MlQxMzYgNzRUMTI2IDcwVDExOCA2N0wxMTQgNjZRMTY1IDIxIDIzOCAyMVEyOTMgMjEgMzIxIDc0UTMzOCAxMDcgMzM4IDE3NVYxOTVRMzM4IDI5MCAyNzQgMzIyUTI1OSAzMjggMjEzIDMyOUwxNzEgMzMwTDE2OCAzMzJRMTY2IDMzNSAxNjYgMzQ4UTE2NiAzNjYgMTc0IDM2NlEyMDIgMzY2IDIzMiAzNzFRMjY2IDM3NiAyOTQgNDEzVDMyMiA1MjVWNTMzUTMyMiA1OTAgMjg3IDYxMlEyNjUgNjI2IDI0MCA2MjZRMjA4IDYyNiAxODEgNjE1VDE0MyA1OTJUMTMyIDU4MEgxMzVRMTM4IDU3OSAxNDMgNTc4VDE1MyA1NzNUMTY1IDU2NlQxNzUgNTU1VDE4MyA1NDBUMTg2IDUyMFExODYgNDk4IDE3MiA0ODFUMTI3IDQ2M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTM0IiBkPSJNNDYyIDBRNDQ0IDMgMzMzIDNRMjE3IDMgMTk5IDBIMTkwVjQ2SDIyMVEyNDEgNDYgMjQ4IDQ2VDI2NSA0OFQyNzkgNTNUMjg2IDYxUTI4NyA2MyAyODcgMTE1VjE2NUgyOFYyMTFMMTc5IDQ0MlEzMzIgNjc0IDMzNCA2NzVRMzM2IDY3NyAzNTUgNjc3SDM3M0wzNzkgNjcxVjIxMUg0NzFWMTY1SDM3OVYxMTRRMzc5IDczIDM3OSA2NlQzODUgNTRRMzkzIDQ3IDQ0MiA0Nkg0NzFWMEg0NjJaTTI5MyAyMTFWNTQ1TDc0IDIxMkwxODMgMjExSDI5M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkUiIGQ9Ik03OCA2MFE3OCA4NCA5NSAxMDJUMTM4IDEyMFExNjIgMTIwIDE4MCAxMDRUMTk5IDYxUTE5OSAzNiAxODIgMThUMTM5IDBUOTYgMTdUNzggNjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zNSIgZD0iTTE2NCAxNTdRMTY0IDEzMyAxNDggMTE3VDEwOSAxMDFIMTAyUTE0OCAyMiAyMjQgMjJRMjk0IDIyIDMyNiA4MlEzNDUgMTE1IDM0NSAyMTBRMzQ1IDMxMyAzMTggMzQ5UTI5MiAzODIgMjYwIDM4MkgyNTRRMTc2IDM4MiAxMzYgMzE0UTEzMiAzMDcgMTI5IDMwNlQxMTQgMzA0UTk3IDMwNCA5NSAzMTBROTMgMzE0IDkzIDQ4NVY2MTRROTMgNjY0IDk4IDY2NFExMDAgNjY2IDEwMiA2NjZRMTAzIDY2NiAxMjMgNjU4VDE3OCA2NDJUMjUzIDYzNFEzMjQgNjM0IDM4OSA2NjJRMzk3IDY2NiA0MDIgNjY2UTQxMCA2NjYgNDEwIDY0OFY2MzVRMzI4IDUzOCAyMDUgNTM4UTE3NCA1MzggMTQ5IDU0NEwxMzkgNTQ2VjM3NFExNTggMzg4IDE2OSAzOTZUMjA1IDQxMlQyNTYgNDIwUTMzNyA0MjAgMzkzIDM1NVQ0NDkgMjAxUTQ0OSAxMDkgMzg1IDQ0VDIyOSAtMjJRMTQ4IC0yMiA5OSAzMlQ1MCAxNTRRNTAgMTc4IDYxIDE5MlQ4NCAyMTBUMTA3IDIxNFExMzIgMjE0IDE0OCAxOTdUMTY0IDE1N1oiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI1NzkwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsNjc2KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI3MjIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxNzIzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMjQ0NiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzMiIHg9IjM0NDYiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI0MTY5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zNCIgeD0iNTE3MCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zNCIgeD0iMjY0NSIgeT0iLTY5OCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iNjMwOCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDczNjQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iNTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zNSIgeD0iNzc5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==) 。
。


哪个估计值更好呢? 还是 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIuOTcyZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgMTI3OS41IDkzNi45IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzIiIGQ9Ik0xMDkgNDI5UTgyIDQyOSA2NiA0NDdUNTAgNDkxUTUwIDU2MiAxMDMgNjE0VDIzNSA2NjZRMzI2IDY2NiAzODcgNjEwVDQ0OSA0NjVRNDQ5IDQyMiA0MjkgMzgzVDM4MSAzMTVUMzAxIDI0MVEyNjUgMjEwIDIwMSAxNDlMMTQyIDkzTDIxOCA5MlEzNzUgOTIgMzg1IDk3UTM5MiA5OSA0MDkgMTg2VjE4OUg0NDlWMTg2UTQ0OCAxODMgNDM2IDk1VDQyMSAzVjBINTBWMTlWMzFRNTAgMzggNTYgNDZUODYgODFRMTE1IDExMyAxMzYgMTM3UTE0NSAxNDcgMTcwIDE3NFQyMDQgMjExVDIzMyAyNDRUMjYxIDI3OFQyODQgMzA4VDMwNSAzNDBUMzIwIDM2OVQzMzMgNDAxVDM0MCA0MzFUMzQzIDQ2NFEzNDMgNTI3IDMwOSA1NzNUMjEyIDYxOVExNzkgNjE5IDE1NCA2MDJUMTE5IDU2OVQxMDkgNTUwUTEwOSA1NDkgMTE0IDU0OVExMzIgNTQ5IDE1MSA1MzVUMTcwIDQ4OVExNzAgNDY0IDE1NCA0NDdUMTA5IDQyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJFIiBkPSJNNzggNjBRNzggODQgOTUgMTAyVDEzOCAxMjBRMTYyIDEyMCAxODAgMTA0VDE5OSA2MVExOTkgMzYgMTgyIDE4VDEzOSAwVDk2IDE3VDc4IDYwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzUiIGQ9Ik0xNjQgMTU3UTE2NCAxMzMgMTQ4IDExN1QxMDkgMTAxSDEwMlExNDggMjIgMjI0IDIyUTI5NCAyMiAzMjYgODJRMzQ1IDExNSAzNDUgMjEwUTM0NSAzMTMgMzE4IDM0OVEyOTIgMzgyIDI2MCAzODJIMjU0UTE3NiAzODIgMTM2IDMxNFExMzIgMzA3IDEyOSAzMDZUMTE0IDMwNFE5NyAzMDQgOTUgMzEwUTkzIDMxNCA5MyA0ODVWNjE0UTkzIDY2NCA5OCA2NjRRMTAwIDY2NiAxMDIgNjY2UTEwMyA2NjYgMTIzIDY1OFQxNzggNjQyVDI1MyA2MzRRMzI0IDYzNCAzODkgNjYyUTM5NyA2NjYgNDAyIDY2NlE0MTAgNjY2IDQxMCA2NDhWNjM1UTMyOCA1MzggMjA1IDUzOFExNzQgNTM4IDE0OSA1NDRMMTM5IDU0NlYzNzRRMTU4IDM4OCAxNjkgMzk2VDIwNSA0MTJUMjU2IDQyMFEzMzcgNDIwIDM5MyAzNTVUNDQ5IDIwMVE0NDkgMTA5IDM4NSA0NFQyMjkgLTIyUTE0OCAtMjIgOTkgMzJUNTAgMTU0UTUwIDE3OCA2MSAxOTJUODQgMjEwVDEwNyAyMTRRMTMyIDIxNCAxNDggMTk3VDE2NCAxNTdaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzUiIHg9Ijc3OSIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 呢?我们将在下面说明,实际上 是无偏的答案, 在统计意义上存在偏差。
呢?我们将在下面说明,实际上 是无偏的答案, 在统计意义上存在偏差。
接下来计算上例的ML估计。如果马尔可夫链的最大似然模型(如图1 c)所示)完全正确,那么在终止之前期望的时间步数是多少呢?对于每个可能的步数 转移概率的最大似然估计(Maximum-Likelihood estimate,ML estimate)是 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuOTk5ZXgiIGhlaWdodD0iNS4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0xLjgzOGV4OyIgdmlld0JveD0iMCAtMTQzNy4yIDg2MC41IDIyMjguNSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMzIiBkPSJNMTI3IDQ2M1ExMDAgNDYzIDg1IDQ4MFQ2OSA1MjRRNjkgNTc5IDExNyA2MjJUMjMzIDY2NVEyNjggNjY1IDI3NyA2NjRRMzUxIDY1MiAzOTAgNjExVDQzMCA1MjJRNDMwIDQ3MCAzOTYgNDIxVDMwMiAzNTBMMjk5IDM0OFEyOTkgMzQ3IDMwOCAzNDVUMzM3IDMzNlQzNzUgMzE1UTQ1NyAyNjIgNDU3IDE3NVE0NTcgOTYgMzk1IDM3VDIzOCAtMjJRMTU4IC0yMiAxMDAgMjFUNDIgMTMwUTQyIDE1OCA2MCAxNzVUMTA1IDE5M1ExMzMgMTkzIDE1MSAxNzVUMTY5IDEzMFExNjkgMTE5IDE2NiAxMTBUMTU5IDk0VDE0OCA4MlQxMzYgNzRUMTI2IDcwVDExOCA2N0wxMTQgNjZRMTY1IDIxIDIzOCAyMVEyOTMgMjEgMzIxIDc0UTMzOCAxMDcgMzM4IDE3NVYxOTVRMzM4IDI5MCAyNzQgMzIyUTI1OSAzMjggMjEzIDMyOUwxNzEgMzMwTDE2OCAzMzJRMTY2IDMzNSAxNjYgMzQ4UTE2NiAzNjYgMTc0IDM2NlEyMDIgMzY2IDIzMiAzNzFRMjY2IDM3NiAyOTQgNDEzVDMyMiA1MjVWNTMzUTMyMiA1OTAgMjg3IDYxMlEyNjUgNjI2IDI0MCA2MjZRMjA4IDYyNiAxODEgNjE1VDE0MyA1OTJUMTMyIDU4MEgxMzVRMTM4IDU3OSAxNDMgNTc4VDE1MyA1NzNUMTY1IDU2NlQxNzUgNTU1VDE4MyA1NDBUMTg2IDUyMFExODYgNDk4IDE3MiA0ODFUMTI3IDQ2M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTM0IiBkPSJNNDYyIDBRNDQ0IDMgMzMzIDNRMjE3IDMgMTk5IDBIMTkwVjQ2SDIyMVEyNDEgNDYgMjQ4IDQ2VDI2NSA0OFQyNzkgNTNUMjg2IDYxUTI4NyA2MyAyODcgMTE1VjE2NUgyOFYyMTFMMTc5IDQ0MlEzMzIgNjc0IDMzNCA2NzVRMzM2IDY3NyAzNTUgNjc3SDM3M0wzNzkgNjcxVjIxMUg0NzFWMTY1SDM3OVYxMTRRMzc5IDczIDM3OSA2NlQzODUgNTRRMzkzIDQ3IDQ0MiA0Nkg0NzFWMEg0NjJaTTI5MyAyMTFWNTQ1TDc0IDIxMkwxODMgMjExSDI5M1oiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI2MjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMzIiB4PSI2MCIgeT0iNjc2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zNCIgeD0iNjAiIHk9Ii02OTgiPjwvdXNlPgo8L2c+CjwvZz4KPC9zdmc+) ,
, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjYuNTg3ZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgMjgzNiA5MzYuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTUzIiBkPSJNNTUgNTA3UTU1IDU5MCAxMTIgNjQ3VDI0MyA3MDRIMjU3UTM0MiA3MDQgNDA1IDY0MUw0MjYgNjcyUTQzMSA2NzkgNDM2IDY4N1Q0NDYgNzAwTDQ0OSA3MDRRNDUwIDcwNCA0NTMgNzA0VDQ1OSA3MDVINDYzUTQ2NiA3MDUgNDcyIDY5OVY0NjJMNDY2IDQ1Nkg0NDhRNDM3IDQ1NiA0MzUgNDU5VDQzMCA0NzlRNDEzIDYwNSAzMjkgNjQ2UTI5MiA2NjIgMjU0IDY2MlEyMDEgNjYyIDE2OCA2MjZUMTM1IDU0MlExMzUgNTA4IDE1MiA0ODBUMjAwIDQzNVEyMTAgNDMxIDI4NiA0MTJUMzcwIDM4OVE0MjcgMzY3IDQ2MyAzMTRUNTAwIDE5MVE1MDAgMTEwIDQ0OCA0NVQzMDEgLTIxUTI0NSAtMjEgMjAxIC00VDE0MCAyN0wxMjIgNDFRMTE4IDM2IDEwNyAyMVQ4NyAtN1Q3OCAtMjFRNzYgLTIyIDY4IC0yMkg2NFE2MSAtMjIgNTUgLTE2VjEwMVE1NSAyMjAgNTYgMjIyUTU4IDIyNyA3NiAyMjdIODlROTUgMjIxIDk1IDIxNFE5NSAxODIgMTA1IDE1MVQxMzkgOTBUMjA1IDQyVDMwNSAyNFEzNTIgMjQgMzg2IDYyVDQyMCAxNTVRNDIwIDE5OCAzOTggMjMzVDM0MCAyODFRMjg0IDI5NSAyNjYgMzAwUTI2MSAzMDEgMjM5IDMwNlQyMDYgMzE0VDE3NCAzMjVUMTQxIDM0M1QxMTIgMzY3VDg1IDQwMlE1NSA0NTEgNTUgNTA3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkQiIGQ9Ik0xMSAxNzlWMjUySDI3N1YxNzlIMTFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03NCIgZD0iTTI3IDQyMlE4MCA0MjYgMTA5IDQ3OFQxNDEgNjAwVjYxNUgxODFWNDMxSDMxNlYzODVIMTgxVjI0MVExODIgMTE2IDE4MiAxMDBUMTg5IDY4UTIwMyAyOSAyMzggMjlRMjgyIDI5IDI5MiAxMDBRMjkzIDEwOCAyOTMgMTQ2VjE4MUgzMzNWMTQ2VjEzNFEzMzMgNTcgMjkxIDE3UTI2NCAtMTAgMjIxIC0xMFExODcgLTEwIDE2MiAyVDEyNCAzM1QxMDUgNjhUOTggMTAwUTk3IDEwNyA5NyAyNDhWMzg1SDE4VjQyMkgyN1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTZGIiBkPSJNMjggMjE0UTI4IDMwOSA5MyAzNzhUMjUwIDQ0OFEzNDAgNDQ4IDQwNSAzODBUNDcxIDIxNVE0NzEgMTIwIDQwNyA1NVQyNTAgLTEwUTE1MyAtMTAgOTEgNTdUMjggMjE0Wk0yNTAgMzBRMzcyIDMwIDM3MiAxOTNWMjI1VjI1MFEzNzIgMjcyIDM3MSAyODhUMzY0IDMyNlQzNDggMzYyVDMxNyAzOTBUMjY4IDQxMFEyNjMgNDExIDI1MiA0MTFRMjIyIDQxMSAxOTUgMzk5UTE1MiAzNzcgMTM5IDMzOFQxMjYgMjQ2VjIyNlExMjYgMTMwIDE0NSA5MVExNzcgMzAgMjUwIDMwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNTQiIGQ9Ik0zNiA0NDNRMzcgNDQ4IDQ2IDU1OFQ1NSA2NzFWNjc3SDY2NlY2NzFRNjY3IDY2NiA2NzYgNTU2VDY4NSA0NDNWNDM3SDY0NVY0NDNRNjQ1IDQ0NSA2NDIgNDc4VDYzMSA1NDRUNjEwIDU5M1E1OTMgNjE0IDU1NSA2MjVRNTM0IDYzMCA0NzggNjMwSDQ1MUg0NDNRNDE3IDYzMCA0MTQgNjE4UTQxMyA2MTYgNDEzIDMzOVY2M1E0MjAgNTMgNDM5IDUwVDUyOCA0Nkg1NThWMEg1NDVMMzYxIDNRMTg2IDEgMTc3IDBIMTY0VjQ2SDE5NFEyNjQgNDYgMjgzIDQ5VDMwOSA2M1YzMzlWNTUwUTMwOSA2MjAgMzA0IDYyNVQyNzEgNjMwSDI0NEgyMjRRMTU0IDYzMCAxMTkgNjAxUTEwMSA1ODUgOTMgNTU0VDgxIDQ4NlQ3NiA0NDNWNDM3SDM2VjQ0M1oiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTUzIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRCIgeD0iNTU2IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03NCIgeD0iODkwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02RiIgeD0iMTI3OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkQiIHg9IjE3ODAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU0IiB4PSIyMTEzIiB5PSIwIj48L3VzZT4KPC9nPgo8L3N2Zz4=) 转移概率的最大似然估计是
转移概率的最大似然估计是 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuOTk5ZXgiIGhlaWdodD0iNS4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0xLjgzOGV4OyIgdmlld0JveD0iMCAtMTQzNy4yIDg2MC41IDIyMjguNSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTM0IiBkPSJNNDYyIDBRNDQ0IDMgMzMzIDNRMjE3IDMgMTk5IDBIMTkwVjQ2SDIyMVEyNDEgNDYgMjQ4IDQ2VDI2NSA0OFQyNzkgNTNUMjg2IDYxUTI4NyA2MyAyODcgMTE1VjE2NUgyOFYyMTFMMTc5IDQ0MlEzMzIgNjc0IDMzNCA2NzVRMzM2IDY3NyAzNTUgNjc3SDM3M0wzNzkgNjcxVjIxMUg0NzFWMTY1SDM3OVYxMTRRMzc5IDczIDM3OSA2NlQzODUgNTRRMzkzIDQ3IDQ0MiA0Nkg0NzFWMEg0NjJaTTI5MyAyMTFWNTQ1TDc0IDIxMkwxODMgMjExSDI5M1oiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI2MjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSI2MCIgeT0iNjc2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zNCIgeD0iNjAiIHk9Ii02OTgiPjwvdXNlPgo8L2c+CjwvZz4KPC9zdmc+) 。没有观察到其他状态的转移,因此估计它们的概率为
。没有观察到其他状态的转移,因此估计它们的概率为 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuMTYyZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgNTAwLjUgOTM2LjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMCIgZD0iTTk2IDU4NVExNTIgNjY2IDI0OSA2NjZRMjk3IDY2NiAzNDUgNjQwVDQyMyA1NDhRNDYwIDQ2NSA0NjAgMzIwUTQ2MCAxNjUgNDE3IDgzUTM5NyA0MSAzNjIgMTZUMzAxIC0xNVQyNTAgLTIyUTIyNCAtMjIgMTk4IC0xNlQxMzcgMTZUODIgODNRMzkgMTY1IDM5IDMyMFEzOSA0OTQgOTYgNTg1Wk0zMjEgNTk3UTI5MSA2MjkgMjUwIDYyOVEyMDggNjI5IDE3OCA1OTdRMTUzIDU3MSAxNDUgNTI1VDEzNyAzMzNRMTM3IDE3NSAxNDUgMTI1VDE4MSA0NlEyMDkgMTYgMjUwIDE2UTI5MCAxNiAzMTggNDZRMzQ3IDc2IDM1NCAxMzBUMzYyIDMzM1EzNjIgNDc4IDM1NCA1MjRUMzIxIDU5N1oiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMwIiB4PSIwIiB5PSIwIj48L3VzZT4KPC9nPgo8L3N2Zz4=) 。那么马尔可夫链的最大似然模型如图1 c)所示。
。那么马尔可夫链的最大似然模型如图1 c)所示。
如果马尔可夫过程的最大似然模型完全正确,我们即认为值函数的ML估计是完全正确的。
接下来计算上例的ML估计。如果马尔可夫链的最大似然模型完全正确,那么在终止之前期望的时间步数是多少呢?对于每个可能的步数 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuMjExZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgNTIxLjUgOTM2LjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkIiIGQ9Ik0xMjEgNjQ3UTEyMSA2NTcgMTI1IDY3MFQxMzcgNjgzUTEzOCA2ODMgMjA5IDY4OFQyODIgNjk0UTI5NCA2OTQgMjk0IDY4NlEyOTQgNjc5IDI0NCA0NzdRMTk0IDI3OSAxOTQgMjcyUTIxMyAyODIgMjIzIDI5MVEyNDcgMzA5IDI5MiAzNTRUMzYyIDQxNVE0MDIgNDQyIDQzOCA0NDJRNDY4IDQ0MiA0ODUgNDIzVDUwMyAzNjlRNTAzIDM0NCA0OTYgMzI3VDQ3NyAzMDJUNDU2IDI5MVQ0MzggMjg4UTQxOCAyODggNDA2IDI5OVQzOTQgMzI4UTM5NCAzNTMgNDEwIDM2OVQ0NDIgMzkwTDQ1OCAzOTNRNDQ2IDQwNSA0MzQgNDA1SDQzMFEzOTggNDAyIDM2NyAzODBUMjk0IDMxNlQyMjggMjU1UTIzMCAyNTQgMjQzIDI1MlQyNjcgMjQ2VDI5MyAyMzhUMzIwIDIyNFQzNDIgMjA2VDM1OSAxODBUMzY1IDE0N1EzNjUgMTMwIDM2MCAxMDZUMzU0IDY2UTM1NCAyNiAzODEgMjZRNDI5IDI2IDQ1OSAxNDVRNDYxIDE1MyA0NzkgMTUzSDQ4M1E0OTkgMTUzIDQ5OSAxNDRRNDk5IDEzOSA0OTYgMTMwUTQ1NSAtMTEgMzc4IC0xMVEzMzMgLTExIDMwNSAxNVQyNzcgOTBRMjc3IDEwOCAyODAgMTIxVDI4MyAxNDVRMjgzIDE2NyAyNjkgMTgzVDIzNCAyMDZUMjAwIDIxN1QxODIgMjIwSDE4MFExNjggMTc4IDE1OSAxMzlUMTQ1IDgxVDEzNiA0NFQxMjkgMjBUMTIyIDdUMTExIC0yUTk4IC0xMSA4MyAtMTFRNjYgLTExIDU3IC0xVDQ4IDE2UTQ4IDI2IDg1IDE3NlQxNTggNDcxTDE5NSA2MTZRMTk2IDYyOSAxODggNjMyVDE0OSA2MzdIMTQ0UTEzNCA2MzcgMTMxIDYzN1QxMjQgNjQwVDEyMSA2NDdaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) ,我们可以计算其发生的概率,然后计算期望:
,我们可以计算其发生的概率,然后计算期望:
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjM1LjYxN2V4IiBoZWlnaHQ9IjE3LjE3NmV4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTguMDA1ZXg7IiB2aWV3Qm94PSIwIC0zOTQ4LjcgMTUzMzQuOSA3Mzk1LjIiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTYiIGQ9Ik01MiA2NDhRNTIgNjcwIDY1IDY4M0g3NlExMTggNjgwIDE4MSA2ODBRMjk5IDY4MCAzMjAgNjgzSDMzMFEzMzYgNjc3IDMzNiA2NzRUMzM0IDY1NlEzMjkgNjQxIDMyNSA2MzdIMzA0UTI4MiA2MzUgMjc0IDYzNVEyNDUgNjMwIDI0MiA2MjBRMjQyIDYxOCAyNzEgMzY5VDMwMSAxMThMMzc0IDIzNVE0NDcgMzUyIDUyMCA0NzFUNTk1IDU5NFE1OTkgNjAxIDU5OSA2MDlRNTk5IDYzMyA1NTUgNjM3UTUzNyA2MzcgNTM3IDY0OFE1MzcgNjQ5IDUzOSA2NjFRNTQyIDY3NSA1NDUgNjc5VDU1OCA2ODNRNTYwIDY4MyA1NzAgNjgzVDYwNCA2ODJUNjY4IDY4MVE3MzcgNjgxIDc1NSA2ODNINzYyUTc2OSA2NzYgNzY5IDY3MlE3NjkgNjU1IDc2MCA2NDBRNzU3IDYzNyA3NDMgNjM3UTczMCA2MzYgNzE5IDYzNVQ2OTggNjMwVDY4MiA2MjNUNjcwIDYxNVQ2NjAgNjA4VDY1MiA1OTlUNjQ1IDU5Mkw0NTIgMjgyUTI3MiAtOSAyNjYgLTE2UTI2MyAtMTggMjU5IC0yMUwyNDEgLTIySDIzNFEyMTYgLTIyIDIxNiAtMTVRMjEzIC05IDE3NyAzMDVRMTM5IDYyMyAxMzggNjI2UTEzMyA2MzcgNzYgNjM3SDU5UTUyIDY0MiA1MiA2NDhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi00RCIgZD0iTTEzMiA2MjJRMTI1IDYyOSAxMjEgNjMxVDEwNSA2MzRUNjIgNjM3SDI5VjY4M0gxMzVRMjIxIDY4MyAyMzIgNjgyVDI0OSA2NzVRMjUwIDY3NCAzNTQgMzk4TDQ1OCAxMjRMNTYyIDM5OFE2NjYgNjc0IDY2OCA2NzVRNjcxIDY4MSA2ODMgNjgyVDc4MSA2ODNIODg3VjYzN0g4NTRRODE0IDYzNiA4MDMgNjM0VDc4NSA2MjJWNjFRNzkxIDUxIDgwMiA0OVQ4NTQgNDZIODg3VjBIODc2UTg1NSAzIDczNiAzUTYwNSAzIDU5NiAwSDU4NVY0Nkg2MThRNjYwIDQ3IDY2OSA0OVQ2ODggNjFWMzQ3UTY4OCA0MjQgNjg4IDQ2MVQ2ODggNTQ2VDY4OCA2MTNMNjg3IDYzMlE0NTQgMTQgNDUwIDdRNDQ2IDEgNDMwIDFUNDEwIDdRNDA5IDkgMjkyIDMxNkwxNzYgNjI0VjYwNlExNzUgNTg4IDE3NSA1NDNUMTc1IDQ2M1QxNzUgMzU2TDE3NiA4NlExODcgNTAgMjYxIDQ2SDI3OFYwSDI2OVEyNTQgMyAxNTQgM1E1MiAzIDM3IDBIMjlWNDZINDZRNzggNDggOTggNTZUMTIyIDY5VDEzMiA4NlY2MjJaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi00QyIgZD0iTTEyOCA2MjJRMTIxIDYyOSAxMTcgNjMxVDEwMSA2MzRUNTggNjM3SDI1VjY4M0gzNlE0OCA2ODAgMTgyIDY4MFEzMjQgNjgwIDM0OCA2ODNIMzYwVjYzN0gzMzNRMjczIDYzNyAyNTggNjM1VDIzMyA2MjJMMjMyIDM0MlYxMjlRMjMyIDU3IDIzNyA1MlEyNDMgNDcgMzEzIDQ3UTM4NCA0NyA0MTAgNTNRNDcwIDcwIDQ5OCAxMTBUNTM2IDIyMVE1MzYgMjI2IDUzNyAyMzhUNTQwIDI2MVQ1NDIgMjcyVDU2MiAyNzNINTgyVjI2OFE1ODAgMjY1IDU2OCAxMzdUNTU0IDVWMEgyNVY0Nkg1OFExMDAgNDcgMTA5IDQ5VDEyOCA2MVY2MjJaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUzIiBkPSJNMzA4IDI0UTM2NyAyNCA0MTYgNzZUNDY2IDE5N1E0NjYgMjYwIDQxNCAyODRRMzA4IDMxMSAyNzggMzIxVDIzNiAzNDFRMTc2IDM4MyAxNzYgNDYyUTE3NiA1MjMgMjA4IDU3M1QyNzMgNjQ4UTMwMiA2NzMgMzQzIDY4OFQ0MDcgNzA0SDQxOEg0MjVRNTIxIDcwNCA1NjQgNjQwUTU2NSA2NDAgNTc3IDY1M1Q2MDMgNjgyVDYyMyA3MDRRNjI0IDcwNCA2MjcgNzA0VDYzMiA3MDVRNjQ1IDcwNSA2NDUgNjk4VDYxNyA1NzdUNTg1IDQ1OVQ1NjkgNDU2UTU0OSA0NTYgNTQ5IDQ2NVE1NDkgNDcxIDU1MCA0NzVRNTUwIDQ3OCA1NTEgNDk0VDU1MyA1MjBRNTUzIDU1NCA1NDQgNTc5VDUyNiA2MTZUNTAxIDY0MVE0NjUgNjYyIDQxOSA2NjJRMzYyIDY2MiAzMTMgNjE2VDI2MyA1MTBRMjYzIDQ4MCAyNzggNDU4VDMxOSA0MjdRMzIzIDQyNSAzODkgNDA4VDQ1NiAzOTBRNDkwIDM3OSA1MjIgMzQyVDU1NCAyNDJRNTU0IDIxNiA1NDYgMTg2UTU0MSAxNjQgNTI4IDEzN1Q0OTIgNzhUNDI2IDE4VDMzMiAtMjBRMzIwIC0yMiAyOTggLTIyUTE5OSAtMjIgMTQ0IDMzTDEzNCA0NEwxMDYgMTNRODMgLTE0IDc4IC0xOFQ2NSAtMjJRNTIgLTIyIDUyIC0xNFE1MiAtMTEgMTEwIDIyMVExMTIgMjI3IDEzMCAyMjdIMTQzUTE0OSAyMjEgMTQ5IDIxNlExNDkgMjE0IDE0OCAyMDdUMTQ0IDE4NlQxNDIgMTUzUTE0NCAxMTQgMTYwIDg3VDIwMyA0N1QyNTUgMjlUMzA4IDI0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjIxMSIgZD0iTTYwIDk0OFE2MyA5NTAgNjY1IDk1MEgxMjY3TDEzMjUgODE1UTEzODQgNjc3IDEzODggNjY5SDEzNDhMMTM0MSA2ODNRMTMyMCA3MjQgMTI4NSA3NjFRMTIzNSA4MDkgMTE3NCA4MzhUMTAzMyA4ODFUODgyIDg5OFQ2OTkgOTAySDU3NEg1NDNIMjUxTDI1OSA4OTFRNzIyIDI1OCA3MjQgMjUyUTcyNSAyNTAgNzI0IDI0NlE3MjEgMjQzIDQ2MCAtNTZMMTk2IC0zNTZRMTk2IC0zNTcgNDA3IC0zNTdRNDU5IC0zNTcgNTQ4IC0zNTdUNjc2IC0zNThRODEyIC0zNTggODk2IC0zNTNUMTA2MyAtMzMyVDEyMDQgLTI4M1QxMzA3IC0xOTZRMTMyOCAtMTcwIDEzNDggLTEyNEgxMzg4UTEzODggLTEyNSAxMzgxIC0xNDVUMTM1NiAtMjEwVDEzMjUgLTI5NEwxMjY3IC00NDlMNjY2IC00NTBRNjQgLTQ1MCA2MSAtNDQ4UTU1IC00NDYgNTUgLTQzOVE1NSAtNDM3IDU3IC00MzNMNTkwIDE3N1E1OTAgMTc4IDU1NyAyMjJUNDUyIDM2NlQzMjIgNTQ0TDU2IDkwOUw1NSA5MjRRNTUgOTQ1IDYwIDk0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02QiIgZD0iTTEyMSA2NDdRMTIxIDY1NyAxMjUgNjcwVDEzNyA2ODNRMTM4IDY4MyAyMDkgNjg4VDI4MiA2OTRRMjk0IDY5NCAyOTQgNjg2UTI5NCA2NzkgMjQ0IDQ3N1ExOTQgMjc5IDE5NCAyNzJRMjEzIDI4MiAyMjMgMjkxUTI0NyAzMDkgMjkyIDM1NFQzNjIgNDE1UTQwMiA0NDIgNDM4IDQ0MlE0NjggNDQyIDQ4NSA0MjNUNTAzIDM2OVE1MDMgMzQ0IDQ5NiAzMjdUNDc3IDMwMlQ0NTYgMjkxVDQzOCAyODhRNDE4IDI4OCA0MDYgMjk5VDM5NCAzMjhRMzk0IDM1MyA0MTAgMzY5VDQ0MiAzOTBMNDU4IDM5M1E0NDYgNDA1IDQzNCA0MDVINDMwUTM5OCA0MDIgMzY3IDM4MFQyOTQgMzE2VDIyOCAyNTVRMjMwIDI1NCAyNDMgMjUyVDI2NyAyNDZUMjkzIDIzOFQzMjAgMjI0VDM0MiAyMDZUMzU5IDE4MFQzNjUgMTQ3UTM2NSAxMzAgMzYwIDEwNlQzNTQgNjZRMzU0IDI2IDM4MSAyNlE0MjkgMjYgNDU5IDE0NVE0NjEgMTUzIDQ3OSAxNTNINDgzUTQ5OSAxNTMgNDk5IDE0NFE0OTkgMTM5IDQ5NiAxMzBRNDU1IC0xMSAzNzggLTExUTMzMyAtMTEgMzA1IDE1VDI3NyA5MFEyNzcgMTA4IDI4MCAxMjFUMjgzIDE0NVEyODMgMTY3IDI2OSAxODNUMjM0IDIwNlQyMDAgMjE3VDE4MiAyMjBIMTgwUTE2OCAxNzggMTU5IDEzOVQxNDUgODFUMTM2IDQ0VDEyOSAyMFQxMjIgN1QxMTEgLTJROTggLTExIDgzIC0xMVE2NiAtMTEgNTcgLTFUNDggMTZRNDggMjYgODUgMTc2VDE1OCA0NzFMMTk1IDYxNlExOTYgNjI5IDE4OCA2MzJUMTQ5IDYzN0gxNDRRMTM0IDYzNyAxMzEgNjM3VDEyNCA2NDBUMTIxIDY0N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMUUiIGQ9Ik01NSAyMTdRNTUgMzA1IDExMSAzNzNUMjU0IDQ0MlEzNDIgNDQyIDQxOSAzODFRNDU3IDM1MCA0OTMgMzAzTDUwNyAyODRMNTE0IDI5NFE2MTggNDQyIDc0NyA0NDJRODMzIDQ0MiA4ODggMzc0VDk0NCAyMTRROTQ0IDEyOCA4ODkgNTlUNzQzIC0xMVE2NTcgLTExIDU4MCA1MFE1NDIgODEgNTA2IDEyOEw0OTIgMTQ3TDQ4NSAxMzdRMzgxIC0xMSAyNTIgLTExUTE2NiAtMTEgMTExIDU3VDU1IDIxN1pNOTA3IDIxN1E5MDcgMjg1IDg2OSAzNDFUNzYxIDM5N1E3NDAgMzk3IDcyMCAzOTJUNjgyIDM3OFQ2NDggMzU5VDYxOSAzMzVUNTk0IDMxMFQ1NzQgMjg1VDU1OSAyNjNUNTQ4IDI0Nkw1NDMgMjM4TDU3NCAxOThRNjA1IDE1OCA2MjIgMTM4VDY2NCA5NFQ3MTQgNjFUNzY1IDUxUTgyNyA1MSA4NjcgMTAwVDkwNyAyMTdaTTkyIDIxNFE5MiAxNDUgMTMxIDg5VDIzOSAzM1EzNTcgMzMgNDU2IDE5M0w0MjUgMjMzUTM2NCAzMTIgMzM0IDMzN1EyODUgMzgwIDIzMyAzODBRMTcxIDM4MCAxMzIgMzMxVDkyIDIxNFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTUwIiBkPSJNMTMwIDYyMlExMjMgNjI5IDExOSA2MzFUMTAzIDYzNFQ2MCA2MzdIMjdWNjgzSDIxNFEyMzcgNjgzIDI3NiA2ODNUMzMxIDY4NFE0MTkgNjg0IDQ3MSA2NzFUNTY3IDYxNlE2MjQgNTYzIDYyNCA0ODlRNjI0IDQyMSA1NzMgMzcyVDQ1MSAzMDdRNDI5IDMwMiAzMjggMzAxSDIzNFYxODFRMjM0IDYyIDIzNyA1OFEyNDUgNDcgMzA0IDQ2SDMzN1YwSDMyNlEzMDUgMyAxODIgM1E0NyAzIDM4IDBIMjdWNDZINjBRMTAyIDQ3IDExMSA0OVQxMzAgNjFWNjIyWk01MDcgNDg4UTUwNyA1MTQgNTA2IDUyOFQ1MDAgNTY0VDQ4MyA1OTdUNDUwIDYyMFQzOTcgNjM1UTM4NSA2MzcgMzA3IDYzN0gyODZRMjM3IDYzNyAyMzQgNjI4UTIzMSA2MjQgMjMxIDQ4M1YzNDJIMzAySDMzOVEzOTAgMzQyIDQyMyAzNDlUNDgxIDM4MlE1MDcgNDExIDUwNyA0ODhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03MiIgZD0iTTM2IDQ2SDUwUTg5IDQ2IDk3IDYwVjY4UTk3IDc3IDk3IDkxVDk4IDEyMlQ5OCAxNjFUOTggMjAzUTk4IDIzNCA5OCAyNjlUOTggMzI4TDk3IDM1MVE5NCAzNzAgODMgMzc2VDM4IDM4NUgyMFY0MDhRMjAgNDMxIDIyIDQzMUwzMiA0MzJRNDIgNDMzIDYwIDQzNFQ5NiA0MzZRMTEyIDQzNyAxMzEgNDM4VDE2MCA0NDFUMTcxIDQ0MkgxNzRWMzczUTIxMyA0NDEgMjcxIDQ0MUgyNzdRMzIyIDQ0MSAzNDMgNDE5VDM2NCAzNzNRMzY0IDM1MiAzNTEgMzM3VDMxMyAzMjJRMjg4IDMyMiAyNzYgMzM4VDI2MyAzNzJRMjYzIDM4MSAyNjUgMzg4VDI3MCA0MDBUMjczIDQwNVEyNzEgNDA3IDI1MCA0MDFRMjM0IDM5MyAyMjYgMzg2UTE3OSAzNDEgMTc5IDIwN1YxNTRRMTc5IDE0MSAxNzkgMTI3VDE3OSAxMDFUMTgwIDgxVDE4MCA2NlY2MVExODEgNTkgMTgzIDU3VDE4OCA1NFQxOTMgNTFUMjAwIDQ5VDIwNyA0OFQyMTYgNDdUMjI1IDQ3VDIzNSA0NlQyNDUgNDZIMjc2VjBIMjY3UTI0OSAzIDE0MCAzUTM3IDMgMjggMEgyMFY0NkgzNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMwIiBkPSJNOTYgNTg1UTE1MiA2NjYgMjQ5IDY2NlEyOTcgNjY2IDM0NSA2NDBUNDIzIDU0OFE0NjAgNDY1IDQ2MCAzMjBRNDYwIDE2NSA0MTcgODNRMzk3IDQxIDM2MiAxNlQzMDEgLTE1VDI1MCAtMjJRMjI0IC0yMiAxOTggLTE2VDEzNyAxNlQ4MiA4M1EzOSAxNjUgMzkgMzIwUTM5IDQ5NCA5NiA1ODVaTTMyMSA1OTdRMjkxIDYyOSAyNTAgNjI5UTIwOCA2MjkgMTc4IDU5N1ExNTMgNTcxIDE0NSA1MjVUMTM3IDMzM1ExMzcgMTc1IDE0NSAxMjVUMTgxIDQ2UTIwOSAxNiAyNTAgMTZRMjkwIDE2IDMxOCA0NlEzNDcgNzYgMzU0IDEzMFQzNjIgMzMzUTM2MiA0NzggMzU0IDUyNFQzMjEgNTk3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkUiIGQ9Ik03OCA2MFE3OCA4NCA5NSAxMDJUMTM4IDEyMFExNjIgMTIwIDE4MCAxMDRUMTk5IDYxUTE5OSAzNiAxODIgMThUMTM5IDBUOTYgMTdUNzggNjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zNyIgZD0iTTU1IDQ1OFE1NiA0NjAgNzIgNTY3TDg4IDY3NFE4OCA2NzYgMTA4IDY3NkgxMjhWNjcyUTEyOCA2NjIgMTQzIDY1NVQxOTUgNjQ2VDM2NCA2NDRINDg1VjYwNUw0MTcgNTEyUTQwOCA1MDAgMzg3IDQ3MlQzNjAgNDM1VDMzOSA0MDNUMzE5IDM2N1QzMDUgMzMwVDI5MiAyODRUMjg0IDIzMFQyNzggMTYyVDI3NSA4MFEyNzUgNjYgMjc1IDUyVDI3NCAyOFYxOVEyNzAgMiAyNTUgLTEwVDIyMSAtMjJRMjEwIC0yMiAyMDAgLTE5VDE3OSAwVDE2OCA0MFExNjggMTk4IDI2NSAzNjhRMjg1IDQwMCAzNDkgNDg5TDM5NSA1NTJIMzAyUTEyOCA1NTIgMTE5IDU0NlExMTMgNTQzIDEwOCA1MjJUOTggNDc5TDk1IDQ1OFY0NTVINTVWNDU4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzUiIGQ9Ik0xNjQgMTU3UTE2NCAxMzMgMTQ4IDExN1QxMDkgMTAxSDEwMlExNDggMjIgMjI0IDIyUTI5NCAyMiAzMjYgODJRMzQ1IDExNSAzNDUgMjEwUTM0NSAzMTMgMzE4IDM0OVEyOTIgMzgyIDI2MCAzODJIMjU0UTE3NiAzODIgMTM2IDMxNFExMzIgMzA3IDEyOSAzMDZUMTE0IDMwNFE5NyAzMDQgOTUgMzEwUTkzIDMxNCA5MyA0ODVWNjE0UTkzIDY2NCA5OCA2NjRRMTAwIDY2NiAxMDIgNjY2UTEwMyA2NjYgMTIzIDY1OFQxNzggNjQyVDI1MyA2MzRRMzI0IDYzNCAzODkgNjYyUTM5NyA2NjYgNDAyIDY2NlE0MTAgNjY2IDQxMCA2NDhWNjM1UTMyOCA1MzggMjA1IDUzOFExNzQgNTM4IDE0OSA1NDRMMTM5IDU0NlYzNzRRMTU4IDM4OCAxNjkgMzk2VDIwNSA0MTJUMjU2IDQyMFEzMzcgNDIwIDM5MyAzNTVUNDQ5IDIwMVE0NDkgMTA5IDM4NSA0NFQyMjkgLTIyUTE0OCAtMjIgOTkgMzJUNTAgMTU0UTUwIDE3OCA2MSAxOTJUODQgMjEwVDEwNyAyMTRRMTMyIDIxNCAxNDggMTk3VDE2NCAxNTdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjEyIiBkPSJNODQgMjM3VDg0IDI1MFQ5OCAyNzBINjc5UTY5NCAyNjIgNjk0IDI1MFQ2NzkgMjMwSDk4UTg0IDIzNyA4NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMkM1IiBkPSJNNzggMjUwUTc4IDI3NCA5NSAyOTJUMTM4IDMxMFExNjIgMzEwIDE4MCAyOTRUMTk5IDI1MVExOTkgMjI2IDE4MiAyMDhUMTM5IDE5MFQ5NiAyMDdUNzggMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzIiIGQ9Ik0xMDkgNDI5UTgyIDQyOSA2NiA0NDdUNTAgNDkxUTUwIDU2MiAxMDMgNjE0VDIzNSA2NjZRMzI2IDY2NiAzODcgNjEwVDQ0OSA0NjVRNDQ5IDQyMiA0MjkgMzgzVDM4MSAzMTVUMzAxIDI0MVEyNjUgMjEwIDIwMSAxNDlMMTQyIDkzTDIxOCA5MlEzNzUgOTIgMzg1IDk3UTM5MiA5OSA0MDkgMTg2VjE4OUg0NDlWMTg2UTQ0OCAxODMgNDM2IDk1VDQyMSAzVjBINTBWMTlWMzFRNTAgMzggNTYgNDZUODYgODFRMTE1IDExMyAxMzYgMTM3UTE0NSAxNDcgMTcwIDE3NFQyMDQgMjExVDIzMyAyNDRUMjYxIDI3OFQyODQgMzA4VDMwNSAzNDBUMzIwIDM2OVQzMzMgNDAxVDM0MCA0MzFUMzQzIDQ2NFEzNDMgNTI3IDMwOSA1NzNUMjEyIDYxOVExNzkgNjE5IDE1NCA2MDJUMTE5IDU2OVQxMDkgNTUwUTEwOSA1NDkgMTE0IDU0OVExMzIgNTQ5IDE1MSA1MzVUMTcwIDQ4OVExNzAgNDY0IDE1NCA0NDdUMTA5IDQyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTM0IiBkPSJNNDYyIDBRNDQ0IDMgMzMzIDNRMjE3IDMgMTk5IDBIMTkwVjQ2SDIyMVEyNDEgNDYgMjQ4IDQ2VDI2NSA0OFQyNzkgNTNUMjg2IDYxUTI4NyA2MyAyODcgMTE1VjE2NUgyOFYyMTFMMTc5IDQ0MlEzMzIgNjc0IDMzNCA2NzVRMzM2IDY3NyAzNTUgNjc3SDM3M0wzNzkgNjcxVjIxMUg0NzFWMTY1SDM3OVYxMTRRMzc5IDczIDM3OSA2NlQzODUgNTRRMzkzIDQ3IDQ0MiA0Nkg0NzFWMEg0NjJaTTI5MyAyMTFWNTQ1TDc0IDIxMkwxODMgMjExSDI5M1oiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjcsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgtMTEsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDIyNjcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4MjUsNDEyKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTREIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNEMiIHg9IjkxNyIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjE4MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTAzNSIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM1OTcsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDIyNjcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjc3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTMzNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODUsLTExMTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjUyMSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxMzAwIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjFFIiB4PSI1MjEiIHk9IjE2MjciPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI5NDUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTUwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iNjgxIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0MTg1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI5MTEiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI1NjUzIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC04MTUpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjc3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTMzNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODUsLTExMTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjUyMSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxMzAwIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjFFIiB4PSI1MjEiIHk9IjE2MjciPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI5NDUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzciIHg9Ijc3OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzUiIHg9IjEyNzkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjIxNjkiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNTU5LDQ3NykiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSI1MjEiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTMwMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyQzUiIHg9IjcwOTkiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3NjAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI3NzkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTM1IiB4PSIxMjc5IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIyMTY5IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyQzUiIHg9IjEwMzgxIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjEwODgyIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC0zMTMyKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzQiIHg9IjEzMzQiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+Cjwvc3ZnPg==)
因此,在该例中,ML估计与首次访问MC方法的估计相同。
定理1 For any undiscounted absorbing Markov chain, the estimates computed by first-visit MC are the reduced-ML estimates, for all states and after all trials.
简化的双状态抽象马尔可夫链
在本文中,我们将介绍如何将任意的undiscounted absorbing Markov chain简化为双状态抽象马尔可夫链(two-state abstracted Markov chain),并将它用在MC方法中。简化的依据是独立关注每个状态。假设我们只对一个状态 的价值感兴趣,并且所有的试验都是从状态 开始。我们可以在不失一般性的情况下做到这一点,因为状态 的价值在试验后的变化不受首次访问该状态之前发生的任何事情的影响。
对于任意的马尔可夫链,试验产生两个序列,一个随机的状态序列, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjMuNDE1ZXgiIGhlaWdodD0iMi44NDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjgzOGV4OyIgdmlld0JveD0iMCAtODYzLjEgMTQ3MC41IDEyMjMuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSI5NzAiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) ,以 开头并以 结尾,以及相关的随机奖励序列
,以 开头并以 结尾,以及相关的随机奖励序列 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjMuMzc0ZXgiIGhlaWdodD0iMi44NDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjgzOGV4OyIgdmlld0JveD0iMCAtODYzLjEgMTQ1Mi41IDEyMjMuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTcyIiBkPSJNMjEgMjg3UTIyIDI5MCAyMyAyOTVUMjggMzE3VDM4IDM0OFQ1MyAzODFUNzMgNDExVDk5IDQzM1QxMzIgNDQyUTE2MSA0NDIgMTgzIDQzMFQyMTQgNDA4VDIyNSAzODhRMjI3IDM4MiAyMjggMzgyVDIzNiAzODlRMjg0IDQ0MSAzNDcgNDQxSDM1MFEzOTggNDQxIDQyMiA0MDBRNDMwIDM4MSA0MzAgMzYzUTQzMCAzMzMgNDE3IDMxNVQzOTEgMjkyVDM2NiAyODhRMzQ2IDI4OCAzMzQgMjk5VDMyMiAzMjhRMzIyIDM3NiAzNzggMzkyUTM1NiA0MDUgMzQyIDQwNVEyODYgNDA1IDIzOSAzMzFRMjI5IDMxNSAyMjQgMjk4VDE5MCAxNjVRMTU2IDI1IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTE0IDE4OVQxNTQgMzY2UTE1NCA0MDUgMTI4IDQwNVExMDcgNDA1IDkyIDM3N1Q2OCAzMTZUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdEIiBkPSJNNjUgNzMxUTY1IDc0NSA2OCA3NDdUODggNzUwUTE3MSA3NTAgMjE2IDcyNVQyNzkgNjcwUTI4OCA2NDkgMjg5IDYzNVQyOTEgNTAxUTI5MiAzNjIgMjkzIDM1N1EzMDYgMzEyIDM0NSAyOTFUNDE3IDI2OVE0MjggMjY5IDQzMSAyNjZUNDM0IDI1MFQ0MzEgMjM0VDQxNyAyMzFRMzgwIDIzMSAzNDUgMjEwVDI5OCAxNTdRMjkzIDE0MyAyOTIgMTIxVDI5MSAtMjhWLTc5UTI5MSAtMTM0IDI4NSAtMTU2VDI1NiAtMTk4UTIwMiAtMjUwIDg5IC0yNTBRNzEgLTI1MCA2OCAtMjQ3VDY1IC0yMzBRNjUgLTIyNCA2NSAtMjIzVDY2IC0yMThUNjkgLTIxNFQ3NyAtMjEzUTkxIC0yMTMgMTA4IC0yMTBUMTQ2IC0yMDBUMTgzIC0xNzdUMjA3IC0xMzlRMjA4IC0xMzQgMjA5IDNMMjEwIDEzOVEyMjMgMTk2IDI4MCAyMzBRMzE1IDI0NyAzMzAgMjUwUTMwNSAyNTcgMjgwIDI3MFEyMjUgMzA0IDIxMiAzNTJMMjEwIDM2MkwyMDkgNDk4UTIwOCA2MzUgMjA3IDY0MFExOTUgNjgwIDE1NCA2OTZUNzcgNzEzUTY4IDcxMyA2NyA3MTZUNjUgNzMxWiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iNTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iOTUyIiB5PSIwIj48L3VzZT4KPC9nPgo8L3N2Zz4=) 。将序列 分成连续的子序列,这些子序列以 开头并在下一次重新访问 之前结束。第
。将序列 分成连续的子序列,这些子序列以 开头并在下一次重新访问 之前结束。第 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjAuODAyZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgMzQ1LjUgOTM2LjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNjkiIGQ9Ik0xODQgNjAwUTE4NCA2MjQgMjAzIDY0MlQyNDcgNjYxUTI2NSA2NjEgMjc3IDY0OVQyOTAgNjE5UTI5MCA1OTYgMjcwIDU3N1QyMjYgNTU3UTIxMSA1NTcgMTk4IDU2N1QxODQgNjAwWk0yMSAyODdRMjEgMjk1IDMwIDMxOFQ1NCAzNjlUOTggNDIwVDE1OCA0NDJRMTk3IDQ0MiAyMjMgNDE5VDI1MCAzNTdRMjUwIDM0MCAyMzYgMzAxVDE5NiAxOTZUMTU0IDgzUTE0OSA2MSAxNDkgNTFRMTQ5IDI2IDE2NiAyNlExNzUgMjYgMTg1IDI5VDIwOCA0M1QyMzUgNzhUMjYwIDEzN1EyNjMgMTQ5IDI2NSAxNTFUMjgyIDE1M1EzMDIgMTUzIDMwMiAxNDNRMzAyIDEzNSAyOTMgMTEyVDI2OCA2MVQyMjMgMTFUMTYxIC0xMVExMjkgLTExIDEwMiAxMFQ3NCA3NFE3NCA5MSA3OSAxMDZUMTIyIDIyMFExNjAgMzIxIDE2NiAzNDFUMTczIDM4MFExNzMgNDA0IDE1NiA0MDRIMTU0UTEyNCA0MDQgOTkgMzcxVDYxIDI4N1E2MCAyODYgNTkgMjg0VDU4IDI4MVQ1NiAyNzlUNTMgMjc4VDQ5IDI3OFQ0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 次重新访问 开始的子序列表示为
次重新访问 开始的子序列表示为 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQuMjE1ZXgiIGhlaWdodD0iMy4wMDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0xLjAwNWV4OyIgdmlld0JveD0iMCAtODYzLjEgMTgxNC44IDEyOTUuNyIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNjkiIGQ9Ik0xODQgNjAwUTE4NCA2MjQgMjAzIDY0MlQyNDcgNjYxUTI2NSA2NjEgMjc3IDY0OVQyOTAgNjE5UTI5MCA1OTYgMjcwIDU3N1QyMjYgNTU3UTIxMSA1NTcgMTk4IDU2N1QxODQgNjAwWk0yMSAyODdRMjEgMjk1IDMwIDMxOFQ1NCAzNjlUOTggNDIwVDE1OCA0NDJRMTk3IDQ0MiAyMjMgNDE5VDI1MCAzNTdRMjUwIDM0MCAyMzYgMzAxVDE5NiAxOTZUMTU0IDgzUTE0OSA2MSAxNDkgNTFRMTQ5IDI2IDE2NiAyNlExNzUgMjYgMTg1IDI5VDIwOCA0M1QyMzUgNzhUMjYwIDEzN1EyNjMgMTQ5IDI2NSAxNTFUMjgyIDE1M1EzMDIgMTUzIDMwMiAxNDNRMzAyIDEzNSAyOTMgMTEyVDI2OCA2MVQyMjMgMTFUMTYxIC0xMVExMjkgLTExIDEwMiAxMFQ3NCA3NFE3NCA5MSA3OSAxMDZUMTIyIDIyMFExNjAgMzIxIDE2NiAzNDFUMTczIDM4MFExNzMgNDA0IDE1NiA0MDRIMTU0UTEyNCA0MDQgOTkgMzcxVDYxIDI4N1E2MCAyODYgNTkgMjg0VDU4IDI4MVQ1NiAyNzlUNTMgMjc4VDQ5IDI3OFQ0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9Ijk3MCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMjA3OSIgeT0iLTQwNSI+PC91c2U+CjwvZz4KPC9zdmc+) 。最后一个这样的子序列是特殊的,因为它以终止状态结束并表示为
。最后一个这样的子序列是特殊的,因为它以终止状态结束并表示为 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQuODA1ZXgiIGhlaWdodD0iMy4wMDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0xLjAwNWV4OyIgdmlld0JveD0iMCAtODYzLjEgMjA2OC43IDEyOTUuNyIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTQiIGQ9Ik00MCA0MzdRMjEgNDM3IDIxIDQ0NVEyMSA0NTAgMzcgNTAxVDcxIDYwMkw4OCA2NTFROTMgNjY5IDEwMSA2NzdINTY5SDY1OVE2OTEgNjc3IDY5NyA2NzZUNzA0IDY2N1E3MDQgNjYxIDY4NyA1NTNUNjY4IDQ0NFE2NjggNDM3IDY0OSA0MzdRNjQwIDQzNyA2MzcgNDM3VDYzMSA0NDJMNjI5IDQ0NVE2MjkgNDUxIDYzNSA0OTBUNjQxIDU1MVE2NDEgNTg2IDYyOCA2MDRUNTczIDYyOVE1NjggNjMwIDUxNSA2MzFRNDY5IDYzMSA0NTcgNjMwVDQzOSA2MjJRNDM4IDYyMSAzNjggMzQzVDI5OCA2MFEyOTggNDggMzg2IDQ2UTQxOCA0NiA0MjcgNDVUNDM2IDM2UTQzNiAzMSA0MzMgMjJRNDI5IDQgNDI0IDFMNDIyIDBRNDE5IDAgNDE1IDBRNDEwIDAgMzYzIDFUMjI4IDJROTkgMiA2NCAwSDQ5UTQzIDYgNDMgOVQ0NSAyN1E0OSA0MCA1NSA0Nkg4M0g5NFExNzQgNDYgMTg5IDU1UTE5MCA1NiAxOTEgNTZRMTk2IDU5IDIwMSA3NlQyNDEgMjMzUTI1OCAzMDEgMjY5IDM0NFEzMzkgNjE5IDMzOSA2MjVRMzM5IDYzMCAzMTAgNjMwSDI3OVEyMTIgNjMwIDE5MSA2MjRRMTQ2IDYxNCAxMjEgNTgzVDY3IDQ2N1E2MCA0NDUgNTcgNDQxVDQzIDQzN0g0MFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9Ijk3MCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMjA3OSIgeT0iLTQwNSI+PC91c2U+CjwvZz4KPC9zdmc+) 。相应的奖励序列类似地表示为
。相应的奖励序列类似地表示为 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQuMTczZXgiIGhlaWdodD0iMy4wMDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0xLjAwNWV4OyIgdmlld0JveD0iMCAtODYzLjEgMTc5Ni44IDEyOTUuNyIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTcyIiBkPSJNMjEgMjg3UTIyIDI5MCAyMyAyOTVUMjggMzE3VDM4IDM0OFQ1MyAzODFUNzMgNDExVDk5IDQzM1QxMzIgNDQyUTE2MSA0NDIgMTgzIDQzMFQyMTQgNDA4VDIyNSAzODhRMjI3IDM4MiAyMjggMzgyVDIzNiAzODlRMjg0IDQ0MSAzNDcgNDQxSDM1MFEzOTggNDQxIDQyMiA0MDBRNDMwIDM4MSA0MzAgMzYzUTQzMCAzMzMgNDE3IDMxNVQzOTEgMjkyVDM2NiAyODhRMzQ2IDI4OCAzMzQgMjk5VDMyMiAzMjhRMzIyIDM3NiAzNzggMzkyUTM1NiA0MDUgMzQyIDQwNVEyODYgNDA1IDIzOSAzMzFRMjI5IDMxNSAyMjQgMjk4VDE5MCAxNjVRMTU2IDI1IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTE0IDE4OVQxNTQgMzY2UTE1NCA0MDUgMTI4IDQwNVExMDcgNDA1IDkyIDM3N1Q2OCAzMTZUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdEIiBkPSJNNjUgNzMxUTY1IDc0NSA2OCA3NDdUODggNzUwUTE3MSA3NTAgMjE2IDcyNVQyNzkgNjcwUTI4OCA2NDkgMjg5IDYzNVQyOTEgNTAxUTI5MiAzNjIgMjkzIDM1N1EzMDYgMzEyIDM0NSAyOTFUNDE3IDI2OVE0MjggMjY5IDQzMSAyNjZUNDM0IDI1MFQ0MzEgMjM0VDQxNyAyMzFRMzgwIDIzMSAzNDUgMjEwVDI5OCAxNTdRMjkzIDE0MyAyOTIgMTIxVDI5MSAtMjhWLTc5UTI5MSAtMTM0IDI4NSAtMTU2VDI1NiAtMTk4UTIwMiAtMjUwIDg5IC0yNTBRNzEgLTI1MCA2OCAtMjQ3VDY1IC0yMzBRNjUgLTIyNCA2NSAtMjIzVDY2IC0yMThUNjkgLTIxNFQ3NyAtMjEzUTkxIC0yMTMgMTA4IC0yMTBUMTQ2IC0yMDBUMTgzIC0xNzdUMjA3IC0xMzlRMjA4IC0xMzQgMjA5IDNMMjEwIDEzOVEyMjMgMTk2IDI4MCAyMzBRMzE1IDI0NyAzMzAgMjUwUTMwNSAyNTcgMjgwIDI3MFEyMjUgMzA0IDIxMiAzNTJMMjEwIDM2MkwyMDkgNDk4UTIwOCA2MzUgMjA3IDY0MFExOTUgNjgwIDE1NCA2OTZUNzcgNzEzUTY4IDcxMyA2NyA3MTZUNjUgNzMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY5IiBkPSJNMTg0IDYwMFExODQgNjI0IDIwMyA2NDJUMjQ3IDY2MVEyNjUgNjYxIDI3NyA2NDlUMjkwIDYxOVEyOTAgNTk2IDI3MCA1NzdUMjI2IDU1N1EyMTEgNTU3IDE5OCA1NjdUMTg0IDYwMFpNMjEgMjg3UTIxIDI5NSAzMCAzMThUNTQgMzY5VDk4IDQyMFQxNTggNDQyUTE5NyA0NDIgMjIzIDQxOVQyNTAgMzU3UTI1MCAzNDAgMjM2IDMwMVQxOTYgMTk2VDE1NCA4M1ExNDkgNjEgMTQ5IDUxUTE0OSAyNiAxNjYgMjZRMTc1IDI2IDE4NSAyOVQyMDggNDNUMjM1IDc4VDI2MCAxMzdRMjYzIDE0OSAyNjUgMTUxVDI4MiAxNTNRMzAyIDE1MyAzMDIgMTQzUTMwMiAxMzUgMjkzIDExMlQyNjggNjFUMjIzIDExVDE2MSAtMTFRMTI5IC0xMSAxMDIgMTBUNzQgNzRRNzQgOTEgNzkgMTA2VDEyMiAyMjBRMTYwIDMyMSAxNjYgMzQxVDE3MyAzODBRMTczIDQwNCAxNTYgNDA0SDE1NFExMjQgNDA0IDk5IDM3MVQ2MSAyODdRNjAgMjg2IDU5IDI4NFQ1OCAyODFUNTYgMjc5VDUzIDI3OFQ0OSAyNzhUNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSI5NTIiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjIwNTQiIHk9Ii00MDUiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) 和
和 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQuNzYzZXgiIGhlaWdodD0iMy4wMDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0xLjAwNWV4OyIgdmlld0JveD0iMCAtODYzLjEgMjA1MC43IDEyOTUuNyIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTcyIiBkPSJNMjEgMjg3UTIyIDI5MCAyMyAyOTVUMjggMzE3VDM4IDM0OFQ1MyAzODFUNzMgNDExVDk5IDQzM1QxMzIgNDQyUTE2MSA0NDIgMTgzIDQzMFQyMTQgNDA4VDIyNSAzODhRMjI3IDM4MiAyMjggMzgyVDIzNiAzODlRMjg0IDQ0MSAzNDcgNDQxSDM1MFEzOTggNDQxIDQyMiA0MDBRNDMwIDM4MSA0MzAgMzYzUTQzMCAzMzMgNDE3IDMxNVQzOTEgMjkyVDM2NiAyODhRMzQ2IDI4OCAzMzQgMjk5VDMyMiAzMjhRMzIyIDM3NiAzNzggMzkyUTM1NiA0MDUgMzQyIDQwNVEyODYgNDA1IDIzOSAzMzFRMjI5IDMxNSAyMjQgMjk4VDE5MCAxNjVRMTU2IDI1IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTE0IDE4OVQxNTQgMzY2UTE1NCA0MDUgMTI4IDQwNVExMDcgNDA1IDkyIDM3N1Q2OCAzMTZUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdEIiBkPSJNNjUgNzMxUTY1IDc0NSA2OCA3NDdUODggNzUwUTE3MSA3NTAgMjE2IDcyNVQyNzkgNjcwUTI4OCA2NDkgMjg5IDYzNVQyOTEgNTAxUTI5MiAzNjIgMjkzIDM1N1EzMDYgMzEyIDM0NSAyOTFUNDE3IDI2OVE0MjggMjY5IDQzMSAyNjZUNDM0IDI1MFQ0MzEgMjM0VDQxNyAyMzFRMzgwIDIzMSAzNDUgMjEwVDI5OCAxNTdRMjkzIDE0MyAyOTIgMTIxVDI5MSAtMjhWLTc5UTI5MSAtMTM0IDI4NSAtMTU2VDI1NiAtMTk4UTIwMiAtMjUwIDg5IC0yNTBRNzEgLTI1MCA2OCAtMjQ3VDY1IC0yMzBRNjUgLTIyNCA2NSAtMjIzVDY2IC0yMThUNjkgLTIxNFQ3NyAtMjEzUTkxIC0yMTMgMTA4IC0yMTBUMTQ2IC0yMDBUMTgzIC0xNzdUMjA3IC0xMzlRMjA4IC0xMzQgMjA5IDNMMjEwIDEzOVEyMjMgMTk2IDI4MCAyMzBRMzE1IDI0NyAzMzAgMjUwUTMwNSAyNTcgMjgwIDI3MFEyMjUgMzA0IDIxMiAzNTJMMjEwIDM2MkwyMDkgNDk4UTIwOCA2MzUgMjA3IDY0MFExOTUgNjgwIDE1NCA2OTZUNzcgNzEzUTY4IDcxMyA2NyA3MTZUNjUgNzMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU0IiBkPSJNNDAgNDM3UTIxIDQzNyAyMSA0NDVRMjEgNDUwIDM3IDUwMVQ3MSA2MDJMODggNjUxUTkzIDY2OSAxMDEgNjc3SDU2OUg2NTlRNjkxIDY3NyA2OTcgNjc2VDcwNCA2NjdRNzA0IDY2MSA2ODcgNTUzVDY2OCA0NDRRNjY4IDQzNyA2NDkgNDM3UTY0MCA0MzcgNjM3IDQzN1Q2MzEgNDQyTDYyOSA0NDVRNjI5IDQ1MSA2MzUgNDkwVDY0MSA1NTFRNjQxIDU4NiA2MjggNjA0VDU3MyA2MjlRNTY4IDYzMCA1MTUgNjMxUTQ2OSA2MzEgNDU3IDYzMFQ0MzkgNjIyUTQzOCA2MjEgMzY4IDM0M1QyOTggNjBRMjk4IDQ4IDM4NiA0NlE0MTggNDYgNDI3IDQ1VDQzNiAzNlE0MzYgMzEgNDMzIDIyUTQyOSA0IDQyNCAxTDQyMiAwUTQxOSAwIDQxNSAwUTQxMCAwIDM2MyAxVDIyOCAyUTk5IDIgNjQgMEg0OVE0MyA2IDQzIDlUNDUgMjdRNDkgNDAgNTUgNDZIODNIOTRRMTc0IDQ2IDE4OSA1NVExOTAgNTYgMTkxIDU2UTE5NiA1OSAyMDEgNzZUMjQxIDIzM1EyNTggMzAxIDI2OSAzNDRRMzM5IDYxOSAzMzkgNjI1UTMzOSA2MzAgMzEwIDYzMEgyNzlRMjEyIDYzMCAxOTEgNjI0UTE0NiA2MTQgMTIxIDU4M1Q2NyA0NjdRNjAgNDQ1IDU3IDQ0MVQ0MyA0MzdINDBaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSI5NTIiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjIwNTQiIHk9Ii00MDUiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) 。由于马尔可夫性,对于所有的
。由于马尔可夫性,对于所有的 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQuODU5ZXgiIGhlaWdodD0iMi42NzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjgzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgMjA5Mi4xIDExNTIuMSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02OSIgZD0iTTE4NCA2MDBRMTg0IDYyNCAyMDMgNjQyVDI0NyA2NjFRMjY1IDY2MSAyNzcgNjQ5VDI5MCA2MTlRMjkwIDU5NiAyNzAgNTc3VDIyNiA1NTdRMjExIDU1NyAxOTggNTY3VDE4NCA2MDBaTTIxIDI4N1EyMSAyOTUgMzAgMzE4VDU0IDM2OVQ5OCA0MjBUMTU4IDQ0MlExOTcgNDQyIDIyMyA0MTlUMjUwIDM1N1EyNTAgMzQwIDIzNiAzMDFUMTk2IDE5NlQxNTQgODNRMTQ5IDYxIDE0OSA1MVExNDkgMjYgMTY2IDI2UTE3NSAyNiAxODUgMjlUMjA4IDQzVDIzNSA3OFQyNjAgMTM3UTI2MyAxNDkgMjY1IDE1MVQyODIgMTUzUTMwMiAxNTMgMzAyIDE0M1EzMDIgMTM1IDI5MyAxMTJUMjY4IDYxVDIyMyAxMVQxNjEgLTExUTEyOSAtMTEgMTAyIDEwVDc0IDc0UTc0IDkxIDc5IDEwNlQxMjIgMjIwUTE2MCAzMjEgMTY2IDM0MVQxNzMgMzgwUTE3MyA0MDQgMTU2IDQwNEgxNTRRMTI0IDQwNCA5OSAzNzFUNjEgMjg3UTYwIDI4NiA1OSAyODRUNTggMjgxVDU2IDI3OVQ1MyAyNzhUNDkgMjc4VDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjI2MCIgZD0iTTE2NiAtMjE1VDE1OSAtMjE1VDE0NyAtMjEyVDE0MSAtMjA0VDEzOSAtMTk3UTEzOSAtMTkwIDE0NCAtMTgzTDMwNiAxMzNINzBRNTYgMTQwIDU2IDE1M1E1NiAxNjggNzIgMTczSDMyN0w0MDYgMzI3SDcyUTU2IDMzMiA1NiAzNDdRNTYgMzYwIDcwIDM2N0g0MjZRNTk3IDcwMiA2MDIgNzA3UTYwNSA3MTYgNjE4IDcxNlE2MjUgNzE2IDYzMCA3MTJUNjM2IDcwM1Q2MzggNjk2UTYzOCA2OTIgNDcxIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEw0NTEgMzI3TDM3MSAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNIMzUxUTE3NSAtMjEwIDE3MCAtMjEyUTE2NiAtMjE1IDE1OSAtMjE1WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZBIiBkPSJNMjk3IDU5NlEyOTcgNjI3IDMxOCA2NDRUMzYxIDY2MVEzNzggNjYxIDM4OSA2NTFUNDAzIDYyM1E0MDMgNTk1IDM4NCA1NzZUMzQwIDU1N1EzMjIgNTU3IDMxMCA1NjdUMjk3IDU5NlpNMjg4IDM3NlEyODggNDA1IDI2MiA0MDVRMjQwIDQwNSAyMjAgMzkzVDE4NSAzNjJUMTYxIDMyNVQxNDQgMjkzTDEzNyAyNzlRMTM1IDI3OCAxMjEgMjc4SDEwN1ExMDEgMjg0IDEwMSAyODZUMTA1IDI5OVExMjYgMzQ4IDE2NCAzOTFUMjUyIDQ0MVEyNTMgNDQxIDI2MCA0NDFUMjcyIDQ0MlEyOTYgNDQxIDMxNiA0MzJRMzQxIDQxOCAzNTQgNDAxVDM2NyAzNDhWMzMyTDMxOCAxMzNRMjY3IC02NyAyNjQgLTc1UTI0NiAtMTI1IDE5NCAtMTY0VDc1IC0yMDRRMjUgLTIwNCA3IC0xODNULTEyIC0xMzdRLTEyIC0xMTAgNyAtOTFUNTMgLTcxUTcwIC03MSA4MiAtODFUOTUgLTExMlE5NSAtMTQ4IDYzIC0xNjdRNjkgLTE2OCA3NyAtMTY4UTExMSAtMTY4IDEzOSAtMTQwVDE4MiAtNzRMMTkzIC0zMlEyMDQgMTEgMjE5IDcyVDI1MSAxOTdUMjc4IDMwOFQyODkgMzY1UTI4OSAzNzIgMjg4IDM3NloiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjI2MCIgeD0iNjIzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkEiIHg9IjE2NzkiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) , 独立于
, 独立于 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQuMzI1ZXgiIGhlaWdodD0iMy4zNDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0xLjMzOGV4OyIgdmlld0JveD0iMCAtODYzLjEgMTg2Mi4yIDE0MzkuMiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkEiIGQ9Ik0yOTcgNTk2UTI5NyA2MjcgMzE4IDY0NFQzNjEgNjYxUTM3OCA2NjEgMzg5IDY1MVQ0MDMgNjIzUTQwMyA1OTUgMzg0IDU3NlQzNDAgNTU3UTMyMiA1NTcgMzEwIDU2N1QyOTcgNTk2Wk0yODggMzc2UTI4OCA0MDUgMjYyIDQwNVEyNDAgNDA1IDIyMCAzOTNUMTg1IDM2MlQxNjEgMzI1VDE0NCAyOTNMMTM3IDI3OVExMzUgMjc4IDEyMSAyNzhIMTA3UTEwMSAyODQgMTAxIDI4NlQxMDUgMjk5UTEyNiAzNDggMTY0IDM5MVQyNTIgNDQxUTI1MyA0NDEgMjYwIDQ0MVQyNzIgNDQyUTI5NiA0NDEgMzE2IDQzMlEzNDEgNDE4IDM1NCA0MDFUMzY3IDM0OFYzMzJMMzE4IDEzM1EyNjcgLTY3IDI2NCAtNzVRMjQ2IC0xMjUgMTk0IC0xNjRUNzUgLTIwNFEyNSAtMjA0IDcgLTE4M1QtMTIgLTEzN1EtMTIgLTExMCA3IC05MVQ1MyAtNzFRNzAgLTcxIDgyIC04MVQ5NSAtMTEyUTk1IC0xNDggNjMgLTE2N1E2OSAtMTY4IDc3IC0xNjhRMTExIC0xNjggMTM5IC0xNDBUMTgyIC03NEwxOTMgLTMyUTIwNCAxMSAyMTkgNzJUMjUxIDE5N1QyNzggMzA4VDI4OSAzNjVRMjg5IDM3MiAyODggMzc2WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iNTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iOTcwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZBIiB4PSIyMDc5IiB5PSItNDA1Ij48L3VzZT4KPC9nPgo8L3N2Zz4=) ,类似地 独立于
,类似地 独立于 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQuMjgzZXgiIGhlaWdodD0iMy4zNDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0xLjMzOGV4OyIgdmlld0JveD0iMCAtODYzLjEgMTg0NC4yIDE0MzkuMiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTcyIiBkPSJNMjEgMjg3UTIyIDI5MCAyMyAyOTVUMjggMzE3VDM4IDM0OFQ1MyAzODFUNzMgNDExVDk5IDQzM1QxMzIgNDQyUTE2MSA0NDIgMTgzIDQzMFQyMTQgNDA4VDIyNSAzODhRMjI3IDM4MiAyMjggMzgyVDIzNiAzODlRMjg0IDQ0MSAzNDcgNDQxSDM1MFEzOTggNDQxIDQyMiA0MDBRNDMwIDM4MSA0MzAgMzYzUTQzMCAzMzMgNDE3IDMxNVQzOTEgMjkyVDM2NiAyODhRMzQ2IDI4OCAzMzQgMjk5VDMyMiAzMjhRMzIyIDM3NiAzNzggMzkyUTM1NiA0MDUgMzQyIDQwNVEyODYgNDA1IDIzOSAzMzFRMjI5IDMxNSAyMjQgMjk4VDE5MCAxNjVRMTU2IDI1IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTE0IDE4OVQxNTQgMzY2UTE1NCA0MDUgMTI4IDQwNVExMDcgNDA1IDkyIDM3N1Q2OCAzMTZUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdEIiBkPSJNNjUgNzMxUTY1IDc0NSA2OCA3NDdUODggNzUwUTE3MSA3NTAgMjE2IDcyNVQyNzkgNjcwUTI4OCA2NDkgMjg5IDYzNVQyOTEgNTAxUTI5MiAzNjIgMjkzIDM1N1EzMDYgMzEyIDM0NSAyOTFUNDE3IDI2OVE0MjggMjY5IDQzMSAyNjZUNDM0IDI1MFQ0MzEgMjM0VDQxNyAyMzFRMzgwIDIzMSAzNDUgMjEwVDI5OCAxNTdRMjkzIDE0MyAyOTIgMTIxVDI5MSAtMjhWLTc5UTI5MSAtMTM0IDI4NSAtMTU2VDI1NiAtMTk4UTIwMiAtMjUwIDg5IC0yNTBRNzEgLTI1MCA2OCAtMjQ3VDY1IC0yMzBRNjUgLTIyNCA2NSAtMjIzVDY2IC0yMThUNjkgLTIxNFQ3NyAtMjEzUTkxIC0yMTMgMTA4IC0yMTBUMTQ2IC0yMDBUMTgzIC0xNzdUMjA3IC0xMzlRMjA4IC0xMzQgMjA5IDNMMjEwIDEzOVEyMjMgMTk2IDI4MCAyMzBRMzE1IDI0NyAzMzAgMjUwUTMwNSAyNTcgMjgwIDI3MFEyMjUgMzA0IDIxMiAzNTJMMjEwIDM2MkwyMDkgNDk4UTIwOCA2MzUgMjA3IDY0MFExOTUgNjgwIDE1NCA2OTZUNzcgNzEzUTY4IDcxMyA2NyA3MTZUNjUgNzMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZBIiBkPSJNMjk3IDU5NlEyOTcgNjI3IDMxOCA2NDRUMzYxIDY2MVEzNzggNjYxIDM4OSA2NTFUNDAzIDYyM1E0MDMgNTk1IDM4NCA1NzZUMzQwIDU1N1EzMjIgNTU3IDMxMCA1NjdUMjk3IDU5NlpNMjg4IDM3NlEyODggNDA1IDI2MiA0MDVRMjQwIDQwNSAyMjAgMzkzVDE4NSAzNjJUMTYxIDMyNVQxNDQgMjkzTDEzNyAyNzlRMTM1IDI3OCAxMjEgMjc4SDEwN1ExMDEgMjg0IDEwMSAyODZUMTA1IDI5OVExMjYgMzQ4IDE2NCAzOTFUMjUyIDQ0MVEyNTMgNDQxIDI2MCA0NDFUMjcyIDQ0MlEyOTYgNDQxIDMxNiA0MzJRMzQxIDQxOCAzNTQgNDAxVDM2NyAzNDhWMzMyTDMxOCAxMzNRMjY3IC02NyAyNjQgLTc1UTI0NiAtMTI1IDE5NCAtMTY0VDc1IC0yMDRRMjUgLTIwNCA3IC0xODNULTEyIC0xMzdRLTEyIC0xMTAgNyAtOTFUNTMgLTcxUTcwIC03MSA4MiAtODFUOTUgLTExMlE5NSAtMTQ4IDYzIC0xNjdRNjkgLTE2OCA3NyAtMTY4UTExMSAtMTY4IDEzOSAtMTQwVDE4MiAtNzRMMTkzIC0zMlEyMDQgMTEgMjE5IDcyVDI1MSAxOTdUMjc4IDMwOFQyODkgMzY1UTI4OSAzNzIgMjg4IDM3NloiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9Ijk1MiIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QSIgeD0iMjA1NCIgeT0iLTQwNSI+PC91c2U+CjwvZz4KPC9zdmc+) 。这是很有意义的,意味着在访问状态 之间实际发生的精确状态序列在首次访问MC方法(或者每次访问MC方法)估计
。这是很有意义的,意味着在访问状态 之间实际发生的精确状态序列在首次访问MC方法(或者每次访问MC方法)估计 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjUuMDc0ZXgiIGhlaWdodD0iMi44NDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjgzOGV4OyIgdmlld0JveD0iMCAtODYzLjEgMjE4NC43IDEyMjMuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NiIgZD0iTTUyIDY0OFE1MiA2NzAgNjUgNjgzSDc2UTExOCA2ODAgMTgxIDY4MFEyOTkgNjgwIDMyMCA2ODNIMzMwUTMzNiA2NzcgMzM2IDY3NFQzMzQgNjU2UTMyOSA2NDEgMzI1IDYzN0gzMDRRMjgyIDYzNSAyNzQgNjM1UTI0NSA2MzAgMjQyIDYyMFEyNDIgNjE4IDI3MSAzNjlUMzAxIDExOEwzNzQgMjM1UTQ0NyAzNTIgNTIwIDQ3MVQ1OTUgNTk0UTU5OSA2MDEgNTk5IDYwOVE1OTkgNjMzIDU1NSA2MzdRNTM3IDYzNyA1MzcgNjQ4UTUzNyA2NDkgNTM5IDY2MVE1NDIgNjc1IDU0NSA2NzlUNTU4IDY4M1E1NjAgNjgzIDU3MCA2ODNUNjA0IDY4MlQ2NjggNjgxUTczNyA2ODEgNzU1IDY4M0g3NjJRNzY5IDY3NiA3NjkgNjcyUTc2OSA2NTUgNzYwIDY0MFE3NTcgNjM3IDc0MyA2MzdRNzMwIDYzNiA3MTkgNjM1VDY5OCA2MzBUNjgyIDYyM1Q2NzAgNjE1VDY2MCA2MDhUNjUyIDU5OVQ2NDUgNTkyTDQ1MiAyODJRMjcyIC05IDI2NiAtMTZRMjYzIC0xOCAyNTkgLTIxTDI0MSAtMjJIMjM0UTIxNiAtMjIgMjE2IC0xNVEyMTMgLTkgMTc3IDMwNVExMzkgNjIzIDEzOCA2MjZRMTMzIDYzNyA3NiA2MzdINTlRNTIgNjQyIDUyIDY0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkzNiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==) 时不起作用。同样,精确的奖励顺序 也无关紧要,因为在MC方法中只使用了访问状态 之间的奖励总和。
时不起作用。同样,精确的奖励顺序 也无关紧要,因为在MC方法中只使用了访问状态 之间的奖励总和。
因此,为了便于分析,可以将任意的undiscounted Markov chain简化为图2下面部分所示的双状态抽象链。
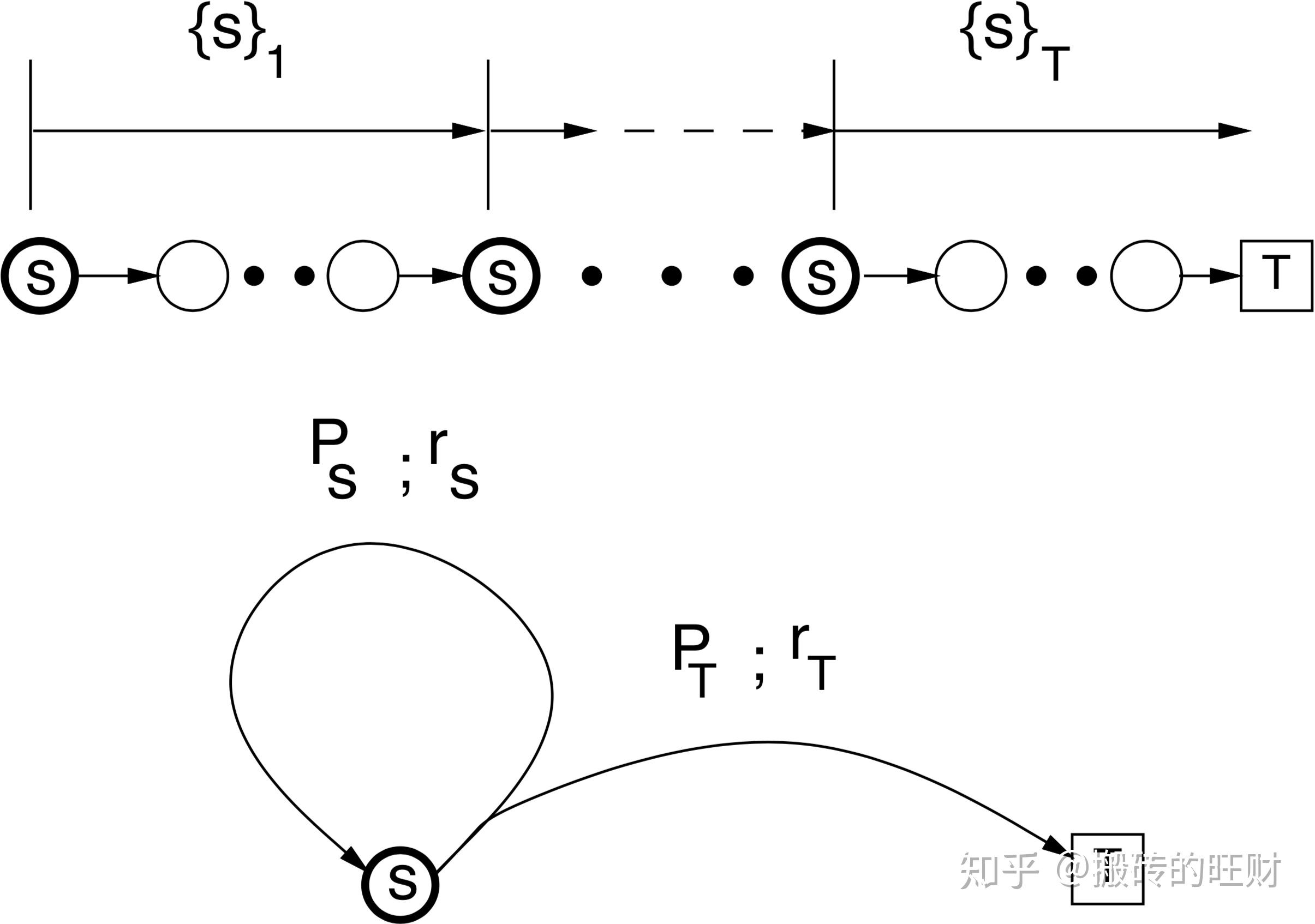
首次访问MC方法 first-visit MC
设 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjMuNjU1ZXgiIGhlaWdodD0iMi44NDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjgzOGV4OyIgdmlld0JveD0iMCAtODYzLjEgMTU3My41IDEyMjMuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc4IiBkPSJNNTIgMjg5UTU5IDMzMSAxMDYgMzg2VDIyMiA0NDJRMjU3IDQ0MiAyODYgNDI0VDMyOSAzNzlRMzcxIDQ0MiA0MzAgNDQyUTQ2NyA0NDIgNDk0IDQyMFQ1MjIgMzYxUTUyMiAzMzIgNTA4IDMxNFQ0ODEgMjkyVDQ1OCAyODhRNDM5IDI4OCA0MjcgMjk5VDQxNSAzMjhRNDE1IDM3NCA0NjUgMzkxUTQ1NCA0MDQgNDI1IDQwNFE0MTIgNDA0IDQwNiA0MDJRMzY4IDM4NiAzNTAgMzM2UTI5MCAxMTUgMjkwIDc4UTI5MCA1MCAzMDYgMzhUMzQxIDI2UTM3OCAyNiA0MTQgNTlUNDYzIDE0MFE0NjYgMTUwIDQ2OSAxNTFUNDg1IDE1M0g0ODlRNTA0IDE1MyA1MDQgMTQ1UTUwNCAxNDQgNTAyIDEzNFE0ODYgNzcgNDQwIDMzVDMzMyAtMTFRMjYzIC0xMSAyMjcgNTJRMTg2IC0xMCAxMzMgLTEwSDEyN1E3OCAtMTAgNTcgMTZUMzUgNzFRMzUgMTAzIDU0IDEyM1Q5OSAxNDNRMTQyIDE0MyAxNDIgMTAxUTE0MiA4MSAxMzAgNjZUMTA3IDQ2VDk0IDQxTDkxIDQwUTkxIDM5IDk3IDM2VDExMyAyOVQxMzIgMjZRMTY4IDI2IDE5NCA3MVEyMDMgODcgMjE3IDEzOVQyNDUgMjQ3VDI2MSAzMTNRMjY2IDM0MCAyNjYgMzUyUTI2NiAzODAgMjUxIDM5MlQyMTcgNDA0UTE3NyA0MDQgMTQyIDM3MlQ5MyAyOTBROTEgMjgxIDg4IDI4MFQ3MiAyNzhINThRNTIgMjg0IDUyIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdEIiBkPSJNNjUgNzMxUTY1IDc0NSA2OCA3NDdUODggNzUwUTE3MSA3NTAgMjE2IDcyNVQyNzkgNjcwUTI4OCA2NDkgMjg5IDYzNVQyOTEgNTAxUTI5MiAzNjIgMjkzIDM1N1EzMDYgMzEyIDM0NSAyOTFUNDE3IDI2OVE0MjggMjY5IDQzMSAyNjZUNDM0IDI1MFQ0MzEgMjM0VDQxNyAyMzFRMzgwIDIzMSAzNDUgMjEwVDI5OCAxNTdRMjkzIDE0MyAyOTIgMTIxVDI5MSAtMjhWLTc5UTI5MSAtMTM0IDI4NSAtMTU2VDI1NiAtMTk4UTIwMiAtMjUwIDg5IC0yNTBRNzEgLTI1MCA2OCAtMjQ3VDY1IC0yMzBRNjUgLTIyNCA2NSAtMjIzVDY2IC0yMThUNjkgLTIxNFQ3NyAtMjEzUTkxIC0yMTMgMTA4IC0yMTBUMTQ2IC0yMDBUMTgzIC0xNzdUMjA3IC0xMzlRMjA4IC0xMzQgMjA5IDNMMjEwIDEzOVEyMjMgMTk2IDI4MCAyMzBRMzE1IDI0NyAzMzAgMjUwUTMwNSAyNTcgMjgwIDI3MFEyMjUgMzA0IDIxMiAzNTJMMjEwIDM2MkwyMDkgNDk4UTIwOCA2MzUgMjA3IDY0MFExOTUgNjgwIDE1NCA2OTZUNzcgNzEzUTY4IDcxMyA2NyA3MTZUNjUgNzMxWiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03OCIgeD0iNTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iMTA3MyIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 代表成对的随机序列
代表成对的随机序列 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEwLjAxOWV4IiBoZWlnaHQ9IjIuODQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMC44MzhleDsiIHZpZXdCb3g9IjAgLTg2My4xIDQzMTMuOCAxMjIzLjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0IiIGQ9Ik00MzQgLTIzMVE0MzQgLTI0NCA0MjggLTI1MEg0MTBRMjgxIC0yNTAgMjMwIC0xODRRMjI1IC0xNzcgMjIyIC0xNzJUMjE3IC0xNjFUMjEzIC0xNDhUMjExIC0xMzNUMjEwIC0xMTFUMjA5IC04NFQyMDkgLTQ3VDIwOSAwUTIwOSAyMSAyMDkgNTNRMjA4IDE0MiAyMDQgMTUzUTIwMyAxNTQgMjAzIDE1NVExODkgMTkxIDE1MyAyMTFUODIgMjMxUTcxIDIzMSA2OCAyMzRUNjUgMjUwVDY4IDI2NlQ4MiAyNjlRMTE2IDI2OSAxNTIgMjg5VDIwMyAzNDVRMjA4IDM1NiAyMDggMzc3VDIwOSA1MjlWNTc5UTIwOSA2MzQgMjE1IDY1NlQyNDQgNjk4UTI3MCA3MjQgMzI0IDc0MFEzNjEgNzQ4IDM3NyA3NDlRMzc5IDc0OSAzOTAgNzQ5VDQwOCA3NTBINDI4UTQzNCA3NDQgNDM0IDczMlE0MzQgNzE5IDQzMSA3MTZRNDI5IDcxMyA0MTUgNzEzUTM2MiA3MTAgMzMyIDY4OVQyOTYgNjQ3UTI5MSA2MzQgMjkxIDQ5OVY0MTdRMjkxIDM3MCAyODggMzUzVDI3MSAzMTRRMjQwIDI3MSAxODQgMjU1TDE3MCAyNTBMMTg0IDI0NVEyMDIgMjM5IDIyMCAyMzBUMjYyIDE5NlQyOTAgMTM3UTI5MSAxMzEgMjkxIDFRMjkxIC0xMzQgMjk2IC0xNDdRMzA2IC0xNzQgMzM5IC0xOTJUNDE1IC0yMTNRNDI5IC0yMTMgNDMxIC0yMTZRNDM0IC0yMTkgNDM0IC0yMzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03RCIgZD0iTTY1IDczMVE2NSA3NDUgNjggNzQ3VDg4IDc1MFExNzEgNzUwIDIxNiA3MjVUMjc5IDY3MFEyODggNjQ5IDI4OSA2MzVUMjkxIDUwMVEyOTIgMzYyIDI5MyAzNTdRMzA2IDMxMiAzNDUgMjkxVDQxNyAyNjlRNDI4IDI2OSA0MzEgMjY2VDQzNCAyNTBUNDMxIDIzNFQ0MTcgMjMxUTM4MCAyMzEgMzQ1IDIxMFQyOTggMTU3UTI5MyAxNDMgMjkyIDEyMVQyOTEgLTI4Vi03OVEyOTEgLTEzNCAyODUgLTE1NlQyNTYgLTE5OFEyMDIgLTI1MCA4OSAtMjUwUTcxIC0yNTAgNjggLTI0N1Q2NSAtMjMwUTY1IC0yMjQgNjUgLTIyM1Q2NiAtMjE4VDY5IC0yMTRUNzcgLTIxM1E5MSAtMjEzIDEwOCAtMjEwVDE0NiAtMjAwVDE4MyAtMTc3VDIwNyAtMTM5UTIwOCAtMTM0IDIwOSAzTDIxMCAxMzlRMjIzIDE5NiAyODAgMjMwUTMxNSAyNDcgMzMwIDI1MFEzMDUgMjU3IDI4MCAyNzBRMjI1IDMwNCAyMTIgMzUyTDIxMCAzNjJMMjA5IDQ5OFEyMDggNjM1IDIwNyA2NDBRMTk1IDY4MCAxNTQgNjk2VDc3IDcxM1E2OCA3MTMgNjcgNzE2VDY1IDczMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJDIiBkPSJNNzggMzVUNzggNjBUOTQgMTAzVDEzNyAxMjFRMTY1IDEyMSAxODcgOTZUMjEwIDhRMjEwIC0yNyAyMDEgLTYwVDE4MCAtMTE3VDE1NCAtMTU4VDEzMCAtMTg1VDExNyAtMTk0UTExMyAtMTk0IDEwNCAtMTg1VDk1IC0xNzJROTUgLTE2OCAxMDYgLTE1NlQxMzEgLTEyNlQxNTcgLTc2VDE3MyAtM1Y5TDE3MiA4UTE3MCA3IDE2NyA2VDE2MSAzVDE1MiAxVDE0MCAwUTExMyAwIDk2IDE3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTcyIiBkPSJNMjEgMjg3UTIyIDI5MCAyMyAyOTVUMjggMzE3VDM4IDM0OFQ1MyAzODFUNzMgNDExVDk5IDQzM1QxMzIgNDQyUTE2MSA0NDIgMTgzIDQzMFQyMTQgNDA4VDIyNSAzODhRMjI3IDM4MiAyMjggMzgyVDIzNiAzODlRMjg0IDQ0MSAzNDcgNDQxSDM1MFEzOTggNDQxIDQyMiA0MDBRNDMwIDM4MSA0MzAgMzYzUTQzMCAzMzMgNDE3IDMxNVQzOTEgMjkyVDM2NiAyODhRMzQ2IDI4OCAzMzQgMjk5VDMyMiAzMjhRMzIyIDM3NiAzNzggMzkyUTM1NiA0MDUgMzQyIDQwNVEyODYgNDA1IDIzOSAzMzFRMjI5IDMxNSAyMjQgMjk4VDE5MCAxNjVRMTU2IDI1IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTE0IDE4OVQxNTQgMzY2UTE1NCA0MDUgMTI4IDQwNVExMDcgNDA1IDkyIDM3N1Q2OCAzMTZUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9Ijk3MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9IjE2MzciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMDgyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSI5NTIiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMzkyNCIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 。
。
首次访问MC方法通过 次试验后得到的序列 估计的 是 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQ5LjIzM2V4IiBoZWlnaHQ9IjMuMTc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMS4wMDVleDsiIHZpZXdCb3g9IjAgLTkzNC45IDIxMTk3LjQgMTM2Ny40IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU2IiBkPSJNNTIgNjQ4UTUyIDY3MCA2NSA2ODNINzZRMTE4IDY4MCAxODEgNjgwUTI5OSA2ODAgMzIwIDY4M0gzMzBRMzM2IDY3NyAzMzYgNjc0VDMzNCA2NTZRMzI5IDY0MSAzMjUgNjM3SDMwNFEyODIgNjM1IDI3NCA2MzVRMjQ1IDYzMCAyNDIgNjIwUTI0MiA2MTggMjcxIDM2OVQzMDEgMTE4TDM3NCAyMzVRNDQ3IDM1MiA1MjAgNDcxVDU5NSA1OTRRNTk5IDYwMSA1OTkgNjA5UTU5OSA2MzMgNTU1IDYzN1E1MzcgNjM3IDUzNyA2NDhRNTM3IDY0OSA1MzkgNjYxUTU0MiA2NzUgNTQ1IDY3OVQ1NTggNjgzUTU2MCA2ODMgNTcwIDY4M1Q2MDQgNjgyVDY2OCA2ODFRNzM3IDY4MSA3NTUgNjgzSDc2MlE3NjkgNjc2IDc2OSA2NzJRNzY5IDY1NSA3NjAgNjQwUTc1NyA2MzcgNzQzIDYzN1E3MzAgNjM2IDcxOSA2MzVUNjk4IDYzMFQ2ODIgNjIzVDY3MCA2MTVUNjYwIDYwOFQ2NTIgNTk5VDY0NSA1OTJMNDUyIDI4MlEyNzIgLTkgMjY2IC0xNlEyNjMgLTE4IDI1OSAtMjFMMjQxIC0yMkgyMzRRMjE2IC0yMiAyMTYgLTE1UTIxMyAtOSAxNzcgMzA1UTEzOSA2MjMgMTM4IDYyNlExMzMgNjM3IDc2IDYzN0g1OVE1MiA2NDIgNTIgNjQ4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQ2IiBkPSJNNDggMVEzMSAxIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc0MlE3NDkgNjc2IDc0OSA2NjlRNzQ5IDY2NCA3MzYgNTU3VDcyMiA0NDdRNzIwIDQ0MCA3MDIgNDQwSDY5MFE2ODMgNDQ1IDY4MyA0NTNRNjgzIDQ1NCA2ODYgNDc3VDY4OSA1MzBRNjg5IDU2MCA2ODIgNTc5VDY2MyA2MTBUNjI2IDYyNlQ1NzUgNjMzVDUwMyA2MzRINDgwUTM5OCA2MzMgMzkzIDYzMVEzODggNjI5IDM4NiA2MjNRMzg1IDYyMiAzNTIgNDkyTDMyMCAzNjNIMzc1UTM3OCAzNjMgMzk4IDM2M1Q0MjYgMzY0VDQ0OCAzNjdUNDcyIDM3NFQ0ODkgMzg2UTUwMiAzOTggNTExIDQxOVQ1MjQgNDU3VDUyOSA0NzVRNTMyIDQ4MCA1NDggNDgwSDU2MFE1NjcgNDc1IDU2NyA0NzBRNTY3IDQ2NyA1MzYgMzM5VDUwMiAyMDdRNTAwIDIwMCA0ODIgMjAwSDQ3MFE0NjMgMjA2IDQ2MyAyMTJRNDYzIDIxNSA0NjggMjM0VDQ3MyAyNzRRNDczIDMwMyA0NTMgMzEwVDM2NCAzMTdIMzA5TDI3NyAxOTBRMjQ1IDY2IDI0NSA2MFEyNDUgNDYgMzM0IDQ2SDM1OVEzNjUgNDAgMzY1IDM5VDM2MyAxOVEzNTkgNiAzNTMgMEgzMzZRMjk1IDIgMTg1IDJRMTIwIDIgODYgMlQ0OCAxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNjYiIGQ9Ik0xMTggLTE2MlExMjAgLTE2MiAxMjQgLTE2NFQxMzUgLTE2N1QxNDcgLTE2OFExNjAgLTE2OCAxNzEgLTE1NVQxODcgLTEyNlExOTcgLTk5IDIyMSAyN1QyNjcgMjY3VDI4OSAzODJWMzg1SDI0MlExOTUgMzg1IDE5MiAzODdRMTg4IDM5MCAxODggMzk3TDE5NSA0MjVRMTk3IDQzMCAyMDMgNDMwVDI1MCA0MzFRMjk4IDQzMSAyOTggNDMyUTI5OCA0MzQgMzA3IDQ4MlQzMTkgNTQwUTM1NiA3MDUgNDY1IDcwNVE1MDIgNzAzIDUyNiA2ODNUNTUwIDYzMFE1NTAgNTk0IDUyOSA1NzhUNDg3IDU2MVE0NDMgNTYxIDQ0MyA2MDNRNDQzIDYyMiA0NTQgNjM2VDQ3OCA2NTdMNDg3IDY2MlE0NzEgNjY4IDQ1NyA2NjhRNDQ1IDY2OCA0MzQgNjU4VDQxOSA2MzBRNDEyIDYwMSA0MDMgNTUyVDM4NyA0NjlUMzgwIDQzM1EzODAgNDMxIDQzNSA0MzFRNDgwIDQzMSA0ODcgNDMwVDQ5OCA0MjRRNDk5IDQyMCA0OTYgNDA3VDQ5MSAzOTFRNDg5IDM4NiA0ODIgMzg2VDQyOCAzODVIMzcyTDM0OSAyNjNRMzAxIDE1IDI4MiAtNDdRMjU1IC0xMzIgMjEyIC0xNzNRMTc1IC0yMDUgMTM5IC0yMDVRMTA3IC0yMDUgODEgLTE4NlQ1NSAtMTMyUTU1IC05NSA3NiAtNzhUMTE4IC02MVExNjIgLTYxIDE2MiAtMTAzUTE2MiAtMTIyIDE1MSAtMTM2VDEyNyAtMTU3TDExOCAtMTYyWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0IiIGQ9Ik00MzQgLTIzMVE0MzQgLTI0NCA0MjggLTI1MEg0MTBRMjgxIC0yNTAgMjMwIC0xODRRMjI1IC0xNzcgMjIyIC0xNzJUMjE3IC0xNjFUMjEzIC0xNDhUMjExIC0xMzNUMjEwIC0xMTFUMjA5IC04NFQyMDkgLTQ3VDIwOSAwUTIwOSAyMSAyMDkgNTNRMjA4IDE0MiAyMDQgMTUzUTIwMyAxNTQgMjAzIDE1NVExODkgMTkxIDE1MyAyMTFUODIgMjMxUTcxIDIzMSA2OCAyMzRUNjUgMjUwVDY4IDI2NlQ4MiAyNjlRMTE2IDI2OSAxNTIgMjg5VDIwMyAzNDVRMjA4IDM1NiAyMDggMzc3VDIwOSA1MjlWNTc5UTIwOSA2MzQgMjE1IDY1NlQyNDQgNjk4UTI3MCA3MjQgMzI0IDc0MFEzNjEgNzQ4IDM3NyA3NDlRMzc5IDc0OSAzOTAgNzQ5VDQwOCA3NTBINDI4UTQzNCA3NDQgNDM0IDczMlE0MzQgNzE5IDQzMSA3MTZRNDI5IDcxMyA0MTUgNzEzUTM2MiA3MTAgMzMyIDY4OVQyOTYgNjQ3UTI5MSA2MzQgMjkxIDQ5OVY0MTdRMjkxIDM3MCAyODggMzUzVDI3MSAzMTRRMjQwIDI3MSAxODQgMjU1TDE3MCAyNTBMMTg0IDI0NVEyMDIgMjM5IDIyMCAyMzBUMjYyIDE5NlQyOTAgMTM3UTI5MSAxMzEgMjkxIDFRMjkxIC0xMzQgMjk2IC0xNDdRMzA2IC0xNzQgMzM5IC0xOTJUNDE1IC0yMTNRNDI5IC0yMTMgNDMxIC0yMTZRNDM0IC0yMTkgNDM0IC0yMzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzgiIGQ9Ik01MiAyODlRNTkgMzMxIDEwNiAzODZUMjIyIDQ0MlEyNTcgNDQyIDI4NiA0MjRUMzI5IDM3OVEzNzEgNDQyIDQzMCA0NDJRNDY3IDQ0MiA0OTQgNDIwVDUyMiAzNjFRNTIyIDMzMiA1MDggMzE0VDQ4MSAyOTJUNDU4IDI4OFE0MzkgMjg4IDQyNyAyOTlUNDE1IDMyOFE0MTUgMzc0IDQ2NSAzOTFRNDU0IDQwNCA0MjUgNDA0UTQxMiA0MDQgNDA2IDQwMlEzNjggMzg2IDM1MCAzMzZRMjkwIDExNSAyOTAgNzhRMjkwIDUwIDMwNiAzOFQzNDEgMjZRMzc4IDI2IDQxNCA1OVQ0NjMgMTQwUTQ2NiAxNTAgNDY5IDE1MVQ0ODUgMTUzSDQ4OVE1MDQgMTUzIDUwNCAxNDVRNTA0IDE0NCA1MDIgMTM0UTQ4NiA3NyA0NDAgMzNUMzMzIC0xMVEyNjMgLTExIDIyNyA1MlExODYgLTEwIDEzMyAtMTBIMTI3UTc4IC0xMCA1NyAxNlQzNSA3MVEzNSAxMDMgNTQgMTIzVDk5IDE0M1ExNDIgMTQzIDE0MiAxMDFRMTQyIDgxIDEzMCA2NlQxMDcgNDZUOTQgNDFMOTEgNDBROTEgMzkgOTcgMzZUMTEzIDI5VDEzMiAyNlExNjggMjYgMTk0IDcxUTIwMyA4NyAyMTcgMTM5VDI0NSAyNDdUMjYxIDMxM1EyNjYgMzQwIDI2NiAzNTJRMjY2IDM4MCAyNTEgMzkyVDIxNyA0MDRRMTc3IDQwNCAxNDIgMzcyVDkzIDI5MFE5MSAyODEgODggMjgwVDcyIDI3OEg1OFE1MiAyODQgNTIgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzIiIGQ9Ik0yMSAyODdRMjIgMjkwIDIzIDI5NVQyOCAzMTdUMzggMzQ4VDUzIDM4MVQ3MyA0MTFUOTkgNDMzVDEzMiA0NDJRMTYxIDQ0MiAxODMgNDMwVDIxNCA0MDhUMjI1IDM4OFEyMjcgMzgyIDIyOCAzODJUMjM2IDM4OVEyODQgNDQxIDM0NyA0NDFIMzUwUTM5OCA0NDEgNDIyIDQwMFE0MzAgMzgxIDQzMCAzNjNRNDMwIDMzMyA0MTcgMzE1VDM5MSAyOTJUMzY2IDI4OFEzNDYgMjg4IDMzNCAyOTlUMzIyIDMyOFEzMjIgMzc2IDM3OCAzOTJRMzU2IDQwNSAzNDIgNDA1UTI4NiA0MDUgMjM5IDMzMVEyMjkgMzE1IDIyNCAyOThUMTkwIDE2NVExNTYgMjUgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTQgMTg5VDE1NCAzNjZRMTU0IDQwNSAxMjggNDA1UTEwNyA0MDUgOTIgMzc3VDY4IDMxNlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzIiIGQ9Ik0xMDkgNDI5UTgyIDQyOSA2NiA0NDdUNTAgNDkxUTUwIDU2MiAxMDMgNjE0VDIzNSA2NjZRMzI2IDY2NiAzODcgNjEwVDQ0OSA0NjVRNDQ5IDQyMiA0MjkgMzgzVDM4MSAzMTVUMzAxIDI0MVEyNjUgMjEwIDIwMSAxNDlMMTQyIDkzTDIxOCA5MlEzNzUgOTIgMzg1IDk3UTM5MiA5OSA0MDkgMTg2VjE4OUg0NDlWMTg2UTQ0OCAxODMgNDM2IDk1VDQyMSAzVjBINTBWMTlWMzFRNTAgMzggNTYgNDZUODYgODFRMTE1IDExMyAxMzYgMTM3UTE0NSAxNDcgMTcwIDE3NFQyMDQgMjExVDIzMyAyNDRUMjYxIDI3OFQyODQgMzA4VDMwNSAzNDBUMzIwIDM2OVQzMzMgNDAxVDM0MCA0MzFUMzQzIDQ2NFEzNDMgNTI3IDMwOSA1NzNUMjEyIDYxOVExNzkgNjE5IDE1NCA2MDJUMTE5IDU2OVQxMDkgNTUwUTEwOSA1NDkgMTE0IDU0OVExMzIgNTQ5IDE1MSA1MzVUMTcwIDQ4OVExNzAgNDY0IDE1NCA0NDdUMTA5IDQyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMzIiBkPSJNMTI3IDQ2M1ExMDAgNDYzIDg1IDQ4MFQ2OSA1MjRRNjkgNTc5IDExNyA2MjJUMjMzIDY2NVEyNjggNjY1IDI3NyA2NjRRMzUxIDY1MiAzOTAgNjExVDQzMCA1MjJRNDMwIDQ3MCAzOTYgNDIxVDMwMiAzNTBMMjk5IDM0OFEyOTkgMzQ3IDMwOCAzNDVUMzM3IDMzNlQzNzUgMzE1UTQ1NyAyNjIgNDU3IDE3NVE0NTcgOTYgMzk1IDM3VDIzOCAtMjJRMTU4IC0yMiAxMDAgMjFUNDIgMTMwUTQyIDE1OCA2MCAxNzVUMTA1IDE5M1ExMzMgMTkzIDE1MSAxNzVUMTY5IDEzMFExNjkgMTE5IDE2NiAxMTBUMTU5IDk0VDE0OCA4MlQxMzYgNzRUMTI2IDcwVDExOCA2N0wxMTQgNjZRMTY1IDIxIDIzOCAyMVEyOTMgMjEgMzIxIDc0UTMzOCAxMDcgMzM4IDE3NVYxOTVRMzM4IDI5MCAyNzQgMzIyUTI1OSAzMjggMjEzIDMyOUwxNzEgMzMwTDE2OCAzMzJRMTY2IDMzNSAxNjYgMzQ4UTE2NiAzNjYgMTc0IDM2NlEyMDIgMzY2IDIzMiAzNzFRMjY2IDM3NiAyOTQgNDEzVDMyMiA1MjVWNTMzUTMyMiA1OTAgMjg3IDYxMlEyNjUgNjI2IDI0MCA2MjZRMjA4IDYyNiAxODEgNjE1VDE0MyA1OTJUMTMyIDU4MEgxMzVRMTM4IDU3OSAxNDMgNTc4VDE1MyA1NzNUMTY1IDU2NlQxNzUgNTU1VDE4MyA1NDBUMTg2IDUyMFExODYgNDk4IDE3MiA0ODFUMTI3IDQ2M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJFIiBkPSJNNzggNjBRNzggODQgOTUgMTAyVDEzOCAxMjBRMTYyIDEyMCAxODAgMTA0VDE5OSA2MVExOTkgMzYgMTgyIDE4VDEzOSAwVDk2IDE3VDc4IDYwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZCIiBkPSJNMTIxIDY0N1ExMjEgNjU3IDEyNSA2NzBUMTM3IDY4M1ExMzggNjgzIDIwOSA2ODhUMjgyIDY5NFEyOTQgNjk0IDI5NCA2ODZRMjk0IDY3OSAyNDQgNDc3UTE5NCAyNzkgMTk0IDI3MlEyMTMgMjgyIDIyMyAyOTFRMjQ3IDMwOSAyOTIgMzU0VDM2MiA0MTVRNDAyIDQ0MiA0MzggNDQyUTQ2OCA0NDIgNDg1IDQyM1Q1MDMgMzY5UTUwMyAzNDQgNDk2IDMyN1Q0NzcgMzAyVDQ1NiAyOTFUNDM4IDI4OFE0MTggMjg4IDQwNiAyOTlUMzk0IDMyOFEzOTQgMzUzIDQxMCAzNjlUNDQyIDM5MEw0NTggMzkzUTQ0NiA0MDUgNDM0IDQwNUg0MzBRMzk4IDQwMiAzNjcgMzgwVDI5NCAzMTZUMjI4IDI1NVEyMzAgMjU0IDI0MyAyNTJUMjY3IDI0NlQyOTMgMjM4VDMyMCAyMjRUMzQyIDIwNlQzNTkgMTgwVDM2NSAxNDdRMzY1IDEzMCAzNjAgMTA2VDM1NCA2NlEzNTQgMjYgMzgxIDI2UTQyOSAyNiA0NTkgMTQ1UTQ2MSAxNTMgNDc5IDE1M0g0ODNRNDk5IDE1MyA0OTkgMTQ0UTQ5OSAxMzkgNDk2IDEzMFE0NTUgLTExIDM3OCAtMTFRMzMzIC0xMSAzMDUgMTVUMjc3IDkwUTI3NyAxMDggMjgwIDEyMVQyODMgMTQ1UTI4MyAxNjcgMjY5IDE4M1QyMzQgMjA2VDIwMCAyMTdUMTgyIDIyMEgxODBRMTY4IDE3OCAxNTkgMTM5VDE0NSA4MVQxMzYgNDRUMTI5IDIwVDEyMiA3VDExMSAtMlE5OCAtMTEgODMgLTExUTY2IC0xMSA1NyAtMVQ0OCAxNlE0OCAyNiA4NSAxNzZUMTU4IDQ3MUwxOTUgNjE2UTE5NiA2MjkgMTg4IDYzMlQxNDkgNjM3SDE0NFExMzQgNjM3IDEzMSA2MzdUMTI0IDY0MFQxMjEgNjQ3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU0IiBkPSJNNDAgNDM3UTIxIDQzNyAyMSA0NDVRMjEgNDUwIDM3IDUwMVQ3MSA2MDJMODggNjUxUTkzIDY2OSAxMDEgNjc3SDU2OUg2NTlRNjkxIDY3NyA2OTcgNjc2VDcwNCA2NjdRNzA0IDY2MSA2ODcgNTUzVDY2OCA0NDRRNjY4IDQzNyA2NDkgNDM3UTY0MCA0MzcgNjM3IDQzN1Q2MzEgNDQyTDYyOSA0NDVRNjI5IDQ1MSA2MzUgNDkwVDY0MSA1NTFRNjQxIDU4NiA2MjggNjA0VDU3MyA2MjlRNTY4IDYzMCA1MTUgNjMxUTQ2OSA2MzEgNDU3IDYzMFQ0MzkgNjIyUTQzOCA2MjEgMzY4IDM0M1QyOTggNjBRMjk4IDQ4IDM4NiA0NlE0MTggNDYgNDI3IDQ1VDQzNiAzNlE0MzYgMzEgNDMzIDIyUTQyOSA0IDQyNCAxTDQyMiAwUTQxOSAwIDQxNSAwUTQxMCAwIDM2MyAxVDIyOCAyUTk5IDIgNjQgMEg0OVE0MyA2IDQzIDlUNDUgMjdRNDkgNDAgNTUgNDZIODNIOTRRMTc0IDQ2IDE4OSA1NVExOTAgNTYgMTkxIDU2UTE5NiA1OSAyMDEgNzZUMjQxIDIzM1EyNTggMzAxIDI2OSAzNDRRMzM5IDYxOSAzMzkgNjI1UTMzOSA2MzAgMzEwIDYzMEgyNzlRMjEyIDYzMCAxOTEgNjI0UTE0NiA2MTQgMTIxIDU4M1Q2NyA0NjdRNjAgNDQ1IDU3IDQ0MVQ0MyA0MzdINDBaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDYiIHg9IjExNjciIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSI4MjUiIHk9Ii00MzUiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjIxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjMxNDgiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02NiIgeD0iNDIwNCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ5MjEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc4IiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSIxMDczIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxOTYzIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI3NTUxIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODYwOCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDUxLC0xNTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjU3NCkiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjU3OCIgeT0iLTI0MyI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMDA3MiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDExMDcyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NTEsLTE1MCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNTc0KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iNTc4IiB5PSItMjQzIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEyNTM2IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTM1MzcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ1MSwtMTUwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMzIiB4PSI1NzgiIHk9Ii0yNDIiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTQ3NzgiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSIxNTU1NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9IjE2MDAyIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iMTY0NDciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxNjg5MiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE3NjcxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NTEsLTE1MCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNTc0KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjU3OCIgeT0iLTI3MSI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxOTE0NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIwMTQ3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=) 。
。
其中 是随机数,代表第 次重新访问状态 , ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIuNjc3ZXgiIGhlaWdodD0iMi4zNDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0xLjAwNWV4OyIgdmlld0JveD0iMCAtNTc2LjEgMTE1Mi41IDEwMDguNiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MiIgZD0iTTIxIDI4N1EyMiAyOTAgMjMgMjk1VDI4IDMxN1QzOCAzNDhUNTMgMzgxVDczIDQxMVQ5OSA0MzNUMTMyIDQ0MlExNjEgNDQyIDE4MyA0MzBUMjE0IDQwOFQyMjUgMzg4UTIyNyAzODIgMjI4IDM4MlQyMzYgMzg5UTI4NCA0NDEgMzQ3IDQ0MUgzNTBRMzk4IDQ0MSA0MjIgNDAwUTQzMCAzODEgNDMwIDM2M1E0MzAgMzMzIDQxNyAzMTVUMzkxIDI5MlQzNjYgMjg4UTM0NiAyODggMzM0IDI5OVQzMjIgMzI4UTMyMiAzNzYgMzc4IDM5MlEzNTYgNDA1IDM0MiA0MDVRMjg2IDQwNSAyMzkgMzMxUTIyOSAzMTUgMjI0IDI5OFQxOTAgMTY1UTE1NiAyNSAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExNCAxODlUMTU0IDM2NlExNTQgNDA1IDEyOCA0MDVRMTA3IDQwNSA5MiAzNzdUNjggMzE2VDU3IDI4MFE1NSAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNjkiIGQ9Ik0xODQgNjAwUTE4NCA2MjQgMjAzIDY0MlQyNDcgNjYxUTI2NSA2NjEgMjc3IDY0OVQyOTAgNjE5UTI5MCA1OTYgMjcwIDU3N1QyMjYgNTU3UTIxMSA1NTcgMTk4IDU2N1QxODQgNjAwWk0yMSAyODdRMjEgMjk1IDMwIDMxOFQ1NCAzNjlUOTggNDIwVDE1OCA0NDJRMTk3IDQ0MiAyMjMgNDE5VDI1MCAzNTdRMjUwIDM0MCAyMzYgMzAxVDE5NiAxOTZUMTU0IDgzUTE0OSA2MSAxNDkgNTFRMTQ5IDI2IDE2NiAyNlExNzUgMjYgMTg1IDI5VDIwOCA0M1QyMzUgNzhUMjYwIDEzN1EyNjMgMTQ5IDI2NSAxNTFUMjgyIDE1M1EzMDIgMTUzIDMwMiAxNDNRMzAyIDEzNSAyOTMgMTEyVDI2OCA2MVQyMjMgMTFUMTYxIC0xMVExMjkgLTExIDEwMiAxMFQ3NCA3NFE3NCA5MSA3OSAxMDZUMTIyIDIyMFExNjAgMzIxIDE2NiAzNDFUMTczIDM4MFExNzMgNDA0IDE1NiA0MDRIMTU0UTEyNCA0MDQgOTkgMzcxVDYxIDI4N1E2MCAyODYgNTkgMjg0VDU4IDI4MVQ1NiAyNzlUNTMgMjc4VDQ5IDI3OFQ0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ1MSwtMTUwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iNTc4IiB5PSItMjM4Ij48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==) 是序列 中各个奖励的总和,
是序列 中各个奖励的总和, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIuNDM4ZXgiIGhlaWdodD0iMi4wMDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyIgdmlld0JveD0iMCAtNTc2LjEgMTA0OS43IDg2NS4xIiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTcyIiBkPSJNMjEgMjg3UTIyIDI5MCAyMyAyOTVUMjggMzE3VDM4IDM0OFQ1MyAzODFUNzMgNDExVDk5IDQzM1QxMzIgNDQyUTE2MSA0NDIgMTgzIDQzMFQyMTQgNDA4VDIyNSAzODhRMjI3IDM4MiAyMjggMzgyVDIzNiAzODlRMjg0IDQ0MSAzNDcgNDQxSDM1MFEzOTggNDQxIDQyMiA0MDBRNDMwIDM4MSA0MzAgMzYzUTQzMCAzMzMgNDE3IDMxNVQzOTEgMjkyVDM2NiAyODhRMzQ2IDI4OCAzMzQgMjk5VDMyMiAzMjhRMzIyIDM3NiAzNzggMzkyUTM1NiA0MDUgMzQyIDQwNVEyODYgNDA1IDIzOSAzMzFRMjI5IDMxNSAyMjQgMjk4VDE5MCAxNjVRMTU2IDI1IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTE0IDE4OVQxNTQgMzY2UTE1NCA0MDUgMTI4IDQwNVExMDcgNDA1IDkyIDM3N1Q2OCAzMTZUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI2MzgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) 是最后一次访问状态 后收到的总的随机奖励。
是最后一次访问状态 后收到的总的随机奖励。
对于所有的 , ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEzLjAzZXgiIGhlaWdodD0iMy4wMDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0xLjAwNWV4OyIgdmlld0JveD0iMCAtODYzLjEgNTYxMC4yIDEyOTUuNyIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NSIgZD0iTTQ5MiAyMTNRNDcyIDIxMyA0NzIgMjI2UTQ3MiAyMzAgNDc3IDI1MFQ0ODIgMjg1UTQ4MiAzMTYgNDYxIDMyM1QzNjQgMzMwSDMxMlEzMTEgMzI4IDI3NyAxOTJUMjQzIDUyUTI0MyA0OCAyNTQgNDhUMzM0IDQ2UTQyOCA0NiA0NTggNDhUNTE4IDYxUTU2NyA3NyA1OTkgMTE3VDY3MCAyNDhRNjgwIDI3MCA2ODMgMjcyUTY5MCAyNzQgNjk4IDI3NFE3MTggMjc0IDcxOCAyNjFRNjEzIDcgNjA4IDJRNjA1IDAgMzIyIDBIMTMzUTMxIDAgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ2IDY2IDIxNSAzNDJUMjg1IDYyMlEyODUgNjI5IDI4MSA2MjlRMjczIDYzMiAyMjggNjM0SDE5N1ExOTEgNjQwIDE5MSA2NDJUMTkzIDY1OVExOTcgNjc2IDIwMyA2ODBINzU3UTc2NCA2NzYgNzY0IDY2OVE3NjQgNjY0IDc1MSA1NTdUNzM3IDQ0N1E3MzUgNDQwIDcxNyA0NDBINzA1UTY5OCA0NDUgNjk4IDQ1M0w3MDEgNDc2UTcwNCA1MDAgNzA0IDUyOFE3MDQgNTU4IDY5NyA1NzhUNjc4IDYwOVQ2NDMgNjI1VDU5NiA2MzJUNTMyIDYzNEg0ODVRMzk3IDYzMyAzOTIgNjMxUTM4OCA2MjkgMzg2IDYyMlEzODUgNjE5IDM1NSA0OTlUMzI0IDM3N1EzNDcgMzc2IDM3MiAzNzZIMzk4UTQ2NCAzNzYgNDg5IDM5MVQ1MzQgNDcyUTUzOCA0ODggNTQwIDQ5MFQ1NTcgNDkzUTU2MiA0OTMgNTY1IDQ5M1Q1NzAgNDkyVDU3MiA0OTFUNTc0IDQ4N1Q1NzcgNDgzTDU0NCAzNTFRNTExIDIxOCA1MDggMjE2UTUwNSAyMTMgNDkyIDIxM1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTcyIiBkPSJNMjEgMjg3UTIyIDI5MCAyMyAyOTVUMjggMzE3VDM4IDM0OFQ1MyAzODFUNzMgNDExVDk5IDQzM1QxMzIgNDQyUTE2MSA0NDIgMTgzIDQzMFQyMTQgNDA4VDIyNSAzODhRMjI3IDM4MiAyMjggMzgyVDIzNiAzODlRMjg0IDQ0MSAzNDcgNDQxSDM1MFEzOTggNDQxIDQyMiA0MDBRNDMwIDM4MSA0MzAgMzYzUTQzMCAzMzMgNDE3IDMxNVQzOTEgMjkyVDM2NiAyODhRMzQ2IDI4OCAzMzQgMjk5VDMyMiAzMjhRMzIyIDM3NiAzNzggMzkyUTM1NiA0MDUgMzQyIDQwNVEyODYgNDA1IDIzOSAzMzFRMjI5IDMxNSAyMjQgMjk4VDE5MCAxNjVRMTU2IDI1IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTE0IDE4OVQxNTQgMzY2UTE1NCA0MDUgMTI4IDQwNVExMDcgNDA1IDkyIDM3N1Q2OCAzMTZUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02OSIgZD0iTTE4NCA2MDBRMTg0IDYyNCAyMDMgNjQyVDI0NyA2NjFRMjY1IDY2MSAyNzcgNjQ5VDI5MCA2MTlRMjkwIDU5NiAyNzAgNTc3VDIyNiA1NTdRMjExIDU1NyAxOTggNTY3VDE4NCA2MDBaTTIxIDI4N1EyMSAyOTUgMzAgMzE4VDU0IDM2OVQ5OCA0MjBUMTU4IDQ0MlExOTcgNDQyIDIyMyA0MTlUMjUwIDM1N1EyNTAgMzQwIDIzNiAzMDFUMTk2IDE5NlQxNTQgODNRMTQ5IDYxIDE0OSA1MVExNDkgMjYgMTY2IDI2UTE3NSAyNiAxODUgMjlUMjA4IDQzVDIzNSA3OFQyNjAgMTM3UTI2MyAxNDkgMjY1IDE1MVQyODIgMTUzUTMwMiAxNTMgMzAyIDE0M1EzMDIgMTM1IDI5MyAxMTJUMjY4IDYxVDIyMyAxMVQxNjEgLTExUTEyOSAtMTEgMTAyIDEwVDc0IDc0UTc0IDkxIDc5IDEwNlQxMjIgMjIwUTE2MCAzMjEgMTY2IDM0MVQxNzMgMzgwUTE3MyA0MDQgMTU2IDQwNEgxNTRRMTI0IDQwNCA5OSAzNzFUNjEgMjg3UTYwIDI4NiA1OSAyODRUNTggMjgxVDU2IDI3OVQ1MyAyNzhUNDkgMjc4VDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MiIgZD0iTTIzMCA2MzdRMjAzIDYzNyAxOTggNjM4VDE5MyA2NDlRMTkzIDY3NiAyMDQgNjgyUTIwNiA2ODMgMzc4IDY4M1E1NTAgNjgyIDU2NCA2ODBRNjIwIDY3MiA2NTggNjUyVDcxMiA2MDZUNzMzIDU2M1Q3MzkgNTI5UTczOSA0ODQgNzEwIDQ0NVQ2NDMgMzg1VDU3NiAzNTFUNTM4IDMzOEw1NDUgMzMzUTYxMiAyOTUgNjEyIDIyM1E2MTIgMjEyIDYwNyAxNjJUNjAyIDgwVjcxUTYwMiA1MyA2MDMgNDNUNjE0IDI1VDY0MCAxNlE2NjggMTYgNjg2IDM4VDcxMiA4NVE3MTcgOTkgNzIwIDEwMlQ3MzUgMTA1UTc1NSAxMDUgNzU1IDkzUTc1NSA3NSA3MzEgMzZRNjkzIC0yMSA2NDEgLTIxSDYzMlE1NzEgLTIxIDUzMSA0VDQ4NyA4MlE0ODcgMTA5IDUwMiAxNjZUNTE3IDIzOVE1MTcgMjkwIDQ3NCAzMTNRNDU5IDMyMCA0NDkgMzIxVDM3OCAzMjNIMzA5TDI3NyAxOTNRMjQ0IDYxIDI0NCA1OVEyNDQgNTUgMjQ1IDU0VDI1MiA1MFQyNjkgNDhUMzAyIDQ2SDMzM1EzMzkgMzggMzM5IDM3VDMzNiAxOVEzMzIgNiAzMjYgMEgzMTFRMjc1IDIgMTgwIDJRMTQ2IDIgMTE3IDJUNzEgMlQ1MCAxUTMzIDEgMzMgMTBRMzMgMTIgMzYgMjRRNDEgNDMgNDYgNDVRNTAgNDYgNjEgNDZINjdROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFEyODcgNjM1IDIzMCA2MzdaTTYzMCA1NTRRNjMwIDU4NiA2MDkgNjA4VDUyMyA2MzZRNTIxIDYzNiA1MDAgNjM2VDQ2MiA2MzdINDQwUTM5MyA2MzcgMzg2IDYyN1EzODUgNjI0IDM1MiA0OTRUMzE5IDM2MVEzMTkgMzYwIDM4OCAzNjBRNDY2IDM2MSA0OTIgMzY3UTU1NiAzNzcgNTkyIDQyNlE2MDggNDQ5IDYxOSA0ODZUNjMwIDU1NFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkzMSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ1MSwtMTUwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iNTc4IiB5PSItMjM4Ij48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjE2NTMiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjMzNjIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NDE4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9zdmc+) 。
。
首次访问MC方法通过 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuMzk1ZXgiIGhlaWdodD0iMS42NzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNTc2LjEgNjAwLjUgNzIxLjYiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkUiIGQ9Ik0yMSAyODdRMjIgMjkzIDI0IDMwM1QzNiAzNDFUNTYgMzg4VDg5IDQyNVQxMzUgNDQyUTE3MSA0NDIgMTk1IDQyNFQyMjUgMzkwVDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzA0IDQ0MiAzODIgNDQyUTQzNiA0NDIgNDY5IDQxNVQ1MDMgMzM2VDQ2NSAxNzlUNDI3IDUyUTQyNyAyNiA0NDQgMjZRNDUwIDI2IDQ1MyAyN1E0ODIgMzIgNTA1IDY1VDU0MCAxNDVRNTQyIDE1MyA1NjAgMTUzUTU4MCAxNTMgNTgwIDE0NVE1ODAgMTQ0IDU3NiAxMzBRNTY4IDEwMSA1NTQgNzNUNTA4IDE3VDQzOSAtMTBRMzkyIC0xMCAzNzEgMTdUMzUwIDczUTM1MCA5MiAzODYgMTkzVDQyMyAzNDVRNDIzIDQwNCAzNzkgNDA0SDM3NFEyODggNDA0IDIyOSAzMDNMMjIyIDI5MUwxODkgMTU3UTE1NiAyNiAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExMiAxODBUMTUyIDM0M1ExNTMgMzQ4IDE1MyAzNjZRMTUzIDQwNSAxMjkgNDA1UTkxIDQwNSA2NiAzMDVRNjAgMjg1IDYwIDI4NFE1OCAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) 次试验后得到的序列
次试验后得到的序列 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIwLjQ5NGV4IiBoZWlnaHQ9IjMuMzQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMC44MzhleDsiIHZpZXdCb3g9IjAgLTEwNzguNCA4ODIzLjkgMTQzOS4yIiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0IiIGQ9Ik00MzQgLTIzMVE0MzQgLTI0NCA0MjggLTI1MEg0MTBRMjgxIC0yNTAgMjMwIC0xODRRMjI1IC0xNzcgMjIyIC0xNzJUMjE3IC0xNjFUMjEzIC0xNDhUMjExIC0xMzNUMjEwIC0xMTFUMjA5IC04NFQyMDkgLTQ3VDIwOSAwUTIwOSAyMSAyMDkgNTNRMjA4IDE0MiAyMDQgMTUzUTIwMyAxNTQgMjAzIDE1NVExODkgMTkxIDE1MyAyMTFUODIgMjMxUTcxIDIzMSA2OCAyMzRUNjUgMjUwVDY4IDI2NlQ4MiAyNjlRMTE2IDI2OSAxNTIgMjg5VDIwMyAzNDVRMjA4IDM1NiAyMDggMzc3VDIwOSA1MjlWNTc5UTIwOSA2MzQgMjE1IDY1NlQyNDQgNjk4UTI3MCA3MjQgMzI0IDc0MFEzNjEgNzQ4IDM3NyA3NDlRMzc5IDc0OSAzOTAgNzQ5VDQwOCA3NTBINDI4UTQzNCA3NDQgNDM0IDczMlE0MzQgNzE5IDQzMSA3MTZRNDI5IDcxMyA0MTUgNzEzUTM2MiA3MTAgMzMyIDY4OVQyOTYgNjQ3UTI5MSA2MzQgMjkxIDQ5OVY0MTdRMjkxIDM3MCAyODggMzUzVDI3MSAzMTRRMjQwIDI3MSAxODQgMjU1TDE3MCAyNTBMMTg0IDI0NVEyMDIgMjM5IDIyMCAyMzBUMjYyIDE5NlQyOTAgMTM3UTI5MSAxMzEgMjkxIDFRMjkxIC0xMzQgMjk2IC0xNDdRMzA2IC0xNzQgMzM5IC0xOTJUNDE1IC0yMTNRNDI5IC0yMTMgNDMxIC0yMTZRNDM0IC0yMTkgNDM0IC0yMzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzgiIGQ9Ik01MiAyODlRNTkgMzMxIDEwNiAzODZUMjIyIDQ0MlEyNTcgNDQyIDI4NiA0MjRUMzI5IDM3OVEzNzEgNDQyIDQzMCA0NDJRNDY3IDQ0MiA0OTQgNDIwVDUyMiAzNjFRNTIyIDMzMiA1MDggMzE0VDQ4MSAyOTJUNDU4IDI4OFE0MzkgMjg4IDQyNyAyOTlUNDE1IDMyOFE0MTUgMzc0IDQ2NSAzOTFRNDU0IDQwNCA0MjUgNDA0UTQxMiA0MDQgNDA2IDQwMlEzNjggMzg2IDM1MCAzMzZRMjkwIDExNSAyOTAgNzhRMjkwIDUwIDMwNiAzOFQzNDEgMjZRMzc4IDI2IDQxNCA1OVQ0NjMgMTQwUTQ2NiAxNTAgNDY5IDE1MVQ0ODUgMTUzSDQ4OVE1MDQgMTUzIDUwNCAxNDVRNTA0IDE0NCA1MDIgMTM0UTQ4NiA3NyA0NDAgMzNUMzMzIC0xMVEyNjMgLTExIDIyNyA1MlExODYgLTEwIDEzMyAtMTBIMTI3UTc4IC0xMCA1NyAxNlQzNSA3MVEzNSAxMDMgNTQgMTIzVDk5IDE0M1ExNDIgMTQzIDE0MiAxMDFRMTQyIDgxIDEzMCA2NlQxMDcgNDZUOTQgNDFMOTEgNDBROTEgMzkgOTcgMzZUMTEzIDI5VDEzMiAyNlExNjggMjYgMTk0IDcxUTIwMyA4NyAyMTcgMTM5VDI0NSAyNDdUMjYxIDMxM1EyNjYgMzQwIDI2NiAzNTJRMjY2IDM4MCAyNTEgMzkyVDIxNyA0MDRRMTc3IDQwNCAxNDIgMzcyVDkzIDI5MFE5MSAyODEgODggMjgwVDcyIDI3OEg1OFE1MiAyODQgNTIgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMSIgZD0iTTIxMyA1NzhMMjAwIDU3M1ExODYgNTY4IDE2MCA1NjNUMTAyIDU1Nkg4M1Y2MDJIMTAyUTE0OSA2MDQgMTg5IDYxN1QyNDUgNjQxVDI3MyA2NjNRMjc1IDY2NiAyODUgNjY2UTI5NCA2NjYgMzAyIDY2MFYzNjFMMzAzIDYxUTMxMCA1NCAzMTUgNTJUMzM5IDQ4VDQwMSA0Nkg0MjdWMEg0MTZRMzk1IDMgMjU3IDNRMTIxIDMgMTAwIDBIODhWNDZIMTE0UTEzNiA0NiAxNTIgNDZUMTc3IDQ3VDE5MyA1MFQyMDEgNTJUMjA3IDU3VDIxMyA2MVY1NzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yQyIgZD0iTTc4IDM1VDc4IDYwVDk0IDEwM1QxMzcgMTIxUTE2NSAxMjEgMTg3IDk2VDIxMCA4UTIxMCAtMjcgMjAxIC02MFQxODAgLTExN1QxNTQgLTE1OFQxMzAgLTE4NVQxMTcgLTE5NFExMTMgLTE5NCAxMDQgLTE4NVQ5NSAtMTcyUTk1IC0xNjggMTA2IC0xNTZUMTMxIC0xMjZUMTU3IC03NlQxNzMgLTNWOUwxNzIgOFExNzAgNyAxNjcgNlQxNjEgM1QxNTIgMVQxNDAgMFExMTMgMCA5NiAxN1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yRSIgZD0iTTc4IDYwUTc4IDg0IDk1IDEwMlQxMzggMTIwUTE2MiAxMjAgMTgwIDEwNFQxOTkgNjFRMTk5IDM2IDE4MiAxOFQxMzkgMFQ5NiAxN1Q3OCA2MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzgiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjEwNzMiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMjIyNSIgeT0iNjc1Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iMjAyNyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI0NzIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzgiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjEwNzMiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMjIyNSIgeT0iNjc1Ij48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJDIiB4PSI0NDk5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iNDk0NSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9IjUzOTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSI1ODM1IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iNjI4MCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDY3MjUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzgiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjEwNzMiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjIyMjUiIHk9IjY3NSI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=) 估计的 是
估计的 是 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjUyLjIzOGV4IiBoZWlnaHQ9IjcuNTA5ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMS44MzhleDsiIHZpZXdCb3g9IjAgLTI0NDEuOCAyMjQ5MS40IDMyMzMuMiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NiIgZD0iTTUyIDY0OFE1MiA2NzAgNjUgNjgzSDc2UTExOCA2ODAgMTgxIDY4MFEyOTkgNjgwIDMyMCA2ODNIMzMwUTMzNiA2NzcgMzM2IDY3NFQzMzQgNjU2UTMyOSA2NDEgMzI1IDYzN0gzMDRRMjgyIDYzNSAyNzQgNjM1UTI0NSA2MzAgMjQyIDYyMFEyNDIgNjE4IDI3MSAzNjlUMzAxIDExOEwzNzQgMjM1UTQ0NyAzNTIgNTIwIDQ3MVQ1OTUgNTk0UTU5OSA2MDEgNTk5IDYwOVE1OTkgNjMzIDU1NSA2MzdRNTM3IDYzNyA1MzcgNjQ4UTUzNyA2NDkgNTM5IDY2MVE1NDIgNjc1IDU0NSA2NzlUNTU4IDY4M1E1NjAgNjgzIDU3MCA2ODNUNjA0IDY4MlQ2NjggNjgxUTczNyA2ODEgNzU1IDY4M0g3NjJRNzY5IDY3NiA3NjkgNjcyUTc2OSA2NTUgNzYwIDY0MFE3NTcgNjM3IDc0MyA2MzdRNzMwIDYzNiA3MTkgNjM1VDY5OCA2MzBUNjgyIDYyM1Q2NzAgNjE1VDY2MCA2MDhUNjUyIDU5OVQ2NDUgNTkyTDQ1MiAyODJRMjcyIC05IDI2NiAtMTZRMjYzIC0xOCAyNTkgLTIxTDI0MSAtMjJIMjM0UTIxNiAtMjIgMjE2IC0xNVEyMTMgLTkgMTc3IDMwNVExMzkgNjIzIDEzOCA2MjZRMTMzIDYzNyA3NiA2MzdINTlRNTIgNjQyIDUyIDY0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NiIgZD0iTTQ4IDFRMzEgMSAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDYgNjYgMjE1IDM0MlQyODUgNjIyUTI4NSA2MjkgMjgxIDYyOVEyNzMgNjMyIDIyOCA2MzRIMTk3UTE5MSA2NDAgMTkxIDY0MlQxOTMgNjU5UTE5NyA2NzYgMjAzIDY4MEg3NDJRNzQ5IDY3NiA3NDkgNjY5UTc0OSA2NjQgNzM2IDU1N1Q3MjIgNDQ3UTcyMCA0NDAgNzAyIDQ0MEg2OTBRNjgzIDQ0NSA2ODMgNDUzUTY4MyA0NTQgNjg2IDQ3N1Q2ODkgNTMwUTY4OSA1NjAgNjgyIDU3OVQ2NjMgNjEwVDYyNiA2MjZUNTc1IDYzM1Q1MDMgNjM0SDQ4MFEzOTggNjMzIDM5MyA2MzFRMzg4IDYyOSAzODYgNjIzUTM4NSA2MjIgMzUyIDQ5MkwzMjAgMzYzSDM3NVEzNzggMzYzIDM5OCAzNjNUNDI2IDM2NFQ0NDggMzY3VDQ3MiAzNzRUNDg5IDM4NlE1MDIgMzk4IDUxMSA0MTlUNTI0IDQ1N1Q1MjkgNDc1UTUzMiA0ODAgNTQ4IDQ4MEg1NjBRNTY3IDQ3NSA1NjcgNDcwUTU2NyA0NjcgNTM2IDMzOVQ1MDIgMjA3UTUwMCAyMDAgNDgyIDIwMEg0NzBRNDYzIDIwNiA0NjMgMjEyUTQ2MyAyMTUgNDY4IDIzNFQ0NzMgMjc0UTQ3MyAzMDMgNDUzIDMxMFQzNjQgMzE3SDMwOUwyNzcgMTkwUTI0NSA2NiAyNDUgNjBRMjQ1IDQ2IDMzNCA0NkgzNTlRMzY1IDQwIDM2NSAzOVQzNjMgMTlRMzU5IDYgMzUzIDBIMzM2UTI5NSAyIDE4NSAyUTEyMCAyIDg2IDJUNDggMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY2IiBkPSJNMTE4IC0xNjJRMTIwIC0xNjIgMTI0IC0xNjRUMTM1IC0xNjdUMTQ3IC0xNjhRMTYwIC0xNjggMTcxIC0xNTVUMTg3IC0xMjZRMTk3IC05OSAyMjEgMjdUMjY3IDI2N1QyODkgMzgyVjM4NUgyNDJRMTk1IDM4NSAxOTIgMzg3UTE4OCAzOTAgMTg4IDM5N0wxOTUgNDI1UTE5NyA0MzAgMjAzIDQzMFQyNTAgNDMxUTI5OCA0MzEgMjk4IDQzMlEyOTggNDM0IDMwNyA0ODJUMzE5IDU0MFEzNTYgNzA1IDQ2NSA3MDVRNTAyIDcwMyA1MjYgNjgzVDU1MCA2MzBRNTUwIDU5NCA1MjkgNTc4VDQ4NyA1NjFRNDQzIDU2MSA0NDMgNjAzUTQ0MyA2MjIgNDU0IDYzNlQ0NzggNjU3TDQ4NyA2NjJRNDcxIDY2OCA0NTcgNjY4UTQ0NSA2NjggNDM0IDY1OFQ0MTkgNjMwUTQxMiA2MDEgNDAzIDU1MlQzODcgNDY5VDM4MCA0MzNRMzgwIDQzMSA0MzUgNDMxUTQ4MCA0MzEgNDg3IDQzMFQ0OTggNDI0UTQ5OSA0MjAgNDk2IDQwN1Q0OTEgMzkxUTQ4OSAzODYgNDgyIDM4NlQ0MjggMzg1SDM3MkwzNDkgMjYzUTMwMSAxNSAyODIgLTQ3UTI1NSAtMTMyIDIxMiAtMTczUTE3NSAtMjA1IDEzOSAtMjA1UTEwNyAtMjA1IDgxIC0xODZUNTUgLTEzMlE1NSAtOTUgNzYgLTc4VDExOCAtNjFRMTYyIC02MSAxNjIgLTEwM1ExNjIgLTEyMiAxNTEgLTEzNlQxMjcgLTE1N0wxMTggLTE2MloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc4IiBkPSJNNTIgMjg5UTU5IDMzMSAxMDYgMzg2VDIyMiA0NDJRMjU3IDQ0MiAyODYgNDI0VDMyOSAzNzlRMzcxIDQ0MiA0MzAgNDQyUTQ2NyA0NDIgNDk0IDQyMFQ1MjIgMzYxUTUyMiAzMzIgNTA4IDMxNFQ0ODEgMjkyVDQ1OCAyODhRNDM5IDI4OCA0MjcgMjk5VDQxNSAzMjhRNDE1IDM3NCA0NjUgMzkxUTQ1NCA0MDQgNDI1IDQwNFE0MTIgNDA0IDQwNiA0MDJRMzY4IDM4NiAzNTAgMzM2UTI5MCAxMTUgMjkwIDc4UTI5MCA1MCAzMDYgMzhUMzQxIDI2UTM3OCAyNiA0MTQgNTlUNDYzIDE0MFE0NjYgMTUwIDQ2OSAxNTFUNDg1IDE1M0g0ODlRNTA0IDE1MyA1MDQgMTQ1UTUwNCAxNDQgNTAyIDEzNFE0ODYgNzcgNDQwIDMzVDMzMyAtMTFRMjYzIC0xMSAyMjcgNTJRMTg2IC0xMCAxMzMgLTEwSDEyN1E3OCAtMTAgNTcgMTZUMzUgNzFRMzUgMTAzIDU0IDEyM1Q5OSAxNDNRMTQyIDE0MyAxNDIgMTAxUTE0MiA4MSAxMzAgNjZUMTA3IDQ2VDk0IDQxTDkxIDQwUTkxIDM5IDk3IDM2VDExMyAyOVQxMzIgMjZRMTY4IDI2IDE5NCA3MVEyMDMgODcgMjE3IDEzOVQyNDUgMjQ3VDI2MSAzMTNRMjY2IDM0MCAyNjYgMzUyUTI2NiAzODAgMjUxIDM5MlQyMTcgNDA0UTE3NyA0MDQgMTQyIDM3MlQ5MyAyOTBROTEgMjgxIDg4IDI4MFQ3MiAyNzhINThRNTIgMjg0IDUyIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdEIiBkPSJNNjUgNzMxUTY1IDc0NSA2OCA3NDdUODggNzUwUTE3MSA3NTAgMjE2IDcyNVQyNzkgNjcwUTI4OCA2NDkgMjg5IDYzNVQyOTEgNTAxUTI5MiAzNjIgMjkzIDM1N1EzMDYgMzEyIDM0NSAyOTFUNDE3IDI2OVE0MjggMjY5IDQzMSAyNjZUNDM0IDI1MFQ0MzEgMjM0VDQxNyAyMzFRMzgwIDIzMSAzNDUgMjEwVDI5OCAxNTdRMjkzIDE0MyAyOTIgMTIxVDI5MSAtMjhWLTc5UTI5MSAtMTM0IDI4NSAtMTU2VDI1NiAtMTk4UTIwMiAtMjUwIDg5IC0yNTBRNzEgLTI1MCA2OCAtMjQ3VDY1IC0yMzBRNjUgLTIyNCA2NSAtMjIzVDY2IC0yMThUNjkgLTIxNFQ3NyAtMjEzUTkxIC0yMTMgMTA4IC0yMTBUMTQ2IC0yMDBUMTgzIC0xNzdUMjA3IC0xMzlRMjA4IC0xMzQgMjA5IDNMMjEwIDEzOVEyMjMgMTk2IDI4MCAyMzBRMzE1IDI0NyAzMzAgMjUwUTMwNSAyNTcgMjgwIDI3MFEyMjUgMzA0IDIxMiAzNTJMMjEwIDM2MkwyMDkgNDk4UTIwOCA2MzUgMjA3IDY0MFExOTUgNjgwIDE1NCA2OTZUNzcgNzEzUTY4IDcxMyA2NyA3MTZUNjUgNzMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkMiIGQ9Ik03OCAzNVQ3OCA2MFQ5NCAxMDNUMTM3IDEyMVExNjUgMTIxIDE4NyA5NlQyMTAgOFEyMTAgLTI3IDIwMSAtNjBUMTgwIC0xMTdUMTU0IC0xNThUMTMwIC0xODVUMTE3IC0xOTRRMTEzIC0xOTQgMTA0IC0xODVUOTUgLTE3MlE5NSAtMTY4IDEwNiAtMTU2VDEzMSAtMTI2VDE1NyAtNzZUMTczIC0zVjlMMTcyIDhRMTcwIDcgMTY3IDZUMTYxIDNUMTUyIDFUMTQwIDBRMTEzIDAgOTYgMTdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMiIgZD0iTTEwOSA0MjlRODIgNDI5IDY2IDQ0N1Q1MCA0OTFRNTAgNTYyIDEwMyA2MTRUMjM1IDY2NlEzMjYgNjY2IDM4NyA2MTBUNDQ5IDQ2NVE0NDkgNDIyIDQyOSAzODNUMzgxIDMxNVQzMDEgMjQxUTI2NSAyMTAgMjAxIDE0OUwxNDIgOTNMMjE4IDkyUTM3NSA5MiAzODUgOTdRMzkyIDk5IDQwOSAxODZWMTg5SDQ0OVYxODZRNDQ4IDE4MyA0MzYgOTVUNDIxIDNWMEg1MFYxOVYzMVE1MCAzOCA1NiA0NlQ4NiA4MVExMTUgMTEzIDEzNiAxMzdRMTQ1IDE0NyAxNzAgMTc0VDIwNCAyMTFUMjMzIDI0NFQyNjEgMjc4VDI4NCAzMDhUMzA1IDM0MFQzMjAgMzY5VDMzMyA0MDFUMzQwIDQzMVQzNDMgNDY0UTM0MyA1MjcgMzA5IDU3M1QyMTIgNjE5UTE3OSA2MTkgMTU0IDYwMlQxMTkgNTY5VDEwOSA1NTBRMTA5IDU0OSAxMTQgNTQ5UTEzMiA1NDkgMTUxIDUzNVQxNzAgNDg5UTE3MCA0NjQgMTU0IDQ0N1QxMDkgNDI5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkUiIGQ9Ik03OCA2MFE3OCA4NCA5NSAxMDJUMTM4IDEyMFExNjIgMTIwIDE4MCAxMDRUMTk5IDYxUTE5OSAzNiAxODIgMThUMTM5IDBUOTYgMTdUNzggNjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oyLTI4IiBkPSJNMTgwIDk2VDE4MCAyNTBUMjA1IDU0MVQyNjYgNzcwVDM1MyA5NDRUNDQ0IDEwNjlUNTI3IDExNTBINTU1UTU2MSAxMTQ0IDU2MSAxMTQxUTU2MSAxMTM3IDU0NSAxMTIwVDUwNCAxMDcyVDQ0NyA5OTVUMzg2IDg3OFQzMzAgNzIxVDI4OCA1MTNUMjcyIDI1MVEyNzIgMTMzIDI4MCA1NlEyOTMgLTg3IDMyNiAtMjA5VDM5OSAtNDA1VDQ3NSAtNTMxVDUzNiAtNjA5VDU2MSAtNjQwUTU2MSAtNjQzIDU1NSAtNjQ5SDUyN1E0ODMgLTYxMiA0NDMgLTU2OFQzNTMgLTQ0M1QyNjYgLTI3MFQyMDUgLTQxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMi0yOSIgZD0iTTM1IDExMzhRMzUgMTE1MCA1MSAxMTUwSDU2SDY5UTExMyAxMTEzIDE1MyAxMDY5VDI0MyA5NDRUMzMwIDc3MVQzOTEgNTQxVDQxNiAyNTBUMzkxIC00MFQzMzAgLTI3MFQyNDMgLTQ0M1QxNTIgLTU2OFQ2OSAtNjQ5SDU2UTQzIC02NDkgMzkgLTY0N1QzNSAtNjM3UTY1IC02MDcgMTEwIC01NDhRMjgzIC0zMTYgMzE2IDU2UTMyNCAxMzMgMzI0IDI1MVEzMjQgMzY4IDMxNiA0NDVRMjc4IDg3NyA0OCAxMTIzUTM2IDExMzcgMzUgMTEzOFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjEtMjIxMSIgZD0iTTYxIDc0OFE2NCA3NTAgNDg5IDc1MEg5MTNMOTU0IDY0MFE5NjUgNjA5IDk3NiA1NzlUOTkzIDUzM1Q5OTkgNTE2SDk3OUw5NTkgNTE3UTkzNiA1NzkgODg2IDYyMVQ3NzcgNjgyUTcyNCA3MDAgNjU1IDcwNVQ0MzYgNzEwSDMxOVExODMgNzEwIDE4MyA3MDlRMTg2IDcwNiAzNDggNDg0VDUxMSAyNTlRNTE3IDI1MCA1MTMgMjQ0TDQ5MCAyMTZRNDY2IDE4OCA0MjAgMTM0VDMzMCAyN0wxNDkgLTE4N1ExNDkgLTE4OCAzNjIgLTE4OFEzODggLTE4OCA0MzYgLTE4OFQ1MDYgLTE4OVE2NzkgLTE4OSA3NzggLTE2MlQ5MzYgLTQzUTk0NiAtMjcgOTU5IDZIOTk5TDkxMyAtMjQ5TDQ4OSAtMjUwUTY1IC0yNTAgNjIgLTI0OFE1NiAtMjQ2IDU2IC0yMzlRNTYgLTIzNCAxMTggLTE2MVExODYgLTgxIDI0NSAtMTFMNDI4IDIwNlE0MjggMjA3IDI0MiA0NjJMNTcgNzE3TDU2IDcyOFE1NiA3NDQgNjEgNzQ4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY5IiBkPSJNMTg0IDYwMFExODQgNjI0IDIwMyA2NDJUMjQ3IDY2MVEyNjUgNjYxIDI3NyA2NDlUMjkwIDYxOVEyOTAgNTk2IDI3MCA1NzdUMjI2IDU1N1EyMTEgNTU3IDE5OCA1NjdUMTg0IDYwMFpNMjEgMjg3UTIxIDI5NSAzMCAzMThUNTQgMzY5VDk4IDQyMFQxNTggNDQyUTE5NyA0NDIgMjIzIDQxOVQyNTAgMzU3UTI1MCAzNDAgMjM2IDMwMVQxOTYgMTk2VDE1NCA4M1ExNDkgNjEgMTQ5IDUxUTE0OSAyNiAxNjYgMjZRMTc1IDI2IDE4NSAyOVQyMDggNDNUMjM1IDc4VDI2MCAxMzdRMjYzIDE0OSAyNjUgMTUxVDI4MiAxNTNRMzAyIDE1MyAzMDIgMTQzUTMwMiAxMzUgMjkzIDExMlQyNjggNjFUMjIzIDExVDE2MSAtMTFRMTI5IC0xMSAxMDIgMTBUNzQgNzRRNzQgOTEgNzkgMTA2VDEyMiAyMjBRMTYwIDMyMSAxNjYgMzQxVDE3MyAzODBRMTczIDQwNCAxNTYgNDA0SDE1NFExMjQgNDA0IDk5IDM3MVQ2MSAyODdRNjAgMjg2IDU5IDI4NFQ1OCAyODFUNTYgMjc5VDUzIDI3OFQ0OSAyNzhUNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDYiIHg9IjExNjciIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iODI1IiB5PSItMjEyIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTYyMSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIzMTQ4IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjYiIHg9IjQyMDQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0OTIxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTk3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc4IiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSIxMDczIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjIyMjUiIHk9IjY3NSI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9IjIwMjciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNDcyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc4IiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSIxMDczIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjIyMjUiIHk9IjY3NSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iNDQ5OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9IjQ5NDUiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSI1MzkwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iNTgzNSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYyODAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzgiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjEwNzMiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjIyMjUiIHk9IjY3NSI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjkiIHg9Ijg5NzYiIHk9Ii0xIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIxNDc3MyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE1NTUxLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzk3LDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNjQyMSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDExNjkpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjE0OTQiIHk9IjY3NSI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwNTYsLTI4NykiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMzQ1IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjExMjQiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY2IiB4PSIyNDcxIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzE4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yOCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU5NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03OCIgeD0iNTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iMTA3MyIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMjIyNSIgeT0iNjc1Ij48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjkiIHg9IjI1MTUiIHk9Ii0xIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIyOTEwIiB5PSItNjg2Ij48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9zdmc+) 。
。
从字面上的意思来理解, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjYuMjhleCIgaGVpZ2h0PSIzLjAwOWV4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTAuODM4ZXg7IiB2aWV3Qm94PSIwIC05MzQuOSAyNzAzLjggMTI5NS43IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU2IiBkPSJNNTIgNjQ4UTUyIDY3MCA2NSA2ODNINzZRMTE4IDY4MCAxODEgNjgwUTI5OSA2ODAgMzIwIDY4M0gzMzBRMzM2IDY3NyAzMzYgNjc0VDMzNCA2NTZRMzI5IDY0MSAzMjUgNjM3SDMwNFEyODIgNjM1IDI3NCA2MzVRMjQ1IDYzMCAyNDIgNjIwUTI0MiA2MTggMjcxIDM2OVQzMDEgMTE4TDM3NCAyMzVRNDQ3IDM1MiA1MjAgNDcxVDU5NSA1OTRRNTk5IDYwMSA1OTkgNjA5UTU5OSA2MzMgNTU1IDYzN1E1MzcgNjM3IDUzNyA2NDhRNTM3IDY0OSA1MzkgNjYxUTU0MiA2NzUgNTQ1IDY3OVQ1NTggNjgzUTU2MCA2ODMgNTcwIDY4M1Q2MDQgNjgyVDY2OCA2ODFRNzM3IDY4MSA3NTUgNjgzSDc2MlE3NjkgNjc2IDc2OSA2NzJRNzY5IDY1NSA3NjAgNjQwUTc1NyA2MzcgNzQzIDYzN1E3MzAgNjM2IDcxOSA2MzVUNjk4IDYzMFQ2ODIgNjIzVDY3MCA2MTVUNjYwIDYwOFQ2NTIgNTk5VDY0NSA1OTJMNDUyIDI4MlEyNzIgLTkgMjY2IC0xNlEyNjMgLTE4IDI1OSAtMjFMMjQxIC0yMkgyMzRRMjE2IC0yMiAyMTYgLTE1UTIxMyAtOSAxNzcgMzA1UTEzOSA2MjMgMTM4IDYyNlExMzMgNjM3IDc2IDYzN0g1OVE1MiA2NDIgNTIgNjQ4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQ2IiBkPSJNNDggMVEzMSAxIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc0MlE3NDkgNjc2IDc0OSA2NjlRNzQ5IDY2NCA3MzYgNTU3VDcyMiA0NDdRNzIwIDQ0MCA3MDIgNDQwSDY5MFE2ODMgNDQ1IDY4MyA0NTNRNjgzIDQ1NCA2ODYgNDc3VDY4OSA1MzBRNjg5IDU2MCA2ODIgNTc5VDY2MyA2MTBUNjI2IDYyNlQ1NzUgNjMzVDUwMyA2MzRINDgwUTM5OCA2MzMgMzkzIDYzMVEzODggNjI5IDM4NiA2MjNRMzg1IDYyMiAzNTIgNDkyTDMyMCAzNjNIMzc1UTM3OCAzNjMgMzk4IDM2M1Q0MjYgMzY0VDQ0OCAzNjdUNDcyIDM3NFQ0ODkgMzg2UTUwMiAzOTggNTExIDQxOVQ1MjQgNDU3VDUyOSA0NzVRNTMyIDQ4MCA1NDggNDgwSDU2MFE1NjcgNDc1IDU2NyA0NzBRNTY3IDQ2NyA1MzYgMzM5VDUwMiAyMDdRNTAwIDIwMCA0ODIgMjAwSDQ3MFE0NjMgMjA2IDQ2MyAyMTJRNDYzIDIxNSA0NjggMjM0VDQ3MyAyNzRRNDczIDMwMyA0NTMgMzEwVDM2NCAzMTdIMzA5TDI3NyAxOTBRMjQ1IDY2IDI0NSA2MFEyNDUgNDYgMzM0IDQ2SDM1OVEzNjUgNDAgMzY1IDM5VDM2MyAxOVEzNTkgNiAzNTMgMEgzMzZRMjk1IDIgMTg1IDJRMTIwIDIgODYgMlQ0OCAxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZFIiBkPSJNMjEgMjg3UTIyIDI5MyAyNCAzMDNUMzYgMzQxVDU2IDM4OFQ4OSA0MjVUMTM1IDQ0MlExNzEgNDQyIDE5NSA0MjRUMjI1IDM5MFQyMzEgMzY5UTIzMSAzNjcgMjMyIDM2N0wyNDMgMzc4UTMwNCA0NDIgMzgyIDQ0MlE0MzYgNDQyIDQ2OSA0MTVUNTAzIDMzNlQ0NjUgMTc5VDQyNyA1MlE0MjcgMjYgNDQ0IDI2UTQ1MCAyNiA0NTMgMjdRNDgyIDMyIDUwNSA2NVQ1NDAgMTQ1UTU0MiAxNTMgNTYwIDE1M1E1ODAgMTUzIDU4MCAxNDVRNTgwIDE0NCA1NzYgMTMwUTU2OCAxMDEgNTU0IDczVDUwOCAxN1Q0MzkgLTEwUTM5MiAtMTAgMzcxIDE3VDM1MCA3M1EzNTAgOTIgMzg2IDE5M1Q0MjMgMzQ1UTQyMyA0MDQgMzc5IDQwNEgzNzRRMjg4IDQwNCAyMjkgMzAzTDIyMiAyOTFMMTg5IDE1N1ExNTYgMjYgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTIgMTgwVDE1MiAzNDNRMTUzIDM0OCAxNTMgMzY2UTE1MyA0MDUgMTI5IDQwNVE5MSA0MDUgNjYgMzA1UTYwIDI4NSA2MCAyODRRNTggMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ2IiB4PSIxMTY3IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjgyNSIgeT0iLTIxMiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjE0NTUiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTg0NCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjIzMTQiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) 只是来自 个样本 估计的平均值,由于马尔可夫性,样本是独立的。
只是来自 个样本 估计的平均值,由于马尔可夫性,样本是独立的。
每次访问MC方法 every-visit MC
每次访问MC方法通过 次试验得到的序列 估计的 值为 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjY3Ljk0MmV4IiBoZWlnaHQ9IjYuMTc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMi4xNzFleDsiIHZpZXdCb3g9IjAgLTE3MjQuMiAyOTI1Mi41IDI2NTkuMSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NiIgZD0iTTUyIDY0OFE1MiA2NzAgNjUgNjgzSDc2UTExOCA2ODAgMTgxIDY4MFEyOTkgNjgwIDMyMCA2ODNIMzMwUTMzNiA2NzcgMzM2IDY3NFQzMzQgNjU2UTMyOSA2NDEgMzI1IDYzN0gzMDRRMjgyIDYzNSAyNzQgNjM1UTI0NSA2MzAgMjQyIDYyMFEyNDIgNjE4IDI3MSAzNjlUMzAxIDExOEwzNzQgMjM1UTQ0NyAzNTIgNTIwIDQ3MVQ1OTUgNTk0UTU5OSA2MDEgNTk5IDYwOVE1OTkgNjMzIDU1NSA2MzdRNTM3IDYzNyA1MzcgNjQ4UTUzNyA2NDkgNTM5IDY2MVE1NDIgNjc1IDU0NSA2NzlUNTU4IDY4M1E1NjAgNjgzIDU3MCA2ODNUNjA0IDY4MlQ2NjggNjgxUTczNyA2ODEgNzU1IDY4M0g3NjJRNzY5IDY3NiA3NjkgNjcyUTc2OSA2NTUgNzYwIDY0MFE3NTcgNjM3IDc0MyA2MzdRNzMwIDYzNiA3MTkgNjM1VDY5OCA2MzBUNjgyIDYyM1Q2NzAgNjE1VDY2MCA2MDhUNjUyIDU5OVQ2NDUgNTkyTDQ1MiAyODJRMjcyIC05IDI2NiAtMTZRMjYzIC0xOCAyNTkgLTIxTDI0MSAtMjJIMjM0UTIxNiAtMjIgMjE2IC0xNVEyMTMgLTkgMTc3IDMwNVExMzkgNjIzIDEzOCA2MjZRMTMzIDYzNyA3NiA2MzdINTlRNTIgNjQyIDUyIDY0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NSIgZD0iTTQ5MiAyMTNRNDcyIDIxMyA0NzIgMjI2UTQ3MiAyMzAgNDc3IDI1MFQ0ODIgMjg1UTQ4MiAzMTYgNDYxIDMyM1QzNjQgMzMwSDMxMlEzMTEgMzI4IDI3NyAxOTJUMjQzIDUyUTI0MyA0OCAyNTQgNDhUMzM0IDQ2UTQyOCA0NiA0NTggNDhUNTE4IDYxUTU2NyA3NyA1OTkgMTE3VDY3MCAyNDhRNjgwIDI3MCA2ODMgMjcyUTY5MCAyNzQgNjk4IDI3NFE3MTggMjc0IDcxOCAyNjFRNjEzIDcgNjA4IDJRNjA1IDAgMzIyIDBIMTMzUTMxIDAgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ2IDY2IDIxNSAzNDJUMjg1IDYyMlEyODUgNjI5IDI4MSA2MjlRMjczIDYzMiAyMjggNjM0SDE5N1ExOTEgNjQwIDE5MSA2NDJUMTkzIDY1OVExOTcgNjc2IDIwMyA2ODBINzU3UTc2NCA2NzYgNzY0IDY2OVE3NjQgNjY0IDc1MSA1NTdUNzM3IDQ0N1E3MzUgNDQwIDcxNyA0NDBINzA1UTY5OCA0NDUgNjk4IDQ1M0w3MDEgNDc2UTcwNCA1MDAgNzA0IDUyOFE3MDQgNTU4IDY5NyA1NzhUNjc4IDYwOVQ2NDMgNjI1VDU5NiA2MzJUNTMyIDYzNEg0ODVRMzk3IDYzMyAzOTIgNjMxUTM4OCA2MjkgMzg2IDYyMlEzODUgNjE5IDM1NSA0OTlUMzI0IDM3N1EzNDcgMzc2IDM3MiAzNzZIMzk4UTQ2NCAzNzYgNDg5IDM5MVQ1MzQgNDcyUTUzOCA0ODggNTQwIDQ5MFQ1NTcgNDkzUTU2MiA0OTMgNTY1IDQ5M1Q1NzAgNDkyVDU3MiA0OTFUNTc0IDQ4N1Q1NzcgNDgzTDU0NCAzNTFRNTExIDIxOCA1MDggMjE2UTUwNSAyMTMgNDkyIDIxM1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc0IiBkPSJNMjYgMzg1UTE5IDM5MiAxOSAzOTVRMTkgMzk5IDIyIDQxMVQyNyA0MjVRMjkgNDMwIDM2IDQzMFQ4NyA0MzFIMTQwTDE1OSA1MTFRMTYyIDUyMiAxNjYgNTQwVDE3MyA1NjZUMTc5IDU4NlQxODcgNjAzVDE5NyA2MTVUMjExIDYyNFQyMjkgNjI2UTI0NyA2MjUgMjU0IDYxNVQyNjEgNTk2UTI2MSA1ODkgMjUyIDU0OVQyMzIgNDcwTDIyMiA0MzNRMjIyIDQzMSAyNzIgNDMxSDMyM1EzMzAgNDI0IDMzMCA0MjBRMzMwIDM5OCAzMTcgMzg1SDIxMEwxNzQgMjQwUTEzNSA4MCAxMzUgNjhRMTM1IDI2IDE2MiAyNlExOTcgMjYgMjMwIDYwVDI4MyAxNDRRMjg1IDE1MCAyODggMTUxVDMwMyAxNTNIMzA3UTMyMiAxNTMgMzIyIDE0NVEzMjIgMTQyIDMxOSAxMzNRMzE0IDExNyAzMDEgOTVUMjY3IDQ4VDIxNiA2VDE1NSAtMTFRMTI1IC0xMSA5OCA0VDU5IDU2UTU3IDY0IDU3IDgzVjEwMUw5MiAyNDFRMTI3IDM4MiAxMjggMzgzUTEyOCAzODUgNzcgMzg1SDI2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0IiIGQ9Ik00MzQgLTIzMVE0MzQgLTI0NCA0MjggLTI1MEg0MTBRMjgxIC0yNTAgMjMwIC0xODRRMjI1IC0xNzcgMjIyIC0xNzJUMjE3IC0xNjFUMjEzIC0xNDhUMjExIC0xMzNUMjEwIC0xMTFUMjA5IC04NFQyMDkgLTQ3VDIwOSAwUTIwOSAyMSAyMDkgNTNRMjA4IDE0MiAyMDQgMTUzUTIwMyAxNTQgMjAzIDE1NVExODkgMTkxIDE1MyAyMTFUODIgMjMxUTcxIDIzMSA2OCAyMzRUNjUgMjUwVDY4IDI2NlQ4MiAyNjlRMTE2IDI2OSAxNTIgMjg5VDIwMyAzNDVRMjA4IDM1NiAyMDggMzc3VDIwOSA1MjlWNTc5UTIwOSA2MzQgMjE1IDY1NlQyNDQgNjk4UTI3MCA3MjQgMzI0IDc0MFEzNjEgNzQ4IDM3NyA3NDlRMzc5IDc0OSAzOTAgNzQ5VDQwOCA3NTBINDI4UTQzNCA3NDQgNDM0IDczMlE0MzQgNzE5IDQzMSA3MTZRNDI5IDcxMyA0MTUgNzEzUTM2MiA3MTAgMzMyIDY4OVQyOTYgNjQ3UTI5MSA2MzQgMjkxIDQ5OVY0MTdRMjkxIDM3MCAyODggMzUzVDI3MSAzMTRRMjQwIDI3MSAxODQgMjU1TDE3MCAyNTBMMTg0IDI0NVEyMDIgMjM5IDIyMCAyMzBUMjYyIDE5NlQyOTAgMTM3UTI5MSAxMzEgMjkxIDFRMjkxIC0xMzQgMjk2IC0xNDdRMzA2IC0xNzQgMzM5IC0xOTJUNDE1IC0yMTNRNDI5IC0yMTMgNDMxIC0yMTZRNDM0IC0yMTkgNDM0IC0yMzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzgiIGQ9Ik01MiAyODlRNTkgMzMxIDEwNiAzODZUMjIyIDQ0MlEyNTcgNDQyIDI4NiA0MjRUMzI5IDM3OVEzNzEgNDQyIDQzMCA0NDJRNDY3IDQ0MiA0OTQgNDIwVDUyMiAzNjFRNTIyIDMzMiA1MDggMzE0VDQ4MSAyOTJUNDU4IDI4OFE0MzkgMjg4IDQyNyAyOTlUNDE1IDMyOFE0MTUgMzc0IDQ2NSAzOTFRNDU0IDQwNCA0MjUgNDA0UTQxMiA0MDQgNDA2IDQwMlEzNjggMzg2IDM1MCAzMzZRMjkwIDExNSAyOTAgNzhRMjkwIDUwIDMwNiAzOFQzNDEgMjZRMzc4IDI2IDQxNCA1OVQ0NjMgMTQwUTQ2NiAxNTAgNDY5IDE1MVQ0ODUgMTUzSDQ4OVE1MDQgMTUzIDUwNCAxNDVRNTA0IDE0NCA1MDIgMTM0UTQ4NiA3NyA0NDAgMzNUMzMzIC0xMVEyNjMgLTExIDIyNyA1MlExODYgLTEwIDEzMyAtMTBIMTI3UTc4IC0xMCA1NyAxNlQzNSA3MVEzNSAxMDMgNTQgMTIzVDk5IDE0M1ExNDIgMTQzIDE0MiAxMDFRMTQyIDgxIDEzMCA2NlQxMDcgNDZUOTQgNDFMOTEgNDBROTEgMzkgOTcgMzZUMTEzIDI5VDEzMiAyNlExNjggMjYgMTk0IDcxUTIwMyA4NyAyMTcgMTM5VDI0NSAyNDdUMjYxIDMxM1EyNjYgMzQwIDI2NiAzNTJRMjY2IDM4MCAyNTEgMzkyVDIxNyA0MDRRMTc3IDQwNCAxNDIgMzcyVDkzIDI5MFE5MSAyODEgODggMjgwVDcyIDI3OEg1OFE1MiAyODQgNTIgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkUiIGQ9Ik0yMSAyODdRMjIgMjkzIDI0IDMwM1QzNiAzNDFUNTYgMzg4VDg5IDQyNVQxMzUgNDQyUTE3MSA0NDIgMTk1IDQyNFQyMjUgMzkwVDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzA0IDQ0MiAzODIgNDQyUTQzNiA0NDIgNDY5IDQxNVQ1MDMgMzM2VDQ2NSAxNzlUNDI3IDUyUTQyNyAyNiA0NDQgMjZRNDUwIDI2IDQ1MyAyN1E0ODIgMzIgNTA1IDY1VDU0MCAxNDVRNTQyIDE1MyA1NjAgMTUzUTU4MCAxNTMgNTgwIDE0NVE1ODAgMTQ0IDU3NiAxMzBRNTY4IDEwMSA1NTQgNzNUNTA4IDE3VDQzOSAtMTBRMzkyIC0xMCAzNzEgMTdUMzUwIDczUTM1MCA5MiAzODYgMTkzVDQyMyAzNDVRNDIzIDQwNCAzNzkgNDA0SDM3NFEyODggNDA0IDIyOSAzMDNMMjIyIDI5MUwxODkgMTU3UTE1NiAyNiAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExMiAxODBUMTUyIDM0M1ExNTMgMzQ4IDE1MyAzNjZRMTUzIDQwNSAxMjkgNDA1UTkxIDQwNSA2NiAzMDVRNjAgMjg1IDYwIDI4NFE1OCAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzUiIGQ9Ik0yMSAyODdRMjEgMjk1IDMwIDMxOFQ1NSAzNzBUOTkgNDIwVDE1OCA0NDJRMjA0IDQ0MiAyMjcgNDE3VDI1MCAzNThRMjUwIDM0MCAyMTYgMjQ2VDE4MiAxMDVRMTgyIDYyIDE5NiA0NVQyMzggMjdUMjkxIDQ0VDMyOCA3OEwzMzkgOTVRMzQxIDk5IDM3NyAyNDdRNDA3IDM2NyA0MTMgMzg3VDQyNyA0MTZRNDQ0IDQzMSA0NjMgNDMxUTQ4MCA0MzEgNDg4IDQyMVQ0OTYgNDAyTDQyMCA4NFE0MTkgNzkgNDE5IDY4UTQxOSA0MyA0MjYgMzVUNDQ3IDI2UTQ2OSAyOSA0ODIgNTdUNTEyIDE0NVE1MTQgMTUzIDUzMiAxNTNRNTUxIDE1MyA1NTEgMTQ0UTU1MCAxMzkgNTQ5IDEzMFQ1NDAgOThUNTIzIDU1VDQ5OCAxN1Q0NjIgLThRNDU0IC0xMCA0MzggLTEwUTM3MiAtMTAgMzQ3IDQ2UTM0NSA0NSAzMzYgMzZUMzE4IDIxVDI5NiA2VDI2NyAtNlQyMzMgLTExUTE4OSAtMTEgMTU1IDdRMTAzIDM4IDEwMyAxMTNRMTAzIDE3MCAxMzggMjYyVDE3MyAzNzlRMTczIDM4MCAxNzMgMzgxUTE3MyAzOTAgMTczIDM5M1QxNjkgNDAwVDE1OCA0MDRIMTU0UTEzMSA0MDQgMTEyIDM4NVQ4MiAzNDRUNjUgMzAyVDU3IDI4MFE1NSAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkQiIGQ9Ik0yMSAyODdRMjIgMjkzIDI0IDMwM1QzNiAzNDFUNTYgMzg4VDg4IDQyNVQxMzIgNDQyVDE3NSA0MzVUMjA1IDQxN1QyMjEgMzk1VDIyOSAzNzZMMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDMgNDQyIDM4NCA0NDJRNDAxIDQ0MiA0MTUgNDQwVDQ0MSA0MzNUNDYwIDQyM1Q0NzUgNDExVDQ4NSAzOThUNDkzIDM4NVQ0OTcgMzczVDUwMCAzNjRUNTAyIDM1N0w1MTAgMzY3UTU3MyA0NDIgNjU5IDQ0MlE3MTMgNDQyIDc0NiA0MTVUNzgwIDMzNlE3ODAgMjg1IDc0MiAxNzhUNzA0IDUwUTcwNSAzNiA3MDkgMzFUNzI0IDI2UTc1MiAyNiA3NzYgNTZUODE1IDEzOFE4MTggMTQ5IDgyMSAxNTFUODM3IDE1M1E4NTcgMTUzIDg1NyAxNDVRODU3IDE0NCA4NTMgMTMwUTg0NSAxMDEgODMxIDczVDc4NSAxN1Q3MTYgLTEwUTY2OSAtMTAgNjQ4IDE3VDYyNyA3M1E2MjcgOTIgNjYzIDE5M1Q3MDAgMzQ1UTcwMCA0MDQgNjU2IDQwNEg2NTFRNTY1IDQwNCA1MDYgMzAzTDQ5OSAyOTFMNDY2IDE1N1E0MzMgMjYgNDI4IDE2UTQxNSAtMTEgMzg1IC0xMVEzNzIgLTExIDM2NCAtNFQzNTMgOFQzNTAgMThRMzUwIDI5IDM4NCAxNjFMNDIwIDMwN1E0MjMgMzIyIDQyMyAzNDVRNDIzIDQwNCAzNzkgNDA0SDM3NFEyODggNDA0IDIyOSAzMDNMMjIyIDI5MUwxODkgMTU3UTE1NiAyNiAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExMiAxODFRMTUxIDMzNSAxNTEgMzQyUTE1NCAzNTcgMTU0IDM2OVExNTQgNDA1IDEyOSA0MDVRMTA3IDQwNSA5MiAzNzdUNjkgMzE2VDU3IDI4MFE1NSAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkIiIGQ9Ik0xMjEgNjQ3UTEyMSA2NTcgMTI1IDY3MFQxMzcgNjgzUTEzOCA2ODMgMjA5IDY4OFQyODIgNjk0UTI5NCA2OTQgMjk0IDY4NlEyOTQgNjc5IDI0NCA0NzdRMTk0IDI3OSAxOTQgMjcyUTIxMyAyODIgMjIzIDI5MVEyNDcgMzA5IDI5MiAzNTRUMzYyIDQxNVE0MDIgNDQyIDQzOCA0NDJRNDY4IDQ0MiA0ODUgNDIzVDUwMyAzNjlRNTAzIDM0NCA0OTYgMzI3VDQ3NyAzMDJUNDU2IDI5MVQ0MzggMjg4UTQxOCAyODggNDA2IDI5OVQzOTQgMzI4UTM5NCAzNTMgNDEwIDM2OVQ0NDIgMzkwTDQ1OCAzOTNRNDQ2IDQwNSA0MzQgNDA1SDQzMFEzOTggNDAyIDM2NyAzODBUMjk0IDMxNlQyMjggMjU1UTIzMCAyNTQgMjQzIDI1MlQyNjcgMjQ2VDI5MyAyMzhUMzIwIDIyNFQzNDIgMjA2VDM1OSAxODBUMzY1IDE0N1EzNjUgMTMwIDM2MCAxMDZUMzU0IDY2UTM1NCAyNiAzODEgMjZRNDI5IDI2IDQ1OSAxNDVRNDYxIDE1MyA0NzkgMTUzSDQ4M1E0OTkgMTUzIDQ5OSAxNDRRNDk5IDEzOSA0OTYgMTMwUTQ1NSAtMTEgMzc4IC0xMVEzMzMgLTExIDMwNSAxNVQyNzcgOTBRMjc3IDEwOCAyODAgMTIxVDI4MyAxNDVRMjgzIDE2NyAyNjkgMTgzVDIzNCAyMDZUMjAwIDIxN1QxODIgMjIwSDE4MFExNjggMTc4IDE1OSAxMzlUMTQ1IDgxVDEzNiA0NFQxMjkgMjBUMTIyIDdUMTExIC0yUTk4IC0xMSA4MyAtMTFRNjYgLTExIDU3IC0xVDQ4IDE2UTQ4IDI2IDg1IDE3NlQxNTggNDcxTDE5NSA2MTZRMTk2IDYyOSAxODggNjMyVDE0OSA2MzdIMTQ0UTEzNCA2MzcgMTMxIDYzN1QxMjQgNjQwVDEyMSA2NDdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yQiIgZD0iTTU2IDIzN1Q1NiAyNTBUNzAgMjcwSDM2OVY0MjBMMzcwIDU3MFEzODAgNTgzIDM4OSA1ODNRNDAyIDU4MyA0MDkgNTY4VjI3MEg3MDdRNzIyIDI2MiA3MjIgMjUwVDcwNyAyMzBINDA5Vi02OFE0MDEgLTgyIDM5MSAtODJIMzg5SDM4N1EzNzUgLTgyIDM2OSAtNjhWMjMwSDcwUTU2IDIzNyA1NiAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzIiIGQ9Ik0yMSAyODdRMjIgMjkwIDIzIDI5NVQyOCAzMTdUMzggMzQ4VDUzIDM4MVQ3MyA0MTFUOTkgNDMzVDEzMiA0NDJRMTYxIDQ0MiAxODMgNDMwVDIxNCA0MDhUMjI1IDM4OFEyMjcgMzgyIDIyOCAzODJUMjM2IDM4OVEyODQgNDQxIDM0NyA0NDFIMzUwUTM5OCA0NDEgNDIyIDQwMFE0MzAgMzgxIDQzMCAzNjNRNDMwIDMzMyA0MTcgMzE1VDM5MSAyOTJUMzY2IDI4OFEzNDYgMjg4IDMzNCAyOTlUMzIyIDMyOFEzMjIgMzc2IDM3OCAzOTJRMzU2IDQwNSAzNDIgNDA1UTI4NiA0MDUgMjM5IDMzMVEyMjkgMzE1IDIyNCAyOThUMTkwIDE2NVExNTYgMjUgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTQgMTg5VDE1NCAzNjZRMTU0IDQwNSAxMjggNDA1UTEwNyA0MDUgOTIgMzc3VDY4IDMxNlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzIiIGQ9Ik0xMDkgNDI5UTgyIDQyOSA2NiA0NDdUNTAgNDkxUTUwIDU2MiAxMDMgNjE0VDIzNSA2NjZRMzI2IDY2NiAzODcgNjEwVDQ0OSA0NjVRNDQ5IDQyMiA0MjkgMzgzVDM4MSAzMTVUMzAxIDI0MVEyNjUgMjEwIDIwMSAxNDlMMTQyIDkzTDIxOCA5MlEzNzUgOTIgMzg1IDk3UTM5MiA5OSA0MDkgMTg2VjE4OUg0NDlWMTg2UTQ0OCAxODMgNDM2IDk1VDQyMSAzVjBINTBWMTlWMzFRNTAgMzggNTYgNDZUODYgODFRMTE1IDExMyAxMzYgMTM3UTE0NSAxNDcgMTcwIDE3NFQyMDQgMjExVDIzMyAyNDRUMjYxIDI3OFQyODQgMzA4VDMwNSAzNDBUMzIwIDM2OVQzMzMgNDAxVDM0MCA0MzFUMzQzIDQ2NFEzNDMgNTI3IDMwOSA1NzNUMjEyIDYxOVExNzkgNjE5IDE1NCA2MDJUMTE5IDU2OVQxMDkgNTUwUTEwOSA1NDkgMTE0IDU0OVExMzIgNTQ5IDE1MSA1MzVUMTcwIDQ4OVExNzAgNDY0IDE1NCA0NDdUMTA5IDQyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJFIiBkPSJNNzggNjBRNzggODQgOTUgMTAyVDEzOCAxMjBRMTYyIDEyMCAxODAgMTA0VDE5OSA2MVExOTkgMzYgMTgyIDE4VDEzOSAwVDk2IDE3VDc4IDYwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU0IiBkPSJNNDAgNDM3UTIxIDQzNyAyMSA0NDVRMjEgNDUwIDM3IDUwMVQ3MSA2MDJMODggNjUxUTkzIDY2OSAxMDEgNjc3SDU2OUg2NTlRNjkxIDY3NyA2OTcgNjc2VDcwNCA2NjdRNzA0IDY2MSA2ODcgNTUzVDY2OCA0NDRRNjY4IDQzNyA2NDkgNDM3UTY0MCA0MzcgNjM3IDQzN1Q2MzEgNDQyTDYyOSA0NDVRNjI5IDQ1MSA2MzUgNDkwVDY0MSA1NTFRNjQxIDU4NiA2MjggNjA0VDU3MyA2MjlRNTY4IDYzMCA1MTUgNjMxUTQ2OSA2MzEgNDU3IDYzMFQ0MzkgNjIyUTQzOCA2MjEgMzY4IDM0M1QyOTggNjBRMjk4IDQ4IDM4NiA0NlE0MTggNDYgNDI3IDQ1VDQzNiAzNlE0MzYgMzEgNDMzIDIyUTQyOSA0IDQyNCAxTDQyMiAwUTQxOSAwIDQxNSAwUTQxMCAwIDM2MyAxVDIyOCAyUTk5IDIgNjQgMEg0OVE0MyA2IDQzIDlUNDUgMjdRNDkgNDAgNTUgNDZIODNIOTRRMTc0IDQ2IDE4OSA1NVExOTAgNTYgMTkxIDU2UTE5NiA1OSAyMDEgNzZUMjQxIDIzM1EyNTggMzAxIDI2OSAzNDRRMzM5IDYxOSAzMzkgNjI1UTMzOSA2MzAgMzEwIDYzMEgyNzlRMjEyIDYzMCAxOTEgNjI0UTE0NiA2MTQgMTIxIDU4M1Q2NyA0NjdRNjAgNDQ1IDU3IDQ0MVQ0MyA0MzdINDBaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9IjExNjciIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSI4MjUiIHk9Ii00MzUiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjMyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjMxNTgiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NCIgeD0iNDIxNSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ3NDMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc4IiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSIxMDczIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxOTYzIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI3MzczIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODE1MiwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM5NywwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjQ1NTEiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw3NzApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzQiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNjEsLTE1MCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzUiIHg9IjYwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RCIgeD0iMTE3MyIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjA3OCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzgiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjEwNzMiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjE5NjMiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTE1MywtNzE1KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNzQzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTc0NCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjEzNDk4IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQyNzcsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxNDQ1NyIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDgzMSkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ1MSwtMTUwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSI1NzgiIHk9Ii0yNDMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjE0NjMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIyNDY0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjk2NCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDUxLC0xNTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjU3NCkiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjU3OCIgeT0iLTI0MyI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI0MjA2IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iNDk4NCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9IjU0MzAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSI1ODc1IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNjMyMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI3MDk4IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzYyMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDUxLC0xNTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjU3NCkiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI1NzgiIHk9Ii0yNzEiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iOTA5NiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwMDk3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNzQzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTc0NCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMjYzNCIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTMyODcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYxMDYsLTcxNSkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9Ijc0MyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjE3NDQiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+Cjwvc3ZnPg==) 。
。
其中 是随机数,代表第 次重新访问状态 。每次重新访问 都有效地开始了另一次试验(如图1所示)。因此,在第 次和第 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQuODA1ZXgiIGhlaWdodD0iMi4zNDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjUwNWV4OyIgdmlld0JveD0iMCAtNzkxLjMgMjA2OC45IDEwMDguNiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02OSIgZD0iTTE4NCA2MDBRMTg0IDYyNCAyMDMgNjQyVDI0NyA2NjFRMjY1IDY2MSAyNzcgNjQ5VDI5MCA2MTlRMjkwIDU5NiAyNzAgNTc3VDIyNiA1NTdRMjExIDU1NyAxOTggNTY3VDE4NCA2MDBaTTIxIDI4N1EyMSAyOTUgMzAgMzE4VDU0IDM2OVQ5OCA0MjBUMTU4IDQ0MlExOTcgNDQyIDIyMyA0MTlUMjUwIDM1N1EyNTAgMzQwIDIzNiAzMDFUMTk2IDE5NlQxNTQgODNRMTQ5IDYxIDE0OSA1MVExNDkgMjYgMTY2IDI2UTE3NSAyNiAxODUgMjlUMjA4IDQzVDIzNSA3OFQyNjAgMTM3UTI2MyAxNDkgMjY1IDE1MVQyODIgMTUzUTMwMiAxNTMgMzAyIDE0M1EzMDIgMTM1IDI5MyAxMTJUMjY4IDYxVDIyMyAxMVQxNjEgLTExUTEyOSAtMTEgMTAyIDEwVDc0IDc0UTc0IDkxIDc5IDEwNlQxMjIgMjIwUTE2MCAzMjEgMTY2IDM0MVQxNzMgMzgwUTE3MyA0MDQgMTU2IDQwNEgxNTRRMTI0IDQwNCA5OSAzNzFUNjEgMjg3UTYwIDI4NiA1OSAyODRUNTggMjgxVDU2IDI3OVQ1MyAyNzhUNDkgMjc4VDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNTY3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTU2OCIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 次访问状态 之间发生的奖励在估计时被包括了 次。每次访问MC通过 次试验后得到的序列 估计的 是
次访问状态 之间发生的奖励在估计时被包括了 次。每次访问MC通过 次试验后得到的序列 估计的 是 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjU1LjYzM2V4IiBoZWlnaHQ9IjguNTA5ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMi44MzhleDsiIHZpZXdCb3g9IjAgLTI0NDEuOCAyMzk1My4xIDM2NjMuNyIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NiIgZD0iTTUyIDY0OFE1MiA2NzAgNjUgNjgzSDc2UTExOCA2ODAgMTgxIDY4MFEyOTkgNjgwIDMyMCA2ODNIMzMwUTMzNiA2NzcgMzM2IDY3NFQzMzQgNjU2UTMyOSA2NDEgMzI1IDYzN0gzMDRRMjgyIDYzNSAyNzQgNjM1UTI0NSA2MzAgMjQyIDYyMFEyNDIgNjE4IDI3MSAzNjlUMzAxIDExOEwzNzQgMjM1UTQ0NyAzNTIgNTIwIDQ3MVQ1OTUgNTk0UTU5OSA2MDEgNTk5IDYwOVE1OTkgNjMzIDU1NSA2MzdRNTM3IDYzNyA1MzcgNjQ4UTUzNyA2NDkgNTM5IDY2MVE1NDIgNjc1IDU0NSA2NzlUNTU4IDY4M1E1NjAgNjgzIDU3MCA2ODNUNjA0IDY4MlQ2NjggNjgxUTczNyA2ODEgNzU1IDY4M0g3NjJRNzY5IDY3NiA3NjkgNjcyUTc2OSA2NTUgNzYwIDY0MFE3NTcgNjM3IDc0MyA2MzdRNzMwIDYzNiA3MTkgNjM1VDY5OCA2MzBUNjgyIDYyM1Q2NzAgNjE1VDY2MCA2MDhUNjUyIDU5OVQ2NDUgNTkyTDQ1MiAyODJRMjcyIC05IDI2NiAtMTZRMjYzIC0xOCAyNTkgLTIxTDI0MSAtMjJIMjM0UTIxNiAtMjIgMjE2IC0xNVEyMTMgLTkgMTc3IDMwNVExMzkgNjIzIDEzOCA2MjZRMTMzIDYzNyA3NiA2MzdINTlRNTIgNjQyIDUyIDY0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NSIgZD0iTTQ5MiAyMTNRNDcyIDIxMyA0NzIgMjI2UTQ3MiAyMzAgNDc3IDI1MFQ0ODIgMjg1UTQ4MiAzMTYgNDYxIDMyM1QzNjQgMzMwSDMxMlEzMTEgMzI4IDI3NyAxOTJUMjQzIDUyUTI0MyA0OCAyNTQgNDhUMzM0IDQ2UTQyOCA0NiA0NTggNDhUNTE4IDYxUTU2NyA3NyA1OTkgMTE3VDY3MCAyNDhRNjgwIDI3MCA2ODMgMjcyUTY5MCAyNzQgNjk4IDI3NFE3MTggMjc0IDcxOCAyNjFRNjEzIDcgNjA4IDJRNjA1IDAgMzIyIDBIMTMzUTMxIDAgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ2IDY2IDIxNSAzNDJUMjg1IDYyMlEyODUgNjI5IDI4MSA2MjlRMjczIDYzMiAyMjggNjM0SDE5N1ExOTEgNjQwIDE5MSA2NDJUMTkzIDY1OVExOTcgNjc2IDIwMyA2ODBINzU3UTc2NCA2NzYgNzY0IDY2OVE3NjQgNjY0IDc1MSA1NTdUNzM3IDQ0N1E3MzUgNDQwIDcxNyA0NDBINzA1UTY5OCA0NDUgNjk4IDQ1M0w3MDEgNDc2UTcwNCA1MDAgNzA0IDUyOFE3MDQgNTU4IDY5NyA1NzhUNjc4IDYwOVQ2NDMgNjI1VDU5NiA2MzJUNTMyIDYzNEg0ODVRMzk3IDYzMyAzOTIgNjMxUTM4OCA2MjkgMzg2IDYyMlEzODUgNjE5IDM1NSA0OTlUMzI0IDM3N1EzNDcgMzc2IDM3MiAzNzZIMzk4UTQ2NCAzNzYgNDg5IDM5MVQ1MzQgNDcyUTUzOCA0ODggNTQwIDQ5MFQ1NTcgNDkzUTU2MiA0OTMgNTY1IDQ5M1Q1NzAgNDkyVDU3MiA0OTFUNTc0IDQ4N1Q1NzcgNDgzTDU0NCAzNTFRNTExIDIxOCA1MDggMjE2UTUwNSAyMTMgNDkyIDIxM1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc0IiBkPSJNMjYgMzg1UTE5IDM5MiAxOSAzOTVRMTkgMzk5IDIyIDQxMVQyNyA0MjVRMjkgNDMwIDM2IDQzMFQ4NyA0MzFIMTQwTDE1OSA1MTFRMTYyIDUyMiAxNjYgNTQwVDE3MyA1NjZUMTc5IDU4NlQxODcgNjAzVDE5NyA2MTVUMjExIDYyNFQyMjkgNjI2UTI0NyA2MjUgMjU0IDYxNVQyNjEgNTk2UTI2MSA1ODkgMjUyIDU0OVQyMzIgNDcwTDIyMiA0MzNRMjIyIDQzMSAyNzIgNDMxSDMyM1EzMzAgNDI0IDMzMCA0MjBRMzMwIDM5OCAzMTcgMzg1SDIxMEwxNzQgMjQwUTEzNSA4MCAxMzUgNjhRMTM1IDI2IDE2MiAyNlExOTcgMjYgMjMwIDYwVDI4MyAxNDRRMjg1IDE1MCAyODggMTUxVDMwMyAxNTNIMzA3UTMyMiAxNTMgMzIyIDE0NVEzMjIgMTQyIDMxOSAxMzNRMzE0IDExNyAzMDEgOTVUMjY3IDQ4VDIxNiA2VDE1NSAtMTFRMTI1IC0xMSA5OCA0VDU5IDU2UTU3IDY0IDU3IDgzVjEwMUw5MiAyNDFRMTI3IDM4MiAxMjggMzgzUTEyOCAzODUgNzcgMzg1SDI2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0IiIGQ9Ik00MzQgLTIzMVE0MzQgLTI0NCA0MjggLTI1MEg0MTBRMjgxIC0yNTAgMjMwIC0xODRRMjI1IC0xNzcgMjIyIC0xNzJUMjE3IC0xNjFUMjEzIC0xNDhUMjExIC0xMzNUMjEwIC0xMTFUMjA5IC04NFQyMDkgLTQ3VDIwOSAwUTIwOSAyMSAyMDkgNTNRMjA4IDE0MiAyMDQgMTUzUTIwMyAxNTQgMjAzIDE1NVExODkgMTkxIDE1MyAyMTFUODIgMjMxUTcxIDIzMSA2OCAyMzRUNjUgMjUwVDY4IDI2NlQ4MiAyNjlRMTE2IDI2OSAxNTIgMjg5VDIwMyAzNDVRMjA4IDM1NiAyMDggMzc3VDIwOSA1MjlWNTc5UTIwOSA2MzQgMjE1IDY1NlQyNDQgNjk4UTI3MCA3MjQgMzI0IDc0MFEzNjEgNzQ4IDM3NyA3NDlRMzc5IDc0OSAzOTAgNzQ5VDQwOCA3NTBINDI4UTQzNCA3NDQgNDM0IDczMlE0MzQgNzE5IDQzMSA3MTZRNDI5IDcxMyA0MTUgNzEzUTM2MiA3MTAgMzMyIDY4OVQyOTYgNjQ3UTI5MSA2MzQgMjkxIDQ5OVY0MTdRMjkxIDM3MCAyODggMzUzVDI3MSAzMTRRMjQwIDI3MSAxODQgMjU1TDE3MCAyNTBMMTg0IDI0NVEyMDIgMjM5IDIyMCAyMzBUMjYyIDE5NlQyOTAgMTM3UTI5MSAxMzEgMjkxIDFRMjkxIC0xMzQgMjk2IC0xNDdRMzA2IC0xNzQgMzM5IC0xOTJUNDE1IC0yMTNRNDI5IC0yMTMgNDMxIC0yMTZRNDM0IC0yMTkgNDM0IC0yMzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzgiIGQ9Ik01MiAyODlRNTkgMzMxIDEwNiAzODZUMjIyIDQ0MlEyNTcgNDQyIDI4NiA0MjRUMzI5IDM3OVEzNzEgNDQyIDQzMCA0NDJRNDY3IDQ0MiA0OTQgNDIwVDUyMiAzNjFRNTIyIDMzMiA1MDggMzE0VDQ4MSAyOTJUNDU4IDI4OFE0MzkgMjg4IDQyNyAyOTlUNDE1IDMyOFE0MTUgMzc0IDQ2NSAzOTFRNDU0IDQwNCA0MjUgNDA0UTQxMiA0MDQgNDA2IDQwMlEzNjggMzg2IDM1MCAzMzZRMjkwIDExNSAyOTAgNzhRMjkwIDUwIDMwNiAzOFQzNDEgMjZRMzc4IDI2IDQxNCA1OVQ0NjMgMTQwUTQ2NiAxNTAgNDY5IDE1MVQ0ODUgMTUzSDQ4OVE1MDQgMTUzIDUwNCAxNDVRNTA0IDE0NCA1MDIgMTM0UTQ4NiA3NyA0NDAgMzNUMzMzIC0xMVEyNjMgLTExIDIyNyA1MlExODYgLTEwIDEzMyAtMTBIMTI3UTc4IC0xMCA1NyAxNlQzNSA3MVEzNSAxMDMgNTQgMTIzVDk5IDE0M1ExNDIgMTQzIDE0MiAxMDFRMTQyIDgxIDEzMCA2NlQxMDcgNDZUOTQgNDFMOTEgNDBROTEgMzkgOTcgMzZUMTEzIDI5VDEzMiAyNlExNjggMjYgMTk0IDcxUTIwMyA4NyAyMTcgMTM5VDI0NSAyNDdUMjYxIDMxM1EyNjYgMzQwIDI2NiAzNTJRMjY2IDM4MCAyNTEgMzkyVDIxNyA0MDRRMTc3IDQwNCAxNDIgMzcyVDkzIDI5MFE5MSAyODEgODggMjgwVDcyIDI3OEg1OFE1MiAyODQgNTIgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMSIgZD0iTTIxMyA1NzhMMjAwIDU3M1ExODYgNTY4IDE2MCA1NjNUMTAyIDU1Nkg4M1Y2MDJIMTAyUTE0OSA2MDQgMTg5IDYxN1QyNDUgNjQxVDI3MyA2NjNRMjc1IDY2NiAyODUgNjY2UTI5NCA2NjYgMzAyIDY2MFYzNjFMMzAzIDYxUTMxMCA1NCAzMTUgNTJUMzM5IDQ4VDQwMSA0Nkg0MjdWMEg0MTZRMzk1IDMgMjU3IDNRMTIxIDMgMTAwIDBIODhWNDZIMTE0UTEzNiA0NiAxNTIgNDZUMTc3IDQ3VDE5MyA1MFQyMDEgNTJUMjA3IDU3VDIxMyA2MVY1NzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yQyIgZD0iTTc4IDM1VDc4IDYwVDk0IDEwM1QxMzcgMTIxUTE2NSAxMjEgMTg3IDk2VDIxMCA4UTIxMCAtMjcgMjAxIC02MFQxODAgLTExN1QxNTQgLTE1OFQxMzAgLTE4NVQxMTcgLTE5NFExMTMgLTE5NCAxMDQgLTE4NVQ5NSAtMTcyUTk1IC0xNjggMTA2IC0xNTZUMTMxIC0xMjZUMTU3IC03NlQxNzMgLTNWOUwxNzIgOFExNzAgNyAxNjcgNlQxNjEgM1QxNTIgMVQxNDAgMFExMTMgMCA5NiAxN1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yRSIgZD0iTTc4IDYwUTc4IDg0IDk1IDEwMlQxMzggMTIwUTE2MiAxMjAgMTgwIDEwNFQxOTkgNjFRMTk5IDM2IDE4MiAxOFQxMzkgMFQ5NiAxN1Q3OCA2MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjgiIGQ9Ik0xODAgOTZUMTgwIDI1MFQyMDUgNTQxVDI2NiA3NzBUMzUzIDk0NFQ0NDQgMTA2OVQ1MjcgMTE1MEg1NTVRNTYxIDExNDQgNTYxIDExNDFRNTYxIDExMzcgNTQ1IDExMjBUNTA0IDEwNzJUNDQ3IDk5NVQzODYgODc4VDMzMCA3MjFUMjg4IDUxM1QyNzIgMjUxUTI3MiAxMzMgMjgwIDU2UTI5MyAtODcgMzI2IC0yMDlUMzk5IC00MDVUNDc1IC01MzFUNTM2IC02MDlUNTYxIC02NDBRNTYxIC02NDMgNTU1IC02NDlINTI3UTQ4MyAtNjEyIDQ0MyAtNTY4VDM1MyAtNDQzVDI2NiAtMjcwVDIwNSAtNDFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oyLTI5IiBkPSJNMzUgMTEzOFEzNSAxMTUwIDUxIDExNTBINTZINjlRMTEzIDExMTMgMTUzIDEwNjlUMjQzIDk0NFQzMzAgNzcxVDM5MSA1NDFUNDE2IDI1MFQzOTEgLTQwVDMzMCAtMjcwVDI0MyAtNDQzVDE1MiAtNTY4VDY5IC02NDlINTZRNDMgLTY0OSAzOSAtNjQ3VDM1IC02MzdRNjUgLTYwNyAxMTAgLTU0OFEyODMgLTMxNiAzMTYgNTZRMzI0IDEzMyAzMjQgMjUxUTMyNCAzNjggMzE2IDQ0NVEyNzggODc3IDQ4IDExMjNRMzYgMTEzNyAzNSAxMTM4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMS0yMjExIiBkPSJNNjEgNzQ4UTY0IDc1MCA0ODkgNzUwSDkxM0w5NTQgNjQwUTk2NSA2MDkgOTc2IDU3OVQ5OTMgNTMzVDk5OSA1MTZIOTc5TDk1OSA1MTdROTM2IDU3OSA4ODYgNjIxVDc3NyA2ODJRNzI0IDcwMCA2NTUgNzA1VDQzNiA3MTBIMzE5UTE4MyA3MTAgMTgzIDcwOVExODYgNzA2IDM0OCA0ODRUNTExIDI1OVE1MTcgMjUwIDUxMyAyNDRMNDkwIDIxNlE0NjYgMTg4IDQyMCAxMzRUMzMwIDI3TDE0OSAtMTg3UTE0OSAtMTg4IDM2MiAtMTg4UTM4OCAtMTg4IDQzNiAtMTg4VDUwNiAtMTg5UTY3OSAtMTg5IDc3OCAtMTYyVDkzNiAtNDNROTQ2IC0yNyA5NTkgNkg5OTlMOTEzIC0yNDlMNDg5IC0yNTBRNjUgLTI1MCA2MiAtMjQ4UTU2IC0yNDYgNTYgLTIzOVE1NiAtMjM0IDExOCAtMTYxUTE4NiAtODEgMjQ1IC0xMUw0MjggMjA2UTQyOCAyMDcgMjQyIDQ2Mkw1NyA3MTdMNTYgNzI4UTU2IDc0NCA2MSA3NDhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNjkiIGQ9Ik0xODQgNjAwUTE4NCA2MjQgMjAzIDY0MlQyNDcgNjYxUTI2NSA2NjEgMjc3IDY0OVQyOTAgNjE5UTI5MCA1OTYgMjcwIDU3N1QyMjYgNTU3UTIxMSA1NTcgMTk4IDU2N1QxODQgNjAwWk0yMSAyODdRMjEgMjk1IDMwIDMxOFQ1NCAzNjlUOTggNDIwVDE1OCA0NDJRMTk3IDQ0MiAyMjMgNDE5VDI1MCAzNTdRMjUwIDM0MCAyMzYgMzAxVDE5NiAxOTZUMTU0IDgzUTE0OSA2MSAxNDkgNTFRMTQ5IDI2IDE2NiAyNlExNzUgMjYgMTg1IDI5VDIwOCA0M1QyMzUgNzhUMjYwIDEzN1EyNjMgMTQ5IDI2NSAxNTFUMjgyIDE1M1EzMDIgMTUzIDMwMiAxNDNRMzAyIDEzNSAyOTMgMTEyVDI2OCA2MVQyMjMgMTFUMTYxIC0xMVExMjkgLTExIDEwMiAxMFQ3NCA3NFE3NCA5MSA3OSAxMDZUMTIyIDIyMFExNjAgMzIxIDE2NiAzNDFUMTczIDM4MFExNzMgNDA0IDE1NiA0MDRIMTU0UTEyNCA0MDQgOTkgMzcxVDYxIDI4N1E2MCAyODYgNTkgMjg0VDU4IDI4MVQ1NiAyNzlUNTMgMjc4VDQ5IDI3OFQ0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03NSIgZD0iTTIxIDI4N1EyMSAyOTUgMzAgMzE4VDU1IDM3MFQ5OSA0MjBUMTU4IDQ0MlEyMDQgNDQyIDIyNyA0MTdUMjUwIDM1OFEyNTAgMzQwIDIxNiAyNDZUMTgyIDEwNVExODIgNjIgMTk2IDQ1VDIzOCAyN1QyOTEgNDRUMzI4IDc4TDMzOSA5NVEzNDEgOTkgMzc3IDI0N1E0MDcgMzY3IDQxMyAzODdUNDI3IDQxNlE0NDQgNDMxIDQ2MyA0MzFRNDgwIDQzMSA0ODggNDIxVDQ5NiA0MDJMNDIwIDg0UTQxOSA3OSA0MTkgNjhRNDE5IDQzIDQyNiAzNVQ0NDcgMjZRNDY5IDI5IDQ4MiA1N1Q1MTIgMTQ1UTUxNCAxNTMgNTMyIDE1M1E1NTEgMTUzIDU1MSAxNDRRNTUwIDEzOSA1NDkgMTMwVDU0MCA5OFQ1MjMgNTVUNDk4IDE3VDQ2MiAtOFE0NTQgLTEwIDQzOCAtMTBRMzcyIC0xMCAzNDcgNDZRMzQ1IDQ1IDMzNiAzNlQzMTggMjFUMjk2IDZUMjY3IC02VDIzMyAtMTFRMTg5IC0xMSAxNTUgN1ExMDMgMzggMTAzIDExM1ExMDMgMTcwIDEzOCAyNjJUMTczIDM3OVExNzMgMzgwIDE3MyAzODFRMTczIDM5MCAxNzMgMzkzVDE2OSA0MDBUMTU4IDQwNEgxNTRRMTMxIDQwNCAxMTIgMzg1VDgyIDM0NFQ2NSAzMDJUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RCIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODggNDI1VDEzMiA0NDJUMTc1IDQzNVQyMDUgNDE3VDIyMSAzOTVUMjI5IDM3NkwyMzEgMzY5UTIzMSAzNjcgMjMyIDM2N0wyNDMgMzc4UTMwMyA0NDIgMzg0IDQ0MlE0MDEgNDQyIDQxNSA0NDBUNDQxIDQzM1Q0NjAgNDIzVDQ3NSA0MTFUNDg1IDM5OFQ0OTMgMzg1VDQ5NyAzNzNUNTAwIDM2NFQ1MDIgMzU3TDUxMCAzNjdRNTczIDQ0MiA2NTkgNDQyUTcxMyA0NDIgNzQ2IDQxNVQ3ODAgMzM2UTc4MCAyODUgNzQyIDE3OFQ3MDQgNTBRNzA1IDM2IDcwOSAzMVQ3MjQgMjZRNzUyIDI2IDc3NiA1NlQ4MTUgMTM4UTgxOCAxNDkgODIxIDE1MVQ4MzcgMTUzUTg1NyAxNTMgODU3IDE0NVE4NTcgMTQ0IDg1MyAxMzBRODQ1IDEwMSA4MzEgNzNUNzg1IDE3VDcxNiAtMTBRNjY5IC0xMCA2NDggMTdUNjI3IDczUTYyNyA5MiA2NjMgMTkzVDcwMCAzNDVRNzAwIDQwNCA2NTYgNDA0SDY1MVE1NjUgNDA0IDUwNiAzMDNMNDk5IDI5MUw0NjYgMTU3UTQzMyAyNiA0MjggMTZRNDE1IC0xMSAzODUgLTExUTM3MiAtMTEgMzY0IC00VDM1MyA4VDM1MCAxOFEzNTAgMjkgMzg0IDE2MUw0MjAgMzA3UTQyMyAzMjIgNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MVExNTEgMzM1IDE1MSAzNDJRMTU0IDM1NyAxNTQgMzY5UTE1NCA0MDUgMTI5IDQwNVExMDcgNDA1IDkyIDM3N1Q2OSAzMTZUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02QiIgZD0iTTEyMSA2NDdRMTIxIDY1NyAxMjUgNjcwVDEzNyA2ODNRMTM4IDY4MyAyMDkgNjg4VDI4MiA2OTRRMjk0IDY5NCAyOTQgNjg2UTI5NCA2NzkgMjQ0IDQ3N1ExOTQgMjc5IDE5NCAyNzJRMjEzIDI4MiAyMjMgMjkxUTI0NyAzMDkgMjkyIDM1NFQzNjIgNDE1UTQwMiA0NDIgNDM4IDQ0MlE0NjggNDQyIDQ4NSA0MjNUNTAzIDM2OVE1MDMgMzQ0IDQ5NiAzMjdUNDc3IDMwMlQ0NTYgMjkxVDQzOCAyODhRNDE4IDI4OCA0MDYgMjk5VDM5NCAzMjhRMzk0IDM1MyA0MTAgMzY5VDQ0MiAzOTBMNDU4IDM5M1E0NDYgNDA1IDQzNCA0MDVINDMwUTM5OCA0MDIgMzY3IDM4MFQyOTQgMzE2VDIyOCAyNTVRMjMwIDI1NCAyNDMgMjUyVDI2NyAyNDZUMjkzIDIzOFQzMjAgMjI0VDM0MiAyMDZUMzU5IDE4MFQzNjUgMTQ3UTM2NSAxMzAgMzYwIDEwNlQzNTQgNjZRMzU0IDI2IDM4MSAyNlE0MjkgMjYgNDU5IDE0NVE0NjEgMTUzIDQ3OSAxNTNINDgzUTQ5OSAxNTMgNDk5IDE0NFE0OTkgMTM5IDQ5NiAxMzBRNDU1IC0xMSAzNzggLTExUTMzMyAtMTEgMzA1IDE1VDI3NyA5MFEyNzcgMTA4IDI4MCAxMjFUMjgzIDE0NVEyODMgMTY3IDI2OSAxODNUMjM0IDIwNlQyMDAgMjE3VDE4MiAyMjBIMTgwUTE2OCAxNzggMTU5IDEzOVQxNDUgODFUMTM2IDQ0VDEyOSAyMFQxMjIgN1QxMTEgLTJROTggLTExIDgzIC0xMVE2NiAtMTEgNTcgLTFUNDggMTZRNDggMjYgODUgMTc2VDE1OCA0NzFMMTk1IDYxNlExOTYgNjI5IDE4OCA2MzJUMTQ5IDYzN0gxNDRRMTM0IDYzNyAxMzEgNjM3VDEyNCA2NDBUMTIxIDY0N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJCIiBkPSJNNTYgMjM3VDU2IDI1MFQ3MCAyNzBIMzY5VjQyMEwzNzAgNTcwUTM4MCA1ODMgMzg5IDU4M1E0MDIgNTgzIDQwOSA1NjhWMjcwSDcwN1E3MjIgMjYyIDcyMiAyNTBUNzA3IDIzMEg0MDlWLTY4UTQwMSAtODIgMzkxIC04MkgzODlIMzg3UTM3NSAtODIgMzY5IC02OFYyMzBINzBRNTYgMjM3IDU2IDI1MFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iMTE2NyIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI4MjUiIHk9Ii0yMTIiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjMyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjMxNTgiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NCIgeD0iNDIxNSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ3NDMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1OTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzgiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjEwNzMiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMjIyNSIgeT0iNjc1Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iMjAyNyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI0NzIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzgiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjEwNzMiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMjIyNSIgeT0iNjc1Ij48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJDIiB4PSI0NDk5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iNDk0NSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9IjUzOTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSI1ODM1IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iNjI4MCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDY3MjUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzgiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjEwNzMiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjIyMjUiIHk9IjY3NSI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjkiIHg9Ijk0MjEiIHk9Ii0xIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIxNTA0MCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE1ODE4LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzk3LDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNzYxNiIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDExNjkpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjE0OTQiIHk9IjY3NSI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwNTYsLTI4NykiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMzQ1IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjExMjQiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIzMDUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM2MSwtMTUwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NSIgeD0iNjAwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZEIiB4PSIxMTczIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQzODMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1OTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzgiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjEwNzMiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjIyMjUiIHk9IjY3NSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTI5IiB4PSIyNTE1IiB5PSItMSI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4ODgsLTgxMikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjEtMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTQ5NCIgeT0iNjc1Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTA1NiwtMjg3KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIzNDUiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTEyNCIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjQ3MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iNzM3IiB5PSItMjEzIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTA4OCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjIwODgiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjI5NzgiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9zdmc+) 。
。
其中 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIuMDExZXgiIGhlaWdodD0iMi41MDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyIgdmlld0JveD0iMCAtNzkxLjMgODY1LjggMTA4MC40IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZCIiBkPSJNMTIxIDY0N1ExMjEgNjU3IDEyNSA2NzBUMTM3IDY4M1ExMzggNjgzIDIwOSA2ODhUMjgyIDY5NFEyOTQgNjk0IDI5NCA2ODZRMjk0IDY3OSAyNDQgNDc3UTE5NCAyNzkgMTk0IDI3MlEyMTMgMjgyIDIyMyAyOTFRMjQ3IDMwOSAyOTIgMzU0VDM2MiA0MTVRNDAyIDQ0MiA0MzggNDQyUTQ2OCA0NDIgNDg1IDQyM1Q1MDMgMzY5UTUwMyAzNDQgNDk2IDMyN1Q0NzcgMzAyVDQ1NiAyOTFUNDM4IDI4OFE0MTggMjg4IDQwNiAyOTlUMzk0IDMyOFEzOTQgMzUzIDQxMCAzNjlUNDQyIDM5MEw0NTggMzkzUTQ0NiA0MDUgNDM0IDQwNUg0MzBRMzk4IDQwMiAzNjcgMzgwVDI5NCAzMTZUMjI4IDI1NVEyMzAgMjU0IDI0MyAyNTJUMjY3IDI0NlQyOTMgMjM4VDMyMCAyMjRUMzQyIDIwNlQzNTkgMTgwVDM2NSAxNDdRMzY1IDEzMCAzNjAgMTA2VDM1NCA2NlEzNTQgMjYgMzgxIDI2UTQyOSAyNiA0NTkgMTQ1UTQ2MSAxNTMgNDc5IDE1M0g0ODNRNDk5IDE1MyA0OTkgMTQ0UTQ5OSAxMzkgNDk2IDEzMFE0NTUgLTExIDM3OCAtMTFRMzMzIC0xMSAzMDUgMTVUMjc3IDkwUTI3NyAxMDggMjgwIDEyMVQyODMgMTQ1UTI4MyAxNjcgMjY5IDE4M1QyMzQgMjA2VDIwMCAyMTdUMTgyIDIyMEgxODBRMTY4IDE3OCAxNTkgMTM5VDE0NSA4MVQxMzYgNDRUMTI5IDIwVDEyMiA3VDExMSAtMlE5OCAtMTEgODMgLTExUTY2IC0xMSA1NyAtMVQ0OCAxNlE0OCAyNiA4NSAxNzZUMTU4IDQ3MUwxOTUgNjE2UTE5NiA2MjkgMTg4IDYzMlQxNDkgNjM3SDE0NFExMzQgNjM3IDEzMSA2MzdUMTI0IDY0MFQxMjEgNjQ3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY5IiBkPSJNMTg0IDYwMFExODQgNjI0IDIwMyA2NDJUMjQ3IDY2MVEyNjUgNjYxIDI3NyA2NDlUMjkwIDYxOVEyOTAgNTk2IDI3MCA1NzdUMjI2IDU1N1EyMTEgNTU3IDE5OCA1NjdUMTg0IDYwMFpNMjEgMjg3UTIxIDI5NSAzMCAzMThUNTQgMzY5VDk4IDQyMFQxNTggNDQyUTE5NyA0NDIgMjIzIDQxOVQyNTAgMzU3UTI1MCAzNDAgMjM2IDMwMVQxOTYgMTk2VDE1NCA4M1ExNDkgNjEgMTQ5IDUxUTE0OSAyNiAxNjYgMjZRMTc1IDI2IDE4NSAyOVQyMDggNDNUMjM1IDc4VDI2MCAxMzdRMjYzIDE0OSAyNjUgMTUxVDI4MiAxNTNRMzAyIDE1MyAzMDIgMTQzUTMwMiAxMzUgMjkzIDExMlQyNjggNjFUMjIzIDExVDE2MSAtMTFRMTI5IC0xMSAxMDIgMTBUNzQgNzRRNzQgOTEgNzkgMTA2VDEyMiAyMjBRMTYwIDMyMSAxNjYgMzQxVDE3MyAzODBRMTczIDQwNCAxNTYgNDA0SDE1NFExMjQgNDA0IDk5IDM3MVQ2MSAyODdRNjAgMjg2IDU5IDI4NFQ1OCAyODFUNTYgMjc5VDUzIDI3OFQ0OSAyNzhUNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjczNyIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9zdmc+) 是第 次试验
是第 次试验 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQuNDU0ZXgiIGhlaWdodD0iMy4zNDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjgzOGV4OyIgdmlld0JveD0iMCAtMTA3OC40IDE5MTcuOCAxNDM5LjIiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03QiIgZD0iTTQzNCAtMjMxUTQzNCAtMjQ0IDQyOCAtMjUwSDQxMFEyODEgLTI1MCAyMzAgLTE4NFEyMjUgLTE3NyAyMjIgLTE3MlQyMTcgLTE2MVQyMTMgLTE0OFQyMTEgLTEzM1QyMTAgLTExMVQyMDkgLTg0VDIwOSAtNDdUMjA5IDBRMjA5IDIxIDIwOSA1M1EyMDggMTQyIDIwNCAxNTNRMjAzIDE1NCAyMDMgMTU1UTE4OSAxOTEgMTUzIDIxMVQ4MiAyMzFRNzEgMjMxIDY4IDIzNFQ2NSAyNTBUNjggMjY2VDgyIDI2OVExMTYgMjY5IDE1MiAyODlUMjAzIDM0NVEyMDggMzU2IDIwOCAzNzdUMjA5IDUyOVY1NzlRMjA5IDYzNCAyMTUgNjU2VDI0NCA2OThRMjcwIDcyNCAzMjQgNzQwUTM2MSA3NDggMzc3IDc0OVEzNzkgNzQ5IDM5MCA3NDlUNDA4IDc1MEg0MjhRNDM0IDc0NCA0MzQgNzMyUTQzNCA3MTkgNDMxIDcxNlE0MjkgNzEzIDQxNSA3MTNRMzYyIDcxMCAzMzIgNjg5VDI5NiA2NDdRMjkxIDYzNCAyOTEgNDk5VjQxN1EyOTEgMzcwIDI4OCAzNTNUMjcxIDMxNFEyNDAgMjcxIDE4NCAyNTVMMTcwIDI1MEwxODQgMjQ1UTIwMiAyMzkgMjIwIDIzMFQyNjIgMTk2VDI5MCAxMzdRMjkxIDEzMSAyOTEgMVEyOTEgLTEzNCAyOTYgLTE0N1EzMDYgLTE3NCAzMzkgLTE5MlQ0MTUgLTIxM1E0MjkgLTIxMyA0MzEgLTIxNlE0MzQgLTIxOSA0MzQgLTIzMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03OCIgZD0iTTUyIDI4OVE1OSAzMzEgMTA2IDM4NlQyMjIgNDQyUTI1NyA0NDIgMjg2IDQyNFQzMjkgMzc5UTM3MSA0NDIgNDMwIDQ0MlE0NjcgNDQyIDQ5NCA0MjBUNTIyIDM2MVE1MjIgMzMyIDUwOCAzMTRUNDgxIDI5MlQ0NTggMjg4UTQzOSAyODggNDI3IDI5OVQ0MTUgMzI4UTQxNSAzNzQgNDY1IDM5MVE0NTQgNDA0IDQyNSA0MDRRNDEyIDQwNCA0MDYgNDAyUTM2OCAzODYgMzUwIDMzNlEyOTAgMTE1IDI5MCA3OFEyOTAgNTAgMzA2IDM4VDM0MSAyNlEzNzggMjYgNDE0IDU5VDQ2MyAxNDBRNDY2IDE1MCA0NjkgMTUxVDQ4NSAxNTNINDg5UTUwNCAxNTMgNTA0IDE0NVE1MDQgMTQ0IDUwMiAxMzRRNDg2IDc3IDQ0MCAzM1QzMzMgLTExUTI2MyAtMTEgMjI3IDUyUTE4NiAtMTAgMTMzIC0xMEgxMjdRNzggLTEwIDU3IDE2VDM1IDcxUTM1IDEwMyA1NCAxMjNUOTkgMTQzUTE0MiAxNDMgMTQyIDEwMVExNDIgODEgMTMwIDY2VDEwNyA0NlQ5NCA0MUw5MSA0MFE5MSAzOSA5NyAzNlQxMTMgMjlUMTMyIDI2UTE2OCAyNiAxOTQgNzFRMjAzIDg3IDIxNyAxMzlUMjQ1IDI0N1QyNjEgMzEzUTI2NiAzNDAgMjY2IDM1MlEyNjYgMzgwIDI1MSAzOTJUMjE3IDQwNFExNzcgNDA0IDE0MiAzNzJUOTMgMjkwUTkxIDI4MSA4OCAyODBUNzIgMjc4SDU4UTUyIDI4NCA1MiAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03RCIgZD0iTTY1IDczMVE2NSA3NDUgNjggNzQ3VDg4IDc1MFExNzEgNzUwIDIxNiA3MjVUMjc5IDY3MFEyODggNjQ5IDI4OSA2MzVUMjkxIDUwMVEyOTIgMzYyIDI5MyAzNTdRMzA2IDMxMiAzNDUgMjkxVDQxNyAyNjlRNDI4IDI2OSA0MzEgMjY2VDQzNCAyNTBUNDMxIDIzNFQ0MTcgMjMxUTM4MCAyMzEgMzQ1IDIxMFQyOTggMTU3UTI5MyAxNDMgMjkyIDEyMVQyOTEgLTI4Vi03OVEyOTEgLTEzNCAyODUgLTE1NlQyNTYgLTE5OFEyMDIgLTI1MCA4OSAtMjUwUTcxIC0yNTAgNjggLTI0N1Q2NSAtMjMwUTY1IC0yMjQgNjUgLTIyM1Q2NiAtMjE4VDY5IC0yMTRUNzcgLTIxM1E5MSAtMjEzIDEwOCAtMjEwVDE0NiAtMjAwVDE4MyAtMTc3VDIwNyAtMTM5UTIwOCAtMTM0IDIwOSAzTDIxMCAxMzlRMjIzIDE5NiAyODAgMjMwUTMxNSAyNDcgMzMwIDI1MFEzMDUgMjU3IDI4MCAyNzBRMjI1IDMwNCAyMTIgMzUyTDIxMCAzNjJMMjA5IDQ5OFEyMDggNjM1IDIwNyA2NDBRMTk1IDY4MCAxNTQgNjk2VDc3IDcxM1E2OCA3MTMgNjcgNzE2VDY1IDczMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02OSIgZD0iTTE4NCA2MDBRMTg0IDYyNCAyMDMgNjQyVDI0NyA2NjFRMjY1IDY2MSAyNzcgNjQ5VDI5MCA2MTlRMjkwIDU5NiAyNzAgNTc3VDIyNiA1NTdRMjExIDU1NyAxOTggNTY3VDE4NCA2MDBaTTIxIDI4N1EyMSAyOTUgMzAgMzE4VDU0IDM2OVQ5OCA0MjBUMTU4IDQ0MlExOTcgNDQyIDIyMyA0MTlUMjUwIDM1N1EyNTAgMzQwIDIzNiAzMDFUMTk2IDE5NlQxNTQgODNRMTQ5IDYxIDE0OSA1MVExNDkgMjYgMTY2IDI2UTE3NSAyNiAxODUgMjlUMjA4IDQzVDIzNSA3OFQyNjAgMTM3UTI2MyAxNDkgMjY1IDE1MVQyODIgMTUzUTMwMiAxNTMgMzAyIDE0M1EzMDIgMTM1IDI5MyAxMTJUMjY4IDYxVDIyMyAxMVQxNjEgLTExUTEyOSAtMTEgMTAyIDEwVDc0IDc0UTc0IDkxIDc5IDEwNlQxMjIgMjIwUTE2MCAzMjEgMTY2IDM0MVQxNzMgMzgwUTE3MyA0MDQgMTU2IDQwNEgxNTRRMTI0IDQwNCA5OSAzNzFUNjEgMjg3UTYwIDI4NiA1OSAyODRUNTggMjgxVDU2IDI3OVQ1MyAyNzhUNDkgMjc4VDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03OCIgeD0iNTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iMTA3MyIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMjIyNSIgeT0iNjc1Ij48L3VzZT4KPC9nPgo8L3N2Zz4=) 中状态 的重访次数。与首次访问MC方法的估计器不同, 次试验的每次访问MC方法的估计器不仅仅是单个试验估计值的平均,这使得它的分析更加复杂。
中状态 的重访次数。与首次访问MC方法的估计器不同, 次试验的每次访问MC方法的估计器不仅仅是单个试验估计值的平均,这使得它的分析更加复杂。
我们可以得出首次访问MC方法和每次访问MC方法的偏差(Bias)和方差(Var)——它们是试验次数 的函数。 均方误差(Mean Squared Error,MSE)是 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEyLjA4M2V4IiBoZWlnaHQ9IjIuODQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMC41MDVleDsiIHZpZXdCb3g9IjAgLTEwMDYuNiA1MjAyLjQgMTIyMy45IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNDIiIGQ9Ik0xMzEgNjIyUTEyNCA2MjkgMTIwIDYzMVQxMDQgNjM0VDYxIDYzN0gyOFY2ODNIMjI5SDI2N0gzNDZRNDIzIDY4MyA0NTkgNjc4VDUzMSA2NTFRNTc0IDYyNyA1OTkgNTkwVDYyNCA1MTJRNjI0IDQ2MSA1ODMgNDE5VDQ3NiAzNjBMNDY2IDM1N1E1MzkgMzQ4IDU5NSAzMDJUNjUxIDE4N1E2NTEgMTE5IDYwMCA2N1Q0NjkgM1E0NTYgMSAyNDIgMEgyOFY0Nkg2MVExMDMgNDcgMTEyIDQ5VDEzMSA2MVY2MjJaTTUxMSA1MTNRNTExIDU2MCA0ODUgNTk0VDQxNiA2MzZRNDE1IDYzNiA0MDMgNjM2VDM3MSA2MzZUMzMzIDYzN1EyNjYgNjM3IDI1MSA2MzZUMjMyIDYyOFEyMjkgNjI0IDIyOSA0OTlWMzc0SDMxMkwzOTYgMzc1TDQwNiAzNzdRNDEwIDM3OCA0MTcgMzgwVDQ0MiAzOTNUNDc0IDQxN1Q0OTkgNDU2VDUxMSA1MTNaTTUzNyAxODhRNTM3IDIzOSA1MDkgMjgyVDQzMCAzMzZMMzI5IDMzN0gyMjlWMjAwVjExNlEyMjkgNTcgMjM0IDUyUTI0MCA0NyAzMzQgNDdIMzgzUTQyNSA0NyA0NDMgNTNRNDg2IDY3IDUxMSAxMDRUNTM3IDE4OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTY5IiBkPSJNNjkgNjA5UTY5IDYzNyA4NyA2NTNUMTMxIDY2OVExNTQgNjY3IDE3MSA2NTJUMTg4IDYwOVExODggNTc5IDE3MSA1NjRUMTI5IDU0OVExMDQgNTQ5IDg3IDU2NFQ2OSA2MDlaTTI0NyAwUTIzMiAzIDE0MyAzUTEzMiAzIDEwNiAzVDU2IDFMMzQgMEgyNlY0Nkg0MlE3MCA0NiA5MSA0OVExMDAgNTMgMTAyIDYwVDEwNCAxMDJWMjA1VjI5M1ExMDQgMzQ1IDEwMiAzNTlUODggMzc4UTc0IDM4NSA0MSAzODVIMzBWNDA4UTMwIDQzMSAzMiA0MzFMNDIgNDMyUTUyIDQzMyA3MCA0MzRUMTA2IDQzNlExMjMgNDM3IDE0MiA0MzhUMTcxIDQ0MVQxODIgNDQySDE4NVY2MlExOTAgNTIgMTk3IDUwVDIzMiA0NkgyNTVWMEgyNDdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi02MSIgZD0iTTEzNyAzMDVUMTE1IDMwNVQ3OCAzMjBUNjMgMzU5UTYzIDM5NCA5NyA0MjFUMjE4IDQ0OFEyOTEgNDQ4IDMzNiA0MTZUMzk2IDM0MFE0MDEgMzI2IDQwMSAzMDlUNDAyIDE5NFYxMjRRNDAyIDc2IDQwNyA1OFQ0MjggNDBRNDQzIDQwIDQ0OCA1NlQ0NTMgMTA5VjE0NUg0OTNWMTA2UTQ5MiA2NiA0OTAgNTlRNDgxIDI5IDQ1NSAxMlQ0MDAgLTZUMzUzIDEyVDMyOSA1NFY1OEwzMjcgNTVRMzI1IDUyIDMyMiA0OVQzMTQgNDBUMzAyIDI5VDI4NyAxN1QyNjkgNlQyNDcgLTJUMjIxIC04VDE5MCAtMTFRMTMwIC0xMSA4MiAyMFQzNCAxMDdRMzQgMTI4IDQxIDE0N1Q2OCAxODhUMTE2IDIyNVQxOTQgMjUzVDMwNCAyNjhIMzE4VjI5MFEzMTggMzI0IDMxMiAzNDBRMjkwIDQxMSAyMTUgNDExUTE5NyA0MTEgMTgxIDQxMFQxNTYgNDA2VDE0OCA0MDNRMTcwIDM4OCAxNzAgMzU5UTE3MCAzMzQgMTU0IDMyMFpNMTI2IDEwNlExMjYgNzUgMTUwIDUxVDIwOSAyNlEyNDcgMjYgMjc2IDQ5VDMxNSAxMDlRMzE3IDExNiAzMTggMTc1UTMxOCAyMzMgMzE3IDIzM1EzMDkgMjMzIDI5NiAyMzJUMjUxIDIyM1QxOTMgMjAzVDE0NyAxNjZUMTI2IDEwNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTczIiBkPSJNMjk1IDMxNlEyOTUgMzU2IDI2OCAzODVUMTkwIDQxNFExNTQgNDE0IDEyOCA0MDFROTggMzgyIDk4IDM0OVE5NyAzNDQgOTggMzM2VDExNCAzMTJUMTU3IDI4N1ExNzUgMjgyIDIwMSAyNzhUMjQ1IDI2OVQyNzcgMjU2UTI5NCAyNDggMzEwIDIzNlQzNDIgMTk1VDM1OSAxMzNRMzU5IDcxIDMyMSAzMVQxOTggLTEwSDE5MFExMzggLTEwIDk0IDI2TDg2IDE5TDc3IDEwUTcxIDQgNjUgLTFMNTQgLTExSDQ2SDQyUTM5IC0xMSAzMyAtNVY3NFYxMzJRMzMgMTUzIDM1IDE1N1Q0NSAxNjJINTRRNjYgMTYyIDcwIDE1OFQ3NSAxNDZUODIgMTE5VDEwMSA3N1ExMzYgMjYgMTk4IDI2UTI5NSAyNiAyOTUgMTA0UTI5NSAxMzMgMjc3IDE1MVEyNTcgMTc1IDE5NCAxODdUMTExIDIxMFE3NSAyMjcgNTQgMjU2VDMzIDMxOFEzMyAzNTcgNTAgMzg0VDkzIDQyNFQxNDMgNDQyVDE4NyA0NDdIMTk4UTIzOCA0NDcgMjY4IDQzMkwyODMgNDI0TDI5MiA0MzFRMzAyIDQ0MCAzMTQgNDQ4SDMyMkgzMjZRMzI5IDQ0OCAzMzUgNDQyVjMxMEwzMjkgMzA0SDMwMVEyOTUgMzEwIDI5NSAzMTZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMiIgZD0iTTEwOSA0MjlRODIgNDI5IDY2IDQ0N1Q1MCA0OTFRNTAgNTYyIDEwMyA2MTRUMjM1IDY2NlEzMjYgNjY2IDM4NyA2MTBUNDQ5IDQ2NVE0NDkgNDIyIDQyOSAzODNUMzgxIDMxNVQzMDEgMjQxUTI2NSAyMTAgMjAxIDE0OUwxNDIgOTNMMjE4IDkyUTM3NSA5MiAzODUgOTdRMzkyIDk5IDQwOSAxODZWMTg5SDQ0OVYxODZRNDQ4IDE4MyA0MzYgOTVUNDIxIDNWMEg1MFYxOVYzMVE1MCAzOCA1NiA0NlQ4NiA4MVExMTUgMTEzIDEzNiAxMzdRMTQ1IDE0NyAxNzAgMTc0VDIwNCAyMTFUMjMzIDI0NFQyNjEgMjc4VDI4NCAzMDhUMzA1IDM0MFQzMjAgMzY5VDMzMyA0MDFUMzQwIDQzMVQzNDMgNDY0UTM0MyA1MjcgMzA5IDU3M1QyMTIgNjE5UTE3OSA2MTkgMTU0IDYwMlQxMTkgNTY5VDEwOSA1NTBRMTA5IDU0OSAxMTQgNTQ5UTEzMiA1NDkgMTUxIDUzNVQxNzAgNDg5UTE3MCA0NjQgMTU0IDQ0N1QxMDkgNDI5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNTYiIGQ9Ik0xMTQgNjIwUTExMyA2MjEgMTEwIDYyNFQxMDcgNjI3VDEwMyA2MzBUOTggNjMyVDkxIDYzNFQ4MCA2MzVUNjcgNjM2VDQ4IDYzN0gxOVY2ODNIMjhRNDYgNjgwIDE1MiA2ODBRMjczIDY4MCAyOTQgNjgzSDMwNVY2MzdIMjg0UTIyMyA2MzQgMjIzIDYyMFEyMjMgNjE4IDMxMyAzNzJUNDA0IDEyNkw0OTAgMzU4UTU3NSA1ODggNTc1IDU5N1E1NzUgNjE2IDU1NCA2MjZUNTA4IDYzN0g1MDNWNjgzSDUxMlE1MjcgNjgwIDYyNyA2ODBRNzE4IDY4MCA3MjQgNjgzSDczMFY2MzdINzIzUTY0OCA2MzcgNjI3IDU5NlE2MjcgNTk1IDUxNSAyOTFUNDAxIC0xNFEzOTYgLTIyIDM4MiAtMjJIMzc0SDM2N1EzNTMgLTIyIDM0OCAtMTRRMzQ2IC0xMiAyMzEgMzAzUTExNCA2MTcgMTE0IDYyMFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTcyIiBkPSJNMzYgNDZINTBRODkgNDYgOTcgNjBWNjhROTcgNzcgOTcgOTFUOTggMTIyVDk4IDE2MVQ5OCAyMDNROTggMjM0IDk4IDI2OVQ5OCAzMjhMOTcgMzUxUTk0IDM3MCA4MyAzNzZUMzggMzg1SDIwVjQwOFEyMCA0MzEgMjIgNDMxTDMyIDQzMlE0MiA0MzMgNjAgNDM0VDk2IDQzNlExMTIgNDM3IDEzMSA0MzhUMTYwIDQ0MVQxNzEgNDQySDE3NFYzNzNRMjEzIDQ0MSAyNzEgNDQxSDI3N1EzMjIgNDQxIDM0MyA0MTlUMzY0IDM3M1EzNjQgMzUyIDM1MSAzMzdUMzEzIDMyMlEyODggMzIyIDI3NiAzMzhUMjYzIDM3MlEyNjMgMzgxIDI2NSAzODhUMjcwIDQwMFQyNzMgNDA1UTI3MSA0MDcgMjUwIDQwMVEyMzQgMzkzIDIyNiAzODZRMTc5IDM0MSAxNzkgMjA3VjE1NFExNzkgMTQxIDE3OSAxMjdUMTc5IDEwMVQxODAgODFUMTgwIDY2VjYxUTE4MSA1OSAxODMgNTdUMTg4IDU0VDE5MyA1MVQyMDAgNDlUMjA3IDQ4VDIxNiA0N1QyMjUgNDdUMjM1IDQ2VDI0NSA0NkgyNzZWMEgyNjdRMjQ5IDMgMTQwIDNRMzcgMyAyOCAwSDIwVjQ2SDM2WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNDIiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTY5IiB4PSI3MDgiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI5ODciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTczIiB4PSIxNDg3IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjI2NjEiIHk9IjU4MyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjI1NTgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNTU4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9zdmc+) 。
。
相关概念说明
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIuMDUyZXgiIGhlaWdodD0iMi4wMDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyIgdmlld0JveD0iMCAtNTc2LjEgODgzLjUgODY1LjEiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzIiIGQ9Ik0yMSAyODdRMjIgMjkwIDIzIDI5NVQyOCAzMTdUMzggMzQ4VDUzIDM4MVQ3MyA0MTFUOTkgNDMzVDEzMiA0NDJRMTYxIDQ0MiAxODMgNDMwVDIxNCA0MDhUMjI1IDM4OFEyMjcgMzgyIDIyOCAzODJUMjM2IDM4OVEyODQgNDQxIDM0NyA0NDFIMzUwUTM5OCA0NDEgNDIyIDQwMFE0MzAgMzgxIDQzMCAzNjNRNDMwIDMzMyA0MTcgMzE1VDM5MSAyOTJUMzY2IDI4OFEzNDYgMjg4IDMzNCAyOTlUMzIyIDMyOFEzMjIgMzc2IDM3OCAzOTJRMzU2IDQwNSAzNDIgNDA1UTI4NiA0MDUgMjM5IDMzMVEyMjkgMzE1IDIyNCAyOThUMTkwIDE2NVExNTYgMjUgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTQgMTg5VDE1NCAzNjZRMTU0IDQwNSAxMjggNDA1UTEwNyA0MDUgOTIgMzc3VDY4IDMxNlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI2MzgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) 和 分别表示与图2中
和 分别表示与图2中 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjUuNzk1ZXgiIGhlaWdodD0iMS44NDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNjQ3LjggMjQ5NS4xIDc5My4zIiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjE5MiIgZD0iTTU2IDIzN1Q1NiAyNTBUNzAgMjcwSDgzNVE3MTkgMzU3IDY5MiA0OTNRNjkyIDQ5NCA2OTIgNDk2VDY5MSA0OTlRNjkxIDUxMSA3MDggNTExSDcxMVE3MjAgNTExIDcyMyA1MTBUNzI5IDUwNlQ3MzIgNDk3VDczNSA0ODFUNzQzIDQ1NlE3NjUgMzg5IDgxNiAzMzZUOTM1IDI2MVE5NDQgMjU4IDk0NCAyNTBROTQ0IDI0NCA5MzkgMjQxVDkxNSAyMzFUODc3IDIxMlE4MzYgMTg2IDgwNiAxNTJUNzYxIDg1VDc0MCAzNVQ3MzIgNFE3MzAgLTYgNzI3IC04VDcxMSAtMTFRNjkxIC0xMSA2OTEgMFE2OTEgNyA2OTYgMjVRNzI4IDE1MSA4MzUgMjMwSDcwUTU2IDIzNyA1NiAyNTBaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIxOTIiIHg9Ijc0NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIyMDI1IiB5PSIwIj48L3VzZT4KPC9nPgo8L3N2Zz4=) 与
与 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjYuMzQxZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgMjczMC4xIDkzNi45IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjE5MiIgZD0iTTU2IDIzN1Q1NiAyNTBUNzAgMjcwSDgzNVE3MTkgMzU3IDY5MiA0OTNRNjkyIDQ5NCA2OTIgNDk2VDY5MSA0OTlRNjkxIDUxMSA3MDggNTExSDcxMVE3MjAgNTExIDcyMyA1MTBUNzI5IDUwNlQ3MzIgNDk3VDczNSA0ODFUNzQzIDQ1NlE3NjUgMzg5IDgxNiAzMzZUOTM1IDI2MVE5NDQgMjU4IDk0NCAyNTBROTQ0IDI0NCA5MzkgMjQxVDkxNSAyMzFUODc3IDIxMlE4MzYgMTg2IDgwNiAxNTJUNzYxIDg1VDc0MCAzNVQ3MzIgNFE3MzAgLTYgNzI3IC04VDcxMSAtMTFRNjkxIC0xMSA2OTEgMFE2OTEgNyA2OTYgMjVRNzI4IDE1MSA4MzUgMjMwSDcwUTU2IDIzNyA1NiAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTQiIGQ9Ik00MCA0MzdRMjEgNDM3IDIxIDQ0NVEyMSA0NTAgMzcgNTAxVDcxIDYwMkw4OCA2NTFROTMgNjY5IDEwMSA2NzdINTY5SDY1OVE2OTEgNjc3IDY5NyA2NzZUNzA0IDY2N1E3MDQgNjYxIDY4NyA1NTNUNjY4IDQ0NFE2NjggNDM3IDY0OSA0MzdRNjQwIDQzNyA2MzcgNDM3VDYzMSA0NDJMNjI5IDQ0NVE2MjkgNDUxIDYzNSA0OTBUNjQxIDU1MVE2NDEgNTg2IDYyOCA2MDRUNTczIDYyOVE1NjggNjMwIDUxNSA2MzFRNDY5IDYzMSA0NTcgNjMwVDQzOSA2MjJRNDM4IDYyMSAzNjggMzQzVDI5OCA2MFEyOTggNDggMzg2IDQ2UTQxOCA0NiA0MjcgNDVUNDM2IDM2UTQzNiAzMSA0MzMgMjJRNDI5IDQgNDI0IDFMNDIyIDBRNDE5IDAgNDE1IDBRNDEwIDAgMzYzIDFUMjI4IDJROTkgMiA2NCAwSDQ5UTQzIDYgNDMgOVQ0NSAyN1E0OSA0MCA1NSA0Nkg4M0g5NFExNzQgNDYgMTg5IDU1UTE5MCA1NiAxOTEgNTZRMTk2IDU5IDIwMSA3NlQyNDEgMjMzUTI1OCAzMDEgMjY5IDM0NFEzMzkgNjE5IDMzOSA2MjVRMzM5IDYzMCAzMTAgNjMwSDI3OVEyMTIgNjMwIDE5MSA2MjRRMTQ2IDYxNCAxMjEgNTgzVDY3IDQ2N1E2MCA0NDUgNTcgNDQxVDQzIDQzN0g0MFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjE5MiIgeD0iNzQ3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjIwMjUiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) 转移有关的随机奖励。
转移有关的随机奖励。
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIuNDI4ZXgiIGhlaWdodD0iMi41MDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyIgdmlld0JveD0iMCAtNzkxLjMgMTA0NS41IDEwODAuNCIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MyIgZD0iTTMwOCAyNFEzNjcgMjQgNDE2IDc2VDQ2NiAxOTdRNDY2IDI2MCA0MTQgMjg0UTMwOCAzMTEgMjc4IDMyMVQyMzYgMzQxUTE3NiAzODMgMTc2IDQ2MlExNzYgNTIzIDIwOCA1NzNUMjczIDY0OFEzMDIgNjczIDM0MyA2ODhUNDA3IDcwNEg0MThINDI1UTUyMSA3MDQgNTY0IDY0MFE1NjUgNjQwIDU3NyA2NTNUNjAzIDY4MlQ2MjMgNzA0UTYyNCA3MDQgNjI3IDcwNFQ2MzIgNzA1UTY0NSA3MDUgNjQ1IDY5OFQ2MTcgNTc3VDU4NSA0NTlUNTY5IDQ1NlE1NDkgNDU2IDU0OSA0NjVRNTQ5IDQ3MSA1NTAgNDc1UTU1MCA0NzggNTUxIDQ5NFQ1NTMgNTIwUTU1MyA1NTQgNTQ0IDU3OVQ1MjYgNjE2VDUwMSA2NDFRNDY1IDY2MiA0MTkgNjYyUTM2MiA2NjIgMzEzIDYxNlQyNjMgNTEwUTI2MyA0ODAgMjc4IDQ1OFQzMTkgNDI3UTMyMyA0MjUgMzg5IDQwOFQ0NTYgMzkwUTQ5MCAzNzkgNTIyIDM0MlQ1NTQgMjQyUTU1NCAyMTYgNTQ2IDE4NlE1NDEgMTY0IDUyOCAxMzdUNDkyIDc4VDQyNiAxOFQzMzIgLTIwUTMyMCAtMjIgMjk4IC0yMlExOTkgLTIyIDE0NCAzM0wxMzQgNDRMMTA2IDEzUTgzIC0xNCA3OCAtMThUNjUgLTIyUTUyIC0yMiA1MiAtMTRRNTIgLTExIDExMCAyMjFRMTEyIDIyNyAxMzAgMjI3SDE0M1ExNDkgMjIxIDE0OSAyMTZRMTQ5IDIxNCAxNDggMjA3VDE0NCAxODZUMTQyIDE1M1ExNDQgMTE0IDE2MCA4N1QyMDMgNDdUMjU1IDI5VDMwOCAyNFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MyIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iODY3IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L3N2Zz4=) 表示从 到 (包括最开始的状态 )可能发生的所有状态序列的集合,
表示从 到 (包括最开始的状态 )可能发生的所有状态序列的集合, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIuODE0ZXgiIGhlaWdodD0iMi41MDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyIgdmlld0JveD0iMCAtNzkxLjMgMTIxMS43IDEwODAuNCIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MyIgZD0iTTMwOCAyNFEzNjcgMjQgNDE2IDc2VDQ2NiAxOTdRNDY2IDI2MCA0MTQgMjg0UTMwOCAzMTEgMjc4IDMyMVQyMzYgMzQxUTE3NiAzODMgMTc2IDQ2MlExNzYgNTIzIDIwOCA1NzNUMjczIDY0OFEzMDIgNjczIDM0MyA2ODhUNDA3IDcwNEg0MThINDI1UTUyMSA3MDQgNTY0IDY0MFE1NjUgNjQwIDU3NyA2NTNUNjAzIDY4MlQ2MjMgNzA0UTYyNCA3MDQgNjI3IDcwNFQ2MzIgNzA1UTY0NSA3MDUgNjQ1IDY5OFQ2MTcgNTc3VDU4NSA0NTlUNTY5IDQ1NlE1NDkgNDU2IDU0OSA0NjVRNTQ5IDQ3MSA1NTAgNDc1UTU1MCA0NzggNTUxIDQ5NFQ1NTMgNTIwUTU1MyA1NTQgNTQ0IDU3OVQ1MjYgNjE2VDUwMSA2NDFRNDY1IDY2MiA0MTkgNjYyUTM2MiA2NjIgMzEzIDYxNlQyNjMgNTEwUTI2MyA0ODAgMjc4IDQ1OFQzMTkgNDI3UTMyMyA0MjUgMzg5IDQwOFQ0NTYgMzkwUTQ5MCAzNzkgNTIyIDM0MlQ1NTQgMjQyUTU1NCAyMTYgNTQ2IDE4NlE1NDEgMTY0IDUyOCAxMzdUNDkyIDc4VDQyNiAxOFQzMzIgLTIwUTMyMCAtMjIgMjk4IC0yMlExOTkgLTIyIDE0NCAzM0wxMzQgNDRMMTA2IDEzUTgzIC0xNCA3OCAtMThUNjUgLTIyUTUyIC0yMiA1MiAtMTRRNTIgLTExIDExMCAyMjFRMTEyIDIyNyAxMzAgMjI3SDE0M1ExNDkgMjIxIDE0OSAyMTZRMTQ5IDIxNCAxNDggMjA3VDE0NCAxODZUMTQyIDE1M1ExNDQgMTE0IDE2MCA4N1QyMDMgNDdUMjU1IDI5VDMwOCAyNFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUzIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI4NjciIHk9Ii0yMTMiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) 表示从 到 (包括状态 )可能发生的所有状态序列的集合。
表示从 到 (包括状态 )可能发生的所有状态序列的集合。
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIuODgyZXgiIGhlaWdodD0iMi41MDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyIgdmlld0JveD0iMCAtNzkxLjMgMTI0MC43IDEwODAuNCIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MCIgZD0iTTI4NyA2MjhRMjg3IDYzNSAyMzAgNjM3UTIwNiA2MzcgMTk5IDYzOFQxOTIgNjQ4UTE5MiA2NDkgMTk0IDY1OVEyMDAgNjc5IDIwMyA2ODFUMzk3IDY4M1E1ODcgNjgyIDYwMCA2ODBRNjY0IDY2OSA3MDcgNjMxVDc1MSA1MzBRNzUxIDQ1MyA2ODUgMzg5UTYxNiAzMjEgNTA3IDMwM1E1MDAgMzAyIDQwMiAzMDFIMzA3TDI3NyAxODJRMjQ3IDY2IDI0NyA1OVEyNDcgNTUgMjQ4IDU0VDI1NSA1MFQyNzIgNDhUMzA1IDQ2SDMzNlEzNDIgMzcgMzQyIDM1UTM0MiAxOSAzMzUgNVEzMzAgMCAzMTkgMFEzMTYgMCAyODIgMVQxODIgMlExMjAgMiA4NyAyVDUxIDFRMzMgMSAzMyAxMVEzMyAxMyAzNiAyNVE0MCA0MSA0NCA0M1Q2NyA0NlE5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4Wk02NDUgNTU0UTY0NSA1NjcgNjQzIDU3NVQ2MzQgNTk3VDYwOSA2MTlUNTYwIDYzNVE1NTMgNjM2IDQ4MCA2MzdRNDYzIDYzNyA0NDUgNjM3VDQxNiA2MzZUNDA0IDYzNlEzOTEgNjM1IDM4NiA2MjdRMzg0IDYyMSAzNjcgNTUwVDMzMiA0MTJUMzE0IDM0NFEzMTQgMzQyIDM5NSAzNDJINDA3SDQzMFE1NDIgMzQyIDU5MCAzOTJRNjE3IDQxOSA2MzEgNDcxVDY0NSA1NTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTQiIGQ9Ik00MCA0MzdRMjEgNDM3IDIxIDQ0NVEyMSA0NTAgMzcgNTAxVDcxIDYwMkw4OCA2NTFROTMgNjY5IDEwMSA2NzdINTY5SDY1OVE2OTEgNjc3IDY5NyA2NzZUNzA0IDY2N1E3MDQgNjYxIDY4NyA1NTNUNjY4IDQ0NFE2NjggNDM3IDY0OSA0MzdRNjQwIDQzNyA2MzcgNDM3VDYzMSA0NDJMNjI5IDQ0NVE2MjkgNDUxIDYzNSA0OTBUNjQxIDU1MVE2NDEgNTg2IDYyOCA2MDRUNTczIDYyOVE1NjggNjMwIDUxNSA2MzFRNDY5IDYzMSA0NTcgNjMwVDQzOSA2MjJRNDM4IDYyMSAzNjggMzQzVDI5OCA2MFEyOTggNDggMzg2IDQ2UTQxOCA0NiA0MjcgNDVUNDM2IDM2UTQzNiAzMSA0MzMgMjJRNDI5IDQgNDI0IDFMNDIyIDBRNDE5IDAgNDE1IDBRNDEwIDAgMzYzIDFUMjI4IDJROTkgMiA2NCAwSDQ5UTQzIDYgNDMgOVQ0NSAyN1E0OSA0MCA1NSA0Nkg4M0g5NFExNzQgNDYgMTg5IDU1UTE5MCA1NiAxOTEgNTZRMTk2IDU5IDIwMSA3NlQyNDEgMjMzUTI1OCAzMDEgMjY5IDM0NFEzMzkgNjE5IDMzOSA2MjVRMzM5IDYzMCAzMTAgNjMwSDI3OVEyMTIgNjMwIDE5MSA2MjRRMTQ2IDYxNCAxMjEgNTgzVDY3IDQ2N1E2MCA0NDUgNTcgNDQxVDQzIDQzN0g0MFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L3N2Zz4=) 和
和 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIuNDk2ZXgiIGhlaWdodD0iMi41MDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyIgdmlld0JveD0iMCAtNzkxLjMgMTA3NC41IDEwODAuNCIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MCIgZD0iTTI4NyA2MjhRMjg3IDYzNSAyMzAgNjM3UTIwNiA2MzcgMTk5IDYzOFQxOTIgNjQ4UTE5MiA2NDkgMTk0IDY1OVEyMDAgNjc5IDIwMyA2ODFUMzk3IDY4M1E1ODcgNjgyIDYwMCA2ODBRNjY0IDY2OSA3MDcgNjMxVDc1MSA1MzBRNzUxIDQ1MyA2ODUgMzg5UTYxNiAzMjEgNTA3IDMwM1E1MDAgMzAyIDQwMiAzMDFIMzA3TDI3NyAxODJRMjQ3IDY2IDI0NyA1OVEyNDcgNTUgMjQ4IDU0VDI1NSA1MFQyNzIgNDhUMzA1IDQ2SDMzNlEzNDIgMzcgMzQyIDM1UTM0MiAxOSAzMzUgNVEzMzAgMCAzMTkgMFEzMTYgMCAyODIgMVQxODIgMlExMjAgMiA4NyAyVDUxIDFRMzMgMSAzMyAxMVEzMyAxMyAzNiAyNVE0MCA0MSA0NCA0M1Q2NyA0NlE5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4Wk02NDUgNTU0UTY0NSA1NjcgNjQzIDU3NVQ2MzQgNTk3VDYwOSA2MTlUNTYwIDYzNVE1NTMgNjM2IDQ4MCA2MzdRNDYzIDYzNyA0NDUgNjM3VDQxNiA2MzZUNDA0IDYzNlEzOTEgNjM1IDM4NiA2MjdRMzg0IDYyMSAzNjcgNTUwVDMzMiA0MTJUMzE0IDM0NFEzMTQgMzQyIDM5NSAzNDJINDA3SDQzMFE1NDIgMzQyIDU5MCAzOTJRNjE3IDQxOSA2MzEgNDcxVDY0NSA1NTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9zdmc+) 分别表示在抽象链中终止和循环的概率。
分别表示在抽象链中终止和循环的概率。
其中 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIxLjg0ZXgiIGhlaWdodD0iNi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0zLjY3MWV4OyIgdmlld0JveD0iMCAtMTA3OC40IDk0MDMuMSAyNjU5LjEiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTAiIGQ9Ik0yODcgNjI4UTI4NyA2MzUgMjMwIDYzN1EyMDYgNjM3IDE5OSA2MzhUMTkyIDY0OFExOTIgNjQ5IDE5NCA2NTlRMjAwIDY3OSAyMDMgNjgxVDM5NyA2ODNRNTg3IDY4MiA2MDAgNjgwUTY2NCA2NjkgNzA3IDYzMVQ3NTEgNTMwUTc1MSA0NTMgNjg1IDM4OVE2MTYgMzIxIDUwNyAzMDNRNTAwIDMwMiA0MDIgMzAxSDMwN0wyNzcgMTgyUTI0NyA2NiAyNDcgNTlRMjQ3IDU1IDI0OCA1NFQyNTUgNTBUMjcyIDQ4VDMwNSA0NkgzMzZRMzQyIDM3IDM0MiAzNVEzNDIgMTkgMzM1IDVRMzMwIDAgMzE5IDBRMzE2IDAgMjgyIDFUMTgyIDJRMTIwIDIgODcgMlQ1MSAxUTMzIDEgMzMgMTFRMzMgMTMgMzYgMjVRNDAgNDEgNDQgNDNUNjcgNDZROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFpNNjQ1IDU1NFE2NDUgNTY3IDY0MyA1NzVUNjM0IDU5N1Q2MDkgNjE5VDU2MCA2MzVRNTUzIDYzNiA0ODAgNjM3UTQ2MyA2MzcgNDQ1IDYzN1Q0MTYgNjM2VDQwNCA2MzZRMzkxIDYzNSAzODYgNjI3UTM4NCA2MjEgMzY3IDU1MFQzMzIgNDEyVDMxNCAzNDRRMzE0IDM0MiAzOTUgMzQySDQwN0g0MzBRNTQyIDM0MiA1OTAgMzkyUTYxNyA0MTkgNjMxIDQ3MVQ2NDUgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU0IiBkPSJNNDAgNDM3UTIxIDQzNyAyMSA0NDVRMjEgNDUwIDM3IDUwMVQ3MSA2MDJMODggNjUxUTkzIDY2OSAxMDEgNjc3SDU2OUg2NTlRNjkxIDY3NyA2OTcgNjc2VDcwNCA2NjdRNzA0IDY2MSA2ODcgNTUzVDY2OCA0NDRRNjY4IDQzNyA2NDkgNDM3UTY0MCA0MzcgNjM3IDQzN1Q2MzEgNDQyTDYyOSA0NDVRNjI5IDQ1MSA2MzUgNDkwVDY0MSA1NTFRNjQxIDU4NiA2MjggNjA0VDU3MyA2MjlRNTY4IDYzMCA1MTUgNjMxUTQ2OSA2MzEgNDU3IDYzMFQ0MzkgNjIyUTQzOCA2MjEgMzY4IDM0M1QyOTggNjBRMjk4IDQ4IDM4NiA0NlE0MTggNDYgNDI3IDQ1VDQzNiAzNlE0MzYgMzEgNDMzIDIyUTQyOSA0IDQyNCAxTDQyMiAwUTQxOSAwIDQxNSAwUTQxMCAwIDM2MyAxVDIyOCAyUTk5IDIgNjQgMEg0OVE0MyA2IDQzIDlUNDUgMjdRNDkgNDAgNTUgNDZIODNIOTRRMTc0IDQ2IDE4OSA1NVExOTAgNTYgMTkxIDU2UTE5NiA1OSAyMDEgNzZUMjQxIDIzM1EyNTggMzAxIDI2OSAzNDRRMzM5IDYxOSAzMzkgNjI1UTMzOSA2MzAgMzEwIDYzMEgyNzlRMjEyIDYzMCAxOTEgNjI0UTE0NiA2MTQgMTIxIDU4M1Q2NyA0NjdRNjAgNDQ1IDU3IDQ0MVQ0MyA0MzdINDBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjIxMSIgZD0iTTYwIDk0OFE2MyA5NTAgNjY1IDk1MEgxMjY3TDEzMjUgODE1UTEzODQgNjc3IDEzODggNjY5SDEzNDhMMTM0MSA2ODNRMTMyMCA3MjQgMTI4NSA3NjFRMTIzNSA4MDkgMTE3NCA4MzhUMTAzMyA4ODFUODgyIDg5OFQ2OTkgOTAySDU3NEg1NDNIMjUxTDI1OSA4OTFRNzIyIDI1OCA3MjQgMjUyUTcyNSAyNTAgNzI0IDI0NlE3MjEgMjQzIDQ2MCAtNTZMMTk2IC0zNTZRMTk2IC0zNTcgNDA3IC0zNTdRNDU5IC0zNTcgNTQ4IC0zNTdUNjc2IC0zNThRODEyIC0zNTggODk2IC0zNTNUMTA2MyAtMzMyVDEyMDQgLTI4M1QxMzA3IC0xOTZRMTMyOCAtMTcwIDEzNDggLTEyNEgxMzg4UTEzODggLTEyNSAxMzgxIC0xNDVUMTM1NiAtMjEwVDEzMjUgLTI5NEwxMjY3IC00NDlMNjY2IC00NTBRNjQgLTQ1MCA2MSAtNDQ4UTU1IC00NDYgNTUgLTQzOVE1NSAtNDM3IDU3IC00MzNMNTkwIDE3N1E1OTAgMTc4IDU1NyAyMjJUNDUyIDM2NlQzMjIgNTQ0TDU2IDkwOUw1NSA5MjRRNTUgOTQ1IDYwIDk0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjA4IiBkPSJNODQgMjUwUTg0IDM3MiAxNjYgNDUwVDM2MCA1MzlRMzYxIDUzOSAzNzcgNTM5VDQxOSA1NDBUNDY5IDU0MEg1NjhRNTgzIDUzMiA1ODMgNTIwUTU4MyA1MTEgNTcwIDUwMUw0NjYgNTAwUTM1NSA0OTkgMzI5IDQ5NFEyODAgNDgyIDI0MiA0NThUMTgzIDQwOVQxNDcgMzU0VDEyOSAzMDZUMTI0IDI3MlYyNzBINTY4UTU4MyAyNjIgNTgzIDI1MFQ1NjggMjMwSDEyNFYyMjhRMTI0IDIwNyAxMzQgMTc3VDE2NyAxMTJUMjMxIDQ4VDMyOCA3UTM1NSAxIDQ2NiAwSDU3MFE1ODMgLTEwIDU4MyAtMjBRNTgzIC0zMiA1NjggLTQwSDQ3MVE0NjQgLTQwIDQ0NiAtNDBUNDE3IC00MVEyNjIgLTQxIDE3MiA0NVE4NCAxMjcgODQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUzIiBkPSJNMzA4IDI0UTM2NyAyNCA0MTYgNzZUNDY2IDE5N1E0NjYgMjYwIDQxNCAyODRRMzA4IDMxMSAyNzggMzIxVDIzNiAzNDFRMTc2IDM4MyAxNzYgNDYyUTE3NiA1MjMgMjA4IDU3M1QyNzMgNjQ4UTMwMiA2NzMgMzQzIDY4OFQ0MDcgNzA0SDQxOEg0MjVRNTIxIDcwNCA1NjQgNjQwUTU2NSA2NDAgNTc3IDY1M1Q2MDMgNjgyVDYyMyA3MDRRNjI0IDcwNCA2MjcgNzA0VDYzMiA3MDVRNjQ1IDcwNSA2NDUgNjk4VDYxNyA1NzdUNTg1IDQ1OVQ1NjkgNDU2UTU0OSA0NTYgNTQ5IDQ2NVE1NDkgNDcxIDU1MCA0NzVRNTUwIDQ3OCA1NTEgNDk0VDU1MyA1MjBRNTUzIDU1NCA1NDQgNTc5VDUyNiA2MTZUNTAxIDY0MVE0NjUgNjYyIDQxOSA2NjJRMzYyIDY2MiAzMTMgNjE2VDI2MyA1MTBRMjYzIDQ4MCAyNzggNDU4VDMxOSA0MjdRMzIzIDQyNSAzODkgNDA4VDQ1NiAzOTBRNDkwIDM3OSA1MjIgMzQyVDU1NCAyNDJRNTU0IDIxNiA1NDYgMTg2UTU0MSAxNjQgNTI4IDEzN1Q0OTIgNzhUNDI2IDE4VDMzMiAtMjBRMzIwIC0yMiAyOTggLTIyUTE5OSAtMjIgMTQ0IDMzTDEzNCA0NEwxMDYgMTNRODMgLTE0IDc4IC0xOFQ2NSAtMjJRNTIgLTIyIDUyIC0xNFE1MiAtMTEgMTEwIDIyMVExMTIgMjI3IDEzMCAyMjdIMTQzUTE0OSAyMjEgMTQ5IDIxNlExNDkgMjE0IDE0OCAyMDdUMTQ0IDE4NlQxNDIgMTUzUTE0NCAxMTQgMTYwIDg3VDIwMyA0N1QyNTUgMjlUMzA4IDI0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIxNTE4IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjU3NCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSI3MjUiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC0xMTQ5KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iOTcwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjU3NCkiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxODExIiB5PSItMzYwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIwOCIgeD0iMjE0MiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE5ODYsMCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTMiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNTc0KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9Ijc1NSIgeT0iLTI1NCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSI1NjM3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjU1NSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9Ijk3MCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMjA3OSIgeT0iLTQwNSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMjQ1OCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=) 。
。
定义 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEyLjQ3OGV4IiBoZWlnaHQ9IjIuNTA5ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMC42NzFleDsiIHZpZXdCb3g9IjAgLTc5MS4zIDUzNzIuNiAxMDgwLjQiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTAiIGQ9Ik0yODcgNjI4UTI4NyA2MzUgMjMwIDYzN1EyMDYgNjM3IDE5OSA2MzhUMTkyIDY0OFExOTIgNjQ5IDE5NCA2NTlRMjAwIDY3OSAyMDMgNjgxVDM5NyA2ODNRNTg3IDY4MiA2MDAgNjgwUTY2NCA2NjkgNzA3IDYzMVQ3NTEgNTMwUTc1MSA0NTMgNjg1IDM4OVE2MTYgMzIxIDUwNyAzMDNRNTAwIDMwMiA0MDIgMzAxSDMwN0wyNzcgMTgyUTI0NyA2NiAyNDcgNTlRMjQ3IDU1IDI0OCA1NFQyNTUgNTBUMjcyIDQ4VDMwNSA0NkgzMzZRMzQyIDM3IDM0MiAzNVEzNDIgMTkgMzM1IDVRMzMwIDAgMzE5IDBRMzE2IDAgMjgyIDFUMTgyIDJRMTIwIDIgODcgMlQ1MSAxUTMzIDEgMzMgMTFRMzMgMTMgMzYgMjVRNDAgNDEgNDQgNDNUNjcgNDZROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFpNNjQ1IDU1NFE2NDUgNTY3IDY0MyA1NzVUNjM0IDU5N1Q2MDkgNjE5VDU2MCA2MzVRNTUzIDYzNiA0ODAgNjM3UTQ2MyA2MzcgNDQ1IDYzN1Q0MTYgNjM2VDQwNCA2MzZRMzkxIDYzNSAzODYgNjI3UTM4NCA2MjEgMzY3IDU1MFQzMzIgNDEyVDMxNCAzNDRRMzE0IDM0MiAzOTUgMzQySDQwN0g0MzBRNTQyIDM0MiA1OTAgMzkyUTYxNyA0MTkgNjMxIDQ3MVQ2NDUgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMSIgZD0iTTIxMyA1NzhMMjAwIDU3M1ExODYgNTY4IDE2MCA1NjNUMTAyIDU1Nkg4M1Y2MDJIMTAyUTE0OSA2MDQgMTg5IDYxN1QyNDUgNjQxVDI3MyA2NjNRMjc1IDY2NiAyODUgNjY2UTI5NCA2NjYgMzAyIDY2MFYzNjFMMzAzIDYxUTMxMCA1NCAzMTUgNTJUMzM5IDQ4VDQwMSA0Nkg0MjdWMEg0MTZRMzk1IDMgMjU3IDNRMTIxIDMgMTAwIDBIODhWNDZIMTE0UTEzNiA0NiAxNTIgNDZUMTc3IDQ3VDE5MyA1MFQyMDEgNTJUMjA3IDU3VDIxMyA2MVY1NzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjEyIiBkPSJNODQgMjM3VDg0IDI1MFQ5OCAyNzBINjc5UTY5NCAyNjIgNjk0IDI1MFQ2NzkgMjMwSDk4UTg0IDIzNyA4NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTQiIGQ9Ik00MCA0MzdRMjEgNDM3IDIxIDQ0NVEyMSA0NTAgMzcgNTAxVDcxIDYwMkw4OCA2NTFROTMgNjY5IDEwMSA2NzdINTY5SDY1OVE2OTEgNjc3IDY5NyA2NzZUNzA0IDY2N1E3MDQgNjYxIDY4NyA1NTNUNjY4IDQ0NFE2NjggNDM3IDY0OSA0MzdRNjQwIDQzNyA2MzcgNDM3VDYzMSA0NDJMNjI5IDQ0NVE2MjkgNDUxIDYzNSA0OTBUNjQxIDU1MVE2NDEgNTg2IDYyOCA2MDRUNTczIDYyOVE1NjggNjMwIDUxNSA2MzFRNDY5IDYzMSA0NTcgNjMwVDQzOSA2MjJRNDM4IDYyMSAzNjggMzQzVDI5OCA2MFEyOTggNDggMzg2IDQ2UTQxOCA0NiA0MjcgNDVUNDM2IDM2UTQzNiAzMSA0MzMgMjJRNDI5IDQgNDI0IDFMNDIyIDBRNDE5IDAgNDE1IDBRNDEwIDAgMzYzIDFUMjI4IDJROTkgMiA2NCAwSDQ5UTQzIDYgNDMgOVQ0NSAyN1E0OSA0MCA1NSA0Nkg4M0g5NFExNzQgNDYgMTg5IDU1UTE5MCA1NiAxOTEgNTZRMTk2IDU5IDIwMSA3NlQyNDEgMjMzUTI1OCAzMDEgMjY5IDM0NFEzMzkgNjE5IDMzOSA2MjVRMzM5IDYzMCAzMTAgNjMwSDI3OVEyMTIgNjMwIDE5MSA2MjRRMTQ2IDYxNCAxMjEgNTgzVDY3IDQ2N1E2MCA0NDUgNTcgNDQxVDQzIDQzN0g0MFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMTM1MiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjI0MDgiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjMxMzEiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0MTMxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=) 。
。
奖励概率定义如下:
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQ2Ljk2NmV4IiBoZWlnaHQ9IjYuMDA5ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy41MDVleDsiIHZpZXdCb3g9IjAgLTEwNzguNCAyMDIyMS4zIDI1ODcuMyIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MCIgZD0iTTI4NyA2MjhRMjg3IDYzNSAyMzAgNjM3UTIwNiA2MzcgMTk5IDYzOFQxOTIgNjQ4UTE5MiA2NDkgMTk0IDY1OVEyMDAgNjc5IDIwMyA2ODFUMzk3IDY4M1E1ODcgNjgyIDYwMCA2ODBRNjY0IDY2OSA3MDcgNjMxVDc1MSA1MzBRNzUxIDQ1MyA2ODUgMzg5UTYxNiAzMjEgNTA3IDMwM1E1MDAgMzAyIDQwMiAzMDFIMzA3TDI3NyAxODJRMjQ3IDY2IDI0NyA1OVEyNDcgNTUgMjQ4IDU0VDI1NSA1MFQyNzIgNDhUMzA1IDQ2SDMzNlEzNDIgMzcgMzQyIDM1UTM0MiAxOSAzMzUgNVEzMzAgMCAzMTkgMFEzMTYgMCAyODIgMVQxODIgMlExMjAgMiA4NyAyVDUxIDFRMzMgMSAzMyAxMVEzMyAxMyAzNiAyNVE0MCA0MSA0NCA0M1Q2NyA0NlE5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4Wk02NDUgNTU0UTY0NSA1NjcgNjQzIDU3NVQ2MzQgNTk3VDYwOSA2MTlUNTYwIDYzNVE1NTMgNjM2IDQ4MCA2MzdRNDYzIDYzNyA0NDUgNjM3VDQxNiA2MzZUNDA0IDYzNlEzOTEgNjM1IDM4NiA2MjdRMzg0IDYyMSAzNjcgNTUwVDMzMiA0MTJUMzE0IDM0NFEzMTQgMzQyIDM5NSAzNDJINDA3SDQzMFE1NDIgMzQyIDU5MCAzOTJRNjE3IDQxOSA2MzEgNDcxVDY0NSA1NTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzIiIGQ9Ik0yMSAyODdRMjIgMjkwIDIzIDI5NVQyOCAzMTdUMzggMzQ4VDUzIDM4MVQ3MyA0MTFUOTkgNDMzVDEzMiA0NDJRMTYxIDQ0MiAxODMgNDMwVDIxNCA0MDhUMjI1IDM4OFEyMjcgMzgyIDIyOCAzODJUMjM2IDM4OVEyODQgNDQxIDM0NyA0NDFIMzUwUTM5OCA0NDEgNDIyIDQwMFE0MzAgMzgxIDQzMCAzNjNRNDMwIDMzMyA0MTcgMzE1VDM5MSAyOTJUMzY2IDI4OFEzNDYgMjg4IDMzNCAyOTlUMzIyIDMyOFEzMjIgMzc2IDM3OCAzOTJRMzU2IDQwNSAzNDIgNDA1UTI4NiA0MDUgMjM5IDMzMVEyMjkgMzE1IDIyNCAyOThUMTkwIDE2NVExNTYgMjUgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTQgMTg5VDE1NCAzNjZRMTU0IDQwNSAxMjggNDA1UTEwNyA0MDUgOTIgMzc3VDY4IDMxNlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZGIiBkPSJNMjAxIC0xMVExMjYgLTExIDgwIDM4VDM0IDE1NlEzNCAyMjEgNjQgMjc5VDE0NiAzODBRMjIyIDQ0MSAzMDEgNDQxUTMzMyA0NDEgMzQxIDQ0MFEzNTQgNDM3IDM2NyA0MzNUNDAyIDQxN1Q0MzggMzg3VDQ2NCAzMzhUNDc2IDI2OFE0NzYgMTYxIDM5MCA3NVQyMDEgLTExWk0xMjEgMTIwUTEyMSA3MCAxNDcgNDhUMjA2IDI2UTI1MCAyNiAyODkgNThUMzUxIDE0MlEzNjAgMTYzIDM3NCAyMTZUMzg4IDMwOFEzODggMzUyIDM3MCAzNzVRMzQ2IDQwNSAzMDYgNDA1UTI0MyA0MDUgMTk1IDM0N1ExNTggMzAzIDE0MCAyMzBUMTIxIDEyMFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02MiIgZD0iTTczIDY0N1E3MyA2NTcgNzcgNjcwVDg5IDY4M1E5MCA2ODMgMTYxIDY4OFQyMzQgNjk0UTI0NiA2OTQgMjQ2IDY4NVQyMTIgNTQyUTIwNCA1MDggMTk1IDQ3MlQxODAgNDE4TDE3NiAzOTlRMTc2IDM5NiAxODIgNDAyUTIzMSA0NDIgMjgzIDQ0MlEzNDUgNDQyIDM4MyAzOTZUNDIyIDI4MFE0MjIgMTY5IDM0MyA3OVQxNzMgLTExUTEyMyAtMTEgODIgMjdUNDAgMTUwVjE1OVE0MCAxODAgNDggMjE3VDk3IDQxNFExNDcgNjExIDE0NyA2MjNUMTA5IDYzN1ExMDQgNjM3IDEwMSA2MzdIOTZRODYgNjM3IDgzIDYzN1Q3NiA2NDBUNzMgNjQ3Wk0zMzYgMzI1VjMzMVEzMzYgNDA1IDI3NSA0MDVRMjU4IDQwNSAyNDAgMzk3VDIwNyAzNzZUMTgxIDM1MlQxNjMgMzMwTDE1NyAzMjJMMTM2IDIzNlExMTQgMTUwIDExNCAxMTRRMTE0IDY2IDEzOCA0MlExNTQgMjYgMTc4IDI2UTIxMSAyNiAyNDUgNThRMjcwIDgxIDI4NSAxMTRUMzE4IDIxOVEzMzYgMjkxIDMzNiAzMjVaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03QiIgZD0iTTQzNCAtMjMxUTQzNCAtMjQ0IDQyOCAtMjUwSDQxMFEyODEgLTI1MCAyMzAgLTE4NFEyMjUgLTE3NyAyMjIgLTE3MlQyMTcgLTE2MVQyMTMgLTE0OFQyMTEgLTEzM1QyMTAgLTExMVQyMDkgLTg0VDIwOSAtNDdUMjA5IDBRMjA5IDIxIDIwOSA1M1EyMDggMTQyIDIwNCAxNTNRMjAzIDE1NCAyMDMgMTU1UTE4OSAxOTEgMTUzIDIxMVQ4MiAyMzFRNzEgMjMxIDY4IDIzNFQ2NSAyNTBUNjggMjY2VDgyIDI2OVExMTYgMjY5IDE1MiAyODlUMjAzIDM0NVEyMDggMzU2IDIwOCAzNzdUMjA5IDUyOVY1NzlRMjA5IDYzNCAyMTUgNjU2VDI0NCA2OThRMjcwIDcyNCAzMjQgNzQwUTM2MSA3NDggMzc3IDc0OVEzNzkgNzQ5IDM5MCA3NDlUNDA4IDc1MEg0MjhRNDM0IDc0NCA0MzQgNzMyUTQzNCA3MTkgNDMxIDcxNlE0MjkgNzEzIDQxNSA3MTNRMzYyIDcxMCAzMzIgNjg5VDI5NiA2NDdRMjkxIDYzNCAyOTEgNDk5VjQxN1EyOTEgMzcwIDI4OCAzNTNUMjcxIDMxNFEyNDAgMjcxIDE4NCAyNTVMMTcwIDI1MEwxODQgMjQ1UTIwMiAyMzkgMjIwIDIzMFQyNjIgMTk2VDI5MCAxMzdRMjkxIDEzMSAyOTEgMVEyOTEgLTEzNCAyOTYgLTE0N1EzMDYgLTE3NCAzMzkgLTE5MlQ0MTUgLTIxM1E0MjkgLTIxMyA0MzEgLTIxNlE0MzQgLTIxOSA0MzQgLTIzMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTcxIiBkPSJNMzMgMTU3UTMzIDI1OCAxMDkgMzQ5VDI4MCA0NDFRMzQwIDQ0MSAzNzIgMzg5UTM3MyAzOTAgMzc3IDM5NVQzODggNDA2VDQwNCA0MThRNDM4IDQ0MiA0NTAgNDQyUTQ1NCA0NDIgNDU3IDQzOVQ0NjAgNDM0UTQ2MCA0MjUgMzkxIDE0OVEzMjAgLTEzNSAzMjAgLTEzOVEzMjAgLTE0NyAzNjUgLTE0OEgzOTBRMzk2IC0xNTYgMzk2IC0xNTdUMzkzIC0xNzVRMzg5IC0xODggMzgzIC0xOTRIMzcwUTMzOSAtMTkyIDI2MiAtMTkyUTIzNCAtMTkyIDIxMSAtMTkyVDE3NCAtMTkyVDE1NyAtMTkzUTE0MyAtMTkzIDE0MyAtMTg1UTE0MyAtMTgyIDE0NSAtMTcwUTE0OSAtMTU0IDE1MiAtMTUxVDE3MiAtMTQ4UTIyMCAtMTQ4IDIzMCAtMTQxUTIzOCAtMTM2IDI1OCAtNTNUMjc5IDMyUTI3OSAzMyAyNzIgMjlRMjI0IC0xMCAxNzIgLTEwUTExNyAtMTAgNzUgMzBUMzMgMTU3Wk0zNTIgMzI2UTMyOSA0MDUgMjc3IDQwNVEyNDIgNDA1IDIxMCAzNzRUMTYwIDI5M1ExMzEgMjE0IDExOSAxMjlRMTE5IDEyNiAxMTkgMTE4VDExOCAxMDZRMTE4IDYxIDEzNiA0NFQxNzkgMjZRMjMzIDI2IDI5MCA5OEwyOTggMTA5TDM1MiAzMjZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03RCIgZD0iTTY1IDczMVE2NSA3NDUgNjggNzQ3VDg4IDc1MFExNzEgNzUwIDIxNiA3MjVUMjc5IDY3MFEyODggNjQ5IDI4OSA2MzVUMjkxIDUwMVEyOTIgMzYyIDI5MyAzNTdRMzA2IDMxMiAzNDUgMjkxVDQxNyAyNjlRNDI4IDI2OSA0MzEgMjY2VDQzNCAyNTBUNDMxIDIzNFQ0MTcgMjMxUTM4MCAyMzEgMzQ1IDIxMFQyOTggMTU3UTI5MyAxNDMgMjkyIDEyMVQyOTEgLTI4Vi03OVEyOTEgLTEzNCAyODUgLTE1NlQyNTYgLTE5OFEyMDIgLTI1MCA4OSAtMjUwUTcxIC0yNTAgNjggLTI0N1Q2NSAtMjMwUTY1IC0yMjQgNjUgLTIyM1Q2NiAtMjE4VDY5IC0yMTRUNzcgLTIxM1E5MSAtMjEzIDEwOCAtMjEwVDE0NiAtMjAwVDE4MyAtMTc3VDIwNyAtMTM5UTIwOCAtMTM0IDIwOSAzTDIxMCAxMzlRMjIzIDE5NiAyODAgMjMwUTMxNSAyNDcgMzMwIDI1MFEzMDUgMjU3IDI4MCAyNzBRMjI1IDMwNCAyMTIgMzUyTDIxMCAzNjJMMjA5IDQ5OFEyMDggNjM1IDIwNyA2NDBRMTk1IDY4MCAxNTQgNjk2VDc3IDcxM1E2OCA3MTMgNjcgNzE2VDY1IDczMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjIwRiIgZD0iTTIyMCA4MTJRMjIwIDgxMyAyMTggODE5VDIxNCA4MjlUMjA4IDg0MFQxOTkgODUzVDE4NSA4NjZUMTY2IDg3OFQxNDAgODg3VDEwNyA4OTNUNjYgODk2SDU2Vjk1MEgxMjIxVjg5NkgxMjExUTEwODAgODk2IDEwNTggODEyVi0zMTFRMTA3NiAtMzk2IDEyMTEgLTM5NkgxMjIxVi00NTBINzI1Vi0zOTZINzM1UTg2NCAtMzk2IDg4OCAtMzE0UTg4OSAtMzEyIDg4OSAtMzExVjg5NkgzODhWMjkyTDM4OSAtMzExUTQwNSAtMzk2IDU0MiAtMzk2SDU1MlYtNDUwSDU2Vi0zOTZINjZRMTk1IC0zOTYgMjE5IC0zMTRRMjIwIC0zMTIgMjIwIC0zMTFWODEyWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjIwOCIgZD0iTTg0IDI1MFE4NCAzNzIgMTY2IDQ1MFQzNjAgNTM5UTM2MSA1MzkgMzc3IDUzOVQ0MTkgNTQwVDQ2OSA1NDBINTY4UTU4MyA1MzIgNTgzIDUyMFE1ODMgNTExIDU3MCA1MDFMNDY2IDUwMFEzNTUgNDk5IDMyOSA0OTRRMjgwIDQ4MiAyNDIgNDU4VDE4MyA0MDlUMTQ3IDM1NFQxMjkgMzA2VDEyNCAyNzJWMjcwSDU2OFE1ODMgMjYyIDU4MyAyNTBUNTY4IDIzMEgxMjRWMjI4UTEyNCAyMDcgMTM0IDE3N1QxNjcgMTEyVDIzMSA0OFQzMjggN1EzNTUgMSA0NjYgMEg1NzBRNTgzIC0xMCA1ODMgLTIwUTU4MyAtMzIgNTY4IC00MEg0NzFRNDY0IC00MCA0NDYgLTQwVDQxNyAtNDFRMjYyIC00MSAxNzIgNDVRODQgMTI3IDg0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MyIgZD0iTTMwOCAyNFEzNjcgMjQgNDE2IDc2VDQ2NiAxOTdRNDY2IDI2MCA0MTQgMjg0UTMwOCAzMTEgMjc4IDMyMVQyMzYgMzQxUTE3NiAzODMgMTc2IDQ2MlExNzYgNTIzIDIwOCA1NzNUMjczIDY0OFEzMDIgNjczIDM0MyA2ODhUNDA3IDcwNEg0MThINDI1UTUyMSA3MDQgNTY0IDY0MFE1NjUgNjQwIDU3NyA2NTNUNjAzIDY4MlQ2MjMgNzA0UTYyNCA3MDQgNjI3IDcwNFQ2MzIgNzA1UTY0NSA3MDUgNjQ1IDY5OFQ2MTcgNTc3VDU4NSA0NTlUNTY5IDQ1NlE1NDkgNDU2IDU0OSA0NjVRNTQ5IDQ3MSA1NTAgNDc1UTU1MCA0NzggNTUxIDQ5NFQ1NTMgNTIwUTU1MyA1NTQgNTQ0IDU3OVQ1MjYgNjE2VDUwMSA2NDFRNDY1IDY2MiA0MTkgNjYyUTM2MiA2NjIgMzEzIDYxNlQyNjMgNTEwUTI2MyA0ODAgMjc4IDQ1OFQzMTkgNDI3UTMyMyA0MjUgMzg5IDQwOFQ0NTYgMzkwUTQ5MCAzNzkgNTIyIDM0MlQ1NTQgMjQyUTU1NCAyMTYgNTQ2IDE4NlE1NDEgMTY0IDUyOCAxMzdUNDkyIDc4VDQyNiAxOFQzMzIgLTIwUTMyMCAtMjIgMjk4IC0yMlExOTkgLTIyIDE0NCAzM0wxMzQgNDRMMTA2IDEzUTgzIC0xNCA3OCAtMThUNjUgLTIyUTUyIC0yMiA1MiAtMTRRNTIgLTExIDExMCAyMjFRMTEyIDIyNyAxMzAgMjI3SDE0M1ExNDkgMjIxIDE0OSAyMTZRMTQ5IDIxNCAxNDggMjA3VDE0NCAxODZUMTQyIDE1M1ExNDQgMTE0IDE2MCA4N1QyMDMgNDdUMjU1IDI5VDMwOCAyNFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdDIiBkPSJNMTM5IC0yNDlIMTM3UTEyNSAtMjQ5IDExOSAtMjM1VjI1MUwxMjAgNzM3UTEzMCA3NTAgMTM5IDc1MFExNTIgNzUwIDE1OSA3MzVWLTIzNVExNTEgLTI0OSAxNDEgLTI0OUgxMzlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oxLTI4IiBkPSJNMTUyIDI1MVExNTIgNjQ2IDM4OCA4NTBINDE2UTQyMiA4NDQgNDIyIDg0MVE0MjIgODM3IDQwMyA4MTZUMzU3IDc1M1QzMDIgNjQ5VDI1NSA0ODJUMjM2IDI1MFEyMzYgMTI0IDI1NSAxOVQzMDEgLTE0N1QzNTYgLTI1MVQ0MDMgLTMxNVQ0MjIgLTM0MFE0MjIgLTM0MyA0MTYgLTM0OUgzODhRMzU5IC0zMjUgMzMyIC0yOTZUMjcxIC0yMTNUMjEyIC05N1QxNzAgNTZUMTUyIDI1MVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjEtMjkiIGQ9Ik0zMDUgMjUxUTMwNSAtMTQ1IDY5IC0zNDlINTZRNDMgLTM0OSAzOSAtMzQ3VDM1IC0zMzhRMzcgLTMzMyA2MCAtMzA3VDEwOCAtMjM5VDE2MCAtMTM2VDIwNCAyN1QyMjEgMjUwVDIwNCA0NzNUMTYwIDYzNlQxMDggNzQwVDYwIDgwN1QzNSA4MzlRMzUgODUwIDUwIDg1MEg1Nkg2OVExOTcgNzQzIDI1NiA1NjZRMzA1IDQyNSAzMDUgMjUxWiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9Ijc1MSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZGIiB4PSIxMjAzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjIiIHg9IjE2ODgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMjg0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI2MzgiIHk9Ii0yMTMiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIxMTYxIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzEiIHg9IjIyMTciIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjMxNzgiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjYyNDEiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3Mjk3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTIyMEYiIHg9IjUwMyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTExNDkpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSI5NzAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjA4IiB4PSIxNDcwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTUxMSwwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MyIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iNzU1IiB5PSItMTg1Ij48L3VzZT4KPC9nPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9Ijk3NTAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDY2OCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9Ijk3MCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTg2MCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjEzMDg0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQwMDIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjEtMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NTgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ1MSwtMTg3KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iOTcwIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIxODY5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzEiIHg9IjI5MjUiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdDIiB4PSIzMzg1IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzgzMSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iNTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iOTcwIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMS0yOSIgeD0iNTc2MCIgeT0iLTEiPjwvdXNlPgo8L2c+CjwvZz4KPC9zdmc+)
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQ5LjU4MmV4IiBoZWlnaHQ9IjYuMTc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy42NzFleDsiIHZpZXdCb3g9IjAgLTEwNzguNCAyMTM0Ny41IDI2NTkuMSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MCIgZD0iTTI4NyA2MjhRMjg3IDYzNSAyMzAgNjM3UTIwNiA2MzcgMTk5IDYzOFQxOTIgNjQ4UTE5MiA2NDkgMTk0IDY1OVEyMDAgNjc5IDIwMyA2ODFUMzk3IDY4M1E1ODcgNjgyIDYwMCA2ODBRNjY0IDY2OSA3MDcgNjMxVDc1MSA1MzBRNzUxIDQ1MyA2ODUgMzg5UTYxNiAzMjEgNTA3IDMwM1E1MDAgMzAyIDQwMiAzMDFIMzA3TDI3NyAxODJRMjQ3IDY2IDI0NyA1OVEyNDcgNTUgMjQ4IDU0VDI1NSA1MFQyNzIgNDhUMzA1IDQ2SDMzNlEzNDIgMzcgMzQyIDM1UTM0MiAxOSAzMzUgNVEzMzAgMCAzMTkgMFEzMTYgMCAyODIgMVQxODIgMlExMjAgMiA4NyAyVDUxIDFRMzMgMSAzMyAxMVEzMyAxMyAzNiAyNVE0MCA0MSA0NCA0M1Q2NyA0NlE5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4Wk02NDUgNTU0UTY0NSA1NjcgNjQzIDU3NVQ2MzQgNTk3VDYwOSA2MTlUNTYwIDYzNVE1NTMgNjM2IDQ4MCA2MzdRNDYzIDYzNyA0NDUgNjM3VDQxNiA2MzZUNDA0IDYzNlEzOTEgNjM1IDM4NiA2MjdRMzg0IDYyMSAzNjcgNTUwVDMzMiA0MTJUMzE0IDM0NFEzMTQgMzQyIDM5NSAzNDJINDA3SDQzMFE1NDIgMzQyIDU5MCAzOTJRNjE3IDQxOSA2MzEgNDcxVDY0NSA1NTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzIiIGQ9Ik0yMSAyODdRMjIgMjkwIDIzIDI5NVQyOCAzMTdUMzggMzQ4VDUzIDM4MVQ3MyA0MTFUOTkgNDMzVDEzMiA0NDJRMTYxIDQ0MiAxODMgNDMwVDIxNCA0MDhUMjI1IDM4OFEyMjcgMzgyIDIyOCAzODJUMjM2IDM4OVEyODQgNDQxIDM0NyA0NDFIMzUwUTM5OCA0NDEgNDIyIDQwMFE0MzAgMzgxIDQzMCAzNjNRNDMwIDMzMyA0MTcgMzE1VDM5MSAyOTJUMzY2IDI4OFEzNDYgMjg4IDMzNCAyOTlUMzIyIDMyOFEzMjIgMzc2IDM3OCAzOTJRMzU2IDQwNSAzNDIgNDA1UTI4NiA0MDUgMjM5IDMzMVEyMjkgMzE1IDIyNCAyOThUMTkwIDE2NVExNTYgMjUgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTQgMTg5VDE1NCAzNjZRMTU0IDQwNSAxMjggNDA1UTEwNyA0MDUgOTIgMzc3VDY4IDMxNlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZGIiBkPSJNMjAxIC0xMVExMjYgLTExIDgwIDM4VDM0IDE1NlEzNCAyMjEgNjQgMjc5VDE0NiAzODBRMjIyIDQ0MSAzMDEgNDQxUTMzMyA0NDEgMzQxIDQ0MFEzNTQgNDM3IDM2NyA0MzNUNDAyIDQxN1Q0MzggMzg3VDQ2NCAzMzhUNDc2IDI2OFE0NzYgMTYxIDM5MCA3NVQyMDEgLTExWk0xMjEgMTIwUTEyMSA3MCAxNDcgNDhUMjA2IDI2UTI1MCAyNiAyODkgNThUMzUxIDE0MlEzNjAgMTYzIDM3NCAyMTZUMzg4IDMwOFEzODggMzUyIDM3MCAzNzVRMzQ2IDQwNSAzMDYgNDA1UTI0MyA0MDUgMTk1IDM0N1ExNTggMzAzIDE0MCAyMzBUMTIxIDEyMFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02MiIgZD0iTTczIDY0N1E3MyA2NTcgNzcgNjcwVDg5IDY4M1E5MCA2ODMgMTYxIDY4OFQyMzQgNjk0UTI0NiA2OTQgMjQ2IDY4NVQyMTIgNTQyUTIwNCA1MDggMTk1IDQ3MlQxODAgNDE4TDE3NiAzOTlRMTc2IDM5NiAxODIgNDAyUTIzMSA0NDIgMjgzIDQ0MlEzNDUgNDQyIDM4MyAzOTZUNDIyIDI4MFE0MjIgMTY5IDM0MyA3OVQxNzMgLTExUTEyMyAtMTEgODIgMjdUNDAgMTUwVjE1OVE0MCAxODAgNDggMjE3VDk3IDQxNFExNDcgNjExIDE0NyA2MjNUMTA5IDYzN1ExMDQgNjM3IDEwMSA2MzdIOTZRODYgNjM3IDgzIDYzN1Q3NiA2NDBUNzMgNjQ3Wk0zMzYgMzI1VjMzMVEzMzYgNDA1IDI3NSA0MDVRMjU4IDQwNSAyNDAgMzk3VDIwNyAzNzZUMTgxIDM1MlQxNjMgMzMwTDE1NyAzMjJMMTM2IDIzNlExMTQgMTUwIDExNCAxMTRRMTE0IDY2IDEzOCA0MlExNTQgMjYgMTc4IDI2UTIxMSAyNiAyNDUgNThRMjcwIDgxIDI4NSAxMTRUMzE4IDIxOVEzMzYgMjkxIDMzNiAzMjVaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03QiIgZD0iTTQzNCAtMjMxUTQzNCAtMjQ0IDQyOCAtMjUwSDQxMFEyODEgLTI1MCAyMzAgLTE4NFEyMjUgLTE3NyAyMjIgLTE3MlQyMTcgLTE2MVQyMTMgLTE0OFQyMTEgLTEzM1QyMTAgLTExMVQyMDkgLTg0VDIwOSAtNDdUMjA5IDBRMjA5IDIxIDIwOSA1M1EyMDggMTQyIDIwNCAxNTNRMjAzIDE1NCAyMDMgMTU1UTE4OSAxOTEgMTUzIDIxMVQ4MiAyMzFRNzEgMjMxIDY4IDIzNFQ2NSAyNTBUNjggMjY2VDgyIDI2OVExMTYgMjY5IDE1MiAyODlUMjAzIDM0NVEyMDggMzU2IDIwOCAzNzdUMjA5IDUyOVY1NzlRMjA5IDYzNCAyMTUgNjU2VDI0NCA2OThRMjcwIDcyNCAzMjQgNzQwUTM2MSA3NDggMzc3IDc0OVEzNzkgNzQ5IDM5MCA3NDlUNDA4IDc1MEg0MjhRNDM0IDc0NCA0MzQgNzMyUTQzNCA3MTkgNDMxIDcxNlE0MjkgNzEzIDQxNSA3MTNRMzYyIDcxMCAzMzIgNjg5VDI5NiA2NDdRMjkxIDYzNCAyOTEgNDk5VjQxN1EyOTEgMzcwIDI4OCAzNTNUMjcxIDMxNFEyNDAgMjcxIDE4NCAyNTVMMTcwIDI1MEwxODQgMjQ1UTIwMiAyMzkgMjIwIDIzMFQyNjIgMTk2VDI5MCAxMzdRMjkxIDEzMSAyOTEgMVEyOTEgLTEzNCAyOTYgLTE0N1EzMDYgLTE3NCAzMzkgLTE5MlQ0MTUgLTIxM1E0MjkgLTIxMyA0MzEgLTIxNlE0MzQgLTIxOSA0MzQgLTIzMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzEiIGQ9Ik0zMyAxNTdRMzMgMjU4IDEwOSAzNDlUMjgwIDQ0MVEzNDAgNDQxIDM3MiAzODlRMzczIDM5MCAzNzcgMzk1VDM4OCA0MDZUNDA0IDQxOFE0MzggNDQyIDQ1MCA0NDJRNDU0IDQ0MiA0NTcgNDM5VDQ2MCA0MzRRNDYwIDQyNSAzOTEgMTQ5UTMyMCAtMTM1IDMyMCAtMTM5UTMyMCAtMTQ3IDM2NSAtMTQ4SDM5MFEzOTYgLTE1NiAzOTYgLTE1N1QzOTMgLTE3NVEzODkgLTE4OCAzODMgLTE5NEgzNzBRMzM5IC0xOTIgMjYyIC0xOTJRMjM0IC0xOTIgMjExIC0xOTJUMTc0IC0xOTJUMTU3IC0xOTNRMTQzIC0xOTMgMTQzIC0xODVRMTQzIC0xODIgMTQ1IC0xNzBRMTQ5IC0xNTQgMTUyIC0xNTFUMTcyIC0xNDhRMjIwIC0xNDggMjMwIC0xNDFRMjM4IC0xMzYgMjU4IC01M1QyNzkgMzJRMjc5IDMzIDI3MiAyOVEyMjQgLTEwIDE3MiAtMTBRMTE3IC0xMCA3NSAzMFQzMyAxNTdaTTM1MiAzMjZRMzI5IDQwNSAyNzcgNDA1UTI0MiA0MDUgMjEwIDM3NFQxNjAgMjkzUTEzMSAyMTQgMTE5IDEyOVExMTkgMTI2IDExOSAxMThUMTE4IDEwNlExMTggNjEgMTM2IDQ0VDE3OSAyNlEyMzMgMjYgMjkwIDk4TDI5OCAxMDlMMzUyIDMyNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdEIiBkPSJNNjUgNzMxUTY1IDc0NSA2OCA3NDdUODggNzUwUTE3MSA3NTAgMjE2IDcyNVQyNzkgNjcwUTI4OCA2NDkgMjg5IDYzNVQyOTEgNTAxUTI5MiAzNjIgMjkzIDM1N1EzMDYgMzEyIDM0NSAyOTFUNDE3IDI2OVE0MjggMjY5IDQzMSAyNjZUNDM0IDI1MFQ0MzEgMjM0VDQxNyAyMzFRMzgwIDIzMSAzNDUgMjEwVDI5OCAxNTdRMjkzIDE0MyAyOTIgMTIxVDI5MSAtMjhWLTc5UTI5MSAtMTM0IDI4NSAtMTU2VDI1NiAtMTk4UTIwMiAtMjUwIDg5IC0yNTBRNzEgLTI1MCA2OCAtMjQ3VDY1IC0yMzBRNjUgLTIyNCA2NSAtMjIzVDY2IC0yMThUNjkgLTIxNFQ3NyAtMjEzUTkxIC0yMTMgMTA4IC0yMTBUMTQ2IC0yMDBUMTgzIC0xNzdUMjA3IC0xMzlRMjA4IC0xMzQgMjA5IDNMMjEwIDEzOVEyMjMgMTk2IDI4MCAyMzBRMzE1IDI0NyAzMzAgMjUwUTMwNSAyNTcgMjgwIDI3MFEyMjUgMzA0IDIxMiAzNTJMMjEwIDM2MkwyMDkgNDk4UTIwOCA2MzUgMjA3IDY0MFExOTUgNjgwIDE1NCA2OTZUNzcgNzEzUTY4IDcxMyA2NyA3MTZUNjUgNzMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMi0yMjBGIiBkPSJNMjIwIDgxMlEyMjAgODEzIDIxOCA4MTlUMjE0IDgyOVQyMDggODQwVDE5OSA4NTNUMTg1IDg2NlQxNjYgODc4VDE0MCA4ODdUMTA3IDg5M1Q2NiA4OTZINTZWOTUwSDEyMjFWODk2SDEyMTFRMTA4MCA4OTYgMTA1OCA4MTJWLTMxMVExMDc2IC0zOTYgMTIxMSAtMzk2SDEyMjFWLTQ1MEg3MjVWLTM5Nkg3MzVRODY0IC0zOTYgODg4IC0zMTRRODg5IC0zMTIgODg5IC0zMTFWODk2SDM4OFYyOTJMMzg5IC0zMTFRNDA1IC0zOTYgNTQyIC0zOTZINTUyVi00NTBINTZWLTM5Nkg2NlExOTUgLTM5NiAyMTkgLTMxNFEyMjAgLTMxMiAyMjAgLTMxMVY4MTJaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjA4IiBkPSJNODQgMjUwUTg0IDM3MiAxNjYgNDUwVDM2MCA1MzlRMzYxIDUzOSAzNzcgNTM5VDQxOSA1NDBUNDY5IDU0MEg1NjhRNTgzIDUzMiA1ODMgNTIwUTU4MyA1MTEgNTcwIDUwMUw0NjYgNTAwUTM1NSA0OTkgMzI5IDQ5NFEyODAgNDgyIDI0MiA0NThUMTgzIDQwOVQxNDcgMzU0VDEyOSAzMDZUMTI0IDI3MlYyNzBINTY4UTU4MyAyNjIgNTgzIDI1MFQ1NjggMjMwSDEyNFYyMjhRMTI0IDIwNyAxMzQgMTc3VDE2NyAxMTJUMjMxIDQ4VDMyOCA3UTM1NSAxIDQ2NiAwSDU3MFE1ODMgLTEwIDU4MyAtMjBRNTgzIC0zMiA1NjggLTQwSDQ3MVE0NjQgLTQwIDQ0NiAtNDBUNDE3IC00MVEyNjIgLTQxIDE3MiA0NVE4NCAxMjcgODQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUzIiBkPSJNMzA4IDI0UTM2NyAyNCA0MTYgNzZUNDY2IDE5N1E0NjYgMjYwIDQxNCAyODRRMzA4IDMxMSAyNzggMzIxVDIzNiAzNDFRMTc2IDM4MyAxNzYgNDYyUTE3NiA1MjMgMjA4IDU3M1QyNzMgNjQ4UTMwMiA2NzMgMzQzIDY4OFQ0MDcgNzA0SDQxOEg0MjVRNTIxIDcwNCA1NjQgNjQwUTU2NSA2NDAgNTc3IDY1M1Q2MDMgNjgyVDYyMyA3MDRRNjI0IDcwNCA2MjcgNzA0VDYzMiA3MDVRNjQ1IDcwNSA2NDUgNjk4VDYxNyA1NzdUNTg1IDQ1OVQ1NjkgNDU2UTU0OSA0NTYgNTQ5IDQ2NVE1NDkgNDcxIDU1MCA0NzVRNTUwIDQ3OCA1NTEgNDk0VDU1MyA1MjBRNTUzIDU1NCA1NDQgNTc5VDUyNiA2MTZUNTAxIDY0MVE0NjUgNjYyIDQxOSA2NjJRMzYyIDY2MiAzMTMgNjE2VDI2MyA1MTBRMjYzIDQ4MCAyNzggNDU4VDMxOSA0MjdRMzIzIDQyNSAzODkgNDA4VDQ1NiAzOTBRNDkwIDM3OSA1MjIgMzQyVDU1NCAyNDJRNTU0IDIxNiA1NDYgMTg2UTU0MSAxNjQgNTI4IDEzN1Q0OTIgNzhUNDI2IDE4VDMzMiAtMjBRMzIwIC0yMiAyOTggLTIyUTE5OSAtMjIgMTQ0IDMzTDEzNCA0NEwxMDYgMTNRODMgLTE0IDc4IC0xOFQ2NSAtMjJRNTIgLTIyIDUyIC0xNFE1MiAtMTEgMTEwIDIyMVExMTIgMjI3IDEzMCAyMjdIMTQzUTE0OSAyMjEgMTQ5IDIxNlExNDkgMjE0IDE0OCAyMDdUMTQ0IDE4NlQxNDIgMTUzUTE0NCAxMTQgMTYwIDg3VDIwMyA0N1QyNTUgMjlUMzA4IDI0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0MiIGQ9Ik0xMzkgLTI0OUgxMzdRMTI1IC0yNDkgMTE5IC0yMzVWMjUxTDEyMCA3MzdRMTMwIDc1MCAxMzkgNzUwUTE1MiA3NTAgMTU5IDczNVYtMjM1UTE1MSAtMjQ5IDE0MSAtMjQ5SDEzOVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSI3NTEiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RiIgeD0iMTIwMyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTYyIiB4PSIxNjg4IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjI4NCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMTMyNyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcxIiB4PSIyMzgzIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSIzMzQ0IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI2NDA3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzQ2MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjBGIiB4PSI4MDgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC0xMTQ5KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iOTcwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjU3NCkiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxODExIiB5PSItMzYwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIwOCIgeD0iMjE0MiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE5ODYsMCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTMiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNTc0KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9Ijc1NSIgeT0iLTI1NCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIxMDUyNiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDExNDQ0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iNTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iOTcwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIyMDc5IiB5PSItNDA1Ij48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIyNDU4IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMTQ0NTgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNTM3NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMTMyNyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcxIiB4PSIyMzgzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QyIgeD0iMjg0NCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDMxMjIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9Ijk3MCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMjA3OSIgeT0iLTQwNSI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI1NTgwIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==)
因此:
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjM0Ljc0N2V4IiBoZWlnaHQ9IjUuNjc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4xNzFleDsiIHZpZXdCb3g9IjAgLTEwNzguNCAxNDk2MC42IDI0NDMuOCIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MiIgZD0iTTIzMCA2MzdRMjAzIDYzNyAxOTggNjM4VDE5MyA2NDlRMTkzIDY3NiAyMDQgNjgyUTIwNiA2ODMgMzc4IDY4M1E1NTAgNjgyIDU2NCA2ODBRNjIwIDY3MiA2NTggNjUyVDcxMiA2MDZUNzMzIDU2M1Q3MzkgNTI5UTczOSA0ODQgNzEwIDQ0NVQ2NDMgMzg1VDU3NiAzNTFUNTM4IDMzOEw1NDUgMzMzUTYxMiAyOTUgNjEyIDIyM1E2MTIgMjEyIDYwNyAxNjJUNjAyIDgwVjcxUTYwMiA1MyA2MDMgNDNUNjE0IDI1VDY0MCAxNlE2NjggMTYgNjg2IDM4VDcxMiA4NVE3MTcgOTkgNzIwIDEwMlQ3MzUgMTA1UTc1NSAxMDUgNzU1IDkzUTc1NSA3NSA3MzEgMzZRNjkzIC0yMSA2NDEgLTIxSDYzMlE1NzEgLTIxIDUzMSA0VDQ4NyA4MlE0ODcgMTA5IDUwMiAxNjZUNTE3IDIzOVE1MTcgMjkwIDQ3NCAzMTNRNDU5IDMyMCA0NDkgMzIxVDM3OCAzMjNIMzA5TDI3NyAxOTNRMjQ0IDYxIDI0NCA1OVEyNDQgNTUgMjQ1IDU0VDI1MiA1MFQyNjkgNDhUMzAyIDQ2SDMzM1EzMzkgMzggMzM5IDM3VDMzNiAxOVEzMzIgNiAzMjYgMEgzMTFRMjc1IDIgMTgwIDJRMTQ2IDIgMTE3IDJUNzEgMlQ1MCAxUTMzIDEgMzMgMTBRMzMgMTIgMzYgMjRRNDEgNDMgNDYgNDVRNTAgNDYgNjEgNDZINjdROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFEyODcgNjM1IDIzMCA2MzdaTTYzMCA1NTRRNjMwIDU4NiA2MDkgNjA4VDUyMyA2MzZRNTIxIDYzNiA1MDAgNjM2VDQ2MiA2MzdINDQwUTM5MyA2MzcgMzg2IDYyN1EzODUgNjI0IDM1MiA0OTRUMzE5IDM2MVEzMTkgMzYwIDM4OCAzNjBRNDY2IDM2MSA0OTIgMzY3UTU1NiAzNzcgNTkyIDQyNlE2MDggNDQ5IDYxOSA0ODZUNjMwIDU1NFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQ1IiBkPSJNNDkyIDIxM1E0NzIgMjEzIDQ3MiAyMjZRNDcyIDIzMCA0NzcgMjUwVDQ4MiAyODVRNDgyIDMxNiA0NjEgMzIzVDM2NCAzMzBIMzEyUTMxMSAzMjggMjc3IDE5MlQyNDMgNTJRMjQzIDQ4IDI1NCA0OFQzMzQgNDZRNDI4IDQ2IDQ1OCA0OFQ1MTggNjFRNTY3IDc3IDU5OSAxMTdUNjcwIDI0OFE2ODAgMjcwIDY4MyAyNzJRNjkwIDI3NCA2OTggMjc0UTcxOCAyNzQgNzE4IDI2MVE2MTMgNyA2MDggMlE2MDUgMCAzMjIgMEgxMzNRMzEgMCAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDYgNjYgMjE1IDM0MlQyODUgNjIyUTI4NSA2MjkgMjgxIDYyOVEyNzMgNjMyIDIyOCA2MzRIMTk3UTE5MSA2NDAgMTkxIDY0MlQxOTMgNjU5UTE5NyA2NzYgMjAzIDY4MEg3NTdRNzY0IDY3NiA3NjQgNjY5UTc2NCA2NjQgNzUxIDU1N1Q3MzcgNDQ3UTczNSA0NDAgNzE3IDQ0MEg3MDVRNjk4IDQ0NSA2OTggNDUzTDcwMSA0NzZRNzA0IDUwMCA3MDQgNTI4UTcwNCA1NTggNjk3IDU3OFQ2NzggNjA5VDY0MyA2MjVUNTk2IDYzMlQ1MzIgNjM0SDQ4NVEzOTcgNjMzIDM5MiA2MzFRMzg4IDYyOSAzODYgNjIyUTM4NSA2MTkgMzU1IDQ5OVQzMjQgMzc3UTM0NyAzNzYgMzcyIDM3NkgzOThRNDY0IDM3NiA0ODkgMzkxVDUzNCA0NzJRNTM4IDQ4OCA1NDAgNDkwVDU1NyA0OTNRNTYyIDQ5MyA1NjUgNDkzVDU3MCA0OTJUNTcyIDQ5MVQ1NzQgNDg3VDU3NyA0ODNMNTQ0IDM1MVE1MTEgMjE4IDUwOCAyMTZRNTA1IDIxMyA0OTIgMjEzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0IiIGQ9Ik00MzQgLTIzMVE0MzQgLTI0NCA0MjggLTI1MEg0MTBRMjgxIC0yNTAgMjMwIC0xODRRMjI1IC0xNzcgMjIyIC0xNzJUMjE3IC0xNjFUMjEzIC0xNDhUMjExIC0xMzNUMjEwIC0xMTFUMjA5IC04NFQyMDkgLTQ3VDIwOSAwUTIwOSAyMSAyMDkgNTNRMjA4IDE0MiAyMDQgMTUzUTIwMyAxNTQgMjAzIDE1NVExODkgMTkxIDE1MyAyMTFUODIgMjMxUTcxIDIzMSA2OCAyMzRUNjUgMjUwVDY4IDI2NlQ4MiAyNjlRMTE2IDI2OSAxNTIgMjg5VDIwMyAzNDVRMjA4IDM1NiAyMDggMzc3VDIwOSA1MjlWNTc5UTIwOSA2MzQgMjE1IDY1NlQyNDQgNjk4UTI3MCA3MjQgMzI0IDc0MFEzNjEgNzQ4IDM3NyA3NDlRMzc5IDc0OSAzOTAgNzQ5VDQwOCA3NTBINDI4UTQzNCA3NDQgNDM0IDczMlE0MzQgNzE5IDQzMSA3MTZRNDI5IDcxMyA0MTUgNzEzUTM2MiA3MTAgMzMyIDY4OVQyOTYgNjQ3UTI5MSA2MzQgMjkxIDQ5OVY0MTdRMjkxIDM3MCAyODggMzUzVDI3MSAzMTRRMjQwIDI3MSAxODQgMjU1TDE3MCAyNTBMMTg0IDI0NVEyMDIgMjM5IDIyMCAyMzBUMjYyIDE5NlQyOTAgMTM3UTI5MSAxMzEgMjkxIDFRMjkxIC0xMzQgMjk2IC0xNDdRMzA2IC0xNzQgMzM5IC0xOTJUNDE1IC0yMTNRNDI5IC0yMTMgNDMxIC0yMTZRNDM0IC0yMTkgNDM0IC0yMzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzIiIGQ9Ik0yMSAyODdRMjIgMjkwIDIzIDI5NVQyOCAzMTdUMzggMzQ4VDUzIDM4MVQ3MyA0MTFUOTkgNDMzVDEzMiA0NDJRMTYxIDQ0MiAxODMgNDMwVDIxNCA0MDhUMjI1IDM4OFEyMjcgMzgyIDIyOCAzODJUMjM2IDM4OVEyODQgNDQxIDM0NyA0NDFIMzUwUTM5OCA0NDEgNDIyIDQwMFE0MzAgMzgxIDQzMCAzNjNRNDMwIDMzMyA0MTcgMzE1VDM5MSAyOTJUMzY2IDI4OFEzNDYgMjg4IDMzNCAyOTlUMzIyIDMyOFEzMjIgMzc2IDM3OCAzOTJRMzU2IDQwNSAzNDIgNDA1UTI4NiA0MDUgMjM5IDMzMVEyMjkgMzE1IDIyNCAyOThUMTkwIDE2NVExNTYgMjUgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTQgMTg5VDE1NCAzNjZRMTU0IDQwNSAxMjggNDA1UTEwNyA0MDUgOTIgMzc3VDY4IDMxNlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oyLTIyMTEiIGQ9Ik02MCA5NDhRNjMgOTUwIDY2NSA5NTBIMTI2N0wxMzI1IDgxNVExMzg0IDY3NyAxMzg4IDY2OUgxMzQ4TDEzNDEgNjgzUTEzMjAgNzI0IDEyODUgNzYxUTEyMzUgODA5IDExNzQgODM4VDEwMzMgODgxVDg4MiA4OThUNjk5IDkwMkg1NzRINTQzSDI1MUwyNTkgODkxUTcyMiAyNTggNzI0IDI1MlE3MjUgMjUwIDcyNCAyNDZRNzIxIDI0MyA0NjAgLTU2TDE5NiAtMzU2UTE5NiAtMzU3IDQwNyAtMzU3UTQ1OSAtMzU3IDU0OCAtMzU3VDY3NiAtMzU4UTgxMiAtMzU4IDg5NiAtMzUzVDEwNjMgLTMzMlQxMjA0IC0yODNUMTMwNyAtMTk2UTEzMjggLTE3MCAxMzQ4IC0xMjRIMTM4OFExMzg4IC0xMjUgMTM4MSAtMTQ1VDEzNTYgLTIxMFQxMzI1IC0yOTRMMTI2NyAtNDQ5TDY2NiAtNDUwUTY0IC00NTAgNjEgLTQ0OFE1NSAtNDQ2IDU1IC00MzlRNTUgLTQzNyA1NyAtNDMzTDU5MCAxNzdRNTkwIDE3OCA1NTcgMjIyVDQ1MiAzNjZUMzIyIDU0NEw1NiA5MDlMNTUgOTI0UTU1IDk0NSA2MCA5NDhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzEiIGQ9Ik0zMyAxNTdRMzMgMjU4IDEwOSAzNDlUMjgwIDQ0MVEzNDAgNDQxIDM3MiAzODlRMzczIDM5MCAzNzcgMzk1VDM4OCA0MDZUNDA0IDQxOFE0MzggNDQyIDQ1MCA0NDJRNDU0IDQ0MiA0NTcgNDM5VDQ2MCA0MzRRNDYwIDQyNSAzOTEgMTQ5UTMyMCAtMTM1IDMyMCAtMTM5UTMyMCAtMTQ3IDM2NSAtMTQ4SDM5MFEzOTYgLTE1NiAzOTYgLTE1N1QzOTMgLTE3NVEzODkgLTE4OCAzODMgLTE5NEgzNzBRMzM5IC0xOTIgMjYyIC0xOTJRMjM0IC0xOTIgMjExIC0xOTJUMTc0IC0xOTJUMTU3IC0xOTNRMTQzIC0xOTMgMTQzIC0xODVRMTQzIC0xODIgMTQ1IC0xNzBRMTQ5IC0xNTQgMTUyIC0xNTFUMTcyIC0xNDhRMjIwIC0xNDggMjMwIC0xNDFRMjM4IC0xMzYgMjU4IC01M1QyNzkgMzJRMjc5IDMzIDI3MiAyOVEyMjQgLTEwIDE3MiAtMTBRMTE3IC0xMCA3NSAzMFQzMyAxNTdaTTM1MiAzMjZRMzI5IDQwNSAyNzcgNDA1UTI0MiA0MDUgMjEwIDM3NFQxNjAgMjkzUTEzMSAyMTQgMTE5IDEyOVExMTkgMTI2IDExOSAxMThUMTE4IDEwNlExMTggNjEgMTM2IDQ0VDE3OSAyNlEyMzMgMjYgMjkwIDk4TDI5OCAxMDlMMzUyIDMyNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MCIgZD0iTTI4NyA2MjhRMjg3IDYzNSAyMzAgNjM3UTIwNiA2MzcgMTk5IDYzOFQxOTIgNjQ4UTE5MiA2NDkgMTk0IDY1OVEyMDAgNjc5IDIwMyA2ODFUMzk3IDY4M1E1ODcgNjgyIDYwMCA2ODBRNjY0IDY2OSA3MDcgNjMxVDc1MSA1MzBRNzUxIDQ1MyA2ODUgMzg5UTYxNiAzMjEgNTA3IDMwM1E1MDAgMzAyIDQwMiAzMDFIMzA3TDI3NyAxODJRMjQ3IDY2IDI0NyA1OVEyNDcgNTUgMjQ4IDU0VDI1NSA1MFQyNzIgNDhUMzA1IDQ2SDMzNlEzNDIgMzcgMzQyIDM1UTM0MiAxOSAzMzUgNVEzMzAgMCAzMTkgMFEzMTYgMCAyODIgMVQxODIgMlExMjAgMiA4NyAyVDUxIDFRMzMgMSAzMyAxMVEzMyAxMyAzNiAyNVE0MCA0MSA0NCA0M1Q2NyA0NlE5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4Wk02NDUgNTU0UTY0NSA1NjcgNjQzIDU3NVQ2MzQgNTk3VDYwOSA2MTlUNTYwIDYzNVE1NTMgNjM2IDQ4MCA2MzdRNDYzIDYzNyA0NDUgNjM3VDQxNiA2MzZUNDA0IDYzNlEzOTEgNjM1IDM4NiA2MjdRMzg0IDYyMSAzNjcgNTUwVDMzMiA0MTJUMzE0IDM0NFEzMTQgMzQyIDM5NSAzNDJINDA3SDQzMFE1NDIgMzQyIDU5MCAzOTJRNjE3IDQxOSA2MzEgNDcxVDY0NSA1NTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkYiIGQ9Ik0yMDEgLTExUTEyNiAtMTEgODAgMzhUMzQgMTU2UTM0IDIyMSA2NCAyNzlUMTQ2IDM4MFEyMjIgNDQxIDMwMSA0NDFRMzMzIDQ0MSAzNDEgNDQwUTM1NCA0MzcgMzY3IDQzM1Q0MDIgNDE3VDQzOCAzODdUNDY0IDMzOFQ0NzYgMjY4UTQ3NiAxNjEgMzkwIDc1VDIwMSAtMTFaTTEyMSAxMjBRMTIxIDcwIDE0NyA0OFQyMDYgMjZRMjUwIDI2IDI4OSA1OFQzNTEgMTQyUTM2MCAxNjMgMzc0IDIxNlQzODggMzA4UTM4OCAzNTIgMzcwIDM3NVEzNDYgNDA1IDMwNiA0MDVRMjQzIDQwNSAxOTUgMzQ3UTE1OCAzMDMgMTQwIDIzMFQxMjEgMTIwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTYyIiBkPSJNNzMgNjQ3UTczIDY1NyA3NyA2NzBUODkgNjgzUTkwIDY4MyAxNjEgNjg4VDIzNCA2OTRRMjQ2IDY5NCAyNDYgNjg1VDIxMiA1NDJRMjA0IDUwOCAxOTUgNDcyVDE4MCA0MThMMTc2IDM5OVExNzYgMzk2IDE4MiA0MDJRMjMxIDQ0MiAyODMgNDQyUTM0NSA0NDIgMzgzIDM5NlQ0MjIgMjgwUTQyMiAxNjkgMzQzIDc5VDE3MyAtMTFRMTIzIC0xMSA4MiAyN1Q0MCAxNTBWMTU5UTQwIDE4MCA0OCAyMTdUOTcgNDE0UTE0NyA2MTEgMTQ3IDYyM1QxMDkgNjM3UTEwNCA2MzcgMTAxIDYzN0g5NlE4NiA2MzcgODMgNjM3VDc2IDY0MFQ3MyA2NDdaTTMzNiAzMjVWMzMxUTMzNiA0MDUgMjc1IDQwNVEyNTggNDA1IDI0MCAzOTdUMjA3IDM3NlQxODEgMzUyVDE2MyAzMzBMMTU3IDMyMkwxMzYgMjM2UTExNCAxNTAgMTE0IDExNFExMTQgNjYgMTM4IDQyUTE1NCAyNiAxNzggMjZRMjExIDI2IDI0NSA1OFEyNzAgODEgMjg1IDExNFQzMTggMjE5UTMzNiAyOTEgMzM2IDMyNVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjE0NjkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iMjUyNSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0NTYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iMTM4MyIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iNTYxOCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDY2NzUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MSIgeD0iNzkxIiB5PSItMTQ4NyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzEiIHg9IjgyODYiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iODk5NiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSI5NzQ4IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkYiIHg9IjEwMTk5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjIiIHg9IjEwNjg1IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTEyODEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjExNjEiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MSIgeD0iMjIxNyIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iMzE3OCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=)
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjM1LjkwNWV4IiBoZWlnaHQ9IjUuNjc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4xNzFleDsiIHZpZXdCb3g9IjAgLTEwNzguNCAxNTQ1OS4xIDI0NDMuOCIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MiIgZD0iTTIzMCA2MzdRMjAzIDYzNyAxOTggNjM4VDE5MyA2NDlRMTkzIDY3NiAyMDQgNjgyUTIwNiA2ODMgMzc4IDY4M1E1NTAgNjgyIDU2NCA2ODBRNjIwIDY3MiA2NTggNjUyVDcxMiA2MDZUNzMzIDU2M1Q3MzkgNTI5UTczOSA0ODQgNzEwIDQ0NVQ2NDMgMzg1VDU3NiAzNTFUNTM4IDMzOEw1NDUgMzMzUTYxMiAyOTUgNjEyIDIyM1E2MTIgMjEyIDYwNyAxNjJUNjAyIDgwVjcxUTYwMiA1MyA2MDMgNDNUNjE0IDI1VDY0MCAxNlE2NjggMTYgNjg2IDM4VDcxMiA4NVE3MTcgOTkgNzIwIDEwMlQ3MzUgMTA1UTc1NSAxMDUgNzU1IDkzUTc1NSA3NSA3MzEgMzZRNjkzIC0yMSA2NDEgLTIxSDYzMlE1NzEgLTIxIDUzMSA0VDQ4NyA4MlE0ODcgMTA5IDUwMiAxNjZUNTE3IDIzOVE1MTcgMjkwIDQ3NCAzMTNRNDU5IDMyMCA0NDkgMzIxVDM3OCAzMjNIMzA5TDI3NyAxOTNRMjQ0IDYxIDI0NCA1OVEyNDQgNTUgMjQ1IDU0VDI1MiA1MFQyNjkgNDhUMzAyIDQ2SDMzM1EzMzkgMzggMzM5IDM3VDMzNiAxOVEzMzIgNiAzMjYgMEgzMTFRMjc1IDIgMTgwIDJRMTQ2IDIgMTE3IDJUNzEgMlQ1MCAxUTMzIDEgMzMgMTBRMzMgMTIgMzYgMjRRNDEgNDMgNDYgNDVRNTAgNDYgNjEgNDZINjdROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFEyODcgNjM1IDIzMCA2MzdaTTYzMCA1NTRRNjMwIDU4NiA2MDkgNjA4VDUyMyA2MzZRNTIxIDYzNiA1MDAgNjM2VDQ2MiA2MzdINDQwUTM5MyA2MzcgMzg2IDYyN1EzODUgNjI0IDM1MiA0OTRUMzE5IDM2MVEzMTkgMzYwIDM4OCAzNjBRNDY2IDM2MSA0OTIgMzY3UTU1NiAzNzcgNTkyIDQyNlE2MDggNDQ5IDYxOSA0ODZUNjMwIDU1NFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDUiIGQ9Ik00OTIgMjEzUTQ3MiAyMTMgNDcyIDIyNlE0NzIgMjMwIDQ3NyAyNTBUNDgyIDI4NVE0ODIgMzE2IDQ2MSAzMjNUMzY0IDMzMEgzMTJRMzExIDMyOCAyNzcgMTkyVDI0MyA1MlEyNDMgNDggMjU0IDQ4VDMzNCA0NlE0MjggNDYgNDU4IDQ4VDUxOCA2MVE1NjcgNzcgNTk5IDExN1Q2NzAgMjQ4UTY4MCAyNzAgNjgzIDI3MlE2OTAgMjc0IDY5OCAyNzRRNzE4IDI3NCA3MTggMjYxUTYxMyA3IDYwOCAyUTYwNSAwIDMyMiAwSDEzM1EzMSAwIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc1N1E3NjQgNjc2IDc2NCA2NjlRNzY0IDY2NCA3NTEgNTU3VDczNyA0NDdRNzM1IDQ0MCA3MTcgNDQwSDcwNVE2OTggNDQ1IDY5OCA0NTNMNzAxIDQ3NlE3MDQgNTAwIDcwNCA1MjhRNzA0IDU1OCA2OTcgNTc4VDY3OCA2MDlUNjQzIDYyNVQ1OTYgNjMyVDUzMiA2MzRINDg1UTM5NyA2MzMgMzkyIDYzMVEzODggNjI5IDM4NiA2MjJRMzg1IDYxOSAzNTUgNDk5VDMyNCAzNzdRMzQ3IDM3NiAzNzIgMzc2SDM5OFE0NjQgMzc2IDQ4OSAzOTFUNTM0IDQ3MlE1MzggNDg4IDU0MCA0OTBUNTU3IDQ5M1E1NjIgNDkzIDU2NSA0OTNUNTcwIDQ5MlQ1NzIgNDkxVDU3NCA0ODdUNTc3IDQ4M0w1NDQgMzUxUTUxMSAyMTggNTA4IDIxNlE1MDUgMjEzIDQ5MiAyMTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03QiIgZD0iTTQzNCAtMjMxUTQzNCAtMjQ0IDQyOCAtMjUwSDQxMFEyODEgLTI1MCAyMzAgLTE4NFEyMjUgLTE3NyAyMjIgLTE3MlQyMTcgLTE2MVQyMTMgLTE0OFQyMTEgLTEzM1QyMTAgLTExMVQyMDkgLTg0VDIwOSAtNDdUMjA5IDBRMjA5IDIxIDIwOSA1M1EyMDggMTQyIDIwNCAxNTNRMjAzIDE1NCAyMDMgMTU1UTE4OSAxOTEgMTUzIDIxMVQ4MiAyMzFRNzEgMjMxIDY4IDIzNFQ2NSAyNTBUNjggMjY2VDgyIDI2OVExMTYgMjY5IDE1MiAyODlUMjAzIDM0NVEyMDggMzU2IDIwOCAzNzdUMjA5IDUyOVY1NzlRMjA5IDYzNCAyMTUgNjU2VDI0NCA2OThRMjcwIDcyNCAzMjQgNzQwUTM2MSA3NDggMzc3IDc0OVEzNzkgNzQ5IDM5MCA3NDlUNDA4IDc1MEg0MjhRNDM0IDc0NCA0MzQgNzMyUTQzNCA3MTkgNDMxIDcxNlE0MjkgNzEzIDQxNSA3MTNRMzYyIDcxMCAzMzIgNjg5VDI5NiA2NDdRMjkxIDYzNCAyOTEgNDk5VjQxN1EyOTEgMzcwIDI4OCAzNTNUMjcxIDMxNFEyNDAgMjcxIDE4NCAyNTVMMTcwIDI1MEwxODQgMjQ1UTIwMiAyMzkgMjIwIDIzMFQyNjIgMTk2VDI5MCAxMzdRMjkxIDEzMSAyOTEgMVEyOTEgLTEzNCAyOTYgLTE0N1EzMDYgLTE3NCAzMzkgLTE5MlQ0MTUgLTIxM1E0MjkgLTIxMyA0MzEgLTIxNlE0MzQgLTIxOSA0MzQgLTIzMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MiIgZD0iTTIxIDI4N1EyMiAyOTAgMjMgMjk1VDI4IDMxN1QzOCAzNDhUNTMgMzgxVDczIDQxMVQ5OSA0MzNUMTMyIDQ0MlExNjEgNDQyIDE4MyA0MzBUMjE0IDQwOFQyMjUgMzg4UTIyNyAzODIgMjI4IDM4MlQyMzYgMzg5UTI4NCA0NDEgMzQ3IDQ0MUgzNTBRMzk4IDQ0MSA0MjIgNDAwUTQzMCAzODEgNDMwIDM2M1E0MzAgMzMzIDQxNyAzMTVUMzkxIDI5MlQzNjYgMjg4UTM0NiAyODggMzM0IDI5OVQzMjIgMzI4UTMyMiAzNzYgMzc4IDM5MlEzNTYgNDA1IDM0MiA0MDVRMjg2IDQwNSAyMzkgMzMxUTIyOSAzMTUgMjI0IDI5OFQxOTAgMTY1UTE1NiAyNSAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExNCAxODlUMTU0IDM2NlExNTQgNDA1IDEyOCA0MDVRMTA3IDQwNSA5MiAzNzdUNjggMzE2VDU3IDI4MFE1NSAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03RCIgZD0iTTY1IDczMVE2NSA3NDUgNjggNzQ3VDg4IDc1MFExNzEgNzUwIDIxNiA3MjVUMjc5IDY3MFEyODggNjQ5IDI4OSA2MzVUMjkxIDUwMVEyOTIgMzYyIDI5MyAzNTdRMzA2IDMxMiAzNDUgMjkxVDQxNyAyNjlRNDI4IDI2OSA0MzEgMjY2VDQzNCAyNTBUNDMxIDIzNFQ0MTcgMjMxUTM4MCAyMzEgMzQ1IDIxMFQyOTggMTU3UTI5MyAxNDMgMjkyIDEyMVQyOTEgLTI4Vi03OVEyOTEgLTEzNCAyODUgLTE1NlQyNTYgLTE5OFEyMDIgLTI1MCA4OSAtMjUwUTcxIC0yNTAgNjggLTI0N1Q2NSAtMjMwUTY1IC0yMjQgNjUgLTIyM1Q2NiAtMjE4VDY5IC0yMTRUNzcgLTIxM1E5MSAtMjEzIDEwOCAtMjEwVDE0NiAtMjAwVDE4MyAtMTc3VDIwNyAtMTM5UTIwOCAtMTM0IDIwOSAzTDIxMCAxMzlRMjIzIDE5NiAyODAgMjMwUTMxNSAyNDcgMzMwIDI1MFEzMDUgMjU3IDI4MCAyNzBRMjI1IDMwNCAyMTIgMzUyTDIxMCAzNjJMMjA5IDQ5OFEyMDggNjM1IDIwNyA2NDBRMTk1IDY4MCAxNTQgNjk2VDc3IDcxM1E2OCA3MTMgNjcgNzE2VDY1IDczMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjIxMSIgZD0iTTYwIDk0OFE2MyA5NTAgNjY1IDk1MEgxMjY3TDEzMjUgODE1UTEzODQgNjc3IDEzODggNjY5SDEzNDhMMTM0MSA2ODNRMTMyMCA3MjQgMTI4NSA3NjFRMTIzNSA4MDkgMTE3NCA4MzhUMTAzMyA4ODFUODgyIDg5OFQ2OTkgOTAySDU3NEg1NDNIMjUxTDI1OSA4OTFRNzIyIDI1OCA3MjQgMjUyUTcyNSAyNTAgNzI0IDI0NlE3MjEgMjQzIDQ2MCAtNTZMMTk2IC0zNTZRMTk2IC0zNTcgNDA3IC0zNTdRNDU5IC0zNTcgNTQ4IC0zNTdUNjc2IC0zNThRODEyIC0zNTggODk2IC0zNTNUMTA2MyAtMzMyVDEyMDQgLTI4M1QxMzA3IC0xOTZRMTMyOCAtMTcwIDEzNDggLTEyNEgxMzg4UTEzODggLTEyNSAxMzgxIC0xNDVUMTM1NiAtMjEwVDEzMjUgLTI5NEwxMjY3IC00NDlMNjY2IC00NTBRNjQgLTQ1MCA2MSAtNDQ4UTU1IC00NDYgNTUgLTQzOVE1NSAtNDM3IDU3IC00MzNMNTkwIDE3N1E1OTAgMTc4IDU1NyAyMjJUNDUyIDM2NlQzMjIgNTQ0TDU2IDkwOUw1NSA5MjRRNTUgOTQ1IDYwIDk0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MSIgZD0iTTMzIDE1N1EzMyAyNTggMTA5IDM0OVQyODAgNDQxUTM0MCA0NDEgMzcyIDM4OVEzNzMgMzkwIDM3NyAzOTVUMzg4IDQwNlQ0MDQgNDE4UTQzOCA0NDIgNDUwIDQ0MlE0NTQgNDQyIDQ1NyA0MzlUNDYwIDQzNFE0NjAgNDI1IDM5MSAxNDlRMzIwIC0xMzUgMzIwIC0xMzlRMzIwIC0xNDcgMzY1IC0xNDhIMzkwUTM5NiAtMTU2IDM5NiAtMTU3VDM5MyAtMTc1UTM4OSAtMTg4IDM4MyAtMTk0SDM3MFEzMzkgLTE5MiAyNjIgLTE5MlEyMzQgLTE5MiAyMTEgLTE5MlQxNzQgLTE5MlQxNTcgLTE5M1ExNDMgLTE5MyAxNDMgLTE4NVExNDMgLTE4MiAxNDUgLTE3MFExNDkgLTE1NCAxNTIgLTE1MVQxNzIgLTE0OFEyMjAgLTE0OCAyMzAgLTE0MVEyMzggLTEzNiAyNTggLTUzVDI3OSAzMlEyNzkgMzMgMjcyIDI5UTIyNCAtMTAgMTcyIC0xMFExMTcgLTEwIDc1IDMwVDMzIDE1N1pNMzUyIDMyNlEzMjkgNDA1IDI3NyA0MDVRMjQyIDQwNSAyMTAgMzc0VDE2MCAyOTNRMTMxIDIxNCAxMTkgMTI5UTExOSAxMjYgMTE5IDExOFQxMTggMTA2UTExOCA2MSAxMzYgNDRUMTc5IDI2UTIzMyAyNiAyOTAgOThMMjk4IDEwOUwzNTIgMzI2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUwIiBkPSJNMjg3IDYyOFEyODcgNjM1IDIzMCA2MzdRMjA2IDYzNyAxOTkgNjM4VDE5MiA2NDhRMTkyIDY0OSAxOTQgNjU5UTIwMCA2NzkgMjAzIDY4MVQzOTcgNjgzUTU4NyA2ODIgNjAwIDY4MFE2NjQgNjY5IDcwNyA2MzFUNzUxIDUzMFE3NTEgNDUzIDY4NSAzODlRNjE2IDMyMSA1MDcgMzAzUTUwMCAzMDIgNDAyIDMwMUgzMDdMMjc3IDE4MlEyNDcgNjYgMjQ3IDU5UTI0NyA1NSAyNDggNTRUMjU1IDUwVDI3MiA0OFQzMDUgNDZIMzM2UTM0MiAzNyAzNDIgMzVRMzQyIDE5IDMzNSA1UTMzMCAwIDMxOSAwUTMxNiAwIDI4MiAxVDE4MiAyUTEyMCAyIDg3IDJUNTEgMVEzMyAxIDMzIDExUTMzIDEzIDM2IDI1UTQwIDQxIDQ0IDQzVDY3IDQ2UTk0IDQ2IDEyNyA0OVExNDEgNTIgMTQ2IDYxUTE0OSA2NSAyMTggMzM5VDI4NyA2MjhaTTY0NSA1NTRRNjQ1IDU2NyA2NDMgNTc1VDYzNCA1OTdUNjA5IDYxOVQ1NjAgNjM1UTU1MyA2MzYgNDgwIDYzN1E0NjMgNjM3IDQ0NSA2MzdUNDE2IDYzNlQ0MDQgNjM2UTM5MSA2MzUgMzg2IDYyN1EzODQgNjIxIDM2NyA1NTBUMzMyIDQxMlQzMTQgMzQ0UTMxNCAzNDIgMzk1IDM0Mkg0MDdINDMwUTU0MiAzNDIgNTkwIDM5MlE2MTcgNDE5IDYzMSA0NzFUNjQ1IDU1NFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RiIgZD0iTTIwMSAtMTFRMTI2IC0xMSA4MCAzOFQzNCAxNTZRMzQgMjIxIDY0IDI3OVQxNDYgMzgwUTIyMiA0NDEgMzAxIDQ0MVEzMzMgNDQxIDM0MSA0NDBRMzU0IDQzNyAzNjcgNDMzVDQwMiA0MTdUNDM4IDM4N1Q0NjQgMzM4VDQ3NiAyNjhRNDc2IDE2MSAzOTAgNzVUMjAxIC0xMVpNMTIxIDEyMFExMjEgNzAgMTQ3IDQ4VDIwNiAyNlEyNTAgMjYgMjg5IDU4VDM1MSAxNDJRMzYwIDE2MyAzNzQgMjE2VDM4OCAzMDhRMzg4IDM1MiAzNzAgMzc1UTM0NiA0MDUgMzA2IDQwNVEyNDMgNDA1IDE5NSAzNDdRMTU4IDMwMyAxNDAgMjMwVDEyMSAxMjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNjIiIGQ9Ik03MyA2NDdRNzMgNjU3IDc3IDY3MFQ4OSA2ODNROTAgNjgzIDE2MSA2ODhUMjM0IDY5NFEyNDYgNjk0IDI0NiA2ODVUMjEyIDU0MlEyMDQgNTA4IDE5NSA0NzJUMTgwIDQxOEwxNzYgMzk5UTE3NiAzOTYgMTgyIDQwMlEyMzEgNDQyIDI4MyA0NDJRMzQ1IDQ0MiAzODMgMzk2VDQyMiAyODBRNDIyIDE2OSAzNDMgNzlUMTczIC0xMVExMjMgLTExIDgyIDI3VDQwIDE1MFYxNTlRNDAgMTgwIDQ4IDIxN1Q5NyA0MTRRMTQ3IDYxMSAxNDcgNjIzVDEwOSA2MzdRMTA0IDYzNyAxMDEgNjM3SDk2UTg2IDYzNyA4MyA2MzdUNzYgNjQwVDczIDY0N1pNMzM2IDMyNVYzMzFRMzM2IDQwNSAyNzUgNDA1UTI1OCA0MDUgMjQwIDM5N1QyMDcgMzc2VDE4MSAzNTJUMTYzIDMzMEwxNTcgMzIyTDEzNiAyMzZRMTE0IDE1MCAxMTQgMTE0UTExNCA2NiAxMzggNDJRMTU0IDI2IDE3OCAyNlEyMTEgMjYgMjQ1IDU4UTI3MCA4MSAyODUgMTE0VDMxOCAyMTlRMzM2IDI5MSAzMzYgMzI1WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMTYzNSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIyNjkxIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzYyMiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSIxNTUwIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI1OTUxIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzAwNywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcxIiB4PSI3OTEiIHk9Ii0xNDg3Ij48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MSIgeD0iODYxOCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSI5MzI5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjEwMDgwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkYiIHg9IjEwNTMyIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjIiIHg9IjExMDE3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTE2MTMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjEzMjciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MSIgeD0iMjM4MyIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iMzM0NCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=)
同理,
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjU3LjU3ZXgiIGhlaWdodD0iNi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0zLjE3MWV4OyIgdmlld0JveD0iMCAtMTI5My43IDI0Nzg3LjEgMjY1OS4xIiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNTYiIGQ9Ik0xMTQgNjIwUTExMyA2MjEgMTEwIDYyNFQxMDcgNjI3VDEwMyA2MzBUOTggNjMyVDkxIDYzNFQ4MCA2MzVUNjcgNjM2VDQ4IDYzN0gxOVY2ODNIMjhRNDYgNjgwIDE1MiA2ODBRMjczIDY4MCAyOTQgNjgzSDMwNVY2MzdIMjg0UTIyMyA2MzQgMjIzIDYyMFEyMjMgNjE4IDMxMyAzNzJUNDA0IDEyNkw0OTAgMzU4UTU3NSA1ODggNTc1IDU5N1E1NzUgNjE2IDU1NCA2MjZUNTA4IDYzN0g1MDNWNjgzSDUxMlE1MjcgNjgwIDYyNyA2ODBRNzE4IDY4MCA3MjQgNjgzSDczMFY2MzdINzIzUTY0OCA2MzcgNjI3IDU5NlE2MjcgNTk1IDUxNSAyOTFUNDAxIC0xNFEzOTYgLTIyIDM4MiAtMjJIMzc0SDM2N1EzNTMgLTIyIDM0OCAtMTRRMzQ2IC0xMiAyMzEgMzAzUTExNCA2MTcgMTE0IDYyMFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTYxIiBkPSJNMTM3IDMwNVQxMTUgMzA1VDc4IDMyMFQ2MyAzNTlRNjMgMzk0IDk3IDQyMVQyMTggNDQ4UTI5MSA0NDggMzM2IDQxNlQzOTYgMzQwUTQwMSAzMjYgNDAxIDMwOVQ0MDIgMTk0VjEyNFE0MDIgNzYgNDA3IDU4VDQyOCA0MFE0NDMgNDAgNDQ4IDU2VDQ1MyAxMDlWMTQ1SDQ5M1YxMDZRNDkyIDY2IDQ5MCA1OVE0ODEgMjkgNDU1IDEyVDQwMCAtNlQzNTMgMTJUMzI5IDU0VjU4TDMyNyA1NVEzMjUgNTIgMzIyIDQ5VDMxNCA0MFQzMDIgMjlUMjg3IDE3VDI2OSA2VDI0NyAtMlQyMjEgLThUMTkwIC0xMVExMzAgLTExIDgyIDIwVDM0IDEwN1EzNCAxMjggNDEgMTQ3VDY4IDE4OFQxMTYgMjI1VDE5NCAyNTNUMzA0IDI2OEgzMThWMjkwUTMxOCAzMjQgMzEyIDM0MFEyOTAgNDExIDIxNSA0MTFRMTk3IDQxMSAxODEgNDEwVDE1NiA0MDZUMTQ4IDQwM1ExNzAgMzg4IDE3MCAzNTlRMTcwIDMzNCAxNTQgMzIwWk0xMjYgMTA2UTEyNiA3NSAxNTAgNTFUMjA5IDI2UTI0NyAyNiAyNzYgNDlUMzE1IDEwOVEzMTcgMTE2IDMxOCAxNzVRMzE4IDIzMyAzMTcgMjMzUTMwOSAyMzMgMjk2IDIzMlQyNTEgMjIzVDE5MyAyMDNUMTQ3IDE2NlQxMjYgMTA2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNzIiIGQ9Ik0zNiA0Nkg1MFE4OSA0NiA5NyA2MFY2OFE5NyA3NyA5NyA5MVQ5OCAxMjJUOTggMTYxVDk4IDIwM1E5OCAyMzQgOTggMjY5VDk4IDMyOEw5NyAzNTFROTQgMzcwIDgzIDM3NlQzOCAzODVIMjBWNDA4UTIwIDQzMSAyMiA0MzFMMzIgNDMyUTQyIDQzMyA2MCA0MzRUOTYgNDM2UTExMiA0MzcgMTMxIDQzOFQxNjAgNDQxVDE3MSA0NDJIMTc0VjM3M1EyMTMgNDQxIDI3MSA0NDFIMjc3UTMyMiA0NDEgMzQzIDQxOVQzNjQgMzczUTM2NCAzNTIgMzUxIDMzN1QzMTMgMzIyUTI4OCAzMjIgMjc2IDMzOFQyNjMgMzcyUTI2MyAzODEgMjY1IDM4OFQyNzAgNDAwVDI3MyA0MDVRMjcxIDQwNyAyNTAgNDAxUTIzNCAzOTMgMjI2IDM4NlExNzkgMzQxIDE3OSAyMDdWMTU0UTE3OSAxNDEgMTc5IDEyN1QxNzkgMTAxVDE4MCA4MVQxODAgNjZWNjFRMTgxIDU5IDE4MyA1N1QxODggNTRUMTkzIDUxVDIwMCA0OVQyMDcgNDhUMjE2IDQ3VDIyNSA0N1QyMzUgNDZUMjQ1IDQ2SDI3NlYwSDI2N1EyNDkgMyAxNDAgM1EzNyAzIDI4IDBIMjBWNDZIMzZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTcyIiBkPSJNMjEgMjg3UTIyIDI5MCAyMyAyOTVUMjggMzE3VDM4IDM0OFQ1MyAzODFUNzMgNDExVDk5IDQzM1QxMzIgNDQyUTE2MSA0NDIgMTgzIDQzMFQyMTQgNDA4VDIyNSAzODhRMjI3IDM4MiAyMjggMzgyVDIzNiAzODlRMjg0IDQ0MSAzNDcgNDQxSDM1MFEzOTggNDQxIDQyMiA0MDBRNDMwIDM4MSA0MzAgMzYzUTQzMCAzMzMgNDE3IDMxNVQzOTEgMjkyVDM2NiAyODhRMzQ2IDI4OCAzMzQgMjk5VDMyMiAzMjhRMzIyIDM3NiAzNzggMzkyUTM1NiA0MDUgMzQyIDQwNVEyODYgNDA1IDIzOSAzMzFRMjI5IDMxNSAyMjQgMjk4VDE5MCAxNjVRMTU2IDI1IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTE0IDE4OVQxNTQgMzY2UTE1NCA0MDUgMTI4IDQwNVExMDcgNDA1IDkyIDM3N1Q2OCAzMTZUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDUiIGQ9Ik00OTIgMjEzUTQ3MiAyMTMgNDcyIDIyNlE0NzIgMjMwIDQ3NyAyNTBUNDgyIDI4NVE0ODIgMzE2IDQ2MSAzMjNUMzY0IDMzMEgzMTJRMzExIDMyOCAyNzcgMTkyVDI0MyA1MlEyNDMgNDggMjU0IDQ4VDMzNCA0NlE0MjggNDYgNDU4IDQ4VDUxOCA2MVE1NjcgNzcgNTk5IDExN1Q2NzAgMjQ4UTY4MCAyNzAgNjgzIDI3MlE2OTAgMjc0IDY5OCAyNzRRNzE4IDI3NCA3MTggMjYxUTYxMyA3IDYwOCAyUTYwNSAwIDMyMiAwSDEzM1EzMSAwIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc1N1E3NjQgNjc2IDc2NCA2NjlRNzY0IDY2NCA3NTEgNTU3VDczNyA0NDdRNzM1IDQ0MCA3MTcgNDQwSDcwNVE2OTggNDQ1IDY5OCA0NTNMNzAxIDQ3NlE3MDQgNTAwIDcwNCA1MjhRNzA0IDU1OCA2OTcgNTc4VDY3OCA2MDlUNjQzIDYyNVQ1OTYgNjMyVDUzMiA2MzRINDg1UTM5NyA2MzMgMzkyIDYzMVEzODggNjI5IDM4NiA2MjJRMzg1IDYxOSAzNTUgNDk5VDMyNCAzNzdRMzQ3IDM3NiAzNzIgMzc2SDM5OFE0NjQgMzc2IDQ4OSAzOTFUNTM0IDQ3MlE1MzggNDg4IDU0MCA0OTBUNTU3IDQ5M1E1NjIgNDkzIDU2NSA0OTNUNTcwIDQ5MlQ1NzIgNDkxVDU3NCA0ODdUNTc3IDQ4M0w1NDQgMzUxUTUxMSAyMTggNTA4IDIxNlE1MDUgMjEzIDQ5MiAyMTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03QiIgZD0iTTQzNCAtMjMxUTQzNCAtMjQ0IDQyOCAtMjUwSDQxMFEyODEgLTI1MCAyMzAgLTE4NFEyMjUgLTE3NyAyMjIgLTE3MlQyMTcgLTE2MVQyMTMgLTE0OFQyMTEgLTEzM1QyMTAgLTExMVQyMDkgLTg0VDIwOSAtNDdUMjA5IDBRMjA5IDIxIDIwOSA1M1EyMDggMTQyIDIwNCAxNTNRMjAzIDE1NCAyMDMgMTU1UTE4OSAxOTEgMTUzIDIxMVQ4MiAyMzFRNzEgMjMxIDY4IDIzNFQ2NSAyNTBUNjggMjY2VDgyIDI2OVExMTYgMjY5IDE1MiAyODlUMjAzIDM0NVEyMDggMzU2IDIwOCAzNzdUMjA5IDUyOVY1NzlRMjA5IDYzNCAyMTUgNjU2VDI0NCA2OThRMjcwIDcyNCAzMjQgNzQwUTM2MSA3NDggMzc3IDc0OVEzNzkgNzQ5IDM5MCA3NDlUNDA4IDc1MEg0MjhRNDM0IDc0NCA0MzQgNzMyUTQzNCA3MTkgNDMxIDcxNlE0MjkgNzEzIDQxNSA3MTNRMzYyIDcxMCAzMzIgNjg5VDI5NiA2NDdRMjkxIDYzNCAyOTEgNDk5VjQxN1EyOTEgMzcwIDI4OCAzNTNUMjcxIDMxNFEyNDAgMjcxIDE4NCAyNTVMMTcwIDI1MEwxODQgMjQ1UTIwMiAyMzkgMjIwIDIzMFQyNjIgMTk2VDI5MCAxMzdRMjkxIDEzMSAyOTEgMVEyOTEgLTEzNCAyOTYgLTE0N1EzMDYgLTE3NCAzMzkgLTE5MlQ0MTUgLTIxM1E0MjkgLTIxMyA0MzEgLTIxNlE0MzQgLTIxOSA0MzQgLTIzMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMTIiIGQ9Ik04NCAyMzdUODQgMjUwVDk4IDI3MEg2NzlRNjk0IDI2MiA2OTQgMjUwVDY3OSAyMzBIOThRODQgMjM3IDg0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MiIgZD0iTTIzMCA2MzdRMjAzIDYzNyAxOTggNjM4VDE5MyA2NDlRMTkzIDY3NiAyMDQgNjgyUTIwNiA2ODMgMzc4IDY4M1E1NTAgNjgyIDU2NCA2ODBRNjIwIDY3MiA2NTggNjUyVDcxMiA2MDZUNzMzIDU2M1Q3MzkgNTI5UTczOSA0ODQgNzEwIDQ0NVQ2NDMgMzg1VDU3NiAzNTFUNTM4IDMzOEw1NDUgMzMzUTYxMiAyOTUgNjEyIDIyM1E2MTIgMjEyIDYwNyAxNjJUNjAyIDgwVjcxUTYwMiA1MyA2MDMgNDNUNjE0IDI1VDY0MCAxNlE2NjggMTYgNjg2IDM4VDcxMiA4NVE3MTcgOTkgNzIwIDEwMlQ3MzUgMTA1UTc1NSAxMDUgNzU1IDkzUTc1NSA3NSA3MzEgMzZRNjkzIC0yMSA2NDEgLTIxSDYzMlE1NzEgLTIxIDUzMSA0VDQ4NyA4MlE0ODcgMTA5IDUwMiAxNjZUNTE3IDIzOVE1MTcgMjkwIDQ3NCAzMTNRNDU5IDMyMCA0NDkgMzIxVDM3OCAzMjNIMzA5TDI3NyAxOTNRMjQ0IDYxIDI0NCA1OVEyNDQgNTUgMjQ1IDU0VDI1MiA1MFQyNjkgNDhUMzAyIDQ2SDMzM1EzMzkgMzggMzM5IDM3VDMzNiAxOVEzMzIgNiAzMjYgMEgzMTFRMjc1IDIgMTgwIDJRMTQ2IDIgMTE3IDJUNzEgMlQ1MCAxUTMzIDEgMzMgMTBRMzMgMTIgMzYgMjRRNDEgNDMgNDYgNDVRNTAgNDYgNjEgNDZINjdROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFEyODcgNjM1IDIzMCA2MzdaTTYzMCA1NTRRNjMwIDU4NiA2MDkgNjA4VDUyMyA2MzZRNTIxIDYzNiA1MDAgNjM2VDQ2MiA2MzdINDQwUTM5MyA2MzcgMzg2IDYyN1EzODUgNjI0IDM1MiA0OTRUMzE5IDM2MVEzMTkgMzYwIDM4OCAzNjBRNDY2IDM2MSA0OTIgMzY3UTU1NiAzNzcgNTkyIDQyNlE2MDggNDQ5IDYxOSA0ODZUNjMwIDU1NFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03RCIgZD0iTTY1IDczMVE2NSA3NDUgNjggNzQ3VDg4IDc1MFExNzEgNzUwIDIxNiA3MjVUMjc5IDY3MFEyODggNjQ5IDI4OSA2MzVUMjkxIDUwMVEyOTIgMzYyIDI5MyAzNTdRMzA2IDMxMiAzNDUgMjkxVDQxNyAyNjlRNDI4IDI2OSA0MzEgMjY2VDQzNCAyNTBUNDMxIDIzNFQ0MTcgMjMxUTM4MCAyMzEgMzQ1IDIxMFQyOTggMTU3UTI5MyAxNDMgMjkyIDEyMVQyOTEgLTI4Vi03OVEyOTEgLTEzNCAyODUgLTE1NlQyNTYgLTE5OFEyMDIgLTI1MCA4OSAtMjUwUTcxIC0yNTAgNjggLTI0N1Q2NSAtMjMwUTY1IC0yMjQgNjUgLTIyM1Q2NiAtMjE4VDY5IC0yMTRUNzcgLTIxM1E5MSAtMjEzIDEwOCAtMjEwVDE0NiAtMjAwVDE4MyAtMTc3VDIwNyAtMTM5UTIwOCAtMTM0IDIwOSAzTDIxMCAxMzlRMjIzIDE5NiAyODAgMjMwUTMxNSAyNDcgMzMwIDI1MFEzMDUgMjU3IDI4MCAyNzBRMjI1IDMwNCAyMTIgMzUyTDIxMCAzNjJMMjA5IDQ5OFEyMDggNjM1IDIwNyA2NDBRMTk1IDY4MCAxNTQgNjk2VDc3IDcxM1E2OCA3MTMgNjcgNzE2VDY1IDczMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItN0IiIGQ9Ik01NDcgLTY0M0w1NDEgLTY0OUg1MjhRNTE1IC02NDkgNTAzIC02NDVRMzI0IC01ODIgMjkzIC00NjZRMjg5IC00NDkgMjg5IC00MjhUMjg3IC0yMDBMMjg2IDQyTDI4NCA1M1EyNzQgOTggMjQ4IDEzNVQxOTYgMTkwVDE0NiAyMjJMMTIxIDIzNVExMTkgMjM5IDExOSAyNTBRMTE5IDI2MiAxMjEgMjY2VDEzMyAyNzNRMjYyIDMzNiAyODQgNDQ5TDI4NiA0NjBMMjg3IDcwMVEyODcgNzM3IDI4NyA3OTRRMjg4IDk0OSAyOTIgOTYzUTI5MyA5NjYgMjkzIDk2N1EzMjUgMTA4MCA1MDggMTE0OFE1MTYgMTE1MCA1MjcgMTE1MEg1NDFMNTQ3IDExNDRWMTEzMFE1NDcgMTExNyA1NDYgMTExNVQ1MzYgMTEwOVE0ODAgMTA4NiA0MzcgMTA0NlQzODEgOTUwTDM3OSA5NDBMMzc4IDY5OVEzNzggNjU3IDM3OCA1OTRRMzc3IDQ1MiAzNzQgNDM4UTM3MyA0MzcgMzczIDQzNlEzNTAgMzQ4IDI0MyAyODJRMTkyIDI1NyAxODYgMjU0TDE3NiAyNTFMMTg4IDI0NVEyMTEgMjM2IDIzNCAyMjNUMjg3IDE4OVQzNDAgMTM1VDM3MyA2NVEzNzMgNjQgMzc0IDYzUTM3NyA0OSAzNzggLTkzUTM3OCAtMTU2IDM3OCAtMTk4TDM3OSAtNDM4TDM4MSAtNDQ5UTM5MyAtNTA0IDQzNiAtNTQ0VDUzNiAtNjA4UTU0NCAtNjExIDU0NSAtNjEzVDU0NyAtNjI5Vi02NDNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oyLTdEIiBkPSJNMTE5IDExMzBRMTE5IDExNDQgMTIxIDExNDdUMTM1IDExNTBIMTM5UTE1MSAxMTUwIDE4MiAxMTM4VDI1MiAxMTA1VDMyNiAxMDQ2VDM3MyA5NjRRMzc4IDk0MiAzNzggNzAyUTM3OCA0NjkgMzc5IDQ2MlEzODYgMzk0IDQzOSAzMzlRNDgyIDI5NiA1MzUgMjcyUTU0NCAyNjggNTQ1IDI2NlQ1NDcgMjUxUTU0NyAyNDEgNTQ3IDIzOFQ1NDIgMjMxVDUzMSAyMjdUNTEwIDIxN1Q0NzcgMTk0UTM5MCAxMjkgMzc5IDM5UTM3OCAzMiAzNzggLTIwMVEzNzggLTQ0MSAzNzMgLTQ2M1EzNDIgLTU4MCAxNjUgLTY0NFExNTIgLTY0OSAxMzkgLTY0OVExMjUgLTY0OSAxMjIgLTY0NlQxMTkgLTYyOVExMTkgLTYyMiAxMTkgLTYxOVQxMjEgLTYxNFQxMjQgLTYxMFQxMzIgLTYwN1QxNDMgLTYwMlExOTUgLTU3OSAyMzUgLTUzOVQyODUgLTQ0N1EyODYgLTQzNSAyODcgLTE5OVQyODkgNTFRMjk0IDc0IDMwMCA5MVQzMjkgMTM4VDM5MCAxOTdRNDEyIDIxMyA0MzYgMjI2VDQ3NSAyNDRMNDg5IDI1MEw0NzIgMjU4UTQ1NSAyNjUgNDMwIDI3OVQzNzcgMzEzVDMyNyAzNjZUMjkzIDQzNFEyODkgNDUxIDI4OSA0NzJUMjg3IDY5OVEyODYgOTQxIDI4NSA5NDhRMjc5IDk3OCAyNjIgMTAwNVQyMjcgMTA0OFQxODQgMTA4MFQxNTEgMTEwMFQxMjkgMTEwOUwxMjcgMTExMFExMTkgMTExMyAxMTkgMTEzMFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjIxMSIgZD0iTTYwIDk0OFE2MyA5NTAgNjY1IDk1MEgxMjY3TDEzMjUgODE1UTEzODQgNjc3IDEzODggNjY5SDEzNDhMMTM0MSA2ODNRMTMyMCA3MjQgMTI4NSA3NjFRMTIzNSA4MDkgMTE3NCA4MzhUMTAzMyA4ODFUODgyIDg5OFQ2OTkgOTAySDU3NEg1NDNIMjUxTDI1OSA4OTFRNzIyIDI1OCA3MjQgMjUyUTcyNSAyNTAgNzI0IDI0NlE3MjEgMjQzIDQ2MCAtNTZMMTk2IC0zNTZRMTk2IC0zNTcgNDA3IC0zNTdRNDU5IC0zNTcgNTQ4IC0zNTdUNjc2IC0zNThRODEyIC0zNTggODk2IC0zNTNUMTA2MyAtMzMyVDEyMDQgLTI4M1QxMzA3IC0xOTZRMTMyOCAtMTcwIDEzNDggLTEyNEgxMzg4UTEzODggLTEyNSAxMzgxIC0xNDVUMTM1NiAtMjEwVDEzMjUgLTI5NEwxMjY3IC00NDlMNjY2IC00NTBRNjQgLTQ1MCA2MSAtNDQ4UTU1IC00NDYgNTUgLTQzOVE1NSAtNDM3IDU3IC00MzNMNTkwIDE3N1E1OTAgMTc4IDU1NyAyMjJUNDUyIDM2NlQzMjIgNTQ0TDU2IDkwOUw1NSA5MjRRNTUgOTQ1IDYwIDk0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MSIgZD0iTTMzIDE1N1EzMyAyNTggMTA5IDM0OVQyODAgNDQxUTM0MCA0NDEgMzcyIDM4OVEzNzMgMzkwIDM3NyAzOTVUMzg4IDQwNlQ0MDQgNDE4UTQzOCA0NDIgNDUwIDQ0MlE0NTQgNDQyIDQ1NyA0MzlUNDYwIDQzNFE0NjAgNDI1IDM5MSAxNDlRMzIwIC0xMzUgMzIwIC0xMzlRMzIwIC0xNDcgMzY1IC0xNDhIMzkwUTM5NiAtMTU2IDM5NiAtMTU3VDM5MyAtMTc1UTM4OSAtMTg4IDM4MyAtMTk0SDM3MFEzMzkgLTE5MiAyNjIgLTE5MlEyMzQgLTE5MiAyMTEgLTE5MlQxNzQgLTE5MlQxNTcgLTE5M1ExNDMgLTE5MyAxNDMgLTE4NVExNDMgLTE4MiAxNDUgLTE3MFExNDkgLTE1NCAxNTIgLTE1MVQxNzIgLTE0OFEyMjAgLTE0OCAyMzAgLTE0MVEyMzggLTEzNiAyNTggLTUzVDI3OSAzMlEyNzkgMzMgMjcyIDI5UTIyNCAtMTAgMTcyIC0xMFExMTcgLTEwIDc1IDMwVDMzIDE1N1pNMzUyIDMyNlEzMjkgNDA1IDI3NyA0MDVRMjQyIDQwNSAyMTAgMzc0VDE2MCAyOTNRMTMxIDIxNCAxMTkgMTI5UTExOSAxMjYgMTE5IDExOFQxMTggMTA2UTExOCA2MSAxMzYgNDRUMTc5IDI2UTIzMyAyNiAyOTAgOThMMjk4IDEwOUwzNTIgMzI2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUwIiBkPSJNMjg3IDYyOFEyODcgNjM1IDIzMCA2MzdRMjA2IDYzNyAxOTkgNjM4VDE5MiA2NDhRMTkyIDY0OSAxOTQgNjU5UTIwMCA2NzkgMjAzIDY4MVQzOTcgNjgzUTU4NyA2ODIgNjAwIDY4MFE2NjQgNjY5IDcwNyA2MzFUNzUxIDUzMFE3NTEgNDUzIDY4NSAzODlRNjE2IDMyMSA1MDcgMzAzUTUwMCAzMDIgNDAyIDMwMUgzMDdMMjc3IDE4MlEyNDcgNjYgMjQ3IDU5UTI0NyA1NSAyNDggNTRUMjU1IDUwVDI3MiA0OFQzMDUgNDZIMzM2UTM0MiAzNyAzNDIgMzVRMzQyIDE5IDMzNSA1UTMzMCAwIDMxOSAwUTMxNiAwIDI4MiAxVDE4MiAyUTEyMCAyIDg3IDJUNTEgMVEzMyAxIDMzIDExUTMzIDEzIDM2IDI1UTQwIDQxIDQ0IDQzVDY3IDQ2UTk0IDQ2IDEyNyA0OVExNDEgNTIgMTQ2IDYxUTE0OSA2NSAyMTggMzM5VDI4NyA2MjhaTTY0NSA1NTRRNjQ1IDU2NyA2NDMgNTc1VDYzNCA1OTdUNjA5IDYxOVQ1NjAgNjM1UTU1MyA2MzYgNDgwIDYzN1E0NjMgNjM3IDQ0NSA2MzdUNDE2IDYzNlQ0MDQgNjM2UTM5MSA2MzUgMzg2IDYyN1EzODQgNjIxIDM2NyA1NTBUMzMyIDQxMlQzMTQgMzQ0UTMxNCAzNDIgMzk1IDM0Mkg0MDdINDMwUTU0MiAzNDIgNTkwIDM5MlE2MTcgNDE5IDYzMSA0NzFUNjQ1IDU1NFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RiIgZD0iTTIwMSAtMTFRMTI2IC0xMSA4MCAzOFQzNCAxNTZRMzQgMjIxIDY0IDI3OVQxNDYgMzgwUTIyMiA0NDEgMzAxIDQ0MVEzMzMgNDQxIDM0MSA0NDBRMzU0IDQzNyAzNjcgNDMzVDQwMiA0MTdUNDM4IDM4N1Q0NjQgMzM4VDQ3NiAyNjhRNDc2IDE2MSAzOTAgNzVUMjAxIC0xMVpNMTIxIDEyMFExMjEgNzAgMTQ3IDQ4VDIwNiAyNlEyNTAgMjYgMjg5IDU4VDM1MSAxNDJRMzYwIDE2MyAzNzQgMjE2VDM4OCAzMDhRMzg4IDM1MiAzNzAgMzc1UTM0NiA0MDUgMzA2IDQwNVEyNDMgNDA1IDE5NSAzNDdRMTU4IDMwMyAxNDAgMjMwVDEyMSAxMjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNjIiIGQ9Ik03MyA2NDdRNzMgNjU3IDc3IDY3MFQ4OSA2ODNROTAgNjgzIDE2MSA2ODhUMjM0IDY5NFEyNDYgNjk0IDI0NiA2ODVUMjEyIDU0MlEyMDQgNTA4IDE5NSA0NzJUMTgwIDQxOEwxNzYgMzk5UTE3NiAzOTYgMTgyIDQwMlEyMzEgNDQyIDI4MyA0NDJRMzQ1IDQ0MiAzODMgMzk2VDQyMiAyODBRNDIyIDE2OSAzNDMgNzlUMTczIC0xMVExMjMgLTExIDgyIDI3VDQwIDE1MFYxNTlRNDAgMTgwIDQ4IDIxN1Q5NyA0MTRRMTQ3IDYxMSAxNDcgNjIzVDEwOSA2MzdRMTA0IDYzNyAxMDEgNjM3SDk2UTg2IDYzNyA4MyA2MzdUNzYgNjQwVDczIDY0N1pNMzM2IDMyNVYzMzFRMzM2IDQwNSAyNzUgNDA1UTI1OCA0MDUgMjQwIDM5N1QyMDcgMzc2VDE4MSAzNTJUMTYzIDMzMEwxNTcgMzIyTDEzNiAyMzZRMTE0IDE1MCAxMTQgMTE0UTExNCA2NiAxMzggNDJRMTU0IDI2IDE3OCAyNlEyMTEgMjYgMjQ1IDU4UTI3MCA4MSAyODUgMTE0VDMxOCAyMTlRMzM2IDI5MSAzMzYgMzI1WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNTYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI3NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTgxMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxMjcyIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIzNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9IjQ4MDYiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1NzM3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTdCIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjY3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI2MzgiIHk9Ii0yMTMiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjExMDUiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMTA2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMzY4NyIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI1NzY1IiB5PSI2NzUiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi03RCIgeD0iNTE5OCIgeT0iLTEiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjExODgxIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTI5MzcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MSIgeD0iNzkxIiB5PSItMTQ4NyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjE0NTQ4IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjE1MzAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkYiIHg9IjE1NzUxIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjIiIHg9IjE2MjM3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTY4MzMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjExNjEiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MSIgeD0iMjIxNyIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iMzE3OCIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjA2NzksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjY4MiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2ODMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIzMjY0IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjUxNjciIHk9IjY3NSI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=)
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjU5LjVleCIgaGVpZ2h0PSI2LjE3NmV4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTMuMTcxZXg7IiB2aWV3Qm94PSIwIC0xMjkzLjcgMjU2MTggMjY1OS4xIiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNTYiIGQ9Ik0xMTQgNjIwUTExMyA2MjEgMTEwIDYyNFQxMDcgNjI3VDEwMyA2MzBUOTggNjMyVDkxIDYzNFQ4MCA2MzVUNjcgNjM2VDQ4IDYzN0gxOVY2ODNIMjhRNDYgNjgwIDE1MiA2ODBRMjczIDY4MCAyOTQgNjgzSDMwNVY2MzdIMjg0UTIyMyA2MzQgMjIzIDYyMFEyMjMgNjE4IDMxMyAzNzJUNDA0IDEyNkw0OTAgMzU4UTU3NSA1ODggNTc1IDU5N1E1NzUgNjE2IDU1NCA2MjZUNTA4IDYzN0g1MDNWNjgzSDUxMlE1MjcgNjgwIDYyNyA2ODBRNzE4IDY4MCA3MjQgNjgzSDczMFY2MzdINzIzUTY0OCA2MzcgNjI3IDU5NlE2MjcgNTk1IDUxNSAyOTFUNDAxIC0xNFEzOTYgLTIyIDM4MiAtMjJIMzc0SDM2N1EzNTMgLTIyIDM0OCAtMTRRMzQ2IC0xMiAyMzEgMzAzUTExNCA2MTcgMTE0IDYyMFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTYxIiBkPSJNMTM3IDMwNVQxMTUgMzA1VDc4IDMyMFQ2MyAzNTlRNjMgMzk0IDk3IDQyMVQyMTggNDQ4UTI5MSA0NDggMzM2IDQxNlQzOTYgMzQwUTQwMSAzMjYgNDAxIDMwOVQ0MDIgMTk0VjEyNFE0MDIgNzYgNDA3IDU4VDQyOCA0MFE0NDMgNDAgNDQ4IDU2VDQ1MyAxMDlWMTQ1SDQ5M1YxMDZRNDkyIDY2IDQ5MCA1OVE0ODEgMjkgNDU1IDEyVDQwMCAtNlQzNTMgMTJUMzI5IDU0VjU4TDMyNyA1NVEzMjUgNTIgMzIyIDQ5VDMxNCA0MFQzMDIgMjlUMjg3IDE3VDI2OSA2VDI0NyAtMlQyMjEgLThUMTkwIC0xMVExMzAgLTExIDgyIDIwVDM0IDEwN1EzNCAxMjggNDEgMTQ3VDY4IDE4OFQxMTYgMjI1VDE5NCAyNTNUMzA0IDI2OEgzMThWMjkwUTMxOCAzMjQgMzEyIDM0MFEyOTAgNDExIDIxNSA0MTFRMTk3IDQxMSAxODEgNDEwVDE1NiA0MDZUMTQ4IDQwM1ExNzAgMzg4IDE3MCAzNTlRMTcwIDMzNCAxNTQgMzIwWk0xMjYgMTA2UTEyNiA3NSAxNTAgNTFUMjA5IDI2UTI0NyAyNiAyNzYgNDlUMzE1IDEwOVEzMTcgMTE2IDMxOCAxNzVRMzE4IDIzMyAzMTcgMjMzUTMwOSAyMzMgMjk2IDIzMlQyNTEgMjIzVDE5MyAyMDNUMTQ3IDE2NlQxMjYgMTA2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNzIiIGQ9Ik0zNiA0Nkg1MFE4OSA0NiA5NyA2MFY2OFE5NyA3NyA5NyA5MVQ5OCAxMjJUOTggMTYxVDk4IDIwM1E5OCAyMzQgOTggMjY5VDk4IDMyOEw5NyAzNTFROTQgMzcwIDgzIDM3NlQzOCAzODVIMjBWNDA4UTIwIDQzMSAyMiA0MzFMMzIgNDMyUTQyIDQzMyA2MCA0MzRUOTYgNDM2UTExMiA0MzcgMTMxIDQzOFQxNjAgNDQxVDE3MSA0NDJIMTc0VjM3M1EyMTMgNDQxIDI3MSA0NDFIMjc3UTMyMiA0NDEgMzQzIDQxOVQzNjQgMzczUTM2NCAzNTIgMzUxIDMzN1QzMTMgMzIyUTI4OCAzMjIgMjc2IDMzOFQyNjMgMzcyUTI2MyAzODEgMjY1IDM4OFQyNzAgNDAwVDI3MyA0MDVRMjcxIDQwNyAyNTAgNDAxUTIzNCAzOTMgMjI2IDM4NlExNzkgMzQxIDE3OSAyMDdWMTU0UTE3OSAxNDEgMTc5IDEyN1QxNzkgMTAxVDE4MCA4MVQxODAgNjZWNjFRMTgxIDU5IDE4MyA1N1QxODggNTRUMTkzIDUxVDIwMCA0OVQyMDcgNDhUMjE2IDQ3VDIyNSA0N1QyMzUgNDZUMjQ1IDQ2SDI3NlYwSDI2N1EyNDkgMyAxNDAgM1EzNyAzIDI4IDBIMjBWNDZIMzZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTcyIiBkPSJNMjEgMjg3UTIyIDI5MCAyMyAyOTVUMjggMzE3VDM4IDM0OFQ1MyAzODFUNzMgNDExVDk5IDQzM1QxMzIgNDQyUTE2MSA0NDIgMTgzIDQzMFQyMTQgNDA4VDIyNSAzODhRMjI3IDM4MiAyMjggMzgyVDIzNiAzODlRMjg0IDQ0MSAzNDcgNDQxSDM1MFEzOTggNDQxIDQyMiA0MDBRNDMwIDM4MSA0MzAgMzYzUTQzMCAzMzMgNDE3IDMxNVQzOTEgMjkyVDM2NiAyODhRMzQ2IDI4OCAzMzQgMjk5VDMyMiAzMjhRMzIyIDM3NiAzNzggMzkyUTM1NiA0MDUgMzQyIDQwNVEyODYgNDA1IDIzOSAzMzFRMjI5IDMxNSAyMjQgMjk4VDE5MCAxNjVRMTU2IDI1IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTE0IDE4OVQxNTQgMzY2UTE1NCA0MDUgMTI4IDQwNVExMDcgNDA1IDkyIDM3N1Q2OCAzMTZUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NSIgZD0iTTQ5MiAyMTNRNDcyIDIxMyA0NzIgMjI2UTQ3MiAyMzAgNDc3IDI1MFQ0ODIgMjg1UTQ4MiAzMTYgNDYxIDMyM1QzNjQgMzMwSDMxMlEzMTEgMzI4IDI3NyAxOTJUMjQzIDUyUTI0MyA0OCAyNTQgNDhUMzM0IDQ2UTQyOCA0NiA0NTggNDhUNTE4IDYxUTU2NyA3NyA1OTkgMTE3VDY3MCAyNDhRNjgwIDI3MCA2ODMgMjcyUTY5MCAyNzQgNjk4IDI3NFE3MTggMjc0IDcxOCAyNjFRNjEzIDcgNjA4IDJRNjA1IDAgMzIyIDBIMTMzUTMxIDAgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ2IDY2IDIxNSAzNDJUMjg1IDYyMlEyODUgNjI5IDI4MSA2MjlRMjczIDYzMiAyMjggNjM0SDE5N1ExOTEgNjQwIDE5MSA2NDJUMTkzIDY1OVExOTcgNjc2IDIwMyA2ODBINzU3UTc2NCA2NzYgNzY0IDY2OVE3NjQgNjY0IDc1MSA1NTdUNzM3IDQ0N1E3MzUgNDQwIDcxNyA0NDBINzA1UTY5OCA0NDUgNjk4IDQ1M0w3MDEgNDc2UTcwNCA1MDAgNzA0IDUyOFE3MDQgNTU4IDY5NyA1NzhUNjc4IDYwOVQ2NDMgNjI1VDU5NiA2MzJUNTMyIDYzNEg0ODVRMzk3IDYzMyAzOTIgNjMxUTM4OCA2MjkgMzg2IDYyMlEzODUgNjE5IDM1NSA0OTlUMzI0IDM3N1EzNDcgMzc2IDM3MiAzNzZIMzk4UTQ2NCAzNzYgNDg5IDM5MVQ1MzQgNDcyUTUzOCA0ODggNTQwIDQ5MFQ1NTcgNDkzUTU2MiA0OTMgNTY1IDQ5M1Q1NzAgNDkyVDU3MiA0OTFUNTc0IDQ4N1Q1NzcgNDgzTDU0NCAzNTFRNTExIDIxOCA1MDggMjE2UTUwNSAyMTMgNDkyIDIxM1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjIxMiIgZD0iTTg0IDIzN1Q4NCAyNTBUOTggMjcwSDY3OVE2OTQgMjYyIDY5NCAyNTBUNjc5IDIzMEg5OFE4NCAyMzcgODQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUyIiBkPSJNMjMwIDYzN1EyMDMgNjM3IDE5OCA2MzhUMTkzIDY0OVExOTMgNjc2IDIwNCA2ODJRMjA2IDY4MyAzNzggNjgzUTU1MCA2ODIgNTY0IDY4MFE2MjAgNjcyIDY1OCA2NTJUNzEyIDYwNlQ3MzMgNTYzVDczOSA1MjlRNzM5IDQ4NCA3MTAgNDQ1VDY0MyAzODVUNTc2IDM1MVQ1MzggMzM4TDU0NSAzMzNRNjEyIDI5NSA2MTIgMjIzUTYxMiAyMTIgNjA3IDE2MlQ2MDIgODBWNzFRNjAyIDUzIDYwMyA0M1Q2MTQgMjVUNjQwIDE2UTY2OCAxNiA2ODYgMzhUNzEyIDg1UTcxNyA5OSA3MjAgMTAyVDczNSAxMDVRNzU1IDEwNSA3NTUgOTNRNzU1IDc1IDczMSAzNlE2OTMgLTIxIDY0MSAtMjFINjMyUTU3MSAtMjEgNTMxIDRUNDg3IDgyUTQ4NyAxMDkgNTAyIDE2NlQ1MTcgMjM5UTUxNyAyOTAgNDc0IDMxM1E0NTkgMzIwIDQ0OSAzMjFUMzc4IDMyM0gzMDlMMjc3IDE5M1EyNDQgNjEgMjQ0IDU5UTI0NCA1NSAyNDUgNTRUMjUyIDUwVDI2OSA0OFQzMDIgNDZIMzMzUTMzOSAzOCAzMzkgMzdUMzM2IDE5UTMzMiA2IDMyNiAwSDMxMVEyNzUgMiAxODAgMlExNDYgMiAxMTcgMlQ3MSAyVDUwIDFRMzMgMSAzMyAxMFEzMyAxMiAzNiAyNFE0MSA0MyA0NiA0NVE1MCA0NiA2MSA0Nkg2N1E5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4UTI4NyA2MzUgMjMwIDYzN1pNNjMwIDU1NFE2MzAgNTg2IDYwOSA2MDhUNTIzIDYzNlE1MjEgNjM2IDUwMCA2MzZUNDYyIDYzN0g0NDBRMzkzIDYzNyAzODYgNjI3UTM4NSA2MjQgMzUyIDQ5NFQzMTkgMzYxUTMxOSAzNjAgMzg4IDM2MFE0NjYgMzYxIDQ5MiAzNjdRNTU2IDM3NyA1OTIgNDI2UTYwOCA0NDkgNjE5IDQ4NlQ2MzAgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzIiIGQ9Ik0xMDkgNDI5UTgyIDQyOSA2NiA0NDdUNTAgNDkxUTUwIDU2MiAxMDMgNjE0VDIzNSA2NjZRMzI2IDY2NiAzODcgNjEwVDQ0OSA0NjVRNDQ5IDQyMiA0MjkgMzgzVDM4MSAzMTVUMzAxIDI0MVEyNjUgMjEwIDIwMSAxNDlMMTQyIDkzTDIxOCA5MlEzNzUgOTIgMzg1IDk3UTM5MiA5OSA0MDkgMTg2VjE4OUg0NDlWMTg2UTQ0OCAxODMgNDM2IDk1VDQyMSAzVjBINTBWMTlWMzFRNTAgMzggNTYgNDZUODYgODFRMTE1IDExMyAxMzYgMTM3UTE0NSAxNDcgMTcwIDE3NFQyMDQgMjExVDIzMyAyNDRUMjYxIDI3OFQyODQgMzA4VDMwNSAzNDBUMzIwIDM2OVQzMzMgNDAxVDM0MCA0MzFUMzQzIDQ2NFEzNDMgNTI3IDMwOSA1NzNUMjEyIDYxOVExNzkgNjE5IDE1NCA2MDJUMTE5IDU2OVQxMDkgNTUwUTEwOSA1NDkgMTE0IDU0OVExMzIgNTQ5IDE1MSA1MzVUMTcwIDQ4OVExNzAgNDY0IDE1NCA0NDdUMTA5IDQyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdEIiBkPSJNNjUgNzMxUTY1IDc0NSA2OCA3NDdUODggNzUwUTE3MSA3NTAgMjE2IDcyNVQyNzkgNjcwUTI4OCA2NDkgMjg5IDYzNVQyOTEgNTAxUTI5MiAzNjIgMjkzIDM1N1EzMDYgMzEyIDM0NSAyOTFUNDE3IDI2OVE0MjggMjY5IDQzMSAyNjZUNDM0IDI1MFQ0MzEgMjM0VDQxNyAyMzFRMzgwIDIzMSAzNDUgMjEwVDI5OCAxNTdRMjkzIDE0MyAyOTIgMTIxVDI5MSAtMjhWLTc5UTI5MSAtMTM0IDI4NSAtMTU2VDI1NiAtMTk4UTIwMiAtMjUwIDg5IC0yNTBRNzEgLTI1MCA2OCAtMjQ3VDY1IC0yMzBRNjUgLTIyNCA2NSAtMjIzVDY2IC0yMThUNjkgLTIxNFQ3NyAtMjEzUTkxIC0yMTMgMTA4IC0yMTBUMTQ2IC0yMDBUMTgzIC0xNzdUMjA3IC0xMzlRMjA4IC0xMzQgMjA5IDNMMjEwIDEzOVEyMjMgMTk2IDI4MCAyMzBRMzE1IDI0NyAzMzAgMjUwUTMwNSAyNTcgMjgwIDI3MFEyMjUgMzA0IDIxMiAzNTJMMjEwIDM2MkwyMDkgNDk4UTIwOCA2MzUgMjA3IDY0MFExOTUgNjgwIDE1NCA2OTZUNzcgNzEzUTY4IDcxMyA2NyA3MTZUNjUgNzMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMi03QiIgZD0iTTU0NyAtNjQzTDU0MSAtNjQ5SDUyOFE1MTUgLTY0OSA1MDMgLTY0NVEzMjQgLTU4MiAyOTMgLTQ2NlEyODkgLTQ0OSAyODkgLTQyOFQyODcgLTIwMEwyODYgNDJMMjg0IDUzUTI3NCA5OCAyNDggMTM1VDE5NiAxOTBUMTQ2IDIyMkwxMjEgMjM1UTExOSAyMzkgMTE5IDI1MFExMTkgMjYyIDEyMSAyNjZUMTMzIDI3M1EyNjIgMzM2IDI4NCA0NDlMMjg2IDQ2MEwyODcgNzAxUTI4NyA3MzcgMjg3IDc5NFEyODggOTQ5IDI5MiA5NjNRMjkzIDk2NiAyOTMgOTY3UTMyNSAxMDgwIDUwOCAxMTQ4UTUxNiAxMTUwIDUyNyAxMTUwSDU0MUw1NDcgMTE0NFYxMTMwUTU0NyAxMTE3IDU0NiAxMTE1VDUzNiAxMTA5UTQ4MCAxMDg2IDQzNyAxMDQ2VDM4MSA5NTBMMzc5IDk0MEwzNzggNjk5UTM3OCA2NTcgMzc4IDU5NFEzNzcgNDUyIDM3NCA0MzhRMzczIDQzNyAzNzMgNDM2UTM1MCAzNDggMjQzIDI4MlExOTIgMjU3IDE4NiAyNTRMMTc2IDI1MUwxODggMjQ1UTIxMSAyMzYgMjM0IDIyM1QyODcgMTg5VDM0MCAxMzVUMzczIDY1UTM3MyA2NCAzNzQgNjNRMzc3IDQ5IDM3OCAtOTNRMzc4IC0xNTYgMzc4IC0xOThMMzc5IC00MzhMMzgxIC00NDlRMzkzIC01MDQgNDM2IC01NDRUNTM2IC02MDhRNTQ0IC02MTEgNTQ1IC02MTNUNTQ3IC02MjlWLTY0M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItN0QiIGQ9Ik0xMTkgMTEzMFExMTkgMTE0NCAxMjEgMTE0N1QxMzUgMTE1MEgxMzlRMTUxIDExNTAgMTgyIDExMzhUMjUyIDExMDVUMzI2IDEwNDZUMzczIDk2NFEzNzggOTQyIDM3OCA3MDJRMzc4IDQ2OSAzNzkgNDYyUTM4NiAzOTQgNDM5IDMzOVE0ODIgMjk2IDUzNSAyNzJRNTQ0IDI2OCA1NDUgMjY2VDU0NyAyNTFRNTQ3IDI0MSA1NDcgMjM4VDU0MiAyMzFUNTMxIDIyN1Q1MTAgMjE3VDQ3NyAxOTRRMzkwIDEyOSAzNzkgMzlRMzc4IDMyIDM3OCAtMjAxUTM3OCAtNDQxIDM3MyAtNDYzUTM0MiAtNTgwIDE2NSAtNjQ0UTE1MiAtNjQ5IDEzOSAtNjQ5UTEyNSAtNjQ5IDEyMiAtNjQ2VDExOSAtNjI5UTExOSAtNjIyIDExOSAtNjE5VDEyMSAtNjE0VDEyNCAtNjEwVDEzMiAtNjA3VDE0MyAtNjAyUTE5NSAtNTc5IDIzNSAtNTM5VDI4NSAtNDQ3UTI4NiAtNDM1IDI4NyAtMTk5VDI4OSA1MVEyOTQgNzQgMzAwIDkxVDMyOSAxMzhUMzkwIDE5N1E0MTIgMjEzIDQzNiAyMjZUNDc1IDI0NEw0ODkgMjUwTDQ3MiAyNThRNDU1IDI2NSA0MzAgMjc5VDM3NyAzMTNUMzI3IDM2NlQyOTMgNDM0UTI4OSA0NTEgMjg5IDQ3MlQyODcgNjk5UTI4NiA5NDEgMjg1IDk0OFEyNzkgOTc4IDI2MiAxMDA1VDIyNyAxMDQ4VDE4NCAxMDgwVDE1MSAxMTAwVDEyOSAxMTA5TDEyNyAxMTEwUTExOSAxMTEzIDExOSAxMTMwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMi0yMjExIiBkPSJNNjAgOTQ4UTYzIDk1MCA2NjUgOTUwSDEyNjdMMTMyNSA4MTVRMTM4NCA2NzcgMTM4OCA2NjlIMTM0OEwxMzQxIDY4M1ExMzIwIDcyNCAxMjg1IDc2MVExMjM1IDgwOSAxMTc0IDgzOFQxMDMzIDg4MVQ4ODIgODk4VDY5OSA5MDJINTc0SDU0M0gyNTFMMjU5IDg5MVE3MjIgMjU4IDcyNCAyNTJRNzI1IDI1MCA3MjQgMjQ2UTcyMSAyNDMgNDYwIC01NkwxOTYgLTM1NlExOTYgLTM1NyA0MDcgLTM1N1E0NTkgLTM1NyA1NDggLTM1N1Q2NzYgLTM1OFE4MTIgLTM1OCA4OTYgLTM1M1QxMDYzIC0zMzJUMTIwNCAtMjgzVDEzMDcgLTE5NlExMzI4IC0xNzAgMTM0OCAtMTI0SDEzODhRMTM4OCAtMTI1IDEzODEgLTE0NVQxMzU2IC0yMTBUMTMyNSAtMjk0TDEyNjcgLTQ0OUw2NjYgLTQ1MFE2NCAtNDUwIDYxIC00NDhRNTUgLTQ0NiA1NSAtNDM5UTU1IC00MzcgNTcgLTQzM0w1OTAgMTc3UTU5MCAxNzggNTU3IDIyMlQ0NTIgMzY2VDMyMiA1NDRMNTYgOTA5TDU1IDkyNFE1NSA5NDUgNjAgOTQ4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTcxIiBkPSJNMzMgMTU3UTMzIDI1OCAxMDkgMzQ5VDI4MCA0NDFRMzQwIDQ0MSAzNzIgMzg5UTM3MyAzOTAgMzc3IDM5NVQzODggNDA2VDQwNCA0MThRNDM4IDQ0MiA0NTAgNDQyUTQ1NCA0NDIgNDU3IDQzOVQ0NjAgNDM0UTQ2MCA0MjUgMzkxIDE0OVEzMjAgLTEzNSAzMjAgLTEzOVEzMjAgLTE0NyAzNjUgLTE0OEgzOTBRMzk2IC0xNTYgMzk2IC0xNTdUMzkzIC0xNzVRMzg5IC0xODggMzgzIC0xOTRIMzcwUTMzOSAtMTkyIDI2MiAtMTkyUTIzNCAtMTkyIDIxMSAtMTkyVDE3NCAtMTkyVDE1NyAtMTkzUTE0MyAtMTkzIDE0MyAtMTg1UTE0MyAtMTgyIDE0NSAtMTcwUTE0OSAtMTU0IDE1MiAtMTUxVDE3MiAtMTQ4UTIyMCAtMTQ4IDIzMCAtMTQxUTIzOCAtMTM2IDI1OCAtNTNUMjc5IDMyUTI3OSAzMyAyNzIgMjlRMjI0IC0xMCAxNzIgLTEwUTExNyAtMTAgNzUgMzBUMzMgMTU3Wk0zNTIgMzI2UTMyOSA0MDUgMjc3IDQwNVEyNDIgNDA1IDIxMCAzNzRUMTYwIDI5M1ExMzEgMjE0IDExOSAxMjlRMTE5IDEyNiAxMTkgMTE4VDExOCAxMDZRMTE4IDYxIDEzNiA0NFQxNzkgMjZRMjMzIDI2IDI5MCA5OEwyOTggMTA5TDM1MiAzMjZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTAiIGQ9Ik0yODcgNjI4UTI4NyA2MzUgMjMwIDYzN1EyMDYgNjM3IDE5OSA2MzhUMTkyIDY0OFExOTIgNjQ5IDE5NCA2NTlRMjAwIDY3OSAyMDMgNjgxVDM5NyA2ODNRNTg3IDY4MiA2MDAgNjgwUTY2NCA2NjkgNzA3IDYzMVQ3NTEgNTMwUTc1MSA0NTMgNjg1IDM4OVE2MTYgMzIxIDUwNyAzMDNRNTAwIDMwMiA0MDIgMzAxSDMwN0wyNzcgMTgyUTI0NyA2NiAyNDcgNTlRMjQ3IDU1IDI0OCA1NFQyNTUgNTBUMjcyIDQ4VDMwNSA0NkgzMzZRMzQyIDM3IDM0MiAzNVEzNDIgMTkgMzM1IDVRMzMwIDAgMzE5IDBRMzE2IDAgMjgyIDFUMTgyIDJRMTIwIDIgODcgMlQ1MSAxUTMzIDEgMzMgMTFRMzMgMTMgMzYgMjVRNDAgNDEgNDQgNDNUNjcgNDZROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFpNNjQ1IDU1NFE2NDUgNTY3IDY0MyA1NzVUNjM0IDU5N1Q2MDkgNjE5VDU2MCA2MzVRNTUzIDYzNiA0ODAgNjM3UTQ2MyA2MzcgNDQ1IDYzN1Q0MTYgNjM2VDQwNCA2MzZRMzkxIDYzNSAzODYgNjI3UTM4NCA2MjEgMzY3IDU1MFQzMzIgNDEyVDMxNCAzNDRRMzE0IDM0MiAzOTUgMzQySDQwN0g0MzBRNTQyIDM0MiA1OTAgMzkyUTYxNyA0MTkgNjMxIDQ3MVQ2NDUgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZGIiBkPSJNMjAxIC0xMVExMjYgLTExIDgwIDM4VDM0IDE1NlEzNCAyMjEgNjQgMjc5VDE0NiAzODBRMjIyIDQ0MSAzMDEgNDQxUTMzMyA0NDEgMzQxIDQ0MFEzNTQgNDM3IDM2NyA0MzNUNDAyIDQxN1Q0MzggMzg3VDQ2NCAzMzhUNDc2IDI2OFE0NzYgMTYxIDM5MCA3NVQyMDEgLTExWk0xMjEgMTIwUTEyMSA3MCAxNDcgNDhUMjA2IDI2UTI1MCAyNiAyODkgNThUMzUxIDE0MlEzNjAgMTYzIDM3NCAyMTZUMzg4IDMwOFEzODggMzUyIDM3MCAzNzVRMzQ2IDQwNSAzMDYgNDA1UTI0MyA0MDUgMTk1IDM0N1ExNTggMzAzIDE0MCAyMzBUMTIxIDEyMFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02MiIgZD0iTTczIDY0N1E3MyA2NTcgNzcgNjcwVDg5IDY4M1E5MCA2ODMgMTYxIDY4OFQyMzQgNjk0UTI0NiA2OTQgMjQ2IDY4NVQyMTIgNTQyUTIwNCA1MDggMTk1IDQ3MlQxODAgNDE4TDE3NiAzOTlRMTc2IDM5NiAxODIgNDAyUTIzMSA0NDIgMjgzIDQ0MlEzNDUgNDQyIDM4MyAzOTZUNDIyIDI4MFE0MjIgMTY5IDM0MyA3OVQxNzMgLTExUTEyMyAtMTEgODIgMjdUNDAgMTUwVjE1OVE0MCAxODAgNDggMjE3VDk3IDQxNFExNDcgNjExIDE0NyA2MjNUMTA5IDYzN1ExMDQgNjM3IDEwMSA2MzdIOTZRODYgNjM3IDgzIDYzN1Q3NiA2NDBUNzMgNjQ3Wk0zMzYgMzI1VjMzMVEzMzYgNDA1IDI3NSA0MDVRMjU4IDQwNSAyNDAgMzk3VDIwNyAzNzZUMTgxIDM1MlQxNjMgMzMwTDE1NyAzMjJMMTM2IDIzNlExMTQgMTUwIDExNCAxMTRRMTE0IDY2IDEzOCA0MlExNTQgMjYgMTc4IDI2UTIxMSAyNiAyNDUgNThRMjcwIDgxIDI4NSAxMTRUMzE4IDIxOVEzMzYgMjkxIDMzNiAzMjVaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODEwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI2MzgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjE0MzkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjM5MTYiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iNDk3MiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU5MDQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItN0IiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2NjcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMTI3MSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIyNzIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI0MDE5IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjYyMzUiIHk9IjY3NSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTdEIiB4PSI1NTMwIiB5PSItMSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMTIzNzkiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzQzNiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcxIiB4PSI3OTEiIHk9Ii0xNDg3Ij48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMTUwNDciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMTU3OTgiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RiIgeD0iMTYyNTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02MiIgeD0iMTY3MzUiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNzMzMiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMTMyNyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcxIiB4PSIyMzgzIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSIzMzQ0IiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMTM0MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iNjgyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTY4MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjM0MzAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iNTQwMiIgeT0iNjc1Ij48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==)
如果原始的马尔可夫链中奖励是状态转移的确定性函数,那么存在与每个 相关的单个 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEuODQ4ZXgiIGhlaWdodD0iMi4wMDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyIgdmlld0JveD0iMCAtNTc2LjEgNzk1LjggODY1LjEiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzIiIGQ9Ik0yMSAyODdRMjIgMjkwIDIzIDI5NVQyOCAzMTdUMzggMzQ4VDUzIDM4MVQ3MyA0MTFUOTkgNDMzVDEzMiA0NDJRMTYxIDQ0MiAxODMgNDMwVDIxNCA0MDhUMjI1IDM4OFEyMjcgMzgyIDIyOCAzODJUMjM2IDM4OVEyODQgNDQxIDM0NyA0NDFIMzUwUTM5OCA0NDEgNDIyIDQwMFE0MzAgMzgxIDQzMCAzNjNRNDMwIDMzMyA0MTcgMzE1VDM5MSAyOTJUMzY2IDI4OFEzNDYgMjg4IDMzNCAyOTlUMzIyIDMyOFEzMjIgMzc2IDM3OCAzOTJRMzU2IDQwNSAzNDIgNDA1UTI4NiA0MDUgMjM5IDMzMVEyMjkgMzE1IDIyNCAyOThUMTkwIDE2NVExNTYgMjUgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTQgMTg5VDE1NCAzNjZRMTU0IDQwNSAxMjggNDA1UTEwNyA0MDUgOTIgMzc3VDY4IDMxNlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY5IiBkPSJNMTg0IDYwMFExODQgNjI0IDIwMyA2NDJUMjQ3IDY2MVEyNjUgNjYxIDI3NyA2NDlUMjkwIDYxOVEyOTAgNTk2IDI3MCA1NzdUMjI2IDU1N1EyMTEgNTU3IDE5OCA1NjdUMTg0IDYwMFpNMjEgMjg3UTIxIDI5NSAzMCAzMThUNTQgMzY5VDk4IDQyMFQxNTggNDQyUTE5NyA0NDIgMjIzIDQxOVQyNTAgMzU3UTI1MCAzNDAgMjM2IDMwMVQxOTYgMTk2VDE1NCA4M1ExNDkgNjEgMTQ5IDUxUTE0OSAyNiAxNjYgMjZRMTc1IDI2IDE4NSAyOVQyMDggNDNUMjM1IDc4VDI2MCAxMzdRMjYzIDE0OSAyNjUgMTUxVDI4MiAxNTNRMzAyIDE1MyAzMDIgMTQzUTMwMiAxMzUgMjkzIDExMlQyNjggNjFUMjIzIDExVDE2MSAtMTFRMTI5IC0xMSAxMDIgMTBUNzQgNzRRNzQgOTEgNzkgMTA2VDEyMiAyMjBRMTYwIDMyMSAxNjYgMzQxVDE3MyAzODBRMTczIDQwNCAxNTYgNDA0SDE1NFExMjQgNDA0IDk5IDM3MVQ2MSAyODdRNjAgMjg2IDU5IDI4NFQ1OCAyODFUNTYgMjc5VDUzIDI3OFQ0OSAyNzhUNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9zdmc+) 。但是,如果原始的马尔可夫链中奖励是随机的,那么存在与每个 相关的一组可能的随机 。还值得注意的是,即使原始的马尔可夫链中的所有个体的奖励都是确定性的,
。但是,如果原始的马尔可夫链中奖励是随机的,那么存在与每个 相关的一组可能的随机 。还值得注意的是,即使原始的马尔可夫链中的所有个体的奖励都是确定性的, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjguMDY2ZXgiIGhlaWdodD0iMi44NDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjgzOGV4OyIgdmlld0JveD0iMCAtODYzLjEgMzQ3Mi43IDEyMjMuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTU2IiBkPSJNMTE0IDYyMFExMTMgNjIxIDExMCA2MjRUMTA3IDYyN1QxMDMgNjMwVDk4IDYzMlQ5MSA2MzRUODAgNjM1VDY3IDYzNlQ0OCA2MzdIMTlWNjgzSDI4UTQ2IDY4MCAxNTIgNjgwUTI3MyA2ODAgMjk0IDY4M0gzMDVWNjM3SDI4NFEyMjMgNjM0IDIyMyA2MjBRMjIzIDYxOCAzMTMgMzcyVDQwNCAxMjZMNDkwIDM1OFE1NzUgNTg4IDU3NSA1OTdRNTc1IDYxNiA1NTQgNjI2VDUwOCA2MzdINTAzVjY4M0g1MTJRNTI3IDY4MCA2MjcgNjgwUTcxOCA2ODAgNzI0IDY4M0g3MzBWNjM3SDcyM1E2NDggNjM3IDYyNyA1OTZRNjI3IDU5NSA1MTUgMjkxVDQwMSAtMTRRMzk2IC0yMiAzODIgLTIySDM3NEgzNjdRMzUzIC0yMiAzNDggLTE0UTM0NiAtMTIgMjMxIDMwM1ExMTQgNjE3IDExNCA2MjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi02MSIgZD0iTTEzNyAzMDVUMTE1IDMwNVQ3OCAzMjBUNjMgMzU5UTYzIDM5NCA5NyA0MjFUMjE4IDQ0OFEyOTEgNDQ4IDMzNiA0MTZUMzk2IDM0MFE0MDEgMzI2IDQwMSAzMDlUNDAyIDE5NFYxMjRRNDAyIDc2IDQwNyA1OFQ0MjggNDBRNDQzIDQwIDQ0OCA1NlQ0NTMgMTA5VjE0NUg0OTNWMTA2UTQ5MiA2NiA0OTAgNTlRNDgxIDI5IDQ1NSAxMlQ0MDAgLTZUMzUzIDEyVDMyOSA1NFY1OEwzMjcgNTVRMzI1IDUyIDMyMiA0OVQzMTQgNDBUMzAyIDI5VDI4NyAxN1QyNjkgNlQyNDcgLTJUMjIxIC04VDE5MCAtMTFRMTMwIC0xMSA4MiAyMFQzNCAxMDdRMzQgMTI4IDQxIDE0N1Q2OCAxODhUMTE2IDIyNVQxOTQgMjUzVDMwNCAyNjhIMzE4VjI5MFEzMTggMzI0IDMxMiAzNDBRMjkwIDQxMSAyMTUgNDExUTE5NyA0MTEgMTgxIDQxMFQxNTYgNDA2VDE0OCA0MDNRMTcwIDM4OCAxNzAgMzU5UTE3MCAzMzQgMTU0IDMyMFpNMTI2IDEwNlExMjYgNzUgMTUwIDUxVDIwOSAyNlEyNDcgMjYgMjc2IDQ5VDMxNSAxMDlRMzE3IDExNiAzMTggMTc1UTMxOCAyMzMgMzE3IDIzM1EzMDkgMjMzIDI5NiAyMzJUMjUxIDIyM1QxOTMgMjAzVDE0NyAxNjZUMTI2IDEwNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTcyIiBkPSJNMzYgNDZINTBRODkgNDYgOTcgNjBWNjhROTcgNzcgOTcgOTFUOTggMTIyVDk4IDE2MVQ5OCAyMDNROTggMjM0IDk4IDI2OVQ5OCAzMjhMOTcgMzUxUTk0IDM3MCA4MyAzNzZUMzggMzg1SDIwVjQwOFEyMCA0MzEgMjIgNDMxTDMyIDQzMlE0MiA0MzMgNjAgNDM0VDk2IDQzNlExMTIgNDM3IDEzMSA0MzhUMTYwIDQ0MVQxNzEgNDQySDE3NFYzNzNRMjEzIDQ0MSAyNzEgNDQxSDI3N1EzMjIgNDQxIDM0MyA0MTlUMzY0IDM3M1EzNjQgMzUyIDM1MSAzMzdUMzEzIDMyMlEyODggMzIyIDI3NiAzMzhUMjYzIDM3MlEyNjMgMzgxIDI2NSAzODhUMjcwIDQwMFQyNzMgNDA1UTI3MSA0MDcgMjUwIDQwMVEyMzQgMzkzIDIyNiAzODZRMTc5IDM0MSAxNzkgMjA3VjE1NFExNzkgMTQxIDE3OSAxMjdUMTc5IDEwMVQxODAgODFUMTgwIDY2VjYxUTE4MSA1OSAxODMgNTdUMTg4IDU0VDE5MyA1MVQyMDAgNDlUMjA3IDQ4VDIxNiA0N1QyMjUgNDdUMjM1IDQ2VDI0NSA0NkgyNzZWMEgyNjdRMjQ5IDMgMTQwIDNRMzcgMyAyOCAwSDIwVjQ2SDM2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MiIgZD0iTTIxIDI4N1EyMiAyOTAgMjMgMjk1VDI4IDMxN1QzOCAzNDhUNTMgMzgxVDczIDQxMVQ5OSA0MzNUMTMyIDQ0MlExNjEgNDQyIDE4MyA0MzBUMjE0IDQwOFQyMjUgMzg4UTIyNyAzODIgMjI4IDM4MlQyMzYgMzg5UTI4NCA0NDEgMzQ3IDQ0MUgzNTBRMzk4IDQ0MSA0MjIgNDAwUTQzMCAzODEgNDMwIDM2M1E0MzAgMzMzIDQxNyAzMTVUMzkxIDI5MlQzNjYgMjg4UTM0NiAyODggMzM0IDI5OVQzMjIgMzI4UTMyMiAzNzYgMzc4IDM5MlEzNTYgNDA1IDM0MiA0MDVRMjg2IDQwNSAyMzkgMzMxUTIyOSAzMTUgMjI0IDI5OFQxOTAgMTY1UTE1NiAyNSAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExNCAxODlUMTU0IDM2NlExNTQgNDA1IDEyOCA0MDVRMTA3IDQwNSA5MiAzNzdUNjggMzE2VDU3IDI4MFE1NSAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE4MTAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTI3MiIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=) 和
和 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjguNDUxZXgiIGhlaWdodD0iMi44NDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjgzOGV4OyIgdmlld0JveD0iMCAtODYzLjEgMzYzOC44IDEyMjMuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTU2IiBkPSJNMTE0IDYyMFExMTMgNjIxIDExMCA2MjRUMTA3IDYyN1QxMDMgNjMwVDk4IDYzMlQ5MSA2MzRUODAgNjM1VDY3IDYzNlQ0OCA2MzdIMTlWNjgzSDI4UTQ2IDY4MCAxNTIgNjgwUTI3MyA2ODAgMjk0IDY4M0gzMDVWNjM3SDI4NFEyMjMgNjM0IDIyMyA2MjBRMjIzIDYxOCAzMTMgMzcyVDQwNCAxMjZMNDkwIDM1OFE1NzUgNTg4IDU3NSA1OTdRNTc1IDYxNiA1NTQgNjI2VDUwOCA2MzdINTAzVjY4M0g1MTJRNTI3IDY4MCA2MjcgNjgwUTcxOCA2ODAgNzI0IDY4M0g3MzBWNjM3SDcyM1E2NDggNjM3IDYyNyA1OTZRNjI3IDU5NSA1MTUgMjkxVDQwMSAtMTRRMzk2IC0yMiAzODIgLTIySDM3NEgzNjdRMzUzIC0yMiAzNDggLTE0UTM0NiAtMTIgMjMxIDMwM1ExMTQgNjE3IDExNCA2MjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi02MSIgZD0iTTEzNyAzMDVUMTE1IDMwNVQ3OCAzMjBUNjMgMzU5UTYzIDM5NCA5NyA0MjFUMjE4IDQ0OFEyOTEgNDQ4IDMzNiA0MTZUMzk2IDM0MFE0MDEgMzI2IDQwMSAzMDlUNDAyIDE5NFYxMjRRNDAyIDc2IDQwNyA1OFQ0MjggNDBRNDQzIDQwIDQ0OCA1NlQ0NTMgMTA5VjE0NUg0OTNWMTA2UTQ5MiA2NiA0OTAgNTlRNDgxIDI5IDQ1NSAxMlQ0MDAgLTZUMzUzIDEyVDMyOSA1NFY1OEwzMjcgNTVRMzI1IDUyIDMyMiA0OVQzMTQgNDBUMzAyIDI5VDI4NyAxN1QyNjkgNlQyNDcgLTJUMjIxIC04VDE5MCAtMTFRMTMwIC0xMSA4MiAyMFQzNCAxMDdRMzQgMTI4IDQxIDE0N1Q2OCAxODhUMTE2IDIyNVQxOTQgMjUzVDMwNCAyNjhIMzE4VjI5MFEzMTggMzI0IDMxMiAzNDBRMjkwIDQxMSAyMTUgNDExUTE5NyA0MTEgMTgxIDQxMFQxNTYgNDA2VDE0OCA0MDNRMTcwIDM4OCAxNzAgMzU5UTE3MCAzMzQgMTU0IDMyMFpNMTI2IDEwNlExMjYgNzUgMTUwIDUxVDIwOSAyNlEyNDcgMjYgMjc2IDQ5VDMxNSAxMDlRMzE3IDExNiAzMTggMTc1UTMxOCAyMzMgMzE3IDIzM1EzMDkgMjMzIDI5NiAyMzJUMjUxIDIyM1QxOTMgMjAzVDE0NyAxNjZUMTI2IDEwNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTcyIiBkPSJNMzYgNDZINTBRODkgNDYgOTcgNjBWNjhROTcgNzcgOTcgOTFUOTggMTIyVDk4IDE2MVQ5OCAyMDNROTggMjM0IDk4IDI2OVQ5OCAzMjhMOTcgMzUxUTk0IDM3MCA4MyAzNzZUMzggMzg1SDIwVjQwOFEyMCA0MzEgMjIgNDMxTDMyIDQzMlE0MiA0MzMgNjAgNDM0VDk2IDQzNlExMTIgNDM3IDEzMSA0MzhUMTYwIDQ0MVQxNzEgNDQySDE3NFYzNzNRMjEzIDQ0MSAyNzEgNDQxSDI3N1EzMjIgNDQxIDM0MyA0MTlUMzY0IDM3M1EzNjQgMzUyIDM1MSAzMzdUMzEzIDMyMlEyODggMzIyIDI3NiAzMzhUMjYzIDM3MlEyNjMgMzgxIDI2NSAzODhUMjcwIDQwMFQyNzMgNDA1UTI3MSA0MDcgMjUwIDQwMVEyMzQgMzkzIDIyNiAzODZRMTc5IDM0MSAxNzkgMjA3VjE1NFExNzkgMTQxIDE3OSAxMjdUMTc5IDEwMVQxODAgODFUMTgwIDY2VjYxUTE4MSA1OSAxODMgNTdUMTg4IDU0VDE5MyA1MVQyMDAgNDlUMjA3IDQ4VDIxNiA0N1QyMjUgNDdUMjM1IDQ2VDI0NSA0NkgyNzZWMEgyNjdRMjQ5IDMgMTQwIDNRMzcgMyAyOCAwSDIwVjQ2SDM2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MiIgZD0iTTIxIDI4N1EyMiAyOTAgMjMgMjk1VDI4IDMxN1QzOCAzNDhUNTMgMzgxVDczIDQxMVQ5OSA0MzNUMTMyIDQ0MlExNjEgNDQyIDE4MyA0MzBUMjE0IDQwOFQyMjUgMzg4UTIyNyAzODIgMjI4IDM4MlQyMzYgMzg5UTI4NCA0NDEgMzQ3IDQ0MUgzNTBRMzk4IDQ0MSA0MjIgNDAwUTQzMCAzODEgNDMwIDM2M1E0MzAgMzMzIDQxNyAzMTVUMzkxIDI5MlQzNjYgMjg4UTM0NiAyODggMzM0IDI5OVQzMjIgMzI4UTMyMiAzNzYgMzc4IDM5MlEzNTYgNDA1IDM0MiA0MDVRMjg2IDQwNSAyMzkgMzMxUTIyOSAzMTUgMjI0IDI5OFQxOTAgMTY1UTE1NiAyNSAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExNCAxODlUMTU0IDM2NlExNTQgNDA1IDEyOCA0MDVRMTA3IDQwNSA5MiAzNzdUNjggMzE2VDU3IDI4MFE1NSAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTQiIGQ9Ik00MCA0MzdRMjEgNDM3IDIxIDQ0NVEyMSA0NTAgMzcgNTAxVDcxIDYwMkw4OCA2NTFROTMgNjY5IDEwMSA2NzdINTY5SDY1OVE2OTEgNjc3IDY5NyA2NzZUNzA0IDY2N1E3MDQgNjYxIDY4NyA1NTNUNjY4IDQ0NFE2NjggNDM3IDY0OSA0MzdRNjQwIDQzNyA2MzcgNDM3VDYzMSA0NDJMNjI5IDQ0NVE2MjkgNDUxIDYzNSA0OTBUNjQxIDU1MVE2NDEgNTg2IDYyOCA2MDRUNTczIDYyOVE1NjggNjMwIDUxNSA2MzFRNDY5IDYzMSA0NTcgNjMwVDQzOSA2MjJRNDM4IDYyMSAzNjggMzQzVDI5OCA2MFEyOTggNDggMzg2IDQ2UTQxOCA0NiA0MjcgNDVUNDM2IDM2UTQzNiAzMSA0MzMgMjJRNDI5IDQgNDI0IDFMNDIyIDBRNDE5IDAgNDE1IDBRNDEwIDAgMzYzIDFUMjI4IDJROTkgMiA2NCAwSDQ5UTQzIDYgNDMgOVQ0NSAyN1E0OSA0MCA1NSA0Nkg4M0g5NFExNzQgNDYgMTg5IDU1UTE5MCA1NiAxOTEgNTZRMTk2IDU5IDIwMSA3NlQyNDEgMjMzUTI1OCAzMDEgMjY5IDM0NFEzMzkgNjE5IDMzOSA2MjVRMzM5IDYzMCAzMTAgNjMwSDI3OVEyMTIgNjMwIDE5MSA2MjRRMTQ2IDYxNCAxMjEgNTgzVDY3IDQ2N1E2MCA0NDUgNTcgNDQxVDQzIDQzN0g0MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNTYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI3NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTgxMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxNDM5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==) 仍然可以大于零,因为 和 将是随机的——从 到 和从 到 存在许多不同的路径。
仍然可以大于零,因为 和 将是随机的——从 到 和从 到 存在许多不同的路径。
注意:
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQwLjEzOGV4IiBoZWlnaHQ9IjExLjg0M2V4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTUuMzM4ZXg7IiB2aWV3Qm94PSIwIC0yODAwLjYgMTcyODEuNSA1MDk4LjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDUiIGQ9Ik00OTIgMjEzUTQ3MiAyMTMgNDcyIDIyNlE0NzIgMjMwIDQ3NyAyNTBUNDgyIDI4NVE0ODIgMzE2IDQ2MSAzMjNUMzY0IDMzMEgzMTJRMzExIDMyOCAyNzcgMTkyVDI0MyA1MlEyNDMgNDggMjU0IDQ4VDMzNCA0NlE0MjggNDYgNDU4IDQ4VDUxOCA2MVE1NjcgNzcgNTk5IDExN1Q2NzAgMjQ4UTY4MCAyNzAgNjgzIDI3MlE2OTAgMjc0IDY5OCAyNzRRNzE4IDI3NCA3MTggMjYxUTYxMyA3IDYwOCAyUTYwNSAwIDMyMiAwSDEzM1EzMSAwIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc1N1E3NjQgNjc2IDc2NCA2NjlRNzY0IDY2NCA3NTEgNTU3VDczNyA0NDdRNzM1IDQ0MCA3MTcgNDQwSDcwNVE2OTggNDQ1IDY5OCA0NTNMNzAxIDQ3NlE3MDQgNTAwIDcwNCA1MjhRNzA0IDU1OCA2OTcgNTc4VDY3OCA2MDlUNjQzIDYyNVQ1OTYgNjMyVDUzMiA2MzRINDg1UTM5NyA2MzMgMzkyIDYzMVEzODggNjI5IDM4NiA2MjJRMzg1IDYxOSAzNTUgNDk5VDMyNCAzNzdRMzQ3IDM3NiAzNzIgMzc2SDM5OFE0NjQgMzc2IDQ4OSAzOTFUNTM0IDQ3MlE1MzggNDg4IDU0MCA0OTBUNTU3IDQ5M1E1NjIgNDkzIDU2NSA0OTNUNTcwIDQ5MlQ1NzIgNDkxVDU3NCA0ODdUNTc3IDQ4M0w1NDQgMzUxUTUxMSAyMTggNTA4IDIxNlE1MDUgMjEzIDQ5MiAyMTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi01QiIgZD0iTTExOCAtMjUwVjc1MEgyNTVWNzEwSDE1OFYtMjEwSDI1NVYtMjUwSDExOFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02NiIgZD0iTTExOCAtMTYyUTEyMCAtMTYyIDEyNCAtMTY0VDEzNSAtMTY3VDE0NyAtMTY4UTE2MCAtMTY4IDE3MSAtMTU1VDE4NyAtMTI2UTE5NyAtOTkgMjIxIDI3VDI2NyAyNjdUMjg5IDM4MlYzODVIMjQyUTE5NSAzODUgMTkyIDM4N1ExODggMzkwIDE4OCAzOTdMMTk1IDQyNVExOTcgNDMwIDIwMyA0MzBUMjUwIDQzMVEyOTggNDMxIDI5OCA0MzJRMjk4IDQzNCAzMDcgNDgyVDMxOSA1NDBRMzU2IDcwNSA0NjUgNzA1UTUwMiA3MDMgNTI2IDY4M1Q1NTAgNjMwUTU1MCA1OTQgNTI5IDU3OFQ0ODcgNTYxUTQ0MyA1NjEgNDQzIDYwM1E0NDMgNjIyIDQ1NCA2MzZUNDc4IDY1N0w0ODcgNjYyUTQ3MSA2NjggNDU3IDY2OFE0NDUgNjY4IDQzNCA2NThUNDE5IDYzMFE0MTIgNjAxIDQwMyA1NTJUMzg3IDQ2OVQzODAgNDMzUTM4MCA0MzEgNDM1IDQzMVE0ODAgNDMxIDQ4NyA0MzBUNDk4IDQyNFE0OTkgNDIwIDQ5NiA0MDdUNDkxIDM5MVE0ODkgMzg2IDQ4MiAzODZUNDI4IDM4NUgzNzJMMzQ5IDI2M1EzMDEgMTUgMjgyIC00N1EyNTUgLTEzMiAyMTIgLTE3M1ExNzUgLTIwNSAxMzkgLTIwNVExMDcgLTIwNSA4MSAtMTg2VDU1IC0xMzJRNTUgLTk1IDc2IC03OFQxMTggLTYxUTE2MiAtNjEgMTYyIC0xMDNRMTYyIC0xMjIgMTUxIC0xMzZUMTI3IC0xNTdMMTE4IC0xNjJaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0IiIGQ9Ik00MzQgLTIzMVE0MzQgLTI0NCA0MjggLTI1MEg0MTBRMjgxIC0yNTAgMjMwIC0xODRRMjI1IC0xNzcgMjIyIC0xNzJUMjE3IC0xNjFUMjEzIC0xNDhUMjExIC0xMzNUMjEwIC0xMTFUMjA5IC04NFQyMDkgLTQ3VDIwOSAwUTIwOSAyMSAyMDkgNTNRMjA4IDE0MiAyMDQgMTUzUTIwMyAxNTQgMjAzIDE1NVExODkgMTkxIDE1MyAyMTFUODIgMjMxUTcxIDIzMSA2OCAyMzRUNjUgMjUwVDY4IDI2NlQ4MiAyNjlRMTE2IDI2OSAxNTIgMjg5VDIwMyAzNDVRMjA4IDM1NiAyMDggMzc3VDIwOSA1MjlWNTc5UTIwOSA2MzQgMjE1IDY1NlQyNDQgNjk4UTI3MCA3MjQgMzI0IDc0MFEzNjEgNzQ4IDM3NyA3NDlRMzc5IDc0OSAzOTAgNzQ5VDQwOCA3NTBINDI4UTQzNCA3NDQgNDM0IDczMlE0MzQgNzE5IDQzMSA3MTZRNDI5IDcxMyA0MTUgNzEzUTM2MiA3MTAgMzMyIDY4OVQyOTYgNjQ3UTI5MSA2MzQgMjkxIDQ5OVY0MTdRMjkxIDM3MCAyODggMzUzVDI3MSAzMTRRMjQwIDI3MSAxODQgMjU1TDE3MCAyNTBMMTg0IDI0NVEyMDIgMjM5IDIyMCAyMzBUMjYyIDE5NlQyOTAgMTM3UTI5MSAxMzEgMjkxIDFRMjkxIC0xMzQgMjk2IC0xNDdRMzA2IC0xNzQgMzM5IC0xOTJUNDE1IC0yMTNRNDI5IC0yMTMgNDMxIC0yMTZRNDM0IC0yMTkgNDM0IC0yMzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzgiIGQ9Ik01MiAyODlRNTkgMzMxIDEwNiAzODZUMjIyIDQ0MlEyNTcgNDQyIDI4NiA0MjRUMzI5IDM3OVEzNzEgNDQyIDQzMCA0NDJRNDY3IDQ0MiA0OTQgNDIwVDUyMiAzNjFRNTIyIDMzMiA1MDggMzE0VDQ4MSAyOTJUNDU4IDI4OFE0MzkgMjg4IDQyNyAyOTlUNDE1IDMyOFE0MTUgMzc0IDQ2NSAzOTFRNDU0IDQwNCA0MjUgNDA0UTQxMiA0MDQgNDA2IDQwMlEzNjggMzg2IDM1MCAzMzZRMjkwIDExNSAyOTAgNzhRMjkwIDUwIDMwNiAzOFQzNDEgMjZRMzc4IDI2IDQxNCA1OVQ0NjMgMTQwUTQ2NiAxNTAgNDY5IDE1MVQ0ODUgMTUzSDQ4OVE1MDQgMTUzIDUwNCAxNDVRNTA0IDE0NCA1MDIgMTM0UTQ4NiA3NyA0NDAgMzNUMzMzIC0xMVEyNjMgLTExIDIyNyA1MlExODYgLTEwIDEzMyAtMTBIMTI3UTc4IC0xMCA1NyAxNlQzNSA3MVEzNSAxMDMgNTQgMTIzVDk5IDE0M1ExNDIgMTQzIDE0MiAxMDFRMTQyIDgxIDEzMCA2NlQxMDcgNDZUOTQgNDFMOTEgNDBROTEgMzkgOTcgMzZUMTEzIDI5VDEzMiAyNlExNjggMjYgMTk0IDcxUTIwMyA4NyAyMTcgMTM5VDI0NSAyNDdUMjYxIDMxM1EyNjYgMzQwIDI2NiAzNTJRMjY2IDM4MCAyNTEgMzkyVDIxNyA0MDRRMTc3IDQwNCAxNDIgMzcyVDkzIDI5MFE5MSAyODEgODggMjgwVDcyIDI3OEg1OFE1MiAyODQgNTIgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTVEIiBkPSJNMjIgNzEwVjc1MEgxNTlWLTI1MEgyMlYtMjEwSDExOVY3MTBIMjJaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjIxMSIgZD0iTTYwIDk0OFE2MyA5NTAgNjY1IDk1MEgxMjY3TDEzMjUgODE1UTEzODQgNjc3IDEzODggNjY5SDEzNDhMMTM0MSA2ODNRMTMyMCA3MjQgMTI4NSA3NjFRMTIzNSA4MDkgMTE3NCA4MzhUMTAzMyA4ODFUODgyIDg5OFQ2OTkgOTAySDU3NEg1NDNIMjUxTDI1OSA4OTFRNzIyIDI1OCA3MjQgMjUyUTcyNSAyNTAgNzI0IDI0NlE3MjEgMjQzIDQ2MCAtNTZMMTk2IC0zNTZRMTk2IC0zNTcgNDA3IC0zNTdRNDU5IC0zNTcgNTQ4IC0zNTdUNjc2IC0zNThRODEyIC0zNTggODk2IC0zNTNUMTA2MyAtMzMyVDEyMDQgLTI4M1QxMzA3IC0xOTZRMTMyOCAtMTcwIDEzNDggLTEyNEgxMzg4UTEzODggLTEyNSAxMzgxIC0xNDVUMTM1NiAtMjEwVDEzMjUgLTI5NEwxMjY3IC00NDlMNjY2IC00NTBRNjQgLTQ1MCA2MSAtNDQ4UTU1IC00NDYgNTUgLTQzOVE1NSAtNDM3IDU3IC00MzNMNTkwIDE3N1E1OTAgMTc4IDU1NyAyMjJUNDUyIDM2NlQzMjIgNTQ0TDU2IDkwOUw1NSA5MjRRNTUgOTQ1IDYwIDk0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MCIgZD0iTTI4NyA2MjhRMjg3IDYzNSAyMzAgNjM3UTIwNiA2MzcgMTk5IDYzOFQxOTIgNjQ4UTE5MiA2NDkgMTk0IDY1OVEyMDAgNjc5IDIwMyA2ODFUMzk3IDY4M1E1ODcgNjgyIDYwMCA2ODBRNjY0IDY2OSA3MDcgNjMxVDc1MSA1MzBRNzUxIDQ1MyA2ODUgMzg5UTYxNiAzMjEgNTA3IDMwM1E1MDAgMzAyIDQwMiAzMDFIMzA3TDI3NyAxODJRMjQ3IDY2IDI0NyA1OVEyNDcgNTUgMjQ4IDU0VDI1NSA1MFQyNzIgNDhUMzA1IDQ2SDMzNlEzNDIgMzcgMzQyIDM1UTM0MiAxOSAzMzUgNVEzMzAgMCAzMTkgMFEzMTYgMCAyODIgMVQxODIgMlExMjAgMiA4NyAyVDUxIDFRMzMgMSAzMyAxMVEzMyAxMyAzNiAyNVE0MCA0MSA0NCA0M1Q2NyA0NlE5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4Wk02NDUgNTU0UTY0NSA1NjcgNjQzIDU3NVQ2MzQgNTk3VDYwOSA2MTlUNTYwIDYzNVE1NTMgNjM2IDQ4MCA2MzdRNDYzIDYzNyA0NDUgNjM3VDQxNiA2MzZUNDA0IDYzNlEzOTEgNjM1IDM4NiA2MjdRMzg0IDYyMSAzNjcgNTUwVDMzMiA0MTJUMzE0IDM0NFEzMTQgMzQyIDM5NSAzNDJINDA3SDQzMFE1NDIgMzQyIDU5MCAzOTJRNjE3IDQxOSA2MzEgNDcxVDY0NSA1NTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkIiIGQ9Ik0xMjEgNjQ3UTEyMSA2NTcgMTI1IDY3MFQxMzcgNjgzUTEzOCA2ODMgMjA5IDY4OFQyODIgNjk0UTI5NCA2OTQgMjk0IDY4NlEyOTQgNjc5IDI0NCA0NzdRMTk0IDI3OSAxOTQgMjcyUTIxMyAyODIgMjIzIDI5MVEyNDcgMzA5IDI5MiAzNTRUMzYyIDQxNVE0MDIgNDQyIDQzOCA0NDJRNDY4IDQ0MiA0ODUgNDIzVDUwMyAzNjlRNTAzIDM0NCA0OTYgMzI3VDQ3NyAzMDJUNDU2IDI5MVQ0MzggMjg4UTQxOCAyODggNDA2IDI5OVQzOTQgMzI4UTM5NCAzNTMgNDEwIDM2OVQ0NDIgMzkwTDQ1OCAzOTNRNDQ2IDQwNSA0MzQgNDA1SDQzMFEzOTggNDAyIDM2NyAzODBUMjk0IDMxNlQyMjggMjU1UTIzMCAyNTQgMjQzIDI1MlQyNjcgMjQ2VDI5MyAyMzhUMzIwIDIyNFQzNDIgMjA2VDM1OSAxODBUMzY1IDE0N1EzNjUgMTMwIDM2MCAxMDZUMzU0IDY2UTM1NCAyNiAzODEgMjZRNDI5IDI2IDQ1OSAxNDVRNDYxIDE1MyA0NzkgMTUzSDQ4M1E0OTkgMTUzIDQ5OSAxNDRRNDk5IDEzOSA0OTYgMTMwUTQ1NSAtMTEgMzc4IC0xMVEzMzMgLTExIDMwNSAxNVQyNzcgOTBRMjc3IDEwOCAyODAgMTIxVDI4MyAxNDVRMjgzIDE2NyAyNjkgMTgzVDIzNCAyMDZUMjAwIDIxN1QxODIgMjIwSDE4MFExNjggMTc4IDE1OSAxMzlUMTQ1IDgxVDEzNiA0NFQxMjkgMjBUMTIyIDdUMTExIC0yUTk4IC0xMSA4MyAtMTFRNjYgLTExIDU3IC0xVDQ4IDE2UTQ4IDI2IDg1IDE3NlQxNTggNDcxTDE5NSA2MTZRMTk2IDYyOSAxODggNjMyVDE0OSA2MzdIMTQ0UTEzNCA2MzcgMTMxIDYzN1QxMjQgNjQwVDEyMSA2NDdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzIiIGQ9Ik0yMSAyODdRMjIgMjkwIDIzIDI5NVQyOCAzMTdUMzggMzQ4VDUzIDM4MVQ3MyA0MTFUOTkgNDMzVDEzMiA0NDJRMTYxIDQ0MiAxODMgNDMwVDIxNCA0MDhUMjI1IDM4OFEyMjcgMzgyIDIyOCAzODJUMjM2IDM4OVEyODQgNDQxIDM0NyA0NDFIMzUwUTM5OCA0NDEgNDIyIDQwMFE0MzAgMzgxIDQzMCAzNjNRNDMwIDMzMyA0MTcgMzE1VDM5MSAyOTJUMzY2IDI4OFEzNDYgMjg4IDMzNCAyOTlUMzIyIDMyOFEzMjIgMzc2IDM3OCAzOTJRMzU2IDQwNSAzNDIgNDA1UTI4NiA0MDUgMjM5IDMzMVEyMjkgMzE1IDIyNCAyOThUMTkwIDE2NVExNTYgMjUgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTQgMTg5VDE1NCAzNjZRMTU0IDQwNSAxMjggNDA1UTEwNyA0MDUgOTIgMzc3VDY4IDMxNlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0MiIGQ9Ik0xMzkgLTI0OUgxMzdRMTI1IC0yNDkgMTE5IC0yMzVWMjUxTDEyMCA3MzdRMTMwIDc1MCAxMzkgNzUwUTE1MiA3NTAgMTU5IDczNVYtMjM1UTE1MSAtMjQ5IDE0MSAtMjQ5SDEzOVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjcsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgtMTEsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDE3MjEpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5MzEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTVCIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjc4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjYiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc4IiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSIxMDczIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxOTYzIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNUQiIHg9IjMzNDgiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NTQ3LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwxNzIxKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzMzQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2NSwtMTE0OSkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03OCIgeD0iNTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjEwNzMiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjI5NDUiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODYzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03OCIgeD0iNTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iMTA3MyIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTk2MyIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjYiIHg9IjYzODIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MDk5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03OCIgeD0iNTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iMTA3MyIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTk2MyIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC05NTYpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjc3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTMzNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI3NjAiIHk9Ii0xNTY5Ij48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMjk0NSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4NjMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjkxMSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTMzMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzM4LC0xODcpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSI5NTEiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzM2MiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02NiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDcxNywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzgiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjEwNzMiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjE5NjMiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0MiIHg9IjMyMzYiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMzUxNCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iNDUzNiIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8L3N2Zz4=) (1)
(1)
其中 是状态 的重访次数。如果 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjUuMzFleCIgaGVpZ2h0PSIyLjE3NmV4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTAuMzM4ZXg7IiB2aWV3Qm94PSIwIC03OTEuMyAyMjg2LjEgOTM2LjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzIiIGQ9Ik0yMSAyODdRMjIgMjkwIDIzIDI5NVQyOCAzMTdUMzggMzQ4VDUzIDM4MVQ3MyA0MTFUOTkgNDMzVDEzMiA0NDJRMTYxIDQ0MiAxODMgNDMwVDIxNCA0MDhUMjI1IDM4OFEyMjcgMzgyIDIyOCAzODJUMjM2IDM4OVEyODQgNDQxIDM0NyA0NDFIMzUwUTM5OCA0NDEgNDIyIDQwMFE0MzAgMzgxIDQzMCAzNjNRNDMwIDMzMyA0MTcgMzE1VDM5MSAyOTJUMzY2IDI4OFEzNDYgMjg4IDMzNCAyOTlUMzIyIDMyOFEzMjIgMzc2IDM3OCAzOTJRMzU2IDQwNSAzNDIgNDA1UTI4NiA0MDUgMjM5IDMzMVEyMjkgMzE1IDIyNCAyOThUMTkwIDE2NVExNTYgMjUgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTQgMTg5VDE1NCAzNjZRMTU0IDQwNSAxMjggNDA1UTEwNyA0MDUgOTIgMzc3VDY4IDMxNlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0MiIGQ9Ik02OTQgLTExVDY5NCAtMTlUNjg4IC0zM1Q2NzggLTQwUTY3MSAtNDAgNTI0IDI5VDIzNCAxNjZMOTAgMjM1UTgzIDI0MCA4MyAyNTBRODMgMjYxIDkxIDI2NlE2NjQgNTQwIDY3OCA1NDBRNjgxIDU0MCA2ODcgNTM0VDY5NCA1MTlUNjg3IDUwNVE2ODYgNTA0IDQxNyAzNzZMMTUxIDI1MEw0MTcgMTI0UTY4NiAtNCA2ODcgLTVRNjk0IC0xMSA2OTQgLTE5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zQyIgeD0iNzI5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTc4NSIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) ,那么
,那么
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjE4LjI0MmV4IiBoZWlnaHQ9IjcuMDA5ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4xNzFleDsiIHZpZXdCb3g9IjAgLTE2NTIuNSA3ODU0LjQgMzAxNy45IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMi0yMjExIiBkPSJNNjAgOTQ4UTYzIDk1MCA2NjUgOTUwSDEyNjdMMTMyNSA4MTVRMTM4NCA2NzcgMTM4OCA2NjlIMTM0OEwxMzQxIDY4M1ExMzIwIDcyNCAxMjg1IDc2MVExMjM1IDgwOSAxMTc0IDgzOFQxMDMzIDg4MVQ4ODIgODk4VDY5OSA5MDJINTc0SDU0M0gyNTFMMjU5IDg5MVE3MjIgMjU4IDcyNCAyNTJRNzI1IDI1MCA3MjQgMjQ2UTcyMSAyNDMgNDYwIC01NkwxOTYgLTM1NlExOTYgLTM1NyA0MDcgLTM1N1E0NTkgLTM1NyA1NDggLTM1N1Q2NzYgLTM1OFE4MTIgLTM1OCA4OTYgLTM1M1QxMDYzIC0zMzJUMTIwNCAtMjgzVDEzMDcgLTE5NlExMzI4IC0xNzAgMTM0OCAtMTI0SDEzODhRMTM4OCAtMTI1IDEzODEgLTE0NVQxMzU2IC0yMTBUMTMyNSAtMjk0TDEyNjcgLTQ0OUw2NjYgLTQ1MFE2NCAtNDUwIDYxIC00NDhRNTUgLTQ0NiA1NSAtNDM5UTU1IC00MzcgNTcgLTQzM0w1OTAgMTc3UTU5MCAxNzggNTU3IDIyMlQ0NTIgMzY2VDMyMiA1NDRMNTYgOTA5TDU1IDkyNFE1NSA5NDUgNjAgOTQ4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY5IiBkPSJNMTg0IDYwMFExODQgNjI0IDIwMyA2NDJUMjQ3IDY2MVEyNjUgNjYxIDI3NyA2NDlUMjkwIDYxOVEyOTAgNTk2IDI3MCA1NzdUMjI2IDU1N1EyMTEgNTU3IDE5OCA1NjdUMTg0IDYwMFpNMjEgMjg3UTIxIDI5NSAzMCAzMThUNTQgMzY5VDk4IDQyMFQxNTggNDQyUTE5NyA0NDIgMjIzIDQxOVQyNTAgMzU3UTI1MCAzNDAgMjM2IDMwMVQxOTYgMTk2VDE1NCA4M1ExNDkgNjEgMTQ5IDUxUTE0OSAyNiAxNjYgMjZRMTc1IDI2IDE4NSAyOVQyMDggNDNUMjM1IDc4VDI2MCAxMzdRMjYzIDE0OSAyNjUgMTUxVDI4MiAxNTNRMzAyIDE1MyAzMDIgMTQzUTMwMiAxMzUgMjkzIDExMlQyNjggNjFUMjIzIDExVDE2MSAtMTFRMTI5IC0xMSAxMDIgMTBUNzQgNzRRNzQgOTEgNzkgMTA2VDEyMiAyMjBRMTYwIDMyMSAxNjYgMzQxVDE3MyAzODBRMTczIDQwNCAxNTYgNDA0SDE1NFExMjQgNDA0IDk5IDM3MVQ2MSAyODdRNjAgMjg2IDU5IDI4NFQ1OCAyODFUNTYgMjc5VDUzIDI3OFQ0OSAyNzhUNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMwIiBkPSJNOTYgNTg1UTE1MiA2NjYgMjQ5IDY2NlEyOTcgNjY2IDM0NSA2NDBUNDIzIDU0OFE0NjAgNDY1IDQ2MCAzMjBRNDYwIDE2NSA0MTcgODNRMzk3IDQxIDM2MiAxNlQzMDEgLTE1VDI1MCAtMjJRMjI0IC0yMiAxOTggLTE2VDEzNyAxNlQ4MiA4M1EzOSAxNjUgMzkgMzIwUTM5IDQ5NCA5NiA1ODVaTTMyMSA1OTdRMjkxIDYyOSAyNTAgNjI5UTIwOCA2MjkgMTc4IDU5N1ExNTMgNTcxIDE0NSA1MjVUMTM3IDMzM1ExMzcgMTc1IDE0NSAxMjVUMTgxIDQ2UTIwOSAxNiAyNTAgMTZRMjkwIDE2IDMxOCA0NlEzNDcgNzYgMzU0IDEzMFQzNjIgMzMzUTM2MiA0NzggMzU0IDUyNFQzMjEgNTk3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjIxRSIgZD0iTTU1IDIxN1E1NSAzMDUgMTExIDM3M1QyNTQgNDQyUTM0MiA0NDIgNDE5IDM4MVE0NTcgMzUwIDQ5MyAzMDNMNTA3IDI4NEw1MTQgMjk0UTYxOCA0NDIgNzQ3IDQ0MlE4MzMgNDQyIDg4OCAzNzRUOTQ0IDIxNFE5NDQgMTI4IDg4OSA1OVQ3NDMgLTExUTY1NyAtMTEgNTgwIDUwUTU0MiA4MSA1MDYgMTI4TDQ5MiAxNDdMNDg1IDEzN1EzODEgLTExIDI1MiAtMTFRMTY2IC0xMSAxMTEgNTdUNTUgMjE3Wk05MDcgMjE3UTkwNyAyODUgODY5IDM0MVQ3NjEgMzk3UTc0MCAzOTcgNzIwIDM5MlQ2ODIgMzc4VDY0OCAzNTlUNjE5IDMzNVQ1OTQgMzEwVDU3NCAyODVUNTU5IDI2M1Q1NDggMjQ2TDU0MyAyMzhMNTc0IDE5OFE2MDUgMTU4IDYyMiAxMzhUNjY0IDk0VDcxNCA2MVQ3NjUgNTFRODI3IDUxIDg2NyAxMDBUOTA3IDIxN1pNOTIgMjE0UTkyIDE0NSAxMzEgODlUMjM5IDMzUTM1NyAzMyA0NTYgMTkzTDQyNSAyMzNRMzY0IDMxMiAzMzQgMzM3UTI4NSAzODAgMjMzIDM4MFExNzEgMzgwIDEzMiAzMzFUOTIgMjE0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTcyIiBkPSJNMjEgMjg3UTIyIDI5MCAyMyAyOTVUMjggMzE3VDM4IDM0OFQ1MyAzODFUNzMgNDExVDk5IDQzM1QxMzIgNDQyUTE2MSA0NDIgMTgzIDQzMFQyMTQgNDA4VDIyNSAzODhRMjI3IDM4MiAyMjggMzgyVDIzNiAzODlRMjg0IDQ0MSAzNDcgNDQxSDM1MFEzOTggNDQxIDQyMiA0MDBRNDMwIDM4MSA0MzAgMzYzUTQzMCAzMzMgNDE3IDMxNVQzOTEgMjkyVDM2NiAyODhRMzQ2IDI4OCAzMzQgMjk5VDMyMiAzMjhRMzIyIDM3NiAzNzggMzkyUTM1NiA0MDUgMzQyIDQwNVEyODYgNDA1IDIzOSAzMzFRMjI5IDMxNSAyMjQgMjk4VDE5MCAxNjVRMTU2IDI1IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTE0IDE4OVQxNTQgMzY2UTE1NCA0MDUgMTI4IDQwNVExMDcgNDA1IDkyIDM3N1Q2OCAzMTZUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMSIgZD0iTTIxMyA1NzhMMjAwIDU3M1ExODYgNTY4IDE2MCA1NjNUMTAyIDU1Nkg4M1Y2MDJIMTAyUTE0OSA2MDQgMTg5IDYxN1QyNDUgNjQxVDI3MyA2NjNRMjc1IDY2NiAyODUgNjY2UTI5NCA2NjYgMzAyIDY2MFYzNjFMMzAzIDYxUTMxMCA1NCAzMTUgNTJUMzM5IDQ4VDQwMSA0Nkg0MjdWMEg0MTZRMzk1IDMgMjU3IDNRMTIxIDMgMTAwIDBIODhWNDZIMTE0UTEzNiA0NiAxNTIgNDZUMTc3IDQ3VDE5MyA1MFQyMDEgNTJUMjA3IDU3VDIxMyA2MVY1NzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjEyIiBkPSJNODQgMjM3VDg0IDI1MFQ5OCAyNzBINjc5UTY5NCAyNjIgNjk0IDI1MFQ2NzkgMjMwSDk4UTg0IDIzNyA4NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDcsLTEwOTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjM0NSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMwIiB4PSIxMTI0IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjFFIiB4PSI1MjEiIHk9IjE2MjciPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMTYxMSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE5NTYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iNjM4IiB5PSI1ODMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjMwMzAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODA4LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzk3LDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMzUyNyIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIxNTM4IiB5PSI2NzYiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtOTcwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSI3MjIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMTcyMyIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMjU2NCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI0MTc3IiB5PSI2NzUiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+Cjwvc3ZnPg==)
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjE5LjY3OGV4IiBoZWlnaHQ9IjYuODQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4wMDVleDsiIHZpZXdCb3g9IjAgLTE2NTIuNSA4NDcyLjUgMjk0Ni4xIiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMi0yMjExIiBkPSJNNjAgOTQ4UTYzIDk1MCA2NjUgOTUwSDEyNjdMMTMyNSA4MTVRMTM4NCA2NzcgMTM4OCA2NjlIMTM0OEwxMzQxIDY4M1ExMzIwIDcyNCAxMjg1IDc2MVExMjM1IDgwOSAxMTc0IDgzOFQxMDMzIDg4MVQ4ODIgODk4VDY5OSA5MDJINTc0SDU0M0gyNTFMMjU5IDg5MVE3MjIgMjU4IDcyNCAyNTJRNzI1IDI1MCA3MjQgMjQ2UTcyMSAyNDMgNDYwIC01NkwxOTYgLTM1NlExOTYgLTM1NyA0MDcgLTM1N1E0NTkgLTM1NyA1NDggLTM1N1Q2NzYgLTM1OFE4MTIgLTM1OCA4OTYgLTM1M1QxMDYzIC0zMzJUMTIwNCAtMjgzVDEzMDcgLTE5NlExMzI4IC0xNzAgMTM0OCAtMTI0SDEzODhRMTM4OCAtMTI1IDEzODEgLTE0NVQxMzU2IC0yMTBUMTMyNSAtMjk0TDEyNjcgLTQ0OUw2NjYgLTQ1MFE2NCAtNDUwIDYxIC00NDhRNTUgLTQ0NiA1NSAtNDM5UTU1IC00MzcgNTcgLTQzM0w1OTAgMTc3UTU5MCAxNzggNTU3IDIyMlQ0NTIgMzY2VDMyMiA1NDRMNTYgOTA5TDU1IDkyNFE1NSA5NDUgNjAgOTQ4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY5IiBkPSJNMTg0IDYwMFExODQgNjI0IDIwMyA2NDJUMjQ3IDY2MVEyNjUgNjYxIDI3NyA2NDlUMjkwIDYxOVEyOTAgNTk2IDI3MCA1NzdUMjI2IDU1N1EyMTEgNTU3IDE5OCA1NjdUMTg0IDYwMFpNMjEgMjg3UTIxIDI5NSAzMCAzMThUNTQgMzY5VDk4IDQyMFQxNTggNDQyUTE5NyA0NDIgMjIzIDQxOVQyNTAgMzU3UTI1MCAzNDAgMjM2IDMwMVQxOTYgMTk2VDE1NCA4M1ExNDkgNjEgMTQ5IDUxUTE0OSAyNiAxNjYgMjZRMTc1IDI2IDE4NSAyOVQyMDggNDNUMjM1IDc4VDI2MCAxMzdRMjYzIDE0OSAyNjUgMTUxVDI4MiAxNTNRMzAyIDE1MyAzMDIgMTQzUTMwMiAxMzUgMjkzIDExMlQyNjggNjFUMjIzIDExVDE2MSAtMTFRMTI5IC0xMSAxMDIgMTBUNzQgNzRRNzQgOTEgNzkgMTA2VDEyMiAyMjBRMTYwIDMyMSAxNjYgMzQxVDE3MyAzODBRMTczIDQwNCAxNTYgNDA0SDE1NFExMjQgNDA0IDk5IDM3MVQ2MSAyODdRNjAgMjg2IDU5IDI4NFQ1OCAyODFUNTYgMjc5VDUzIDI3OFQ0OSAyNzhUNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMwIiBkPSJNOTYgNTg1UTE1MiA2NjYgMjQ5IDY2NlEyOTcgNjY2IDM0NSA2NDBUNDIzIDU0OFE0NjAgNDY1IDQ2MCAzMjBRNDYwIDE2NSA0MTcgODNRMzk3IDQxIDM2MiAxNlQzMDEgLTE1VDI1MCAtMjJRMjI0IC0yMiAxOTggLTE2VDEzNyAxNlQ4MiA4M1EzOSAxNjUgMzkgMzIwUTM5IDQ5NCA5NiA1ODVaTTMyMSA1OTdRMjkxIDYyOSAyNTAgNjI5UTIwOCA2MjkgMTc4IDU5N1ExNTMgNTcxIDE0NSA1MjVUMTM3IDMzM1ExMzcgMTc1IDE0NSAxMjVUMTgxIDQ2UTIwOSAxNiAyNTAgMTZRMjkwIDE2IDMxOCA0NlEzNDcgNzYgMzU0IDEzMFQzNjIgMzMzUTM2MiA0NzggMzU0IDUyNFQzMjEgNTk3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjIxRSIgZD0iTTU1IDIxN1E1NSAzMDUgMTExIDM3M1QyNTQgNDQyUTM0MiA0NDIgNDE5IDM4MVE0NTcgMzUwIDQ5MyAzMDNMNTA3IDI4NEw1MTQgMjk0UTYxOCA0NDIgNzQ3IDQ0MlE4MzMgNDQyIDg4OCAzNzRUOTQ0IDIxNFE5NDQgMTI4IDg4OSA1OVQ3NDMgLTExUTY1NyAtMTEgNTgwIDUwUTU0MiA4MSA1MDYgMTI4TDQ5MiAxNDdMNDg1IDEzN1EzODEgLTExIDI1MiAtMTFRMTY2IC0xMSAxMTEgNTdUNTUgMjE3Wk05MDcgMjE3UTkwNyAyODUgODY5IDM0MVQ3NjEgMzk3UTc0MCAzOTcgNzIwIDM5MlQ2ODIgMzc4VDY0OCAzNTlUNjE5IDMzNVQ1OTQgMzEwVDU3NCAyODVUNTU5IDI2M1Q1NDggMjQ2TDU0MyAyMzhMNTc0IDE5OFE2MDUgMTU4IDYyMiAxMzhUNjY0IDk0VDcxNCA2MVQ3NjUgNTFRODI3IDUxIDg2NyAxMDBUOTA3IDIxN1pNOTIgMjE0UTkyIDE0NSAxMzEgODlUMjM5IDMzUTM1NyAzMyA0NTYgMTkzTDQyNSAyMzNRMzY0IDMxMiAzMzQgMzM3UTI4NSAzODAgMjMzIDM4MFExNzEgMzgwIDEzMiAzMzFUOTIgMjE0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzIiIGQ9Ik0xMDkgNDI5UTgyIDQyOSA2NiA0NDdUNTAgNDkxUTUwIDU2MiAxMDMgNjE0VDIzNSA2NjZRMzI2IDY2NiAzODcgNjEwVDQ0OSA0NjVRNDQ5IDQyMiA0MjkgMzgzVDM4MSAzMTVUMzAxIDI0MVEyNjUgMjEwIDIwMSAxNDlMMTQyIDkzTDIxOCA5MlEzNzUgOTIgMzg1IDk3UTM5MiA5OSA0MDkgMTg2VjE4OUg0NDlWMTg2UTQ0OCAxODMgNDM2IDk1VDQyMSAzVjBINTBWMTlWMzFRNTAgMzggNTYgNDZUODYgODFRMTE1IDExMyAxMzYgMTM3UTE0NSAxNDcgMTcwIDE3NFQyMDQgMjExVDIzMyAyNDRUMjYxIDI3OFQyODQgMzA4VDMwNSAzNDBUMzIwIDM2OVQzMzMgNDAxVDM0MCA0MzFUMzQzIDQ2NFEzNDMgNTI3IDMwOSA1NzNUMjEyIDYxOVExNzkgNjE5IDE1NCA2MDJUMTE5IDU2OVQxMDkgNTUwUTEwOSA1NDkgMTE0IDU0OVExMzIgNTQ5IDE1MSA1MzVUMTcwIDQ4OVExNzAgNDY0IDE1NCA0NDdUMTA5IDQyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MiIgZD0iTTIxIDI4N1EyMiAyOTAgMjMgMjk1VDI4IDMxN1QzOCAzNDhUNTMgMzgxVDczIDQxMVQ5OSA0MzNUMTMyIDQ0MlExNjEgNDQyIDE4MyA0MzBUMjE0IDQwOFQyMjUgMzg4UTIyNyAzODIgMjI4IDM4MlQyMzYgMzg5UTI4NCA0NDEgMzQ3IDQ0MUgzNTBRMzk4IDQ0MSA0MjIgNDAwUTQzMCAzODEgNDMwIDM2M1E0MzAgMzMzIDQxNyAzMTVUMzkxIDI5MlQzNjYgMjg4UTM0NiAyODggMzM0IDI5OVQzMjIgMzI4UTMyMiAzNzYgMzc4IDM5MlEzNTYgNDA1IDM0MiA0MDVRMjg2IDQwNSAyMzkgMzMxUTIyOSAzMTUgMjI0IDI5OFQxOTAgMTY1UTE1NiAyNSAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExNCAxODlUMTU0IDM2NlExNTQgNDA1IDEyOCA0MDVRMTA3IDQwNSA5MiAzNzdUNjggMzE2VDU3IDI4MFE1NSAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjEyIiBkPSJNODQgMjM3VDg0IDI1MFQ5OCAyNzBINjc5UTY5NCAyNjIgNjk0IDI1MFQ2NzkgMjMwSDk4UTg0IDIzNyA4NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMyIgZD0iTTEyNyA0NjNRMTAwIDQ2MyA4NSA0ODBUNjkgNTI0UTY5IDU3OSAxMTcgNjIyVDIzMyA2NjVRMjY4IDY2NSAyNzcgNjY0UTM1MSA2NTIgMzkwIDYxMVQ0MzAgNTIyUTQzMCA0NzAgMzk2IDQyMVQzMDIgMzUwTDI5OSAzNDhRMjk5IDM0NyAzMDggMzQ1VDMzNyAzMzZUMzc1IDMxNVE0NTcgMjYyIDQ1NyAxNzVRNDU3IDk2IDM5NSAzN1QyMzggLTIyUTE1OCAtMjIgMTAwIDIxVDQyIDEzMFE0MiAxNTggNjAgMTc1VDEwNSAxOTNRMTMzIDE5MyAxNTEgMTc1VDE2OSAxMzBRMTY5IDExOSAxNjYgMTEwVDE1OSA5NFQxNDggODJUMTM2IDc0VDEyNiA3MFQxMTggNjdMMTE0IDY2UTE2NSAyMSAyMzggMjFRMjkzIDIxIDMyMSA3NFEzMzggMTA3IDMzOCAxNzVWMTk1UTMzOCAyOTAgMjc0IDMyMlEyNTkgMzI4IDIxMyAzMjlMMTcxIDMzMEwxNjggMzMyUTE2NiAzMzUgMTY2IDM0OFExNjYgMzY2IDE3NCAzNjZRMjAyIDM2NiAyMzIgMzcxUTI2NiAzNzYgMjk0IDQxM1QzMjIgNTI1VjUzM1EzMjIgNTkwIDI4NyA2MTJRMjY1IDYyNiAyNDAgNjI2UTIwOCA2MjYgMTgxIDYxNVQxNDMgNTkyVDEzMiA1ODBIMTM1UTEzOCA1NzkgMTQzIDU3OFQxNTMgNTczVDE2NSA1NjZUMTc1IDU1NVQxODMgNTQwVDE4NiA1MjBRMTg2IDQ5OCAxNzIgNDgxVDEyNyA0NjNaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDcsLTEwOTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjM0NSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMwIiB4PSIxMTI0IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjFFIiB4PSI1MjEiIHk9IjE2MjciPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjExLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iNDg4IiB5PSI1ODMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI0MTAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iNjM4IiB5PSI1ODMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjM0ODQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0MjYyLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzk3LDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMzY5MiIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDc3MCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYxOCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNzIyIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjE3MjMiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjI1NjQiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQyLC05NjkpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjcyMiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIxNzIzIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIyNTY0IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzMiIHg9IjQxNzciIHk9IjY3NSI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9zdmc+)
定理2 状态![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIwLjY1MWV4IiBoZWlnaHQ9IjUuNTA5ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMi4xNzFleDsiIHZpZXdCb3g9IjAgLTE0MzcuMiA4ODkxLjUgMjM3MiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NiIgZD0iTTUyIDY0OFE1MiA2NzAgNjUgNjgzSDc2UTExOCA2ODAgMTgxIDY4MFEyOTkgNjgwIDMyMCA2ODNIMzMwUTMzNiA2NzcgMzM2IDY3NFQzMzQgNjU2UTMyOSA2NDEgMzI1IDYzN0gzMDRRMjgyIDYzNSAyNzQgNjM1UTI0NSA2MzAgMjQyIDYyMFEyNDIgNjE4IDI3MSAzNjlUMzAxIDExOEwzNzQgMjM1UTQ0NyAzNTIgNTIwIDQ3MVQ1OTUgNTk0UTU5OSA2MDEgNTk5IDYwOVE1OTkgNjMzIDU1NSA2MzdRNTM3IDYzNyA1MzcgNjQ4UTUzNyA2NDkgNTM5IDY2MVE1NDIgNjc1IDU0NSA2NzlUNTU4IDY4M1E1NjAgNjgzIDU3MCA2ODNUNjA0IDY4MlQ2NjggNjgxUTczNyA2ODEgNzU1IDY4M0g3NjJRNzY5IDY3NiA3NjkgNjcyUTc2OSA2NTUgNzYwIDY0MFE3NTcgNjM3IDc0MyA2MzdRNzMwIDYzNiA3MTkgNjM1VDY5OCA2MzBUNjgyIDYyM1Q2NzAgNjE1VDY2MCA2MDhUNjUyIDU5OVQ2NDUgNTkyTDQ1MiAyODJRMjcyIC05IDI2NiAtMTZRMjYzIC0xOCAyNTkgLTIxTDI0MSAtMjJIMjM0UTIxNiAtMjIgMjE2IC0xNVEyMTMgLTkgMTc3IDMwNVExMzkgNjIzIDEzOCA2MjZRMTMzIDYzNyA3NiA2MzdINTlRNTIgNjQyIDUyIDY0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUyIiBkPSJNMjMwIDYzN1EyMDMgNjM3IDE5OCA2MzhUMTkzIDY0OVExOTMgNjc2IDIwNCA2ODJRMjA2IDY4MyAzNzggNjgzUTU1MCA2ODIgNTY0IDY4MFE2MjAgNjcyIDY1OCA2NTJUNzEyIDYwNlQ3MzMgNTYzVDczOSA1MjlRNzM5IDQ4NCA3MTAgNDQ1VDY0MyAzODVUNTc2IDM1MVQ1MzggMzM4TDU0NSAzMzNRNjEyIDI5NSA2MTIgMjIzUTYxMiAyMTIgNjA3IDE2MlQ2MDIgODBWNzFRNjAyIDUzIDYwMyA0M1Q2MTQgMjVUNjQwIDE2UTY2OCAxNiA2ODYgMzhUNzEyIDg1UTcxNyA5OSA3MjAgMTAyVDczNSAxMDVRNzU1IDEwNSA3NTUgOTNRNzU1IDc1IDczMSAzNlE2OTMgLTIxIDY0MSAtMjFINjMyUTU3MSAtMjEgNTMxIDRUNDg3IDgyUTQ4NyAxMDkgNTAyIDE2NlQ1MTcgMjM5UTUxNyAyOTAgNDc0IDMxM1E0NTkgMzIwIDQ0OSAzMjFUMzc4IDMyM0gzMDlMMjc3IDE5M1EyNDQgNjEgMjQ0IDU5UTI0NCA1NSAyNDUgNTRUMjUyIDUwVDI2OSA0OFQzMDIgNDZIMzMzUTMzOSAzOCAzMzkgMzdUMzM2IDE5UTMzMiA2IDMyNiAwSDMxMVEyNzUgMiAxODAgMlExNDYgMiAxMTcgMlQ3MSAyVDUwIDFRMzMgMSAzMyAxMFEzMyAxMiAzNiAyNFE0MSA0MyA0NiA0NVE1MCA0NiA2MSA0Nkg2N1E5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4UTI4NyA2MzUgMjMwIDYzN1pNNjMwIDU1NFE2MzAgNTg2IDYwOSA2MDhUNTIzIDYzNlE1MjEgNjM2IDUwMCA2MzZUNDYyIDYzN0g0NDBRMzkzIDYzNyAzODYgNjI3UTM4NSA2MjQgMzUyIDQ5NFQzMTkgMzYxUTMxOSAzNjAgMzg4IDM2MFE0NjYgMzYxIDQ5MiAzNjdRNTU2IDM3NyA1OTIgNDI2UTYwOCA0NDkgNjE5IDQ4NlQ2MzAgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU0IiBkPSJNNDAgNDM3UTIxIDQzNyAyMSA0NDVRMjEgNDUwIDM3IDUwMVQ3MSA2MDJMODggNjUxUTkzIDY2OSAxMDEgNjc3SDU2OUg2NTlRNjkxIDY3NyA2OTcgNjc2VDcwNCA2NjdRNzA0IDY2MSA2ODcgNTUzVDY2OCA0NDRRNjY4IDQzNyA2NDkgNDM3UTY0MCA0MzcgNjM3IDQzN1Q2MzEgNDQyTDYyOSA0NDVRNjI5IDQ1MSA2MzUgNDkwVDY0MSA1NTFRNjQxIDU4NiA2MjggNjA0VDU3MyA2MjlRNTY4IDYzMCA1MTUgNjMxUTQ2OSA2MzEgNDU3IDYzMFQ0MzkgNjIyUTQzOCA2MjEgMzY4IDM0M1QyOTggNjBRMjk4IDQ4IDM4NiA0NlE0MTggNDYgNDI3IDQ1VDQzNiAzNlE0MzYgMzEgNDMzIDIyUTQyOSA0IDQyNCAxTDQyMiAwUTQxOSAwIDQxNSAwUTQxMCAwIDM2MyAxVDIyOCAyUTk5IDIgNjQgMEg0OVE0MyA2IDQzIDlUNDUgMjdRNDkgNDAgNTUgNDZIODNIOTRRMTc0IDQ2IDE4OSA1NVExOTAgNTYgMTkxIDU2UTE5NiA1OSAyMDEgNzZUMjQxIDIzM1EyNTggMzAxIDI2OSAzNDRRMzM5IDYxOSAzMzkgNjI1UTMzOSA2MzAgMzEwIDYzMEgyNzlRMjEyIDYzMCAxOTEgNjI0UTE0NiA2MTQgMTIxIDU4M1Q2NyA0NjdRNjAgNDQ1IDU3IDQ0MVQ0MyA0MzdINDBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yQiIgZD0iTTU2IDIzN1Q1NiAyNTBUNzAgMjcwSDM2OVY0MjBMMzcwIDU3MFEzODAgNTgzIDM4OSA1ODNRNDAyIDU4MyA0MDkgNTY4VjI3MEg3MDdRNzIyIDI2MiA3MjIgMjUwVDcwNyAyMzBINDA5Vi02OFE0MDEgLTgyIDM5MSAtODJIMzg5SDM4N1EzNzUgLTgyIDM2OSAtNjhWMjMwSDcwUTU2IDIzNyA1NiAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTAiIGQ9Ik0yODcgNjI4UTI4NyA2MzUgMjMwIDYzN1EyMDYgNjM3IDE5OSA2MzhUMTkyIDY0OFExOTIgNjQ5IDE5NCA2NTlRMjAwIDY3OSAyMDMgNjgxVDM5NyA2ODNRNTg3IDY4MiA2MDAgNjgwUTY2NCA2NjkgNzA3IDYzMVQ3NTEgNTMwUTc1MSA0NTMgNjg1IDM4OVE2MTYgMzIxIDUwNyAzMDNRNTAwIDMwMiA0MDIgMzAxSDMwN0wyNzcgMTgyUTI0NyA2NiAyNDcgNTlRMjQ3IDU1IDI0OCA1NFQyNTUgNTBUMjcyIDQ4VDMwNSA0NkgzMzZRMzQyIDM3IDM0MiAzNVEzNDIgMTkgMzM1IDVRMzMwIDAgMzE5IDBRMzE2IDAgMjgyIDFUMTgyIDJRMTIwIDIgODcgMlQ1MSAxUTMzIDEgMzMgMTFRMzMgMTMgMzYgMjVRNDAgNDEgNDQgNDNUNjcgNDZROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFpNNjQ1IDU1NFE2NDUgNTY3IDY0MyA1NzVUNjM0IDU5N1Q2MDkgNjE5VDU2MCA2MzVRNTUzIDYzNiA0ODAgNjM3UTQ2MyA2MzcgNDQ1IDYzN1Q0MTYgNjM2VDQwNCA2MzZRMzkxIDYzNSAzODYgNjI3UTM4NCA2MjEgMzY3IDU1MFQzMzIgNDEyVDMxNCAzNDRRMzE0IDM0MiAzOTUgMzQySDQwN0g0MzBRNTQyIDM0MiA1OTAgMzkyUTYxNyA0MTkgNjMxIDQ3MVQ2NDUgNTU0WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTM2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI0NjIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNTE4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjUwOTgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1ODc3LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQyLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTM2MCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0Myw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzY5OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==)
证明:
图2中状态 的值可以从Bellman方程推导出:
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjUyLjEwOGV4IiBoZWlnaHQ9IjEwLjE3NmV4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTMuOTI1ZXg7IG1hcmdpbi1ib3R0b206IC0wLjkxM2V4OyIgdmlld0JveD0iMCAtMjI5OC4zIDIyNDM1LjMgNDM4MS4zIiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU2IiBkPSJNNTIgNjQ4UTUyIDY3MCA2NSA2ODNINzZRMTE4IDY4MCAxODEgNjgwUTI5OSA2ODAgMzIwIDY4M0gzMzBRMzM2IDY3NyAzMzYgNjc0VDMzNCA2NTZRMzI5IDY0MSAzMjUgNjM3SDMwNFEyODIgNjM1IDI3NCA2MzVRMjQ1IDYzMCAyNDIgNjIwUTI0MiA2MTggMjcxIDM2OVQzMDEgMTE4TDM3NCAyMzVRNDQ3IDM1MiA1MjAgNDcxVDU5NSA1OTRRNTk5IDYwMSA1OTkgNjA5UTU5OSA2MzMgNTU1IDYzN1E1MzcgNjM3IDUzNyA2NDhRNTM3IDY0OSA1MzkgNjYxUTU0MiA2NzUgNTQ1IDY3OVQ1NTggNjgzUTU2MCA2ODMgNTcwIDY4M1Q2MDQgNjgyVDY2OCA2ODFRNzM3IDY4MSA3NTUgNjgzSDc2MlE3NjkgNjc2IDc2OSA2NzJRNzY5IDY1NSA3NjAgNjQwUTc1NyA2MzcgNzQzIDYzN1E3MzAgNjM2IDcxOSA2MzVUNjk4IDYzMFQ2ODIgNjIzVDY3MCA2MTVUNjYwIDYwOFQ2NTIgNTk5VDY0NSA1OTJMNDUyIDI4MlEyNzIgLTkgMjY2IC0xNlEyNjMgLTE4IDI1OSAtMjFMMjQxIC0yMkgyMzRRMjE2IC0yMiAyMTYgLTE1UTIxMyAtOSAxNzcgMzA1UTEzOSA2MjMgMTM4IDYyNlExMzMgNjM3IDc2IDYzN0g1OVE1MiA2NDIgNTIgNjQ4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTAiIGQ9Ik0yODcgNjI4UTI4NyA2MzUgMjMwIDYzN1EyMDYgNjM3IDE5OSA2MzhUMTkyIDY0OFExOTIgNjQ5IDE5NCA2NTlRMjAwIDY3OSAyMDMgNjgxVDM5NyA2ODNRNTg3IDY4MiA2MDAgNjgwUTY2NCA2NjkgNzA3IDYzMVQ3NTEgNTMwUTc1MSA0NTMgNjg1IDM4OVE2MTYgMzIxIDUwNyAzMDNRNTAwIDMwMiA0MDIgMzAxSDMwN0wyNzcgMTgyUTI0NyA2NiAyNDcgNTlRMjQ3IDU1IDI0OCA1NFQyNTUgNTBUMjcyIDQ4VDMwNSA0NkgzMzZRMzQyIDM3IDM0MiAzNVEzNDIgMTkgMzM1IDVRMzMwIDAgMzE5IDBRMzE2IDAgMjgyIDFUMTgyIDJRMTIwIDIgODcgMlQ1MSAxUTMzIDEgMzMgMTFRMzMgMTMgMzYgMjVRNDAgNDEgNDQgNDNUNjcgNDZROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFpNNjQ1IDU1NFE2NDUgNTY3IDY0MyA1NzVUNjM0IDU5N1Q2MDkgNjE5VDU2MCA2MzVRNTUzIDYzNiA0ODAgNjM3UTQ2MyA2MzcgNDQ1IDYzN1Q0MTYgNjM2VDQwNCA2MzZRMzkxIDYzNSAzODYgNjI3UTM4NCA2MjEgMzY3IDU1MFQzMzIgNDEyVDMxNCAzNDRRMzE0IDM0MiAzOTUgMzQySDQwN0g0MzBRNTQyIDM0MiA1OTAgMzkyUTYxNyA0MTkgNjMxIDQ3MVQ2NDUgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUyIiBkPSJNMjMwIDYzN1EyMDMgNjM3IDE5OCA2MzhUMTkzIDY0OVExOTMgNjc2IDIwNCA2ODJRMjA2IDY4MyAzNzggNjgzUTU1MCA2ODIgNTY0IDY4MFE2MjAgNjcyIDY1OCA2NTJUNzEyIDYwNlQ3MzMgNTYzVDczOSA1MjlRNzM5IDQ4NCA3MTAgNDQ1VDY0MyAzODVUNTc2IDM1MVQ1MzggMzM4TDU0NSAzMzNRNjEyIDI5NSA2MTIgMjIzUTYxMiAyMTIgNjA3IDE2MlQ2MDIgODBWNzFRNjAyIDUzIDYwMyA0M1Q2MTQgMjVUNjQwIDE2UTY2OCAxNiA2ODYgMzhUNzEyIDg1UTcxNyA5OSA3MjAgMTAyVDczNSAxMDVRNzU1IDEwNSA3NTUgOTNRNzU1IDc1IDczMSAzNlE2OTMgLTIxIDY0MSAtMjFINjMyUTU3MSAtMjEgNTMxIDRUNDg3IDgyUTQ4NyAxMDkgNTAyIDE2NlQ1MTcgMjM5UTUxNyAyOTAgNDc0IDMxM1E0NTkgMzIwIDQ0OSAzMjFUMzc4IDMyM0gzMDlMMjc3IDE5M1EyNDQgNjEgMjQ0IDU5UTI0NCA1NSAyNDUgNTRUMjUyIDUwVDI2OSA0OFQzMDIgNDZIMzMzUTMzOSAzOCAzMzkgMzdUMzM2IDE5UTMzMiA2IDMyNiAwSDMxMVEyNzUgMiAxODAgMlExNDYgMiAxMTcgMlQ3MSAyVDUwIDFRMzMgMSAzMyAxMFEzMyAxMiAzNiAyNFE0MSA0MyA0NiA0NVE1MCA0NiA2MSA0Nkg2N1E5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4UTI4NyA2MzUgMjMwIDYzN1pNNjMwIDU1NFE2MzAgNTg2IDYwOSA2MDhUNTIzIDYzNlE1MjEgNjM2IDUwMCA2MzZUNDYyIDYzN0g0NDBRMzkzIDYzNyAzODYgNjI3UTM4NSA2MjQgMzUyIDQ5NFQzMTkgMzYxUTMxOSAzNjAgMzg4IDM2MFE0NjYgMzYxIDQ5MiAzNjdRNTU2IDM3NyA1OTIgNDI2UTYwOCA0NDkgNjE5IDQ4NlQ2MzAgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU0IiBkPSJNNDAgNDM3UTIxIDQzNyAyMSA0NDVRMjEgNDUwIDM3IDUwMVQ3MSA2MDJMODggNjUxUTkzIDY2OSAxMDEgNjc3SDU2OUg2NTlRNjkxIDY3NyA2OTcgNjc2VDcwNCA2NjdRNzA0IDY2MSA2ODcgNTUzVDY2OCA0NDRRNjY4IDQzNyA2NDkgNDM3UTY0MCA0MzcgNjM3IDQzN1Q2MzEgNDQyTDYyOSA0NDVRNjI5IDQ1MSA2MzUgNDkwVDY0MSA1NTFRNjQxIDU4NiA2MjggNjA0VDU3MyA2MjlRNTY4IDYzMCA1MTUgNjMxUTQ2OSA2MzEgNDU3IDYzMFQ0MzkgNjIyUTQzOCA2MjEgMzY4IDM0M1QyOTggNjBRMjk4IDQ4IDM4NiA0NlE0MTggNDYgNDI3IDQ1VDQzNiAzNlE0MzYgMzEgNDMzIDIyUTQyOSA0IDQyNCAxTDQyMiAwUTQxOSAwIDQxNSAwUTQxMCAwIDM2MyAxVDIyOCAyUTk5IDIgNjQgMEg0OVE0MyA2IDQzIDlUNDUgMjdRNDkgNDAgNTUgNDZIODNIOTRRMTc0IDQ2IDE4OSA1NVExOTAgNTYgMTkxIDU2UTE5NiA1OSAyMDEgNzZUMjQxIDIzM1EyNTggMzAxIDI2OSAzNDRRMzM5IDYxOSAzMzkgNjI1UTMzOSA2MzAgMzEwIDYzMEgyNzlRMjEyIDYzMCAxOTEgNjI0UTE0NiA2MTQgMTIxIDU4M1Q2NyA0NjdRNjAgNDQ1IDU3IDQ0MVQ0MyA0MzdINDBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMUQyIiBkPSJNNTgwIDUxNFE1ODAgNTI1IDU5NiA1MjVRNjAxIDUyNSA2MDQgNTI1VDYwOSA1MjVUNjEzIDUyNFQ2MTUgNTIzVDYxNyA1MjBUNjE5IDUxN1Q2MjIgNTEyUTY1OSA0MzggNzIwIDM4MVQ4MzEgMzAwVDkyNyAyNjNROTQ0IDI1OCA5NDQgMjUwVDkzNSAyMzlUODk4IDIyOFQ4NDAgMjA0UTY5NiAxMzQgNjIyIC0xMlE2MTggLTIxIDYxNSAtMjJUNjAwIC0yNFE1ODAgLTI0IDU4MCAtMTdRNTgwIC0xMyA1ODUgMFE2MjAgNjkgNjcxIDEyM0w2ODEgMTMzSDcwUTU2IDE0MCA1NiAxNTNRNTYgMTY4IDcyIDE3M0g3MjVMNzM1IDE4MVE3NzQgMjExIDg1MiAyNTBRODUxIDI1MSA4MzQgMjU5VDc4OSAyODNUNzM1IDMxOUw3MjUgMzI3SDcyUTU2IDMzMiA1NiAzNDdRNTYgMzYwIDcwIDM2N0g2ODFMNjcxIDM3N1E2MzggNDEyIDYwOSA0NThUNTgwIDUxNFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMwIiBkPSJNOTYgNTg1UTE1MiA2NjYgMjQ5IDY2NlEyOTcgNjY2IDM0NSA2NDBUNDIzIDU0OFE0NjAgNDY1IDQ2MCAzMjBRNDYwIDE2NSA0MTcgODNRMzk3IDQxIDM2MiAxNlQzMDEgLTE1VDI1MCAtMjJRMjI0IC0yMiAxOTggLTE2VDEzNyAxNlQ4MiA4M1EzOSAxNjUgMzkgMzIwUTM5IDQ5NCA5NiA1ODVaTTMyMSA1OTdRMjkxIDYyOSAyNTAgNjI5UTIwOCA2MjkgMTc4IDU5N1ExNTMgNTcxIDE0NSA1MjVUMTM3IDMzM1ExMzcgMTc1IDE0NSAxMjVUMTgxIDQ2UTIwOSAxNiAyNTAgMTZRMjkwIDE2IDMxOCA0NlEzNDcgNzYgMzU0IDEzMFQzNjIgMzMzUTM2MiA0NzggMzU0IDUyNFQzMjEgNTk3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNUYiIGQ9Ik0wIC02MlYtMjVINDk5Vi02MkgwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjIxMiIgZD0iTTg0IDIzN1Q4NCAyNTBUOTggMjcwSDY3OVE2OTQgMjYyIDY5NCAyNTBUNjc5IDIzMEg5OFE4NCAyMzcgODQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2NywwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKC0xMSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjFEMiIgeD0iMzM3NyIgeT0iMzgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC0xMzEzKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjgyNSIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjE0NTkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMwIiB4PSIyNTE1IiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC02MDUpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSItODUiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjkuNjIzMDUyNjE0NDY3MzMsMCkgc2NhbGUoMy40MzY0MTM1Nzg1MjcwMTQsMSkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMjMyMSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMUQyIiB4PSIzMzc3IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQzNjgsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDEzODkpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5MzYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjQ2MiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM1MTgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NzU5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTQxMyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIyNDE0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzM1MCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjQ5ODgiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEwMzYwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTEzNjAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjc2OCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjE1NzkiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNTgwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjgyNSIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI0MTUxIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsMzgpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5MzYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjQ2MiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM1MTgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NTkzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjYwMDYiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MDA3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjgwODIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5MDE4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEwNDg5IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTE0ODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjczMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxNDMxMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE1MzEwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTY1NTEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iODI1IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTEzMTMpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjcyMiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE3MjMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjMxODciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMzc0MyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ2NzksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iNjIwNiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDcyNjIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4MzM2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9Ijk3NTAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDc1MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDExOTkxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9zdmc+)
因此,
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9Ijc4LjI0MWV4IiBoZWlnaHQ9IjUuNjc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMi4zMzhleDsiIHZpZXdCb3g9IjAgLTE0MzcuMiAzMzY4Ni45IDI0NDMuOCIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NiIgZD0iTTUyIDY0OFE1MiA2NzAgNjUgNjgzSDc2UTExOCA2ODAgMTgxIDY4MFEyOTkgNjgwIDMyMCA2ODNIMzMwUTMzNiA2NzcgMzM2IDY3NFQzMzQgNjU2UTMyOSA2NDEgMzI1IDYzN0gzMDRRMjgyIDYzNSAyNzQgNjM1UTI0NSA2MzAgMjQyIDYyMFEyNDIgNjE4IDI3MSAzNjlUMzAxIDExOEwzNzQgMjM1UTQ0NyAzNTIgNTIwIDQ3MVQ1OTUgNTk0UTU5OSA2MDEgNTk5IDYwOVE1OTkgNjMzIDU1NSA2MzdRNTM3IDYzNyA1MzcgNjQ4UTUzNyA2NDkgNTM5IDY2MVE1NDIgNjc1IDU0NSA2NzlUNTU4IDY4M1E1NjAgNjgzIDU3MCA2ODNUNjA0IDY4MlQ2NjggNjgxUTczNyA2ODEgNzU1IDY4M0g3NjJRNzY5IDY3NiA3NjkgNjcyUTc2OSA2NTUgNzYwIDY0MFE3NTcgNjM3IDc0MyA2MzdRNzMwIDYzNiA3MTkgNjM1VDY5OCA2MzBUNjgyIDYyM1Q2NzAgNjE1VDY2MCA2MDhUNjUyIDU5OVQ2NDUgNTkyTDQ1MiAyODJRMjcyIC05IDI2NiAtMTZRMjYzIC0xOCAyNTkgLTIxTDI0MSAtMjJIMjM0UTIxNiAtMjIgMjE2IC0xNVEyMTMgLTkgMTc3IDMwNVExMzkgNjIzIDEzOCA2MjZRMTMzIDYzNyA3NiA2MzdINTlRNTIgNjQyIDUyIDY0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUwIiBkPSJNMjg3IDYyOFEyODcgNjM1IDIzMCA2MzdRMjA2IDYzNyAxOTkgNjM4VDE5MiA2NDhRMTkyIDY0OSAxOTQgNjU5UTIwMCA2NzkgMjAzIDY4MVQzOTcgNjgzUTU4NyA2ODIgNjAwIDY4MFE2NjQgNjY5IDcwNyA2MzFUNzUxIDUzMFE3NTEgNDUzIDY4NSAzODlRNjE2IDMyMSA1MDcgMzAzUTUwMCAzMDIgNDAyIDMwMUgzMDdMMjc3IDE4MlEyNDcgNjYgMjQ3IDU5UTI0NyA1NSAyNDggNTRUMjU1IDUwVDI3MiA0OFQzMDUgNDZIMzM2UTM0MiAzNyAzNDIgMzVRMzQyIDE5IDMzNSA1UTMzMCAwIDMxOSAwUTMxNiAwIDI4MiAxVDE4MiAyUTEyMCAyIDg3IDJUNTEgMVEzMyAxIDMzIDExUTMzIDEzIDM2IDI1UTQwIDQxIDQ0IDQzVDY3IDQ2UTk0IDQ2IDEyNyA0OVExNDEgNTIgMTQ2IDYxUTE0OSA2NSAyMTggMzM5VDI4NyA2MjhaTTY0NSA1NTRRNjQ1IDU2NyA2NDMgNTc1VDYzNCA1OTdUNjA5IDYxOVQ1NjAgNjM1UTU1MyA2MzYgNDgwIDYzN1E0NjMgNjM3IDQ0NSA2MzdUNDE2IDYzNlQ0MDQgNjM2UTM5MSA2MzUgMzg2IDYyN1EzODQgNjIxIDM2NyA1NTBUMzMyIDQxMlQzMTQgMzQ0UTMxNCAzNDIgMzk1IDM0Mkg0MDdINDMwUTU0MiAzNDIgNTkwIDM5MlE2MTcgNDE5IDYzMSA0NzFUNjQ1IDU1NFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MiIgZD0iTTIzMCA2MzdRMjAzIDYzNyAxOTggNjM4VDE5MyA2NDlRMTkzIDY3NiAyMDQgNjgyUTIwNiA2ODMgMzc4IDY4M1E1NTAgNjgyIDU2NCA2ODBRNjIwIDY3MiA2NTggNjUyVDcxMiA2MDZUNzMzIDU2M1Q3MzkgNTI5UTczOSA0ODQgNzEwIDQ0NVQ2NDMgMzg1VDU3NiAzNTFUNTM4IDMzOEw1NDUgMzMzUTYxMiAyOTUgNjEyIDIyM1E2MTIgMjEyIDYwNyAxNjJUNjAyIDgwVjcxUTYwMiA1MyA2MDMgNDNUNjE0IDI1VDY0MCAxNlE2NjggMTYgNjg2IDM4VDcxMiA4NVE3MTcgOTkgNzIwIDEwMlQ3MzUgMTA1UTc1NSAxMDUgNzU1IDkzUTc1NSA3NSA3MzEgMzZRNjkzIC0yMSA2NDEgLTIxSDYzMlE1NzEgLTIxIDUzMSA0VDQ4NyA4MlE0ODcgMTA5IDUwMiAxNjZUNTE3IDIzOVE1MTcgMjkwIDQ3NCAzMTNRNDU5IDMyMCA0NDkgMzIxVDM3OCAzMjNIMzA5TDI3NyAxOTNRMjQ0IDYxIDI0NCA1OVEyNDQgNTUgMjQ1IDU0VDI1MiA1MFQyNjkgNDhUMzAyIDQ2SDMzM1EzMzkgMzggMzM5IDM3VDMzNiAxOVEzMzIgNiAzMjYgMEgzMTFRMjc1IDIgMTgwIDJRMTQ2IDIgMTE3IDJUNzEgMlQ1MCAxUTMzIDEgMzMgMTBRMzMgMTIgMzYgMjRRNDEgNDMgNDYgNDVRNTAgNDYgNjEgNDZINjdROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFEyODcgNjM1IDIzMCA2MzdaTTYzMCA1NTRRNjMwIDU4NiA2MDkgNjA4VDUyMyA2MzZRNTIxIDYzNiA1MDAgNjM2VDQ2MiA2MzdINDQwUTM5MyA2MzcgMzg2IDYyN1EzODUgNjI0IDM1MiA0OTRUMzE5IDM2MVEzMTkgMzYwIDM4OCAzNjBRNDY2IDM2MSA0OTIgMzY3UTU1NiAzNzcgNTkyIDQyNlE2MDggNDQ5IDYxOSA0ODZUNjMwIDU1NFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJCIiBkPSJNNTYgMjM3VDU2IDI1MFQ3MCAyNzBIMzY5VjQyMEwzNzAgNTcwUTM4MCA1ODMgMzg5IDU4M1E0MDIgNTgzIDQwOSA1NjhWMjcwSDcwN1E3MjIgMjYyIDcyMiAyNTBUNzA3IDIzMEg0MDlWLTY4UTQwMSAtODIgMzkxIC04MkgzODlIMzg3UTM3NSAtODIgMzY5IC02OFYyMzBINzBRNTYgMjM3IDU2IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjIxMiIgZD0iTTg0IDIzN1Q4NCAyNTBUOTggMjcwSDY3OVE2OTQgMjYyIDY5NCAyNTBUNjc5IDIzMEg5OFE4NCAyMzcgODQgMjUwWiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTM2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI0NjIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzMjQwLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzk3LDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNjIwNyIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTA3NCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIyNDg4IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQ4OCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ3MjksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNzA0LC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iNzIyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTcyMywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjEwMjQzIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTEwMjIsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIyOTE3IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzI1LDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTA3NCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iNzIyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTcyMywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjE0NjgwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTU0NTgsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIyOTE3IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTU5LDY3NikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTI0MCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iNzIyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTcyMywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjE5MTE2IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTk4OTUsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIyMzg1IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDc0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTcyLC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjIzMDIxIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjM3OTksMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIyNzE4IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsNjc2KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjQwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzM4LC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI3MjU3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjgwMzYsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMzYwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQzLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyOTkxNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIzMTMyOCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDMyMzI5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9zdmc+)
定理3 首次访问MC方法是无偏的,即![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjM1LjkzNWV4IiBoZWlnaHQ9IjMuMzQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMS4wMDVleDsiIHZpZXdCb3g9IjAgLTEwMDYuNiAxNTQ3MiAxNDM5LjIiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi00MiIgZD0iTTEzMSA2MjJRMTI0IDYyOSAxMjAgNjMxVDEwNCA2MzRUNjEgNjM3SDI4VjY4M0gyMjlIMjY3SDM0NlE0MjMgNjgzIDQ1OSA2NzhUNTMxIDY1MVE1NzQgNjI3IDU5OSA1OTBUNjI0IDUxMlE2MjQgNDYxIDU4MyA0MTlUNDc2IDM2MEw0NjYgMzU3UTUzOSAzNDggNTk1IDMwMlQ2NTEgMTg3UTY1MSAxMTkgNjAwIDY3VDQ2OSAzUTQ1NiAxIDI0MiAwSDI4VjQ2SDYxUTEwMyA0NyAxMTIgNDlUMTMxIDYxVjYyMlpNNTExIDUxM1E1MTEgNTYwIDQ4NSA1OTRUNDE2IDYzNlE0MTUgNjM2IDQwMyA2MzZUMzcxIDYzNlQzMzMgNjM3UTI2NiA2MzcgMjUxIDYzNlQyMzIgNjI4UTIyOSA2MjQgMjI5IDQ5OVYzNzRIMzEyTDM5NiAzNzVMNDA2IDM3N1E0MTAgMzc4IDQxNyAzODBUNDQyIDM5M1Q0NzQgNDE3VDQ5OSA0NTZUNTExIDUxM1pNNTM3IDE4OFE1MzcgMjM5IDUwOSAyODJUNDMwIDMzNkwzMjkgMzM3SDIyOVYyMDBWMTE2UTIyOSA1NyAyMzQgNTJRMjQwIDQ3IDMzNCA0N0gzODNRNDI1IDQ3IDQ0MyA1M1E0ODYgNjcgNTExIDEwNFQ1MzcgMTg4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNjkiIGQ9Ik02OSA2MDlRNjkgNjM3IDg3IDY1M1QxMzEgNjY5UTE1NCA2NjcgMTcxIDY1MlQxODggNjA5UTE4OCA1NzkgMTcxIDU2NFQxMjkgNTQ5UTEwNCA1NDkgODcgNTY0VDY5IDYwOVpNMjQ3IDBRMjMyIDMgMTQzIDNRMTMyIDMgMTA2IDNUNTYgMUwzNCAwSDI2VjQ2SDQyUTcwIDQ2IDkxIDQ5UTEwMCA1MyAxMDIgNjBUMTA0IDEwMlYyMDVWMjkzUTEwNCAzNDUgMTAyIDM1OVQ4OCAzNzhRNzQgMzg1IDQxIDM4NUgzMFY0MDhRMzAgNDMxIDMyIDQzMUw0MiA0MzJRNTIgNDMzIDcwIDQzNFQxMDYgNDM2UTEyMyA0MzcgMTQyIDQzOFQxNzEgNDQxVDE4MiA0NDJIMTg1VjYyUTE5MCA1MiAxOTcgNTBUMjMyIDQ2SDI1NVYwSDI0N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTYxIiBkPSJNMTM3IDMwNVQxMTUgMzA1VDc4IDMyMFQ2MyAzNTlRNjMgMzk0IDk3IDQyMVQyMTggNDQ4UTI5MSA0NDggMzM2IDQxNlQzOTYgMzQwUTQwMSAzMjYgNDAxIDMwOVQ0MDIgMTk0VjEyNFE0MDIgNzYgNDA3IDU4VDQyOCA0MFE0NDMgNDAgNDQ4IDU2VDQ1MyAxMDlWMTQ1SDQ5M1YxMDZRNDkyIDY2IDQ5MCA1OVE0ODEgMjkgNDU1IDEyVDQwMCAtNlQzNTMgMTJUMzI5IDU0VjU4TDMyNyA1NVEzMjUgNTIgMzIyIDQ5VDMxNCA0MFQzMDIgMjlUMjg3IDE3VDI2OSA2VDI0NyAtMlQyMjEgLThUMTkwIC0xMVExMzAgLTExIDgyIDIwVDM0IDEwN1EzNCAxMjggNDEgMTQ3VDY4IDE4OFQxMTYgMjI1VDE5NCAyNTNUMzA0IDI2OEgzMThWMjkwUTMxOCAzMjQgMzEyIDM0MFEyOTAgNDExIDIxNSA0MTFRMTk3IDQxMSAxODEgNDEwVDE1NiA0MDZUMTQ4IDQwM1ExNzAgMzg4IDE3MCAzNTlRMTcwIDMzNCAxNTQgMzIwWk0xMjYgMTA2UTEyNiA3NSAxNTAgNTFUMjA5IDI2UTI0NyAyNiAyNzYgNDlUMzE1IDEwOVEzMTcgMTE2IDMxOCAxNzVRMzE4IDIzMyAzMTcgMjMzUTMwOSAyMzMgMjk2IDIzMlQyNTEgMjIzVDE5MyAyMDNUMTQ3IDE2NlQxMjYgMTA2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNzMiIGQ9Ik0yOTUgMzE2UTI5NSAzNTYgMjY4IDM4NVQxOTAgNDE0UTE1NCA0MTQgMTI4IDQwMVE5OCAzODIgOTggMzQ5UTk3IDM0NCA5OCAzMzZUMTE0IDMxMlQxNTcgMjg3UTE3NSAyODIgMjAxIDI3OFQyNDUgMjY5VDI3NyAyNTZRMjk0IDI0OCAzMTAgMjM2VDM0MiAxOTVUMzU5IDEzM1EzNTkgNzEgMzIxIDMxVDE5OCAtMTBIMTkwUTEzOCAtMTAgOTQgMjZMODYgMTlMNzcgMTBRNzEgNCA2NSAtMUw1NCAtMTFINDZINDJRMzkgLTExIDMzIC01Vjc0VjEzMlEzMyAxNTMgMzUgMTU3VDQ1IDE2Mkg1NFE2NiAxNjIgNzAgMTU4VDc1IDE0NlQ4MiAxMTlUMTAxIDc3UTEzNiAyNiAxOTggMjZRMjk1IDI2IDI5NSAxMDRRMjk1IDEzMyAyNzcgMTUxUTI1NyAxNzUgMTk0IDE4N1QxMTEgMjEwUTc1IDIyNyA1NCAyNTZUMzMgMzE4UTMzIDM1NyA1MCAzODRUOTMgNDI0VDE0MyA0NDJUMTg3IDQ0N0gxOThRMjM4IDQ0NyAyNjggNDMyTDI4MyA0MjRMMjkyIDQzMVEzMDIgNDQwIDMxNCA0NDhIMzIySDMyNlEzMjkgNDQ4IDMzNSA0NDJWMzEwTDMyOSAzMDRIMzAxUTI5NSAzMTAgMjk1IDMxNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NiIgZD0iTTQ4IDFRMzEgMSAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDYgNjYgMjE1IDM0MlQyODUgNjIyUTI4NSA2MjkgMjgxIDYyOVEyNzMgNjMyIDIyOCA2MzRIMTk3UTE5MSA2NDAgMTkxIDY0MlQxOTMgNjU5UTE5NyA2NzYgMjAzIDY4MEg3NDJRNzQ5IDY3NiA3NDkgNjY5UTc0OSA2NjQgNzM2IDU1N1Q3MjIgNDQ3UTcyMCA0NDAgNzAyIDQ0MEg2OTBRNjgzIDQ0NSA2ODMgNDUzUTY4MyA0NTQgNjg2IDQ3N1Q2ODkgNTMwUTY4OSA1NjAgNjgyIDU3OVQ2NjMgNjEwVDYyNiA2MjZUNTc1IDYzM1Q1MDMgNjM0SDQ4MFEzOTggNjMzIDM5MyA2MzFRMzg4IDYyOSAzODYgNjIzUTM4NSA2MjIgMzUyIDQ5MkwzMjAgMzYzSDM3NVEzNzggMzYzIDM5OCAzNjNUNDI2IDM2NFQ0NDggMzY3VDQ3MiAzNzRUNDg5IDM4NlE1MDIgMzk4IDUxMSA0MTlUNTI0IDQ1N1Q1MjkgNDc1UTUzMiA0ODAgNTQ4IDQ4MEg1NjBRNTY3IDQ3NSA1NjcgNDcwUTU2NyA0NjcgNTM2IDMzOVQ1MDIgMjA3UTUwMCAyMDAgNDgyIDIwMEg0NzBRNDYzIDIwNiA0NjMgMjEyUTQ2MyAyMTUgNDY4IDIzNFQ0NzMgMjc0UTQ3MyAzMDMgNDUzIDMxMFQzNjQgMzE3SDMwOUwyNzcgMTkwUTI0NSA2NiAyNDUgNjBRMjQ1IDQ2IDMzNCA0NkgzNTlRMzY1IDQwIDM2NSAzOVQzNjMgMTlRMzU5IDYgMzUzIDBIMzM2UTI5NSAyIDE4NSAyUTEyMCAyIDg2IDJUNDggMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU2IiBkPSJNNTIgNjQ4UTUyIDY3MCA2NSA2ODNINzZRMTE4IDY4MCAxODEgNjgwUTI5OSA2ODAgMzIwIDY4M0gzMzBRMzM2IDY3NyAzMzYgNjc0VDMzNCA2NTZRMzI5IDY0MSAzMjUgNjM3SDMwNFEyODIgNjM1IDI3NCA2MzVRMjQ1IDYzMCAyNDIgNjIwUTI0MiA2MTggMjcxIDM2OVQzMDEgMTE4TDM3NCAyMzVRNDQ3IDM1MiA1MjAgNDcxVDU5NSA1OTRRNTk5IDYwMSA1OTkgNjA5UTU5OSA2MzMgNTU1IDYzN1E1MzcgNjM3IDUzNyA2NDhRNTM3IDY0OSA1MzkgNjYxUTU0MiA2NzUgNTQ1IDY3OVQ1NTggNjgzUTU2MCA2ODMgNTcwIDY4M1Q2MDQgNjgyVDY2OCA2ODFRNzM3IDY4MSA3NTUgNjgzSDc2MlE3NjkgNjc2IDc2OSA2NzJRNzY5IDY1NSA3NjAgNjQwUTc1NyA2MzcgNzQzIDYzN1E3MzAgNjM2IDcxOSA2MzVUNjk4IDYzMFQ2ODIgNjIzVDY3MCA2MTVUNjYwIDYwOFQ2NTIgNTk5VDY0NSA1OTJMNDUyIDI4MlEyNzIgLTkgMjY2IC0xNlEyNjMgLTE4IDI1OSAtMjFMMjQxIC0yMkgyMzRRMjE2IC0yMiAyMTYgLTE1UTIxMyAtOSAxNzcgMzA1UTEzOSA2MjMgMTM4IDYyNlExMzMgNjM3IDc2IDYzN0g1OVE1MiA2NDIgNTIgNjQ4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjIxMiIgZD0iTTg0IDIzN1Q4NCAyNTBUOTggMjcwSDY3OVE2OTQgMjYyIDY5NCAyNTBUNjc5IDIzMEg5OFE4NCAyMzcgODQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQ1IiBkPSJNNDkyIDIxM1E0NzIgMjEzIDQ3MiAyMjZRNDcyIDIzMCA0NzcgMjUwVDQ4MiAyODVRNDgyIDMxNiA0NjEgMzIzVDM2NCAzMzBIMzEyUTMxMSAzMjggMjc3IDE5MlQyNDMgNTJRMjQzIDQ4IDI1NCA0OFQzMzQgNDZRNDI4IDQ2IDQ1OCA0OFQ1MTggNjFRNTY3IDc3IDU5OSAxMTdUNjcwIDI0OFE2ODAgMjcwIDY4MyAyNzJRNjkwIDI3NCA2OTggMjc0UTcxOCAyNzQgNzE4IDI2MVE2MTMgNyA2MDggMlE2MDUgMCAzMjIgMEgxMzNRMzEgMCAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDYgNjYgMjE1IDM0MlQyODUgNjIyUTI4NSA2MjkgMjgxIDYyOVEyNzMgNjMyIDIyOCA2MzRIMTk3UTE5MSA2NDAgMTkxIDY0MlQxOTMgNjU5UTE5NyA2NzYgMjAzIDY4MEg3NTdRNzY0IDY3NiA3NjQgNjY5UTc2NCA2NjQgNzUxIDU1N1Q3MzcgNDQ3UTczNSA0NDAgNzE3IDQ0MEg3MDVRNjk4IDQ0NSA2OTggNDUzTDcwMSA0NzZRNzA0IDUwMCA3MDQgNTI4UTcwNCA1NTggNjk3IDU3OFQ2NzggNjA5VDY0MyA2MjVUNTk2IDYzMlQ1MzIgNjM0SDQ4NVEzOTcgNjMzIDM5MiA2MzFRMzg4IDYyOSAzODYgNjIyUTM4NSA2MTkgMzU1IDQ5OVQzMjQgMzc3UTM0NyAzNzYgMzcyIDM3NkgzOThRNDY0IDM3NiA0ODkgMzkxVDUzNCA0NzJRNTM4IDQ4OCA1NDAgNDkwVDU1NyA0OTNRNTYyIDQ5MyA1NjUgNDkzVDU3MCA0OTJUNTcyIDQ5MVQ1NzQgNDg3VDU3NyA0ODNMNTQ0IDM1MVE1MTEgMjE4IDUwOCAyMTZRNTA1IDIxMyA0OTIgMjEzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0IiIGQ9Ik00MzQgLTIzMVE0MzQgLTI0NCA0MjggLTI1MEg0MTBRMjgxIC0yNTAgMjMwIC0xODRRMjI1IC0xNzcgMjIyIC0xNzJUMjE3IC0xNjFUMjEzIC0xNDhUMjExIC0xMzNUMjEwIC0xMTFUMjA5IC04NFQyMDkgLTQ3VDIwOSAwUTIwOSAyMSAyMDkgNTNRMjA4IDE0MiAyMDQgMTUzUTIwMyAxNTQgMjAzIDE1NVExODkgMTkxIDE1MyAyMTFUODIgMjMxUTcxIDIzMSA2OCAyMzRUNjUgMjUwVDY4IDI2NlQ4MiAyNjlRMTE2IDI2OSAxNTIgMjg5VDIwMyAzNDVRMjA4IDM1NiAyMDggMzc3VDIwOSA1MjlWNTc5UTIwOSA2MzQgMjE1IDY1NlQyNDQgNjk4UTI3MCA3MjQgMzI0IDc0MFEzNjEgNzQ4IDM3NyA3NDlRMzc5IDc0OSAzOTAgNzQ5VDQwOCA3NTBINDI4UTQzNCA3NDQgNDM0IDczMlE0MzQgNzE5IDQzMSA3MTZRNDI5IDcxMyA0MTUgNzEzUTM2MiA3MTAgMzMyIDY4OVQyOTYgNjQ3UTI5MSA2MzQgMjkxIDQ5OVY0MTdRMjkxIDM3MCAyODggMzUzVDI3MSAzMTRRMjQwIDI3MSAxODQgMjU1TDE3MCAyNTBMMTg0IDI0NVEyMDIgMjM5IDIyMCAyMzBUMjYyIDE5NlQyOTAgMTM3UTI5MSAxMzEgMjkxIDFRMjkxIC0xMzQgMjk2IC0xNDdRMzA2IC0xNzQgMzM5IC0xOTJUNDE1IC0yMTNRNDI5IC0yMTMgNDMxIC0yMTZRNDM0IC0yMTkgNDM0IC0yMzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03RCIgZD0iTTY1IDczMVE2NSA3NDUgNjggNzQ3VDg4IDc1MFExNzEgNzUwIDIxNiA3MjVUMjc5IDY3MFEyODggNjQ5IDI4OSA2MzVUMjkxIDUwMVEyOTIgMzYyIDI5MyAzNTdRMzA2IDMxMiAzNDUgMjkxVDQxNyAyNjlRNDI4IDI2OSA0MzEgMjY2VDQzNCAyNTBUNDMxIDIzNFQ0MTcgMjMxUTM4MCAyMzEgMzQ1IDIxMFQyOTggMTU3UTI5MyAxNDMgMjkyIDEyMVQyOTEgLTI4Vi03OVEyOTEgLTEzNCAyODUgLTE1NlQyNTYgLTE5OFEyMDIgLTI1MCA4OSAtMjUwUTcxIC0yNTAgNjggLTI0N1Q2NSAtMjMwUTY1IC0yMjQgNjUgLTIyM1Q2NiAtMjE4VDY5IC0yMTRUNzcgLTIxM1E5MSAtMjEzIDEwOCAtMjEwVDE0NiAtMjAwVDE4MyAtMTc3VDIwNyAtMTM5UTIwOCAtMTM0IDIwOSAzTDIxMCAxMzlRMjIzIDE5NiAyODAgMjMwUTMxNSAyNDcgMzMwIDI1MFEzMDUgMjU3IDI4MCAyNzBRMjI1IDMwNCAyMTIgMzUyTDIxMCAzNjJMMjA5IDQ5OFEyMDggNjM1IDIwNyA2NDBRMTk1IDY4MCAxNTQgNjk2VDc3IDcxM1E2OCA3MTMgNjcgNzE2VDY1IDczMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjEtN0IiIGQ9Ik00NzcgLTM0M0w0NzEgLTM0OUg0NThRNDMyIC0zNDkgMzY3IC0zMjVUMjczIC0yNjNRMjU4IC0yNDUgMjUwIC0yMTJMMjQ5IC01MVEyNDkgLTI3IDI0OSAxMlEyNDggMTE4IDI0NCAxMjhRMjQzIDEyOSAyNDMgMTMwUTIyMCAxODkgMTIxIDIyOFExMDkgMjMyIDEwNyAyMzVUMTA1IDI1MFExMDUgMjU2IDEwNSAyNTdUMTA1IDI2MVQxMDcgMjY1VDExMSAyNjhUMTE4IDI3MlQxMjggMjc2VDE0MiAyODNUMTYyIDI5MVEyMjQgMzI0IDI0MyAzNzFRMjQzIDM3MiAyNDQgMzczUTI0OCAzODQgMjQ5IDQ2OVEyNDkgNDc1IDI0OSA0ODlRMjQ5IDUyOCAyNDkgNTUyTDI1MCA3MTRRMjUzIDcyOCAyNTYgNzM2VDI3MSA3NjFUMjk5IDc4OVQzNDcgODE2VDQyMiA4NDNRNDQwIDg0OSA0NDEgODQ5SDQ0M1E0NDUgODQ5IDQ0NyA4NDlUNDUyIDg1MFQ0NTcgODUwSDQ3MUw0NzcgODQ0VjgzMFE0NzcgODIwIDQ3NiA4MTdUNDcwIDgxMVQ0NTkgODA3VDQzNyA4MDFUNDA0IDc4NVEzNTMgNzYwIDMzOCA3MjRRMzMzIDcxMCAzMzMgNTUwUTMzMyA1MjYgMzMzIDQ5MlQzMzQgNDQ3UTMzNCAzOTMgMzI3IDM2OFQyOTUgMzE4UTI1NyAyODAgMTgxIDI1NUwxNjkgMjUxTDE4NCAyNDVRMzE4IDE5OCAzMzIgMTEyUTMzMyAxMDYgMzMzIC00OVEzMzMgLTIwOSAzMzggLTIyM1EzNTEgLTI1NSAzOTEgLTI3N1Q0NjkgLTMwOVE0NzcgLTMxMSA0NzcgLTMyOVYtMzQzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMS03RCIgZD0iTTExMCA4NDlMMTE1IDg1MFExMjAgODUwIDEyNSA4NTBRMTUxIDg1MCAyMTUgODI2VDMwOSA3NjRRMzI0IDc0NyAzMzIgNzE0TDMzMyA1NTJRMzMzIDUyOCAzMzMgNDg5UTMzNCAzODMgMzM4IDM3M1EzMzkgMzcyIDMzOSAzNzFRMzUzIDMzNiAzOTEgMzEwVDQ2OSAyNzFRNDc3IDI2OCA0NzcgMjUxUTQ3NyAyNDEgNDc2IDIzN1Q0NzIgMjMyVDQ1NiAyMjVUNDI4IDIxNFEzNTcgMTc5IDMzOSAxMzBRMzM5IDEyOSAzMzggMTI4UTMzNCAxMTcgMzMzIDMyUTMzMyAyNiAzMzMgMTJRMzMzIC0yNyAzMzMgLTUxTDMzMiAtMjEyUTMyOCAtMjI4IDMyMyAtMjQwVDMwMiAtMjcxVDI1NSAtMzA3VDE3NSAtMzM4UTEzOSAtMzQ5IDEyNSAtMzQ5VDEwOCAtMzQ2VDEwNSAtMzI5UTEwNSAtMzE0IDEwNyAtMzEyVDEzMCAtMzA0UTIzMyAtMjcxIDI0OCAtMjA5UTI0OSAtMjAzIDI0OSAtNDlWNTdRMjQ5IDEwNiAyNTMgMTI1VDI3MyAxNjdRMzA3IDIxMyAzOTggMjQ1TDQxMyAyNTFMNDAxIDI1NVEyNjUgMzAwIDI1MCAzODlRMjQ5IDM5NSAyNDkgNTUwUTI0OSA3MTAgMjQ0IDcyNFEyMjQgNzc0IDExMiA4MTFRMTA1IDgxMyAxMDUgODMwUTEwNSA4NDUgMTEwIDg0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMwIiBkPSJNOTYgNTg1UTE1MiA2NjYgMjQ5IDY2NlEyOTcgNjY2IDM0NSA2NDBUNDIzIDU0OFE0NjAgNDY1IDQ2MCAzMjBRNDYwIDE2NSA0MTcgODNRMzk3IDQxIDM2MiAxNlQzMDEgLTE1VDI1MCAtMjJRMjI0IC0yMiAxOTggLTE2VDEzNyAxNlQ4MiA4M1EzOSAxNjUgMzkgMzIwUTM5IDQ5NCA5NiA1ODVaTTMyMSA1OTdRMjkxIDYyOSAyNTAgNjI5UTIwOCA2MjkgMTc4IDU5N1ExNTMgNTcxIDE0NSA1MjVUMTM3IDMzM1ExMzcgMTc1IDE0NSAxMjVUMTgxIDQ2UTIwOSAxNiAyNTAgMTZRMjkwIDE2IDMxOCA0NlEzNDcgNzYgMzU0IDEzMFQzNjIgMzMzUTM2MiA0NzggMzU0IDUyNFQzMjEgNTk3WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNDIiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTY5IiB4PSI3MDgiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI5ODciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTczIiB4PSIxNDg3IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ2IiB4PSIyNjYxIiB5PSI1ODEiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjI2NjEiIHk9Ii0zNTAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNjc4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjQyMDQiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iNTI2MSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYxOTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSI3NjY4IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9Ijg2NjgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5NTk5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTdCIiB4PSIwIiB5PSItMSI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU4MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ2IiB4PSIxMTY3IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjgyNSIgeT0iLTIxMiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2MjEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjEtN0QiIHg9IjM0NTMiIHk9Ii0xIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIxMzkxNSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzAiIHg9IjE0OTcxIiB5PSIwIj48L3VzZT4KPC9nPgo8L3N2Zz4=)
因为从开始状态 到终止状态 的样本路径上的总奖励根据定义是对所有这些路径的期望总奖励的无偏估计。因此,来自 个独立样本路径的估计平均值也是无偏的。
证明:
对于单次试验而言,首次访问MC方法是无偏的,由(1)得:
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjU1LjY5NWV4IiBoZWlnaHQ9IjU5LjE3NmV4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTI5LjAwNWV4OyIgdmlld0JveD0iMCAtMTI5OTAuNCAyMzk3OS45IDI1NDc4LjQiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDUiIGQ9Ik00OTIgMjEzUTQ3MiAyMTMgNDcyIDIyNlE0NzIgMjMwIDQ3NyAyNTBUNDgyIDI4NVE0ODIgMzE2IDQ2MSAzMjNUMzY0IDMzMEgzMTJRMzExIDMyOCAyNzcgMTkyVDI0MyA1MlEyNDMgNDggMjU0IDQ4VDMzNCA0NlE0MjggNDYgNDU4IDQ4VDUxOCA2MVE1NjcgNzcgNTk5IDExN1Q2NzAgMjQ4UTY4MCAyNzAgNjgzIDI3MlE2OTAgMjc0IDY5OCAyNzRRNzE4IDI3NCA3MTggMjYxUTYxMyA3IDYwOCAyUTYwNSAwIDMyMiAwSDEzM1EzMSAwIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc1N1E3NjQgNjc2IDc2NCA2NjlRNzY0IDY2NCA3NTEgNTU3VDczNyA0NDdRNzM1IDQ0MCA3MTcgNDQwSDcwNVE2OTggNDQ1IDY5OCA0NTNMNzAxIDQ3NlE3MDQgNTAwIDcwNCA1MjhRNzA0IDU1OCA2OTcgNTc4VDY3OCA2MDlUNjQzIDYyNVQ1OTYgNjMyVDUzMiA2MzRINDg1UTM5NyA2MzMgMzkyIDYzMVEzODggNjI5IDM4NiA2MjJRMzg1IDYxOSAzNTUgNDk5VDMyNCAzNzdRMzQ3IDM3NiAzNzIgMzc2SDM5OFE0NjQgMzc2IDQ4OSAzOTFUNTM0IDQ3MlE1MzggNDg4IDU0MCA0OTBUNTU3IDQ5M1E1NjIgNDkzIDU2NSA0OTNUNTcwIDQ5MlQ1NzIgNDkxVDU3NCA0ODdUNTc3IDQ4M0w1NDQgMzUxUTUxMSAyMTggNTA4IDIxNlE1MDUgMjEzIDQ5MiAyMTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03QiIgZD0iTTQzNCAtMjMxUTQzNCAtMjQ0IDQyOCAtMjUwSDQxMFEyODEgLTI1MCAyMzAgLTE4NFEyMjUgLTE3NyAyMjIgLTE3MlQyMTcgLTE2MVQyMTMgLTE0OFQyMTEgLTEzM1QyMTAgLTExMVQyMDkgLTg0VDIwOSAtNDdUMjA5IDBRMjA5IDIxIDIwOSA1M1EyMDggMTQyIDIwNCAxNTNRMjAzIDE1NCAyMDMgMTU1UTE4OSAxOTEgMTUzIDIxMVQ4MiAyMzFRNzEgMjMxIDY4IDIzNFQ2NSAyNTBUNjggMjY2VDgyIDI2OVExMTYgMjY5IDE1MiAyODlUMjAzIDM0NVEyMDggMzU2IDIwOCAzNzdUMjA5IDUyOVY1NzlRMjA5IDYzNCAyMTUgNjU2VDI0NCA2OThRMjcwIDcyNCAzMjQgNzQwUTM2MSA3NDggMzc3IDc0OVEzNzkgNzQ5IDM5MCA3NDlUNDA4IDc1MEg0MjhRNDM0IDc0NCA0MzQgNzMyUTQzNCA3MTkgNDMxIDcxNlE0MjkgNzEzIDQxNSA3MTNRMzYyIDcxMCAzMzIgNjg5VDI5NiA2NDdRMjkxIDYzNCAyOTEgNDk5VjQxN1EyOTEgMzcwIDI4OCAzNTNUMjcxIDMxNFEyNDAgMjcxIDE4NCAyNTVMMTcwIDI1MEwxODQgMjQ1UTIwMiAyMzkgMjIwIDIzMFQyNjIgMTk2VDI5MCAxMzdRMjkxIDEzMSAyOTEgMVEyOTEgLTEzNCAyOTYgLTE0N1EzMDYgLTE3NCAzMzkgLTE5MlQ0MTUgLTIxM1E0MjkgLTIxMyA0MzEgLTIxNlE0MzQgLTIxOSA0MzQgLTIzMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NiIgZD0iTTUyIDY0OFE1MiA2NzAgNjUgNjgzSDc2UTExOCA2ODAgMTgxIDY4MFEyOTkgNjgwIDMyMCA2ODNIMzMwUTMzNiA2NzcgMzM2IDY3NFQzMzQgNjU2UTMyOSA2NDEgMzI1IDYzN0gzMDRRMjgyIDYzNSAyNzQgNjM1UTI0NSA2MzAgMjQyIDYyMFEyNDIgNjE4IDI3MSAzNjlUMzAxIDExOEwzNzQgMjM1UTQ0NyAzNTIgNTIwIDQ3MVQ1OTUgNTk0UTU5OSA2MDEgNTk5IDYwOVE1OTkgNjMzIDU1NSA2MzdRNTM3IDYzNyA1MzcgNjQ4UTUzNyA2NDkgNTM5IDY2MVE1NDIgNjc1IDU0NSA2NzlUNTU4IDY4M1E1NjAgNjgzIDU3MCA2ODNUNjA0IDY4MlQ2NjggNjgxUTczNyA2ODEgNzU1IDY4M0g3NjJRNzY5IDY3NiA3NjkgNjcyUTc2OSA2NTUgNzYwIDY0MFE3NTcgNjM3IDc0MyA2MzdRNzMwIDYzNiA3MTkgNjM1VDY5OCA2MzBUNjgyIDYyM1Q2NzAgNjE1VDY2MCA2MDhUNjUyIDU5OVQ2NDUgNTkyTDQ1MiAyODJRMjcyIC05IDI2NiAtMTZRMjYzIC0xOCAyNTkgLTIxTDI0MSAtMjJIMjM0UTIxNiAtMjIgMjE2IC0xNVEyMTMgLTkgMTc3IDMwNVExMzkgNjIzIDEzOCA2MjZRMTMzIDYzNyA3NiA2MzdINTlRNTIgNjQyIDUyIDY0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NiIgZD0iTTQ4IDFRMzEgMSAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDYgNjYgMjE1IDM0MlQyODUgNjIyUTI4NSA2MjkgMjgxIDYyOVEyNzMgNjMyIDIyOCA2MzRIMTk3UTE5MSA2NDAgMTkxIDY0MlQxOTMgNjU5UTE5NyA2NzYgMjAzIDY4MEg3NDJRNzQ5IDY3NiA3NDkgNjY5UTc0OSA2NjQgNzM2IDU1N1Q3MjIgNDQ3UTcyMCA0NDAgNzAyIDQ0MEg2OTBRNjgzIDQ0NSA2ODMgNDUzUTY4MyA0NTQgNjg2IDQ3N1Q2ODkgNTMwUTY4OSA1NjAgNjgyIDU3OVQ2NjMgNjEwVDYyNiA2MjZUNTc1IDYzM1Q1MDMgNjM0SDQ4MFEzOTggNjMzIDM5MyA2MzFRMzg4IDYyOSAzODYgNjIzUTM4NSA2MjIgMzUyIDQ5MkwzMjAgMzYzSDM3NVEzNzggMzYzIDM5OCAzNjNUNDI2IDM2NFQ0NDggMzY3VDQ3MiAzNzRUNDg5IDM4NlE1MDIgMzk4IDUxMSA0MTlUNTI0IDQ1N1Q1MjkgNDc1UTUzMiA0ODAgNTQ4IDQ4MEg1NjBRNTY3IDQ3NSA1NjcgNDcwUTU2NyA0NjcgNTM2IDMzOVQ1MDIgMjA3UTUwMCAyMDAgNDgyIDIwMEg0NzBRNDYzIDIwNiA0NjMgMjEyUTQ2MyAyMTUgNDY4IDIzNFQ0NzMgMjc0UTQ3MyAzMDMgNDUzIDMxMFQzNjQgMzE3SDMwOUwyNzcgMTkwUTI0NSA2NiAyNDUgNjBRMjQ1IDQ2IDMzNCA0NkgzNTlRMzY1IDQwIDM2NSAzOVQzNjMgMTlRMzU5IDYgMzUzIDBIMzM2UTI5NSAyIDE4NSAyUTEyMCAyIDg2IDJUNDggMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdEIiBkPSJNNjUgNzMxUTY1IDc0NSA2OCA3NDdUODggNzUwUTE3MSA3NTAgMjE2IDcyNVQyNzkgNjcwUTI4OCA2NDkgMjg5IDYzNVQyOTEgNTAxUTI5MiAzNjIgMjkzIDM1N1EzMDYgMzEyIDM0NSAyOTFUNDE3IDI2OVE0MjggMjY5IDQzMSAyNjZUNDM0IDI1MFQ0MzEgMjM0VDQxNyAyMzFRMzgwIDIzMSAzNDUgMjEwVDI5OCAxNTdRMjkzIDE0MyAyOTIgMTIxVDI5MSAtMjhWLTc5UTI5MSAtMTM0IDI4NSAtMTU2VDI1NiAtMTk4UTIwMiAtMjUwIDg5IC0yNTBRNzEgLTI1MCA2OCAtMjQ3VDY1IC0yMzBRNjUgLTIyNCA2NSAtMjIzVDY2IC0yMThUNjkgLTIxNFQ3NyAtMjEzUTkxIC0yMTMgMTA4IC0yMTBUMTQ2IC0yMDBUMTgzIC0xNzdUMjA3IC0xMzlRMjA4IC0xMzQgMjA5IDNMMjEwIDEzOVEyMjMgMTk2IDI4MCAyMzBRMzE1IDI0NyAzMzAgMjUwUTMwNSAyNTcgMjgwIDI3MFEyMjUgMzA0IDIxMiAzNTJMMjEwIDM2MkwyMDkgNDk4UTIwOCA2MzUgMjA3IDY0MFExOTUgNjgwIDE1NCA2OTZUNzcgNzEzUTY4IDcxMyA2NyA3MTZUNjUgNzMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMS03QiIgZD0iTTQ3NyAtMzQzTDQ3MSAtMzQ5SDQ1OFE0MzIgLTM0OSAzNjcgLTMyNVQyNzMgLTI2M1EyNTggLTI0NSAyNTAgLTIxMkwyNDkgLTUxUTI0OSAtMjcgMjQ5IDEyUTI0OCAxMTggMjQ0IDEyOFEyNDMgMTI5IDI0MyAxMzBRMjIwIDE4OSAxMjEgMjI4UTEwOSAyMzIgMTA3IDIzNVQxMDUgMjUwUTEwNSAyNTYgMTA1IDI1N1QxMDUgMjYxVDEwNyAyNjVUMTExIDI2OFQxMTggMjcyVDEyOCAyNzZUMTQyIDI4M1QxNjIgMjkxUTIyNCAzMjQgMjQzIDM3MVEyNDMgMzcyIDI0NCAzNzNRMjQ4IDM4NCAyNDkgNDY5UTI0OSA0NzUgMjQ5IDQ4OVEyNDkgNTI4IDI0OSA1NTJMMjUwIDcxNFEyNTMgNzI4IDI1NiA3MzZUMjcxIDc2MVQyOTkgNzg5VDM0NyA4MTZUNDIyIDg0M1E0NDAgODQ5IDQ0MSA4NDlINDQzUTQ0NSA4NDkgNDQ3IDg0OVQ0NTIgODUwVDQ1NyA4NTBINDcxTDQ3NyA4NDRWODMwUTQ3NyA4MjAgNDc2IDgxN1Q0NzAgODExVDQ1OSA4MDdUNDM3IDgwMVQ0MDQgNzg1UTM1MyA3NjAgMzM4IDcyNFEzMzMgNzEwIDMzMyA1NTBRMzMzIDUyNiAzMzMgNDkyVDMzNCA0NDdRMzM0IDM5MyAzMjcgMzY4VDI5NSAzMThRMjU3IDI4MCAxODEgMjU1TDE2OSAyNTFMMTg0IDI0NVEzMTggMTk4IDMzMiAxMTJRMzMzIDEwNiAzMzMgLTQ5UTMzMyAtMjA5IDMzOCAtMjIzUTM1MSAtMjU1IDM5MSAtMjc3VDQ2OSAtMzA5UTQ3NyAtMzExIDQ3NyAtMzI5Vi0zNDNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oxLTdEIiBkPSJNMTEwIDg0OUwxMTUgODUwUTEyMCA4NTAgMTI1IDg1MFExNTEgODUwIDIxNSA4MjZUMzA5IDc2NFEzMjQgNzQ3IDMzMiA3MTRMMzMzIDU1MlEzMzMgNTI4IDMzMyA0ODlRMzM0IDM4MyAzMzggMzczUTMzOSAzNzIgMzM5IDM3MVEzNTMgMzM2IDM5MSAzMTBUNDY5IDI3MVE0NzcgMjY4IDQ3NyAyNTFRNDc3IDI0MSA0NzYgMjM3VDQ3MiAyMzJUNDU2IDIyNVQ0MjggMjE0UTM1NyAxNzkgMzM5IDEzMFEzMzkgMTI5IDMzOCAxMjhRMzM0IDExNyAzMzMgMzJRMzMzIDI2IDMzMyAxMlEzMzMgLTI3IDMzMyAtNTFMMzMyIC0yMTJRMzI4IC0yMjggMzIzIC0yNDBUMzAyIC0yNzFUMjU1IC0zMDdUMTc1IC0zMzhRMTM5IC0zNDkgMTI1IC0zNDlUMTA4IC0zNDZUMTA1IC0zMjlRMTA1IC0zMTQgMTA3IC0zMTJUMTMwIC0zMDRRMjMzIC0yNzEgMjQ4IC0yMDlRMjQ5IC0yMDMgMjQ5IC00OVY1N1EyNDkgMTA2IDI1MyAxMjVUMjczIDE2N1EzMDcgMjEzIDM5OCAyNDVMNDEzIDI1MUw0MDEgMjU1UTI2NSAzMDAgMjUwIDM4OVEyNDkgMzk1IDI0OSA1NTBRMjQ5IDcxMCAyNDQgNzI0UTIyNCA3NzQgMTEyIDgxMVExMDUgODEzIDEwNSA4MzBRMTA1IDg0NSAxMTAgODQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzgiIGQ9Ik01MiAyODlRNTkgMzMxIDEwNiAzODZUMjIyIDQ0MlEyNTcgNDQyIDI4NiA0MjRUMzI5IDM3OVEzNzEgNDQyIDQzMCA0NDJRNDY3IDQ0MiA0OTQgNDIwVDUyMiAzNjFRNTIyIDMzMiA1MDggMzE0VDQ4MSAyOTJUNDU4IDI4OFE0MzkgMjg4IDQyNyAyOTlUNDE1IDMyOFE0MTUgMzc0IDQ2NSAzOTFRNDU0IDQwNCA0MjUgNDA0UTQxMiA0MDQgNDA2IDQwMlEzNjggMzg2IDM1MCAzMzZRMjkwIDExNSAyOTAgNzhRMjkwIDUwIDMwNiAzOFQzNDEgMjZRMzc4IDI2IDQxNCA1OVQ0NjMgMTQwUTQ2NiAxNTAgNDY5IDE1MVQ0ODUgMTUzSDQ4OVE1MDQgMTUzIDUwNCAxNDVRNTA0IDE0NCA1MDIgMTM0UTQ4NiA3NyA0NDAgMzNUMzMzIC0xMVEyNjMgLTExIDIyNyA1MlExODYgLTEwIDEzMyAtMTBIMTI3UTc4IC0xMCA1NyAxNlQzNSA3MVEzNSAxMDMgNTQgMTIzVDk5IDE0M1ExNDIgMTQzIDE0MiAxMDFRMTQyIDgxIDEzMCA2NlQxMDcgNDZUOTQgNDFMOTEgNDBROTEgMzkgOTcgMzZUMTEzIDI5VDEzMiAyNlExNjggMjYgMTk0IDcxUTIwMyA4NyAyMTcgMTM5VDI0NSAyNDdUMjYxIDMxM1EyNjYgMzQwIDI2NiAzNTJRMjY2IDM4MCAyNTEgMzkyVDIxNyA0MDRRMTc3IDQwNCAxNDIgMzcyVDkzIDI5MFE5MSAyODEgODggMjgwVDcyIDI3OEg1OFE1MiAyODQgNTIgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNUIiIGQ9Ik0xMTggLTI1MFY3NTBIMjU1VjcxMEgxNThWLTIxMEgyNTVWLTI1MEgxMThaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNjYiIGQ9Ik0xMTggLTE2MlExMjAgLTE2MiAxMjQgLTE2NFQxMzUgLTE2N1QxNDcgLTE2OFExNjAgLTE2OCAxNzEgLTE1NVQxODcgLTEyNlExOTcgLTk5IDIyMSAyN1QyNjcgMjY3VDI4OSAzODJWMzg1SDI0MlExOTUgMzg1IDE5MiAzODdRMTg4IDM5MCAxODggMzk3TDE5NSA0MjVRMTk3IDQzMCAyMDMgNDMwVDI1MCA0MzFRMjk4IDQzMSAyOTggNDMyUTI5OCA0MzQgMzA3IDQ4MlQzMTkgNTQwUTM1NiA3MDUgNDY1IDcwNVE1MDIgNzAzIDUyNiA2ODNUNTUwIDYzMFE1NTAgNTk0IDUyOSA1NzhUNDg3IDU2MVE0NDMgNTYxIDQ0MyA2MDNRNDQzIDYyMiA0NTQgNjM2VDQ3OCA2NTdMNDg3IDY2MlE0NzEgNjY4IDQ1NyA2NjhRNDQ1IDY2OCA0MzQgNjU4VDQxOSA2MzBRNDEyIDYwMSA0MDMgNTUyVDM4NyA0NjlUMzgwIDQzM1EzODAgNDMxIDQzNSA0MzFRNDgwIDQzMSA0ODcgNDMwVDQ5OCA0MjRRNDk5IDQyMCA0OTYgNDA3VDQ5MSAzOTFRNDg5IDM4NiA0ODIgMzg2VDQyOCAzODVIMzcyTDM0OSAyNjNRMzAxIDE1IDI4MiAtNDdRMjU1IC0xMzIgMjEyIC0xNzNRMTc1IC0yMDUgMTM5IC0yMDVRMTA3IC0yMDUgODEgLTE4NlQ1NSAtMTMyUTU1IC05NSA3NiAtNzhUMTE4IC02MVExNjIgLTYxIDE2MiAtMTAzUTE2MiAtMTIyIDE1MSAtMTM2VDEyNyAtMTU3TDExOCAtMTYyWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNUQiIGQ9Ik0yMiA3MTBWNzUwSDE1OVYtMjUwSDIyVi0yMTBIMTE5VjcxMEgyMloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjIxMSIgZD0iTTYwIDk0OFE2MyA5NTAgNjY1IDk1MEgxMjY3TDEzMjUgODE1UTEzODQgNjc3IDEzODggNjY5SDEzNDhMMTM0MSA2ODNRMTMyMCA3MjQgMTI4NSA3NjFRMTIzNSA4MDkgMTE3NCA4MzhUMTAzMyA4ODFUODgyIDg5OFQ2OTkgOTAySDU3NEg1NDNIMjUxTDI1OSA4OTFRNzIyIDI1OCA3MjQgMjUyUTcyNSAyNTAgNzI0IDI0NlE3MjEgMjQzIDQ2MCAtNTZMMTk2IC0zNTZRMTk2IC0zNTcgNDA3IC0zNTdRNDU5IC0zNTcgNTQ4IC0zNTdUNjc2IC0zNThRODEyIC0zNTggODk2IC0zNTNUMTA2MyAtMzMyVDEyMDQgLTI4M1QxMzA3IC0xOTZRMTMyOCAtMTcwIDEzNDggLTEyNEgxMzg4UTEzODggLTEyNSAxMzgxIC0xNDVUMTM1NiAtMjEwVDEzMjUgLTI5NEwxMjY3IC00NDlMNjY2IC00NTBRNjQgLTQ1MCA2MSAtNDQ4UTU1IC00NDYgNTUgLTQzOVE1NSAtNDM3IDU3IC00MzNMNTkwIDE3N1E1OTAgMTc4IDU1NyAyMjJUNDUyIDM2NlQzMjIgNTQ0TDU2IDkwOUw1NSA5MjRRNTUgOTQ1IDYwIDk0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02QiIgZD0iTTEyMSA2NDdRMTIxIDY1NyAxMjUgNjcwVDEzNyA2ODNRMTM4IDY4MyAyMDkgNjg4VDI4MiA2OTRRMjk0IDY5NCAyOTQgNjg2UTI5NCA2NzkgMjQ0IDQ3N1ExOTQgMjc5IDE5NCAyNzJRMjEzIDI4MiAyMjMgMjkxUTI0NyAzMDkgMjkyIDM1NFQzNjIgNDE1UTQwMiA0NDIgNDM4IDQ0MlE0NjggNDQyIDQ4NSA0MjNUNTAzIDM2OVE1MDMgMzQ0IDQ5NiAzMjdUNDc3IDMwMlQ0NTYgMjkxVDQzOCAyODhRNDE4IDI4OCA0MDYgMjk5VDM5NCAzMjhRMzk0IDM1MyA0MTAgMzY5VDQ0MiAzOTBMNDU4IDM5M1E0NDYgNDA1IDQzNCA0MDVINDMwUTM5OCA0MDIgMzY3IDM4MFQyOTQgMzE2VDIyOCAyNTVRMjMwIDI1NCAyNDMgMjUyVDI2NyAyNDZUMjkzIDIzOFQzMjAgMjI0VDM0MiAyMDZUMzU5IDE4MFQzNjUgMTQ3UTM2NSAxMzAgMzYwIDEwNlQzNTQgNjZRMzU0IDI2IDM4MSAyNlE0MjkgMjYgNDU5IDE0NVE0NjEgMTUzIDQ3OSAxNTNINDgzUTQ5OSAxNTMgNDk5IDE0NFE0OTkgMTM5IDQ5NiAxMzBRNDU1IC0xMSAzNzggLTExUTMzMyAtMTEgMzA1IDE1VDI3NyA5MFEyNzcgMTA4IDI4MCAxMjFUMjgzIDE0NVEyODMgMTY3IDI2OSAxODNUMjM0IDIwNlQyMDAgMjE3VDE4MiAyMjBIMTgwUTE2OCAxNzggMTU5IDEzOVQxNDUgODFUMTM2IDQ0VDEyOSAyMFQxMjIgN1QxMTEgLTJROTggLTExIDgzIC0xMVE2NiAtMTEgNTcgLTFUNDggMTZRNDggMjYgODUgMTc2VDE1OCA0NzFMMTk1IDYxNlExOTYgNjI5IDE4OCA2MzJUMTQ5IDYzN0gxNDRRMTM0IDYzNyAxMzEgNjM3VDEyNCA2NDBUMTIxIDY0N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MCIgZD0iTTI4NyA2MjhRMjg3IDYzNSAyMzAgNjM3UTIwNiA2MzcgMTk5IDYzOFQxOTIgNjQ4UTE5MiA2NDkgMTk0IDY1OVEyMDAgNjc5IDIwMyA2ODFUMzk3IDY4M1E1ODcgNjgyIDYwMCA2ODBRNjY0IDY2OSA3MDcgNjMxVDc1MSA1MzBRNzUxIDQ1MyA2ODUgMzg5UTYxNiAzMjEgNTA3IDMwM1E1MDAgMzAyIDQwMiAzMDFIMzA3TDI3NyAxODJRMjQ3IDY2IDI0NyA1OVEyNDcgNTUgMjQ4IDU0VDI1NSA1MFQyNzIgNDhUMzA1IDQ2SDMzNlEzNDIgMzcgMzQyIDM1UTM0MiAxOSAzMzUgNVEzMzAgMCAzMTkgMFEzMTYgMCAyODIgMVQxODIgMlExMjAgMiA4NyAyVDUxIDFRMzMgMSAzMyAxMVEzMyAxMyAzNiAyNVE0MCA0MSA0NCA0M1Q2NyA0NlE5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4Wk02NDUgNTU0UTY0NSA1NjcgNjQzIDU3NVQ2MzQgNTk3VDYwOSA2MTlUNTYwIDYzNVE1NTMgNjM2IDQ4MCA2MzdRNDYzIDYzNyA0NDUgNjM3VDQxNiA2MzZUNDA0IDYzNlEzOTEgNjM1IDM4NiA2MjdRMzg0IDYyMSAzNjcgNTUwVDMzMiA0MTJUMzE0IDM0NFEzMTQgMzQyIDM5NSAzNDJINDA3SDQzMFE1NDIgMzQyIDU5MCAzOTJRNjE3IDQxOSA2MzEgNDcxVDY0NSA1NTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzIiIGQ9Ik0yMSAyODdRMjIgMjkwIDIzIDI5NVQyOCAzMTdUMzggMzQ4VDUzIDM4MVQ3MyA0MTFUOTkgNDMzVDEzMiA0NDJRMTYxIDQ0MiAxODMgNDMwVDIxNCA0MDhUMjI1IDM4OFEyMjcgMzgyIDIyOCAzODJUMjM2IDM4OVEyODQgNDQxIDM0NyA0NDFIMzUwUTM5OCA0NDEgNDIyIDQwMFE0MzAgMzgxIDQzMCAzNjNRNDMwIDMzMyA0MTcgMzE1VDM5MSAyOTJUMzY2IDI4OFEzNDYgMjg4IDMzNCAyOTlUMzIyIDMyOFEzMjIgMzc2IDM3OCAzOTJRMzU2IDQwNSAzNDIgNDA1UTI4NiA0MDUgMjM5IDMzMVEyMjkgMzE1IDIyNCAyOThUMTkwIDE2NVExNTYgMjUgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTQgMTg5VDE1NCAzNjZRMTU0IDQwNSAxMjggNDA1UTEwNyA0MDUgOTIgMzc3VDY4IDMxNlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0MiIGQ9Ik0xMzkgLTI0OUgxMzdRMTI1IC0yNDkgMTE5IC0yMzVWMjUxTDEyMCA3MzdRMTMwIDc1MCAxMzkgNzUwUTE1MiA3NTAgMTU5IDczNVYtMjM1UTE1MSAtMjQ5IDE0MSAtMjQ5SDEzOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUyIiBkPSJNMjMwIDYzN1EyMDMgNjM3IDE5OCA2MzhUMTkzIDY0OVExOTMgNjc2IDIwNCA2ODJRMjA2IDY4MyAzNzggNjgzUTU1MCA2ODIgNTY0IDY4MFE2MjAgNjcyIDY1OCA2NTJUNzEyIDYwNlQ3MzMgNTYzVDczOSA1MjlRNzM5IDQ4NCA3MTAgNDQ1VDY0MyAzODVUNTc2IDM1MVQ1MzggMzM4TDU0NSAzMzNRNjEyIDI5NSA2MTIgMjIzUTYxMiAyMTIgNjA3IDE2MlQ2MDIgODBWNzFRNjAyIDUzIDYwMyA0M1Q2MTQgMjVUNjQwIDE2UTY2OCAxNiA2ODYgMzhUNzEyIDg1UTcxNyA5OSA3MjAgMTAyVDczNSAxMDVRNzU1IDEwNSA3NTUgOTNRNzU1IDc1IDczMSAzNlE2OTMgLTIxIDY0MSAtMjFINjMyUTU3MSAtMjEgNTMxIDRUNDg3IDgyUTQ4NyAxMDkgNTAyIDE2NlQ1MTcgMjM5UTUxNyAyOTAgNDc0IDMxM1E0NTkgMzIwIDQ0OSAzMjFUMzc4IDMyM0gzMDlMMjc3IDE5M1EyNDQgNjEgMjQ0IDU5UTI0NCA1NSAyNDUgNTRUMjUyIDUwVDI2OSA0OFQzMDIgNDZIMzMzUTMzOSAzOCAzMzkgMzdUMzM2IDE5UTMzMiA2IDMyNiAwSDMxMVEyNzUgMiAxODAgMlExNDYgMiAxMTcgMlQ3MSAyVDUwIDFRMzMgMSAzMyAxMFEzMyAxMiAzNiAyNFE0MSA0MyA0NiA0NVE1MCA0NiA2MSA0Nkg2N1E5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4UTI4NyA2MzUgMjMwIDYzN1pNNjMwIDU1NFE2MzAgNTg2IDYwOSA2MDhUNTIzIDYzNlE1MjEgNjM2IDUwMCA2MzZUNDYyIDYzN0g0NDBRMzkzIDYzNyAzODYgNjI3UTM4NSA2MjQgMzUyIDQ5NFQzMTkgMzYxUTMxOSAzNjAgMzg4IDM2MFE0NjYgMzYxIDQ5MiAzNjdRNTU2IDM3NyA1OTIgNDI2UTYwOCA0NDkgNjE5IDQ4NlQ2MzAgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMS0yOCIgZD0iTTE1MiAyNTFRMTUyIDY0NiAzODggODUwSDQxNlE0MjIgODQ0IDQyMiA4NDFRNDIyIDgzNyA0MDMgODE2VDM1NyA3NTNUMzAyIDY0OVQyNTUgNDgyVDIzNiAyNTBRMjM2IDEyNCAyNTUgMTlUMzAxIC0xNDdUMzU2IC0yNTFUNDAzIC0zMTVUNDIyIC0zNDBRNDIyIC0zNDMgNDE2IC0zNDlIMzg4UTM1OSAtMzI1IDMzMiAtMjk2VDI3MSAtMjEzVDIxMiAtOTdUMTcwIDU2VDE1MiAyNTFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oxLTI5IiBkPSJNMzA1IDI1MVEzMDUgLTE0NSA2OSAtMzQ5SDU2UTQzIC0zNDkgMzkgLTM0N1QzNSAtMzM4UTM3IC0zMzMgNjAgLTMwN1QxMDggLTIzOVQxNjAgLTEzNlQyMDQgMjdUMjIxIDI1MFQyMDQgNDczVDE2MCA2MzZUMTA4IDc0MFQ2MCA4MDdUMzUgODM5UTM1IDg1MCA1MCA4NTBINTZINjlRMTk3IDc0MyAyNTYgNTY2UTMwNSA0MjUgMzA1IDI1MVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjQtNUIiIGQ9Ik0yNjkgLTEyNDlWMTc1MEg1NzdWMTY3N0gzNDJWLTExNzZINTc3Vi0xMjQ5SDI2OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjQtNUQiIGQ9Ik01IDE2NzdWMTc1MEgzMTNWLTEyNDlINVYtMTE3NkgyNDBWMTY3N0g1WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY5IiBkPSJNMTg0IDYwMFExODQgNjI0IDIwMyA2NDJUMjQ3IDY2MVEyNjUgNjYxIDI3NyA2NDlUMjkwIDYxOVEyOTAgNTk2IDI3MCA1NzdUMjI2IDU1N1EyMTEgNTU3IDE5OCA1NjdUMTg0IDYwMFpNMjEgMjg3UTIxIDI5NSAzMCAzMThUNTQgMzY5VDk4IDQyMFQxNTggNDQyUTE5NyA0NDIgMjIzIDQxOVQyNTAgMzU3UTI1MCAzNDAgMjM2IDMwMVQxOTYgMTk2VDE1NCA4M1ExNDkgNjEgMTQ5IDUxUTE0OSAyNiAxNjYgMjZRMTc1IDI2IDE4NSAyOVQyMDggNDNUMjM1IDc4VDI2MCAxMzdRMjYzIDE0OSAyNjUgMTUxVDI4MiAxNTNRMzAyIDE1MyAzMDIgMTQzUTMwMiAxMzUgMjkzIDExMlQyNjggNjFUMjIzIDExVDE2MSAtMTFRMTI5IC0xMSAxMDIgMTBUNzQgNzRRNzQgOTEgNzkgMTA2VDEyMiAyMjBRMTYwIDMyMSAxNjYgMzQxVDE3MyAzODBRMTczIDQwNCAxNTYgNDA0SDE1NFExMjQgNDA0IDk5IDM3MVQ2MSAyODdRNjAgMjg2IDU5IDI4NFQ1OCAyODFUNTYgMjc5VDUzIDI3OFQ0OSAyNzhUNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMCIgZD0iTTk2IDU4NVExNTIgNjY2IDI0OSA2NjZRMjk3IDY2NiAzNDUgNjQwVDQyMyA1NDhRNDYwIDQ2NSA0NjAgMzIwUTQ2MCAxNjUgNDE3IDgzUTM5NyA0MSAzNjIgMTZUMzAxIC0xNVQyNTAgLTIyUTIyNCAtMjIgMTk4IC0xNlQxMzcgMTZUODIgODNRMzkgMTY1IDM5IDMyMFEzOSA0OTQgOTYgNTg1Wk0zMjEgNTk3UTI5MSA2MjkgMjUwIDYyOVEyMDggNjI5IDE3OCA1OTdRMTUzIDU3MSAxNDUgNTI1VDEzNyAzMzNRMTM3IDE3NSAxNDUgMTI1VDE4MSA0NlEyMDkgMTYgMjUwIDE2UTI5MCAxNiAzMTggNDZRMzQ3IDc2IDM1NCAxMzBUMzYyIDMzM1EzNjIgNDc4IDM1NCA1MjRUMzIxIDU5N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMUUiIGQ9Ik01NSAyMTdRNTUgMzA1IDExMSAzNzNUMjU0IDQ0MlEzNDIgNDQyIDQxOSAzODFRNDU3IDM1MCA0OTMgMzAzTDUwNyAyODRMNTE0IDI5NFE2MTggNDQyIDc0NyA0NDJRODMzIDQ0MiA4ODggMzc0VDk0NCAyMTRROTQ0IDEyOCA4ODkgNTlUNzQzIC0xMVE2NTcgLTExIDU4MCA1MFE1NDIgODEgNTA2IDEyOEw0OTIgMTQ3TDQ4NSAxMzdRMzgxIC0xMSAyNTIgLTExUTE2NiAtMTEgMTExIDU3VDU1IDIxN1pNOTA3IDIxN1E5MDcgMjg1IDg2OSAzNDFUNzYxIDM5N1E3NDAgMzk3IDcyMCAzOTJUNjgyIDM3OFQ2NDggMzU5VDYxOSAzMzVUNTk0IDMxMFQ1NzQgMjg1VDU1OSAyNjNUNTQ4IDI0Nkw1NDMgMjM4TDU3NCAxOThRNjA1IDE1OCA2MjIgMTM4VDY2NCA5NFQ3MTQgNjFUNzY1IDUxUTgyNyA1MSA4NjcgMTAwVDkwNyAyMTdaTTkyIDIxNFE5MiAxNDUgMTMxIDg5VDIzOSAzM1EzNTcgMzMgNDU2IDE5M0w0MjUgMjMzUTM2NCAzMTIgMzM0IDMzN1EyODUgMzgwIDIzMyAzODBRMTcxIDM4MCAxMzIgMzMxVDkyIDIxNFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMTIiIGQ9Ik04NCAyMzdUODQgMjUwVDk4IDI3MEg2NzlRNjk0IDI2MiA2OTQgMjUwVDY3OSAyMzBIOThRODQgMjM3IDg0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMUQyIiBkPSJNNTgwIDUxNFE1ODAgNTI1IDU5NiA1MjVRNjAxIDUyNSA2MDQgNTI1VDYwOSA1MjVUNjEzIDUyNFQ2MTUgNTIzVDYxNyA1MjBUNjE5IDUxN1Q2MjIgNTEyUTY1OSA0MzggNzIwIDM4MVQ4MzEgMzAwVDkyNyAyNjNROTQ0IDI1OCA5NDQgMjUwVDkzNSAyMzlUODk4IDIyOFQ4NDAgMjA0UTY5NiAxMzQgNjIyIC0xMlE2MTggLTIxIDYxNSAtMjJUNjAwIC0yNFE1ODAgLTI0IDU4MCAtMTdRNTgwIC0xMyA1ODUgMFE2MjAgNjkgNjcxIDEyM0w2ODEgMTMzSDcwUTU2IDE0MCA1NiAxNTNRNTYgMTY4IDcyIDE3M0g3MjVMNzM1IDE4MVE3NzQgMjExIDg1MiAyNTBRODUxIDI1MSA4MzQgMjU5VDc4OSAyODNUNzM1IDMxOUw3MjUgMzI3SDcyUTU2IDMzMiA1NiAzNDdRNTYgMzYwIDcwIDM2N0g2ODFMNjcxIDM3N1E2MzggNDEyIDYwOSA0NThUNTgwIDUxNFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjcsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgtMTEsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDEyMDMzKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTMxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTdCIiB4PSIwIiB5PSItMSI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU4MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ2IiB4PSIxMTY3IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iODI1IiB5PSItNDM1Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTYyMSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMS03RCIgeD0iMzQ1MyIgeT0iLTEiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0OTU4LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwxMjAzMykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIyNzciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzM0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MzgsLTE4NykiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03OCIgeD0iNTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjEwNzMiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQ1MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNUIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNzgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02NiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDcxNywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzgiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjEwNzMiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjE5NjMiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01RCIgeD0iMzM0OCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDEwNDE4KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzMzQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNzYwIiB5PSItMTU2OSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjI5NDUiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODYzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI5MTEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUzMzAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDczOCwtMTg3KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iOTUxIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDczNjIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjYiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc4IiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSIxMDczIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxOTYzIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdDIiB4PSIzMjM2IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjM1MTQiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjQ1MzYiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCw3OTQ5KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzMzQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNzYwIiB5PSItMTU2OSI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjk0NSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQxODUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTEwOSIgeT0iNDk5Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU2MDUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MjEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTkzNSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI5MzUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI0NjgzIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsNTQ4MCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIyNzciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzM0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjc0MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI3NjAiIHk9Ii0xNTY5Ij48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0MzUyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDU4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MjEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTEwOSIgeT0iNDk5Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjE5OTYiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyOTk3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjExMDkiIHk9IjQ5OSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEyIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0MjUwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTI5IiB4PSI2MDY2IiB5PSItMSI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDIyMTIpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjc3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTMzNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI3NDEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtNUIiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1ODMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzNTgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNzYwIiB5PSItMTU2OSI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjk2OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMS0yOCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ1OCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTIxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjExMDkiIHk9IjQ5OSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEyIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMS0yOSIgeD0iMjIzMyIgeT0iLTEiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjU4ODMiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2ODgzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDg0MDgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNzYwIiB5PSItMTU2OSI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTAwMTksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjEtMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NTgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTEwOSIgeT0iNDk5Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMS0yOSIgeD0iMTcxMSIgeT0iLTEiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTVEIiB4PSIxMjc3MiIgeT0iLTEiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwtOTAyKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2NiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQ3LC0xMDkwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIzNDUiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMCIgeD0iMTEyNCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxRSIgeD0iNTIxIiB5PSIxNjI3Ij48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMTc3NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIxMjMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iNjM4IiB5PSI1ODMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjMxOTYiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTc1LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzk3LDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMzUyNyIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIxNTM4IiB5PSI2NzYiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtOTcwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSI3MjIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMTcyMyIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMjU2NCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI0MTc3IiB5PSI2NzUiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIxRDIiIHg9IjgyOTgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5NTc3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4NSwtMTExMCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iNTIxIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzAiIHg9IjEzMDAiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMUUiIHg9IjUyMSIgeT0iMTYyNyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjExMTg4IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTE3MDksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTEwOSIgeT0iNDk5Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjEzMjQwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQwMTksMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI0MTUwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTUzOCw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTk3MCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iNzIyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTcyMywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMzE4NyIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI1MDU4IiB5PSI2NzUiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTM5OTIpIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTY2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4NSwtMTExMCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iNTIxIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzAiIHg9IjEzMDAiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMUUiIHg9IjUyMSIgeT0iMTYyNyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTc3NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSI2MzgiIHk9IjU4MyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjg1MSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM2MjksMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIyMjk0IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iODk3IiB5PSI2NzYiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNjg3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjcyMiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIxNzIzIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMUQyIiB4PSI2NzIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzk5OCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODUsLTExMTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjUyMSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMwIiB4PSIxMzAwIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjFFIiB4PSI1MjEiIHk9IjE2MjciPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDk2MDksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSIxNTE5IiB5PSI1ODMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjExMzA2IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwODQsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIyOTE3IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTIwOCIgeT0iNjc2Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSI3MjIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNzIzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC03MjY4KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzMzQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNzQxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTVCIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTgzLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNDE1MCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE1MzgsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC05NzApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjcyMiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE3MjMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjMxODciIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iNTA1OCIgeT0iNjc1Ij48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQzOTAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNTgwNCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDY1ODMsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIyOTE3IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTIwOCIgeT0iNjc2Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSI3MjIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNzIzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTk2MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaNC01RCIgeD0iMTE5MDQiIHk9Ii0xIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTEwMTgwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwNTYsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMzYwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQzLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyOTM0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjQzNDgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MzQ5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwtMTIxMzQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjc3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjEzMzQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMjcwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9zdmc+)
因为 次试验后的估计值 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjYuNjY3ZXgiIGhlaWdodD0iMy4wMDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjgzOGV4OyIgdmlld0JveD0iMCAtOTM0LjkgMjg3MC41IDEyOTUuNyIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NiIgZD0iTTUyIDY0OFE1MiA2NzAgNjUgNjgzSDc2UTExOCA2ODAgMTgxIDY4MFEyOTkgNjgwIDMyMCA2ODNIMzMwUTMzNiA2NzcgMzM2IDY3NFQzMzQgNjU2UTMyOSA2NDEgMzI1IDYzN0gzMDRRMjgyIDYzNSAyNzQgNjM1UTI0NSA2MzAgMjQyIDYyMFEyNDIgNjE4IDI3MSAzNjlUMzAxIDExOEwzNzQgMjM1UTQ0NyAzNTIgNTIwIDQ3MVQ1OTUgNTk0UTU5OSA2MDEgNTk5IDYwOVE1OTkgNjMzIDU1NSA2MzdRNTM3IDYzNyA1MzcgNjQ4UTUzNyA2NDkgNTM5IDY2MVE1NDIgNjc1IDU0NSA2NzlUNTU4IDY4M1E1NjAgNjgzIDU3MCA2ODNUNjA0IDY4MlQ2NjggNjgxUTczNyA2ODEgNzU1IDY4M0g3NjJRNzY5IDY3NiA3NjkgNjcyUTc2OSA2NTUgNzYwIDY0MFE3NTcgNjM3IDc0MyA2MzdRNzMwIDYzNiA3MTkgNjM1VDY5OCA2MzBUNjgyIDYyM1Q2NzAgNjE1VDY2MCA2MDhUNjUyIDU5OVQ2NDUgNTkyTDQ1MiAyODJRMjcyIC05IDI2NiAtMTZRMjYzIC0xOCAyNTkgLTIxTDI0MSAtMjJIMjM0UTIxNiAtMjIgMjE2IC0xNVEyMTMgLTkgMTc3IDMwNVExMzkgNjIzIDEzOCA2MjZRMTMzIDYzNyA3NiA2MzdINTlRNTIgNjQyIDUyIDY0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NiIgZD0iTTQ4IDFRMzEgMSAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDYgNjYgMjE1IDM0MlQyODUgNjIyUTI4NSA2MjkgMjgxIDYyOVEyNzMgNjMyIDIyOCA2MzRIMTk3UTE5MSA2NDAgMTkxIDY0MlQxOTMgNjU5UTE5NyA2NzYgMjAzIDY4MEg3NDJRNzQ5IDY3NiA3NDkgNjY5UTc0OSA2NjQgNzM2IDU1N1Q3MjIgNDQ3UTcyMCA0NDAgNzAyIDQ0MEg2OTBRNjgzIDQ0NSA2ODMgNDUzUTY4MyA0NTQgNjg2IDQ3N1Q2ODkgNTMwUTY4OSA1NjAgNjgyIDU3OVQ2NjMgNjEwVDYyNiA2MjZUNTc1IDYzM1Q1MDMgNjM0SDQ4MFEzOTggNjMzIDM5MyA2MzFRMzg4IDYyOSAzODYgNjIzUTM4NSA2MjIgMzUyIDQ5MkwzMjAgMzYzSDM3NVEzNzggMzYzIDM5OCAzNjNUNDI2IDM2NFQ0NDggMzY3VDQ3MiAzNzRUNDg5IDM4NlE1MDIgMzk4IDUxMSA0MTlUNTI0IDQ1N1Q1MjkgNDc1UTUzMiA0ODAgNTQ4IDQ4MEg1NjBRNTY3IDQ3NSA1NjcgNDcwUTU2NyA0NjcgNTM2IDMzOVQ1MDIgMjA3UTUwMCAyMDAgNDgyIDIwMEg0NzBRNDYzIDIwNiA0NjMgMjEyUTQ2MyAyMTUgNDY4IDIzNFQ0NzMgMjc0UTQ3MyAzMDMgNDUzIDMxMFQzNjQgMzE3SDMwOUwyNzcgMTkwUTI0NSA2NiAyNDUgNjBRMjQ1IDQ2IDMzNCA0NkgzNTlRMzY1IDQwIDM2NSAzOVQzNjMgMTlRMzU5IDYgMzUzIDBIMzM2UTI5NSAyIDE4NSAyUTEyMCAyIDg2IDJUNDggMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NiIgeD0iMTE2NyIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI4MjUiIHk9Ii0yMTIiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjIxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9zdmc+) 是 个独立估计样本的平均值,每个估计值都是无偏的,所以 次试验估计也是无偏的。
是 个独立估计样本的平均值,每个估计值都是无偏的,所以 次试验估计也是无偏的。
定理4 每次访问MC方法是有偏的,(
时每次访问MC方法变为无偏的)
证明:
对于单次试验而言,每次访问MC方法的偏差是:
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjYzLjIzMWV4IiBoZWlnaHQ9IjY2LjE3NmV4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTMyLjUwNWV4OyIgdmlld0JveD0iMCAtMTQ0OTcuMyAyNzIyNC41IDI4NDkyLjMiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDUiIGQ9Ik00OTIgMjEzUTQ3MiAyMTMgNDcyIDIyNlE0NzIgMjMwIDQ3NyAyNTBUNDgyIDI4NVE0ODIgMzE2IDQ2MSAzMjNUMzY0IDMzMEgzMTJRMzExIDMyOCAyNzcgMTkyVDI0MyA1MlEyNDMgNDggMjU0IDQ4VDMzNCA0NlE0MjggNDYgNDU4IDQ4VDUxOCA2MVE1NjcgNzcgNTk5IDExN1Q2NzAgMjQ4UTY4MCAyNzAgNjgzIDI3MlE2OTAgMjc0IDY5OCAyNzRRNzE4IDI3NCA3MTggMjYxUTYxMyA3IDYwOCAyUTYwNSAwIDMyMiAwSDEzM1EzMSAwIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc1N1E3NjQgNjc2IDc2NCA2NjlRNzY0IDY2NCA3NTEgNTU3VDczNyA0NDdRNzM1IDQ0MCA3MTcgNDQwSDcwNVE2OTggNDQ1IDY5OCA0NTNMNzAxIDQ3NlE3MDQgNTAwIDcwNCA1MjhRNzA0IDU1OCA2OTcgNTc4VDY3OCA2MDlUNjQzIDYyNVQ1OTYgNjMyVDUzMiA2MzRINDg1UTM5NyA2MzMgMzkyIDYzMVEzODggNjI5IDM4NiA2MjJRMzg1IDYxOSAzNTUgNDk5VDMyNCAzNzdRMzQ3IDM3NiAzNzIgMzc2SDM5OFE0NjQgMzc2IDQ4OSAzOTFUNTM0IDQ3MlE1MzggNDg4IDU0MCA0OTBUNTU3IDQ5M1E1NjIgNDkzIDU2NSA0OTNUNTcwIDQ5MlQ1NzIgNDkxVDU3NCA0ODdUNTc3IDQ4M0w1NDQgMzUxUTUxMSAyMTggNTA4IDIxNlE1MDUgMjEzIDQ5MiAyMTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03QiIgZD0iTTQzNCAtMjMxUTQzNCAtMjQ0IDQyOCAtMjUwSDQxMFEyODEgLTI1MCAyMzAgLTE4NFEyMjUgLTE3NyAyMjIgLTE3MlQyMTcgLTE2MVQyMTMgLTE0OFQyMTEgLTEzM1QyMTAgLTExMVQyMDkgLTg0VDIwOSAtNDdUMjA5IDBRMjA5IDIxIDIwOSA1M1EyMDggMTQyIDIwNCAxNTNRMjAzIDE1NCAyMDMgMTU1UTE4OSAxOTEgMTUzIDIxMVQ4MiAyMzFRNzEgMjMxIDY4IDIzNFQ2NSAyNTBUNjggMjY2VDgyIDI2OVExMTYgMjY5IDE1MiAyODlUMjAzIDM0NVEyMDggMzU2IDIwOCAzNzdUMjA5IDUyOVY1NzlRMjA5IDYzNCAyMTUgNjU2VDI0NCA2OThRMjcwIDcyNCAzMjQgNzQwUTM2MSA3NDggMzc3IDc0OVEzNzkgNzQ5IDM5MCA3NDlUNDA4IDc1MEg0MjhRNDM0IDc0NCA0MzQgNzMyUTQzNCA3MTkgNDMxIDcxNlE0MjkgNzEzIDQxNSA3MTNRMzYyIDcxMCAzMzIgNjg5VDI5NiA2NDdRMjkxIDYzNCAyOTEgNDk5VjQxN1EyOTEgMzcwIDI4OCAzNTNUMjcxIDMxNFEyNDAgMjcxIDE4NCAyNTVMMTcwIDI1MEwxODQgMjQ1UTIwMiAyMzkgMjIwIDIzMFQyNjIgMTk2VDI5MCAxMzdRMjkxIDEzMSAyOTEgMVEyOTEgLTEzNCAyOTYgLTE0N1EzMDYgLTE3NCAzMzkgLTE5MlQ0MTUgLTIxM1E0MjkgLTIxMyA0MzEgLTIxNlE0MzQgLTIxOSA0MzQgLTIzMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NiIgZD0iTTUyIDY0OFE1MiA2NzAgNjUgNjgzSDc2UTExOCA2ODAgMTgxIDY4MFEyOTkgNjgwIDMyMCA2ODNIMzMwUTMzNiA2NzcgMzM2IDY3NFQzMzQgNjU2UTMyOSA2NDEgMzI1IDYzN0gzMDRRMjgyIDYzNSAyNzQgNjM1UTI0NSA2MzAgMjQyIDYyMFEyNDIgNjE4IDI3MSAzNjlUMzAxIDExOEwzNzQgMjM1UTQ0NyAzNTIgNTIwIDQ3MVQ1OTUgNTk0UTU5OSA2MDEgNTk5IDYwOVE1OTkgNjMzIDU1NSA2MzdRNTM3IDYzNyA1MzcgNjQ4UTUzNyA2NDkgNTM5IDY2MVE1NDIgNjc1IDU0NSA2NzlUNTU4IDY4M1E1NjAgNjgzIDU3MCA2ODNUNjA0IDY4MlQ2NjggNjgxUTczNyA2ODEgNzU1IDY4M0g3NjJRNzY5IDY3NiA3NjkgNjcyUTc2OSA2NTUgNzYwIDY0MFE3NTcgNjM3IDc0MyA2MzdRNzMwIDYzNiA3MTkgNjM1VDY5OCA2MzBUNjgyIDYyM1Q2NzAgNjE1VDY2MCA2MDhUNjUyIDU5OVQ2NDUgNTkyTDQ1MiAyODJRMjcyIC05IDI2NiAtMTZRMjYzIC0xOCAyNTkgLTIxTDI0MSAtMjJIMjM0UTIxNiAtMjIgMjE2IC0xNVEyMTMgLTkgMTc3IDMwNVExMzkgNjIzIDEzOCA2MjZRMTMzIDYzNyA3NiA2MzdINTlRNTIgNjQyIDUyIDY0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdEIiBkPSJNNjUgNzMxUTY1IDc0NSA2OCA3NDdUODggNzUwUTE3MSA3NTAgMjE2IDcyNVQyNzkgNjcwUTI4OCA2NDkgMjg5IDYzNVQyOTEgNTAxUTI5MiAzNjIgMjkzIDM1N1EzMDYgMzEyIDM0NSAyOTFUNDE3IDI2OVE0MjggMjY5IDQzMSAyNjZUNDM0IDI1MFQ0MzEgMjM0VDQxNyAyMzFRMzgwIDIzMSAzNDUgMjEwVDI5OCAxNTdRMjkzIDE0MyAyOTIgMTIxVDI5MSAtMjhWLTc5UTI5MSAtMTM0IDI4NSAtMTU2VDI1NiAtMTk4UTIwMiAtMjUwIDg5IC0yNTBRNzEgLTI1MCA2OCAtMjQ3VDY1IC0yMzBRNjUgLTIyNCA2NSAtMjIzVDY2IC0yMThUNjkgLTIxNFQ3NyAtMjEzUTkxIC0yMTMgMTA4IC0yMTBUMTQ2IC0yMDBUMTgzIC0xNzdUMjA3IC0xMzlRMjA4IC0xMzQgMjA5IDNMMjEwIDEzOVEyMjMgMTk2IDI4MCAyMzBRMzE1IDI0NyAzMzAgMjUwUTMwNSAyNTcgMjgwIDI3MFEyMjUgMzA0IDIxMiAzNTJMMjEwIDM2MkwyMDkgNDk4UTIwOCA2MzUgMjA3IDY0MFExOTUgNjgwIDE1NCA2OTZUNzcgNzEzUTY4IDcxMyA2NyA3MTZUNjUgNzMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMS03QiIgZD0iTTQ3NyAtMzQzTDQ3MSAtMzQ5SDQ1OFE0MzIgLTM0OSAzNjcgLTMyNVQyNzMgLTI2M1EyNTggLTI0NSAyNTAgLTIxMkwyNDkgLTUxUTI0OSAtMjcgMjQ5IDEyUTI0OCAxMTggMjQ0IDEyOFEyNDMgMTI5IDI0MyAxMzBRMjIwIDE4OSAxMjEgMjI4UTEwOSAyMzIgMTA3IDIzNVQxMDUgMjUwUTEwNSAyNTYgMTA1IDI1N1QxMDUgMjYxVDEwNyAyNjVUMTExIDI2OFQxMTggMjcyVDEyOCAyNzZUMTQyIDI4M1QxNjIgMjkxUTIyNCAzMjQgMjQzIDM3MVEyNDMgMzcyIDI0NCAzNzNRMjQ4IDM4NCAyNDkgNDY5UTI0OSA0NzUgMjQ5IDQ4OVEyNDkgNTI4IDI0OSA1NTJMMjUwIDcxNFEyNTMgNzI4IDI1NiA3MzZUMjcxIDc2MVQyOTkgNzg5VDM0NyA4MTZUNDIyIDg0M1E0NDAgODQ5IDQ0MSA4NDlINDQzUTQ0NSA4NDkgNDQ3IDg0OVQ0NTIgODUwVDQ1NyA4NTBINDcxTDQ3NyA4NDRWODMwUTQ3NyA4MjAgNDc2IDgxN1Q0NzAgODExVDQ1OSA4MDdUNDM3IDgwMVQ0MDQgNzg1UTM1MyA3NjAgMzM4IDcyNFEzMzMgNzEwIDMzMyA1NTBRMzMzIDUyNiAzMzMgNDkyVDMzNCA0NDdRMzM0IDM5MyAzMjcgMzY4VDI5NSAzMThRMjU3IDI4MCAxODEgMjU1TDE2OSAyNTFMMTg0IDI0NVEzMTggMTk4IDMzMiAxMTJRMzMzIDEwNiAzMzMgLTQ5UTMzMyAtMjA5IDMzOCAtMjIzUTM1MSAtMjU1IDM5MSAtMjc3VDQ2OSAtMzA5UTQ3NyAtMzExIDQ3NyAtMzI5Vi0zNDNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oxLTdEIiBkPSJNMTEwIDg0OUwxMTUgODUwUTEyMCA4NTAgMTI1IDg1MFExNTEgODUwIDIxNSA4MjZUMzA5IDc2NFEzMjQgNzQ3IDMzMiA3MTRMMzMzIDU1MlEzMzMgNTI4IDMzMyA0ODlRMzM0IDM4MyAzMzggMzczUTMzOSAzNzIgMzM5IDM3MVEzNTMgMzM2IDM5MSAzMTBUNDY5IDI3MVE0NzcgMjY4IDQ3NyAyNTFRNDc3IDI0MSA0NzYgMjM3VDQ3MiAyMzJUNDU2IDIyNVQ0MjggMjE0UTM1NyAxNzkgMzM5IDEzMFEzMzkgMTI5IDMzOCAxMjhRMzM0IDExNyAzMzMgMzJRMzMzIDI2IDMzMyAxMlEzMzMgLTI3IDMzMyAtNTFMMzMyIC0yMTJRMzI4IC0yMjggMzIzIC0yNDBUMzAyIC0yNzFUMjU1IC0zMDdUMTc1IC0zMzhRMTM5IC0zNDkgMTI1IC0zNDlUMTA4IC0zNDZUMTA1IC0zMjlRMTA1IC0zMTQgMTA3IC0zMTJUMTMwIC0zMDRRMjMzIC0yNzEgMjQ4IC0yMDlRMjQ5IC0yMDMgMjQ5IC00OVY1N1EyNDkgMTA2IDI1MyAxMjVUMjczIDE2N1EzMDcgMjEzIDM5OCAyNDVMNDEzIDI1MUw0MDEgMjU1UTI2NSAzMDAgMjUwIDM4OVEyNDkgMzk1IDI0OSA1NTBRMjQ5IDcxMCAyNDQgNzI0UTIyNCA3NzQgMTEyIDgxMVExMDUgODEzIDEwNSA4MzBRMTA1IDg0NSAxMTAgODQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzgiIGQ9Ik01MiAyODlRNTkgMzMxIDEwNiAzODZUMjIyIDQ0MlEyNTcgNDQyIDI4NiA0MjRUMzI5IDM3OVEzNzEgNDQyIDQzMCA0NDJRNDY3IDQ0MiA0OTQgNDIwVDUyMiAzNjFRNTIyIDMzMiA1MDggMzE0VDQ4MSAyOTJUNDU4IDI4OFE0MzkgMjg4IDQyNyAyOTlUNDE1IDMyOFE0MTUgMzc0IDQ2NSAzOTFRNDU0IDQwNCA0MjUgNDA0UTQxMiA0MDQgNDA2IDQwMlEzNjggMzg2IDM1MCAzMzZRMjkwIDExNSAyOTAgNzhRMjkwIDUwIDMwNiAzOFQzNDEgMjZRMzc4IDI2IDQxNCA1OVQ0NjMgMTQwUTQ2NiAxNTAgNDY5IDE1MVQ0ODUgMTUzSDQ4OVE1MDQgMTUzIDUwNCAxNDVRNTA0IDE0NCA1MDIgMTM0UTQ4NiA3NyA0NDAgMzNUMzMzIC0xMVEyNjMgLTExIDIyNyA1MlExODYgLTEwIDEzMyAtMTBIMTI3UTc4IC0xMCA1NyAxNlQzNSA3MVEzNSAxMDMgNTQgMTIzVDk5IDE0M1ExNDIgMTQzIDE0MiAxMDFRMTQyIDgxIDEzMCA2NlQxMDcgNDZUOTQgNDFMOTEgNDBROTEgMzkgOTcgMzZUMTEzIDI5VDEzMiAyNlExNjggMjYgMTk0IDcxUTIwMyA4NyAyMTcgMTM5VDI0NSAyNDdUMjYxIDMxM1EyNjYgMzQwIDI2NiAzNTJRMjY2IDM4MCAyNTEgMzkyVDIxNyA0MDRRMTc3IDQwNCAxNDIgMzcyVDkzIDI5MFE5MSAyODEgODggMjgwVDcyIDI3OEg1OFE1MiAyODQgNTIgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNUIiIGQ9Ik0xMTggLTI1MFY3NTBIMjU1VjcxMEgxNThWLTIxMEgyNTVWLTI1MEgxMThaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzQiIGQ9Ik0yNiAzODVRMTkgMzkyIDE5IDM5NVExOSAzOTkgMjIgNDExVDI3IDQyNVEyOSA0MzAgMzYgNDMwVDg3IDQzMUgxNDBMMTU5IDUxMVExNjIgNTIyIDE2NiA1NDBUMTczIDU2NlQxNzkgNTg2VDE4NyA2MDNUMTk3IDYxNVQyMTEgNjI0VDIyOSA2MjZRMjQ3IDYyNSAyNTQgNjE1VDI2MSA1OTZRMjYxIDU4OSAyNTIgNTQ5VDIzMiA0NzBMMjIyIDQzM1EyMjIgNDMxIDI3MiA0MzFIMzIzUTMzMCA0MjQgMzMwIDQyMFEzMzAgMzk4IDMxNyAzODVIMjEwTDE3NCAyNDBRMTM1IDgwIDEzNSA2OFExMzUgMjYgMTYyIDI2UTE5NyAyNiAyMzAgNjBUMjgzIDE0NFEyODUgMTUwIDI4OCAxNTFUMzAzIDE1M0gzMDdRMzIyIDE1MyAzMjIgMTQ1UTMyMiAxNDIgMzE5IDEzM1EzMTQgMTE3IDMwMSA5NVQyNjcgNDhUMjE2IDZUMTU1IC0xMVExMjUgLTExIDk4IDRUNTkgNTZRNTcgNjQgNTcgODNWMTAxTDkyIDI0MVExMjcgMzgyIDEyOCAzODNRMTI4IDM4NSA3NyAzODVIMjZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi01RCIgZD0iTTIyIDcxMFY3NTBIMTU5Vi0yNTBIMjJWLTIxMEgxMTlWNzEwSDIyWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMi0yMjExIiBkPSJNNjAgOTQ4UTYzIDk1MCA2NjUgOTUwSDEyNjdMMTMyNSA4MTVRMTM4NCA2NzcgMTM4OCA2NjlIMTM0OEwxMzQxIDY4M1ExMzIwIDcyNCAxMjg1IDc2MVExMjM1IDgwOSAxMTc0IDgzOFQxMDMzIDg4MVQ4ODIgODk4VDY5OSA5MDJINTc0SDU0M0gyNTFMMjU5IDg5MVE3MjIgMjU4IDcyNCAyNTJRNzI1IDI1MCA3MjQgMjQ2UTcyMSAyNDMgNDYwIC01NkwxOTYgLTM1NlExOTYgLTM1NyA0MDcgLTM1N1E0NTkgLTM1NyA1NDggLTM1N1Q2NzYgLTM1OFE4MTIgLTM1OCA4OTYgLTM1M1QxMDYzIC0zMzJUMTIwNCAtMjgzVDEzMDcgLTE5NlExMzI4IC0xNzAgMTM0OCAtMTI0SDEzODhRMTM4OCAtMTI1IDEzODEgLTE0NVQxMzU2IC0yMTBUMTMyNSAtMjk0TDEyNjcgLTQ0OUw2NjYgLTQ1MFE2NCAtNDUwIDYxIC00NDhRNTUgLTQ0NiA1NSAtNDM5UTU1IC00MzcgNTcgLTQzM0w1OTAgMTc3UTU5MCAxNzggNTU3IDIyMlQ0NTIgMzY2VDMyMiA1NDRMNTYgOTA5TDU1IDkyNFE1NSA5NDUgNjAgOTQ4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZCIiBkPSJNMTIxIDY0N1ExMjEgNjU3IDEyNSA2NzBUMTM3IDY4M1ExMzggNjgzIDIwOSA2ODhUMjgyIDY5NFEyOTQgNjk0IDI5NCA2ODZRMjk0IDY3OSAyNDQgNDc3UTE5NCAyNzkgMTk0IDI3MlEyMTMgMjgyIDIyMyAyOTFRMjQ3IDMwOSAyOTIgMzU0VDM2MiA0MTVRNDAyIDQ0MiA0MzggNDQyUTQ2OCA0NDIgNDg1IDQyM1Q1MDMgMzY5UTUwMyAzNDQgNDk2IDMyN1Q0NzcgMzAyVDQ1NiAyOTFUNDM4IDI4OFE0MTggMjg4IDQwNiAyOTlUMzk0IDMyOFEzOTQgMzUzIDQxMCAzNjlUNDQyIDM5MEw0NTggMzkzUTQ0NiA0MDUgNDM0IDQwNUg0MzBRMzk4IDQwMiAzNjcgMzgwVDI5NCAzMTZUMjI4IDI1NVEyMzAgMjU0IDI0MyAyNTJUMjY3IDI0NlQyOTMgMjM4VDMyMCAyMjRUMzQyIDIwNlQzNTkgMTgwVDM2NSAxNDdRMzY1IDEzMCAzNjAgMTA2VDM1NCA2NlEzNTQgMjYgMzgxIDI2UTQyOSAyNiA0NTkgMTQ1UTQ2MSAxNTMgNDc5IDE1M0g0ODNRNDk5IDE1MyA0OTkgMTQ0UTQ5OSAxMzkgNDk2IDEzMFE0NTUgLTExIDM3OCAtMTFRMzMzIC0xMSAzMDUgMTVUMjc3IDkwUTI3NyAxMDggMjgwIDEyMVQyODMgMTQ1UTI4MyAxNjcgMjY5IDE4M1QyMzQgMjA2VDIwMCAyMTdUMTgyIDIyMEgxODBRMTY4IDE3OCAxNTkgMTM5VDE0NSA4MVQxMzYgNDRUMTI5IDIwVDEyMiA3VDExMSAtMlE5OCAtMTEgODMgLTExUTY2IC0xMSA1NyAtMVQ0OCAxNlE0OCAyNiA4NSAxNzZUMTU4IDQ3MUwxOTUgNjE2UTE5NiA2MjkgMTg4IDYzMlQxNDkgNjM3SDE0NFExMzQgNjM3IDEzMSA2MzdUMTI0IDY0MFQxMjEgNjQ3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUwIiBkPSJNMjg3IDYyOFEyODcgNjM1IDIzMCA2MzdRMjA2IDYzNyAxOTkgNjM4VDE5MiA2NDhRMTkyIDY0OSAxOTQgNjU5UTIwMCA2NzkgMjAzIDY4MVQzOTcgNjgzUTU4NyA2ODIgNjAwIDY4MFE2NjQgNjY5IDcwNyA2MzFUNzUxIDUzMFE3NTEgNDUzIDY4NSAzODlRNjE2IDMyMSA1MDcgMzAzUTUwMCAzMDIgNDAyIDMwMUgzMDdMMjc3IDE4MlEyNDcgNjYgMjQ3IDU5UTI0NyA1NSAyNDggNTRUMjU1IDUwVDI3MiA0OFQzMDUgNDZIMzM2UTM0MiAzNyAzNDIgMzVRMzQyIDE5IDMzNSA1UTMzMCAwIDMxOSAwUTMxNiAwIDI4MiAxVDE4MiAyUTEyMCAyIDg3IDJUNTEgMVEzMyAxIDMzIDExUTMzIDEzIDM2IDI1UTQwIDQxIDQ0IDQzVDY3IDQ2UTk0IDQ2IDEyNyA0OVExNDEgNTIgMTQ2IDYxUTE0OSA2NSAyMTggMzM5VDI4NyA2MjhaTTY0NSA1NTRRNjQ1IDU2NyA2NDMgNTc1VDYzNCA1OTdUNjA5IDYxOVQ1NjAgNjM1UTU1MyA2MzYgNDgwIDYzN1E0NjMgNjM3IDQ0NSA2MzdUNDE2IDYzNlQ0MDQgNjM2UTM5MSA2MzUgMzg2IDYyN1EzODQgNjIxIDM2NyA1NTBUMzMyIDQxMlQzMTQgMzQ0UTMxNCAzNDIgMzk1IDM0Mkg0MDdINDMwUTU0MiAzNDIgNTkwIDM5MlE2MTcgNDE5IDYzMSA0NzFUNjQ1IDU1NFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MiIgZD0iTTIxIDI4N1EyMiAyOTAgMjMgMjk1VDI4IDMxN1QzOCAzNDhUNTMgMzgxVDczIDQxMVQ5OSA0MzNUMTMyIDQ0MlExNjEgNDQyIDE4MyA0MzBUMjE0IDQwOFQyMjUgMzg4UTIyNyAzODIgMjI4IDM4MlQyMzYgMzg5UTI4NCA0NDEgMzQ3IDQ0MUgzNTBRMzk4IDQ0MSA0MjIgNDAwUTQzMCAzODEgNDMwIDM2M1E0MzAgMzMzIDQxNyAzMTVUMzkxIDI5MlQzNjYgMjg4UTM0NiAyODggMzM0IDI5OVQzMjIgMzI4UTMyMiAzNzYgMzc4IDM5MlEzNTYgNDA1IDM0MiA0MDVRMjg2IDQwNSAyMzkgMzMxUTIyOSAzMTUgMjI0IDI5OFQxOTAgMTY1UTE1NiAyNSAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExNCAxODlUMTU0IDM2NlExNTQgNDA1IDEyOCA0MDVRMTA3IDQwNSA5MiAzNzdUNjggMzE2VDU3IDI4MFE1NSAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03QyIgZD0iTTEzOSAtMjQ5SDEzN1ExMjUgLTI0OSAxMTkgLTIzNVYyNTFMMTIwIDczN1ExMzAgNzUwIDEzOSA3NTBRMTUyIDc1MCAxNTkgNzM1Vi0yMzVRMTUxIC0yNDkgMTQxIC0yNDlIMTM5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU0IiBkPSJNNDAgNDM3UTIxIDQzNyAyMSA0NDVRMjEgNDUwIDM3IDUwMVQ3MSA2MDJMODggNjUxUTkzIDY2OSAxMDEgNjc3SDU2OUg2NTlRNjkxIDY3NyA2OTcgNjc2VDcwNCA2NjdRNzA0IDY2MSA2ODcgNTUzVDY2OCA0NDRRNjY4IDQzNyA2NDkgNDM3UTY0MCA0MzcgNjM3IDQzN1Q2MzEgNDQyTDYyOSA0NDVRNjI5IDQ1MSA2MzUgNDkwVDY0MSA1NTFRNjQxIDU4NiA2MjggNjA0VDU3MyA2MjlRNTY4IDYzMCA1MTUgNjMxUTQ2OSA2MzEgNDU3IDYzMFQ0MzkgNjIyUTQzOCA2MjEgMzY4IDM0M1QyOTggNjBRMjk4IDQ4IDM4NiA0NlE0MTggNDYgNDI3IDQ1VDQzNiAzNlE0MzYgMzEgNDMzIDIyUTQyOSA0IDQyNCAxTDQyMiAwUTQxOSAwIDQxNSAwUTQxMCAwIDM2MyAxVDIyOCAyUTk5IDIgNjQgMEg0OVE0MyA2IDQzIDlUNDUgMjdRNDkgNDAgNTUgNDZIODNIOTRRMTc0IDQ2IDE4OSA1NVExOTAgNTYgMTkxIDU2UTE5NiA1OSAyMDEgNzZUMjQxIDIzM1EyNTggMzAxIDI2OSAzNDRRMzM5IDYxOSAzMzkgNjI1UTMzOSA2MzAgMzEwIDYzMEgyNzlRMjEyIDYzMCAxOTEgNjI0UTE0NiA2MTQgMTIxIDU4M1Q2NyA0NjdRNjAgNDQ1IDU3IDQ0MVQ0MyA0MzdINDBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTIiIGQ9Ik0yMzAgNjM3UTIwMyA2MzcgMTk4IDYzOFQxOTMgNjQ5UTE5MyA2NzYgMjA0IDY4MlEyMDYgNjgzIDM3OCA2ODNRNTUwIDY4MiA1NjQgNjgwUTYyMCA2NzIgNjU4IDY1MlQ3MTIgNjA2VDczMyA1NjNUNzM5IDUyOVE3MzkgNDg0IDcxMCA0NDVUNjQzIDM4NVQ1NzYgMzUxVDUzOCAzMzhMNTQ1IDMzM1E2MTIgMjk1IDYxMiAyMjNRNjEyIDIxMiA2MDcgMTYyVDYwMiA4MFY3MVE2MDIgNTMgNjAzIDQzVDYxNCAyNVQ2NDAgMTZRNjY4IDE2IDY4NiAzOFQ3MTIgODVRNzE3IDk5IDcyMCAxMDJUNzM1IDEwNVE3NTUgMTA1IDc1NSA5M1E3NTUgNzUgNzMxIDM2UTY5MyAtMjEgNjQxIC0yMUg2MzJRNTcxIC0yMSA1MzEgNFQ0ODcgODJRNDg3IDEwOSA1MDIgMTY2VDUxNyAyMzlRNTE3IDI5MCA0NzQgMzEzUTQ1OSAzMjAgNDQ5IDMyMVQzNzggMzIzSDMwOUwyNzcgMTkzUTI0NCA2MSAyNDQgNTlRMjQ0IDU1IDI0NSA1NFQyNTIgNTBUMjY5IDQ4VDMwMiA0NkgzMzNRMzM5IDM4IDMzOSAzN1QzMzYgMTlRMzMyIDYgMzI2IDBIMzExUTI3NSAyIDE4MCAyUTE0NiAyIDExNyAyVDcxIDJUNTAgMVEzMyAxIDMzIDEwUTMzIDEyIDM2IDI0UTQxIDQzIDQ2IDQ1UTUwIDQ2IDYxIDQ2SDY3UTk0IDQ2IDEyNyA0OVExNDEgNTIgMTQ2IDYxUTE0OSA2NSAyMTggMzM5VDI4NyA2MjhRMjg3IDYzNSAyMzAgNjM3Wk02MzAgNTU0UTYzMCA1ODYgNjA5IDYwOFQ1MjMgNjM2UTUyMSA2MzYgNTAwIDYzNlQ0NjIgNjM3SDQ0MFEzOTMgNjM3IDM4NiA2MjdRMzg1IDYyNCAzNTIgNDk0VDMxOSAzNjFRMzE5IDM2MCAzODggMzYwUTQ2NiAzNjEgNDkyIDM2N1E1NTYgMzc3IDU5MiA0MjZRNjA4IDQ0OSA2MTkgNDg2VDYzMCA1NTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yQiIgZD0iTTU2IDIzN1Q1NiAyNTBUNzAgMjcwSDM2OVY0MjBMMzcwIDU3MFEzODAgNTgzIDM4OSA1ODNRNDAyIDU4MyA0MDkgNTY4VjI3MEg3MDdRNzIyIDI2MiA3MjIgMjUwVDcwNyAyMzBINDA5Vi02OFE0MDEgLTgyIDM5MSAtODJIMzg5SDM4N1EzNzUgLTgyIDM2OSAtNjhWMjMwSDcwUTU2IDIzNyA1NiAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMiIgZD0iTTEwOSA0MjlRODIgNDI5IDY2IDQ0N1Q1MCA0OTFRNTAgNTYyIDEwMyA2MTRUMjM1IDY2NlEzMjYgNjY2IDM4NyA2MTBUNDQ5IDQ2NVE0NDkgNDIyIDQyOSAzODNUMzgxIDMxNVQzMDEgMjQxUTI2NSAyMTAgMjAxIDE0OUwxNDIgOTNMMjE4IDkyUTM3NSA5MiAzODUgOTdRMzkyIDk5IDQwOSAxODZWMTg5SDQ0OVYxODZRNDQ4IDE4MyA0MzYgOTVUNDIxIDNWMEg1MFYxOVYzMVE1MCAzOCA1NiA0NlQ4NiA4MVExMTUgMTEzIDEzNiAxMzdRMTQ1IDE0NyAxNzAgMTc0VDIwNCAyMTFUMjMzIDI0NFQyNjEgMjc4VDI4NCAzMDhUMzA1IDM0MFQzMjAgMzY5VDMzMyA0MDFUMzQwIDQzMVQzNDMgNDY0UTM0MyA1MjcgMzA5IDU3M1QyMTIgNjE5UTE3OSA2MTkgMTU0IDYwMlQxMTkgNTY5VDEwOSA1NTBRMTA5IDU0OSAxMTQgNTQ5UTEzMiA1NDkgMTUxIDUzNVQxNzAgNDg5UTE3MCA0NjQgMTU0IDQ0N1QxMDkgNDI5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkUiIGQ9Ik03OCA2MFE3OCA4NCA5NSAxMDJUMTM4IDEyMFExNjIgMTIwIDE4MCAxMDRUMTk5IDYxUTE5OSAzNiAxODIgMThUMTM5IDBUOTYgMTdUNzggNjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1ozLTI4IiBkPSJNNzAxIC05NDBRNzAxIC05NDMgNjk1IC05NDlINjY0UTY2MiAtOTQ3IDYzNiAtOTIyVDU5MSAtODc5VDUzNyAtODE4VDQ3NSAtNzM3VDQxMiAtNjM2VDM1MCAtNTExVDI5NSAtMzYyVDI1MCAtMTg2VDIyMSAxN1QyMDkgMjUxUTIwOSA5NjIgNTczIDEzNjFRNTk2IDEzODYgNjE2IDE0MDVUNjQ5IDE0MzdUNjY0IDE0NTBINjk1UTcwMSAxNDQ0IDcwMSAxNDQxUTcwMSAxNDM2IDY4MSAxNDE1VDYyOSAxMzU2VDU1NyAxMjYxVDQ3NiAxMTE4VDQwMCA5MjdUMzQwIDY3NVQzMDggMzU5UTMwNiAzMjEgMzA2IDI1MFEzMDYgLTEzOSA0MDAgLTQzMFQ2OTAgLTkyNFE3MDEgLTkzNiA3MDEgLTk0MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjMtMjkiIGQ9Ik0zNCAxNDM4UTM0IDE0NDYgMzcgMTQ0OFQ1MCAxNDUwSDU2SDcxUTczIDE0NDggOTkgMTQyM1QxNDQgMTM4MFQxOTggMTMxOVQyNjAgMTIzOFQzMjMgMTEzN1QzODUgMTAxM1Q0NDAgODY0VDQ4NSA2ODhUNTE0IDQ4NVQ1MjYgMjUxUTUyNiAxMzQgNTE5IDUzUTQ3MiAtNTE5IDE2MiAtODYwUTEzOSAtODg1IDExOSAtOTA0VDg2IC05MzZUNzEgLTk0OUg1NlE0MyAtOTQ5IDM5IC05NDdUMzQgLTkzN1E4OCAtODgzIDE0MCAtODEzUTQyOCAtNDMwIDQyOCAyNTFRNDI4IDQ1MyA0MDIgNjI4VDMzOCA5MjJUMjQ1IDExNDZUMTQ1IDEzMDlUNDYgMTQyNVE0NCAxNDI3IDQyIDE0MjlUMzkgMTQzM1QzNiAxNDM2TDM0IDE0MzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oxLTI4IiBkPSJNMTUyIDI1MVExNTIgNjQ2IDM4OCA4NTBINDE2UTQyMiA4NDQgNDIyIDg0MVE0MjIgODM3IDQwMyA4MTZUMzU3IDc1M1QzMDIgNjQ5VDI1NSA0ODJUMjM2IDI1MFEyMzYgMTI0IDI1NSAxOVQzMDEgLTE0N1QzNTYgLTI1MVQ0MDMgLTMxNVQ0MjIgLTM0MFE0MjIgLTM0MyA0MTYgLTM0OUgzODhRMzU5IC0zMjUgMzMyIC0yOTZUMjcxIC0yMTNUMjEyIC05N1QxNzAgNTZUMTUyIDI1MVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjEtMjkiIGQ9Ik0zMDUgMjUxUTMwNSAtMTQ1IDY5IC0zNDlINTZRNDMgLTM0OSAzOSAtMzQ3VDM1IC0zMzhRMzcgLTMzMyA2MCAtMzA3VDEwOCAtMjM5VDE2MCAtMTM2VDIwNCAyN1QyMjEgMjUwVDIwNCA0NzNUMTYwIDYzNlQxMDggNzQwVDYwIDgwN1QzNSA4MzlRMzUgODUwIDUwIDg1MEg1Nkg2OVExOTcgNzQzIDI1NiA1NjZRMzA1IDQyNSAzMDUgMjUxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaNC0yOCIgZD0iTTc1OCAtMTIzN1Q3NTggLTEyNDBUNzUyIC0xMjQ5SDczNlE3MTggLTEyNDkgNzE3IC0xMjQ4UTcxMSAtMTI0NSA2NzIgLTExOTlRMjM3IC03MDYgMjM3IDI1MVQ2NzIgMTcwMFE2OTcgMTczMCA3MTYgMTc0OVE3MTggMTc1MCA3MzUgMTc1MEg3NTJRNzU4IDE3NDQgNzU4IDE3NDFRNzU4IDE3MzcgNzQwIDE3MTNUNjg5IDE2NDRUNjE5IDE1MzdUNTQwIDEzODBUNDYzIDExNzZRMzQ4IDgwMiAzNDggMjUxUTM0OCAtMjQyIDQ0MSAtNTk5VDc0NCAtMTIxOFE3NTggLTEyMzcgNzU4IC0xMjQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaNC0yOSIgZD0iTTMzIDE3NDFRMzMgMTc1MCA1MSAxNzUwSDYwSDY1UTczIDE3NTAgODEgMTc0M1QxMTkgMTcwMFE1NTQgMTIwNyA1NTQgMjUxUTU1NCAtNzA3IDExOSAtMTE5OVE3NiAtMTI1MCA2NiAtMTI1MFE2NSAtMTI1MCA2MiAtMTI1MFQ1NiAtMTI0OVE1NSAtMTI0OSA1MyAtMTI0OVQ0OSAtMTI1MFEzMyAtMTI1MCAzMyAtMTIzOVEzMyAtMTIzNiA1MCAtMTIxNFQ5OCAtMTE1MFQxNjMgLTEwNTJUMjM4IC05MTBUMzExIC03MjdRNDQzIC0zMzUgNDQzIDI1MVE0NDMgNDAyIDQzNiA1MzJUNDA1IDgzMVQzMzkgMTE0MlQyMjQgMTQzOFQ1MCAxNzE2UTMzIDE3MzcgMzMgMTc0MVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02OSIgZD0iTTE4NCA2MDBRMTg0IDYyNCAyMDMgNjQyVDI0NyA2NjFRMjY1IDY2MSAyNzcgNjQ5VDI5MCA2MTlRMjkwIDU5NiAyNzAgNTc3VDIyNiA1NTdRMjExIDU1NyAxOTggNTY3VDE4NCA2MDBaTTIxIDI4N1EyMSAyOTUgMzAgMzE4VDU0IDM2OVQ5OCA0MjBUMTU4IDQ0MlExOTcgNDQyIDIyMyA0MTlUMjUwIDM1N1EyNTAgMzQwIDIzNiAzMDFUMTk2IDE5NlQxNTQgODNRMTQ5IDYxIDE0OSA1MVExNDkgMjYgMTY2IDI2UTE3NSAyNiAxODUgMjlUMjA4IDQzVDIzNSA3OFQyNjAgMTM3UTI2MyAxNDkgMjY1IDE1MVQyODIgMTUzUTMwMiAxNTMgMzAyIDE0M1EzMDIgMTM1IDI5MyAxMTJUMjY4IDYxVDIyMyAxMVQxNjEgLTExUTEyOSAtMTEgMTAyIDEwVDc0IDc0UTc0IDkxIDc5IDEwNlQxMjIgMjIwUTE2MCAzMjEgMTY2IDM0MVQxNzMgMzgwUTE3MyA0MDQgMTU2IDQwNEgxNTRRMTI0IDQwNCA5OSAzNzFUNjEgMjg3UTYwIDI4NiA1OSAyODRUNTggMjgxVDU2IDI3OVQ1MyAyNzhUNDkgMjc4VDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzAiIGQ9Ik05NiA1ODVRMTUyIDY2NiAyNDkgNjY2UTI5NyA2NjYgMzQ1IDY0MFQ0MjMgNTQ4UTQ2MCA0NjUgNDYwIDMyMFE0NjAgMTY1IDQxNyA4M1EzOTcgNDEgMzYyIDE2VDMwMSAtMTVUMjUwIC0yMlEyMjQgLTIyIDE5OCAtMTZUMTM3IDE2VDgyIDgzUTM5IDE2NSAzOSAzMjBRMzkgNDk0IDk2IDU4NVpNMzIxIDU5N1EyOTEgNjI5IDI1MCA2MjlRMjA4IDYyOSAxNzggNTk3UTE1MyA1NzEgMTQ1IDUyNVQxMzcgMzMzUTEzNyAxNzUgMTQ1IDEyNVQxODEgNDZRMjA5IDE2IDI1MCAxNlEyOTAgMTYgMzE4IDQ2UTM0NyA3NiAzNTQgMTMwVDM2MiAzMzNRMzYyIDQ3OCAzNTQgNTI0VDMyMSA1OTdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjFFIiBkPSJNNTUgMjE3UTU1IDMwNSAxMTEgMzczVDI1NCA0NDJRMzQyIDQ0MiA0MTkgMzgxUTQ1NyAzNTAgNDkzIDMwM0w1MDcgMjg0TDUxNCAyOTRRNjE4IDQ0MiA3NDcgNDQyUTgzMyA0NDIgODg4IDM3NFQ5NDQgMjE0UTk0NCAxMjggODg5IDU5VDc0MyAtMTFRNjU3IC0xMSA1ODAgNTBRNTQyIDgxIDUwNiAxMjhMNDkyIDE0N0w0ODUgMTM3UTM4MSAtMTEgMjUyIC0xMVExNjYgLTExIDExMSA1N1Q1NSAyMTdaTTkwNyAyMTdROTA3IDI4NSA4NjkgMzQxVDc2MSAzOTdRNzQwIDM5NyA3MjAgMzkyVDY4MiAzNzhUNjQ4IDM1OVQ2MTkgMzM1VDU5NCAzMTBUNTc0IDI4NVQ1NTkgMjYzVDU0OCAyNDZMNTQzIDIzOEw1NzQgMTk4UTYwNSAxNTggNjIyIDEzOFQ2NjQgOTRUNzE0IDYxVDc2NSA1MVE4MjcgNTEgODY3IDEwMFQ5MDcgMjE3Wk05MiAyMTRROTIgMTQ1IDEzMSA4OVQyMzkgMzNRMzU3IDMzIDQ1NiAxOTNMNDI1IDIzM1EzNjQgMzEyIDMzNCAzMzdRMjg1IDM4MCAyMzMgMzgwUTE3MSAzODAgMTMyIDMzMVQ5MiAyMTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjEyIiBkPSJNODQgMjM3VDg0IDI1MFQ5OCAyNzBINjc5UTY5NCAyNjIgNjk0IDI1MFQ2NzkgMjMwSDk4UTg0IDIzNyA4NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMUQyIiBkPSJNNTgwIDUxNFE1ODAgNTI1IDU5NiA1MjVRNjAxIDUyNSA2MDQgNTI1VDYwOSA1MjVUNjEzIDUyNFQ2MTUgNTIzVDYxNyA1MjBUNjE5IDUxN1Q2MjIgNTEyUTY1OSA0MzggNzIwIDM4MVQ4MzEgMzAwVDkyNyAyNjNROTQ0IDI1OCA5NDQgMjUwVDkzNSAyMzlUODk4IDIyOFQ4NDAgMjA0UTY5NiAxMzQgNjIyIC0xMlE2MTggLTIxIDYxNSAtMjJUNjAwIC0yNFE1ODAgLTI0IDU4MCAtMTdRNTgwIC0xMyA1ODUgMFE2MjAgNjkgNjcxIDEyM0w2ODEgMTMzSDcwUTU2IDE0MCA1NiAxNTNRNTYgMTY4IDcyIDE3M0g3MjVMNzM1IDE4MVE3NzQgMjExIDg1MiAyNTBRODUxIDI1MSA4MzQgMjU5VDc4OSAyODNUNzM1IDMxOUw3MjUgMzI3SDcyUTU2IDMzMiA1NiAzNDdRNTYgMzYwIDcwIDM2N0g2ODFMNjcxIDM3N1E2MzggNDEyIDYwOSA0NThUNTgwIDUxNFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjcsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgtMTEsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDEzNTQ0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTMxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTdCIiB4PSIwIiB5PSItMSI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU4MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIxMTY3IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iODI1IiB5PSItNDM1Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTYzMiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMS03RCIgeD0iMzQ2NCIgeT0iLTEiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0OTY4LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwxMzU0NCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIyNzciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzM0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MzgsLTE4NykiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03OCIgeD0iNTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjEwNzMiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQ1MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNUIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNzgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUyOCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzgiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjEwNzMiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjE5NjMiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01RCIgeD0iMzE1OSIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDExOTI5KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzMzQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNzYwIiB5PSItMTU2OSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjI5NDUiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODYzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI5MTEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUzMzAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDczOCwtMTg3KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iOTUxIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDczNjIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzQiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MjgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc4IiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSIxMDczIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxOTYzIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdDIiB4PSIzMDQ3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjMzMjUiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjQzNDciIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCw4ODkwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzMzQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNzYwIiB5PSItMTU2OSI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjk0NSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQxODUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTEwOSIgeT0iNDk5Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU2MDUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjMtMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MzYsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxNDYwMyIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDc3MCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjE0MTMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIyNDE0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjkxNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI0MTA2IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iNDg4NCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9IjUzMzAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSI1Nzc1IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNjIyMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI2OTk4IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzUyMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI4OTM0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTkzNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9Ijc0MyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjE3NDQiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjI2MzQiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzMTI1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjE3OSwtNzE1KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNzQzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTc0NCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMy0yOSIgeD0iMTU1NzkiIHk9Ii0xIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsNTkyMikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIyNzciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzM0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9Ijc2MCIgeT0iLTE1NjkiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI5NDUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0MTg1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjExMDkiIHk9IjQ5OSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEyIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1NjA1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1ozLTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzM2LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNjQxIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjYwIiB5PSI2NzYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI3MCIgeT0iLTY4NyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODgxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjIyOTUiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzMjk1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1ozLTI5IiB4PSI1MzkwIiB5PSItMSI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDI2NTMpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjc3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTMzNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI3NDEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3OTIsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI2MjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSI2MCIgeT0iNjc2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iNjAiIHk9Ii02ODciPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDg2MCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMjE4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9Ijc2MCIgeT0iLTE1NjkiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4MjksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjEtMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NTgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUyMSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIxMTA5IiB5PSI0OTkiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjEtMjkiIHg9IjIyMzMiIHk9Ii0xIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI2NzQzIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzc0NCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5MjY4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9Ijc2MCIgeT0iLTE1NjkiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwODc5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDU4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjExMDkiIHk9IjQ5OSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEyIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjEtMjkiIHg9IjE3MTEiIHk9Ii0xIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaNC0yOSIgeD0iMTM4NDIiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwtNDYyKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2NiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQ3LC0xMDkwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIzNDUiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMCIgeD0iMTEyNCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxRSIgeD0iNTIxIiB5PSIxNjI3Ij48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMTc3NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIxMjMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iNjM4IiB5PSI1ODMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjMxOTYiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTc1LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzk3LDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMzUyNyIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIxNTM4IiB5PSI2NzYiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtOTcwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSI3MjIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMTcyMyIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMjU2NCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI0MTc3IiB5PSI2NzUiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIxRDIiIHg9IjgyOTgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5NTc3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4NSwtMTExMCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iNTIxIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzAiIHg9IjEzMDAiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMUUiIHg9IjUyMSIgeT0iMTYyNyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjExMTg4IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTE3MDksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTEwOSIgeT0iNDk5Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjEzMjQwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQwMTksMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI0MTUwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTUzOCw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTk3MCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iNzIyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTcyMywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMzE4NyIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI1MDU4IiB5PSI2NzUiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTM1NTEpIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTY2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4NSwtMTExMCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iNTIxIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzAiIHg9IjEzMDAiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMUUiIHg9IjUyMSIgeT0iMTYyNyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTc3NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSI2MzgiIHk9IjU4MyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjg1MSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM2MjksMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIyMjk0IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iODk3IiB5PSI2NzYiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNjg3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjcyMiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIxNzIzIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMUQyIiB4PSI2NzIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzk5OCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODUsLTExMTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjUyMSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMwIiB4PSIxMzAwIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjFFIiB4PSI1MjEiIHk9IjE2MjciPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDk2MDksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSIxNTE5IiB5PSI1ODMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjExMzA2IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwODQsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIyOTE3IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTIwOCIgeT0iNjc2Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSI3MjIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNzIzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC02ODI4KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzMzQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNzQxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzkyLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNjIwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iNjAiIHk9IjY3NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjYwIiB5PSItNjg3Ij48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4NjAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjA1MSwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjQxNTAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNTM4LDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtOTcwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSI3MjIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNzIzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIzMTg3IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjUwNTgiIHk9IjY3NSI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjY2NjUiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3NjY1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkwMjMsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIyOTE3IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTIwOCIgeT0iNjc2Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSI3MjIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNzIzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtMjkiIHg9IjEyOTczIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTEwMTMwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzMzQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNzQxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzkyLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNjIwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iNjAiIHk9IjY3NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjYwIiB5PSItNjg3Ij48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4NjAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjA1MSwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEzNjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDMsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC04MzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii00NDYiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIzODc0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDg3NSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MjMzLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTM2MCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjQzMCIgeT0iNjc2Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtMjkiIHg9Ijg2MjYiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwtMTMwNDIpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjc3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTA1NiwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM5NywwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjE4NjEiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTMsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MzUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNDg0OCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU4NDksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8L3N2Zz4=)
那么, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9Ijc3Ljk0OWV4IiBoZWlnaHQ9IjYuMTc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMi41MDVleDsiIHZpZXdCb3g9IjAgLTE1ODAuNyAzMzU2MS40IDI2NTkuMSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTQyIiBkPSJNMTMxIDYyMlExMjQgNjI5IDEyMCA2MzFUMTA0IDYzNFQ2MSA2MzdIMjhWNjgzSDIyOUgyNjdIMzQ2UTQyMyA2ODMgNDU5IDY3OFQ1MzEgNjUxUTU3NCA2MjcgNTk5IDU5MFQ2MjQgNTEyUTYyNCA0NjEgNTgzIDQxOVQ0NzYgMzYwTDQ2NiAzNTdRNTM5IDM0OCA1OTUgMzAyVDY1MSAxODdRNjUxIDExOSA2MDAgNjdUNDY5IDNRNDU2IDEgMjQyIDBIMjhWNDZINjFRMTAzIDQ3IDExMiA0OVQxMzEgNjFWNjIyWk01MTEgNTEzUTUxMSA1NjAgNDg1IDU5NFQ0MTYgNjM2UTQxNSA2MzYgNDAzIDYzNlQzNzEgNjM2VDMzMyA2MzdRMjY2IDYzNyAyNTEgNjM2VDIzMiA2MjhRMjI5IDYyNCAyMjkgNDk5VjM3NEgzMTJMMzk2IDM3NUw0MDYgMzc3UTQxMCAzNzggNDE3IDM4MFQ0NDIgMzkzVDQ3NCA0MTdUNDk5IDQ1NlQ1MTEgNTEzWk01MzcgMTg4UTUzNyAyMzkgNTA5IDI4MlQ0MzAgMzM2TDMyOSAzMzdIMjI5VjIwMFYxMTZRMjI5IDU3IDIzNCA1MlEyNDAgNDcgMzM0IDQ3SDM4M1E0MjUgNDcgNDQzIDUzUTQ4NiA2NyA1MTEgMTA0VDUzNyAxODhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi02OSIgZD0iTTY5IDYwOVE2OSA2MzcgODcgNjUzVDEzMSA2NjlRMTU0IDY2NyAxNzEgNjUyVDE4OCA2MDlRMTg4IDU3OSAxNzEgNTY0VDEyOSA1NDlRMTA0IDU0OSA4NyA1NjRUNjkgNjA5Wk0yNDcgMFEyMzIgMyAxNDMgM1ExMzIgMyAxMDYgM1Q1NiAxTDM0IDBIMjZWNDZINDJRNzAgNDYgOTEgNDlRMTAwIDUzIDEwMiA2MFQxMDQgMTAyVjIwNVYyOTNRMTA0IDM0NSAxMDIgMzU5VDg4IDM3OFE3NCAzODUgNDEgMzg1SDMwVjQwOFEzMCA0MzEgMzIgNDMxTDQyIDQzMlE1MiA0MzMgNzAgNDM0VDEwNiA0MzZRMTIzIDQzNyAxNDIgNDM4VDE3MSA0NDFUMTgyIDQ0MkgxODVWNjJRMTkwIDUyIDE5NyA1MFQyMzIgNDZIMjU1VjBIMjQ3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNjEiIGQ9Ik0xMzcgMzA1VDExNSAzMDVUNzggMzIwVDYzIDM1OVE2MyAzOTQgOTcgNDIxVDIxOCA0NDhRMjkxIDQ0OCAzMzYgNDE2VDM5NiAzNDBRNDAxIDMyNiA0MDEgMzA5VDQwMiAxOTRWMTI0UTQwMiA3NiA0MDcgNThUNDI4IDQwUTQ0MyA0MCA0NDggNTZUNDUzIDEwOVYxNDVINDkzVjEwNlE0OTIgNjYgNDkwIDU5UTQ4MSAyOSA0NTUgMTJUNDAwIC02VDM1MyAxMlQzMjkgNTRWNThMMzI3IDU1UTMyNSA1MiAzMjIgNDlUMzE0IDQwVDMwMiAyOVQyODcgMTdUMjY5IDZUMjQ3IC0yVDIyMSAtOFQxOTAgLTExUTEzMCAtMTEgODIgMjBUMzQgMTA3UTM0IDEyOCA0MSAxNDdUNjggMTg4VDExNiAyMjVUMTk0IDI1M1QzMDQgMjY4SDMxOFYyOTBRMzE4IDMyNCAzMTIgMzQwUTI5MCA0MTEgMjE1IDQxMVExOTcgNDExIDE4MSA0MTBUMTU2IDQwNlQxNDggNDAzUTE3MCAzODggMTcwIDM1OVExNzAgMzM0IDE1NCAzMjBaTTEyNiAxMDZRMTI2IDc1IDE1MCA1MVQyMDkgMjZRMjQ3IDI2IDI3NiA0OVQzMTUgMTA5UTMxNyAxMTYgMzE4IDE3NVEzMTggMjMzIDMxNyAyMzNRMzA5IDIzMyAyOTYgMjMyVDI1MSAyMjNUMTkzIDIwM1QxNDcgMTY2VDEyNiAxMDZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03MyIgZD0iTTI5NSAzMTZRMjk1IDM1NiAyNjggMzg1VDE5MCA0MTRRMTU0IDQxNCAxMjggNDAxUTk4IDM4MiA5OCAzNDlROTcgMzQ0IDk4IDMzNlQxMTQgMzEyVDE1NyAyODdRMTc1IDI4MiAyMDEgMjc4VDI0NSAyNjlUMjc3IDI1NlEyOTQgMjQ4IDMxMCAyMzZUMzQyIDE5NVQzNTkgMTMzUTM1OSA3MSAzMjEgMzFUMTk4IC0xMEgxOTBRMTM4IC0xMCA5NCAyNkw4NiAxOUw3NyAxMFE3MSA0IDY1IC0xTDU0IC0xMUg0Nkg0MlEzOSAtMTEgMzMgLTVWNzRWMTMyUTMzIDE1MyAzNSAxNTdUNDUgMTYySDU0UTY2IDE2MiA3MCAxNThUNzUgMTQ2VDgyIDExOVQxMDEgNzdRMTM2IDI2IDE5OCAyNlEyOTUgMjYgMjk1IDEwNFEyOTUgMTMzIDI3NyAxNTFRMjU3IDE3NSAxOTQgMTg3VDExMSAyMTBRNzUgMjI3IDU0IDI1NlQzMyAzMThRMzMgMzU3IDUwIDM4NFQ5MyA0MjRUMTQzIDQ0MlQxODcgNDQ3SDE5OFEyMzggNDQ3IDI2OCA0MzJMMjgzIDQyNEwyOTIgNDMxUTMwMiA0NDAgMzE0IDQ0OEgzMjJIMzI2UTMyOSA0NDggMzM1IDQ0MlYzMTBMMzI5IDMwNEgzMDFRMjk1IDMxMCAyOTUgMzE2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQ1IiBkPSJNNDkyIDIxM1E0NzIgMjEzIDQ3MiAyMjZRNDcyIDIzMCA0NzcgMjUwVDQ4MiAyODVRNDgyIDMxNiA0NjEgMzIzVDM2NCAzMzBIMzEyUTMxMSAzMjggMjc3IDE5MlQyNDMgNTJRMjQzIDQ4IDI1NCA0OFQzMzQgNDZRNDI4IDQ2IDQ1OCA0OFQ1MTggNjFRNTY3IDc3IDU5OSAxMTdUNjcwIDI0OFE2ODAgMjcwIDY4MyAyNzJRNjkwIDI3NCA2OTggMjc0UTcxOCAyNzQgNzE4IDI2MVE2MTMgNyA2MDggMlE2MDUgMCAzMjIgMEgxMzNRMzEgMCAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDYgNjYgMjE1IDM0MlQyODUgNjIyUTI4NSA2MjkgMjgxIDYyOVEyNzMgNjMyIDIyOCA2MzRIMTk3UTE5MSA2NDAgMTkxIDY0MlQxOTMgNjU5UTE5NyA2NzYgMjAzIDY4MEg3NTdRNzY0IDY3NiA3NjQgNjY5UTc2NCA2NjQgNzUxIDU1N1Q3MzcgNDQ3UTczNSA0NDAgNzE3IDQ0MEg3MDVRNjk4IDQ0NSA2OTggNDUzTDcwMSA0NzZRNzA0IDUwMCA3MDQgNTI4UTcwNCA1NTggNjk3IDU3OFQ2NzggNjA5VDY0MyA2MjVUNTk2IDYzMlQ1MzIgNjM0SDQ4NVEzOTcgNjMzIDM5MiA2MzFRMzg4IDYyOSAzODYgNjIyUTM4NSA2MTkgMzU1IDQ5OVQzMjQgMzc3UTM0NyAzNzYgMzcyIDM3NkgzOThRNDY0IDM3NiA0ODkgMzkxVDUzNCA0NzJRNTM4IDQ4OCA1NDAgNDkwVDU1NyA0OTNRNTYyIDQ5MyA1NjUgNDkzVDU3MCA0OTJUNTcyIDQ5MVQ1NzQgNDg3VDU3NyA0ODNMNTQ0IDM1MVE1MTEgMjE4IDUwOCAyMTZRNTA1IDIxMyA0OTIgMjEzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTYiIGQ9Ik01MiA2NDhRNTIgNjcwIDY1IDY4M0g3NlExMTggNjgwIDE4MSA2ODBRMjk5IDY4MCAzMjAgNjgzSDMzMFEzMzYgNjc3IDMzNiA2NzRUMzM0IDY1NlEzMjkgNjQxIDMyNSA2MzdIMzA0UTI4MiA2MzUgMjc0IDYzNVEyNDUgNjMwIDI0MiA2MjBRMjQyIDYxOCAyNzEgMzY5VDMwMSAxMThMMzc0IDIzNVE0NDcgMzUyIDUyMCA0NzFUNTk1IDU5NFE1OTkgNjAxIDU5OSA2MDlRNTk5IDYzMyA1NTUgNjM3UTUzNyA2MzcgNTM3IDY0OFE1MzcgNjQ5IDUzOSA2NjFRNTQyIDY3NSA1NDUgNjc5VDU1OCA2ODNRNTYwIDY4MyA1NzAgNjgzVDYwNCA2ODJUNjY4IDY4MVE3MzcgNjgxIDc1NSA2ODNINzYyUTc2OSA2NzYgNzY5IDY3MlE3NjkgNjU1IDc2MCA2NDBRNzU3IDYzNyA3NDMgNjM3UTczMCA2MzYgNzE5IDYzNVQ2OTggNjMwVDY4MiA2MjNUNjcwIDYxNVQ2NjAgNjA4VDY1MiA1OTlUNjQ1IDU5Mkw0NTIgMjgyUTI3MiAtOSAyNjYgLTE2UTI2MyAtMTggMjU5IC0yMUwyNDEgLTIySDIzNFEyMTYgLTIyIDIxNiAtMTVRMjEzIC05IDE3NyAzMDVRMTM5IDYyMyAxMzggNjI2UTEzMyA2MzcgNzYgNjM3SDU5UTUyIDY0MiA1MiA2NDhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjEyIiBkPSJNODQgMjM3VDg0IDI1MFQ5OCAyNzBINjc5UTY5NCAyNjIgNjk0IDI1MFQ2NzkgMjMwSDk4UTg0IDIzNyA4NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03QiIgZD0iTTQzNCAtMjMxUTQzNCAtMjQ0IDQyOCAtMjUwSDQxMFEyODEgLTI1MCAyMzAgLTE4NFEyMjUgLTE3NyAyMjIgLTE3MlQyMTcgLTE2MVQyMTMgLTE0OFQyMTEgLTEzM1QyMTAgLTExMVQyMDkgLTg0VDIwOSAtNDdUMjA5IDBRMjA5IDIxIDIwOSA1M1EyMDggMTQyIDIwNCAxNTNRMjAzIDE1NCAyMDMgMTU1UTE4OSAxOTEgMTUzIDIxMVQ4MiAyMzFRNzEgMjMxIDY4IDIzNFQ2NSAyNTBUNjggMjY2VDgyIDI2OVExMTYgMjY5IDE1MiAyODlUMjAzIDM0NVEyMDggMzU2IDIwOCAzNzdUMjA5IDUyOVY1NzlRMjA5IDYzNCAyMTUgNjU2VDI0NCA2OThRMjcwIDcyNCAzMjQgNzQwUTM2MSA3NDggMzc3IDc0OVEzNzkgNzQ5IDM5MCA3NDlUNDA4IDc1MEg0MjhRNDM0IDc0NCA0MzQgNzMyUTQzNCA3MTkgNDMxIDcxNlE0MjkgNzEzIDQxNSA3MTNRMzYyIDcxMCAzMzIgNjg5VDI5NiA2NDdRMjkxIDYzNCAyOTEgNDk5VjQxN1EyOTEgMzcwIDI4OCAzNTNUMjcxIDMxNFEyNDAgMjcxIDE4NCAyNTVMMTcwIDI1MEwxODQgMjQ1UTIwMiAyMzkgMjIwIDIzMFQyNjIgMTk2VDI5MCAxMzdRMjkxIDEzMSAyOTEgMVEyOTEgLTEzNCAyOTYgLTE0N1EzMDYgLTE3NCAzMzkgLTE5MlQ0MTUgLTIxM1E0MjkgLTIxMyA0MzEgLTIxNlE0MzQgLTIxOSA0MzQgLTIzMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdEIiBkPSJNNjUgNzMxUTY1IDc0NSA2OCA3NDdUODggNzUwUTE3MSA3NTAgMjE2IDcyNVQyNzkgNjcwUTI4OCA2NDkgMjg5IDYzNVQyOTEgNTAxUTI5MiAzNjIgMjkzIDM1N1EzMDYgMzEyIDM0NSAyOTFUNDE3IDI2OVE0MjggMjY5IDQzMSAyNjZUNDM0IDI1MFQ0MzEgMjM0VDQxNyAyMzFRMzgwIDIzMSAzNDUgMjEwVDI5OCAxNTdRMjkzIDE0MyAyOTIgMTIxVDI5MSAtMjhWLTc5UTI5MSAtMTM0IDI4NSAtMTU2VDI1NiAtMTk4UTIwMiAtMjUwIDg5IC0yNTBRNzEgLTI1MCA2OCAtMjQ3VDY1IC0yMzBRNjUgLTIyNCA2NSAtMjIzVDY2IC0yMThUNjkgLTIxNFQ3NyAtMjEzUTkxIC0yMTMgMTA4IC0yMTBUMTQ2IC0yMDBUMTgzIC0xNzdUMjA3IC0xMzlRMjA4IC0xMzQgMjA5IDNMMjEwIDEzOVEyMjMgMTk2IDI4MCAyMzBRMzE1IDI0NyAzMzAgMjUwUTMwNSAyNTcgMjgwIDI3MFEyMjUgMzA0IDIxMiAzNTJMMjEwIDM2MkwyMDkgNDk4UTIwOCA2MzUgMjA3IDY0MFExOTUgNjgwIDE1NCA2OTZUNzcgNzEzUTY4IDcxMyA2NyA3MTZUNjUgNzMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMS03QiIgZD0iTTQ3NyAtMzQzTDQ3MSAtMzQ5SDQ1OFE0MzIgLTM0OSAzNjcgLTMyNVQyNzMgLTI2M1EyNTggLTI0NSAyNTAgLTIxMkwyNDkgLTUxUTI0OSAtMjcgMjQ5IDEyUTI0OCAxMTggMjQ0IDEyOFEyNDMgMTI5IDI0MyAxMzBRMjIwIDE4OSAxMjEgMjI4UTEwOSAyMzIgMTA3IDIzNVQxMDUgMjUwUTEwNSAyNTYgMTA1IDI1N1QxMDUgMjYxVDEwNyAyNjVUMTExIDI2OFQxMTggMjcyVDEyOCAyNzZUMTQyIDI4M1QxNjIgMjkxUTIyNCAzMjQgMjQzIDM3MVEyNDMgMzcyIDI0NCAzNzNRMjQ4IDM4NCAyNDkgNDY5UTI0OSA0NzUgMjQ5IDQ4OVEyNDkgNTI4IDI0OSA1NTJMMjUwIDcxNFEyNTMgNzI4IDI1NiA3MzZUMjcxIDc2MVQyOTkgNzg5VDM0NyA4MTZUNDIyIDg0M1E0NDAgODQ5IDQ0MSA4NDlINDQzUTQ0NSA4NDkgNDQ3IDg0OVQ0NTIgODUwVDQ1NyA4NTBINDcxTDQ3NyA4NDRWODMwUTQ3NyA4MjAgNDc2IDgxN1Q0NzAgODExVDQ1OSA4MDdUNDM3IDgwMVQ0MDQgNzg1UTM1MyA3NjAgMzM4IDcyNFEzMzMgNzEwIDMzMyA1NTBRMzMzIDUyNiAzMzMgNDkyVDMzNCA0NDdRMzM0IDM5MyAzMjcgMzY4VDI5NSAzMThRMjU3IDI4MCAxODEgMjU1TDE2OSAyNTFMMTg0IDI0NVEzMTggMTk4IDMzMiAxMTJRMzMzIDEwNiAzMzMgLTQ5UTMzMyAtMjA5IDMzOCAtMjIzUTM1MSAtMjU1IDM5MSAtMjc3VDQ2OSAtMzA5UTQ3NyAtMzExIDQ3NyAtMzI5Vi0zNDNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oxLTdEIiBkPSJNMTEwIDg0OUwxMTUgODUwUTEyMCA4NTAgMTI1IDg1MFExNTEgODUwIDIxNSA4MjZUMzA5IDc2NFEzMjQgNzQ3IDMzMiA3MTRMMzMzIDU1MlEzMzMgNTI4IDMzMyA0ODlRMzM0IDM4MyAzMzggMzczUTMzOSAzNzIgMzM5IDM3MVEzNTMgMzM2IDM5MSAzMTBUNDY5IDI3MVE0NzcgMjY4IDQ3NyAyNTFRNDc3IDI0MSA0NzYgMjM3VDQ3MiAyMzJUNDU2IDIyNVQ0MjggMjE0UTM1NyAxNzkgMzM5IDEzMFEzMzkgMTI5IDMzOCAxMjhRMzM0IDExNyAzMzMgMzJRMzMzIDI2IDMzMyAxMlEzMzMgLTI3IDMzMyAtNTFMMzMyIC0yMTJRMzI4IC0yMjggMzIzIC0yNDBUMzAyIC0yNzFUMjU1IC0zMDdUMTc1IC0zMzhRMTM5IC0zNDkgMTI1IC0zNDlUMTA4IC0zNDZUMTA1IC0zMjlRMTA1IC0zMTQgMTA3IC0zMTJUMTMwIC0zMDRRMjMzIC0yNzEgMjQ4IC0yMDlRMjQ5IC0yMDMgMjQ5IC00OVY1N1EyNDkgMTA2IDI1MyAxMjVUMjczIDE2N1EzMDcgMjEzIDM5OCAyNDVMNDEzIDI1MUw0MDEgMjU1UTI2NSAzMDAgMjUwIDM4OVEyNDkgMzk1IDI0OSA1NTBRMjQ5IDcxMCAyNDQgNzI0UTIyNCA3NzQgMTEyIDgxMVExMDUgODEzIDEwNSA4MzBRMTA1IDg0NSAxMTAgODQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUyIiBkPSJNMjMwIDYzN1EyMDMgNjM3IDE5OCA2MzhUMTkzIDY0OVExOTMgNjc2IDIwNCA2ODJRMjA2IDY4MyAzNzggNjgzUTU1MCA2ODIgNTY0IDY4MFE2MjAgNjcyIDY1OCA2NTJUNzEyIDYwNlQ3MzMgNTYzVDczOSA1MjlRNzM5IDQ4NCA3MTAgNDQ1VDY0MyAzODVUNTc2IDM1MVQ1MzggMzM4TDU0NSAzMzNRNjEyIDI5NSA2MTIgMjIzUTYxMiAyMTIgNjA3IDE2MlQ2MDIgODBWNzFRNjAyIDUzIDYwMyA0M1Q2MTQgMjVUNjQwIDE2UTY2OCAxNiA2ODYgMzhUNzEyIDg1UTcxNyA5OSA3MjAgMTAyVDczNSAxMDVRNzU1IDEwNSA3NTUgOTNRNzU1IDc1IDczMSAzNlE2OTMgLTIxIDY0MSAtMjFINjMyUTU3MSAtMjEgNTMxIDRUNDg3IDgyUTQ4NyAxMDkgNTAyIDE2NlQ1MTcgMjM5UTUxNyAyOTAgNDc0IDMxM1E0NTkgMzIwIDQ0OSAzMjFUMzc4IDMyM0gzMDlMMjc3IDE5M1EyNDQgNjEgMjQ0IDU5UTI0NCA1NSAyNDUgNTRUMjUyIDUwVDI2OSA0OFQzMDIgNDZIMzMzUTMzOSAzOCAzMzkgMzdUMzM2IDE5UTMzMiA2IDMyNiAwSDMxMVEyNzUgMiAxODAgMlExNDYgMiAxMTcgMlQ3MSAyVDUwIDFRMzMgMSAzMyAxMFEzMyAxMiAzNiAyNFE0MSA0MyA0NiA0NVE1MCA0NiA2MSA0Nkg2N1E5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4UTI4NyA2MzUgMjMwIDYzN1pNNjMwIDU1NFE2MzAgNTg2IDYwOSA2MDhUNTIzIDYzNlE1MjEgNjM2IDUwMCA2MzZUNDYyIDYzN0g0NDBRMzkzIDYzNyAzODYgNjI3UTM4NSA2MjQgMzUyIDQ5NFQzMTkgMzYxUTMxOSAzNjAgMzg4IDM2MFE0NjYgMzYxIDQ5MiAzNjdRNTU2IDM3NyA1OTIgNDI2UTYwOCA0NDkgNjE5IDQ4NlQ2MzAgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU0IiBkPSJNNDAgNDM3UTIxIDQzNyAyMSA0NDVRMjEgNDUwIDM3IDUwMVQ3MSA2MDJMODggNjUxUTkzIDY2OSAxMDEgNjc3SDU2OUg2NTlRNjkxIDY3NyA2OTcgNjc2VDcwNCA2NjdRNzA0IDY2MSA2ODcgNTUzVDY2OCA0NDRRNjY4IDQzNyA2NDkgNDM3UTY0MCA0MzcgNjM3IDQzN1Q2MzEgNDQyTDYyOSA0NDVRNjI5IDQ1MSA2MzUgNDkwVDY0MSA1NTFRNjQxIDU4NiA2MjggNjA0VDU3MyA2MjlRNTY4IDYzMCA1MTUgNjMxUTQ2OSA2MzEgNDU3IDYzMFQ0MzkgNjIyUTQzOCA2MjEgMzY4IDM0M1QyOTggNjBRMjk4IDQ4IDM4NiA0NlE0MTggNDYgNDI3IDQ1VDQzNiAzNlE0MzYgMzEgNDMzIDIyUTQyOSA0IDQyNCAxTDQyMiAwUTQxOSAwIDQxNSAwUTQxMCAwIDM2MyAxVDIyOCAyUTk5IDIgNjQgMEg0OVE0MyA2IDQzIDlUNDUgMjdRNDkgNDAgNTUgNDZIODNIOTRRMTc0IDQ2IDE4OSA1NVExOTAgNTYgMTkxIDU2UTE5NiA1OSAyMDEgNzZUMjQxIDIzM1EyNTggMzAxIDI2OSAzNDRRMzM5IDYxOSAzMzkgNjI1UTMzOSA2MzAgMzEwIDYzMEgyNzlRMjEyIDYzMCAxOTEgNjI0UTE0NiA2MTQgMTIxIDU4M1Q2NyA0NjdRNjAgNDQ1IDU3IDQ0MVQ0MyA0MzdINDBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yQiIgZD0iTTU2IDIzN1Q1NiAyNTBUNzAgMjcwSDM2OVY0MjBMMzcwIDU3MFEzODAgNTgzIDM4OSA1ODNRNDAyIDU4MyA0MDkgNTY4VjI3MEg3MDdRNzIyIDI2MiA3MjIgMjUwVDcwNyAyMzBINDA5Vi02OFE0MDEgLTgyIDM5MSAtODJIMzg5SDM4N1EzNzUgLTgyIDM2OSAtNjhWMjMwSDcwUTU2IDIzNyA1NiAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTAiIGQ9Ik0yODcgNjI4UTI4NyA2MzUgMjMwIDYzN1EyMDYgNjM3IDE5OSA2MzhUMTkyIDY0OFExOTIgNjQ5IDE5NCA2NTlRMjAwIDY3OSAyMDMgNjgxVDM5NyA2ODNRNTg3IDY4MiA2MDAgNjgwUTY2NCA2NjkgNzA3IDYzMVQ3NTEgNTMwUTc1MSA0NTMgNjg1IDM4OVE2MTYgMzIxIDUwNyAzMDNRNTAwIDMwMiA0MDIgMzAxSDMwN0wyNzcgMTgyUTI0NyA2NiAyNDcgNTlRMjQ3IDU1IDI0OCA1NFQyNTUgNTBUMjcyIDQ4VDMwNSA0NkgzMzZRMzQyIDM3IDM0MiAzNVEzNDIgMTkgMzM1IDVRMzMwIDAgMzE5IDBRMzE2IDAgMjgyIDFUMTgyIDJRMTIwIDIgODcgMlQ1MSAxUTMzIDEgMzMgMTFRMzMgMTMgMzYgMjVRNDAgNDEgNDQgNDNUNjcgNDZROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFpNNjQ1IDU1NFE2NDUgNTY3IDY0MyA1NzVUNjM0IDU5N1Q2MDkgNjE5VDU2MCA2MzVRNTUzIDYzNiA0ODAgNjM3UTQ2MyA2MzcgNDQ1IDYzN1Q0MTYgNjM2VDQwNCA2MzZRMzkxIDYzNSAzODYgNjI3UTM4NCA2MjEgMzY3IDU1MFQzMzIgNDEyVDMxNCAzNDRRMzE0IDM0MiAzOTUgMzQySDQwN0g0MzBRNTQyIDM0MiA1OTAgMzkyUTYxNyA0MTkgNjMxIDQ3MVQ2NDUgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzIiIGQ9Ik0xMDkgNDI5UTgyIDQyOSA2NiA0NDdUNTAgNDkxUTUwIDU2MiAxMDMgNjE0VDIzNSA2NjZRMzI2IDY2NiAzODcgNjEwVDQ0OSA0NjVRNDQ5IDQyMiA0MjkgMzgzVDM4MSAzMTVUMzAxIDI0MVEyNjUgMjEwIDIwMSAxNDlMMTQyIDkzTDIxOCA5MlEzNzUgOTIgMzg1IDk3UTM5MiA5OSA0MDkgMTg2VjE4OUg0NDlWMTg2UTQ0OCAxODMgNDM2IDk1VDQyMSAzVjBINTBWMTlWMzFRNTAgMzggNTYgNDZUODYgODFRMTE1IDExMyAxMzYgMTM3UTE0NSAxNDcgMTcwIDE3NFQyMDQgMjExVDIzMyAyNDRUMjYxIDI3OFQyODQgMzA4VDMwNSAzNDBUMzIwIDM2OVQzMzMgNDAxVDM0MCA0MzFUMzQzIDQ2NFEzNDMgNTI3IDMwOSA1NzNUMjEyIDYxOVExNzkgNjE5IDE1NCA2MDJUMTE5IDU2OVQxMDkgNTUwUTEwOSA1NDkgMTE0IDU0OVExMzIgNTQ5IDE1MSA1MzVUMTcwIDQ4OVExNzAgNDY0IDE1NCA0NDdUMTA5IDQyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjMtMjgiIGQ9Ik03MDEgLTk0MFE3MDEgLTk0MyA2OTUgLTk0OUg2NjRRNjYyIC05NDcgNjM2IC05MjJUNTkxIC04NzlUNTM3IC04MThUNDc1IC03MzdUNDEyIC02MzZUMzUwIC01MTFUMjk1IC0zNjJUMjUwIC0xODZUMjIxIDE3VDIwOSAyNTFRMjA5IDk2MiA1NzMgMTM2MVE1OTYgMTM4NiA2MTYgMTQwNVQ2NDkgMTQzN1Q2NjQgMTQ1MEg2OTVRNzAxIDE0NDQgNzAxIDE0NDFRNzAxIDE0MzYgNjgxIDE0MTVUNjI5IDEzNTZUNTU3IDEyNjFUNDc2IDExMThUNDAwIDkyN1QzNDAgNjc1VDMwOCAzNTlRMzA2IDMyMSAzMDYgMjUwUTMwNiAtMTM5IDQwMCAtNDMwVDY5MCAtOTI0UTcwMSAtOTM2IDcwMSAtOTQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMy0yOSIgZD0iTTM0IDE0MzhRMzQgMTQ0NiAzNyAxNDQ4VDUwIDE0NTBINTZINzFRNzMgMTQ0OCA5OSAxNDIzVDE0NCAxMzgwVDE5OCAxMzE5VDI2MCAxMjM4VDMyMyAxMTM3VDM4NSAxMDEzVDQ0MCA4NjRUNDg1IDY4OFQ1MTQgNDg1VDUyNiAyNTFRNTI2IDEzNCA1MTkgNTNRNDcyIC01MTkgMTYyIC04NjBRMTM5IC04ODUgMTE5IC05MDRUODYgLTkzNlQ3MSAtOTQ5SDU2UTQzIC05NDkgMzkgLTk0N1QzNCAtOTM3UTg4IC04ODMgMTQwIC04MTNRNDI4IC00MzAgNDI4IDI1MVE0MjggNDUzIDQwMiA2MjhUMzM4IDkyMlQyNDUgMTE0NlQxNDUgMTMwOVQ0NiAxNDI1UTQ0IDE0MjcgNDIgMTQyOVQzOSAxNDMzVDM2IDE0MzZMMzQgMTQzOFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTQyIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02OSIgeD0iNzA4IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iOTg3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MyIgeD0iMTQ4NyIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iMjY2MSIgeT0iNTgxIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjI2NjEiIHk9Ii0zNTAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNjg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjQyMTUiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iNTI3MSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYyMDcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSI3Njc4IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9Ijg2NzkiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5NjEwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTdCIiB4PSIwIiB5PSItMSI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU4MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIxMTY3IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iODI1IiB5PSItNDM1Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTYzMiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMS03RCIgeD0iMzQ2NCIgeT0iLTEiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjEzOTM2IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQ5OTIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTY1NzIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNzM1MSwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEzNjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDMsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE5MTczLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMjA1ODciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMTU4OCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMy0yOCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDczNiwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjE4NjEiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTMsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMTAxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjM1MTQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NTE1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1ozLTI5IiB4PSI2NjA5IiB5PSItMSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjkyMTIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyOTk5MCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM5NywwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjE4NjEiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTMsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDMyMzY5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9zdmc+) 。
。
在 次试验后计算偏差有点复杂,需要用组合数学 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjcuNmV4IiBoZWlnaHQ9IjIuODQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMC44MzhleDsiIHZpZXdCb3g9IjAgLTg2My4xIDMyNzIuMyAxMjIzLjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDIiIGQ9Ik0yMzEgNjM3UTIwNCA2MzcgMTk5IDYzOFQxOTQgNjQ5UTE5NCA2NzYgMjA1IDY4MlEyMDYgNjgzIDMzNSA2ODNRNTk0IDY4MyA2MDggNjgxUTY3MSA2NzEgNzEzIDYzNlQ3NTYgNTQ0UTc1NiA0ODAgNjk4IDQyOVQ1NjUgMzYwTDU1NSAzNTdRNjE5IDM0OCA2NjAgMzExVDcwMiAyMTlRNzAyIDE0NiA2MzAgNzhUNDUzIDFRNDQ2IDAgMjQyIDBRNDIgMCAzOSAyUTM1IDUgMzUgMTBRMzUgMTcgMzcgMjRRNDIgNDMgNDcgNDVRNTEgNDYgNjIgNDZINjhROTUgNDYgMTI4IDQ5UTE0MiA1MiAxNDcgNjFRMTUwIDY1IDIxOSAzMzlUMjg4IDYyOFEyODggNjM1IDIzMSA2MzdaTTY0OSA1NDRRNjQ5IDU3NCA2MzQgNjAwVDU4NSA2MzRRNTc4IDYzNiA0OTMgNjM3UTQ3MyA2MzcgNDUxIDYzN1Q0MTYgNjM2SDQwM1EzODggNjM1IDM4NCA2MjZRMzgyIDYyMiAzNTIgNTA2UTM1MiA1MDMgMzUxIDUwMEwzMjAgMzc0SDQwMVE0ODIgMzc0IDQ5NCAzNzZRNTU0IDM4NiA2MDEgNDM0VDY0OSA1NDRaTTU5NSAyMjlRNTk1IDI3MyA1NzIgMzAyVDUxMiAzMzZRNTA2IDMzNyA0MjkgMzM3UTMxMSAzMzcgMzEwIDMzNlEzMTAgMzM0IDI5MyAyNjNUMjU4IDEyMkwyNDAgNTJRMjQwIDQ4IDI1MiA0OFQzMzMgNDZRNDIyIDQ2IDQyOSA0N1E0OTEgNTQgNTQzIDEwNVQ1OTUgMjI5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNCIiBkPSJNNzggMzcwUTc4IDM5NCA5NSA0MTJUMTM4IDQzMFExNjIgNDMwIDE4MCA0MTRUMTk5IDM3MVExOTkgMzQ2IDE4MiAzMjhUMTM5IDMxMFQ5NiAzMjdUNzggMzcwWk03OCA2MFE3OCA4NSA5NCAxMDNUMTM3IDEyMVEyMDIgMTIxIDIwMiA4UTIwMiAtNDQgMTgzIC05NFQxNDQgLTE2OVQxMTggLTE5NFExMTUgLTE5NCAxMDYgLTE4NlQ5NSAtMTc0UTk0IC0xNzEgMTA3IC0xNTVUMTM3IC0xMDdUMTYwIC0zOFExNjEgLTMyIDE2MiAtMjJUMTY1IC00VDE2NSA0UTE2NSA1IDE2MSA0VDE0MiAwUTExMCAwIDk0IDE4VDc4IDYwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZCIiBkPSJNMTIxIDY0N1ExMjEgNjU3IDEyNSA2NzBUMTM3IDY4M1ExMzggNjgzIDIwOSA2ODhUMjgyIDY5NFEyOTQgNjk0IDI5NCA2ODZRMjk0IDY3OSAyNDQgNDc3UTE5NCAyNzkgMTk0IDI3MlEyMTMgMjgyIDIyMyAyOTFRMjQ3IDMwOSAyOTIgMzU0VDM2MiA0MTVRNDAyIDQ0MiA0MzggNDQyUTQ2OCA0NDIgNDg1IDQyM1Q1MDMgMzY5UTUwMyAzNDQgNDk2IDMyN1Q0NzcgMzAyVDQ1NiAyOTFUNDM4IDI4OFE0MTggMjg4IDQwNiAyOTlUMzk0IDMyOFEzOTQgMzUzIDQxMCAzNjlUNDQyIDM5MEw0NTggMzkzUTQ0NiA0MDUgNDM0IDQwNUg0MzBRMzk4IDQwMiAzNjcgMzgwVDI5NCAzMTZUMjI4IDI1NVEyMzAgMjU0IDI0MyAyNTJUMjY3IDI0NlQyOTMgMjM4VDMyMCAyMjRUMzQyIDIwNlQzNTkgMTgwVDM2NSAxNDdRMzY1IDEzMCAzNjAgMTA2VDM1NCA2NlEzNTQgMjYgMzgxIDI2UTQyOSAyNiA0NTkgMTQ1UTQ2MSAxNTMgNDc5IDE1M0g0ODNRNDk5IDE1MyA0OTkgMTQ0UTQ5OSAxMzkgNDk2IDEzMFE0NTUgLTExIDM3OCAtMTFRMzMzIC0xMSAzMDUgMTVUMjc3IDkwUTI3NyAxMDggMjgwIDEyMVQyODMgMTQ1UTI4MyAxNjcgMjY5IDE4M1QyMzQgMjA2VDIwMCAyMTdUMTgyIDIyMEgxODBRMTY4IDE3OCAxNTkgMTM5VDE0NSA4MVQxMzYgNDRUMTI5IDIwVDEyMiA3VDExMSAtMlE5OCAtMTEgODMgLTExUTY2IC0xMSA1NyAtMVQ0OCAxNlE0OCAyNiA4NSAxNzZUMTU4IDQ3MUwxOTUgNjE2UTE5NiA2MjkgMTg4IDYzMlQxNDkgNjM3SDE0NFExMzQgNjM3IDEzMSA2MzdUMTI0IDY0MFQxMjEgNjQ3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5MjYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNCIiB4PSI2MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTA0NSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTk1NiIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=) 的形式表示 。我们可以把 看作是将 分解成 个非负整数的不同方式的个数——其次序被认为是重要的。因此得到,
的形式表示 。我们可以把 看作是将 分解成 个非负整数的不同方式的个数——其次序被认为是重要的。因此得到, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjI0LjMyMWV4IiBoZWlnaHQ9IjYuMTc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMi41MDVleDsiIHZpZXdCb3g9IjAgLTE1ODAuNyAxMDQ3MS4zIDI2NTkuMSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00MiIgZD0iTTIzMSA2MzdRMjA0IDYzNyAxOTkgNjM4VDE5NCA2NDlRMTk0IDY3NiAyMDUgNjgyUTIwNiA2ODMgMzM1IDY4M1E1OTQgNjgzIDYwOCA2ODFRNjcxIDY3MSA3MTMgNjM2VDc1NiA1NDRRNzU2IDQ4MCA2OTggNDI5VDU2NSAzNjBMNTU1IDM1N1E2MTkgMzQ4IDY2MCAzMTFUNzAyIDIxOVE3MDIgMTQ2IDYzMCA3OFQ0NTMgMVE0NDYgMCAyNDIgMFE0MiAwIDM5IDJRMzUgNSAzNSAxMFEzNSAxNyAzNyAyNFE0MiA0MyA0NyA0NVE1MSA0NiA2MiA0Nkg2OFE5NSA0NiAxMjggNDlRMTQyIDUyIDE0NyA2MVExNTAgNjUgMjE5IDMzOVQyODggNjI4UTI4OCA2MzUgMjMxIDYzN1pNNjQ5IDU0NFE2NDkgNTc0IDYzNCA2MDBUNTg1IDYzNFE1NzggNjM2IDQ5MyA2MzdRNDczIDYzNyA0NTEgNjM3VDQxNiA2MzZINDAzUTM4OCA2MzUgMzg0IDYyNlEzODIgNjIyIDM1MiA1MDZRMzUyIDUwMyAzNTEgNTAwTDMyMCAzNzRINDAxUTQ4MiAzNzQgNDk0IDM3NlE1NTQgMzg2IDYwMSA0MzRUNjQ5IDU0NFpNNTk1IDIyOVE1OTUgMjczIDU3MiAzMDJUNTEyIDMzNlE1MDYgMzM3IDQyOSAzMzdRMzExIDMzNyAzMTAgMzM2UTMxMCAzMzQgMjkzIDI2M1QyNTggMTIyTDI0MCA1MlEyNDAgNDggMjUyIDQ4VDMzMyA0NlE0MjIgNDYgNDI5IDQ3UTQ5MSA1NCA1NDMgMTA1VDU5NSAyMjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZFIiBkPSJNMjEgMjg3UTIyIDI5MyAyNCAzMDNUMzYgMzQxVDU2IDM4OFQ4OSA0MjVUMTM1IDQ0MlExNzEgNDQyIDE5NSA0MjRUMjI1IDM5MFQyMzEgMzY5UTIzMSAzNjcgMjMyIDM2N0wyNDMgMzc4UTMwNCA0NDIgMzgyIDQ0MlE0MzYgNDQyIDQ2OSA0MTVUNTAzIDMzNlQ0NjUgMTc5VDQyNyA1MlE0MjcgMjYgNDQ0IDI2UTQ1MCAyNiA0NTMgMjdRNDgyIDMyIDUwNSA2NVQ1NDAgMTQ1UTU0MiAxNTMgNTYwIDE1M1E1ODAgMTUzIDU4MCAxNDVRNTgwIDE0NCA1NzYgMTMwUTU2OCAxMDEgNTU0IDczVDUwOCAxN1Q0MzkgLTEwUTM5MiAtMTAgMzcxIDE3VDM1MCA3M1EzNTAgOTIgMzg2IDE5M1Q0MjMgMzQ1UTQyMyA0MDQgMzc5IDQwNEgzNzRRMjg4IDQwNCAyMjkgMzAzTDIyMiAyOTFMMTg5IDE1N1ExNTYgMjYgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTIgMTgwVDE1MiAzNDNRMTUzIDM0OCAxNTMgMzY2UTE1MyA0MDUgMTI5IDQwNVE5MSA0MDUgNjYgMzA1UTYwIDI4NSA2MCAyODRRNTggMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0IiIGQ9Ik03OCAzNzBRNzggMzk0IDk1IDQxMlQxMzggNDMwUTE2MiA0MzAgMTgwIDQxNFQxOTkgMzcxUTE5OSAzNDYgMTgyIDMyOFQxMzkgMzEwVDk2IDMyN1Q3OCAzNzBaTTc4IDYwUTc4IDg1IDk0IDEwM1QxMzcgMTIxUTIwMiAxMjEgMjAyIDhRMjAyIC00NCAxODMgLTk0VDE0NCAtMTY5VDExOCAtMTk0UTExNSAtMTk0IDEwNiAtMTg2VDk1IC0xNzRROTQgLTE3MSAxMDcgLTE1NVQxMzcgLTEwN1QxNjAgLTM4UTE2MSAtMzIgMTYyIC0yMlQxNjUgLTRUMTY1IDRRMTY1IDUgMTYxIDRUMTQyIDBRMTEwIDAgOTQgMThUNzggNjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkIiIGQ9Ik0xMjEgNjQ3UTEyMSA2NTcgMTI1IDY3MFQxMzcgNjgzUTEzOCA2ODMgMjA5IDY4OFQyODIgNjk0UTI5NCA2OTQgMjk0IDY4NlEyOTQgNjc5IDI0NCA0NzdRMTk0IDI3OSAxOTQgMjcyUTIxMyAyODIgMjIzIDI5MVEyNDcgMzA5IDI5MiAzNTRUMzYyIDQxNVE0MDIgNDQyIDQzOCA0NDJRNDY4IDQ0MiA0ODUgNDIzVDUwMyAzNjlRNTAzIDM0NCA0OTYgMzI3VDQ3NyAzMDJUNDU2IDI5MVQ0MzggMjg4UTQxOCAyODggNDA2IDI5OVQzOTQgMzI4UTM5NCAzNTMgNDEwIDM2OVQ0NDIgMzkwTDQ1OCAzOTNRNDQ2IDQwNSA0MzQgNDA1SDQzMFEzOTggNDAyIDM2NyAzODBUMjk0IDMxNlQyMjggMjU1UTIzMCAyNTQgMjQzIDI1MlQyNjcgMjQ2VDI5MyAyMzhUMzIwIDIyNFQzNDIgMjA2VDM1OSAxODBUMzY1IDE0N1EzNjUgMTMwIDM2MCAxMDZUMzU0IDY2UTM1NCAyNiAzODEgMjZRNDI5IDI2IDQ1OSAxNDVRNDYxIDE1MyA0NzkgMTUzSDQ4M1E0OTkgMTUzIDQ5OSAxNDRRNDk5IDEzOSA0OTYgMTMwUTQ1NSAtMTEgMzc4IC0xMVEzMzMgLTExIDMwNSAxNVQyNzcgOTBRMjc3IDEwOCAyODAgMTIxVDI4MyAxNDVRMjgzIDE2NyAyNjkgMTgzVDIzNCAyMDZUMjAwIDIxN1QxODIgMjIwSDE4MFExNjggMTc4IDE1OSAxMzlUMTQ1IDgxVDEzNiA0NFQxMjkgMjBUMTIyIDdUMTExIC0yUTk4IC0xMSA4MyAtMTFRNjYgLTExIDU3IC0xVDQ4IDE2UTQ4IDI2IDg1IDE3NlQxNTggNDcxTDE5NSA2MTZRMTk2IDYyOSAxODggNjMyVDE0OSA2MzdIMTQ0UTEzNCA2MzcgMTMxIDYzN1QxMjQgNjQwVDEyMSA2NDdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjIxMiIgZD0iTTg0IDIzN1Q4NCAyNTBUOTggMjcwSDY3OVE2OTQgMjYyIDY5NCAyNTBUNjc5IDIzMEg5OFE4NCAyMzcgODQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMy0yOCIgZD0iTTcwMSAtOTQwUTcwMSAtOTQzIDY5NSAtOTQ5SDY2NFE2NjIgLTk0NyA2MzYgLTkyMlQ1OTEgLTg3OVQ1MzcgLTgxOFQ0NzUgLTczN1Q0MTIgLTYzNlQzNTAgLTUxMVQyOTUgLTM2MlQyNTAgLTE4NlQyMjEgMTdUMjA5IDI1MVEyMDkgOTYyIDU3MyAxMzYxUTU5NiAxMzg2IDYxNiAxNDA1VDY0OSAxNDM3VDY2NCAxNDUwSDY5NVE3MDEgMTQ0NCA3MDEgMTQ0MVE3MDEgMTQzNiA2ODEgMTQxNVQ2MjkgMTM1NlQ1NTcgMTI2MVQ0NzYgMTExOFQ0MDAgOTI3VDM0MCA2NzVUMzA4IDM1OVEzMDYgMzIxIDMwNiAyNTBRMzA2IC0xMzkgNDAwIC00MzBUNjkwIC05MjRRNzAxIC05MzYgNzAxIC05NDBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1ozLTI5IiBkPSJNMzQgMTQzOFEzNCAxNDQ2IDM3IDE0NDhUNTAgMTQ1MEg1Nkg3MVE3MyAxNDQ4IDk5IDE0MjNUMTQ0IDEzODBUMTk4IDEzMTlUMjYwIDEyMzhUMzIzIDExMzdUMzg1IDEwMTNUNDQwIDg2NFQ0ODUgNjg4VDUxNCA0ODVUNTI2IDI1MVE1MjYgMTM0IDUxOSA1M1E0NzIgLTUxOSAxNjIgLTg2MFExMzkgLTg4NSAxMTkgLTkwNFQ4NiAtOTM2VDcxIC05NDlINTZRNDMgLTk0OSAzOSAtOTQ3VDM0IC05MzdRODggLTg4MyAxNDAgLTgxM1E0MjggLTQzMCA0MjggMjUxUTQyOCA0NTMgNDAyIDYyOFQzMzggOTIyVDI0NSAxMTQ2VDE0NSAxMzA5VDQ2IDE0MjVRNDQgMTQyNyA0MiAxNDI5VDM5IDE0MzNUMzYgMTQzNkwzNCAxNDM4WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQyIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTI2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zQiIgeD0iNjAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjEwNDUiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjE5NTYiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjM1NTAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NjA2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1ozLTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTAzLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoLTExLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCw2NTApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI3NDMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTc0NCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMjU2NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjM1NjciIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDg3MiwtNzUwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSI4MjIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxODIzIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1ozLTI5IiB4PSI1MTI4IiB5PSItMSI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=) 。进一步假设
。进一步假设 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIxLjQxMWV4IiBoZWlnaHQ9IjIuODQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMC44MzhleDsiIHZpZXdCb3g9IjAgLTg2My4xIDkyMTguOCAxMjIzLjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDIiIGQ9Ik0yMzEgNjM3UTIwNCA2MzcgMTk5IDYzOFQxOTQgNjQ5UTE5NCA2NzYgMjA1IDY4MlEyMDYgNjgzIDMzNSA2ODNRNTk0IDY4MyA2MDggNjgxUTY3MSA2NzEgNzEzIDYzNlQ3NTYgNTQ0UTc1NiA0ODAgNjk4IDQyOVQ1NjUgMzYwTDU1NSAzNTdRNjE5IDM0OCA2NjAgMzExVDcwMiAyMTlRNzAyIDE0NiA2MzAgNzhUNDUzIDFRNDQ2IDAgMjQyIDBRNDIgMCAzOSAyUTM1IDUgMzUgMTBRMzUgMTcgMzcgMjRRNDIgNDMgNDcgNDVRNTEgNDYgNjIgNDZINjhROTUgNDYgMTI4IDQ5UTE0MiA1MiAxNDcgNjFRMTUwIDY1IDIxOSAzMzlUMjg4IDYyOFEyODggNjM1IDIzMSA2MzdaTTY0OSA1NDRRNjQ5IDU3NCA2MzQgNjAwVDU4NSA2MzRRNTc4IDYzNiA0OTMgNjM3UTQ3MyA2MzcgNDUxIDYzN1Q0MTYgNjM2SDQwM1EzODggNjM1IDM4NCA2MjZRMzgyIDYyMiAzNTIgNTA2UTM1MiA1MDMgMzUxIDUwMEwzMjAgMzc0SDQwMVE0ODIgMzc0IDQ5NCAzNzZRNTU0IDM4NiA2MDEgNDM0VDY0OSA1NDRaTTU5NSAyMjlRNTk1IDI3MyA1NzIgMzAyVDUxMiAzMzZRNTA2IDMzNyA0MjkgMzM3UTMxMSAzMzcgMzEwIDMzNlEzMTAgMzM0IDI5MyAyNjNUMjU4IDEyMkwyNDAgNTJRMjQwIDQ4IDI1MiA0OFQzMzMgNDZRNDIyIDQ2IDQyOSA0N1E0OTEgNTQgNTQzIDEwNVQ1OTUgMjI5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNCIiBkPSJNNzggMzcwUTc4IDM5NCA5NSA0MTJUMTM4IDQzMFExNjIgNDMwIDE4MCA0MTRUMTk5IDM3MVExOTkgMzQ2IDE4MiAzMjhUMTM5IDMxMFQ5NiAzMjdUNzggMzcwWk03OCA2MFE3OCA4NSA5NCAxMDNUMTM3IDEyMVEyMDIgMTIxIDIwMiA4UTIwMiAtNDQgMTgzIC05NFQxNDQgLTE2OVQxMTggLTE5NFExMTUgLTE5NCAxMDYgLTE4NlQ5NSAtMTc0UTk0IC0xNzEgMTA3IC0xNTVUMTM3IC0xMDdUMTYwIC0zOFExNjEgLTMyIDE2MiAtMjJUMTY1IC00VDE2NSA0UTE2NSA1IDE2MSA0VDE0MiAwUTExMCAwIDk0IDE4VDc4IDYwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZCIiBkPSJNMTIxIDY0N1ExMjEgNjU3IDEyNSA2NzBUMTM3IDY4M1ExMzggNjgzIDIwOSA2ODhUMjgyIDY5NFEyOTQgNjk0IDI5NCA2ODZRMjk0IDY3OSAyNDQgNDc3UTE5NCAyNzkgMTk0IDI3MlEyMTMgMjgyIDIyMyAyOTFRMjQ3IDMwOSAyOTIgMzU0VDM2MiA0MTVRNDAyIDQ0MiA0MzggNDQyUTQ2OCA0NDIgNDg1IDQyM1Q1MDMgMzY5UTUwMyAzNDQgNDk2IDMyN1Q0NzcgMzAyVDQ1NiAyOTFUNDM4IDI4OFE0MTggMjg4IDQwNiAyOTlUMzk0IDMyOFEzOTQgMzUzIDQxMCAzNjlUNDQyIDM5MEw0NTggMzkzUTQ0NiA0MDUgNDM0IDQwNUg0MzBRMzk4IDQwMiAzNjcgMzgwVDI5NCAzMTZUMjI4IDI1NVEyMzAgMjU0IDI0MyAyNTJUMjY3IDI0NlQyOTMgMjM4VDMyMCAyMjRUMzQyIDIwNlQzNTkgMTgwVDM2NSAxNDdRMzY1IDEzMCAzNjAgMTA2VDM1NCA2NlEzNTQgMjYgMzgxIDI2UTQyOSAyNiA0NTkgMTQ1UTQ2MSAxNTMgNDc5IDE1M0g0ODNRNDk5IDE1MyA0OTkgMTQ0UTQ5OSAxMzkgNDk2IDEzMFE0NTUgLTExIDM3OCAtMTFRMzMzIC0xMSAzMDUgMTVUMjc3IDkwUTI3NyAxMDggMjgwIDEyMVQyODMgMTQ1UTI4MyAxNjcgMjY5IDE4M1QyMzQgMjA2VDIwMCAyMTdUMTgyIDIyMEgxODBRMTY4IDE3OCAxNTkgMTM5VDE0NSA4MVQxMzYgNDRUMTI5IDIwVDEyMiA3VDExMSAtMlE5OCAtMTEgODMgLTExUTY2IC0xMSA1NyAtMVQ0OCAxNlE0OCAyNiA4NSAxNzZUMTU4IDQ3MUwxOTUgNjE2UTE5NiA2MjkgMTg4IDYzMlQxNDkgNjM3SDE0NFExMzQgNjM3IDEzMSA2MzdUMTI0IDY0MFQxMjEgNjQ3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkMiIGQ9Ik03OCAzNVQ3OCA2MFQ5NCAxMDNUMTM3IDEyMVExNjUgMTIxIDE4NyA5NlQyMTAgOFEyMTAgLTI3IDIwMSAtNjBUMTgwIC0xMTdUMTU0IC0xNThUMTMwIC0xODVUMTE3IC0xOTRRMTEzIC0xOTQgMTA0IC0xODVUOTUgLTE3MlE5NSAtMTY4IDEwNiAtMTU2VDEzMSAtMTI2VDE1NyAtNzZUMTczIC0zVjlMMTcyIDhRMTcwIDcgMTY3IDZUMTYxIDNUMTUyIDFUMTQwIDBRMTEzIDAgOTYgMTdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMiIgZD0iTTEwOSA0MjlRODIgNDI5IDY2IDQ0N1Q1MCA0OTFRNTAgNTYyIDEwMyA2MTRUMjM1IDY2NlEzMjYgNjY2IDM4NyA2MTBUNDQ5IDQ2NVE0NDkgNDIyIDQyOSAzODNUMzgxIDMxNVQzMDEgMjQxUTI2NSAyMTAgMjAxIDE0OUwxNDIgOTNMMjE4IDkyUTM3NSA5MiAzODUgOTdRMzkyIDk5IDQwOSAxODZWMTg5SDQ0OVYxODZRNDQ4IDE4MyA0MzYgOTVUNDIxIDNWMEg1MFYxOVYzMVE1MCAzOCA1NiA0NlQ4NiA4MVExMTUgMTEzIDEzNiAxMzdRMTQ1IDE0NyAxNzAgMTc0VDIwNCAyMTFUMjMzIDI0NFQyNjEgMjc4VDI4NCAzMDhUMzA1IDM0MFQzMjAgMzY5VDMzMyA0MDFUMzQwIDQzMVQzNDMgNDY0UTM0MyA1MjcgMzA5IDU3M1QyMTIgNjE5UTE3OSA2MTkgMTU0IDYwMlQxMTkgNTY5VDEwOSA1NTBRMTA5IDU0OSAxMTQgNTQ5UTEzMiA1NDkgMTUxIDUzNVQxNzAgNDg5UTE3MCA0NjQgMTU0IDQ0N1QxMDkgNDI5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkUiIGQ9Ik03OCA2MFE3OCA4NCA5NSAxMDJUMTM4IDEyMFExNjIgMTIwIDE4MCAxMDRUMTk5IDYxUTE5OSAzNiAxODIgMThUMTM5IDBUOTYgMTdUNzggNjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03QyIgZD0iTTEzOSAtMjQ5SDEzN1ExMjUgLTI0OSAxMTkgLTIzNVYyNTFMMTIwIDczN1ExMzAgNzUwIDEzOSA3NTBRMTUyIDc1MCAxNTkgNzM1Vi0yMzVRMTUxIC0yNDkgMTQxIC0yNDlIMTM5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5MjYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNCIiB4PSI2MDAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDQ1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iNzM3IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJDIiB4PSIyMDIxIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjQ2NiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjczNyIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iMzQ0MSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9IjM4ODYiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSI0MzMxIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iNDc3NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9IjUyMjIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1NjY3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjczNyIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QyIgeD0iNjcxMyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI2OTkyIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI3OTAzIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==) 是可以获得从
是可以获得从 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIuMjY1ZXgiIGhlaWdodD0iMi41MDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyIgdmlld0JveD0iMCAtNzkxLjMgOTc1LjQgMTA4MC40IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZCIiBkPSJNMTIxIDY0N1ExMjEgNjU3IDEyNSA2NzBUMTM3IDY4M1ExMzggNjgzIDIwOSA2ODhUMjgyIDY5NFEyOTQgNjk0IDI5NCA2ODZRMjk0IDY3OSAyNDQgNDc3UTE5NCAyNzkgMTk0IDI3MlEyMTMgMjgyIDIyMyAyOTFRMjQ3IDMwOSAyOTIgMzU0VDM2MiA0MTVRNDAyIDQ0MiA0MzggNDQyUTQ2OCA0NDIgNDg1IDQyM1Q1MDMgMzY5UTUwMyAzNDQgNDk2IDMyN1Q0NzcgMzAyVDQ1NiAyOTFUNDM4IDI4OFE0MTggMjg4IDQwNiAyOTlUMzk0IDMyOFEzOTQgMzUzIDQxMCAzNjlUNDQyIDM5MEw0NTggMzkzUTQ0NiA0MDUgNDM0IDQwNUg0MzBRMzk4IDQwMiAzNjcgMzgwVDI5NCAzMTZUMjI4IDI1NVEyMzAgMjU0IDI0MyAyNTJUMjY3IDI0NlQyOTMgMjM4VDMyMCAyMjRUMzQyIDIwNlQzNTkgMTgwVDM2NSAxNDdRMzY1IDEzMCAzNjAgMTA2VDM1NCA2NlEzNTQgMjYgMzgxIDI2UTQyOSAyNiA0NTkgMTQ1UTQ2MSAxNTMgNDc5IDE1M0g0ODNRNDk5IDE1MyA0OTkgMTQ0UTQ5OSAxMzkgNDk2IDEzMFE0NTUgLTExIDM3OCAtMTFRMzMzIC0xMSAzMDUgMTVUMjc3IDkwUTI3NyAxMDggMjgwIDEyMVQyODMgMTQ1UTI4MyAxNjcgMjY5IDE4M1QyMzQgMjA2VDIwMCAyMTdUMTgyIDIyMEgxODBRMTY4IDE3OCAxNTkgMTM5VDE0NSA4MVQxMzYgNDRUMTI5IDIwVDEyMiA3VDExMSAtMlE5OCAtMTEgODMgLTExUTY2IC0xMSA1NyAtMVQ0OCAxNlE0OCAyNiA4NSAxNzZUMTU4IDQ3MUwxOTUgNjE2UTE5NiA2MjkgMTg4IDYzMlQxNDkgNjM3SDE0NFExMzQgNjM3IDEzMSA2MzdUMTI0IDY0MFQxMjEgNjQ3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjczNyIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9zdmc+) 到
到 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIuNDNleCIgaGVpZ2h0PSIyLjUwOWV4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTAuNjcxZXg7IiB2aWV3Qm94PSIwIC03OTEuMyAxMDQ2LjEgMTA4MC40IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZCIiBkPSJNMTIxIDY0N1ExMjEgNjU3IDEyNSA2NzBUMTM3IDY4M1ExMzggNjgzIDIwOSA2ODhUMjgyIDY5NFEyOTQgNjk0IDI5NCA2ODZRMjk0IDY3OSAyNDQgNDc3UTE5NCAyNzkgMTk0IDI3MlEyMTMgMjgyIDIyMyAyOTFRMjQ3IDMwOSAyOTIgMzU0VDM2MiA0MTVRNDAyIDQ0MiA0MzggNDQyUTQ2OCA0NDIgNDg1IDQyM1Q1MDMgMzY5UTUwMyAzNDQgNDk2IDMyN1Q0NzcgMzAyVDQ1NiAyOTFUNDM4IDI4OFE0MTggMjg4IDQwNiAyOTlUMzk0IDMyOFEzOTQgMzUzIDQxMCAzNjlUNDQyIDM5MEw0NTggMzkzUTQ0NiA0MDUgNDM0IDQwNUg0MzBRMzk4IDQwMiAzNjcgMzgwVDI5NCAzMTZUMjI4IDI1NVEyMzAgMjU0IDI0MyAyNTJUMjY3IDI0NlQyOTMgMjM4VDMyMCAyMjRUMzQyIDIwNlQzNTkgMTgwVDM2NSAxNDdRMzY1IDEzMCAzNjAgMTA2VDM1NCA2NlEzNTQgMjYgMzgxIDI2UTQyOSAyNiA0NTkgMTQ1UTQ2MSAxNTMgNDc5IDE1M0g0ODNRNDk5IDE1MyA0OTkgMTQ0UTQ5OSAxMzkgNDk2IDEzMFE0NTUgLTExIDM3OCAtMTFRMzMzIC0xMSAzMDUgMTVUMjc3IDkwUTI3NyAxMDggMjgwIDEyMVQyODMgMTQ1UTI4MyAxNjcgMjY5IDE4M1QyMzQgMjA2VDIwMCAyMTdUMTgyIDIyMEgxODBRMTY4IDE3OCAxNTkgMTM5VDE0NSA4MVQxMzYgNDRUMTI5IDIwVDEyMiA3VDExMSAtMlE5OCAtMTEgODMgLTExUTY2IC0xMSA1NyAtMVQ0OCAxNlE0OCAyNiA4NSAxNzZUMTU4IDQ3MUwxOTUgNjE2UTE5NiA2MjkgMTg4IDYzMlQxNDkgNjM3SDE0NFExMzQgNjM3IDEzMSA2MzdUMTI0IDY0MFQxMjEgNjQ3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZFIiBkPSJNMjEgMjg3UTIyIDI5MyAyNCAzMDNUMzYgMzQxVDU2IDM4OFQ4OSA0MjVUMTM1IDQ0MlExNzEgNDQyIDE5NSA0MjRUMjI1IDM5MFQyMzEgMzY5UTIzMSAzNjcgMjMyIDM2N0wyNDMgMzc4UTMwNCA0NDIgMzgyIDQ0MlE0MzYgNDQyIDQ2OSA0MTVUNTAzIDMzNlQ0NjUgMTc5VDQyNyA1MlE0MjcgMjYgNDQ0IDI2UTQ1MCAyNiA0NTMgMjdRNDgyIDMyIDUwNSA2NVQ1NDAgMTQ1UTU0MiAxNTMgNTYwIDE1M1E1ODAgMTUzIDU4MCAxNDVRNTgwIDE0NCA1NzYgMTMwUTU2OCAxMDEgNTU0IDczVDUwOCAxN1Q0MzkgLTEwUTM5MiAtMTAgMzcxIDE3VDM1MCA3M1EzNTAgOTIgMzg2IDE5M1Q0MjMgMzQ1UTQyMyA0MDQgMzc5IDQwNEgzNzRRMjg4IDQwNCAyMjkgMzAzTDIyMiAyOTFMMTg5IDE1N1ExNTYgMjYgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTIgMTgwVDE1MiAzNDNRMTUzIDM0OCAxNTMgMzY2UTE1MyA0MDUgMTI5IDQwNVE5MSA0MDUgNjYgMzA1UTYwIDI4NSA2MCAyODRRNTggMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI3MzciIHk9Ii0yMTMiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) 的不同方式的数量——可以忽略顺序。注意,
的不同方式的数量——可以忽略顺序。注意, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQwLjY1ZXgiIGhlaWdodD0iNS42NzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0zLjE3MWV4OyIgdmlld0JveD0iMCAtMTA3OC40IDE3NTAyIDI0NDMuOCIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjIxMSIgZD0iTTYwIDk0OFE2MyA5NTAgNjY1IDk1MEgxMjY3TDEzMjUgODE1UTEzODQgNjc3IDEzODggNjY5SDEzNDhMMTM0MSA2ODNRMTMyMCA3MjQgMTI4NSA3NjFRMTIzNSA4MDkgMTE3NCA4MzhUMTAzMyA4ODFUODgyIDg5OFQ2OTkgOTAySDU3NEg1NDNIMjUxTDI1OSA4OTFRNzIyIDI1OCA3MjQgMjUyUTcyNSAyNTAgNzI0IDI0NlE3MjEgMjQzIDQ2MCAtNTZMMTk2IC0zNTZRMTk2IC0zNTcgNDA3IC0zNTdRNDU5IC0zNTcgNTQ4IC0zNTdUNjc2IC0zNThRODEyIC0zNTggODk2IC0zNTNUMTA2MyAtMzMyVDEyMDQgLTI4M1QxMzA3IC0xOTZRMTMyOCAtMTcwIDEzNDggLTEyNEgxMzg4UTEzODggLTEyNSAxMzgxIC0xNDVUMTM1NiAtMjEwVDEzMjUgLTI5NEwxMjY3IC00NDlMNjY2IC00NTBRNjQgLTQ1MCA2MSAtNDQ4UTU1IC00NDYgNTUgLTQzOVE1NSAtNDM3IDU3IC00MzNMNTkwIDE3N1E1OTAgMTc4IDU1NyAyMjJUNDUyIDM2NlQzMjIgNTQ0TDU2IDkwOUw1NSA5MjRRNTUgOTQ1IDYwIDk0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTY2IiBkPSJNMjczIDBRMjU1IDMgMTQ2IDNRNDMgMyAzNCAwSDI2VjQ2SDQyUTcwIDQ2IDkxIDQ5UTk5IDUyIDEwMyA2MFExMDQgNjIgMTA0IDIyNFYzODVIMzNWNDMxSDEwNFY0OTdMMTA1IDU2NEwxMDcgNTc0UTEyNiA2MzkgMTcxIDY2OFQyNjYgNzA0UTI2NyA3MDQgMjc1IDcwNFQyODkgNzA1UTMzMCA3MDIgMzUxIDY3OVQzNzIgNjI3UTM3MiA2MDQgMzU4IDU5MFQzMjEgNTc2VDI4NCA1OTBUMjcwIDYyN1EyNzAgNjQ3IDI4OCA2NjdIMjg0UTI4MCA2NjggMjczIDY2OFEyNDUgNjY4IDIyMyA2NDdUMTg5IDU5MlExODMgNTcyIDE4MiA0OTdWNDMxSDI5M1YzODVIMTg1VjIyNVExODUgNjMgMTg2IDYxVDE4OSA1N1QxOTQgNTRUMTk5IDUxVDIwNiA0OVQyMTMgNDhUMjIyIDQ3VDIzMSA0N1QyNDEgNDZUMjUxIDQ2SDI4MlYwSDI3M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTYxIiBkPSJNMTM3IDMwNVQxMTUgMzA1VDc4IDMyMFQ2MyAzNTlRNjMgMzk0IDk3IDQyMVQyMTggNDQ4UTI5MSA0NDggMzM2IDQxNlQzOTYgMzQwUTQwMSAzMjYgNDAxIDMwOVQ0MDIgMTk0VjEyNFE0MDIgNzYgNDA3IDU4VDQyOCA0MFE0NDMgNDAgNDQ4IDU2VDQ1MyAxMDlWMTQ1SDQ5M1YxMDZRNDkyIDY2IDQ5MCA1OVE0ODEgMjkgNDU1IDEyVDQwMCAtNlQzNTMgMTJUMzI5IDU0VjU4TDMyNyA1NVEzMjUgNTIgMzIyIDQ5VDMxNCA0MFQzMDIgMjlUMjg3IDE3VDI2OSA2VDI0NyAtMlQyMjEgLThUMTkwIC0xMVExMzAgLTExIDgyIDIwVDM0IDEwN1EzNCAxMjggNDEgMTQ3VDY4IDE4OFQxMTYgMjI1VDE5NCAyNTNUMzA0IDI2OEgzMThWMjkwUTMxOCAzMjQgMzEyIDM0MFEyOTAgNDExIDIxNSA0MTFRMTk3IDQxMSAxODEgNDEwVDE1NiA0MDZUMTQ4IDQwM1ExNzAgMzg4IDE3MCAzNTlRMTcwIDMzNCAxNTQgMzIwWk0xMjYgMTA2UTEyNiA3NSAxNTAgNTFUMjA5IDI2UTI0NyAyNiAyNzYgNDlUMzE1IDEwOVEzMTcgMTE2IDMxOCAxNzVRMzE4IDIzMyAzMTcgMjMzUTMwOSAyMzMgMjk2IDIzMlQyNTEgMjIzVDE5MyAyMDNUMTQ3IDE2NlQxMjYgMTA2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNjMiIGQ9Ik0zNzAgMzA1VDM0OSAzMDVUMzEzIDMyMFQyOTcgMzU4UTI5NyAzODEgMzEyIDM5NlEzMTcgNDAxIDMxNyA0MDJUMzA3IDQwNFEyODEgNDA4IDI1OCA0MDhRMjA5IDQwOCAxNzggMzc2UTEzMSAzMjkgMTMxIDIxOVExMzEgMTM3IDE2MiA5MFEyMDMgMjkgMjcyIDI5UTMxMyAyOSAzMzggNTVUMzc0IDExN1EzNzYgMTI1IDM3OSAxMjdUMzk1IDEyOUg0MDlRNDE1IDEyMyA0MTUgMTIwUTQxNSAxMTYgNDExIDEwNFQzOTUgNzFUMzY2IDMzVDMxOCAyVDI0OSAtMTFRMTYzIC0xMSA5OSA1M1QzNCAyMTRRMzQgMzE4IDk5IDM4M1QyNTAgNDQ4VDM3MCA0MjFUNDA0IDM1N1E0MDQgMzM0IDM4NyAzMjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03NCIgZD0iTTI3IDQyMlE4MCA0MjYgMTA5IDQ3OFQxNDEgNjAwVjYxNUgxODFWNDMxSDMxNlYzODVIMTgxVjI0MVExODIgMTE2IDE4MiAxMDBUMTg5IDY4UTIwMyAyOSAyMzggMjlRMjgyIDI5IDI5MiAxMDBRMjkzIDEwOCAyOTMgMTQ2VjE4MUgzMzNWMTQ2VjEzNFEzMzMgNTcgMjkxIDE3UTI2NCAtMTAgMjIxIC0xMFExODcgLTEwIDE2MiAyVDEyNCAzM1QxMDUgNjhUOTggMTAwUTk3IDEwNyA5NyAyNDhWMzg1SDE4VjQyMkgyN1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTZGIiBkPSJNMjggMjE0UTI4IDMwOSA5MyAzNzhUMjUwIDQ0OFEzNDAgNDQ4IDQwNSAzODBUNDcxIDIxNVE0NzEgMTIwIDQwNyA1NVQyNTAgLTEwUTE1MyAtMTAgOTEgNTdUMjggMjE0Wk0yNTAgMzBRMzcyIDMwIDM3MiAxOTNWMjI1VjI1MFEzNzIgMjcyIDM3MSAyODhUMzY0IDMyNlQzNDggMzYyVDMxNyAzOTBUMjY4IDQxMFEyNjMgNDExIDI1MiA0MTFRMjIyIDQxMSAxOTUgMzk5UTE1MiAzNzcgMTM5IDMzOFQxMjYgMjQ2VjIyNlExMjYgMTMwIDE0NSA5MVExNzcgMzAgMjUwIDMwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNzIiIGQ9Ik0zNiA0Nkg1MFE4OSA0NiA5NyA2MFY2OFE5NyA3NyA5NyA5MVQ5OCAxMjJUOTggMTYxVDk4IDIwM1E5OCAyMzQgOTggMjY5VDk4IDMyOEw5NyAzNTFROTQgMzcwIDgzIDM3NlQzOCAzODVIMjBWNDA4UTIwIDQzMSAyMiA0MzFMMzIgNDMyUTQyIDQzMyA2MCA0MzRUOTYgNDM2UTExMiA0MzcgMTMxIDQzOFQxNjAgNDQxVDE3MSA0NDJIMTc0VjM3M1EyMTMgNDQxIDI3MSA0NDFIMjc3UTMyMiA0NDEgMzQzIDQxOVQzNjQgMzczUTM2NCAzNTIgMzUxIDMzN1QzMTMgMzIyUTI4OCAzMjIgMjc2IDMzOFQyNjMgMzcyUTI2MyAzODEgMjY1IDM4OFQyNzAgNDAwVDI3MyA0MDVRMjcxIDQwNyAyNTAgNDAxUTIzNCAzOTMgMjI2IDM4NlExNzkgMzQxIDE3OSAyMDdWMTU0UTE3OSAxNDEgMTc5IDEyN1QxNzkgMTAxVDE4MCA4MVQxODAgNjZWNjFRMTgxIDU5IDE4MyA1N1QxODggNTRUMTkzIDUxVDIwMCA0OVQyMDcgNDhUMjE2IDQ3VDIyNSA0N1QyMzUgNDZUMjQ1IDQ2SDI3NlYwSDI2N1EyNDkgMyAxNDAgM1EzNyAzIDI4IDBIMjBWNDZIMzZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03MyIgZD0iTTI5NSAzMTZRMjk1IDM1NiAyNjggMzg1VDE5MCA0MTRRMTU0IDQxNCAxMjggNDAxUTk4IDM4MiA5OCAzNDlROTcgMzQ0IDk4IDMzNlQxMTQgMzEyVDE1NyAyODdRMTc1IDI4MiAyMDEgMjc4VDI0NSAyNjlUMjc3IDI1NlEyOTQgMjQ4IDMxMCAyMzZUMzQyIDE5NVQzNTkgMTMzUTM1OSA3MSAzMjEgMzFUMTk4IC0xMEgxOTBRMTM4IC0xMCA5NCAyNkw4NiAxOUw3NyAxMFE3MSA0IDY1IC0xTDU0IC0xMUg0Nkg0MlEzOSAtMTEgMzMgLTVWNzRWMTMyUTMzIDE1MyAzNSAxNTdUNDUgMTYySDU0UTY2IDE2MiA3MCAxNThUNzUgMTQ2VDgyIDExOVQxMDEgNzdRMTM2IDI2IDE5OCAyNlEyOTUgMjYgMjk1IDEwNFEyOTUgMTMzIDI3NyAxNTFRMjU3IDE3NSAxOTQgMTg3VDExMSAyMTBRNzUgMjI3IDU0IDI1NlQzMyAzMThRMzMgMzU3IDUwIDM4NFQ5MyA0MjRUMTQzIDQ0MlQxODcgNDQ3SDE5OFEyMzggNDQ3IDI2OCA0MzJMMjgzIDQyNEwyOTIgNDMxUTMwMiA0NDAgMzE0IDQ0OEgzMjJIMzI2UTMyOSA0NDggMzM1IDQ0MlYzMTBMMzI5IDMwNEgzMDFRMjk1IDMxMCAyOTUgMzE2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZCIiBkPSJNMTIxIDY0N1ExMjEgNjU3IDEyNSA2NzBUMTM3IDY4M1ExMzggNjgzIDIwOSA2ODhUMjgyIDY5NFEyOTQgNjk0IDI5NCA2ODZRMjk0IDY3OSAyNDQgNDc3UTE5NCAyNzkgMTk0IDI3MlEyMTMgMjgyIDIyMyAyOTFRMjQ3IDMwOSAyOTIgMzU0VDM2MiA0MTVRNDAyIDQ0MiA0MzggNDQyUTQ2OCA0NDIgNDg1IDQyM1Q1MDMgMzY5UTUwMyAzNDQgNDk2IDMyN1Q0NzcgMzAyVDQ1NiAyOTFUNDM4IDI4OFE0MTggMjg4IDQwNiAyOTlUMzk0IDMyOFEzOTQgMzUzIDQxMCAzNjlUNDQyIDM5MEw0NTggMzkzUTQ0NiA0MDUgNDM0IDQwNUg0MzBRMzk4IDQwMiAzNjcgMzgwVDI5NCAzMTZUMjI4IDI1NVEyMzAgMjU0IDI0MyAyNTJUMjY3IDI0NlQyOTMgMjM4VDMyMCAyMjRUMzQyIDIwNlQzNTkgMTgwVDM2NSAxNDdRMzY1IDEzMCAzNjAgMTA2VDM1NCA2NlEzNTQgMjYgMzgxIDI2UTQyOSAyNiA0NTkgMTQ1UTQ2MSAxNTMgNDc5IDE1M0g0ODNRNDk5IDE1MyA0OTkgMTQ0UTQ5OSAxMzkgNDk2IDEzMFE0NTUgLTExIDM3OCAtMTFRMzMzIC0xMSAzMDUgMTVUMjc3IDkwUTI3NyAxMDggMjgwIDEyMVQyODMgMTQ1UTI4MyAxNjcgMjY5IDE4M1QyMzQgMjA2VDIwMCAyMTdUMTgyIDIyMEgxODBRMTY4IDE3OCAxNTkgMTM5VDE0NSA4MVQxMzYgNDRUMTI5IDIwVDEyMiA3VDExMSAtMlE5OCAtMTEgODMgLTExUTY2IC0xMSA1NyAtMVQ0OCAxNlE0OCAyNiA4NSAxNzZUMTU4IDQ3MUwxOTUgNjE2UTE5NiA2MjkgMTg4IDYzMlQxNDkgNjM3SDE0NFExMzQgNjM3IDEzMSA2MzdUMTI0IDY0MFQxMjEgNjQ3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQyIiBkPSJNMjMxIDYzN1EyMDQgNjM3IDE5OSA2MzhUMTk0IDY0OVExOTQgNjc2IDIwNSA2ODJRMjA2IDY4MyAzMzUgNjgzUTU5NCA2ODMgNjA4IDY4MVE2NzEgNjcxIDcxMyA2MzZUNzU2IDU0NFE3NTYgNDgwIDY5OCA0MjlUNTY1IDM2MEw1NTUgMzU3UTYxOSAzNDggNjYwIDMxMVQ3MDIgMjE5UTcwMiAxNDYgNjMwIDc4VDQ1MyAxUTQ0NiAwIDI0MiAwUTQyIDAgMzkgMlEzNSA1IDM1IDEwUTM1IDE3IDM3IDI0UTQyIDQzIDQ3IDQ1UTUxIDQ2IDYyIDQ2SDY4UTk1IDQ2IDEyOCA0OVExNDIgNTIgMTQ3IDYxUTE1MCA2NSAyMTkgMzM5VDI4OCA2MjhRMjg4IDYzNSAyMzEgNjM3Wk02NDkgNTQ0UTY0OSA1NzQgNjM0IDYwMFQ1ODUgNjM0UTU3OCA2MzYgNDkzIDYzN1E0NzMgNjM3IDQ1MSA2MzdUNDE2IDYzNkg0MDNRMzg4IDYzNSAzODQgNjI2UTM4MiA2MjIgMzUyIDUwNlEzNTIgNTAzIDM1MSA1MDBMMzIwIDM3NEg0MDFRNDgyIDM3NCA0OTQgMzc2UTU1NCAzODYgNjAxIDQzNFQ2NDkgNTQ0Wk01OTUgMjI5UTU5NSAyNzMgNTcyIDMwMlQ1MTIgMzM2UTUwNiAzMzcgNDI5IDMzN1EzMTEgMzM3IDMxMCAzMzZRMzEwIDMzNCAyOTMgMjYzVDI1OCAxMjJMMjQwIDUyUTI0MCA0OCAyNTIgNDhUMzMzIDQ2UTQyMiA0NiA0MjkgNDdRNDkxIDU0IDU0MyAxMDVUNTk1IDIyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkUiIGQ9Ik0yMSAyODdRMjIgMjkzIDI0IDMwM1QzNiAzNDFUNTYgMzg4VDg5IDQyNVQxMzUgNDQyUTE3MSA0NDIgMTk1IDQyNFQyMjUgMzkwVDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzA0IDQ0MiAzODIgNDQyUTQzNiA0NDIgNDY5IDQxNVQ1MDMgMzM2VDQ2NSAxNzlUNDI3IDUyUTQyNyAyNiA0NDQgMjZRNDUwIDI2IDQ1MyAyN1E0ODIgMzIgNTA1IDY1VDU0MCAxNDVRNTQyIDE1MyA1NjAgMTUzUTU4MCAxNTMgNTgwIDE0NVE1ODAgMTQ0IDU3NiAxMzBRNTY4IDEwMSA1NTQgNzNUNTA4IDE3VDQzOSAtMTBRMzkyIC0xMCAzNzEgMTdUMzUwIDczUTM1MCA5MiAzODYgMTkzVDQyMyAzNDVRNDIzIDQwNCAzNzkgNDA0SDM3NFEyODggNDA0IDIyOSAzMDNMMjIyIDI5MUwxODkgMTU3UTE1NiAyNiAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExMiAxODBUMTUyIDM0M1ExNTMgMzQ4IDE1MyAzNjZRMTUzIDQwNSAxMjkgNDA1UTkxIDQwNSA2NiAzMDVRNjAgMjg1IDYwIDI4NFE1OCAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zQiIgZD0iTTc4IDM3MFE3OCAzOTQgOTUgNDEyVDEzOCA0MzBRMTYyIDQzMCAxODAgNDE0VDE5OSAzNzFRMTk5IDM0NiAxODIgMzI4VDEzOSAzMTBUOTYgMzI3VDc4IDM3MFpNNzggNjBRNzggODUgOTQgMTAzVDEzNyAxMjFRMjAyIDEyMSAyMDIgOFEyMDIgLTQ0IDE4MyAtOTRUMTQ0IC0xNjlUMTE4IC0xOTRRMTE1IC0xOTQgMTA2IC0xODZUOTUgLTE3NFE5NCAtMTcxIDEwNyAtMTU1VDEzNyAtMTA3VDE2MCAtMzhRMTYxIC0zMiAxNjIgLTIyVDE2NSAtNFQxNjUgNFExNjUgNSAxNjEgNFQxNDIgMFExMTAgMCA5NCAxOFQ3OCA2MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJDIiBkPSJNNzggMzVUNzggNjBUOTQgMTAzVDEzNyAxMjFRMTY1IDEyMSAxODcgOTZUMjEwIDhRMjEwIC0yNyAyMDEgLTYwVDE4MCAtMTE3VDE1NCAtMTU4VDEzMCAtMTg1VDExNyAtMTk0UTExMyAtMTk0IDEwNCAtMTg1VDk1IC0xNzJROTUgLTE2OCAxMDYgLTE1NlQxMzEgLTEyNlQxNTcgLTc2VDE3MyAtM1Y5TDE3MiA4UTE3MCA3IDE2NyA2VDE2MSAzVDE1MiAxVDE0MCAwUTExMyAwIDk2IDE3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzIiIGQ9Ik0xMDkgNDI5UTgyIDQyOSA2NiA0NDdUNTAgNDkxUTUwIDU2MiAxMDMgNjE0VDIzNSA2NjZRMzI2IDY2NiAzODcgNjEwVDQ0OSA0NjVRNDQ5IDQyMiA0MjkgMzgzVDM4MSAzMTVUMzAxIDI0MVEyNjUgMjEwIDIwMSAxNDlMMTQyIDkzTDIxOCA5MlEzNzUgOTIgMzg1IDk3UTM5MiA5OSA0MDkgMTg2VjE4OUg0NDlWMTg2UTQ0OCAxODMgNDM2IDk1VDQyMSAzVjBINTBWMTlWMzFRNTAgMzggNTYgNDZUODYgODFRMTE1IDExMyAxMzYgMTM3UTE0NSAxNDcgMTcwIDE3NFQyMDQgMjExVDIzMyAyNDRUMjYxIDI3OFQyODQgMzA4VDMwNSAzNDBUMzIwIDM2OVQzMzMgNDAxVDM0MCA0MzFUMzQzIDQ2NFEzNDMgNTI3IDMwOSA1NzNUMjEyIDYxOVExNzkgNjE5IDE1NCA2MDJUMTE5IDU2OVQxMDkgNTUwUTEwOSA1NDkgMTE0IDU0OVExMzIgNTQ5IDE1MSA1MzVUMTcwIDQ4OVExNzAgNDY0IDE1NCA0NDdUMTA5IDQyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJFIiBkPSJNNzggNjBRNzggODQgOTUgMTAyVDEzOCAxMjBRMTYyIDEyMCAxODAgMTA0VDE5OSA2MVExOTkgMzYgMTgyIDE4VDEzOSAwVDk2IDE3VDc4IDYwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0MiIGQ9Ik0xMzkgLTI0OUgxMzdRMTI1IC0yNDkgMTE5IC0yMzVWMjUxTDEyMCA3MzdRMTMwIDc1MCAxMzkgNzUwUTE1MiA3NTAgMTU5IDczNVYtMjM1UTE1MSAtMjQ5IDE0MSAtMjQ5SDEzOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTIyMTEiIHg9IjEwMzIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC0xMTE3KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTY2Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9IjMwNiIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYzIiB4PSI4MDciIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03NCIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTZGIiB4PSIxNjQwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjIxNDEiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MyIgeD0iMjUzMyIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTZGIiB4PSIzMjgyIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjYiIHg9IjM3ODIiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjQ0NDIiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQyIiB4PSIzNjc2IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDYwMiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0IiIHg9IjYwMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwNDUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSI3MzciIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9IjIwMjEiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNDY2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iNzM3IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJDIiB4PSIzNDQxIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iMzg4NiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9IjQzMzEiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSI0Nzc3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iNTIyMiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU2NjcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iNzM3IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdDIiB4PSI2NzEzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjY5OTIiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijc5MDMiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjEzMTczIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDIiIHg9IjE0MjI5IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTUxNTUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNCIiB4PSI2MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTA0NSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTk1NiIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=) 。我们使用上标来区分来自不同试验的奖励,例如,
。我们使用上标来区分来自不同试验的奖励,例如, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIuMTAzZXgiIGhlaWdodD0iMy41MDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0xLjMzOGV4OyIgdmlld0JveD0iMCAtOTM0LjkgOTA1LjQgMTUxMC45IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTcyIiBkPSJNMjEgMjg3UTIyIDI5MCAyMyAyOTVUMjggMzE3VDM4IDM0OFQ1MyAzODFUNzMgNDExVDk5IDQzM1QxMzIgNDQyUTE2MSA0NDIgMTgzIDQzMFQyMTQgNDA4VDIyNSAzODhRMjI3IDM4MiAyMjggMzgyVDIzNiAzODlRMjg0IDQ0MSAzNDcgNDQxSDM1MFEzOTggNDQxIDQyMiA0MDBRNDMwIDM4MSA0MzAgMzYzUTQzMCAzMzMgNDE3IDMxNVQzOTEgMjkyVDM2NiAyODhRMzQ2IDI4OCAzMzQgMjk5VDMyMiAzMjhRMzIyIDM3NiAzNzggMzkyUTM1NiA0MDUgMzQyIDQwNVEyODYgNDA1IDIzOSAzMzFRMjI5IDMxNSAyMjQgMjk4VDE5MCAxNjVRMTU2IDI1IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTE0IDE4OVQxNTQgMzY2UTE1NCA0MDUgMTI4IDQwNVExMDcgNDA1IDkyIDM3N1Q2OCAzMTZUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkEiIGQ9Ik0yOTcgNTk2UTI5NyA2MjcgMzE4IDY0NFQzNjEgNjYxUTM3OCA2NjEgMzg5IDY1MVQ0MDMgNjIzUTQwMyA1OTUgMzg0IDU3NlQzNDAgNTU3UTMyMiA1NTcgMzEwIDU2N1QyOTcgNTk2Wk0yODggMzc2UTI4OCA0MDUgMjYyIDQwNVEyNDAgNDA1IDIyMCAzOTNUMTg1IDM2MlQxNjEgMzI1VDE0NCAyOTNMMTM3IDI3OVExMzUgMjc4IDEyMSAyNzhIMTA3UTEwMSAyODQgMTAxIDI4NlQxMDUgMjk5UTEyNiAzNDggMTY0IDM5MVQyNTIgNDQxUTI1MyA0NDEgMjYwIDQ0MVQyNzIgNDQyUTI5NiA0NDEgMzE2IDQzMlEzNDEgNDE4IDM1NCA0MDFUMzY3IDM0OFYzMzJMMzE4IDEzM1EyNjcgLTY3IDI2NCAtNzVRMjQ2IC0xMjUgMTk0IC0xNjRUNzUgLTIwNFEyNSAtMjA0IDcgLTE4M1QtMTIgLTEzN1EtMTIgLTExMCA3IC05MVQ1MyAtNzFRNzAgLTcxIDgyIC04MVQ5NSAtMTEyUTk1IC0xNDggNjMgLTE2N1E2OSAtMTY4IDc3IC0xNjhRMTExIC0xNjggMTM5IC0xNDBUMTgyIC03NEwxOTMgLTMyUTIwNCAxMSAyMTkgNzJUMjUxIDE5N1QyNzggMzA4VDI4OSAzNjVRMjg5IDM3MiAyODggMzc2WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjYzOCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZBIiB4PSI2MzgiIHk9Ii00MzAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) 指的是在第2次试验中第
指的是在第2次试验中第 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjAuOTg1ZXgiIGhlaWdodD0iMi41MDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyBtYXJnaW4tbGVmdDogLTAuMDI3ZXg7IiB2aWV3Qm94PSItMTEuNSAtNzkxLjMgNDI0IDEwODAuNCIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02QSIgZD0iTTI5NyA1OTZRMjk3IDYyNyAzMTggNjQ0VDM2MSA2NjFRMzc4IDY2MSAzODkgNjUxVDQwMyA2MjNRNDAzIDU5NSAzODQgNTc2VDM0MCA1NTdRMzIyIDU1NyAzMTAgNTY3VDI5NyA1OTZaTTI4OCAzNzZRMjg4IDQwNSAyNjIgNDA1UTI0MCA0MDUgMjIwIDM5M1QxODUgMzYyVDE2MSAzMjVUMTQ0IDI5M0wxMzcgMjc5UTEzNSAyNzggMTIxIDI3OEgxMDdRMTAxIDI4NCAxMDEgMjg2VDEwNSAyOTlRMTI2IDM0OCAxNjQgMzkxVDI1MiA0NDFRMjUzIDQ0MSAyNjAgNDQxVDI3MiA0NDJRMjk2IDQ0MSAzMTYgNDMyUTM0MSA0MTggMzU0IDQwMVQzNjcgMzQ4VjMzMkwzMTggMTMzUTI2NyAtNjcgMjY0IC03NVEyNDYgLTEyNSAxOTQgLTE2NFQ3NSAtMjA0UTI1IC0yMDQgNyAtMTgzVC0xMiAtMTM3US0xMiAtMTEwIDcgLTkxVDUzIC03MVE3MCAtNzEgODIgLTgxVDk1IC0xMTJROTUgLTE0OCA2MyAtMTY3UTY5IC0xNjggNzcgLTE2OFExMTEgLTE2OCAxMzkgLTE0MFQxODIgLTc0TDE5MyAtMzJRMjA0IDExIDIxOSA3MlQyNTEgMTk3VDI3OCAzMDhUMjg5IDM2NVEyODkgMzcyIDI4OCAzNzZaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkEiIHg9IjAiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) 次和
次和 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQuOTg4ZXgiIGhlaWdodD0iMi41MDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyBtYXJnaW4tbGVmdDogLTAuMDI3ZXg7IiB2aWV3Qm94PSItMTEuNSAtNzkxLjMgMjE0Ny40IDEwODAuNCIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02QSIgZD0iTTI5NyA1OTZRMjk3IDYyNyAzMTggNjQ0VDM2MSA2NjFRMzc4IDY2MSAzODkgNjUxVDQwMyA2MjNRNDAzIDU5NSAzODQgNTc2VDM0MCA1NTdRMzIyIDU1NyAzMTAgNTY3VDI5NyA1OTZaTTI4OCAzNzZRMjg4IDQwNSAyNjIgNDA1UTI0MCA0MDUgMjIwIDM5M1QxODUgMzYyVDE2MSAzMjVUMTQ0IDI5M0wxMzcgMjc5UTEzNSAyNzggMTIxIDI3OEgxMDdRMTAxIDI4NCAxMDEgMjg2VDEwNSAyOTlRMTI2IDM0OCAxNjQgMzkxVDI1MiA0NDFRMjUzIDQ0MSAyNjAgNDQxVDI3MiA0NDJRMjk2IDQ0MSAzMTYgNDMyUTM0MSA0MTggMzU0IDQwMVQzNjcgMzQ4VjMzMkwzMTggMTMzUTI2NyAtNjcgMjY0IC03NVEyNDYgLTEyNSAxOTQgLTE2NFQ3NSAtMjA0UTI1IC0yMDQgNyAtMTgzVC0xMiAtMTM3US0xMiAtMTEwIDcgLTkxVDUzIC03MVE3MCAtNzEgODIgLTgxVDk1IC0xMTJROTUgLTE0OCA2MyAtMTY3UTY5IC0xNjggNzcgLTE2OFExMTEgLTE2OCAxMzkgLTE0MFQxODIgLTc0TDE5MyAtMzJRMjA0IDExIDIxOSA3MlQyNTEgMTk3VDI3OCAzMDhUMjg5IDM2NVEyODkgMzcyIDI4OCAzNzZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yQiIgZD0iTTU2IDIzN1Q1NiAyNTBUNzAgMjcwSDM2OVY0MjBMMzcwIDU3MFEzODAgNTgzIDM4OSA1ODNRNDAyIDU4MyA0MDkgNTY4VjI3MEg3MDdRNzIyIDI2MiA3MjIgMjUwVDcwNyAyMzBINDA5Vi02OFE0MDEgLTgyIDM5MSAtODJIMzg5SDM4N1EzNzUgLTgyIDM2OSAtNjhWMjMwSDcwUTU2IDIzNyA1NiAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMSIgZD0iTTIxMyA1NzhMMjAwIDU3M1ExODYgNTY4IDE2MCA1NjNUMTAyIDU1Nkg4M1Y2MDJIMTAyUTE0OSA2MDQgMTg5IDYxN1QyNDUgNjQxVDI3MyA2NjNRMjc1IDY2NiAyODUgNjY2UTI5NCA2NjYgMzAyIDY2MFYzNjFMMzAzIDYxUTMxMCA1NCAzMTUgNTJUMzM5IDQ4VDQwMSA0Nkg0MjdWMEg0MTZRMzk1IDMgMjU3IDNRMTIxIDMgMTAwIDBIODhWNDZIMTE0UTEzNiA0NiAxNTIgNDZUMTc3IDQ3VDE5MyA1MFQyMDEgNTJUMjA3IDU3VDIxMyA2MVY1NzhaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI2MzQiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxNjM1IiB5PSIwIj48L3VzZT4KPC9nPgo8L3N2Zz4=) 次访问 之间收到的总的随机奖励。
次访问 之间收到的总的随机奖励。
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9Ijg2Ljg3NmV4IiBoZWlnaHQ9IjM0LjE3NmV4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTE2LjUwNWV4OyIgdmlld0JveD0iMCAtNzYwOC41IDM3NDA0LjYgMTQ3MTQuNiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NSIgZD0iTTQ5MiAyMTNRNDcyIDIxMyA0NzIgMjI2UTQ3MiAyMzAgNDc3IDI1MFQ0ODIgMjg1UTQ4MiAzMTYgNDYxIDMyM1QzNjQgMzMwSDMxMlEzMTEgMzI4IDI3NyAxOTJUMjQzIDUyUTI0MyA0OCAyNTQgNDhUMzM0IDQ2UTQyOCA0NiA0NTggNDhUNTE4IDYxUTU2NyA3NyA1OTkgMTE3VDY3MCAyNDhRNjgwIDI3MCA2ODMgMjcyUTY5MCAyNzQgNjk4IDI3NFE3MTggMjc0IDcxOCAyNjFRNjEzIDcgNjA4IDJRNjA1IDAgMzIyIDBIMTMzUTMxIDAgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ2IDY2IDIxNSAzNDJUMjg1IDYyMlEyODUgNjI5IDI4MSA2MjlRMjczIDYzMiAyMjggNjM0SDE5N1ExOTEgNjQwIDE5MSA2NDJUMTkzIDY1OVExOTcgNjc2IDIwMyA2ODBINzU3UTc2NCA2NzYgNzY0IDY2OVE3NjQgNjY0IDc1MSA1NTdUNzM3IDQ0N1E3MzUgNDQwIDcxNyA0NDBINzA1UTY5OCA0NDUgNjk4IDQ1M0w3MDEgNDc2UTcwNCA1MDAgNzA0IDUyOFE3MDQgNTU4IDY5NyA1NzhUNjc4IDYwOVQ2NDMgNjI1VDU5NiA2MzJUNTMyIDYzNEg0ODVRMzk3IDYzMyAzOTIgNjMxUTM4OCA2MjkgMzg2IDYyMlEzODUgNjE5IDM1NSA0OTlUMzI0IDM3N1EzNDcgMzc2IDM3MiAzNzZIMzk4UTQ2NCAzNzYgNDg5IDM5MVQ1MzQgNDcyUTUzOCA0ODggNTQwIDQ5MFQ1NTcgNDkzUTU2MiA0OTMgNTY1IDQ5M1Q1NzAgNDkyVDU3MiA0OTFUNTc0IDQ4N1Q1NzcgNDgzTDU0NCAzNTFRNTExIDIxOCA1MDggMjE2UTUwNSAyMTMgNDkyIDIxM1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU2IiBkPSJNNTIgNjQ4UTUyIDY3MCA2NSA2ODNINzZRMTE4IDY4MCAxODEgNjgwUTI5OSA2ODAgMzIwIDY4M0gzMzBRMzM2IDY3NyAzMzYgNjc0VDMzNCA2NTZRMzI5IDY0MSAzMjUgNjM3SDMwNFEyODIgNjM1IDI3NCA2MzVRMjQ1IDYzMCAyNDIgNjIwUTI0MiA2MTggMjcxIDM2OVQzMDEgMTE4TDM3NCAyMzVRNDQ3IDM1MiA1MjAgNDcxVDU5NSA1OTRRNTk5IDYwMSA1OTkgNjA5UTU5OSA2MzMgNTU1IDYzN1E1MzcgNjM3IDUzNyA2NDhRNTM3IDY0OSA1MzkgNjYxUTU0MiA2NzUgNTQ1IDY3OVQ1NTggNjgzUTU2MCA2ODMgNTcwIDY4M1Q2MDQgNjgyVDY2OCA2ODFRNzM3IDY4MSA3NTUgNjgzSDc2MlE3NjkgNjc2IDc2OSA2NzJRNzY5IDY1NSA3NjAgNjQwUTc1NyA2MzcgNzQzIDYzN1E3MzAgNjM2IDcxOSA2MzVUNjk4IDYzMFQ2ODIgNjIzVDY3MCA2MTVUNjYwIDYwOFQ2NTIgNTk5VDY0NSA1OTJMNDUyIDI4MlEyNzIgLTkgMjY2IC0xNlEyNjMgLTE4IDI1OSAtMjFMMjQxIC0yMkgyMzRRMjE2IC0yMiAyMTYgLTE1UTIxMyAtOSAxNzcgMzA1UTEzOSA2MjMgMTM4IDYyNlExMzMgNjM3IDc2IDYzN0g1OVE1MiA2NDIgNTIgNjQ4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZFIiBkPSJNMjEgMjg3UTIyIDI5MyAyNCAzMDNUMzYgMzQxVDU2IDM4OFQ4OSA0MjVUMTM1IDQ0MlExNzEgNDQyIDE5NSA0MjRUMjI1IDM5MFQyMzEgMzY5UTIzMSAzNjcgMjMyIDM2N0wyNDMgMzc4UTMwNCA0NDIgMzgyIDQ0MlE0MzYgNDQyIDQ2OSA0MTVUNTAzIDMzNlQ0NjUgMTc5VDQyNyA1MlE0MjcgMjYgNDQ0IDI2UTQ1MCAyNiA0NTMgMjdRNDgyIDMyIDUwNSA2NVQ1NDAgMTQ1UTU0MiAxNTMgNTYwIDE1M1E1ODAgMTUzIDU4MCAxNDVRNTgwIDE0NCA1NzYgMTMwUTU2OCAxMDEgNTU0IDczVDUwOCAxN1Q0MzkgLTEwUTM5MiAtMTAgMzcxIDE3VDM1MCA3M1EzNTAgOTIgMzg2IDE5M1Q0MjMgMzQ1UTQyMyA0MDQgMzc5IDQwNEgzNzRRMjg4IDQwNCAyMjkgMzAzTDIyMiAyOTFMMTg5IDE1N1ExNTYgMjYgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTIgMTgwVDE1MiAzNDNRMTUzIDM0OCAxNTMgMzY2UTE1MyA0MDUgMTI5IDQwNVE5MSA0MDUgNjYgMzA1UTYwIDI4NSA2MCAyODRRNTggMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oxLTdCIiBkPSJNNDc3IC0zNDNMNDcxIC0zNDlINDU4UTQzMiAtMzQ5IDM2NyAtMzI1VDI3MyAtMjYzUTI1OCAtMjQ1IDI1MCAtMjEyTDI0OSAtNTFRMjQ5IC0yNyAyNDkgMTJRMjQ4IDExOCAyNDQgMTI4UTI0MyAxMjkgMjQzIDEzMFEyMjAgMTg5IDEyMSAyMjhRMTA5IDIzMiAxMDcgMjM1VDEwNSAyNTBRMTA1IDI1NiAxMDUgMjU3VDEwNSAyNjFUMTA3IDI2NVQxMTEgMjY4VDExOCAyNzJUMTI4IDI3NlQxNDIgMjgzVDE2MiAyOTFRMjI0IDMyNCAyNDMgMzcxUTI0MyAzNzIgMjQ0IDM3M1EyNDggMzg0IDI0OSA0NjlRMjQ5IDQ3NSAyNDkgNDg5UTI0OSA1MjggMjQ5IDU1MkwyNTAgNzE0UTI1MyA3MjggMjU2IDczNlQyNzEgNzYxVDI5OSA3ODlUMzQ3IDgxNlQ0MjIgODQzUTQ0MCA4NDkgNDQxIDg0OUg0NDNRNDQ1IDg0OSA0NDcgODQ5VDQ1MiA4NTBUNDU3IDg1MEg0NzFMNDc3IDg0NFY4MzBRNDc3IDgyMCA0NzYgODE3VDQ3MCA4MTFUNDU5IDgwN1Q0MzcgODAxVDQwNCA3ODVRMzUzIDc2MCAzMzggNzI0UTMzMyA3MTAgMzMzIDU1MFEzMzMgNTI2IDMzMyA0OTJUMzM0IDQ0N1EzMzQgMzkzIDMyNyAzNjhUMjk1IDMxOFEyNTcgMjgwIDE4MSAyNTVMMTY5IDI1MUwxODQgMjQ1UTMxOCAxOTggMzMyIDExMlEzMzMgMTA2IDMzMyAtNDlRMzMzIC0yMDkgMzM4IC0yMjNRMzUxIC0yNTUgMzkxIC0yNzdUNDY5IC0zMDlRNDc3IC0zMTEgNDc3IC0zMjlWLTM0M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjEtN0QiIGQ9Ik0xMTAgODQ5TDExNSA4NTBRMTIwIDg1MCAxMjUgODUwUTE1MSA4NTAgMjE1IDgyNlQzMDkgNzY0UTMyNCA3NDcgMzMyIDcxNEwzMzMgNTUyUTMzMyA1MjggMzMzIDQ4OVEzMzQgMzgzIDMzOCAzNzNRMzM5IDM3MiAzMzkgMzcxUTM1MyAzMzYgMzkxIDMxMFQ0NjkgMjcxUTQ3NyAyNjggNDc3IDI1MVE0NzcgMjQxIDQ3NiAyMzdUNDcyIDIzMlQ0NTYgMjI1VDQyOCAyMTRRMzU3IDE3OSAzMzkgMTMwUTMzOSAxMjkgMzM4IDEyOFEzMzQgMTE3IDMzMyAzMlEzMzMgMjYgMzMzIDEyUTMzMyAtMjcgMzMzIC01MUwzMzIgLTIxMlEzMjggLTIyOCAzMjMgLTI0MFQzMDIgLTI3MVQyNTUgLTMwN1QxNzUgLTMzOFExMzkgLTM0OSAxMjUgLTM0OVQxMDggLTM0NlQxMDUgLTMyOVExMDUgLTMxNCAxMDcgLTMxMlQxMzAgLTMwNFEyMzMgLTI3MSAyNDggLTIwOVEyNDkgLTIwMyAyNDkgLTQ5VjU3UTI0OSAxMDYgMjUzIDEyNVQyNzMgMTY3UTMwNyAyMTMgMzk4IDI0NUw0MTMgMjUxTDQwMSAyNTVRMjY1IDMwMCAyNTAgMzg5UTI0OSAzOTUgMjQ5IDU1MFEyNDkgNzEwIDI0NCA3MjRRMjI0IDc3NCAxMTIgODExUTEwNSA4MTMgMTA1IDgzMFExMDUgODQ1IDExMCA4NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03OCIgZD0iTTUyIDI4OVE1OSAzMzEgMTA2IDM4NlQyMjIgNDQyUTI1NyA0NDIgMjg2IDQyNFQzMjkgMzc5UTM3MSA0NDIgNDMwIDQ0MlE0NjcgNDQyIDQ5NCA0MjBUNTIyIDM2MVE1MjIgMzMyIDUwOCAzMTRUNDgxIDI5MlQ0NTggMjg4UTQzOSAyODggNDI3IDI5OVQ0MTUgMzI4UTQxNSAzNzQgNDY1IDM5MVE0NTQgNDA0IDQyNSA0MDRRNDEyIDQwNCA0MDYgNDAyUTM2OCAzODYgMzUwIDMzNlEyOTAgMTE1IDI5MCA3OFEyOTAgNTAgMzA2IDM4VDM0MSAyNlEzNzggMjYgNDE0IDU5VDQ2MyAxNDBRNDY2IDE1MCA0NjkgMTUxVDQ4NSAxNTNINDg5UTUwNCAxNTMgNTA0IDE0NVE1MDQgMTQ0IDUwMiAxMzRRNDg2IDc3IDQ0MCAzM1QzMzMgLTExUTI2MyAtMTEgMjI3IDUyUTE4NiAtMTAgMTMzIC0xMEgxMjdRNzggLTEwIDU3IDE2VDM1IDcxUTM1IDEwMyA1NCAxMjNUOTkgMTQzUTE0MiAxNDMgMTQyIDEwMVExNDIgODEgMTMwIDY2VDEwNyA0NlQ5NCA0MUw5MSA0MFE5MSAzOSA5NyAzNlQxMTMgMjlUMTMyIDI2UTE2OCAyNiAxOTQgNzFRMjAzIDg3IDIxNyAxMzlUMjQ1IDI0N1QyNjEgMzEzUTI2NiAzNDAgMjY2IDM1MlEyNjYgMzgwIDI1MSAzOTJUMjE3IDQwNFExNzcgNDA0IDE0MiAzNzJUOTMgMjkwUTkxIDI4MSA4OCAyODBUNzIgMjc4SDU4UTUyIDI4NCA1MiAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oxLTIyMTEiIGQ9Ik02MSA3NDhRNjQgNzUwIDQ4OSA3NTBIOTEzTDk1NCA2NDBROTY1IDYwOSA5NzYgNTc5VDk5MyA1MzNUOTk5IDUxNkg5NzlMOTU5IDUxN1E5MzYgNTc5IDg4NiA2MjFUNzc3IDY4MlE3MjQgNzAwIDY1NSA3MDVUNDM2IDcxMEgzMTlRMTgzIDcxMCAxODMgNzA5UTE4NiA3MDYgMzQ4IDQ4NFQ1MTEgMjU5UTUxNyAyNTAgNTEzIDI0NEw0OTAgMjE2UTQ2NiAxODggNDIwIDEzNFQzMzAgMjdMMTQ5IC0xODdRMTQ5IC0xODggMzYyIC0xODhRMzg4IC0xODggNDM2IC0xODhUNTA2IC0xODlRNjc5IC0xODkgNzc4IC0xNjJUOTM2IC00M1E5NDYgLTI3IDk1OSA2SDk5OUw5MTMgLTI0OUw0ODkgLTI1MFE2NSAtMjUwIDYyIC0yNDhRNTYgLTI0NiA1NiAtMjM5UTU2IC0yMzQgMTE4IC0xNjFRMTg2IC04MSAyNDUgLTExTDQyOCAyMDZRNDI4IDIwNyAyNDIgNDYyTDU3IDcxN0w1NiA3MjhRNTYgNzQ0IDYxIDc0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02OSIgZD0iTTE4NCA2MDBRMTg0IDYyNCAyMDMgNjQyVDI0NyA2NjFRMjY1IDY2MSAyNzcgNjQ5VDI5MCA2MTlRMjkwIDU5NiAyNzAgNTc3VDIyNiA1NTdRMjExIDU1NyAxOTggNTY3VDE4NCA2MDBaTTIxIDI4N1EyMSAyOTUgMzAgMzE4VDU0IDM2OVQ5OCA0MjBUMTU4IDQ0MlExOTcgNDQyIDIyMyA0MTlUMjUwIDM1N1EyNTAgMzQwIDIzNiAzMDFUMTk2IDE5NlQxNTQgODNRMTQ5IDYxIDE0OSA1MVExNDkgMjYgMTY2IDI2UTE3NSAyNiAxODUgMjlUMjA4IDQzVDIzNSA3OFQyNjAgMTM3UTI2MyAxNDkgMjY1IDE1MVQyODIgMTUzUTMwMiAxNTMgMzAyIDE0M1EzMDIgMTM1IDI5MyAxMTJUMjY4IDYxVDIyMyAxMVQxNjEgLTExUTEyOSAtMTEgMTAyIDEwVDc0IDc0UTc0IDkxIDc5IDEwNlQxMjIgMjIwUTE2MCAzMjEgMTY2IDM0MVQxNzMgMzgwUTE3MyA0MDQgMTU2IDQwNEgxNTRRMTI0IDQwNCA5OSAzNzFUNjEgMjg3UTYwIDI4NiA1OSAyODRUNTggMjgxVDU2IDI3OVQ1MyAyNzhUNDkgMjc4VDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc0IiBkPSJNMjYgMzg1UTE5IDM5MiAxOSAzOTVRMTkgMzk5IDIyIDQxMVQyNyA0MjVRMjkgNDMwIDM2IDQzMFQ4NyA0MzFIMTQwTDE1OSA1MTFRMTYyIDUyMiAxNjYgNTQwVDE3MyA1NjZUMTc5IDU4NlQxODcgNjAzVDE5NyA2MTVUMjExIDYyNFQyMjkgNjI2UTI0NyA2MjUgMjU0IDYxNVQyNjEgNTk2UTI2MSA1ODkgMjUyIDU0OVQyMzIgNDcwTDIyMiA0MzNRMjIyIDQzMSAyNzIgNDMxSDMyM1EzMzAgNDI0IDMzMCA0MjBRMzMwIDM5OCAzMTcgMzg1SDIxMEwxNzQgMjQwUTEzNSA4MCAxMzUgNjhRMTM1IDI2IDE2MiAyNlExOTcgMjYgMjMwIDYwVDI4MyAxNDRRMjg1IDE1MCAyODggMTUxVDMwMyAxNTNIMzA3UTMyMiAxNTMgMzIyIDE0NVEzMjIgMTQyIDMxOSAxMzNRMzE0IDExNyAzMDEgOTVUMjY3IDQ4VDIxNiA2VDE1NSAtMTFRMTI1IC0xMSA5OCA0VDU5IDU2UTU3IDY0IDU3IDgzVjEwMUw5MiAyNDFRMTI3IDM4MiAxMjggMzgzUTEyOCAzODUgNzcgMzg1SDI2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc1IiBkPSJNMjEgMjg3UTIxIDI5NSAzMCAzMThUNTUgMzcwVDk5IDQyMFQxNTggNDQyUTIwNCA0NDIgMjI3IDQxN1QyNTAgMzU4UTI1MCAzNDAgMjE2IDI0NlQxODIgMTA1UTE4MiA2MiAxOTYgNDVUMjM4IDI3VDI5MSA0NFQzMjggNzhMMzM5IDk1UTM0MSA5OSAzNzcgMjQ3UTQwNyAzNjcgNDEzIDM4N1Q0MjcgNDE2UTQ0NCA0MzEgNDYzIDQzMVE0ODAgNDMxIDQ4OCA0MjFUNDk2IDQwMkw0MjAgODRRNDE5IDc5IDQxOSA2OFE0MTkgNDMgNDI2IDM1VDQ0NyAyNlE0NjkgMjkgNDgyIDU3VDUxMiAxNDVRNTE0IDE1MyA1MzIgMTUzUTU1MSAxNTMgNTUxIDE0NFE1NTAgMTM5IDU0OSAxMzBUNTQwIDk4VDUyMyA1NVQ0OTggMTdUNDYyIC04UTQ1NCAtMTAgNDM4IC0xMFEzNzIgLTEwIDM0NyA0NlEzNDUgNDUgMzM2IDM2VDMxOCAyMVQyOTYgNlQyNjcgLTZUMjMzIC0xMVExODkgLTExIDE1NSA3UTEwMyAzOCAxMDMgMTEzUTEwMyAxNzAgMTM4IDI2MlQxNzMgMzc5UTE3MyAzODAgMTczIDM4MVExNzMgMzkwIDE3MyAzOTNUMTY5IDQwMFQxNTggNDA0SDE1NFExMzEgNDA0IDExMiAzODVUODIgMzQ0VDY1IDMwMlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZEIiBkPSJNMjEgMjg3UTIyIDI5MyAyNCAzMDNUMzYgMzQxVDU2IDM4OFQ4OCA0MjVUMTMyIDQ0MlQxNzUgNDM1VDIwNSA0MTdUMjIxIDM5NVQyMjkgMzc2TDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzAzIDQ0MiAzODQgNDQyUTQwMSA0NDIgNDE1IDQ0MFQ0NDEgNDMzVDQ2MCA0MjNUNDc1IDQxMVQ0ODUgMzk4VDQ5MyAzODVUNDk3IDM3M1Q1MDAgMzY0VDUwMiAzNTdMNTEwIDM2N1E1NzMgNDQyIDY1OSA0NDJRNzEzIDQ0MiA3NDYgNDE1VDc4MCAzMzZRNzgwIDI4NSA3NDIgMTc4VDcwNCA1MFE3MDUgMzYgNzA5IDMxVDcyNCAyNlE3NTIgMjYgNzc2IDU2VDgxNSAxMzhRODE4IDE0OSA4MjEgMTUxVDgzNyAxNTNRODU3IDE1MyA4NTcgMTQ1UTg1NyAxNDQgODUzIDEzMFE4NDUgMTAxIDgzMSA3M1Q3ODUgMTdUNzE2IC0xMFE2NjkgLTEwIDY0OCAxN1Q2MjcgNzNRNjI3IDkyIDY2MyAxOTNUNzAwIDM0NVE3MDAgNDA0IDY1NiA0MDRINjUxUTU2NSA0MDQgNTA2IDMwM0w0OTkgMjkxTDQ2NiAxNTdRNDMzIDI2IDQyOCAxNlE0MTUgLTExIDM4NSAtMTFRMzcyIC0xMSAzNjQgLTRUMzUzIDhUMzUwIDE4UTM1MCAyOSAzODQgMTYxTDQyMCAzMDdRNDIzIDMyMiA0MjMgMzQ1UTQyMyA0MDQgMzc5IDQwNEgzNzRRMjg4IDQwNCAyMjkgMzAzTDIyMiAyOTFMMTg5IDE1N1ExNTYgMjYgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTIgMTgxUTE1MSAzMzUgMTUxIDM0MlExNTQgMzU3IDE1NCAzNjlRMTU0IDQwNSAxMjkgNDA1UTEwNyA0MDUgOTIgMzc3VDY5IDMxNlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMi0yOCIgZD0iTTE4MCA5NlQxODAgMjUwVDIwNSA1NDFUMjY2IDc3MFQzNTMgOTQ0VDQ0NCAxMDY5VDUyNyAxMTUwSDU1NVE1NjEgMTE0NCA1NjEgMTE0MVE1NjEgMTEzNyA1NDUgMTEyMFQ1MDQgMTA3MlQ0NDcgOTk1VDM4NiA4NzhUMzMwIDcyMVQyODggNTEzVDI3MiAyNTFRMjcyIDEzMyAyODAgNTZRMjkzIC04NyAzMjYgLTIwOVQzOTkgLTQwNVQ0NzUgLTUzMVQ1MzYgLTYwOVQ1NjEgLTY0MFE1NjEgLTY0MyA1NTUgLTY0OUg1MjdRNDgzIC02MTIgNDQzIC01NjhUMzUzIC00NDNUMjY2IC0yNzBUMjA1IC00MVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjkiIGQ9Ik0zNSAxMTM4UTM1IDExNTAgNTEgMTE1MEg1Nkg2OVExMTMgMTExMyAxNTMgMTA2OVQyNDMgOTQ0VDMzMCA3NzFUMzkxIDU0MVQ0MTYgMjUwVDM5MSAtNDBUMzMwIC0yNzBUMjQzIC00NDNUMTUyIC01NjhUNjkgLTY0OUg1NlE0MyAtNjQ5IDM5IC02NDdUMzUgLTYzN1E2NSAtNjA3IDExMCAtNTQ4UTI4MyAtMzE2IDMxNiA1NlEzMjQgMTMzIDMyNCAyNTFRMzI0IDM2OCAzMTYgNDQ1UTI3OCA4NzcgNDggMTEyM1EzNiAxMTM3IDM1IDExMzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkIiIGQ9Ik0xMjEgNjQ3UTEyMSA2NTcgMTI1IDY3MFQxMzcgNjgzUTEzOCA2ODMgMjA5IDY4OFQyODIgNjk0UTI5NCA2OTQgMjk0IDY4NlEyOTQgNjc5IDI0NCA0NzdRMTk0IDI3OSAxOTQgMjcyUTIxMyAyODIgMjIzIDI5MVEyNDcgMzA5IDI5MiAzNTRUMzYyIDQxNVE0MDIgNDQyIDQzOCA0NDJRNDY4IDQ0MiA0ODUgNDIzVDUwMyAzNjlRNTAzIDM0NCA0OTYgMzI3VDQ3NyAzMDJUNDU2IDI5MVQ0MzggMjg4UTQxOCAyODggNDA2IDI5OVQzOTQgMzI4UTM5NCAzNTMgNDEwIDM2OVQ0NDIgMzkwTDQ1OCAzOTNRNDQ2IDQwNSA0MzQgNDA1SDQzMFEzOTggNDAyIDM2NyAzODBUMjk0IDMxNlQyMjggMjU1UTIzMCAyNTQgMjQzIDI1MlQyNjcgMjQ2VDI5MyAyMzhUMzIwIDIyNFQzNDIgMjA2VDM1OSAxODBUMzY1IDE0N1EzNjUgMTMwIDM2MCAxMDZUMzU0IDY2UTM1NCAyNiAzODEgMjZRNDI5IDI2IDQ1OSAxNDVRNDYxIDE1MyA0NzkgMTUzSDQ4M1E0OTkgMTUzIDQ5OSAxNDRRNDk5IDEzOSA0OTYgMTMwUTQ1NSAtMTEgMzc4IC0xMVEzMzMgLTExIDMwNSAxNVQyNzcgOTBRMjc3IDEwOCAyODAgMTIxVDI4MyAxNDVRMjgzIDE2NyAyNjkgMTgzVDIzNCAyMDZUMjAwIDIxN1QxODIgMjIwSDE4MFExNjggMTc4IDE1OSAxMzlUMTQ1IDgxVDEzNiA0NFQxMjkgMjBUMTIyIDdUMTExIC0yUTk4IC0xMSA4MyAtMTFRNjYgLTExIDU3IC0xVDQ4IDE2UTQ4IDI2IDg1IDE3NlQxNTggNDcxTDE5NSA2MTZRMTk2IDYyOSAxODggNjMyVDE0OSA2MzdIMTQ0UTEzNCA2MzcgMTMxIDYzN1QxMjQgNjQwVDEyMSA2NDdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yQiIgZD0iTTU2IDIzN1Q1NiAyNTBUNzAgMjcwSDM2OVY0MjBMMzcwIDU3MFEzODAgNTgzIDM4OSA1ODNRNDAyIDU4MyA0MDkgNTY4VjI3MEg3MDdRNzIyIDI2MiA3MjIgMjUwVDcwNyAyMzBINDA5Vi02OFE0MDEgLTgyIDM5MSAtODJIMzg5SDM4N1EzNzUgLTgyIDM2OSAtNjhWMjMwSDcwUTU2IDIzNyA1NiAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1o0LTIzQTciIGQ9Ik03MTIgODk5TDcxOCA4OTNWODc2Vjg2NVE3MTggODU0IDcwNCA4NDZRNjI3IDc5MyA1NzcgNzEwVDUxMCA1MjVRNTEwIDUyNCA1MDkgNTIxUTUwNSA0OTMgNTA0IDM0OVE1MDQgMzQ1IDUwNCAzMzRRNTA0IDI3NyA1MDQgMjQwUTUwNCAtMiA1MDMgLTRRNTAyIC04IDQ5NCAtOVQ0NDQgLTEwUTM5MiAtMTAgMzkwIC05UTM4NyAtOCAzODYgLTVRMzg0IDUgMzg0IDIzMFEzODQgMjYyIDM4NCAzMTJUMzgzIDM4MlEzODMgNDgxIDM5MiA1MzVUNDM0IDY1NlE1MTAgODA2IDY2NCA4OTJMNjc3IDg5OUg3MTJaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1o0LTIzQTkiIGQ9Ik03MTggLTg5M0w3MTIgLTg5OUg2NzdMNjY2IC04OTNRNTQyIC04MjUgNDY4IC03MTRUMzg1IC00NzZRMzg0IC00NjYgMzg0IC0yODJRMzg0IDMgMzg1IDVMMzg5IDlRMzkyIDEwIDQ0NCAxMFE0ODYgMTAgNDk0IDlUNTAzIDRRNTA0IDIgNTA0IC0yMzlWLTMxMFYtMzY2UTUwNCAtNDcwIDUwOCAtNTEzVDUzMCAtNjA5UTU0NiAtNjU3IDU2OSAtNjk4VDYxNyAtNzY3VDY2MSAtODEyVDY5OSAtODQzVDcxNyAtODU2VDcxOCAtODc2Vi04OTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1o0LTIzQTgiIGQ9Ik0zODkgMTE1OVEzOTEgMTE2MCA0NTUgMTE2MFE0OTYgMTE2MCA0OTggMTE1OVE1MDEgMTE1OCA1MDIgMTE1NVE1MDQgMTE0NSA1MDQgOTI0UTUwNCA2OTEgNTAzIDY4MlE0OTQgNTQ5IDQyNSA0MzlUMjQzIDI1OUwyMjkgMjUwTDI0MyAyNDFRMzQ5IDE3NSA0MjEgNjZUNTAzIC0xODJRNTA0IC0xOTEgNTA0IC00MjRRNTA0IC02MDAgNTA0IC02MjlUNDk5IC02NTlINDk4UTQ5NiAtNjYwIDQ0NCAtNjYwVDM5MCAtNjU5UTM4NyAtNjU4IDM4NiAtNjU1UTM4NCAtNjQ1IDM4NCAtNDI1Vi0yODJRMzg0IC0xNzYgMzc3IC0xMTZUMzQyIDEwUTMyNSA1NCAzMDEgOTJUMjU1IDE1NVQyMTQgMTk2VDE4MyAyMjJUMTcxIDIzMlExNzAgMjMzIDE3MCAyNTBUMTcxIDI2OFExNzEgMjY5IDE5MSAyODRUMjQwIDMzMVQzMDAgNDA3VDM1NCA1MjRUMzgzIDY3OVEzODQgNjkxIDM4NCA5MjVRMzg0IDExNTIgMzg1IDExNTVMMzg5IDExNTlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1o0LTIzQUEiIGQ9Ik0zODQgMTUwVjI2NlEzODQgMzA0IDM4OSAzMDlRMzkxIDMxMCA0NTUgMzEwUTQ5NiAzMTAgNDk4IDMwOVE1MDIgMzA4IDUwMyAyOThRNTA0IDI4MyA1MDQgMTUwUTUwNCAzMiA1MDQgMTJUNDk5IC05SDQ5OFE0OTYgLTEwIDQ0NCAtMTBUMzkwIC05UTM4NiAtOCAzODUgMlEzODQgMTcgMzg0IDE1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjQtMjNBQiIgZD0iTTE3MCA4NzVRMTcwIDg5MiAxNzIgODk1VDE4OSA4OTlIMTk0SDIxMUwyMjIgODkzUTM0NSA4MjYgNDIwIDcxNVQ1MDMgNDc2UTUwNCA0NjcgNTA0IDIzMFE1MDQgNTEgNTA0IDIxVDQ5OSAtOUg0OThRNDk2IC0xMCA0NDQgLTEwUTQwMiAtMTAgMzk0IC05VDM4NSAtNFEzODQgLTIgMzg0IDI0MFYzMTFWMzY2UTM4NCA0NjkgMzgwIDUxM1QzNTggNjA5UTM0MiA2NTcgMzE5IDY5OFQyNzEgNzY3VDIyNyA4MTJUMTg5IDg0M1QxNzEgODU2VDE3MCA4NzVaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1o0LTIzQUQiIGQ9Ik0zODQgLTIzOVYtNTdRMzg0IDQgMzg5IDlRMzkxIDEwIDQ1NSAxMFE0OTYgMTAgNDk4IDlRNTAxIDggNTAyIDVRNTA0IC01IDUwNCAtMjMwUTUwNCAtMjYxIDUwNCAtMzExVDUwNSAtMzgxUTUwNSAtNDg2IDQ5MiAtNTUxVDQzNSAtNjkxUTM1NyAtODIwIDIyMiAtODkzTDIxMSAtODk5SDE5NVExNzYgLTg5OSAxNzMgLTg5NlQxNzAgLTg3NFExNzAgLTg1OCAxNzEgLTg1NVQxODQgLTg0NlEyNjIgLTc5MyAzMTIgLTcwOVQzNzggLTUyNVEzNzggLTUyNCAzNzkgLTUyMlEzODMgLTQ5MyAzODQgLTM1MVEzODQgLTM0NSAzODQgLTMzNFEzODQgLTI3NiAzODQgLTIzOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjQtMjNBQyIgZD0iTTM4OSAxMTU5UTM5MSAxMTYwIDQ1NSAxMTYwUTQ5NiAxMTYwIDQ5OCAxMTU5UTUwMSAxMTU4IDUwMiAxMTU1UTUwNCAxMTQ1IDUwNCA5MjVWNzgyUTUwNCA2NzYgNTExIDYxNlQ1NDYgNDkwUTU2MyA0NDYgNTg3IDQwOFQ2MzMgMzQ1VDY3NCAzMDRUNzA1IDI3OFQ3MTcgMjY4UTcxOCAyNjcgNzE4IDI1MFQ3MTcgMjMyUTcxNyAyMzEgNjk3IDIxNlQ2NDggMTY5VDU4OCA5M1Q1MzQgLTI0VDUwNSAtMTc5UTUwNCAtMTkxIDUwNCAtNDI1UTUwNCAtNjAwIDUwNCAtNjI5VDQ5OSAtNjU5SDQ5OFE0OTYgLTY2MCA0NDQgLTY2MFQzOTAgLTY1OVEzODcgLTY1OCAzODYgLTY1NVEzODQgLTY0NSAzODQgLTQyNFEzODQgLTE5MSAzODUgLTE4MlEzOTQgLTQ5IDQ2MyA2MVQ2NDUgMjQxTDY1OSAyNTBMNjQ1IDI1OVE1MzkgMzI1IDQ2NyA0MzRUMzg1IDY4MlEzODQgNjkyIDM4NCA4NzNRMzg0IDExNTMgMzg1IDExNTVMMzg5IDExNTlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oyLTIyMTEiIGQ9Ik02MCA5NDhRNjMgOTUwIDY2NSA5NTBIMTI2N0wxMzI1IDgxNVExMzg0IDY3NyAxMzg4IDY2OUgxMzQ4TDEzNDEgNjgzUTEzMjAgNzI0IDEyODUgNzYxUTEyMzUgODA5IDExNzQgODM4VDEwMzMgODgxVDg4MiA4OThUNjk5IDkwMkg1NzRINTQzSDI1MUwyNTkgODkxUTcyMiAyNTggNzI0IDI1MlE3MjUgMjUwIDcyNCAyNDZRNzIxIDI0MyA0NjAgLTU2TDE5NiAtMzU2UTE5NiAtMzU3IDQwNyAtMzU3UTQ1OSAtMzU3IDU0OCAtMzU3VDY3NiAtMzU4UTgxMiAtMzU4IDg5NiAtMzUzVDEwNjMgLTMzMlQxMjA0IC0yODNUMTMwNyAtMTk2UTEzMjggLTE3MCAxMzQ4IC0xMjRIMTM4OFExMzg4IC0xMjUgMTM4MSAtMTQ1VDEzNTYgLTIxMFQxMzI1IC0yOTRMMTI2NyAtNDQ5TDY2NiAtNDUwUTY0IC00NTAgNjEgLTQ0OFE1NSAtNDQ2IDU1IC00MzlRNTUgLTQzNyA1NyAtNDMzTDU5MCAxNzdRNTkwIDE3OCA1NTcgMjIyVDQ1MiAzNjZUMzIyIDU0NEw1NiA5MDlMNTUgOTI0UTU1IDk0NSA2MCA5NDhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yQyIgZD0iTTc4IDM1VDc4IDYwVDk0IDEwM1QxMzcgMTIxUTE2NSAxMjEgMTg3IDk2VDIxMCA4UTIxMCAtMjcgMjAxIC02MFQxODAgLTExN1QxNTQgLTE1OFQxMzAgLTE4NVQxMTcgLTE5NFExMTMgLTE5NCAxMDQgLTE4NVQ5NSAtMTcyUTk1IC0xNjggMTA2IC0xNTZUMTMxIC0xMjZUMTU3IC03NlQxNzMgLTNWOUwxNzIgOFExNzAgNyAxNjcgNlQxNjEgM1QxNTIgMVQxNDAgMFExMTMgMCA5NiAxN1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yRSIgZD0iTTc4IDYwUTc4IDg0IDk1IDEwMlQxMzggMTIwUTE2MiAxMjAgMTgwIDEwNFQxOTkgNjFRMTk5IDM2IDE4MiAxOFQxMzkgMFQ5NiAxN1Q3OCA2MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MCIgZD0iTTI4NyA2MjhRMjg3IDYzNSAyMzAgNjM3UTIwNiA2MzcgMTk5IDYzOFQxOTIgNjQ4UTE5MiA2NDkgMTk0IDY1OVEyMDAgNjc5IDIwMyA2ODFUMzk3IDY4M1E1ODcgNjgyIDYwMCA2ODBRNjY0IDY2OSA3MDcgNjMxVDc1MSA1MzBRNzUxIDQ1MyA2ODUgMzg5UTYxNiAzMjEgNTA3IDMwM1E1MDAgMzAyIDQwMiAzMDFIMzA3TDI3NyAxODJRMjQ3IDY2IDI0NyA1OVEyNDcgNTUgMjQ4IDU0VDI1NSA1MFQyNzIgNDhUMzA1IDQ2SDMzNlEzNDIgMzcgMzQyIDM1UTM0MiAxOSAzMzUgNVEzMzAgMCAzMTkgMFEzMTYgMCAyODIgMVQxODIgMlExMjAgMiA4NyAyVDUxIDFRMzMgMSAzMyAxMVEzMyAxMyAzNiAyNVE0MCA0MSA0NCA0M1Q2NyA0NlE5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4Wk02NDUgNTU0UTY0NSA1NjcgNjQzIDU3NVQ2MzQgNTk3VDYwOSA2MTlUNTYwIDYzNVE1NTMgNjM2IDQ4MCA2MzdRNDYzIDYzNyA0NDUgNjM3VDQxNiA2MzZUNDA0IDYzNlEzOTEgNjM1IDM4NiA2MjdRMzg0IDYyMSAzNjcgNTUwVDMzMiA0MTJUMzE0IDM0NFEzMTQgMzQyIDM5NSAzNDJINDA3SDQzMFE1NDIgMzQyIDU5MCAzOTJRNjE3IDQxOSA2MzEgNDcxVDY0NSA1NTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzIiIGQ9Ik0yMSAyODdRMjIgMjkwIDIzIDI5NVQyOCAzMTdUMzggMzQ4VDUzIDM4MVQ3MyA0MTFUOTkgNDMzVDEzMiA0NDJRMTYxIDQ0MiAxODMgNDMwVDIxNCA0MDhUMjI1IDM4OFEyMjcgMzgyIDIyOCAzODJUMjM2IDM4OVEyODQgNDQxIDM0NyA0NDFIMzUwUTM5OCA0NDEgNDIyIDQwMFE0MzAgMzgxIDQzMCAzNjNRNDMwIDMzMyA0MTcgMzE1VDM5MSAyOTJUMzY2IDI4OFEzNDYgMjg4IDMzNCAyOTlUMzIyIDMyOFEzMjIgMzc2IDM3OCAzOTJRMzU2IDQwNSAzNDIgNDA1UTI4NiA0MDUgMjM5IDMzMVEyMjkgMzE1IDIyNCAyOThUMTkwIDE2NVExNTYgMjUgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTQgMTg5VDE1NCAzNjZRMTU0IDQwNSAxMjggNDA1UTEwNyA0MDUgOTIgMzc3VDY4IDMxNlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZBIiBkPSJNMjk3IDU5NlEyOTcgNjI3IDMxOCA2NDRUMzYxIDY2MVEzNzggNjYxIDM4OSA2NTFUNDAzIDYyM1E0MDMgNTk1IDM4NCA1NzZUMzQwIDU1N1EzMjIgNTU3IDMxMCA1NjdUMjk3IDU5NlpNMjg4IDM3NlEyODggNDA1IDI2MiA0MDVRMjQwIDQwNSAyMjAgMzkzVDE4NSAzNjJUMTYxIDMyNVQxNDQgMjkzTDEzNyAyNzlRMTM1IDI3OCAxMjEgMjc4SDEwN1ExMDEgMjg0IDEwMSAyODZUMTA1IDI5OVExMjYgMzQ4IDE2NCAzOTFUMjUyIDQ0MVEyNTMgNDQxIDI2MCA0NDFUMjcyIDQ0MlEyOTYgNDQxIDMxNiA0MzJRMzQxIDQxOCAzNTQgNDAxVDM2NyAzNDhWMzMyTDMxOCAxMzNRMjY3IC02NyAyNjQgLTc1UTI0NiAtMTI1IDE5NCAtMTY0VDc1IC0yMDRRMjUgLTIwNCA3IC0xODNULTEyIC0xMzdRLTEyIC0xMTAgNyAtOTFUNTMgLTcxUTcwIC03MSA4MiAtODFUOTUgLTExMlE5NSAtMTQ4IDYzIC0xNjdRNjkgLTE2OCA3NyAtMTY4UTExMSAtMTY4IDEzOSAtMTQwVDE4MiAtNzRMMTkzIC0zMlEyMDQgMTEgMjE5IDcyVDI1MSAxOTdUMjc4IDMwOFQyODkgMzY1UTI4OSAzNzIgMjg4IDM3NloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdDIiBkPSJNMTM5IC0yNDlIMTM3UTEyNSAtMjQ5IDExOSAtMjM1VjI1MUwxMjAgNzM3UTEzMCA3NTAgMTM5IDc1MFExNTIgNzUwIDE1OSA3MzVWLTIzNVExNTEgLTI0OSAxNDEgLTI0OUgxMzlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi02NiIgZD0iTTI3MyAwUTI1NSAzIDE0NiAzUTQzIDMgMzQgMEgyNlY0Nkg0MlE3MCA0NiA5MSA0OVE5OSA1MiAxMDMgNjBRMTA0IDYyIDEwNCAyMjRWMzg1SDMzVjQzMUgxMDRWNDk3TDEwNSA1NjRMMTA3IDU3NFExMjYgNjM5IDE3MSA2NjhUMjY2IDcwNFEyNjcgNzA0IDI3NSA3MDRUMjg5IDcwNVEzMzAgNzAyIDM1MSA2NzlUMzcyIDYyN1EzNzIgNjA0IDM1OCA1OTBUMzIxIDU3NlQyODQgNTkwVDI3MCA2MjdRMjcwIDY0NyAyODggNjY3SDI4NFEyODAgNjY4IDI3MyA2NjhRMjQ1IDY2OCAyMjMgNjQ3VDE4OSA1OTJRMTgzIDU3MiAxODIgNDk3VjQzMUgyOTNWMzg1SDE4NVYyMjVRMTg1IDYzIDE4NiA2MVQxODkgNTdUMTk0IDU0VDE5OSA1MVQyMDYgNDlUMjEzIDQ4VDIyMiA0N1QyMzEgNDdUMjQxIDQ2VDI1MSA0NkgyODJWMEgyNzNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi02MSIgZD0iTTEzNyAzMDVUMTE1IDMwNVQ3OCAzMjBUNjMgMzU5UTYzIDM5NCA5NyA0MjFUMjE4IDQ0OFEyOTEgNDQ4IDMzNiA0MTZUMzk2IDM0MFE0MDEgMzI2IDQwMSAzMDlUNDAyIDE5NFYxMjRRNDAyIDc2IDQwNyA1OFQ0MjggNDBRNDQzIDQwIDQ0OCA1NlQ0NTMgMTA5VjE0NUg0OTNWMTA2UTQ5MiA2NiA0OTAgNTlRNDgxIDI5IDQ1NSAxMlQ0MDAgLTZUMzUzIDEyVDMyOSA1NFY1OEwzMjcgNTVRMzI1IDUyIDMyMiA0OVQzMTQgNDBUMzAyIDI5VDI4NyAxN1QyNjkgNlQyNDcgLTJUMjIxIC04VDE5MCAtMTFRMTMwIC0xMSA4MiAyMFQzNCAxMDdRMzQgMTI4IDQxIDE0N1Q2OCAxODhUMTE2IDIyNVQxOTQgMjUzVDMwNCAyNjhIMzE4VjI5MFEzMTggMzI0IDMxMiAzNDBRMjkwIDQxMSAyMTUgNDExUTE5NyA0MTEgMTgxIDQxMFQxNTYgNDA2VDE0OCA0MDNRMTcwIDM4OCAxNzAgMzU5UTE3MCAzMzQgMTU0IDMyMFpNMTI2IDEwNlExMjYgNzUgMTUwIDUxVDIwOSAyNlEyNDcgMjYgMjc2IDQ5VDMxNSAxMDlRMzE3IDExNiAzMTggMTc1UTMxOCAyMzMgMzE3IDIzM1EzMDkgMjMzIDI5NiAyMzJUMjUxIDIyM1QxOTMgMjAzVDE0NyAxNjZUMTI2IDEwNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTYzIiBkPSJNMzcwIDMwNVQzNDkgMzA1VDMxMyAzMjBUMjk3IDM1OFEyOTcgMzgxIDMxMiAzOTZRMzE3IDQwMSAzMTcgNDAyVDMwNyA0MDRRMjgxIDQwOCAyNTggNDA4UTIwOSA0MDggMTc4IDM3NlExMzEgMzI5IDEzMSAyMTlRMTMxIDEzNyAxNjIgOTBRMjAzIDI5IDI3MiAyOVEzMTMgMjkgMzM4IDU1VDM3NCAxMTdRMzc2IDEyNSAzNzkgMTI3VDM5NSAxMjlINDA5UTQxNSAxMjMgNDE1IDEyMFE0MTUgMTE2IDQxMSAxMDRUMzk1IDcxVDM2NiAzM1QzMTggMlQyNDkgLTExUTE2MyAtMTEgOTkgNTNUMzQgMjE0UTM0IDMxOCA5OSAzODNUMjUwIDQ0OFQzNzAgNDIxVDQwNCAzNTdRNDA0IDMzNCAzODcgMzIwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNzQiIGQ9Ik0yNyA0MjJRODAgNDI2IDEwOSA0NzhUMTQxIDYwMFY2MTVIMTgxVjQzMUgzMTZWMzg1SDE4MVYyNDFRMTgyIDExNiAxODIgMTAwVDE4OSA2OFEyMDMgMjkgMjM4IDI5UTI4MiAyOSAyOTIgMTAwUTI5MyAxMDggMjkzIDE0NlYxODFIMzMzVjE0NlYxMzRRMzMzIDU3IDI5MSAxN1EyNjQgLTEwIDIyMSAtMTBRMTg3IC0xMCAxNjIgMlQxMjQgMzNUMTA1IDY4VDk4IDEwMFE5NyAxMDcgOTcgMjQ4VjM4NUgxOFY0MjJIMjdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi02RiIgZD0iTTI4IDIxNFEyOCAzMDkgOTMgMzc4VDI1MCA0NDhRMzQwIDQ0OCA0MDUgMzgwVDQ3MSAyMTVRNDcxIDEyMCA0MDcgNTVUMjUwIC0xMFExNTMgLTEwIDkxIDU3VDI4IDIxNFpNMjUwIDMwUTM3MiAzMCAzNzIgMTkzVjIyNVYyNTBRMzcyIDI3MiAzNzEgMjg4VDM2NCAzMjZUMzQ4IDM2MlQzMTcgMzkwVDI2OCA0MTBRMjYzIDQxMSAyNTIgNDExUTIyMiA0MTEgMTk1IDM5OVExNTIgMzc3IDEzOSAzMzhUMTI2IDI0NlYyMjZRMTI2IDEzMCAxNDUgOTFRMTc3IDMwIDI1MCAzMFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTcyIiBkPSJNMzYgNDZINTBRODkgNDYgOTcgNjBWNjhROTcgNzcgOTcgOTFUOTggMTIyVDk4IDE2MVQ5OCAyMDNROTggMjM0IDk4IDI2OVQ5OCAzMjhMOTcgMzUxUTk0IDM3MCA4MyAzNzZUMzggMzg1SDIwVjQwOFEyMCA0MzEgMjIgNDMxTDMyIDQzMlE0MiA0MzMgNjAgNDM0VDk2IDQzNlExMTIgNDM3IDEzMSA0MzhUMTYwIDQ0MVQxNzEgNDQySDE3NFYzNzNRMjEzIDQ0MSAyNzEgNDQxSDI3N1EzMjIgNDQxIDM0MyA0MTlUMzY0IDM3M1EzNjQgMzUyIDM1MSAzMzdUMzEzIDMyMlEyODggMzIyIDI3NiAzMzhUMjYzIDM3MlEyNjMgMzgxIDI2NSAzODhUMjcwIDQwMFQyNzMgNDA1UTI3MSA0MDcgMjUwIDQwMVEyMzQgMzkzIDIyNiAzODZRMTc5IDM0MSAxNzkgMjA3VjE1NFExNzkgMTQxIDE3OSAxMjdUMTc5IDEwMVQxODAgODFUMTgwIDY2VjYxUTE4MSA1OSAxODMgNTdUMTg4IDU0VDE5MyA1MVQyMDAgNDlUMjA3IDQ4VDIxNiA0N1QyMjUgNDdUMjM1IDQ2VDI0NSA0NkgyNzZWMEgyNjdRMjQ5IDMgMTQwIDNRMzcgMyAyOCAwSDIwVjQ2SDM2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNzMiIGQ9Ik0yOTUgMzE2UTI5NSAzNTYgMjY4IDM4NVQxOTAgNDE0UTE1NCA0MTQgMTI4IDQwMVE5OCAzODIgOTggMzQ5UTk3IDM0NCA5OCAzMzZUMTE0IDMxMlQxNTcgMjg3UTE3NSAyODIgMjAxIDI3OFQyNDUgMjY5VDI3NyAyNTZRMjk0IDI0OCAzMTAgMjM2VDM0MiAxOTVUMzU5IDEzM1EzNTkgNzEgMzIxIDMxVDE5OCAtMTBIMTkwUTEzOCAtMTAgOTQgMjZMODYgMTlMNzcgMTBRNzEgNCA2NSAtMUw1NCAtMTFINDZINDJRMzkgLTExIDMzIC01Vjc0VjEzMlEzMyAxNTMgMzUgMTU3VDQ1IDE2Mkg1NFE2NiAxNjIgNzAgMTU4VDc1IDE0NlQ4MiAxMTlUMTAxIDc3UTEzNiAyNiAxOTggMjZRMjk1IDI2IDI5NSAxMDRRMjk1IDEzMyAyNzcgMTUxUTI1NyAxNzUgMTk0IDE4N1QxMTEgMjEwUTc1IDIyNyA1NCAyNTZUMzMgMzE4UTMzIDM1NyA1MCAzODRUOTMgNDI0VDE0MyA0NDJUMTg3IDQ0N0gxOThRMjM4IDQ0NyAyNjggNDMyTDI4MyA0MjRMMjkyIDQzMVEzMDIgNDQwIDMxNCA0NDhIMzIySDMyNlEzMjkgNDQ4IDMzNSA0NDJWMzEwTDMyOSAzMDRIMzAxUTI5NSAzMTAgMjk1IDMxNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00MiIgZD0iTTIzMSA2MzdRMjA0IDYzNyAxOTkgNjM4VDE5NCA2NDlRMTk0IDY3NiAyMDUgNjgyUTIwNiA2ODMgMzM1IDY4M1E1OTQgNjgzIDYwOCA2ODFRNjcxIDY3MSA3MTMgNjM2VDc1NiA1NDRRNzU2IDQ4MCA2OTggNDI5VDU2NSAzNjBMNTU1IDM1N1E2MTkgMzQ4IDY2MCAzMTFUNzAyIDIxOVE3MDIgMTQ2IDYzMCA3OFQ0NTMgMVE0NDYgMCAyNDIgMFE0MiAwIDM5IDJRMzUgNSAzNSAxMFEzNSAxNyAzNyAyNFE0MiA0MyA0NyA0NVE1MSA0NiA2MiA0Nkg2OFE5NSA0NiAxMjggNDlRMTQyIDUyIDE0NyA2MVExNTAgNjUgMjE5IDMzOVQyODggNjI4UTI4OCA2MzUgMjMxIDYzN1pNNjQ5IDU0NFE2NDkgNTc0IDYzNCA2MDBUNTg1IDYzNFE1NzggNjM2IDQ5MyA2MzdRNDczIDYzNyA0NTEgNjM3VDQxNiA2MzZINDAzUTM4OCA2MzUgMzg0IDYyNlEzODIgNjIyIDM1MiA1MDZRMzUyIDUwMyAzNTEgNTAwTDMyMCAzNzRINDAxUTQ4MiAzNzQgNDk0IDM3NlE1NTQgMzg2IDYwMSA0MzRUNjQ5IDU0NFpNNTk1IDIyOVE1OTUgMjczIDU3MiAzMDJUNTEyIDMzNlE1MDYgMzM3IDQyOSAzMzdRMzExIDMzNyAzMTAgMzM2UTMxMCAzMzQgMjkzIDI2M1QyNTggMTIyTDI0MCA1MlEyNDAgNDggMjUyIDQ4VDMzMyA0NlE0MjIgNDYgNDI5IDQ3UTQ5MSA1NCA1NDMgMTA1VDU5NSAyMjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zQiIgZD0iTTc4IDM3MFE3OCAzOTQgOTUgNDEyVDEzOCA0MzBRMTYyIDQzMCAxODAgNDE0VDE5OSAzNzFRMTk5IDM0NiAxODIgMzI4VDEzOSAzMTBUOTYgMzI3VDc4IDM3MFpNNzggNjBRNzggODUgOTQgMTAzVDEzNyAxMjFRMjAyIDEyMSAyMDIgOFEyMDIgLTQ0IDE4MyAtOTRUMTQ0IC0xNjlUMTE4IC0xOTRRMTE1IC0xOTQgMTA2IC0xODZUOTUgLTE3NFE5NCAtMTcxIDEwNyAtMTU1VDEzNyAtMTA3VDE2MCAtMzhRMTYxIC0zMiAxNjIgLTIyVDE2NSAtNFQxNjUgNFExNjUgNSAxNjEgNFQxNDIgMFExMTAgMCA5NCAxOFQ3OCA2MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTVCIiBkPSJNMTE4IC0yNTBWNzUwSDI1NVY3MTBIMTU4Vi0yMTBIMjU1Vi0yNTBIMTE4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUyIiBkPSJNMjMwIDYzN1EyMDMgNjM3IDE5OCA2MzhUMTkzIDY0OVExOTMgNjc2IDIwNCA2ODJRMjA2IDY4MyAzNzggNjgzUTU1MCA2ODIgNTY0IDY4MFE2MjAgNjcyIDY1OCA2NTJUNzEyIDYwNlQ3MzMgNTYzVDczOSA1MjlRNzM5IDQ4NCA3MTAgNDQ1VDY0MyAzODVUNTc2IDM1MVQ1MzggMzM4TDU0NSAzMzNRNjEyIDI5NSA2MTIgMjIzUTYxMiAyMTIgNjA3IDE2MlQ2MDIgODBWNzFRNjAyIDUzIDYwMyA0M1Q2MTQgMjVUNjQwIDE2UTY2OCAxNiA2ODYgMzhUNzEyIDg1UTcxNyA5OSA3MjAgMTAyVDczNSAxMDVRNzU1IDEwNSA3NTUgOTNRNzU1IDc1IDczMSAzNlE2OTMgLTIxIDY0MSAtMjFINjMyUTU3MSAtMjEgNTMxIDRUNDg3IDgyUTQ4NyAxMDkgNTAyIDE2NlQ1MTcgMjM5UTUxNyAyOTAgNDc0IDMxM1E0NTkgMzIwIDQ0OSAzMjFUMzc4IDMyM0gzMDlMMjc3IDE5M1EyNDQgNjEgMjQ0IDU5UTI0NCA1NSAyNDUgNTRUMjUyIDUwVDI2OSA0OFQzMDIgNDZIMzMzUTMzOSAzOCAzMzkgMzdUMzM2IDE5UTMzMiA2IDMyNiAwSDMxMVEyNzUgMiAxODAgMlExNDYgMiAxMTcgMlQ3MSAyVDUwIDFRMzMgMSAzMyAxMFEzMyAxMiAzNiAyNFE0MSA0MyA0NiA0NVE1MCA0NiA2MSA0Nkg2N1E5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4UTI4NyA2MzUgMjMwIDYzN1pNNjMwIDU1NFE2MzAgNTg2IDYwOSA2MDhUNTIzIDYzNlE1MjEgNjM2IDUwMCA2MzZUNDYyIDYzN0g0NDBRMzkzIDYzNyAzODYgNjI3UTM4NSA2MjQgMzUyIDQ5NFQzMTkgMzYxUTMxOSAzNjAgMzg4IDM2MFE0NjYgMzYxIDQ5MiAzNjdRNTU2IDM3NyA1OTIgNDI2UTYwOCA0NDkgNjE5IDQ4NlQ2MzAgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU0IiBkPSJNNDAgNDM3UTIxIDQzNyAyMSA0NDVRMjEgNDUwIDM3IDUwMVQ3MSA2MDJMODggNjUxUTkzIDY2OSAxMDEgNjc3SDU2OUg2NTlRNjkxIDY3NyA2OTcgNjc2VDcwNCA2NjdRNzA0IDY2MSA2ODcgNTUzVDY2OCA0NDRRNjY4IDQzNyA2NDkgNDM3UTY0MCA0MzcgNjM3IDQzN1Q2MzEgNDQyTDYyOSA0NDVRNjI5IDQ1MSA2MzUgNDkwVDY0MSA1NTFRNjQxIDU4NiA2MjggNjA0VDU3MyA2MjlRNTY4IDYzMCA1MTUgNjMxUTQ2OSA2MzEgNDU3IDYzMFQ0MzkgNjIyUTQzOCA2MjEgMzY4IDM0M1QyOTggNjBRMjk4IDQ4IDM4NiA0NlE0MTggNDYgNDI3IDQ1VDQzNiAzNlE0MzYgMzEgNDMzIDIyUTQyOSA0IDQyNCAxTDQyMiAwUTQxOSAwIDQxNSAwUTQxMCAwIDM2MyAxVDIyOCAyUTk5IDIgNjQgMEg0OVE0MyA2IDQzIDlUNDUgMjdRNDkgNDAgNTUgNDZIODNIOTRRMTc0IDQ2IDE4OSA1NVExOTAgNTYgMTkxIDU2UTE5NiA1OSAyMDEgNzZUMjQxIDIzM1EyNTggMzAxIDI2OSAzNDRRMzM5IDYxOSAzMzkgNjI1UTMzOSA2MzAgMzEwIDYzMEgyNzlRMjEyIDYzMCAxOTEgNjI0UTE0NiA2MTQgMTIxIDU4M1Q2NyA0NjdRNjAgNDQ1IDU3IDQ0MVQ0MyA0MzdINDBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi01RCIgZD0iTTIyIDcxMFY3NTBIMTU5Vi0yNTBIMjJWLTIxMEgxMTlWNzEwSDIyWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaNC01QiIgZD0iTTI2OSAtMTI0OVYxNzUwSDU3N1YxNjc3SDM0MlYtMTE3Nkg1NzdWLTEyNDlIMjY5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaNC01RCIgZD0iTTUgMTY3N1YxNzUwSDMxM1YtMTI0OUg1Vi0xMTc2SDI0MFYxNjc3SDVaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1o0LTI4IiBkPSJNNzU4IC0xMjM3VDc1OCAtMTI0MFQ3NTIgLTEyNDlINzM2UTcxOCAtMTI0OSA3MTcgLTEyNDhRNzExIC0xMjQ1IDY3MiAtMTE5OVEyMzcgLTcwNiAyMzcgMjUxVDY3MiAxNzAwUTY5NyAxNzMwIDcxNiAxNzQ5UTcxOCAxNzUwIDczNSAxNzUwSDc1MlE3NTggMTc0NCA3NTggMTc0MVE3NTggMTczNyA3NDAgMTcxM1Q2ODkgMTY0NFQ2MTkgMTUzN1Q1NDAgMTM4MFQ0NjMgMTE3NlEzNDggODAyIDM0OCAyNTFRMzQ4IC0yNDIgNDQxIC01OTlUNzQ0IC0xMjE4UTc1OCAtMTIzNyA3NTggLTEyNDBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1o0LTI5IiBkPSJNMzMgMTc0MVEzMyAxNzUwIDUxIDE3NTBINjBINjVRNzMgMTc1MCA4MSAxNzQzVDExOSAxNzAwUTU1NCAxMjA3IDU1NCAyNTFRNTU0IC03MDcgMTE5IC0xMTk5UTc2IC0xMjUwIDY2IC0xMjUwUTY1IC0xMjUwIDYyIC0xMjUwVDU2IC0xMjQ5UTU1IC0xMjQ5IDUzIC0xMjQ5VDQ5IC0xMjUwUTMzIC0xMjUwIDMzIC0xMjM5UTMzIC0xMjM2IDUwIC0xMjE0VDk4IC0xMTUwVDE2MyAtMTA1MlQyMzggLTkxMFQzMTEgLTcyN1E0NDMgLTMzNSA0NDMgMjUxUTQ0MyA0MDIgNDM2IDUzMlQ0MDUgODMxVDMzOSAxMTQyVDIyNCAxNDM4VDUwIDE3MTZRMzMgMTczNyAzMyAxNzQxWiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2NywwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKC0xMSwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsNTE1OCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkzMSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMS03QiIgeD0iMCIgeT0iLTEiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1ODMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iMTE2NyIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI4MjUiIHk9Ii0yMTIiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjMyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTdEIiB4PSIzNDY0IiB5PSItMSI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ5NjgsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDUxNTgpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjc3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTMzNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzM4LC0xODcpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzgiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSIxMDczIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0NTEsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDIzMjApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTIzQTciIHg9IjAiIHk9Ii05MDAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC0xMTk3LjQ5NTcyMjA0OTY4OTQpIHNjYWxlKDEsMS4wODE5Nzk4MTM2NjQ1OTY0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaNC0yM0FBIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtMjNBOCIgeD0iMCIgeT0iLTIzMjEiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC0zMjY3Ljg5MzIyMjA0OTY4OTUpIHNjYWxlKDEsMS4wODE5Nzk4MTM2NjQ1OTY0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaNC0yM0FBIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtMjNBOSIgeD0iMCIgeT0iLTMyNDEiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDg4OSwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9Ijc3ODMiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwxMTY5KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMS0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIxNDk0IiB5PSI2NzUiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDU2LC0yODcpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjM0NSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxMTI0IiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNDcxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzQiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNjEsLTE1MCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzUiIHg9IjYwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RCIgeD0iMTE3MyIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NTUwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTk3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc4IiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSIxMDczIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSIyMjI1IiB5PSI2NzUiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yOSIgeD0iMjUxNSIgeT0iLTEiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTcxLC04MTIpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjE0OTQiIHk9IjY3NSI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwNTYsLTI4NykiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMzQ1IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjExMjQiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI0NzEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjczNyIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEwODgiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIyMDg4IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIyOTc4IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4OTEyLDIzMjApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTIzQUIiIHg9IjAiIHk9Ii05MDAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC0xMTk3LjQ5NTcyMjA0OTY4OTQpIHNjYWxlKDEsMS4wODE5Nzk4MTM2NjQ1OTY0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaNC0yM0FBIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtMjNBQyIgeD0iMCIgeT0iLTIzMjEiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC0zMjY3Ljg5MzIyMjA0OTY4OTUpIHNjYWxlKDEsMS4wODE5Nzk4MTM2NjQ1OTY0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaNC0yM0FBIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtMjNBRCIgeD0iMCIgeT0iLTMyNDEiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDEwODcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjc3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTMzNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSI5ODciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC0xMTEwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSI2NDIiIHk9Ii0yNDMiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iMTAyNyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkyMywwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI2NDIiIHk9Ii0yNDMiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJDIiB4PSIyMzM0IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9IjI2MTIiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iMjg5MSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSIzMTY5IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9IjM0NDgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNjM1LDApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjU3NCkiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI2NDIiIHk9Ii0xODUiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iNDkyMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU4MzgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iNzM3IiB5PSItMjEzIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iOTc1IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQyMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjczNyIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iMjM5NSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9IjI4NDEiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSIzMjg2IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iMzczMSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9IjQxNzYiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NjIxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjczNyIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI2MDU3IiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjQ1MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzM4LC0xODcpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSI5NTEiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQ0ODQsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDE5NTApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTIzQTciIHg9IjAiIHk9Ii05MDAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtMjNBOCIgeD0iMCIgeT0iLTE5NTEiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtMjNBOSIgeD0iMCIgeT0iLTI1MDIiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDg4OSwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjY3MTQiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw5NzEpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjE0OTQiIHk9IjY3NSI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwNTYsLTI4NykiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMzQ1IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjExMjQiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI0NzEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjEtMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwNTYsNDg3KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iNjQyIiB5PSItMjM4Ij48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDU2LC0zMDgpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZBIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjQxMiIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxMTkxIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZBIiB4PSI0OTkxIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTQwMywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSI2MzgiIHk9IjQ5OSI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ1MSwtMTUwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QSIgeD0iNTc4IiB5PSItMjM4Ij48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDM3LC04MTIpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjE0OTQiIHk9IjY3NSI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwNTYsLTI4NykiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMzQ1IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjExMjQiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI0NzEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjczNyIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEwODgiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIyMDg4IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIyOTc4IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QyIgeD0iNjk1NCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDcyMzMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSI3MzciIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9IjgyMDgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4NjUzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iNzM3IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJDIiB4PSI5NjI5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iMTAwNzQiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSIxMDUxOSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9IjEwOTY0IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iMTE0MDkiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMTg1NCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI3MzciIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTM3OTAsMTk1MCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtMjNBQiIgeD0iMCIgeT0iLTkwMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaNC0yM0FDIiB4PSIwIiB5PSItMTk1MSI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaNC0yM0FEIiB4PSIwIiB5PSItMjUwMiI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTI0MTQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjc3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTMzNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI3NjAiIHk9Ii0xNTY5Ij48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMjk0NSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4NjMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjkxMSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTMzMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIxMDMyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwtMTExNykiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02NiI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSIzMDYiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MyIgeD0iODA3IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzQiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02RiIgeD0iMTY0MCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIyMTQxIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzMiIHg9IjI1MzMiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02RiIgeD0iMzI4MiIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTY2IiB4PSIzNzgyIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI0NDQyIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQyIiB4PSI5MDA3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTkzMywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0IiIHg9IjYwMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwNDUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSI3MzciIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9IjIwMjEiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNDY2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iNzM3IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJDIiB4PSIzNDQxIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iMzg4NiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9IjQzMzEiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSI0Nzc3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iNTIyMiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU2NjcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iNzM3IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdDIiB4PSI2NzEzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjY5OTIiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijc5MDMiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE4MzkyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTVCIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTgzLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNjk5MiIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDgxNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjEtMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTQ5NCIgeT0iNjc1Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTA1NiwtMjg3KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIzNDUiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTEyNCIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjQ3MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSI3MzciIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM1MDQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjczNyIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEwODgiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIyMDg4IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIyOTc4IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2MDAsLTc3MSkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjY3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNzQzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjE3NDQiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjI3MzQiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MjMyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9Ijg2NDYiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5NjQ3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTVEIiB4PSIxMTU4OCIgeT0iLTEiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwtNTcyOSkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIyNzciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzM0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjI5MTMiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTE0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUyNzIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3OTIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNzYwIiB5PSItMTU2OSI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2MTEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTEwOSIgeT0iNDk5Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii00NDYiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI5MjAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTEwOSIgeT0iNDk5Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQzMzksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMTAzMiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTExMTcpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjYiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iMzA2IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjMiIHg9IjgwNyIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTc0IiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNkYiIHg9IjE2NDAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMjE0MSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTczIiB4PSIyNTMzIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNkYiIHg9IjMyODIiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02NiIgeD0iMzc4MiIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNDQ0MiIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00MiIgeD0iODAxNiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDg5NDIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNCIiB4PSI2MDAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDQ1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iNzM3IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJDIiB4PSIyMDIxIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjQ2NiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjczNyIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iMzQ0MSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9IjM4ODYiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSI0MzMxIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iNDc3NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9IjUyMjIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1NjY3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjczNyIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QyIgeD0iNjcxMyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI2OTkyIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI3OTAzIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNzQwMSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaNC01QiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU4MywwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjY0MzUiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw4MTQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjE0OTQiIHk9IjY3NSI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwNTYsLTI4NykiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMzQ1IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjExMjQiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI0NzEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjczNyIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTI1NSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIyMzI2IiB5PSI2NzUiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjQ3OTIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNTc5MyIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTMyMSwtNzcxKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2NjcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI3NDMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTc0NCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMjczNCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTVEIiB4PSI3MjU4IiB5PSItMSI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtMjkiIHg9IjI2MDM2IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8L2c+Cjwvc3ZnPg==)
又,
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjY1LjQ4NGV4IiBoZWlnaHQ9IjcuNTA5ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4xNzFleDsiIHZpZXdCb3g9IjAgLTE4NjcuNyAyODE5NC42IDMyMzMuMiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjIxMSIgZD0iTTYwIDk0OFE2MyA5NTAgNjY1IDk1MEgxMjY3TDEzMjUgODE1UTEzODQgNjc3IDEzODggNjY5SDEzNDhMMTM0MSA2ODNRMTMyMCA3MjQgMTI4NSA3NjFRMTIzNSA4MDkgMTE3NCA4MzhUMTAzMyA4ODFUODgyIDg5OFQ2OTkgOTAySDU3NEg1NDNIMjUxTDI1OSA4OTFRNzIyIDI1OCA3MjQgMjUyUTcyNSAyNTAgNzI0IDI0NlE3MjEgMjQzIDQ2MCAtNTZMMTk2IC0zNTZRMTk2IC0zNTcgNDA3IC0zNTdRNDU5IC0zNTcgNTQ4IC0zNTdUNjc2IC0zNThRODEyIC0zNTggODk2IC0zNTNUMTA2MyAtMzMyVDEyMDQgLTI4M1QxMzA3IC0xOTZRMTMyOCAtMTcwIDEzNDggLTEyNEgxMzg4UTEzODggLTEyNSAxMzgxIC0xNDVUMTM1NiAtMjEwVDEzMjUgLTI5NEwxMjY3IC00NDlMNjY2IC00NTBRNjQgLTQ1MCA2MSAtNDQ4UTU1IC00NDYgNTUgLTQzOVE1NSAtNDM3IDU3IC00MzNMNTkwIDE3N1E1OTAgMTc4IDU1NyAyMjJUNDUyIDM2NlQzMjIgNTQ0TDU2IDkwOUw1NSA5MjRRNTUgOTQ1IDYwIDk0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTY2IiBkPSJNMjczIDBRMjU1IDMgMTQ2IDNRNDMgMyAzNCAwSDI2VjQ2SDQyUTcwIDQ2IDkxIDQ5UTk5IDUyIDEwMyA2MFExMDQgNjIgMTA0IDIyNFYzODVIMzNWNDMxSDEwNFY0OTdMMTA1IDU2NEwxMDcgNTc0UTEyNiA2MzkgMTcxIDY2OFQyNjYgNzA0UTI2NyA3MDQgMjc1IDcwNFQyODkgNzA1UTMzMCA3MDIgMzUxIDY3OVQzNzIgNjI3UTM3MiA2MDQgMzU4IDU5MFQzMjEgNTc2VDI4NCA1OTBUMjcwIDYyN1EyNzAgNjQ3IDI4OCA2NjdIMjg0UTI4MCA2NjggMjczIDY2OFEyNDUgNjY4IDIyMyA2NDdUMTg5IDU5MlExODMgNTcyIDE4MiA0OTdWNDMxSDI5M1YzODVIMTg1VjIyNVExODUgNjMgMTg2IDYxVDE4OSA1N1QxOTQgNTRUMTk5IDUxVDIwNiA0OVQyMTMgNDhUMjIyIDQ3VDIzMSA0N1QyNDEgNDZUMjUxIDQ2SDI4MlYwSDI3M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTYxIiBkPSJNMTM3IDMwNVQxMTUgMzA1VDc4IDMyMFQ2MyAzNTlRNjMgMzk0IDk3IDQyMVQyMTggNDQ4UTI5MSA0NDggMzM2IDQxNlQzOTYgMzQwUTQwMSAzMjYgNDAxIDMwOVQ0MDIgMTk0VjEyNFE0MDIgNzYgNDA3IDU4VDQyOCA0MFE0NDMgNDAgNDQ4IDU2VDQ1MyAxMDlWMTQ1SDQ5M1YxMDZRNDkyIDY2IDQ5MCA1OVE0ODEgMjkgNDU1IDEyVDQwMCAtNlQzNTMgMTJUMzI5IDU0VjU4TDMyNyA1NVEzMjUgNTIgMzIyIDQ5VDMxNCA0MFQzMDIgMjlUMjg3IDE3VDI2OSA2VDI0NyAtMlQyMjEgLThUMTkwIC0xMVExMzAgLTExIDgyIDIwVDM0IDEwN1EzNCAxMjggNDEgMTQ3VDY4IDE4OFQxMTYgMjI1VDE5NCAyNTNUMzA0IDI2OEgzMThWMjkwUTMxOCAzMjQgMzEyIDM0MFEyOTAgNDExIDIxNSA0MTFRMTk3IDQxMSAxODEgNDEwVDE1NiA0MDZUMTQ4IDQwM1ExNzAgMzg4IDE3MCAzNTlRMTcwIDMzNCAxNTQgMzIwWk0xMjYgMTA2UTEyNiA3NSAxNTAgNTFUMjA5IDI2UTI0NyAyNiAyNzYgNDlUMzE1IDEwOVEzMTcgMTE2IDMxOCAxNzVRMzE4IDIzMyAzMTcgMjMzUTMwOSAyMzMgMjk2IDIzMlQyNTEgMjIzVDE5MyAyMDNUMTQ3IDE2NlQxMjYgMTA2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNjMiIGQ9Ik0zNzAgMzA1VDM0OSAzMDVUMzEzIDMyMFQyOTcgMzU4UTI5NyAzODEgMzEyIDM5NlEzMTcgNDAxIDMxNyA0MDJUMzA3IDQwNFEyODEgNDA4IDI1OCA0MDhRMjA5IDQwOCAxNzggMzc2UTEzMSAzMjkgMTMxIDIxOVExMzEgMTM3IDE2MiA5MFEyMDMgMjkgMjcyIDI5UTMxMyAyOSAzMzggNTVUMzc0IDExN1EzNzYgMTI1IDM3OSAxMjdUMzk1IDEyOUg0MDlRNDE1IDEyMyA0MTUgMTIwUTQxNSAxMTYgNDExIDEwNFQzOTUgNzFUMzY2IDMzVDMxOCAyVDI0OSAtMTFRMTYzIC0xMSA5OSA1M1QzNCAyMTRRMzQgMzE4IDk5IDM4M1QyNTAgNDQ4VDM3MCA0MjFUNDA0IDM1N1E0MDQgMzM0IDM4NyAzMjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03NCIgZD0iTTI3IDQyMlE4MCA0MjYgMTA5IDQ3OFQxNDEgNjAwVjYxNUgxODFWNDMxSDMxNlYzODVIMTgxVjI0MVExODIgMTE2IDE4MiAxMDBUMTg5IDY4UTIwMyAyOSAyMzggMjlRMjgyIDI5IDI5MiAxMDBRMjkzIDEwOCAyOTMgMTQ2VjE4MUgzMzNWMTQ2VjEzNFEzMzMgNTcgMjkxIDE3UTI2NCAtMTAgMjIxIC0xMFExODcgLTEwIDE2MiAyVDEyNCAzM1QxMDUgNjhUOTggMTAwUTk3IDEwNyA5NyAyNDhWMzg1SDE4VjQyMkgyN1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTZGIiBkPSJNMjggMjE0UTI4IDMwOSA5MyAzNzhUMjUwIDQ0OFEzNDAgNDQ4IDQwNSAzODBUNDcxIDIxNVE0NzEgMTIwIDQwNyA1NVQyNTAgLTEwUTE1MyAtMTAgOTEgNTdUMjggMjE0Wk0yNTAgMzBRMzcyIDMwIDM3MiAxOTNWMjI1VjI1MFEzNzIgMjcyIDM3MSAyODhUMzY0IDMyNlQzNDggMzYyVDMxNyAzOTBUMjY4IDQxMFEyNjMgNDExIDI1MiA0MTFRMjIyIDQxMSAxOTUgMzk5UTE1MiAzNzcgMTM5IDMzOFQxMjYgMjQ2VjIyNlExMjYgMTMwIDE0NSA5MVExNzcgMzAgMjUwIDMwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNzIiIGQ9Ik0zNiA0Nkg1MFE4OSA0NiA5NyA2MFY2OFE5NyA3NyA5NyA5MVQ5OCAxMjJUOTggMTYxVDk4IDIwM1E5OCAyMzQgOTggMjY5VDk4IDMyOEw5NyAzNTFROTQgMzcwIDgzIDM3NlQzOCAzODVIMjBWNDA4UTIwIDQzMSAyMiA0MzFMMzIgNDMyUTQyIDQzMyA2MCA0MzRUOTYgNDM2UTExMiA0MzcgMTMxIDQzOFQxNjAgNDQxVDE3MSA0NDJIMTc0VjM3M1EyMTMgNDQxIDI3MSA0NDFIMjc3UTMyMiA0NDEgMzQzIDQxOVQzNjQgMzczUTM2NCAzNTIgMzUxIDMzN1QzMTMgMzIyUTI4OCAzMjIgMjc2IDMzOFQyNjMgMzcyUTI2MyAzODEgMjY1IDM4OFQyNzAgNDAwVDI3MyA0MDVRMjcxIDQwNyAyNTAgNDAxUTIzNCAzOTMgMjI2IDM4NlExNzkgMzQxIDE3OSAyMDdWMTU0UTE3OSAxNDEgMTc5IDEyN1QxNzkgMTAxVDE4MCA4MVQxODAgNjZWNjFRMTgxIDU5IDE4MyA1N1QxODggNTRUMTkzIDUxVDIwMCA0OVQyMDcgNDhUMjE2IDQ3VDIyNSA0N1QyMzUgNDZUMjQ1IDQ2SDI3NlYwSDI2N1EyNDkgMyAxNDAgM1EzNyAzIDI4IDBIMjBWNDZIMzZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03MyIgZD0iTTI5NSAzMTZRMjk1IDM1NiAyNjggMzg1VDE5MCA0MTRRMTU0IDQxNCAxMjggNDAxUTk4IDM4MiA5OCAzNDlROTcgMzQ0IDk4IDMzNlQxMTQgMzEyVDE1NyAyODdRMTc1IDI4MiAyMDEgMjc4VDI0NSAyNjlUMjc3IDI1NlEyOTQgMjQ4IDMxMCAyMzZUMzQyIDE5NVQzNTkgMTMzUTM1OSA3MSAzMjEgMzFUMTk4IC0xMEgxOTBRMTM4IC0xMCA5NCAyNkw4NiAxOUw3NyAxMFE3MSA0IDY1IC0xTDU0IC0xMUg0Nkg0MlEzOSAtMTEgMzMgLTVWNzRWMTMyUTMzIDE1MyAzNSAxNTdUNDUgMTYySDU0UTY2IDE2MiA3MCAxNThUNzUgMTQ2VDgyIDExOVQxMDEgNzdRMTM2IDI2IDE5OCAyNlEyOTUgMjYgMjk1IDEwNFEyOTUgMTMzIDI3NyAxNTFRMjU3IDE3NSAxOTQgMTg3VDExMSAyMTBRNzUgMjI3IDU0IDI1NlQzMyAzMThRMzMgMzU3IDUwIDM4NFQ5MyA0MjRUMTQzIDQ0MlQxODcgNDQ3SDE5OFEyMzggNDQ3IDI2OCA0MzJMMjgzIDQyNEwyOTIgNDMxUTMwMiA0NDAgMzE0IDQ0OEgzMjJIMzI2UTMyOSA0NDggMzM1IDQ0MlYzMTBMMzI5IDMwNEgzMDFRMjk1IDMxMCAyOTUgMzE2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZCIiBkPSJNMTIxIDY0N1ExMjEgNjU3IDEyNSA2NzBUMTM3IDY4M1ExMzggNjgzIDIwOSA2ODhUMjgyIDY5NFEyOTQgNjk0IDI5NCA2ODZRMjk0IDY3OSAyNDQgNDc3UTE5NCAyNzkgMTk0IDI3MlEyMTMgMjgyIDIyMyAyOTFRMjQ3IDMwOSAyOTIgMzU0VDM2MiA0MTVRNDAyIDQ0MiA0MzggNDQyUTQ2OCA0NDIgNDg1IDQyM1Q1MDMgMzY5UTUwMyAzNDQgNDk2IDMyN1Q0NzcgMzAyVDQ1NiAyOTFUNDM4IDI4OFE0MTggMjg4IDQwNiAyOTlUMzk0IDMyOFEzOTQgMzUzIDQxMCAzNjlUNDQyIDM5MEw0NTggMzkzUTQ0NiA0MDUgNDM0IDQwNUg0MzBRMzk4IDQwMiAzNjcgMzgwVDI5NCAzMTZUMjI4IDI1NVEyMzAgMjU0IDI0MyAyNTJUMjY3IDI0NlQyOTMgMjM4VDMyMCAyMjRUMzQyIDIwNlQzNTkgMTgwVDM2NSAxNDdRMzY1IDEzMCAzNjAgMTA2VDM1NCA2NlEzNTQgMjYgMzgxIDI2UTQyOSAyNiA0NTkgMTQ1UTQ2MSAxNTMgNDc5IDE1M0g0ODNRNDk5IDE1MyA0OTkgMTQ0UTQ5OSAxMzkgNDk2IDEzMFE0NTUgLTExIDM3OCAtMTFRMzMzIC0xMSAzMDUgMTVUMjc3IDkwUTI3NyAxMDggMjgwIDEyMVQyODMgMTQ1UTI4MyAxNjcgMjY5IDE4M1QyMzQgMjA2VDIwMCAyMTdUMTgyIDIyMEgxODBRMTY4IDE3OCAxNTkgMTM5VDE0NSA4MVQxMzYgNDRUMTI5IDIwVDEyMiA3VDExMSAtMlE5OCAtMTEgODMgLTExUTY2IC0xMSA1NyAtMVQ0OCAxNlE0OCAyNiA4NSAxNzZUMTU4IDQ3MUwxOTUgNjE2UTE5NiA2MjkgMTg4IDYzMlQxNDkgNjM3SDE0NFExMzQgNjM3IDEzMSA2MzdUMTI0IDY0MFQxMjEgNjQ3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQyIiBkPSJNMjMxIDYzN1EyMDQgNjM3IDE5OSA2MzhUMTk0IDY0OVExOTQgNjc2IDIwNSA2ODJRMjA2IDY4MyAzMzUgNjgzUTU5NCA2ODMgNjA4IDY4MVE2NzEgNjcxIDcxMyA2MzZUNzU2IDU0NFE3NTYgNDgwIDY5OCA0MjlUNTY1IDM2MEw1NTUgMzU3UTYxOSAzNDggNjYwIDMxMVQ3MDIgMjE5UTcwMiAxNDYgNjMwIDc4VDQ1MyAxUTQ0NiAwIDI0MiAwUTQyIDAgMzkgMlEzNSA1IDM1IDEwUTM1IDE3IDM3IDI0UTQyIDQzIDQ3IDQ1UTUxIDQ2IDYyIDQ2SDY4UTk1IDQ2IDEyOCA0OVExNDIgNTIgMTQ3IDYxUTE1MCA2NSAyMTkgMzM5VDI4OCA2MjhRMjg4IDYzNSAyMzEgNjM3Wk02NDkgNTQ0UTY0OSA1NzQgNjM0IDYwMFQ1ODUgNjM0UTU3OCA2MzYgNDkzIDYzN1E0NzMgNjM3IDQ1MSA2MzdUNDE2IDYzNkg0MDNRMzg4IDYzNSAzODQgNjI2UTM4MiA2MjIgMzUyIDUwNlEzNTIgNTAzIDM1MSA1MDBMMzIwIDM3NEg0MDFRNDgyIDM3NCA0OTQgMzc2UTU1NCAzODYgNjAxIDQzNFQ2NDkgNTQ0Wk01OTUgMjI5UTU5NSAyNzMgNTcyIDMwMlQ1MTIgMzM2UTUwNiAzMzcgNDI5IDMzN1EzMTEgMzM3IDMxMCAzMzZRMzEwIDMzNCAyOTMgMjYzVDI1OCAxMjJMMjQwIDUyUTI0MCA0OCAyNTIgNDhUMzMzIDQ2UTQyMiA0NiA0MjkgNDdRNDkxIDU0IDU0MyAxMDVUNTk1IDIyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkUiIGQ9Ik0yMSAyODdRMjIgMjkzIDI0IDMwM1QzNiAzNDFUNTYgMzg4VDg5IDQyNVQxMzUgNDQyUTE3MSA0NDIgMTk1IDQyNFQyMjUgMzkwVDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzA0IDQ0MiAzODIgNDQyUTQzNiA0NDIgNDY5IDQxNVQ1MDMgMzM2VDQ2NSAxNzlUNDI3IDUyUTQyNyAyNiA0NDQgMjZRNDUwIDI2IDQ1MyAyN1E0ODIgMzIgNTA1IDY1VDU0MCAxNDVRNTQyIDE1MyA1NjAgMTUzUTU4MCAxNTMgNTgwIDE0NVE1ODAgMTQ0IDU3NiAxMzBRNTY4IDEwMSA1NTQgNzNUNTA4IDE3VDQzOSAtMTBRMzkyIC0xMCAzNzEgMTdUMzUwIDczUTM1MCA5MiAzODYgMTkzVDQyMyAzNDVRNDIzIDQwNCAzNzkgNDA0SDM3NFEyODggNDA0IDIyOSAzMDNMMjIyIDI5MUwxODkgMTU3UTE1NiAyNiAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExMiAxODBUMTUyIDM0M1ExNTMgMzQ4IDE1MyAzNjZRMTUzIDQwNSAxMjkgNDA1UTkxIDQwNSA2NiAzMDVRNjAgMjg1IDYwIDI4NFE1OCAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zQiIgZD0iTTc4IDM3MFE3OCAzOTQgOTUgNDEyVDEzOCA0MzBRMTYyIDQzMCAxODAgNDE0VDE5OSAzNzFRMTk5IDM0NiAxODIgMzI4VDEzOSAzMTBUOTYgMzI3VDc4IDM3MFpNNzggNjBRNzggODUgOTQgMTAzVDEzNyAxMjFRMjAyIDEyMSAyMDIgOFEyMDIgLTQ0IDE4MyAtOTRUMTQ0IC0xNjlUMTE4IC0xOTRRMTE1IC0xOTQgMTA2IC0xODZUOTUgLTE3NFE5NCAtMTcxIDEwNyAtMTU1VDEzNyAtMTA3VDE2MCAtMzhRMTYxIC0zMiAxNjIgLTIyVDE2NSAtNFQxNjUgNFExNjUgNSAxNjEgNFQxNDIgMFExMTAgMCA5NCAxOFQ3OCA2MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJDIiBkPSJNNzggMzVUNzggNjBUOTQgMTAzVDEzNyAxMjFRMTY1IDEyMSAxODcgOTZUMjEwIDhRMjEwIC0yNyAyMDEgLTYwVDE4MCAtMTE3VDE1NCAtMTU4VDEzMCAtMTg1VDExNyAtMTk0UTExMyAtMTk0IDEwNCAtMTg1VDk1IC0xNzJROTUgLTE2OCAxMDYgLTE1NlQxMzEgLTEyNlQxNTcgLTc2VDE3MyAtM1Y5TDE3MiA4UTE3MCA3IDE2NyA2VDE2MSAzVDE1MiAxVDE0MCAwUTExMyAwIDk2IDE3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzIiIGQ9Ik0xMDkgNDI5UTgyIDQyOSA2NiA0NDdUNTAgNDkxUTUwIDU2MiAxMDMgNjE0VDIzNSA2NjZRMzI2IDY2NiAzODcgNjEwVDQ0OSA0NjVRNDQ5IDQyMiA0MjkgMzgzVDM4MSAzMTVUMzAxIDI0MVEyNjUgMjEwIDIwMSAxNDlMMTQyIDkzTDIxOCA5MlEzNzUgOTIgMzg1IDk3UTM5MiA5OSA0MDkgMTg2VjE4OUg0NDlWMTg2UTQ0OCAxODMgNDM2IDk1VDQyMSAzVjBINTBWMTlWMzFRNTAgMzggNTYgNDZUODYgODFRMTE1IDExMyAxMzYgMTM3UTE0NSAxNDcgMTcwIDE3NFQyMDQgMjExVDIzMyAyNDRUMjYxIDI3OFQyODQgMzA4VDMwNSAzNDBUMzIwIDM2OVQzMzMgNDAxVDM0MCA0MzFUMzQzIDQ2NFEzNDMgNTI3IDMwOSA1NzNUMjEyIDYxOVExNzkgNjE5IDE1NCA2MDJUMTE5IDU2OVQxMDkgNTUwUTEwOSA1NDkgMTE0IDU0OVExMzIgNTQ5IDE1MSA1MzVUMTcwIDQ4OVExNzAgNDY0IDE1NCA0NDdUMTA5IDQyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJFIiBkPSJNNzggNjBRNzggODQgOTUgMTAyVDEzOCAxMjBRMTYyIDEyMCAxODAgMTA0VDE5OSA2MVExOTkgMzYgMTgyIDE4VDEzOSAwVDk2IDE3VDc4IDYwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0MiIGQ9Ik0xMzkgLTI0OUgxMzdRMTI1IC0yNDkgMTE5IC0yMzVWMjUxTDEyMCA3MzdRMTMwIDc1MCAxMzkgNzUwUTE1MiA3NTAgMTU5IDczNVYtMjM1UTE1MSAtMjQ5IDE0MSAtMjQ5SDEzOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNUIiIGQ9Ik0xMTggLTI1MFY3NTBIMjU1VjcxMEgxNThWLTIxMEgyNTVWLTI1MEgxMThaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oxLTIyMTEiIGQ9Ik02MSA3NDhRNjQgNzUwIDQ4OSA3NTBIOTEzTDk1NCA2NDBROTY1IDYwOSA5NzYgNTc5VDk5MyA1MzNUOTk5IDUxNkg5NzlMOTU5IDUxN1E5MzYgNTc5IDg4NiA2MjFUNzc3IDY4MlE3MjQgNzAwIDY1NSA3MDVUNDM2IDcxMEgzMTlRMTgzIDcxMCAxODMgNzA5UTE4NiA3MDYgMzQ4IDQ4NFQ1MTEgMjU5UTUxNyAyNTAgNTEzIDI0NEw0OTAgMjE2UTQ2NiAxODggNDIwIDEzNFQzMzAgMjdMMTQ5IC0xODdRMTQ5IC0xODggMzYyIC0xODhRMzg4IC0xODggNDM2IC0xODhUNTA2IC0xODlRNjc5IC0xODkgNzc4IC0xNjJUOTM2IC00M1E5NDYgLTI3IDk1OSA2SDk5OUw5MTMgLTI0OUw0ODkgLTI1MFE2NSAtMjUwIDYyIC0yNDhRNTYgLTI0NiA1NiAtMjM5UTU2IC0yMzQgMTE4IC0xNjFRMTg2IC04MSAyNDUgLTExTDQyOCAyMDZRNDI4IDIwNyAyNDIgNDYyTDU3IDcxN0w1NiA3MjhRNTYgNzQ0IDYxIDc0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02OSIgZD0iTTE4NCA2MDBRMTg0IDYyNCAyMDMgNjQyVDI0NyA2NjFRMjY1IDY2MSAyNzcgNjQ5VDI5MCA2MTlRMjkwIDU5NiAyNzAgNTc3VDIyNiA1NTdRMjExIDU1NyAxOTggNTY3VDE4NCA2MDBaTTIxIDI4N1EyMSAyOTUgMzAgMzE4VDU0IDM2OVQ5OCA0MjBUMTU4IDQ0MlExOTcgNDQyIDIyMyA0MTlUMjUwIDM1N1EyNTAgMzQwIDIzNiAzMDFUMTk2IDE5NlQxNTQgODNRMTQ5IDYxIDE0OSA1MVExNDkgMjYgMTY2IDI2UTE3NSAyNiAxODUgMjlUMjA4IDQzVDIzNSA3OFQyNjAgMTM3UTI2MyAxNDkgMjY1IDE1MVQyODIgMTUzUTMwMiAxNTMgMzAyIDE0M1EzMDIgMTM1IDI5MyAxMTJUMjY4IDYxVDIyMyAxMVQxNjEgLTExUTEyOSAtMTEgMTAyIDEwVDc0IDc0UTc0IDkxIDc5IDEwNlQxMjIgMjIwUTE2MCAzMjEgMTY2IDM0MVQxNzMgMzgwUTE3MyA0MDQgMTU2IDQwNEgxNTRRMTI0IDQwNCA5OSAzNzFUNjEgMjg3UTYwIDI4NiA1OSAyODRUNTggMjgxVDU2IDI3OVQ1MyAyNzhUNDkgMjc4VDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yQiIgZD0iTTU2IDIzN1Q1NiAyNTBUNzAgMjcwSDM2OVY0MjBMMzcwIDU3MFEzODAgNTgzIDM4OSA1ODNRNDAyIDU4MyA0MDkgNTY4VjI3MEg3MDdRNzIyIDI2MiA3MjIgMjUwVDcwNyAyMzBINDA5Vi02OFE0MDEgLTgyIDM5MSAtODJIMzg5SDM4N1EzNzUgLTgyIDM2OSAtNjhWMjMwSDcwUTU2IDIzNyA1NiAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi01RCIgZD0iTTIyIDcxMFY3NTBIMTU5Vi0yNTBIMjJWLTIxMEgxMTlWNzEwSDIyWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaNC01QiIgZD0iTTI2OSAtMTI0OVYxNzUwSDU3N1YxNjc3SDM0MlYtMTE3Nkg1NzdWLTEyNDlIMjY5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaNC01RCIgZD0iTTUgMTY3N1YxNzUwSDMxM1YtMTI0OUg1Vi0xMTc2SDI0MFYxNjc3SDVaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTIyMTEiIHg9IjEwMzIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC0xMTE3KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTY2Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9IjMwNiIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYzIiB4PSI4MDciIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03NCIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTZGIiB4PSIxNjQwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjIxNDEiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MyIgeD0iMjUzMyIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTZGIiB4PSIzMjgyIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjYiIHg9IjM3ODIiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjQ0NDIiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQyIiB4PSIzNjc2IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDYwMiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0IiIHg9IjYwMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwNDUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSI3MzciIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9IjIwMjEiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNDY2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iNzM3IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJDIiB4PSIzNDQxIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iMzg4NiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9IjQzMzEiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSI0Nzc3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iNTIyMiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU2NjcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iNzM3IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdDIiB4PSI2NzEzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjY5OTIiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijc5MDMiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzMDYyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTVCIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTgzLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNjQzNSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDgxNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjEtMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTQ5NCIgeT0iNjc1Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTA1NiwtMjg3KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIzNDUiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTEyNCIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjQ3MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iNzM3IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxMjU1IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjIzMjYiIHk9IjY3NSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNDc5MiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI1NzkzIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzIxLC03NzEpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDY2NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9Ijc0MyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIxNzQ0IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIyNzM0IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtNUQiIHg9IjcyNTgiIHk9Ii0xIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIyMTE4MiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIxOTYwLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzk3LDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMjQ0MyIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI5NjEiIHk9IjY3NiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC02ODcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI4MjIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxODIzIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDIiIHg9IjI0OTIyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjU4NDgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNCIiB4PSI2MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTA0NSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTk1NiIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=) (2)
(2)
以及,
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjI2LjcyN2V4IiBoZWlnaHQ9IjcuMDA5ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4xNzFleDsiIHZpZXdCb3g9IjAgLTE2NTIuNSAxMTUwNy4zIDMwMTcuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjIxMSIgZD0iTTYwIDk0OFE2MyA5NTAgNjY1IDk1MEgxMjY3TDEzMjUgODE1UTEzODQgNjc3IDEzODggNjY5SDEzNDhMMTM0MSA2ODNRMTMyMCA3MjQgMTI4NSA3NjFRMTIzNSA4MDkgMTE3NCA4MzhUMTAzMyA4ODFUODgyIDg5OFQ2OTkgOTAySDU3NEg1NDNIMjUxTDI1OSA4OTFRNzIyIDI1OCA3MjQgMjUyUTcyNSAyNTAgNzI0IDI0NlE3MjEgMjQzIDQ2MCAtNTZMMTk2IC0zNTZRMTk2IC0zNTcgNDA3IC0zNTdRNDU5IC0zNTcgNTQ4IC0zNTdUNjc2IC0zNThRODEyIC0zNTggODk2IC0zNTNUMTA2MyAtMzMyVDEyMDQgLTI4M1QxMzA3IC0xOTZRMTMyOCAtMTcwIDEzNDggLTEyNEgxMzg4UTEzODggLTEyNSAxMzgxIC0xNDVUMTM1NiAtMjEwVDEzMjUgLTI5NEwxMjY3IC00NDlMNjY2IC00NTBRNjQgLTQ1MCA2MSAtNDQ4UTU1IC00NDYgNTUgLTQzOVE1NSAtNDM3IDU3IC00MzNMNTkwIDE3N1E1OTAgMTc4IDU1NyAyMjJUNDUyIDM2NlQzMjIgNTQ0TDU2IDkwOUw1NSA5MjRRNTUgOTQ1IDYwIDk0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02QiIgZD0iTTEyMSA2NDdRMTIxIDY1NyAxMjUgNjcwVDEzNyA2ODNRMTM4IDY4MyAyMDkgNjg4VDI4MiA2OTRRMjk0IDY5NCAyOTQgNjg2UTI5NCA2NzkgMjQ0IDQ3N1ExOTQgMjc5IDE5NCAyNzJRMjEzIDI4MiAyMjMgMjkxUTI0NyAzMDkgMjkyIDM1NFQzNjIgNDE1UTQwMiA0NDIgNDM4IDQ0MlE0NjggNDQyIDQ4NSA0MjNUNTAzIDM2OVE1MDMgMzQ0IDQ5NiAzMjdUNDc3IDMwMlQ0NTYgMjkxVDQzOCAyODhRNDE4IDI4OCA0MDYgMjk5VDM5NCAzMjhRMzk0IDM1MyA0MTAgMzY5VDQ0MiAzOTBMNDU4IDM5M1E0NDYgNDA1IDQzNCA0MDVINDMwUTM5OCA0MDIgMzY3IDM4MFQyOTQgMzE2VDIyOCAyNTVRMjMwIDI1NCAyNDMgMjUyVDI2NyAyNDZUMjkzIDIzOFQzMjAgMjI0VDM0MiAyMDZUMzU5IDE4MFQzNjUgMTQ3UTM2NSAxMzAgMzYwIDEwNlQzNTQgNjZRMzU0IDI2IDM4MSAyNlE0MjkgMjYgNDU5IDE0NVE0NjEgMTUzIDQ3OSAxNTNINDgzUTQ5OSAxNTMgNDk5IDE0NFE0OTkgMTM5IDQ5NiAxMzBRNDU1IC0xMSAzNzggLTExUTMzMyAtMTEgMzA1IDE1VDI3NyA5MFEyNzcgMTA4IDI4MCAxMjFUMjgzIDE0NVEyODMgMTY3IDI2OSAxODNUMjM0IDIwNlQyMDAgMjE3VDE4MiAyMjBIMTgwUTE2OCAxNzggMTU5IDEzOVQxNDUgODFUMTM2IDQ0VDEyOSAyMFQxMjIgN1QxMTEgLTJROTggLTExIDgzIC0xMVE2NiAtMTEgNTcgLTFUNDggMTZRNDggMjYgODUgMTc2VDE1OCA0NzFMMTk1IDYxNlExOTYgNjI5IDE4OCA2MzJUMTQ5IDYzN0gxNDRRMTM0IDYzNyAxMzEgNjM3VDEyNCA2NDBUMTIxIDY0N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzAiIGQ9Ik05NiA1ODVRMTUyIDY2NiAyNDkgNjY2UTI5NyA2NjYgMzQ1IDY0MFQ0MjMgNTQ4UTQ2MCA0NjUgNDYwIDMyMFE0NjAgMTY1IDQxNyA4M1EzOTcgNDEgMzYyIDE2VDMwMSAtMTVUMjUwIC0yMlEyMjQgLTIyIDE5OCAtMTZUMTM3IDE2VDgyIDgzUTM5IDE2NSAzOSAzMjBRMzkgNDk0IDk2IDU4NVpNMzIxIDU5N1EyOTEgNjI5IDI1MCA2MjlRMjA4IDYyOSAxNzggNTk3UTE1MyA1NzEgMTQ1IDUyNVQxMzcgMzMzUTEzNyAxNzUgMTQ1IDEyNVQxODEgNDZRMjA5IDE2IDI1MCAxNlEyOTAgMTYgMzE4IDQ2UTM0NyA3NiAzNTQgMTMwVDM2MiAzMzNRMzYyIDQ3OCAzNTQgNTI0VDMyMSA1OTdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjFFIiBkPSJNNTUgMjE3UTU1IDMwNSAxMTEgMzczVDI1NCA0NDJRMzQyIDQ0MiA0MTkgMzgxUTQ1NyAzNTAgNDkzIDMwM0w1MDcgMjg0TDUxNCAyOTRRNjE4IDQ0MiA3NDcgNDQyUTgzMyA0NDIgODg4IDM3NFQ5NDQgMjE0UTk0NCAxMjggODg5IDU5VDc0MyAtMTFRNjU3IC0xMSA1ODAgNTBRNTQyIDgxIDUwNiAxMjhMNDkyIDE0N0w0ODUgMTM3UTM4MSAtMTEgMjUyIC0xMVExNjYgLTExIDExMSA1N1Q1NSAyMTdaTTkwNyAyMTdROTA3IDI4NSA4NjkgMzQxVDc2MSAzOTdRNzQwIDM5NyA3MjAgMzkyVDY4MiAzNzhUNjQ4IDM1OVQ2MTkgMzM1VDU5NCAzMTBUNTc0IDI4NVQ1NTkgMjYzVDU0OCAyNDZMNTQzIDIzOEw1NzQgMTk4UTYwNSAxNTggNjIyIDEzOFQ2NjQgOTRUNzE0IDYxVDc2NSA1MVE4MjcgNTEgODY3IDEwMFQ5MDcgMjE3Wk05MiAyMTRROTIgMTQ1IDEzMSA4OVQyMzkgMzNRMzU3IDMzIDQ1NiAxOTNMNDI1IDIzM1EzNjQgMzEyIDMzNCAzMzdRMjg1IDM4MCAyMzMgMzgwUTE3MSAzODAgMTMyIDMzMVQ5MiAyMTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTAiIGQ9Ik0yODcgNjI4UTI4NyA2MzUgMjMwIDYzN1EyMDYgNjM3IDE5OSA2MzhUMTkyIDY0OFExOTIgNjQ5IDE5NCA2NTlRMjAwIDY3OSAyMDMgNjgxVDM5NyA2ODNRNTg3IDY4MiA2MDAgNjgwUTY2NCA2NjkgNzA3IDYzMVQ3NTEgNTMwUTc1MSA0NTMgNjg1IDM4OVE2MTYgMzIxIDUwNyAzMDNRNTAwIDMwMiA0MDIgMzAxSDMwN0wyNzcgMTgyUTI0NyA2NiAyNDcgNTlRMjQ3IDU1IDI0OCA1NFQyNTUgNTBUMjcyIDQ4VDMwNSA0NkgzMzZRMzQyIDM3IDM0MiAzNVEzNDIgMTkgMzM1IDVRMzMwIDAgMzE5IDBRMzE2IDAgMjgyIDFUMTgyIDJRMTIwIDIgODcgMlQ1MSAxUTMzIDEgMzMgMTFRMzMgMTMgMzYgMjVRNDAgNDEgNDQgNDNUNjcgNDZROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFpNNjQ1IDU1NFE2NDUgNTY3IDY0MyA1NzVUNjM0IDU5N1Q2MDkgNjE5VDU2MCA2MzVRNTUzIDYzNiA0ODAgNjM3UTQ2MyA2MzcgNDQ1IDYzN1Q0MTYgNjM2VDQwNCA2MzZRMzkxIDYzNSAzODYgNjI3UTM4NCA2MjEgMzY3IDU1MFQzMzIgNDEyVDMxNCAzNDRRMzE0IDM0MiAzOTUgMzQySDQwN0g0MzBRNTQyIDM0MiA1OTAgMzkyUTYxNyA0MTkgNjMxIDQ3MVQ2NDUgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZFIiBkPSJNMjEgMjg3UTIyIDI5MyAyNCAzMDNUMzYgMzQxVDU2IDM4OFQ4OSA0MjVUMTM1IDQ0MlExNzEgNDQyIDE5NSA0MjRUMjI1IDM5MFQyMzEgMzY5UTIzMSAzNjcgMjMyIDM2N0wyNDMgMzc4UTMwNCA0NDIgMzgyIDQ0MlE0MzYgNDQyIDQ2OSA0MTVUNTAzIDMzNlQ0NjUgMTc5VDQyNyA1MlE0MjcgMjYgNDQ0IDI2UTQ1MCAyNiA0NTMgMjdRNDgyIDMyIDUwNSA2NVQ1NDAgMTQ1UTU0MiAxNTMgNTYwIDE1M1E1ODAgMTUzIDU4MCAxNDVRNTgwIDE0NCA1NzYgMTMwUTU2OCAxMDEgNTU0IDczVDUwOCAxN1Q0MzkgLTEwUTM5MiAtMTAgMzcxIDE3VDM1MCA3M1EzNTAgOTIgMzg2IDE5M1Q0MjMgMzQ1UTQyMyA0MDQgMzc5IDQwNEgzNzRRMjg4IDQwNCAyMjkgMzAzTDIyMiAyOTFMMTg5IDE1N1ExNTYgMjYgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTIgMTgwVDE1MiAzNDNRMTUzIDM0OCAxNTMgMzY2UTE1MyA0MDUgMTI5IDQwNVE5MSA0MDUgNjYgMzA1UTYwIDI4NSA2MCAyODRRNTggMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU0IiBkPSJNNDAgNDM3UTIxIDQzNyAyMSA0NDVRMjEgNDUwIDM3IDUwMVQ3MSA2MDJMODggNjUxUTkzIDY2OSAxMDEgNjc3SDU2OUg2NTlRNjkxIDY3NyA2OTcgNjc2VDcwNCA2NjdRNzA0IDY2MSA2ODcgNTUzVDY2OCA0NDRRNjY4IDQzNyA2NDkgNDM3UTY0MCA0MzcgNjM3IDQzN1Q2MzEgNDQyTDYyOSA0NDVRNjI5IDQ1MSA2MzUgNDkwVDY0MSA1NTFRNjQxIDU4NiA2MjggNjA0VDU3MyA2MjlRNTY4IDYzMCA1MTUgNjMxUTQ2OSA2MzEgNDU3IDYzMFQ0MzkgNjIyUTQzOCA2MjEgMzY4IDM0M1QyOTggNjBRMjk4IDQ4IDM4NiA0NlE0MTggNDYgNDI3IDQ1VDQzNiAzNlE0MzYgMzEgNDMzIDIyUTQyOSA0IDQyNCAxTDQyMiAwUTQxOSAwIDQxNSAwUTQxMCAwIDM2MyAxVDIyOCAyUTk5IDIgNjQgMEg0OVE0MyA2IDQzIDlUNDUgMjdRNDkgNDAgNTUgNDZIODNIOTRRMTc0IDQ2IDE4OSA1NVExOTAgNTYgMTkxIDU2UTE5NiA1OSAyMDEgNzZUMjQxIDIzM1EyNTggMzAxIDI2OSAzNDRRMzM5IDYxOSAzMzkgNjI1UTMzOSA2MzAgMzEwIDYzMEgyNzlRMjEyIDYzMCAxOTEgNjI0UTE0NiA2MTQgMTIxIDU4M1Q2NyA0NjdRNjAgNDQ1IDU3IDQ0MVQ0MyA0MzdINDBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDIiIGQ9Ik0yMzEgNjM3UTIwNCA2MzcgMTk5IDYzOFQxOTQgNjQ5UTE5NCA2NzYgMjA1IDY4MlEyMDYgNjgzIDMzNSA2ODNRNTk0IDY4MyA2MDggNjgxUTY3MSA2NzEgNzEzIDYzNlQ3NTYgNTQ0UTc1NiA0ODAgNjk4IDQyOVQ1NjUgMzYwTDU1NSAzNTdRNjE5IDM0OCA2NjAgMzExVDcwMiAyMTlRNzAyIDE0NiA2MzAgNzhUNDUzIDFRNDQ2IDAgMjQyIDBRNDIgMCAzOSAyUTM1IDUgMzUgMTBRMzUgMTcgMzcgMjRRNDIgNDMgNDcgNDVRNTEgNDYgNjIgNDZINjhROTUgNDYgMTI4IDQ5UTE0MiA1MiAxNDcgNjFRMTUwIDY1IDIxOSAzMzlUMjg4IDYyOFEyODggNjM1IDIzMSA2MzdaTTY0OSA1NDRRNjQ5IDU3NCA2MzQgNjAwVDU4NSA2MzRRNTc4IDYzNiA0OTMgNjM3UTQ3MyA2MzcgNDUxIDYzN1Q0MTYgNjM2SDQwM1EzODggNjM1IDM4NCA2MjZRMzgyIDYyMiAzNTIgNTA2UTM1MiA1MDMgMzUxIDUwMEwzMjAgMzc0SDQwMVE0ODIgMzc0IDQ5NCAzNzZRNTU0IDM4NiA2MDEgNDM0VDY0OSA1NDRaTTU5NSAyMjlRNTk1IDI3MyA1NzIgMzAyVDUxMiAzMzZRNTA2IDMzNyA0MjkgMzM3UTMxMSAzMzcgMzEwIDMzNlEzMTAgMzM0IDI5MyAyNjNUMjU4IDEyMkwyNDAgNTJRMjQwIDQ4IDI1MiA0OFQzMzMgNDZRNDIyIDQ2IDQyOSA0N1E0OTEgNTQgNTQzIDEwNVQ1OTUgMjI5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNCIiBkPSJNNzggMzcwUTc4IDM5NCA5NSA0MTJUMTM4IDQzMFExNjIgNDMwIDE4MCA0MTRUMTk5IDM3MVExOTkgMzQ2IDE4MiAzMjhUMTM5IDMxMFQ5NiAzMjdUNzggMzcwWk03OCA2MFE3OCA4NSA5NCAxMDNUMTM3IDEyMVEyMDIgMTIxIDIwMiA4UTIwMiAtNDQgMTgzIC05NFQxNDQgLTE2OVQxMTggLTE5NFExMTUgLTE5NCAxMDYgLTE4NlQ5NSAtMTc0UTk0IC0xNzEgMTA3IC0xNTVUMTM3IC0xMDdUMTYwIC0zOFExNjEgLTMyIDE2MiAtMjJUMTY1IC00VDE2NSA0UTE2NSA1IDE2MSA0VDE0MiAwUTExMCAwIDk0IDE4VDc4IDYwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4NSwtMTExMCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iNTIxIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzAiIHg9IjEzMDAiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMUUiIHg9IjUyMSIgeT0iMTYyNyI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2MTEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTEwOSIgeT0iNDk5Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI4NjQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTEwOSIgeT0iNDk5Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii00NDYiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQyIiB4PSI0MTczIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTA5OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0IiIHg9IjYwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIxMDQ1IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxOTU2IiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3NDQ1LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjg2LDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNzIwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9Ijk5IiB5PSI2NzYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iNjAiIHk9Ii02ODYiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iODg1MCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDk2MjgsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMzYwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQzLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+Cjwvc3ZnPg==)
所以得到,
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjMzLjM3NmV4IiBoZWlnaHQ9IjUuNTA5ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMi4xNzFleDsiIHZpZXdCb3g9IjAgLTE0MzcuMiAxNDM3MCAyMzcyIiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQ1IiBkPSJNNDkyIDIxM1E0NzIgMjEzIDQ3MiAyMjZRNDcyIDIzMCA0NzcgMjUwVDQ4MiAyODVRNDgyIDMxNiA0NjEgMzIzVDM2NCAzMzBIMzEyUTMxMSAzMjggMjc3IDE5MlQyNDMgNTJRMjQzIDQ4IDI1NCA0OFQzMzQgNDZRNDI4IDQ2IDQ1OCA0OFQ1MTggNjFRNTY3IDc3IDU5OSAxMTdUNjcwIDI0OFE2ODAgMjcwIDY4MyAyNzJRNjkwIDI3NCA2OTggMjc0UTcxOCAyNzQgNzE4IDI2MVE2MTMgNyA2MDggMlE2MDUgMCAzMjIgMEgxMzNRMzEgMCAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDYgNjYgMjE1IDM0MlQyODUgNjIyUTI4NSA2MjkgMjgxIDYyOVEyNzMgNjMyIDIyOCA2MzRIMTk3UTE5MSA2NDAgMTkxIDY0MlQxOTMgNjU5UTE5NyA2NzYgMjAzIDY4MEg3NTdRNzY0IDY3NiA3NjQgNjY5UTc2NCA2NjQgNzUxIDU1N1Q3MzcgNDQ3UTczNSA0NDAgNzE3IDQ0MEg3MDVRNjk4IDQ0NSA2OTggNDUzTDcwMSA0NzZRNzA0IDUwMCA3MDQgNTI4UTcwNCA1NTggNjk3IDU3OFQ2NzggNjA5VDY0MyA2MjVUNTk2IDYzMlQ1MzIgNjM0SDQ4NVEzOTcgNjMzIDM5MiA2MzFRMzg4IDYyOSAzODYgNjIyUTM4NSA2MTkgMzU1IDQ5OVQzMjQgMzc3UTM0NyAzNzYgMzcyIDM3NkgzOThRNDY0IDM3NiA0ODkgMzkxVDUzNCA0NzJRNTM4IDQ4OCA1NDAgNDkwVDU1NyA0OTNRNTYyIDQ5MyA1NjUgNDkzVDU3MCA0OTJUNTcyIDQ5MVQ1NzQgNDg3VDU3NyA0ODNMNTQ0IDM1MVE1MTEgMjE4IDUwOCAyMTZRNTA1IDIxMyA0OTIgMjEzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0IiIGQ9Ik00MzQgLTIzMVE0MzQgLTI0NCA0MjggLTI1MEg0MTBRMjgxIC0yNTAgMjMwIC0xODRRMjI1IC0xNzcgMjIyIC0xNzJUMjE3IC0xNjFUMjEzIC0xNDhUMjExIC0xMzNUMjEwIC0xMTFUMjA5IC04NFQyMDkgLTQ3VDIwOSAwUTIwOSAyMSAyMDkgNTNRMjA4IDE0MiAyMDQgMTUzUTIwMyAxNTQgMjAzIDE1NVExODkgMTkxIDE1MyAyMTFUODIgMjMxUTcxIDIzMSA2OCAyMzRUNjUgMjUwVDY4IDI2NlQ4MiAyNjlRMTE2IDI2OSAxNTIgMjg5VDIwMyAzNDVRMjA4IDM1NiAyMDggMzc3VDIwOSA1MjlWNTc5UTIwOSA2MzQgMjE1IDY1NlQyNDQgNjk4UTI3MCA3MjQgMzI0IDc0MFEzNjEgNzQ4IDM3NyA3NDlRMzc5IDc0OSAzOTAgNzQ5VDQwOCA3NTBINDI4UTQzNCA3NDQgNDM0IDczMlE0MzQgNzE5IDQzMSA3MTZRNDI5IDcxMyA0MTUgNzEzUTM2MiA3MTAgMzMyIDY4OVQyOTYgNjQ3UTI5MSA2MzQgMjkxIDQ5OVY0MTdRMjkxIDM3MCAyODggMzUzVDI3MSAzMTRRMjQwIDI3MSAxODQgMjU1TDE3MCAyNTBMMTg0IDI0NVEyMDIgMjM5IDIyMCAyMzBUMjYyIDE5NlQyOTAgMTM3UTI5MSAxMzEgMjkxIDFRMjkxIC0xMzQgMjk2IC0xNDdRMzA2IC0xNzQgMzM5IC0xOTJUNDE1IC0yMTNRNDI5IC0yMTMgNDMxIC0yMTZRNDM0IC0yMTkgNDM0IC0yMzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTYiIGQ9Ik01MiA2NDhRNTIgNjcwIDY1IDY4M0g3NlExMTggNjgwIDE4MSA2ODBRMjk5IDY4MCAzMjAgNjgzSDMzMFEzMzYgNjc3IDMzNiA2NzRUMzM0IDY1NlEzMjkgNjQxIDMyNSA2MzdIMzA0UTI4MiA2MzUgMjc0IDYzNVEyNDUgNjMwIDI0MiA2MjBRMjQyIDYxOCAyNzEgMzY5VDMwMSAxMThMMzc0IDIzNVE0NDcgMzUyIDUyMCA0NzFUNTk1IDU5NFE1OTkgNjAxIDU5OSA2MDlRNTk5IDYzMyA1NTUgNjM3UTUzNyA2MzcgNTM3IDY0OFE1MzcgNjQ5IDUzOSA2NjFRNTQyIDY3NSA1NDUgNjc5VDU1OCA2ODNRNTYwIDY4MyA1NzAgNjgzVDYwNCA2ODJUNjY4IDY4MVE3MzcgNjgxIDc1NSA2ODNINzYyUTc2OSA2NzYgNzY5IDY3MlE3NjkgNjU1IDc2MCA2NDBRNzU3IDYzNyA3NDMgNjM3UTczMCA2MzYgNzE5IDYzNVQ2OTggNjMwVDY4MiA2MjNUNjcwIDYxNVQ2NjAgNjA4VDY1MiA1OTlUNjQ1IDU5Mkw0NTIgMjgyUTI3MiAtOSAyNjYgLTE2UTI2MyAtMTggMjU5IC0yMUwyNDEgLTIySDIzNFEyMTYgLTIyIDIxNiAtMTVRMjEzIC05IDE3NyAzMDVRMTM5IDYyMyAxMzggNjI2UTEzMyA2MzcgNzYgNjM3SDU5UTUyIDY0MiA1MiA2NDhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkUiIGQ9Ik0yMSAyODdRMjIgMjkzIDI0IDMwM1QzNiAzNDFUNTYgMzg4VDg5IDQyNVQxMzUgNDQyUTE3MSA0NDIgMTk1IDQyNFQyMjUgMzkwVDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzA0IDQ0MiAzODIgNDQyUTQzNiA0NDIgNDY5IDQxNVQ1MDMgMzM2VDQ2NSAxNzlUNDI3IDUyUTQyNyAyNiA0NDQgMjZRNDUwIDI2IDQ1MyAyN1E0ODIgMzIgNTA1IDY1VDU0MCAxNDVRNTQyIDE1MyA1NjAgMTUzUTU4MCAxNTMgNTgwIDE0NVE1ODAgMTQ0IDU3NiAxMzBRNTY4IDEwMSA1NTQgNzNUNTA4IDE3VDQzOSAtMTBRMzkyIC0xMCAzNzEgMTdUMzUwIDczUTM1MCA5MiAzODYgMTkzVDQyMyAzNDVRNDIzIDQwNCAzNzkgNDA0SDM3NFEyODggNDA0IDIyOSAzMDNMMjIyIDI5MUwxODkgMTU3UTE1NiAyNiAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExMiAxODBUMTUyIDM0M1ExNTMgMzQ4IDE1MyAzNjZRMTUzIDQwNSAxMjkgNDA1UTkxIDQwNSA2NiAzMDVRNjAgMjg1IDYwIDI4NFE1OCAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03RCIgZD0iTTY1IDczMVE2NSA3NDUgNjggNzQ3VDg4IDc1MFExNzEgNzUwIDIxNiA3MjVUMjc5IDY3MFEyODggNjQ5IDI4OSA2MzVUMjkxIDUwMVEyOTIgMzYyIDI5MyAzNTdRMzA2IDMxMiAzNDUgMjkxVDQxNyAyNjlRNDI4IDI2OSA0MzEgMjY2VDQzNCAyNTBUNDMxIDIzNFQ0MTcgMjMxUTM4MCAyMzEgMzQ1IDIxMFQyOTggMTU3UTI5MyAxNDMgMjkyIDEyMVQyOTEgLTI4Vi03OVEyOTEgLTEzNCAyODUgLTE1NlQyNTYgLTE5OFEyMDIgLTI1MCA4OSAtMjUwUTcxIC0yNTAgNjggLTI0N1Q2NSAtMjMwUTY1IC0yMjQgNjUgLTIyM1Q2NiAtMjE4VDY5IC0yMTRUNzcgLTIxM1E5MSAtMjEzIDEwOCAtMjEwVDE0NiAtMjAwVDE4MyAtMTc3VDIwNyAtMTM5UTIwOCAtMTM0IDIwOSAzTDIxMCAxMzlRMjIzIDE5NiAyODAgMjMwUTMxNSAyNDcgMzMwIDI1MFEzMDUgMjU3IDI4MCAyNzBRMjI1IDMwNCAyMTIgMzUyTDIxMCAzNjJMMjA5IDQ5OFEyMDggNjM1IDIwNyA2NDBRMTk1IDY4MCAxNTQgNjk2VDc3IDcxM1E2OCA3MTMgNjcgNzE2VDY1IDczMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjEtN0IiIGQ9Ik00NzcgLTM0M0w0NzEgLTM0OUg0NThRNDMyIC0zNDkgMzY3IC0zMjVUMjczIC0yNjNRMjU4IC0yNDUgMjUwIC0yMTJMMjQ5IC01MVEyNDkgLTI3IDI0OSAxMlEyNDggMTE4IDI0NCAxMjhRMjQzIDEyOSAyNDMgMTMwUTIyMCAxODkgMTIxIDIyOFExMDkgMjMyIDEwNyAyMzVUMTA1IDI1MFExMDUgMjU2IDEwNSAyNTdUMTA1IDI2MVQxMDcgMjY1VDExMSAyNjhUMTE4IDI3MlQxMjggMjc2VDE0MiAyODNUMTYyIDI5MVEyMjQgMzI0IDI0MyAzNzFRMjQzIDM3MiAyNDQgMzczUTI0OCAzODQgMjQ5IDQ2OVEyNDkgNDc1IDI0OSA0ODlRMjQ5IDUyOCAyNDkgNTUyTDI1MCA3MTRRMjUzIDcyOCAyNTYgNzM2VDI3MSA3NjFUMjk5IDc4OVQzNDcgODE2VDQyMiA4NDNRNDQwIDg0OSA0NDEgODQ5SDQ0M1E0NDUgODQ5IDQ0NyA4NDlUNDUyIDg1MFQ0NTcgODUwSDQ3MUw0NzcgODQ0VjgzMFE0NzcgODIwIDQ3NiA4MTdUNDcwIDgxMVQ0NTkgODA3VDQzNyA4MDFUNDA0IDc4NVEzNTMgNzYwIDMzOCA3MjRRMzMzIDcxMCAzMzMgNTUwUTMzMyA1MjYgMzMzIDQ5MlQzMzQgNDQ3UTMzNCAzOTMgMzI3IDM2OFQyOTUgMzE4UTI1NyAyODAgMTgxIDI1NUwxNjkgMjUxTDE4NCAyNDVRMzE4IDE5OCAzMzIgMTEyUTMzMyAxMDYgMzMzIC00OVEzMzMgLTIwOSAzMzggLTIyM1EzNTEgLTI1NSAzOTEgLTI3N1Q0NjkgLTMwOVE0NzcgLTMxMSA0NzcgLTMyOVYtMzQzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMS03RCIgZD0iTTExMCA4NDlMMTE1IDg1MFExMjAgODUwIDEyNSA4NTBRMTUxIDg1MCAyMTUgODI2VDMwOSA3NjRRMzI0IDc0NyAzMzIgNzE0TDMzMyA1NTJRMzMzIDUyOCAzMzMgNDg5UTMzNCAzODMgMzM4IDM3M1EzMzkgMzcyIDMzOSAzNzFRMzUzIDMzNiAzOTEgMzEwVDQ2OSAyNzFRNDc3IDI2OCA0NzcgMjUxUTQ3NyAyNDEgNDc2IDIzN1Q0NzIgMjMyVDQ1NiAyMjVUNDI4IDIxNFEzNTcgMTc5IDMzOSAxMzBRMzM5IDEyOSAzMzggMTI4UTMzNCAxMTcgMzMzIDMyUTMzMyAyNiAzMzMgMTJRMzMzIC0yNyAzMzMgLTUxTDMzMiAtMjEyUTMyOCAtMjI4IDMyMyAtMjQwVDMwMiAtMjcxVDI1NSAtMzA3VDE3NSAtMzM4UTEzOSAtMzQ5IDEyNSAtMzQ5VDEwOCAtMzQ2VDEwNSAtMzI5UTEwNSAtMzE0IDEwNyAtMzEyVDEzMCAtMzA0UTIzMyAtMjcxIDI0OCAtMjA5UTI0OSAtMjAzIDI0OSAtNDlWNTdRMjQ5IDEwNiAyNTMgMTI1VDI3MyAxNjdRMzA3IDIxMyAzOTggMjQ1TDQxMyAyNTFMNDAxIDI1NVEyNjUgMzAwIDI1MCAzODlRMjQ5IDM5NSAyNDkgNTUwUTI0OSA3MTAgMjQ0IDcyNFEyMjQgNzc0IDExMiA4MTFRMTA1IDgxMyAxMDUgODMwUTEwNSA4NDUgMTEwIDg0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUyIiBkPSJNMjMwIDYzN1EyMDMgNjM3IDE5OCA2MzhUMTkzIDY0OVExOTMgNjc2IDIwNCA2ODJRMjA2IDY4MyAzNzggNjgzUTU1MCA2ODIgNTY0IDY4MFE2MjAgNjcyIDY1OCA2NTJUNzEyIDYwNlQ3MzMgNTYzVDczOSA1MjlRNzM5IDQ4NCA3MTAgNDQ1VDY0MyAzODVUNTc2IDM1MVQ1MzggMzM4TDU0NSAzMzNRNjEyIDI5NSA2MTIgMjIzUTYxMiAyMTIgNjA3IDE2MlQ2MDIgODBWNzFRNjAyIDUzIDYwMyA0M1Q2MTQgMjVUNjQwIDE2UTY2OCAxNiA2ODYgMzhUNzEyIDg1UTcxNyA5OSA3MjAgMTAyVDczNSAxMDVRNzU1IDEwNSA3NTUgOTNRNzU1IDc1IDczMSAzNlE2OTMgLTIxIDY0MSAtMjFINjMyUTU3MSAtMjEgNTMxIDRUNDg3IDgyUTQ4NyAxMDkgNTAyIDE2NlQ1MTcgMjM5UTUxNyAyOTAgNDc0IDMxM1E0NTkgMzIwIDQ0OSAzMjFUMzc4IDMyM0gzMDlMMjc3IDE5M1EyNDQgNjEgMjQ0IDU5UTI0NCA1NSAyNDUgNTRUMjUyIDUwVDI2OSA0OFQzMDIgNDZIMzMzUTMzOSAzOCAzMzkgMzdUMzM2IDE5UTMzMiA2IDMyNiAwSDMxMVEyNzUgMiAxODAgMlExNDYgMiAxMTcgMlQ3MSAyVDUwIDFRMzMgMSAzMyAxMFEzMyAxMiAzNiAyNFE0MSA0MyA0NiA0NVE1MCA0NiA2MSA0Nkg2N1E5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4UTI4NyA2MzUgMjMwIDYzN1pNNjMwIDU1NFE2MzAgNTg2IDYwOSA2MDhUNTIzIDYzNlE1MjEgNjM2IDUwMCA2MzZUNDYyIDYzN0g0NDBRMzkzIDYzNyAzODYgNjI3UTM4NSA2MjQgMzUyIDQ5NFQzMTkgMzYxUTMxOSAzNjAgMzg4IDM2MFE0NjYgMzYxIDQ5MiAzNjdRNTU2IDM3NyA1OTIgNDI2UTYwOCA0NDkgNjE5IDQ4NlQ2MzAgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU0IiBkPSJNNDAgNDM3UTIxIDQzNyAyMSA0NDVRMjEgNDUwIDM3IDUwMVQ3MSA2MDJMODggNjUxUTkzIDY2OSAxMDEgNjc3SDU2OUg2NTlRNjkxIDY3NyA2OTcgNjc2VDcwNCA2NjdRNzA0IDY2MSA2ODcgNTUzVDY2OCA0NDRRNjY4IDQzNyA2NDkgNDM3UTY0MCA0MzcgNjM3IDQzN1Q2MzEgNDQyTDYyOSA0NDVRNjI5IDQ1MSA2MzUgNDkwVDY0MSA1NTFRNjQxIDU4NiA2MjggNjA0VDU3MyA2MjlRNTY4IDYzMCA1MTUgNjMxUTQ2OSA2MzEgNDU3IDYzMFQ0MzkgNjIyUTQzOCA2MjEgMzY4IDM0M1QyOTggNjBRMjk4IDQ4IDM4NiA0NlE0MTggNDYgNDI3IDQ1VDQzNiAzNlE0MzYgMzEgNDMzIDIyUTQyOSA0IDQyNCAxTDQyMiAwUTQxOSAwIDQxNSAwUTQxMCAwIDM2MyAxVDIyOCAyUTk5IDIgNjQgMEg0OVE0MyA2IDQzIDlUNDUgMjdRNDkgNDAgNTUgNDZIODNIOTRRMTc0IDQ2IDE4OSA1NVExOTAgNTYgMTkxIDU2UTE5NiA1OSAyMDEgNzZUMjQxIDIzM1EyNTggMzAxIDI2OSAzNDRRMzM5IDYxOSAzMzkgNjI1UTMzOSA2MzAgMzEwIDYzMEgyNzlRMjEyIDYzMCAxOTEgNjI0UTE0NiA2MTQgMTIxIDU4M1Q2NyA0NjdRNjAgNDQ1IDU3IDQ0MVQ0MyA0MzdINDBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yQiIgZD0iTTU2IDIzN1Q1NiAyNTBUNzAgMjcwSDM2OVY0MjBMMzcwIDU3MFEzODAgNTgzIDM4OSA1ODNRNDAyIDU4MyA0MDkgNTY4VjI3MEg3MDdRNzIyIDI2MiA3MjIgMjUwVDcwNyAyMzBINDA5Vi02OFE0MDEgLTgyIDM5MSAtODJIMzg5SDM4N1EzNzUgLTgyIDM2OSAtNjhWMjMwSDcwUTU2IDIzNyA1NiAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMSIgZD0iTTIxMyA1NzhMMjAwIDU3M1ExODYgNTY4IDE2MCA1NjNUMTAyIDU1Nkg4M1Y2MDJIMTAyUTE0OSA2MDQgMTg5IDYxN1QyNDUgNjQxVDI3MyA2NjNRMjc1IDY2NiAyODUgNjY2UTI5NCA2NjYgMzAyIDY2MFYzNjFMMzAzIDYxUTMxMCA1NCAzMTUgNTJUMzM5IDQ4VDQwMSA0Nkg0MjdWMEg0MTZRMzk1IDMgMjU3IDNRMTIxIDMgMTAwIDBIODhWNDZIMTE0UTEzNiA0NiAxNTIgNDZUMTc3IDQ3VDE5MyA1MFQyMDEgNTJUMjA3IDU3VDIxMyA2MVY1NzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTAiIGQ9Ik0yODcgNjI4UTI4NyA2MzUgMjMwIDYzN1EyMDYgNjM3IDE5OSA2MzhUMTkyIDY0OFExOTIgNjQ5IDE5NCA2NTlRMjAwIDY3OSAyMDMgNjgxVDM5NyA2ODNRNTg3IDY4MiA2MDAgNjgwUTY2NCA2NjkgNzA3IDYzMVQ3NTEgNTMwUTc1MSA0NTMgNjg1IDM4OVE2MTYgMzIxIDUwNyAzMDNRNTAwIDMwMiA0MDIgMzAxSDMwN0wyNzcgMTgyUTI0NyA2NiAyNDcgNTlRMjQ3IDU1IDI0OCA1NFQyNTUgNTBUMjcyIDQ4VDMwNSA0NkgzMzZRMzQyIDM3IDM0MiAzNVEzNDIgMTkgMzM1IDVRMzMwIDAgMzE5IDBRMzE2IDAgMjgyIDFUMTgyIDJRMTIwIDIgODcgMlQ1MSAxUTMzIDEgMzMgMTFRMzMgMTMgMzYgMjVRNDAgNDEgNDQgNDNUNjcgNDZROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFpNNjQ1IDU1NFE2NDUgNTY3IDY0MyA1NzVUNjM0IDU5N1Q2MDkgNjE5VDU2MCA2MzVRNTUzIDYzNiA0ODAgNjM3UTQ2MyA2MzcgNDQ1IDYzN1Q0MTYgNjM2VDQwNCA2MzZRMzkxIDYzNSAzODYgNjI3UTM4NCA2MjEgMzY3IDU1MFQzMzIgNDEyVDMxNCAzNDRRMzE0IDM0MiAzOTUgMzQySDQwN0g0MzBRNTQyIDM0MiA1OTAgMzkyUTYxNyA0MTkgNjMxIDQ3MVQ2NDUgNTU0WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTMxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTdCIiB4PSIwIiB5PSItMSI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU4MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIxMTY3IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjgyNSIgeT0iLTIxMiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2MzIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjEtN0QiIHg9IjM0NjQiIHk9Ii0xIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI1MjU3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjMxMywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI3ODkzIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODY3MSwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjI0NDMiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iOTIxIiB5PSI2NzYiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNjg3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iODIyIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTgyMyIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDExNTc3LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTM2MCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0Myw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTMxNzgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=)
因此 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQ3LjU0MWV4IiBoZWlnaHQ9IjUuNTA5ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMi4xNzFleDsiIHZpZXdCb3g9IjAgLTE0MzcuMiAyMDQ2OC44IDIzNzIiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi00MiIgZD0iTTEzMSA2MjJRMTI0IDYyOSAxMjAgNjMxVDEwNCA2MzRUNjEgNjM3SDI4VjY4M0gyMjlIMjY3SDM0NlE0MjMgNjgzIDQ1OSA2NzhUNTMxIDY1MVE1NzQgNjI3IDU5OSA1OTBUNjI0IDUxMlE2MjQgNDYxIDU4MyA0MTlUNDc2IDM2MEw0NjYgMzU3UTUzOSAzNDggNTk1IDMwMlQ2NTEgMTg3UTY1MSAxMTkgNjAwIDY3VDQ2OSAzUTQ1NiAxIDI0MiAwSDI4VjQ2SDYxUTEwMyA0NyAxMTIgNDlUMTMxIDYxVjYyMlpNNTExIDUxM1E1MTEgNTYwIDQ4NSA1OTRUNDE2IDYzNlE0MTUgNjM2IDQwMyA2MzZUMzcxIDYzNlQzMzMgNjM3UTI2NiA2MzcgMjUxIDYzNlQyMzIgNjI4UTIyOSA2MjQgMjI5IDQ5OVYzNzRIMzEyTDM5NiAzNzVMNDA2IDM3N1E0MTAgMzc4IDQxNyAzODBUNDQyIDM5M1Q0NzQgNDE3VDQ5OSA0NTZUNTExIDUxM1pNNTM3IDE4OFE1MzcgMjM5IDUwOSAyODJUNDMwIDMzNkwzMjkgMzM3SDIyOVYyMDBWMTE2UTIyOSA1NyAyMzQgNTJRMjQwIDQ3IDMzNCA0N0gzODNRNDI1IDQ3IDQ0MyA1M1E0ODYgNjcgNTExIDEwNFQ1MzcgMTg4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNjkiIGQ9Ik02OSA2MDlRNjkgNjM3IDg3IDY1M1QxMzEgNjY5UTE1NCA2NjcgMTcxIDY1MlQxODggNjA5UTE4OCA1NzkgMTcxIDU2NFQxMjkgNTQ5UTEwNCA1NDkgODcgNTY0VDY5IDYwOVpNMjQ3IDBRMjMyIDMgMTQzIDNRMTMyIDMgMTA2IDNUNTYgMUwzNCAwSDI2VjQ2SDQyUTcwIDQ2IDkxIDQ5UTEwMCA1MyAxMDIgNjBUMTA0IDEwMlYyMDVWMjkzUTEwNCAzNDUgMTAyIDM1OVQ4OCAzNzhRNzQgMzg1IDQxIDM4NUgzMFY0MDhRMzAgNDMxIDMyIDQzMUw0MiA0MzJRNTIgNDMzIDcwIDQzNFQxMDYgNDM2UTEyMyA0MzcgMTQyIDQzOFQxNzEgNDQxVDE4MiA0NDJIMTg1VjYyUTE5MCA1MiAxOTcgNTBUMjMyIDQ2SDI1NVYwSDI0N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTYxIiBkPSJNMTM3IDMwNVQxMTUgMzA1VDc4IDMyMFQ2MyAzNTlRNjMgMzk0IDk3IDQyMVQyMTggNDQ4UTI5MSA0NDggMzM2IDQxNlQzOTYgMzQwUTQwMSAzMjYgNDAxIDMwOVQ0MDIgMTk0VjEyNFE0MDIgNzYgNDA3IDU4VDQyOCA0MFE0NDMgNDAgNDQ4IDU2VDQ1MyAxMDlWMTQ1SDQ5M1YxMDZRNDkyIDY2IDQ5MCA1OVE0ODEgMjkgNDU1IDEyVDQwMCAtNlQzNTMgMTJUMzI5IDU0VjU4TDMyNyA1NVEzMjUgNTIgMzIyIDQ5VDMxNCA0MFQzMDIgMjlUMjg3IDE3VDI2OSA2VDI0NyAtMlQyMjEgLThUMTkwIC0xMVExMzAgLTExIDgyIDIwVDM0IDEwN1EzNCAxMjggNDEgMTQ3VDY4IDE4OFQxMTYgMjI1VDE5NCAyNTNUMzA0IDI2OEgzMThWMjkwUTMxOCAzMjQgMzEyIDM0MFEyOTAgNDExIDIxNSA0MTFRMTk3IDQxMSAxODEgNDEwVDE1NiA0MDZUMTQ4IDQwM1ExNzAgMzg4IDE3MCAzNTlRMTcwIDMzNCAxNTQgMzIwWk0xMjYgMTA2UTEyNiA3NSAxNTAgNTFUMjA5IDI2UTI0NyAyNiAyNzYgNDlUMzE1IDEwOVEzMTcgMTE2IDMxOCAxNzVRMzE4IDIzMyAzMTcgMjMzUTMwOSAyMzMgMjk2IDIzMlQyNTEgMjIzVDE5MyAyMDNUMTQ3IDE2NlQxMjYgMTA2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNzMiIGQ9Ik0yOTUgMzE2UTI5NSAzNTYgMjY4IDM4NVQxOTAgNDE0UTE1NCA0MTQgMTI4IDQwMVE5OCAzODIgOTggMzQ5UTk3IDM0NCA5OCAzMzZUMTE0IDMxMlQxNTcgMjg3UTE3NSAyODIgMjAxIDI3OFQyNDUgMjY5VDI3NyAyNTZRMjk0IDI0OCAzMTAgMjM2VDM0MiAxOTVUMzU5IDEzM1EzNTkgNzEgMzIxIDMxVDE5OCAtMTBIMTkwUTEzOCAtMTAgOTQgMjZMODYgMTlMNzcgMTBRNzEgNCA2NSAtMUw1NCAtMTFINDZINDJRMzkgLTExIDMzIC01Vjc0VjEzMlEzMyAxNTMgMzUgMTU3VDQ1IDE2Mkg1NFE2NiAxNjIgNzAgMTU4VDc1IDE0NlQ4MiAxMTlUMTAxIDc3UTEzNiAyNiAxOTggMjZRMjk1IDI2IDI5NSAxMDRRMjk1IDEzMyAyNzcgMTUxUTI1NyAxNzUgMTk0IDE4N1QxMTEgMjEwUTc1IDIyNyA1NCAyNTZUMzMgMzE4UTMzIDM1NyA1MCAzODRUOTMgNDI0VDE0MyA0NDJUMTg3IDQ0N0gxOThRMjM4IDQ0NyAyNjggNDMyTDI4MyA0MjRMMjkyIDQzMVEzMDIgNDQwIDMxNCA0NDhIMzIySDMyNlEzMjkgNDQ4IDMzNSA0NDJWMzEwTDMyOSAzMDRIMzAxUTI5NSAzMTAgMjk1IDMxNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NSIgZD0iTTQ5MiAyMTNRNDcyIDIxMyA0NzIgMjI2UTQ3MiAyMzAgNDc3IDI1MFQ0ODIgMjg1UTQ4MiAzMTYgNDYxIDMyM1QzNjQgMzMwSDMxMlEzMTEgMzI4IDI3NyAxOTJUMjQzIDUyUTI0MyA0OCAyNTQgNDhUMzM0IDQ2UTQyOCA0NiA0NTggNDhUNTE4IDYxUTU2NyA3NyA1OTkgMTE3VDY3MCAyNDhRNjgwIDI3MCA2ODMgMjcyUTY5MCAyNzQgNjk4IDI3NFE3MTggMjc0IDcxOCAyNjFRNjEzIDcgNjA4IDJRNjA1IDAgMzIyIDBIMTMzUTMxIDAgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ2IDY2IDIxNSAzNDJUMjg1IDYyMlEyODUgNjI5IDI4MSA2MjlRMjczIDYzMiAyMjggNjM0SDE5N1ExOTEgNjQwIDE5MSA2NDJUMTkzIDY1OVExOTcgNjc2IDIwMyA2ODBINzU3UTc2NCA2NzYgNzY0IDY2OVE3NjQgNjY0IDc1MSA1NTdUNzM3IDQ0N1E3MzUgNDQwIDcxNyA0NDBINzA1UTY5OCA0NDUgNjk4IDQ1M0w3MDEgNDc2UTcwNCA1MDAgNzA0IDUyOFE3MDQgNTU4IDY5NyA1NzhUNjc4IDYwOVQ2NDMgNjI1VDU5NiA2MzJUNTMyIDYzNEg0ODVRMzk3IDYzMyAzOTIgNjMxUTM4OCA2MjkgMzg2IDYyMlEzODUgNjE5IDM1NSA0OTlUMzI0IDM3N1EzNDcgMzc2IDM3MiAzNzZIMzk4UTQ2NCAzNzYgNDg5IDM5MVQ1MzQgNDcyUTUzOCA0ODggNTQwIDQ5MFQ1NTcgNDkzUTU2MiA0OTMgNTY1IDQ5M1Q1NzAgNDkyVDU3MiA0OTFUNTc0IDQ4N1Q1NzcgNDgzTDU0NCAzNTFRNTExIDIxOCA1MDggMjE2UTUwNSAyMTMgNDkyIDIxM1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU2IiBkPSJNNTIgNjQ4UTUyIDY3MCA2NSA2ODNINzZRMTE4IDY4MCAxODEgNjgwUTI5OSA2ODAgMzIwIDY4M0gzMzBRMzM2IDY3NyAzMzYgNjc0VDMzNCA2NTZRMzI5IDY0MSAzMjUgNjM3SDMwNFEyODIgNjM1IDI3NCA2MzVRMjQ1IDYzMCAyNDIgNjIwUTI0MiA2MTggMjcxIDM2OVQzMDEgMTE4TDM3NCAyMzVRNDQ3IDM1MiA1MjAgNDcxVDU5NSA1OTRRNTk5IDYwMSA1OTkgNjA5UTU5OSA2MzMgNTU1IDYzN1E1MzcgNjM3IDUzNyA2NDhRNTM3IDY0OSA1MzkgNjYxUTU0MiA2NzUgNTQ1IDY3OVQ1NTggNjgzUTU2MCA2ODMgNTcwIDY4M1Q2MDQgNjgyVDY2OCA2ODFRNzM3IDY4MSA3NTUgNjgzSDc2MlE3NjkgNjc2IDc2OSA2NzJRNzY5IDY1NSA3NjAgNjQwUTc1NyA2MzcgNzQzIDYzN1E3MzAgNjM2IDcxOSA2MzVUNjk4IDYzMFQ2ODIgNjIzVDY3MCA2MTVUNjYwIDYwOFQ2NTIgNTk5VDY0NSA1OTJMNDUyIDI4MlEyNzIgLTkgMjY2IC0xNlEyNjMgLTE4IDI1OSAtMjFMMjQxIC0yMkgyMzRRMjE2IC0yMiAyMTYgLTE1UTIxMyAtOSAxNzcgMzA1UTEzOSA2MjMgMTM4IDYyNlExMzMgNjM3IDc2IDYzN0g1OVE1MiA2NDIgNTIgNjQ4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjIxMiIgZD0iTTg0IDIzN1Q4NCAyNTBUOTggMjcwSDY3OVE2OTQgMjYyIDY5NCAyNTBUNjc5IDIzMEg5OFE4NCAyMzcgODQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0IiIGQ9Ik00MzQgLTIzMVE0MzQgLTI0NCA0MjggLTI1MEg0MTBRMjgxIC0yNTAgMjMwIC0xODRRMjI1IC0xNzcgMjIyIC0xNzJUMjE3IC0xNjFUMjEzIC0xNDhUMjExIC0xMzNUMjEwIC0xMTFUMjA5IC04NFQyMDkgLTQ3VDIwOSAwUTIwOSAyMSAyMDkgNTNRMjA4IDE0MiAyMDQgMTUzUTIwMyAxNTQgMjAzIDE1NVExODkgMTkxIDE1MyAyMTFUODIgMjMxUTcxIDIzMSA2OCAyMzRUNjUgMjUwVDY4IDI2NlQ4MiAyNjlRMTE2IDI2OSAxNTIgMjg5VDIwMyAzNDVRMjA4IDM1NiAyMDggMzc3VDIwOSA1MjlWNTc5UTIwOSA2MzQgMjE1IDY1NlQyNDQgNjk4UTI3MCA3MjQgMzI0IDc0MFEzNjEgNzQ4IDM3NyA3NDlRMzc5IDc0OSAzOTAgNzQ5VDQwOCA3NTBINDI4UTQzNCA3NDQgNDM0IDczMlE0MzQgNzE5IDQzMSA3MTZRNDI5IDcxMyA0MTUgNzEzUTM2MiA3MTAgMzMyIDY4OVQyOTYgNjQ3UTI5MSA2MzQgMjkxIDQ5OVY0MTdRMjkxIDM3MCAyODggMzUzVDI3MSAzMTRRMjQwIDI3MSAxODQgMjU1TDE3MCAyNTBMMTg0IDI0NVEyMDIgMjM5IDIyMCAyMzBUMjYyIDE5NlQyOTAgMTM3UTI5MSAxMzEgMjkxIDFRMjkxIC0xMzQgMjk2IC0xNDdRMzA2IC0xNzQgMzM5IC0xOTJUNDE1IC0yMTNRNDI5IC0yMTMgNDMxIC0yMTZRNDM0IC0yMTkgNDM0IC0yMzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03RCIgZD0iTTY1IDczMVE2NSA3NDUgNjggNzQ3VDg4IDc1MFExNzEgNzUwIDIxNiA3MjVUMjc5IDY3MFEyODggNjQ5IDI4OSA2MzVUMjkxIDUwMVEyOTIgMzYyIDI5MyAzNTdRMzA2IDMxMiAzNDUgMjkxVDQxNyAyNjlRNDI4IDI2OSA0MzEgMjY2VDQzNCAyNTBUNDMxIDIzNFQ0MTcgMjMxUTM4MCAyMzEgMzQ1IDIxMFQyOTggMTU3UTI5MyAxNDMgMjkyIDEyMVQyOTEgLTI4Vi03OVEyOTEgLTEzNCAyODUgLTE1NlQyNTYgLTE5OFEyMDIgLTI1MCA4OSAtMjUwUTcxIC0yNTAgNjggLTI0N1Q2NSAtMjMwUTY1IC0yMjQgNjUgLTIyM1Q2NiAtMjE4VDY5IC0yMTRUNzcgLTIxM1E5MSAtMjEzIDEwOCAtMjEwVDE0NiAtMjAwVDE4MyAtMTc3VDIwNyAtMTM5UTIwOCAtMTM0IDIwOSAzTDIxMCAxMzlRMjIzIDE5NiAyODAgMjMwUTMxNSAyNDcgMzMwIDI1MFEzMDUgMjU3IDI4MCAyNzBRMjI1IDMwNCAyMTIgMzUyTDIxMCAzNjJMMjA5IDQ5OFEyMDggNjM1IDIwNyA2NDBRMTk1IDY4MCAxNTQgNjk2VDc3IDcxM1E2OCA3MTMgNjcgNzE2VDY1IDczMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjEtN0IiIGQ9Ik00NzcgLTM0M0w0NzEgLTM0OUg0NThRNDMyIC0zNDkgMzY3IC0zMjVUMjczIC0yNjNRMjU4IC0yNDUgMjUwIC0yMTJMMjQ5IC01MVEyNDkgLTI3IDI0OSAxMlEyNDggMTE4IDI0NCAxMjhRMjQzIDEyOSAyNDMgMTMwUTIyMCAxODkgMTIxIDIyOFExMDkgMjMyIDEwNyAyMzVUMTA1IDI1MFExMDUgMjU2IDEwNSAyNTdUMTA1IDI2MVQxMDcgMjY1VDExMSAyNjhUMTE4IDI3MlQxMjggMjc2VDE0MiAyODNUMTYyIDI5MVEyMjQgMzI0IDI0MyAzNzFRMjQzIDM3MiAyNDQgMzczUTI0OCAzODQgMjQ5IDQ2OVEyNDkgNDc1IDI0OSA0ODlRMjQ5IDUyOCAyNDkgNTUyTDI1MCA3MTRRMjUzIDcyOCAyNTYgNzM2VDI3MSA3NjFUMjk5IDc4OVQzNDcgODE2VDQyMiA4NDNRNDQwIDg0OSA0NDEgODQ5SDQ0M1E0NDUgODQ5IDQ0NyA4NDlUNDUyIDg1MFQ0NTcgODUwSDQ3MUw0NzcgODQ0VjgzMFE0NzcgODIwIDQ3NiA4MTdUNDcwIDgxMVQ0NTkgODA3VDQzNyA4MDFUNDA0IDc4NVEzNTMgNzYwIDMzOCA3MjRRMzMzIDcxMCAzMzMgNTUwUTMzMyA1MjYgMzMzIDQ5MlQzMzQgNDQ3UTMzNCAzOTMgMzI3IDM2OFQyOTUgMzE4UTI1NyAyODAgMTgxIDI1NUwxNjkgMjUxTDE4NCAyNDVRMzE4IDE5OCAzMzIgMTEyUTMzMyAxMDYgMzMzIC00OVEzMzMgLTIwOSAzMzggLTIyM1EzNTEgLTI1NSAzOTEgLTI3N1Q0NjkgLTMwOVE0NzcgLTMxMSA0NzcgLTMyOVYtMzQzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMS03RCIgZD0iTTExMCA4NDlMMTE1IDg1MFExMjAgODUwIDEyNSA4NTBRMTUxIDg1MCAyMTUgODI2VDMwOSA3NjRRMzI0IDc0NyAzMzIgNzE0TDMzMyA1NTJRMzMzIDUyOCAzMzMgNDg5UTMzNCAzODMgMzM4IDM3M1EzMzkgMzcyIDMzOSAzNzFRMzUzIDMzNiAzOTEgMzEwVDQ2OSAyNzFRNDc3IDI2OCA0NzcgMjUxUTQ3NyAyNDEgNDc2IDIzN1Q0NzIgMjMyVDQ1NiAyMjVUNDI4IDIxNFEzNTcgMTc5IDMzOSAxMzBRMzM5IDEyOSAzMzggMTI4UTMzNCAxMTcgMzMzIDMyUTMzMyAyNiAzMzMgMTJRMzMzIC0yNyAzMzMgLTUxTDMzMiAtMjEyUTMyOCAtMjI4IDMyMyAtMjQwVDMwMiAtMjcxVDI1NSAtMzA3VDE3NSAtMzM4UTEzOSAtMzQ5IDEyNSAtMzQ5VDEwOCAtMzQ2VDEwNSAtMzI5UTEwNSAtMzE0IDEwNyAtMzEyVDEzMCAtMzA0UTIzMyAtMjcxIDI0OCAtMjA5UTI0OSAtMjAzIDI0OSAtNDlWNTdRMjQ5IDEwNiAyNTMgMTI1VDI3MyAxNjdRMzA3IDIxMyAzOTggMjQ1TDQxMyAyNTFMNDAxIDI1NVEyNjUgMzAwIDI1MCAzODlRMjQ5IDM5NSAyNDkgNTUwUTI0OSA3MTAgMjQ0IDcyNFEyMjQgNzc0IDExMiA4MTFRMTA1IDgxMyAxMDUgODMwUTEwNSA4NDUgMTEwIDg0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJCIiBkPSJNNTYgMjM3VDU2IDI1MFQ3MCAyNzBIMzY5VjQyMEwzNzAgNTcwUTM4MCA1ODMgMzg5IDU4M1E0MDIgNTgzIDQwOSA1NjhWMjcwSDcwN1E3MjIgMjYyIDcyMiAyNTBUNzA3IDIzMEg0MDlWLTY4UTQwMSAtODIgMzkxIC04MkgzODlIMzg3UTM3NSAtODIgMzY5IC02OFYyMzBINzBRNTYgMjM3IDU2IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MCIgZD0iTTI4NyA2MjhRMjg3IDYzNSAyMzAgNjM3UTIwNiA2MzcgMTk5IDYzOFQxOTIgNjQ4UTE5MiA2NDkgMTk0IDY1OVEyMDAgNjc5IDIwMyA2ODFUMzk3IDY4M1E1ODcgNjgyIDYwMCA2ODBRNjY0IDY2OSA3MDcgNjMxVDc1MSA1MzBRNzUxIDQ1MyA2ODUgMzg5UTYxNiAzMjEgNTA3IDMwM1E1MDAgMzAyIDQwMiAzMDFIMzA3TDI3NyAxODJRMjQ3IDY2IDI0NyA1OVEyNDcgNTUgMjQ4IDU0VDI1NSA1MFQyNzIgNDhUMzA1IDQ2SDMzNlEzNDIgMzcgMzQyIDM1UTM0MiAxOSAzMzUgNVEzMzAgMCAzMTkgMFEzMTYgMCAyODIgMVQxODIgMlExMjAgMiA4NyAyVDUxIDFRMzMgMSAzMyAxMVEzMyAxMyAzNiAyNVE0MCA0MSA0NCA0M1Q2NyA0NlE5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4Wk02NDUgNTU0UTY0NSA1NjcgNjQzIDU3NVQ2MzQgNTk3VDYwOSA2MTlUNTYwIDYzNVE1NTMgNjM2IDQ4MCA2MzdRNDYzIDYzNyA0NDUgNjM3VDQxNiA2MzZUNDA0IDYzNlEzOTEgNjM1IDM4NiA2MjdRMzg0IDYyMSAzNjcgNTUwVDMzMiA0MTJUMzE0IDM0NFEzMTQgMzQyIDM5NSAzNDJINDA3SDQzMFE1NDIgMzQyIDU5MCAzOTJRNjE3IDQxOSA2MzEgNDcxVDY0NSA1NTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTQiIGQ9Ik00MCA0MzdRMjEgNDM3IDIxIDQ0NVEyMSA0NTAgMzcgNTAxVDcxIDYwMkw4OCA2NTFROTMgNjY5IDEwMSA2NzdINTY5SDY1OVE2OTEgNjc3IDY5NyA2NzZUNzA0IDY2N1E3MDQgNjYxIDY4NyA1NTNUNjY4IDQ0NFE2NjggNDM3IDY0OSA0MzdRNjQwIDQzNyA2MzcgNDM3VDYzMSA0NDJMNjI5IDQ0NVE2MjkgNDUxIDYzNSA0OTBUNjQxIDU1MVE2NDEgNTg2IDYyOCA2MDRUNTczIDYyOVE1NjggNjMwIDUxNSA2MzFRNDY5IDYzMSA0NTcgNjMwVDQzOSA2MjJRNDM4IDYyMSAzNjggMzQzVDI5OCA2MFEyOTggNDggMzg2IDQ2UTQxOCA0NiA0MjcgNDVUNDM2IDM2UTQzNiAzMSA0MzMgMjJRNDI5IDQgNDI0IDFMNDIyIDBRNDE5IDAgNDE1IDBRNDEwIDAgMzYzIDFUMjI4IDJROTkgMiA2NCAwSDQ5UTQzIDYgNDMgOVQ0NSAyN1E0OSA0MCA1NSA0Nkg4M0g5NFExNzQgNDYgMTg5IDU1UTE5MCA1NiAxOTEgNTZRMTk2IDU5IDIwMSA3NlQyNDEgMjMzUTI1OCAzMDEgMjY5IDM0NFEzMzkgNjE5IDMzOSA2MjVRMzM5IDYzMCAzMTAgNjMwSDI3OVEyMTIgNjMwIDE5MSA2MjRRMTQ2IDYxNCAxMjEgNTgzVDY3IDQ2N1E2MCA0NDUgNTcgNDQxVDQzIDQzN0g0MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MiIgZD0iTTIzMCA2MzdRMjAzIDYzNyAxOTggNjM4VDE5MyA2NDlRMTkzIDY3NiAyMDQgNjgyUTIwNiA2ODMgMzc4IDY4M1E1NTAgNjgyIDU2NCA2ODBRNjIwIDY3MiA2NTggNjUyVDcxMiA2MDZUNzMzIDU2M1Q3MzkgNTI5UTczOSA0ODQgNzEwIDQ0NVQ2NDMgMzg1VDU3NiAzNTFUNTM4IDMzOEw1NDUgMzMzUTYxMiAyOTUgNjEyIDIyM1E2MTIgMjEyIDYwNyAxNjJUNjAyIDgwVjcxUTYwMiA1MyA2MDMgNDNUNjE0IDI1VDY0MCAxNlE2NjggMTYgNjg2IDM4VDcxMiA4NVE3MTcgOTkgNzIwIDEwMlQ3MzUgMTA1UTc1NSAxMDUgNzU1IDkzUTc1NSA3NSA3MzEgMzZRNjkzIC0yMSA2NDEgLTIxSDYzMlE1NzEgLTIxIDUzMSA0VDQ4NyA4MlE0ODcgMTA5IDUwMiAxNjZUNTE3IDIzOVE1MTcgMjkwIDQ3NCAzMTNRNDU5IDMyMCA0NDkgMzIxVDM3OCAzMjNIMzA5TDI3NyAxOTNRMjQ0IDYxIDI0NCA1OVEyNDQgNTUgMjQ1IDU0VDI1MiA1MFQyNjkgNDhUMzAyIDQ2SDMzM1EzMzkgMzggMzM5IDM3VDMzNiAxOVEzMzIgNiAzMjYgMEgzMTFRMjc1IDIgMTgwIDJRMTQ2IDIgMTE3IDJUNzEgMlQ1MCAxUTMzIDEgMzMgMTBRMzMgMTIgMzYgMjRRNDEgNDMgNDYgNDVRNTAgNDYgNjEgNDZINjdROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFEyODcgNjM1IDIzMCA2MzdaTTYzMCA1NTRRNjMwIDU4NiA2MDkgNjA4VDUyMyA2MzZRNTIxIDYzNiA1MDAgNjM2VDQ2MiA2MzdINDQwUTM5MyA2MzcgMzg2IDYyN1EzODUgNjI0IDM1MiA0OTRUMzE5IDM2MVEzMTkgMzYwIDM4OCAzNjBRNDY2IDM2MSA0OTIgMzY3UTU1NiAzNzcgNTkyIDQyNlE2MDggNDQ5IDYxOSA0ODZUNjMwIDU1NFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTQyIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02OSIgeD0iNzA4IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iOTg3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MyIgeD0iMTQ4NyIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iMjY2MSIgeT0iNTgxIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIyNjYxIiB5PSItMzUwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjY4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI0MjE1IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjUyNzEiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MjA3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iNzY3OCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSI4Njc5IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTYxMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMS03QiIgeD0iMCIgeT0iLTEiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1ODMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iMTE2NyIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI4MjUiIHk9Ii0yMTIiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjMyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTdEIiB4PSIzNDY0IiB5PSItMSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMTM5MzYiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDcxNCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM5NywwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjI0NDMiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSI5NzEiIHk9IjY3NiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC02ODcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI4MjIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxODIzIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTc2NzYsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMzYwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQzLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxOTI3NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==) 。这也证明了每次访问MC方法在 时是无偏的。
。这也证明了每次访问MC方法在 时是无偏的。
给出(2)的证明:
将 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjcuNDczZXgiIGhlaWdodD0iMi44NDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjgzOGV4OyIgdmlld0JveD0iMCAtODYzLjEgMzIxNy4zIDEyMjMuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNCIiBkPSJNNzggMzcwUTc4IDM5NCA5NSA0MTJUMTM4IDQzMFExNjIgNDMwIDE4MCA0MTRUMTk5IDM3MVExOTkgMzQ2IDE4MiAzMjhUMTM5IDMxMFQ5NiAzMjdUNzggMzcwWk03OCA2MFE3OCA4NSA5NCAxMDNUMTM3IDEyMVEyMDIgMTIxIDIwMiA4UTIwMiAtNDQgMTgzIC05NFQxNDQgLTE2OVQxMTggLTE5NFExMTUgLTE5NCAxMDYgLTE4NlQ5NSAtMTc0UTk0IC0xNzEgMTA3IC0xNTVUMTM3IC0xMDdUMTYwIC0zOFExNjEgLTMyIDE2MiAtMjJUMTY1IC00VDE2NSA0UTE2NSA1IDE2MSA0VDE0MiAwUTExMCAwIDk0IDE4VDc4IDYwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZCIiBkPSJNMTIxIDY0N1ExMjEgNjU3IDEyNSA2NzBUMTM3IDY4M1ExMzggNjgzIDIwOSA2ODhUMjgyIDY5NFEyOTQgNjk0IDI5NCA2ODZRMjk0IDY3OSAyNDQgNDc3UTE5NCAyNzkgMTk0IDI3MlEyMTMgMjgyIDIyMyAyOTFRMjQ3IDMwOSAyOTIgMzU0VDM2MiA0MTVRNDAyIDQ0MiA0MzggNDQyUTQ2OCA0NDIgNDg1IDQyM1Q1MDMgMzY5UTUwMyAzNDQgNDk2IDMyN1Q0NzcgMzAyVDQ1NiAyOTFUNDM4IDI4OFE0MTggMjg4IDQwNiAyOTlUMzk0IDMyOFEzOTQgMzUzIDQxMCAzNjlUNDQyIDM5MEw0NTggMzkzUTQ0NiA0MDUgNDM0IDQwNUg0MzBRMzk4IDQwMiAzNjcgMzgwVDI5NCAzMTZUMjI4IDI1NVEyMzAgMjU0IDI0MyAyNTJUMjY3IDI0NlQyOTMgMjM4VDMyMCAyMjRUMzQyIDIwNlQzNTkgMTgwVDM2NSAxNDdRMzY1IDEzMCAzNjAgMTA2VDM1NCA2NlEzNTQgMjYgMzgxIDI2UTQyOSAyNiA0NTkgMTQ1UTQ2MSAxNTMgNDc5IDE1M0g0ODNRNDk5IDE1MyA0OTkgMTQ0UTQ5OSAxMzkgNDk2IDEzMFE0NTUgLTExIDM3OCAtMTFRMzMzIC0xMSAzMDUgMTVUMjc3IDkwUTI3NyAxMDggMjgwIDEyMVQyODMgMTQ1UTI4MyAxNjcgMjY5IDE4M1QyMzQgMjA2VDIwMCAyMTdUMTgyIDIyMEgxODBRMTY4IDE3OCAxNTkgMTM5VDE0NSA4MVQxMzYgNDRUMTI5IDIwVDEyMiA3VDExMSAtMlE5OCAtMTEgODMgLTExUTY2IC0xMSA1NyAtMVQ0OCAxNlE0OCAyNiA4NSAxNzZUMTU4IDQ3MUwxOTUgNjE2UTE5NiA2MjkgMTg4IDYzMlQxNDkgNjM3SDE0NFExMzQgNjM3IDEzMSA2MzdUMTI0IDY0MFQxMjEgNjQ3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4NzEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNCIiB4PSI2MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTA0NSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTk1NiIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=) 定义为 平方因子的所有因子分解的总和:
定义为 平方因子的所有因子分解的总和:
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQ5LjUyNmV4IiBoZWlnaHQ9IjcuMDA5ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4xNzFleDsiIHZpZXdCb3g9IjAgLTE2NTIuNSAyMTMyMy41IDMwMTcuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNCIiBkPSJNNzggMzcwUTc4IDM5NCA5NSA0MTJUMTM4IDQzMFExNjIgNDMwIDE4MCA0MTRUMTk5IDM3MVExOTkgMzQ2IDE4MiAzMjhUMTM5IDMxMFQ5NiAzMjdUNzggMzcwWk03OCA2MFE3OCA4NSA5NCAxMDNUMTM3IDEyMVEyMDIgMTIxIDIwMiA4UTIwMiAtNDQgMTgzIC05NFQxNDQgLTE2OVQxMTggLTE5NFExMTUgLTE5NCAxMDYgLTE4NlQ5NSAtMTc0UTk0IC0xNzEgMTA3IC0xNTVUMTM3IC0xMDdUMTYwIC0zOFExNjEgLTMyIDE2MiAtMjJUMTY1IC00VDE2NSA0UTE2NSA1IDE2MSA0VDE0MiAwUTExMCAwIDk0IDE4VDc4IDYwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZCIiBkPSJNMTIxIDY0N1ExMjEgNjU3IDEyNSA2NzBUMTM3IDY4M1ExMzggNjgzIDIwOSA2ODhUMjgyIDY5NFEyOTQgNjk0IDI5NCA2ODZRMjk0IDY3OSAyNDQgNDc3UTE5NCAyNzkgMTk0IDI3MlEyMTMgMjgyIDIyMyAyOTFRMjQ3IDMwOSAyOTIgMzU0VDM2MiA0MTVRNDAyIDQ0MiA0MzggNDQyUTQ2OCA0NDIgNDg1IDQyM1Q1MDMgMzY5UTUwMyAzNDQgNDk2IDMyN1Q0NzcgMzAyVDQ1NiAyOTFUNDM4IDI4OFE0MTggMjg4IDQwNiAyOTlUMzk0IDMyOFEzOTQgMzUzIDQxMCAzNjlUNDQyIDM5MEw0NTggMzkzUTQ0NiA0MDUgNDM0IDQwNUg0MzBRMzk4IDQwMiAzNjcgMzgwVDI5NCAzMTZUMjI4IDI1NVEyMzAgMjU0IDI0MyAyNTJUMjY3IDI0NlQyOTMgMjM4VDMyMCAyMjRUMzQyIDIwNlQzNTkgMTgwVDM2NSAxNDdRMzY1IDEzMCAzNjAgMTA2VDM1NCA2NlEzNTQgMjYgMzgxIDI2UTQyOSAyNiA0NTkgMTQ1UTQ2MSAxNTMgNDc5IDE1M0g0ODNRNDk5IDE1MyA0OTkgMTQ0UTQ5OSAxMzkgNDk2IDEzMFE0NTUgLTExIDM3OCAtMTFRMzMzIC0xMSAzMDUgMTVUMjc3IDkwUTI3NyAxMDggMjgwIDEyMVQyODMgMTQ1UTI4MyAxNjcgMjY5IDE4M1QyMzQgMjA2VDIwMCAyMTdUMTgyIDIyMEgxODBRMTY4IDE3OCAxNTkgMTM5VDE0NSA4MVQxMzYgNDRUMTI5IDIwVDEyMiA3VDExMSAtMlE5OCAtMTEgODMgLTExUTY2IC0xMSA1NyAtMVQ0OCAxNlE0OCAyNiA4NSAxNzZUMTU4IDQ3MUwxOTUgNjE2UTE5NiA2MjkgMTg4IDYzMlQxNDkgNjM3SDE0NFExMzQgNjM3IDEzMSA2MzdUMTI0IDY0MFQxMjEgNjQ3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjIxMSIgZD0iTTYwIDk0OFE2MyA5NTAgNjY1IDk1MEgxMjY3TDEzMjUgODE1UTEzODQgNjc3IDEzODggNjY5SDEzNDhMMTM0MSA2ODNRMTMyMCA3MjQgMTI4NSA3NjFRMTIzNSA4MDkgMTE3NCA4MzhUMTAzMyA4ODFUODgyIDg5OFQ2OTkgOTAySDU3NEg1NDNIMjUxTDI1OSA4OTFRNzIyIDI1OCA3MjQgMjUyUTcyNSAyNTAgNzI0IDI0NlE3MjEgMjQzIDQ2MCAtNTZMMTk2IC0zNTZRMTk2IC0zNTcgNDA3IC0zNTdRNDU5IC0zNTcgNTQ4IC0zNTdUNjc2IC0zNThRODEyIC0zNTggODk2IC0zNTNUMTA2MyAtMzMyVDEyMDQgLTI4M1QxMzA3IC0xOTZRMTMyOCAtMTcwIDEzNDggLTEyNEgxMzg4UTEzODggLTEyNSAxMzgxIC0xNDVUMTM1NiAtMjEwVDEzMjUgLTI5NEwxMjY3IC00NDlMNjY2IC00NTBRNjQgLTQ1MCA2MSAtNDQ4UTU1IC00NDYgNTUgLTQzOVE1NSAtNDM3IDU3IC00MzNMNTkwIDE3N1E1OTAgMTc4IDU1NyAyMjJUNDUyIDM2NlQzMjIgNTQ0TDU2IDkwOUw1NSA5MjRRNTUgOTQ1IDYwIDk0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTY2IiBkPSJNMjczIDBRMjU1IDMgMTQ2IDNRNDMgMyAzNCAwSDI2VjQ2SDQyUTcwIDQ2IDkxIDQ5UTk5IDUyIDEwMyA2MFExMDQgNjIgMTA0IDIyNFYzODVIMzNWNDMxSDEwNFY0OTdMMTA1IDU2NEwxMDcgNTc0UTEyNiA2MzkgMTcxIDY2OFQyNjYgNzA0UTI2NyA3MDQgMjc1IDcwNFQyODkgNzA1UTMzMCA3MDIgMzUxIDY3OVQzNzIgNjI3UTM3MiA2MDQgMzU4IDU5MFQzMjEgNTc2VDI4NCA1OTBUMjcwIDYyN1EyNzAgNjQ3IDI4OCA2NjdIMjg0UTI4MCA2NjggMjczIDY2OFEyNDUgNjY4IDIyMyA2NDdUMTg5IDU5MlExODMgNTcyIDE4MiA0OTdWNDMxSDI5M1YzODVIMTg1VjIyNVExODUgNjMgMTg2IDYxVDE4OSA1N1QxOTQgNTRUMTk5IDUxVDIwNiA0OVQyMTMgNDhUMjIyIDQ3VDIzMSA0N1QyNDEgNDZUMjUxIDQ2SDI4MlYwSDI3M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTYxIiBkPSJNMTM3IDMwNVQxMTUgMzA1VDc4IDMyMFQ2MyAzNTlRNjMgMzk0IDk3IDQyMVQyMTggNDQ4UTI5MSA0NDggMzM2IDQxNlQzOTYgMzQwUTQwMSAzMjYgNDAxIDMwOVQ0MDIgMTk0VjEyNFE0MDIgNzYgNDA3IDU4VDQyOCA0MFE0NDMgNDAgNDQ4IDU2VDQ1MyAxMDlWMTQ1SDQ5M1YxMDZRNDkyIDY2IDQ5MCA1OVE0ODEgMjkgNDU1IDEyVDQwMCAtNlQzNTMgMTJUMzI5IDU0VjU4TDMyNyA1NVEzMjUgNTIgMzIyIDQ5VDMxNCA0MFQzMDIgMjlUMjg3IDE3VDI2OSA2VDI0NyAtMlQyMjEgLThUMTkwIC0xMVExMzAgLTExIDgyIDIwVDM0IDEwN1EzNCAxMjggNDEgMTQ3VDY4IDE4OFQxMTYgMjI1VDE5NCAyNTNUMzA0IDI2OEgzMThWMjkwUTMxOCAzMjQgMzEyIDM0MFEyOTAgNDExIDIxNSA0MTFRMTk3IDQxMSAxODEgNDEwVDE1NiA0MDZUMTQ4IDQwM1ExNzAgMzg4IDE3MCAzNTlRMTcwIDMzNCAxNTQgMzIwWk0xMjYgMTA2UTEyNiA3NSAxNTAgNTFUMjA5IDI2UTI0NyAyNiAyNzYgNDlUMzE1IDEwOVEzMTcgMTE2IDMxOCAxNzVRMzE4IDIzMyAzMTcgMjMzUTMwOSAyMzMgMjk2IDIzMlQyNTEgMjIzVDE5MyAyMDNUMTQ3IDE2NlQxMjYgMTA2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNjMiIGQ9Ik0zNzAgMzA1VDM0OSAzMDVUMzEzIDMyMFQyOTcgMzU4UTI5NyAzODEgMzEyIDM5NlEzMTcgNDAxIDMxNyA0MDJUMzA3IDQwNFEyODEgNDA4IDI1OCA0MDhRMjA5IDQwOCAxNzggMzc2UTEzMSAzMjkgMTMxIDIxOVExMzEgMTM3IDE2MiA5MFEyMDMgMjkgMjcyIDI5UTMxMyAyOSAzMzggNTVUMzc0IDExN1EzNzYgMTI1IDM3OSAxMjdUMzk1IDEyOUg0MDlRNDE1IDEyMyA0MTUgMTIwUTQxNSAxMTYgNDExIDEwNFQzOTUgNzFUMzY2IDMzVDMxOCAyVDI0OSAtMTFRMTYzIC0xMSA5OSA1M1QzNCAyMTRRMzQgMzE4IDk5IDM4M1QyNTAgNDQ4VDM3MCA0MjFUNDA0IDM1N1E0MDQgMzM0IDM4NyAzMjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03NCIgZD0iTTI3IDQyMlE4MCA0MjYgMTA5IDQ3OFQxNDEgNjAwVjYxNUgxODFWNDMxSDMxNlYzODVIMTgxVjI0MVExODIgMTE2IDE4MiAxMDBUMTg5IDY4UTIwMyAyOSAyMzggMjlRMjgyIDI5IDI5MiAxMDBRMjkzIDEwOCAyOTMgMTQ2VjE4MUgzMzNWMTQ2VjEzNFEzMzMgNTcgMjkxIDE3UTI2NCAtMTAgMjIxIC0xMFExODcgLTEwIDE2MiAyVDEyNCAzM1QxMDUgNjhUOTggMTAwUTk3IDEwNyA5NyAyNDhWMzg1SDE4VjQyMkgyN1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTZGIiBkPSJNMjggMjE0UTI4IDMwOSA5MyAzNzhUMjUwIDQ0OFEzNDAgNDQ4IDQwNSAzODBUNDcxIDIxNVE0NzEgMTIwIDQwNyA1NVQyNTAgLTEwUTE1MyAtMTAgOTEgNTdUMjggMjE0Wk0yNTAgMzBRMzcyIDMwIDM3MiAxOTNWMjI1VjI1MFEzNzIgMjcyIDM3MSAyODhUMzY0IDMyNlQzNDggMzYyVDMxNyAzOTBUMjY4IDQxMFEyNjMgNDExIDI1MiA0MTFRMjIyIDQxMSAxOTUgMzk5UTE1MiAzNzcgMTM5IDMzOFQxMjYgMjQ2VjIyNlExMjYgMTMwIDE0NSA5MVExNzcgMzAgMjUwIDMwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNzIiIGQ9Ik0zNiA0Nkg1MFE4OSA0NiA5NyA2MFY2OFE5NyA3NyA5NyA5MVQ5OCAxMjJUOTggMTYxVDk4IDIwM1E5OCAyMzQgOTggMjY5VDk4IDMyOEw5NyAzNTFROTQgMzcwIDgzIDM3NlQzOCAzODVIMjBWNDA4UTIwIDQzMSAyMiA0MzFMMzIgNDMyUTQyIDQzMyA2MCA0MzRUOTYgNDM2UTExMiA0MzcgMTMxIDQzOFQxNjAgNDQxVDE3MSA0NDJIMTc0VjM3M1EyMTMgNDQxIDI3MSA0NDFIMjc3UTMyMiA0NDEgMzQzIDQxOVQzNjQgMzczUTM2NCAzNTIgMzUxIDMzN1QzMTMgMzIyUTI4OCAzMjIgMjc2IDMzOFQyNjMgMzcyUTI2MyAzODEgMjY1IDM4OFQyNzAgNDAwVDI3MyA0MDVRMjcxIDQwNyAyNTAgNDAxUTIzNCAzOTMgMjI2IDM4NlExNzkgMzQxIDE3OSAyMDdWMTU0UTE3OSAxNDEgMTc5IDEyN1QxNzkgMTAxVDE4MCA4MVQxODAgNjZWNjFRMTgxIDU5IDE4MyA1N1QxODggNTRUMTkzIDUxVDIwMCA0OVQyMDcgNDhUMjE2IDQ3VDIyNSA0N1QyMzUgNDZUMjQ1IDQ2SDI3NlYwSDI2N1EyNDkgMyAxNDAgM1EzNyAzIDI4IDBIMjBWNDZIMzZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03MyIgZD0iTTI5NSAzMTZRMjk1IDM1NiAyNjggMzg1VDE5MCA0MTRRMTU0IDQxNCAxMjggNDAxUTk4IDM4MiA5OCAzNDlROTcgMzQ0IDk4IDMzNlQxMTQgMzEyVDE1NyAyODdRMTc1IDI4MiAyMDEgMjc4VDI0NSAyNjlUMjc3IDI1NlEyOTQgMjQ4IDMxMCAyMzZUMzQyIDE5NVQzNTkgMTMzUTM1OSA3MSAzMjEgMzFUMTk4IC0xMEgxOTBRMTM4IC0xMCA5NCAyNkw4NiAxOUw3NyAxMFE3MSA0IDY1IC0xTDU0IC0xMUg0Nkg0MlEzOSAtMTEgMzMgLTVWNzRWMTMyUTMzIDE1MyAzNSAxNTdUNDUgMTYySDU0UTY2IDE2MiA3MCAxNThUNzUgMTQ2VDgyIDExOVQxMDEgNzdRMTM2IDI2IDE5OCAyNlEyOTUgMjYgMjk1IDEwNFEyOTUgMTMzIDI3NyAxNTFRMjU3IDE3NSAxOTQgMTg3VDExMSAyMTBRNzUgMjI3IDU0IDI1NlQzMyAzMThRMzMgMzU3IDUwIDM4NFQ5MyA0MjRUMTQzIDQ0MlQxODcgNDQ3SDE5OFEyMzggNDQ3IDI2OCA0MzJMMjgzIDQyNEwyOTIgNDMxUTMwMiA0NDAgMzE0IDQ0OEgzMjJIMzI2UTMyOSA0NDggMzM1IDQ0MlYzMTBMMzI5IDMwNEgzMDFRMjk1IDMxMCAyOTUgMzE2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQyIiBkPSJNMjMxIDYzN1EyMDQgNjM3IDE5OSA2MzhUMTk0IDY0OVExOTQgNjc2IDIwNSA2ODJRMjA2IDY4MyAzMzUgNjgzUTU5NCA2ODMgNjA4IDY4MVE2NzEgNjcxIDcxMyA2MzZUNzU2IDU0NFE3NTYgNDgwIDY5OCA0MjlUNTY1IDM2MEw1NTUgMzU3UTYxOSAzNDggNjYwIDMxMVQ3MDIgMjE5UTcwMiAxNDYgNjMwIDc4VDQ1MyAxUTQ0NiAwIDI0MiAwUTQyIDAgMzkgMlEzNSA1IDM1IDEwUTM1IDE3IDM3IDI0UTQyIDQzIDQ3IDQ1UTUxIDQ2IDYyIDQ2SDY4UTk1IDQ2IDEyOCA0OVExNDIgNTIgMTQ3IDYxUTE1MCA2NSAyMTkgMzM5VDI4OCA2MjhRMjg4IDYzNSAyMzEgNjM3Wk02NDkgNTQ0UTY0OSA1NzQgNjM0IDYwMFQ1ODUgNjM0UTU3OCA2MzYgNDkzIDYzN1E0NzMgNjM3IDQ1MSA2MzdUNDE2IDYzNkg0MDNRMzg4IDYzNSAzODQgNjI2UTM4MiA2MjIgMzUyIDUwNlEzNTIgNTAzIDM1MSA1MDBMMzIwIDM3NEg0MDFRNDgyIDM3NCA0OTQgMzc2UTU1NCAzODYgNjAxIDQzNFQ2NDkgNTQ0Wk01OTUgMjI5UTU5NSAyNzMgNTcyIDMwMlQ1MTIgMzM2UTUwNiAzMzcgNDI5IDMzN1EzMTEgMzM3IDMxMCAzMzZRMzEwIDMzNCAyOTMgMjYzVDI1OCAxMjJMMjQwIDUyUTI0MCA0OCAyNTIgNDhUMzMzIDQ2UTQyMiA0NiA0MjkgNDdRNDkxIDU0IDU0MyAxMDVUNTk1IDIyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJDIiBkPSJNNzggMzVUNzggNjBUOTQgMTAzVDEzNyAxMjFRMTY1IDEyMSAxODcgOTZUMjEwIDhRMjEwIC0yNyAyMDEgLTYwVDE4MCAtMTE3VDE1NCAtMTU4VDEzMCAtMTg1VDExNyAtMTk0UTExMyAtMTk0IDEwNCAtMTg1VDk1IC0xNzJROTUgLTE2OCAxMDYgLTE1NlQxMzEgLTEyNlQxNTcgLTc2VDE3MyAtM1Y5TDE3MiA4UTE3MCA3IDE2NyA2VDE2MSAzVDE1MiAxVDE0MCAwUTExMyAwIDk2IDE3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzIiIGQ9Ik0xMDkgNDI5UTgyIDQyOSA2NiA0NDdUNTAgNDkxUTUwIDU2MiAxMDMgNjE0VDIzNSA2NjZRMzI2IDY2NiAzODcgNjEwVDQ0OSA0NjVRNDQ5IDQyMiA0MjkgMzgzVDM4MSAzMTVUMzAxIDI0MVEyNjUgMjEwIDIwMSAxNDlMMTQyIDkzTDIxOCA5MlEzNzUgOTIgMzg1IDk3UTM5MiA5OSA0MDkgMTg2VjE4OUg0NDlWMTg2UTQ0OCAxODMgNDM2IDk1VDQyMSAzVjBINTBWMTlWMzFRNTAgMzggNTYgNDZUODYgODFRMTE1IDExMyAxMzYgMTM3UTE0NSAxNDcgMTcwIDE3NFQyMDQgMjExVDIzMyAyNDRUMjYxIDI3OFQyODQgMzA4VDMwNSAzNDBUMzIwIDM2OVQzMzMgNDAxVDM0MCA0MzFUMzQzIDQ2NFEzNDMgNTI3IDMwOSA1NzNUMjEyIDYxOVExNzkgNjE5IDE1NCA2MDJUMTE5IDU2OVQxMDkgNTUwUTEwOSA1NDkgMTE0IDU0OVExMzIgNTQ5IDE1MSA1MzVUMTcwIDQ4OVExNzAgNDY0IDE1NCA0NDdUMTA5IDQyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJFIiBkPSJNNzggNjBRNzggODQgOTUgMTAyVDEzOCAxMjBRMTYyIDEyMCAxODAgMTA0VDE5OSA2MVExOTkgMzYgMTgyIDE4VDEzOSAwVDk2IDE3VDc4IDYwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0MiIGQ9Ik0xMzkgLTI0OUgxMzdRMTI1IC0yNDkgMTE5IC0yMzVWMjUxTDEyMCA3MzdRMTMwIDc1MCAxMzkgNzUwUTE1MiA3NTAgMTU5IDczNVYtMjM1UTE1MSAtMjQ5IDE0MSAtMjQ5SDEzOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02OSIgZD0iTTE4NCA2MDBRMTg0IDYyNCAyMDMgNjQyVDI0NyA2NjFRMjY1IDY2MSAyNzcgNjQ5VDI5MCA2MTlRMjkwIDU5NiAyNzAgNTc3VDIyNiA1NTdRMjExIDU1NyAxOTggNTY3VDE4NCA2MDBaTTIxIDI4N1EyMSAyOTUgMzAgMzE4VDU0IDM2OVQ5OCA0MjBUMTU4IDQ0MlExOTcgNDQyIDIyMyA0MTlUMjUwIDM1N1EyNTAgMzQwIDIzNiAzMDFUMTk2IDE5NlQxNTQgODNRMTQ5IDYxIDE0OSA1MVExNDkgMjYgMTY2IDI2UTE3NSAyNiAxODUgMjlUMjA4IDQzVDIzNSA3OFQyNjAgMTM3UTI2MyAxNDkgMjY1IDE1MVQyODIgMTUzUTMwMiAxNTMgMzAyIDE0M1EzMDIgMTM1IDI5MyAxMTJUMjY4IDYxVDIyMyAxMVQxNjEgLTExUTEyOSAtMTEgMTAyIDEwVDc0IDc0UTc0IDkxIDc5IDEwNlQxMjIgMjIwUTE2MCAzMjEgMTY2IDM0MVQxNzMgMzgwUTE3MyA0MDQgMTU2IDQwNEgxNTRRMTI0IDQwNCA5OSAzNzFUNjEgMjg3UTYwIDI4NiA1OSAyODRUNTggMjgxVDU2IDI3OVQ1MyAyNzhUNDkgMjc4VDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODcxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zQiIgeD0iNjAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjEwNDUiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjE5NTYiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjM0OTUiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NTUxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTIyMTEiIHg9IjEwMzIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC0xMTE3KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTY2Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9IjMwNiIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYzIiB4PSI4MDciIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03NCIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTZGIiB4PSIxNjQwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjIxNDEiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MyIgeD0iMjUzMyIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTZGIiB4PSIzMjgyIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjYiIHg9IjM3ODIiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjQ0NDIiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDIiIHg9IjgyMjgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5MTU0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zQiIgeD0iNjAwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTA0NSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjczNyIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iMjAyMSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI0NjYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI3MzciIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9IjM0NDEiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSIzODg2IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iNDMzMSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9IjQ3NzciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJDIiB4PSI1MjIyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTY2NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI3MzciIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0MiIHg9IjY3MTMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNjk5MiIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iNzkwMyIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTc2MTMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0NywtMTA5MCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMzQ1IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjExMjQiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iNzIxIiB5PSIxNjI3Ij48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxOTIyNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iNzM3IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxMjU1IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjIzMjYiIHk9IjY3NSI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=)
存在以下事实:
fact 1: ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjI5Ljg0MmV4IiBoZWlnaHQ9IjcuNjc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4zMzhleDsiIHZpZXdCb3g9IjAgLTE4NjcuNyAxMjg0OC44IDMzMDQuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjIxMSIgZD0iTTYwIDk0OFE2MyA5NTAgNjY1IDk1MEgxMjY3TDEzMjUgODE1UTEzODQgNjc3IDEzODggNjY5SDEzNDhMMTM0MSA2ODNRMTMyMCA3MjQgMTI4NSA3NjFRMTIzNSA4MDkgMTE3NCA4MzhUMTAzMyA4ODFUODgyIDg5OFQ2OTkgOTAySDU3NEg1NDNIMjUxTDI1OSA4OTFRNzIyIDI1OCA3MjQgMjUyUTcyNSAyNTAgNzI0IDI0NlE3MjEgMjQzIDQ2MCAtNTZMMTk2IC0zNTZRMTk2IC0zNTcgNDA3IC0zNTdRNDU5IC0zNTcgNTQ4IC0zNTdUNjc2IC0zNThRODEyIC0zNTggODk2IC0zNTNUMTA2MyAtMzMyVDEyMDQgLTI4M1QxMzA3IC0xOTZRMTMyOCAtMTcwIDEzNDggLTEyNEgxMzg4UTEzODggLTEyNSAxMzgxIC0xNDVUMTM1NiAtMjEwVDEzMjUgLTI5NEwxMjY3IC00NDlMNjY2IC00NTBRNjQgLTQ1MCA2MSAtNDQ4UTU1IC00NDYgNTUgLTQzOVE1NSAtNDM3IDU3IC00MzNMNTkwIDE3N1E1OTAgMTc4IDU1NyAyMjJUNDUyIDM2NlQzMjIgNTQ0TDU2IDkwOUw1NSA5MjRRNTUgOTQ1IDYwIDk0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02QSIgZD0iTTI5NyA1OTZRMjk3IDYyNyAzMTggNjQ0VDM2MSA2NjFRMzc4IDY2MSAzODkgNjUxVDQwMyA2MjNRNDAzIDU5NSAzODQgNTc2VDM0MCA1NTdRMzIyIDU1NyAzMTAgNTY3VDI5NyA1OTZaTTI4OCAzNzZRMjg4IDQwNSAyNjIgNDA1UTI0MCA0MDUgMjIwIDM5M1QxODUgMzYyVDE2MSAzMjVUMTQ0IDI5M0wxMzcgMjc5UTEzNSAyNzggMTIxIDI3OEgxMDdRMTAxIDI4NCAxMDEgMjg2VDEwNSAyOTlRMTI2IDM0OCAxNjQgMzkxVDI1MiA0NDFRMjUzIDQ0MSAyNjAgNDQxVDI3MiA0NDJRMjk2IDQ0MSAzMTYgNDMyUTM0MSA0MTggMzU0IDQwMVQzNjcgMzQ4VjMzMkwzMTggMTMzUTI2NyAtNjcgMjY0IC03NVEyNDYgLTEyNSAxOTQgLTE2NFQ3NSAtMjA0UTI1IC0yMDQgNyAtMTgzVC0xMiAtMTM3US0xMiAtMTEwIDcgLTkxVDUzIC03MVE3MCAtNzEgODIgLTgxVDk1IC0xMTJROTUgLTE0OCA2MyAtMTY3UTY5IC0xNjggNzcgLTE2OFExMTEgLTE2OCAxMzkgLTE0MFQxODIgLTc0TDE5MyAtMzJRMjA0IDExIDIxOSA3MlQyNTEgMTk3VDI3OCAzMDhUMjg5IDM2NVEyODkgMzcyIDI4OCAzNzZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMwIiBkPSJNOTYgNTg1UTE1MiA2NjYgMjQ5IDY2NlEyOTcgNjY2IDM0NSA2NDBUNDIzIDU0OFE0NjAgNDY1IDQ2MCAzMjBRNDYwIDE2NSA0MTcgODNRMzk3IDQxIDM2MiAxNlQzMDEgLTE1VDI1MCAtMjJRMjI0IC0yMiAxOTggLTE2VDEzNyAxNlQ4MiA4M1EzOSAxNjUgMzkgMzIwUTM5IDQ5NCA5NiA1ODVaTTMyMSA1OTdRMjkxIDYyOSAyNTAgNjI5UTIwOCA2MjkgMTc4IDU5N1ExNTMgNTcxIDE0NSA1MjVUMTM3IDMzM1ExMzcgMTc1IDE0NSAxMjVUMTgxIDQ2UTIwOSAxNiAyNTAgMTZRMjkwIDE2IDMxOCA0NlEzNDcgNzYgMzU0IDEzMFQzNjIgMzMzUTM2MiA0NzggMzU0IDUyNFQzMjEgNTk3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZCIiBkPSJNMTIxIDY0N1ExMjEgNjU3IDEyNSA2NzBUMTM3IDY4M1ExMzggNjgzIDIwOSA2ODhUMjgyIDY5NFEyOTQgNjk0IDI5NCA2ODZRMjk0IDY3OSAyNDQgNDc3UTE5NCAyNzkgMTk0IDI3MlEyMTMgMjgyIDIyMyAyOTFRMjQ3IDMwOSAyOTIgMzU0VDM2MiA0MTVRNDAyIDQ0MiA0MzggNDQyUTQ2OCA0NDIgNDg1IDQyM1Q1MDMgMzY5UTUwMyAzNDQgNDk2IDMyN1Q0NzcgMzAyVDQ1NiAyOTFUNDM4IDI4OFE0MTggMjg4IDQwNiAyOTlUMzk0IDMyOFEzOTQgMzUzIDQxMCAzNjlUNDQyIDM5MEw0NTggMzkzUTQ0NiA0MDUgNDM0IDQwNUg0MzBRMzk4IDQwMiAzNjcgMzgwVDI5NCAzMTZUMjI4IDI1NVEyMzAgMjU0IDI0MyAyNTJUMjY3IDI0NlQyOTMgMjM4VDMyMCAyMjRUMzQyIDIwNlQzNTkgMTgwVDM2NSAxNDdRMzY1IDEzMCAzNjAgMTA2VDM1NCA2NlEzNTQgMjYgMzgxIDI2UTQyOSAyNiA0NTkgMTQ1UTQ2MSAxNTMgNDc5IDE1M0g0ODNRNDk5IDE1MyA0OTkgMTQ0UTQ5OSAxMzkgNDk2IDEzMFE0NTUgLTExIDM3OCAtMTFRMzMzIC0xMSAzMDUgMTVUMjc3IDkwUTI3NyAxMDggMjgwIDEyMVQyODMgMTQ1UTI4MyAxNjcgMjY5IDE4M1QyMzQgMjA2VDIwMCAyMTdUMTgyIDIyMEgxODBRMTY4IDE3OCAxNTkgMTM5VDE0NSA4MVQxMzYgNDRUMTI5IDIwVDEyMiA3VDExMSAtMlE5OCAtMTEgODMgLTExUTY2IC0xMSA1NyAtMVQ0OCAxNlE0OCAyNiA4NSAxNzZUMTU4IDQ3MUwxOTUgNjE2UTE5NiA2MjkgMTg4IDYzMlQxNDkgNjM3SDE0NFExMzQgNjM3IDEzMSA2MzdUMTI0IDY0MFQxMjEgNjQ3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQyIiBkPSJNMjMxIDYzN1EyMDQgNjM3IDE5OSA2MzhUMTk0IDY0OVExOTQgNjc2IDIwNSA2ODJRMjA2IDY4MyAzMzUgNjgzUTU5NCA2ODMgNjA4IDY4MVE2NzEgNjcxIDcxMyA2MzZUNzU2IDU0NFE3NTYgNDgwIDY5OCA0MjlUNTY1IDM2MEw1NTUgMzU3UTYxOSAzNDggNjYwIDMxMVQ3MDIgMjE5UTcwMiAxNDYgNjMwIDc4VDQ1MyAxUTQ0NiAwIDI0MiAwUTQyIDAgMzkgMlEzNSA1IDM1IDEwUTM1IDE3IDM3IDI0UTQyIDQzIDQ3IDQ1UTUxIDQ2IDYyIDQ2SDY4UTk1IDQ2IDEyOCA0OVExNDIgNTIgMTQ3IDYxUTE1MCA2NSAyMTkgMzM5VDI4OCA2MjhRMjg4IDYzNSAyMzEgNjM3Wk02NDkgNTQ0UTY0OSA1NzQgNjM0IDYwMFQ1ODUgNjM0UTU3OCA2MzYgNDkzIDYzN1E0NzMgNjM3IDQ1MSA2MzdUNDE2IDYzNkg0MDNRMzg4IDYzNSAzODQgNjI2UTM4MiA2MjIgMzUyIDUwNlEzNTIgNTAzIDM1MSA1MDBMMzIwIDM3NEg0MDFRNDgyIDM3NCA0OTQgMzc2UTU1NCAzODYgNjAxIDQzNFQ2NDkgNTQ0Wk01OTUgMjI5UTU5NSAyNzMgNTcyIDMwMlQ1MTIgMzM2UTUwNiAzMzcgNDI5IDMzN1EzMTEgMzM3IDMxMCAzMzZRMzEwIDMzNCAyOTMgMjYzVDI1OCAxMjJMMjQwIDUyUTI0MCA0OCAyNTIgNDhUMzMzIDQ2UTQyMiA0NiA0MjkgNDdRNDkxIDU0IDU0MyAxMDVUNTk1IDIyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkUiIGQ9Ik0yMSAyODdRMjIgMjkzIDI0IDMwM1QzNiAzNDFUNTYgMzg4VDg5IDQyNVQxMzUgNDQyUTE3MSA0NDIgMTk1IDQyNFQyMjUgMzkwVDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzA0IDQ0MiAzODIgNDQyUTQzNiA0NDIgNDY5IDQxNVQ1MDMgMzM2VDQ2NSAxNzlUNDI3IDUyUTQyNyAyNiA0NDQgMjZRNDUwIDI2IDQ1MyAyN1E0ODIgMzIgNTA1IDY1VDU0MCAxNDVRNTQyIDE1MyA1NjAgMTUzUTU4MCAxNTMgNTgwIDE0NVE1ODAgMTQ0IDU3NiAxMzBRNTY4IDEwMSA1NTQgNzNUNTA4IDE3VDQzOSAtMTBRMzkyIC0xMCAzNzEgMTdUMzUwIDczUTM1MCA5MiAzODYgMTkzVDQyMyAzNDVRNDIzIDQwNCAzNzkgNDA0SDM3NFEyODggNDA0IDIyOSAzMDNMMjIyIDI5MUwxODkgMTU3UTE1NiAyNiAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExMiAxODBUMTUyIDM0M1ExNTMgMzQ4IDE1MyAzNjZRMTUzIDQwNSAxMjkgNDA1UTkxIDQwNSA2NiAzMDVRNjAgMjg1IDYwIDI4NFE1OCAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zQiIgZD0iTTc4IDM3MFE3OCAzOTQgOTUgNDEyVDEzOCA0MzBRMTYyIDQzMCAxODAgNDE0VDE5OSAzNzFRMTk5IDM0NiAxODIgMzI4VDEzOSAzMTBUOTYgMzI3VDc4IDM3MFpNNzggNjBRNzggODUgOTQgMTAzVDEzNyAxMjFRMjAyIDEyMSAyMDIgOFEyMDIgLTQ0IDE4MyAtOTRUMTQ0IC0xNjlUMTE4IC0xOTRRMTE1IC0xOTQgMTA2IC0xODZUOTUgLTE3NFE5NCAtMTcxIDEwNyAtMTU1VDEzNyAtMTA3VDE2MCAtMzhRMTYxIC0zMiAxNjIgLTIyVDE2NSAtNFQxNjUgNFExNjUgNSAxNjEgNFQxNDIgMFExMTAgMCA5NCAxOFQ3OCA2MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMTIiIGQ9Ik04NCAyMzdUODQgMjUwVDk4IDI3MEg2NzlRNjk0IDI2MiA2OTQgMjUwVDY3OSAyMzBIOThRODQgMjM3IDg0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTI0LC0xMDkwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI0MTIiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMCIgeD0iMTE5MSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI3NjAiIHk9IjE2MjciPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00MiIgeD0iMTYxMSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI1MzcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNCIiB4PSI2MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTA0NSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMTc4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZBIiB4PSIyNzkwIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIzNTkyIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI2Nzk2IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDIiIHg9Ijc4NTIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4Nzc5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iODIyIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTgyMyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0IiIHg9IjIzMjMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMjc2OSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMzY4MCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=)
fact 2: ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjMyLjg0OGV4IiBoZWlnaHQ9IjcuNjc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4zMzhleDsiIHZpZXdCb3g9IjAgLTE4NjcuNyAxNDE0Mi44IDMzMDQuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjIxMSIgZD0iTTYwIDk0OFE2MyA5NTAgNjY1IDk1MEgxMjY3TDEzMjUgODE1UTEzODQgNjc3IDEzODggNjY5SDEzNDhMMTM0MSA2ODNRMTMyMCA3MjQgMTI4NSA3NjFRMTIzNSA4MDkgMTE3NCA4MzhUMTAzMyA4ODFUODgyIDg5OFQ2OTkgOTAySDU3NEg1NDNIMjUxTDI1OSA4OTFRNzIyIDI1OCA3MjQgMjUyUTcyNSAyNTAgNzI0IDI0NlE3MjEgMjQzIDQ2MCAtNTZMMTk2IC0zNTZRMTk2IC0zNTcgNDA3IC0zNTdRNDU5IC0zNTcgNTQ4IC0zNTdUNjc2IC0zNThRODEyIC0zNTggODk2IC0zNTNUMTA2MyAtMzMyVDEyMDQgLTI4M1QxMzA3IC0xOTZRMTMyOCAtMTcwIDEzNDggLTEyNEgxMzg4UTEzODggLTEyNSAxMzgxIC0xNDVUMTM1NiAtMjEwVDEzMjUgLTI5NEwxMjY3IC00NDlMNjY2IC00NTBRNjQgLTQ1MCA2MSAtNDQ4UTU1IC00NDYgNTUgLTQzOVE1NSAtNDM3IDU3IC00MzNMNTkwIDE3N1E1OTAgMTc4IDU1NyAyMjJUNDUyIDM2NlQzMjIgNTQ0TDU2IDkwOUw1NSA5MjRRNTUgOTQ1IDYwIDk0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02QSIgZD0iTTI5NyA1OTZRMjk3IDYyNyAzMTggNjQ0VDM2MSA2NjFRMzc4IDY2MSAzODkgNjUxVDQwMyA2MjNRNDAzIDU5NSAzODQgNTc2VDM0MCA1NTdRMzIyIDU1NyAzMTAgNTY3VDI5NyA1OTZaTTI4OCAzNzZRMjg4IDQwNSAyNjIgNDA1UTI0MCA0MDUgMjIwIDM5M1QxODUgMzYyVDE2MSAzMjVUMTQ0IDI5M0wxMzcgMjc5UTEzNSAyNzggMTIxIDI3OEgxMDdRMTAxIDI4NCAxMDEgMjg2VDEwNSAyOTlRMTI2IDM0OCAxNjQgMzkxVDI1MiA0NDFRMjUzIDQ0MSAyNjAgNDQxVDI3MiA0NDJRMjk2IDQ0MSAzMTYgNDMyUTM0MSA0MTggMzU0IDQwMVQzNjcgMzQ4VjMzMkwzMTggMTMzUTI2NyAtNjcgMjY0IC03NVEyNDYgLTEyNSAxOTQgLTE2NFQ3NSAtMjA0UTI1IC0yMDQgNyAtMTgzVC0xMiAtMTM3US0xMiAtMTEwIDcgLTkxVDUzIC03MVE3MCAtNzEgODIgLTgxVDk1IC0xMTJROTUgLTE0OCA2MyAtMTY3UTY5IC0xNjggNzcgLTE2OFExMTEgLTE2OCAxMzkgLTE0MFQxODIgLTc0TDE5MyAtMzJRMjA0IDExIDIxOSA3MlQyNTEgMTk3VDI3OCAzMDhUMjg5IDM2NVEyODkgMzcyIDI4OCAzNzZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMwIiBkPSJNOTYgNTg1UTE1MiA2NjYgMjQ5IDY2NlEyOTcgNjY2IDM0NSA2NDBUNDIzIDU0OFE0NjAgNDY1IDQ2MCAzMjBRNDYwIDE2NSA0MTcgODNRMzk3IDQxIDM2MiAxNlQzMDEgLTE1VDI1MCAtMjJRMjI0IC0yMiAxOTggLTE2VDEzNyAxNlQ4MiA4M1EzOSAxNjUgMzkgMzIwUTM5IDQ5NCA5NiA1ODVaTTMyMSA1OTdRMjkxIDYyOSAyNTAgNjI5UTIwOCA2MjkgMTc4IDU5N1ExNTMgNTcxIDE0NSA1MjVUMTM3IDMzM1ExMzcgMTc1IDE0NSAxMjVUMTgxIDQ2UTIwOSAxNiAyNTAgMTZRMjkwIDE2IDMxOCA0NlEzNDcgNzYgMzU0IDEzMFQzNjIgMzMzUTM2MiA0NzggMzU0IDUyNFQzMjEgNTk3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZCIiBkPSJNMTIxIDY0N1ExMjEgNjU3IDEyNSA2NzBUMTM3IDY4M1ExMzggNjgzIDIwOSA2ODhUMjgyIDY5NFEyOTQgNjk0IDI5NCA2ODZRMjk0IDY3OSAyNDQgNDc3UTE5NCAyNzkgMTk0IDI3MlEyMTMgMjgyIDIyMyAyOTFRMjQ3IDMwOSAyOTIgMzU0VDM2MiA0MTVRNDAyIDQ0MiA0MzggNDQyUTQ2OCA0NDIgNDg1IDQyM1Q1MDMgMzY5UTUwMyAzNDQgNDk2IDMyN1Q0NzcgMzAyVDQ1NiAyOTFUNDM4IDI4OFE0MTggMjg4IDQwNiAyOTlUMzk0IDMyOFEzOTQgMzUzIDQxMCAzNjlUNDQyIDM5MEw0NTggMzkzUTQ0NiA0MDUgNDM0IDQwNUg0MzBRMzk4IDQwMiAzNjcgMzgwVDI5NCAzMTZUMjI4IDI1NVEyMzAgMjU0IDI0MyAyNTJUMjY3IDI0NlQyOTMgMjM4VDMyMCAyMjRUMzQyIDIwNlQzNTkgMTgwVDM2NSAxNDdRMzY1IDEzMCAzNjAgMTA2VDM1NCA2NlEzNTQgMjYgMzgxIDI2UTQyOSAyNiA0NTkgMTQ1UTQ2MSAxNTMgNDc5IDE1M0g0ODNRNDk5IDE1MyA0OTkgMTQ0UTQ5OSAxMzkgNDk2IDEzMFE0NTUgLTExIDM3OCAtMTFRMzMzIC0xMSAzMDUgMTVUMjc3IDkwUTI3NyAxMDggMjgwIDEyMVQyODMgMTQ1UTI4MyAxNjcgMjY5IDE4M1QyMzQgMjA2VDIwMCAyMTdUMTgyIDIyMEgxODBRMTY4IDE3OCAxNTkgMTM5VDE0NSA4MVQxMzYgNDRUMTI5IDIwVDEyMiA3VDExMSAtMlE5OCAtMTEgODMgLTExUTY2IC0xMSA1NyAtMVQ0OCAxNlE0OCAyNiA4NSAxNzZUMTU4IDQ3MUwxOTUgNjE2UTE5NiA2MjkgMTg4IDYzMlQxNDkgNjM3SDE0NFExMzQgNjM3IDEzMSA2MzdUMTI0IDY0MFQxMjEgNjQ3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQyIiBkPSJNMjMxIDYzN1EyMDQgNjM3IDE5OSA2MzhUMTk0IDY0OVExOTQgNjc2IDIwNSA2ODJRMjA2IDY4MyAzMzUgNjgzUTU5NCA2ODMgNjA4IDY4MVE2NzEgNjcxIDcxMyA2MzZUNzU2IDU0NFE3NTYgNDgwIDY5OCA0MjlUNTY1IDM2MEw1NTUgMzU3UTYxOSAzNDggNjYwIDMxMVQ3MDIgMjE5UTcwMiAxNDYgNjMwIDc4VDQ1MyAxUTQ0NiAwIDI0MiAwUTQyIDAgMzkgMlEzNSA1IDM1IDEwUTM1IDE3IDM3IDI0UTQyIDQzIDQ3IDQ1UTUxIDQ2IDYyIDQ2SDY4UTk1IDQ2IDEyOCA0OVExNDIgNTIgMTQ3IDYxUTE1MCA2NSAyMTkgMzM5VDI4OCA2MjhRMjg4IDYzNSAyMzEgNjM3Wk02NDkgNTQ0UTY0OSA1NzQgNjM0IDYwMFQ1ODUgNjM0UTU3OCA2MzYgNDkzIDYzN1E0NzMgNjM3IDQ1MSA2MzdUNDE2IDYzNkg0MDNRMzg4IDYzNSAzODQgNjI2UTM4MiA2MjIgMzUyIDUwNlEzNTIgNTAzIDM1MSA1MDBMMzIwIDM3NEg0MDFRNDgyIDM3NCA0OTQgMzc2UTU1NCAzODYgNjAxIDQzNFQ2NDkgNTQ0Wk01OTUgMjI5UTU5NSAyNzMgNTcyIDMwMlQ1MTIgMzM2UTUwNiAzMzcgNDI5IDMzN1EzMTEgMzM3IDMxMCAzMzZRMzEwIDMzNCAyOTMgMjYzVDI1OCAxMjJMMjQwIDUyUTI0MCA0OCAyNTIgNDhUMzMzIDQ2UTQyMiA0NiA0MjkgNDdRNDkxIDU0IDU0MyAxMDVUNTk1IDIyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkUiIGQ9Ik0yMSAyODdRMjIgMjkzIDI0IDMwM1QzNiAzNDFUNTYgMzg4VDg5IDQyNVQxMzUgNDQyUTE3MSA0NDIgMTk1IDQyNFQyMjUgMzkwVDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzA0IDQ0MiAzODIgNDQyUTQzNiA0NDIgNDY5IDQxNVQ1MDMgMzM2VDQ2NSAxNzlUNDI3IDUyUTQyNyAyNiA0NDQgMjZRNDUwIDI2IDQ1MyAyN1E0ODIgMzIgNTA1IDY1VDU0MCAxNDVRNTQyIDE1MyA1NjAgMTUzUTU4MCAxNTMgNTgwIDE0NVE1ODAgMTQ0IDU3NiAxMzBRNTY4IDEwMSA1NTQgNzNUNTA4IDE3VDQzOSAtMTBRMzkyIC0xMCAzNzEgMTdUMzUwIDczUTM1MCA5MiAzODYgMTkzVDQyMyAzNDVRNDIzIDQwNCAzNzkgNDA0SDM3NFEyODggNDA0IDIyOSAzMDNMMjIyIDI5MUwxODkgMTU3UTE1NiAyNiAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExMiAxODBUMTUyIDM0M1ExNTMgMzQ4IDE1MyAzNjZRMTUzIDQwNSAxMjkgNDA1UTkxIDQwNSA2NiAzMDVRNjAgMjg1IDYwIDI4NFE1OCAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zQiIgZD0iTTc4IDM3MFE3OCAzOTQgOTUgNDEyVDEzOCA0MzBRMTYyIDQzMCAxODAgNDE0VDE5OSAzNzFRMTk5IDM0NiAxODIgMzI4VDEzOSAzMTBUOTYgMzI3VDc4IDM3MFpNNzggNjBRNzggODUgOTQgMTAzVDEzNyAxMjFRMjAyIDEyMSAyMDIgOFEyMDIgLTQ0IDE4MyAtOTRUMTQ0IC0xNjlUMTE4IC0xOTRRMTE1IC0xOTQgMTA2IC0xODZUOTUgLTE3NFE5NCAtMTcxIDEwNyAtMTU1VDEzNyAtMTA3VDE2MCAtMzhRMTYxIC0zMiAxNjIgLTIyVDE2NSAtNFQxNjUgNFExNjUgNSAxNjEgNFQxNDIgMFExMTAgMCA5NCAxOFQ3OCA2MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMTIiIGQ9Ik04NCAyMzdUODQgMjUwVDk4IDI3MEg2NzlRNjk0IDI2MiA2OTQgMjUwVDY3OSAyMzBIOThRODQgMjM3IDg0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTI0LC0xMDkwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI0MTIiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMCIgeD0iMTE5MSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI3NjAiIHk9IjE2MjciPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QSIgeD0iMTYxMSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQyIiB4PSIyMDIzIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjk0OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0IiIHg9IjYwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIxMDQ1IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIxNzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkEiIHg9IjI3OTAiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjM1OTIiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjcyMDkiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3OTg3LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzk3LDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNTYzNyIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDc3MCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQyIiB4PSI1MjEiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDQ3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iODIyIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTgyMyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0IiIHg9IjIzMjMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMjc2OSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMzY4MCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjU2LC02ODcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI4MjIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxODIzIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8L3N2Zz4=)
fact 3: ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjMyLjU2M2V4IiBoZWlnaHQ9IjcuNjc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4zMzhleDsiIHZpZXdCb3g9IjAgLTE4NjcuNyAxNDAyMC4yIDMzMDQuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjIxMSIgZD0iTTYwIDk0OFE2MyA5NTAgNjY1IDk1MEgxMjY3TDEzMjUgODE1UTEzODQgNjc3IDEzODggNjY5SDEzNDhMMTM0MSA2ODNRMTMyMCA3MjQgMTI4NSA3NjFRMTIzNSA4MDkgMTE3NCA4MzhUMTAzMyA4ODFUODgyIDg5OFQ2OTkgOTAySDU3NEg1NDNIMjUxTDI1OSA4OTFRNzIyIDI1OCA3MjQgMjUyUTcyNSAyNTAgNzI0IDI0NlE3MjEgMjQzIDQ2MCAtNTZMMTk2IC0zNTZRMTk2IC0zNTcgNDA3IC0zNTdRNDU5IC0zNTcgNTQ4IC0zNTdUNjc2IC0zNThRODEyIC0zNTggODk2IC0zNTNUMTA2MyAtMzMyVDEyMDQgLTI4M1QxMzA3IC0xOTZRMTMyOCAtMTcwIDEzNDggLTEyNEgxMzg4UTEzODggLTEyNSAxMzgxIC0xNDVUMTM1NiAtMjEwVDEzMjUgLTI5NEwxMjY3IC00NDlMNjY2IC00NTBRNjQgLTQ1MCA2MSAtNDQ4UTU1IC00NDYgNTUgLTQzOVE1NSAtNDM3IDU3IC00MzNMNTkwIDE3N1E1OTAgMTc4IDU1NyAyMjJUNDUyIDM2NlQzMjIgNTQ0TDU2IDkwOUw1NSA5MjRRNTUgOTQ1IDYwIDk0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02QSIgZD0iTTI5NyA1OTZRMjk3IDYyNyAzMTggNjQ0VDM2MSA2NjFRMzc4IDY2MSAzODkgNjUxVDQwMyA2MjNRNDAzIDU5NSAzODQgNTc2VDM0MCA1NTdRMzIyIDU1NyAzMTAgNTY3VDI5NyA1OTZaTTI4OCAzNzZRMjg4IDQwNSAyNjIgNDA1UTI0MCA0MDUgMjIwIDM5M1QxODUgMzYyVDE2MSAzMjVUMTQ0IDI5M0wxMzcgMjc5UTEzNSAyNzggMTIxIDI3OEgxMDdRMTAxIDI4NCAxMDEgMjg2VDEwNSAyOTlRMTI2IDM0OCAxNjQgMzkxVDI1MiA0NDFRMjUzIDQ0MSAyNjAgNDQxVDI3MiA0NDJRMjk2IDQ0MSAzMTYgNDMyUTM0MSA0MTggMzU0IDQwMVQzNjcgMzQ4VjMzMkwzMTggMTMzUTI2NyAtNjcgMjY0IC03NVEyNDYgLTEyNSAxOTQgLTE2NFQ3NSAtMjA0UTI1IC0yMDQgNyAtMTgzVC0xMiAtMTM3US0xMiAtMTEwIDcgLTkxVDUzIC03MVE3MCAtNzEgODIgLTgxVDk1IC0xMTJROTUgLTE0OCA2MyAtMTY3UTY5IC0xNjggNzcgLTE2OFExMTEgLTE2OCAxMzkgLTE0MFQxODIgLTc0TDE5MyAtMzJRMjA0IDExIDIxOSA3MlQyNTEgMTk3VDI3OCAzMDhUMjg5IDM2NVEyODkgMzcyIDI4OCAzNzZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMwIiBkPSJNOTYgNTg1UTE1MiA2NjYgMjQ5IDY2NlEyOTcgNjY2IDM0NSA2NDBUNDIzIDU0OFE0NjAgNDY1IDQ2MCAzMjBRNDYwIDE2NSA0MTcgODNRMzk3IDQxIDM2MiAxNlQzMDEgLTE1VDI1MCAtMjJRMjI0IC0yMiAxOTggLTE2VDEzNyAxNlQ4MiA4M1EzOSAxNjUgMzkgMzIwUTM5IDQ5NCA5NiA1ODVaTTMyMSA1OTdRMjkxIDYyOSAyNTAgNjI5UTIwOCA2MjkgMTc4IDU5N1ExNTMgNTcxIDE0NSA1MjVUMTM3IDMzM1ExMzcgMTc1IDE0NSAxMjVUMTgxIDQ2UTIwOSAxNiAyNTAgMTZRMjkwIDE2IDMxOCA0NlEzNDcgNzYgMzU0IDEzMFQzNjIgMzMzUTM2MiA0NzggMzU0IDUyNFQzMjEgNTk3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZCIiBkPSJNMTIxIDY0N1ExMjEgNjU3IDEyNSA2NzBUMTM3IDY4M1ExMzggNjgzIDIwOSA2ODhUMjgyIDY5NFEyOTQgNjk0IDI5NCA2ODZRMjk0IDY3OSAyNDQgNDc3UTE5NCAyNzkgMTk0IDI3MlEyMTMgMjgyIDIyMyAyOTFRMjQ3IDMwOSAyOTIgMzU0VDM2MiA0MTVRNDAyIDQ0MiA0MzggNDQyUTQ2OCA0NDIgNDg1IDQyM1Q1MDMgMzY5UTUwMyAzNDQgNDk2IDMyN1Q0NzcgMzAyVDQ1NiAyOTFUNDM4IDI4OFE0MTggMjg4IDQwNiAyOTlUMzk0IDMyOFEzOTQgMzUzIDQxMCAzNjlUNDQyIDM5MEw0NTggMzkzUTQ0NiA0MDUgNDM0IDQwNUg0MzBRMzk4IDQwMiAzNjcgMzgwVDI5NCAzMTZUMjI4IDI1NVEyMzAgMjU0IDI0MyAyNTJUMjY3IDI0NlQyOTMgMjM4VDMyMCAyMjRUMzQyIDIwNlQzNTkgMTgwVDM2NSAxNDdRMzY1IDEzMCAzNjAgMTA2VDM1NCA2NlEzNTQgMjYgMzgxIDI2UTQyOSAyNiA0NTkgMTQ1UTQ2MSAxNTMgNDc5IDE1M0g0ODNRNDk5IDE1MyA0OTkgMTQ0UTQ5OSAxMzkgNDk2IDEzMFE0NTUgLTExIDM3OCAtMTFRMzMzIC0xMSAzMDUgMTVUMjc3IDkwUTI3NyAxMDggMjgwIDEyMVQyODMgMTQ1UTI4MyAxNjcgMjY5IDE4M1QyMzQgMjA2VDIwMCAyMTdUMTgyIDIyMEgxODBRMTY4IDE3OCAxNTkgMTM5VDE0NSA4MVQxMzYgNDRUMTI5IDIwVDEyMiA3VDExMSAtMlE5OCAtMTEgODMgLTExUTY2IC0xMSA1NyAtMVQ0OCAxNlE0OCAyNiA4NSAxNzZUMTU4IDQ3MUwxOTUgNjE2UTE5NiA2MjkgMTg4IDYzMlQxNDkgNjM3SDE0NFExMzQgNjM3IDEzMSA2MzdUMTI0IDY0MFQxMjEgNjQ3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzIiIGQ9Ik0xMDkgNDI5UTgyIDQyOSA2NiA0NDdUNTAgNDkxUTUwIDU2MiAxMDMgNjE0VDIzNSA2NjZRMzI2IDY2NiAzODcgNjEwVDQ0OSA0NjVRNDQ5IDQyMiA0MjkgMzgzVDM4MSAzMTVUMzAxIDI0MVEyNjUgMjEwIDIwMSAxNDlMMTQyIDkzTDIxOCA5MlEzNzUgOTIgMzg1IDk3UTM5MiA5OSA0MDkgMTg2VjE4OUg0NDlWMTg2UTQ0OCAxODMgNDM2IDk1VDQyMSAzVjBINTBWMTlWMzFRNTAgMzggNTYgNDZUODYgODFRMTE1IDExMyAxMzYgMTM3UTE0NSAxNDcgMTcwIDE3NFQyMDQgMjExVDIzMyAyNDRUMjYxIDI3OFQyODQgMzA4VDMwNSAzNDBUMzIwIDM2OVQzMzMgNDAxVDM0MCA0MzFUMzQzIDQ2NFEzNDMgNTI3IDMwOSA1NzNUMjEyIDYxOVExNzkgNjE5IDE1NCA2MDJUMTE5IDU2OVQxMDkgNTUwUTEwOSA1NDkgMTE0IDU0OVExMzIgNTQ5IDE1MSA1MzVUMTcwIDQ4OVExNzAgNDY0IDE1NCA0NDdUMTA5IDQyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00MiIgZD0iTTIzMSA2MzdRMjA0IDYzNyAxOTkgNjM4VDE5NCA2NDlRMTk0IDY3NiAyMDUgNjgyUTIwNiA2ODMgMzM1IDY4M1E1OTQgNjgzIDYwOCA2ODFRNjcxIDY3MSA3MTMgNjM2VDc1NiA1NDRRNzU2IDQ4MCA2OTggNDI5VDU2NSAzNjBMNTU1IDM1N1E2MTkgMzQ4IDY2MCAzMTFUNzAyIDIxOVE3MDIgMTQ2IDYzMCA3OFQ0NTMgMVE0NDYgMCAyNDIgMFE0MiAwIDM5IDJRMzUgNSAzNSAxMFEzNSAxNyAzNyAyNFE0MiA0MyA0NyA0NVE1MSA0NiA2MiA0Nkg2OFE5NSA0NiAxMjggNDlRMTQyIDUyIDE0NyA2MVExNTAgNjUgMjE5IDMzOVQyODggNjI4UTI4OCA2MzUgMjMxIDYzN1pNNjQ5IDU0NFE2NDkgNTc0IDYzNCA2MDBUNTg1IDYzNFE1NzggNjM2IDQ5MyA2MzdRNDczIDYzNyA0NTEgNjM3VDQxNiA2MzZINDAzUTM4OCA2MzUgMzg0IDYyNlEzODIgNjIyIDM1MiA1MDZRMzUyIDUwMyAzNTEgNTAwTDMyMCAzNzRINDAxUTQ4MiAzNzQgNDk0IDM3NlE1NTQgMzg2IDYwMSA0MzRUNjQ5IDU0NFpNNTk1IDIyOVE1OTUgMjczIDU3MiAzMDJUNTEyIDMzNlE1MDYgMzM3IDQyOSAzMzdRMzExIDMzNyAzMTAgMzM2UTMxMCAzMzQgMjkzIDI2M1QyNTggMTIyTDI0MCA1MlEyNDAgNDggMjUyIDQ4VDMzMyA0NlE0MjIgNDYgNDI5IDQ3UTQ5MSA1NCA1NDMgMTA1VDU5NSAyMjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZFIiBkPSJNMjEgMjg3UTIyIDI5MyAyNCAzMDNUMzYgMzQxVDU2IDM4OFQ4OSA0MjVUMTM1IDQ0MlExNzEgNDQyIDE5NSA0MjRUMjI1IDM5MFQyMzEgMzY5UTIzMSAzNjcgMjMyIDM2N0wyNDMgMzc4UTMwNCA0NDIgMzgyIDQ0MlE0MzYgNDQyIDQ2OSA0MTVUNTAzIDMzNlQ0NjUgMTc5VDQyNyA1MlE0MjcgMjYgNDQ0IDI2UTQ1MCAyNiA0NTMgMjdRNDgyIDMyIDUwNSA2NVQ1NDAgMTQ1UTU0MiAxNTMgNTYwIDE1M1E1ODAgMTUzIDU4MCAxNDVRNTgwIDE0NCA1NzYgMTMwUTU2OCAxMDEgNTU0IDczVDUwOCAxN1Q0MzkgLTEwUTM5MiAtMTAgMzcxIDE3VDM1MCA3M1EzNTAgOTIgMzg2IDE5M1Q0MjMgMzQ1UTQyMyA0MDQgMzc5IDQwNEgzNzRRMjg4IDQwNCAyMjkgMzAzTDIyMiAyOTFMMTg5IDE1N1ExNTYgMjYgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTIgMTgwVDE1MiAzNDNRMTUzIDM0OCAxNTMgMzY2UTE1MyA0MDUgMTI5IDQwNVE5MSA0MDUgNjYgMzA1UTYwIDI4NSA2MCAyODRRNTggMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0IiIGQ9Ik03OCAzNzBRNzggMzk0IDk1IDQxMlQxMzggNDMwUTE2MiA0MzAgMTgwIDQxNFQxOTkgMzcxUTE5OSAzNDYgMTgyIDMyOFQxMzkgMzEwVDk2IDMyN1Q3OCAzNzBaTTc4IDYwUTc4IDg1IDk0IDEwM1QxMzcgMTIxUTIwMiAxMjEgMjAyIDhRMjAyIC00NCAxODMgLTk0VDE0NCAtMTY5VDExOCAtMTk0UTExNSAtMTk0IDEwNiAtMTg2VDk1IC0xNzRROTQgLTE3MSAxMDcgLTE1NVQxMzcgLTEwN1QxNjAgLTM4UTE2MSAtMzIgMTYyIC0yMlQxNjUgLTRUMTY1IDRRMTY1IDUgMTYxIDRUMTQyIDBRMTEwIDAgOTQgMThUNzggNjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjEyIiBkPSJNODQgMjM3VDg0IDI1MFQ5OCAyNzBINjc5UTY5NCAyNjIgNjk0IDI1MFQ2NzkgMjMwSDk4UTg0IDIzNyA4NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTI0LC0xMDkwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI0MTIiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMCIgeD0iMTE5MSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI3NjAiIHk9IjE2MjciPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjExLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iNTgzIiB5PSI1ODMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQyIiB4PSIyNDc3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQwMywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0IiIHg9IjYwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIxMDQ1IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIxNzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkEiIHg9IjI3OTAiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjM1OTIiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9Ijc2NjMiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4NDQxLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzk3LDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNTA2MCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDc3MCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDg3MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjgyMiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjE4MjMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNCIiB4PSIyMzIzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjI3NjkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjM2ODAiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTM2OCwtNjg3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iODIyIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTgyMyIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9zdmc+)
fact 4: ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQ1LjgzOGV4IiBoZWlnaHQ9IjcuNjc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4zMzhleDsiIHZpZXdCb3g9IjAgLTE4NjcuNyAxOTczNS45IDMzMDQuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJCIiBkPSJNNTYgMjM3VDU2IDI1MFQ3MCAyNzBIMzY5VjQyMEwzNzAgNTcwUTM4MCA1ODMgMzg5IDU4M1E0MDIgNTgzIDQwOSA1NjhWMjcwSDcwN1E3MjIgMjYyIDcyMiAyNTBUNzA3IDIzMEg0MDlWLTY4UTQwMSAtODIgMzkxIC04MkgzODlIMzg3UTM3NSAtODIgMzY5IC02OFYyMzBINzBRNTYgMjM3IDU2IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNCIiBkPSJNNzggMzcwUTc4IDM5NCA5NSA0MTJUMTM4IDQzMFExNjIgNDMwIDE4MCA0MTRUMTk5IDM3MVExOTkgMzQ2IDE4MiAzMjhUMTM5IDMxMFQ5NiAzMjdUNzggMzcwWk03OCA2MFE3OCA4NSA5NCAxMDNUMTM3IDEyMVEyMDIgMTIxIDIwMiA4UTIwMiAtNDQgMTgzIC05NFQxNDQgLTE2OVQxMTggLTE5NFExMTUgLTE5NCAxMDYgLTE4NlQ5NSAtMTc0UTk0IC0xNzEgMTA3IC0xNTVUMTM3IC0xMDdUMTYwIC0zOFExNjEgLTMyIDE2MiAtMjJUMTY1IC00VDE2NSA0UTE2NSA1IDE2MSA0VDE0MiAwUTExMCAwIDk0IDE4VDc4IDYwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZCIiBkPSJNMTIxIDY0N1ExMjEgNjU3IDEyNSA2NzBUMTM3IDY4M1ExMzggNjgzIDIwOSA2ODhUMjgyIDY5NFEyOTQgNjk0IDI5NCA2ODZRMjk0IDY3OSAyNDQgNDc3UTE5NCAyNzkgMTk0IDI3MlEyMTMgMjgyIDIyMyAyOTFRMjQ3IDMwOSAyOTIgMzU0VDM2MiA0MTVRNDAyIDQ0MiA0MzggNDQyUTQ2OCA0NDIgNDg1IDQyM1Q1MDMgMzY5UTUwMyAzNDQgNDk2IDMyN1Q0NzcgMzAyVDQ1NiAyOTFUNDM4IDI4OFE0MTggMjg4IDQwNiAyOTlUMzk0IDMyOFEzOTQgMzUzIDQxMCAzNjlUNDQyIDM5MEw0NTggMzkzUTQ0NiA0MDUgNDM0IDQwNUg0MzBRMzk4IDQwMiAzNjcgMzgwVDI5NCAzMTZUMjI4IDI1NVEyMzAgMjU0IDI0MyAyNTJUMjY3IDI0NlQyOTMgMjM4VDMyMCAyMjRUMzQyIDIwNlQzNTkgMTgwVDM2NSAxNDdRMzY1IDEzMCAzNjAgMTA2VDM1NCA2NlEzNTQgMjYgMzgxIDI2UTQyOSAyNiA0NTkgMTQ1UTQ2MSAxNTMgNDc5IDE1M0g0ODNRNDk5IDE1MyA0OTkgMTQ0UTQ5OSAxMzkgNDk2IDEzMFE0NTUgLTExIDM3OCAtMTFRMzMzIC0xMSAzMDUgMTVUMjc3IDkwUTI3NyAxMDggMjgwIDEyMVQyODMgMTQ1UTI4MyAxNjcgMjY5IDE4M1QyMzQgMjA2VDIwMCAyMTdUMTgyIDIyMEgxODBRMTY4IDE3OCAxNTkgMTM5VDE0NSA4MVQxMzYgNDRUMTI5IDIwVDEyMiA3VDExMSAtMlE5OCAtMTEgODMgLTExUTY2IC0xMSA1NyAtMVQ0OCAxNlE0OCAyNiA4NSAxNzZUMTU4IDQ3MUwxOTUgNjE2UTE5NiA2MjkgMTg4IDYzMlQxNDkgNjM3SDE0NFExMzQgNjM3IDEzMSA2MzdUMTI0IDY0MFQxMjEgNjQ3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjIxMSIgZD0iTTYwIDk0OFE2MyA5NTAgNjY1IDk1MEgxMjY3TDEzMjUgODE1UTEzODQgNjc3IDEzODggNjY5SDEzNDhMMTM0MSA2ODNRMTMyMCA3MjQgMTI4NSA3NjFRMTIzNSA4MDkgMTE3NCA4MzhUMTAzMyA4ODFUODgyIDg5OFQ2OTkgOTAySDU3NEg1NDNIMjUxTDI1OSA4OTFRNzIyIDI1OCA3MjQgMjUyUTcyNSAyNTAgNzI0IDI0NlE3MjEgMjQzIDQ2MCAtNTZMMTk2IC0zNTZRMTk2IC0zNTcgNDA3IC0zNTdRNDU5IC0zNTcgNTQ4IC0zNTdUNjc2IC0zNThRODEyIC0zNTggODk2IC0zNTNUMTA2MyAtMzMyVDEyMDQgLTI4M1QxMzA3IC0xOTZRMTMyOCAtMTcwIDEzNDggLTEyNEgxMzg4UTEzODggLTEyNSAxMzgxIC0xNDVUMTM1NiAtMjEwVDEzMjUgLTI5NEwxMjY3IC00NDlMNjY2IC00NTBRNjQgLTQ1MCA2MSAtNDQ4UTU1IC00NDYgNTUgLTQzOVE1NSAtNDM3IDU3IC00MzNMNTkwIDE3N1E1OTAgMTc4IDU1NyAyMjJUNDUyIDM2NlQzMjIgNTQ0TDU2IDkwOUw1NSA5MjRRNTUgOTQ1IDYwIDk0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02QSIgZD0iTTI5NyA1OTZRMjk3IDYyNyAzMTggNjQ0VDM2MSA2NjFRMzc4IDY2MSAzODkgNjUxVDQwMyA2MjNRNDAzIDU5NSAzODQgNTc2VDM0MCA1NTdRMzIyIDU1NyAzMTAgNTY3VDI5NyA1OTZaTTI4OCAzNzZRMjg4IDQwNSAyNjIgNDA1UTI0MCA0MDUgMjIwIDM5M1QxODUgMzYyVDE2MSAzMjVUMTQ0IDI5M0wxMzcgMjc5UTEzNSAyNzggMTIxIDI3OEgxMDdRMTAxIDI4NCAxMDEgMjg2VDEwNSAyOTlRMTI2IDM0OCAxNjQgMzkxVDI1MiA0NDFRMjUzIDQ0MSAyNjAgNDQxVDI3MiA0NDJRMjk2IDQ0MSAzMTYgNDMyUTM0MSA0MTggMzU0IDQwMVQzNjcgMzQ4VjMzMkwzMTggMTMzUTI2NyAtNjcgMjY0IC03NVEyNDYgLTEyNSAxOTQgLTE2NFQ3NSAtMjA0UTI1IC0yMDQgNyAtMTgzVC0xMiAtMTM3US0xMiAtMTEwIDcgLTkxVDUzIC03MVE3MCAtNzEgODIgLTgxVDk1IC0xMTJROTUgLTE0OCA2MyAtMTY3UTY5IC0xNjggNzcgLTE2OFExMTEgLTE2OCAxMzkgLTE0MFQxODIgLTc0TDE5MyAtMzJRMjA0IDExIDIxOSA3MlQyNTEgMTk3VDI3OCAzMDhUMjg5IDM2NVEyODkgMzcyIDI4OCAzNzZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMCIgZD0iTTk2IDU4NVExNTIgNjY2IDI0OSA2NjZRMjk3IDY2NiAzNDUgNjQwVDQyMyA1NDhRNDYwIDQ2NSA0NjAgMzIwUTQ2MCAxNjUgNDE3IDgzUTM5NyA0MSAzNjIgMTZUMzAxIC0xNVQyNTAgLTIyUTIyNCAtMjIgMTk4IC0xNlQxMzcgMTZUODIgODNRMzkgMTY1IDM5IDMyMFEzOSA0OTQgOTYgNTg1Wk0zMjEgNTk3UTI5MSA2MjkgMjUwIDYyOVEyMDggNjI5IDE3OCA1OTdRMTUzIDU3MSAxNDUgNTI1VDEzNyAzMzNRMTM3IDE3NSAxNDUgMTI1VDE4MSA0NlEyMDkgMTYgMjUwIDE2UTI5MCAxNiAzMTggNDZRMzQ3IDc2IDM1NCAxMzBUMzYyIDMzM1EzNjIgNDc4IDM1NCA1MjRUMzIxIDU5N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMTIiIGQ9Ik04NCAyMzdUODQgMjUwVDk4IDI3MEg2NzlRNjk0IDI2MiA2OTQgMjUwVDY3OSAyMzBIOThRODQgMjM3IDg0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDIiIGQ9Ik0yMzEgNjM3UTIwNCA2MzcgMTk5IDYzOFQxOTQgNjQ5UTE5NCA2NzYgMjA1IDY4MlEyMDYgNjgzIDMzNSA2ODNRNTk0IDY4MyA2MDggNjgxUTY3MSA2NzEgNzEzIDYzNlQ3NTYgNTQ0UTc1NiA0ODAgNjk4IDQyOVQ1NjUgMzYwTDU1NSAzNTdRNjE5IDM0OCA2NjAgMzExVDcwMiAyMTlRNzAyIDE0NiA2MzAgNzhUNDUzIDFRNDQ2IDAgMjQyIDBRNDIgMCAzOSAyUTM1IDUgMzUgMTBRMzUgMTcgMzcgMjRRNDIgNDMgNDcgNDVRNTEgNDYgNjIgNDZINjhROTUgNDYgMTI4IDQ5UTE0MiA1MiAxNDcgNjFRMTUwIDY1IDIxOSAzMzlUMjg4IDYyOFEyODggNjM1IDIzMSA2MzdaTTY0OSA1NDRRNjQ5IDU3NCA2MzQgNjAwVDU4NSA2MzRRNTc4IDYzNiA0OTMgNjM3UTQ3MyA2MzcgNDUxIDYzN1Q0MTYgNjM2SDQwM1EzODggNjM1IDM4NCA2MjZRMzgyIDYyMiAzNTIgNTA2UTM1MiA1MDMgMzUxIDUwMEwzMjAgMzc0SDQwMVE0ODIgMzc0IDQ5NCAzNzZRNTU0IDM4NiA2MDEgNDM0VDY0OSA1NDRaTTU5NSAyMjlRNTk1IDI3MyA1NzIgMzAyVDUxMiAzMzZRNTA2IDMzNyA0MjkgMzM3UTMxMSAzMzcgMzEwIDMzNlEzMTAgMzM0IDI5MyAyNjNUMjU4IDEyMkwyNDAgNTJRMjQwIDQ4IDI1MiA0OFQzMzMgNDZRNDIyIDQ2IDQyOSA0N1E0OTEgNTQgNTQzIDEwNVQ1OTUgMjI5WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODcxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iODIyIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTgyMyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0IiIHg9IjIzMjMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMjc2OSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMzY4MCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iNTIxOCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYyNzQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyNCwtMTA5MCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iNDEyIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzAiIHg9IjExOTEiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNzYwIiB5PSIxNjI3Ij48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iNzg4NSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDg3NTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNCIiB4PSI2MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTA0NSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMTc4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZBIiB4PSIyNzkwIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIzNTkyIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMjk2MSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzOTYxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iNTgzIiB5PSI1ODMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQyIiB4PSIxNDgyOCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE1NzU0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zQiIgeD0iNjAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjEwNDUiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjE3ODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QSIgeD0iMjc5MCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMzU5MiIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=)
fact 3和fact 4暗示着, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjM2LjIwOGV4IiBoZWlnaHQ9IjcuNjc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4zMzhleDsiIHZpZXdCb3g9IjAgLTE4NjcuNyAxNTU4OS40IDMzMDQuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJCIiBkPSJNNTYgMjM3VDU2IDI1MFQ3MCAyNzBIMzY5VjQyMEwzNzAgNTcwUTM4MCA1ODMgMzg5IDU4M1E0MDIgNTgzIDQwOSA1NjhWMjcwSDcwN1E3MjIgMjYyIDcyMiAyNTBUNzA3IDIzMEg0MDlWLTY4UTQwMSAtODIgMzkxIC04MkgzODlIMzg3UTM3NSAtODIgMzY5IC02OFYyMzBINzBRNTYgMjM3IDU2IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNCIiBkPSJNNzggMzcwUTc4IDM5NCA5NSA0MTJUMTM4IDQzMFExNjIgNDMwIDE4MCA0MTRUMTk5IDM3MVExOTkgMzQ2IDE4MiAzMjhUMTM5IDMxMFQ5NiAzMjdUNzggMzcwWk03OCA2MFE3OCA4NSA5NCAxMDNUMTM3IDEyMVEyMDIgMTIxIDIwMiA4UTIwMiAtNDQgMTgzIC05NFQxNDQgLTE2OVQxMTggLTE5NFExMTUgLTE5NCAxMDYgLTE4NlQ5NSAtMTc0UTk0IC0xNzEgMTA3IC0xNTVUMTM3IC0xMDdUMTYwIC0zOFExNjEgLTMyIDE2MiAtMjJUMTY1IC00VDE2NSA0UTE2NSA1IDE2MSA0VDE0MiAwUTExMCAwIDk0IDE4VDc4IDYwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZCIiBkPSJNMTIxIDY0N1ExMjEgNjU3IDEyNSA2NzBUMTM3IDY4M1ExMzggNjgzIDIwOSA2ODhUMjgyIDY5NFEyOTQgNjk0IDI5NCA2ODZRMjk0IDY3OSAyNDQgNDc3UTE5NCAyNzkgMTk0IDI3MlEyMTMgMjgyIDIyMyAyOTFRMjQ3IDMwOSAyOTIgMzU0VDM2MiA0MTVRNDAyIDQ0MiA0MzggNDQyUTQ2OCA0NDIgNDg1IDQyM1Q1MDMgMzY5UTUwMyAzNDQgNDk2IDMyN1Q0NzcgMzAyVDQ1NiAyOTFUNDM4IDI4OFE0MTggMjg4IDQwNiAyOTlUMzk0IDMyOFEzOTQgMzUzIDQxMCAzNjlUNDQyIDM5MEw0NTggMzkzUTQ0NiA0MDUgNDM0IDQwNUg0MzBRMzk4IDQwMiAzNjcgMzgwVDI5NCAzMTZUMjI4IDI1NVEyMzAgMjU0IDI0MyAyNTJUMjY3IDI0NlQyOTMgMjM4VDMyMCAyMjRUMzQyIDIwNlQzNTkgMTgwVDM2NSAxNDdRMzY1IDEzMCAzNjAgMTA2VDM1NCA2NlEzNTQgMjYgMzgxIDI2UTQyOSAyNiA0NTkgMTQ1UTQ2MSAxNTMgNDc5IDE1M0g0ODNRNDk5IDE1MyA0OTkgMTQ0UTQ5OSAxMzkgNDk2IDEzMFE0NTUgLTExIDM3OCAtMTFRMzMzIC0xMSAzMDUgMTVUMjc3IDkwUTI3NyAxMDggMjgwIDEyMVQyODMgMTQ1UTI4MyAxNjcgMjY5IDE4M1QyMzQgMjA2VDIwMCAyMTdUMTgyIDIyMEgxODBRMTY4IDE3OCAxNTkgMTM5VDE0NSA4MVQxMzYgNDRUMTI5IDIwVDEyMiA3VDExMSAtMlE5OCAtMTEgODMgLTExUTY2IC0xMSA1NyAtMVQ0OCAxNlE0OCAyNiA4NSAxNzZUMTU4IDQ3MUwxOTUgNjE2UTE5NiA2MjkgMTg4IDYzMlQxNDkgNjM3SDE0NFExMzQgNjM3IDEzMSA2MzdUMTI0IDY0MFQxMjEgNjQ3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjIxMSIgZD0iTTYwIDk0OFE2MyA5NTAgNjY1IDk1MEgxMjY3TDEzMjUgODE1UTEzODQgNjc3IDEzODggNjY5SDEzNDhMMTM0MSA2ODNRMTMyMCA3MjQgMTI4NSA3NjFRMTIzNSA4MDkgMTE3NCA4MzhUMTAzMyA4ODFUODgyIDg5OFQ2OTkgOTAySDU3NEg1NDNIMjUxTDI1OSA4OTFRNzIyIDI1OCA3MjQgMjUyUTcyNSAyNTAgNzI0IDI0NlE3MjEgMjQzIDQ2MCAtNTZMMTk2IC0zNTZRMTk2IC0zNTcgNDA3IC0zNTdRNDU5IC0zNTcgNTQ4IC0zNTdUNjc2IC0zNThRODEyIC0zNTggODk2IC0zNTNUMTA2MyAtMzMyVDEyMDQgLTI4M1QxMzA3IC0xOTZRMTMyOCAtMTcwIDEzNDggLTEyNEgxMzg4UTEzODggLTEyNSAxMzgxIC0xNDVUMTM1NiAtMjEwVDEzMjUgLTI5NEwxMjY3IC00NDlMNjY2IC00NTBRNjQgLTQ1MCA2MSAtNDQ4UTU1IC00NDYgNTUgLTQzOVE1NSAtNDM3IDU3IC00MzNMNTkwIDE3N1E1OTAgMTc4IDU1NyAyMjJUNDUyIDM2NlQzMjIgNTQ0TDU2IDkwOUw1NSA5MjRRNTUgOTQ1IDYwIDk0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02QSIgZD0iTTI5NyA1OTZRMjk3IDYyNyAzMTggNjQ0VDM2MSA2NjFRMzc4IDY2MSAzODkgNjUxVDQwMyA2MjNRNDAzIDU5NSAzODQgNTc2VDM0MCA1NTdRMzIyIDU1NyAzMTAgNTY3VDI5NyA1OTZaTTI4OCAzNzZRMjg4IDQwNSAyNjIgNDA1UTI0MCA0MDUgMjIwIDM5M1QxODUgMzYyVDE2MSAzMjVUMTQ0IDI5M0wxMzcgMjc5UTEzNSAyNzggMTIxIDI3OEgxMDdRMTAxIDI4NCAxMDEgMjg2VDEwNSAyOTlRMTI2IDM0OCAxNjQgMzkxVDI1MiA0NDFRMjUzIDQ0MSAyNjAgNDQxVDI3MiA0NDJRMjk2IDQ0MSAzMTYgNDMyUTM0MSA0MTggMzU0IDQwMVQzNjcgMzQ4VjMzMkwzMTggMTMzUTI2NyAtNjcgMjY0IC03NVEyNDYgLTEyNSAxOTQgLTE2NFQ3NSAtMjA0UTI1IC0yMDQgNyAtMTgzVC0xMiAtMTM3US0xMiAtMTEwIDcgLTkxVDUzIC03MVE3MCAtNzEgODIgLTgxVDk1IC0xMTJROTUgLTE0OCA2MyAtMTY3UTY5IC0xNjggNzcgLTE2OFExMTEgLTE2OCAxMzkgLTE0MFQxODIgLTc0TDE5MyAtMzJRMjA0IDExIDIxOSA3MlQyNTEgMTk3VDI3OCAzMDhUMjg5IDM2NVEyODkgMzcyIDI4OCAzNzZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMCIgZD0iTTk2IDU4NVExNTIgNjY2IDI0OSA2NjZRMjk3IDY2NiAzNDUgNjQwVDQyMyA1NDhRNDYwIDQ2NSA0NjAgMzIwUTQ2MCAxNjUgNDE3IDgzUTM5NyA0MSAzNjIgMTZUMzAxIC0xNVQyNTAgLTIyUTIyNCAtMjIgMTk4IC0xNlQxMzcgMTZUODIgODNRMzkgMTY1IDM5IDMyMFEzOSA0OTQgOTYgNTg1Wk0zMjEgNTk3UTI5MSA2MjkgMjUwIDYyOVEyMDggNjI5IDE3OCA1OTdRMTUzIDU3MSAxNDUgNTI1VDEzNyAzMzNRMTM3IDE3NSAxNDUgMTI1VDE4MSA0NlEyMDkgMTYgMjUwIDE2UTI5MCAxNiAzMTggNDZRMzQ3IDc2IDM1NCAxMzBUMzYyIDMzM1EzNjIgNDc4IDM1NCA1MjRUMzIxIDU5N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMTIiIGQ9Ik04NCAyMzdUODQgMjUwVDk4IDI3MEg2NzlRNjk0IDI2MiA2OTQgMjUwVDY3OSAyMzBIOThRODQgMjM3IDg0IDI1MFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDg3MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjgyMiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjE4MjMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNCIiB4PSIyMzIzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjI3NjkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjM2ODAiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjUyMTgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1OTk3LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzk3LDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMjQ0MyIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDY3NikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjgyMiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjE4MjMiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI5MjEiIHk9Ii02ODYiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTEyNSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTI0LC0xMDkwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI0MTIiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMCIgeD0iMTE5MSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI3NjAiIHk9IjE2MjciPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDczNiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDExNjA3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zQiIgeD0iNjAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjEwNDUiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjE3ODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QSIgeD0iMjc5MCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMzU5MiIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=)
证明一下:
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjU1Ljg1OWV4IiBoZWlnaHQ9IjQ1LjE3NmV4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTIyLjAwNWV4OyIgdmlld0JveD0iMCAtOTk3Ni41IDI0MDUwLjIgMTk0NTAuNyIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJCIiBkPSJNNTYgMjM3VDU2IDI1MFQ3MCAyNzBIMzY5VjQyMEwzNzAgNTcwUTM4MCA1ODMgMzg5IDU4M1E0MDIgNTgzIDQwOSA1NjhWMjcwSDcwN1E3MjIgMjYyIDcyMiAyNTBUNzA3IDIzMEg0MDlWLTY4UTQwMSAtODIgMzkxIC04MkgzODlIMzg3UTM3NSAtODIgMzY5IC02OFYyMzBINzBRNTYgMjM3IDU2IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNCIiBkPSJNNzggMzcwUTc4IDM5NCA5NSA0MTJUMTM4IDQzMFExNjIgNDMwIDE4MCA0MTRUMTk5IDM3MVExOTkgMzQ2IDE4MiAzMjhUMTM5IDMxMFQ5NiAzMjdUNzggMzcwWk03OCA2MFE3OCA4NSA5NCAxMDNUMTM3IDEyMVEyMDIgMTIxIDIwMiA4UTIwMiAtNDQgMTgzIC05NFQxNDQgLTE2OVQxMTggLTE5NFExMTUgLTE5NCAxMDYgLTE4NlQ5NSAtMTc0UTk0IC0xNzEgMTA3IC0xNTVUMTM3IC0xMDdUMTYwIC0zOFExNjEgLTMyIDE2MiAtMjJUMTY1IC00VDE2NSA0UTE2NSA1IDE2MSA0VDE0MiAwUTExMCAwIDk0IDE4VDc4IDYwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZCIiBkPSJNMTIxIDY0N1ExMjEgNjU3IDEyNSA2NzBUMTM3IDY4M1ExMzggNjgzIDIwOSA2ODhUMjgyIDY5NFEyOTQgNjk0IDI5NCA2ODZRMjk0IDY3OSAyNDQgNDc3UTE5NCAyNzkgMTk0IDI3MlEyMTMgMjgyIDIyMyAyOTFRMjQ3IDMwOSAyOTIgMzU0VDM2MiA0MTVRNDAyIDQ0MiA0MzggNDQyUTQ2OCA0NDIgNDg1IDQyM1Q1MDMgMzY5UTUwMyAzNDQgNDk2IDMyN1Q0NzcgMzAyVDQ1NiAyOTFUNDM4IDI4OFE0MTggMjg4IDQwNiAyOTlUMzk0IDMyOFEzOTQgMzUzIDQxMCAzNjlUNDQyIDM5MEw0NTggMzkzUTQ0NiA0MDUgNDM0IDQwNUg0MzBRMzk4IDQwMiAzNjcgMzgwVDI5NCAzMTZUMjI4IDI1NVEyMzAgMjU0IDI0MyAyNTJUMjY3IDI0NlQyOTMgMjM4VDMyMCAyMjRUMzQyIDIwNlQzNTkgMTgwVDM2NSAxNDdRMzY1IDEzMCAzNjAgMTA2VDM1NCA2NlEzNTQgMjYgMzgxIDI2UTQyOSAyNiA0NTkgMTQ1UTQ2MSAxNTMgNDc5IDE1M0g0ODNRNDk5IDE1MyA0OTkgMTQ0UTQ5OSAxMzkgNDk2IDEzMFE0NTUgLTExIDM3OCAtMTFRMzMzIC0xMSAzMDUgMTVUMjc3IDkwUTI3NyAxMDggMjgwIDEyMVQyODMgMTQ1UTI4MyAxNjcgMjY5IDE4M1QyMzQgMjA2VDIwMCAyMTdUMTgyIDIyMEgxODBRMTY4IDE3OCAxNTkgMTM5VDE0NSA4MVQxMzYgNDRUMTI5IDIwVDEyMiA3VDExMSAtMlE5OCAtMTEgODMgLTExUTY2IC0xMSA1NyAtMVQ0OCAxNlE0OCAyNiA4NSAxNzZUMTU4IDQ3MUwxOTUgNjE2UTE5NiA2MjkgMTg4IDYzMlQxNDkgNjM3SDE0NFExMzQgNjM3IDEzMSA2MzdUMTI0IDY0MFQxMjEgNjQ3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjIxMSIgZD0iTTYwIDk0OFE2MyA5NTAgNjY1IDk1MEgxMjY3TDEzMjUgODE1UTEzODQgNjc3IDEzODggNjY5SDEzNDhMMTM0MSA2ODNRMTMyMCA3MjQgMTI4NSA3NjFRMTIzNSA4MDkgMTE3NCA4MzhUMTAzMyA4ODFUODgyIDg5OFQ2OTkgOTAySDU3NEg1NDNIMjUxTDI1OSA4OTFRNzIyIDI1OCA3MjQgMjUyUTcyNSAyNTAgNzI0IDI0NlE3MjEgMjQzIDQ2MCAtNTZMMTk2IC0zNTZRMTk2IC0zNTcgNDA3IC0zNTdRNDU5IC0zNTcgNTQ4IC0zNTdUNjc2IC0zNThRODEyIC0zNTggODk2IC0zNTNUMTA2MyAtMzMyVDEyMDQgLTI4M1QxMzA3IC0xOTZRMTMyOCAtMTcwIDEzNDggLTEyNEgxMzg4UTEzODggLTEyNSAxMzgxIC0xNDVUMTM1NiAtMjEwVDEzMjUgLTI5NEwxMjY3IC00NDlMNjY2IC00NTBRNjQgLTQ1MCA2MSAtNDQ4UTU1IC00NDYgNTUgLTQzOVE1NSAtNDM3IDU3IC00MzNMNTkwIDE3N1E1OTAgMTc4IDU1NyAyMjJUNDUyIDM2NlQzMjIgNTQ0TDU2IDkwOUw1NSA5MjRRNTUgOTQ1IDYwIDk0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02QSIgZD0iTTI5NyA1OTZRMjk3IDYyNyAzMTggNjQ0VDM2MSA2NjFRMzc4IDY2MSAzODkgNjUxVDQwMyA2MjNRNDAzIDU5NSAzODQgNTc2VDM0MCA1NTdRMzIyIDU1NyAzMTAgNTY3VDI5NyA1OTZaTTI4OCAzNzZRMjg4IDQwNSAyNjIgNDA1UTI0MCA0MDUgMjIwIDM5M1QxODUgMzYyVDE2MSAzMjVUMTQ0IDI5M0wxMzcgMjc5UTEzNSAyNzggMTIxIDI3OEgxMDdRMTAxIDI4NCAxMDEgMjg2VDEwNSAyOTlRMTI2IDM0OCAxNjQgMzkxVDI1MiA0NDFRMjUzIDQ0MSAyNjAgNDQxVDI3MiA0NDJRMjk2IDQ0MSAzMTYgNDMyUTM0MSA0MTggMzU0IDQwMVQzNjcgMzQ4VjMzMkwzMTggMTMzUTI2NyAtNjcgMjY0IC03NVEyNDYgLTEyNSAxOTQgLTE2NFQ3NSAtMjA0UTI1IC0yMDQgNyAtMTgzVC0xMiAtMTM3US0xMiAtMTEwIDcgLTkxVDUzIC03MVE3MCAtNzEgODIgLTgxVDk1IC0xMTJROTUgLTE0OCA2MyAtMTY3UTY5IC0xNjggNzcgLTE2OFExMTEgLTE2OCAxMzkgLTE0MFQxODIgLTc0TDE5MyAtMzJRMjA0IDExIDIxOSA3MlQyNTEgMTk3VDI3OCAzMDhUMjg5IDM2NVEyODkgMzcyIDI4OCAzNzZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMCIgZD0iTTk2IDU4NVExNTIgNjY2IDI0OSA2NjZRMjk3IDY2NiAzNDUgNjQwVDQyMyA1NDhRNDYwIDQ2NSA0NjAgMzIwUTQ2MCAxNjUgNDE3IDgzUTM5NyA0MSAzNjIgMTZUMzAxIC0xNVQyNTAgLTIyUTIyNCAtMjIgMTk4IC0xNlQxMzcgMTZUODIgODNRMzkgMTY1IDM5IDMyMFEzOSA0OTQgOTYgNTg1Wk0zMjEgNTk3UTI5MSA2MjkgMjUwIDYyOVEyMDggNjI5IDE3OCA1OTdRMTUzIDU3MSAxNDUgNTI1VDEzNyAzMzNRMTM3IDE3NSAxNDUgMTI1VDE4MSA0NlEyMDkgMTYgMjUwIDE2UTI5MCAxNiAzMTggNDZRMzQ3IDc2IDM1NCAxMzBUMzYyIDMzM1EzNjIgNDc4IDM1NCA1MjRUMzIxIDU5N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMTIiIGQ9Ik04NCAyMzdUODQgMjUwVDk4IDI3MEg2NzlRNjk0IDI2MiA2OTQgMjUwVDY3OSAyMzBIOThRODQgMjM3IDg0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDIiIGQ9Ik0yMzEgNjM3UTIwNCA2MzcgMTk5IDYzOFQxOTQgNjQ5UTE5NCA2NzYgMjA1IDY4MlEyMDYgNjgzIDMzNSA2ODNRNTk0IDY4MyA2MDggNjgxUTY3MSA2NzEgNzEzIDYzNlQ3NTYgNTQ0UTc1NiA0ODAgNjk4IDQyOVQ1NjUgMzYwTDU1NSAzNTdRNjE5IDM0OCA2NjAgMzExVDcwMiAyMTlRNzAyIDE0NiA2MzAgNzhUNDUzIDFRNDQ2IDAgMjQyIDBRNDIgMCAzOSAyUTM1IDUgMzUgMTBRMzUgMTcgMzcgMjRRNDIgNDMgNDcgNDVRNTEgNDYgNjIgNDZINjhROTUgNDYgMTI4IDQ5UTE0MiA1MiAxNDcgNjFRMTUwIDY1IDIxOSAzMzlUMjg4IDYyOFEyODggNjM1IDIzMSA2MzdaTTY0OSA1NDRRNjQ5IDU3NCA2MzQgNjAwVDU4NSA2MzRRNTc4IDYzNiA0OTMgNjM3UTQ3MyA2MzcgNDUxIDYzN1Q0MTYgNjM2SDQwM1EzODggNjM1IDM4NCA2MjZRMzgyIDYyMiAzNTIgNTA2UTM1MiA1MDMgMzUxIDUwMEwzMjAgMzc0SDQwMVE0ODIgMzc0IDQ5NCAzNzZRNTU0IDM4NiA2MDEgNDM0VDY0OSA1NDRaTTU5NSAyMjlRNTk1IDI3MyA1NzIgMzAyVDUxMiAzMzZRNTA2IDMzNyA0MjkgMzM3UTMxMSAzMzcgMzEwIDMzNlEzMTAgMzM0IDI5MyAyNjNUMjU4IDEyMkwyNDAgNTJRMjQwIDQ4IDI1MiA0OFQzMzMgNDZRNDIyIDQ2IDQyOSA0N1E0OTEgNTQgNTQzIDEwNVQ1OTUgMjI5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjFEMiIgZD0iTTU4MCA1MTRRNTgwIDUyNSA1OTYgNTI1UTYwMSA1MjUgNjA0IDUyNVQ2MDkgNTI1VDYxMyA1MjRUNjE1IDUyM1Q2MTcgNTIwVDYxOSA1MTdUNjIyIDUxMlE2NTkgNDM4IDcyMCAzODFUODMxIDMwMFQ5MjcgMjYzUTk0NCAyNTggOTQ0IDI1MFQ5MzUgMjM5VDg5OCAyMjhUODQwIDIwNFE2OTYgMTM0IDYyMiAtMTJRNjE4IC0yMSA2MTUgLTIyVDYwMCAtMjRRNTgwIC0yNCA1ODAgLTE3UTU4MCAtMTMgNTg1IDBRNjIwIDY5IDY3MSAxMjNMNjgxIDEzM0g3MFE1NiAxNDAgNTYgMTUzUTU2IDE2OCA3MiAxNzNINzI1TDczNSAxODFRNzc0IDIxMSA4NTIgMjUwUTg1MSAyNTEgODM0IDI1OVQ3ODkgMjgzVDczNSAzMTlMNzI1IDMyN0g3MlE1NiAzMzIgNTYgMzQ3UTU2IDM2MCA3MCAzNjdINjgxTDY3MSAzNzdRNjM4IDQxMiA2MDkgNDU4VDU4MCA1MTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1ozLTI4IiBkPSJNNzAxIC05NDBRNzAxIC05NDMgNjk1IC05NDlINjY0UTY2MiAtOTQ3IDYzNiAtOTIyVDU5MSAtODc5VDUzNyAtODE4VDQ3NSAtNzM3VDQxMiAtNjM2VDM1MCAtNTExVDI5NSAtMzYyVDI1MCAtMTg2VDIyMSAxN1QyMDkgMjUxUTIwOSA5NjIgNTczIDEzNjFRNTk2IDEzODYgNjE2IDE0MDVUNjQ5IDE0MzdUNjY0IDE0NTBINjk1UTcwMSAxNDQ0IDcwMSAxNDQxUTcwMSAxNDM2IDY4MSAxNDE1VDYyOSAxMzU2VDU1NyAxMjYxVDQ3NiAxMTE4VDQwMCA5MjdUMzQwIDY3NVQzMDggMzU5UTMwNiAzMjEgMzA2IDI1MFEzMDYgLTEzOSA0MDAgLTQzMFQ2OTAgLTkyNFE3MDEgLTkzNiA3MDEgLTk0MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjMtMjkiIGQ9Ik0zNCAxNDM4UTM0IDE0NDYgMzcgMTQ0OFQ1MCAxNDUwSDU2SDcxUTczIDE0NDggOTkgMTQyM1QxNDQgMTM4MFQxOTggMTMxOVQyNjAgMTIzOFQzMjMgMTEzN1QzODUgMTAxM1Q0NDAgODY0VDQ4NSA2ODhUNTE0IDQ4NVQ1MjYgMjUxUTUyNiAxMzQgNTE5IDUzUTQ3MiAtNTE5IDE2MiAtODYwUTEzOSAtODg1IDExOSAtOTA0VDg2IC05MzZUNzEgLTk0OUg1NlE0MyAtOTQ5IDM5IC05NDdUMzQgLTkzN1E4OCAtODgzIDE0MCAtODEzUTQyOCAtNDMwIDQyOCAyNTFRNDI4IDQ1MyA0MDIgNjI4VDMzOCA5MjJUMjQ1IDExNDZUMTQ1IDEzMDlUNDYgMTQyNVE0NCAxNDI3IDQyIDE0MjlUMzkgMTQzM1QzNiAxNDM2TDM0IDE0MzhaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTY3LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoLTExLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCw4MDk5KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODcxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iODIyIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTgyMyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0IiIHg9IjIzMjMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMjc2OSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMzY4MCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ5MzAsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDgwOTkpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjc3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTMzNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTI0LC0xMDkwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI0MTIiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMCIgeD0iMTE5MSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI3NjAiIHk9IjE2MjciPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIyOTQ1IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzgxNiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0IiIHg9IjYwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIxMDQ1IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIxNzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkEiIHg9IjI3OTAiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjM1OTIiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjgwMjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5MDIwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iNTgzIiB5PSI1ODMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQyIiB4PSI5ODg3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTA4MTMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNCIiB4PSI2MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTA0NSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMTc4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZBIiB4PSIyNzkwIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIzNTkyIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsNDcyMikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIyNzciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzM0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjQsLTEwOTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZBIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjQxMiIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMwIiB4PSIxMTkxIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9Ijc2MCIgeT0iMTYyNyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjI5NDUiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODE2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zQiIgeD0iNjAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjEwNDUiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjE3ODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QSIgeD0iMjc5MCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMzU5MiIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iODAyMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkwMjAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyNCwtMTA5MCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iNDEyIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzAiIHg9IjExOTEiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNzYwIiB5PSIxNjI3Ij48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDYzMiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZBIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjU4MyIgeT0iNTgzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00MiIgeD0iMTE0OTgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjQyNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0IiIHg9IjYwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIxMDQ1IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIxNzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkEiIHg9IjI3OTAiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjM1OTIiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwxMzQ1KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzMzQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyNCwtMTA5MCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iNDEyIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzAiIHg9IjExOTEiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNzYwIiB5PSIxNjI3Ij48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMjk0NSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4MTYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNCIiB4PSI2MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTA0NSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMTc4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZBIiB4PSIyNzkwIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIzNTkyIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI4MDIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODc5OCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjUwNjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw3NzApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4NzEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI4MjIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxODIzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zQiIgeD0iMjMyMyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIyNzY5IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIzNjgwIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzNjgsLTY4NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjgyMiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjE4MjMiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTEwODkpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMUQyIiB4PSIyNzciIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTMzMzEpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1ozLTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzM2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iNzIyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTUwMSwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjI0NDMiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSI5NzEiIHk9IjY3NiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC02ODcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI4MjIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxODIzIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjMtMjkiIHg9IjUxNDMiIHk9Ii0xIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjYwNDciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2OTE4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iODIyIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTgyMyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0IiIHg9IjIzMjMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMjc2OSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMzY4MCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMTEyNjUiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjMyMSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTI0LC0xMDkwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI0MTIiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMCIgeD0iMTE5MSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI3NjAiIHk9IjE2MjciPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMzkzMyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0ODA0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zQiIgeD0iNjAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjEwNDUiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjE3ODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QSIgeD0iMjc5MCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMzU5MiIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC01NzY2KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjFEMiIgeD0iMjc3IiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC04MDA4KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODcxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iODIyIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTgyMyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0IiIHg9IjIzMjMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMjc2OSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMzY4MCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iNTIxOCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU5OTcsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIyNDQzIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsNjc2KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iODIyIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTgyMyIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjkyMSIgeT0iLTY4NiI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5MTI1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjQsLTEwOTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZBIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjQxMiIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMwIiB4PSIxMTkxIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9Ijc2MCIgeT0iMTYyNyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzM2IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTE2MDcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNCIiB4PSI2MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTA0NSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMTc4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZBIiB4PSIyNzkwIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIzNTkyIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8L2c+Cjwvc3ZnPg==)
使用fact 1、fact 2、fact 3,我们可以证明 是递归的解,
因此证明了,
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9Ijg1LjYyMmV4IiBoZWlnaHQ9IjIyLjg0M2V4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTEwLjYwMmV4OyBtYXJnaW4tYm90dG9tOiAtMC4yMzZleDsiIHZpZXdCb3g9IjAgLTUxNjguNiAzNjg2NSA5ODM1IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMi0yMjExIiBkPSJNNjAgOTQ4UTYzIDk1MCA2NjUgOTUwSDEyNjdMMTMyNSA4MTVRMTM4NCA2NzcgMTM4OCA2NjlIMTM0OEwxMzQxIDY4M1ExMzIwIDcyNCAxMjg1IDc2MVExMjM1IDgwOSAxMTc0IDgzOFQxMDMzIDg4MVQ4ODIgODk4VDY5OSA5MDJINTc0SDU0M0gyNTFMMjU5IDg5MVE3MjIgMjU4IDcyNCAyNTJRNzI1IDI1MCA3MjQgMjQ2UTcyMSAyNDMgNDYwIC01NkwxOTYgLTM1NlExOTYgLTM1NyA0MDcgLTM1N1E0NTkgLTM1NyA1NDggLTM1N1Q2NzYgLTM1OFE4MTIgLTM1OCA4OTYgLTM1M1QxMDYzIC0zMzJUMTIwNCAtMjgzVDEzMDcgLTE5NlExMzI4IC0xNzAgMTM0OCAtMTI0SDEzODhRMTM4OCAtMTI1IDEzODEgLTE0NVQxMzU2IC0yMTBUMTMyNSAtMjk0TDEyNjcgLTQ0OUw2NjYgLTQ1MFE2NCAtNDUwIDYxIC00NDhRNTUgLTQ0NiA1NSAtNDM5UTU1IC00MzcgNTcgLTQzM0w1OTAgMTc3UTU5MCAxNzggNTU3IDIyMlQ0NTIgMzY2VDMyMiA1NDRMNTYgOTA5TDU1IDkyNFE1NSA5NDUgNjAgOTQ4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNjYiIGQ9Ik0yNzMgMFEyNTUgMyAxNDYgM1E0MyAzIDM0IDBIMjZWNDZINDJRNzAgNDYgOTEgNDlROTkgNTIgMTAzIDYwUTEwNCA2MiAxMDQgMjI0VjM4NUgzM1Y0MzFIMTA0VjQ5N0wxMDUgNTY0TDEwNyA1NzRRMTI2IDYzOSAxNzEgNjY4VDI2NiA3MDRRMjY3IDcwNCAyNzUgNzA0VDI4OSA3MDVRMzMwIDcwMiAzNTEgNjc5VDM3MiA2MjdRMzcyIDYwNCAzNTggNTkwVDMyMSA1NzZUMjg0IDU5MFQyNzAgNjI3UTI3MCA2NDcgMjg4IDY2N0gyODRRMjgwIDY2OCAyNzMgNjY4UTI0NSA2NjggMjIzIDY0N1QxODkgNTkyUTE4MyA1NzIgMTgyIDQ5N1Y0MzFIMjkzVjM4NUgxODVWMjI1UTE4NSA2MyAxODYgNjFUMTg5IDU3VDE5NCA1NFQxOTkgNTFUMjA2IDQ5VDIxMyA0OFQyMjIgNDdUMjMxIDQ3VDI0MSA0NlQyNTEgNDZIMjgyVjBIMjczWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNjEiIGQ9Ik0xMzcgMzA1VDExNSAzMDVUNzggMzIwVDYzIDM1OVE2MyAzOTQgOTcgNDIxVDIxOCA0NDhRMjkxIDQ0OCAzMzYgNDE2VDM5NiAzNDBRNDAxIDMyNiA0MDEgMzA5VDQwMiAxOTRWMTI0UTQwMiA3NiA0MDcgNThUNDI4IDQwUTQ0MyA0MCA0NDggNTZUNDUzIDEwOVYxNDVINDkzVjEwNlE0OTIgNjYgNDkwIDU5UTQ4MSAyOSA0NTUgMTJUNDAwIC02VDM1MyAxMlQzMjkgNTRWNThMMzI3IDU1UTMyNSA1MiAzMjIgNDlUMzE0IDQwVDMwMiAyOVQyODcgMTdUMjY5IDZUMjQ3IC0yVDIyMSAtOFQxOTAgLTExUTEzMCAtMTEgODIgMjBUMzQgMTA3UTM0IDEyOCA0MSAxNDdUNjggMTg4VDExNiAyMjVUMTk0IDI1M1QzMDQgMjY4SDMxOFYyOTBRMzE4IDMyNCAzMTIgMzQwUTI5MCA0MTEgMjE1IDQxMVExOTcgNDExIDE4MSA0MTBUMTU2IDQwNlQxNDggNDAzUTE3MCAzODggMTcwIDM1OVExNzAgMzM0IDE1NCAzMjBaTTEyNiAxMDZRMTI2IDc1IDE1MCA1MVQyMDkgMjZRMjQ3IDI2IDI3NiA0OVQzMTUgMTA5UTMxNyAxMTYgMzE4IDE3NVEzMTggMjMzIDMxNyAyMzNRMzA5IDIzMyAyOTYgMjMyVDI1MSAyMjNUMTkzIDIwM1QxNDcgMTY2VDEyNiAxMDZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi02MyIgZD0iTTM3MCAzMDVUMzQ5IDMwNVQzMTMgMzIwVDI5NyAzNThRMjk3IDM4MSAzMTIgMzk2UTMxNyA0MDEgMzE3IDQwMlQzMDcgNDA0UTI4MSA0MDggMjU4IDQwOFEyMDkgNDA4IDE3OCAzNzZRMTMxIDMyOSAxMzEgMjE5UTEzMSAxMzcgMTYyIDkwUTIwMyAyOSAyNzIgMjlRMzEzIDI5IDMzOCA1NVQzNzQgMTE3UTM3NiAxMjUgMzc5IDEyN1QzOTUgMTI5SDQwOVE0MTUgMTIzIDQxNSAxMjBRNDE1IDExNiA0MTEgMTA0VDM5NSA3MVQzNjYgMzNUMzE4IDJUMjQ5IC0xMVExNjMgLTExIDk5IDUzVDM0IDIxNFEzNCAzMTggOTkgMzgzVDI1MCA0NDhUMzcwIDQyMVQ0MDQgMzU3UTQwNCAzMzQgMzg3IDMyMFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTc0IiBkPSJNMjcgNDIyUTgwIDQyNiAxMDkgNDc4VDE0MSA2MDBWNjE1SDE4MVY0MzFIMzE2VjM4NUgxODFWMjQxUTE4MiAxMTYgMTgyIDEwMFQxODkgNjhRMjAzIDI5IDIzOCAyOVEyODIgMjkgMjkyIDEwMFEyOTMgMTA4IDI5MyAxNDZWMTgxSDMzM1YxNDZWMTM0UTMzMyA1NyAyOTEgMTdRMjY0IC0xMCAyMjEgLTEwUTE4NyAtMTAgMTYyIDJUMTI0IDMzVDEwNSA2OFQ5OCAxMDBROTcgMTA3IDk3IDI0OFYzODVIMThWNDIySDI3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNkYiIGQ9Ik0yOCAyMTRRMjggMzA5IDkzIDM3OFQyNTAgNDQ4UTM0MCA0NDggNDA1IDM4MFQ0NzEgMjE1UTQ3MSAxMjAgNDA3IDU1VDI1MCAtMTBRMTUzIC0xMCA5MSA1N1QyOCAyMTRaTTI1MCAzMFEzNzIgMzAgMzcyIDE5M1YyMjVWMjUwUTM3MiAyNzIgMzcxIDI4OFQzNjQgMzI2VDM0OCAzNjJUMzE3IDM5MFQyNjggNDEwUTI2MyA0MTEgMjUyIDQxMVEyMjIgNDExIDE5NSAzOTlRMTUyIDM3NyAxMzkgMzM4VDEyNiAyNDZWMjI2UTEyNiAxMzAgMTQ1IDkxUTE3NyAzMCAyNTAgMzBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03MiIgZD0iTTM2IDQ2SDUwUTg5IDQ2IDk3IDYwVjY4UTk3IDc3IDk3IDkxVDk4IDEyMlQ5OCAxNjFUOTggMjAzUTk4IDIzNCA5OCAyNjlUOTggMzI4TDk3IDM1MVE5NCAzNzAgODMgMzc2VDM4IDM4NUgyMFY0MDhRMjAgNDMxIDIyIDQzMUwzMiA0MzJRNDIgNDMzIDYwIDQzNFQ5NiA0MzZRMTEyIDQzNyAxMzEgNDM4VDE2MCA0NDFUMTcxIDQ0MkgxNzRWMzczUTIxMyA0NDEgMjcxIDQ0MUgyNzdRMzIyIDQ0MSAzNDMgNDE5VDM2NCAzNzNRMzY0IDM1MiAzNTEgMzM3VDMxMyAzMjJRMjg4IDMyMiAyNzYgMzM4VDI2MyAzNzJRMjYzIDM4MSAyNjUgMzg4VDI3MCA0MDBUMjczIDQwNVEyNzEgNDA3IDI1MCA0MDFRMjM0IDM5MyAyMjYgMzg2UTE3OSAzNDEgMTc5IDIwN1YxNTRRMTc5IDE0MSAxNzkgMTI3VDE3OSAxMDFUMTgwIDgxVDE4MCA2NlY2MVExODEgNTkgMTgzIDU3VDE4OCA1NFQxOTMgNTFUMjAwIDQ5VDIwNyA0OFQyMTYgNDdUMjI1IDQ3VDIzNSA0NlQyNDUgNDZIMjc2VjBIMjY3UTI0OSAzIDE0MCAzUTM3IDMgMjggMEgyMFY0NkgzNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTczIiBkPSJNMjk1IDMxNlEyOTUgMzU2IDI2OCAzODVUMTkwIDQxNFExNTQgNDE0IDEyOCA0MDFROTggMzgyIDk4IDM0OVE5NyAzNDQgOTggMzM2VDExNCAzMTJUMTU3IDI4N1ExNzUgMjgyIDIwMSAyNzhUMjQ1IDI2OVQyNzcgMjU2UTI5NCAyNDggMzEwIDIzNlQzNDIgMTk1VDM1OSAxMzNRMzU5IDcxIDMyMSAzMVQxOTggLTEwSDE5MFExMzggLTEwIDk0IDI2TDg2IDE5TDc3IDEwUTcxIDQgNjUgLTFMNTQgLTExSDQ2SDQyUTM5IC0xMSAzMyAtNVY3NFYxMzJRMzMgMTUzIDM1IDE1N1Q0NSAxNjJINTRRNjYgMTYyIDcwIDE1OFQ3NSAxNDZUODIgMTE5VDEwMSA3N1ExMzYgMjYgMTk4IDI2UTI5NSAyNiAyOTUgMTA0UTI5NSAxMzMgMjc3IDE1MVEyNTcgMTc1IDE5NCAxODdUMTExIDIxMFE3NSAyMjcgNTQgMjU2VDMzIDMxOFEzMyAzNTcgNTAgMzg0VDkzIDQyNFQxNDMgNDQyVDE4NyA0NDdIMTk4UTIzOCA0NDcgMjY4IDQzMkwyODMgNDI0TDI5MiA0MzFRMzAyIDQ0MCAzMTQgNDQ4SDMyMkgzMjZRMzI5IDQ0OCAzMzUgNDQyVjMxMEwzMjkgMzA0SDMwMVEyOTUgMzEwIDI5NSAzMTZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkIiIGQ9Ik0xMjEgNjQ3UTEyMSA2NTcgMTI1IDY3MFQxMzcgNjgzUTEzOCA2ODMgMjA5IDY4OFQyODIgNjk0UTI5NCA2OTQgMjk0IDY4NlEyOTQgNjc5IDI0NCA0NzdRMTk0IDI3OSAxOTQgMjcyUTIxMyAyODIgMjIzIDI5MVEyNDcgMzA5IDI5MiAzNTRUMzYyIDQxNVE0MDIgNDQyIDQzOCA0NDJRNDY4IDQ0MiA0ODUgNDIzVDUwMyAzNjlRNTAzIDM0NCA0OTYgMzI3VDQ3NyAzMDJUNDU2IDI5MVQ0MzggMjg4UTQxOCAyODggNDA2IDI5OVQzOTQgMzI4UTM5NCAzNTMgNDEwIDM2OVQ0NDIgMzkwTDQ1OCAzOTNRNDQ2IDQwNSA0MzQgNDA1SDQzMFEzOTggNDAyIDM2NyAzODBUMjk0IDMxNlQyMjggMjU1UTIzMCAyNTQgMjQzIDI1MlQyNjcgMjQ2VDI5MyAyMzhUMzIwIDIyNFQzNDIgMjA2VDM1OSAxODBUMzY1IDE0N1EzNjUgMTMwIDM2MCAxMDZUMzU0IDY2UTM1NCAyNiAzODEgMjZRNDI5IDI2IDQ1OSAxNDVRNDYxIDE1MyA0NzkgMTUzSDQ4M1E0OTkgMTUzIDQ5OSAxNDRRNDk5IDEzOSA0OTYgMTMwUTQ1NSAtMTEgMzc4IC0xMVEzMzMgLTExIDMwNSAxNVQyNzcgOTBRMjc3IDEwOCAyODAgMTIxVDI4MyAxNDVRMjgzIDE2NyAyNjkgMTgzVDIzNCAyMDZUMjAwIDIxN1QxODIgMjIwSDE4MFExNjggMTc4IDE1OSAxMzlUMTQ1IDgxVDEzNiA0NFQxMjkgMjBUMTIyIDdUMTExIC0yUTk4IC0xMSA4MyAtMTFRNjYgLTExIDU3IC0xVDQ4IDE2UTQ4IDI2IDg1IDE3NlQxNTggNDcxTDE5NSA2MTZRMTk2IDYyOSAxODggNjMyVDE0OSA2MzdIMTQ0UTEzNCA2MzcgMTMxIDYzN1QxMjQgNjQwVDEyMSA2NDdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDIiIGQ9Ik0yMzEgNjM3UTIwNCA2MzcgMTk5IDYzOFQxOTQgNjQ5UTE5NCA2NzYgMjA1IDY4MlEyMDYgNjgzIDMzNSA2ODNRNTk0IDY4MyA2MDggNjgxUTY3MSA2NzEgNzEzIDYzNlQ3NTYgNTQ0UTc1NiA0ODAgNjk4IDQyOVQ1NjUgMzYwTDU1NSAzNTdRNjE5IDM0OCA2NjAgMzExVDcwMiAyMTlRNzAyIDE0NiA2MzAgNzhUNDUzIDFRNDQ2IDAgMjQyIDBRNDIgMCAzOSAyUTM1IDUgMzUgMTBRMzUgMTcgMzcgMjRRNDIgNDMgNDcgNDVRNTEgNDYgNjIgNDZINjhROTUgNDYgMTI4IDQ5UTE0MiA1MiAxNDcgNjFRMTUwIDY1IDIxOSAzMzlUMjg4IDYyOFEyODggNjM1IDIzMSA2MzdaTTY0OSA1NDRRNjQ5IDU3NCA2MzQgNjAwVDU4NSA2MzRRNTc4IDYzNiA0OTMgNjM3UTQ3MyA2MzcgNDUxIDYzN1Q0MTYgNjM2SDQwM1EzODggNjM1IDM4NCA2MjZRMzgyIDYyMiAzNTIgNTA2UTM1MiA1MDMgMzUxIDUwMEwzMjAgMzc0SDQwMVE0ODIgMzc0IDQ5NCAzNzZRNTU0IDM4NiA2MDEgNDM0VDY0OSA1NDRaTTU5NSAyMjlRNTk1IDI3MyA1NzIgMzAyVDUxMiAzMzZRNTA2IDMzNyA0MjkgMzM3UTMxMSAzMzcgMzEwIDMzNlEzMTAgMzM0IDI5MyAyNjNUMjU4IDEyMkwyNDAgNTJRMjQwIDQ4IDI1MiA0OFQzMzMgNDZRNDIyIDQ2IDQyOSA0N1E0OTEgNTQgNTQzIDEwNVQ1OTUgMjI5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNCIiBkPSJNNzggMzcwUTc4IDM5NCA5NSA0MTJUMTM4IDQzMFExNjIgNDMwIDE4MCA0MTRUMTk5IDM3MVExOTkgMzQ2IDE4MiAzMjhUMTM5IDMxMFQ5NiAzMjdUNzggMzcwWk03OCA2MFE3OCA4NSA5NCAxMDNUMTM3IDEyMVEyMDIgMTIxIDIwMiA4UTIwMiAtNDQgMTgzIC05NFQxNDQgLTE2OVQxMTggLTE5NFExMTUgLTE5NCAxMDYgLTE4NlQ5NSAtMTc0UTk0IC0xNzEgMTA3IC0xNTVUMTM3IC0xMDdUMTYwIC0zOFExNjEgLTMyIDE2MiAtMjJUMTY1IC00VDE2NSA0UTE2NSA1IDE2MSA0VDE0MiAwUTExMCAwIDk0IDE4VDc4IDYwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkMiIGQ9Ik03OCAzNVQ3OCA2MFQ5NCAxMDNUMTM3IDEyMVExNjUgMTIxIDE4NyA5NlQyMTAgOFEyMTAgLTI3IDIwMSAtNjBUMTgwIC0xMTdUMTU0IC0xNThUMTMwIC0xODVUMTE3IC0xOTRRMTEzIC0xOTQgMTA0IC0xODVUOTUgLTE3MlE5NSAtMTY4IDEwNiAtMTU2VDEzMSAtMTI2VDE1NyAtNzZUMTczIC0zVjlMMTcyIDhRMTcwIDcgMTY3IDZUMTYxIDNUMTUyIDFUMTQwIDBRMTEzIDAgOTYgMTdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMiIgZD0iTTEwOSA0MjlRODIgNDI5IDY2IDQ0N1Q1MCA0OTFRNTAgNTYyIDEwMyA2MTRUMjM1IDY2NlEzMjYgNjY2IDM4NyA2MTBUNDQ5IDQ2NVE0NDkgNDIyIDQyOSAzODNUMzgxIDMxNVQzMDEgMjQxUTI2NSAyMTAgMjAxIDE0OUwxNDIgOTNMMjE4IDkyUTM3NSA5MiAzODUgOTdRMzkyIDk5IDQwOSAxODZWMTg5SDQ0OVYxODZRNDQ4IDE4MyA0MzYgOTVUNDIxIDNWMEg1MFYxOVYzMVE1MCAzOCA1NiA0NlQ4NiA4MVExMTUgMTEzIDEzNiAxMzdRMTQ1IDE0NyAxNzAgMTc0VDIwNCAyMTFUMjMzIDI0NFQyNjEgMjc4VDI4NCAzMDhUMzA1IDM0MFQzMjAgMzY5VDMzMyA0MDFUMzQwIDQzMVQzNDMgNDY0UTM0MyA1MjcgMzA5IDU3M1QyMTIgNjE5UTE3OSA2MTkgMTU0IDYwMlQxMTkgNTY5VDEwOSA1NTBRMTA5IDU0OSAxMTQgNTQ5UTEzMiA1NDkgMTUxIDUzNVQxNzAgNDg5UTE3MCA0NjQgMTU0IDQ0N1QxMDkgNDI5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkUiIGQ9Ik03OCA2MFE3OCA4NCA5NSAxMDJUMTM4IDEyMFExNjIgMTIwIDE4MCAxMDRUMTk5IDYxUTE5OSAzNiAxODIgMThUMTM5IDBUOTYgMTdUNzggNjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03QyIgZD0iTTEzOSAtMjQ5SDEzN1ExMjUgLTI0OSAxMTkgLTIzNVYyNTFMMTIwIDczN1ExMzAgNzUwIDEzOSA3NTBRMTUyIDc1MCAxNTkgNzM1Vi0yMzVRMTUxIC0yNDkgMTQxIC0yNDlIMTM5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi01QiIgZD0iTTExOCAtMjUwVjc1MEgyNTVWNzEwSDE1OFYtMjEwSDI1NVYtMjUwSDExOFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02OSIgZD0iTTE4NCA2MDBRMTg0IDYyNCAyMDMgNjQyVDI0NyA2NjFRMjY1IDY2MSAyNzcgNjQ5VDI5MCA2MTlRMjkwIDU5NiAyNzAgNTc3VDIyNiA1NTdRMjExIDU1NyAxOTggNTY3VDE4NCA2MDBaTTIxIDI4N1EyMSAyOTUgMzAgMzE4VDU0IDM2OVQ5OCA0MjBUMTU4IDQ0MlExOTcgNDQyIDIyMyA0MTlUMjUwIDM1N1EyNTAgMzQwIDIzNiAzMDFUMTk2IDE5NlQxNTQgODNRMTQ5IDYxIDE0OSA1MVExNDkgMjYgMTY2IDI2UTE3NSAyNiAxODUgMjlUMjA4IDQzVDIzNSA3OFQyNjAgMTM3UTI2MyAxNDkgMjY1IDE1MVQyODIgMTUzUTMwMiAxNTMgMzAyIDE0M1EzMDIgMTM1IDI5MyAxMTJUMjY4IDYxVDIyMyAxMVQxNjEgLTExUTEyOSAtMTEgMTAyIDEwVDc0IDc0UTc0IDkxIDc5IDEwNlQxMjIgMjIwUTE2MCAzMjEgMTY2IDM0MVQxNzMgMzgwUTE3MyA0MDQgMTU2IDQwNEgxNTRRMTI0IDQwNCA5OSAzNzFUNjEgMjg3UTYwIDI4NiA1OSAyODRUNTggMjgxVDU2IDI3OVQ1MyAyNzhUNDkgMjc4VDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi01RCIgZD0iTTIyIDcxMFY3NTBIMTU5Vi0yNTBIMjJWLTIxMEgxMTlWNzEwSDIyWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaNC01QiIgZD0iTTI2OSAtMTI0OVYxNzUwSDU3N1YxNjc3SDM0MlYtMTE3Nkg1NzdWLTEyNDlIMjY5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaNC01RCIgZD0iTTUgMTY3N1YxNzUwSDMxM1YtMTI0OUg1Vi0xMTc2SDI0MFYxNjc3SDVaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yQiIgZD0iTTU2IDIzN1Q1NiAyNTBUNzAgMjcwSDM2OVY0MjBMMzcwIDU3MFEzODAgNTgzIDM4OSA1ODNRNDAyIDU4MyA0MDkgNTY4VjI3MEg3MDdRNzIyIDI2MiA3MjIgMjUwVDcwNyAyMzBINDA5Vi02OFE0MDEgLTgyIDM5MSAtODJIMzg5SDM4N1EzNzUgLTgyIDM2OSAtNjhWMjMwSDcwUTU2IDIzNyA1NiAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjEyIiBkPSJNODQgMjM3VDg0IDI1MFQ5OCAyNzBINjc5UTY5NCAyNjIgNjk0IDI1MFQ2NzkgMjMwSDk4UTg0IDIzNyA4NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMUQyIiBkPSJNNTgwIDUxNFE1ODAgNTI1IDU5NiA1MjVRNjAxIDUyNSA2MDQgNTI1VDYwOSA1MjVUNjEzIDUyNFQ2MTUgNTIzVDYxNyA1MjBUNjE5IDUxN1Q2MjIgNTEyUTY1OSA0MzggNzIwIDM4MVQ4MzEgMzAwVDkyNyAyNjNROTQ0IDI1OCA5NDQgMjUwVDkzNSAyMzlUODk4IDIyOFQ4NDAgMjA0UTY5NiAxMzQgNjIyIC0xMlE2MTggLTIxIDYxNSAtMjJUNjAwIC0yNFE1ODAgLTI0IDU4MCAtMTdRNTgwIC0xMyA1ODUgMFE2MjAgNjkgNjcxIDEyM0w2ODEgMTMzSDcwUTU2IDE0MCA1NiAxNTNRNTYgMTY4IDcyIDE3M0g3MjVMNzM1IDE4MVE3NzQgMjExIDg1MiAyNTBRODUxIDI1MSA4MzQgMjU5VDc4OSAyODNUNzM1IDMxOUw3MjUgMzI3SDcyUTU2IDMzMiA1NiAzNDdRNTYgMzYwIDcwIDM2N0g2ODFMNjcxIDM3N1E2MzggNDEyIDYwOSA0NThUNTgwIDUxNFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjEtMjIxMSIgZD0iTTYxIDc0OFE2NCA3NTAgNDg5IDc1MEg5MTNMOTU0IDY0MFE5NjUgNjA5IDk3NiA1NzlUOTkzIDUzM1Q5OTkgNTE2SDk3OUw5NTkgNTE3UTkzNiA1NzkgODg2IDYyMVQ3NzcgNjgyUTcyNCA3MDAgNjU1IDcwNVQ0MzYgNzEwSDMxOVExODMgNzEwIDE4MyA3MDlRMTg2IDcwNiAzNDggNDg0VDUxMSAyNTlRNTE3IDI1MCA1MTMgMjQ0TDQ5MCAyMTZRNDY2IDE4OCA0MjAgMTM0VDMzMCAyN0wxNDkgLTE4N1ExNDkgLTE4OCAzNjIgLTE4OFEzODggLTE4OCA0MzYgLTE4OFQ1MDYgLTE4OVE2NzkgLTE4OSA3NzggLTE2MlQ5MzYgLTQzUTk0NiAtMjcgOTU5IDZIOTk5TDkxMyAtMjQ5TDQ4OSAtMjUwUTY1IC0yNTAgNjIgLTI0OFE1NiAtMjQ2IDU2IC0yMzlRNTYgLTIzNCAxMTggLTE2MVExODYgLTgxIDI0NSAtMTFMNDI4IDIwNlE0MjggMjA3IDI0MiA0NjJMNTcgNzE3TDU2IDcyOFE1NiA3NDQgNjEgNzQ4WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2NywwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKC0xMSwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsMzMxNCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMTAzMiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTExMTcpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjYiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iMzA2IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjMiIHg9IjgwNyIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTc0IiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNkYiIHg9IjE2NDAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMjE0MSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTczIiB4PSIyNTMzIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNkYiIHg9IjMyODIiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02NiIgeD0iMzc4MiIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNDQ0MiIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00MiIgeD0iMzg0MyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ3NjksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNCIiB4PSI2MDAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDQ1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iNzM3IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJDIiB4PSIyMDIxIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjQ2NiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjczNyIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iMzQ0MSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9IjM4ODYiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSI0MzMxIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iNDc3NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9IjUyMjIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1NjY3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjczNyIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QyIgeD0iNjcxMyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI2OTkyIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI3OTAzIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzIyOCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaNC01QiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU4MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQ3LC0xMDkwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIzNDUiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTEyNCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI3MjEiIHk9IjE2MjciPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjExLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSI3MzciIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjEyNTUiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMjMyNiIgeT0iNjc1Ij48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaNC01RCIgeD0iNDI5MyIgeT0iLTEiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjE4MzgzIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTkxNjIsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI2MTU2IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsNzcwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjg4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTI0NCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIyMjQ0IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIzMDY3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iNDA2OCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iNDk1OCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxOTE2LC02ODcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI4MjIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxODIzIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDIiIHg9IjI1ODM1IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjY3NjIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNCIiB4PSI2MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTA0NSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTk1NiIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMUQyIiB4PSIyOTM4NiIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTY2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTIyMTEiIHg9IjEwMzIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC0xMTE3KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTY2Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9IjMwNiIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYzIiB4PSI4MDciIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03NCIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTZGIiB4PSIxNjQwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjIxNDEiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MyIgeD0iMjUzMyIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTZGIiB4PSIzMjgyIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjYiIHg9IjM3ODIiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjQ0NDIiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDIiIHg9IjM4NDMiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NzY5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zQiIgeD0iNjAwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTA0NSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjczNyIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iMjAyMSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI0NjYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI3MzciIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9IjM0NDEiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSIzODg2IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iNDMzMSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9IjQ3NzciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJDIiB4PSI1MjIyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTY2NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI3MzciIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0MiIHg9IjY3MTMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNjk5MiIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iNzkwMyIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTMyMjgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtNUIiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1ODMsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI0NjkwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsODE0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMS0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIxNDk0IiB5PSI2NzUiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDU2LC0yODcpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjM0NSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxMTI0IiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNDcxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSI3MzciIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjEyNTUiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMjMyNiIgeT0iNjc1Ij48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ0OSwtNzcxKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2NjcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI3NDMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTc0NCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMjczNCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTVEIiB4PSI1NTE0IiB5PSItMSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTk1NDgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMDMyNywwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjM5MTEiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTY5NCIgeT0iNjc2Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTc3MSkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjY3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNzQzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjE3NDQiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjI3MzQiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQyIiB4PSIyNDcwMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI1NjI2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zQiIgeD0iNjAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjEwNDUiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjE5NTYiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI4MjUwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjkwMjksMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIyNDQzIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9Ijk2MSIgeT0iNjc2Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTY4NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjgyMiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjE4MjMiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00MiIgeD0iMzE5OTAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzMjkxNywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0IiIHg9IjYwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIxMDQ1IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxOTU2IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIxRDIiIHg9IjM1NTQwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwtMzMxNSkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMTAzMiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTExMTcpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjYiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iMzA2IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjMiIHg9IjgwNyIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTc0IiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNkYiIHg9IjE2NDAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMjE0MSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTczIiB4PSIyNTMzIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNkYiIHg9IjMyODIiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02NiIgeD0iMzc4MiIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNDQ0MiIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00MiIgeD0iMzg0MyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ3NjksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNCIiB4PSI2MDAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDQ1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iNzM3IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJDIiB4PSIyMDIxIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjQ2NiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjczNyIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iMzQ0MSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9IjM4ODYiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSI0MzMxIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iNDc3NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkMiIHg9IjUyMjIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1NjY3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjczNyIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QyIgeD0iNjcxMyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI2OTkyIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI3OTAzIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzIyOCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaNC01QiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU4MywwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjY0MzUiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw4MTQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjE0OTQiIHk9IjY3NSI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwNTYsLTI4NykiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMzQ1IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjExMjQiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI0NzEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjczNyIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTI1NSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIyMzI2IiB5PSI2NzUiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjQ3OTIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNTc5MyIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTMyMSwtNzcxKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2NjcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI3NDMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTc0NCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMjczNCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTVEIiB4PSI3MjU4IiB5PSItMSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjEzNDgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMjEyNywwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM5NywwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjI0NDMiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iOTYxIiB5PSI2NzYiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNjg3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iODIyIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTgyMyIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQyIiB4PSIyNTA4OCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI2MDE1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zQiIgeD0iNjAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjEwNDUiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjE5NTYiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9zdmc+)
定理5 首次访问MC方法的方差为![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjYxLjU2ZXgiIGhlaWdodD0iNy41MDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0zLjE3MWV4OyIgdmlld0JveD0iMCAtMTg2Ny43IDI2NTA1IDMyMzMuMiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTU2IiBkPSJNMTE0IDYyMFExMTMgNjIxIDExMCA2MjRUMTA3IDYyN1QxMDMgNjMwVDk4IDYzMlQ5MSA2MzRUODAgNjM1VDY3IDYzNlQ0OCA2MzdIMTlWNjgzSDI4UTQ2IDY4MCAxNTIgNjgwUTI3MyA2ODAgMjk0IDY4M0gzMDVWNjM3SDI4NFEyMjMgNjM0IDIyMyA2MjBRMjIzIDYxOCAzMTMgMzcyVDQwNCAxMjZMNDkwIDM1OFE1NzUgNTg4IDU3NSA1OTdRNTc1IDYxNiA1NTQgNjI2VDUwOCA2MzdINTAzVjY4M0g1MTJRNTI3IDY4MCA2MjcgNjgwUTcxOCA2ODAgNzI0IDY4M0g3MzBWNjM3SDcyM1E2NDggNjM3IDYyNyA1OTZRNjI3IDU5NSA1MTUgMjkxVDQwMSAtMTRRMzk2IC0yMiAzODIgLTIySDM3NEgzNjdRMzUzIC0yMiAzNDggLTE0UTM0NiAtMTIgMjMxIDMwM1ExMTQgNjE3IDExNCA2MjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi02MSIgZD0iTTEzNyAzMDVUMTE1IDMwNVQ3OCAzMjBUNjMgMzU5UTYzIDM5NCA5NyA0MjFUMjE4IDQ0OFEyOTEgNDQ4IDMzNiA0MTZUMzk2IDM0MFE0MDEgMzI2IDQwMSAzMDlUNDAyIDE5NFYxMjRRNDAyIDc2IDQwNyA1OFQ0MjggNDBRNDQzIDQwIDQ0OCA1NlQ0NTMgMTA5VjE0NUg0OTNWMTA2UTQ5MiA2NiA0OTAgNTlRNDgxIDI5IDQ1NSAxMlQ0MDAgLTZUMzUzIDEyVDMyOSA1NFY1OEwzMjcgNTVRMzI1IDUyIDMyMiA0OVQzMTQgNDBUMzAyIDI5VDI4NyAxN1QyNjkgNlQyNDcgLTJUMjIxIC04VDE5MCAtMTFRMTMwIC0xMSA4MiAyMFQzNCAxMDdRMzQgMTI4IDQxIDE0N1Q2OCAxODhUMTE2IDIyNVQxOTQgMjUzVDMwNCAyNjhIMzE4VjI5MFEzMTggMzI0IDMxMiAzNDBRMjkwIDQxMSAyMTUgNDExUTE5NyA0MTEgMTgxIDQxMFQxNTYgNDA2VDE0OCA0MDNRMTcwIDM4OCAxNzAgMzU5UTE3MCAzMzQgMTU0IDMyMFpNMTI2IDEwNlExMjYgNzUgMTUwIDUxVDIwOSAyNlEyNDcgMjYgMjc2IDQ5VDMxNSAxMDlRMzE3IDExNiAzMTggMTc1UTMxOCAyMzMgMzE3IDIzM1EzMDkgMjMzIDI5NiAyMzJUMjUxIDIyM1QxOTMgMjAzVDE0NyAxNjZUMTI2IDEwNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTcyIiBkPSJNMzYgNDZINTBRODkgNDYgOTcgNjBWNjhROTcgNzcgOTcgOTFUOTggMTIyVDk4IDE2MVQ5OCAyMDNROTggMjM0IDk4IDI2OVQ5OCAzMjhMOTcgMzUxUTk0IDM3MCA4MyAzNzZUMzggMzg1SDIwVjQwOFEyMCA0MzEgMjIgNDMxTDMyIDQzMlE0MiA0MzMgNjAgNDM0VDk2IDQzNlExMTIgNDM3IDEzMSA0MzhUMTYwIDQ0MVQxNzEgNDQySDE3NFYzNzNRMjEzIDQ0MSAyNzEgNDQxSDI3N1EzMjIgNDQxIDM0MyA0MTlUMzY0IDM3M1EzNjQgMzUyIDM1MSAzMzdUMzEzIDMyMlEyODggMzIyIDI3NiAzMzhUMjYzIDM3MlEyNjMgMzgxIDI2NSAzODhUMjcwIDQwMFQyNzMgNDA1UTI3MSA0MDcgMjUwIDQwMVEyMzQgMzkzIDIyNiAzODZRMTc5IDM0MSAxNzkgMjA3VjE1NFExNzkgMTQxIDE3OSAxMjdUMTc5IDEwMVQxODAgODFUMTgwIDY2VjYxUTE4MSA1OSAxODMgNTdUMTg4IDU0VDE5MyA1MVQyMDAgNDlUMjA3IDQ4VDIxNiA0N1QyMjUgNDdUMjM1IDQ2VDI0NSA0NkgyNzZWMEgyNjdRMjQ5IDMgMTQwIDNRMzcgMyAyOCAwSDIwVjQ2SDM2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQ2IiBkPSJNNDggMVEzMSAxIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc0MlE3NDkgNjc2IDc0OSA2NjlRNzQ5IDY2NCA3MzYgNTU3VDcyMiA0NDdRNzIwIDQ0MCA3MDIgNDQwSDY5MFE2ODMgNDQ1IDY4MyA0NTNRNjgzIDQ1NCA2ODYgNDc3VDY4OSA1MzBRNjg5IDU2MCA2ODIgNTc5VDY2MyA2MTBUNjI2IDYyNlQ1NzUgNjMzVDUwMyA2MzRINDgwUTM5OCA2MzMgMzkzIDYzMVEzODggNjI5IDM4NiA2MjNRMzg1IDYyMiAzNTIgNDkyTDMyMCAzNjNIMzc1UTM3OCAzNjMgMzk4IDM2M1Q0MjYgMzY0VDQ0OCAzNjdUNDcyIDM3NFQ0ODkgMzg2UTUwMiAzOTggNTExIDQxOVQ1MjQgNDU3VDUyOSA0NzVRNTMyIDQ4MCA1NDggNDgwSDU2MFE1NjcgNDc1IDU2NyA0NzBRNTY3IDQ2NyA1MzYgMzM5VDUwMiAyMDdRNTAwIDIwMCA0ODIgMjAwSDQ3MFE0NjMgMjA2IDQ2MyAyMTJRNDYzIDIxNSA0NjggMjM0VDQ3MyAyNzRRNDczIDMwMyA0NTMgMzEwVDM2NCAzMTdIMzA5TDI3NyAxOTBRMjQ1IDY2IDI0NSA2MFEyNDUgNDYgMzM0IDQ2SDM1OVEzNjUgNDAgMzY1IDM5VDM2MyAxOVEzNTkgNiAzNTMgMEgzMzZRMjk1IDIgMTg1IDJRMTIwIDIgODYgMlQ0OCAxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZFIiBkPSJNMjEgMjg3UTIyIDI5MyAyNCAzMDNUMzYgMzQxVDU2IDM4OFQ4OSA0MjVUMTM1IDQ0MlExNzEgNDQyIDE5NSA0MjRUMjI1IDM5MFQyMzEgMzY5UTIzMSAzNjcgMjMyIDM2N0wyNDMgMzc4UTMwNCA0NDIgMzgyIDQ0MlE0MzYgNDQyIDQ2OSA0MTVUNTAzIDMzNlQ0NjUgMTc5VDQyNyA1MlE0MjcgMjYgNDQ0IDI2UTQ1MCAyNiA0NTMgMjdRNDgyIDMyIDUwNSA2NVQ1NDAgMTQ1UTU0MiAxNTMgNTYwIDE1M1E1ODAgMTUzIDU4MCAxNDVRNTgwIDE0NCA1NzYgMTMwUTU2OCAxMDEgNTU0IDczVDUwOCAxN1Q0MzkgLTEwUTM5MiAtMTAgMzcxIDE3VDM1MCA3M1EzNTAgOTIgMzg2IDE5M1Q0MjMgMzQ1UTQyMyA0MDQgMzc5IDQwNEgzNzRRMjg4IDQwNCAyMjkgMzAzTDIyMiAyOTFMMTg5IDE1N1ExNTYgMjYgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTIgMTgwVDE1MiAzNDNRMTUzIDM0OCAxNTMgMzY2UTE1MyA0MDUgMTI5IDQwNVE5MSA0MDUgNjYgMzA1UTYwIDI4NSA2MCAyODRRNTggMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMSIgZD0iTTIxMyA1NzhMMjAwIDU3M1ExODYgNTY4IDE2MCA1NjNUMTAyIDU1Nkg4M1Y2MDJIMTAyUTE0OSA2MDQgMTg5IDYxN1QyNDUgNjQxVDI3MyA2NjNRMjc1IDY2NiAyODUgNjY2UTI5NCA2NjYgMzAyIDY2MFYzNjFMMzAzIDYxUTMxMCA1NCAzMTUgNTJUMzM5IDQ4VDQwMSA0Nkg0MjdWMEg0MTZRMzk1IDMgMjU3IDNRMTIxIDMgMTAwIDBIODhWNDZIMTE0UTEzNiA0NiAxNTIgNDZUMTc3IDQ3VDE5MyA1MFQyMDEgNTJUMjA3IDU3VDIxMyA2MVY1NzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi01QiIgZD0iTTExOCAtMjUwVjc1MEgyNTVWNzEwSDE1OFYtMjEwSDI1NVYtMjUwSDExOFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MiIgZD0iTTIxIDI4N1EyMiAyOTAgMjMgMjk1VDI4IDMxN1QzOCAzNDhUNTMgMzgxVDczIDQxMVQ5OSA0MzNUMTMyIDQ0MlExNjEgNDQyIDE4MyA0MzBUMjE0IDQwOFQyMjUgMzg4UTIyNyAzODIgMjI4IDM4MlQyMzYgMzg5UTI4NCA0NDEgMzQ3IDQ0MUgzNTBRMzk4IDQ0MSA0MjIgNDAwUTQzMCAzODEgNDMwIDM2M1E0MzAgMzMzIDQxNyAzMTVUMzkxIDI5MlQzNjYgMjg4UTM0NiAyODggMzM0IDI5OVQzMjIgMzI4UTMyMiAzNzYgMzc4IDM5MlEzNTYgNDA1IDM0MiA0MDVRMjg2IDQwNSAyMzkgMzMxUTIyOSAzMTUgMjI0IDI5OFQxOTAgMTY1UTE1NiAyNSAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExNCAxODlUMTU0IDM2NlExNTQgNDA1IDEyOCA0MDVRMTA3IDQwNSA5MiAzNzdUNjggMzE2VDU3IDI4MFE1NSAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTQiIGQ9Ik00MCA0MzdRMjEgNDM3IDIxIDQ0NVEyMSA0NTAgMzcgNTAxVDcxIDYwMkw4OCA2NTFROTMgNjY5IDEwMSA2NzdINTY5SDY1OVE2OTEgNjc3IDY5NyA2NzZUNzA0IDY2N1E3MDQgNjYxIDY4NyA1NTNUNjY4IDQ0NFE2NjggNDM3IDY0OSA0MzdRNjQwIDQzNyA2MzcgNDM3VDYzMSA0NDJMNjI5IDQ0NVE2MjkgNDUxIDYzNSA0OTBUNjQxIDU1MVE2NDEgNTg2IDYyOCA2MDRUNTczIDYyOVE1NjggNjMwIDUxNSA2MzFRNDY5IDYzMSA0NTcgNjMwVDQzOSA2MjJRNDM4IDYyMSAzNjggMzQzVDI5OCA2MFEyOTggNDggMzg2IDQ2UTQxOCA0NiA0MjcgNDVUNDM2IDM2UTQzNiAzMSA0MzMgMjJRNDI5IDQgNDI0IDFMNDIyIDBRNDE5IDAgNDE1IDBRNDEwIDAgMzYzIDFUMjI4IDJROTkgMiA2NCAwSDQ5UTQzIDYgNDMgOVQ0NSAyN1E0OSA0MCA1NSA0Nkg4M0g5NFExNzQgNDYgMTg5IDU1UTE5MCA1NiAxOTEgNTZRMTk2IDU5IDIwMSA3NlQyNDEgMjMzUTI1OCAzMDEgMjY5IDM0NFEzMzkgNjE5IDMzOSA2MjVRMzM5IDYzMCAzMTAgNjMwSDI3OVEyMTIgNjMwIDE5MSA2MjRRMTQ2IDYxNCAxMjEgNTgzVDY3IDQ2N1E2MCA0NDUgNTcgNDQxVDQzIDQzN0g0MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJCIiBkPSJNNTYgMjM3VDU2IDI1MFQ3MCAyNzBIMzY5VjQyMEwzNzAgNTcwUTM4MCA1ODMgMzg5IDU4M1E0MDIgNTgzIDQwOSA1NjhWMjcwSDcwN1E3MjIgMjYyIDcyMiAyNTBUNzA3IDIzMEg0MDlWLTY4UTQwMSAtODIgMzkxIC04MkgzODlIMzg3UTM3NSAtODIgMzY5IC02OFYyMzBINzBRNTYgMjM3IDU2IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MCIgZD0iTTI4NyA2MjhRMjg3IDYzNSAyMzAgNjM3UTIwNiA2MzcgMTk5IDYzOFQxOTIgNjQ4UTE5MiA2NDkgMTk0IDY1OVEyMDAgNjc5IDIwMyA2ODFUMzk3IDY4M1E1ODcgNjgyIDYwMCA2ODBRNjY0IDY2OSA3MDcgNjMxVDc1MSA1MzBRNzUxIDQ1MyA2ODUgMzg5UTYxNiAzMjEgNTA3IDMwM1E1MDAgMzAyIDQwMiAzMDFIMzA3TDI3NyAxODJRMjQ3IDY2IDI0NyA1OVEyNDcgNTUgMjQ4IDU0VDI1NSA1MFQyNzIgNDhUMzA1IDQ2SDMzNlEzNDIgMzcgMzQyIDM1UTM0MiAxOSAzMzUgNVEzMzAgMCAzMTkgMFEzMTYgMCAyODIgMVQxODIgMlExMjAgMiA4NyAyVDUxIDFRMzMgMSAzMyAxMVEzMyAxMyAzNiAyNVE0MCA0MSA0NCA0M1Q2NyA0NlE5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4Wk02NDUgNTU0UTY0NSA1NjcgNjQzIDU3NVQ2MzQgNTk3VDYwOSA2MTlUNTYwIDYzNVE1NTMgNjM2IDQ4MCA2MzdRNDYzIDYzNyA0NDUgNjM3VDQxNiA2MzZUNDA0IDYzNlEzOTEgNjM1IDM4NiA2MjdRMzg0IDYyMSAzNjcgNTUwVDMzMiA0MTJUMzE0IDM0NFEzMTQgMzQyIDM5NSAzNDJINDA3SDQzMFE1NDIgMzQyIDU5MCAzOTJRNjE3IDQxOSA2MzEgNDcxVDY0NSA1NTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMiIgZD0iTTEwOSA0MjlRODIgNDI5IDY2IDQ0N1Q1MCA0OTFRNTAgNTYyIDEwMyA2MTRUMjM1IDY2NlEzMjYgNjY2IDM4NyA2MTBUNDQ5IDQ2NVE0NDkgNDIyIDQyOSAzODNUMzgxIDMxNVQzMDEgMjQxUTI2NSAyMTAgMjAxIDE0OUwxNDIgOTNMMjE4IDkyUTM3NSA5MiAzODUgOTdRMzkyIDk5IDQwOSAxODZWMTg5SDQ0OVYxODZRNDQ4IDE4MyA0MzYgOTVUNDIxIDNWMEg1MFYxOVYzMVE1MCAzOCA1NiA0NlQ4NiA4MVExMTUgMTEzIDEzNiAxMzdRMTQ1IDE0NyAxNzAgMTc0VDIwNCAyMTFUMjMzIDI0NFQyNjEgMjc4VDI4NCAzMDhUMzA1IDM0MFQzMjAgMzY5VDMzMyA0MDFUMzQwIDQzMVQzNDMgNDY0UTM0MyA1MjcgMzA5IDU3M1QyMTIgNjE5UTE3OSA2MTkgMTU0IDYwMlQxMTkgNTY5VDEwOSA1NTBRMTA5IDU0OSAxMTQgNTQ5UTEzMiA1NDkgMTUxIDUzNVQxNzAgNDg5UTE3MCA0NjQgMTU0IDQ0N1QxMDkgNDI5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUyIiBkPSJNMjMwIDYzN1EyMDMgNjM3IDE5OCA2MzhUMTkzIDY0OVExOTMgNjc2IDIwNCA2ODJRMjA2IDY4MyAzNzggNjgzUTU1MCA2ODIgNTY0IDY4MFE2MjAgNjcyIDY1OCA2NTJUNzEyIDYwNlQ3MzMgNTYzVDczOSA1MjlRNzM5IDQ4NCA3MTAgNDQ1VDY0MyAzODVUNTc2IDM1MVQ1MzggMzM4TDU0NSAzMzNRNjEyIDI5NSA2MTIgMjIzUTYxMiAyMTIgNjA3IDE2MlQ2MDIgODBWNzFRNjAyIDUzIDYwMyA0M1Q2MTQgMjVUNjQwIDE2UTY2OCAxNiA2ODYgMzhUNzEyIDg1UTcxNyA5OSA3MjAgMTAyVDczNSAxMDVRNzU1IDEwNSA3NTUgOTNRNzU1IDc1IDczMSAzNlE2OTMgLTIxIDY0MSAtMjFINjMyUTU3MSAtMjEgNTMxIDRUNDg3IDgyUTQ4NyAxMDkgNTAyIDE2NlQ1MTcgMjM5UTUxNyAyOTAgNDc0IDMxM1E0NTkgMzIwIDQ0OSAzMjFUMzc4IDMyM0gzMDlMMjc3IDE5M1EyNDQgNjEgMjQ0IDU5UTI0NCA1NSAyNDUgNTRUMjUyIDUwVDI2OSA0OFQzMDIgNDZIMzMzUTMzOSAzOCAzMzkgMzdUMzM2IDE5UTMzMiA2IDMyNiAwSDMxMVEyNzUgMiAxODAgMlExNDYgMiAxMTcgMlQ3MSAyVDUwIDFRMzMgMSAzMyAxMFEzMyAxMiAzNiAyNFE0MSA0MyA0NiA0NVE1MCA0NiA2MSA0Nkg2N1E5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4UTI4NyA2MzUgMjMwIDYzN1pNNjMwIDU1NFE2MzAgNTg2IDYwOSA2MDhUNTIzIDYzNlE1MjEgNjM2IDUwMCA2MzZUNDYyIDYzN0g0NDBRMzkzIDYzNyAzODYgNjI3UTM4NSA2MjQgMzUyIDQ5NFQzMTkgMzYxUTMxOSAzNjAgMzg4IDM2MFE0NjYgMzYxIDQ5MiAzNjdRNTU2IDM3NyA1OTIgNDI2UTYwOCA0NDkgNjE5IDQ4NlQ2MzAgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNUQiIGQ9Ik0yMiA3MTBWNzUwSDE1OVYtMjUwSDIyVi0yMTBIMTE5VjcxMEgyMloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjQtNUIiIGQ9Ik0yNjkgLTEyNDlWMTc1MEg1NzdWMTY3N0gzNDJWLTExNzZINTc3Vi0xMjQ5SDI2OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjQtNUQiIGQ9Ik01IDE2NzdWMTc1MEgzMTNWLTEyNDlINVYtMTE3NkgyNDBWMTY3N0g1WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNTYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI3NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ2IiB4PSIyMzI0IiB5PSI1ODEiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjIzMjQiIHk9Ii0zNTAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNDQwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjM5NjYiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NzQ0LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzk3LDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMzgwOCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDc3MCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NiIgeD0iMjMyNCIgeT0iNTgxIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjIzMjQiIHk9Ii0zNTAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNDQwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjE2MDQiIHk9Ii02ODYiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iOTM0OSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwMTI3LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzk3LDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNzIwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTEwIiB5PSI2NzYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iNjAiIHk9Ii02ODYiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTEzNjUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtNUIiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1ODMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE4MTAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTQzOSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMzg2MSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ2MzksMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMzYwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQzLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2NDYyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDgyNzIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTI3MiIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTAxNTciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDkzNSwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEzNjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDMsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC04MzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii00NDYiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjc1OCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwNzQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtNUQiIHg9IjE0NTU1IiB5PSItMSI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=)
证明:
我们首先计算一次试验得到的序列 的方差,
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9Ijg3LjY5NGV4IiBoZWlnaHQ9IjY1LjE3NmV4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTMxLjc5ZXg7IG1hcmdpbi1ib3R0b206IC0wLjIxNWV4OyIgdmlld0JveD0iMCAtMTQyODIgMzc3NTcuMiAyODA2MS44IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNTYiIGQ9Ik0xMTQgNjIwUTExMyA2MjEgMTEwIDYyNFQxMDcgNjI3VDEwMyA2MzBUOTggNjMyVDkxIDYzNFQ4MCA2MzVUNjcgNjM2VDQ4IDYzN0gxOVY2ODNIMjhRNDYgNjgwIDE1MiA2ODBRMjczIDY4MCAyOTQgNjgzSDMwNVY2MzdIMjg0UTIyMyA2MzQgMjIzIDYyMFEyMjMgNjE4IDMxMyAzNzJUNDA0IDEyNkw0OTAgMzU4UTU3NSA1ODggNTc1IDU5N1E1NzUgNjE2IDU1NCA2MjZUNTA4IDYzN0g1MDNWNjgzSDUxMlE1MjcgNjgwIDYyNyA2ODBRNzE4IDY4MCA3MjQgNjgzSDczMFY2MzdINzIzUTY0OCA2MzcgNjI3IDU5NlE2MjcgNTk1IDUxNSAyOTFUNDAxIC0xNFEzOTYgLTIyIDM4MiAtMjJIMzc0SDM2N1EzNTMgLTIyIDM0OCAtMTRRMzQ2IC0xMiAyMzEgMzAzUTExNCA2MTcgMTE0IDYyMFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTYxIiBkPSJNMTM3IDMwNVQxMTUgMzA1VDc4IDMyMFQ2MyAzNTlRNjMgMzk0IDk3IDQyMVQyMTggNDQ4UTI5MSA0NDggMzM2IDQxNlQzOTYgMzQwUTQwMSAzMjYgNDAxIDMwOVQ0MDIgMTk0VjEyNFE0MDIgNzYgNDA3IDU4VDQyOCA0MFE0NDMgNDAgNDQ4IDU2VDQ1MyAxMDlWMTQ1SDQ5M1YxMDZRNDkyIDY2IDQ5MCA1OVE0ODEgMjkgNDU1IDEyVDQwMCAtNlQzNTMgMTJUMzI5IDU0VjU4TDMyNyA1NVEzMjUgNTIgMzIyIDQ5VDMxNCA0MFQzMDIgMjlUMjg3IDE3VDI2OSA2VDI0NyAtMlQyMjEgLThUMTkwIC0xMVExMzAgLTExIDgyIDIwVDM0IDEwN1EzNCAxMjggNDEgMTQ3VDY4IDE4OFQxMTYgMjI1VDE5NCAyNTNUMzA0IDI2OEgzMThWMjkwUTMxOCAzMjQgMzEyIDM0MFEyOTAgNDExIDIxNSA0MTFRMTk3IDQxMSAxODEgNDEwVDE1NiA0MDZUMTQ4IDQwM1ExNzAgMzg4IDE3MCAzNTlRMTcwIDMzNCAxNTQgMzIwWk0xMjYgMTA2UTEyNiA3NSAxNTAgNTFUMjA5IDI2UTI0NyAyNiAyNzYgNDlUMzE1IDEwOVEzMTcgMTE2IDMxOCAxNzVRMzE4IDIzMyAzMTcgMjMzUTMwOSAyMzMgMjk2IDIzMlQyNTEgMjIzVDE5MyAyMDNUMTQ3IDE2NlQxMjYgMTA2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNzIiIGQ9Ik0zNiA0Nkg1MFE4OSA0NiA5NyA2MFY2OFE5NyA3NyA5NyA5MVQ5OCAxMjJUOTggMTYxVDk4IDIwM1E5OCAyMzQgOTggMjY5VDk4IDMyOEw5NyAzNTFROTQgMzcwIDgzIDM3NlQzOCAzODVIMjBWNDA4UTIwIDQzMSAyMiA0MzFMMzIgNDMyUTQyIDQzMyA2MCA0MzRUOTYgNDM2UTExMiA0MzcgMTMxIDQzOFQxNjAgNDQxVDE3MSA0NDJIMTc0VjM3M1EyMTMgNDQxIDI3MSA0NDFIMjc3UTMyMiA0NDEgMzQzIDQxOVQzNjQgMzczUTM2NCAzNTIgMzUxIDMzN1QzMTMgMzIyUTI4OCAzMjIgMjc2IDMzOFQyNjMgMzcyUTI2MyAzODEgMjY1IDM4OFQyNzAgNDAwVDI3MyA0MDVRMjcxIDQwNyAyNTAgNDAxUTIzNCAzOTMgMjI2IDM4NlExNzkgMzQxIDE3OSAyMDdWMTU0UTE3OSAxNDEgMTc5IDEyN1QxNzkgMTAxVDE4MCA4MVQxODAgNjZWNjFRMTgxIDU5IDE4MyA1N1QxODggNTRUMTkzIDUxVDIwMCA0OVQyMDcgNDhUMjE2IDQ3VDIyNSA0N1QyMzUgNDZUMjQ1IDQ2SDI3NlYwSDI2N1EyNDkgMyAxNDAgM1EzNyAzIDI4IDBIMjBWNDZIMzZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDYiIGQ9Ik00OCAxUTMxIDEgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ2IDY2IDIxNSAzNDJUMjg1IDYyMlEyODUgNjI5IDI4MSA2MjlRMjczIDYzMiAyMjggNjM0SDE5N1ExOTEgNjQwIDE5MSA2NDJUMTkzIDY1OVExOTcgNjc2IDIwMyA2ODBINzQyUTc0OSA2NzYgNzQ5IDY2OVE3NDkgNjY0IDczNiA1NTdUNzIyIDQ0N1E3MjAgNDQwIDcwMiA0NDBINjkwUTY4MyA0NDUgNjgzIDQ1M1E2ODMgNDU0IDY4NiA0NzdUNjg5IDUzMFE2ODkgNTYwIDY4MiA1NzlUNjYzIDYxMFQ2MjYgNjI2VDU3NSA2MzNUNTAzIDYzNEg0ODBRMzk4IDYzMyAzOTMgNjMxUTM4OCA2MjkgMzg2IDYyM1EzODUgNjIyIDM1MiA0OTJMMzIwIDM2M0gzNzVRMzc4IDM2MyAzOTggMzYzVDQyNiAzNjRUNDQ4IDM2N1Q0NzIgMzc0VDQ4OSAzODZRNTAyIDM5OCA1MTEgNDE5VDUyNCA0NTdUNTI5IDQ3NVE1MzIgNDgwIDU0OCA0ODBINTYwUTU2NyA0NzUgNTY3IDQ3MFE1NjcgNDY3IDUzNiAzMzlUNTAyIDIwN1E1MDAgMjAwIDQ4MiAyMDBINDcwUTQ2MyAyMDYgNDYzIDIxMlE0NjMgMjE1IDQ2OCAyMzRUNDczIDI3NFE0NzMgMzAzIDQ1MyAzMTBUMzY0IDMxN0gzMDlMMjc3IDE5MFEyNDUgNjYgMjQ1IDYwUTI0NSA0NiAzMzQgNDZIMzU5UTM2NSA0MCAzNjUgMzlUMzYzIDE5UTM1OSA2IDM1MyAwSDMzNlEyOTUgMiAxODUgMlExMjAgMiA4NiAyVDQ4IDFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMSIgZD0iTTIxMyA1NzhMMjAwIDU3M1ExODYgNTY4IDE2MCA1NjNUMTAyIDU1Nkg4M1Y2MDJIMTAyUTE0OSA2MDQgMTg5IDYxN1QyNDUgNjQxVDI3MyA2NjNRMjc1IDY2NiAyODUgNjY2UTI5NCA2NjYgMzAyIDY2MFYzNjFMMzAzIDYxUTMxMCA1NCAzMTUgNTJUMzM5IDQ4VDQwMSA0Nkg0MjdWMEg0MTZRMzk1IDMgMjU3IDNRMTIxIDMgMTAwIDBIODhWNDZIMTE0UTEzNiA0NiAxNTIgNDZUMTc3IDQ3VDE5MyA1MFQyMDEgNTJUMjA3IDU3VDIxMyA2MVY1NzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NSIgZD0iTTQ5MiAyMTNRNDcyIDIxMyA0NzIgMjI2UTQ3MiAyMzAgNDc3IDI1MFQ0ODIgMjg1UTQ4MiAzMTYgNDYxIDMyM1QzNjQgMzMwSDMxMlEzMTEgMzI4IDI3NyAxOTJUMjQzIDUyUTI0MyA0OCAyNTQgNDhUMzM0IDQ2UTQyOCA0NiA0NTggNDhUNTE4IDYxUTU2NyA3NyA1OTkgMTE3VDY3MCAyNDhRNjgwIDI3MCA2ODMgMjcyUTY5MCAyNzQgNjk4IDI3NFE3MTggMjc0IDcxOCAyNjFRNjEzIDcgNjA4IDJRNjA1IDAgMzIyIDBIMTMzUTMxIDAgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ2IDY2IDIxNSAzNDJUMjg1IDYyMlEyODUgNjI5IDI4MSA2MjlRMjczIDYzMiAyMjggNjM0SDE5N1ExOTEgNjQwIDE5MSA2NDJUMTkzIDY1OVExOTcgNjc2IDIwMyA2ODBINzU3UTc2NCA2NzYgNzY0IDY2OVE3NjQgNjY0IDc1MSA1NTdUNzM3IDQ0N1E3MzUgNDQwIDcxNyA0NDBINzA1UTY5OCA0NDUgNjk4IDQ1M0w3MDEgNDc2UTcwNCA1MDAgNzA0IDUyOFE3MDQgNTU4IDY5NyA1NzhUNjc4IDYwOVQ2NDMgNjI1VDU5NiA2MzJUNTMyIDYzNEg0ODVRMzk3IDYzMyAzOTIgNjMxUTM4OCA2MjkgMzg2IDYyMlEzODUgNjE5IDM1NSA0OTlUMzI0IDM3N1EzNDcgMzc2IDM3MiAzNzZIMzk4UTQ2NCAzNzYgNDg5IDM5MVQ1MzQgNDcyUTUzOCA0ODggNTQwIDQ5MFQ1NTcgNDkzUTU2MiA0OTMgNTY1IDQ5M1Q1NzAgNDkyVDU3MiA0OTFUNTc0IDQ4N1Q1NzcgNDgzTDU0NCAzNTFRNTExIDIxOCA1MDggMjE2UTUwNSAyMTMgNDkyIDIxM1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc4IiBkPSJNNTIgMjg5UTU5IDMzMSAxMDYgMzg2VDIyMiA0NDJRMjU3IDQ0MiAyODYgNDI0VDMyOSAzNzlRMzcxIDQ0MiA0MzAgNDQyUTQ2NyA0NDIgNDk0IDQyMFQ1MjIgMzYxUTUyMiAzMzIgNTA4IDMxNFQ0ODEgMjkyVDQ1OCAyODhRNDM5IDI4OCA0MjcgMjk5VDQxNSAzMjhRNDE1IDM3NCA0NjUgMzkxUTQ1NCA0MDQgNDI1IDQwNFE0MTIgNDA0IDQwNiA0MDJRMzY4IDM4NiAzNTAgMzM2UTI5MCAxMTUgMjkwIDc4UTI5MCA1MCAzMDYgMzhUMzQxIDI2UTM3OCAyNiA0MTQgNTlUNDYzIDE0MFE0NjYgMTUwIDQ2OSAxNTFUNDg1IDE1M0g0ODlRNTA0IDE1MyA1MDQgMTQ1UTUwNCAxNDQgNTAyIDEzNFE0ODYgNzcgNDQwIDMzVDMzMyAtMTFRMjYzIC0xMSAyMjcgNTJRMTg2IC0xMCAxMzMgLTEwSDEyN1E3OCAtMTAgNTcgMTZUMzUgNzFRMzUgMTAzIDU0IDEyM1Q5OSAxNDNRMTQyIDE0MyAxNDIgMTAxUTE0MiA4MSAxMzAgNjZUMTA3IDQ2VDk0IDQxTDkxIDQwUTkxIDM5IDk3IDM2VDExMyAyOVQxMzIgMjZRMTY4IDI2IDE5NCA3MVEyMDMgODcgMjE3IDEzOVQyNDUgMjQ3VDI2MSAzMTNRMjY2IDM0MCAyNjYgMzUyUTI2NiAzODAgMjUxIDM5MlQyMTcgNDA0UTE3NyA0MDQgMTQyIDM3MlQ5MyAyOTBROTEgMjgxIDg4IDI4MFQ3MiAyNzhINThRNTIgMjg0IDUyIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdEIiBkPSJNNjUgNzMxUTY1IDc0NSA2OCA3NDdUODggNzUwUTE3MSA3NTAgMjE2IDcyNVQyNzkgNjcwUTI4OCA2NDkgMjg5IDYzNVQyOTEgNTAxUTI5MiAzNjIgMjkzIDM1N1EzMDYgMzEyIDM0NSAyOTFUNDE3IDI2OVE0MjggMjY5IDQzMSAyNjZUNDM0IDI1MFQ0MzEgMjM0VDQxNyAyMzFRMzgwIDIzMSAzNDUgMjEwVDI5OCAxNTdRMjkzIDE0MyAyOTIgMTIxVDI5MSAtMjhWLTc5UTI5MSAtMTM0IDI4NSAtMTU2VDI1NiAtMTk4UTIwMiAtMjUwIDg5IC0yNTBRNzEgLTI1MCA2OCAtMjQ3VDY1IC0yMzBRNjUgLTIyNCA2NSAtMjIzVDY2IC0yMThUNjkgLTIxNFQ3NyAtMjEzUTkxIC0yMTMgMTA4IC0yMTBUMTQ2IC0yMDBUMTgzIC0xNzdUMjA3IC0xMzlRMjA4IC0xMzQgMjA5IDNMMjEwIDEzOVEyMjMgMTk2IDI4MCAyMzBRMzE1IDI0NyAzMzAgMjUwUTMwNSAyNTcgMjgwIDI3MFEyMjUgMzA0IDIxMiAzNTJMMjEwIDM2MkwyMDkgNDk4UTIwOCA2MzUgMjA3IDY0MFExOTUgNjgwIDE1NCA2OTZUNzcgNzEzUTY4IDcxMyA2NyA3MTZUNjUgNzMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY2IiBkPSJNMTE4IC0xNjJRMTIwIC0xNjIgMTI0IC0xNjRUMTM1IC0xNjdUMTQ3IC0xNjhRMTYwIC0xNjggMTcxIC0xNTVUMTg3IC0xMjZRMTk3IC05OSAyMjEgMjdUMjY3IDI2N1QyODkgMzgyVjM4NUgyNDJRMTk1IDM4NSAxOTIgMzg3UTE4OCAzOTAgMTg4IDM5N0wxOTUgNDI1UTE5NyA0MzAgMjAzIDQzMFQyNTAgNDMxUTI5OCA0MzEgMjk4IDQzMlEyOTggNDM0IDMwNyA0ODJUMzE5IDU0MFEzNTYgNzA1IDQ2NSA3MDVRNTAyIDcwMyA1MjYgNjgzVDU1MCA2MzBRNTUwIDU5NCA1MjkgNTc4VDQ4NyA1NjFRNDQzIDU2MSA0NDMgNjAzUTQ0MyA2MjIgNDU0IDYzNlQ0NzggNjU3TDQ4NyA2NjJRNDcxIDY2OCA0NTcgNjY4UTQ0NSA2NjggNDM0IDY1OFQ0MTkgNjMwUTQxMiA2MDEgNDAzIDU1MlQzODcgNDY5VDM4MCA0MzNRMzgwIDQzMSA0MzUgNDMxUTQ4MCA0MzEgNDg3IDQzMFQ0OTggNDI0UTQ5OSA0MjAgNDk2IDQwN1Q0OTEgMzkxUTQ4OSAzODYgNDgyIDM4NlQ0MjggMzg1SDM3MkwzNDkgMjYzUTMwMSAxNSAyODIgLTQ3UTI1NSAtMTMyIDIxMiAtMTczUTE3NSAtMjA1IDEzOSAtMjA1UTEwNyAtMjA1IDgxIC0xODZUNTUgLTEzMlE1NSAtOTUgNzYgLTc4VDExOCAtNjFRMTYyIC02MSAxNjIgLTEwM1ExNjIgLTEyMiAxNTEgLTEzNlQxMjcgLTE1N0wxMTggLTE2MloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMTIiIGQ9Ik04NCAyMzdUODQgMjUwVDk4IDI3MEg2NzlRNjk0IDI2MiA2OTQgMjUwVDY3OSAyMzBIOThRODQgMjM3IDg0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NiIgZD0iTTUyIDY0OFE1MiA2NzAgNjUgNjgzSDc2UTExOCA2ODAgMTgxIDY4MFEyOTkgNjgwIDMyMCA2ODNIMzMwUTMzNiA2NzcgMzM2IDY3NFQzMzQgNjU2UTMyOSA2NDEgMzI1IDYzN0gzMDRRMjgyIDYzNSAyNzQgNjM1UTI0NSA2MzAgMjQyIDYyMFEyNDIgNjE4IDI3MSAzNjlUMzAxIDExOEwzNzQgMjM1UTQ0NyAzNTIgNTIwIDQ3MVQ1OTUgNTk0UTU5OSA2MDEgNTk5IDYwOVE1OTkgNjMzIDU1NSA2MzdRNTM3IDYzNyA1MzcgNjQ4UTUzNyA2NDkgNTM5IDY2MVE1NDIgNjc1IDU0NSA2NzlUNTU4IDY4M1E1NjAgNjgzIDU3MCA2ODNUNjA0IDY4MlQ2NjggNjgxUTczNyA2ODEgNzU1IDY4M0g3NjJRNzY5IDY3NiA3NjkgNjcyUTc2OSA2NTUgNzYwIDY0MFE3NTcgNjM3IDc0MyA2MzdRNzMwIDYzNiA3MTkgNjM1VDY5OCA2MzBUNjgyIDYyM1Q2NzAgNjE1VDY2MCA2MDhUNjUyIDU5OVQ2NDUgNTkyTDQ1MiAyODJRMjcyIC05IDI2NiAtMTZRMjYzIC0xOCAyNTkgLTIxTDI0MSAtMjJIMjM0UTIxNiAtMjIgMjE2IC0xNVEyMTMgLTkgMTc3IDMwNVExMzkgNjIzIDEzOCA2MjZRMTMzIDYzNyA3NiA2MzdINTlRNTIgNjQyIDUyIDY0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oyLTdCIiBkPSJNNTQ3IC02NDNMNTQxIC02NDlINTI4UTUxNSAtNjQ5IDUwMyAtNjQ1UTMyNCAtNTgyIDI5MyAtNDY2UTI4OSAtNDQ5IDI4OSAtNDI4VDI4NyAtMjAwTDI4NiA0MkwyODQgNTNRMjc0IDk4IDI0OCAxMzVUMTk2IDE5MFQxNDYgMjIyTDEyMSAyMzVRMTE5IDIzOSAxMTkgMjUwUTExOSAyNjIgMTIxIDI2NlQxMzMgMjczUTI2MiAzMzYgMjg0IDQ0OUwyODYgNDYwTDI4NyA3MDFRMjg3IDczNyAyODcgNzk0UTI4OCA5NDkgMjkyIDk2M1EyOTMgOTY2IDI5MyA5NjdRMzI1IDEwODAgNTA4IDExNDhRNTE2IDExNTAgNTI3IDExNTBINTQxTDU0NyAxMTQ0VjExMzBRNTQ3IDExMTcgNTQ2IDExMTVUNTM2IDExMDlRNDgwIDEwODYgNDM3IDEwNDZUMzgxIDk1MEwzNzkgOTQwTDM3OCA2OTlRMzc4IDY1NyAzNzggNTk0UTM3NyA0NTIgMzc0IDQzOFEzNzMgNDM3IDM3MyA0MzZRMzUwIDM0OCAyNDMgMjgyUTE5MiAyNTcgMTg2IDI1NEwxNzYgMjUxTDE4OCAyNDVRMjExIDIzNiAyMzQgMjIzVDI4NyAxODlUMzQwIDEzNVQzNzMgNjVRMzczIDY0IDM3NCA2M1EzNzcgNDkgMzc4IC05M1EzNzggLTE1NiAzNzggLTE5OEwzNzkgLTQzOEwzODEgLTQ0OVEzOTMgLTUwNCA0MzYgLTU0NFQ1MzYgLTYwOFE1NDQgLTYxMSA1NDUgLTYxM1Q1NDcgLTYyOVYtNjQzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMi03RCIgZD0iTTExOSAxMTMwUTExOSAxMTQ0IDEyMSAxMTQ3VDEzNSAxMTUwSDEzOVExNTEgMTE1MCAxODIgMTEzOFQyNTIgMTEwNVQzMjYgMTA0NlQzNzMgOTY0UTM3OCA5NDIgMzc4IDcwMlEzNzggNDY5IDM3OSA0NjJRMzg2IDM5NCA0MzkgMzM5UTQ4MiAyOTYgNTM1IDI3MlE1NDQgMjY4IDU0NSAyNjZUNTQ3IDI1MVE1NDcgMjQxIDU0NyAyMzhUNTQyIDIzMVQ1MzEgMjI3VDUxMCAyMTdUNDc3IDE5NFEzOTAgMTI5IDM3OSAzOVEzNzggMzIgMzc4IC0yMDFRMzc4IC00NDEgMzczIC00NjNRMzQyIC01ODAgMTY1IC02NDRRMTUyIC02NDkgMTM5IC02NDlRMTI1IC02NDkgMTIyIC02NDZUMTE5IC02MjlRMTE5IC02MjIgMTE5IC02MTlUMTIxIC02MTRUMTI0IC02MTBUMTMyIC02MDdUMTQzIC02MDJRMTk1IC01NzkgMjM1IC01MzlUMjg1IC00NDdRMjg2IC00MzUgMjg3IC0xOTlUMjg5IDUxUTI5NCA3NCAzMDAgOTFUMzI5IDEzOFQzOTAgMTk3UTQxMiAyMTMgNDM2IDIyNlQ0NzUgMjQ0TDQ4OSAyNTBMNDcyIDI1OFE0NTUgMjY1IDQzMCAyNzlUMzc3IDMxM1QzMjcgMzY2VDI5MyA0MzRRMjg5IDQ1MSAyODkgNDcyVDI4NyA2OTlRMjg2IDk0MSAyODUgOTQ4UTI3OSA5NzggMjYyIDEwMDVUMjI3IDEwNDhUMTg0IDEwODBUMTUxIDExMDBUMTI5IDExMDlMMTI3IDExMTBRMTE5IDExMTMgMTE5IDExMzBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oyLTIyMTEiIGQ9Ik02MCA5NDhRNjMgOTUwIDY2NSA5NTBIMTI2N0wxMzI1IDgxNVExMzg0IDY3NyAxMzg4IDY2OUgxMzQ4TDEzNDEgNjgzUTEzMjAgNzI0IDEyODUgNzYxUTEyMzUgODA5IDExNzQgODM4VDEwMzMgODgxVDg4MiA4OThUNjk5IDkwMkg1NzRINTQzSDI1MUwyNTkgODkxUTcyMiAyNTggNzI0IDI1MlE3MjUgMjUwIDcyNCAyNDZRNzIxIDI0MyA0NjAgLTU2TDE5NiAtMzU2UTE5NiAtMzU3IDQwNyAtMzU3UTQ1OSAtMzU3IDU0OCAtMzU3VDY3NiAtMzU4UTgxMiAtMzU4IDg5NiAtMzUzVDEwNjMgLTMzMlQxMjA0IC0yODNUMTMwNyAtMTk2UTEzMjggLTE3MCAxMzQ4IC0xMjRIMTM4OFExMzg4IC0xMjUgMTM4MSAtMTQ1VDEzNTYgLTIxMFQxMzI1IC0yOTRMMTI2NyAtNDQ5TDY2NiAtNDUwUTY0IC00NTAgNjEgLTQ0OFE1NSAtNDQ2IDU1IC00MzlRNTUgLTQzNyA1NyAtNDMzTDU5MCAxNzdRNTkwIDE3OCA1NTcgMjIyVDQ1MiAzNjZUMzIyIDU0NEw1NiA5MDlMNTUgOTI0UTU1IDk0NSA2MCA5NDhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkIiIGQ9Ik0xMjEgNjQ3UTEyMSA2NTcgMTI1IDY3MFQxMzcgNjgzUTEzOCA2ODMgMjA5IDY4OFQyODIgNjk0UTI5NCA2OTQgMjk0IDY4NlEyOTQgNjc5IDI0NCA0NzdRMTk0IDI3OSAxOTQgMjcyUTIxMyAyODIgMjIzIDI5MVEyNDcgMzA5IDI5MiAzNTRUMzYyIDQxNVE0MDIgNDQyIDQzOCA0NDJRNDY4IDQ0MiA0ODUgNDIzVDUwMyAzNjlRNTAzIDM0NCA0OTYgMzI3VDQ3NyAzMDJUNDU2IDI5MVQ0MzggMjg4UTQxOCAyODggNDA2IDI5OVQzOTQgMzI4UTM5NCAzNTMgNDEwIDM2OVQ0NDIgMzkwTDQ1OCAzOTNRNDQ2IDQwNSA0MzQgNDA1SDQzMFEzOTggNDAyIDM2NyAzODBUMjk0IDMxNlQyMjggMjU1UTIzMCAyNTQgMjQzIDI1MlQyNjcgMjQ2VDI5MyAyMzhUMzIwIDIyNFQzNDIgMjA2VDM1OSAxODBUMzY1IDE0N1EzNjUgMTMwIDM2MCAxMDZUMzU0IDY2UTM1NCAyNiAzODEgMjZRNDI5IDI2IDQ1OSAxNDVRNDYxIDE1MyA0NzkgMTUzSDQ4M1E0OTkgMTUzIDQ5OSAxNDRRNDk5IDEzOSA0OTYgMTMwUTQ1NSAtMTEgMzc4IC0xMVEzMzMgLTExIDMwNSAxNVQyNzcgOTBRMjc3IDEwOCAyODAgMTIxVDI4MyAxNDVRMjgzIDE2NyAyNjkgMTgzVDIzNCAyMDZUMjAwIDIxN1QxODIgMjIwSDE4MFExNjggMTc4IDE1OSAxMzlUMTQ1IDgxVDEzNiA0NFQxMjkgMjBUMTIyIDdUMTExIC0yUTk4IC0xMSA4MyAtMTFRNjYgLTExIDU3IC0xVDQ4IDE2UTQ4IDI2IDg1IDE3NlQxNTggNDcxTDE5NSA2MTZRMTk2IDYyOSAxODggNjMyVDE0OSA2MzdIMTQ0UTEzNCA2MzcgMTMxIDYzN1QxMjQgNjQwVDEyMSA2NDdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTAiIGQ9Ik0yODcgNjI4UTI4NyA2MzUgMjMwIDYzN1EyMDYgNjM3IDE5OSA2MzhUMTkyIDY0OFExOTIgNjQ5IDE5NCA2NTlRMjAwIDY3OSAyMDMgNjgxVDM5NyA2ODNRNTg3IDY4MiA2MDAgNjgwUTY2NCA2NjkgNzA3IDYzMVQ3NTEgNTMwUTc1MSA0NTMgNjg1IDM4OVE2MTYgMzIxIDUwNyAzMDNRNTAwIDMwMiA0MDIgMzAxSDMwN0wyNzcgMTgyUTI0NyA2NiAyNDcgNTlRMjQ3IDU1IDI0OCA1NFQyNTUgNTBUMjcyIDQ4VDMwNSA0NkgzMzZRMzQyIDM3IDM0MiAzNVEzNDIgMTkgMzM1IDVRMzMwIDAgMzE5IDBRMzE2IDAgMjgyIDFUMTgyIDJRMTIwIDIgODcgMlQ1MSAxUTMzIDEgMzMgMTFRMzMgMTMgMzYgMjVRNDAgNDEgNDQgNDNUNjcgNDZROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFpNNjQ1IDU1NFE2NDUgNTY3IDY0MyA1NzVUNjM0IDU5N1Q2MDkgNjE5VDU2MCA2MzVRNTUzIDYzNiA0ODAgNjM3UTQ2MyA2MzcgNDQ1IDYzN1Q0MTYgNjM2VDQwNCA2MzZRMzkxIDYzNSAzODYgNjI3UTM4NCA2MjEgMzY3IDU1MFQzMzIgNDEyVDMxNCAzNDRRMzE0IDM0MiAzOTUgMzQySDQwN0g0MzBRNTQyIDM0MiA1OTAgMzkyUTYxNyA0MTkgNjMxIDQ3MVQ2NDUgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTcyIiBkPSJNMjEgMjg3UTIyIDI5MCAyMyAyOTVUMjggMzE3VDM4IDM0OFQ1MyAzODFUNzMgNDExVDk5IDQzM1QxMzIgNDQyUTE2MSA0NDIgMTgzIDQzMFQyMTQgNDA4VDIyNSAzODhRMjI3IDM4MiAyMjggMzgyVDIzNiAzODlRMjg0IDQ0MSAzNDcgNDQxSDM1MFEzOTggNDQxIDQyMiA0MDBRNDMwIDM4MSA0MzAgMzYzUTQzMCAzMzMgNDE3IDMxNVQzOTEgMjkyVDM2NiAyODhRMzQ2IDI4OCAzMzQgMjk5VDMyMiAzMjhRMzIyIDM3NiAzNzggMzkyUTM1NiA0MDUgMzQyIDQwNVEyODYgNDA1IDIzOSAzMzFRMjI5IDMxNSAyMjQgMjk4VDE5MCAxNjVRMTU2IDI1IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTE0IDE4OVQxNTQgMzY2UTE1NCA0MDUgMTI4IDQwNVExMDcgNDA1IDkyIDM3N1Q2OCAzMTZUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdDIiBkPSJNMTM5IC0yNDlIMTM3UTEyNSAtMjQ5IDExOSAtMjM1VjI1MUwxMjAgNzM3UTEzMCA3NTAgMTM5IDc1MFExNTIgNzUwIDE1OSA3MzVWLTIzNVExNTEgLTI0OSAxNDEgLTI0OUgxMzlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTQiIGQ9Ik00MCA0MzdRMjEgNDM3IDIxIDQ0NVEyMSA0NTAgMzcgNTAxVDcxIDYwMkw4OCA2NTFROTMgNjY5IDEwMSA2NzdINTY5SDY1OVE2OTEgNjc3IDY5NyA2NzZUNzA0IDY2N1E3MDQgNjYxIDY4NyA1NTNUNjY4IDQ0NFE2NjggNDM3IDY0OSA0MzdRNjQwIDQzNyA2MzcgNDM3VDYzMSA0NDJMNjI5IDQ0NVE2MjkgNDUxIDYzNSA0OTBUNjQxIDU1MVE2NDEgNTg2IDYyOCA2MDRUNTczIDYyOVE1NjggNjMwIDUxNSA2MzFRNDY5IDYzMSA0NTcgNjMwVDQzOSA2MjJRNDM4IDYyMSAzNjggMzQzVDI5OCA2MFEyOTggNDggMzg2IDQ2UTQxOCA0NiA0MjcgNDVUNDM2IDM2UTQzNiAzMSA0MzMgMjJRNDI5IDQgNDI0IDFMNDIyIDBRNDE5IDAgNDE1IDBRNDEwIDAgMzYzIDFUMjI4IDJROTkgMiA2NCAwSDQ5UTQzIDYgNDMgOVQ0NSAyN1E0OSA0MCA1NSA0Nkg4M0g5NFExNzQgNDYgMTg5IDU1UTE5MCA1NiAxOTEgNTZRMTk2IDU5IDIwMSA3NlQyNDEgMjMzUTI1OCAzMDEgMjY5IDM0NFEzMzkgNjE5IDMzOSA2MjVRMzM5IDYzMCAzMTAgNjMwSDI3OVEyMTIgNjMwIDE5MSA2MjRRMTQ2IDYxNCAxMjEgNTgzVDY3IDQ2N1E2MCA0NDUgNTcgNDQxVDQzIDQzN0g0MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02OSIgZD0iTTE4NCA2MDBRMTg0IDYyNCAyMDMgNjQyVDI0NyA2NjFRMjY1IDY2MSAyNzcgNjQ5VDI5MCA2MTlRMjkwIDU5NiAyNzAgNTc3VDIyNiA1NTdRMjExIDU1NyAxOTggNTY3VDE4NCA2MDBaTTIxIDI4N1EyMSAyOTUgMzAgMzE4VDU0IDM2OVQ5OCA0MjBUMTU4IDQ0MlExOTcgNDQyIDIyMyA0MTlUMjUwIDM1N1EyNTAgMzQwIDIzNiAzMDFUMTk2IDE5NlQxNTQgODNRMTQ5IDYxIDE0OSA1MVExNDkgMjYgMTY2IDI2UTE3NSAyNiAxODUgMjlUMjA4IDQzVDIzNSA3OFQyNjAgMTM3UTI2MyAxNDkgMjY1IDE1MVQyODIgMTUzUTMwMiAxNTMgMzAyIDE0M1EzMDIgMTM1IDI5MyAxMTJUMjY4IDYxVDIyMyAxMVQxNjEgLTExUTEyOSAtMTEgMTAyIDEwVDc0IDc0UTc0IDkxIDc5IDEwNlQxMjIgMjIwUTE2MCAzMjEgMTY2IDM0MVQxNzMgMzgwUTE3MyA0MDQgMTU2IDQwNEgxNTRRMTI0IDQwNCA5OSAzNzFUNjEgMjg3UTYwIDI4NiA1OSAyODRUNTggMjgxVDU2IDI3OVQ1MyAyNzhUNDkgMjc4VDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaNC0yOCIgZD0iTTc1OCAtMTIzN1Q3NTggLTEyNDBUNzUyIC0xMjQ5SDczNlE3MTggLTEyNDkgNzE3IC0xMjQ4UTcxMSAtMTI0NSA2NzIgLTExOTlRMjM3IC03MDYgMjM3IDI1MVQ2NzIgMTcwMFE2OTcgMTczMCA3MTYgMTc0OVE3MTggMTc1MCA3MzUgMTc1MEg3NTJRNzU4IDE3NDQgNzU4IDE3NDFRNzU4IDE3MzcgNzQwIDE3MTNUNjg5IDE2NDRUNjE5IDE1MzdUNTQwIDEzODBUNDYzIDExNzZRMzQ4IDgwMiAzNDggMjUxUTM0OCAtMjQyIDQ0MSAtNTk5VDc0NCAtMTIxOFE3NTggLTEyMzcgNzU4IC0xMjQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaNC0yOSIgZD0iTTMzIDE3NDFRMzMgMTc1MCA1MSAxNzUwSDYwSDY1UTczIDE3NTAgODEgMTc0M1QxMTkgMTcwMFE1NTQgMTIwNyA1NTQgMjUxUTU1NCAtNzA3IDExOSAtMTE5OVE3NiAtMTI1MCA2NiAtMTI1MFE2NSAtMTI1MCA2MiAtMTI1MFQ1NiAtMTI0OVE1NSAtMTI0OSA1MyAtMTI0OVQ0OSAtMTI1MFEzMyAtMTI1MCAzMyAtMTIzOVEzMyAtMTIzNiA1MCAtMTIxNFQ5OCAtMTE1MFQxNjMgLTEwNTJUMjM4IC05MTBUMzExIC03MjdRNDQzIC0zMzUgNDQzIDI1MVE0NDMgNDAyIDQzNiA1MzJUNDA1IDgzMVQzMzkgMTE0MlQyMjQgMTQzOFQ1MCAxNzE2UTMzIDE3MzcgMzMgMTc0MVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MiIgZD0iTTIzMCA2MzdRMjAzIDYzNyAxOTggNjM4VDE5MyA2NDlRMTkzIDY3NiAyMDQgNjgyUTIwNiA2ODMgMzc4IDY4M1E1NTAgNjgyIDU2NCA2ODBRNjIwIDY3MiA2NTggNjUyVDcxMiA2MDZUNzMzIDU2M1Q3MzkgNTI5UTczOSA0ODQgNzEwIDQ0NVQ2NDMgMzg1VDU3NiAzNTFUNTM4IDMzOEw1NDUgMzMzUTYxMiAyOTUgNjEyIDIyM1E2MTIgMjEyIDYwNyAxNjJUNjAyIDgwVjcxUTYwMiA1MyA2MDMgNDNUNjE0IDI1VDY0MCAxNlE2NjggMTYgNjg2IDM4VDcxMiA4NVE3MTcgOTkgNzIwIDEwMlQ3MzUgMTA1UTc1NSAxMDUgNzU1IDkzUTc1NSA3NSA3MzEgMzZRNjkzIC0yMSA2NDEgLTIxSDYzMlE1NzEgLTIxIDUzMSA0VDQ4NyA4MlE0ODcgMTA5IDUwMiAxNjZUNTE3IDIzOVE1MTcgMjkwIDQ3NCAzMTNRNDU5IDMyMCA0NDkgMzIxVDM3OCAzMjNIMzA5TDI3NyAxOTNRMjQ0IDYxIDI0NCA1OVEyNDQgNTUgMjQ1IDU0VDI1MiA1MFQyNjkgNDhUMzAyIDQ2SDMzM1EzMzkgMzggMzM5IDM3VDMzNiAxOVEzMzIgNiAzMjYgMEgzMTFRMjc1IDIgMTgwIDJRMTQ2IDIgMTE3IDJUNzEgMlQ1MCAxUTMzIDEgMzMgMTBRMzMgMTIgMzYgMjRRNDEgNDMgNDYgNDVRNTAgNDYgNjEgNDZINjdROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFEyODcgNjM1IDIzMCA2MzdaTTYzMCA1NTRRNjMwIDU4NiA2MDkgNjA4VDUyMyA2MzZRNTIxIDYzNiA1MDAgNjM2VDQ2MiA2MzdINDQwUTM5MyA2MzcgMzg2IDYyN1EzODUgNjI0IDM1MiA0OTRUMzE5IDM2MVEzMTkgMzYwIDM4OCAzNjBRNDY2IDM2MSA0OTIgMzY3UTU1NiAzNzcgNTkyIDQyNlE2MDggNDQ5IDYxOSA0ODZUNjMwIDU1NFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjMtMjgiIGQ9Ik03MDEgLTk0MFE3MDEgLTk0MyA2OTUgLTk0OUg2NjRRNjYyIC05NDcgNjM2IC05MjJUNTkxIC04NzlUNTM3IC04MThUNDc1IC03MzdUNDEyIC02MzZUMzUwIC01MTFUMjk1IC0zNjJUMjUwIC0xODZUMjIxIDE3VDIwOSAyNTFRMjA5IDk2MiA1NzMgMTM2MVE1OTYgMTM4NiA2MTYgMTQwNVQ2NDkgMTQzN1Q2NjQgMTQ1MEg2OTVRNzAxIDE0NDQgNzAxIDE0NDFRNzAxIDE0MzYgNjgxIDE0MTVUNjI5IDEzNTZUNTU3IDEyNjFUNDc2IDExMThUNDAwIDkyN1QzNDAgNjc1VDMwOCAzNTlRMzA2IDMyMSAzMDYgMjUwUTMwNiAtMTM5IDQwMCAtNDMwVDY5MCAtOTI0UTcwMSAtOTM2IDcwMSAtOTQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMy0yOSIgZD0iTTM0IDE0MzhRMzQgMTQ0NiAzNyAxNDQ4VDUwIDE0NTBINTZINzFRNzMgMTQ0OCA5OSAxNDIzVDE0NCAxMzgwVDE5OCAxMzE5VDI2MCAxMjM4VDMyMyAxMTM3VDM4NSAxMDEzVDQ0MCA4NjRUNDg1IDY4OFQ1MTQgNDg1VDUyNiAyNTFRNTI2IDEzNCA1MTkgNTNRNDcyIC01MTkgMTYyIC04NjBRMTM5IC04ODUgMTE5IC05MDRUODYgLTkzNlQ3MSAtOTQ5SDU2UTQzIC05NDkgMzkgLTk0N1QzNCAtOTM3UTg4IC04ODMgMTQwIC04MTNRNDI4IC00MzAgNDI4IDI1MVE0MjggNDUzIDQwMiA2MjhUMzM4IDkyMlQyNDUgMTE0NlQxNDUgMTMwOVQ0NiAxNDI1UTQ0IDE0MjcgNDIgMTQyOVQzOSAxNDMzVDM2IDE0MzZMMzQgMTQzOFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjQtMjNBNyIgZD0iTTcxMiA4OTlMNzE4IDg5M1Y4NzZWODY1UTcxOCA4NTQgNzA0IDg0NlE2MjcgNzkzIDU3NyA3MTBUNTEwIDUyNVE1MTAgNTI0IDUwOSA1MjFRNTA1IDQ5MyA1MDQgMzQ5UTUwNCAzNDUgNTA0IDMzNFE1MDQgMjc3IDUwNCAyNDBRNTA0IC0yIDUwMyAtNFE1MDIgLTggNDk0IC05VDQ0NCAtMTBRMzkyIC0xMCAzOTAgLTlRMzg3IC04IDM4NiAtNVEzODQgNSAzODQgMjMwUTM4NCAyNjIgMzg0IDMxMlQzODMgMzgyUTM4MyA0ODEgMzkyIDUzNVQ0MzQgNjU2UTUxMCA4MDYgNjY0IDg5Mkw2NzcgODk5SDcxMloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjQtMjNBOSIgZD0iTTcxOCAtODkzTDcxMiAtODk5SDY3N0w2NjYgLTg5M1E1NDIgLTgyNSA0NjggLTcxNFQzODUgLTQ3NlEzODQgLTQ2NiAzODQgLTI4MlEzODQgMyAzODUgNUwzODkgOVEzOTIgMTAgNDQ0IDEwUTQ4NiAxMCA0OTQgOVQ1MDMgNFE1MDQgMiA1MDQgLTIzOVYtMzEwVi0zNjZRNTA0IC00NzAgNTA4IC01MTNUNTMwIC02MDlRNTQ2IC02NTcgNTY5IC02OThUNjE3IC03NjdUNjYxIC04MTJUNjk5IC04NDNUNzE3IC04NTZUNzE4IC04NzZWLTg5M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjQtMjNBOCIgZD0iTTM4OSAxMTU5UTM5MSAxMTYwIDQ1NSAxMTYwUTQ5NiAxMTYwIDQ5OCAxMTU5UTUwMSAxMTU4IDUwMiAxMTU1UTUwNCAxMTQ1IDUwNCA5MjRRNTA0IDY5MSA1MDMgNjgyUTQ5NCA1NDkgNDI1IDQzOVQyNDMgMjU5TDIyOSAyNTBMMjQzIDI0MVEzNDkgMTc1IDQyMSA2NlQ1MDMgLTE4MlE1MDQgLTE5MSA1MDQgLTQyNFE1MDQgLTYwMCA1MDQgLTYyOVQ0OTkgLTY1OUg0OThRNDk2IC02NjAgNDQ0IC02NjBUMzkwIC02NTlRMzg3IC02NTggMzg2IC02NTVRMzg0IC02NDUgMzg0IC00MjVWLTI4MlEzODQgLTE3NiAzNzcgLTExNlQzNDIgMTBRMzI1IDU0IDMwMSA5MlQyNTUgMTU1VDIxNCAxOTZUMTgzIDIyMlQxNzEgMjMyUTE3MCAyMzMgMTcwIDI1MFQxNzEgMjY4UTE3MSAyNjkgMTkxIDI4NFQyNDAgMzMxVDMwMCA0MDdUMzU0IDUyNFQzODMgNjc5UTM4NCA2OTEgMzg0IDkyNVEzODQgMTE1MiAzODUgMTE1NUwzODkgMTE1OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjQtMjNBQiIgZD0iTTE3MCA4NzVRMTcwIDg5MiAxNzIgODk1VDE4OSA4OTlIMTk0SDIxMUwyMjIgODkzUTM0NSA4MjYgNDIwIDcxNVQ1MDMgNDc2UTUwNCA0NjcgNTA0IDIzMFE1MDQgNTEgNTA0IDIxVDQ5OSAtOUg0OThRNDk2IC0xMCA0NDQgLTEwUTQwMiAtMTAgMzk0IC05VDM4NSAtNFEzODQgLTIgMzg0IDI0MFYzMTFWMzY2UTM4NCA0NjkgMzgwIDUxM1QzNTggNjA5UTM0MiA2NTcgMzE5IDY5OFQyNzEgNzY3VDIyNyA4MTJUMTg5IDg0M1QxNzEgODU2VDE3MCA4NzVaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1o0LTIzQUQiIGQ9Ik0zODQgLTIzOVYtNTdRMzg0IDQgMzg5IDlRMzkxIDEwIDQ1NSAxMFE0OTYgMTAgNDk4IDlRNTAxIDggNTAyIDVRNTA0IC01IDUwNCAtMjMwUTUwNCAtMjYxIDUwNCAtMzExVDUwNSAtMzgxUTUwNSAtNDg2IDQ5MiAtNTUxVDQzNSAtNjkxUTM1NyAtODIwIDIyMiAtODkzTDIxMSAtODk5SDE5NVExNzYgLTg5OSAxNzMgLTg5NlQxNzAgLTg3NFExNzAgLTg1OCAxNzEgLTg1NVQxODQgLTg0NlEyNjIgLTc5MyAzMTIgLTcwOVQzNzggLTUyNVEzNzggLTUyNCAzNzkgLTUyMlEzODMgLTQ5MyAzODQgLTM1MVEzODQgLTM0NSAzODQgLTMzNFEzODQgLTI3NiAzODQgLTIzOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjQtMjNBQyIgZD0iTTM4OSAxMTU5UTM5MSAxMTYwIDQ1NSAxMTYwUTQ5NiAxMTYwIDQ5OCAxMTU5UTUwMSAxMTU4IDUwMiAxMTU1UTUwNCAxMTQ1IDUwNCA5MjVWNzgyUTUwNCA2NzYgNTExIDYxNlQ1NDYgNDkwUTU2MyA0NDYgNTg3IDQwOFQ2MzMgMzQ1VDY3NCAzMDRUNzA1IDI3OFQ3MTcgMjY4UTcxOCAyNjcgNzE4IDI1MFQ3MTcgMjMyUTcxNyAyMzEgNjk3IDIxNlQ2NDggMTY5VDU4OCA5M1Q1MzQgLTI0VDUwNSAtMTc5UTUwNCAtMTkxIDUwNCAtNDI1UTUwNCAtNjAwIDUwNCAtNjI5VDQ5OSAtNjU5SDQ5OFE0OTYgLTY2MCA0NDQgLTY2MFQzOTAgLTY1OVEzODcgLTY1OCAzODYgLTY1NVEzODQgLTY0NSAzODQgLTQyNFEzODQgLTE5MSAzODUgLTE4MlEzOTQgLTQ5IDQ2MyA2MVQ2NDUgMjQxTDY1OSAyNTBMNjQ1IDI1OVE1MzkgMzI1IDQ2NyA0MzRUMzg1IDY4MlEzODQgNjkyIDM4NCA4NzNRMzg0IDExNTMgMzg1IDExNTVMMzg5IDExNTlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oxLTI4IiBkPSJNMTUyIDI1MVExNTIgNjQ2IDM4OCA4NTBINDE2UTQyMiA4NDQgNDIyIDg0MVE0MjIgODM3IDQwMyA4MTZUMzU3IDc1M1QzMDIgNjQ5VDI1NSA0ODJUMjM2IDI1MFEyMzYgMTI0IDI1NSAxOVQzMDEgLTE0N1QzNTYgLTI1MVQ0MDMgLTMxNVQ0MjIgLTM0MFE0MjIgLTM0MyA0MTYgLTM0OUgzODhRMzU5IC0zMjUgMzMyIC0yOTZUMjcxIC0yMTNUMjEyIC05N1QxNzAgNTZUMTUyIDI1MVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjEtMjkiIGQ9Ik0zMDUgMjUxUTMwNSAtMTQ1IDY5IC0zNDlINTZRNDMgLTM0OSAzOSAtMzQ3VDM1IC0zMzhRMzcgLTMzMyA2MCAtMzA3VDEwOCAtMjM5VDE2MCAtMTM2VDIwNCAyN1QyMjEgMjUwVDIwNCA0NzNUMTYwIDYzNlQxMDggNzQwVDYwIDgwN1QzNSA4MzlRMzUgODUwIDUwIDg1MEg1Nkg2OVExOTcgNzQzIDI1NiA1NjZRMzA1IDQyNSAzMDUgMjUxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjI2MCIgZD0iTTE2NiAtMjE1VDE1OSAtMjE1VDE0NyAtMjEyVDE0MSAtMjA0VDEzOSAtMTk3UTEzOSAtMTkwIDE0NCAtMTgzTDMwNiAxMzNINzBRNTYgMTQwIDU2IDE1M1E1NiAxNjggNzIgMTczSDMyN0w0MDYgMzI3SDcyUTU2IDMzMiA1NiAzNDdRNTYgMzYwIDcwIDM2N0g0MjZRNTk3IDcwMiA2MDIgNzA3UTYwNSA3MTYgNjE4IDcxNlE2MjUgNzE2IDYzMCA3MTJUNjM2IDcwM1Q2MzggNjk2UTYzOCA2OTIgNDcxIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEw0NTEgMzI3TDM3MSAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNIMzUxUTE3NSAtMjEwIDE3MCAtMjEyUTE2NiAtMjE1IDE1OSAtMjE1WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZBIiBkPSJNMjk3IDU5NlEyOTcgNjI3IDMxOCA2NDRUMzYxIDY2MVEzNzggNjYxIDM4OSA2NTFUNDAzIDYyM1E0MDMgNTk1IDM4NCA1NzZUMzQwIDU1N1EzMjIgNTU3IDMxMCA1NjdUMjk3IDU5NlpNMjg4IDM3NlEyODggNDA1IDI2MiA0MDVRMjQwIDQwNSAyMjAgMzkzVDE4NSAzNjJUMTYxIDMyNVQxNDQgMjkzTDEzNyAyNzlRMTM1IDI3OCAxMjEgMjc4SDEwN1ExMDEgMjg0IDEwMSAyODZUMTA1IDI5OVExMjYgMzQ4IDE2NCAzOTFUMjUyIDQ0MVEyNTMgNDQxIDI2MCA0NDFUMjcyIDQ0MlEyOTYgNDQxIDMxNiA0MzJRMzQxIDQxOCAzNTQgNDAxVDM2NyAzNDhWMzMyTDMxOCAxMzNRMjY3IC02NyAyNjQgLTc1UTI0NiAtMTI1IDE5NCAtMTY0VDc1IC0yMDRRMjUgLTIwNCA3IC0xODNULTEyIC0xMzdRLTEyIC0xMTAgNyAtOTFUNTMgLTcxUTcwIC03MSA4MiAtODFUOTUgLTExMlE5NSAtMTQ4IDYzIC0xNjdRNjkgLTE2OCA3NyAtMTY4UTExMSAtMTY4IDEzOSAtMTQwVDE4MiAtNzRMMTkzIC0zMlEyMDQgMTEgMjE5IDcyVDI1MSAxOTdUMjc4IDMwOFQyODkgMzY1UTI4OSAzNzIgMjg4IDM3NloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjQtN0IiIGQ9Ik02NjEgLTEyNDNMNjU1IC0xMjQ5SDYyMkw2MDQgLTEyNDBRNTAzIC0xMTkwIDQzNCAtMTEwN1QzNDggLTkwOVEzNDYgLTg5NyAzNDYgLTQ5OUwzNDUgLTk4TDM0MyAtODJRMzM1IDMgMjg3IDg3VDE1NyAyMjNRMTQ2IDIzMiAxNDUgMjM2UTE0NCAyNDAgMTQ0IDI1MFExNDQgMjY1IDE0NSAyNjhUMTU3IDI3OFEyNDIgMzMzIDI4OCA0MTdUMzQzIDU4M0wzNDUgNjAwTDM0NiAxMDAxUTM0NiAxMzk4IDM0OCAxNDEwUTM3OSAxNjIyIDYwMCAxNzM5TDYyMiAxNzUwSDY1NUw2NjEgMTc0NFYxNzI3VjE3MjFRNjYxIDE3MTIgNjYxIDE3MTBUNjU3IDE3MDVUNjQ4IDE3MDBUNjMwIDE2OTBUNjAyIDE2NjhRNTg5IDE2NTkgNTc0IDE2NDNUNTMxIDE1OTNUNDg0IDE1MDhUNDU5IDEzOThRNDU4IDEzODkgNDU4IDEwMDFRNDU4IDYxNCA0NTcgNjA1UTQ0MSA0MzUgMzAxIDMxNlEyNTQgMjc3IDIwMiAyNTFMMjUwIDIyMlEyNjAgMjE2IDMwMSAxODVRNDQzIDY2IDQ1NyAtMTA0UTQ1OCAtMTEzIDQ1OCAtNTAxUTQ1OCAtODg4IDQ1OSAtODk3UTQ2MyAtOTQ0IDQ3OCAtOTg4VDUwOSAtMTA2MFQ1NDggLTExMTRUNTgwIC0xMTQ5VDYwMiAtMTE2N1E2MjAgLTExODMgNjM0IC0xMTkyVDY1MyAtMTIwMlQ2NTkgLTEyMDdUNjYxIC0xMjIwVi0xMjI2Vi0xMjQzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaNC03RCIgZD0iTTE0NCAxNzI3UTE0NCAxNzQzIDE0NiAxNzQ2VDE2MiAxNzUwSDE2N0gxODNMMjAzIDE3NDBRMjc0IDE3MDUgMzI1IDE2NThUNDAzIDE1NjJUNDQwIDE0NzhUNDU2IDE0MTBRNDU4IDEzOTggNDU4IDEwMDFRNDU5IDY2MSA0NTkgNjI0VDQ2NSA1NThRNDcwIDUyNiA0ODAgNDk2VDUwMiA0NDFUNTI5IDM5NVQ1NTkgMzU2VDU4OCAzMjVUNjE1IDMwMVQ2MzcgMjg0VDY1NCAyNzNMNjYwIDI2OVYyNjZRNjYwIDI2MyA2NjAgMjU5VDY2MSAyNTBWMjM5UTY2MSAyMzYgNjYxIDIzNFQ2NjAgMjMyVDY1NiAyMjlUNjQ5IDIyNFE1NzcgMTc5IDUyOCAxMDVUNDY1IC01N1E0NjAgLTg2IDQ2MCAtMTIzVDQ1OCAtNDk5Vi02NjFRNDU4IC04NTcgNDU3IC04OTNUNDQ3IC05NTVRNDI1IC0xMDQ4IDM1OSAtMTEyMFQyMDMgLTEyMzlMMTgzIC0xMjQ5SDE2OFExNTAgLTEyNDkgMTQ3IC0xMjQ2VDE0NCAtMTIyNlExNDQgLTEyMTMgMTQ1IC0xMjEwVDE1MyAtMTIwMlExNjkgLTExOTMgMTg2IC0xMTgxVDIzMiAtMTE0MFQyODIgLTEwODFUMzIyIC0xMDAwVDM0NSAtODk3UTM0NiAtODg4IDM0NiAtNTAxUTM0NiAtMTEzIDM0NyAtMTA0UTM1OSA1OCA1MDMgMTg0UTU1NCAyMjYgNjAzIDI1MFE1MDQgMjk5IDQzMCAzOTNUMzQ3IDYwNVEzNDYgNjE0IDM0NiAxMDAyUTM0NiAxMzg5IDM0NSAxMzk4UTMzOCAxNDkzIDI4OCAxNTczVDE1MyAxNzAzUTE0NiAxNzA3IDE0NSAxNzEwVDE0NCAxNzI3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNUIiIGQ9Ik0xMTggLTI1MFY3NTBIMjU1VjcxMEgxNThWLTIxMEgyNTVWLTI1MEgxMThaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi01RCIgZD0iTTIyIDcxMFY3NTBIMTU5Vi0yNTBIMjJWLTIxMEgxMTlWNzEwSDIyWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaNC01QiIgZD0iTTI2OSAtMTI0OVYxNzUwSDU3N1YxNjc3SDM0MlYtMTE3Nkg1NzdWLTEyNDlIMjY5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaNC01RCIgZD0iTTUgMTY3N1YxNzUwSDMxM1YtMTI0OUg1Vi0xMTc2SDI0MFYxNjc3SDVaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTY3LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoLTExLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwxMzAzNikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NiIgeD0iMjMyNCIgeT0iNTgxIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjIzMjQiIHk9Ii0zNTAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNDQwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNjc4LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwxMzAzNikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIyNzciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzM0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MzgsLTE4NykiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03OCIgeD0iNTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjEwNzMiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQ1MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi03QiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDY2NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjYiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzgiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjEwNzMiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMjY4MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMzI5MSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSI0MjkyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTIyOCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjY4NjYiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTAyNjEiIHk9IjY3NSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTdEIiB4PSI4Mzc3IiB5PSItMSI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDEwOTM1KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzMzQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNzYwIiB5PSItMTU2OSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjI5NDUiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODYzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI5MTEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUzMzAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDczOCwtMTg3KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iOTUxIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDczNjIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItN0IiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2NjcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY2IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzE3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc4IiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSIxMDczIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjI2ODAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjMyOTEiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iNDI5MiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUyMjgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI2ODY2IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwMjYxIiB5PSI2NzUiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdDIiB4PSI3NzEwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9Ijc5ODgiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi03RCIgeD0iOTE3NyIgeT0iLTEiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCw3NDY4KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzMzQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNzYwIiB5PSItMTU2OSI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjk0NSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQxODUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTEwOSIgeT0iNDk5Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU0MzgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDczOCwtMTg3KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iOTUxIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDc0NzEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzgiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjEwNzMiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkyMTEsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDE5NDkpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTIzQTciIHg9IjAiIHk9Ii05MDAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtMjNBOCIgeD0iMCIgeT0iLTE5NTAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtMjNBOSIgeD0iMCIgeT0iLTI1MDAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDg4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaNC0yOCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDc5MiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaNC0yOCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDc5MiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQ3LC0xMDkwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIzNDUiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTEyNCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI3NjAiIHk9IjE2MjciPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjExLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NTEsLTE1MCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNTc0KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjU3OCIgeT0iLTIzOCI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIyOTg1IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzk4NiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI2MzgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTI5IiB4PSI1ODI4IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSI2ODQzIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzg0NCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMy0yOCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDczNiwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEzNjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDMsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjMwMTQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0MDE1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1ozLTI5IiB4PSI2MTA5IiB5PSItMSI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtMjkiIHg9IjE1NDgyIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjIzMDE2IiB5PSIyMDkwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QyIgeD0iMTY3MjgiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTcwMDciIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE4NDE4LDE5NDkpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTIzQUIiIHg9IjAiIHk9Ii05MDAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtMjNBQyIgeD0iMCIgeT0iLTE5NTAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtMjNBRCIgeD0iMCIgeT0iLTI1MDAiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDM5NjgpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjc3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTMzNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI3NjAiIHk9Ii0xNTY5Ij48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyOTQ1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDE4NSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIxMTA5IiB5PSI0OTkiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTQzOCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzM4LC0xODcpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSI5NTEiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzMwNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaNC03QiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDgwNiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQ3LC0xMDkwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIzNDUiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTEyNCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI3NjAiIHk9IjE2MjciPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjExLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDU4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iNjM4IiB5PSI0ODgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NTEsLTE1MCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNTc0KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjU3OCIgeT0iLTIzOCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTM3NCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjIzNzUiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyODc1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzkyNSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDUxLC0xNTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjU3NCkiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSI1NzgiIHk9Ii0yMzgiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjEtMjkiIHg9IjU1MzYiIHk9Ii0xIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI3ODI4IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iODgyOSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDk0OTYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE3OSwtMTEyNSkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjYwIiB4PSIzNDUiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkEiIHg9IjExMjQiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTExMDcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ1MSwtMTUwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iNTc4IiB5PSItMjM4Ij48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMjYwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NTEsLTE1MCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNTc0KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkEiIHg9IjU3OCIgeT0iLTIzOCI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMzY3MyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0Njc0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iNjM4IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjYzOCIgeT0iLTQ0NiI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTU5NDUiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjcyNCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEzNjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MSw2NzYpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC04MzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii00NDYiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODU0NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwNzQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTk5ODIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIyMDk4MyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIxNDg0LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTM2MCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0Myw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjMwODQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjQyNzYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQxNjQsLTM1NTkpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwMDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMDc0IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii00NDYiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMjU4MCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM1ODEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0NywtMTA5MCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMzQ1IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjExMjQiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNzYwIiB5PSIxNjI3Ij48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI1MTkyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTY5MiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDUxLC0xNTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjU3NCkiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSI1NzgiIHk9Ii0yMzgiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzAxMiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMy0yOCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDczNiwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEzNjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDMsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjMwMTQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0MDE1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1ozLTI5IiB4PSI2MTA5IiB5PSItMSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIxNDA4MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjE1MDgwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTU1ODEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjc5NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMy0yOCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDczNiwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEzNjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDMsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjMwMTQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0MDE1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1ozLTI5IiB4PSI2MTA5IiB5PSItMSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QyIgeD0iMjM4MTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMjQwODgiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtN0QiIHg9IjI0NjEwIiB5PSItMSI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC0yODkyKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzMzQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNzYwIiB5PSItMTU2OSI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjk0NSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQxODUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTEwOSIgeT0iNDk5Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU0MzgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtNUIiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1ODMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDczOCwtMTg3KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iOTUxIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMDMyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTdCIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODA2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDcsLTEwOTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjM0NSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxMTI0IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9Ijc2MCIgeT0iMTYyNyI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2MTEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjEtMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NTgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI2MzgiIHk9IjQ4OCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ1MSwtMTUwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iNTc4IiB5PSItMjM4Ij48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjEzNzQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMzc1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA3NCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEyIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMS0yOSIgeD0iNDA0NyIgeT0iLTEiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjYzMzkiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MzQwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDU4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iNjM4IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjYzOCIgeT0iLTQ0NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMTI3MSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIyNzIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMDc0IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii00NDYiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTI5IiB4PSI0MDg4IiB5PSItMSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QyIgeD0iMTIwNTMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTIzMzIiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaNC03RCIgeD0iMTM2NjAiIHk9Ii0xIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxNjcyMSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE3NzIyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iNzM3IiB5PSI1ODMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE4Njk3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA3NCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEyIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIyMDEzMyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjIxMTMzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjIxNjM0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjIxNTUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjMzNDcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTM0MzIpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDc3OCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEzNjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MSw2NzYpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC04MzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii00NDYiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNjAxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA3NCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEyIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI0MDM3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTAzNywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwNzQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTQ0NiI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNjYxNyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9Ijc2MTgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4MTE4LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTM2MCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0Myw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTcxOSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDkxMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjEyNDkwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTM0OTEiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMTM5OTIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDUxMywwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEzNjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDMsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2MTE0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA3NCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEyIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjE3NTQ5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTg1NTAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxOTA1MSwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEzNjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDMsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIwNjUxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIxODQzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMjM0MjMiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNDQyMywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwNzQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTQ0NiI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIyNjAwMyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjI3MDA0IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjI3NTA0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjgwMjYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjkyMTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTVEIiB4PSIzMDU3NSIgeT0iLTEiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwtOTYyNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIyNzciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzM0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9Ijc2MCIgeT0iLTE1NjkiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI5NDUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0MTg1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjExMDkiIHk9IjQ5OSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEyIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1NjA1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTVCIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTgzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MjEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjMzMSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxMjcyIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI0MjE2IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTIxNywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNTYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI3NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MDI3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI2MzgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjE0MzkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjkwNzgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDA3OCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwNzQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTEyOTIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjMtMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MzYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iNzQzIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTUyMiwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEzNjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDMsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1ozLTI5IiB4PSI0MDgxIiB5PSItMSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI2ODEzIiB5PSIxNjY1Ij48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaNC01RCIgeD0iMTcxNDciIHk9Ii0xIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTEyNTM2KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwNTYsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMzYwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQzLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtODM3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExMDkiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItNDQ2Ij48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjkzNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwNzQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNDM3MCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUzNzEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzE4MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxNDM5IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI5MjMyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTAwMTAsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMzYwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQzLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMTgzMywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNTYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI3NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzY0MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxMjcyIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8L2c+Cjwvc3ZnPg==)
第一项是由于对状态 的重访次数的变化引起的方差,第二项是由于随机奖励引起的方差。在 次试验后首次访问MC方法估计是 次独立试验样本的平均值,因此, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIxLjA2OWV4IiBoZWlnaHQ9IjYuMDA5ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMS44MzhleDsiIHZpZXdCb3g9IjAgLTE3OTYgOTA3MS4zIDI1ODcuMyIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTU2IiBkPSJNMTE0IDYyMFExMTMgNjIxIDExMCA2MjRUMTA3IDYyN1QxMDMgNjMwVDk4IDYzMlQ5MSA2MzRUODAgNjM1VDY3IDYzNlQ0OCA2MzdIMTlWNjgzSDI4UTQ2IDY4MCAxNTIgNjgwUTI3MyA2ODAgMjk0IDY4M0gzMDVWNjM3SDI4NFEyMjMgNjM0IDIyMyA2MjBRMjIzIDYxOCAzMTMgMzcyVDQwNCAxMjZMNDkwIDM1OFE1NzUgNTg4IDU3NSA1OTdRNTc1IDYxNiA1NTQgNjI2VDUwOCA2MzdINTAzVjY4M0g1MTJRNTI3IDY4MCA2MjcgNjgwUTcxOCA2ODAgNzI0IDY4M0g3MzBWNjM3SDcyM1E2NDggNjM3IDYyNyA1OTZRNjI3IDU5NSA1MTUgMjkxVDQwMSAtMTRRMzk2IC0yMiAzODIgLTIySDM3NEgzNjdRMzUzIC0yMiAzNDggLTE0UTM0NiAtMTIgMjMxIDMwM1ExMTQgNjE3IDExNCA2MjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi02MSIgZD0iTTEzNyAzMDVUMTE1IDMwNVQ3OCAzMjBUNjMgMzU5UTYzIDM5NCA5NyA0MjFUMjE4IDQ0OFEyOTEgNDQ4IDMzNiA0MTZUMzk2IDM0MFE0MDEgMzI2IDQwMSAzMDlUNDAyIDE5NFYxMjRRNDAyIDc2IDQwNyA1OFQ0MjggNDBRNDQzIDQwIDQ0OCA1NlQ0NTMgMTA5VjE0NUg0OTNWMTA2UTQ5MiA2NiA0OTAgNTlRNDgxIDI5IDQ1NSAxMlQ0MDAgLTZUMzUzIDEyVDMyOSA1NFY1OEwzMjcgNTVRMzI1IDUyIDMyMiA0OVQzMTQgNDBUMzAyIDI5VDI4NyAxN1QyNjkgNlQyNDcgLTJUMjIxIC04VDE5MCAtMTFRMTMwIC0xMSA4MiAyMFQzNCAxMDdRMzQgMTI4IDQxIDE0N1Q2OCAxODhUMTE2IDIyNVQxOTQgMjUzVDMwNCAyNjhIMzE4VjI5MFEzMTggMzI0IDMxMiAzNDBRMjkwIDQxMSAyMTUgNDExUTE5NyA0MTEgMTgxIDQxMFQxNTYgNDA2VDE0OCA0MDNRMTcwIDM4OCAxNzAgMzU5UTE3MCAzMzQgMTU0IDMyMFpNMTI2IDEwNlExMjYgNzUgMTUwIDUxVDIwOSAyNlEyNDcgMjYgMjc2IDQ5VDMxNSAxMDlRMzE3IDExNiAzMTggMTc1UTMxOCAyMzMgMzE3IDIzM1EzMDkgMjMzIDI5NiAyMzJUMjUxIDIyM1QxOTMgMjAzVDE0NyAxNjZUMTI2IDEwNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTcyIiBkPSJNMzYgNDZINTBRODkgNDYgOTcgNjBWNjhROTcgNzcgOTcgOTFUOTggMTIyVDk4IDE2MVQ5OCAyMDNROTggMjM0IDk4IDI2OVQ5OCAzMjhMOTcgMzUxUTk0IDM3MCA4MyAzNzZUMzggMzg1SDIwVjQwOFEyMCA0MzEgMjIgNDMxTDMyIDQzMlE0MiA0MzMgNjAgNDM0VDk2IDQzNlExMTIgNDM3IDEzMSA0MzhUMTYwIDQ0MVQxNzEgNDQySDE3NFYzNzNRMjEzIDQ0MSAyNzEgNDQxSDI3N1EzMjIgNDQxIDM0MyA0MTlUMzY0IDM3M1EzNjQgMzUyIDM1MSAzMzdUMzEzIDMyMlEyODggMzIyIDI3NiAzMzhUMjYzIDM3MlEyNjMgMzgxIDI2NSAzODhUMjcwIDQwMFQyNzMgNDA1UTI3MSA0MDcgMjUwIDQwMVEyMzQgMzkzIDIyNiAzODZRMTc5IDM0MSAxNzkgMjA3VjE1NFExNzkgMTQxIDE3OSAxMjdUMTc5IDEwMVQxODAgODFUMTgwIDY2VjYxUTE4MSA1OSAxODMgNTdUMTg4IDU0VDE5MyA1MVQyMDAgNDlUMjA3IDQ4VDIxNiA0N1QyMjUgNDdUMjM1IDQ2VDI0NSA0NkgyNzZWMEgyNjdRMjQ5IDMgMTQwIDNRMzcgMyAyOCAwSDIwVjQ2SDM2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQ2IiBkPSJNNDggMVEzMSAxIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc0MlE3NDkgNjc2IDc0OSA2NjlRNzQ5IDY2NCA3MzYgNTU3VDcyMiA0NDdRNzIwIDQ0MCA3MDIgNDQwSDY5MFE2ODMgNDQ1IDY4MyA0NTNRNjgzIDQ1NCA2ODYgNDc3VDY4OSA1MzBRNjg5IDU2MCA2ODIgNTc5VDY2MyA2MTBUNjI2IDYyNlQ1NzUgNjMzVDUwMyA2MzRINDgwUTM5OCA2MzMgMzkzIDYzMVEzODggNjI5IDM4NiA2MjNRMzg1IDYyMiAzNTIgNDkyTDMyMCAzNjNIMzc1UTM3OCAzNjMgMzk4IDM2M1Q0MjYgMzY0VDQ0OCAzNjdUNDcyIDM3NFQ0ODkgMzg2UTUwMiAzOTggNTExIDQxOVQ1MjQgNDU3VDUyOSA0NzVRNTMyIDQ4MCA1NDggNDgwSDU2MFE1NjcgNDc1IDU2NyA0NzBRNTY3IDQ2NyA1MzYgMzM5VDUwMiAyMDdRNTAwIDIwMCA0ODIgMjAwSDQ3MFE0NjMgMjA2IDQ2MyAyMTJRNDYzIDIxNSA0NjggMjM0VDQ3MyAyNzRRNDczIDMwMyA0NTMgMzEwVDM2NCAzMTdIMzA5TDI3NyAxOTBRMjQ1IDY2IDI0NSA2MFEyNDUgNDYgMzM0IDQ2SDM1OVEzNjUgNDAgMzY1IDM5VDM2MyAxOVEzNTkgNiAzNTMgMEgzMzZRMjk1IDIgMTg1IDJRMTIwIDIgODYgMlQ0OCAxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZFIiBkPSJNMjEgMjg3UTIyIDI5MyAyNCAzMDNUMzYgMzQxVDU2IDM4OFQ4OSA0MjVUMTM1IDQ0MlExNzEgNDQyIDE5NSA0MjRUMjI1IDM5MFQyMzEgMzY5UTIzMSAzNjcgMjMyIDM2N0wyNDMgMzc4UTMwNCA0NDIgMzgyIDQ0MlE0MzYgNDQyIDQ2OSA0MTVUNTAzIDMzNlQ0NjUgMTc5VDQyNyA1MlE0MjcgMjYgNDQ0IDI2UTQ1MCAyNiA0NTMgMjdRNDgyIDMyIDUwNSA2NVQ1NDAgMTQ1UTU0MiAxNTMgNTYwIDE1M1E1ODAgMTUzIDU4MCAxNDVRNTgwIDE0NCA1NzYgMTMwUTU2OCAxMDEgNTU0IDczVDUwOCAxN1Q0MzkgLTEwUTM5MiAtMTAgMzcxIDE3VDM1MCA3M1EzNTAgOTIgMzg2IDE5M1Q0MjMgMzQ1UTQyMyA0MDQgMzc5IDQwNEgzNzRRMjg4IDQwNCAyMjkgMzAzTDIyMiAyOTFMMTg5IDE1N1ExNTYgMjYgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTIgMTgwVDE1MiAzNDNRMTUzIDM0OCAxNTMgMzY2UTE1MyA0MDUgMTI5IDQwNVE5MSA0MDUgNjYgMzA1UTYwIDI4NSA2MCAyODRRNTggMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMSIgZD0iTTIxMyA1NzhMMjAwIDU3M1ExODYgNTY4IDE2MCA1NjNUMTAyIDU1Nkg4M1Y2MDJIMTAyUTE0OSA2MDQgMTg5IDYxN1QyNDUgNjQxVDI3MyA2NjNRMjc1IDY2NiAyODUgNjY2UTI5NCA2NjYgMzAyIDY2MFYzNjFMMzAzIDYxUTMxMCA1NCAzMTUgNTJUMzM5IDQ4VDQwMSA0Nkg0MjdWMEg0MTZRMzk1IDMgMjU3IDNRMTIxIDMgMTAwIDBIODhWNDZIMTE0UTEzNiA0NiAxNTIgNDZUMTc3IDQ3VDE5MyA1MFQyMDEgNTJUMjA3IDU3VDIxMyA2MVY1NzhaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDYiIHg9IjIzMjQiIHk9IjU4MSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMjMyNCIgeT0iLTM1MCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI0NDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMzk2NiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ3NDQsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIzODA4IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsNzcwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNTYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI3NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ2IiB4PSIyMzI0IiB5PSI1ODEiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMjMyNCIgeT0iLTM1MCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI0NDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTYwNCIgeT0iLTY4NiI+PC91c2U+CjwvZz4KPC9nPgo8L2c+Cjwvc3ZnPg==) 。
。
定理6 首次访问MC方法的MSE是![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9Ijc3LjA1OWV4IiBoZWlnaHQ9IjcuNTA5ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4xNzFleDsiIHZpZXdCb3g9IjAgLTE4NjcuNyAzMzE3OCAzMjMzLjIiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi00RCIgZD0iTTEzMiA2MjJRMTI1IDYyOSAxMjEgNjMxVDEwNSA2MzRUNjIgNjM3SDI5VjY4M0gxMzVRMjIxIDY4MyAyMzIgNjgyVDI0OSA2NzVRMjUwIDY3NCAzNTQgMzk4TDQ1OCAxMjRMNTYyIDM5OFE2NjYgNjc0IDY2OCA2NzVRNjcxIDY4MSA2ODMgNjgyVDc4MSA2ODNIODg3VjYzN0g4NTRRODE0IDYzNiA4MDMgNjM0VDc4NSA2MjJWNjFRNzkxIDUxIDgwMiA0OVQ4NTQgNDZIODg3VjBIODc2UTg1NSAzIDczNiAzUTYwNSAzIDU5NiAwSDU4NVY0Nkg2MThRNjYwIDQ3IDY2OSA0OVQ2ODggNjFWMzQ3UTY4OCA0MjQgNjg4IDQ2MVQ2ODggNTQ2VDY4OCA2MTNMNjg3IDYzMlE0NTQgMTQgNDUwIDdRNDQ2IDEgNDMwIDFUNDEwIDdRNDA5IDkgMjkyIDMxNkwxNzYgNjI0VjYwNlExNzUgNTg4IDE3NSA1NDNUMTc1IDQ2M1QxNzUgMzU2TDE3NiA4NlExODcgNTAgMjYxIDQ2SDI3OFYwSDI2OVEyNTQgMyAxNTQgM1E1MiAzIDM3IDBIMjlWNDZINDZRNzggNDggOTggNTZUMTIyIDY5VDEzMiA4NlY2MjJaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi01MyIgZD0iTTU1IDUwN1E1NSA1OTAgMTEyIDY0N1QyNDMgNzA0SDI1N1EzNDIgNzA0IDQwNSA2NDFMNDI2IDY3MlE0MzEgNjc5IDQzNiA2ODdUNDQ2IDcwMEw0NDkgNzA0UTQ1MCA3MDQgNDUzIDcwNFQ0NTkgNzA1SDQ2M1E0NjYgNzA1IDQ3MiA2OTlWNDYyTDQ2NiA0NTZINDQ4UTQzNyA0NTYgNDM1IDQ1OVQ0MzAgNDc5UTQxMyA2MDUgMzI5IDY0NlEyOTIgNjYyIDI1NCA2NjJRMjAxIDY2MiAxNjggNjI2VDEzNSA1NDJRMTM1IDUwOCAxNTIgNDgwVDIwMCA0MzVRMjEwIDQzMSAyODYgNDEyVDM3MCAzODlRNDI3IDM2NyA0NjMgMzE0VDUwMCAxOTFRNTAwIDExMCA0NDggNDVUMzAxIC0yMVEyNDUgLTIxIDIwMSAtNFQxNDAgMjdMMTIyIDQxUTExOCAzNiAxMDcgMjFUODcgLTdUNzggLTIxUTc2IC0yMiA2OCAtMjJINjRRNjEgLTIyIDU1IC0xNlYxMDFRNTUgMjIwIDU2IDIyMlE1OCAyMjcgNzYgMjI3SDg5UTk1IDIyMSA5NSAyMTRROTUgMTgyIDEwNSAxNTFUMTM5IDkwVDIwNSA0MlQzMDUgMjRRMzUyIDI0IDM4NiA2MlQ0MjAgMTU1UTQyMCAxOTggMzk4IDIzM1QzNDAgMjgxUTI4NCAyOTUgMjY2IDMwMFEyNjEgMzAxIDIzOSAzMDZUMjA2IDMxNFQxNzQgMzI1VDE0MSAzNDNUMTEyIDM2N1Q4NSA0MDJRNTUgNDUxIDU1IDUwN1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTQ1IiBkPSJNMTI4IDYxOVExMjEgNjI2IDExNyA2MjhUMTAxIDYzMVQ1OCA2MzRIMjVWNjgwSDU5N1Y2NzZRNTk5IDY3MCA2MTEgNTYwVDYyNSA0NDRWNDQwSDU4NVY0NDRRNTg0IDQ0NyA1ODIgNDY1UTU3OCA1MDAgNTcwIDUyNlQ1NTMgNTcxVDUyOCA2MDFUNDk4IDYxOVQ0NTcgNjI5VDQxMSA2MzNUMzUzIDYzNFEyNjYgNjM0IDI1MSA2MzNUMjMzIDYyMlEyMzMgNjIyIDIzMyA2MjFRMjMyIDYxOSAyMzIgNDk3VjM3NkgyODZRMzU5IDM3OCAzNzcgMzg1UTQxMyA0MDEgNDE2IDQ2OVE0MTYgNDcxIDQxNiA0NzNWNDkzSDQ1NlYyMTNINDE2VjIzM1E0MTUgMjY4IDQwOCAyODhUMzgzIDMxN1QzNDkgMzI4VDI5NyAzMzBRMjkwIDMzMCAyODYgMzMwSDIzMlYxOTZWMTE0UTIzMiA1NyAyMzcgNTJRMjQzIDQ3IDI4OSA0N0gzNDBIMzkxUTQyOCA0NyA0NTIgNTBUNTA1IDYyVDU1MiA5MlQ1ODQgMTQ2UTU5NCAxNzIgNTk5IDIwMFQ2MDcgMjQ3VDYxMiAyNzBWMjczSDY1MlYyNzBRNjUxIDI2NyA2MzIgMTM3VDYxMCAzVjBIMjVWNDZINThRMTAwIDQ3IDEwOSA0OVQxMjggNjFWNjE5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQ2IiBkPSJNNDggMVEzMSAxIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc0MlE3NDkgNjc2IDc0OSA2NjlRNzQ5IDY2NCA3MzYgNTU3VDcyMiA0NDdRNzIwIDQ0MCA3MDIgNDQwSDY5MFE2ODMgNDQ1IDY4MyA0NTNRNjgzIDQ1NCA2ODYgNDc3VDY4OSA1MzBRNjg5IDU2MCA2ODIgNTc5VDY2MyA2MTBUNjI2IDYyNlQ1NzUgNjMzVDUwMyA2MzRINDgwUTM5OCA2MzMgMzkzIDYzMVEzODggNjI5IDM4NiA2MjNRMzg1IDYyMiAzNTIgNDkyTDMyMCAzNjNIMzc1UTM3OCAzNjMgMzk4IDM2M1Q0MjYgMzY0VDQ0OCAzNjdUNDcyIDM3NFQ0ODkgMzg2UTUwMiAzOTggNTExIDQxOVQ1MjQgNDU3VDUyOSA0NzVRNTMyIDQ4MCA1NDggNDgwSDU2MFE1NjcgNDc1IDU2NyA0NzBRNTY3IDQ2NyA1MzYgMzM5VDUwMiAyMDdRNTAwIDIwMCA0ODIgMjAwSDQ3MFE0NjMgMjA2IDQ2MyAyMTJRNDYzIDIxNSA0NjggMjM0VDQ3MyAyNzRRNDczIDMwMyA0NTMgMzEwVDM2NCAzMTdIMzA5TDI3NyAxOTBRMjQ1IDY2IDI0NSA2MFEyNDUgNDYgMzM0IDQ2SDM1OVEzNjUgNDAgMzY1IDM5VDM2MyAxOVEzNTkgNiAzNTMgMEgzMzZRMjk1IDIgMTg1IDJRMTIwIDIgODYgMlQ0OCAxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZFIiBkPSJNMjEgMjg3UTIyIDI5MyAyNCAzMDNUMzYgMzQxVDU2IDM4OFQ4OSA0MjVUMTM1IDQ0MlExNzEgNDQyIDE5NSA0MjRUMjI1IDM5MFQyMzEgMzY5UTIzMSAzNjcgMjMyIDM2N0wyNDMgMzc4UTMwNCA0NDIgMzgyIDQ0MlE0MzYgNDQyIDQ2OSA0MTVUNTAzIDMzNlQ0NjUgMTc5VDQyNyA1MlE0MjcgMjYgNDQ0IDI2UTQ1MCAyNiA0NTMgMjdRNDgyIDMyIDUwNSA2NVQ1NDAgMTQ1UTU0MiAxNTMgNTYwIDE1M1E1ODAgMTUzIDU4MCAxNDVRNTgwIDE0NCA1NzYgMTMwUTU2OCAxMDEgNTU0IDczVDUwOCAxN1Q0MzkgLTEwUTM5MiAtMTAgMzcxIDE3VDM1MCA3M1EzNTAgOTIgMzg2IDE5M1Q0MjMgMzQ1UTQyMyA0MDQgMzc5IDQwNEgzNzRRMjg4IDQwNCAyMjkgMzAzTDIyMiAyOTFMMTg5IDE1N1ExNTYgMjYgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTIgMTgwVDE1MiAzNDNRMTUzIDM0OCAxNTMgMzY2UTE1MyA0MDUgMTI5IDQwNVE5MSA0MDUgNjYgMzA1UTYwIDI4NSA2MCAyODRRNTggMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi00MiIgZD0iTTEzMSA2MjJRMTI0IDYyOSAxMjAgNjMxVDEwNCA2MzRUNjEgNjM3SDI4VjY4M0gyMjlIMjY3SDM0NlE0MjMgNjgzIDQ1OSA2NzhUNTMxIDY1MVE1NzQgNjI3IDU5OSA1OTBUNjI0IDUxMlE2MjQgNDYxIDU4MyA0MTlUNDc2IDM2MEw0NjYgMzU3UTUzOSAzNDggNTk1IDMwMlQ2NTEgMTg3UTY1MSAxMTkgNjAwIDY3VDQ2OSAzUTQ1NiAxIDI0MiAwSDI4VjQ2SDYxUTEwMyA0NyAxMTIgNDlUMTMxIDYxVjYyMlpNNTExIDUxM1E1MTEgNTYwIDQ4NSA1OTRUNDE2IDYzNlE0MTUgNjM2IDQwMyA2MzZUMzcxIDYzNlQzMzMgNjM3UTI2NiA2MzcgMjUxIDYzNlQyMzIgNjI4UTIyOSA2MjQgMjI5IDQ5OVYzNzRIMzEyTDM5NiAzNzVMNDA2IDM3N1E0MTAgMzc4IDQxNyAzODBUNDQyIDM5M1Q0NzQgNDE3VDQ5OSA0NTZUNTExIDUxM1pNNTM3IDE4OFE1MzcgMjM5IDUwOSAyODJUNDMwIDMzNkwzMjkgMzM3SDIyOVYyMDBWMTE2UTIyOSA1NyAyMzQgNTJRMjQwIDQ3IDMzNCA0N0gzODNRNDI1IDQ3IDQ0MyA1M1E0ODYgNjcgNTExIDEwNFQ1MzcgMTg4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNjkiIGQ9Ik02OSA2MDlRNjkgNjM3IDg3IDY1M1QxMzEgNjY5UTE1NCA2NjcgMTcxIDY1MlQxODggNjA5UTE4OCA1NzkgMTcxIDU2NFQxMjkgNTQ5UTEwNCA1NDkgODcgNTY0VDY5IDYwOVpNMjQ3IDBRMjMyIDMgMTQzIDNRMTMyIDMgMTA2IDNUNTYgMUwzNCAwSDI2VjQ2SDQyUTcwIDQ2IDkxIDQ5UTEwMCA1MyAxMDIgNjBUMTA0IDEwMlYyMDVWMjkzUTEwNCAzNDUgMTAyIDM1OVQ4OCAzNzhRNzQgMzg1IDQxIDM4NUgzMFY0MDhRMzAgNDMxIDMyIDQzMUw0MiA0MzJRNTIgNDMzIDcwIDQzNFQxMDYgNDM2UTEyMyA0MzcgMTQyIDQzOFQxNzEgNDQxVDE4MiA0NDJIMTg1VjYyUTE5MCA1MiAxOTcgNTBUMjMyIDQ2SDI1NVYwSDI0N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTYxIiBkPSJNMTM3IDMwNVQxMTUgMzA1VDc4IDMyMFQ2MyAzNTlRNjMgMzk0IDk3IDQyMVQyMTggNDQ4UTI5MSA0NDggMzM2IDQxNlQzOTYgMzQwUTQwMSAzMjYgNDAxIDMwOVQ0MDIgMTk0VjEyNFE0MDIgNzYgNDA3IDU4VDQyOCA0MFE0NDMgNDAgNDQ4IDU2VDQ1MyAxMDlWMTQ1SDQ5M1YxMDZRNDkyIDY2IDQ5MCA1OVE0ODEgMjkgNDU1IDEyVDQwMCAtNlQzNTMgMTJUMzI5IDU0VjU4TDMyNyA1NVEzMjUgNTIgMzIyIDQ5VDMxNCA0MFQzMDIgMjlUMjg3IDE3VDI2OSA2VDI0NyAtMlQyMjEgLThUMTkwIC0xMVExMzAgLTExIDgyIDIwVDM0IDEwN1EzNCAxMjggNDEgMTQ3VDY4IDE4OFQxMTYgMjI1VDE5NCAyNTNUMzA0IDI2OEgzMThWMjkwUTMxOCAzMjQgMzEyIDM0MFEyOTAgNDExIDIxNSA0MTFRMTk3IDQxMSAxODEgNDEwVDE1NiA0MDZUMTQ4IDQwM1ExNzAgMzg4IDE3MCAzNTlRMTcwIDMzNCAxNTQgMzIwWk0xMjYgMTA2UTEyNiA3NSAxNTAgNTFUMjA5IDI2UTI0NyAyNiAyNzYgNDlUMzE1IDEwOVEzMTcgMTE2IDMxOCAxNzVRMzE4IDIzMyAzMTcgMjMzUTMwOSAyMzMgMjk2IDIzMlQyNTEgMjIzVDE5MyAyMDNUMTQ3IDE2NlQxMjYgMTA2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNzMiIGQ9Ik0yOTUgMzE2UTI5NSAzNTYgMjY4IDM4NVQxOTAgNDE0UTE1NCA0MTQgMTI4IDQwMVE5OCAzODIgOTggMzQ5UTk3IDM0NCA5OCAzMzZUMTE0IDMxMlQxNTcgMjg3UTE3NSAyODIgMjAxIDI3OFQyNDUgMjY5VDI3NyAyNTZRMjk0IDI0OCAzMTAgMjM2VDM0MiAxOTVUMzU5IDEzM1EzNTkgNzEgMzIxIDMxVDE5OCAtMTBIMTkwUTEzOCAtMTAgOTQgMjZMODYgMTlMNzcgMTBRNzEgNCA2NSAtMUw1NCAtMTFINDZINDJRMzkgLTExIDMzIC01Vjc0VjEzMlEzMyAxNTMgMzUgMTU3VDQ1IDE2Mkg1NFE2NiAxNjIgNzAgMTU4VDc1IDE0NlQ4MiAxMTlUMTAxIDc3UTEzNiAyNiAxOTggMjZRMjk1IDI2IDI5NSAxMDRRMjk1IDEzMyAyNzcgMTUxUTI1NyAxNzUgMTk0IDE4N1QxMTEgMjEwUTc1IDIyNyA1NCAyNTZUMzMgMzE4UTMzIDM1NyA1MCAzODRUOTMgNDI0VDE0MyA0NDJUMTg3IDQ0N0gxOThRMjM4IDQ0NyAyNjggNDMyTDI4MyA0MjRMMjkyIDQzMVEzMDIgNDQwIDMxNCA0NDhIMzIySDMyNlEzMjkgNDQ4IDMzNSA0NDJWMzEwTDMyOSAzMDRIMzAxUTI5NSAzMTAgMjk1IDMxNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjEtMjgiIGQ9Ik0xNTIgMjUxUTE1MiA2NDYgMzg4IDg1MEg0MTZRNDIyIDg0NCA0MjIgODQxUTQyMiA4MzcgNDAzIDgxNlQzNTcgNzUzVDMwMiA2NDlUMjU1IDQ4MlQyMzYgMjUwUTIzNiAxMjQgMjU1IDE5VDMwMSAtMTQ3VDM1NiAtMjUxVDQwMyAtMzE1VDQyMiAtMzQwUTQyMiAtMzQzIDQxNiAtMzQ5SDM4OFEzNTkgLTMyNSAzMzIgLTI5NlQyNzEgLTIxM1QyMTIgLTk3VDE3MCA1NlQxNTIgMjUxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMS0yOSIgZD0iTTMwNSAyNTFRMzA1IC0xNDUgNjkgLTM0OUg1NlE0MyAtMzQ5IDM5IC0zNDdUMzUgLTMzOFEzNyAtMzMzIDYwIC0zMDdUMTA4IC0yMzlUMTYwIC0xMzZUMjA0IDI3VDIyMSAyNTBUMjA0IDQ3M1QxNjAgNjM2VDEwOCA3NDBUNjAgODA3VDM1IDgzOVEzNSA4NTAgNTAgODUwSDU2SDY5UTE5NyA3NDMgMjU2IDU2NlEzMDUgNDI1IDMwNSAyNTFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMiIgZD0iTTEwOSA0MjlRODIgNDI5IDY2IDQ0N1Q1MCA0OTFRNTAgNTYyIDEwMyA2MTRUMjM1IDY2NlEzMjYgNjY2IDM4NyA2MTBUNDQ5IDQ2NVE0NDkgNDIyIDQyOSAzODNUMzgxIDMxNVQzMDEgMjQxUTI2NSAyMTAgMjAxIDE0OUwxNDIgOTNMMjE4IDkyUTM3NSA5MiAzODUgOTdRMzkyIDk5IDQwOSAxODZWMTg5SDQ0OVYxODZRNDQ4IDE4MyA0MzYgOTVUNDIxIDNWMEg1MFYxOVYzMVE1MCAzOCA1NiA0NlQ4NiA4MVExMTUgMTEzIDEzNiAxMzdRMTQ1IDE0NyAxNzAgMTc0VDIwNCAyMTFUMjMzIDI0NFQyNjEgMjc4VDI4NCAzMDhUMzA1IDM0MFQzMjAgMzY5VDMzMyA0MDFUMzQwIDQzMVQzNDMgNDY0UTM0MyA1MjcgMzA5IDU3M1QyMTIgNjE5UTE3OSA2MTkgMTU0IDYwMlQxMTkgNTY5VDEwOSA1NTBRMTA5IDU0OSAxMTQgNTQ5UTEzMiA1NDkgMTUxIDUzNVQxNzAgNDg5UTE3MCA0NjQgMTU0IDQ0N1QxMDkgNDI5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNTYiIGQ9Ik0xMTQgNjIwUTExMyA2MjEgMTEwIDYyNFQxMDcgNjI3VDEwMyA2MzBUOTggNjMyVDkxIDYzNFQ4MCA2MzVUNjcgNjM2VDQ4IDYzN0gxOVY2ODNIMjhRNDYgNjgwIDE1MiA2ODBRMjczIDY4MCAyOTQgNjgzSDMwNVY2MzdIMjg0UTIyMyA2MzQgMjIzIDYyMFEyMjMgNjE4IDMxMyAzNzJUNDA0IDEyNkw0OTAgMzU4UTU3NSA1ODggNTc1IDU5N1E1NzUgNjE2IDU1NCA2MjZUNTA4IDYzN0g1MDNWNjgzSDUxMlE1MjcgNjgwIDYyNyA2ODBRNzE4IDY4MCA3MjQgNjgzSDczMFY2MzdINzIzUTY0OCA2MzcgNjI3IDU5NlE2MjcgNTk1IDUxNSAyOTFUNDAxIC0xNFEzOTYgLTIyIDM4MiAtMjJIMzc0SDM2N1EzNTMgLTIyIDM0OCAtMTRRMzQ2IC0xMiAyMzEgMzAzUTExNCA2MTcgMTE0IDYyMFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTcyIiBkPSJNMzYgNDZINTBRODkgNDYgOTcgNjBWNjhROTcgNzcgOTcgOTFUOTggMTIyVDk4IDE2MVQ5OCAyMDNROTggMjM0IDk4IDI2OVQ5OCAzMjhMOTcgMzUxUTk0IDM3MCA4MyAzNzZUMzggMzg1SDIwVjQwOFEyMCA0MzEgMjIgNDMxTDMyIDQzMlE0MiA0MzMgNjAgNDM0VDk2IDQzNlExMTIgNDM3IDEzMSA0MzhUMTYwIDQ0MVQxNzEgNDQySDE3NFYzNzNRMjEzIDQ0MSAyNzEgNDQxSDI3N1EzMjIgNDQxIDM0MyA0MTlUMzY0IDM3M1EzNjQgMzUyIDM1MSAzMzdUMzEzIDMyMlEyODggMzIyIDI3NiAzMzhUMjYzIDM3MlEyNjMgMzgxIDI2NSAzODhUMjcwIDQwMFQyNzMgNDA1UTI3MSA0MDcgMjUwIDQwMVEyMzQgMzkzIDIyNiAzODZRMTc5IDM0MSAxNzkgMjA3VjE1NFExNzkgMTQxIDE3OSAxMjdUMTc5IDEwMVQxODAgODFUMTgwIDY2VjYxUTE4MSA1OSAxODMgNTdUMTg4IDU0VDE5MyA1MVQyMDAgNDlUMjA3IDQ4VDIxNiA0N1QyMjUgNDdUMjM1IDQ2VDI0NSA0NkgyNzZWMEgyNjdRMjQ5IDMgMTQwIDNRMzcgMyAyOCAwSDIwVjQ2SDM2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNUIiIGQ9Ik0xMTggLTI1MFY3NTBIMjU1VjcxMEgxNThWLTIxMEgyNTVWLTI1MEgxMThaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzIiIGQ9Ik0yMSAyODdRMjIgMjkwIDIzIDI5NVQyOCAzMTdUMzggMzQ4VDUzIDM4MVQ3MyA0MTFUOTkgNDMzVDEzMiA0NDJRMTYxIDQ0MiAxODMgNDMwVDIxNCA0MDhUMjI1IDM4OFEyMjcgMzgyIDIyOCAzODJUMjM2IDM4OVEyODQgNDQxIDM0NyA0NDFIMzUwUTM5OCA0NDEgNDIyIDQwMFE0MzAgMzgxIDQzMCAzNjNRNDMwIDMzMyA0MTcgMzE1VDM5MSAyOTJUMzY2IDI4OFEzNDYgMjg4IDMzNCAyOTlUMzIyIDMyOFEzMjIgMzc2IDM3OCAzOTJRMzU2IDQwNSAzNDIgNDA1UTI4NiA0MDUgMjM5IDMzMVEyMjkgMzE1IDIyNCAyOThUMTkwIDE2NVExNTYgMjUgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTQgMTg5VDE1NCAzNjZRMTU0IDQwNSAxMjggNDA1UTEwNyA0MDUgOTIgMzc3VDY4IDMxNlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU0IiBkPSJNNDAgNDM3UTIxIDQzNyAyMSA0NDVRMjEgNDUwIDM3IDUwMVQ3MSA2MDJMODggNjUxUTkzIDY2OSAxMDEgNjc3SDU2OUg2NTlRNjkxIDY3NyA2OTcgNjc2VDcwNCA2NjdRNzA0IDY2MSA2ODcgNTUzVDY2OCA0NDRRNjY4IDQzNyA2NDkgNDM3UTY0MCA0MzcgNjM3IDQzN1Q2MzEgNDQyTDYyOSA0NDVRNjI5IDQ1MSA2MzUgNDkwVDY0MSA1NTFRNjQxIDU4NiA2MjggNjA0VDU3MyA2MjlRNTY4IDYzMCA1MTUgNjMxUTQ2OSA2MzEgNDU3IDYzMFQ0MzkgNjIyUTQzOCA2MjEgMzY4IDM0M1QyOTggNjBRMjk4IDQ4IDM4NiA0NlE0MTggNDYgNDI3IDQ1VDQzNiAzNlE0MzYgMzEgNDMzIDIyUTQyOSA0IDQyNCAxTDQyMiAwUTQxOSAwIDQxNSAwUTQxMCAwIDM2MyAxVDIyOCAyUTk5IDIgNjQgMEg0OVE0MyA2IDQzIDlUNDUgMjdRNDkgNDAgNTUgNDZIODNIOTRRMTc0IDQ2IDE4OSA1NVExOTAgNTYgMTkxIDU2UTE5NiA1OSAyMDEgNzZUMjQxIDIzM1EyNTggMzAxIDI2OSAzNDRRMzM5IDYxOSAzMzkgNjI1UTMzOSA2MzAgMzEwIDYzMEgyNzlRMjEyIDYzMCAxOTEgNjI0UTE0NiA2MTQgMTIxIDU4M1Q2NyA0NjdRNjAgNDQ1IDU3IDQ0MVQ0MyA0MzdINDBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTAiIGQ9Ik0yODcgNjI4UTI4NyA2MzUgMjMwIDYzN1EyMDYgNjM3IDE5OSA2MzhUMTkyIDY0OFExOTIgNjQ5IDE5NCA2NTlRMjAwIDY3OSAyMDMgNjgxVDM5NyA2ODNRNTg3IDY4MiA2MDAgNjgwUTY2NCA2NjkgNzA3IDYzMVQ3NTEgNTMwUTc1MSA0NTMgNjg1IDM4OVE2MTYgMzIxIDUwNyAzMDNRNTAwIDMwMiA0MDIgMzAxSDMwN0wyNzcgMTgyUTI0NyA2NiAyNDcgNTlRMjQ3IDU1IDI0OCA1NFQyNTUgNTBUMjcyIDQ4VDMwNSA0NkgzMzZRMzQyIDM3IDM0MiAzNVEzNDIgMTkgMzM1IDVRMzMwIDAgMzE5IDBRMzE2IDAgMjgyIDFUMTgyIDJRMTIwIDIgODcgMlQ1MSAxUTMzIDEgMzMgMTFRMzMgMTMgMzYgMjVRNDAgNDEgNDQgNDNUNjcgNDZROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFpNNjQ1IDU1NFE2NDUgNTY3IDY0MyA1NzVUNjM0IDU5N1Q2MDkgNjE5VDU2MCA2MzVRNTUzIDYzNiA0ODAgNjM3UTQ2MyA2MzcgNDQ1IDYzN1Q0MTYgNjM2VDQwNCA2MzZRMzkxIDYzNSAzODYgNjI3UTM4NCA2MjEgMzY3IDU1MFQzMzIgNDEyVDMxNCAzNDRRMzE0IDM0MiAzOTUgMzQySDQwN0g0MzBRNTQyIDM0MiA1OTAgMzkyUTYxNyA0MTkgNjMxIDQ3MVQ2NDUgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUyIiBkPSJNMjMwIDYzN1EyMDMgNjM3IDE5OCA2MzhUMTkzIDY0OVExOTMgNjc2IDIwNCA2ODJRMjA2IDY4MyAzNzggNjgzUTU1MCA2ODIgNTY0IDY4MFE2MjAgNjcyIDY1OCA2NTJUNzEyIDYwNlQ3MzMgNTYzVDczOSA1MjlRNzM5IDQ4NCA3MTAgNDQ1VDY0MyAzODVUNTc2IDM1MVQ1MzggMzM4TDU0NSAzMzNRNjEyIDI5NSA2MTIgMjIzUTYxMiAyMTIgNjA3IDE2MlQ2MDIgODBWNzFRNjAyIDUzIDYwMyA0M1Q2MTQgMjVUNjQwIDE2UTY2OCAxNiA2ODYgMzhUNzEyIDg1UTcxNyA5OSA3MjAgMTAyVDczNSAxMDVRNzU1IDEwNSA3NTUgOTNRNzU1IDc1IDczMSAzNlE2OTMgLTIxIDY0MSAtMjFINjMyUTU3MSAtMjEgNTMxIDRUNDg3IDgyUTQ4NyAxMDkgNTAyIDE2NlQ1MTcgMjM5UTUxNyAyOTAgNDc0IDMxM1E0NTkgMzIwIDQ0OSAzMjFUMzc4IDMyM0gzMDlMMjc3IDE5M1EyNDQgNjEgMjQ0IDU5UTI0NCA1NSAyNDUgNTRUMjUyIDUwVDI2OSA0OFQzMDIgNDZIMzMzUTMzOSAzOCAzMzkgMzdUMzM2IDE5UTMzMiA2IDMyNiAwSDMxMVEyNzUgMiAxODAgMlExNDYgMiAxMTcgMlQ3MSAyVDUwIDFRMzMgMSAzMyAxMFEzMyAxMiAzNiAyNFE0MSA0MyA0NiA0NVE1MCA0NiA2MSA0Nkg2N1E5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4UTI4NyA2MzUgMjMwIDYzN1pNNjMwIDU1NFE2MzAgNTg2IDYwOSA2MDhUNTIzIDYzNlE1MjEgNjM2IDUwMCA2MzZUNDYyIDYzN0g0NDBRMzkzIDYzNyAzODYgNjI3UTM4NSA2MjQgMzUyIDQ5NFQzMTkgMzYxUTMxOSAzNjAgMzg4IDM2MFE0NjYgMzYxIDQ5MiAzNjdRNTU2IDM3NyA1OTIgNDI2UTYwOCA0NDkgNjE5IDQ4NlQ2MzAgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNUQiIGQ9Ik0yMiA3MTBWNzUwSDE1OVYtMjUwSDIyVi0yMTBIMTE5VjcxMEgyMloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjQtNUIiIGQ9Ik0yNjkgLTEyNDlWMTc1MEg1NzdWMTY3N0gzNDJWLTExNzZINTc3Vi0xMjQ5SDI2OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjQtNUQiIGQ9Ik01IDE2NzdWMTc1MEgzMTNWLTEyNDlINVYtMTE3NkgyNDBWMTY3N0g1WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNEQiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTUzIiB4PSI5MTciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTQ1IiB4PSIxNDc0IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ2IiB4PSIzMDQ4IiB5PSI2MTIiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjMwNDgiIHk9Ii0zNTAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyOTUyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjQ0NzgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1NTM0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDU4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi00MiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjkiIHg9IjcwOCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijk4NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzMiIHg9IjE0ODciIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDYiIHg9IjI2NjEiIHk9IjU4MSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMjY2MSIgeT0iLTM1MCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI2NzgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjEtMjkiIHg9IjQzODUiIHk9Ii0xIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjY4NTAiIHk9Ijg3NiI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTEwNTQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjA1NSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNTYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI3NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ2IiB4PSIyMzI0IiB5PSI1ODEiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjIzMjQiIHk9Ii0zNTAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0NDk1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjE2MDIyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTY4MDAsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI3MjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxMTAiIHk9IjY3NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI2MCIgeT0iLTY4NiI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODAzOCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaNC01QiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU4MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNTYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI3NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTgxMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxNDM5IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIzODYxIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDYzOSwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEzNjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDMsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDY0NjIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODI3MiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxMjcyIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMDE1NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwOTM1LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQyLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTM2MCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0Myw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTgzNykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTQ0NiI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyNzU4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA3NCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEyIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaNC01RCIgeD0iMTQ1NTUiIHk9Ii0xIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==)
定理7 一次试验后每次访问MC方法的方差受到以下限制:
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjU0Ljk4NGV4IiBoZWlnaHQ9IjYuNjc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4wMDVleDsiIHZpZXdCb3g9IjAgLTE1ODAuNyAyMzY3My41IDI4NzQuNCIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTU2IiBkPSJNMTE0IDYyMFExMTMgNjIxIDExMCA2MjRUMTA3IDYyN1QxMDMgNjMwVDk4IDYzMlQ5MSA2MzRUODAgNjM1VDY3IDYzNlQ0OCA2MzdIMTlWNjgzSDI4UTQ2IDY4MCAxNTIgNjgwUTI3MyA2ODAgMjk0IDY4M0gzMDVWNjM3SDI4NFEyMjMgNjM0IDIyMyA2MjBRMjIzIDYxOCAzMTMgMzcyVDQwNCAxMjZMNDkwIDM1OFE1NzUgNTg4IDU3NSA1OTdRNTc1IDYxNiA1NTQgNjI2VDUwOCA2MzdINTAzVjY4M0g1MTJRNTI3IDY4MCA2MjcgNjgwUTcxOCA2ODAgNzI0IDY4M0g3MzBWNjM3SDcyM1E2NDggNjM3IDYyNyA1OTZRNjI3IDU5NSA1MTUgMjkxVDQwMSAtMTRRMzk2IC0yMiAzODIgLTIySDM3NEgzNjdRMzUzIC0yMiAzNDggLTE0UTM0NiAtMTIgMjMxIDMwM1ExMTQgNjE3IDExNCA2MjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi02MSIgZD0iTTEzNyAzMDVUMTE1IDMwNVQ3OCAzMjBUNjMgMzU5UTYzIDM5NCA5NyA0MjFUMjE4IDQ0OFEyOTEgNDQ4IDMzNiA0MTZUMzk2IDM0MFE0MDEgMzI2IDQwMSAzMDlUNDAyIDE5NFYxMjRRNDAyIDc2IDQwNyA1OFQ0MjggNDBRNDQzIDQwIDQ0OCA1NlQ0NTMgMTA5VjE0NUg0OTNWMTA2UTQ5MiA2NiA0OTAgNTlRNDgxIDI5IDQ1NSAxMlQ0MDAgLTZUMzUzIDEyVDMyOSA1NFY1OEwzMjcgNTVRMzI1IDUyIDMyMiA0OVQzMTQgNDBUMzAyIDI5VDI4NyAxN1QyNjkgNlQyNDcgLTJUMjIxIC04VDE5MCAtMTFRMTMwIC0xMSA4MiAyMFQzNCAxMDdRMzQgMTI4IDQxIDE0N1Q2OCAxODhUMTE2IDIyNVQxOTQgMjUzVDMwNCAyNjhIMzE4VjI5MFEzMTggMzI0IDMxMiAzNDBRMjkwIDQxMSAyMTUgNDExUTE5NyA0MTEgMTgxIDQxMFQxNTYgNDA2VDE0OCA0MDNRMTcwIDM4OCAxNzAgMzU5UTE3MCAzMzQgMTU0IDMyMFpNMTI2IDEwNlExMjYgNzUgMTUwIDUxVDIwOSAyNlEyNDcgMjYgMjc2IDQ5VDMxNSAxMDlRMzE3IDExNiAzMTggMTc1UTMxOCAyMzMgMzE3IDIzM1EzMDkgMjMzIDI5NiAyMzJUMjUxIDIyM1QxOTMgMjAzVDE0NyAxNjZUMTI2IDEwNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTcyIiBkPSJNMzYgNDZINTBRODkgNDYgOTcgNjBWNjhROTcgNzcgOTcgOTFUOTggMTIyVDk4IDE2MVQ5OCAyMDNROTggMjM0IDk4IDI2OVQ5OCAzMjhMOTcgMzUxUTk0IDM3MCA4MyAzNzZUMzggMzg1SDIwVjQwOFEyMCA0MzEgMjIgNDMxTDMyIDQzMlE0MiA0MzMgNjAgNDM0VDk2IDQzNlExMTIgNDM3IDEzMSA0MzhUMTYwIDQ0MVQxNzEgNDQySDE3NFYzNzNRMjEzIDQ0MSAyNzEgNDQxSDI3N1EzMjIgNDQxIDM0MyA0MTlUMzY0IDM3M1EzNjQgMzUyIDM1MSAzMzdUMzEzIDMyMlEyODggMzIyIDI3NiAzMzhUMjYzIDM3MlEyNjMgMzgxIDI2NSAzODhUMjcwIDQwMFQyNzMgNDA1UTI3MSA0MDcgMjUwIDQwMVEyMzQgMzkzIDIyNiAzODZRMTc5IDM0MSAxNzkgMjA3VjE1NFExNzkgMTQxIDE3OSAxMjdUMTc5IDEwMVQxODAgODFUMTgwIDY2VjYxUTE4MSA1OSAxODMgNTdUMTg4IDU0VDE5MyA1MVQyMDAgNDlUMjA3IDQ4VDIxNiA0N1QyMjUgNDdUMjM1IDQ2VDI0NSA0NkgyNzZWMEgyNjdRMjQ5IDMgMTQwIDNRMzcgMyAyOCAwSDIwVjQ2SDM2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MiIgZD0iTTIxIDI4N1EyMiAyOTAgMjMgMjk1VDI4IDMxN1QzOCAzNDhUNTMgMzgxVDczIDQxMVQ5OSA0MzNUMTMyIDQ0MlExNjEgNDQyIDE4MyA0MzBUMjE0IDQwOFQyMjUgMzg4UTIyNyAzODIgMjI4IDM4MlQyMzYgMzg5UTI4NCA0NDEgMzQ3IDQ0MUgzNTBRMzk4IDQ0MSA0MjIgNDAwUTQzMCAzODEgNDMwIDM2M1E0MzAgMzMzIDQxNyAzMTVUMzkxIDI5MlQzNjYgMjg4UTM0NiAyODggMzM0IDI5OVQzMjIgMzI4UTMyMiAzNzYgMzc4IDM5MlEzNTYgNDA1IDM0MiA0MDVRMjg2IDQwNSAyMzkgMzMxUTIyOSAzMTUgMjI0IDI5OFQxOTAgMTY1UTE1NiAyNSAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExNCAxODlUMTU0IDM2NlExNTQgNDA1IDEyOCA0MDVRMTA3IDQwNSA5MiAzNzdUNjggMzE2VDU3IDI4MFE1NSAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTVCIiBkPSJNMTE4IC0yNTBWNzUwSDI1NVY3MTBIMTU4Vi0yMTBIMjU1Vi0yNTBIMTE4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUwIiBkPSJNMjg3IDYyOFEyODcgNjM1IDIzMCA2MzdRMjA2IDYzNyAxOTkgNjM4VDE5MiA2NDhRMTkyIDY0OSAxOTQgNjU5UTIwMCA2NzkgMjAzIDY4MVQzOTcgNjgzUTU4NyA2ODIgNjAwIDY4MFE2NjQgNjY5IDcwNyA2MzFUNzUxIDUzMFE3NTEgNDUzIDY4NSAzODlRNjE2IDMyMSA1MDcgMzAzUTUwMCAzMDIgNDAyIDMwMUgzMDdMMjc3IDE4MlEyNDcgNjYgMjQ3IDU5UTI0NyA1NSAyNDggNTRUMjU1IDUwVDI3MiA0OFQzMDUgNDZIMzM2UTM0MiAzNyAzNDIgMzVRMzQyIDE5IDMzNSA1UTMzMCAwIDMxOSAwUTMxNiAwIDI4MiAxVDE4MiAyUTEyMCAyIDg3IDJUNTEgMVEzMyAxIDMzIDExUTMzIDEzIDM2IDI1UTQwIDQxIDQ0IDQzVDY3IDQ2UTk0IDQ2IDEyNyA0OVExNDEgNTIgMTQ2IDYxUTE0OSA2NSAyMTggMzM5VDI4NyA2MjhaTTY0NSA1NTRRNjQ1IDU2NyA2NDMgNTc1VDYzNCA1OTdUNjA5IDYxOVQ1NjAgNjM1UTU1MyA2MzYgNDgwIDYzN1E0NjMgNjM3IDQ0NSA2MzdUNDE2IDYzNlQ0MDQgNjM2UTM5MSA2MzUgMzg2IDYyN1EzODQgNjIxIDM2NyA1NTBUMzMyIDQxMlQzMTQgMzQ0UTMxNCAzNDIgMzk1IDM0Mkg0MDdINDMwUTU0MiAzNDIgNTkwIDM5MlE2MTcgNDE5IDYzMSA0NzFUNjQ1IDU1NFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMzIiBkPSJNMTI3IDQ2M1ExMDAgNDYzIDg1IDQ4MFQ2OSA1MjRRNjkgNTc5IDExNyA2MjJUMjMzIDY2NVEyNjggNjY1IDI3NyA2NjRRMzUxIDY1MiAzOTAgNjExVDQzMCA1MjJRNDMwIDQ3MCAzOTYgNDIxVDMwMiAzNTBMMjk5IDM0OFEyOTkgMzQ3IDMwOCAzNDVUMzM3IDMzNlQzNzUgMzE1UTQ1NyAyNjIgNDU3IDE3NVE0NTcgOTYgMzk1IDM3VDIzOCAtMjJRMTU4IC0yMiAxMDAgMjFUNDIgMTMwUTQyIDE1OCA2MCAxNzVUMTA1IDE5M1ExMzMgMTkzIDE1MSAxNzVUMTY5IDEzMFExNjkgMTE5IDE2NiAxMTBUMTU5IDk0VDE0OCA4MlQxMzYgNzRUMTI2IDcwVDExOCA2N0wxMTQgNjZRMTY1IDIxIDIzOCAyMVEyOTMgMjEgMzIxIDc0UTMzOCAxMDcgMzM4IDE3NVYxOTVRMzM4IDI5MCAyNzQgMzIyUTI1OSAzMjggMjEzIDMyOUwxNzEgMzMwTDE2OCAzMzJRMTY2IDMzNSAxNjYgMzQ4UTE2NiAzNjYgMTc0IDM2NlEyMDIgMzY2IDIzMiAzNzFRMjY2IDM3NiAyOTQgNDEzVDMyMiA1MjVWNTMzUTMyMiA1OTAgMjg3IDYxMlEyNjUgNjI2IDI0MCA2MjZRMjA4IDYyNiAxODEgNjE1VDE0MyA1OTJUMTMyIDU4MEgxMzVRMTM4IDU3OSAxNDMgNTc4VDE1MyA1NzNUMTY1IDU2NlQxNzUgNTU1VDE4MyA1NDBUMTg2IDUyMFExODYgNDk4IDE3MiA0ODFUMTI3IDQ2M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjIxMiIgZD0iTTg0IDIzN1Q4NCAyNTBUOTggMjcwSDY3OVE2OTQgMjYyIDY5NCAyNTBUNjc5IDIzMEg5OFE4NCAyMzcgODQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzYiIGQ9Ik00MiAzMTNRNDIgNDc2IDEyMyA1NzFUMzAzIDY2NlEzNzIgNjY2IDQwMiA2MzBUNDMyIDU1MFE0MzIgNTI1IDQxOCA1MTBUMzc5IDQ5NVEzNTYgNDk1IDM0MSA1MDlUMzI2IDU0OFEzMjYgNTkyIDM3MyA2MDFRMzUxIDYyMyAzMTEgNjI2UTI0MCA2MjYgMTk0IDU2NlExNDcgNTAwIDE0NyAzNjRMMTQ4IDM2MFExNTMgMzY2IDE1NiAzNzNRMTk3IDQzMyAyNjMgNDMzSDI2N1EzMTMgNDMzIDM0OCA0MTRRMzcyIDQwMCAzOTYgMzc0VDQzNSAzMTdRNDU2IDI2OCA0NTYgMjEwVjE5MlE0NTYgMTY5IDQ1MSAxNDlRNDQwIDkwIDM4NyAzNFQyNTMgLTIyUTIyNSAtMjIgMTk5IC0xNFQxNDMgMTZUOTIgNzVUNTYgMTcyVDQyIDMxM1pNMjU3IDM5N1EyMjcgMzk3IDIwNSAzODBUMTcxIDMzNVQxNTQgMjc4VDE0OCAyMTZRMTQ4IDEzMyAxNjAgOTdUMTk4IDM5UTIyMiAyMSAyNTEgMjFRMzAyIDIxIDMyOSA1OVEzNDIgNzcgMzQ3IDEwNFQzNTIgMjA5UTM1MiAyODkgMzQ3IDMxNlQzMjkgMzYxUTMwMiAzOTcgMjU3IDM5N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTVEIiBkPSJNMjIgNzEwVjc1MEgxNTlWLTI1MEgyMlYtMjEwSDExOVY3MTBIMjJaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1ozLTVCIiBkPSJNMjQ3IC05NDlWMTQ1MEg1MTZWMTM4OEgzMDlWLTg4N0g1MTZWLTk0OUgyNDdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1ozLTVEIiBkPSJNMTEgMTM4OFYxNDUwSDI4MFYtOTQ5SDExVi04ODdIMjE4VjEzODhIMTFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yQiIgZD0iTTU2IDIzN1Q1NiAyNTBUNzAgMjcwSDM2OVY0MjBMMzcwIDU3MFEzODAgNTgzIDM4OSA1ODNRNDAyIDU4MyA0MDkgNTY4VjI3MEg3MDdRNzIyIDI2MiA3MjIgMjUwVDcwNyAyMzBINDA5Vi02OFE0MDEgLTgyIDM5MSAtODJIMzg5SDM4N1EzNzUgLTgyIDM2OSAtNjhWMjMwSDcwUTU2IDIzNyA1NiAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zNCIgZD0iTTQ2MiAwUTQ0NCAzIDMzMyAzUTIxNyAzIDE5OSAwSDE5MFY0NkgyMjFRMjQxIDQ2IDI0OCA0NlQyNjUgNDhUMjc5IDUzVDI4NiA2MVEyODcgNjMgMjg3IDExNVYxNjVIMjhWMjExTDE3OSA0NDJRMzMyIDY3NCAzMzQgNjc1UTMzNiA2NzcgMzU1IDY3N0gzNzNMMzc5IDY3MVYyMTFINDcxVjE2NUgzNzlWMTE0UTM3OSA3MyAzNzkgNjZUMzg1IDU0UTM5MyA0NyA0NDIgNDZINDcxVjBINDYyWk0yOTMgMjExVjU0NUw3NCAyMTJMMTgzIDIxMUgyOTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMiIgZD0iTTEwOSA0MjlRODIgNDI5IDY2IDQ0N1Q1MCA0OTFRNTAgNTYyIDEwMyA2MTRUMjM1IDY2NlEzMjYgNjY2IDM4NyA2MTBUNDQ5IDQ2NVE0NDkgNDIyIDQyOSAzODNUMzgxIDMxNVQzMDEgMjQxUTI2NSAyMTAgMjAxIDE0OUwxNDIgOTNMMjE4IDkyUTM3NSA5MiAzODUgOTdRMzkyIDk5IDQwOSAxODZWMTg5SDQ0OVYxODZRNDQ4IDE4MyA0MzYgOTVUNDIxIDNWMEg1MFYxOVYzMVE1MCAzOCA1NiA0NlQ4NiA4MVExMTUgMTEzIDEzNiAxMzdRMTQ1IDE0NyAxNzAgMTc0VDIwNCAyMTFUMjMzIDI0NFQyNjEgMjc4VDI4NCAzMDhUMzA1IDM0MFQzMjAgMzY5VDMzMyA0MDFUMzQwIDQzMVQzNDMgNDY0UTM0MyA1MjcgMzA5IDU3M1QyMTIgNjE5UTE3OSA2MTkgMTU0IDYwMlQxMTkgNTY5VDEwOSA1NTBRMTA5IDU0OSAxMTQgNTQ5UTEzMiA1NDkgMTUxIDUzNVQxNzAgNDg5UTE3MCA0NjQgMTU0IDQ0N1QxMDkgNDI5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUyIiBkPSJNMjMwIDYzN1EyMDMgNjM3IDE5OCA2MzhUMTkzIDY0OVExOTMgNjc2IDIwNCA2ODJRMjA2IDY4MyAzNzggNjgzUTU1MCA2ODIgNTY0IDY4MFE2MjAgNjcyIDY1OCA2NTJUNzEyIDYwNlQ3MzMgNTYzVDczOSA1MjlRNzM5IDQ4NCA3MTAgNDQ1VDY0MyAzODVUNTc2IDM1MVQ1MzggMzM4TDU0NSAzMzNRNjEyIDI5NSA2MTIgMjIzUTYxMiAyMTIgNjA3IDE2MlQ2MDIgODBWNzFRNjAyIDUzIDYwMyA0M1Q2MTQgMjVUNjQwIDE2UTY2OCAxNiA2ODYgMzhUNzEyIDg1UTcxNyA5OSA3MjAgMTAyVDczNSAxMDVRNzU1IDEwNSA3NTUgOTNRNzU1IDc1IDczMSAzNlE2OTMgLTIxIDY0MSAtMjFINjMyUTU3MSAtMjEgNTMxIDRUNDg3IDgyUTQ4NyAxMDkgNTAyIDE2NlQ1MTcgMjM5UTUxNyAyOTAgNDc0IDMxM1E0NTkgMzIwIDQ0OSAzMjFUMzc4IDMyM0gzMDlMMjc3IDE5M1EyNDQgNjEgMjQ0IDU5UTI0NCA1NSAyNDUgNTRUMjUyIDUwVDI2OSA0OFQzMDIgNDZIMzMzUTMzOSAzOCAzMzkgMzdUMzM2IDE5UTMzMiA2IDMyNiAwSDMxMVEyNzUgMiAxODAgMlExNDYgMiAxMTcgMlQ3MSAyVDUwIDFRMzMgMSAzMyAxMFEzMyAxMiAzNiAyNFE0MSA0MyA0NiA0NVE1MCA0NiA2MSA0Nkg2N1E5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4UTI4NyA2MzUgMjMwIDYzN1pNNjMwIDU1NFE2MzAgNTg2IDYwOSA2MDhUNTIzIDYzNlE1MjEgNjM2IDUwMCA2MzZUNDYyIDYzN0g0NDBRMzkzIDYzNyAzODYgNjI3UTM4NSA2MjQgMzUyIDQ5NFQzMTkgMzYxUTMxOSAzNjAgMzg4IDM2MFE0NjYgMzYxIDQ5MiAzNjdRNTU2IDM3NyA1OTIgNDI2UTYwOCA0NDkgNjE5IDQ4NlQ2MzAgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjI2NCIgZD0iTTY3NCA2MzZRNjgyIDYzNiA2ODggNjMwVDY5NCA2MTVUNjg3IDYwMVE2ODYgNjAwIDQxNyA0NzJMMTUxIDM0NkwzOTkgMjI4UTY4NyA5MiA2OTEgODdRNjk0IDgxIDY5NCA3NlE2OTQgNTggNjc2IDU2SDY3MEwzODIgMTkyUTkyIDMyOSA5MCAzMzFRODMgMzM2IDgzIDM0OFE4NCAzNTkgOTYgMzY1UTEwNCAzNjkgMzgyIDUwMFQ2NjUgNjM0UTY2OSA2MzYgNjc0IDYzNlpNODQgLTExOFE4NCAtMTA4IDk5IC05OEg2NzhRNjk0IC0xMDQgNjk0IC0xMThRNjk0IC0xMzAgNjc5IC0xMzhIOThRODQgLTEzMSA4NCAtMTE4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQ1IiBkPSJNNDkyIDIxM1E0NzIgMjEzIDQ3MiAyMjZRNDcyIDIzMCA0NzcgMjUwVDQ4MiAyODVRNDgyIDMxNiA0NjEgMzIzVDM2NCAzMzBIMzEyUTMxMSAzMjggMjc3IDE5MlQyNDMgNTJRMjQzIDQ4IDI1NCA0OFQzMzQgNDZRNDI4IDQ2IDQ1OCA0OFQ1MTggNjFRNTY3IDc3IDU5OSAxMTdUNjcwIDI0OFE2ODAgMjcwIDY4MyAyNzJRNjkwIDI3NCA2OTggMjc0UTcxOCAyNzQgNzE4IDI2MVE2MTMgNyA2MDggMlE2MDUgMCAzMjIgMEgxMzNRMzEgMCAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDYgNjYgMjE1IDM0MlQyODUgNjIyUTI4NSA2MjkgMjgxIDYyOVEyNzMgNjMyIDIyOCA2MzRIMTk3UTE5MSA2NDAgMTkxIDY0MlQxOTMgNjU5UTE5NyA2NzYgMjAzIDY4MEg3NTdRNzY0IDY3NiA3NjQgNjY5UTc2NCA2NjQgNzUxIDU1N1Q3MzcgNDQ3UTczNSA0NDAgNzE3IDQ0MEg3MDVRNjk4IDQ0NSA2OTggNDUzTDcwMSA0NzZRNzA0IDUwMCA3MDQgNTI4UTcwNCA1NTggNjk3IDU3OFQ2NzggNjA5VDY0MyA2MjVUNTk2IDYzMlQ1MzIgNjM0SDQ4NVEzOTcgNjMzIDM5MiA2MzFRMzg4IDYyOSAzODYgNjIyUTM4NSA2MTkgMzU1IDQ5OVQzMjQgMzc3UTM0NyAzNzYgMzcyIDM3NkgzOThRNDY0IDM3NiA0ODkgMzkxVDUzNCA0NzJRNTM4IDQ4OCA1NDAgNDkwVDU1NyA0OTNRNTYyIDQ5MyA1NjUgNDkzVDU3MCA0OTJUNTcyIDQ5MVQ1NzQgNDg3VDU3NyA0ODNMNTQ0IDM1MVE1MTEgMjE4IDUwOCAyMTZRNTA1IDIxMyA0OTIgMjEzWiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNTYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI3NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTgxMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxMjcyIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNjM5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1ozLTVCIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTI4LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTg2MSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM5Myw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMzIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMjMyMyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDMxMDEsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI2MjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSI2MCIgeT0iNjc2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zNiIgeD0iNjAiIHk9Ii02ODciPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjMtNUQiIHg9IjQ3MTMiIHk9Ii0xIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI5MTAzIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTAxMDMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTE5MTQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTQzOSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTM5NjQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDc0MywwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjYyMCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjYwIiB5PSI2NzYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTM0IiB4PSI2MCIgeT0iLTY5OCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNTgyNiwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEzNjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDMsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC04MzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii00NDYiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNzQyNiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwNzQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjY0IiB4PSIxODkxNyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE5OTc0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9IjIzMjQiIHk9IjU4MSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIyMzI0IiB5PSItMzUwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMjQyNSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==)
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjUwLjE0NWV4IiBoZWlnaHQ9IjYuNjc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4wMDVleDsiIHZpZXdCb3g9IjAgLTE1ODAuNyAyMTU5MC4xIDI4NzQuNCIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTU2IiBkPSJNMTE0IDYyMFExMTMgNjIxIDExMCA2MjRUMTA3IDYyN1QxMDMgNjMwVDk4IDYzMlQ5MSA2MzRUODAgNjM1VDY3IDYzNlQ0OCA2MzdIMTlWNjgzSDI4UTQ2IDY4MCAxNTIgNjgwUTI3MyA2ODAgMjk0IDY4M0gzMDVWNjM3SDI4NFEyMjMgNjM0IDIyMyA2MjBRMjIzIDYxOCAzMTMgMzcyVDQwNCAxMjZMNDkwIDM1OFE1NzUgNTg4IDU3NSA1OTdRNTc1IDYxNiA1NTQgNjI2VDUwOCA2MzdINTAzVjY4M0g1MTJRNTI3IDY4MCA2MjcgNjgwUTcxOCA2ODAgNzI0IDY4M0g3MzBWNjM3SDcyM1E2NDggNjM3IDYyNyA1OTZRNjI3IDU5NSA1MTUgMjkxVDQwMSAtMTRRMzk2IC0yMiAzODIgLTIySDM3NEgzNjdRMzUzIC0yMiAzNDggLTE0UTM0NiAtMTIgMjMxIDMwM1ExMTQgNjE3IDExNCA2MjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi02MSIgZD0iTTEzNyAzMDVUMTE1IDMwNVQ3OCAzMjBUNjMgMzU5UTYzIDM5NCA5NyA0MjFUMjE4IDQ0OFEyOTEgNDQ4IDMzNiA0MTZUMzk2IDM0MFE0MDEgMzI2IDQwMSAzMDlUNDAyIDE5NFYxMjRRNDAyIDc2IDQwNyA1OFQ0MjggNDBRNDQzIDQwIDQ0OCA1NlQ0NTMgMTA5VjE0NUg0OTNWMTA2UTQ5MiA2NiA0OTAgNTlRNDgxIDI5IDQ1NSAxMlQ0MDAgLTZUMzUzIDEyVDMyOSA1NFY1OEwzMjcgNTVRMzI1IDUyIDMyMiA0OVQzMTQgNDBUMzAyIDI5VDI4NyAxN1QyNjkgNlQyNDcgLTJUMjIxIC04VDE5MCAtMTFRMTMwIC0xMSA4MiAyMFQzNCAxMDdRMzQgMTI4IDQxIDE0N1Q2OCAxODhUMTE2IDIyNVQxOTQgMjUzVDMwNCAyNjhIMzE4VjI5MFEzMTggMzI0IDMxMiAzNDBRMjkwIDQxMSAyMTUgNDExUTE5NyA0MTEgMTgxIDQxMFQxNTYgNDA2VDE0OCA0MDNRMTcwIDM4OCAxNzAgMzU5UTE3MCAzMzQgMTU0IDMyMFpNMTI2IDEwNlExMjYgNzUgMTUwIDUxVDIwOSAyNlEyNDcgMjYgMjc2IDQ5VDMxNSAxMDlRMzE3IDExNiAzMTggMTc1UTMxOCAyMzMgMzE3IDIzM1EzMDkgMjMzIDI5NiAyMzJUMjUxIDIyM1QxOTMgMjAzVDE0NyAxNjZUMTI2IDEwNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTcyIiBkPSJNMzYgNDZINTBRODkgNDYgOTcgNjBWNjhROTcgNzcgOTcgOTFUOTggMTIyVDk4IDE2MVQ5OCAyMDNROTggMjM0IDk4IDI2OVQ5OCAzMjhMOTcgMzUxUTk0IDM3MCA4MyAzNzZUMzggMzg1SDIwVjQwOFEyMCA0MzEgMjIgNDMxTDMyIDQzMlE0MiA0MzMgNjAgNDM0VDk2IDQzNlExMTIgNDM3IDEzMSA0MzhUMTYwIDQ0MVQxNzEgNDQySDE3NFYzNzNRMjEzIDQ0MSAyNzEgNDQxSDI3N1EzMjIgNDQxIDM0MyA0MTlUMzY0IDM3M1EzNjQgMzUyIDM1MSAzMzdUMzEzIDMyMlEyODggMzIyIDI3NiAzMzhUMjYzIDM3MlEyNjMgMzgxIDI2NSAzODhUMjcwIDQwMFQyNzMgNDA1UTI3MSA0MDcgMjUwIDQwMVEyMzQgMzkzIDIyNiAzODZRMTc5IDM0MSAxNzkgMjA3VjE1NFExNzkgMTQxIDE3OSAxMjdUMTc5IDEwMVQxODAgODFUMTgwIDY2VjYxUTE4MSA1OSAxODMgNTdUMTg4IDU0VDE5MyA1MVQyMDAgNDlUMjA3IDQ4VDIxNiA0N1QyMjUgNDdUMjM1IDQ2VDI0NSA0NkgyNzZWMEgyNjdRMjQ5IDMgMTQwIDNRMzcgMyAyOCAwSDIwVjQ2SDM2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQ1IiBkPSJNNDkyIDIxM1E0NzIgMjEzIDQ3MiAyMjZRNDcyIDIzMCA0NzcgMjUwVDQ4MiAyODVRNDgyIDMxNiA0NjEgMzIzVDM2NCAzMzBIMzEyUTMxMSAzMjggMjc3IDE5MlQyNDMgNTJRMjQzIDQ4IDI1NCA0OFQzMzQgNDZRNDI4IDQ2IDQ1OCA0OFQ1MTggNjFRNTY3IDc3IDU5OSAxMTdUNjcwIDI0OFE2ODAgMjcwIDY4MyAyNzJRNjkwIDI3NCA2OTggMjc0UTcxOCAyNzQgNzE4IDI2MVE2MTMgNyA2MDggMlE2MDUgMCAzMjIgMEgxMzNRMzEgMCAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDYgNjYgMjE1IDM0MlQyODUgNjIyUTI4NSA2MjkgMjgxIDYyOVEyNzMgNjMyIDIyOCA2MzRIMTk3UTE5MSA2NDAgMTkxIDY0MlQxOTMgNjU5UTE5NyA2NzYgMjAzIDY4MEg3NTdRNzY0IDY3NiA3NjQgNjY5UTc2NCA2NjQgNzUxIDU1N1Q3MzcgNDQ3UTczNSA0NDAgNzE3IDQ0MEg3MDVRNjk4IDQ0NSA2OTggNDUzTDcwMSA0NzZRNzA0IDUwMCA3MDQgNTI4UTcwNCA1NTggNjk3IDU3OFQ2NzggNjA5VDY0MyA2MjVUNTk2IDYzMlQ1MzIgNjM0SDQ4NVEzOTcgNjMzIDM5MiA2MzFRMzg4IDYyOSAzODYgNjIyUTM4NSA2MTkgMzU1IDQ5OVQzMjQgMzc3UTM0NyAzNzYgMzcyIDM3NkgzOThRNDY0IDM3NiA0ODkgMzkxVDUzNCA0NzJRNTM4IDQ4OCA1NDAgNDkwVDU1NyA0OTNRNTYyIDQ5MyA1NjUgNDkzVDU3MCA0OTJUNTcyIDQ5MVQ1NzQgNDg3VDU3NyA0ODNMNTQ0IDM1MVE1MTEgMjE4IDUwOCAyMTZRNTA1IDIxMyA0OTIgMjEzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjI2NCIgZD0iTTY3NCA2MzZRNjgyIDYzNiA2ODggNjMwVDY5NCA2MTVUNjg3IDYwMVE2ODYgNjAwIDQxNyA0NzJMMTUxIDM0NkwzOTkgMjI4UTY4NyA5MiA2OTEgODdRNjk0IDgxIDY5NCA3NlE2OTQgNTggNjc2IDU2SDY3MEwzODIgMTkyUTkyIDMyOSA5MCAzMzFRODMgMzM2IDgzIDM0OFE4NCAzNTkgOTYgMzY1UTEwNCAzNjkgMzgyIDUwMFQ2NjUgNjM0UTY2OSA2MzYgNjc0IDYzNlpNODQgLTExOFE4NCAtMTA4IDk5IC05OEg2NzhRNjk0IC0xMDQgNjk0IC0xMThRNjk0IC0xMzAgNjc5IC0xMzhIOThRODQgLTEzMSA4NCAtMTE4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTcyIiBkPSJNMjEgMjg3UTIyIDI5MCAyMyAyOTVUMjggMzE3VDM4IDM0OFQ1MyAzODFUNzMgNDExVDk5IDQzM1QxMzIgNDQyUTE2MSA0NDIgMTgzIDQzMFQyMTQgNDA4VDIyNSAzODhRMjI3IDM4MiAyMjggMzgyVDIzNiAzODlRMjg0IDQ0MSAzNDcgNDQxSDM1MFEzOTggNDQxIDQyMiA0MDBRNDMwIDM4MSA0MzAgMzYzUTQzMCAzMzMgNDE3IDMxNVQzOTEgMjkyVDM2NiAyODhRMzQ2IDI4OCAzMzQgMjk5VDMyMiAzMjhRMzIyIDM3NiAzNzggMzkyUTM1NiA0MDUgMzQyIDQwNVEyODYgNDA1IDIzOSAzMzFRMjI5IDMxNSAyMjQgMjk4VDE5MCAxNjVRMTU2IDI1IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTE0IDE4OVQxNTQgMzY2UTE1NCA0MDUgMTI4IDQwNVExMDcgNDA1IDkyIDM3N1Q2OCAzMTZUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTVCIiBkPSJNMTE4IC0yNTBWNzUwSDI1NVY3MTBIMTU4Vi0yMTBIMjU1Vi0yNTBIMTE4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUwIiBkPSJNMjg3IDYyOFEyODcgNjM1IDIzMCA2MzdRMjA2IDYzNyAxOTkgNjM4VDE5MiA2NDhRMTkyIDY0OSAxOTQgNjU5UTIwMCA2NzkgMjAzIDY4MVQzOTcgNjgzUTU4NyA2ODIgNjAwIDY4MFE2NjQgNjY5IDcwNyA2MzFUNzUxIDUzMFE3NTEgNDUzIDY4NSAzODlRNjE2IDMyMSA1MDcgMzAzUTUwMCAzMDIgNDAyIDMwMUgzMDdMMjc3IDE4MlEyNDcgNjYgMjQ3IDU5UTI0NyA1NSAyNDggNTRUMjU1IDUwVDI3MiA0OFQzMDUgNDZIMzM2UTM0MiAzNyAzNDIgMzVRMzQyIDE5IDMzNSA1UTMzMCAwIDMxOSAwUTMxNiAwIDI4MiAxVDE4MiAyUTEyMCAyIDg3IDJUNTEgMVEzMyAxIDMzIDExUTMzIDEzIDM2IDI1UTQwIDQxIDQ0IDQzVDY3IDQ2UTk0IDQ2IDEyNyA0OVExNDEgNTIgMTQ2IDYxUTE0OSA2NSAyMTggMzM5VDI4NyA2MjhaTTY0NSA1NTRRNjQ1IDU2NyA2NDMgNTc1VDYzNCA1OTdUNjA5IDYxOVQ1NjAgNjM1UTU1MyA2MzYgNDgwIDYzN1E0NjMgNjM3IDQ0NSA2MzdUNDE2IDYzNlQ0MDQgNjM2UTM5MSA2MzUgMzg2IDYyN1EzODQgNjIxIDM2NyA1NTBUMzMyIDQxMlQzMTQgMzQ0UTMxNCAzNDIgMzk1IDM0Mkg0MDdINDMwUTU0MiAzNDIgNTkwIDM5MlE2MTcgNDE5IDYzMSA0NzFUNjQ1IDU1NFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMzIiBkPSJNMTI3IDQ2M1ExMDAgNDYzIDg1IDQ4MFQ2OSA1MjRRNjkgNTc5IDExNyA2MjJUMjMzIDY2NVEyNjggNjY1IDI3NyA2NjRRMzUxIDY1MiAzOTAgNjExVDQzMCA1MjJRNDMwIDQ3MCAzOTYgNDIxVDMwMiAzNTBMMjk5IDM0OFEyOTkgMzQ3IDMwOCAzNDVUMzM3IDMzNlQzNzUgMzE1UTQ1NyAyNjIgNDU3IDE3NVE0NTcgOTYgMzk1IDM3VDIzOCAtMjJRMTU4IC0yMiAxMDAgMjFUNDIgMTMwUTQyIDE1OCA2MCAxNzVUMTA1IDE5M1ExMzMgMTkzIDE1MSAxNzVUMTY5IDEzMFExNjkgMTE5IDE2NiAxMTBUMTU5IDk0VDE0OCA4MlQxMzYgNzRUMTI2IDcwVDExOCA2N0wxMTQgNjZRMTY1IDIxIDIzOCAyMVEyOTMgMjEgMzIxIDc0UTMzOCAxMDcgMzM4IDE3NVYxOTVRMzM4IDI5MCAyNzQgMzIyUTI1OSAzMjggMjEzIDMyOUwxNzEgMzMwTDE2OCAzMzJRMTY2IDMzNSAxNjYgMzQ4UTE2NiAzNjYgMTc0IDM2NlEyMDIgMzY2IDIzMiAzNzFRMjY2IDM3NiAyOTQgNDEzVDMyMiA1MjVWNTMzUTMyMiA1OTAgMjg3IDYxMlEyNjUgNjI2IDI0MCA2MjZRMjA4IDYyNiAxODEgNjE1VDE0MyA1OTJUMTMyIDU4MEgxMzVRMTM4IDU3OSAxNDMgNTc4VDE1MyA1NzNUMTY1IDU2NlQxNzUgNTU1VDE4MyA1NDBUMTg2IDUyMFExODYgNDk4IDE3MiA0ODFUMTI3IDQ2M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNUQiIGQ9Ik0yMiA3MTBWNzUwSDE1OVYtMjUwSDIyVi0yMTBIMTE5VjcxMEgyMloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjMtNUIiIGQ9Ik0yNDcgLTk0OVYxNDUwSDUxNlYxMzg4SDMwOVYtODg3SDUxNlYtOTQ5SDI0N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjMtNUQiIGQ9Ik0xMSAxMzg4VjE0NTBIMjgwVi05NDlIMTFWLTg4N0gyMThWMTM4OEgxMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJCIiBkPSJNNTYgMjM3VDU2IDI1MFQ3MCAyNzBIMzY5VjQyMEwzNzAgNTcwUTM4MCA1ODMgMzg5IDU4M1E0MDIgNTgzIDQwOSA1NjhWMjcwSDcwN1E3MjIgMjYyIDcyMiAyNTBUNzA3IDIzMEg0MDlWLTY4UTQwMSAtODIgMzkxIC04MkgzODlIMzg3UTM3NSAtODIgMzY5IC02OFYyMzBINzBRNTYgMjM3IDU2IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTM0IiBkPSJNNDYyIDBRNDQ0IDMgMzMzIDNRMjE3IDMgMTk5IDBIMTkwVjQ2SDIyMVEyNDEgNDYgMjQ4IDQ2VDI2NSA0OFQyNzkgNTNUMjg2IDYxUTI4NyA2MyAyODcgMTE1VjE2NUgyOFYyMTFMMTc5IDQ0MlEzMzIgNjc0IDMzNCA2NzVRMzM2IDY3NyAzNTUgNjc3SDM3M0wzNzkgNjcxVjIxMUg0NzFWMTY1SDM3OVYxMTRRMzc5IDczIDM3OSA2NlQzODUgNTRRMzkzIDQ3IDQ0MiA0Nkg0NzFWMEg0NjJaTTI5MyAyMTFWNTQ1TDc0IDIxMkwxODMgMjExSDI5M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTIiIGQ9Ik0yMzAgNjM3UTIwMyA2MzcgMTk4IDYzOFQxOTMgNjQ5UTE5MyA2NzYgMjA0IDY4MlEyMDYgNjgzIDM3OCA2ODNRNTUwIDY4MiA1NjQgNjgwUTYyMCA2NzIgNjU4IDY1MlQ3MTIgNjA2VDczMyA1NjNUNzM5IDUyOVE3MzkgNDg0IDcxMCA0NDVUNjQzIDM4NVQ1NzYgMzUxVDUzOCAzMzhMNTQ1IDMzM1E2MTIgMjk1IDYxMiAyMjNRNjEyIDIxMiA2MDcgMTYyVDYwMiA4MFY3MVE2MDIgNTMgNjAzIDQzVDYxNCAyNVQ2NDAgMTZRNjY4IDE2IDY4NiAzOFQ3MTIgODVRNzE3IDk5IDcyMCAxMDJUNzM1IDEwNVE3NTUgMTA1IDc1NSA5M1E3NTUgNzUgNzMxIDM2UTY5MyAtMjEgNjQxIC0yMUg2MzJRNTcxIC0yMSA1MzEgNFQ0ODcgODJRNDg3IDEwOSA1MDIgMTY2VDUxNyAyMzlRNTE3IDI5MCA0NzQgMzEzUTQ1OSAzMjAgNDQ5IDMyMVQzNzggMzIzSDMwOUwyNzcgMTkzUTI0NCA2MSAyNDQgNTlRMjQ0IDU1IDI0NSA1NFQyNTIgNTBUMjY5IDQ4VDMwMiA0NkgzMzNRMzM5IDM4IDMzOSAzN1QzMzYgMTlRMzMyIDYgMzI2IDBIMzExUTI3NSAyIDE4MCAyUTE0NiAyIDExNyAyVDcxIDJUNTAgMVEzMyAxIDMzIDEwUTMzIDEyIDM2IDI0UTQxIDQzIDQ2IDQ1UTUwIDQ2IDYxIDQ2SDY3UTk0IDQ2IDEyNyA0OVExNDEgNTIgMTQ2IDYxUTE0OSA2NSAyMTggMzM5VDI4NyA2MjhRMjg3IDYzNSAyMzAgNjM3Wk02MzAgNTU0UTYzMCA1ODYgNjA5IDYwOFQ1MjMgNjM2UTUyMSA2MzYgNTAwIDYzNlQ0NjIgNjM3SDQ0MFEzOTMgNjM3IDM4NiA2MjdRMzg1IDYyNCAzNTIgNDk0VDMxOSAzNjFRMzE5IDM2MCAzODggMzYwUTQ2NiAzNjEgNDkyIDM2N1E1NTYgMzc3IDU5MiA0MjZRNjA4IDQ0OSA2MTkgNDg2VDYzMCA1NTRaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9IjIzMjQiIHk9IjU4MSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIyMzI0IiB5PSItMzUwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjQ1MCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyNjQiIHg9IjM5NzciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MDMzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDY4NDMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTI3MiIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODY3MiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMy01QiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUyOCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjE4NjEiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTMsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMyIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMy01RCIgeD0iMjYyOSIgeT0iLTEiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEyMDUzIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTMwNTMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQ4NjMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTQzOSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTY5MTQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNzY5MywwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjYyMCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjYwIiB5PSI2NzYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTM0IiB4PSI2MCIgeT0iLTY5OCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODc3NSwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEzNjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDMsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC04MzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii00NDYiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMDM3NiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwNzQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=)
证明:
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjgxLjcxNWV4IiBoZWlnaHQ9IjUwLjg0M2V4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTI0LjgzOGV4OyIgdmlld0JveD0iMCAtMTExOTYuNCAzNTE4Mi43IDIxODkwLjUiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi01NiIgZD0iTTExNCA2MjBRMTEzIDYyMSAxMTAgNjI0VDEwNyA2MjdUMTAzIDYzMFQ5OCA2MzJUOTEgNjM0VDgwIDYzNVQ2NyA2MzZUNDggNjM3SDE5VjY4M0gyOFE0NiA2ODAgMTUyIDY4MFEyNzMgNjgwIDI5NCA2ODNIMzA1VjYzN0gyODRRMjIzIDYzNCAyMjMgNjIwUTIyMyA2MTggMzEzIDM3MlQ0MDQgMTI2TDQ5MCAzNThRNTc1IDU4OCA1NzUgNTk3UTU3NSA2MTYgNTU0IDYyNlQ1MDggNjM3SDUwM1Y2ODNINTEyUTUyNyA2ODAgNjI3IDY4MFE3MTggNjgwIDcyNCA2ODNINzMwVjYzN0g3MjNRNjQ4IDYzNyA2MjcgNTk2UTYyNyA1OTUgNTE1IDI5MVQ0MDEgLTE0UTM5NiAtMjIgMzgyIC0yMkgzNzRIMzY3UTM1MyAtMjIgMzQ4IC0xNFEzNDYgLTEyIDIzMSAzMDNRMTE0IDYxNyAxMTQgNjIwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNjEiIGQ9Ik0xMzcgMzA1VDExNSAzMDVUNzggMzIwVDYzIDM1OVE2MyAzOTQgOTcgNDIxVDIxOCA0NDhRMjkxIDQ0OCAzMzYgNDE2VDM5NiAzNDBRNDAxIDMyNiA0MDEgMzA5VDQwMiAxOTRWMTI0UTQwMiA3NiA0MDcgNThUNDI4IDQwUTQ0MyA0MCA0NDggNTZUNDUzIDEwOVYxNDVINDkzVjEwNlE0OTIgNjYgNDkwIDU5UTQ4MSAyOSA0NTUgMTJUNDAwIC02VDM1MyAxMlQzMjkgNTRWNThMMzI3IDU1UTMyNSA1MiAzMjIgNDlUMzE0IDQwVDMwMiAyOVQyODcgMTdUMjY5IDZUMjQ3IC0yVDIyMSAtOFQxOTAgLTExUTEzMCAtMTEgODIgMjBUMzQgMTA3UTM0IDEyOCA0MSAxNDdUNjggMTg4VDExNiAyMjVUMTk0IDI1M1QzMDQgMjY4SDMxOFYyOTBRMzE4IDMyNCAzMTIgMzQwUTI5MCA0MTEgMjE1IDQxMVExOTcgNDExIDE4MSA0MTBUMTU2IDQwNlQxNDggNDAzUTE3MCAzODggMTcwIDM1OVExNzAgMzM0IDE1NCAzMjBaTTEyNiAxMDZRMTI2IDc1IDE1MCA1MVQyMDkgMjZRMjQ3IDI2IDI3NiA0OVQzMTUgMTA5UTMxNyAxMTYgMzE4IDE3NVEzMTggMjMzIDMxNyAyMzNRMzA5IDIzMyAyOTYgMjMyVDI1MSAyMjNUMTkzIDIwM1QxNDcgMTY2VDEyNiAxMDZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03MiIgZD0iTTM2IDQ2SDUwUTg5IDQ2IDk3IDYwVjY4UTk3IDc3IDk3IDkxVDk4IDEyMlQ5OCAxNjFUOTggMjAzUTk4IDIzNCA5OCAyNjlUOTggMzI4TDk3IDM1MVE5NCAzNzAgODMgMzc2VDM4IDM4NUgyMFY0MDhRMjAgNDMxIDIyIDQzMUwzMiA0MzJRNDIgNDMzIDYwIDQzNFQ5NiA0MzZRMTEyIDQzNyAxMzEgNDM4VDE2MCA0NDFUMTcxIDQ0MkgxNzRWMzczUTIxMyA0NDEgMjcxIDQ0MUgyNzdRMzIyIDQ0MSAzNDMgNDE5VDM2NCAzNzNRMzY0IDM1MiAzNTEgMzM3VDMxMyAzMjJRMjg4IDMyMiAyNzYgMzM4VDI2MyAzNzJRMjYzIDM4MSAyNjUgMzg4VDI3MCA0MDBUMjczIDQwNVEyNzEgNDA3IDI1MCA0MDFRMjM0IDM5MyAyMjYgMzg2UTE3OSAzNDEgMTc5IDIwN1YxNTRRMTc5IDE0MSAxNzkgMTI3VDE3OSAxMDFUMTgwIDgxVDE4MCA2NlY2MVExODEgNTkgMTgzIDU3VDE4OCA1NFQxOTMgNTFUMjAwIDQ5VDIwNyA0OFQyMTYgNDdUMjI1IDQ3VDIzNSA0NlQyNDUgNDZIMjc2VjBIMjY3UTI0OSAzIDE0MCAzUTM3IDMgMjggMEgyMFY0NkgzNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NSIgZD0iTTQ5MiAyMTNRNDcyIDIxMyA0NzIgMjI2UTQ3MiAyMzAgNDc3IDI1MFQ0ODIgMjg1UTQ4MiAzMTYgNDYxIDMyM1QzNjQgMzMwSDMxMlEzMTEgMzI4IDI3NyAxOTJUMjQzIDUyUTI0MyA0OCAyNTQgNDhUMzM0IDQ2UTQyOCA0NiA0NTggNDhUNTE4IDYxUTU2NyA3NyA1OTkgMTE3VDY3MCAyNDhRNjgwIDI3MCA2ODMgMjcyUTY5MCAyNzQgNjk4IDI3NFE3MTggMjc0IDcxOCAyNjFRNjEzIDcgNjA4IDJRNjA1IDAgMzIyIDBIMTMzUTMxIDAgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ2IDY2IDIxNSAzNDJUMjg1IDYyMlEyODUgNjI5IDI4MSA2MjlRMjczIDYzMiAyMjggNjM0SDE5N1ExOTEgNjQwIDE5MSA2NDJUMTkzIDY1OVExOTcgNjc2IDIwMyA2ODBINzU3UTc2NCA2NzYgNzY0IDY2OVE3NjQgNjY0IDc1MSA1NTdUNzM3IDQ0N1E3MzUgNDQwIDcxNyA0NDBINzA1UTY5OCA0NDUgNjk4IDQ1M0w3MDEgNDc2UTcwNCA1MDAgNzA0IDUyOFE3MDQgNTU4IDY5NyA1NzhUNjc4IDYwOVQ2NDMgNjI1VDU5NiA2MzJUNTMyIDYzNEg0ODVRMzk3IDYzMyAzOTIgNjMxUTM4OCA2MjkgMzg2IDYyMlEzODUgNjE5IDM1NSA0OTlUMzI0IDM3N1EzNDcgMzc2IDM3MiAzNzZIMzk4UTQ2NCAzNzYgNDg5IDM5MVQ1MzQgNDcyUTUzOCA0ODggNTQwIDQ5MFQ1NTcgNDkzUTU2MiA0OTMgNTY1IDQ5M1Q1NzAgNDkyVDU3MiA0OTFUNTc0IDQ4N1Q1NzcgNDgzTDU0NCAzNTFRNTExIDIxOCA1MDggMjE2UTUwNSAyMTMgNDkyIDIxM1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0IiIGQ9Ik00MzQgLTIzMVE0MzQgLTI0NCA0MjggLTI1MEg0MTBRMjgxIC0yNTAgMjMwIC0xODRRMjI1IC0xNzcgMjIyIC0xNzJUMjE3IC0xNjFUMjEzIC0xNDhUMjExIC0xMzNUMjEwIC0xMTFUMjA5IC04NFQyMDkgLTQ3VDIwOSAwUTIwOSAyMSAyMDkgNTNRMjA4IDE0MiAyMDQgMTUzUTIwMyAxNTQgMjAzIDE1NVExODkgMTkxIDE1MyAyMTFUODIgMjMxUTcxIDIzMSA2OCAyMzRUNjUgMjUwVDY4IDI2NlQ4MiAyNjlRMTE2IDI2OSAxNTIgMjg5VDIwMyAzNDVRMjA4IDM1NiAyMDggMzc3VDIwOSA1MjlWNTc5UTIwOSA2MzQgMjE1IDY1NlQyNDQgNjk4UTI3MCA3MjQgMzI0IDc0MFEzNjEgNzQ4IDM3NyA3NDlRMzc5IDc0OSAzOTAgNzQ5VDQwOCA3NTBINDI4UTQzNCA3NDQgNDM0IDczMlE0MzQgNzE5IDQzMSA3MTZRNDI5IDcxMyA0MTUgNzEzUTM2MiA3MTAgMzMyIDY4OVQyOTYgNjQ3UTI5MSA2MzQgMjkxIDQ5OVY0MTdRMjkxIDM3MCAyODggMzUzVDI3MSAzMTRRMjQwIDI3MSAxODQgMjU1TDE3MCAyNTBMMTg0IDI0NVEyMDIgMjM5IDIyMCAyMzBUMjYyIDE5NlQyOTAgMTM3UTI5MSAxMzEgMjkxIDFRMjkxIC0xMzQgMjk2IC0xNDdRMzA2IC0xNzQgMzM5IC0xOTJUNDE1IC0yMTNRNDI5IC0yMTMgNDMxIC0yMTZRNDM0IC0yMTkgNDM0IC0yMzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzgiIGQ9Ik01MiAyODlRNTkgMzMxIDEwNiAzODZUMjIyIDQ0MlEyNTcgNDQyIDI4NiA0MjRUMzI5IDM3OVEzNzEgNDQyIDQzMCA0NDJRNDY3IDQ0MiA0OTQgNDIwVDUyMiAzNjFRNTIyIDMzMiA1MDggMzE0VDQ4MSAyOTJUNDU4IDI4OFE0MzkgMjg4IDQyNyAyOTlUNDE1IDMyOFE0MTUgMzc0IDQ2NSAzOTFRNDU0IDQwNCA0MjUgNDA0UTQxMiA0MDQgNDA2IDQwMlEzNjggMzg2IDM1MCAzMzZRMjkwIDExNSAyOTAgNzhRMjkwIDUwIDMwNiAzOFQzNDEgMjZRMzc4IDI2IDQxNCA1OVQ0NjMgMTQwUTQ2NiAxNTAgNDY5IDE1MVQ0ODUgMTUzSDQ4OVE1MDQgMTUzIDUwNCAxNDVRNTA0IDE0NCA1MDIgMTM0UTQ4NiA3NyA0NDAgMzNUMzMzIC0xMVEyNjMgLTExIDIyNyA1MlExODYgLTEwIDEzMyAtMTBIMTI3UTc4IC0xMCA1NyAxNlQzNSA3MVEzNSAxMDMgNTQgMTIzVDk5IDE0M1ExNDIgMTQzIDE0MiAxMDFRMTQyIDgxIDEzMCA2NlQxMDcgNDZUOTQgNDFMOTEgNDBROTEgMzkgOTcgMzZUMTEzIDI5VDEzMiAyNlExNjggMjYgMTk0IDcxUTIwMyA4NyAyMTcgMTM5VDI0NSAyNDdUMjYxIDMxM1EyNjYgMzQwIDI2NiAzNTJRMjY2IDM4MCAyNTEgMzkyVDIxNyA0MDRRMTc3IDQwNCAxNDIgMzcyVDkzIDI5MFE5MSAyODEgODggMjgwVDcyIDI3OEg1OFE1MiAyODQgNTIgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzQiIGQ9Ik0yNiAzODVRMTkgMzkyIDE5IDM5NVExOSAzOTkgMjIgNDExVDI3IDQyNVEyOSA0MzAgMzYgNDMwVDg3IDQzMUgxNDBMMTU5IDUxMVExNjIgNTIyIDE2NiA1NDBUMTczIDU2NlQxNzkgNTg2VDE4NyA2MDNUMTk3IDYxNVQyMTEgNjI0VDIyOSA2MjZRMjQ3IDYyNSAyNTQgNjE1VDI2MSA1OTZRMjYxIDU4OSAyNTIgNTQ5VDIzMiA0NzBMMjIyIDQzM1EyMjIgNDMxIDI3MiA0MzFIMzIzUTMzMCA0MjQgMzMwIDQyMFEzMzAgMzk4IDMxNyAzODVIMjEwTDE3NCAyNDBRMTM1IDgwIDEzNSA2OFExMzUgMjYgMTYyIDI2UTE5NyAyNiAyMzAgNjBUMjgzIDE0NFEyODUgMTUwIDI4OCAxNTFUMzAzIDE1M0gzMDdRMzIyIDE1MyAzMjIgMTQ1UTMyMiAxNDIgMzE5IDEzM1EzMTQgMTE3IDMwMSA5NVQyNjcgNDhUMjE2IDZUMTU1IC0xMVExMjUgLTExIDk4IDRUNTkgNTZRNTcgNjQgNTcgODNWMTAxTDkyIDI0MVExMjcgMzgyIDEyOCAzODNRMTI4IDM4NSA3NyAzODVIMjZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjEyIiBkPSJNODQgMjM3VDg0IDI1MFQ5OCAyNzBINjc5UTY5NCAyNjIgNjk0IDI1MFQ2NzkgMjMwSDk4UTg0IDIzNyA4NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMiIgZD0iTTEwOSA0MjlRODIgNDI5IDY2IDQ0N1Q1MCA0OTFRNTAgNTYyIDEwMyA2MTRUMjM1IDY2NlEzMjYgNjY2IDM4NyA2MTBUNDQ5IDQ2NVE0NDkgNDIyIDQyOSAzODNUMzgxIDMxNVQzMDEgMjQxUTI2NSAyMTAgMjAxIDE0OUwxNDIgOTNMMjE4IDkyUTM3NSA5MiAzODUgOTdRMzkyIDk5IDQwOSAxODZWMTg5SDQ0OVYxODZRNDQ4IDE4MyA0MzYgOTVUNDIxIDNWMEg1MFYxOVYzMVE1MCAzOCA1NiA0NlQ4NiA4MVExMTUgMTEzIDEzNiAxMzdRMTQ1IDE0NyAxNzAgMTc0VDIwNCAyMTFUMjMzIDI0NFQyNjEgMjc4VDI4NCAzMDhUMzA1IDM0MFQzMjAgMzY5VDMzMyA0MDFUMzQwIDQzMVQzNDMgNDY0UTM0MyA1MjcgMzA5IDU3M1QyMTIgNjE5UTE3OSA2MTkgMTU0IDYwMlQxMTkgNTY5VDEwOSA1NTBRMTA5IDU0OSAxMTQgNTQ5UTEzMiA1NDkgMTUxIDUzNVQxNzAgNDg5UTE3MCA0NjQgMTU0IDQ0N1QxMDkgNDI5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMi03QiIgZD0iTTU0NyAtNjQzTDU0MSAtNjQ5SDUyOFE1MTUgLTY0OSA1MDMgLTY0NVEzMjQgLTU4MiAyOTMgLTQ2NlEyODkgLTQ0OSAyODkgLTQyOFQyODcgLTIwMEwyODYgNDJMMjg0IDUzUTI3NCA5OCAyNDggMTM1VDE5NiAxOTBUMTQ2IDIyMkwxMjEgMjM1UTExOSAyMzkgMTE5IDI1MFExMTkgMjYyIDEyMSAyNjZUMTMzIDI3M1EyNjIgMzM2IDI4NCA0NDlMMjg2IDQ2MEwyODcgNzAxUTI4NyA3MzcgMjg3IDc5NFEyODggOTQ5IDI5MiA5NjNRMjkzIDk2NiAyOTMgOTY3UTMyNSAxMDgwIDUwOCAxMTQ4UTUxNiAxMTUwIDUyNyAxMTUwSDU0MUw1NDcgMTE0NFYxMTMwUTU0NyAxMTE3IDU0NiAxMTE1VDUzNiAxMTA5UTQ4MCAxMDg2IDQzNyAxMDQ2VDM4MSA5NTBMMzc5IDk0MEwzNzggNjk5UTM3OCA2NTcgMzc4IDU5NFEzNzcgNDUyIDM3NCA0MzhRMzczIDQzNyAzNzMgNDM2UTM1MCAzNDggMjQzIDI4MlExOTIgMjU3IDE4NiAyNTRMMTc2IDI1MUwxODggMjQ1UTIxMSAyMzYgMjM0IDIyM1QyODcgMTg5VDM0MCAxMzVUMzczIDY1UTM3MyA2NCAzNzQgNjNRMzc3IDQ5IDM3OCAtOTNRMzc4IC0xNTYgMzc4IC0xOThMMzc5IC00MzhMMzgxIC00NDlRMzkzIC01MDQgNDM2IC01NDRUNTM2IC02MDhRNTQ0IC02MTEgNTQ1IC02MTNUNTQ3IC02MjlWLTY0M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItN0QiIGQ9Ik0xMTkgMTEzMFExMTkgMTE0NCAxMjEgMTE0N1QxMzUgMTE1MEgxMzlRMTUxIDExNTAgMTgyIDExMzhUMjUyIDExMDVUMzI2IDEwNDZUMzczIDk2NFEzNzggOTQyIDM3OCA3MDJRMzc4IDQ2OSAzNzkgNDYyUTM4NiAzOTQgNDM5IDMzOVE0ODIgMjk2IDUzNSAyNzJRNTQ0IDI2OCA1NDUgMjY2VDU0NyAyNTFRNTQ3IDI0MSA1NDcgMjM4VDU0MiAyMzFUNTMxIDIyN1Q1MTAgMjE3VDQ3NyAxOTRRMzkwIDEyOSAzNzkgMzlRMzc4IDMyIDM3OCAtMjAxUTM3OCAtNDQxIDM3MyAtNDYzUTM0MiAtNTgwIDE2NSAtNjQ0UTE1MiAtNjQ5IDEzOSAtNjQ5UTEyNSAtNjQ5IDEyMiAtNjQ2VDExOSAtNjI5UTExOSAtNjIyIDExOSAtNjE5VDEyMSAtNjE0VDEyNCAtNjEwVDEzMiAtNjA3VDE0MyAtNjAyUTE5NSAtNTc5IDIzNSAtNTM5VDI4NSAtNDQ3UTI4NiAtNDM1IDI4NyAtMTk5VDI4OSA1MVEyOTQgNzQgMzAwIDkxVDMyOSAxMzhUMzkwIDE5N1E0MTIgMjEzIDQzNiAyMjZUNDc1IDI0NEw0ODkgMjUwTDQ3MiAyNThRNDU1IDI2NSA0MzAgMjc5VDM3NyAzMTNUMzI3IDM2NlQyOTMgNDM0UTI4OSA0NTEgMjg5IDQ3MlQyODcgNjk5UTI4NiA5NDEgMjg1IDk0OFEyNzkgOTc4IDI2MiAxMDA1VDIyNyAxMDQ4VDE4NCAxMDgwVDE1MSAxMTAwVDEyOSAxMTA5TDEyNyAxMTEwUTExOSAxMTEzIDExOSAxMTMwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMi0yMjExIiBkPSJNNjAgOTQ4UTYzIDk1MCA2NjUgOTUwSDEyNjdMMTMyNSA4MTVRMTM4NCA2NzcgMTM4OCA2NjlIMTM0OEwxMzQxIDY4M1ExMzIwIDcyNCAxMjg1IDc2MVExMjM1IDgwOSAxMTc0IDgzOFQxMDMzIDg4MVQ4ODIgODk4VDY5OSA5MDJINTc0SDU0M0gyNTFMMjU5IDg5MVE3MjIgMjU4IDcyNCAyNTJRNzI1IDI1MCA3MjQgMjQ2UTcyMSAyNDMgNDYwIC01NkwxOTYgLTM1NlExOTYgLTM1NyA0MDcgLTM1N1E0NTkgLTM1NyA1NDggLTM1N1Q2NzYgLTM1OFE4MTIgLTM1OCA4OTYgLTM1M1QxMDYzIC0zMzJUMTIwNCAtMjgzVDEzMDcgLTE5NlExMzI4IC0xNzAgMTM0OCAtMTI0SDEzODhRMTM4OCAtMTI1IDEzODEgLTE0NVQxMzU2IC0yMTBUMTMyNSAtMjk0TDEyNjcgLTQ0OUw2NjYgLTQ1MFE2NCAtNDUwIDYxIC00NDhRNTUgLTQ0NiA1NSAtNDM5UTU1IC00MzcgNTcgLTQzM0w1OTAgMTc3UTU5MCAxNzggNTU3IDIyMlQ0NTIgMzY2VDMyMiA1NDRMNTYgOTA5TDU1IDkyNFE1NSA5NDUgNjAgOTQ4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUwIiBkPSJNMjg3IDYyOFEyODcgNjM1IDIzMCA2MzdRMjA2IDYzNyAxOTkgNjM4VDE5MiA2NDhRMTkyIDY0OSAxOTQgNjU5UTIwMCA2NzkgMjAzIDY4MVQzOTcgNjgzUTU4NyA2ODIgNjAwIDY4MFE2NjQgNjY5IDcwNyA2MzFUNzUxIDUzMFE3NTEgNDUzIDY4NSAzODlRNjE2IDMyMSA1MDcgMzAzUTUwMCAzMDIgNDAyIDMwMUgzMDdMMjc3IDE4MlEyNDcgNjYgMjQ3IDU5UTI0NyA1NSAyNDggNTRUMjU1IDUwVDI3MiA0OFQzMDUgNDZIMzM2UTM0MiAzNyAzNDIgMzVRMzQyIDE5IDMzNSA1UTMzMCAwIDMxOSAwUTMxNiAwIDI4MiAxVDE4MiAyUTEyMCAyIDg3IDJUNTEgMVEzMyAxIDMzIDExUTMzIDEzIDM2IDI1UTQwIDQxIDQ0IDQzVDY3IDQ2UTk0IDQ2IDEyNyA0OVExNDEgNTIgMTQ2IDYxUTE0OSA2NSAyMTggMzM5VDI4NyA2MjhaTTY0NSA1NTRRNjQ1IDU2NyA2NDMgNTc1VDYzNCA1OTdUNjA5IDYxOVQ1NjAgNjM1UTU1MyA2MzYgNDgwIDYzN1E0NjMgNjM3IDQ0NSA2MzdUNDE2IDYzNlQ0MDQgNjM2UTM5MSA2MzUgMzg2IDYyN1EzODQgNjIxIDM2NyA1NTBUMzMyIDQxMlQzMTQgMzQ0UTMxNCAzNDIgMzk1IDM0Mkg0MDdINDMwUTU0MiAzNDIgNTkwIDM5MlE2MTcgNDE5IDYzMSA0NzFUNjQ1IDU1NFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTVCIiBkPSJNMTE4IC0yNTBWNzUwSDI1NVY3MTBIMTU4Vi0yMTBIMjU1Vi0yNTBIMTE4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTcyIiBkPSJNMjEgMjg3UTIyIDI5MCAyMyAyOTVUMjggMzE3VDM4IDM0OFQ1MyAzODFUNzMgNDExVDk5IDQzM1QxMzIgNDQyUTE2MSA0NDIgMTgzIDQzMFQyMTQgNDA4VDIyNSAzODhRMjI3IDM4MiAyMjggMzgyVDIzNiAzODlRMjg0IDQ0MSAzNDcgNDQxSDM1MFEzOTggNDQxIDQyMiA0MDBRNDMwIDM4MSA0MzAgMzYzUTQzMCAzMzMgNDE3IDMxNVQzOTEgMjkyVDM2NiAyODhRMzQ2IDI4OCAzMzQgMjk5VDMyMiAzMjhRMzIyIDM3NiAzNzggMzkyUTM1NiA0MDUgMzQyIDQwNVEyODYgNDA1IDIzOSAzMzFRMjI5IDMxNSAyMjQgMjk4VDE5MCAxNjVRMTU2IDI1IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTE0IDE4OVQxNTQgMzY2UTE1NCA0MDUgMTI4IDQwNVExMDcgNDA1IDkyIDM3N1Q2OCAzMTZUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJCIiBkPSJNNTYgMjM3VDU2IDI1MFQ3MCAyNzBIMzY5VjQyMEwzNzAgNTcwUTM4MCA1ODMgMzg5IDU4M1E0MDIgNTgzIDQwOSA1NjhWMjcwSDcwN1E3MjIgMjYyIDcyMiAyNTBUNzA3IDIzMEg0MDlWLTY4UTQwMSAtODIgMzkxIC04MkgzODlIMzg3UTM3NSAtODIgMzY5IC02OFYyMzBINzBRNTYgMjM3IDU2IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJFIiBkPSJNNzggNjBRNzggODQgOTUgMTAyVDEzOCAxMjBRMTYyIDEyMCAxODAgMTA0VDE5OSA2MVExOTkgMzYgMTgyIDE4VDEzOSAwVDk2IDE3VDc4IDYwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZCIiBkPSJNMTIxIDY0N1ExMjEgNjU3IDEyNSA2NzBUMTM3IDY4M1ExMzggNjgzIDIwOSA2ODhUMjgyIDY5NFEyOTQgNjk0IDI5NCA2ODZRMjk0IDY3OSAyNDQgNDc3UTE5NCAyNzkgMTk0IDI3MlEyMTMgMjgyIDIyMyAyOTFRMjQ3IDMwOSAyOTIgMzU0VDM2MiA0MTVRNDAyIDQ0MiA0MzggNDQyUTQ2OCA0NDIgNDg1IDQyM1Q1MDMgMzY5UTUwMyAzNDQgNDk2IDMyN1Q0NzcgMzAyVDQ1NiAyOTFUNDM4IDI4OFE0MTggMjg4IDQwNiAyOTlUMzk0IDMyOFEzOTQgMzUzIDQxMCAzNjlUNDQyIDM5MEw0NTggMzkzUTQ0NiA0MDUgNDM0IDQwNUg0MzBRMzk4IDQwMiAzNjcgMzgwVDI5NCAzMTZUMjI4IDI1NVEyMzAgMjU0IDI0MyAyNTJUMjY3IDI0NlQyOTMgMjM4VDMyMCAyMjRUMzQyIDIwNlQzNTkgMTgwVDM2NSAxNDdRMzY1IDEzMCAzNjAgMTA2VDM1NCA2NlEzNTQgMjYgMzgxIDI2UTQyOSAyNiA0NTkgMTQ1UTQ2MSAxNTMgNDc5IDE1M0g0ODNRNDk5IDE1MyA0OTkgMTQ0UTQ5OSAxMzkgNDk2IDEzMFE0NTUgLTExIDM3OCAtMTFRMzMzIC0xMSAzMDUgMTVUMjc3IDkwUTI3NyAxMDggMjgwIDEyMVQyODMgMTQ1UTI4MyAxNjcgMjY5IDE4M1QyMzQgMjA2VDIwMCAyMTdUMTgyIDIyMEgxODBRMTY4IDE3OCAxNTkgMTM5VDE0NSA4MVQxMzYgNDRUMTI5IDIwVDEyMiA3VDExMSAtMlE5OCAtMTEgODMgLTExUTY2IC0xMSA1NyAtMVQ0OCAxNlE0OCAyNiA4NSAxNzZUMTU4IDQ3MUwxOTUgNjE2UTE5NiA2MjkgMTg4IDYzMlQxNDkgNjM3SDE0NFExMzQgNjM3IDEzMSA2MzdUMTI0IDY0MFQxMjEgNjQ3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU0IiBkPSJNNDAgNDM3UTIxIDQzNyAyMSA0NDVRMjEgNDUwIDM3IDUwMVQ3MSA2MDJMODggNjUxUTkzIDY2OSAxMDEgNjc3SDU2OUg2NTlRNjkxIDY3NyA2OTcgNjc2VDcwNCA2NjdRNzA0IDY2MSA2ODcgNTUzVDY2OCA0NDRRNjY4IDQzNyA2NDkgNDM3UTY0MCA0MzcgNjM3IDQzN1Q2MzEgNDQyTDYyOSA0NDVRNjI5IDQ1MSA2MzUgNDkwVDY0MSA1NTFRNjQxIDU4NiA2MjggNjA0VDU3MyA2MjlRNTY4IDYzMCA1MTUgNjMxUTQ2OSA2MzEgNDU3IDYzMFQ0MzkgNjIyUTQzOCA2MjEgMzY4IDM0M1QyOTggNjBRMjk4IDQ4IDM4NiA0NlE0MTggNDYgNDI3IDQ1VDQzNiAzNlE0MzYgMzEgNDMzIDIyUTQyOSA0IDQyNCAxTDQyMiAwUTQxOSAwIDQxNSAwUTQxMCAwIDM2MyAxVDIyOCAyUTk5IDIgNjQgMEg0OVE0MyA2IDQzIDlUNDUgMjdRNDkgNDAgNTUgNDZIODNIOTRRMTc0IDQ2IDE4OSA1NVExOTAgNTYgMTkxIDU2UTE5NiA1OSAyMDEgNzZUMjQxIDIzM1EyNTggMzAxIDI2OSAzNDRRMzM5IDYxOSAzMzkgNjI1UTMzOSA2MzAgMzEwIDYzMEgyNzlRMjEyIDYzMCAxOTEgNjI0UTE0NiA2MTQgMTIxIDU4M1Q2NyA0NjdRNjAgNDQ1IDU3IDQ0MVQ0MyA0MzdINDBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTIiIGQ9Ik0yMzAgNjM3UTIwMyA2MzcgMTk4IDYzOFQxOTMgNjQ5UTE5MyA2NzYgMjA0IDY4MlEyMDYgNjgzIDM3OCA2ODNRNTUwIDY4MiA1NjQgNjgwUTYyMCA2NzIgNjU4IDY1MlQ3MTIgNjA2VDczMyA1NjNUNzM5IDUyOVE3MzkgNDg0IDcxMCA0NDVUNjQzIDM4NVQ1NzYgMzUxVDUzOCAzMzhMNTQ1IDMzM1E2MTIgMjk1IDYxMiAyMjNRNjEyIDIxMiA2MDcgMTYyVDYwMiA4MFY3MVE2MDIgNTMgNjAzIDQzVDYxNCAyNVQ2NDAgMTZRNjY4IDE2IDY4NiAzOFQ3MTIgODVRNzE3IDk5IDcyMCAxMDJUNzM1IDEwNVE3NTUgMTA1IDc1NSA5M1E3NTUgNzUgNzMxIDM2UTY5MyAtMjEgNjQxIC0yMUg2MzJRNTcxIC0yMSA1MzEgNFQ0ODcgODJRNDg3IDEwOSA1MDIgMTY2VDUxNyAyMzlRNTE3IDI5MCA0NzQgMzEzUTQ1OSAzMjAgNDQ5IDMyMVQzNzggMzIzSDMwOUwyNzcgMTkzUTI0NCA2MSAyNDQgNTlRMjQ0IDU1IDI0NSA1NFQyNTIgNTBUMjY5IDQ4VDMwMiA0NkgzMzNRMzM5IDM4IDMzOSAzN1QzMzYgMTlRMzMyIDYgMzI2IDBIMzExUTI3NSAyIDE4MCAyUTE0NiAyIDExNyAyVDcxIDJUNTAgMVEzMyAxIDMzIDEwUTMzIDEyIDM2IDI0UTQxIDQzIDQ2IDQ1UTUwIDQ2IDYxIDQ2SDY3UTk0IDQ2IDEyNyA0OVExNDEgNTIgMTQ2IDYxUTE0OSA2NSAyMTggMzM5VDI4NyA2MjhRMjg3IDYzNSAyMzAgNjM3Wk02MzAgNTU0UTYzMCA1ODYgNjA5IDYwOFQ1MjMgNjM2UTUyMSA2MzYgNTAwIDYzNlQ0NjIgNjM3SDQ0MFEzOTMgNjM3IDM4NiA2MjdRMzg1IDYyNCAzNTIgNDk0VDMxOSAzNjFRMzE5IDM2MCAzODggMzYwUTQ2NiAzNjEgNDkyIDM2N1E1NTYgMzc3IDU5MiA0MjZRNjA4IDQ0OSA2MTkgNDg2VDYzMCA1NTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1ozLTI4IiBkPSJNNzAxIC05NDBRNzAxIC05NDMgNjk1IC05NDlINjY0UTY2MiAtOTQ3IDYzNiAtOTIyVDU5MSAtODc5VDUzNyAtODE4VDQ3NSAtNzM3VDQxMiAtNjM2VDM1MCAtNTExVDI5NSAtMzYyVDI1MCAtMTg2VDIyMSAxN1QyMDkgMjUxUTIwOSA5NjIgNTczIDEzNjFRNTk2IDEzODYgNjE2IDE0MDVUNjQ5IDE0MzdUNjY0IDE0NTBINjk1UTcwMSAxNDQ0IDcwMSAxNDQxUTcwMSAxNDM2IDY4MSAxNDE1VDYyOSAxMzU2VDU1NyAxMjYxVDQ3NiAxMTE4VDQwMCA5MjdUMzQwIDY3NVQzMDggMzU5UTMwNiAzMjEgMzA2IDI1MFEzMDYgLTEzOSA0MDAgLTQzMFQ2OTAgLTkyNFE3MDEgLTkzNiA3MDEgLTk0MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjMtMjkiIGQ9Ik0zNCAxNDM4UTM0IDE0NDYgMzcgMTQ0OFQ1MCAxNDUwSDU2SDcxUTczIDE0NDggOTkgMTQyM1QxNDQgMTM4MFQxOTggMTMxOVQyNjAgMTIzOFQzMjMgMTEzN1QzODUgMTAxM1Q0NDAgODY0VDQ4NSA2ODhUNTE0IDQ4NVQ1MjYgMjUxUTUyNiAxMzQgNTE5IDUzUTQ3MiAtNTE5IDE2MiAtODYwUTEzOSAtODg1IDExOSAtOTA0VDg2IC05MzZUNzEgLTk0OUg1NlE0MyAtOTQ5IDM5IC05NDdUMzQgLTkzN1E4OCAtODgzIDE0MCAtODEzUTQyOCAtNDMwIDQyOCAyNTFRNDI4IDQ1MyA0MDIgNjI4VDMzOCA5MjJUMjQ1IDExNDZUMTQ1IDEzMDlUNDYgMTQyNVE0NCAxNDI3IDQyIDE0MjlUMzkgMTQzM1QzNiAxNDM2TDM0IDE0MzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi01RCIgZD0iTTIyIDcxMFY3NTBIMTU5Vi0yNTBIMjJWLTIxMEgxMTlWNzEwSDIyWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMy01QiIgZD0iTTI0NyAtOTQ5VjE0NTBINTE2VjEzODhIMzA5Vi04ODdINTE2Vi05NDlIMjQ3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMy01RCIgZD0iTTExIDEzODhWMTQ1MEgyODBWLTk0OUgxMVYtODg3SDIxOFYxMzg4SDExWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY5IiBkPSJNMTg0IDYwMFExODQgNjI0IDIwMyA2NDJUMjQ3IDY2MVEyNjUgNjYxIDI3NyA2NDlUMjkwIDYxOVEyOTAgNTk2IDI3MCA1NzdUMjI2IDU1N1EyMTEgNTU3IDE5OCA1NjdUMTg0IDYwMFpNMjEgMjg3UTIxIDI5NSAzMCAzMThUNTQgMzY5VDk4IDQyMFQxNTggNDQyUTE5NyA0NDIgMjIzIDQxOVQyNTAgMzU3UTI1MCAzNDAgMjM2IDMwMVQxOTYgMTk2VDE1NCA4M1ExNDkgNjEgMTQ5IDUxUTE0OSAyNiAxNjYgMjZRMTc1IDI2IDE4NSAyOVQyMDggNDNUMjM1IDc4VDI2MCAxMzdRMjYzIDE0OSAyNjUgMTUxVDI4MiAxNTNRMzAyIDE1MyAzMDIgMTQzUTMwMiAxMzUgMjkzIDExMlQyNjggNjFUMjIzIDExVDE2MSAtMTFRMTI5IC0xMSAxMDIgMTBUNzQgNzRRNzQgOTEgNzkgMTA2VDEyMiAyMjBRMTYwIDMyMSAxNjYgMzQxVDE3MyAzODBRMTczIDQwNCAxNTYgNDA0SDE1NFExMjQgNDA0IDk5IDM3MVQ2MSAyODdRNjAgMjg2IDU5IDI4NFQ1OCAyODFUNTYgMjc5VDUzIDI3OFQ0OSAyNzhUNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1o0LTI4IiBkPSJNNzU4IC0xMjM3VDc1OCAtMTI0MFQ3NTIgLTEyNDlINzM2UTcxOCAtMTI0OSA3MTcgLTEyNDhRNzExIC0xMjQ1IDY3MiAtMTE5OVEyMzcgLTcwNiAyMzcgMjUxVDY3MiAxNzAwUTY5NyAxNzMwIDcxNiAxNzQ5UTcxOCAxNzUwIDczNSAxNzUwSDc1MlE3NTggMTc0NCA3NTggMTc0MVE3NTggMTczNyA3NDAgMTcxM1Q2ODkgMTY0NFQ2MTkgMTUzN1Q1NDAgMTM4MFQ0NjMgMTE3NlEzNDggODAyIDM0OCAyNTFRMzQ4IC0yNDIgNDQxIC01OTlUNzQ0IC0xMjE4UTc1OCAtMTIzNyA3NTggLTEyNDBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1o0LTI5IiBkPSJNMzMgMTc0MVEzMyAxNzUwIDUxIDE3NTBINjBINjVRNzMgMTc1MCA4MSAxNzQzVDExOSAxNzAwUTU1NCAxMjA3IDU1NCAyNTFRNTU0IC03MDcgMTE5IC0xMTk5UTc2IC0xMjUwIDY2IC0xMjUwUTY1IC0xMjUwIDYyIC0xMjUwVDU2IC0xMjQ5UTU1IC0xMjQ5IDUzIC0xMjQ5VDQ5IC0xMjUwUTMzIC0xMjUwIDMzIC0xMjM5UTMzIC0xMjM2IDUwIC0xMjE0VDk4IC0xMTUwVDE2MyAtMTA1MlQyMzggLTkxMFQzMTEgLTcyN1E0NDMgLTMzNSA0NDMgMjUxUTQ0MyA0MDIgNDM2IDUzMlQ0MDUgODMxVDMzOSAxMTQyVDIyNCAxNDM4VDUwIDE3MTZRMzMgMTczNyAzMyAxNzQxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjI2MCIgZD0iTTE2NiAtMjE1VDE1OSAtMjE1VDE0NyAtMjEyVDE0MSAtMjA0VDEzOSAtMTk3UTEzOSAtMTkwIDE0NCAtMTgzTDMwNiAxMzNINzBRNTYgMTQwIDU2IDE1M1E1NiAxNjggNzIgMTczSDMyN0w0MDYgMzI3SDcyUTU2IDMzMiA1NiAzNDdRNTYgMzYwIDcwIDM2N0g0MjZRNTk3IDcwMiA2MDIgNzA3UTYwNSA3MTYgNjE4IDcxNlE2MjUgNzE2IDYzMCA3MTJUNjM2IDcwM1Q2MzggNjk2UTYzOCA2OTIgNDcxIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEw0NTEgMzI3TDM3MSAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNIMzUxUTE3NSAtMjEwIDE3MCAtMjEyUTE2NiAtMjE1IDE1OSAtMjE1WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZBIiBkPSJNMjk3IDU5NlEyOTcgNjI3IDMxOCA2NDRUMzYxIDY2MVEzNzggNjYxIDM4OSA2NTFUNDAzIDYyM1E0MDMgNTk1IDM4NCA1NzZUMzQwIDU1N1EzMjIgNTU3IDMxMCA1NjdUMjk3IDU5NlpNMjg4IDM3NlEyODggNDA1IDI2MiA0MDVRMjQwIDQwNSAyMjAgMzkzVDE4NSAzNjJUMTYxIDMyNVQxNDQgMjkzTDEzNyAyNzlRMTM1IDI3OCAxMjEgMjc4SDEwN1ExMDEgMjg0IDEwMSAyODZUMTA1IDI5OVExMjYgMzQ4IDE2NCAzOTFUMjUyIDQ0MVEyNTMgNDQxIDI2MCA0NDFUMjcyIDQ0MlEyOTYgNDQxIDMxNiA0MzJRMzQxIDQxOCAzNTQgNDAxVDM2NyAzNDhWMzMyTDMxOCAxMzNRMjY3IC02NyAyNjQgLTc1UTI0NiAtMTI1IDE5NCAtMTY0VDc1IC0yMDRRMjUgLTIwNCA3IC0xODNULTEyIC0xMzdRLTEyIC0xMTAgNyAtOTFUNTMgLTcxUTcwIC03MSA4MiAtODFUOTUgLTExMlE5NSAtMTQ4IDYzIC0xNjdRNjkgLTE2OCA3NyAtMTY4UTExMSAtMTY4IDEzOSAtMTQwVDE4MiAtNzRMMTkzIC0zMlEyMDQgMTEgMjE5IDcyVDI1MSAxOTdUMjc4IDMwOFQyODkgMzY1UTI4OSAzNzIgMjg4IDM3NloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTM0IiBkPSJNNDYyIDBRNDQ0IDMgMzMzIDNRMjE3IDMgMTk5IDBIMTkwVjQ2SDIyMVEyNDEgNDYgMjQ4IDQ2VDI2NSA0OFQyNzkgNTNUMjg2IDYxUTI4NyA2MyAyODcgMTE1VjE2NUgyOFYyMTFMMTc5IDQ0MlEzMzIgNjc0IDMzNCA2NzVRMzM2IDY3NyAzNTUgNjc3SDM3M0wzNzkgNjcxVjIxMUg0NzFWMTY1SDM3OVYxMTRRMzc5IDczIDM3OSA2NlQzODUgNTRRMzkzIDQ3IDQ0MiA0Nkg0NzFWMEg0NjJaTTI5MyAyMTFWNTQ1TDc0IDIxMkwxODMgMjExSDI5M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdDIiBkPSJNMTM5IC0yNDlIMTM3UTEyNSAtMjQ5IDExOSAtMjM1VjI1MUwxMjAgNzM3UTEzMCA3NTAgMTM5IDc1MFExNTIgNzUwIDE1OSA3MzVWLTIzNVExNTEgLTI0OSAxNDEgLTI0OUgxMzlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1o0LTdCIiBkPSJNNjYxIC0xMjQzTDY1NSAtMTI0OUg2MjJMNjA0IC0xMjQwUTUwMyAtMTE5MCA0MzQgLTExMDdUMzQ4IC05MDlRMzQ2IC04OTcgMzQ2IC00OTlMMzQ1IC05OEwzNDMgLTgyUTMzNSAzIDI4NyA4N1QxNTcgMjIzUTE0NiAyMzIgMTQ1IDIzNlExNDQgMjQwIDE0NCAyNTBRMTQ0IDI2NSAxNDUgMjY4VDE1NyAyNzhRMjQyIDMzMyAyODggNDE3VDM0MyA1ODNMMzQ1IDYwMEwzNDYgMTAwMVEzNDYgMTM5OCAzNDggMTQxMFEzNzkgMTYyMiA2MDAgMTczOUw2MjIgMTc1MEg2NTVMNjYxIDE3NDRWMTcyN1YxNzIxUTY2MSAxNzEyIDY2MSAxNzEwVDY1NyAxNzA1VDY0OCAxNzAwVDYzMCAxNjkwVDYwMiAxNjY4UTU4OSAxNjU5IDU3NCAxNjQzVDUzMSAxNTkzVDQ4NCAxNTA4VDQ1OSAxMzk4UTQ1OCAxMzg5IDQ1OCAxMDAxUTQ1OCA2MTQgNDU3IDYwNVE0NDEgNDM1IDMwMSAzMTZRMjU0IDI3NyAyMDIgMjUxTDI1MCAyMjJRMjYwIDIxNiAzMDEgMTg1UTQ0MyA2NiA0NTcgLTEwNFE0NTggLTExMyA0NTggLTUwMVE0NTggLTg4OCA0NTkgLTg5N1E0NjMgLTk0NCA0NzggLTk4OFQ1MDkgLTEwNjBUNTQ4IC0xMTE0VDU4MCAtMTE0OVQ2MDIgLTExNjdRNjIwIC0xMTgzIDYzNCAtMTE5MlQ2NTMgLTEyMDJUNjU5IC0xMjA3VDY2MSAtMTIyMFYtMTIyNlYtMTI0M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjQtN0QiIGQ9Ik0xNDQgMTcyN1ExNDQgMTc0MyAxNDYgMTc0NlQxNjIgMTc1MEgxNjdIMTgzTDIwMyAxNzQwUTI3NCAxNzA1IDMyNSAxNjU4VDQwMyAxNTYyVDQ0MCAxNDc4VDQ1NiAxNDEwUTQ1OCAxMzk4IDQ1OCAxMDAxUTQ1OSA2NjEgNDU5IDYyNFQ0NjUgNTU4UTQ3MCA1MjYgNDgwIDQ5NlQ1MDIgNDQxVDUyOSAzOTVUNTU5IDM1NlQ1ODggMzI1VDYxNSAzMDFUNjM3IDI4NFQ2NTQgMjczTDY2MCAyNjlWMjY2UTY2MCAyNjMgNjYwIDI1OVQ2NjEgMjUwVjIzOVE2NjEgMjM2IDY2MSAyMzRUNjYwIDIzMlQ2NTYgMjI5VDY0OSAyMjRRNTc3IDE3OSA1MjggMTA1VDQ2NSAtNTdRNDYwIC04NiA0NjAgLTEyM1Q0NTggLTQ5OVYtNjYxUTQ1OCAtODU3IDQ1NyAtODkzVDQ0NyAtOTU1UTQyNSAtMTA0OCAzNTkgLTExMjBUMjAzIC0xMjM5TDE4MyAtMTI0OUgxNjhRMTUwIC0xMjQ5IDE0NyAtMTI0NlQxNDQgLTEyMjZRMTQ0IC0xMjEzIDE0NSAtMTIxMFQxNTMgLTEyMDJRMTY5IC0xMTkzIDE4NiAtMTE4MVQyMzIgLTExNDBUMjgyIC0xMDgxVDMyMiAtMTAwMFQzNDUgLTg5N1EzNDYgLTg4OCAzNDYgLTUwMVEzNDYgLTExMyAzNDcgLTEwNFEzNTkgNTggNTAzIDE4NFE1NTQgMjI2IDYwMyAyNTBRNTA0IDI5OSA0MzAgMzkzVDM0NyA2MDVRMzQ2IDYxNCAzNDYgMTAwMlEzNDYgMTM4OSAzNDUgMTM5OFEzMzggMTQ5MyAyODggMTU3M1QxNTMgMTcwM1ExNDYgMTcwNyAxNDUgMTcxMFQxNDQgMTcyN1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTM2IiBkPSJNNDIgMzEzUTQyIDQ3NiAxMjMgNTcxVDMwMyA2NjZRMzcyIDY2NiA0MDIgNjMwVDQzMiA1NTBRNDMyIDUyNSA0MTggNTEwVDM3OSA0OTVRMzU2IDQ5NSAzNDEgNTA5VDMyNiA1NDhRMzI2IDU5MiAzNzMgNjAxUTM1MSA2MjMgMzExIDYyNlEyNDAgNjI2IDE5NCA1NjZRMTQ3IDUwMCAxNDcgMzY0TDE0OCAzNjBRMTUzIDM2NiAxNTYgMzczUTE5NyA0MzMgMjYzIDQzM0gyNjdRMzEzIDQzMyAzNDggNDE0UTM3MiA0MDAgMzk2IDM3NFQ0MzUgMzE3UTQ1NiAyNjggNDU2IDIxMFYxOTJRNDU2IDE2OSA0NTEgMTQ5UTQ0MCA5MCAzODcgMzRUMjUzIC0yMlEyMjUgLTIyIDE5OSAtMTRUMTQzIDE2VDkyIDc1VDU2IDE3MlQ0MiAzMTNaTTI1NyAzOTdRMjI3IDM5NyAyMDUgMzgwVDE3MSAzMzVUMTU0IDI3OFQxNDggMjE2UTE0OCAxMzMgMTYwIDk3VDE5OCAzOVEyMjIgMjEgMjUxIDIxUTMwMiAyMSAzMjkgNTlRMzQyIDc3IDM0NyAxMDRUMzUyIDIwOVEzNTIgMjg5IDM0NyAzMTZUMzI5IDM2MVEzMDIgMzk3IDI1NyAzOTdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1o0LTVCIiBkPSJNMjY5IC0xMjQ5VjE3NTBINTc3VjE2NzdIMzQyVi0xMTc2SDU3N1YtMTI0OUgyNjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1o0LTVEIiBkPSJNNSAxNjc3VjE3NTBIMzEzVi0xMjQ5SDVWLTExNzZIMjQwVjE2NzdINVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjcsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgtMTEsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDk5NDEpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9IjIzMjQiIHk9IjU4MSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIyMzI0IiB5PSItMzUwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjQ1MCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzY4OCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsOTk0MSkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIyNzciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzM0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MzgsLTE4NykiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03OCIgeD0iNTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjEwNzMiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQ1MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi03QiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDY2NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUyOCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzgiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjEwNzMiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjE5NjMiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMzEwMiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSI0MTAzIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTAzNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03NCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUyOCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzgiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjEwNzMiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjE5NjMiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iMzM4MSIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI5MzA1IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEzNzExIiB5PSI2NzUiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi03RCIgeD0iMTA4MTYiIHk9Ii0xIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsNzIwOSkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIyNzciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzM0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjUsLTExNDkpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzgiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSIxMDczIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIyOTQ1IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg2MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzgiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjEwNzMiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjE5NjMiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYzODIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjMtNUIiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MjgsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxNDQ1NyIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDgzMSkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ1MSwtMTUwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSI1NzgiIHk9Ii0yNDMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjE0NjMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIyNDY0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjk2NCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDUxLC0xNTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjU3NCkiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjU3OCIgeT0iLTI0MyI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI0MjA2IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iNDk4NCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9IjU0MzAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSI1ODc1IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNjMyMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI3MDk4IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzYyMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDUxLC0xNTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjU3NCkiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI1NzgiIHk9Ii0yNzEiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iOTA5NiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwMDk3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNzQzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTc0NCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMjYzNCIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTMyODcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYxMDYsLTcxNSkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9Ijc0MyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjE3NDQiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIxNDkxOSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE1OTIwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1ozLTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzM2LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTg2MSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM5Myw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIxMDEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMzUxNCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ1MTUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjMtMjkiIHg9IjY2MDkiIHk9Ii0xIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMy01RCIgeD0iMjM3OTQiIHk9Ii0xIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjM0Mzk4IiB5PSIxODUyIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsMzczMikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIyNzciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzM0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9Ijc2MCIgeT0iLTE1NjkiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIyOTQ1IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg2MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iOTExIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MzMwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MzgsLTE4NykiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iNTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9Ijk1MSIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MTk2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTdCIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODA2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDcsLTEwOTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjM0NSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxMTI0IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9Ijc2MCIgeT0iMTYyNyI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2MTEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3OTIsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIzNTk3IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTM5OSw2NzYpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iNDg4IiB5PSI1MTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC05NzApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNzQzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTc0NCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMjYzNCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI0Mjc2IiB5PSI2NzUiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzgzNywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjYzOCIgeT0iNDg4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDUxLC0xNTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjU3NCkiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSI1NzgiIHk9Ii0yMzgiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNTIxMiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjYyMTMiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2NzEzLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMjM2NCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSIxMDA5IiB5PSI2NzYiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzE1KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNzQzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTc0NCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkzMTgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ1MSwtMTUwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iNTc4IiB5PSItMjM4Ij48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwNDcxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtMjkiIHg9IjEyMzEzIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxNDkzOSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE1OTQwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iNjM4IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjYzOCIgeT0iLTQ0NiI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE4NTQsLTMxNzYpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwMDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE3OSwtMTEyNSkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjYwIiB4PSIzNDUiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkEiIHg9IjExMjQiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjQ0NSwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI4NiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjM1OTciIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMTY5LDcyNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZBIiB4PSI4NDYiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC05NzApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNzQzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTc0NCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMjYzNCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI0Mjc2IiB5PSI2NzUiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2NDQ5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NTEsLTE1MCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNTc0KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjU3OCIgeT0iLTIzOCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3NjAyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NTEsLTE1MCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNTc0KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkEiIHg9IjU3OCIgeT0iLTIzOCI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI5MDE1IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTc5NCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjE4NjEiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzMTEsNjc2KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExMDkiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEyIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtODM3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzQiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTQ0NiI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIxMTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMDc0IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEzNTUzIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQzMzEsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMzYwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQzLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjE1NCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNzM0NSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxODkyNSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE5OTI2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA3NCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDc0IiB5PSItNDQ2Ij48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTY3MzQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTAwMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2NjcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0NywtMTA5MCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMzQ1IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjExMjQiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNzYwIiB5PSIxNjI3Ij48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzMTEyLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjg2LDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMjM2NCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSIxMDA5IiB5PSI2NzYiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzE1KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNzQzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTc0NCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU4ODQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ1MSwtMTUwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iNTc4IiB5PSItMjM4Ij48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDcyMDMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjMtMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MzYsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxODYxIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzkzLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjEwMSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIzNTE0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDUxNSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMy0yOSIgeD0iNjYwOSIgeT0iLTEiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMTQ3NzEiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxNTc3MiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2MjcyLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTg2MSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM5Myw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTgzNzQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTk1NjUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjIwODM3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMjE4MzgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMjMzOCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMzY5NiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI2MzgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0MiIHg9IjI0NzQ1IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjI1MDI0IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTdEIiB4PSIyNTU0NSIgeT0iLTEiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwtNjMwMykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIyNzciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzM0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTIyMTEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9Ijc2MCIgeT0iLTE1NjkiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI5NDUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0MTg1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjExMDkiIHk9IjQ5OSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEyIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1NjA1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTVCIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTgzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODEwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI2MzgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjE0MzkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjM4NjEiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NjM5LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQyLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNDMzMiIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDc3MCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDY4OCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEyNDQiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIyMjQ0IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIzMTM0IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDMyMCwtNzcxKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzYiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2NjcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI3NDMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxNzQ0IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIyNjM0IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5NDM0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDExMjQ0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI2MzgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjEyNzIiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEzMTI5IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTM5MDcsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMzMzIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsNjc2KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwNzQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zNCIgeD0iNDE2IiB5PSItNjk4Ij48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE1NzAzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1ozLTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzM2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9Ijc0MyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE1MjIsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMzYwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQzLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMy0yOSIgeD0iNDA4MSIgeT0iLTEiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iNjgxMyIgeT0iMTY2NSI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtNUQiIHg9IjIxNTU4IiB5PSItMSI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC05Mzc1KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzMzQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzE0NCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxNDM5IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI1MTk1IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTk3MywwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEzMzMiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw2NzYpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA3NCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEyIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTM0IiB4PSI0MTYiIHk9Ii02OTgiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzc2OSwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEzNjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDMsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC04MzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii00NDYiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI5NTkyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTA1OTIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTI0MDIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTI3MiIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQyMzIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNzYwIiB5PSItMTU2OSI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTU4NDMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNzA4MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIxMTA5IiB5PSI0OTkiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTgzMzYsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI0MzMyIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsNzcwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjg4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTI0NCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjIyNDQiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjMxMzQiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzIwLC03NzEpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zNiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDY2NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9Ijc0MyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjE3NDQiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjI2MzQiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9zdmc+)
注意, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQzLjE0NmV4IiBoZWlnaHQ9IjYuNTA5ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMi42NzFleDsiIHZpZXdCb3g9IjAgLTE2NTIuNSAxODU3Ni44IDI4MDIuNiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02QiIgZD0iTTEyMSA2NDdRMTIxIDY1NyAxMjUgNjcwVDEzNyA2ODNRMTM4IDY4MyAyMDkgNjg4VDI4MiA2OTRRMjk0IDY5NCAyOTQgNjg2UTI5NCA2NzkgMjQ0IDQ3N1ExOTQgMjc5IDE5NCAyNzJRMjEzIDI4MiAyMjMgMjkxUTI0NyAzMDkgMjkyIDM1NFQzNjIgNDE1UTQwMiA0NDIgNDM4IDQ0MlE0NjggNDQyIDQ4NSA0MjNUNTAzIDM2OVE1MDMgMzQ0IDQ5NiAzMjdUNDc3IDMwMlQ0NTYgMjkxVDQzOCAyODhRNDE4IDI4OCA0MDYgMjk5VDM5NCAzMjhRMzk0IDM1MyA0MTAgMzY5VDQ0MiAzOTBMNDU4IDM5M1E0NDYgNDA1IDQzNCA0MDVINDMwUTM5OCA0MDIgMzY3IDM4MFQyOTQgMzE2VDIyOCAyNTVRMjMwIDI1NCAyNDMgMjUyVDI2NyAyNDZUMjkzIDIzOFQzMjAgMjI0VDM0MiAyMDZUMzU5IDE4MFQzNjUgMTQ3UTM2NSAxMzAgMzYwIDEwNlQzNTQgNjZRMzU0IDI2IDM4MSAyNlE0MjkgMjYgNDU5IDE0NVE0NjEgMTUzIDQ3OSAxNTNINDgzUTQ5OSAxNTMgNDk5IDE0NFE0OTkgMTM5IDQ5NiAxMzBRNDU1IC0xMSAzNzggLTExUTMzMyAtMTEgMzA1IDE1VDI3NyA5MFEyNzcgMTA4IDI4MCAxMjFUMjgzIDE0NVEyODMgMTY3IDI2OSAxODNUMjM0IDIwNlQyMDAgMjE3VDE4MiAyMjBIMTgwUTE2OCAxNzggMTU5IDEzOVQxNDUgODFUMTM2IDQ0VDEyOSAyMFQxMjIgN1QxMTEgLTJROTggLTExIDgzIC0xMVE2NiAtMTEgNTcgLTFUNDggMTZRNDggMjYgODUgMTc2VDE1OCA0NzFMMTk1IDYxNlExOTYgNjI5IDE4OCA2MzJUMTQ5IDYzN0gxNDRRMTM0IDYzNyAxMzEgNjM3VDEyNCA2NDBUMTIxIDY0N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMzIiBkPSJNMTI3IDQ2M1ExMDAgNDYzIDg1IDQ4MFQ2OSA1MjRRNjkgNTc5IDExNyA2MjJUMjMzIDY2NVEyNjggNjY1IDI3NyA2NjRRMzUxIDY1MiAzOTAgNjExVDQzMCA1MjJRNDMwIDQ3MCAzOTYgNDIxVDMwMiAzNTBMMjk5IDM0OFEyOTkgMzQ3IDMwOCAzNDVUMzM3IDMzNlQzNzUgMzE1UTQ1NyAyNjIgNDU3IDE3NVE0NTcgOTYgMzk1IDM3VDIzOCAtMjJRMTU4IC0yMiAxMDAgMjFUNDIgMTMwUTQyIDE1OCA2MCAxNzVUMTA1IDE5M1ExMzMgMTkzIDE1MSAxNzVUMTY5IDEzMFExNjkgMTE5IDE2NiAxMTBUMTU5IDk0VDE0OCA4MlQxMzYgNzRUMTI2IDcwVDExOCA2N0wxMTQgNjZRMTY1IDIxIDIzOCAyMVEyOTMgMjEgMzIxIDc0UTMzOCAxMDcgMzM4IDE3NVYxOTVRMzM4IDI5MCAyNzQgMzIyUTI1OSAzMjggMjEzIDMyOUwxNzEgMzMwTDE2OCAzMzJRMTY2IDMzNSAxNjYgMzQ4UTE2NiAzNjYgMTc0IDM2NlEyMDIgMzY2IDIzMiAzNzFRMjY2IDM3NiAyOTQgNDEzVDMyMiA1MjVWNTMzUTMyMiA1OTAgMjg3IDYxMlEyNjUgNjI2IDI0MCA2MjZRMjA4IDYyNiAxODEgNjE1VDE0MyA1OTJUMTMyIDU4MEgxMzVRMTM4IDU3OSAxNDMgNTc4VDE1MyA1NzNUMTY1IDU2NlQxNzUgNTU1VDE4MyA1NDBUMTg2IDUyMFExODYgNDk4IDE3MiA0ODFUMTI3IDQ2M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMTIiIGQ9Ik04NCAyMzdUODQgMjUwVDk4IDI3MEg2NzlRNjk0IDI2MiA2OTQgMjUwVDY3OSAyMzBIOThRODQgMjM3IDg0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTM2IiBkPSJNNDIgMzEzUTQyIDQ3NiAxMjMgNTcxVDMwMyA2NjZRMzcyIDY2NiA0MDIgNjMwVDQzMiA1NTBRNDMyIDUyNSA0MTggNTEwVDM3OSA0OTVRMzU2IDQ5NSAzNDEgNTA5VDMyNiA1NDhRMzI2IDU5MiAzNzMgNjAxUTM1MSA2MjMgMzExIDYyNlEyNDAgNjI2IDE5NCA1NjZRMTQ3IDUwMCAxNDcgMzY0TDE0OCAzNjBRMTUzIDM2NiAxNTYgMzczUTE5NyA0MzMgMjYzIDQzM0gyNjdRMzEzIDQzMyAzNDggNDE0UTM3MiA0MDAgMzk2IDM3NFQ0MzUgMzE3UTQ1NiAyNjggNDU2IDIxMFYxOTJRNDU2IDE2OSA0NTEgMTQ5UTQ0MCA5MCAzODcgMzRUMjUzIC0yMlEyMjUgLTIyIDE5OSAtMTRUMTQzIDE2VDkyIDc1VDU2IDE3MlQ0MiAzMTNaTTI1NyAzOTdRMjI3IDM5NyAyMDUgMzgwVDE3MSAzMzVUMTU0IDI3OFQxNDggMjE2UTE0OCAxMzMgMTYwIDk3VDE5OCAzOVEyMjIgMjEgMjUxIDIxUTMwMiAyMSAzMjkgNTlRMzQyIDc3IDM0NyAxMDRUMzUyIDIwOVEzNTIgMjg5IDM0NyAzMTZUMzI5IDM2MVEzMDIgMzk3IDI1NyAzOTdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjY0IiBkPSJNNjc0IDYzNlE2ODIgNjM2IDY4OCA2MzBUNjk0IDYxNVQ2ODcgNjAxUTY4NiA2MDAgNDE3IDQ3MkwxNTEgMzQ2TDM5OSAyMjhRNjg3IDkyIDY5MSA4N1E2OTQgODEgNjk0IDc2UTY5NCA1OCA2NzYgNTZINjcwTDM4MiAxOTJROTIgMzI5IDkwIDMzMVE4MyAzMzYgODMgMzQ4UTg0IDM1OSA5NiAzNjVRMTA0IDM2OSAzODIgNTAwVDY2NSA2MzRRNjY5IDYzNiA2NzQgNjM2Wk04NCAtMTE4UTg0IC0xMDggOTkgLTk4SDY3OFE2OTQgLTEwNCA2OTQgLTExOFE2OTQgLTEzMCA2NzkgLTEzOEg5OFE4NCAtMTMxIDg0IC0xMThaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzIiIGQ9Ik0xMDkgNDI5UTgyIDQyOSA2NiA0NDdUNTAgNDkxUTUwIDU2MiAxMDMgNjE0VDIzNSA2NjZRMzI2IDY2NiAzODcgNjEwVDQ0OSA0NjVRNDQ5IDQyMiA0MjkgMzgzVDM4MSAzMTVUMzAxIDI0MVEyNjUgMjEwIDIwMSAxNDlMMTQyIDkzTDIxOCA5MlEzNzUgOTIgMzg1IDk3UTM5MiA5OSA0MDkgMTg2VjE4OUg0NDlWMTg2UTQ0OCAxODMgNDM2IDk1VDQyMSAzVjBINTBWMTlWMzFRNTAgMzggNTYgNDZUODYgODFRMTE1IDExMyAxMzYgMTM3UTE0NSAxNDcgMTcwIDE3NFQyMDQgMjExVDIzMyAyNDRUMjYxIDI3OFQyODQgMzA4VDMwNSAzNDBUMzIwIDM2OVQzMzMgNDAxVDM0MCA0MzFUMzQzIDQ2NFEzNDMgNTI3IDMwOSA1NzNUMjEyIDYxOVExNzkgNjE5IDE1NCA2MDJUMTE5IDU2OVQxMDkgNTUwUTEwOSA1NDkgMTE0IDU0OVExMzIgNTQ5IDE1MSA1MzVUMTcwIDQ4OVExNzAgNDY0IDE1NCA0NDdUMTA5IDQyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJCIiBkPSJNNTYgMjM3VDU2IDI1MFQ3MCAyNzBIMzY5VjQyMEwzNzAgNTcwUTM4MCA1ODMgMzg5IDU4M1E0MDIgNTgzIDQwOSA1NjhWMjcwSDcwN1E3MjIgMjYyIDcyMiAyNTBUNzA3IDIzMEg0MDlWLTY4UTQwMSAtODIgMzkxIC04MkgzODlIMzg3UTM3NSAtODIgMzY5IC02OFYyMzBINzBRNTYgMjM3IDU2IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNjQxIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjYwIiB5PSI2NzYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMzIiB4PSI3MCIgeT0iLTY4NiI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIxMTAzIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTg4MiwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjYyMCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjYwIiB5PSI2NzYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTM2IiB4PSI2MCIgeT0iLTY4NyI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyNjQiIHg9IjMyNDIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0MDIxLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzk3LDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNDMzMiIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDc3MCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDY4OCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjUwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEyNDQiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIyMjQ0IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIzMTM0IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDMyMCwtNzcxKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzYiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2NjcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI3NDMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxNzQ0IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIyNjM0IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI5MTQ5IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTkyNywwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM5NywwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjY0MSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSI2MCIgeT0iNjc2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMyIgeD0iNzAiIHk9Ii02ODYiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIxMTMwOSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMDg3LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQyLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMzgxMSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIxNjQ0IiB5PSI2NzYiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzcxKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzYiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2NjcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI3NDMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxNzQ0IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIyNjM0IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyNjQiIHg9IjE2NjM5IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTc0MTcsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI2NDEiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iNjAiIHk9IjY3NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzMiIHg9IjcwIiB5PSItNjg2Ij48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9zdmc+) 。
。
因此,
定理8 一次试验后,,因为
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjM2LjYxN2V4IiBoZWlnaHQ9IjMuODQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMS4wMDVleDsiIHZpZXdCb3g9IjAgLTEyMjEuOSAxNTc2NS41IDE2NTQuNSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi00MiIgZD0iTTEzMSA2MjJRMTI0IDYyOSAxMjAgNjMxVDEwNCA2MzRUNjEgNjM3SDI4VjY4M0gyMjlIMjY3SDM0NlE0MjMgNjgzIDQ1OSA2NzhUNTMxIDY1MVE1NzQgNjI3IDU5OSA1OTBUNjI0IDUxMlE2MjQgNDYxIDU4MyA0MTlUNDc2IDM2MEw0NjYgMzU3UTUzOSAzNDggNTk1IDMwMlQ2NTEgMTg3UTY1MSAxMTkgNjAwIDY3VDQ2OSAzUTQ1NiAxIDI0MiAwSDI4VjQ2SDYxUTEwMyA0NyAxMTIgNDlUMTMxIDYxVjYyMlpNNTExIDUxM1E1MTEgNTYwIDQ4NSA1OTRUNDE2IDYzNlE0MTUgNjM2IDQwMyA2MzZUMzcxIDYzNlQzMzMgNjM3UTI2NiA2MzcgMjUxIDYzNlQyMzIgNjI4UTIyOSA2MjQgMjI5IDQ5OVYzNzRIMzEyTDM5NiAzNzVMNDA2IDM3N1E0MTAgMzc4IDQxNyAzODBUNDQyIDM5M1Q0NzQgNDE3VDQ5OSA0NTZUNTExIDUxM1pNNTM3IDE4OFE1MzcgMjM5IDUwOSAyODJUNDMwIDMzNkwzMjkgMzM3SDIyOVYyMDBWMTE2UTIyOSA1NyAyMzQgNTJRMjQwIDQ3IDMzNCA0N0gzODNRNDI1IDQ3IDQ0MyA1M1E0ODYgNjcgNTExIDEwNFQ1MzcgMTg4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNjkiIGQ9Ik02OSA2MDlRNjkgNjM3IDg3IDY1M1QxMzEgNjY5UTE1NCA2NjcgMTcxIDY1MlQxODggNjA5UTE4OCA1NzkgMTcxIDU2NFQxMjkgNTQ5UTEwNCA1NDkgODcgNTY0VDY5IDYwOVpNMjQ3IDBRMjMyIDMgMTQzIDNRMTMyIDMgMTA2IDNUNTYgMUwzNCAwSDI2VjQ2SDQyUTcwIDQ2IDkxIDQ5UTEwMCA1MyAxMDIgNjBUMTA0IDEwMlYyMDVWMjkzUTEwNCAzNDUgMTAyIDM1OVQ4OCAzNzhRNzQgMzg1IDQxIDM4NUgzMFY0MDhRMzAgNDMxIDMyIDQzMUw0MiA0MzJRNTIgNDMzIDcwIDQzNFQxMDYgNDM2UTEyMyA0MzcgMTQyIDQzOFQxNzEgNDQxVDE4MiA0NDJIMTg1VjYyUTE5MCA1MiAxOTcgNTBUMjMyIDQ2SDI1NVYwSDI0N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTYxIiBkPSJNMTM3IDMwNVQxMTUgMzA1VDc4IDMyMFQ2MyAzNTlRNjMgMzk0IDk3IDQyMVQyMTggNDQ4UTI5MSA0NDggMzM2IDQxNlQzOTYgMzQwUTQwMSAzMjYgNDAxIDMwOVQ0MDIgMTk0VjEyNFE0MDIgNzYgNDA3IDU4VDQyOCA0MFE0NDMgNDAgNDQ4IDU2VDQ1MyAxMDlWMTQ1SDQ5M1YxMDZRNDkyIDY2IDQ5MCA1OVE0ODEgMjkgNDU1IDEyVDQwMCAtNlQzNTMgMTJUMzI5IDU0VjU4TDMyNyA1NVEzMjUgNTIgMzIyIDQ5VDMxNCA0MFQzMDIgMjlUMjg3IDE3VDI2OSA2VDI0NyAtMlQyMjEgLThUMTkwIC0xMVExMzAgLTExIDgyIDIwVDM0IDEwN1EzNCAxMjggNDEgMTQ3VDY4IDE4OFQxMTYgMjI1VDE5NCAyNTNUMzA0IDI2OEgzMThWMjkwUTMxOCAzMjQgMzEyIDM0MFEyOTAgNDExIDIxNSA0MTFRMTk3IDQxMSAxODEgNDEwVDE1NiA0MDZUMTQ4IDQwM1ExNzAgMzg4IDE3MCAzNTlRMTcwIDMzNCAxNTQgMzIwWk0xMjYgMTA2UTEyNiA3NSAxNTAgNTFUMjA5IDI2UTI0NyAyNiAyNzYgNDlUMzE1IDEwOVEzMTcgMTE2IDMxOCAxNzVRMzE4IDIzMyAzMTcgMjMzUTMwOSAyMzMgMjk2IDIzMlQyNTEgMjIzVDE5MyAyMDNUMTQ3IDE2NlQxMjYgMTA2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNzMiIGQ9Ik0yOTUgMzE2UTI5NSAzNTYgMjY4IDM4NVQxOTAgNDE0UTE1NCA0MTQgMTI4IDQwMVE5OCAzODIgOTggMzQ5UTk3IDM0NCA5OCAzMzZUMTE0IDMxMlQxNTcgMjg3UTE3NSAyODIgMjAxIDI3OFQyNDUgMjY5VDI3NyAyNTZRMjk0IDI0OCAzMTAgMjM2VDM0MiAxOTVUMzU5IDEzM1EzNTkgNzEgMzIxIDMxVDE5OCAtMTBIMTkwUTEzOCAtMTAgOTQgMjZMODYgMTlMNzcgMTBRNzEgNCA2NSAtMUw1NCAtMTFINDZINDJRMzkgLTExIDMzIC01Vjc0VjEzMlEzMyAxNTMgMzUgMTU3VDQ1IDE2Mkg1NFE2NiAxNjIgNzAgMTU4VDc1IDE0NlQ4MiAxMTlUMTAxIDc3UTEzNiAyNiAxOTggMjZRMjk1IDI2IDI5NSAxMDRRMjk1IDEzMyAyNzcgMTUxUTI1NyAxNzUgMTk0IDE4N1QxMTEgMjEwUTc1IDIyNyA1NCAyNTZUMzMgMzE4UTMzIDM1NyA1MCAzODRUOTMgNDI0VDE0MyA0NDJUMTg3IDQ0N0gxOThRMjM4IDQ0NyAyNjggNDMyTDI4MyA0MjRMMjkyIDQzMVEzMDIgNDQwIDMxNCA0NDhIMzIySDMyNlEzMjkgNDQ4IDMzNSA0NDJWMzEwTDMyOSAzMDRIMzAxUTI5NSAzMTAgMjk1IDMxNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NSIgZD0iTTQ5MiAyMTNRNDcyIDIxMyA0NzIgMjI2UTQ3MiAyMzAgNDc3IDI1MFQ0ODIgMjg1UTQ4MiAzMTYgNDYxIDMyM1QzNjQgMzMwSDMxMlEzMTEgMzI4IDI3NyAxOTJUMjQzIDUyUTI0MyA0OCAyNTQgNDhUMzM0IDQ2UTQyOCA0NiA0NTggNDhUNTE4IDYxUTU2NyA3NyA1OTkgMTE3VDY3MCAyNDhRNjgwIDI3MCA2ODMgMjcyUTY5MCAyNzQgNjk4IDI3NFE3MTggMjc0IDcxOCAyNjFRNjEzIDcgNjA4IDJRNjA1IDAgMzIyIDBIMTMzUTMxIDAgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ2IDY2IDIxNSAzNDJUMjg1IDYyMlEyODUgNjI5IDI4MSA2MjlRMjczIDYzMiAyMjggNjM0SDE5N1ExOTEgNjQwIDE5MSA2NDJUMTkzIDY1OVExOTcgNjc2IDIwMyA2ODBINzU3UTc2NCA2NzYgNzY0IDY2OVE3NjQgNjY0IDc1MSA1NTdUNzM3IDQ0N1E3MzUgNDQwIDcxNyA0NDBINzA1UTY5OCA0NDUgNjk4IDQ1M0w3MDEgNDc2UTcwNCA1MDAgNzA0IDUyOFE3MDQgNTU4IDY5NyA1NzhUNjc4IDYwOVQ2NDMgNjI1VDU5NiA2MzJUNTMyIDYzNEg0ODVRMzk3IDYzMyAzOTIgNjMxUTM4OCA2MjkgMzg2IDYyMlEzODUgNjE5IDM1NSA0OTlUMzI0IDM3N1EzNDcgMzc2IDM3MiAzNzZIMzk4UTQ2NCAzNzYgNDg5IDM5MVQ1MzQgNDcyUTUzOCA0ODggNTQwIDQ5MFQ1NTcgNDkzUTU2MiA0OTMgNTY1IDQ5M1Q1NzAgNDkyVDU3MiA0OTFUNTc0IDQ4N1Q1NzcgNDgzTDU0NCAzNTFRNTExIDIxOCA1MDggMjE2UTUwNSAyMTMgNDkyIDIxM1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMS0yOCIgZD0iTTE1MiAyNTFRMTUyIDY0NiAzODggODUwSDQxNlE0MjIgODQ0IDQyMiA4NDFRNDIyIDgzNyA0MDMgODE2VDM1NyA3NTNUMzAyIDY0OVQyNTUgNDgyVDIzNiAyNTBRMjM2IDEyNCAyNTUgMTlUMzAxIC0xNDdUMzU2IC0yNTFUNDAzIC0zMTVUNDIyIC0zNDBRNDIyIC0zNDMgNDE2IC0zNDlIMzg4UTM1OSAtMzI1IDMzMiAtMjk2VDI3MSAtMjEzVDIxMiAtOTdUMTcwIDU2VDE1MiAyNTFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oxLTI5IiBkPSJNMzA1IDI1MVEzMDUgLTE0NSA2OSAtMzQ5SDU2UTQzIC0zNDkgMzkgLTM0N1QzNSAtMzM4UTM3IC0zMzMgNjAgLTMwN1QxMDggLTIzOVQxNjAgLTEzNlQyMDQgMjdUMjIxIDI1MFQyMDQgNDczVDE2MCA2MzZUMTA4IDc0MFQ2MCA4MDdUMzUgODM5UTM1IDg1MCA1MCA4NTBINTZINjlRMTk3IDc0MyAyNTYgNTY2UTMwNSA0MjUgMzA1IDI1MVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yQiIgZD0iTTU2IDIzN1Q1NiAyNTBUNzAgMjcwSDM2OVY0MjBMMzcwIDU3MFEzODAgNTgzIDM4OSA1ODNRNDAyIDU4MyA0MDkgNTY4VjI3MEg3MDdRNzIyIDI2MiA3MjIgMjUwVDcwNyAyMzBINDA5Vi02OFE0MDEgLTgyIDM5MSAtODJIMzg5SDM4N1EzNzUgLTgyIDM2OSAtNjhWMjMwSDcwUTU2IDIzNyA1NiAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi01NiIgZD0iTTExNCA2MjBRMTEzIDYyMSAxMTAgNjI0VDEwNyA2MjdUMTAzIDYzMFQ5OCA2MzJUOTEgNjM0VDgwIDYzNVQ2NyA2MzZUNDggNjM3SDE5VjY4M0gyOFE0NiA2ODAgMTUyIDY4MFEyNzMgNjgwIDI5NCA2ODNIMzA1VjYzN0gyODRRMjIzIDYzNCAyMjMgNjIwUTIyMyA2MTggMzEzIDM3MlQ0MDQgMTI2TDQ5MCAzNThRNTc1IDU4OCA1NzUgNTk3UTU3NSA2MTYgNTU0IDYyNlQ1MDggNjM3SDUwM1Y2ODNINTEyUTUyNyA2ODAgNjI3IDY4MFE3MTggNjgwIDcyNCA2ODNINzMwVjYzN0g3MjNRNjQ4IDYzNyA2MjcgNTk2UTYyNyA1OTUgNTE1IDI5MVQ0MDEgLTE0UTM5NiAtMjIgMzgyIC0yMkgzNzRIMzY3UTM1MyAtMjIgMzQ4IC0xNFEzNDYgLTEyIDIzMSAzMDNRMTE0IDYxNyAxMTQgNjIwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNzIiIGQ9Ik0zNiA0Nkg1MFE4OSA0NiA5NyA2MFY2OFE5NyA3NyA5NyA5MVQ5OCAxMjJUOTggMTYxVDk4IDIwM1E5OCAyMzQgOTggMjY5VDk4IDMyOEw5NyAzNTFROTQgMzcwIDgzIDM3NlQzOCAzODVIMjBWNDA4UTIwIDQzMSAyMiA0MzFMMzIgNDMyUTQyIDQzMyA2MCA0MzRUOTYgNDM2UTExMiA0MzcgMTMxIDQzOFQxNjAgNDQxVDE3MSA0NDJIMTc0VjM3M1EyMTMgNDQxIDI3MSA0NDFIMjc3UTMyMiA0NDEgMzQzIDQxOVQzNjQgMzczUTM2NCAzNTIgMzUxIDMzN1QzMTMgMzIyUTI4OCAzMjIgMjc2IDMzOFQyNjMgMzcyUTI2MyAzODEgMjY1IDM4OFQyNzAgNDAwVDI3MyA0MDVRMjcxIDQwNyAyNTAgNDAxUTIzNCAzOTMgMjI2IDM4NlExNzkgMzQxIDE3OSAyMDdWMTU0UTE3OSAxNDEgMTc5IDEyN1QxNzkgMTAxVDE4MCA4MVQxODAgNjZWNjFRMTgxIDU5IDE4MyA1N1QxODggNTRUMTkzIDUxVDIwMCA0OVQyMDcgNDhUMjE2IDQ3VDIyNSA0N1QyMzUgNDZUMjQ1IDQ2SDI3NlYwSDI2N1EyNDkgMyAxNDAgM1EzNyAzIDI4IDBIMjBWNDZIMzZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjY0IiBkPSJNNjc0IDYzNlE2ODIgNjM2IDY4OCA2MzBUNjk0IDYxNVQ2ODcgNjAxUTY4NiA2MDAgNDE3IDQ3MkwxNTEgMzQ2TDM5OSAyMjhRNjg3IDkyIDY5MSA4N1E2OTQgODEgNjk0IDc2UTY5NCA1OCA2NzYgNTZINjcwTDM4MiAxOTJROTIgMzI5IDkwIDMzMVE4MyAzMzYgODMgMzQ4UTg0IDM1OSA5NiAzNjVRMTA0IDM2OSAzODIgNTAwVDY2NSA2MzRRNjY5IDYzNiA2NzQgNjM2Wk04NCAtMTE4UTg0IC0xMDggOTkgLTk4SDY3OFE2OTQgLTEwNCA2OTQgLTExOFE2OTQgLTEzMCA2NzkgLTEzOEg5OFE4NCAtMTMxIDg0IC0xMThaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi00RCIgZD0iTTEzMiA2MjJRMTI1IDYyOSAxMjEgNjMxVDEwNSA2MzRUNjIgNjM3SDI5VjY4M0gxMzVRMjIxIDY4MyAyMzIgNjgyVDI0OSA2NzVRMjUwIDY3NCAzNTQgMzk4TDQ1OCAxMjRMNTYyIDM5OFE2NjYgNjc0IDY2OCA2NzVRNjcxIDY4MSA2ODMgNjgyVDc4MSA2ODNIODg3VjYzN0g4NTRRODE0IDYzNiA4MDMgNjM0VDc4NSA2MjJWNjFRNzkxIDUxIDgwMiA0OVQ4NTQgNDZIODg3VjBIODc2UTg1NSAzIDczNiAzUTYwNSAzIDU5NiAwSDU4NVY0Nkg2MThRNjYwIDQ3IDY2OSA0OVQ2ODggNjFWMzQ3UTY4OCA0MjQgNjg4IDQ2MVQ2ODggNTQ2VDY4OCA2MTNMNjg3IDYzMlE0NTQgMTQgNDUwIDdRNDQ2IDEgNDMwIDFUNDEwIDdRNDA5IDkgMjkyIDMxNkwxNzYgNjI0VjYwNlExNzUgNTg4IDE3NSA1NDNUMTc1IDQ2M1QxNzUgMzU2TDE3NiA4NlExODcgNTAgMjYxIDQ2SDI3OFYwSDI2OVEyNTQgMyAxNTQgM1E1MiAzIDM3IDBIMjlWNDZINDZRNzggNDggOTggNTZUMTIyIDY5VDEzMiA4NlY2MjJaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi01MyIgZD0iTTU1IDUwN1E1NSA1OTAgMTEyIDY0N1QyNDMgNzA0SDI1N1EzNDIgNzA0IDQwNSA2NDFMNDI2IDY3MlE0MzEgNjc5IDQzNiA2ODdUNDQ2IDcwMEw0NDkgNzA0UTQ1MCA3MDQgNDUzIDcwNFQ0NTkgNzA1SDQ2M1E0NjYgNzA1IDQ3MiA2OTlWNDYyTDQ2NiA0NTZINDQ4UTQzNyA0NTYgNDM1IDQ1OVQ0MzAgNDc5UTQxMyA2MDUgMzI5IDY0NlEyOTIgNjYyIDI1NCA2NjJRMjAxIDY2MiAxNjggNjI2VDEzNSA1NDJRMTM1IDUwOCAxNTIgNDgwVDIwMCA0MzVRMjEwIDQzMSAyODYgNDEyVDM3MCAzODlRNDI3IDM2NyA0NjMgMzE0VDUwMCAxOTFRNTAwIDExMCA0NDggNDVUMzAxIC0yMVEyNDUgLTIxIDIwMSAtNFQxNDAgMjdMMTIyIDQxUTExOCAzNiAxMDcgMjFUODcgLTdUNzggLTIxUTc2IC0yMiA2OCAtMjJINjRRNjEgLTIyIDU1IC0xNlYxMDFRNTUgMjIwIDU2IDIyMlE1OCAyMjcgNzYgMjI3SDg5UTk1IDIyMSA5NSAyMTRROTUgMTgyIDEwNSAxNTFUMTM5IDkwVDIwNSA0MlQzMDUgMjRRMzUyIDI0IDM4NiA2MlQ0MjAgMTU1UTQyMCAxOTggMzk4IDIzM1QzNDAgMjgxUTI4NCAyOTUgMjY2IDMwMFEyNjEgMzAxIDIzOSAzMDZUMjA2IDMxNFQxNzQgMzI1VDE0MSAzNDNUMTEyIDM2N1Q4NSA0MDJRNTUgNDUxIDU1IDUwN1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTQ1IiBkPSJNMTI4IDYxOVExMjEgNjI2IDExNyA2MjhUMTAxIDYzMVQ1OCA2MzRIMjVWNjgwSDU5N1Y2NzZRNTk5IDY3MCA2MTEgNTYwVDYyNSA0NDRWNDQwSDU4NVY0NDRRNTg0IDQ0NyA1ODIgNDY1UTU3OCA1MDAgNTcwIDUyNlQ1NTMgNTcxVDUyOCA2MDFUNDk4IDYxOVQ0NTcgNjI5VDQxMSA2MzNUMzUzIDYzNFEyNjYgNjM0IDI1MSA2MzNUMjMzIDYyMlEyMzMgNjIyIDIzMyA2MjFRMjMyIDYxOSAyMzIgNDk3VjM3NkgyODZRMzU5IDM3OCAzNzcgMzg1UTQxMyA0MDEgNDE2IDQ2OVE0MTYgNDcxIDQxNiA0NzNWNDkzSDQ1NlYyMTNINDE2VjIzM1E0MTUgMjY4IDQwOCAyODhUMzgzIDMxN1QzNDkgMzI4VDI5NyAzMzBRMjkwIDMzMCAyODYgMzMwSDIzMlYxOTZWMTE0UTIzMiA1NyAyMzcgNTJRMjQzIDQ3IDI4OSA0N0gzNDBIMzkxUTQyOCA0NyA0NTIgNTBUNTA1IDYyVDU1MiA5MlQ1ODQgMTQ2UTU5NCAxNzIgNTk5IDIwMFQ2MDcgMjQ3VDYxMiAyNzBWMjczSDY1MlYyNzBRNjUxIDI2NyA2MzIgMTM3VDYxMCAzVjBIMjVWNDZINThRMTAwIDQ3IDEwOSA0OVQxMjggNjFWNjE5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQ2IiBkPSJNNDggMVEzMSAxIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc0MlE3NDkgNjc2IDc0OSA2NjlRNzQ5IDY2NCA3MzYgNTU3VDcyMiA0NDdRNzIwIDQ0MCA3MDIgNDQwSDY5MFE2ODMgNDQ1IDY4MyA0NTNRNjgzIDQ1NCA2ODYgNDc3VDY4OSA1MzBRNjg5IDU2MCA2ODIgNTc5VDY2MyA2MTBUNjI2IDYyNlQ1NzUgNjMzVDUwMyA2MzRINDgwUTM5OCA2MzMgMzkzIDYzMVEzODggNjI5IDM4NiA2MjNRMzg1IDYyMiAzNTIgNDkyTDMyMCAzNjNIMzc1UTM3OCAzNjMgMzk4IDM2M1Q0MjYgMzY0VDQ0OCAzNjdUNDcyIDM3NFQ0ODkgMzg2UTUwMiAzOTggNTExIDQxOVQ1MjQgNDU3VDUyOSA0NzVRNTMyIDQ4MCA1NDggNDgwSDU2MFE1NjcgNDc1IDU2NyA0NzBRNTY3IDQ2NyA1MzYgMzM5VDUwMiAyMDdRNTAwIDIwMCA0ODIgMjAwSDQ3MFE0NjMgMjA2IDQ2MyAyMTJRNDYzIDIxNSA0NjggMjM0VDQ3MyAyNzRRNDczIDMwMyA0NTMgMzEwVDM2NCAzMTdIMzA5TDI3NyAxOTBRMjQ1IDY2IDI0NSA2MFEyNDUgNDYgMzM0IDQ2SDM1OVEzNjUgNDAgMzY1IDM5VDM2MyAxOVEzNTkgNiAzNTMgMEgzMzZRMjk1IDIgMTg1IDJRMTIwIDIgODYgMlQ0OCAxWiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMS0yOCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ1OCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNDIiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTY5IiB4PSI3MDgiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI5ODciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTczIiB4PSIxNDg3IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIyNjYxIiB5PSI1ODEiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMjY2MSIgeT0iLTM1MCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI2ODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjEtMjkiIHg9IjQzOTYiIHk9Ii0xIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjY4NjUiIHk9Ijg3NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjU1MzAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2NTMxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9IjIzMjQiIHk9IjU4MSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIyMzI0IiB5PSItMzUwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4OTgyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjI2NCIgeD0iMTA1MDgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMTU2NCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNEQiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTUzIiB4PSI5MTciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTQ1IiB4PSIxNDc0IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ2IiB4PSIzMDQ4IiB5PSI2MTIiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMzA0OCIgeT0iLTM1MCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQ1MTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=)
定理9 存在,使得,对于所有的
,
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIwLjI1OGV4IiBoZWlnaHQ9IjMuMTc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMC44MzhleDsiIHZpZXdCb3g9IjAgLTEwMDYuNiA4NzIxLjkgMTM2Ny40IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNTYiIGQ9Ik0xMTQgNjIwUTExMyA2MjEgMTEwIDYyNFQxMDcgNjI3VDEwMyA2MzBUOTggNjMyVDkxIDYzNFQ4MCA2MzVUNjcgNjM2VDQ4IDYzN0gxOVY2ODNIMjhRNDYgNjgwIDE1MiA2ODBRMjczIDY4MCAyOTQgNjgzSDMwNVY2MzdIMjg0UTIyMyA2MzQgMjIzIDYyMFEyMjMgNjE4IDMxMyAzNzJUNDA0IDEyNkw0OTAgMzU4UTU3NSA1ODggNTc1IDU5N1E1NzUgNjE2IDU1NCA2MjZUNTA4IDYzN0g1MDNWNjgzSDUxMlE1MjcgNjgwIDYyNyA2ODBRNzE4IDY4MCA3MjQgNjgzSDczMFY2MzdINzIzUTY0OCA2MzcgNjI3IDU5NlE2MjcgNTk1IDUxNSAyOTFUNDAxIC0xNFEzOTYgLTIyIDM4MiAtMjJIMzc0SDM2N1EzNTMgLTIyIDM0OCAtMTRRMzQ2IC0xMiAyMzEgMzAzUTExNCA2MTcgMTE0IDYyMFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTYxIiBkPSJNMTM3IDMwNVQxMTUgMzA1VDc4IDMyMFQ2MyAzNTlRNjMgMzk0IDk3IDQyMVQyMTggNDQ4UTI5MSA0NDggMzM2IDQxNlQzOTYgMzQwUTQwMSAzMjYgNDAxIDMwOVQ0MDIgMTk0VjEyNFE0MDIgNzYgNDA3IDU4VDQyOCA0MFE0NDMgNDAgNDQ4IDU2VDQ1MyAxMDlWMTQ1SDQ5M1YxMDZRNDkyIDY2IDQ5MCA1OVE0ODEgMjkgNDU1IDEyVDQwMCAtNlQzNTMgMTJUMzI5IDU0VjU4TDMyNyA1NVEzMjUgNTIgMzIyIDQ5VDMxNCA0MFQzMDIgMjlUMjg3IDE3VDI2OSA2VDI0NyAtMlQyMjEgLThUMTkwIC0xMVExMzAgLTExIDgyIDIwVDM0IDEwN1EzNCAxMjggNDEgMTQ3VDY4IDE4OFQxMTYgMjI1VDE5NCAyNTNUMzA0IDI2OEgzMThWMjkwUTMxOCAzMjQgMzEyIDM0MFEyOTAgNDExIDIxNSA0MTFRMTk3IDQxMSAxODEgNDEwVDE1NiA0MDZUMTQ4IDQwM1ExNzAgMzg4IDE3MCAzNTlRMTcwIDMzNCAxNTQgMzIwWk0xMjYgMTA2UTEyNiA3NSAxNTAgNTFUMjA5IDI2UTI0NyAyNiAyNzYgNDlUMzE1IDEwOVEzMTcgMTE2IDMxOCAxNzVRMzE4IDIzMyAzMTcgMjMzUTMwOSAyMzMgMjk2IDIzMlQyNTEgMjIzVDE5MyAyMDNUMTQ3IDE2NlQxMjYgMTA2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNzIiIGQ9Ik0zNiA0Nkg1MFE4OSA0NiA5NyA2MFY2OFE5NyA3NyA5NyA5MVQ5OCAxMjJUOTggMTYxVDk4IDIwM1E5OCAyMzQgOTggMjY5VDk4IDMyOEw5NyAzNTFROTQgMzcwIDgzIDM3NlQzOCAzODVIMjBWNDA4UTIwIDQzMSAyMiA0MzFMMzIgNDMyUTQyIDQzMyA2MCA0MzRUOTYgNDM2UTExMiA0MzcgMTMxIDQzOFQxNjAgNDQxVDE3MSA0NDJIMTc0VjM3M1EyMTMgNDQxIDI3MSA0NDFIMjc3UTMyMiA0NDEgMzQzIDQxOVQzNjQgMzczUTM2NCAzNTIgMzUxIDMzN1QzMTMgMzIyUTI4OCAzMjIgMjc2IDMzOFQyNjMgMzcyUTI2MyAzODEgMjY1IDM4OFQyNzAgNDAwVDI3MyA0MDVRMjcxIDQwNyAyNTAgNDAxUTIzNCAzOTMgMjI2IDM4NlExNzkgMzQxIDE3OSAyMDdWMTU0UTE3OSAxNDEgMTc5IDEyN1QxNzkgMTAxVDE4MCA4MVQxODAgNjZWNjFRMTgxIDU5IDE4MyA1N1QxODggNTRUMTkzIDUxVDIwMCA0OVQyMDcgNDhUMjE2IDQ3VDIyNSA0N1QyMzUgNDZUMjQ1IDQ2SDI3NlYwSDI2N1EyNDkgMyAxNDAgM1EzNyAzIDI4IDBIMjBWNDZIMzZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDUiIGQ9Ik00OTIgMjEzUTQ3MiAyMTMgNDcyIDIyNlE0NzIgMjMwIDQ3NyAyNTBUNDgyIDI4NVE0ODIgMzE2IDQ2MSAzMjNUMzY0IDMzMEgzMTJRMzExIDMyOCAyNzcgMTkyVDI0MyA1MlEyNDMgNDggMjU0IDQ4VDMzNCA0NlE0MjggNDYgNDU4IDQ4VDUxOCA2MVE1NjcgNzcgNTk5IDExN1Q2NzAgMjQ4UTY4MCAyNzAgNjgzIDI3MlE2OTAgMjc0IDY5OCAyNzRRNzE4IDI3NCA3MTggMjYxUTYxMyA3IDYwOCAyUTYwNSAwIDMyMiAwSDEzM1EzMSAwIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc1N1E3NjQgNjc2IDc2NCA2NjlRNzY0IDY2NCA3NTEgNTU3VDczNyA0NDdRNzM1IDQ0MCA3MTcgNDQwSDcwNVE2OTggNDQ1IDY5OCA0NTNMNzAxIDQ3NlE3MDQgNTAwIDcwNCA1MjhRNzA0IDU1OCA2OTcgNTc4VDY3OCA2MDlUNjQzIDYyNVQ1OTYgNjMyVDUzMiA2MzRINDg1UTM5NyA2MzMgMzkyIDYzMVEzODggNjI5IDM4NiA2MjJRMzg1IDYxOSAzNTUgNDk5VDMyNCAzNzdRMzQ3IDM3NiAzNzIgMzc2SDM5OFE0NjQgMzc2IDQ4OSAzOTFUNTM0IDQ3MlE1MzggNDg4IDU0MCA0OTBUNTU3IDQ5M1E1NjIgNDkzIDU2NSA0OTNUNTcwIDQ5MlQ1NzIgNDkxVDU3NCA0ODdUNTc3IDQ4M0w1NDQgMzUxUTUxMSAyMTggNTA4IDIxNlE1MDUgMjEzIDQ5MiAyMTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkUiIGQ9Ik0yMSAyODdRMjIgMjkzIDI0IDMwM1QzNiAzNDFUNTYgMzg4VDg5IDQyNVQxMzUgNDQyUTE3MSA0NDIgMTk1IDQyNFQyMjUgMzkwVDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzA0IDQ0MiAzODIgNDQyUTQzNiA0NDIgNDY5IDQxNVQ1MDMgMzM2VDQ2NSAxNzlUNDI3IDUyUTQyNyAyNiA0NDQgMjZRNDUwIDI2IDQ1MyAyN1E0ODIgMzIgNTA1IDY1VDU0MCAxNDVRNTQyIDE1MyA1NjAgMTUzUTU4MCAxNTMgNTgwIDE0NVE1ODAgMTQ0IDU3NiAxMzBRNTY4IDEwMSA1NTQgNzNUNTA4IDE3VDQzOSAtMTBRMzkyIC0xMCAzNzEgMTdUMzUwIDczUTM1MCA5MiAzODYgMTkzVDQyMyAzNDVRNDIzIDQwNCAzNzkgNDA0SDM3NFEyODggNDA0IDIyOSAzMDNMMjIyIDI5MUwxODkgMTU3UTE1NiAyNiAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExMiAxODBUMTUyIDM0M1ExNTMgMzQ4IDE1MyAzNjZRMTUzIDQwNSAxMjkgNDA1UTkxIDQwNSA2NiAzMDVRNjAgMjg1IDYwIDI4NFE1OCAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjY1IiBkPSJNODMgNjE2UTgzIDYyNCA4OSA2MzBUOTkgNjM2UTEwNyA2MzYgMjUzIDU2OFQ1NDMgNDMxVDY4NyAzNjFRNjk0IDM1NiA2OTQgMzQ2VDY4NyAzMzFRNjg1IDMyOSAzOTUgMTkyTDEwNyA1NkgxMDFRODMgNTggODMgNzZRODMgNzcgODMgNzlRODIgODYgOTggOTVRMTE3IDEwNSAyNDggMTY3UTMyNiAyMDQgMzc4IDIyOEw2MjYgMzQ2TDM2MCA0NzJRMjkxIDUwNSAyMDAgNTQ4UTExMiA1ODkgOTggNTk3VDgzIDYxNlpNODQgLTExOFE4NCAtMTA4IDk5IC05OEg2NzhRNjk0IC0xMDQgNjk0IC0xMThRNjk0IC0xMzAgNjc5IC0xMzhIOThRODQgLTEzMSA4NCAtMTE4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQ2IiBkPSJNNDggMVEzMSAxIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc0MlE3NDkgNjc2IDc0OSA2NjlRNzQ5IDY2NCA3MzYgNTU3VDcyMiA0NDdRNzIwIDQ0MCA3MDIgNDQwSDY5MFE2ODMgNDQ1IDY4MyA0NTNRNjgzIDQ1NCA2ODYgNDc3VDY4OSA1MzBRNjg5IDU2MCA2ODIgNTc5VDY2MyA2MTBUNjI2IDYyNlQ1NzUgNjMzVDUwMyA2MzRINDgwUTM5OCA2MzMgMzkzIDYzMVEzODggNjI5IDM4NiA2MjNRMzg1IDYyMiAzNTIgNDkyTDMyMCAzNjNIMzc1UTM3OCAzNjMgMzk4IDM2M1Q0MjYgMzY0VDQ0OCAzNjdUNDcyIDM3NFQ0ODkgMzg2UTUwMiAzOTggNTExIDQxOVQ1MjQgNDU3VDUyOSA0NzVRNTMyIDQ4MCA1NDggNDgwSDU2MFE1NjcgNDc1IDU2NyA0NzBRNTY3IDQ2NyA1MzYgMzM5VDUwMiAyMDdRNTAwIDIwMCA0ODIgMjAwSDQ3MFE0NjMgMjA2IDQ2MyAyMTJRNDYzIDIxNSA0NjggMjM0VDQ3MyAyNzRRNDczIDMwMyA0NTMgMzEwVDM2NCAzMTdIMzA5TDI3NyAxOTBRMjQ1IDY2IDI0NSA2MFEyNDUgNDYgMzM0IDQ2SDM1OVEzNjUgNDAgMzY1IDM5VDM2MyAxOVEzNTkgNiAzNTMgMEgzMzZRMjk1IDIgMTg1IDJRMTIwIDIgODYgMlQ0OCAxWiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNTYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI3NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIyMzI0IiB5PSI1ODEiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjIzMjQiIHk9Ii0zNTAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNDUwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjI2NSIgeD0iMzk3NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMzMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NiIgeD0iMjMyNCIgeT0iNTgxIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIyMzI0IiB5PSItMzUwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3NDczLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9zdmc+)
推论 存在![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjYxLjEzN2V4IiBoZWlnaHQ9IjMuODQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMS4wMDVleDsiIHZpZXdCb3g9IjAgLTEyMjEuOSAyNjMyMi45IDE2NTQuNSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTREIiBkPSJNMTMyIDYyMlExMjUgNjI5IDEyMSA2MzFUMTA1IDYzNFQ2MiA2MzdIMjlWNjgzSDEzNVEyMjEgNjgzIDIzMiA2ODJUMjQ5IDY3NVEyNTAgNjc0IDM1NCAzOThMNDU4IDEyNEw1NjIgMzk4UTY2NiA2NzQgNjY4IDY3NVE2NzEgNjgxIDY4MyA2ODJUNzgxIDY4M0g4ODdWNjM3SDg1NFE4MTQgNjM2IDgwMyA2MzRUNzg1IDYyMlY2MVE3OTEgNTEgODAyIDQ5VDg1NCA0Nkg4ODdWMEg4NzZRODU1IDMgNzM2IDNRNjA1IDMgNTk2IDBINTg1VjQ2SDYxOFE2NjAgNDcgNjY5IDQ5VDY4OCA2MVYzNDdRNjg4IDQyNCA2ODggNDYxVDY4OCA1NDZUNjg4IDYxM0w2ODcgNjMyUTQ1NCAxNCA0NTAgN1E0NDYgMSA0MzAgMVQ0MTAgN1E0MDkgOSAyOTIgMzE2TDE3NiA2MjRWNjA2UTE3NSA1ODggMTc1IDU0M1QxNzUgNDYzVDE3NSAzNTZMMTc2IDg2UTE4NyA1MCAyNjEgNDZIMjc4VjBIMjY5UTI1NCAzIDE1NCAzUTUyIDMgMzcgMEgyOVY0Nkg0NlE3OCA0OCA5OCA1NlQxMjIgNjlUMTMyIDg2VjYyMloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTUzIiBkPSJNNTUgNTA3UTU1IDU5MCAxMTIgNjQ3VDI0MyA3MDRIMjU3UTM0MiA3MDQgNDA1IDY0MUw0MjYgNjcyUTQzMSA2NzkgNDM2IDY4N1Q0NDYgNzAwTDQ0OSA3MDRRNDUwIDcwNCA0NTMgNzA0VDQ1OSA3MDVINDYzUTQ2NiA3MDUgNDcyIDY5OVY0NjJMNDY2IDQ1Nkg0NDhRNDM3IDQ1NiA0MzUgNDU5VDQzMCA0NzlRNDEzIDYwNSAzMjkgNjQ2UTI5MiA2NjIgMjU0IDY2MlEyMDEgNjYyIDE2OCA2MjZUMTM1IDU0MlExMzUgNTA4IDE1MiA0ODBUMjAwIDQzNVEyMTAgNDMxIDI4NiA0MTJUMzcwIDM4OVE0MjcgMzY3IDQ2MyAzMTRUNTAwIDE5MVE1MDAgMTEwIDQ0OCA0NVQzMDEgLTIxUTI0NSAtMjEgMjAxIC00VDE0MCAyN0wxMjIgNDFRMTE4IDM2IDEwNyAyMVQ4NyAtN1Q3OCAtMjFRNzYgLTIyIDY4IC0yMkg2NFE2MSAtMjIgNTUgLTE2VjEwMVE1NSAyMjAgNTYgMjIyUTU4IDIyNyA3NiAyMjdIODlROTUgMjIxIDk1IDIxNFE5NSAxODIgMTA1IDE1MVQxMzkgOTBUMjA1IDQyVDMwNSAyNFEzNTIgMjQgMzg2IDYyVDQyMCAxNTVRNDIwIDE5OCAzOTggMjMzVDM0MCAyODFRMjg0IDI5NSAyNjYgMzAwUTI2MSAzMDEgMjM5IDMwNlQyMDYgMzE0VDE3NCAzMjVUMTQxIDM0M1QxMTIgMzY3VDg1IDQwMlE1NSA0NTEgNTUgNTA3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNDUiIGQ9Ik0xMjggNjE5UTEyMSA2MjYgMTE3IDYyOFQxMDEgNjMxVDU4IDYzNEgyNVY2ODBINTk3VjY3NlE1OTkgNjcwIDYxMSA1NjBUNjI1IDQ0NFY0NDBINTg1VjQ0NFE1ODQgNDQ3IDU4MiA0NjVRNTc4IDUwMCA1NzAgNTI2VDU1MyA1NzFUNTI4IDYwMVQ0OTggNjE5VDQ1NyA2MjlUNDExIDYzM1QzNTMgNjM0UTI2NiA2MzQgMjUxIDYzM1QyMzMgNjIyUTIzMyA2MjIgMjMzIDYyMVEyMzIgNjE5IDIzMiA0OTdWMzc2SDI4NlEzNTkgMzc4IDM3NyAzODVRNDEzIDQwMSA0MTYgNDY5UTQxNiA0NzEgNDE2IDQ3M1Y0OTNINDU2VjIxM0g0MTZWMjMzUTQxNSAyNjggNDA4IDI4OFQzODMgMzE3VDM0OSAzMjhUMjk3IDMzMFEyOTAgMzMwIDI4NiAzMzBIMjMyVjE5NlYxMTRRMjMyIDU3IDIzNyA1MlEyNDMgNDcgMjg5IDQ3SDM0MEgzOTFRNDI4IDQ3IDQ1MiA1MFQ1MDUgNjJUNTUyIDkyVDU4NCAxNDZRNTk0IDE3MiA1OTkgMjAwVDYwNyAyNDdUNjEyIDI3MFYyNzNINjUyVjI3MFE2NTEgMjY3IDYzMiAxMzdUNjEwIDNWMEgyNVY0Nkg1OFExMDAgNDcgMTA5IDQ5VDEyOCA2MVY2MTlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDUiIGQ9Ik00OTIgMjEzUTQ3MiAyMTMgNDcyIDIyNlE0NzIgMjMwIDQ3NyAyNTBUNDgyIDI4NVE0ODIgMzE2IDQ2MSAzMjNUMzY0IDMzMEgzMTJRMzExIDMyOCAyNzcgMTkyVDI0MyA1MlEyNDMgNDggMjU0IDQ4VDMzNCA0NlE0MjggNDYgNDU4IDQ4VDUxOCA2MVE1NjcgNzcgNTk5IDExN1Q2NzAgMjQ4UTY4MCAyNzAgNjgzIDI3MlE2OTAgMjc0IDY5OCAyNzRRNzE4IDI3NCA3MTggMjYxUTYxMyA3IDYwOCAyUTYwNSAwIDMyMiAwSDEzM1EzMSAwIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc1N1E3NjQgNjc2IDc2NCA2NjlRNzY0IDY2NCA3NTEgNTU3VDczNyA0NDdRNzM1IDQ0MCA3MTcgNDQwSDcwNVE2OTggNDQ1IDY5OCA0NTNMNzAxIDQ3NlE3MDQgNTAwIDcwNCA1MjhRNzA0IDU1OCA2OTcgNTc4VDY3OCA2MDlUNjQzIDYyNVQ1OTYgNjMyVDUzMiA2MzRINDg1UTM5NyA2MzMgMzkyIDYzMVEzODggNjI5IDM4NiA2MjJRMzg1IDYxOSAzNTUgNDk5VDMyNCAzNzdRMzQ3IDM3NiAzNzIgMzc2SDM5OFE0NjQgMzc2IDQ4OSAzOTFUNTM0IDQ3MlE1MzggNDg4IDU0MCA0OTBUNTU3IDQ5M1E1NjIgNDkzIDU2NSA0OTNUNTcwIDQ5MlQ1NzIgNDkxVDU3NCA0ODdUNTc3IDQ4M0w1NDQgMzUxUTUxMSAyMTggNTA4IDIxNlE1MDUgMjEzIDQ5MiAyMTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkUiIGQ9Ik0yMSAyODdRMjIgMjkzIDI0IDMwM1QzNiAzNDFUNTYgMzg4VDg5IDQyNVQxMzUgNDQyUTE3MSA0NDIgMTk1IDQyNFQyMjUgMzkwVDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzA0IDQ0MiAzODIgNDQyUTQzNiA0NDIgNDY5IDQxNVQ1MDMgMzM2VDQ2NSAxNzlUNDI3IDUyUTQyNyAyNiA0NDQgMjZRNDUwIDI2IDQ1MyAyN1E0ODIgMzIgNTA1IDY1VDU0MCAxNDVRNTQyIDE1MyA1NjAgMTUzUTU4MCAxNTMgNTgwIDE0NVE1ODAgMTQ0IDU3NiAxMzBRNTY4IDEwMSA1NTQgNzNUNTA4IDE3VDQzOSAtMTBRMzkyIC0xMCAzNzEgMTdUMzUwIDczUTM1MCA5MiAzODYgMTkzVDQyMyAzNDVRNDIzIDQwNCAzNzkgNDA0SDM3NFEyODggNDA0IDIyOSAzMDNMMjIyIDI5MUwxODkgMTU3UTE1NiAyNiAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExMiAxODBUMTUyIDM0M1ExNTMgMzQ4IDE1MyAzNjZRMTUzIDQwNSAxMjkgNDA1UTkxIDQwNSA2NiAzMDVRNjAgMjg1IDYwIDI4NFE1OCAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTQyIiBkPSJNMTMxIDYyMlExMjQgNjI5IDEyMCA2MzFUMTA0IDYzNFQ2MSA2MzdIMjhWNjgzSDIyOUgyNjdIMzQ2UTQyMyA2ODMgNDU5IDY3OFQ1MzEgNjUxUTU3NCA2MjcgNTk5IDU5MFQ2MjQgNTEyUTYyNCA0NjEgNTgzIDQxOVQ0NzYgMzYwTDQ2NiAzNTdRNTM5IDM0OCA1OTUgMzAyVDY1MSAxODdRNjUxIDExOSA2MDAgNjdUNDY5IDNRNDU2IDEgMjQyIDBIMjhWNDZINjFRMTAzIDQ3IDExMiA0OVQxMzEgNjFWNjIyWk01MTEgNTEzUTUxMSA1NjAgNDg1IDU5NFQ0MTYgNjM2UTQxNSA2MzYgNDAzIDYzNlQzNzEgNjM2VDMzMyA2MzdRMjY2IDYzNyAyNTEgNjM2VDIzMiA2MjhRMjI5IDYyNCAyMjkgNDk5VjM3NEgzMTJMMzk2IDM3NUw0MDYgMzc3UTQxMCAzNzggNDE3IDM4MFQ0NDIgMzkzVDQ3NCA0MTdUNDk5IDQ1NlQ1MTEgNTEzWk01MzcgMTg4UTUzNyAyMzkgNTA5IDI4MlQ0MzAgMzM2TDMyOSAzMzdIMjI5VjIwMFYxMTZRMjI5IDU3IDIzNCA1MlEyNDAgNDcgMzM0IDQ3SDM4M1E0MjUgNDcgNDQzIDUzUTQ4NiA2NyA1MTEgMTA0VDUzNyAxODhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi02OSIgZD0iTTY5IDYwOVE2OSA2MzcgODcgNjUzVDEzMSA2NjlRMTU0IDY2NyAxNzEgNjUyVDE4OCA2MDlRMTg4IDU3OSAxNzEgNTY0VDEyOSA1NDlRMTA0IDU0OSA4NyA1NjRUNjkgNjA5Wk0yNDcgMFEyMzIgMyAxNDMgM1ExMzIgMyAxMDYgM1Q1NiAxTDM0IDBIMjZWNDZINDJRNzAgNDYgOTEgNDlRMTAwIDUzIDEwMiA2MFQxMDQgMTAyVjIwNVYyOTNRMTA0IDM0NSAxMDIgMzU5VDg4IDM3OFE3NCAzODUgNDEgMzg1SDMwVjQwOFEzMCA0MzEgMzIgNDMxTDQyIDQzMlE1MiA0MzMgNzAgNDM0VDEwNiA0MzZRMTIzIDQzNyAxNDIgNDM4VDE3MSA0NDFUMTgyIDQ0MkgxODVWNjJRMTkwIDUyIDE5NyA1MFQyMzIgNDZIMjU1VjBIMjQ3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNjEiIGQ9Ik0xMzcgMzA1VDExNSAzMDVUNzggMzIwVDYzIDM1OVE2MyAzOTQgOTcgNDIxVDIxOCA0NDhRMjkxIDQ0OCAzMzYgNDE2VDM5NiAzNDBRNDAxIDMyNiA0MDEgMzA5VDQwMiAxOTRWMTI0UTQwMiA3NiA0MDcgNThUNDI4IDQwUTQ0MyA0MCA0NDggNTZUNDUzIDEwOVYxNDVINDkzVjEwNlE0OTIgNjYgNDkwIDU5UTQ4MSAyOSA0NTUgMTJUNDAwIC02VDM1MyAxMlQzMjkgNTRWNThMMzI3IDU1UTMyNSA1MiAzMjIgNDlUMzE0IDQwVDMwMiAyOVQyODcgMTdUMjY5IDZUMjQ3IC0yVDIyMSAtOFQxOTAgLTExUTEzMCAtMTEgODIgMjBUMzQgMTA3UTM0IDEyOCA0MSAxNDdUNjggMTg4VDExNiAyMjVUMTk0IDI1M1QzMDQgMjY4SDMxOFYyOTBRMzE4IDMyNCAzMTIgMzQwUTI5MCA0MTEgMjE1IDQxMVExOTcgNDExIDE4MSA0MTBUMTU2IDQwNlQxNDggNDAzUTE3MCAzODggMTcwIDM1OVExNzAgMzM0IDE1NCAzMjBaTTEyNiAxMDZRMTI2IDc1IDE1MCA1MVQyMDkgMjZRMjQ3IDI2IDI3NiA0OVQzMTUgMTA5UTMxNyAxMTYgMzE4IDE3NVEzMTggMjMzIDMxNyAyMzNRMzA5IDIzMyAyOTYgMjMyVDI1MSAyMjNUMTkzIDIwM1QxNDcgMTY2VDEyNiAxMDZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03MyIgZD0iTTI5NSAzMTZRMjk1IDM1NiAyNjggMzg1VDE5MCA0MTRRMTU0IDQxNCAxMjggNDAxUTk4IDM4MiA5OCAzNDlROTcgMzQ0IDk4IDMzNlQxMTQgMzEyVDE1NyAyODdRMTc1IDI4MiAyMDEgMjc4VDI0NSAyNjlUMjc3IDI1NlEyOTQgMjQ4IDMxMCAyMzZUMzQyIDE5NVQzNTkgMTMzUTM1OSA3MSAzMjEgMzFUMTk4IC0xMEgxOTBRMTM4IC0xMCA5NCAyNkw4NiAxOUw3NyAxMFE3MSA0IDY1IC0xTDU0IC0xMUg0Nkg0MlEzOSAtMTEgMzMgLTVWNzRWMTMyUTMzIDE1MyAzNSAxNTdUNDUgMTYySDU0UTY2IDE2MiA3MCAxNThUNzUgMTQ2VDgyIDExOVQxMDEgNzdRMTM2IDI2IDE5OCAyNlEyOTUgMjYgMjk1IDEwNFEyOTUgMTMzIDI3NyAxNTFRMjU3IDE3NSAxOTQgMTg3VDExMSAyMTBRNzUgMjI3IDU0IDI1NlQzMyAzMThRMzMgMzU3IDUwIDM4NFQ5MyA0MjRUMTQzIDQ0MlQxODcgNDQ3SDE5OFEyMzggNDQ3IDI2OCA0MzJMMjgzIDQyNEwyOTIgNDMxUTMwMiA0NDAgMzE0IDQ0OEgzMjJIMzI2UTMyOSA0NDggMzM1IDQ0MlYzMTBMMzI5IDMwNEgzMDFRMjk1IDMxMCAyOTUgMzE2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMS0yOCIgZD0iTTE1MiAyNTFRMTUyIDY0NiAzODggODUwSDQxNlE0MjIgODQ0IDQyMiA4NDFRNDIyIDgzNyA0MDMgODE2VDM1NyA3NTNUMzAyIDY0OVQyNTUgNDgyVDIzNiAyNTBRMjM2IDEyNCAyNTUgMTlUMzAxIC0xNDdUMzU2IC0yNTFUNDAzIC0zMTVUNDIyIC0zNDBRNDIyIC0zNDMgNDE2IC0zNDlIMzg4UTM1OSAtMzI1IDMzMiAtMjk2VDI3MSAtMjEzVDIxMiAtOTdUMTcwIDU2VDE1MiAyNTFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oxLTI5IiBkPSJNMzA1IDI1MVEzMDUgLTE0NSA2OSAtMzQ5SDU2UTQzIC0zNDkgMzkgLTM0N1QzNSAtMzM4UTM3IC0zMzMgNjAgLTMwN1QxMDggLTIzOVQxNjAgLTEzNlQyMDQgMjdUMjIxIDI1MFQyMDQgNDczVDE2MCA2MzZUMTA4IDc0MFQ2MCA4MDdUMzUgODM5UTM1IDg1MCA1MCA4NTBINTZINjlRMTk3IDc0MyAyNTYgNTY2UTMwNSA0MjUgMzA1IDI1MVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yQiIgZD0iTTU2IDIzN1Q1NiAyNTBUNzAgMjcwSDM2OVY0MjBMMzcwIDU3MFEzODAgNTgzIDM4OSA1ODNRNDAyIDU4MyA0MDkgNTY4VjI3MEg3MDdRNzIyIDI2MiA3MjIgMjUwVDcwNyAyMzBINDA5Vi02OFE0MDEgLTgyIDM5MSAtODJIMzg5SDM4N1EzNzUgLTgyIDM2OSAtNjhWMjMwSDcwUTU2IDIzNyA1NiAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi01NiIgZD0iTTExNCA2MjBRMTEzIDYyMSAxMTAgNjI0VDEwNyA2MjdUMTAzIDYzMFQ5OCA2MzJUOTEgNjM0VDgwIDYzNVQ2NyA2MzZUNDggNjM3SDE5VjY4M0gyOFE0NiA2ODAgMTUyIDY4MFEyNzMgNjgwIDI5NCA2ODNIMzA1VjYzN0gyODRRMjIzIDYzNCAyMjMgNjIwUTIyMyA2MTggMzEzIDM3MlQ0MDQgMTI2TDQ5MCAzNThRNTc1IDU4OCA1NzUgNTk3UTU3NSA2MTYgNTU0IDYyNlQ1MDggNjM3SDUwM1Y2ODNINTEyUTUyNyA2ODAgNjI3IDY4MFE3MTggNjgwIDcyNCA2ODNINzMwVjYzN0g3MjNRNjQ4IDYzNyA2MjcgNTk2UTYyNyA1OTUgNTE1IDI5MVQ0MDEgLTE0UTM5NiAtMjIgMzgyIC0yMkgzNzRIMzY3UTM1MyAtMjIgMzQ4IC0xNFEzNDYgLTEyIDIzMSAzMDNRMTE0IDYxNyAxMTQgNjIwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNzIiIGQ9Ik0zNiA0Nkg1MFE4OSA0NiA5NyA2MFY2OFE5NyA3NyA5NyA5MVQ5OCAxMjJUOTggMTYxVDk4IDIwM1E5OCAyMzQgOTggMjY5VDk4IDMyOEw5NyAzNTFROTQgMzcwIDgzIDM3NlQzOCAzODVIMjBWNDA4UTIwIDQzMSAyMiA0MzFMMzIgNDMyUTQyIDQzMyA2MCA0MzRUOTYgNDM2UTExMiA0MzcgMTMxIDQzOFQxNjAgNDQxVDE3MSA0NDJIMTc0VjM3M1EyMTMgNDQxIDI3MSA0NDFIMjc3UTMyMiA0NDEgMzQzIDQxOVQzNjQgMzczUTM2NCAzNTIgMzUxIDMzN1QzMTMgMzIyUTI4OCAzMjIgMjc2IDMzOFQyNjMgMzcyUTI2MyAzODEgMjY1IDM4OFQyNzAgNDAwVDI3MyA0MDVRMjcxIDQwNyAyNTAgNDAxUTIzNCAzOTMgMjI2IDM4NlExNzkgMzQxIDE3OSAyMDdWMTU0UTE3OSAxNDEgMTc5IDEyN1QxNzkgMTAxVDE4MCA4MVQxODAgNjZWNjFRMTgxIDU5IDE4MyA1N1QxODggNTRUMTkzIDUxVDIwMCA0OVQyMDcgNDhUMjE2IDQ3VDIyNSA0N1QyMzUgNDZUMjQ1IDQ2SDI3NlYwSDI2N1EyNDkgMyAxNDAgM1EzNyAzIDI4IDBIMjBWNDZIMzZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDYiIGQ9Ik00OCAxUTMxIDEgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ2IDY2IDIxNSAzNDJUMjg1IDYyMlEyODUgNjI5IDI4MSA2MjlRMjczIDYzMiAyMjggNjM0SDE5N1ExOTEgNjQwIDE5MSA2NDJUMTkzIDY1OVExOTcgNjc2IDIwMyA2ODBINzQyUTc0OSA2NzYgNzQ5IDY2OVE3NDkgNjY0IDczNiA1NTdUNzIyIDQ0N1E3MjAgNDQwIDcwMiA0NDBINjkwUTY4MyA0NDUgNjgzIDQ1M1E2ODMgNDU0IDY4NiA0NzdUNjg5IDUzMFE2ODkgNTYwIDY4MiA1NzlUNjYzIDYxMFQ2MjYgNjI2VDU3NSA2MzNUNTAzIDYzNEg0ODBRMzk4IDYzMyAzOTMgNjMxUTM4OCA2MjkgMzg2IDYyM1EzODUgNjIyIDM1MiA0OTJMMzIwIDM2M0gzNzVRMzc4IDM2MyAzOTggMzYzVDQyNiAzNjRUNDQ4IDM2N1Q0NzIgMzc0VDQ4OSAzODZRNTAyIDM5OCA1MTEgNDE5VDUyNCA0NTdUNTI5IDQ3NVE1MzIgNDgwIDU0OCA0ODBINTYwUTU2NyA0NzUgNTY3IDQ3MFE1NjcgNDY3IDUzNiAzMzlUNTAyIDIwN1E1MDAgMjAwIDQ4MiAyMDBINDcwUTQ2MyAyMDYgNDYzIDIxMlE0NjMgMjE1IDQ2OCAyMzRUNDczIDI3NFE0NzMgMzAzIDQ1MyAzMTBUMzY0IDMxN0gzMDlMMjc3IDE5MFEyNDUgNjYgMjQ1IDYwUTI0NSA0NiAzMzQgNDZIMzU5UTM2NSA0MCAzNjUgMzlUMzYzIDE5UTM1OSA2IDM1MyAwSDMzNlEyOTUgMiAxODUgMlExMjAgMiA4NiAyVDQ4IDFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjY1IiBkPSJNODMgNjE2UTgzIDYyNCA4OSA2MzBUOTkgNjM2UTEwNyA2MzYgMjUzIDU2OFQ1NDMgNDMxVDY4NyAzNjFRNjk0IDM1NiA2OTQgMzQ2VDY4NyAzMzFRNjg1IDMyOSAzOTUgMTkyTDEwNyA1NkgxMDFRODMgNTggODMgNzZRODMgNzcgODMgNzlRODIgODYgOTggOTVRMTE3IDEwNSAyNDggMTY3UTMyNiAyMDQgMzc4IDIyOEw2MjYgMzQ2TDM2MCA0NzJRMjkxIDUwNSAyMDAgNTQ4UTExMiA1ODkgOTggNTk3VDgzIDYxNlpNODQgLTExOFE4NCAtMTA4IDk5IC05OEg2NzhRNjk0IC0xMDQgNjk0IC0xMThRNjk0IC0xMzAgNjc5IC0xMzhIOThRODQgLTEzMSA4NCAtMTE4WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNEQiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTUzIiB4PSI5MTciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTQ1IiB4PSIxNDc0IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIzMDQ4IiB5PSI2MTIiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjMwNDgiIHk9Ii0zNTAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyOTYyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjQ0ODkiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1NTQ1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDU4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi00MiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjkiIHg9IjcwOCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijk4NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzMiIHg9IjE0ODciIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9IjI2NjEiIHk9IjU4MSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMjY2MSIgeT0iLTM1MCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI2ODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjEtMjkiIHg9IjQzOTYiIHk9Ii0xIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjY4NjUiIHk9Ijg3NiI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTEwNzYiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjA3NiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNTYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI3NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ2IiB4PSIyMzI0IiB5PSI1ODEiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjIzMjQiIHk9Ii0zNTAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0NTE3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjI2NSIgeD0iMTYwNDMiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNzA5OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNEQiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTUzIiB4PSI5MTciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTQ1IiB4PSIxNDc0IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ2IiB4PSIzMDQ4IiB5PSI2MTIiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjMwNDgiIHk9Ii0zNTAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIwMDUxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjIxNTc4IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjI2MzQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NiIgeD0iMjMyNCIgeT0iNTgxIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIyMzI0IiB5PSItMzUwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNTA3NCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==)
图3显示了MSE发生交叉的实例。在 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjYuMzI1ZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgMjcyMy4xIDkzNi45IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTRFIiBkPSJNMjM0IDYzN1EyMzEgNjM3IDIyNiA2MzdRMjAxIDYzNyAxOTYgNjM4VDE5MSA2NDlRMTkxIDY3NiAyMDIgNjgyUTIwNCA2ODMgMjk5IDY4M1EzNzYgNjgzIDM4NyA2ODNUNDAxIDY3N1E2MTIgMTgxIDYxNiAxNjhMNjcwIDM4MVE3MjMgNTkyIDcyMyA2MDZRNzIzIDYzMyA2NTkgNjM3UTYzNSA2MzcgNjM1IDY0OFE2MzUgNjUwIDYzNyA2NjBRNjQxIDY3NiA2NDMgNjc5VDY1MyA2ODNRNjU2IDY4MyA2ODQgNjgyVDc2NyA2ODBRODE3IDY4MCA4NDMgNjgxVDg3MyA2ODJRODg4IDY4MiA4ODggNjcyUTg4OCA2NTAgODgwIDY0MlE4NzggNjM3IDg1OCA2MzdRNzg3IDYzMyA3NjkgNTk3TDYyMCA3UTYxOCAwIDU5OSAwUTU4NSAwIDU4MiAyUTU3OSA1IDQ1MyAzMDVMMzI2IDYwNEwyNjEgMzQ0UTE5NiA4OCAxOTYgNzlRMjAxIDQ2IDI2OCA0NkgyNzhRMjg0IDQxIDI4NCAzOFQyODIgMTlRMjc4IDYgMjcyIDBIMjU5UTIyOCAyIDE1MSAyUTEyMyAyIDEwMCAyVDYzIDJUNDYgMVEzMSAxIDMxIDEwUTMxIDE0IDM0IDI2VDM5IDQwUTQxIDQ2IDYyIDQ2UTEzMCA0OSAxNTAgODVRMTU0IDkxIDIyMSAzNjJMMjg5IDYzNFEyODcgNjM1IDIzNCA2MzdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTM1IiBkPSJNMTY0IDE1N1ExNjQgMTMzIDE0OCAxMTdUMTA5IDEwMUgxMDJRMTQ4IDIyIDIyNCAyMlEyOTQgMjIgMzI2IDgyUTM0NSAxMTUgMzQ1IDIxMFEzNDUgMzEzIDMxOCAzNDlRMjkyIDM4MiAyNjAgMzgySDI1NFExNzYgMzgyIDEzNiAzMTRRMTMyIDMwNyAxMjkgMzA2VDExNCAzMDRROTcgMzA0IDk1IDMxMFE5MyAzMTQgOTMgNDg1VjYxNFE5MyA2NjQgOTggNjY0UTEwMCA2NjYgMTAyIDY2NlExMDMgNjY2IDEyMyA2NThUMTc4IDY0MlQyNTMgNjM0UTMyNCA2MzQgMzg5IDY2MlEzOTcgNjY2IDQwMiA2NjZRNDEwIDY2NiA0MTAgNjQ4VjYzNVEzMjggNTM4IDIwNSA1MzhRMTc0IDUzOCAxNDkgNTQ0TDEzOSA1NDZWMzc0UTE1OCAzODggMTY5IDM5NlQyMDUgNDEyVDI1NiA0MjBRMzM3IDQyMCAzOTMgMzU1VDQ0OSAyMDFRNDQ5IDEwOSAzODUgNDRUMjI5IC0yMlExNDggLTIyIDk5IDMyVDUwIDE1NFE1MCAxNzggNjEgMTkyVDg0IDIxMFQxMDcgMjE0UTEzMiAyMTQgMTQ4IDE5N1QxNjQgMTU3WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTRFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMTE2NiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzUiIHg9IjIyMjIiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) 时发生交叉。通常,交叉可以在一次试验时发生。例如,如果问题中唯一的非零奖励是终止,则
时发生交叉。通常,交叉可以在一次试验时发生。例如,如果问题中唯一的非零奖励是终止,则 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjcuMDI4ZXgiIGhlaWdodD0iMi41MDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjY3MWV4OyIgdmlld0JveD0iMCAtNzkxLjMgMzAyNiAxMDgwLjQiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTIiIGQ9Ik0yMzAgNjM3UTIwMyA2MzcgMTk4IDYzOFQxOTMgNjQ5UTE5MyA2NzYgMjA0IDY4MlEyMDYgNjgzIDM3OCA2ODNRNTUwIDY4MiA1NjQgNjgwUTYyMCA2NzIgNjU4IDY1MlQ3MTIgNjA2VDczMyA1NjNUNzM5IDUyOVE3MzkgNDg0IDcxMCA0NDVUNjQzIDM4NVQ1NzYgMzUxVDUzOCAzMzhMNTQ1IDMzM1E2MTIgMjk1IDYxMiAyMjNRNjEyIDIxMiA2MDcgMTYyVDYwMiA4MFY3MVE2MDIgNTMgNjAzIDQzVDYxNCAyNVQ2NDAgMTZRNjY4IDE2IDY4NiAzOFQ3MTIgODVRNzE3IDk5IDcyMCAxMDJUNzM1IDEwNVE3NTUgMTA1IDc1NSA5M1E3NTUgNzUgNzMxIDM2UTY5MyAtMjEgNjQxIC0yMUg2MzJRNTcxIC0yMSA1MzEgNFQ0ODcgODJRNDg3IDEwOSA1MDIgMTY2VDUxNyAyMzlRNTE3IDI5MCA0NzQgMzEzUTQ1OSAzMjAgNDQ5IDMyMVQzNzggMzIzSDMwOUwyNzcgMTkzUTI0NCA2MSAyNDQgNTlRMjQ0IDU1IDI0NSA1NFQyNTIgNTBUMjY5IDQ4VDMwMiA0NkgzMzNRMzM5IDM4IDMzOSAzN1QzMzYgMTlRMzMyIDYgMzI2IDBIMzExUTI3NSAyIDE4MCAyUTE0NiAyIDExNyAyVDcxIDJUNTAgMVEzMyAxIDMzIDEwUTMzIDEyIDM2IDI0UTQxIDQzIDQ2IDQ1UTUwIDQ2IDYxIDQ2SDY3UTk0IDQ2IDEyNyA0OVExNDEgNTIgMTQ2IDYxUTE0OSA2NSAyMTggMzM5VDI4NyA2MjhRMjg3IDYzNSAyMzAgNjM3Wk02MzAgNTU0UTYzMCA1ODYgNjA5IDYwOFQ1MjMgNjM2UTUyMSA2MzYgNTAwIDYzNlQ0NjIgNjM3SDQ0MFEzOTMgNjM3IDM4NiA2MjdRMzg1IDYyNCAzNTIgNDk0VDMxOSAzNjFRMzE5IDM2MCAzODggMzYwUTQ2NiAzNjEgNDkyIDM2N1E1NTYgMzc3IDU5MiA0MjZRNjA4IDQ0OSA2MTkgNDg2VDYzMCA1NTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMwIiBkPSJNOTYgNTg1UTE1MiA2NjYgMjQ5IDY2NlEyOTcgNjY2IDM0NSA2NDBUNDIzIDU0OFE0NjAgNDY1IDQ2MCAzMjBRNDYwIDE2NSA0MTcgODNRMzk3IDQxIDM2MiAxNlQzMDEgLTE1VDI1MCAtMjJRMjI0IC0yMiAxOTggLTE2VDEzNyAxNlQ4MiA4M1EzOSAxNjUgMzkgMzIwUTM5IDQ5NCA5NiA1ODVaTTMyMSA1OTdRMjkxIDYyOSAyNTAgNjI5UTIwOCA2MjkgMTc4IDU5N1ExNTMgNTcxIDE0NSA1MjVUMTM3IDMzM1ExMzcgMTc1IDE0NSAxMjVUMTgxIDQ2UTIwOSAxNiAyNTAgMTZRMjkwIDE2IDMxOCA0NlEzNDcgNzYgMzU0IDEzMFQzNjIgMzMzUTM2MiA0NzggMzU0IDUyNFQzMjEgNTk3WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMTQ2OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzAiIHg9IjI1MjUiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) ,
, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEyLjMyNmV4IiBoZWlnaHQ9IjIuODQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMC44MzhleDsiIHZpZXdCb3g9IjAgLTg2My4xIDUzMDcuMiAxMjIzLjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi01NiIgZD0iTTExNCA2MjBRMTEzIDYyMSAxMTAgNjI0VDEwNyA2MjdUMTAzIDYzMFQ5OCA2MzJUOTEgNjM0VDgwIDYzNVQ2NyA2MzZUNDggNjM3SDE5VjY4M0gyOFE0NiA2ODAgMTUyIDY4MFEyNzMgNjgwIDI5NCA2ODNIMzA1VjYzN0gyODRRMjIzIDYzNCAyMjMgNjIwUTIyMyA2MTggMzEzIDM3MlQ0MDQgMTI2TDQ5MCAzNThRNTc1IDU4OCA1NzUgNTk3UTU3NSA2MTYgNTU0IDYyNlQ1MDggNjM3SDUwM1Y2ODNINTEyUTUyNyA2ODAgNjI3IDY4MFE3MTggNjgwIDcyNCA2ODNINzMwVjYzN0g3MjNRNjQ4IDYzNyA2MjcgNTk2UTYyNyA1OTUgNTE1IDI5MVQ0MDEgLTE0UTM5NiAtMjIgMzgyIC0yMkgzNzRIMzY3UTM1MyAtMjIgMzQ4IC0xNFEzNDYgLTEyIDIzMSAzMDNRMTE0IDYxNyAxMTQgNjIwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNjEiIGQ9Ik0xMzcgMzA1VDExNSAzMDVUNzggMzIwVDYzIDM1OVE2MyAzOTQgOTcgNDIxVDIxOCA0NDhRMjkxIDQ0OCAzMzYgNDE2VDM5NiAzNDBRNDAxIDMyNiA0MDEgMzA5VDQwMiAxOTRWMTI0UTQwMiA3NiA0MDcgNThUNDI4IDQwUTQ0MyA0MCA0NDggNTZUNDUzIDEwOVYxNDVINDkzVjEwNlE0OTIgNjYgNDkwIDU5UTQ4MSAyOSA0NTUgMTJUNDAwIC02VDM1MyAxMlQzMjkgNTRWNThMMzI3IDU1UTMyNSA1MiAzMjIgNDlUMzE0IDQwVDMwMiAyOVQyODcgMTdUMjY5IDZUMjQ3IC0yVDIyMSAtOFQxOTAgLTExUTEzMCAtMTEgODIgMjBUMzQgMTA3UTM0IDEyOCA0MSAxNDdUNjggMTg4VDExNiAyMjVUMTk0IDI1M1QzMDQgMjY4SDMxOFYyOTBRMzE4IDMyNCAzMTIgMzQwUTI5MCA0MTEgMjE1IDQxMVExOTcgNDExIDE4MSA0MTBUMTU2IDQwNlQxNDggNDAzUTE3MCAzODggMTcwIDM1OVExNzAgMzM0IDE1NCAzMjBaTTEyNiAxMDZRMTI2IDc1IDE1MCA1MVQyMDkgMjZRMjQ3IDI2IDI3NiA0OVQzMTUgMTA5UTMxNyAxMTYgMzE4IDE3NVEzMTggMjMzIDMxNyAyMzNRMzA5IDIzMyAyOTYgMjMyVDI1MSAyMjNUMTkzIDIwM1QxNDcgMTY2VDEyNiAxMDZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03MiIgZD0iTTM2IDQ2SDUwUTg5IDQ2IDk3IDYwVjY4UTk3IDc3IDk3IDkxVDk4IDEyMlQ5OCAxNjFUOTggMjAzUTk4IDIzNCA5OCAyNjlUOTggMzI4TDk3IDM1MVE5NCAzNzAgODMgMzc2VDM4IDM4NUgyMFY0MDhRMjAgNDMxIDIyIDQzMUwzMiA0MzJRNDIgNDMzIDYwIDQzNFQ5NiA0MzZRMTEyIDQzNyAxMzEgNDM4VDE2MCA0NDFUMTcxIDQ0MkgxNzRWMzczUTIxMyA0NDEgMjcxIDQ0MUgyNzdRMzIyIDQ0MSAzNDMgNDE5VDM2NCAzNzNRMzY0IDM1MiAzNTEgMzM3VDMxMyAzMjJRMjg4IDMyMiAyNzYgMzM4VDI2MyAzNzJRMjYzIDM4MSAyNjUgMzg4VDI3MCA0MDBUMjczIDQwNVEyNzEgNDA3IDI1MCA0MDFRMjM0IDM5MyAyMjYgMzg2UTE3OSAzNDEgMTc5IDIwN1YxNTRRMTc5IDE0MSAxNzkgMTI3VDE3OSAxMDFUMTgwIDgxVDE4MCA2NlY2MVExODEgNTkgMTgzIDU3VDE4OCA1NFQxOTMgNTFUMjAwIDQ5VDIwNyA0OFQyMTYgNDdUMjI1IDQ3VDIzNSA0NlQyNDUgNDZIMjc2VjBIMjY3UTI0OSAzIDE0MCAzUTM3IDMgMjggMEgyMFY0NkgzNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzIiIGQ9Ik0yMSAyODdRMjIgMjkwIDIzIDI5NVQyOCAzMTdUMzggMzQ4VDUzIDM4MVQ3MyA0MTFUOTkgNDMzVDEzMiA0NDJRMTYxIDQ0MiAxODMgNDMwVDIxNCA0MDhUMjI1IDM4OFEyMjcgMzgyIDIyOCAzODJUMjM2IDM4OVEyODQgNDQxIDM0NyA0NDFIMzUwUTM5OCA0NDEgNDIyIDQwMFE0MzAgMzgxIDQzMCAzNjNRNDMwIDMzMyA0MTcgMzE1VDM5MSAyOTJUMzY2IDI4OFEzNDYgMjg4IDMzNCAyOTlUMzIyIDMyOFEzMjIgMzc2IDM3OCAzOTJRMzU2IDQwNSAzNDIgNDA1UTI4NiA0MDUgMjM5IDMzMVEyMjkgMzE1IDIyNCAyOThUMTkwIDE2NVExNTYgMjUgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTQgMTg5VDE1NCAzNjZRMTU0IDQwNSAxMjggNDA1UTEwNyA0MDUgOTIgMzc3VDY4IDMxNlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMwIiBkPSJNOTYgNTg1UTE1MiA2NjYgMjQ5IDY2NlEyOTcgNjY2IDM0NSA2NDBUNDIzIDU0OFE0NjAgNDY1IDQ2MCAzMjBRNDYwIDE2NSA0MTcgODNRMzk3IDQxIDM2MiAxNlQzMDEgLTE1VDI1MCAtMjJRMjI0IC0yMiAxOTggLTE2VDEzNyAxNlQ4MiA4M1EzOSAxNjUgMzkgMzIwUTM5IDQ5NCA5NiA1ODVaTTMyMSA1OTdRMjkxIDYyOSAyNTAgNjI5UTIwOCA2MjkgMTc4IDU5N1ExNTMgNTcxIDE0NSA1MjVUMTM3IDMzM1ExMzcgMTc1IDE0NSAxMjVUMTgxIDQ2UTIwOSAxNiAyNTAgMTZRMjkwIDE2IDMxOCA0NlEzNDcgNzYgMzU0IDEzMFQzNjIgMzMzUTM2MiA0NzggMzU0IDUyNFQzMjEgNTk3WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNTYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI3NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTgxMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxMjcyIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIzNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMCIgeD0iNDgwNiIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) ,这反过来暗示
,这反过来暗示 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjEwLjEyZXgiIGhlaWdodD0iMy4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjgzOGV4OyIgdmlld0JveD0iMCAtMTAwNi42IDQzNTcuMSAxMzY3LjQiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi00MiIgZD0iTTEzMSA2MjJRMTI0IDYyOSAxMjAgNjMxVDEwNCA2MzRUNjEgNjM3SDI4VjY4M0gyMjlIMjY3SDM0NlE0MjMgNjgzIDQ1OSA2NzhUNTMxIDY1MVE1NzQgNjI3IDU5OSA1OTBUNjI0IDUxMlE2MjQgNDYxIDU4MyA0MTlUNDc2IDM2MEw0NjYgMzU3UTUzOSAzNDggNTk1IDMwMlQ2NTEgMTg3UTY1MSAxMTkgNjAwIDY3VDQ2OSAzUTQ1NiAxIDI0MiAwSDI4VjQ2SDYxUTEwMyA0NyAxMTIgNDlUMTMxIDYxVjYyMlpNNTExIDUxM1E1MTEgNTYwIDQ4NSA1OTRUNDE2IDYzNlE0MTUgNjM2IDQwMyA2MzZUMzcxIDYzNlQzMzMgNjM3UTI2NiA2MzcgMjUxIDYzNlQyMzIgNjI4UTIyOSA2MjQgMjI5IDQ5OVYzNzRIMzEyTDM5NiAzNzVMNDA2IDM3N1E0MTAgMzc4IDQxNyAzODBUNDQyIDM5M1Q0NzQgNDE3VDQ5OSA0NTZUNTExIDUxM1pNNTM3IDE4OFE1MzcgMjM5IDUwOSAyODJUNDMwIDMzNkwzMjkgMzM3SDIyOVYyMDBWMTE2UTIyOSA1NyAyMzQgNTJRMjQwIDQ3IDMzNCA0N0gzODNRNDI1IDQ3IDQ0MyA1M1E0ODYgNjcgNTExIDEwNFQ1MzcgMTg4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNjkiIGQ9Ik02OSA2MDlRNjkgNjM3IDg3IDY1M1QxMzEgNjY5UTE1NCA2NjcgMTcxIDY1MlQxODggNjA5UTE4OCA1NzkgMTcxIDU2NFQxMjkgNTQ5UTEwNCA1NDkgODcgNTY0VDY5IDYwOVpNMjQ3IDBRMjMyIDMgMTQzIDNRMTMyIDMgMTA2IDNUNTYgMUwzNCAwSDI2VjQ2SDQyUTcwIDQ2IDkxIDQ5UTEwMCA1MyAxMDIgNjBUMTA0IDEwMlYyMDVWMjkzUTEwNCAzNDUgMTAyIDM1OVQ4OCAzNzhRNzQgMzg1IDQxIDM4NUgzMFY0MDhRMzAgNDMxIDMyIDQzMUw0MiA0MzJRNTIgNDMzIDcwIDQzNFQxMDYgNDM2UTEyMyA0MzcgMTQyIDQzOFQxNzEgNDQxVDE4MiA0NDJIMTg1VjYyUTE5MCA1MiAxOTcgNTBUMjMyIDQ2SDI1NVYwSDI0N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTYxIiBkPSJNMTM3IDMwNVQxMTUgMzA1VDc4IDMyMFQ2MyAzNTlRNjMgMzk0IDk3IDQyMVQyMTggNDQ4UTI5MSA0NDggMzM2IDQxNlQzOTYgMzQwUTQwMSAzMjYgNDAxIDMwOVQ0MDIgMTk0VjEyNFE0MDIgNzYgNDA3IDU4VDQyOCA0MFE0NDMgNDAgNDQ4IDU2VDQ1MyAxMDlWMTQ1SDQ5M1YxMDZRNDkyIDY2IDQ5MCA1OVE0ODEgMjkgNDU1IDEyVDQwMCAtNlQzNTMgMTJUMzI5IDU0VjU4TDMyNyA1NVEzMjUgNTIgMzIyIDQ5VDMxNCA0MFQzMDIgMjlUMjg3IDE3VDI2OSA2VDI0NyAtMlQyMjEgLThUMTkwIC0xMVExMzAgLTExIDgyIDIwVDM0IDEwN1EzNCAxMjggNDEgMTQ3VDY4IDE4OFQxMTYgMjI1VDE5NCAyNTNUMzA0IDI2OEgzMThWMjkwUTMxOCAzMjQgMzEyIDM0MFEyOTAgNDExIDIxNSA0MTFRMTk3IDQxMSAxODEgNDEwVDE1NiA0MDZUMTQ4IDQwM1ExNzAgMzg4IDE3MCAzNTlRMTcwIDMzNCAxNTQgMzIwWk0xMjYgMTA2UTEyNiA3NSAxNTAgNTFUMjA5IDI2UTI0NyAyNiAyNzYgNDlUMzE1IDEwOVEzMTcgMTE2IDMxOCAxNzVRMzE4IDIzMyAzMTcgMjMzUTMwOSAyMzMgMjk2IDIzMlQyNTEgMjIzVDE5MyAyMDNUMTQ3IDE2NlQxMjYgMTA2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNzMiIGQ9Ik0yOTUgMzE2UTI5NSAzNTYgMjY4IDM4NVQxOTAgNDE0UTE1NCA0MTQgMTI4IDQwMVE5OCAzODIgOTggMzQ5UTk3IDM0NCA5OCAzMzZUMTE0IDMxMlQxNTcgMjg3UTE3NSAyODIgMjAxIDI3OFQyNDUgMjY5VDI3NyAyNTZRMjk0IDI0OCAzMTAgMjM2VDM0MiAxOTVUMzU5IDEzM1EzNTkgNzEgMzIxIDMxVDE5OCAtMTBIMTkwUTEzOCAtMTAgOTQgMjZMODYgMTlMNzcgMTBRNzEgNCA2NSAtMUw1NCAtMTFINDZINDJRMzkgLTExIDMzIC01Vjc0VjEzMlEzMyAxNTMgMzUgMTU3VDQ1IDE2Mkg1NFE2NiAxNjIgNzAgMTU4VDc1IDE0NlQ4MiAxMTlUMTAxIDc3UTEzNiAyNiAxOTggMjZRMjk1IDI2IDI5NSAxMDRRMjk1IDEzMyAyNzcgMTUxUTI1NyAxNzUgMTk0IDE4N1QxMTEgMjEwUTc1IDIyNyA1NCAyNTZUMzMgMzE4UTMzIDM1NyA1MCAzODRUOTMgNDI0VDE0MyA0NDJUMTg3IDQ0N0gxOThRMjM4IDQ0NyAyNjggNDMyTDI4MyA0MjRMMjkyIDQzMVEzMDIgNDQwIDMxNCA0NDhIMzIySDMyNlEzMjkgNDQ4IDMzNSA0NDJWMzEwTDMyOSAzMDRIMzAxUTI5NSAzMTAgMjk1IDMxNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NSIgZD0iTTQ5MiAyMTNRNDcyIDIxMyA0NzIgMjI2UTQ3MiAyMzAgNDc3IDI1MFQ0ODIgMjg1UTQ4MiAzMTYgNDYxIDMyM1QzNjQgMzMwSDMxMlEzMTEgMzI4IDI3NyAxOTJUMjQzIDUyUTI0MyA0OCAyNTQgNDhUMzM0IDQ2UTQyOCA0NiA0NTggNDhUNTE4IDYxUTU2NyA3NyA1OTkgMTE3VDY3MCAyNDhRNjgwIDI3MCA2ODMgMjcyUTY5MCAyNzQgNjk4IDI3NFE3MTggMjc0IDcxOCAyNjFRNjEzIDcgNjA4IDJRNjA1IDAgMzIyIDBIMTMzUTMxIDAgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ2IDY2IDIxNSAzNDJUMjg1IDYyMlEyODUgNjI5IDI4MSA2MjlRMjczIDYzMiAyMjggNjM0SDE5N1ExOTEgNjQwIDE5MSA2NDJUMTkzIDY1OVExOTcgNjc2IDIwMyA2ODBINzU3UTc2NCA2NzYgNzY0IDY2OVE3NjQgNjY0IDc1MSA1NTdUNzM3IDQ0N1E3MzUgNDQwIDcxNyA0NDBINzA1UTY5OCA0NDUgNjk4IDQ1M0w3MDEgNDc2UTcwNCA1MDAgNzA0IDUyOFE3MDQgNTU4IDY5NyA1NzhUNjc4IDYwOVQ2NDMgNjI1VDU5NiA2MzJUNTMyIDYzNEg0ODVRMzk3IDYzMyAzOTIgNjMxUTM4OCA2MjkgMzg2IDYyMlEzODUgNjE5IDM1NSA0OTlUMzI0IDM3N1EzNDcgMzc2IDM3MiAzNzZIMzk4UTQ2NCAzNzYgNDg5IDM5MVQ1MzQgNDcyUTUzOCA0ODggNTQwIDQ5MFQ1NTcgNDkzUTU2MiA0OTMgNTY1IDQ5M1Q1NzAgNDkyVDU3MiA0OTFUNTc0IDQ4N1Q1NzcgNDgzTDU0NCAzNTFRNTExIDIxOCA1MDggMjE2UTUwNSAyMTMgNDkyIDIxM1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzAiIGQ9Ik05NiA1ODVRMTUyIDY2NiAyNDkgNjY2UTI5NyA2NjYgMzQ1IDY0MFQ0MjMgNTQ4UTQ2MCA0NjUgNDYwIDMyMFE0NjAgMTY1IDQxNyA4M1EzOTcgNDEgMzYyIDE2VDMwMSAtMTVUMjUwIC0yMlEyMjQgLTIyIDE5OCAtMTZUMTM3IDE2VDgyIDgzUTM5IDE2NSAzOSAzMjBRMzkgNDk0IDk2IDU4NVpNMzIxIDU5N1EyOTEgNjI5IDI1MCA2MjlRMjA4IDYyOSAxNzggNTk3UTE1MyA1NzEgMTQ1IDUyNVQxMzcgMzMzUTEzNyAxNzUgMTQ1IDEyNVQxODEgNDZRMjA5IDE2IDI1MCAxNlEyOTAgMTYgMzE4IDQ2UTM0NyA3NiAzNTQgMTMwVDM2MiAzMzNRMzYyIDQ3OCAzNTQgNTI0VDMyMSA1OTdaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi00MiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjkiIHg9IjcwOCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijk4NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzMiIHg9IjE0ODciIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9IjI2NjEiIHk9IjU4MSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMjY2MSIgeT0iLTM1MCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI4MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMwIiB4PSIzODU2IiB5PSIwIj48L3VzZT4KPC9nPgo8L3N2Zz4=) ,对于所有 ,
,对于所有 , ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIwLjI1OGV4IiBoZWlnaHQ9IjMuMTc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMC44MzhleDsiIHZpZXdCb3g9IjAgLTEwMDYuNiA4NzIxLjkgMTM2Ny40IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNTYiIGQ9Ik0xMTQgNjIwUTExMyA2MjEgMTEwIDYyNFQxMDcgNjI3VDEwMyA2MzBUOTggNjMyVDkxIDYzNFQ4MCA2MzVUNjcgNjM2VDQ4IDYzN0gxOVY2ODNIMjhRNDYgNjgwIDE1MiA2ODBRMjczIDY4MCAyOTQgNjgzSDMwNVY2MzdIMjg0UTIyMyA2MzQgMjIzIDYyMFEyMjMgNjE4IDMxMyAzNzJUNDA0IDEyNkw0OTAgMzU4UTU3NSA1ODggNTc1IDU5N1E1NzUgNjE2IDU1NCA2MjZUNTA4IDYzN0g1MDNWNjgzSDUxMlE1MjcgNjgwIDYyNyA2ODBRNzE4IDY4MCA3MjQgNjgzSDczMFY2MzdINzIzUTY0OCA2MzcgNjI3IDU5NlE2MjcgNTk1IDUxNSAyOTFUNDAxIC0xNFEzOTYgLTIyIDM4MiAtMjJIMzc0SDM2N1EzNTMgLTIyIDM0OCAtMTRRMzQ2IC0xMiAyMzEgMzAzUTExNCA2MTcgMTE0IDYyMFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTYxIiBkPSJNMTM3IDMwNVQxMTUgMzA1VDc4IDMyMFQ2MyAzNTlRNjMgMzk0IDk3IDQyMVQyMTggNDQ4UTI5MSA0NDggMzM2IDQxNlQzOTYgMzQwUTQwMSAzMjYgNDAxIDMwOVQ0MDIgMTk0VjEyNFE0MDIgNzYgNDA3IDU4VDQyOCA0MFE0NDMgNDAgNDQ4IDU2VDQ1MyAxMDlWMTQ1SDQ5M1YxMDZRNDkyIDY2IDQ5MCA1OVE0ODEgMjkgNDU1IDEyVDQwMCAtNlQzNTMgMTJUMzI5IDU0VjU4TDMyNyA1NVEzMjUgNTIgMzIyIDQ5VDMxNCA0MFQzMDIgMjlUMjg3IDE3VDI2OSA2VDI0NyAtMlQyMjEgLThUMTkwIC0xMVExMzAgLTExIDgyIDIwVDM0IDEwN1EzNCAxMjggNDEgMTQ3VDY4IDE4OFQxMTYgMjI1VDE5NCAyNTNUMzA0IDI2OEgzMThWMjkwUTMxOCAzMjQgMzEyIDM0MFEyOTAgNDExIDIxNSA0MTFRMTk3IDQxMSAxODEgNDEwVDE1NiA0MDZUMTQ4IDQwM1ExNzAgMzg4IDE3MCAzNTlRMTcwIDMzNCAxNTQgMzIwWk0xMjYgMTA2UTEyNiA3NSAxNTAgNTFUMjA5IDI2UTI0NyAyNiAyNzYgNDlUMzE1IDEwOVEzMTcgMTE2IDMxOCAxNzVRMzE4IDIzMyAzMTcgMjMzUTMwOSAyMzMgMjk2IDIzMlQyNTEgMjIzVDE5MyAyMDNUMTQ3IDE2NlQxMjYgMTA2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNzIiIGQ9Ik0zNiA0Nkg1MFE4OSA0NiA5NyA2MFY2OFE5NyA3NyA5NyA5MVQ5OCAxMjJUOTggMTYxVDk4IDIwM1E5OCAyMzQgOTggMjY5VDk4IDMyOEw5NyAzNTFROTQgMzcwIDgzIDM3NlQzOCAzODVIMjBWNDA4UTIwIDQzMSAyMiA0MzFMMzIgNDMyUTQyIDQzMyA2MCA0MzRUOTYgNDM2UTExMiA0MzcgMTMxIDQzOFQxNjAgNDQxVDE3MSA0NDJIMTc0VjM3M1EyMTMgNDQxIDI3MSA0NDFIMjc3UTMyMiA0NDEgMzQzIDQxOVQzNjQgMzczUTM2NCAzNTIgMzUxIDMzN1QzMTMgMzIyUTI4OCAzMjIgMjc2IDMzOFQyNjMgMzcyUTI2MyAzODEgMjY1IDM4OFQyNzAgNDAwVDI3MyA0MDVRMjcxIDQwNyAyNTAgNDAxUTIzNCAzOTMgMjI2IDM4NlExNzkgMzQxIDE3OSAyMDdWMTU0UTE3OSAxNDEgMTc5IDEyN1QxNzkgMTAxVDE4MCA4MVQxODAgNjZWNjFRMTgxIDU5IDE4MyA1N1QxODggNTRUMTkzIDUxVDIwMCA0OVQyMDcgNDhUMjE2IDQ3VDIyNSA0N1QyMzUgNDZUMjQ1IDQ2SDI3NlYwSDI2N1EyNDkgMyAxNDAgM1EzNyAzIDI4IDBIMjBWNDZIMzZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDUiIGQ9Ik00OTIgMjEzUTQ3MiAyMTMgNDcyIDIyNlE0NzIgMjMwIDQ3NyAyNTBUNDgyIDI4NVE0ODIgMzE2IDQ2MSAzMjNUMzY0IDMzMEgzMTJRMzExIDMyOCAyNzcgMTkyVDI0MyA1MlEyNDMgNDggMjU0IDQ4VDMzNCA0NlE0MjggNDYgNDU4IDQ4VDUxOCA2MVE1NjcgNzcgNTk5IDExN1Q2NzAgMjQ4UTY4MCAyNzAgNjgzIDI3MlE2OTAgMjc0IDY5OCAyNzRRNzE4IDI3NCA3MTggMjYxUTYxMyA3IDYwOCAyUTYwNSAwIDMyMiAwSDEzM1EzMSAwIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc1N1E3NjQgNjc2IDc2NCA2NjlRNzY0IDY2NCA3NTEgNTU3VDczNyA0NDdRNzM1IDQ0MCA3MTcgNDQwSDcwNVE2OTggNDQ1IDY5OCA0NTNMNzAxIDQ3NlE3MDQgNTAwIDcwNCA1MjhRNzA0IDU1OCA2OTcgNTc4VDY3OCA2MDlUNjQzIDYyNVQ1OTYgNjMyVDUzMiA2MzRINDg1UTM5NyA2MzMgMzkyIDYzMVEzODggNjI5IDM4NiA2MjJRMzg1IDYxOSAzNTUgNDk5VDMyNCAzNzdRMzQ3IDM3NiAzNzIgMzc2SDM5OFE0NjQgMzc2IDQ4OSAzOTFUNTM0IDQ3MlE1MzggNDg4IDU0MCA0OTBUNTU3IDQ5M1E1NjIgNDkzIDU2NSA0OTNUNTcwIDQ5MlQ1NzIgNDkxVDU3NCA0ODdUNTc3IDQ4M0w1NDQgMzUxUTUxMSAyMTggNTA4IDIxNlE1MDUgMjEzIDQ5MiAyMTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMSIgZD0iTTIxMyA1NzhMMjAwIDU3M1ExODYgNTY4IDE2MCA1NjNUMTAyIDU1Nkg4M1Y2MDJIMTAyUTE0OSA2MDQgMTg5IDYxN1QyNDUgNjQxVDI3MyA2NjNRMjc1IDY2NiAyODUgNjY2UTI5NCA2NjYgMzAyIDY2MFYzNjFMMzAzIDYxUTMxMCA1NCAzMTUgNTJUMzM5IDQ4VDQwMSA0Nkg0MjdWMEg0MTZRMzk1IDMgMjU3IDNRMTIxIDMgMTAwIDBIODhWNDZIMTE0UTEzNiA0NiAxNTIgNDZUMTc3IDQ3VDE5MyA1MFQyMDEgNTJUMjA3IDU3VDIxMyA2MVY1NzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NiIgZD0iTTQ4IDFRMzEgMSAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDYgNjYgMjE1IDM0MlQyODUgNjIyUTI4NSA2MjkgMjgxIDYyOVEyNzMgNjMyIDIyOCA2MzRIMTk3UTE5MSA2NDAgMTkxIDY0MlQxOTMgNjU5UTE5NyA2NzYgMjAzIDY4MEg3NDJRNzQ5IDY3NiA3NDkgNjY5UTc0OSA2NjQgNzM2IDU1N1Q3MjIgNDQ3UTcyMCA0NDAgNzAyIDQ0MEg2OTBRNjgzIDQ0NSA2ODMgNDUzUTY4MyA0NTQgNjg2IDQ3N1Q2ODkgNTMwUTY4OSA1NjAgNjgyIDU3OVQ2NjMgNjEwVDYyNiA2MjZUNTc1IDYzM1Q1MDMgNjM0SDQ4MFEzOTggNjMzIDM5MyA2MzFRMzg4IDYyOSAzODYgNjIzUTM4NSA2MjIgMzUyIDQ5MkwzMjAgMzYzSDM3NVEzNzggMzYzIDM5OCAzNjNUNDI2IDM2NFQ0NDggMzY3VDQ3MiAzNzRUNDg5IDM4NlE1MDIgMzk4IDUxMSA0MTlUNTI0IDQ1N1Q1MjkgNDc1UTUzMiA0ODAgNTQ4IDQ4MEg1NjBRNTY3IDQ3NSA1NjcgNDcwUTU2NyA0NjcgNTM2IDMzOVQ1MDIgMjA3UTUwMCAyMDAgNDgyIDIwMEg0NzBRNDYzIDIwNiA0NjMgMjEyUTQ2MyAyMTUgNDY4IDIzNFQ0NzMgMjc0UTQ3MyAzMDMgNDUzIDMxMFQzNjQgMzE3SDMwOUwyNzcgMTkwUTI0NSA2NiAyNDUgNjBRMjQ1IDQ2IDMzNCA0NkgzNTlRMzY1IDQwIDM2NSAzOVQzNjMgMTlRMzU5IDYgMzUzIDBIMzM2UTI5NSAyIDE4NSAyUTEyMCAyIDg2IDJUNDggMVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iMjMyNCIgeT0iNTgxIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjIzMjQiIHk9Ii0zNTAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNDUwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjM5NzciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MDMzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDYiIHg9IjIzMjQiIHk9IjU4MSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIyMzI0IiB5PSItMzUwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3NDczLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9zdmc+) ,因此
,因此 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIyLjYzNmV4IiBoZWlnaHQ9IjMuMTc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMC44MzhleDsiIHZpZXdCb3g9IjAgLTEwMDYuNiA5NzQ1LjkgMTM2Ny40IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNEQiIGQ9Ik0xMzIgNjIyUTEyNSA2MjkgMTIxIDYzMVQxMDUgNjM0VDYyIDYzN0gyOVY2ODNIMTM1UTIyMSA2ODMgMjMyIDY4MlQyNDkgNjc1UTI1MCA2NzQgMzU0IDM5OEw0NTggMTI0TDU2MiAzOThRNjY2IDY3NCA2NjggNjc1UTY3MSA2ODEgNjgzIDY4MlQ3ODEgNjgzSDg4N1Y2MzdIODU0UTgxNCA2MzYgODAzIDYzNFQ3ODUgNjIyVjYxUTc5MSA1MSA4MDIgNDlUODU0IDQ2SDg4N1YwSDg3NlE4NTUgMyA3MzYgM1E2MDUgMyA1OTYgMEg1ODVWNDZINjE4UTY2MCA0NyA2NjkgNDlUNjg4IDYxVjM0N1E2ODggNDI0IDY4OCA0NjFUNjg4IDU0NlQ2ODggNjEzTDY4NyA2MzJRNDU0IDE0IDQ1MCA3UTQ0NiAxIDQzMCAxVDQxMCA3UTQwOSA5IDI5MiAzMTZMMTc2IDYyNFY2MDZRMTc1IDU4OCAxNzUgNTQzVDE3NSA0NjNUMTc1IDM1NkwxNzYgODZRMTg3IDUwIDI2MSA0NkgyNzhWMEgyNjlRMjU0IDMgMTU0IDNRNTIgMyAzNyAwSDI5VjQ2SDQ2UTc4IDQ4IDk4IDU2VDEyMiA2OVQxMzIgODZWNjIyWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNTMiIGQ9Ik01NSA1MDdRNTUgNTkwIDExMiA2NDdUMjQzIDcwNEgyNTdRMzQyIDcwNCA0MDUgNjQxTDQyNiA2NzJRNDMxIDY3OSA0MzYgNjg3VDQ0NiA3MDBMNDQ5IDcwNFE0NTAgNzA0IDQ1MyA3MDRUNDU5IDcwNUg0NjNRNDY2IDcwNSA0NzIgNjk5VjQ2Mkw0NjYgNDU2SDQ0OFE0MzcgNDU2IDQzNSA0NTlUNDMwIDQ3OVE0MTMgNjA1IDMyOSA2NDZRMjkyIDY2MiAyNTQgNjYyUTIwMSA2NjIgMTY4IDYyNlQxMzUgNTQyUTEzNSA1MDggMTUyIDQ4MFQyMDAgNDM1UTIxMCA0MzEgMjg2IDQxMlQzNzAgMzg5UTQyNyAzNjcgNDYzIDMxNFQ1MDAgMTkxUTUwMCAxMTAgNDQ4IDQ1VDMwMSAtMjFRMjQ1IC0yMSAyMDEgLTRUMTQwIDI3TDEyMiA0MVExMTggMzYgMTA3IDIxVDg3IC03VDc4IC0yMVE3NiAtMjIgNjggLTIySDY0UTYxIC0yMiA1NSAtMTZWMTAxUTU1IDIyMCA1NiAyMjJRNTggMjI3IDc2IDIyN0g4OVE5NSAyMjEgOTUgMjE0UTk1IDE4MiAxMDUgMTUxVDEzOSA5MFQyMDUgNDJUMzA1IDI0UTM1MiAyNCAzODYgNjJUNDIwIDE1NVE0MjAgMTk4IDM5OCAyMzNUMzQwIDI4MVEyODQgMjk1IDI2NiAzMDBRMjYxIDMwMSAyMzkgMzA2VDIwNiAzMTRUMTc0IDMyNVQxNDEgMzQzVDExMiAzNjdUODUgNDAyUTU1IDQ1MSA1NSA1MDdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi00NSIgZD0iTTEyOCA2MTlRMTIxIDYyNiAxMTcgNjI4VDEwMSA2MzFUNTggNjM0SDI1VjY4MEg1OTdWNjc2UTU5OSA2NzAgNjExIDU2MFQ2MjUgNDQ0VjQ0MEg1ODVWNDQ0UTU4NCA0NDcgNTgyIDQ2NVE1NzggNTAwIDU3MCA1MjZUNTUzIDU3MVQ1MjggNjAxVDQ5OCA2MTlUNDU3IDYyOVQ0MTEgNjMzVDM1MyA2MzRRMjY2IDYzNCAyNTEgNjMzVDIzMyA2MjJRMjMzIDYyMiAyMzMgNjIxUTIzMiA2MTkgMjMyIDQ5N1YzNzZIMjg2UTM1OSAzNzggMzc3IDM4NVE0MTMgNDAxIDQxNiA0NjlRNDE2IDQ3MSA0MTYgNDczVjQ5M0g0NTZWMjEzSDQxNlYyMzNRNDE1IDI2OCA0MDggMjg4VDM4MyAzMTdUMzQ5IDMyOFQyOTcgMzMwUTI5MCAzMzAgMjg2IDMzMEgyMzJWMTk2VjExNFEyMzIgNTcgMjM3IDUyUTI0MyA0NyAyODkgNDdIMzQwSDM5MVE0MjggNDcgNDUyIDUwVDUwNSA2MlQ1NTIgOTJUNTg0IDE0NlE1OTQgMTcyIDU5OSAyMDBUNjA3IDI0N1Q2MTIgMjcwVjI3M0g2NTJWMjcwUTY1MSAyNjcgNjMyIDEzN1Q2MTAgM1YwSDI1VjQ2SDU4UTEwMCA0NyAxMDkgNDlUMTI4IDYxVjYxOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NSIgZD0iTTQ5MiAyMTNRNDcyIDIxMyA0NzIgMjI2UTQ3MiAyMzAgNDc3IDI1MFQ0ODIgMjg1UTQ4MiAzMTYgNDYxIDMyM1QzNjQgMzMwSDMxMlEzMTEgMzI4IDI3NyAxOTJUMjQzIDUyUTI0MyA0OCAyNTQgNDhUMzM0IDQ2UTQyOCA0NiA0NTggNDhUNTE4IDYxUTU2NyA3NyA1OTkgMTE3VDY3MCAyNDhRNjgwIDI3MCA2ODMgMjcyUTY5MCAyNzQgNjk4IDI3NFE3MTggMjc0IDcxOCAyNjFRNjEzIDcgNjA4IDJRNjA1IDAgMzIyIDBIMTMzUTMxIDAgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ2IDY2IDIxNSAzNDJUMjg1IDYyMlEyODUgNjI5IDI4MSA2MjlRMjczIDYzMiAyMjggNjM0SDE5N1ExOTEgNjQwIDE5MSA2NDJUMTkzIDY1OVExOTcgNjc2IDIwMyA2ODBINzU3UTc2NCA2NzYgNzY0IDY2OVE3NjQgNjY0IDc1MSA1NTdUNzM3IDQ0N1E3MzUgNDQwIDcxNyA0NDBINzA1UTY5OCA0NDUgNjk4IDQ1M0w3MDEgNDc2UTcwNCA1MDAgNzA0IDUyOFE3MDQgNTU4IDY5NyA1NzhUNjc4IDYwOVQ2NDMgNjI1VDU5NiA2MzJUNTMyIDYzNEg0ODVRMzk3IDYzMyAzOTIgNjMxUTM4OCA2MjkgMzg2IDYyMlEzODUgNjE5IDM1NSA0OTlUMzI0IDM3N1EzNDcgMzc2IDM3MiAzNzZIMzk4UTQ2NCAzNzYgNDg5IDM5MVQ1MzQgNDcyUTUzOCA0ODggNTQwIDQ5MFQ1NTcgNDkzUTU2MiA0OTMgNTY1IDQ5M1Q1NzAgNDkyVDU3MiA0OTFUNTc0IDQ4N1Q1NzcgNDgzTDU0NCAzNTFRNTExIDIxOCA1MDggMjE2UTUwNSAyMTMgNDkyIDIxM1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQ2IiBkPSJNNDggMVEzMSAxIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc0MlE3NDkgNjc2IDc0OSA2NjlRNzQ5IDY2NCA3MzYgNTU3VDcyMiA0NDdRNzIwIDQ0MCA3MDIgNDQwSDY5MFE2ODMgNDQ1IDY4MyA0NTNRNjgzIDQ1NCA2ODYgNDc3VDY4OSA1MzBRNjg5IDU2MCA2ODIgNTc5VDY2MyA2MTBUNjI2IDYyNlQ1NzUgNjMzVDUwMyA2MzRINDgwUTM5OCA2MzMgMzkzIDYzMVEzODggNjI5IDM4NiA2MjNRMzg1IDYyMiAzNTIgNDkyTDMyMCAzNjNIMzc1UTM3OCAzNjMgMzk4IDM2M1Q0MjYgMzY0VDQ0OCAzNjdUNDcyIDM3NFQ0ODkgMzg2UTUwMiAzOTggNTExIDQxOVQ1MjQgNDU3VDUyOSA0NzVRNTMyIDQ4MCA1NDggNDgwSDU2MFE1NjcgNDc1IDU2NyA0NzBRNTY3IDQ2NyA1MzYgMzM5VDUwMiAyMDdRNTAwIDIwMCA0ODIgMjAwSDQ3MFE0NjMgMjA2IDQ2MyAyMTJRNDYzIDIxNSA0NjggMjM0VDQ3MyAyNzRRNDczIDMwMyA0NTMgMzEwVDM2NCAzMTdIMzA5TDI3NyAxOTBRMjQ1IDY2IDI0NSA2MFEyNDUgNDYgMzM0IDQ2SDM1OVEzNjUgNDAgMzY1IDM5VDM2MyAxOVEzNTkgNiAzNTMgMEgzMzZRMjk1IDIgMTg1IDJRMTIwIDIgODYgMlQ0OCAxWiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNEQiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTUzIiB4PSI5MTciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTQ1IiB4PSIxNDc0IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIzMDQ4IiB5PSI2MTIiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMzA0OCIgeT0iLTM1MCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI5NjIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iNDQ4OSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU1NDUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTREIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01MyIgeD0iOTE3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi00NSIgeD0iMTQ3NCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NiIgeD0iMzA0OCIgeT0iNjEyIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjMwNDgiIHk9Ii0zNTAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDg0OTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=) 。
。
证明:
对于每次访问蒙特卡洛估计, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjI4LjAzOGV4IiBoZWlnaHQ9IjguNTA5ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMi44MzhleDsiIHZpZXdCb3g9IjAgLTI0NDEuOCAxMjA3MiAzNjYzLjciIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTYiIGQ9Ik01MiA2NDhRNTIgNjcwIDY1IDY4M0g3NlExMTggNjgwIDE4MSA2ODBRMjk5IDY4MCAzMjAgNjgzSDMzMFEzMzYgNjc3IDMzNiA2NzRUMzM0IDY1NlEzMjkgNjQxIDMyNSA2MzdIMzA0UTI4MiA2MzUgMjc0IDYzNVEyNDUgNjMwIDI0MiA2MjBRMjQyIDYxOCAyNzEgMzY5VDMwMSAxMThMMzc0IDIzNVE0NDcgMzUyIDUyMCA0NzFUNTk1IDU5NFE1OTkgNjAxIDU5OSA2MDlRNTk5IDYzMyA1NTUgNjM3UTUzNyA2MzcgNTM3IDY0OFE1MzcgNjQ5IDUzOSA2NjFRNTQyIDY3NSA1NDUgNjc5VDU1OCA2ODNRNTYwIDY4MyA1NzAgNjgzVDYwNCA2ODJUNjY4IDY4MVE3MzcgNjgxIDc1NSA2ODNINzYyUTc2OSA2NzYgNzY5IDY3MlE3NjkgNjU1IDc2MCA2NDBRNzU3IDYzNyA3NDMgNjM3UTczMCA2MzYgNzE5IDYzNVQ2OTggNjMwVDY4MiA2MjNUNjcwIDYxNVQ2NjAgNjA4VDY1MiA1OTlUNjQ1IDU5Mkw0NTIgMjgyUTI3MiAtOSAyNjYgLTE2UTI2MyAtMTggMjU5IC0yMUwyNDEgLTIySDIzNFEyMTYgLTIyIDIxNiAtMTVRMjEzIC05IDE3NyAzMDVRMTM5IDYyMyAxMzggNjI2UTEzMyA2MzcgNzYgNjM3SDU5UTUyIDY0MiA1MiA2NDhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDUiIGQ9Ik00OTIgMjEzUTQ3MiAyMTMgNDcyIDIyNlE0NzIgMjMwIDQ3NyAyNTBUNDgyIDI4NVE0ODIgMzE2IDQ2MSAzMjNUMzY0IDMzMEgzMTJRMzExIDMyOCAyNzcgMTkyVDI0MyA1MlEyNDMgNDggMjU0IDQ4VDMzNCA0NlE0MjggNDYgNDU4IDQ4VDUxOCA2MVE1NjcgNzcgNTk5IDExN1Q2NzAgMjQ4UTY4MCAyNzAgNjgzIDI3MlE2OTAgMjc0IDY5OCAyNzRRNzE4IDI3NCA3MTggMjYxUTYxMyA3IDYwOCAyUTYwNSAwIDMyMiAwSDEzM1EzMSAwIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc1N1E3NjQgNjc2IDc2NCA2NjlRNzY0IDY2NCA3NTEgNTU3VDczNyA0NDdRNzM1IDQ0MCA3MTcgNDQwSDcwNVE2OTggNDQ1IDY5OCA0NTNMNzAxIDQ3NlE3MDQgNTAwIDcwNCA1MjhRNzA0IDU1OCA2OTcgNTc4VDY3OCA2MDlUNjQzIDYyNVQ1OTYgNjMyVDUzMiA2MzRINDg1UTM5NyA2MzMgMzkyIDYzMVEzODggNjI5IDM4NiA2MjJRMzg1IDYxOSAzNTUgNDk5VDMyNCAzNzdRMzQ3IDM3NiAzNzIgMzc2SDM5OFE0NjQgMzc2IDQ4OSAzOTFUNTM0IDQ3MlE1MzggNDg4IDU0MCA0OTBUNTU3IDQ5M1E1NjIgNDkzIDU2NSA0OTNUNTcwIDQ5MlQ1NzIgNDkxVDU3NCA0ODdUNTc3IDQ4M0w1NDQgMzUxUTUxMSAyMTggNTA4IDIxNlE1MDUgMjEzIDQ5MiAyMTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkUiIGQ9Ik0yMSAyODdRMjIgMjkzIDI0IDMwM1QzNiAzNDFUNTYgMzg4VDg5IDQyNVQxMzUgNDQyUTE3MSA0NDIgMTk1IDQyNFQyMjUgMzkwVDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzA0IDQ0MiAzODIgNDQyUTQzNiA0NDIgNDY5IDQxNVQ1MDMgMzM2VDQ2NSAxNzlUNDI3IDUyUTQyNyAyNiA0NDQgMjZRNDUwIDI2IDQ1MyAyN1E0ODIgMzIgNTA1IDY1VDU0MCAxNDVRNTQyIDE1MyA1NjAgMTUzUTU4MCAxNTMgNTgwIDE0NVE1ODAgMTQ0IDU3NiAxMzBRNTY4IDEwMSA1NTQgNzNUNTA4IDE3VDQzOSAtMTBRMzkyIC0xMCAzNzEgMTdUMzUwIDczUTM1MCA5MiAzODYgMTkzVDQyMyAzNDVRNDIzIDQwNCAzNzkgNDA0SDM3NFEyODggNDA0IDIyOSAzMDNMMjIyIDI5MUwxODkgMTU3UTE1NiAyNiAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExMiAxODBUMTUyIDM0M1ExNTMgMzQ4IDE1MyAzNjZRMTUzIDQwNSAxMjkgNDA1UTkxIDQwNSA2NiAzMDVRNjAgMjg1IDYwIDI4NFE1OCAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjEtMjIxMSIgZD0iTTYxIDc0OFE2NCA3NTAgNDg5IDc1MEg5MTNMOTU0IDY0MFE5NjUgNjA5IDk3NiA1NzlUOTkzIDUzM1Q5OTkgNTE2SDk3OUw5NTkgNTE3UTkzNiA1NzkgODg2IDYyMVQ3NzcgNjgyUTcyNCA3MDAgNjU1IDcwNVQ0MzYgNzEwSDMxOVExODMgNzEwIDE4MyA3MDlRMTg2IDcwNiAzNDggNDg0VDUxMSAyNTlRNTE3IDI1MCA1MTMgMjQ0TDQ5MCAyMTZRNDY2IDE4OCA0MjAgMTM0VDMzMCAyN0wxNDkgLTE4N1ExNDkgLTE4OCAzNjIgLTE4OFEzODggLTE4OCA0MzYgLTE4OFQ1MDYgLTE4OVE2NzkgLTE4OSA3NzggLTE2MlQ5MzYgLTQzUTk0NiAtMjcgOTU5IDZIOTk5TDkxMyAtMjQ5TDQ4OSAtMjUwUTY1IC0yNTAgNjIgLTI0OFE1NiAtMjQ2IDU2IC0yMzlRNTYgLTIzNCAxMTggLTE2MVExODYgLTgxIDI0NSAtMTFMNDI4IDIwNlE0MjggMjA3IDI0MiA0NjJMNTcgNzE3TDU2IDcyOFE1NiA3NDQgNjEgNzQ4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY5IiBkPSJNMTg0IDYwMFExODQgNjI0IDIwMyA2NDJUMjQ3IDY2MVEyNjUgNjYxIDI3NyA2NDlUMjkwIDYxOVEyOTAgNTk2IDI3MCA1NzdUMjI2IDU1N1EyMTEgNTU3IDE5OCA1NjdUMTg0IDYwMFpNMjEgMjg3UTIxIDI5NSAzMCAzMThUNTQgMzY5VDk4IDQyMFQxNTggNDQyUTE5NyA0NDIgMjIzIDQxOVQyNTAgMzU3UTI1MCAzNDAgMjM2IDMwMVQxOTYgMTk2VDE1NCA4M1ExNDkgNjEgMTQ5IDUxUTE0OSAyNiAxNjYgMjZRMTc1IDI2IDE4NSAyOVQyMDggNDNUMjM1IDc4VDI2MCAxMzdRMjYzIDE0OSAyNjUgMTUxVDI4MiAxNTNRMzAyIDE1MyAzMDIgMTQzUTMwMiAxMzUgMjkzIDExMlQyNjggNjFUMjIzIDExVDE2MSAtMTFRMTI5IC0xMSAxMDIgMTBUNzQgNzRRNzQgOTEgNzkgMTA2VDEyMiAyMjBRMTYwIDMyMSAxNjYgMzQxVDE3MyAzODBRMTczIDQwNCAxNTYgNDA0SDE1NFExMjQgNDA0IDk5IDM3MVQ2MSAyODdRNjAgMjg2IDU5IDI4NFQ1OCAyODFUNTYgMjc5VDUzIDI3OFQ0OSAyNzhUNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMSIgZD0iTTIxMyA1NzhMMjAwIDU3M1ExODYgNTY4IDE2MCA1NjNUMTAyIDU1Nkg4M1Y2MDJIMTAyUTE0OSA2MDQgMTg5IDYxN1QyNDUgNjQxVDI3MyA2NjNRMjc1IDY2NiAyODUgNjY2UTI5NCA2NjYgMzAyIDY2MFYzNjFMMzAzIDYxUTMxMCA1NCAzMTUgNTJUMzM5IDQ4VDQwMSA0Nkg0MjdWMEg0MTZRMzk1IDMgMjU3IDNRMTIxIDMgMTAwIDBIODhWNDZIMTE0UTEzNiA0NiAxNTIgNDZUMTc3IDQ3VDE5MyA1MFQyMDEgNTJUMjA3IDU3VDIxMyA2MVY1NzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzQiIGQ9Ik0yNiAzODVRMTkgMzkyIDE5IDM5NVExOSAzOTkgMjIgNDExVDI3IDQyNVEyOSA0MzAgMzYgNDMwVDg3IDQzMUgxNDBMMTU5IDUxMVExNjIgNTIyIDE2NiA1NDBUMTczIDU2NlQxNzkgNTg2VDE4NyA2MDNUMTk3IDYxNVQyMTEgNjI0VDIyOSA2MjZRMjQ3IDYyNSAyNTQgNjE1VDI2MSA1OTZRMjYxIDU4OSAyNTIgNTQ5VDIzMiA0NzBMMjIyIDQzM1EyMjIgNDMxIDI3MiA0MzFIMzIzUTMzMCA0MjQgMzMwIDQyMFEzMzAgMzk4IDMxNyAzODVIMjEwTDE3NCAyNDBRMTM1IDgwIDEzNSA2OFExMzUgMjYgMTYyIDI2UTE5NyAyNiAyMzAgNjBUMjgzIDE0NFEyODUgMTUwIDI4OCAxNTFUMzAzIDE1M0gzMDdRMzIyIDE1MyAzMjIgMTQ1UTMyMiAxNDIgMzE5IDEzM1EzMTQgMTE3IDMwMSA5NVQyNjcgNDhUMjE2IDZUMTU1IC0xMVExMjUgLTExIDk4IDRUNTkgNTZRNTcgNjQgNTcgODNWMTAxTDkyIDI0MVExMjcgMzgyIDEyOCAzODNRMTI4IDM4NSA3NyAzODVIMjZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzUiIGQ9Ik0yMSAyODdRMjEgMjk1IDMwIDMxOFQ1NSAzNzBUOTkgNDIwVDE1OCA0NDJRMjA0IDQ0MiAyMjcgNDE3VDI1MCAzNThRMjUwIDM0MCAyMTYgMjQ2VDE4MiAxMDVRMTgyIDYyIDE5NiA0NVQyMzggMjdUMjkxIDQ0VDMyOCA3OEwzMzkgOTVRMzQxIDk5IDM3NyAyNDdRNDA3IDM2NyA0MTMgMzg3VDQyNyA0MTZRNDQ0IDQzMSA0NjMgNDMxUTQ4MCA0MzEgNDg4IDQyMVQ0OTYgNDAyTDQyMCA4NFE0MTkgNzkgNDE5IDY4UTQxOSA0MyA0MjYgMzVUNDQ3IDI2UTQ2OSAyOSA0ODIgNTdUNTEyIDE0NVE1MTQgMTUzIDUzMiAxNTNRNTUxIDE1MyA1NTEgMTQ0UTU1MCAxMzkgNTQ5IDEzMFQ1NDAgOThUNTIzIDU1VDQ5OCAxN1Q0NjIgLThRNDU0IC0xMCA0MzggLTEwUTM3MiAtMTAgMzQ3IDQ2UTM0NSA0NSAzMzYgMzZUMzE4IDIxVDI5NiA2VDI2NyAtNlQyMzMgLTExUTE4OSAtMTEgMTU1IDdRMTAzIDM4IDEwMyAxMTNRMTAzIDE3MCAxMzggMjYyVDE3MyAzNzlRMTczIDM4MCAxNzMgMzgxUTE3MyAzOTAgMTczIDM5M1QxNjkgNDAwVDE1OCA0MDRIMTU0UTEzMSA0MDQgMTEyIDM4NVQ4MiAzNDRUNjUgMzAyVDU3IDI4MFE1NSAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkQiIGQ9Ik0yMSAyODdRMjIgMjkzIDI0IDMwM1QzNiAzNDFUNTYgMzg4VDg4IDQyNVQxMzIgNDQyVDE3NSA0MzVUMjA1IDQxN1QyMjEgMzk1VDIyOSAzNzZMMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDMgNDQyIDM4NCA0NDJRNDAxIDQ0MiA0MTUgNDQwVDQ0MSA0MzNUNDYwIDQyM1Q0NzUgNDExVDQ4NSAzOThUNDkzIDM4NVQ0OTcgMzczVDUwMCAzNjRUNTAyIDM1N0w1MTAgMzY3UTU3MyA0NDIgNjU5IDQ0MlE3MTMgNDQyIDc0NiA0MTVUNzgwIDMzNlE3ODAgMjg1IDc0MiAxNzhUNzA0IDUwUTcwNSAzNiA3MDkgMzFUNzI0IDI2UTc1MiAyNiA3NzYgNTZUODE1IDEzOFE4MTggMTQ5IDgyMSAxNTFUODM3IDE1M1E4NTcgMTUzIDg1NyAxNDVRODU3IDE0NCA4NTMgMTMwUTg0NSAxMDEgODMxIDczVDc4NSAxN1Q3MTYgLTEwUTY2OSAtMTAgNjQ4IDE3VDYyNyA3M1E2MjcgOTIgNjYzIDE5M1Q3MDAgMzQ1UTcwMCA0MDQgNjU2IDQwNEg2NTFRNTY1IDQwNCA1MDYgMzAzTDQ5OSAyOTFMNDY2IDE1N1E0MzMgMjYgNDI4IDE2UTQxNSAtMTEgMzg1IC0xMVEzNzIgLTExIDM2NCAtNFQzNTMgOFQzNTAgMThRMzUwIDI5IDM4NCAxNjFMNDIwIDMwN1E0MjMgMzIyIDQyMyAzNDVRNDIzIDQwNCAzNzkgNDA0SDM3NFEyODggNDA0IDIyOSAzMDNMMjIyIDI5MUwxODkgMTU3UTE1NiAyNiAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExMiAxODFRMTUxIDMzNSAxNTEgMzQyUTE1NCAzNTcgMTU0IDM2OVExNTQgNDA1IDEyOSA0MDVRMTA3IDQwNSA5MiAzNzdUNjkgMzE2VDU3IDI4MFE1NSAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03QiIgZD0iTTQzNCAtMjMxUTQzNCAtMjQ0IDQyOCAtMjUwSDQxMFEyODEgLTI1MCAyMzAgLTE4NFEyMjUgLTE3NyAyMjIgLTE3MlQyMTcgLTE2MVQyMTMgLTE0OFQyMTEgLTEzM1QyMTAgLTExMVQyMDkgLTg0VDIwOSAtNDdUMjA5IDBRMjA5IDIxIDIwOSA1M1EyMDggMTQyIDIwNCAxNTNRMjAzIDE1NCAyMDMgMTU1UTE4OSAxOTEgMTUzIDIxMVQ4MiAyMzFRNzEgMjMxIDY4IDIzNFQ2NSAyNTBUNjggMjY2VDgyIDI2OVExMTYgMjY5IDE1MiAyODlUMjAzIDM0NVEyMDggMzU2IDIwOCAzNzdUMjA5IDUyOVY1NzlRMjA5IDYzNCAyMTUgNjU2VDI0NCA2OThRMjcwIDcyNCAzMjQgNzQwUTM2MSA3NDggMzc3IDc0OVEzNzkgNzQ5IDM5MCA3NDlUNDA4IDc1MEg0MjhRNDM0IDc0NCA0MzQgNzMyUTQzNCA3MTkgNDMxIDcxNlE0MjkgNzEzIDQxNSA3MTNRMzYyIDcxMCAzMzIgNjg5VDI5NiA2NDdRMjkxIDYzNCAyOTEgNDk5VjQxN1EyOTEgMzcwIDI4OCAzNTNUMjcxIDMxNFEyNDAgMjcxIDE4NCAyNTVMMTcwIDI1MEwxODQgMjQ1UTIwMiAyMzkgMjIwIDIzMFQyNjIgMTk2VDI5MCAxMzdRMjkxIDEzMSAyOTEgMVEyOTEgLTEzNCAyOTYgLTE0N1EzMDYgLTE3NCAzMzkgLTE5MlQ0MTUgLTIxM1E0MjkgLTIxMyA0MzEgLTIxNlE0MzQgLTIxOSA0MzQgLTIzMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03OCIgZD0iTTUyIDI4OVE1OSAzMzEgMTA2IDM4NlQyMjIgNDQyUTI1NyA0NDIgMjg2IDQyNFQzMjkgMzc5UTM3MSA0NDIgNDMwIDQ0MlE0NjcgNDQyIDQ5NCA0MjBUNTIyIDM2MVE1MjIgMzMyIDUwOCAzMTRUNDgxIDI5MlQ0NTggMjg4UTQzOSAyODggNDI3IDI5OVQ0MTUgMzI4UTQxNSAzNzQgNDY1IDM5MVE0NTQgNDA0IDQyNSA0MDRRNDEyIDQwNCA0MDYgNDAyUTM2OCAzODYgMzUwIDMzNlEyOTAgMTE1IDI5MCA3OFEyOTAgNTAgMzA2IDM4VDM0MSAyNlEzNzggMjYgNDE0IDU5VDQ2MyAxNDBRNDY2IDE1MCA0NjkgMTUxVDQ4NSAxNTNINDg5UTUwNCAxNTMgNTA0IDE0NVE1MDQgMTQ0IDUwMiAxMzRRNDg2IDc3IDQ0MCAzM1QzMzMgLTExUTI2MyAtMTEgMjI3IDUyUTE4NiAtMTAgMTMzIC0xMEgxMjdRNzggLTEwIDU3IDE2VDM1IDcxUTM1IDEwMyA1NCAxMjNUOTkgMTQzUTE0MiAxNDMgMTQyIDEwMVExNDIgODEgMTMwIDY2VDEwNyA0NlQ5NCA0MUw5MSA0MFE5MSAzOSA5NyAzNlQxMTMgMjlUMTMyIDI2UTE2OCAyNiAxOTQgNzFRMjAzIDg3IDIxNyAxMzlUMjQ1IDI0N1QyNjEgMzEzUTI2NiAzNDAgMjY2IDM1MlEyNjYgMzgwIDI1MSAzOTJUMjE3IDQwNFExNzcgNDA0IDE0MiAzNzJUOTMgMjkwUTkxIDI4MSA4OCAyODBUNzIgMjc4SDU4UTUyIDI4NCA1MiAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03RCIgZD0iTTY1IDczMVE2NSA3NDUgNjggNzQ3VDg4IDc1MFExNzEgNzUwIDIxNiA3MjVUMjc5IDY3MFEyODggNjQ5IDI4OSA2MzVUMjkxIDUwMVEyOTIgMzYyIDI5MyAzNTdRMzA2IDMxMiAzNDUgMjkxVDQxNyAyNjlRNDI4IDI2OSA0MzEgMjY2VDQzNCAyNTBUNDMxIDIzNFQ0MTcgMjMxUTM4MCAyMzEgMzQ1IDIxMFQyOTggMTU3UTI5MyAxNDMgMjkyIDEyMVQyOTEgLTI4Vi03OVEyOTEgLTEzNCAyODUgLTE1NlQyNTYgLTE5OFEyMDIgLTI1MCA4OSAtMjUwUTcxIC0yNTAgNjggLTI0N1Q2NSAtMjMwUTY1IC0yMjQgNjUgLTIyM1Q2NiAtMjE4VDY5IC0yMTRUNzcgLTIxM1E5MSAtMjEzIDEwOCAtMjEwVDE0NiAtMjAwVDE4MyAtMTc3VDIwNyAtMTM5UTIwOCAtMTM0IDIwOSAzTDIxMCAxMzlRMjIzIDE5NiAyODAgMjMwUTMxNSAyNDcgMzMwIDI1MFEzMDUgMjU3IDI4MCAyNzBRMjI1IDMwNCAyMTIgMzUyTDIxMCAzNjJMMjA5IDQ5OFEyMDggNjM1IDIwNyA2NDBRMTk1IDY4MCAxNTQgNjk2VDc3IDcxM1E2OCA3MTMgNjcgNzE2VDY1IDczMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjgiIGQ9Ik0xODAgOTZUMTgwIDI1MFQyMDUgNTQxVDI2NiA3NzBUMzUzIDk0NFQ0NDQgMTA2OVQ1MjcgMTE1MEg1NTVRNTYxIDExNDQgNTYxIDExNDFRNTYxIDExMzcgNTQ1IDExMjBUNTA0IDEwNzJUNDQ3IDk5NVQzODYgODc4VDMzMCA3MjFUMjg4IDUxM1QyNzIgMjUxUTI3MiAxMzMgMjgwIDU2UTI5MyAtODcgMzI2IC0yMDlUMzk5IC00MDVUNDc1IC01MzFUNTM2IC02MDlUNTYxIC02NDBRNTYxIC02NDMgNTU1IC02NDlINTI3UTQ4MyAtNjEyIDQ0MyAtNTY4VDM1MyAtNDQzVDI2NiAtMjcwVDIwNSAtNDFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oyLTI5IiBkPSJNMzUgMTEzOFEzNSAxMTUwIDUxIDExNTBINTZINjlRMTEzIDExMTMgMTUzIDEwNjlUMjQzIDk0NFQzMzAgNzcxVDM5MSA1NDFUNDE2IDI1MFQzOTEgLTQwVDMzMCAtMjcwVDI0MyAtNDQzVDE1MiAtNTY4VDY5IC02NDlINTZRNDMgLTY0OSAzOSAtNjQ3VDM1IC02MzdRNjUgLTYwNyAxMTAgLTU0OFEyODMgLTMxNiAzMTYgNTZRMzI0IDEzMyAzMjQgMjUxUTMyNCAzNjggMzE2IDQ0NVEyNzggODc3IDQ4IDExMjNRMzYgMTEzNyAzNSAxMTM4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZCIiBkPSJNMTIxIDY0N1ExMjEgNjU3IDEyNSA2NzBUMTM3IDY4M1ExMzggNjgzIDIwOSA2ODhUMjgyIDY5NFEyOTQgNjk0IDI5NCA2ODZRMjk0IDY3OSAyNDQgNDc3UTE5NCAyNzkgMTk0IDI3MlEyMTMgMjgyIDIyMyAyOTFRMjQ3IDMwOSAyOTIgMzU0VDM2MiA0MTVRNDAyIDQ0MiA0MzggNDQyUTQ2OCA0NDIgNDg1IDQyM1Q1MDMgMzY5UTUwMyAzNDQgNDk2IDMyN1Q0NzcgMzAyVDQ1NiAyOTFUNDM4IDI4OFE0MTggMjg4IDQwNiAyOTlUMzk0IDMyOFEzOTQgMzUzIDQxMCAzNjlUNDQyIDM5MEw0NTggMzkzUTQ0NiA0MDUgNDM0IDQwNUg0MzBRMzk4IDQwMiAzNjcgMzgwVDI5NCAzMTZUMjI4IDI1NVEyMzAgMjU0IDI0MyAyNTJUMjY3IDI0NlQyOTMgMjM4VDMyMCAyMjRUMzQyIDIwNlQzNTkgMTgwVDM2NSAxNDdRMzY1IDEzMCAzNjAgMTA2VDM1NCA2NlEzNTQgMjYgMzgxIDI2UTQyOSAyNiA0NTkgMTQ1UTQ2MSAxNTMgNDc5IDE1M0g0ODNRNDk5IDE1MyA0OTkgMTQ0UTQ5OSAxMzkgNDk2IDEzMFE0NTUgLTExIDM3OCAtMTFRMzMzIC0xMSAzMDUgMTVUMjc3IDkwUTI3NyAxMDggMjgwIDEyMVQyODMgMTQ1UTI4MyAxNjcgMjY5IDE4M1QyMzQgMjA2VDIwMCAyMTdUMTgyIDIyMEgxODBRMTY4IDE3OCAxNTkgMTM5VDE0NSA4MVQxMzYgNDRUMTI5IDIwVDEyMiA3VDExMSAtMlE5OCAtMTEgODMgLTExUTY2IC0xMSA1NyAtMVQ0OCAxNlE0OCAyNiA4NSAxNzZUMTU4IDQ3MUwxOTUgNjE2UTE5NiA2MjkgMTg4IDYzMlQxNDkgNjM3SDE0NFExMzQgNjM3IDEzMSA2MzdUMTI0IDY0MFQxMjEgNjQ3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIxMTY3IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjgyNSIgeT0iLTIxMiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2MzIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMzE1OCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM5MzcsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI3NjE2IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsMTE2OSkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjEtMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTQ5NCIgeT0iNjc1Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTA1NiwtMjg3KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIzNDUiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTEyNCIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjMwNSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc0IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzYxLC0xNTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc1IiB4PSI2MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkQiIHg9IjExNzMiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDM4MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yOCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU5NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03OCIgeD0iNTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iMTA3MyIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMjIyNSIgeT0iNjc1Ij48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjkiIHg9IjI1MTUiIHk9Ii0xIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDg4OCwtODEyKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMS0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIxNDk0IiB5PSI2NzUiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDU2LC0yODcpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjM0NSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxMTI0IiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNDcxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSI3MzciIHk9Ii0yMTMiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMDg4IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMjA4OCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMjk3OCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8L3N2Zz4=)
重写为, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjUzLjIyN2V4IiBoZWlnaHQ9IjExLjY3NmV4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTQuNjcxZXg7IiB2aWV3Qm94PSIwIC0zMDE1LjkgMjI5MTcgNTAyNy4xIiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU2IiBkPSJNNTIgNjQ4UTUyIDY3MCA2NSA2ODNINzZRMTE4IDY4MCAxODEgNjgwUTI5OSA2ODAgMzIwIDY4M0gzMzBRMzM2IDY3NyAzMzYgNjc0VDMzNCA2NTZRMzI5IDY0MSAzMjUgNjM3SDMwNFEyODIgNjM1IDI3NCA2MzVRMjQ1IDYzMCAyNDIgNjIwUTI0MiA2MTggMjcxIDM2OVQzMDEgMTE4TDM3NCAyMzVRNDQ3IDM1MiA1MjAgNDcxVDU5NSA1OTRRNTk5IDYwMSA1OTkgNjA5UTU5OSA2MzMgNTU1IDYzN1E1MzcgNjM3IDUzNyA2NDhRNTM3IDY0OSA1MzkgNjYxUTU0MiA2NzUgNTQ1IDY3OVQ1NTggNjgzUTU2MCA2ODMgNTcwIDY4M1Q2MDQgNjgyVDY2OCA2ODFRNzM3IDY4MSA3NTUgNjgzSDc2MlE3NjkgNjc2IDc2OSA2NzJRNzY5IDY1NSA3NjAgNjQwUTc1NyA2MzcgNzQzIDYzN1E3MzAgNjM2IDcxOSA2MzVUNjk4IDYzMFQ2ODIgNjIzVDY3MCA2MTVUNjYwIDYwOFQ2NTIgNTk5VDY0NSA1OTJMNDUyIDI4MlEyNzIgLTkgMjY2IC0xNlEyNjMgLTE4IDI1OSAtMjFMMjQxIC0yMkgyMzRRMjE2IC0yMiAyMTYgLTE1UTIxMyAtOSAxNzcgMzA1UTEzOSA2MjMgMTM4IDYyNlExMzMgNjM3IDc2IDYzN0g1OVE1MiA2NDIgNTIgNjQ4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQ1IiBkPSJNNDkyIDIxM1E0NzIgMjEzIDQ3MiAyMjZRNDcyIDIzMCA0NzcgMjUwVDQ4MiAyODVRNDgyIDMxNiA0NjEgMzIzVDM2NCAzMzBIMzEyUTMxMSAzMjggMjc3IDE5MlQyNDMgNTJRMjQzIDQ4IDI1NCA0OFQzMzQgNDZRNDI4IDQ2IDQ1OCA0OFQ1MTggNjFRNTY3IDc3IDU5OSAxMTdUNjcwIDI0OFE2ODAgMjcwIDY4MyAyNzJRNjkwIDI3NCA2OTggMjc0UTcxOCAyNzQgNzE4IDI2MVE2MTMgNyA2MDggMlE2MDUgMCAzMjIgMEgxMzNRMzEgMCAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDYgNjYgMjE1IDM0MlQyODUgNjIyUTI4NSA2MjkgMjgxIDYyOVEyNzMgNjMyIDIyOCA2MzRIMTk3UTE5MSA2NDAgMTkxIDY0MlQxOTMgNjU5UTE5NyA2NzYgMjAzIDY4MEg3NTdRNzY0IDY3NiA3NjQgNjY5UTc2NCA2NjQgNzUxIDU1N1Q3MzcgNDQ3UTczNSA0NDAgNzE3IDQ0MEg3MDVRNjk4IDQ0NSA2OTggNDUzTDcwMSA0NzZRNzA0IDUwMCA3MDQgNTI4UTcwNCA1NTggNjk3IDU3OFQ2NzggNjA5VDY0MyA2MjVUNTk2IDYzMlQ1MzIgNjM0SDQ4NVEzOTcgNjMzIDM5MiA2MzFRMzg4IDYyOSAzODYgNjIyUTM4NSA2MTkgMzU1IDQ5OVQzMjQgMzc3UTM0NyAzNzYgMzcyIDM3NkgzOThRNDY0IDM3NiA0ODkgMzkxVDUzNCA0NzJRNTM4IDQ4OCA1NDAgNDkwVDU1NyA0OTNRNTYyIDQ5MyA1NjUgNDkzVDU3MCA0OTJUNTcyIDQ5MVQ1NzQgNDg3VDU3NyA0ODNMNTQ0IDM1MVE1MTEgMjE4IDUwOCAyMTZRNTA1IDIxMyA0OTIgMjEzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZFIiBkPSJNMjEgMjg3UTIyIDI5MyAyNCAzMDNUMzYgMzQxVDU2IDM4OFQ4OSA0MjVUMTM1IDQ0MlExNzEgNDQyIDE5NSA0MjRUMjI1IDM5MFQyMzEgMzY5UTIzMSAzNjcgMjMyIDM2N0wyNDMgMzc4UTMwNCA0NDIgMzgyIDQ0MlE0MzYgNDQyIDQ2OSA0MTVUNTAzIDMzNlQ0NjUgMTc5VDQyNyA1MlE0MjcgMjYgNDQ0IDI2UTQ1MCAyNiA0NTMgMjdRNDgyIDMyIDUwNSA2NVQ1NDAgMTQ1UTU0MiAxNTMgNTYwIDE1M1E1ODAgMTUzIDU4MCAxNDVRNTgwIDE0NCA1NzYgMTMwUTU2OCAxMDEgNTU0IDczVDUwOCAxN1Q0MzkgLTEwUTM5MiAtMTAgMzcxIDE3VDM1MCA3M1EzNTAgOTIgMzg2IDE5M1Q0MjMgMzQ1UTQyMyA0MDQgMzc5IDQwNEgzNzRRMjg4IDQwNCAyMjkgMzAzTDIyMiAyOTFMMTg5IDE1N1ExNTYgMjYgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTIgMTgwVDE1MiAzNDNRMTUzIDM0OCAxNTMgMzY2UTE1MyA0MDUgMTI5IDQwNVE5MSA0MDUgNjYgMzA1UTYwIDI4NSA2MCAyODRRNTggMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMSIgZD0iTTIxMyA1NzhMMjAwIDU3M1ExODYgNTY4IDE2MCA1NjNUMTAyIDU1Nkg4M1Y2MDJIMTAyUTE0OSA2MDQgMTg5IDYxN1QyNDUgNjQxVDI3MyA2NjNRMjc1IDY2NiAyODUgNjY2UTI5NCA2NjYgMzAyIDY2MFYzNjFMMzAzIDYxUTMxMCA1NCAzMTUgNTJUMzM5IDQ4VDQwMSA0Nkg0MjdWMEg0MTZRMzk1IDMgMjU3IDNRMTIxIDMgMTAwIDBIODhWNDZIMTE0UTEzNiA0NiAxNTIgNDZUMTc3IDQ3VDE5MyA1MFQyMDEgNTJUMjA3IDU3VDIxMyA2MVY1NzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oxLTIyMTEiIGQ9Ik02MSA3NDhRNjQgNzUwIDQ4OSA3NTBIOTEzTDk1NCA2NDBROTY1IDYwOSA5NzYgNTc5VDk5MyA1MzNUOTk5IDUxNkg5NzlMOTU5IDUxN1E5MzYgNTc5IDg4NiA2MjFUNzc3IDY4MlE3MjQgNzAwIDY1NSA3MDVUNDM2IDcxMEgzMTlRMTgzIDcxMCAxODMgNzA5UTE4NiA3MDYgMzQ4IDQ4NFQ1MTEgMjU5UTUxNyAyNTAgNTEzIDI0NEw0OTAgMjE2UTQ2NiAxODggNDIwIDEzNFQzMzAgMjdMMTQ5IC0xODdRMTQ5IC0xODggMzYyIC0xODhRMzg4IC0xODggNDM2IC0xODhUNTA2IC0xODlRNjc5IC0xODkgNzc4IC0xNjJUOTM2IC00M1E5NDYgLTI3IDk1OSA2SDk5OUw5MTMgLTI0OUw0ODkgLTI1MFE2NSAtMjUwIDYyIC0yNDhRNTYgLTI0NiA1NiAtMjM5UTU2IC0yMzQgMTE4IC0xNjFRMTg2IC04MSAyNDUgLTExTDQyOCAyMDZRNDI4IDIwNyAyNDIgNDYyTDU3IDcxN0w1NiA3MjhRNTYgNzQ0IDYxIDc0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02OSIgZD0iTTE4NCA2MDBRMTg0IDYyNCAyMDMgNjQyVDI0NyA2NjFRMjY1IDY2MSAyNzcgNjQ5VDI5MCA2MTlRMjkwIDU5NiAyNzAgNTc3VDIyNiA1NTdRMjExIDU1NyAxOTggNTY3VDE4NCA2MDBaTTIxIDI4N1EyMSAyOTUgMzAgMzE4VDU0IDM2OVQ5OCA0MjBUMTU4IDQ0MlExOTcgNDQyIDIyMyA0MTlUMjUwIDM1N1EyNTAgMzQwIDIzNiAzMDFUMTk2IDE5NlQxNTQgODNRMTQ5IDYxIDE0OSA1MVExNDkgMjYgMTY2IDI2UTE3NSAyNiAxODUgMjlUMjA4IDQzVDIzNSA3OFQyNjAgMTM3UTI2MyAxNDkgMjY1IDE1MVQyODIgMTUzUTMwMiAxNTMgMzAyIDE0M1EzMDIgMTM1IDI5MyAxMTJUMjY4IDYxVDIyMyAxMVQxNjEgLTExUTEyOSAtMTEgMTAyIDEwVDc0IDc0UTc0IDkxIDc5IDEwNlQxMjIgMjIwUTE2MCAzMjEgMTY2IDM0MVQxNzMgMzgwUTE3MyA0MDQgMTU2IDQwNEgxNTRRMTI0IDQwNCA5OSAzNzFUNjEgMjg3UTYwIDI4NiA1OSAyODRUNTggMjgxVDU2IDI3OVQ1MyAyNzhUNDkgMjc4VDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc0IiBkPSJNMjYgMzg1UTE5IDM5MiAxOSAzOTVRMTkgMzk5IDIyIDQxMVQyNyA0MjVRMjkgNDMwIDM2IDQzMFQ4NyA0MzFIMTQwTDE1OSA1MTFRMTYyIDUyMiAxNjYgNTQwVDE3MyA1NjZUMTc5IDU4NlQxODcgNjAzVDE5NyA2MTVUMjExIDYyNFQyMjkgNjI2UTI0NyA2MjUgMjU0IDYxNVQyNjEgNTk2UTI2MSA1ODkgMjUyIDU0OVQyMzIgNDcwTDIyMiA0MzNRMjIyIDQzMSAyNzIgNDMxSDMyM1EzMzAgNDI0IDMzMCA0MjBRMzMwIDM5OCAzMTcgMzg1SDIxMEwxNzQgMjQwUTEzNSA4MCAxMzUgNjhRMTM1IDI2IDE2MiAyNlExOTcgMjYgMjMwIDYwVDI4MyAxNDRRMjg1IDE1MCAyODggMTUxVDMwMyAxNTNIMzA3UTMyMiAxNTMgMzIyIDE0NVEzMjIgMTQyIDMxOSAxMzNRMzE0IDExNyAzMDEgOTVUMjY3IDQ4VDIxNiA2VDE1NSAtMTFRMTI1IC0xMSA5OCA0VDU5IDU2UTU3IDY0IDU3IDgzVjEwMUw5MiAyNDFRMTI3IDM4MiAxMjggMzgzUTEyOCAzODUgNzcgMzg1SDI2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc1IiBkPSJNMjEgMjg3UTIxIDI5NSAzMCAzMThUNTUgMzcwVDk5IDQyMFQxNTggNDQyUTIwNCA0NDIgMjI3IDQxN1QyNTAgMzU4UTI1MCAzNDAgMjE2IDI0NlQxODIgMTA1UTE4MiA2MiAxOTYgNDVUMjM4IDI3VDI5MSA0NFQzMjggNzhMMzM5IDk1UTM0MSA5OSAzNzcgMjQ3UTQwNyAzNjcgNDEzIDM4N1Q0MjcgNDE2UTQ0NCA0MzEgNDYzIDQzMVE0ODAgNDMxIDQ4OCA0MjFUNDk2IDQwMkw0MjAgODRRNDE5IDc5IDQxOSA2OFE0MTkgNDMgNDI2IDM1VDQ0NyAyNlE0NjkgMjkgNDgyIDU3VDUxMiAxNDVRNTE0IDE1MyA1MzIgMTUzUTU1MSAxNTMgNTUxIDE0NFE1NTAgMTM5IDU0OSAxMzBUNTQwIDk4VDUyMyA1NVQ0OTggMTdUNDYyIC04UTQ1NCAtMTAgNDM4IC0xMFEzNzIgLTEwIDM0NyA0NlEzNDUgNDUgMzM2IDM2VDMxOCAyMVQyOTYgNlQyNjcgLTZUMjMzIC0xMVExODkgLTExIDE1NSA3UTEwMyAzOCAxMDMgMTEzUTEwMyAxNzAgMTM4IDI2MlQxNzMgMzc5UTE3MyAzODAgMTczIDM4MVExNzMgMzkwIDE3MyAzOTNUMTY5IDQwMFQxNTggNDA0SDE1NFExMzEgNDA0IDExMiAzODVUODIgMzQ0VDY1IDMwMlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZEIiBkPSJNMjEgMjg3UTIyIDI5MyAyNCAzMDNUMzYgMzQxVDU2IDM4OFQ4OCA0MjVUMTMyIDQ0MlQxNzUgNDM1VDIwNSA0MTdUMjIxIDM5NVQyMjkgMzc2TDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzAzIDQ0MiAzODQgNDQyUTQwMSA0NDIgNDE1IDQ0MFQ0NDEgNDMzVDQ2MCA0MjNUNDc1IDQxMVQ0ODUgMzk4VDQ5MyAzODVUNDk3IDM3M1Q1MDAgMzY0VDUwMiAzNTdMNTEwIDM2N1E1NzMgNDQyIDY1OSA0NDJRNzEzIDQ0MiA3NDYgNDE1VDc4MCAzMzZRNzgwIDI4NSA3NDIgMTc4VDcwNCA1MFE3MDUgMzYgNzA5IDMxVDcyNCAyNlE3NTIgMjYgNzc2IDU2VDgxNSAxMzhRODE4IDE0OSA4MjEgMTUxVDgzNyAxNTNRODU3IDE1MyA4NTcgMTQ1UTg1NyAxNDQgODUzIDEzMFE4NDUgMTAxIDgzMSA3M1Q3ODUgMTdUNzE2IC0xMFE2NjkgLTEwIDY0OCAxN1Q2MjcgNzNRNjI3IDkyIDY2MyAxOTNUNzAwIDM0NVE3MDAgNDA0IDY1NiA0MDRINjUxUTU2NSA0MDQgNTA2IDMwM0w0OTkgMjkxTDQ2NiAxNTdRNDMzIDI2IDQyOCAxNlE0MTUgLTExIDM4NSAtMTFRMzcyIC0xMSAzNjQgLTRUMzUzIDhUMzUwIDE4UTM1MCAyOSAzODQgMTYxTDQyMCAzMDdRNDIzIDMyMiA0MjMgMzQ1UTQyMyA0MDQgMzc5IDQwNEgzNzRRMjg4IDQwNCAyMjkgMzAzTDIyMiAyOTFMMTg5IDE1N1ExNTYgMjYgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTIgMTgxUTE1MSAzMzUgMTUxIDM0MlExNTQgMzU3IDE1NCAzNjlRMTU0IDQwNSAxMjkgNDA1UTEwNyA0MDUgOTIgMzc3VDY5IDMxNlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0IiIGQ9Ik00MzQgLTIzMVE0MzQgLTI0NCA0MjggLTI1MEg0MTBRMjgxIC0yNTAgMjMwIC0xODRRMjI1IC0xNzcgMjIyIC0xNzJUMjE3IC0xNjFUMjEzIC0xNDhUMjExIC0xMzNUMjEwIC0xMTFUMjA5IC04NFQyMDkgLTQ3VDIwOSAwUTIwOSAyMSAyMDkgNTNRMjA4IDE0MiAyMDQgMTUzUTIwMyAxNTQgMjAzIDE1NVExODkgMTkxIDE1MyAyMTFUODIgMjMxUTcxIDIzMSA2OCAyMzRUNjUgMjUwVDY4IDI2NlQ4MiAyNjlRMTE2IDI2OSAxNTIgMjg5VDIwMyAzNDVRMjA4IDM1NiAyMDggMzc3VDIwOSA1MjlWNTc5UTIwOSA2MzQgMjE1IDY1NlQyNDQgNjk4UTI3MCA3MjQgMzI0IDc0MFEzNjEgNzQ4IDM3NyA3NDlRMzc5IDc0OSAzOTAgNzQ5VDQwOCA3NTBINDI4UTQzNCA3NDQgNDM0IDczMlE0MzQgNzE5IDQzMSA3MTZRNDI5IDcxMyA0MTUgNzEzUTM2MiA3MTAgMzMyIDY4OVQyOTYgNjQ3UTI5MSA2MzQgMjkxIDQ5OVY0MTdRMjkxIDM3MCAyODggMzUzVDI3MSAzMTRRMjQwIDI3MSAxODQgMjU1TDE3MCAyNTBMMTg0IDI0NVEyMDIgMjM5IDIyMCAyMzBUMjYyIDE5NlQyOTAgMTM3UTI5MSAxMzEgMjkxIDFRMjkxIC0xMzQgMjk2IC0xNDdRMzA2IC0xNzQgMzM5IC0xOTJUNDE1IC0yMTNRNDI5IC0yMTMgNDMxIC0yMTZRNDM0IC0yMTkgNDM0IC0yMzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzgiIGQ9Ik01MiAyODlRNTkgMzMxIDEwNiAzODZUMjIyIDQ0MlEyNTcgNDQyIDI4NiA0MjRUMzI5IDM3OVEzNzEgNDQyIDQzMCA0NDJRNDY3IDQ0MiA0OTQgNDIwVDUyMiAzNjFRNTIyIDMzMiA1MDggMzE0VDQ4MSAyOTJUNDU4IDI4OFE0MzkgMjg4IDQyNyAyOTlUNDE1IDMyOFE0MTUgMzc0IDQ2NSAzOTFRNDU0IDQwNCA0MjUgNDA0UTQxMiA0MDQgNDA2IDQwMlEzNjggMzg2IDM1MCAzMzZRMjkwIDExNSAyOTAgNzhRMjkwIDUwIDMwNiAzOFQzNDEgMjZRMzc4IDI2IDQxNCA1OVQ0NjMgMTQwUTQ2NiAxNTAgNDY5IDE1MVQ0ODUgMTUzSDQ4OVE1MDQgMTUzIDUwNCAxNDVRNTA0IDE0NCA1MDIgMTM0UTQ4NiA3NyA0NDAgMzNUMzMzIC0xMVEyNjMgLTExIDIyNyA1MlExODYgLTEwIDEzMyAtMTBIMTI3UTc4IC0xMCA1NyAxNlQzNSA3MVEzNSAxMDMgNTQgMTIzVDk5IDE0M1ExNDIgMTQzIDE0MiAxMDFRMTQyIDgxIDEzMCA2NlQxMDcgNDZUOTQgNDFMOTEgNDBROTEgMzkgOTcgMzZUMTEzIDI5VDEzMiAyNlExNjggMjYgMTk0IDcxUTIwMyA4NyAyMTcgMTM5VDI0NSAyNDdUMjYxIDMxM1EyNjYgMzQwIDI2NiAzNTJRMjY2IDM4MCAyNTEgMzkyVDIxNyA0MDRRMTc3IDQwNCAxNDIgMzcyVDkzIDI5MFE5MSAyODEgODggMjgwVDcyIDI3OEg1OFE1MiAyODQgNTIgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oyLTI4IiBkPSJNMTgwIDk2VDE4MCAyNTBUMjA1IDU0MVQyNjYgNzcwVDM1MyA5NDRUNDQ0IDEwNjlUNTI3IDExNTBINTU1UTU2MSAxMTQ0IDU2MSAxMTQxUTU2MSAxMTM3IDU0NSAxMTIwVDUwNCAxMDcyVDQ0NyA5OTVUMzg2IDg3OFQzMzAgNzIxVDI4OCA1MTNUMjcyIDI1MVEyNzIgMTMzIDI4MCA1NlEyOTMgLTg3IDMyNiAtMjA5VDM5OSAtNDA1VDQ3NSAtNTMxVDUzNiAtNjA5VDU2MSAtNjQwUTU2MSAtNjQzIDU1NSAtNjQ5SDUyN1E0ODMgLTYxMiA0NDMgLTU2OFQzNTMgLTQ0M1QyNjYgLTI3MFQyMDUgLTQxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMi0yOSIgZD0iTTM1IDExMzhRMzUgMTE1MCA1MSAxMTUwSDU2SDY5UTExMyAxMTEzIDE1MyAxMDY5VDI0MyA5NDRUMzMwIDc3MVQzOTEgNTQxVDQxNiAyNTBUMzkxIC00MFQzMzAgLTI3MFQyNDMgLTQ0M1QxNTIgLTU2OFQ2OSAtNjQ5SDU2UTQzIC02NDkgMzkgLTY0N1QzNSAtNjM3UTY1IC02MDcgMTEwIC01NDhRMjgzIC0zMTYgMzE2IDU2UTMyNCAxMzMgMzI0IDI1MVEzMjQgMzY4IDMxNiA0NDVRMjc4IDg3NyA0OCAxMTIzUTM2IDExMzcgMzUgMTEzOFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02QiIgZD0iTTEyMSA2NDdRMTIxIDY1NyAxMjUgNjcwVDEzNyA2ODNRMTM4IDY4MyAyMDkgNjg4VDI4MiA2OTRRMjk0IDY5NCAyOTQgNjg2UTI5NCA2NzkgMjQ0IDQ3N1ExOTQgMjc5IDE5NCAyNzJRMjEzIDI4MiAyMjMgMjkxUTI0NyAzMDkgMjkyIDM1NFQzNjIgNDE1UTQwMiA0NDIgNDM4IDQ0MlE0NjggNDQyIDQ4NSA0MjNUNTAzIDM2OVE1MDMgMzQ0IDQ5NiAzMjdUNDc3IDMwMlQ0NTYgMjkxVDQzOCAyODhRNDE4IDI4OCA0MDYgMjk5VDM5NCAzMjhRMzk0IDM1MyA0MTAgMzY5VDQ0MiAzOTBMNDU4IDM5M1E0NDYgNDA1IDQzNCA0MDVINDMwUTM5OCA0MDIgMzY3IDM4MFQyOTQgMzE2VDIyOCAyNTVRMjMwIDI1NCAyNDMgMjUyVDI2NyAyNDZUMjkzIDIzOFQzMjAgMjI0VDM0MiAyMDZUMzU5IDE4MFQzNjUgMTQ3UTM2NSAxMzAgMzYwIDEwNlQzNTQgNjZRMzU0IDI2IDM4MSAyNlE0MjkgMjYgNDU5IDE0NVE0NjEgMTUzIDQ3OSAxNTNINDgzUTQ5OSAxNTMgNDk5IDE0NFE0OTkgMTM5IDQ5NiAxMzBRNDU1IC0xMSAzNzggLTExUTMzMyAtMTEgMzA1IDE1VDI3NyA5MFEyNzcgMTA4IDI4MCAxMjFUMjgzIDE0NVEyODMgMTY3IDI2OSAxODNUMjM0IDIwNlQyMDAgMjE3VDE4MiAyMjBIMTgwUTE2OCAxNzggMTU5IDEzOVQxNDUgODFUMTM2IDQ0VDEyOSAyMFQxMjIgN1QxMTEgLTJROTggLTExIDgzIC0xMVE2NiAtMTEgNTcgLTFUNDggMTZRNDggMjYgODUgMTc2VDE1OCA0NzFMMTk1IDYxNlExOTYgNjI5IDE4OCA2MzJUMTQ5IDYzN0gxNDRRMTM0IDYzNyAxMzEgNjM3VDEyNCA2NDBUMTIxIDY0N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJCIiBkPSJNNTYgMjM3VDU2IDI1MFQ3MCAyNzBIMzY5VjQyMEwzNzAgNTcwUTM4MCA1ODMgMzg5IDU4M1E0MDIgNTgzIDQwOSA1NjhWMjcwSDcwN1E3MjIgMjYyIDcyMiAyNTBUNzA3IDIzMEg0MDlWLTY4UTQwMSAtODIgMzkxIC04MkgzODlIMzg3UTM3NSAtODIgMzY5IC02OFYyMzBINzBRNTYgMjM3IDU2IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MCIgZD0iTTI4NyA2MjhRMjg3IDYzNSAyMzAgNjM3UTIwNiA2MzcgMTk5IDYzOFQxOTIgNjQ4UTE5MiA2NDkgMTk0IDY1OVEyMDAgNjc5IDIwMyA2ODFUMzk3IDY4M1E1ODcgNjgyIDYwMCA2ODBRNjY0IDY2OSA3MDcgNjMxVDc1MSA1MzBRNzUxIDQ1MyA2ODUgMzg5UTYxNiAzMjEgNTA3IDMwM1E1MDAgMzAyIDQwMiAzMDFIMzA3TDI3NyAxODJRMjQ3IDY2IDI0NyA1OVEyNDcgNTUgMjQ4IDU0VDI1NSA1MFQyNzIgNDhUMzA1IDQ2SDMzNlEzNDIgMzcgMzQyIDM1UTM0MiAxOSAzMzUgNVEzMzAgMCAzMTkgMFEzMTYgMCAyODIgMVQxODIgMlExMjAgMiA4NyAyVDUxIDFRMzMgMSAzMyAxMVEzMyAxMyAzNiAyNVE0MCA0MSA0NCA0M1Q2NyA0NlE5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4Wk02NDUgNTU0UTY0NSA1NjcgNjQzIDU3NVQ2MzQgNTk3VDYwOSA2MTlUNTYwIDYzNVE1NTMgNjM2IDQ4MCA2MzdRNDYzIDYzNyA0NDUgNjM3VDQxNiA2MzZUNDA0IDYzNlEzOTEgNjM1IDM4NiA2MjdRMzg0IDYyMSAzNjcgNTUwVDMzMiA0MTJUMzE0IDM0NFEzMTQgMzQyIDM5NSAzNDJINDA3SDQzMFE1NDIgMzQyIDU5MCAzOTJRNjE3IDQxOSA2MzEgNDcxVDY0NSA1NTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTQiIGQ9Ik00MCA0MzdRMjEgNDM3IDIxIDQ0NVEyMSA0NTAgMzcgNTAxVDcxIDYwMkw4OCA2NTFROTMgNjY5IDEwMSA2NzdINTY5SDY1OVE2OTEgNjc3IDY5NyA2NzZUNzA0IDY2N1E3MDQgNjYxIDY4NyA1NTNUNjY4IDQ0NFE2NjggNDM3IDY0OSA0MzdRNjQwIDQzNyA2MzcgNDM3VDYzMSA0NDJMNjI5IDQ0NVE2MjkgNDUxIDYzNSA0OTBUNjQxIDU1MVE2NDEgNTg2IDYyOCA2MDRUNTczIDYyOVE1NjggNjMwIDUxNSA2MzFRNDY5IDYzMSA0NTcgNjMwVDQzOSA2MjJRNDM4IDYyMSAzNjggMzQzVDI5OCA2MFEyOTggNDggMzg2IDQ2UTQxOCA0NiA0MjcgNDVUNDM2IDM2UTQzNiAzMSA0MzMgMjJRNDI5IDQgNDI0IDFMNDIyIDBRNDE5IDAgNDE1IDBRNDEwIDAgMzYzIDFUMjI4IDJROTkgMiA2NCAwSDQ5UTQzIDYgNDMgOVQ0NSAyN1E0OSA0MCA1NSA0Nkg4M0g5NFExNzQgNDYgMTg5IDU1UTE5MCA1NiAxOTEgNTZRMTk2IDU5IDIwMSA3NlQyNDEgMjMzUTI1OCAzMDEgMjY5IDM0NFEzMzkgNjE5IDMzOSA2MjVRMzM5IDYzMCAzMTAgNjMwSDI3OVEyMTIgNjMwIDE5MSA2MjRRMTQ2IDYxNCAxMjEgNTgzVDY3IDQ2N1E2MCA0NDUgNTcgNDQxVDQzIDQzN0g0MFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iMTE2NyIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI4MjUiIHk9Ii0yMTIiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjMyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjMxNTgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTM3LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzk3LDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNjkxMiIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDExNzIpIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNTQ0IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjEzNCIgeT0iNjI5Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI4NCIgeT0iLTQ4OCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzg0LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNTc2NyIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDkwNCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTIyMTEiIHg9IjAiIHk9Ii0xIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjU3NCkiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIxMzAxIiB5PSI1MzgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3NDcsLTIwOCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNTc0KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNTc0KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMzQ1IiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjU3NCkiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjExMjQiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE5MTcsMCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzQiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNTUsLTEwNykiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNTc0KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNTc0KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzUiIHg9IjYwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RCIgeD0iMTE3MyIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIxLDApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yOCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQyMiwwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc4IiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iMTA3MyIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMTkzOCIgeT0iNTM4Ij48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTI5IiB4PSIyNTUxIiB5PSItMSI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjEzLC00NzYpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTQwLDApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNTMsMCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI3NSwwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iNjQyIiB5PSItMjM4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjkwMSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxNjgwIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMjU3MCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjM0NjAiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTYyLC0xMjQzKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjU0NCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxMzQiIHk9IjYyOSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iODQiIHk9Ii00ODgiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDc4NCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjM5NjMiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw2NTkpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSlNaMS0yMjExIiB4PSIwIiB5PSItMSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTMwMSIgeT0iNTM4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzQ3LC0yMDgpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjU3NCkiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjU3NCkiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjM0NSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxMTI0IiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNzUwLDApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNzUsMCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNTc0KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjY0MiIgeT0iLTIzOCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI5MDEiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTY4MCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjI1NzAiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzEwLC00NzYpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTQwLDApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNTMsMCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI3NSwwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iNjQyIiB5PSItMjM4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjkwMSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxNjgwIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMjU3MCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjM0NjAiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjExNjQ1IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTI0MjMsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI5OTc1IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsMTE2OSkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI1NDQiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0PgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTM0IiB5PSI2MjkiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9Ijg0IiB5PSItNDg4Ij48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5NTEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjEtMjIxMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTQ5NCIgeT0iNjc1Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTA1NiwtMjg3KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIzNDUiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTEyNCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDY2MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc0IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzYxLC0xNTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc1IiB4PSI2MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkQiIHg9IjExNzMiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjc0MiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yOCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU5NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03OCIgeD0iNTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iMTA3MyIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMjIyNSIgeT0iNjc1Ij48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjkiIHg9IjI1MTUiIHk9Ii0xIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDg4OCwtOTM3KSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjU0NCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxMzQiIHk9IjYyOSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iODQiIHk9Ii00ODgiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDk1MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMS0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIxNDk0IiB5PSI2NzUiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDU2LC0yODcpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjM0NSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxMTI0IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MjMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0ODMwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSI3MzciIHk9Ii0yMTMiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMDg4IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMjA4OCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMjk3OCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8L3N2Zz4=)
因为,对于所有的 , ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjE5LjEyN2V4IiBoZWlnaHQ9IjUuNTA5ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMi4xNzFleDsiIHZpZXdCb3g9IjAgLTE0MzcuMiA4MjM1LjEgMjM3MiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NSIgZD0iTTQ5MiAyMTNRNDcyIDIxMyA0NzIgMjI2UTQ3MiAyMzAgNDc3IDI1MFQ0ODIgMjg1UTQ4MiAzMTYgNDYxIDMyM1QzNjQgMzMwSDMxMlEzMTEgMzI4IDI3NyAxOTJUMjQzIDUyUTI0MyA0OCAyNTQgNDhUMzM0IDQ2UTQyOCA0NiA0NTggNDhUNTE4IDYxUTU2NyA3NyA1OTkgMTE3VDY3MCAyNDhRNjgwIDI3MCA2ODMgMjcyUTY5MCAyNzQgNjk4IDI3NFE3MTggMjc0IDcxOCAyNjFRNjEzIDcgNjA4IDJRNjA1IDAgMzIyIDBIMTMzUTMxIDAgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ2IDY2IDIxNSAzNDJUMjg1IDYyMlEyODUgNjI5IDI4MSA2MjlRMjczIDYzMiAyMjggNjM0SDE5N1ExOTEgNjQwIDE5MSA2NDJUMTkzIDY1OVExOTcgNjc2IDIwMyA2ODBINzU3UTc2NCA2NzYgNzY0IDY2OVE3NjQgNjY0IDc1MSA1NTdUNzM3IDQ0N1E3MzUgNDQwIDcxNyA0NDBINzA1UTY5OCA0NDUgNjk4IDQ1M0w3MDEgNDc2UTcwNCA1MDAgNzA0IDUyOFE3MDQgNTU4IDY5NyA1NzhUNjc4IDYwOVQ2NDMgNjI1VDU5NiA2MzJUNTMyIDYzNEg0ODVRMzk3IDYzMyAzOTIgNjMxUTM4OCA2MjkgMzg2IDYyMlEzODUgNjE5IDM1NSA0OTlUMzI0IDM3N1EzNDcgMzc2IDM3MiAzNzZIMzk4UTQ2NCAzNzYgNDg5IDM5MVQ1MzQgNDcyUTUzOCA0ODggNTQwIDQ5MFQ1NTcgNDkzUTU2MiA0OTMgNTY1IDQ5M1Q1NzAgNDkyVDU3MiA0OTFUNTc0IDQ4N1Q1NzcgNDgzTDU0NCAzNTFRNTExIDIxOCA1MDggMjE2UTUwNSAyMTMgNDkyIDIxM1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02QiIgZD0iTTEyMSA2NDdRMTIxIDY1NyAxMjUgNjcwVDEzNyA2ODNRMTM4IDY4MyAyMDkgNjg4VDI4MiA2OTRRMjk0IDY5NCAyOTQgNjg2UTI5NCA2NzkgMjQ0IDQ3N1ExOTQgMjc5IDE5NCAyNzJRMjEzIDI4MiAyMjMgMjkxUTI0NyAzMDkgMjkyIDM1NFQzNjIgNDE1UTQwMiA0NDIgNDM4IDQ0MlE0NjggNDQyIDQ4NSA0MjNUNTAzIDM2OVE1MDMgMzQ0IDQ5NiAzMjdUNDc3IDMwMlQ0NTYgMjkxVDQzOCAyODhRNDE4IDI4OCA0MDYgMjk5VDM5NCAzMjhRMzk0IDM1MyA0MTAgMzY5VDQ0MiAzOTBMNDU4IDM5M1E0NDYgNDA1IDQzNCA0MDVINDMwUTM5OCA0MDIgMzY3IDM4MFQyOTQgMzE2VDIyOCAyNTVRMjMwIDI1NCAyNDMgMjUyVDI2NyAyNDZUMjkzIDIzOFQzMjAgMjI0VDM0MiAyMDZUMzU5IDE4MFQzNjUgMTQ3UTM2NSAxMzAgMzYwIDEwNlQzNTQgNjZRMzU0IDI2IDM4MSAyNlE0MjkgMjYgNDU5IDE0NVE0NjEgMTUzIDQ3OSAxNTNINDgzUTQ5OSAxNTMgNDk5IDE0NFE0OTkgMTM5IDQ5NiAxMzBRNDU1IC0xMSAzNzggLTExUTMzMyAtMTEgMzA1IDE1VDI3NyA5MFEyNzcgMTA4IDI4MCAxMjFUMjgzIDE0NVEyODMgMTY3IDI2OSAxODNUMjM0IDIwNlQyMDAgMjE3VDE4MiAyMjBIMTgwUTE2OCAxNzggMTU5IDEzOVQxNDUgODFUMTM2IDQ0VDEyOSAyMFQxMjIgN1QxMTEgLTJROTggLTExIDgzIC0xMVE2NiAtMTEgNTcgLTFUNDggMTZRNDggMjYgODUgMTc2VDE1OCA0NzFMMTk1IDYxNlExOTYgNjI5IDE4OCA2MzJUMTQ5IDYzN0gxNDRRMTM0IDYzNyAxMzEgNjM3VDEyNCA2NDBUMTIxIDY0N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02OSIgZD0iTTE4NCA2MDBRMTg0IDYyNCAyMDMgNjQyVDI0NyA2NjFRMjY1IDY2MSAyNzcgNjQ5VDI5MCA2MTlRMjkwIDU5NiAyNzAgNTc3VDIyNiA1NTdRMjExIDU1NyAxOTggNTY3VDE4NCA2MDBaTTIxIDI4N1EyMSAyOTUgMzAgMzE4VDU0IDM2OVQ5OCA0MjBUMTU4IDQ0MlExOTcgNDQyIDIyMyA0MTlUMjUwIDM1N1EyNTAgMzQwIDIzNiAzMDFUMTk2IDE5NlQxNTQgODNRMTQ5IDYxIDE0OSA1MVExNDkgMjYgMTY2IDI2UTE3NSAyNiAxODUgMjlUMjA4IDQzVDIzNSA3OFQyNjAgMTM3UTI2MyAxNDkgMjY1IDE1MVQyODIgMTUzUTMwMiAxNTMgMzAyIDE0M1EzMDIgMTM1IDI5MyAxMTJUMjY4IDYxVDIyMyAxMVQxNjEgLTExUTEyOSAtMTEgMTAyIDEwVDc0IDc0UTc0IDkxIDc5IDEwNlQxMjIgMjIwUTE2MCAzMjEgMTY2IDM0MVQxNzMgMzgwUTE3MyA0MDQgMTU2IDQwNEgxNTRRMTI0IDQwNCA5OSAzNzFUNjEgMjg3UTYwIDI4NiA1OSAyODRUNTggMjgxVDU2IDI3OVQ1MyAyNzhUNDkgMjc4VDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03RCIgZD0iTTY1IDczMVE2NSA3NDUgNjggNzQ3VDg4IDc1MFExNzEgNzUwIDIxNiA3MjVUMjc5IDY3MFEyODggNjQ5IDI4OSA2MzVUMjkxIDUwMVEyOTIgMzYyIDI5MyAzNTdRMzA2IDMxMiAzNDUgMjkxVDQxNyAyNjlRNDI4IDI2OSA0MzEgMjY2VDQzNCAyNTBUNDMxIDIzNFQ0MTcgMjMxUTM4MCAyMzEgMzQ1IDIxMFQyOTggMTU3UTI5MyAxNDMgMjkyIDEyMVQyOTEgLTI4Vi03OVEyOTEgLTEzNCAyODUgLTE1NlQyNTYgLTE5OFEyMDIgLTI1MCA4OSAtMjUwUTcxIC0yNTAgNjggLTI0N1Q2NSAtMjMwUTY1IC0yMjQgNjUgLTIyM1Q2NiAtMjE4VDY5IC0yMTRUNzcgLTIxM1E5MSAtMjEzIDEwOCAtMjEwVDE0NiAtMjAwVDE4MyAtMTc3VDIwNyAtMTM5UTIwOCAtMTM0IDIwOSAzTDIxMCAxMzlRMjIzIDE5NiAyODAgMjMwUTMxNSAyNDcgMzMwIDI1MFEzMDUgMjU3IDI4MCAyNzBRMjI1IDMwNCAyMTIgMzUyTDIxMCAzNjJMMjA5IDQ5OFEyMDggNjM1IDIwNyA2NDBRMTk1IDY4MCAxNTQgNjk2VDc3IDcxM1E2OCA3MTMgNjcgNzE2VDY1IDczMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUwIiBkPSJNMjg3IDYyOFEyODcgNjM1IDIzMCA2MzdRMjA2IDYzNyAxOTkgNjM4VDE5MiA2NDhRMTkyIDY0OSAxOTQgNjU5UTIwMCA2NzkgMjAzIDY4MVQzOTcgNjgzUTU4NyA2ODIgNjAwIDY4MFE2NjQgNjY5IDcwNyA2MzFUNzUxIDUzMFE3NTEgNDUzIDY4NSAzODlRNjE2IDMyMSA1MDcgMzAzUTUwMCAzMDIgNDAyIDMwMUgzMDdMMjc3IDE4MlEyNDcgNjYgMjQ3IDU5UTI0NyA1NSAyNDggNTRUMjU1IDUwVDI3MiA0OFQzMDUgNDZIMzM2UTM0MiAzNyAzNDIgMzVRMzQyIDE5IDMzNSA1UTMzMCAwIDMxOSAwUTMxNiAwIDI4MiAxVDE4MiAyUTEyMCAyIDg3IDJUNTEgMVEzMyAxIDMzIDExUTMzIDEzIDM2IDI1UTQwIDQxIDQ0IDQzVDY3IDQ2UTk0IDQ2IDEyNyA0OVExNDEgNTIgMTQ2IDYxUTE0OSA2NSAyMTggMzM5VDI4NyA2MjhaTTY0NSA1NTRRNjQ1IDU2NyA2NDMgNTc1VDYzNCA1OTdUNjA5IDYxOVQ1NjAgNjM1UTU1MyA2MzYgNDgwIDYzN1E0NjMgNjM3IDQ0NSA2MzdUNDE2IDYzNlQ0MDQgNjM2UTM5MSA2MzUgMzg2IDYyN1EzODQgNjIxIDM2NyA1NTBUMzMyIDQxMlQzMTQgMzQ0UTMxNCAzNDIgMzk1IDM0Mkg0MDdINDMwUTU0MiAzNDIgNTkwIDM5MlE2MTcgNDE5IDYzMSA0NzFUNjQ1IDU1NFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTMxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iNzM3IiB5PSItMjEzIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTA4OCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjIwODgiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjI5NzgiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0QiIHg9IjM4NjgiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjU1NzgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MzU2LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzk3LDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTM2MCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjQzMCIgeT0iNjc2Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8L3N2Zz4=) ,并且,
,并且, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjI4LjM3NWV4IiBoZWlnaHQ9IjQuODQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMS44MzhleDsiIHZpZXdCb3g9IjAgLTEyOTMuNyAxMjIxNy4xIDIwODUiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDUiIGQ9Ik00OTIgMjEzUTQ3MiAyMTMgNDcyIDIyNlE0NzIgMjMwIDQ3NyAyNTBUNDgyIDI4NVE0ODIgMzE2IDQ2MSAzMjNUMzY0IDMzMEgzMTJRMzExIDMyOCAyNzcgMTkyVDI0MyA1MlEyNDMgNDggMjU0IDQ4VDMzNCA0NlE0MjggNDYgNDU4IDQ4VDUxOCA2MVE1NjcgNzcgNTk5IDExN1Q2NzAgMjQ4UTY4MCAyNzAgNjgzIDI3MlE2OTAgMjc0IDY5OCAyNzRRNzE4IDI3NCA3MTggMjYxUTYxMyA3IDYwOCAyUTYwNSAwIDMyMiAwSDEzM1EzMSAwIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc1N1E3NjQgNjc2IDc2NCA2NjlRNzY0IDY2NCA3NTEgNTU3VDczNyA0NDdRNzM1IDQ0MCA3MTcgNDQwSDcwNVE2OTggNDQ1IDY5OCA0NTNMNzAxIDQ3NlE3MDQgNTAwIDcwNCA1MjhRNzA0IDU1OCA2OTcgNTc4VDY3OCA2MDlUNjQzIDYyNVQ1OTYgNjMyVDUzMiA2MzRINDg1UTM5NyA2MzMgMzkyIDYzMVEzODggNjI5IDM4NiA2MjJRMzg1IDYxOSAzNTUgNDk5VDMyNCAzNzdRMzQ3IDM3NiAzNzIgMzc2SDM5OFE0NjQgMzc2IDQ4OSAzOTFUNTM0IDQ3MlE1MzggNDg4IDU0MCA0OTBUNTU3IDQ5M1E1NjIgNDkzIDU2NSA0OTNUNTcwIDQ5MlQ1NzIgNDkxVDU3NCA0ODdUNTc3IDQ4M0w1NDQgMzUxUTUxMSAyMTggNTA4IDIxNlE1MDUgMjEzIDQ5MiAyMTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03QiIgZD0iTTQzNCAtMjMxUTQzNCAtMjQ0IDQyOCAtMjUwSDQxMFEyODEgLTI1MCAyMzAgLTE4NFEyMjUgLTE3NyAyMjIgLTE3MlQyMTcgLTE2MVQyMTMgLTE0OFQyMTEgLTEzM1QyMTAgLTExMVQyMDkgLTg0VDIwOSAtNDdUMjA5IDBRMjA5IDIxIDIwOSA1M1EyMDggMTQyIDIwNCAxNTNRMjAzIDE1NCAyMDMgMTU1UTE4OSAxOTEgMTUzIDIxMVQ4MiAyMzFRNzEgMjMxIDY4IDIzNFQ2NSAyNTBUNjggMjY2VDgyIDI2OVExMTYgMjY5IDE1MiAyODlUMjAzIDM0NVEyMDggMzU2IDIwOCAzNzdUMjA5IDUyOVY1NzlRMjA5IDYzNCAyMTUgNjU2VDI0NCA2OThRMjcwIDcyNCAzMjQgNzQwUTM2MSA3NDggMzc3IDc0OVEzNzkgNzQ5IDM5MCA3NDlUNDA4IDc1MEg0MjhRNDM0IDc0NCA0MzQgNzMyUTQzNCA3MTkgNDMxIDcxNlE0MjkgNzEzIDQxNSA3MTNRMzYyIDcxMCAzMzIgNjg5VDI5NiA2NDdRMjkxIDYzNCAyOTEgNDk5VjQxN1EyOTEgMzcwIDI4OCAzNTNUMjcxIDMxNFEyNDAgMjcxIDE4NCAyNTVMMTcwIDI1MEwxODQgMjQ1UTIwMiAyMzkgMjIwIDIzMFQyNjIgMTk2VDI5MCAxMzdRMjkxIDEzMSAyOTEgMVEyOTEgLTEzNCAyOTYgLTE0N1EzMDYgLTE3NCAzMzkgLTE5MlQ0MTUgLTIxM1E0MjkgLTIxMyA0MzEgLTIxNlE0MzQgLTIxOSA0MzQgLTIzMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MCIgZD0iTTI4NyA2MjhRMjg3IDYzNSAyMzAgNjM3UTIwNiA2MzcgMTk5IDYzOFQxOTIgNjQ4UTE5MiA2NDkgMTk0IDY1OVEyMDAgNjc5IDIwMyA2ODFUMzk3IDY4M1E1ODcgNjgyIDYwMCA2ODBRNjY0IDY2OSA3MDcgNjMxVDc1MSA1MzBRNzUxIDQ1MyA2ODUgMzg5UTYxNiAzMjEgNTA3IDMwM1E1MDAgMzAyIDQwMiAzMDFIMzA3TDI3NyAxODJRMjQ3IDY2IDI0NyA1OVEyNDcgNTUgMjQ4IDU0VDI1NSA1MFQyNzIgNDhUMzA1IDQ2SDMzNlEzNDIgMzcgMzQyIDM1UTM0MiAxOSAzMzUgNVEzMzAgMCAzMTkgMFEzMTYgMCAyODIgMVQxODIgMlExMjAgMiA4NyAyVDUxIDFRMzMgMSAzMyAxMVEzMyAxMyAzNiAyNVE0MCA0MSA0NCA0M1Q2NyA0NlE5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4Wk02NDUgNTU0UTY0NSA1NjcgNjQzIDU3NVQ2MzQgNTk3VDYwOSA2MTlUNTYwIDYzNVE1NTMgNjM2IDQ4MCA2MzdRNDYzIDYzNyA0NDUgNjM3VDQxNiA2MzZUNDA0IDYzNlEzOTEgNjM1IDM4NiA2MjdRMzg0IDYyMSAzNjcgNTUwVDMzMiA0MTJUMzE0IDM0NFEzMTQgMzQyIDM5NSAzNDJINDA3SDQzMFE1NDIgMzQyIDU5MCAzOTJRNjE3IDQxOSA2MzEgNDcxVDY0NSA1NTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTQiIGQ9Ik00MCA0MzdRMjEgNDM3IDIxIDQ0NVEyMSA0NTAgMzcgNTAxVDcxIDYwMkw4OCA2NTFROTMgNjY5IDEwMSA2NzdINTY5SDY1OVE2OTEgNjc3IDY5NyA2NzZUNzA0IDY2N1E3MDQgNjYxIDY4NyA1NTNUNjY4IDQ0NFE2NjggNDM3IDY0OSA0MzdRNjQwIDQzNyA2MzcgNDM3VDYzMSA0NDJMNjI5IDQ0NVE2MjkgNDUxIDYzNSA0OTBUNjQxIDU1MVE2NDEgNTg2IDYyOCA2MDRUNTczIDYyOVE1NjggNjMwIDUxNSA2MzFRNDY5IDYzMSA0NTcgNjMwVDQzOSA2MjJRNDM4IDYyMSAzNjggMzQzVDI5OCA2MFEyOTggNDggMzg2IDQ2UTQxOCA0NiA0MjcgNDVUNDM2IDM2UTQzNiAzMSA0MzMgMjJRNDI5IDQgNDI0IDFMNDIyIDBRNDE5IDAgNDE1IDBRNDEwIDAgMzYzIDFUMjI4IDJROTkgMiA2NCAwSDQ5UTQzIDYgNDMgOVQ0NSAyN1E0OSA0MCA1NSA0Nkg4M0g5NFExNzQgNDYgMTg5IDU1UTE5MCA1NiAxOTEgNTZRMTk2IDU5IDIwMSA3NlQyNDEgMjMzUTI1OCAzMDEgMjY5IDM0NFEzMzkgNjE5IDMzOSA2MjVRMzM5IDYzMCAzMTAgNjMwSDI3OVEyMTIgNjMwIDE5MSA2MjRRMTQ2IDYxNCAxMjEgNTgzVDY3IDQ2N1E2MCA0NDUgNTcgNDQxVDQzIDQzN0g0MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03NCIgZD0iTTI2IDM4NVExOSAzOTIgMTkgMzk1UTE5IDM5OSAyMiA0MTFUMjcgNDI1UTI5IDQzMCAzNiA0MzBUODcgNDMxSDE0MEwxNTkgNTExUTE2MiA1MjIgMTY2IDU0MFQxNzMgNTY2VDE3OSA1ODZUMTg3IDYwM1QxOTcgNjE1VDIxMSA2MjRUMjI5IDYyNlEyNDcgNjI1IDI1NCA2MTVUMjYxIDU5NlEyNjEgNTg5IDI1MiA1NDlUMjMyIDQ3MEwyMjIgNDMzUTIyMiA0MzEgMjcyIDQzMUgzMjNRMzMwIDQyNCAzMzAgNDIwUTMzMCAzOTggMzE3IDM4NUgyMTBMMTc0IDI0MFExMzUgODAgMTM1IDY4UTEzNSAyNiAxNjIgMjZRMTk3IDI2IDIzMCA2MFQyODMgMTQ0UTI4NSAxNTAgMjg4IDE1MVQzMDMgMTUzSDMwN1EzMjIgMTUzIDMyMiAxNDVRMzIyIDE0MiAzMTkgMTMzUTMxNCAxMTcgMzAxIDk1VDI2NyA0OFQyMTYgNlQxNTUgLTExUTEyNSAtMTEgOTggNFQ1OSA1NlE1NyA2NCA1NyA4M1YxMDFMOTIgMjQxUTEyNyAzODIgMTI4IDM4M1ExMjggMzg1IDc3IDM4NUgyNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03NSIgZD0iTTIxIDI4N1EyMSAyOTUgMzAgMzE4VDU1IDM3MFQ5OSA0MjBUMTU4IDQ0MlEyMDQgNDQyIDIyNyA0MTdUMjUwIDM1OFEyNTAgMzQwIDIxNiAyNDZUMTgyIDEwNVExODIgNjIgMTk2IDQ1VDIzOCAyN1QyOTEgNDRUMzI4IDc4TDMzOSA5NVEzNDEgOTkgMzc3IDI0N1E0MDcgMzY3IDQxMyAzODdUNDI3IDQxNlE0NDQgNDMxIDQ2MyA0MzFRNDgwIDQzMSA0ODggNDIxVDQ5NiA0MDJMNDIwIDg0UTQxOSA3OSA0MTkgNjhRNDE5IDQzIDQyNiAzNVQ0NDcgMjZRNDY5IDI5IDQ4MiA1N1Q1MTIgMTQ1UTUxNCAxNTMgNTMyIDE1M1E1NTEgMTUzIDU1MSAxNDRRNTUwIDEzOSA1NDkgMTMwVDU0MCA5OFQ1MjMgNTVUNDk4IDE3VDQ2MiAtOFE0NTQgLTEwIDQzOCAtMTBRMzcyIC0xMCAzNDcgNDZRMzQ1IDQ1IDMzNiAzNlQzMTggMjFUMjk2IDZUMjY3IC02VDIzMyAtMTFRMTg5IC0xMSAxNTUgN1ExMDMgMzggMTAzIDExM1ExMDMgMTcwIDEzOCAyNjJUMTczIDM3OVExNzMgMzgwIDE3MyAzODFRMTczIDM5MCAxNzMgMzkzVDE2OSA0MDBUMTU4IDQwNEgxNTRRMTMxIDQwNCAxMTIgMzg1VDgyIDM0NFQ2NSAzMDJUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RCIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODggNDI1VDEzMiA0NDJUMTc1IDQzNVQyMDUgNDE3VDIyMSAzOTVUMjI5IDM3NkwyMzEgMzY5UTIzMSAzNjcgMjMyIDM2N0wyNDMgMzc4UTMwMyA0NDIgMzg0IDQ0MlE0MDEgNDQyIDQxNSA0NDBUNDQxIDQzM1Q0NjAgNDIzVDQ3NSA0MTFUNDg1IDM5OFQ0OTMgMzg1VDQ5NyAzNzNUNTAwIDM2NFQ1MDIgMzU3TDUxMCAzNjdRNTczIDQ0MiA2NTkgNDQyUTcxMyA0NDIgNzQ2IDQxNVQ3ODAgMzM2UTc4MCAyODUgNzQyIDE3OFQ3MDQgNTBRNzA1IDM2IDcwOSAzMVQ3MjQgMjZRNzUyIDI2IDc3NiA1NlQ4MTUgMTM4UTgxOCAxNDkgODIxIDE1MVQ4MzcgMTUzUTg1NyAxNTMgODU3IDE0NVE4NTcgMTQ0IDg1MyAxMzBRODQ1IDEwMSA4MzEgNzNUNzg1IDE3VDcxNiAtMTBRNjY5IC0xMCA2NDggMTdUNjI3IDczUTYyNyA5MiA2NjMgMTkzVDcwMCAzNDVRNzAwIDQwNCA2NTYgNDA0SDY1MVE1NjUgNDA0IDUwNiAzMDNMNDk5IDI5MUw0NjYgMTU3UTQzMyAyNiA0MjggMTZRNDE1IC0xMSAzODUgLTExUTM3MiAtMTEgMzY0IC00VDM1MyA4VDM1MCAxOFEzNTAgMjkgMzg0IDE2MUw0MjAgMzA3UTQyMyAzMjIgNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MVExNTEgMzM1IDE1MSAzNDJRMTU0IDM1NyAxNTQgMzY5UTE1NCA0MDUgMTI5IDQwNVExMDcgNDA1IDkyIDM3N1Q2OSAzMTZUNTcgMjgwUTU1IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzgiIGQ9Ik01MiAyODlRNTkgMzMxIDEwNiAzODZUMjIyIDQ0MlEyNTcgNDQyIDI4NiA0MjRUMzI5IDM3OVEzNzEgNDQyIDQzMCA0NDJRNDY3IDQ0MiA0OTQgNDIwVDUyMiAzNjFRNTIyIDMzMiA1MDggMzE0VDQ4MSAyOTJUNDU4IDI4OFE0MzkgMjg4IDQyNyAyOTlUNDE1IDMyOFE0MTUgMzc0IDQ2NSAzOTFRNDU0IDQwNCA0MjUgNDA0UTQxMiA0MDQgNDA2IDQwMlEzNjggMzg2IDM1MCAzMzZRMjkwIDExNSAyOTAgNzhRMjkwIDUwIDMwNiAzOFQzNDEgMjZRMzc4IDI2IDQxNCA1OVQ0NjMgMTQwUTQ2NiAxNTAgNDY5IDE1MVQ0ODUgMTUzSDQ4OVE1MDQgMTUzIDUwNCAxNDVRNTA0IDE0NCA1MDIgMTM0UTQ4NiA3NyA0NDAgMzNUMzMzIC0xMVEyNjMgLTExIDIyNyA1MlExODYgLTEwIDEzMyAtMTBIMTI3UTc4IC0xMCA1NyAxNlQzNSA3MVEzNSAxMDMgNTQgMTIzVDk5IDE0M1ExNDIgMTQzIDE0MiAxMDFRMTQyIDgxIDEzMCA2NlQxMDcgNDZUOTQgNDFMOTEgNDBROTEgMzkgOTcgMzZUMTEzIDI5VDEzMiAyNlExNjggMjYgMTk0IDcxUTIwMyA4NyAyMTcgMTM5VDI0NSAyNDdUMjYxIDMxM1EyNjYgMzQwIDI2NiAzNTJRMjY2IDM4MCAyNTEgMzkyVDIxNyA0MDRRMTc3IDQwNCAxNDIgMzcyVDkzIDI5MFE5MSAyODEgODggMjgwVDcyIDI3OEg1OFE1MiAyODQgNTIgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNjkiIGQ9Ik0xODQgNjAwUTE4NCA2MjQgMjAzIDY0MlQyNDcgNjYxUTI2NSA2NjEgMjc3IDY0OVQyOTAgNjE5UTI5MCA1OTYgMjcwIDU3N1QyMjYgNTU3UTIxMSA1NTcgMTk4IDU2N1QxODQgNjAwWk0yMSAyODdRMjEgMjk1IDMwIDMxOFQ1NCAzNjlUOTggNDIwVDE1OCA0NDJRMTk3IDQ0MiAyMjMgNDE5VDI1MCAzNTdRMjUwIDM0MCAyMzYgMzAxVDE5NiAxOTZUMTU0IDgzUTE0OSA2MSAxNDkgNTFRMTQ5IDI2IDE2NiAyNlExNzUgMjYgMTg1IDI5VDIwOCA0M1QyMzUgNzhUMjYwIDEzN1EyNjMgMTQ5IDI2NSAxNTFUMjgyIDE1M1EzMDIgMTUzIDMwMiAxNDNRMzAyIDEzNSAyOTMgMTEyVDI2OCA2MVQyMjMgMTFUMTYxIC0xMVExMjkgLTExIDEwMiAxMFQ3NCA3NFE3NCA5MSA3OSAxMDZUMTIyIDIyMFExNjAgMzIxIDE2NiAzNDFUMTczIDM4MFExNzMgNDA0IDE1NiA0MDRIMTU0UTEyNCA0MDQgOTkgMzcxVDYxIDI4N1E2MCAyODYgNTkgMjg0VDU4IDI4MVQ1NiAyNzlUNTMgMjc4VDQ5IDI3OFQ0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMi0yOCIgZD0iTTE4MCA5NlQxODAgMjUwVDIwNSA1NDFUMjY2IDc3MFQzNTMgOTQ0VDQ0NCAxMDY5VDUyNyAxMTUwSDU1NVE1NjEgMTE0NCA1NjEgMTE0MVE1NjEgMTEzNyA1NDUgMTEyMFQ1MDQgMTA3MlQ0NDcgOTk1VDM4NiA4NzhUMzMwIDcyMVQyODggNTEzVDI3MiAyNTFRMjcyIDEzMyAyODAgNTZRMjkzIC04NyAzMjYgLTIwOVQzOTkgLTQwNVQ0NzUgLTUzMVQ1MzYgLTYwOVQ1NjEgLTY0MFE1NjEgLTY0MyA1NTUgLTY0OUg1MjdRNDgzIC02MTIgNDQzIC01NjhUMzUzIC00NDNUMjY2IC0yNzBUMjA1IC00MVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjkiIGQ9Ik0zNSAxMTM4UTM1IDExNTAgNTEgMTE1MEg1Nkg2OVExMTMgMTExMyAxNTMgMTA2OVQyNDMgOTQ0VDMzMCA3NzFUMzkxIDU0MVQ0MTYgMjUwVDM5MSAtNDBUMzMwIC0yNzBUMjQzIC00NDNUMTUyIC01NjhUNjkgLTY0OUg1NlE0MyAtNjQ5IDM5IC02NDdUMzUgLTYzN1E2NSAtNjA3IDExMCAtNTQ4UTI4MyAtMzE2IDMxNiA1NlEzMjQgMTMzIDMyNCAyNTFRMzI0IDM2OCAzMTYgNDQ1UTI3OCA4NzcgNDggMTEyM1EzNiAxMTM3IDM1IDExMzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oyLTdCIiBkPSJNNTQ3IC02NDNMNTQxIC02NDlINTI4UTUxNSAtNjQ5IDUwMyAtNjQ1UTMyNCAtNTgyIDI5MyAtNDY2UTI4OSAtNDQ5IDI4OSAtNDI4VDI4NyAtMjAwTDI4NiA0MkwyODQgNTNRMjc0IDk4IDI0OCAxMzVUMTk2IDE5MFQxNDYgMjIyTDEyMSAyMzVRMTE5IDIzOSAxMTkgMjUwUTExOSAyNjIgMTIxIDI2NlQxMzMgMjczUTI2MiAzMzYgMjg0IDQ0OUwyODYgNDYwTDI4NyA3MDFRMjg3IDczNyAyODcgNzk0UTI4OCA5NDkgMjkyIDk2M1EyOTMgOTY2IDI5MyA5NjdRMzI1IDEwODAgNTA4IDExNDhRNTE2IDExNTAgNTI3IDExNTBINTQxTDU0NyAxMTQ0VjExMzBRNTQ3IDExMTcgNTQ2IDExMTVUNTM2IDExMDlRNDgwIDEwODYgNDM3IDEwNDZUMzgxIDk1MEwzNzkgOTQwTDM3OCA2OTlRMzc4IDY1NyAzNzggNTk0UTM3NyA0NTIgMzc0IDQzOFEzNzMgNDM3IDM3MyA0MzZRMzUwIDM0OCAyNDMgMjgyUTE5MiAyNTcgMTg2IDI1NEwxNzYgMjUxTDE4OCAyNDVRMjExIDIzNiAyMzQgMjIzVDI4NyAxODlUMzQwIDEzNVQzNzMgNjVRMzczIDY0IDM3NCA2M1EzNzcgNDkgMzc4IC05M1EzNzggLTE1NiAzNzggLTE5OEwzNzkgLTQzOEwzODEgLTQ0OVEzOTMgLTUwNCA0MzYgLTU0NFQ1MzYgLTYwOFE1NDQgLTYxMSA1NDUgLTYxM1Q1NDcgLTYyOVYtNjQzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMi03RCIgZD0iTTExOSAxMTMwUTExOSAxMTQ0IDEyMSAxMTQ3VDEzNSAxMTUwSDEzOVExNTEgMTE1MCAxODIgMTEzOFQyNTIgMTEwNVQzMjYgMTA0NlQzNzMgOTY0UTM3OCA5NDIgMzc4IDcwMlEzNzggNDY5IDM3OSA0NjJRMzg2IDM5NCA0MzkgMzM5UTQ4MiAyOTYgNTM1IDI3MlE1NDQgMjY4IDU0NSAyNjZUNTQ3IDI1MVE1NDcgMjQxIDU0NyAyMzhUNTQyIDIzMVQ1MzEgMjI3VDUxMCAyMTdUNDc3IDE5NFEzOTAgMTI5IDM3OSAzOVEzNzggMzIgMzc4IC0yMDFRMzc4IC00NDEgMzczIC00NjNRMzQyIC01ODAgMTY1IC02NDRRMTUyIC02NDkgMTM5IC02NDlRMTI1IC02NDkgMTIyIC02NDZUMTE5IC02MjlRMTE5IC02MjIgMTE5IC02MTlUMTIxIC02MTRUMTI0IC02MTBUMTMyIC02MDdUMTQzIC02MDJRMTk1IC01NzkgMjM1IC01MzlUMjg1IC00NDdRMjg2IC00MzUgMjg3IC0xOTlUMjg5IDUxUTI5NCA3NCAzMDAgOTFUMzI5IDEzOFQzOTAgMTk3UTQxMiAyMTMgNDM2IDIyNlQ0NzUgMjQ0TDQ4OSAyNTBMNDcyIDI1OFE0NTUgMjY1IDQzMCAyNzlUMzc3IDMxM1QzMjcgMzY2VDI5MyA0MzRRMjg5IDQ1MSAyODkgNDcyVDI4NyA2OTlRMjg2IDk0MSAyODUgOTQ4UTI3OSA5NzggMjYyIDEwMDVUMjI3IDEwNDhUMTg0IDEwODBUMTUxIDExMDBUMTI5IDExMDlMMTI3IDExMTBRMTE5IDExMTMgMTE5IDExMzBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NiIgZD0iTTUyIDY0OFE1MiA2NzAgNjUgNjgzSDc2UTExOCA2ODAgMTgxIDY4MFEyOTkgNjgwIDMyMCA2ODNIMzMwUTMzNiA2NzcgMzM2IDY3NFQzMzQgNjU2UTMyOSA2NDEgMzI1IDYzN0gzMDRRMjgyIDYzNSAyNzQgNjM1UTI0NSA2MzAgMjQyIDYyMFEyNDIgNjE4IDI3MSAzNjlUMzAxIDExOEwzNzQgMjM1UTQ0NyAzNTIgNTIwIDQ3MVQ1OTUgNTk0UTU5OSA2MDEgNTk5IDYwOVE1OTkgNjMzIDU1NSA2MzdRNTM3IDYzNyA1MzcgNjQ4UTUzNyA2NDkgNTM5IDY2MVE1NDIgNjc1IDU0NSA2NzlUNTU4IDY4M1E1NjAgNjgzIDU3MCA2ODNUNjA0IDY4MlQ2NjggNjgxUTczNyA2ODEgNzU1IDY4M0g3NjJRNzY5IDY3NiA3NjkgNjcyUTc2OSA2NTUgNzYwIDY0MFE3NTcgNjM3IDc0MyA2MzdRNzMwIDYzNiA3MTkgNjM1VDY5OCA2MzBUNjgyIDYyM1Q2NzAgNjE1VDY2MCA2MDhUNjUyIDU5OVQ2NDUgNTkyTDQ1MiAyODJRMjcyIC05IDI2NiAtMTZRMjYzIC0xOCAyNTkgLTIxTDI0MSAtMjJIMjM0UTIxNiAtMjIgMjE2IC0xNVEyMTMgLTkgMTc3IDMwNVExMzkgNjIzIDEzOCA2MjZRMTMzIDYzNyA3NiA2MzdINTlRNTIgNjQyIDUyIDY0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkzMSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi03QiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDY2NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjQwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzQiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNjEsLTE1MCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzUiIHg9IjYwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RCIgeD0iMTE3MyIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzMzE5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTk3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc4IiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSIxMDczIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSIyMjI1IiB5PSI2NzUiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yOSIgeD0iMjUxNSIgeT0iLTEiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTdEIiB4PSI3MDk5IiB5PSItMSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iODk3NiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIxMDAzMiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwOTY4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9zdmc+) ,
, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjE5Ljg0ZXgiIGhlaWdodD0iMi44NDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjgzOGV4OyIgdmlld0JveD0iMCAtODYzLjEgODU0Mi4zIDEyMjMuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NSIgZD0iTTQ5MiAyMTNRNDcyIDIxMyA0NzIgMjI2UTQ3MiAyMzAgNDc3IDI1MFQ0ODIgMjg1UTQ4MiAzMTYgNDYxIDMyM1QzNjQgMzMwSDMxMlEzMTEgMzI4IDI3NyAxOTJUMjQzIDUyUTI0MyA0OCAyNTQgNDhUMzM0IDQ2UTQyOCA0NiA0NTggNDhUNTE4IDYxUTU2NyA3NyA1OTkgMTE3VDY3MCAyNDhRNjgwIDI3MCA2ODMgMjcyUTY5MCAyNzQgNjk4IDI3NFE3MTggMjc0IDcxOCAyNjFRNjEzIDcgNjA4IDJRNjA1IDAgMzIyIDBIMTMzUTMxIDAgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ2IDY2IDIxNSAzNDJUMjg1IDYyMlEyODUgNjI5IDI4MSA2MjlRMjczIDYzMiAyMjggNjM0SDE5N1ExOTEgNjQwIDE5MSA2NDJUMTkzIDY1OVExOTcgNjc2IDIwMyA2ODBINzU3UTc2NCA2NzYgNzY0IDY2OVE3NjQgNjY0IDc1MSA1NTdUNzM3IDQ0N1E3MzUgNDQwIDcxNyA0NDBINzA1UTY5OCA0NDUgNjk4IDQ1M0w3MDEgNDc2UTcwNCA1MDAgNzA0IDUyOFE3MDQgNTU4IDY5NyA1NzhUNjc4IDYwOVQ2NDMgNjI1VDU5NiA2MzJUNTMyIDYzNEg0ODVRMzk3IDYzMyAzOTIgNjMxUTM4OCA2MjkgMzg2IDYyMlEzODUgNjE5IDM1NSA0OTlUMzI0IDM3N1EzNDcgMzc2IDM3MiAzNzZIMzk4UTQ2NCAzNzYgNDg5IDM5MVQ1MzQgNDcyUTUzOCA0ODggNTQwIDQ5MFQ1NTcgNDkzUTU2MiA0OTMgNTY1IDQ5M1Q1NzAgNDkyVDU3MiA0OTFUNTc0IDQ4N1Q1NzcgNDgzTDU0NCAzNTFRNTExIDIxOCA1MDggMjE2UTUwNSAyMTMgNDkyIDIxM1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUwIiBkPSJNMjg3IDYyOFEyODcgNjM1IDIzMCA2MzdRMjA2IDYzNyAxOTkgNjM4VDE5MiA2NDhRMTkyIDY0OSAxOTQgNjU5UTIwMCA2NzkgMjAzIDY4MVQzOTcgNjgzUTU4NyA2ODIgNjAwIDY4MFE2NjQgNjY5IDcwNyA2MzFUNzUxIDUzMFE3NTEgNDUzIDY4NSAzODlRNjE2IDMyMSA1MDcgMzAzUTUwMCAzMDIgNDAyIDMwMUgzMDdMMjc3IDE4MlEyNDcgNjYgMjQ3IDU5UTI0NyA1NSAyNDggNTRUMjU1IDUwVDI3MiA0OFQzMDUgNDZIMzM2UTM0MiAzNyAzNDIgMzVRMzQyIDE5IDMzNSA1UTMzMCAwIDMxOSAwUTMxNiAwIDI4MiAxVDE4MiAyUTEyMCAyIDg3IDJUNTEgMVEzMyAxIDMzIDExUTMzIDEzIDM2IDI1UTQwIDQxIDQ0IDQzVDY3IDQ2UTk0IDQ2IDEyNyA0OVExNDEgNTIgMTQ2IDYxUTE0OSA2NSAyMTggMzM5VDI4NyA2MjhaTTY0NSA1NTRRNjQ1IDU2NyA2NDMgNTc1VDYzNCA1OTdUNjA5IDYxOVQ1NjAgNjM1UTU1MyA2MzYgNDgwIDYzN1E0NjMgNjM3IDQ0NSA2MzdUNDE2IDYzNlQ0MDQgNjM2UTM5MSA2MzUgMzg2IDYyN1EzODQgNjIxIDM2NyA1NTBUMzMyIDQxMlQzMTQgMzQ0UTMxNCAzNDIgMzk1IDM0Mkg0MDdINDMwUTU0MiAzNDIgNTkwIDM5MlE2MTcgNDE5IDYzMSA0NzFUNjQ1IDU1NFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02QiIgZD0iTTEyMSA2NDdRMTIxIDY1NyAxMjUgNjcwVDEzNyA2ODNRMTM4IDY4MyAyMDkgNjg4VDI4MiA2OTRRMjk0IDY5NCAyOTQgNjg2UTI5NCA2NzkgMjQ0IDQ3N1ExOTQgMjc5IDE5NCAyNzJRMjEzIDI4MiAyMjMgMjkxUTI0NyAzMDkgMjkyIDM1NFQzNjIgNDE1UTQwMiA0NDIgNDM4IDQ0MlE0NjggNDQyIDQ4NSA0MjNUNTAzIDM2OVE1MDMgMzQ0IDQ5NiAzMjdUNDc3IDMwMlQ0NTYgMjkxVDQzOCAyODhRNDE4IDI4OCA0MDYgMjk5VDM5NCAzMjhRMzk0IDM1MyA0MTAgMzY5VDQ0MiAzOTBMNDU4IDM5M1E0NDYgNDA1IDQzNCA0MDVINDMwUTM5OCA0MDIgMzY3IDM4MFQyOTQgMzE2VDIyOCAyNTVRMjMwIDI1NCAyNDMgMjUyVDI2NyAyNDZUMjkzIDIzOFQzMjAgMjI0VDM0MiAyMDZUMzU5IDE4MFQzNjUgMTQ3UTM2NSAxMzAgMzYwIDEwNlQzNTQgNjZRMzU0IDI2IDM4MSAyNlE0MjkgMjYgNDU5IDE0NVE0NjEgMTUzIDQ3OSAxNTNINDgzUTQ5OSAxNTMgNDk5IDE0NFE0OTkgMTM5IDQ5NiAxMzBRNDU1IC0xMSAzNzggLTExUTMzMyAtMTEgMzA1IDE1VDI3NyA5MFEyNzcgMTA4IDI4MCAxMjFUMjgzIDE0NVEyODMgMTY3IDI2OSAxODNUMjM0IDIwNlQyMDAgMjE3VDE4MiAyMjBIMTgwUTE2OCAxNzggMTU5IDEzOVQxNDUgODFUMTM2IDQ0VDEyOSAyMFQxMjIgN1QxMTEgLTJROTggLTExIDgzIC0xMVE2NiAtMTEgNTcgLTFUNDggMTZRNDggMjYgODUgMTc2VDE1OCA0NzFMMTk1IDYxNlExOTYgNjI5IDE4OCA2MzJUMTQ5IDYzN0gxNDRRMTM0IDYzNyAxMzEgNjM3VDEyNCA2NDBUMTIxIDY0N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02OSIgZD0iTTE4NCA2MDBRMTg0IDYyNCAyMDMgNjQyVDI0NyA2NjFRMjY1IDY2MSAyNzcgNjQ5VDI5MCA2MTlRMjkwIDU5NiAyNzAgNTc3VDIyNiA1NTdRMjExIDU1NyAxOTggNTY3VDE4NCA2MDBaTTIxIDI4N1EyMSAyOTUgMzAgMzE4VDU0IDM2OVQ5OCA0MjBUMTU4IDQ0MlExOTcgNDQyIDIyMyA0MTlUMjUwIDM1N1EyNTAgMzQwIDIzNiAzMDFUMTk2IDE5NlQxNTQgODNRMTQ5IDYxIDE0OSA1MVExNDkgMjYgMTY2IDI2UTE3NSAyNiAxODUgMjlUMjA4IDQzVDIzNSA3OFQyNjAgMTM3UTI2MyAxNDkgMjY1IDE1MVQyODIgMTUzUTMwMiAxNTMgMzAyIDE0M1EzMDIgMTM1IDI5MyAxMTJUMjY4IDYxVDIyMyAxMVQxNjEgLTExUTEyOSAtMTEgMTAyIDEwVDc0IDc0UTc0IDkxIDc5IDEwNlQxMjIgMjIwUTE2MCAzMjEgMTY2IDM0MVQxNzMgMzgwUTE3MyA0MDQgMTU2IDQwNEgxNTRRMTI0IDQwNCA5OSAzNzFUNjEgMjg3UTYwIDI4NiA1OSAyODRUNTggMjgxVDU2IDI3OVQ1MyAyNzhUNDkgMjc4VDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03RCIgZD0iTTY1IDczMVE2NSA3NDUgNjggNzQ3VDg4IDc1MFExNzEgNzUwIDIxNiA3MjVUMjc5IDY3MFEyODggNjQ5IDI4OSA2MzVUMjkxIDUwMVEyOTIgMzYyIDI5MyAzNTdRMzA2IDMxMiAzNDUgMjkxVDQxNyAyNjlRNDI4IDI2OSA0MzEgMjY2VDQzNCAyNTBUNDMxIDIzNFQ0MTcgMjMxUTM4MCAyMzEgMzQ1IDIxMFQyOTggMTU3UTI5MyAxNDMgMjkyIDEyMVQyOTEgLTI4Vi03OVEyOTEgLTEzNCAyODUgLTE1NlQyNTYgLTE5OFEyMDIgLTI1MCA4OSAtMjUwUTcxIC0yNTAgNjggLTI0N1Q2NSAtMjMwUTY1IC0yMjQgNjUgLTIyM1Q2NiAtMjE4VDY5IC0yMTRUNzcgLTIxM1E5MSAtMjEzIDEwOCAtMjEwVDE0NiAtMjAwVDE4MyAtMTc3VDIwNyAtMTM5UTIwOCAtMTM0IDIwOSAzTDIxMCAxMzlRMjIzIDE5NiAyODAgMjMwUTMxNSAyNDcgMzMwIDI1MFEzMDUgMjU3IDI4MCAyNzBRMjI1IDMwNCAyMTIgMzUyTDIxMCAzNjJMMjA5IDQ5OFEyMDggNjM1IDIwNyA2NDBRMTk1IDY4MCAxNTQgNjk2VDc3IDcxM1E2OCA3MTMgNjcgNzE2VDY1IDczMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTMxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDA3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY5IiB4PSI3MzciIHk9Ii0yMTMiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMDg4IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMjA4OCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMjk3OCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdEIiB4PSI1Mjc2IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI2OTg1IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iODA0MSIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 。
。
考虑一个方程,
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIxLjY1MWV4IiBoZWlnaHQ9IjcuMzQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4wMDVleDsiIHZpZXdCb3g9IjAgLTE4NjcuNyA5MzIyLjEgMzE2MS40IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY2IiBkPSJNMTE4IC0xNjJRMTIwIC0xNjIgMTI0IC0xNjRUMTM1IC0xNjdUMTQ3IC0xNjhRMTYwIC0xNjggMTcxIC0xNTVUMTg3IC0xMjZRMTk3IC05OSAyMjEgMjdUMjY3IDI2N1QyODkgMzgyVjM4NUgyNDJRMTk1IDM4NSAxOTIgMzg3UTE4OCAzOTAgMTg4IDM5N0wxOTUgNDI1UTE5NyA0MzAgMjAzIDQzMFQyNTAgNDMxUTI5OCA0MzEgMjk4IDQzMlEyOTggNDM0IDMwNyA0ODJUMzE5IDU0MFEzNTYgNzA1IDQ2NSA3MDVRNTAyIDcwMyA1MjYgNjgzVDU1MCA2MzBRNTUwIDU5NCA1MjkgNTc4VDQ4NyA1NjFRNDQzIDU2MSA0NDMgNjAzUTQ0MyA2MjIgNDU0IDYzNlQ0NzggNjU3TDQ4NyA2NjJRNDcxIDY2OCA0NTcgNjY4UTQ0NSA2NjggNDM0IDY1OFQ0MTkgNjMwUTQxMiA2MDEgNDAzIDU1MlQzODcgNDY5VDM4MCA0MzNRMzgwIDQzMSA0MzUgNDMxUTQ4MCA0MzEgNDg3IDQzMFQ0OTggNDI0UTQ5OSA0MjAgNDk2IDQwN1Q0OTEgMzkxUTQ4OSAzODYgNDgyIDM4NlQ0MjggMzg1SDM3MkwzNDkgMjYzUTMwMSAxNSAyODIgLTQ3UTI1NSAtMTMyIDIxMiAtMTczUTE3NSAtMjA1IDEzOSAtMjA1UTEwNyAtMjA1IDgxIC0xODZUNTUgLTEzMlE1NSAtOTUgNzYgLTc4VDExOCAtNjFRMTYyIC02MSAxNjIgLTEwM1ExNjIgLTEyMiAxNTEgLTEzNlQxMjcgLTE1N0wxMTggLTE2MloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktM0I0IiBkPSJNMTk1IDYwOVExOTUgNjU2IDIyNyA2ODZUMzAyIDcxN1EzMTkgNzE2IDM1MSA3MDlUNDA3IDY5N1Q0MzMgNjkwUTQ1MSA2ODIgNDUxIDY2MlE0NTEgNjQ0IDQzOCA2MjhUNDAzIDYxMlEzODIgNjEyIDM0OCA2NDFUMjg4IDY3MVQyNDkgNjU3VDIzNSA2MjhRMjM1IDU4NCAzMzQgNDYzUTQwMSAzNzkgNDAxIDI5MlE0MDEgMTY5IDM0MCA4MFQyMDUgLTEwSDE5OFExMjcgLTEwIDgzIDM2VDM2IDE1M1EzNiAyODYgMTUxIDM4MlExOTEgNDEzIDI1MiA0MzRRMjUyIDQzNSAyNDUgNDQ5VDIzMCA0ODFUMjE0IDUyMVQyMDEgNTY2VDE5NSA2MDlaTTExMiAxMzBRMTEyIDgzIDEzNiA1NVQyMDQgMjdRMjMzIDI3IDI1NiA1MVQyOTEgMTExVDMwOSAxNzhUMzE2IDIzMlEzMTYgMjY3IDMwOSAyOThUMjk1IDM0NFQyNjkgNDAwTDI1OSAzOTZRMjE1IDM4MSAxODMgMzQyVDEzNyAyNTZUMTE4IDE3OVQxMTIgMTMwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NiIgZD0iTTUyIDY0OFE1MiA2NzAgNjUgNjgzSDc2UTExOCA2ODAgMTgxIDY4MFEyOTkgNjgwIDMyMCA2ODNIMzMwUTMzNiA2NzcgMzM2IDY3NFQzMzQgNjU2UTMyOSA2NDEgMzI1IDYzN0gzMDRRMjgyIDYzNSAyNzQgNjM1UTI0NSA2MzAgMjQyIDYyMFEyNDIgNjE4IDI3MSAzNjlUMzAxIDExOEwzNzQgMjM1UTQ0NyAzNTIgNTIwIDQ3MVQ1OTUgNTk0UTU5OSA2MDEgNTk5IDYwOVE1OTkgNjMzIDU1NSA2MzdRNTM3IDYzNyA1MzcgNjQ4UTUzNyA2NDkgNTM5IDY2MVE1NDIgNjc1IDU0NSA2NzlUNTU4IDY4M1E1NjAgNjgzIDU3MCA2ODNUNjA0IDY4MlQ2NjggNjgxUTczNyA2ODEgNzU1IDY4M0g3NjJRNzY5IDY3NiA3NjkgNjcyUTc2OSA2NTUgNzYwIDY0MFE3NTcgNjM3IDc0MyA2MzdRNzMwIDYzNiA3MTkgNjM1VDY5OCA2MzBUNjgyIDYyM1Q2NzAgNjE1VDY2MCA2MDhUNjUyIDU5OVQ2NDUgNTkyTDQ1MiAyODJRMjcyIC05IDI2NiAtMTZRMjYzIC0xOCAyNTkgLTIxTDI0MSAtMjJIMjM0UTIxNiAtMjIgMjE2IC0xNVEyMTMgLTkgMTc3IDMwNVExMzkgNjIzIDEzOCA2MjZRMTMzIDYzNyA3NiA2MzdINTlRNTIgNjQyIDUyIDY0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJCIiBkPSJNNTYgMjM3VDU2IDI1MFQ3MCAyNzBIMzY5VjQyMEwzNzAgNTcwUTM4MCA1ODMgMzg5IDU4M1E0MDIgNTgzIDQwOSA1NjhWMjcwSDcwN1E3MjIgMjYyIDcyMiAyNTBUNzA3IDIzMEg0MDlWLTY4UTQwMSAtODIgMzkxIC04MkgzODlIMzg3UTM3NSAtODIgMzY5IC02OFYyMzBINzBRNTYgMjM3IDU2IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tQUYiIGQ9Ik02OSA1NDRWNTkwSDQzMFY1NDRINjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMSIgZD0iTTIxMyA1NzhMMjAwIDU3M1ExODYgNTY4IDE2MCA1NjNUMTAyIDU1Nkg4M1Y2MDJIMTAyUTE0OSA2MDQgMTg5IDYxN1QyNDUgNjQxVDI3MyA2NjNRMjc1IDY2NiAyODUgNjY2UTI5NCA2NjYgMzAyIDY2MFYzNjFMMzAzIDYxUTMxMCA1NCAzMTUgNTJUMzM5IDQ4VDQwMSA0Nkg0MjdWMEg0MTZRMzk1IDMgMjU3IDNRMTIxIDMgMTAwIDBIODhWNDZIMTE0UTEzNiA0NiAxNTIgNDZUMTc3IDQ3VDE5MyA1MFQyMDEgNTJUMjA3IDU3VDIxMyA2MVY1NzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNEIiIGQ9Ik0yODUgNjI4UTI4NSA2MzUgMjI4IDYzN1EyMDUgNjM3IDE5OCA2MzhUMTkxIDY0N1ExOTEgNjQ5IDE5MyA2NjFRMTk5IDY4MSAyMDMgNjgyUTIwNSA2ODMgMjE0IDY4M0gyMTlRMjYwIDY4MSAzNTUgNjgxUTM4OSA2ODEgNDE4IDY4MVQ0NjMgNjgyVDQ4MyA2ODJRNTAwIDY4MiA1MDAgNjc0UTUwMCA2NjkgNDk3IDY2MFE0OTYgNjU4IDQ5NiA2NTRUNDk1IDY0OFQ0OTMgNjQ0VDQ5MCA2NDFUNDg2IDYzOVQ0NzkgNjM4VDQ3MCA2MzdUNDU2IDYzN1E0MTYgNjM2IDQwNSA2MzRUMzg3IDYyM0wzMDYgMzA1UTMwNyAzMDUgNDkwIDQ0OVQ2NzggNTk3UTY5MiA2MTEgNjkyIDYyMFE2OTIgNjM1IDY2NyA2MzdRNjUxIDYzNyA2NTEgNjQ4UTY1MSA2NTAgNjU0IDY2MlQ2NTkgNjc3UTY2MiA2ODIgNjc2IDY4MlE2ODAgNjgyIDcxMSA2ODFUNzkxIDY4MFE4MTQgNjgwIDgzOSA2ODFUODY5IDY4MlE4ODkgNjgyIDg4OSA2NzJRODg5IDY1MCA4ODEgNjQyUTg3OCA2MzcgODYyIDYzN1E3ODcgNjMyIDcyNiA1ODZRNzEwIDU3NiA2NTYgNTM0VDU1NiA0NTVMNTA5IDQxOEw1MTggMzk2UTUyNyAzNzQgNTQ2IDMyOVQ1ODEgMjQ0UTY1NiA2NyA2NjEgNjFRNjYzIDU5IDY2NiA1N1E2ODAgNDcgNzE3IDQ2SDczOFE3NDQgMzggNzQ0IDM3VDc0MSAxOVE3MzcgNiA3MzEgMEg3MjBRNjgwIDMgNjI1IDNRNTAzIDMgNDg4IDBINDc4UTQ3MiA2IDQ3MiA5VDQ3NCAyN1E0NzggNDAgNDgwIDQzVDQ5MSA0Nkg0OTRRNTQ0IDQ2IDU0NCA3MVE1NDQgNzUgNTE3IDE0MVQ0ODUgMjE2TDQyNyAzNTRMMzU5IDMwMUwyOTEgMjQ4TDI2OCAxNTVRMjQ1IDYzIDI0NSA1OFEyNDUgNTEgMjUzIDQ5VDMwMyA0NkgzMzRRMzQwIDM3IDM0MCAzNVEzNDAgMTkgMzMzIDVRMzI4IDAgMzE3IDBRMzE0IDAgMjgwIDFUMTgwIDJRMTE4IDIgODUgMlQ0OSAxUTMxIDEgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ3IDY1IDIxNiAzMzlUMjg1IDYyOFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iNjkzIiB5PSItMjEzIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTE4MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS0zQjQiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg0MSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjY5MCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0NjgsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI1MzM1IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsNzcwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTM2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjI0MDYiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS0zQjQiIHg9IjM0MDciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODU5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjI0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzgsNDk0KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSItNzAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMTcuOTIyNTA0MTY2NjgxLDApIHNjYWxlKDAuNzU5ODcxMDY1NjI4MzgwNiwxKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiIgeD0iNTY1IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjExNzYiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODM1LC0xMDM4KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI3MjIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS0zQjQiIHg9IjE3MjMiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMTc0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNEIiIHg9IjI0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjYsNTAwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSItNzAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODIuMzA2MTYwNjc2Mzc2MjcsMCkgc2NhbGUoMS40ODQ2MDY1NDc3MzA5MzYzLDEpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSI4MjciIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTM2NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8L3N2Zz4=)
其中,
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQwLjE3NWV4IiBoZWlnaHQ9IjYuODQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4wMDVleDsiIHZpZXdCb3g9IjAgLTE2NTIuNSAxNzI5Ny40IDI5NDYuMSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tQUYiIGQ9Ik02OSA1NDRWNTkwSDQzMFY1NDRINjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkUiIGQ9Ik0yMSAyODdRMjIgMjkzIDI0IDMwM1QzNiAzNDFUNTYgMzg4VDg5IDQyNVQxMzUgNDQyUTE3MSA0NDIgMTk1IDQyNFQyMjUgMzkwVDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzA0IDQ0MiAzODIgNDQyUTQzNiA0NDIgNDY5IDQxNVQ1MDMgMzM2VDQ2NSAxNzlUNDI3IDUyUTQyNyAyNiA0NDQgMjZRNDUwIDI2IDQ1MyAyN1E0ODIgMzIgNTA1IDY1VDU0MCAxNDVRNTQyIDE1MyA1NjAgMTUzUTU4MCAxNTMgNTgwIDE0NVE1ODAgMTQ0IDU3NiAxMzBRNTY4IDEwMSA1NTQgNzNUNTA4IDE3VDQzOSAtMTBRMzkyIC0xMCAzNzEgMTdUMzUwIDczUTM1MCA5MiAzODYgMTkzVDQyMyAzNDVRNDIzIDQwNCAzNzkgNDA0SDM3NFEyODggNDA0IDIyOSAzMDNMMjIyIDI5MUwxODkgMTU3UTE1NiAyNiAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExMiAxODBUMTUyIDM0M1ExNTMgMzQ4IDE1MyAzNjZRMTUzIDQwNSAxMjkgNDA1UTkxIDQwNSA2NiAzMDVRNjAgMjg1IDYwIDI4NFE1OCAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMUEiIGQ9Ik05NSAxNzhRODkgMTc4IDgxIDE4NlQ3MiAyMDBUMTAzIDIzMFQxNjkgMjgwVDIwNyAzMDlRMjA5IDMxMSAyMTIgMzExSDIxM1EyMTkgMzExIDIyNyAyOTRUMjgxIDE3N1EzMDAgMTM0IDMxMiAxMDhMMzk3IC03N1EzOTggLTc3IDUwMSAxMzZUNzA3IDU2NVQ4MTQgNzg2UTgyMCA4MDAgODM0IDgwMFE4NDEgODAwIDg0NiA3OTRUODUzIDc4MlY3NzZMNjIwIDI5M0wzODUgLTE5M1EzODEgLTIwMCAzNjYgLTIwMFEzNTcgLTIwMCAzNTQgLTE5N1EzNTIgLTE5NSAyNTYgMTVMMTYwIDIyNUwxNDQgMjE0UTEyOSAyMDIgMTEzIDE5MFQ5NSAxNzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oyLTIyMTEiIGQ9Ik02MCA5NDhRNjMgOTUwIDY2NSA5NTBIMTI2N0wxMzI1IDgxNVExMzg0IDY3NyAxMzg4IDY2OUgxMzQ4TDEzNDEgNjgzUTEzMjAgNzI0IDEyODUgNzYxUTEyMzUgODA5IDExNzQgODM4VDEwMzMgODgxVDg4MiA4OThUNjk5IDkwMkg1NzRINTQzSDI1MUwyNTkgODkxUTcyMiAyNTggNzI0IDI1MlE3MjUgMjUwIDcyNCAyNDZRNzIxIDI0MyA0NjAgLTU2TDE5NiAtMzU2UTE5NiAtMzU3IDQwNyAtMzU3UTQ1OSAtMzU3IDU0OCAtMzU3VDY3NiAtMzU4UTgxMiAtMzU4IDg5NiAtMzUzVDEwNjMgLTMzMlQxMjA0IC0yODNUMTMwNyAtMTk2UTEzMjggLTE3MCAxMzQ4IC0xMjRIMTM4OFExMzg4IC0xMjUgMTM4MSAtMTQ1VDEzNTYgLTIxMFQxMzI1IC0yOTRMMTI2NyAtNDQ5TDY2NiAtNDUwUTY0IC00NTAgNjEgLTQ0OFE1NSAtNDQ2IDU1IC00MzlRNTUgLTQzNyA1NyAtNDMzTDU5MCAxNzdRNTkwIDE3OCA1NTcgMjIyVDQ1MiAzNjZUMzIyIDU0NEw1NiA5MDlMNTUgOTI0UTU1IDk0NSA2MCA5NDhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNjkiIGQ9Ik0xODQgNjAwUTE4NCA2MjQgMjAzIDY0MlQyNDcgNjYxUTI2NSA2NjEgMjc3IDY0OVQyOTAgNjE5UTI5MCA1OTYgMjcwIDU3N1QyMjYgNTU3UTIxMSA1NTcgMTk4IDU2N1QxODQgNjAwWk0yMSAyODdRMjEgMjk1IDMwIDMxOFQ1NCAzNjlUOTggNDIwVDE1OCA0NDJRMTk3IDQ0MiAyMjMgNDE5VDI1MCAzNTdRMjUwIDM0MCAyMzYgMzAxVDE5NiAxOTZUMTU0IDgzUTE0OSA2MSAxNDkgNTFRMTQ5IDI2IDE2NiAyNlExNzUgMjYgMTg1IDI5VDIwOCA0M1QyMzUgNzhUMjYwIDEzN1EyNjMgMTQ5IDI2NSAxNTFUMjgyIDE1M1EzMDIgMTUzIDMwMiAxNDNRMzAyIDEzNSAyOTMgMTEyVDI2OCA2MVQyMjMgMTFUMTYxIC0xMVExMjkgLTExIDEwMiAxMFQ3NCA3NFE3NCA5MSA3OSAxMDZUMTIyIDIyMFExNjAgMzIxIDE2NiAzNDFUMTczIDM4MFExNzMgNDA0IDE1NiA0MDRIMTU0UTEyNCA0MDQgOTkgMzcxVDYxIDI4N1E2MCAyODYgNTkgMjg0VDU4IDI4MVQ1NiAyNzlUNTMgMjc4VDQ5IDI3OFQ0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTAiIGQ9Ik0yODcgNjI4UTI4NyA2MzUgMjMwIDYzN1EyMDYgNjM3IDE5OSA2MzhUMTkyIDY0OFExOTIgNjQ5IDE5NCA2NTlRMjAwIDY3OSAyMDMgNjgxVDM5NyA2ODNRNTg3IDY4MiA2MDAgNjgwUTY2NCA2NjkgNzA3IDYzMVQ3NTEgNTMwUTc1MSA0NTMgNjg1IDM4OVE2MTYgMzIxIDUwNyAzMDNRNTAwIDMwMiA0MDIgMzAxSDMwN0wyNzcgMTgyUTI0NyA2NiAyNDcgNTlRMjQ3IDU1IDI0OCA1NFQyNTUgNTBUMjcyIDQ4VDMwNSA0NkgzMzZRMzQyIDM3IDM0MiAzNVEzNDIgMTkgMzM1IDVRMzMwIDAgMzE5IDBRMzE2IDAgMjgyIDFUMTgyIDJRMTIwIDIgODcgMlQ1MSAxUTMzIDEgMzMgMTFRMzMgMTMgMzYgMjVRNDAgNDEgNDQgNDNUNjcgNDZROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFpNNjQ1IDU1NFE2NDUgNTY3IDY0MyA1NzVUNjM0IDU5N1Q2MDkgNjE5VDU2MCA2MzVRNTUzIDYzNiA0ODAgNjM3UTQ2MyA2MzcgNDQ1IDYzN1Q0MTYgNjM2VDQwNCA2MzZRMzkxIDYzNSAzODYgNjI3UTM4NCA2MjEgMzY3IDU1MFQzMzIgNDEyVDMxNCAzNDRRMzE0IDM0MiAzOTUgMzQySDQwN0g0MzBRNTQyIDM0MiA1OTAgMzkyUTYxNyA0MTkgNjMxIDQ3MVQ2NDUgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc0IiBkPSJNMjYgMzg1UTE5IDM5MiAxOSAzOTVRMTkgMzk5IDIyIDQxMVQyNyA0MjVRMjkgNDMwIDM2IDQzMFQ4NyA0MzFIMTQwTDE1OSA1MTFRMTYyIDUyMiAxNjYgNTQwVDE3MyA1NjZUMTc5IDU4NlQxODcgNjAzVDE5NyA2MTVUMjExIDYyNFQyMjkgNjI2UTI0NyA2MjUgMjU0IDYxNVQyNjEgNTk2UTI2MSA1ODkgMjUyIDU0OVQyMzIgNDcwTDIyMiA0MzNRMjIyIDQzMSAyNzIgNDMxSDMyM1EzMzAgNDI0IDMzMCA0MjBRMzMwIDM5OCAzMTcgMzg1SDIxMEwxNzQgMjQwUTEzNSA4MCAxMzUgNjhRMTM1IDI2IDE2MiAyNlExOTcgMjYgMjMwIDYwVDI4MyAxNDRRMjg1IDE1MCAyODggMTUxVDMwMyAxNTNIMzA3UTMyMiAxNTMgMzIyIDE0NVEzMjIgMTQyIDMxOSAxMzNRMzE0IDExNyAzMDEgOTVUMjY3IDQ4VDIxNiA2VDE1NSAtMTFRMTI1IC0xMSA5OCA0VDU5IDU2UTU3IDY0IDU3IDgzVjEwMUw5MiAyNDFRMTI3IDM4MiAxMjggMzgzUTEyOCAzODUgNzcgMzg1SDI2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTc1IiBkPSJNMjEgMjg3UTIxIDI5NSAzMCAzMThUNTUgMzcwVDk5IDQyMFQxNTggNDQyUTIwNCA0NDIgMjI3IDQxN1QyNTAgMzU4UTI1MCAzNDAgMjE2IDI0NlQxODIgMTA1UTE4MiA2MiAxOTYgNDVUMjM4IDI3VDI5MSA0NFQzMjggNzhMMzM5IDk1UTM0MSA5OSAzNzcgMjQ3UTQwNyAzNjcgNDEzIDM4N1Q0MjcgNDE2UTQ0NCA0MzEgNDYzIDQzMVE0ODAgNDMxIDQ4OCA0MjFUNDk2IDQwMkw0MjAgODRRNDE5IDc5IDQxOSA2OFE0MTkgNDMgNDI2IDM1VDQ0NyAyNlE0NjkgMjkgNDgyIDU3VDUxMiAxNDVRNTE0IDE1MyA1MzIgMTUzUTU1MSAxNTMgNTUxIDE0NFE1NTAgMTM5IDU0OSAxMzBUNTQwIDk4VDUyMyA1NVQ0OTggMTdUNDYyIC04UTQ1NCAtMTAgNDM4IC0xMFEzNzIgLTEwIDM0NyA0NlEzNDUgNDUgMzM2IDM2VDMxOCAyMVQyOTYgNlQyNjcgLTZUMjMzIC0xMVExODkgLTExIDE1NSA3UTEwMyAzOCAxMDMgMTEzUTEwMyAxNzAgMTM4IDI2MlQxNzMgMzc5UTE3MyAzODAgMTczIDM4MVExNzMgMzkwIDE3MyAzOTNUMTY5IDQwMFQxNTggNDA0SDE1NFExMzEgNDA0IDExMiAzODVUODIgMzQ0VDY1IDMwMlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZEIiBkPSJNMjEgMjg3UTIyIDI5MyAyNCAzMDNUMzYgMzQxVDU2IDM4OFQ4OCA0MjVUMTMyIDQ0MlQxNzUgNDM1VDIwNSA0MTdUMjIxIDM5NVQyMjkgMzc2TDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzAzIDQ0MiAzODQgNDQyUTQwMSA0NDIgNDE1IDQ0MFQ0NDEgNDMzVDQ2MCA0MjNUNDc1IDQxMVQ0ODUgMzk4VDQ5MyAzODVUNDk3IDM3M1Q1MDAgMzY0VDUwMiAzNTdMNTEwIDM2N1E1NzMgNDQyIDY1OSA0NDJRNzEzIDQ0MiA3NDYgNDE1VDc4MCAzMzZRNzgwIDI4NSA3NDIgMTc4VDcwNCA1MFE3MDUgMzYgNzA5IDMxVDcyNCAyNlE3NTIgMjYgNzc2IDU2VDgxNSAxMzhRODE4IDE0OSA4MjEgMTUxVDgzNyAxNTNRODU3IDE1MyA4NTcgMTQ1UTg1NyAxNDQgODUzIDEzMFE4NDUgMTAxIDgzMSA3M1Q3ODUgMTdUNzE2IC0xMFE2NjkgLTEwIDY0OCAxN1Q2MjcgNzNRNjI3IDkyIDY2MyAxOTNUNzAwIDM0NVE3MDAgNDA0IDY1NiA0MDRINjUxUTU2NSA0MDQgNTA2IDMwM0w0OTkgMjkxTDQ2NiAxNTdRNDMzIDI2IDQyOCAxNlE0MTUgLTExIDM4NSAtMTFRMzcyIC0xMSAzNjQgLTRUMzUzIDhUMzUwIDE4UTM1MCAyOSAzODQgMTYxTDQyMCAzMDdRNDIzIDMyMiA0MjMgMzQ1UTQyMyA0MDQgMzc5IDQwNEgzNzRRMjg4IDQwNCAyMjkgMzAzTDIyMiAyOTFMMTg5IDE1N1ExNTYgMjYgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTIgMTgxUTE1MSAzMzUgMTUxIDM0MlExNTQgMzU3IDE1NCAzNjlRMTU0IDQwNSAxMjkgNDA1UTEwNyA0MDUgOTIgMzc3VDY5IDMxNlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0IiIGQ9Ik00MzQgLTIzMVE0MzQgLTI0NCA0MjggLTI1MEg0MTBRMjgxIC0yNTAgMjMwIC0xODRRMjI1IC0xNzcgMjIyIC0xNzJUMjE3IC0xNjFUMjEzIC0xNDhUMjExIC0xMzNUMjEwIC0xMTFUMjA5IC04NFQyMDkgLTQ3VDIwOSAwUTIwOSAyMSAyMDkgNTNRMjA4IDE0MiAyMDQgMTUzUTIwMyAxNTQgMjAzIDE1NVExODkgMTkxIDE1MyAyMTFUODIgMjMxUTcxIDIzMSA2OCAyMzRUNjUgMjUwVDY4IDI2NlQ4MiAyNjlRMTE2IDI2OSAxNTIgMjg5VDIwMyAzNDVRMjA4IDM1NiAyMDggMzc3VDIwOSA1MjlWNTc5UTIwOSA2MzQgMjE1IDY1NlQyNDQgNjk4UTI3MCA3MjQgMzI0IDc0MFEzNjEgNzQ4IDM3NyA3NDlRMzc5IDc0OSAzOTAgNzQ5VDQwOCA3NTBINDI4UTQzNCA3NDQgNDM0IDczMlE0MzQgNzE5IDQzMSA3MTZRNDI5IDcxMyA0MTUgNzEzUTM2MiA3MTAgMzMyIDY4OVQyOTYgNjQ3UTI5MSA2MzQgMjkxIDQ5OVY0MTdRMjkxIDM3MCAyODggMzUzVDI3MSAzMTRRMjQwIDI3MSAxODQgMjU1TDE3MCAyNTBMMTg0IDI0NVEyMDIgMjM5IDIyMCAyMzBUMjYyIDE5NlQyOTAgMTM3UTI5MSAxMzEgMjkxIDFRMjkxIC0xMzQgMjk2IC0xNDdRMzA2IC0xNzQgMzM5IC0xOTJUNDE1IC0yMTNRNDI5IC0yMTMgNDMxIC0yMTZRNDM0IC0yMTkgNDM0IC0yMzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzgiIGQ9Ik01MiAyODlRNTkgMzMxIDEwNiAzODZUMjIyIDQ0MlEyNTcgNDQyIDI4NiA0MjRUMzI5IDM3OVEzNzEgNDQyIDQzMCA0NDJRNDY3IDQ0MiA0OTQgNDIwVDUyMiAzNjFRNTIyIDMzMiA1MDggMzE0VDQ4MSAyOTJUNDU4IDI4OFE0MzkgMjg4IDQyNyAyOTlUNDE1IDMyOFE0MTUgMzc0IDQ2NSAzOTFRNDU0IDQwNCA0MjUgNDA0UTQxMiA0MDQgNDA2IDQwMlEzNjggMzg2IDM1MCAzMzZRMjkwIDExNSAyOTAgNzhRMjkwIDUwIDMwNiAzOFQzNDEgMjZRMzc4IDI2IDQxNCA1OVQ0NjMgMTQwUTQ2NiAxNTAgNDY5IDE1MVQ0ODUgMTUzSDQ4OVE1MDQgMTUzIDUwNCAxNDVRNTA0IDE0NCA1MDIgMTM0UTQ4NiA3NyA0NDAgMzNUMzMzIC0xMVEyNjMgLTExIDIyNyA1MlExODYgLTEwIDEzMyAtMTBIMTI3UTc4IC0xMCA1NyAxNlQzNSA3MVEzNSAxMDMgNTQgMTIzVDk5IDE0M1ExNDIgMTQzIDE0MiAxMDFRMTQyIDgxIDEzMCA2NlQxMDcgNDZUOTQgNDFMOTEgNDBROTEgMzkgOTcgMzZUMTEzIDI5VDEzMiAyNlExNjggMjYgMTk0IDcxUTIwMyA4NyAyMTcgMTM5VDI0NSAyNDdUMjYxIDMxM1EyNjYgMzQwIDI2NiAzNTJRMjY2IDM4MCAyNTEgMzkyVDIxNyA0MDRRMTc3IDQwNCAxNDIgMzcyVDkzIDI5MFE5MSAyODEgODggMjgwVDcyIDI3OEg1OFE1MiAyODQgNTIgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjgiIGQ9Ik0xODAgOTZUMTgwIDI1MFQyMDUgNTQxVDI2NiA3NzBUMzUzIDk0NFQ0NDQgMTA2OVQ1MjcgMTE1MEg1NTVRNTYxIDExNDQgNTYxIDExNDFRNTYxIDExMzcgNTQ1IDExMjBUNTA0IDEwNzJUNDQ3IDk5NVQzODYgODc4VDMzMCA3MjFUMjg4IDUxM1QyNzIgMjUxUTI3MiAxMzMgMjgwIDU2UTI5MyAtODcgMzI2IC0yMDlUMzk5IC00MDVUNDc1IC01MzFUNTM2IC02MDlUNTYxIC02NDBRNTYxIC02NDMgNTU1IC02NDlINTI3UTQ4MyAtNjEyIDQ0MyAtNTY4VDM1MyAtNDQzVDI2NiAtMjcwVDIwNSAtNDFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oyLTI5IiBkPSJNMzUgMTEzOFEzNSAxMTUwIDUxIDExNTBINTZINjlRMTEzIDExMTMgMTUzIDEwNjlUMjQzIDk0NFQzMzAgNzcxVDM5MSA1NDFUNDE2IDI1MFQzOTEgLTQwVDMzMCAtMjcwVDI0MyAtNDQzVDE1MiAtNTY4VDY5IC02NDlINTZRNDMgLTY0OSAzOSAtNjQ3VDM1IC02MzdRNjUgLTYwNyAxMTAgLTU0OFEyODMgLTMxNiAzMTYgNTZRMzI0IDEzMyAzMjQgMjUxUTMyNCAzNjggMzE2IDQ0NVEyNzggODc3IDQ4IDExMjNRMzYgMTEzNyAzNSAxMTM4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjIxMiIgZD0iTTg0IDIzN1Q4NCAyNTBUOTggMjcwSDY3OVE2OTQgMjYyIDY5NCAyNTBUNjc5IDIzMEg5OFE4NCAyMzcgODQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU2IiBkPSJNNTIgNjQ4UTUyIDY3MCA2NSA2ODNINzZRMTE4IDY4MCAxODEgNjgwUTI5OSA2ODAgMzIwIDY4M0gzMzBRMzM2IDY3NyAzMzYgNjc0VDMzNCA2NTZRMzI5IDY0MSAzMjUgNjM3SDMwNFEyODIgNjM1IDI3NCA2MzVRMjQ1IDYzMCAyNDIgNjIwUTI0MiA2MTggMjcxIDM2OVQzMDEgMTE4TDM3NCAyMzVRNDQ3IDM1MiA1MjAgNDcxVDU5NSA1OTRRNTk5IDYwMSA1OTkgNjA5UTU5OSA2MzMgNTU1IDYzN1E1MzcgNjM3IDUzNyA2NDhRNTM3IDY0OSA1MzkgNjYxUTU0MiA2NzUgNTQ1IDY3OVQ1NTggNjgzUTU2MCA2ODMgNTcwIDY4M1Q2MDQgNjgyVDY2OCA2ODFRNzM3IDY4MSA3NTUgNjgzSDc2MlE3NjkgNjc2IDc2OSA2NzJRNzY5IDY1NSA3NjAgNjQwUTc1NyA2MzcgNzQzIDYzN1E3MzAgNjM2IDcxOSA2MzVUNjk4IDYzMFQ2ODIgNjIzVDY3MCA2MTVUNjYwIDYwOFQ2NTIgNTk5VDY0NSA1OTJMNDUyIDI4MlEyNzIgLTkgMjY2IC0xNlEyNjMgLTE4IDI1OSAtMjFMMjQxIC0yMkgyMzRRMjE2IC0yMiAyMTYgLTE1UTIxMyAtOSAxNzcgMzA1UTEzOSA2MjMgMTM4IDYyNlExMzMgNjM3IDc2IDYzN0g1OVE1MiA2NDIgNTIgNjQ4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIyNCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDc4LDQ5NCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiIgeD0iLTcwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjE3LjkyMjUwNDE2NjY4MSwwKSBzY2FsZSgwLjc1OTg3MTA2NTYyODM4MDYsMSkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiIHg9IjU2NSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIxMTc2IiB5PSItMjEzIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMTYzNCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI0MTIsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxNTU0IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iNTI2IiB5PSI2NzYiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtODAzKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxQSIgeD0iMCIgeT0iLTc4Ij48L3VzZT4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNjAwIiBoZWlnaHQ9IjYwIiB4PSI4MzMiIHk9IjY2MyI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iODMzIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDY1MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQ3LC0xMDkwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIzNDUiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTEyNCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI3MjEiIHk9IjE2MjciPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYyNjIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1OTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTI0MCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc0IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzYxLC0xNTApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTc1IiB4PSI2MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkQiIHg9IjExNzMiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzMxOSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yOCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU5NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0IiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03OCIgeD0iNTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03RCIgeD0iMTA3MyIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMjIyNSIgeT0iNjc1Ij48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjkiIHg9IjI1MTUiIHk9Ii0xIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjY2NTQiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iNzY1NSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDg1OTEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjkiIHg9IjEwNDM3IiB5PSItMSI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=)
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjMxLjc1OGV4IiBoZWlnaHQ9IjYuODQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4wMDVleDsiIHZpZXdCb3g9IjAgLTE2NTIuNSAxMzY3My41IDI5NDYuMSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00QiIgZD0iTTI4NSA2MjhRMjg1IDYzNSAyMjggNjM3UTIwNSA2MzcgMTk4IDYzOFQxOTEgNjQ3UTE5MSA2NDkgMTkzIDY2MVExOTkgNjgxIDIwMyA2ODJRMjA1IDY4MyAyMTQgNjgzSDIxOVEyNjAgNjgxIDM1NSA2ODFRMzg5IDY4MSA0MTggNjgxVDQ2MyA2ODJUNDgzIDY4MlE1MDAgNjgyIDUwMCA2NzRRNTAwIDY2OSA0OTcgNjYwUTQ5NiA2NTggNDk2IDY1NFQ0OTUgNjQ4VDQ5MyA2NDRUNDkwIDY0MVQ0ODYgNjM5VDQ3OSA2MzhUNDcwIDYzN1Q0NTYgNjM3UTQxNiA2MzYgNDA1IDYzNFQzODcgNjIzTDMwNiAzMDVRMzA3IDMwNSA0OTAgNDQ5VDY3OCA1OTdRNjkyIDYxMSA2OTIgNjIwUTY5MiA2MzUgNjY3IDYzN1E2NTEgNjM3IDY1MSA2NDhRNjUxIDY1MCA2NTQgNjYyVDY1OSA2NzdRNjYyIDY4MiA2NzYgNjgyUTY4MCA2ODIgNzExIDY4MVQ3OTEgNjgwUTgxNCA2ODAgODM5IDY4MVQ4NjkgNjgyUTg4OSA2ODIgODg5IDY3MlE4ODkgNjUwIDg4MSA2NDJRODc4IDYzNyA4NjIgNjM3UTc4NyA2MzIgNzI2IDU4NlE3MTAgNTc2IDY1NiA1MzRUNTU2IDQ1NUw1MDkgNDE4TDUxOCAzOTZRNTI3IDM3NCA1NDYgMzI5VDU4MSAyNDRRNjU2IDY3IDY2MSA2MVE2NjMgNTkgNjY2IDU3UTY4MCA0NyA3MTcgNDZINzM4UTc0NCAzOCA3NDQgMzdUNzQxIDE5UTczNyA2IDczMSAwSDcyMFE2ODAgMyA2MjUgM1E1MDMgMyA0ODggMEg0NzhRNDcyIDYgNDcyIDlUNDc0IDI3UTQ3OCA0MCA0ODAgNDNUNDkxIDQ2SDQ5NFE1NDQgNDYgNTQ0IDcxUTU0NCA3NSA1MTcgMTQxVDQ4NSAyMTZMNDI3IDM1NEwzNTkgMzAxTDI5MSAyNDhMMjY4IDE1NVEyNDUgNjMgMjQ1IDU4UTI0NSA1MSAyNTMgNDlUMzAzIDQ2SDMzNFEzNDAgMzcgMzQwIDM1UTM0MCAxOSAzMzMgNVEzMjggMCAzMTcgMFEzMTQgMCAyODAgMVQxODAgMlExMTggMiA4NSAyVDQ5IDFRMzEgMSAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDcgNjUgMjE2IDMzOVQyODUgNjI4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tQUYiIGQ9Ik02OSA1NDRWNTkwSDQzMFY1NDRINjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkUiIGQ9Ik0yMSAyODdRMjIgMjkzIDI0IDMwM1QzNiAzNDFUNTYgMzg4VDg5IDQyNVQxMzUgNDQyUTE3MSA0NDIgMTk1IDQyNFQyMjUgMzkwVDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzA0IDQ0MiAzODIgNDQyUTQzNiA0NDIgNDY5IDQxNVQ1MDMgMzM2VDQ2NSAxNzlUNDI3IDUyUTQyNyAyNiA0NDQgMjZRNDUwIDI2IDQ1MyAyN1E0ODIgMzIgNTA1IDY1VDU0MCAxNDVRNTQyIDE1MyA1NjAgMTUzUTU4MCAxNTMgNTgwIDE0NVE1ODAgMTQ0IDU3NiAxMzBRNTY4IDEwMSA1NTQgNzNUNTA4IDE3VDQzOSAtMTBRMzkyIC0xMCAzNzEgMTdUMzUwIDczUTM1MCA5MiAzODYgMTkzVDQyMyAzNDVRNDIzIDQwNCAzNzkgNDA0SDM3NFEyODggNDA0IDIyOSAzMDNMMjIyIDI5MUwxODkgMTU3UTE1NiAyNiAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExMiAxODBUMTUyIDM0M1ExNTMgMzQ4IDE1MyAzNjZRMTUzIDQwNSAxMjkgNDA1UTkxIDQwNSA2NiAzMDVRNjAgMjg1IDYwIDI4NFE1OCAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMUEiIGQ9Ik05NSAxNzhRODkgMTc4IDgxIDE4NlQ3MiAyMDBUMTAzIDIzMFQxNjkgMjgwVDIwNyAzMDlRMjA5IDMxMSAyMTIgMzExSDIxM1EyMTkgMzExIDIyNyAyOTRUMjgxIDE3N1EzMDAgMTM0IDMxMiAxMDhMMzk3IC03N1EzOTggLTc3IDUwMSAxMzZUNzA3IDU2NVQ4MTQgNzg2UTgyMCA4MDAgODM0IDgwMFE4NDEgODAwIDg0NiA3OTRUODUzIDc4MlY3NzZMNjIwIDI5M0wzODUgLTE5M1EzODEgLTIwMCAzNjYgLTIwMFEzNTcgLTIwMCAzNTQgLTE5N1EzNTIgLTE5NSAyNTYgMTVMMTYwIDIyNUwxNDQgMjE0UTEyOSAyMDIgMTEzIDE5MFQ5NSAxNzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oyLTIyMTEiIGQ9Ik02MCA5NDhRNjMgOTUwIDY2NSA5NTBIMTI2N0wxMzI1IDgxNVExMzg0IDY3NyAxMzg4IDY2OUgxMzQ4TDEzNDEgNjgzUTEzMjAgNzI0IDEyODUgNzYxUTEyMzUgODA5IDExNzQgODM4VDEwMzMgODgxVDg4MiA4OThUNjk5IDkwMkg1NzRINTQzSDI1MUwyNTkgODkxUTcyMiAyNTggNzI0IDI1MlE3MjUgMjUwIDcyNCAyNDZRNzIxIDI0MyA0NjAgLTU2TDE5NiAtMzU2UTE5NiAtMzU3IDQwNyAtMzU3UTQ1OSAtMzU3IDU0OCAtMzU3VDY3NiAtMzU4UTgxMiAtMzU4IDg5NiAtMzUzVDEwNjMgLTMzMlQxMjA0IC0yODNUMTMwNyAtMTk2UTEzMjggLTE3MCAxMzQ4IC0xMjRIMTM4OFExMzg4IC0xMjUgMTM4MSAtMTQ1VDEzNTYgLTIxMFQxMzI1IC0yOTRMMTI2NyAtNDQ5TDY2NiAtNDUwUTY0IC00NTAgNjEgLTQ0OFE1NSAtNDQ2IDU1IC00MzlRNTUgLTQzNyA1NyAtNDMzTDU5MCAxNzdRNTkwIDE3OCA1NTcgMjIyVDQ1MiAzNjZUMzIyIDU0NEw1NiA5MDlMNTUgOTI0UTU1IDk0NSA2MCA5NDhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNjkiIGQ9Ik0xODQgNjAwUTE4NCA2MjQgMjAzIDY0MlQyNDcgNjYxUTI2NSA2NjEgMjc3IDY0OVQyOTAgNjE5UTI5MCA1OTYgMjcwIDU3N1QyMjYgNTU3UTIxMSA1NTcgMTk4IDU2N1QxODQgNjAwWk0yMSAyODdRMjEgMjk1IDMwIDMxOFQ1NCAzNjlUOTggNDIwVDE1OCA0NDJRMTk3IDQ0MiAyMjMgNDE5VDI1MCAzNTdRMjUwIDM0MCAyMzYgMzAxVDE5NiAxOTZUMTU0IDgzUTE0OSA2MSAxNDkgNTFRMTQ5IDI2IDE2NiAyNlExNzUgMjYgMTg1IDI5VDIwOCA0M1QyMzUgNzhUMjYwIDEzN1EyNjMgMTQ5IDI2NSAxNTFUMjgyIDE1M1EzMDIgMTUzIDMwMiAxNDNRMzAyIDEzNSAyOTMgMTEyVDI2OCA2MVQyMjMgMTFUMTYxIC0xMVExMjkgLTExIDEwMiAxMFQ3NCA3NFE3NCA5MSA3OSAxMDZUMTIyIDIyMFExNjAgMzIxIDE2NiAzNDFUMTczIDM4MFExNzMgNDA0IDE1NiA0MDRIMTU0UTEyNCA0MDQgOTkgMzcxVDYxIDI4N1E2MCAyODYgNTkgMjg0VDU4IDI4MVQ1NiAyNzlUNTMgMjc4VDQ5IDI3OFQ0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTAiIGQ9Ik0yODcgNjI4UTI4NyA2MzUgMjMwIDYzN1EyMDYgNjM3IDE5OSA2MzhUMTkyIDY0OFExOTIgNjQ5IDE5NCA2NTlRMjAwIDY3OSAyMDMgNjgxVDM5NyA2ODNRNTg3IDY4MiA2MDAgNjgwUTY2NCA2NjkgNzA3IDYzMVQ3NTEgNTMwUTc1MSA0NTMgNjg1IDM4OVE2MTYgMzIxIDUwNyAzMDNRNTAwIDMwMiA0MDIgMzAxSDMwN0wyNzcgMTgyUTI0NyA2NiAyNDcgNTlRMjQ3IDU1IDI0OCA1NFQyNTUgNTBUMjcyIDQ4VDMwNSA0NkgzMzZRMzQyIDM3IDM0MiAzNVEzNDIgMTkgMzM1IDVRMzMwIDAgMzE5IDBRMzE2IDAgMjgyIDFUMTgyIDJRMTIwIDIgODcgMlQ1MSAxUTMzIDEgMzMgMTFRMzMgMTMgMzYgMjVRNDAgNDEgNDQgNDNUNjcgNDZROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFpNNjQ1IDU1NFE2NDUgNTY3IDY0MyA1NzVUNjM0IDU5N1Q2MDkgNjE5VDU2MCA2MzVRNTUzIDYzNiA0ODAgNjM3UTQ2MyA2MzcgNDQ1IDYzN1Q0MTYgNjM2VDQwNCA2MzZRMzkxIDYzNSAzODYgNjI3UTM4NCA2MjEgMzY3IDU1MFQzMzIgNDEyVDMxNCAzNDRRMzE0IDM0MiAzOTUgMzQySDQwN0g0MzBRNTQyIDM0MiA1OTAgMzkyUTYxNyA0MTkgNjMxIDQ3MVQ2NDUgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU0IiBkPSJNNDAgNDM3UTIxIDQzNyAyMSA0NDVRMjEgNDUwIDM3IDUwMVQ3MSA2MDJMODggNjUxUTkzIDY2OSAxMDEgNjc3SDU2OUg2NTlRNjkxIDY3NyA2OTcgNjc2VDcwNCA2NjdRNzA0IDY2MSA2ODcgNTUzVDY2OCA0NDRRNjY4IDQzNyA2NDkgNDM3UTY0MCA0MzcgNjM3IDQzN1Q2MzEgNDQyTDYyOSA0NDVRNjI5IDQ1MSA2MzUgNDkwVDY0MSA1NTFRNjQxIDU4NiA2MjggNjA0VDU3MyA2MjlRNTY4IDYzMCA1MTUgNjMxUTQ2OSA2MzEgNDU3IDYzMFQ0MzkgNjIyUTQzOCA2MjEgMzY4IDM0M1QyOTggNjBRMjk4IDQ4IDM4NiA0NlE0MTggNDYgNDI3IDQ1VDQzNiAzNlE0MzYgMzEgNDMzIDIyUTQyOSA0IDQyNCAxTDQyMiAwUTQxOSAwIDQxNSAwUTQxMCAwIDM2MyAxVDIyOCAyUTk5IDIgNjQgMEg0OVE0MyA2IDQzIDlUNDUgMjdRNDkgNDAgNTUgNDZIODNIOTRRMTc0IDQ2IDE4OSA1NVExOTAgNTYgMTkxIDU2UTE5NiA1OSAyMDEgNzZUMjQxIDIzM1EyNTggMzAxIDI2OSAzNDRRMzM5IDYxOSAzMzkgNjI1UTMzOSA2MzAgMzEwIDYzMEgyNzlRMjEyIDYzMCAxOTEgNjI0UTE0NiA2MTQgMTIxIDU4M1Q2NyA0NjdRNjAgNDQ1IDU3IDQ0MVQ0MyA0MzdINDBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkIiIGQ9Ik0xMjEgNjQ3UTEyMSA2NTcgMTI1IDY3MFQxMzcgNjgzUTEzOCA2ODMgMjA5IDY4OFQyODIgNjk0UTI5NCA2OTQgMjk0IDY4NlEyOTQgNjc5IDI0NCA0NzdRMTk0IDI3OSAxOTQgMjcyUTIxMyAyODIgMjIzIDI5MVEyNDcgMzA5IDI5MiAzNTRUMzYyIDQxNVE0MDIgNDQyIDQzOCA0NDJRNDY4IDQ0MiA0ODUgNDIzVDUwMyAzNjlRNTAzIDM0NCA0OTYgMzI3VDQ3NyAzMDJUNDU2IDI5MVQ0MzggMjg4UTQxOCAyODggNDA2IDI5OVQzOTQgMzI4UTM5NCAzNTMgNDEwIDM2OVQ0NDIgMzkwTDQ1OCAzOTNRNDQ2IDQwNSA0MzQgNDA1SDQzMFEzOTggNDAyIDM2NyAzODBUMjk0IDMxNlQyMjggMjU1UTIzMCAyNTQgMjQzIDI1MlQyNjcgMjQ2VDI5MyAyMzhUMzIwIDIyNFQzNDIgMjA2VDM1OSAxODBUMzY1IDE0N1EzNjUgMTMwIDM2MCAxMDZUMzU0IDY2UTM1NCAyNiAzODEgMjZRNDI5IDI2IDQ1OSAxNDVRNDYxIDE1MyA0NzkgMTUzSDQ4M1E0OTkgMTUzIDQ5OSAxNDRRNDk5IDEzOSA0OTYgMTMwUTQ1NSAtMTEgMzc4IC0xMVEzMzMgLTExIDMwNSAxNVQyNzcgOTBRMjc3IDEwOCAyODAgMTIxVDI4MyAxNDVRMjgzIDE2NyAyNjkgMTgzVDIzNCAyMDZUMjAwIDIxN1QxODIgMjIwSDE4MFExNjggMTc4IDE1OSAxMzlUMTQ1IDgxVDEzNiA0NFQxMjkgMjBUMTIyIDdUMTExIC0yUTk4IC0xMSA4MyAtMTFRNjYgLTExIDU3IC0xVDQ4IDE2UTQ4IDI2IDg1IDE3NlQxNTggNDcxTDE5NSA2MTZRMTk2IDYyOSAxODggNjMyVDE0OSA2MzdIMTQ0UTEzNCA2MzcgMTMxIDYzN1QxMjQgNjQwVDEyMSA2NDdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yQiIgZD0iTTU2IDIzN1Q1NiAyNTBUNzAgMjcwSDM2OVY0MjBMMzcwIDU3MFEzODAgNTgzIDM4OSA1ODNRNDAyIDU4MyA0MDkgNTY4VjI3MEg3MDdRNzIyIDI2MiA3MjIgMjUwVDcwNyAyMzBINDA5Vi02OFE0MDEgLTgyIDM5MSAtODJIMzg5SDM4N1EzNzUgLTgyIDM2OSAtNjhWMjMwSDcwUTU2IDIzNyA1NiAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMTIiIGQ9Ik04NCAyMzdUODQgMjUwVDk4IDI3MEg2NzlRNjk0IDI2MiA2OTQgMjUwVDY3OSAyMzBIOThRODQgMjM3IDg0IDI1MFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00QiIgeD0iMjQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNiw1MDApIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiIHg9Ii03MCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE4Mi4zMDYxNjA2NzYzNzYyNywwKSBzY2FsZSgxLjQ4NDYwNjU0NzczMDkzNjMsMSkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiIHg9IjgyNyIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIxMzY0IiB5PSItMjEzIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMTc2NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI1NDUsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxNTU0IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iNTI2IiB5PSI2NzYiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtODAzKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxQSIgeD0iMCIgeT0iLTc4Ij48L3VzZT4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNjAwIiBoZWlnaHQ9IjYwIiB4PSI4MzMiIHk9IjY2MyI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iODMzIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDc4NCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yMjExIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQ3LC0xMDkwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02OSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIzNDUiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTEyNCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI3MjEiIHk9IjE2MjciPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYzOTUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0MDcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjczNyIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEwODgiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIyMDg4IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIyOTc4IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjQ5OTciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSI1OTk4IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI2ODg4IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==)
值得注意的是,
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjI5Ljc2NGV4IiBoZWlnaHQ9IjQuODQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMS44MzhleDsiIHZpZXdCb3g9IjAgLTEyOTMuNyAxMjgxNS4xIDIwODUiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjAwIiBkPSJNMCA2NzNRMCA2ODQgNyA2ODlUMjAgNjk0UTMyIDY5NCAzOCA2ODBUODIgNTY3TDEyNiA0NTFINDMwTDQ3MyA1NjZRNDgzIDU5MyA0OTQgNjIyVDUxMiA2NjhUNTE5IDY4NVE1MjQgNjk0IDUzOCA2OTRRNTU2IDY5MiA1NTYgNjc0UTU1NiA2NzAgNDI2IDMyOVQyOTMgLTE1UTI4OCAtMjIgMjc4IC0yMlQyNjMgLTE1UTI2MCAtMTEgMTMxIDMyOFQwIDY3M1pNNDE0IDQxMFE0MTQgNDExIDI3OCA0MTFUMTQyIDQxMEwyNzggNTVMNDE0IDQxMFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJDIiBkPSJNNzggMzVUNzggNjBUOTQgMTAzVDEzNyAxMjFRMTY1IDEyMSAxODcgOTZUMjEwIDhRMjEwIC0yNyAyMDEgLTYwVDE4MCAtMTE3VDE1NCAtMTU4VDEzMCAtMTg1VDExNyAtMTk0UTExMyAtMTk0IDEwNCAtMTg1VDk1IC0xNzJROTUgLTE2OCAxMDYgLTE1NlQxMzEgLTEyNlQxNTcgLTc2VDE3MyAtM1Y5TDE3MiA4UTE3MCA3IDE2NyA2VDE2MSAzVDE1MiAxVDE0MCAwUTExMyAwIDk2IDE3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQ1IiBkPSJNNDkyIDIxM1E0NzIgMjEzIDQ3MiAyMjZRNDcyIDIzMCA0NzcgMjUwVDQ4MiAyODVRNDgyIDMxNiA0NjEgMzIzVDM2NCAzMzBIMzEyUTMxMSAzMjggMjc3IDE5MlQyNDMgNTJRMjQzIDQ4IDI1NCA0OFQzMzQgNDZRNDI4IDQ2IDQ1OCA0OFQ1MTggNjFRNTY3IDc3IDU5OSAxMTdUNjcwIDI0OFE2ODAgMjcwIDY4MyAyNzJRNjkwIDI3NCA2OTggMjc0UTcxOCAyNzQgNzE4IDI2MVE2MTMgNyA2MDggMlE2MDUgMCAzMjIgMEgxMzNRMzEgMCAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDYgNjYgMjE1IDM0MlQyODUgNjIyUTI4NSA2MjkgMjgxIDYyOVEyNzMgNjMyIDIyOCA2MzRIMTk3UTE5MSA2NDAgMTkxIDY0MlQxOTMgNjU5UTE5NyA2NzYgMjAzIDY4MEg3NTdRNzY0IDY3NiA3NjQgNjY5UTc2NCA2NjQgNzUxIDU1N1Q3MzcgNDQ3UTczNSA0NDAgNzE3IDQ0MEg3MDVRNjk4IDQ0NSA2OTggNDUzTDcwMSA0NzZRNzA0IDUwMCA3MDQgNTI4UTcwNCA1NTggNjk3IDU3OFQ2NzggNjA5VDY0MyA2MjVUNTk2IDYzMlQ1MzIgNjM0SDQ4NVEzOTcgNjMzIDM5MiA2MzFRMzg4IDYyOSAzODYgNjIyUTM4NSA2MTkgMzU1IDQ5OVQzMjQgMzc3UTM0NyAzNzYgMzcyIDM3NkgzOThRNDY0IDM3NiA0ODkgMzkxVDUzNCA0NzJRNTM4IDQ4OCA1NDAgNDkwVDU1NyA0OTNRNTYyIDQ5MyA1NjUgNDkzVDU3MCA0OTJUNTcyIDQ5MVQ1NzQgNDg3VDU3NyA0ODNMNTQ0IDM1MVE1MTEgMjE4IDUwOCAyMTZRNTA1IDIxMyA0OTIgMjEzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tQUYiIGQ9Ik02OSA1NDRWNTkwSDQzMFY1NDRINjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjgiIGQ9Ik0xODAgOTZUMTgwIDI1MFQyMDUgNTQxVDI2NiA3NzBUMzUzIDk0NFQ0NDQgMTA2OVQ1MjcgMTE1MEg1NTVRNTYxIDExNDQgNTYxIDExNDFRNTYxIDExMzcgNTQ1IDExMjBUNTA0IDEwNzJUNDQ3IDk5NVQzODYgODc4VDMzMCA3MjFUMjg4IDUxM1QyNzIgMjUxUTI3MiAxMzMgMjgwIDU2UTI5MyAtODcgMzI2IC0yMDlUMzk5IC00MDVUNDc1IC01MzFUNTM2IC02MDlUNTYxIC02NDBRNTYxIC02NDMgNTU1IC02NDlINTI3UTQ4MyAtNjEyIDQ0MyAtNTY4VDM1MyAtNDQzVDI2NiAtMjcwVDIwNSAtNDFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oyLTI5IiBkPSJNMzUgMTEzOFEzNSAxMTUwIDUxIDExNTBINTZINjlRMTEzIDExMTMgMTUzIDEwNjlUMjQzIDk0NFQzMzAgNzcxVDM5MSA1NDFUNDE2IDI1MFQzOTEgLTQwVDMzMCAtMjcwVDI0MyAtNDQzVDE1MiAtNTY4VDY5IC02NDlINTZRNDMgLTY0OSAzOSAtNjQ3VDM1IC02MzdRNjUgLTYwNyAxMTAgLTU0OFEyODMgLTMxNiAzMTYgNTZRMzI0IDEzMyAzMjQgMjUxUTMyNCAzNjggMzE2IDQ0NVEyNzggODc3IDQ4IDExMjNRMzYgMTEzNyAzNSAxMTM4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMCIgZD0iTTk2IDU4NVExNTIgNjY2IDI0OSA2NjZRMjk3IDY2NiAzNDUgNjQwVDQyMyA1NDhRNDYwIDQ2NSA0NjAgMzIwUTQ2MCAxNjUgNDE3IDgzUTM5NyA0MSAzNjIgMTZUMzAxIC0xNVQyNTAgLTIyUTIyNCAtMjIgMTk4IC0xNlQxMzcgMTZUODIgODNRMzkgMTY1IDM5IDMyMFEzOSA0OTQgOTYgNTg1Wk0zMjEgNTk3UTI5MSA2MjkgMjUwIDYyOVEyMDggNjI5IDE3OCA1OTdRMTUzIDU3MSAxNDUgNTI1VDEzNyAzMzNRMTM3IDE3NSAxNDUgMTI1VDE4MSA0NlEyMDkgMTYgMjUwIDE2UTI5MCAxNiAzMTggNDZRMzQ3IDc2IDM1NCAxMzBUMzYyIDMzM1EzNjIgNDc4IDM1NCA1MjRUMzIxIDU5N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00QiIgZD0iTTI4NSA2MjhRMjg1IDYzNSAyMjggNjM3UTIwNSA2MzcgMTk4IDYzOFQxOTEgNjQ3UTE5MSA2NDkgMTkzIDY2MVExOTkgNjgxIDIwMyA2ODJRMjA1IDY4MyAyMTQgNjgzSDIxOVEyNjAgNjgxIDM1NSA2ODFRMzg5IDY4MSA0MTggNjgxVDQ2MyA2ODJUNDgzIDY4MlE1MDAgNjgyIDUwMCA2NzRRNTAwIDY2OSA0OTcgNjYwUTQ5NiA2NTggNDk2IDY1NFQ0OTUgNjQ4VDQ5MyA2NDRUNDkwIDY0MVQ0ODYgNjM5VDQ3OSA2MzhUNDcwIDYzN1Q0NTYgNjM3UTQxNiA2MzYgNDA1IDYzNFQzODcgNjIzTDMwNiAzMDVRMzA3IDMwNSA0OTAgNDQ5VDY3OCA1OTdRNjkyIDYxMSA2OTIgNjIwUTY5MiA2MzUgNjY3IDYzN1E2NTEgNjM3IDY1MSA2NDhRNjUxIDY1MCA2NTQgNjYyVDY1OSA2NzdRNjYyIDY4MiA2NzYgNjgyUTY4MCA2ODIgNzExIDY4MVQ3OTEgNjgwUTgxNCA2ODAgODM5IDY4MVQ4NjkgNjgyUTg4OSA2ODIgODg5IDY3MlE4ODkgNjUwIDg4MSA2NDJRODc4IDYzNyA4NjIgNjM3UTc4NyA2MzIgNzI2IDU4NlE3MTAgNTc2IDY1NiA1MzRUNTU2IDQ1NUw1MDkgNDE4TDUxOCAzOTZRNTI3IDM3NCA1NDYgMzI5VDU4MSAyNDRRNjU2IDY3IDY2MSA2MVE2NjMgNTkgNjY2IDU3UTY4MCA0NyA3MTcgNDZINzM4UTc0NCAzOCA3NDQgMzdUNzQxIDE5UTczNyA2IDczMSAwSDcyMFE2ODAgMyA2MjUgM1E1MDMgMyA0ODggMEg0NzhRNDcyIDYgNDcyIDlUNDc0IDI3UTQ3OCA0MCA0ODAgNDNUNDkxIDQ2SDQ5NFE1NDQgNDYgNTQ0IDcxUTU0NCA3NSA1MTcgMTQxVDQ4NSAyMTZMNDI3IDM1NEwzNTkgMzAxTDI5MSAyNDhMMjY4IDE1NVEyNDUgNjMgMjQ1IDU4UTI0NSA1MSAyNTMgNDlUMzAzIDQ2SDMzNFEzNDAgMzcgMzQwIDM1UTM0MCAxOSAzMzMgNVEzMjggMCAzMTcgMFEzMTQgMCAyODAgMVQxODAgMlExMTggMiA4NSAyVDQ5IDFRMzEgMSAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDcgNjUgMjE2IDMzOVQyODUgNjI4WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIwMCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI1NTYiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJDIiB4PSIxMTU3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9IjE2MDIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNTMzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTk3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjI0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzgsNDk0KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSItNzAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMTcuOTIyNTA0MTY2NjgxLDApIHNjYWxlKDAuNzU5ODcxMDY1NjI4MzgwNiwxKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiIgeD0iNTY1IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjExNzYiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yOSIgeD0iMTk1NCIgeT0iLTEiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjUzNjIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMwIiB4PSI2NDE5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQyIgeD0iNjkxOSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSI3MzY0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODI5NSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yOCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU5NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTRCIiB4PSIyNCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI2LDUwMCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiIgeD0iLTcwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTgyLjMwNjE2MDY3NjM3NjI3LDApIHNjYWxlKDEuNDg0NjA2NTQ3NzMwOTM2MywxKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiIgeD0iODI3IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjEzNjQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi0yOSIgeD0iMjA4NyIgeT0iLTEiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjExMjU4IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMCIgeD0iMTIzMTQiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==)
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIwLjEyM2V4IiBoZWlnaHQ9IjYuNTA5ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMi44MzhleDsiIHZpZXdCb3g9IjAgLTE1ODAuNyA4NjYzLjkgMjgwMi42IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY2IiBkPSJNMTE4IC0xNjJRMTIwIC0xNjIgMTI0IC0xNjRUMTM1IC0xNjdUMTQ3IC0xNjhRMTYwIC0xNjggMTcxIC0xNTVUMTg3IC0xMjZRMTk3IC05OSAyMjEgMjdUMjY3IDI2N1QyODkgMzgyVjM4NUgyNDJRMTk1IDM4NSAxOTIgMzg3UTE4OCAzOTAgMTg4IDM5N0wxOTUgNDI1UTE5NyA0MzAgMjAzIDQzMFQyNTAgNDMxUTI5OCA0MzEgMjk4IDQzMlEyOTggNDM0IDMwNyA0ODJUMzE5IDU0MFEzNTYgNzA1IDQ2NSA3MDVRNTAyIDcwMyA1MjYgNjgzVDU1MCA2MzBRNTUwIDU5NCA1MjkgNTc4VDQ4NyA1NjFRNDQzIDU2MSA0NDMgNjAzUTQ0MyA2MjIgNDU0IDYzNlQ0NzggNjU3TDQ4NyA2NjJRNDcxIDY2OCA0NTcgNjY4UTQ0NSA2NjggNDM0IDY1OFQ0MTkgNjMwUTQxMiA2MDEgNDAzIDU1MlQzODcgNDY5VDM4MCA0MzNRMzgwIDQzMSA0MzUgNDMxUTQ4MCA0MzEgNDg3IDQzMFQ0OTggNDI0UTQ5OSA0MjAgNDk2IDQwN1Q0OTEgMzkxUTQ4OSAzODYgNDgyIDM4NlQ0MjggMzg1SDM3MkwzNDkgMjYzUTMwMSAxNSAyODIgLTQ3UTI1NSAtMTMyIDIxMiAtMTczUTE3NSAtMjA1IDEzOSAtMjA1UTEwNyAtMjA1IDgxIC0xODZUNTUgLTEzMlE1NSAtOTUgNzYgLTc4VDExOCAtNjFRMTYyIC02MSAxNjIgLTEwM1ExNjIgLTEyMiAxNTEgLTEzNlQxMjcgLTE1N0wxMTggLTE2MloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMSIgZD0iTTIxMyA1NzhMMjAwIDU3M1ExODYgNTY4IDE2MCA1NjNUMTAyIDU1Nkg4M1Y2MDJIMTAyUTE0OSA2MDQgMTg5IDYxN1QyNDUgNjQxVDI3MyA2NjNRMjc1IDY2NiAyODUgNjY2UTI5NCA2NjYgMzAyIDY2MFYzNjFMMzAzIDYxUTMxMCA1NCAzMTUgNTJUMzM5IDQ4VDQwMSA0Nkg0MjdWMEg0MTZRMzk1IDMgMjU3IDNRMTIxIDMgMTAwIDBIODhWNDZIMTE0UTEzNiA0NiAxNTIgNDZUMTc3IDQ3VDE5MyA1MFQyMDEgNTJUMjA3IDU3VDIxMyA2MVY1NzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjFBIiBkPSJNOTUgMTc4UTg5IDE3OCA4MSAxODZUNzIgMjAwVDEwMyAyMzBUMTY5IDI4MFQyMDcgMzA5UTIwOSAzMTEgMjEyIDMxMUgyMTNRMjE5IDMxMSAyMjcgMjk0VDI4MSAxNzdRMzAwIDEzNCAzMTIgMTA4TDM5NyAtNzdRMzk4IC03NyA1MDEgMTM2VDcwNyA1NjVUODE0IDc4NlE4MjAgODAwIDgzNCA4MDBRODQxIDgwMCA4NDYgNzk0VDg1MyA3ODJWNzc2TDYyMCAyOTNMMzg1IC0xOTNRMzgxIC0yMDAgMzY2IC0yMDBRMzU3IC0yMDAgMzU0IC0xOTdRMzUyIC0xOTUgMjU2IDE1TDE2MCAyMjVMMTQ0IDIxNFExMjkgMjAyIDExMyAxOTBUOTUgMTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1ozLTI4IiBkPSJNNzAxIC05NDBRNzAxIC05NDMgNjk1IC05NDlINjY0UTY2MiAtOTQ3IDYzNiAtOTIyVDU5MSAtODc5VDUzNyAtODE4VDQ3NSAtNzM3VDQxMiAtNjM2VDM1MCAtNTExVDI5NSAtMzYyVDI1MCAtMTg2VDIyMSAxN1QyMDkgMjUxUTIwOSA5NjIgNTczIDEzNjFRNTk2IDEzODYgNjE2IDE0MDVUNjQ5IDE0MzdUNjY0IDE0NTBINjk1UTcwMSAxNDQ0IDcwMSAxNDQxUTcwMSAxNDM2IDY4MSAxNDE1VDYyOSAxMzU2VDU1NyAxMjYxVDQ3NiAxMTE4VDQwMCA5MjdUMzQwIDY3NVQzMDggMzU5UTMwNiAzMjEgMzA2IDI1MFEzMDYgLTEzOSA0MDAgLTQzMFQ2OTAgLTkyNFE3MDEgLTkzNiA3MDEgLTk0MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjMtMjkiIGQ9Ik0zNCAxNDM4UTM0IDE0NDYgMzcgMTQ0OFQ1MCAxNDUwSDU2SDcxUTczIDE0NDggOTkgMTQyM1QxNDQgMTM4MFQxOTggMTMxOVQyNjAgMTIzOFQzMjMgMTEzN1QzODUgMTAxM1Q0NDAgODY0VDQ4NSA2ODhUNTE0IDQ4NVQ1MjYgMjUxUTUyNiAxMzQgNTE5IDUzUTQ3MiAtNTE5IDE2MiAtODYwUTEzOSAtODg1IDExOSAtOTA0VDg2IC05MzZUNzEgLTk0OUg1NlE0MyAtOTQ5IDM5IC05NDdUMzQgLTkzN1E4OCAtODgzIDE0MCAtODEzUTQyOCAtNDMwIDQyOCAyNTFRNDI4IDQ1MyA0MDIgNjI4VDMzOCA5MjJUMjQ1IDExNDZUMTQ1IDEzMDlUNDYgMTQyNVE0NCAxNDI3IDQyIDE0MjlUMzkgMTQzM1QzNiAxNDM2TDM0IDE0MzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NiIgZD0iTTUyIDY0OFE1MiA2NzAgNjUgNjgzSDc2UTExOCA2ODAgMTgxIDY4MFEyOTkgNjgwIDMyMCA2ODNIMzMwUTMzNiA2NzcgMzM2IDY3NFQzMzQgNjU2UTMyOSA2NDEgMzI1IDYzN0gzMDRRMjgyIDYzNSAyNzQgNjM1UTI0NSA2MzAgMjQyIDYyMFEyNDIgNjE4IDI3MSAzNjlUMzAxIDExOEwzNzQgMjM1UTQ0NyAzNTIgNTIwIDQ3MVQ1OTUgNTk0UTU5OSA2MDEgNTk5IDYwOVE1OTkgNjMzIDU1NSA2MzdRNTM3IDYzNyA1MzcgNjQ4UTUzNyA2NDkgNTM5IDY2MVE1NDIgNjc1IDU0NSA2NzlUNTU4IDY4M1E1NjAgNjgzIDU3MCA2ODNUNjA0IDY4MlQ2NjggNjgxUTczNyA2ODEgNzU1IDY4M0g3NjJRNzY5IDY3NiA3NjkgNjcyUTc2OSA2NTUgNzYwIDY0MFE3NTcgNjM3IDc0MyA2MzdRNzMwIDYzNiA3MTkgNjM1VDY5OCA2MzBUNjgyIDYyM1Q2NzAgNjE1VDY2MCA2MDhUNjUyIDU5OVQ2NDUgNTkyTDQ1MiAyODJRMjcyIC05IDI2NiAtMTZRMjYzIC0xOCAyNTkgLTIxTDI0MSAtMjJIMjM0UTIxNiAtMjIgMjE2IC0xNVEyMTMgLTkgMTc3IDMwNVExMzkgNjIzIDEzOCA2MjZRMTMzIDYzNyA3NiA2MzdINTlRNTIgNjQyIDUyIDY0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NSIgZD0iTTQ5MiAyMTNRNDcyIDIxMyA0NzIgMjI2UTQ3MiAyMzAgNDc3IDI1MFQ0ODIgMjg1UTQ4MiAzMTYgNDYxIDMyM1QzNjQgMzMwSDMxMlEzMTEgMzI4IDI3NyAxOTJUMjQzIDUyUTI0MyA0OCAyNTQgNDhUMzM0IDQ2UTQyOCA0NiA0NTggNDhUNTE4IDYxUTU2NyA3NyA1OTkgMTE3VDY3MCAyNDhRNjgwIDI3MCA2ODMgMjcyUTY5MCAyNzQgNjk4IDI3NFE3MTggMjc0IDcxOCAyNjFRNjEzIDcgNjA4IDJRNjA1IDAgMzIyIDBIMTMzUTMxIDAgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ2IDY2IDIxNSAzNDJUMjg1IDYyMlEyODUgNjI5IDI4MSA2MjlRMjczIDYzMiAyMjggNjM0SDE5N1ExOTEgNjQwIDE5MSA2NDJUMTkzIDY1OVExOTcgNjc2IDIwMyA2ODBINzU3UTc2NCA2NzYgNzY0IDY2OVE3NjQgNjY0IDc1MSA1NTdUNzM3IDQ0N1E3MzUgNDQwIDcxNyA0NDBINzA1UTY5OCA0NDUgNjk4IDQ1M0w3MDEgNDc2UTcwNCA1MDAgNzA0IDUyOFE3MDQgNTU4IDY5NyA1NzhUNjc4IDYwOVQ2NDMgNjI1VDU5NiA2MzJUNTMyIDYzNEg0ODVRMzk3IDYzMyAzOTIgNjMxUTM4OCA2MjkgMzg2IDYyMlEzODUgNjE5IDM1NSA0OTlUMzI0IDM3N1EzNDcgMzc2IDM3MiAzNzZIMzk4UTQ2NCAzNzYgNDg5IDM5MVQ1MzQgNDcyUTUzOCA0ODggNTQwIDQ5MFQ1NTcgNDkzUTU2MiA0OTMgNTY1IDQ5M1Q1NzAgNDkyVDU3MiA0OTFUNTc0IDQ4N1Q1NzcgNDgzTDU0NCAzNTFRNTExIDIxOCA1MDggMjE2UTUwNSAyMTMgNDkyIDIxM1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iNjkzIiB5PSItMjEzIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTE4MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMy0yOCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDczNiwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjE1NTQiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSI1MjYiIHk9IjY3NiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC04MDMpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjFBIiB4PSIwIiB5PSItNzgiPjwvdXNlPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI2MDAiIGhlaWdodD0iNjAiIHg9IjgzMyIgeT0iNjYzIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI4MzMiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjMtMjkiIHg9IjI1MzAiIHk9Ii0xIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI0NzI2IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTc4MiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIxMTY3IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjgyNSIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzQxNSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==)
因此, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQ5Ljk5N2V4IiBoZWlnaHQ9IjcuNTA5ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4xNzFleDsiIHZpZXdCb3g9IjAgLTE4NjcuNyAyMTUyNi4zIDMyMzMuMiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTU2IiBkPSJNMTE0IDYyMFExMTMgNjIxIDExMCA2MjRUMTA3IDYyN1QxMDMgNjMwVDk4IDYzMlQ5MSA2MzRUODAgNjM1VDY3IDYzNlQ0OCA2MzdIMTlWNjgzSDI4UTQ2IDY4MCAxNTIgNjgwUTI3MyA2ODAgMjk0IDY4M0gzMDVWNjM3SDI4NFEyMjMgNjM0IDIyMyA2MjBRMjIzIDYxOCAzMTMgMzcyVDQwNCAxMjZMNDkwIDM1OFE1NzUgNTg4IDU3NSA1OTdRNTc1IDYxNiA1NTQgNjI2VDUwOCA2MzdINTAzVjY4M0g1MTJRNTI3IDY4MCA2MjcgNjgwUTcxOCA2ODAgNzI0IDY4M0g3MzBWNjM3SDcyM1E2NDggNjM3IDYyNyA1OTZRNjI3IDU5NSA1MTUgMjkxVDQwMSAtMTRRMzk2IC0yMiAzODIgLTIySDM3NEgzNjdRMzUzIC0yMiAzNDggLTE0UTM0NiAtMTIgMjMxIDMwM1ExMTQgNjE3IDExNCA2MjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi02MSIgZD0iTTEzNyAzMDVUMTE1IDMwNVQ3OCAzMjBUNjMgMzU5UTYzIDM5NCA5NyA0MjFUMjE4IDQ0OFEyOTEgNDQ4IDMzNiA0MTZUMzk2IDM0MFE0MDEgMzI2IDQwMSAzMDlUNDAyIDE5NFYxMjRRNDAyIDc2IDQwNyA1OFQ0MjggNDBRNDQzIDQwIDQ0OCA1NlQ0NTMgMTA5VjE0NUg0OTNWMTA2UTQ5MiA2NiA0OTAgNTlRNDgxIDI5IDQ1NSAxMlQ0MDAgLTZUMzUzIDEyVDMyOSA1NFY1OEwzMjcgNTVRMzI1IDUyIDMyMiA0OVQzMTQgNDBUMzAyIDI5VDI4NyAxN1QyNjkgNlQyNDcgLTJUMjIxIC04VDE5MCAtMTFRMTMwIC0xMSA4MiAyMFQzNCAxMDdRMzQgMTI4IDQxIDE0N1Q2OCAxODhUMTE2IDIyNVQxOTQgMjUzVDMwNCAyNjhIMzE4VjI5MFEzMTggMzI0IDMxMiAzNDBRMjkwIDQxMSAyMTUgNDExUTE5NyA0MTEgMTgxIDQxMFQxNTYgNDA2VDE0OCA0MDNRMTcwIDM4OCAxNzAgMzU5UTE3MCAzMzQgMTU0IDMyMFpNMTI2IDEwNlExMjYgNzUgMTUwIDUxVDIwOSAyNlEyNDcgMjYgMjc2IDQ5VDMxNSAxMDlRMzE3IDExNiAzMTggMTc1UTMxOCAyMzMgMzE3IDIzM1EzMDkgMjMzIDI5NiAyMzJUMjUxIDIyM1QxOTMgMjAzVDE0NyAxNjZUMTI2IDEwNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTcyIiBkPSJNMzYgNDZINTBRODkgNDYgOTcgNjBWNjhROTcgNzcgOTcgOTFUOTggMTIyVDk4IDE2MVQ5OCAyMDNROTggMjM0IDk4IDI2OVQ5OCAzMjhMOTcgMzUxUTk0IDM3MCA4MyAzNzZUMzggMzg1SDIwVjQwOFEyMCA0MzEgMjIgNDMxTDMyIDQzMlE0MiA0MzMgNjAgNDM0VDk2IDQzNlExMTIgNDM3IDEzMSA0MzhUMTYwIDQ0MVQxNzEgNDQySDE3NFYzNzNRMjEzIDQ0MSAyNzEgNDQxSDI3N1EzMjIgNDQxIDM0MyA0MTlUMzY0IDM3M1EzNjQgMzUyIDM1MSAzMzdUMzEzIDMyMlEyODggMzIyIDI3NiAzMzhUMjYzIDM3MlEyNjMgMzgxIDI2NSAzODhUMjcwIDQwMFQyNzMgNDA1UTI3MSA0MDcgMjUwIDQwMVEyMzQgMzkzIDIyNiAzODZRMTc5IDM0MSAxNzkgMjA3VjE1NFExNzkgMTQxIDE3OSAxMjdUMTc5IDEwMVQxODAgODFUMTgwIDY2VjYxUTE4MSA1OSAxODMgNTdUMTg4IDU0VDE5MyA1MVQyMDAgNDlUMjA3IDQ4VDIxNiA0N1QyMjUgNDdUMjM1IDQ2VDI0NSA0NkgyNzZWMEgyNjdRMjQ5IDMgMTQwIDNRMzcgMyAyOCAwSDIwVjQ2SDM2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQ1IiBkPSJNNDkyIDIxM1E0NzIgMjEzIDQ3MiAyMjZRNDcyIDIzMCA0NzcgMjUwVDQ4MiAyODVRNDgyIDMxNiA0NjEgMzIzVDM2NCAzMzBIMzEyUTMxMSAzMjggMjc3IDE5MlQyNDMgNTJRMjQzIDQ4IDI1NCA0OFQzMzQgNDZRNDI4IDQ2IDQ1OCA0OFQ1MTggNjFRNTY3IDc3IDU5OSAxMTdUNjcwIDI0OFE2ODAgMjcwIDY4MyAyNzJRNjkwIDI3NCA2OTggMjc0UTcxOCAyNzQgNzE4IDI2MVE2MTMgNyA2MDggMlE2MDUgMCAzMjIgMEgxMzNRMzEgMCAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDYgNjYgMjE1IDM0MlQyODUgNjIyUTI4NSA2MjkgMjgxIDYyOVEyNzMgNjMyIDIyOCA2MzRIMTk3UTE5MSA2NDAgMTkxIDY0MlQxOTMgNjU5UTE5NyA2NzYgMjAzIDY4MEg3NTdRNzY0IDY3NiA3NjQgNjY5UTc2NCA2NjQgNzUxIDU1N1Q3MzcgNDQ3UTczNSA0NDAgNzE3IDQ0MEg3MDVRNjk4IDQ0NSA2OTggNDUzTDcwMSA0NzZRNzA0IDUwMCA3MDQgNTI4UTcwNCA1NTggNjk3IDU3OFQ2NzggNjA5VDY0MyA2MjVUNTk2IDYzMlQ1MzIgNjM0SDQ4NVEzOTcgNjMzIDM5MiA2MzFRMzg4IDYyOSAzODYgNjIyUTM4NSA2MTkgMzU1IDQ5OVQzMjQgMzc3UTM0NyAzNzYgMzcyIDM3NkgzOThRNDY0IDM3NiA0ODkgMzkxVDUzNCA0NzJRNTM4IDQ4OCA1NDAgNDkwVDU1NyA0OTNRNTYyIDQ5MyA1NjUgNDkzVDU3MCA0OTJUNTcyIDQ5MVQ1NzQgNDg3VDU3NyA0ODNMNTQ0IDM1MVE1MTEgMjE4IDUwOCAyMTZRNTA1IDIxMyA0OTIgMjEzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZFIiBkPSJNMjEgMjg3UTIyIDI5MyAyNCAzMDNUMzYgMzQxVDU2IDM4OFQ4OSA0MjVUMTM1IDQ0MlExNzEgNDQyIDE5NSA0MjRUMjI1IDM5MFQyMzEgMzY5UTIzMSAzNjcgMjMyIDM2N0wyNDMgMzc4UTMwNCA0NDIgMzgyIDQ0MlE0MzYgNDQyIDQ2OSA0MTVUNTAzIDMzNlQ0NjUgMTc5VDQyNyA1MlE0MjcgMjYgNDQ0IDI2UTQ1MCAyNiA0NTMgMjdRNDgyIDMyIDUwNSA2NVQ1NDAgMTQ1UTU0MiAxNTMgNTYwIDE1M1E1ODAgMTUzIDU4MCAxNDVRNTgwIDE0NCA1NzYgMTMwUTU2OCAxMDEgNTU0IDczVDUwOCAxN1Q0MzkgLTEwUTM5MiAtMTAgMzcxIDE3VDM1MCA3M1EzNTAgOTIgMzg2IDE5M1Q0MjMgMzQ1UTQyMyA0MDQgMzc5IDQwNEgzNzRRMjg4IDQwNCAyMjkgMzAzTDIyMiAyOTFMMTg5IDE1N1ExNTYgMjYgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTIgMTgwVDE1MiAzNDNRMTUzIDM0OCAxNTMgMzY2UTE1MyA0MDUgMTI5IDQwNVE5MSA0MDUgNjYgMzA1UTYwIDI4NSA2MCAyODRRNTggMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03QiIgZD0iTTQzNCAtMjMxUTQzNCAtMjQ0IDQyOCAtMjUwSDQxMFEyODEgLTI1MCAyMzAgLTE4NFEyMjUgLTE3NyAyMjIgLTE3MlQyMTcgLTE2MVQyMTMgLTE0OFQyMTEgLTEzM1QyMTAgLTExMVQyMDkgLTg0VDIwOSAtNDdUMjA5IDBRMjA5IDIxIDIwOSA1M1EyMDggMTQyIDIwNCAxNTNRMjAzIDE1NCAyMDMgMTU1UTE4OSAxOTEgMTUzIDIxMVQ4MiAyMzFRNzEgMjMxIDY4IDIzNFQ2NSAyNTBUNjggMjY2VDgyIDI2OVExMTYgMjY5IDE1MiAyODlUMjAzIDM0NVEyMDggMzU2IDIwOCAzNzdUMjA5IDUyOVY1NzlRMjA5IDYzNCAyMTUgNjU2VDI0NCA2OThRMjcwIDcyNCAzMjQgNzQwUTM2MSA3NDggMzc3IDc0OVEzNzkgNzQ5IDM5MCA3NDlUNDA4IDc1MEg0MjhRNDM0IDc0NCA0MzQgNzMyUTQzNCA3MTkgNDMxIDcxNlE0MjkgNzEzIDQxNSA3MTNRMzYyIDcxMCAzMzIgNjg5VDI5NiA2NDdRMjkxIDYzNCAyOTEgNDk5VjQxN1EyOTEgMzcwIDI4OCAzNTNUMjcxIDMxNFEyNDAgMjcxIDE4NCAyNTVMMTcwIDI1MEwxODQgMjQ1UTIwMiAyMzkgMjIwIDIzMFQyNjIgMTk2VDI5MCAxMzdRMjkxIDEzMSAyOTEgMVEyOTEgLTEzNCAyOTYgLTE0N1EzMDYgLTE3NCAzMzkgLTE5MlQ0MTUgLTIxM1E0MjkgLTIxMyA0MzEgLTIxNlE0MzQgLTIxOSA0MzQgLTIzMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02NiIgZD0iTTExOCAtMTYyUTEyMCAtMTYyIDEyNCAtMTY0VDEzNSAtMTY3VDE0NyAtMTY4UTE2MCAtMTY4IDE3MSAtMTU1VDE4NyAtMTI2UTE5NyAtOTkgMjIxIDI3VDI2NyAyNjdUMjg5IDM4MlYzODVIMjQyUTE5NSAzODUgMTkyIDM4N1ExODggMzkwIDE4OCAzOTdMMTk1IDQyNVExOTcgNDMwIDIwMyA0MzBUMjUwIDQzMVEyOTggNDMxIDI5OCA0MzJRMjk4IDQzNCAzMDcgNDgyVDMxOSA1NDBRMzU2IDcwNSA0NjUgNzA1UTUwMiA3MDMgNTI2IDY4M1Q1NTAgNjMwUTU1MCA1OTQgNTI5IDU3OFQ0ODcgNTYxUTQ0MyA1NjEgNDQzIDYwM1E0NDMgNjIyIDQ1NCA2MzZUNDc4IDY1N0w0ODcgNjYyUTQ3MSA2NjggNDU3IDY2OFE0NDUgNjY4IDQzNCA2NThUNDE5IDYzMFE0MTIgNjAxIDQwMyA1NTJUMzg3IDQ2OVQzODAgNDMzUTM4MCA0MzEgNDM1IDQzMVE0ODAgNDMxIDQ4NyA0MzBUNDk4IDQyNFE0OTkgNDIwIDQ5NiA0MDdUNDkxIDM5MVE0ODkgMzg2IDQ4MiAzODZUNDI4IDM4NUgzNzJMMzQ5IDI2M1EzMDEgMTUgMjgyIC00N1EyNTUgLTEzMiAyMTIgLTE3M1ExNzUgLTIwNSAxMzkgLTIwNVExMDcgLTIwNSA4MSAtMTg2VDU1IC0xMzJRNTUgLTk1IDc2IC03OFQxMTggLTYxUTE2MiAtNjEgMTYyIC0xMDNRMTYyIC0xMjIgMTUxIC0xMzZUMTI3IC0xNTdMMTE4IC0xNjJaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMSIgZD0iTTIxMyA1NzhMMjAwIDU3M1ExODYgNTY4IDE2MCA1NjNUMTAyIDU1Nkg4M1Y2MDJIMTAyUTE0OSA2MDQgMTg5IDYxN1QyNDUgNjQxVDI3MyA2NjNRMjc1IDY2NiAyODUgNjY2UTI5NCA2NjYgMzAyIDY2MFYzNjFMMzAzIDYxUTMxMCA1NCAzMTUgNTJUMzM5IDQ4VDQwMSA0Nkg0MjdWMEg0MTZRMzk1IDMgMjU3IDNRMTIxIDMgMTAwIDBIODhWNDZIMTE0UTEzNiA0NiAxNTIgNDZUMTc3IDQ3VDE5MyA1MFQyMDEgNTJUMjA3IDU3VDIxMyA2MVY1NzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjFBIiBkPSJNOTUgMTc4UTg5IDE3OCA4MSAxODZUNzIgMjAwVDEwMyAyMzBUMTY5IDI4MFQyMDcgMzA5UTIwOSAzMTEgMjEyIDMxMUgyMTNRMjE5IDMxMSAyMjcgMjk0VDI4MSAxNzdRMzAwIDEzNCAzMTIgMTA4TDM5NyAtNzdRMzk4IC03NyA1MDEgMTM2VDcwNyA1NjVUODE0IDc4NlE4MjAgODAwIDgzNCA4MDBRODQxIDgwMCA4NDYgNzk0VDg1MyA3ODJWNzc2TDYyMCAyOTNMMzg1IC0xOTNRMzgxIC0yMDAgMzY2IC0yMDBRMzU3IC0yMDAgMzU0IC0xOTdRMzUyIC0xOTUgMjU2IDE1TDE2MCAyMjVMMTQ0IDIxNFExMjkgMjAyIDExMyAxOTBUOTUgMTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMy0yOCIgZD0iTTcwMSAtOTQwUTcwMSAtOTQzIDY5NSAtOTQ5SDY2NFE2NjIgLTk0NyA2MzYgLTkyMlQ1OTEgLTg3OVQ1MzcgLTgxOFQ0NzUgLTczN1Q0MTIgLTYzNlQzNTAgLTUxMVQyOTUgLTM2MlQyNTAgLTE4NlQyMjEgMTdUMjA5IDI1MVEyMDkgOTYyIDU3MyAxMzYxUTU5NiAxMzg2IDYxNiAxNDA1VDY0OSAxNDM3VDY2NCAxNDUwSDY5NVE3MDEgMTQ0NCA3MDEgMTQ0MVE3MDEgMTQzNiA2ODEgMTQxNVQ2MjkgMTM1NlQ1NTcgMTI2MVQ0NzYgMTExOFQ0MDAgOTI3VDM0MCA2NzVUMzA4IDM1OVEzMDYgMzIxIDMwNiAyNTBRMzA2IC0xMzkgNDAwIC00MzBUNjkwIC05MjRRNzAxIC05MzYgNzAxIC05NDBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1ozLTI5IiBkPSJNMzQgMTQzOFEzNCAxNDQ2IDM3IDE0NDhUNTAgMTQ1MEg1Nkg3MVE3MyAxNDQ4IDk5IDE0MjNUMTQ0IDEzODBUMTk4IDEzMTlUMjYwIDEyMzhUMzIzIDExMzdUMzg1IDEwMTNUNDQwIDg2NFQ0ODUgNjg4VDUxNCA0ODVUNTI2IDI1MVE1MjYgMTM0IDUxOSA1M1E0NzIgLTUxOSAxNjIgLTg2MFExMzkgLTg4NSAxMTkgLTkwNFQ4NiAtOTM2VDcxIC05NDlINTZRNDMgLTk0OSAzOSAtOTQ3VDM0IC05MzdRODggLTg4MyAxNDAgLTgxM1E0MjggLTQzMCA0MjggMjUxUTQyOCA0NTMgNDAyIDYyOFQzMzggOTIyVDI0NSAxMTQ2VDE0NSAxMzA5VDQ2IDE0MjVRNDQgMTQyNyA0MiAxNDI5VDM5IDE0MzNUMzYgMTQzNkwzNCAxNDM4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzIiIGQ9Ik0xMDkgNDI5UTgyIDQyOSA2NiA0NDdUNTAgNDkxUTUwIDU2MiAxMDMgNjE0VDIzNSA2NjZRMzI2IDY2NiAzODcgNjEwVDQ0OSA0NjVRNDQ5IDQyMiA0MjkgMzgzVDM4MSAzMTVUMzAxIDI0MVEyNjUgMjEwIDIwMSAxNDlMMTQyIDkzTDIxOCA5MlEzNzUgOTIgMzg1IDk3UTM5MiA5OSA0MDkgMTg2VjE4OUg0NDlWMTg2UTQ0OCAxODMgNDM2IDk1VDQyMSAzVjBINTBWMTlWMzFRNTAgMzggNTYgNDZUODYgODFRMTE1IDExMyAxMzYgMTM3UTE0NSAxNDcgMTcwIDE3NFQyMDQgMjExVDIzMyAyNDRUMjYxIDI3OFQyODQgMzA4VDMwNSAzNDBUMzIwIDM2OVQzMzMgNDAxVDM0MCA0MzFUMzQzIDQ2NFEzNDMgNTI3IDMwOSA1NzNUMjEyIDYxOVExNzkgNjE5IDE1NCA2MDJUMTE5IDU2OVQxMDkgNTUwUTEwOSA1NDkgMTE0IDU0OVExMzIgNTQ5IDE1MSA1MzVUMTcwIDQ4OVExNzAgNDY0IDE1NCA0NDdUMTA5IDQyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdEIiBkPSJNNjUgNzMxUTY1IDc0NSA2OCA3NDdUODggNzUwUTE3MSA3NTAgMjE2IDcyNVQyNzkgNjcwUTI4OCA2NDkgMjg5IDYzNVQyOTEgNTAxUTI5MiAzNjIgMjkzIDM1N1EzMDYgMzEyIDM0NSAyOTFUNDE3IDI2OVE0MjggMjY5IDQzMSAyNjZUNDM0IDI1MFQ0MzEgMjM0VDQxNyAyMzFRMzgwIDIzMSAzNDUgMjEwVDI5OCAxNTdRMjkzIDE0MyAyOTIgMTIxVDI5MSAtMjhWLTc5UTI5MSAtMTM0IDI4NSAtMTU2VDI1NiAtMTk4UTIwMiAtMjUwIDg5IC0yNTBRNzEgLTI1MCA2OCAtMjQ3VDY1IC0yMzBRNjUgLTIyNCA2NSAtMjIzVDY2IC0yMThUNjkgLTIxNFQ3NyAtMjEzUTkxIC0yMTMgMTA4IC0yMTBUMTQ2IC0yMDBUMTgzIC0xNzdUMjA3IC0xMzlRMjA4IC0xMzQgMjA5IDNMMjEwIDEzOVEyMjMgMTk2IDI4MCAyMzBRMzE1IDI0NyAzMzAgMjUwUTMwNSAyNTcgMjgwIDI3MFEyMjUgMzA0IDIxMiAzNTJMMjEwIDM2MkwyMDkgNDk4UTIwOCA2MzUgMjA3IDY0MFExOTUgNjgwIDE1NCA2OTZUNzcgNzEzUTY4IDcxMyA2NyA3MTZUNjUgNzMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaNC03QiIgZD0iTTY2MSAtMTI0M0w2NTUgLTEyNDlINjIyTDYwNCAtMTI0MFE1MDMgLTExOTAgNDM0IC0xMTA3VDM0OCAtOTA5UTM0NiAtODk3IDM0NiAtNDk5TDM0NSAtOThMMzQzIC04MlEzMzUgMyAyODcgODdUMTU3IDIyM1ExNDYgMjMyIDE0NSAyMzZRMTQ0IDI0MCAxNDQgMjUwUTE0NCAyNjUgMTQ1IDI2OFQxNTcgMjc4UTI0MiAzMzMgMjg4IDQxN1QzNDMgNTgzTDM0NSA2MDBMMzQ2IDEwMDFRMzQ2IDEzOTggMzQ4IDE0MTBRMzc5IDE2MjIgNjAwIDE3MzlMNjIyIDE3NTBINjU1TDY2MSAxNzQ0VjE3MjdWMTcyMVE2NjEgMTcxMiA2NjEgMTcxMFQ2NTcgMTcwNVQ2NDggMTcwMFQ2MzAgMTY5MFQ2MDIgMTY2OFE1ODkgMTY1OSA1NzQgMTY0M1Q1MzEgMTU5M1Q0ODQgMTUwOFQ0NTkgMTM5OFE0NTggMTM4OSA0NTggMTAwMVE0NTggNjE0IDQ1NyA2MDVRNDQxIDQzNSAzMDEgMzE2UTI1NCAyNzcgMjAyIDI1MUwyNTAgMjIyUTI2MCAyMTYgMzAxIDE4NVE0NDMgNjYgNDU3IC0xMDRRNDU4IC0xMTMgNDU4IC01MDFRNDU4IC04ODggNDU5IC04OTdRNDYzIC05NDQgNDc4IC05ODhUNTA5IC0xMDYwVDU0OCAtMTExNFQ1ODAgLTExNDlUNjAyIC0xMTY3UTYyMCAtMTE4MyA2MzQgLTExOTJUNjUzIC0xMjAyVDY1OSAtMTIwN1Q2NjEgLTEyMjBWLTEyMjZWLTEyNDNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1o0LTdEIiBkPSJNMTQ0IDE3MjdRMTQ0IDE3NDMgMTQ2IDE3NDZUMTYyIDE3NTBIMTY3SDE4M0wyMDMgMTc0MFEyNzQgMTcwNSAzMjUgMTY1OFQ0MDMgMTU2MlQ0NDAgMTQ3OFQ0NTYgMTQxMFE0NTggMTM5OCA0NTggMTAwMVE0NTkgNjYxIDQ1OSA2MjRUNDY1IDU1OFE0NzAgNTI2IDQ4MCA0OTZUNTAyIDQ0MVQ1MjkgMzk1VDU1OSAzNTZUNTg4IDMyNVQ2MTUgMzAxVDYzNyAyODRUNjU0IDI3M0w2NjAgMjY5VjI2NlE2NjAgMjYzIDY2MCAyNTlUNjYxIDI1MFYyMzlRNjYxIDIzNiA2NjEgMjM0VDY2MCAyMzJUNjU2IDIyOVQ2NDkgMjI0UTU3NyAxNzkgNTI4IDEwNVQ0NjUgLTU3UTQ2MCAtODYgNDYwIC0xMjNUNDU4IC00OTlWLTY2MVE0NTggLTg1NyA0NTcgLTg5M1Q0NDcgLTk1NVE0MjUgLTEwNDggMzU5IC0xMTIwVDIwMyAtMTIzOUwxODMgLTEyNDlIMTY4UTE1MCAtMTI0OSAxNDcgLTEyNDZUMTQ0IC0xMjI2UTE0NCAtMTIxMyAxNDUgLTEyMTBUMTUzIC0xMjAyUTE2OSAtMTE5MyAxODYgLTExODFUMjMyIC0xMTQwVDI4MiAtMTA4MVQzMjIgLTEwMDBUMzQ1IC04OTdRMzQ2IC04ODggMzQ2IC01MDFRMzQ2IC0xMTMgMzQ3IC0xMDRRMzU5IDU4IDUwMyAxODRRNTU0IDIyNiA2MDMgMjUwUTUwNCAyOTkgNDMwIDM5M1QzNDcgNjA1UTM0NiA2MTQgMzQ2IDEwMDJRMzQ2IDEzODkgMzQ1IDEzOThRMzM4IDE0OTMgMjg4IDE1NzNUMTUzIDE3MDNRMTQ2IDE3MDcgMTQ1IDE3MTBUMTQ0IDE3MjdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjEyIiBkPSJNODQgMjM3VDg0IDI1MFQ5OCAyNzBINjc5UTY5NCAyNjIgNjk0IDI1MFQ2NzkgMjMwSDk4UTg0IDIzNyA4NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTYiIGQ9Ik01MiA2NDhRNTIgNjcwIDY1IDY4M0g3NlExMTggNjgwIDE4MSA2ODBRMjk5IDY4MCAzMjAgNjgzSDMzMFEzMzYgNjc3IDMzNiA2NzRUMzM0IDY1NlEzMjkgNjQxIDMyNSA2MzdIMzA0UTI4MiA2MzUgMjc0IDYzNVEyNDUgNjMwIDI0MiA2MjBRMjQyIDYxOCAyNzEgMzY5VDMwMSAxMThMMzc0IDIzNVE0NDcgMzUyIDUyMCA0NzFUNTk1IDU5NFE1OTkgNjAxIDU5OSA2MDlRNTk5IDYzMyA1NTUgNjM3UTUzNyA2MzcgNTM3IDY0OFE1MzcgNjQ5IDUzOSA2NjFRNTQyIDY3NSA1NDUgNjc5VDU1OCA2ODNRNTYwIDY4MyA1NzAgNjgzVDYwNCA2ODJUNjY4IDY4MVE3MzcgNjgxIDc1NSA2ODNINzYyUTc2OSA2NzYgNzY5IDY3MlE3NjkgNjU1IDc2MCA2NDBRNzU3IDYzNyA3NDMgNjM3UTczMCA2MzYgNzE5IDYzNVQ2OTggNjMwVDY4MiA2MjNUNjcwIDYxNVQ2NjAgNjA4VDY1MiA1OTlUNjQ1IDU5Mkw0NTIgMjgyUTI3MiAtOSAyNjYgLTE2UTI2MyAtMTggMjU5IC0yMUwyNDEgLTIySDIzNFEyMTYgLTIyIDIxNiAtMTVRMjEzIC05IDE3NyAzMDVRMTM5IDYyMyAxMzggNjI2UTEzMyA2MzcgNzYgNjM3SDU5UTUyIDY0MiA1MiA2NDhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oxLTdCIiBkPSJNNDc3IC0zNDNMNDcxIC0zNDlINDU4UTQzMiAtMzQ5IDM2NyAtMzI1VDI3MyAtMjYzUTI1OCAtMjQ1IDI1MCAtMjEyTDI0OSAtNTFRMjQ5IC0yNyAyNDkgMTJRMjQ4IDExOCAyNDQgMTI4UTI0MyAxMjkgMjQzIDEzMFEyMjAgMTg5IDEyMSAyMjhRMTA5IDIzMiAxMDcgMjM1VDEwNSAyNTBRMTA1IDI1NiAxMDUgMjU3VDEwNSAyNjFUMTA3IDI2NVQxMTEgMjY4VDExOCAyNzJUMTI4IDI3NlQxNDIgMjgzVDE2MiAyOTFRMjI0IDMyNCAyNDMgMzcxUTI0MyAzNzIgMjQ0IDM3M1EyNDggMzg0IDI0OSA0NjlRMjQ5IDQ3NSAyNDkgNDg5UTI0OSA1MjggMjQ5IDU1MkwyNTAgNzE0UTI1MyA3MjggMjU2IDczNlQyNzEgNzYxVDI5OSA3ODlUMzQ3IDgxNlQ0MjIgODQzUTQ0MCA4NDkgNDQxIDg0OUg0NDNRNDQ1IDg0OSA0NDcgODQ5VDQ1MiA4NTBUNDU3IDg1MEg0NzFMNDc3IDg0NFY4MzBRNDc3IDgyMCA0NzYgODE3VDQ3MCA4MTFUNDU5IDgwN1Q0MzcgODAxVDQwNCA3ODVRMzUzIDc2MCAzMzggNzI0UTMzMyA3MTAgMzMzIDU1MFEzMzMgNTI2IDMzMyA0OTJUMzM0IDQ0N1EzMzQgMzkzIDMyNyAzNjhUMjk1IDMxOFEyNTcgMjgwIDE4MSAyNTVMMTY5IDI1MUwxODQgMjQ1UTMxOCAxOTggMzMyIDExMlEzMzMgMTA2IDMzMyAtNDlRMzMzIC0yMDkgMzM4IC0yMjNRMzUxIC0yNTUgMzkxIC0yNzdUNDY5IC0zMDlRNDc3IC0zMTEgNDc3IC0zMjlWLTM0M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjEtN0QiIGQ9Ik0xMTAgODQ5TDExNSA4NTBRMTIwIDg1MCAxMjUgODUwUTE1MSA4NTAgMjE1IDgyNlQzMDkgNzY0UTMyNCA3NDcgMzMyIDcxNEwzMzMgNTUyUTMzMyA1MjggMzMzIDQ4OVEzMzQgMzgzIDMzOCAzNzNRMzM5IDM3MiAzMzkgMzcxUTM1MyAzMzYgMzkxIDMxMFQ0NjkgMjcxUTQ3NyAyNjggNDc3IDI1MVE0NzcgMjQxIDQ3NiAyMzdUNDcyIDIzMlQ0NTYgMjI1VDQyOCAyMTRRMzU3IDE3OSAzMzkgMTMwUTMzOSAxMjkgMzM4IDEyOFEzMzQgMTE3IDMzMyAzMlEzMzMgMjYgMzMzIDEyUTMzMyAtMjcgMzMzIC01MUwzMzIgLTIxMlEzMjggLTIyOCAzMjMgLTI0MFQzMDIgLTI3MVQyNTUgLTMwN1QxNzUgLTMzOFExMzkgLTM0OSAxMjUgLTM0OVQxMDggLTM0NlQxMDUgLTMyOVExMDUgLTMxNCAxMDcgLTMxMlQxMzAgLTMwNFEyMzMgLTI3MSAyNDggLTIwOVEyNDkgLTIwMyAyNDkgLTQ5VjU3UTI0OSAxMDYgMjUzIDEyNVQyNzMgMTY3UTMwNyAyMTMgMzk4IDI0NUw0MTMgMjUxTDQwMSAyNTVRMjY1IDMwMCAyNTAgMzg5UTI0OSAzOTUgMjQ5IDU1MFEyNDkgNzEwIDI0NCA3MjRRMjI0IDc3NCAxMTIgODExUTEwNSA4MTMgMTA1IDgzMFExMDUgODQ1IDExMCA4NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oxLTI4IiBkPSJNMTUyIDI1MVExNTIgNjQ2IDM4OCA4NTBINDE2UTQyMiA4NDQgNDIyIDg0MVE0MjIgODM3IDQwMyA4MTZUMzU3IDc1M1QzMDIgNjQ5VDI1NSA0ODJUMjM2IDI1MFEyMzYgMTI0IDI1NSAxOVQzMDEgLTE0N1QzNTYgLTI1MVQ0MDMgLTMxNVQ0MjIgLTM0MFE0MjIgLTM0MyA0MTYgLTM0OUgzODhRMzU5IC0zMjUgMzMyIC0yOTZUMjcxIC0yMTNUMjEyIC05N1QxNzAgNTZUMTUyIDI1MVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjEtMjkiIGQ9Ik0zMDUgMjUxUTMwNSAtMTQ1IDY5IC0zNDlINTZRNDMgLTM0OSAzOSAtMzQ3VDM1IC0zMzhRMzcgLTMzMyA2MCAtMzA3VDEwOCAtMjM5VDE2MCAtMTM2VDIwNCAyN1QyMjEgMjUwVDIwNCA0NzNUMTYwIDYzNlQxMDggNzQwVDYwIDgwN1QzNSA4MzlRMzUgODUwIDUwIDg1MEg1Nkg2OVExOTcgNzQzIDI1NiA1NjZRMzA1IDQyNSAzMDUgMjUxWiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNTYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI3NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIyMzI0IiB5PSI1ODEiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjIzMjQiIHk9Ii0zNTAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNDUwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjM5NzciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iNTAzMyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU5NjQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtN0IiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4MDYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjMtMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MzYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iNjkzIiB5PSItMjEzIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTE4MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMy0yOCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDczNiwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjE1NTQiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSI1MjYiIHk9IjY3NiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC04MDMpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjFBIiB4PSIwIiB5PSItNzgiPjwvdXNlPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI2MDAiIGhlaWdodD0iNjAiIHg9IjgzMyIgeT0iNjYzIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI4MzMiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjMtMjkiIHg9IjI1MzAiIHk9Ii0xIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMy0yOSIgeD0iNTE4NSIgeT0iLTEiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iODM3NCIgeT0iMTY2NSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTdEIiB4PSI3MTgyIiB5PSItMSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIxNDE3NSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE1MTc2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDU4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5MzEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjEtN0IiIHg9IjAiIHk9Ii0xIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTgzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9IjExNjciIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iODI1IiB5PSItMjEyIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTYzMiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMS03RCIgeD0iMzQ2NCIgeT0iLTEiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTI5IiB4PSI1NDM3IiB5PSItMSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI4MzM4IiB5PSI4MTciPjwvdXNlPgo8L2c+CjwvZz4KPC9zdmc+)
利用泰勒展开,
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9Ijg3LjEyZXgiIGhlaWdodD0iNy4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0zLjMzOGV4OyIgdmlld0JveD0iMCAtMTY1Mi41IDM3NTA5LjcgMzA4OS42IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY2IiBkPSJNMTE4IC0xNjJRMTIwIC0xNjIgMTI0IC0xNjRUMTM1IC0xNjdUMTQ3IC0xNjhRMTYwIC0xNjggMTcxIC0xNTVUMTg3IC0xMjZRMTk3IC05OSAyMjEgMjdUMjY3IDI2N1QyODkgMzgyVjM4NUgyNDJRMTk1IDM4NSAxOTIgMzg3UTE4OCAzOTAgMTg4IDM5N0wxOTUgNDI1UTE5NyA0MzAgMjAzIDQzMFQyNTAgNDMxUTI5OCA0MzEgMjk4IDQzMlEyOTggNDM0IDMwNyA0ODJUMzE5IDU0MFEzNTYgNzA1IDQ2NSA3MDVRNTAyIDcwMyA1MjYgNjgzVDU1MCA2MzBRNTUwIDU5NCA1MjkgNTc4VDQ4NyA1NjFRNDQzIDU2MSA0NDMgNjAzUTQ0MyA2MjIgNDU0IDYzNlQ0NzggNjU3TDQ4NyA2NjJRNDcxIDY2OCA0NTcgNjY4UTQ0NSA2NjggNDM0IDY1OFQ0MTkgNjMwUTQxMiA2MDEgNDAzIDU1MlQzODcgNDY5VDM4MCA0MzNRMzgwIDQzMSA0MzUgNDMxUTQ4MCA0MzEgNDg3IDQzMFQ0OTggNDI0UTQ5OSA0MjAgNDk2IDQwN1Q0OTEgMzkxUTQ4OSAzODYgNDgyIDM4NlQ0MjggMzg1SDM3MkwzNDkgMjYzUTMwMSAxNSAyODIgLTQ3UTI1NSAtMTMyIDIxMiAtMTczUTE3NSAtMjA1IDEzOSAtMjA1UTEwNyAtMjA1IDgxIC0xODZUNTUgLTEzMlE1NSAtOTUgNzYgLTc4VDExOCAtNjFRMTYyIC02MSAxNjIgLTEwM1ExNjIgLTEyMiAxNTEgLTEzNlQxMjcgLTE1N0wxMTggLTE2MloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkUiIGQ9Ik0yMSAyODdRMjIgMjkzIDI0IDMwM1QzNiAzNDFUNTYgMzg4VDg5IDQyNVQxMzUgNDQyUTE3MSA0NDIgMTk1IDQyNFQyMjUgMzkwVDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzA0IDQ0MiAzODIgNDQyUTQzNiA0NDIgNDY5IDQxNVQ1MDMgMzM2VDQ2NSAxNzlUNDI3IDUyUTQyNyAyNiA0NDQgMjZRNDUwIDI2IDQ1MyAyN1E0ODIgMzIgNTA1IDY1VDU0MCAxNDVRNTQyIDE1MyA1NjAgMTUzUTU4MCAxNTMgNTgwIDE0NVE1ODAgMTQ0IDU3NiAxMzBRNTY4IDEwMSA1NTQgNzNUNTA4IDE3VDQzOSAtMTBRMzkyIC0xMCAzNzEgMTdUMzUwIDczUTM1MCA5MiAzODYgMTkzVDQyMyAzNDVRNDIzIDQwNCAzNzkgNDA0SDM3NFEyODggNDA0IDIyOSAzMDNMMjIyIDI5MUwxODkgMTU3UTE1NiAyNiAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExMiAxODBUMTUyIDM0M1ExNTMgMzQ4IDE1MyAzNjZRMTUzIDQwNSAxMjkgNDA1UTkxIDQwNSA2NiAzMDVRNjAgMjg1IDYwIDI4NFE1OCAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjIxQSIgZD0iTTk1IDE3OFE4OSAxNzggODEgMTg2VDcyIDIwMFQxMDMgMjMwVDE2OSAyODBUMjA3IDMwOVEyMDkgMzExIDIxMiAzMTFIMjEzUTIxOSAzMTEgMjI3IDI5NFQyODEgMTc3UTMwMCAxMzQgMzEyIDEwOEwzOTcgLTc3UTM5OCAtNzcgNTAxIDEzNlQ3MDcgNTY1VDgxNCA3ODZRODIwIDgwMCA4MzQgODAwUTg0MSA4MDAgODQ2IDc5NFQ4NTMgNzgyVjc3Nkw2MjAgMjkzTDM4NSAtMTkzUTM4MSAtMjAwIDM2NiAtMjAwUTM1NyAtMjAwIDM1NCAtMTk3UTM1MiAtMTk1IDI1NiAxNUwxNjAgMjI1TDE0NCAyMTRRMTI5IDIwMiAxMTMgMTkwVDk1IDE3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMy0yOCIgZD0iTTcwMSAtOTQwUTcwMSAtOTQzIDY5NSAtOTQ5SDY2NFE2NjIgLTk0NyA2MzYgLTkyMlQ1OTEgLTg3OVQ1MzcgLTgxOFQ0NzUgLTczN1Q0MTIgLTYzNlQzNTAgLTUxMVQyOTUgLTM2MlQyNTAgLTE4NlQyMjEgMTdUMjA5IDI1MVEyMDkgOTYyIDU3MyAxMzYxUTU5NiAxMzg2IDYxNiAxNDA1VDY0OSAxNDM3VDY2NCAxNDUwSDY5NVE3MDEgMTQ0NCA3MDEgMTQ0MVE3MDEgMTQzNiA2ODEgMTQxNVQ2MjkgMTM1NlQ1NTcgMTI2MVQ0NzYgMTExOFQ0MDAgOTI3VDM0MCA2NzVUMzA4IDM1OVEzMDYgMzIxIDMwNiAyNTBRMzA2IC0xMzkgNDAwIC00MzBUNjkwIC05MjRRNzAxIC05MzYgNzAxIC05NDBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1ozLTI5IiBkPSJNMzQgMTQzOFEzNCAxNDQ2IDM3IDE0NDhUNTAgMTQ1MEg1Nkg3MVE3MyAxNDQ4IDk5IDE0MjNUMTQ0IDEzODBUMTk4IDEzMTlUMjYwIDEyMzhUMzIzIDExMzdUMzg1IDEwMTNUNDQwIDg2NFQ0ODUgNjg4VDUxNCA0ODVUNTI2IDI1MVE1MjYgMTM0IDUxOSA1M1E0NzIgLTUxOSAxNjIgLTg2MFExMzkgLTg4NSAxMTkgLTkwNFQ4NiAtOTM2VDcxIC05NDlINTZRNDMgLTk0OSAzOSAtOTQ3VDM0IC05MzdRODggLTg4MyAxNDAgLTgxM1E0MjggLTQzMCA0MjggMjUxUTQyOCA0NTMgNDAyIDYyOFQzMzggOTIyVDI0NSAxMTQ2VDE0NSAxMzA5VDQ2IDE0MjVRNDQgMTQyNyA0MiAxNDI5VDM5IDE0MzNUMzYgMTQzNkwzNCAxNDM4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMCIgZD0iTTk2IDU4NVExNTIgNjY2IDI0OSA2NjZRMjk3IDY2NiAzNDUgNjQwVDQyMyA1NDhRNDYwIDQ2NSA0NjAgMzIwUTQ2MCAxNjUgNDE3IDgzUTM5NyA0MSAzNjIgMTZUMzAxIC0xNVQyNTAgLTIyUTIyNCAtMjIgMTk4IC0xNlQxMzcgMTZUODIgODNRMzkgMTY1IDM5IDMyMFEzOSA0OTQgOTYgNTg1Wk0zMjEgNTk3UTI5MSA2MjkgMjUwIDYyOVEyMDggNjI5IDE3OCA1OTdRMTUzIDU3MSAxNDUgNTI1VDEzNyAzMzNRMTM3IDE3NSAxNDUgMTI1VDE4MSA0NlEyMDkgMTYgMjUwIDE2UTI5MCAxNiAzMTggNDZRMzQ3IDc2IDM1NCAxMzBUMzYyIDMzM1EzNjIgNDc4IDM1NCA1MjRUMzIxIDU5N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJCIiBkPSJNNTYgMjM3VDU2IDI1MFQ3MCAyNzBIMzY5VjQyMEwzNzAgNTcwUTM4MCA1ODMgMzg5IDU4M1E0MDIgNTgzIDQwOSA1NjhWMjcwSDcwN1E3MjIgMjYyIDcyMiAyNTBUNzA3IDIzMEg0MDlWLTY4UTQwMSAtODIgMzkxIC04MkgzODlIMzg3UTM3NSAtODIgMzY5IC02OFYyMzBINzBRNTYgMjM3IDU2IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMDIiIGQ9Ik0yMDIgNTA4UTE3OSA1MDggMTY5IDUyMFQxNTggNTQ3UTE1OCA1NTcgMTY0IDU3N1QxODUgNjI0VDIzMCA2NzVUMzAxIDcxMEwzMzMgNzE1SDM0NVEzNzggNzE1IDM4NCA3MTRRNDQ3IDcwMyA0ODkgNjYxVDU0OSA1NjhUNTY2IDQ1N1E1NjYgMzYyIDUxOSAyNDBUNDAyIDUzUTMyMSAtMjIgMjIzIC0yMlExMjMgLTIyIDczIDU2UTQyIDEwMiA0MiAxNDhWMTU5UTQyIDI3NiAxMjkgMzcwVDMyMiA0NjVRMzgzIDQ2NSA0MTQgNDM0VDQ1NSAzNjdMNDU4IDM3OFE0NzggNDYxIDQ3OCA1MTVRNDc4IDYwMyA0MzcgNjM5VDM0NCA2NzZRMjY2IDY3NiAyMjMgNjEyUTI2NCA2MDYgMjY0IDU3MlEyNjQgNTQ3IDI0NiA1MjhUMjAyIDUwOFpNNDMwIDMwNlE0MzAgMzcyIDQwMSA0MDBUMzMzIDQyOFEyNzAgNDI4IDIyMiAzODJRMTk3IDM1NCAxODMgMzIzVDE1MCAyMjFRMTMyIDE0OSAxMzIgMTE2UTEzMiAyMSAyMzIgMjFRMjQ0IDIxIDI1MCAyMlEzMjcgMzUgMzc0IDExMlEzODkgMTM3IDQwOSAxOTZUNDMwIDMwNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS0zQjQiIGQ9Ik0xOTUgNjA5UTE5NSA2NTYgMjI3IDY4NlQzMDIgNzE3UTMxOSA3MTYgMzUxIDcwOVQ0MDcgNjk3VDQzMyA2OTBRNDUxIDY4MiA0NTEgNjYyUTQ1MSA2NDQgNDM4IDYyOFQ0MDMgNjEyUTM4MiA2MTIgMzQ4IDY0MVQyODggNjcxVDI0OSA2NTdUMjM1IDYyOFEyMzUgNTg0IDMzNCA0NjNRNDAxIDM3OSA0MDEgMjkyUTQwMSAxNjkgMzQwIDgwVDIwNSAtMTBIMTk4UTEyNyAtMTAgODMgMzZUMzYgMTUzUTM2IDI4NiAxNTEgMzgyUTE5MSA0MTMgMjUyIDQzNFEyNTIgNDM1IDI0NSA0NDlUMjMwIDQ4MVQyMTQgNTIxVDIwMSA1NjZUMTk1IDYwOVpNMTEyIDEzMFExMTIgODMgMTM2IDU1VDIwNCAyN1EyMzMgMjcgMjU2IDUxVDI5MSAxMTFUMzA5IDE3OFQzMTYgMjMyUTMxNiAyNjcgMzA5IDI5OFQyOTUgMzQ0VDI2OSA0MDBMMjU5IDM5NlEyMTUgMzgxIDE4MyAzNDJUMTM3IDI1NlQxMTggMTc5VDExMiAxMzBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03QyIgZD0iTTEzOSAtMjQ5SDEzN1ExMjUgLTI0OSAxMTkgLTIzNVYyNTFMMTIwIDczN1ExMzAgNzUwIDEzOSA3NTBRMTUyIDc1MCAxNTkgNzM1Vi0yMzVRMTUxIC0yNDkgMTQxIC0yNDlIMTM5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjEiIGQ9Ik03OCA2NjFRNzggNjgyIDk2IDY5OVQxMzggNzE2VDE4MCA3MDBUMTk5IDY2MVExOTkgNjU0IDE3OSA0MzJUMTU4IDIwNlExNTYgMTk4IDEzOSAxOThRMTIxIDE5OCAxMTkgMjA2UTExOCAyMDkgOTggNDMxVDc4IDY2MVpNNzkgNjFRNzkgODkgOTcgMTA1VDE0MSAxMjFRMTY0IDExOSAxODEgMTA0VDE5OCA2MVExOTggMzEgMTgxIDE2VDEzOSAxUTExNCAxIDk3IDE2VDc5IDYxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzMiIGQ9Ik0xMjcgNDYzUTEwMCA0NjMgODUgNDgwVDY5IDUyNFE2OSA1NzkgMTE3IDYyMlQyMzMgNjY1UTI2OCA2NjUgMjc3IDY2NFEzNTEgNjUyIDM5MCA2MTFUNDMwIDUyMlE0MzAgNDcwIDM5NiA0MjFUMzAyIDM1MEwyOTkgMzQ4UTI5OSAzNDcgMzA4IDM0NVQzMzcgMzM2VDM3NSAzMTVRNDU3IDI2MiA0NTcgMTc1UTQ1NyA5NiAzOTUgMzdUMjM4IC0yMlExNTggLTIyIDEwMCAyMVQ0MiAxMzBRNDIgMTU4IDYwIDE3NVQxMDUgMTkzUTEzMyAxOTMgMTUxIDE3NVQxNjkgMTMwUTE2OSAxMTkgMTY2IDExMFQxNTkgOTRUMTQ4IDgyVDEzNiA3NFQxMjYgNzBUMTE4IDY3TDExNCA2NlExNjUgMjEgMjM4IDIxUTI5MyAyMSAzMjEgNzRRMzM4IDEwNyAzMzggMTc1VjE5NVEzMzggMjkwIDI3NCAzMjJRMjU5IDMyOCAyMTMgMzI5TDE3MSAzMzBMMTY4IDMzMlExNjYgMzM1IDE2NiAzNDhRMTY2IDM2NiAxNzQgMzY2UTIwMiAzNjYgMjMyIDM3MVEyNjYgMzc2IDI5NCA0MTNUMzIyIDUyNVY1MzNRMzIyIDU5MCAyODcgNjEyUTI2NSA2MjYgMjQwIDYyNlEyMDggNjI2IDE4MSA2MTVUMTQzIDU5MlQxMzIgNTgwSDEzNVExMzggNTc5IDE0MyA1NzhUMTUzIDU3M1QxNjUgNTY2VDE3NSA1NTVUMTgzIDU0MFQxODYgNTIwUTE4NiA0OTggMTcyIDQ4MVQxMjcgNDYzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkUiIGQ9Ik03OCA2MFE3OCA4NCA5NSAxMDJUMTM4IDEyMFExNjIgMTIwIDE4MCAxMDRUMTk5IDYxUTE5OSAzNiAxODIgMThUMTM5IDBUOTYgMTdUNzggNjBaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjYiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iODA0IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjY5MyIgeT0iLTIxMiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDExODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjMtMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MzYsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxNTU0IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iNTI2IiB5PSI2NzYiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtODAzKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxQSIgeD0iMCIgeT0iLTc4Ij48L3VzZT4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNjAwIiBoZWlnaHQ9IjYwIiB4PSI4MzMiIHk9IjY2MyI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iODMzIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1ozLTI5IiB4PSIyNTMwIiB5PSItMSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iNDczMyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU3OTAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI4MDQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iNjkzIiB5PSItMjEyIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2OTc5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzAiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg5MCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iODQ4MSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkyNTksMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxNTU0IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iNTI2IiB5PSI2NzYiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtODAzKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxQSIgeD0iMCIgeT0iLTc4Ij48L3VzZT4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNjAwIiBoZWlnaHQ9IjYwIiB4PSI4MzMiIHk9IjY2MyI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iODMzIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTEyNzUsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMTM5IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjAyIiB4PSIyODUiIHk9IjY3NiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03MzgpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjAyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktM0I0IiB4PSI1NjciIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjY1NCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjgwNCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI2OTMiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzODQzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTNCNCIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODQxIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNTI0MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0MiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNzgsLTI4NikiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktM0I0IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjQ1MSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMwIiB4PSIxMjMwIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjE3MDY1IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTc4NDMsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxNDk5IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iNDk5IiB5PSI2NzYiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzM3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iNjAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMSIgeD0iMTEwMSIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE5ODA1LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTU5NSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI4MSw2NzYpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjAyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjgxNyIgeT0iNTEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzgwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIwMiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU2NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTNCNCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI2NDEiIHk9IjQwOCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjE2NDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI4MDQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iNjkzIiB5PSItMjEyIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMjgyOSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS0zQjQiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg0MSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjQyMjYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdDIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjc4LC0yODYpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTNCNCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI0NTEiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMCIgeD0iMTIzMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIyNjA1MSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI2ODI5LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQyLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMjI0NiIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9Ijg3MyIgeT0iNjc2Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTEyOTYpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MDAsNTA4KSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjQwNyIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMTQ2Ij48L3JlY3Q+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMzIiB4PSIxMDQiIHk9IjY2OSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMDQiIHk9Ii02OTgiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMyIgeD0iMTM0NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjEiIHg9IjE4NDgiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyOTUzOCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjE1OTUiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyODEsNjc2KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIwMiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMzIiB4PSI4MTciIHk9IjUxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTc4MCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMDIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1NjcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS0zQjQiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMyIgeD0iNjQxIiB5PSI0MDgiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDMxMzczLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjYiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iODA0IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjY5MyIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzI1NjMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktM0I0IiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NDEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDMzOTYwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QyIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI3OCwtMjg2KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS0zQjQiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iNDUxIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzAiIHg9IjEyMzAiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMzU1NjIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSIzNjM0MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9IjM2Nzg2IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iMzcyMzEiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==)
因此,
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9Ijc1ZXgiIGhlaWdodD0iMTQuNjc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMTAuODM4ZXg7IG1heC13aWR0aDogNDUwOyIgdmlld0JveD0iMCAtMTY1Mi41IDMyMjkxLjUgNjMxOC44IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNTYiIGQ9Ik0xMTQgNjIwUTExMyA2MjEgMTEwIDYyNFQxMDcgNjI3VDEwMyA2MzBUOTggNjMyVDkxIDYzNFQ4MCA2MzVUNjcgNjM2VDQ4IDYzN0gxOVY2ODNIMjhRNDYgNjgwIDE1MiA2ODBRMjczIDY4MCAyOTQgNjgzSDMwNVY2MzdIMjg0UTIyMyA2MzQgMjIzIDYyMFEyMjMgNjE4IDMxMyAzNzJUNDA0IDEyNkw0OTAgMzU4UTU3NSA1ODggNTc1IDU5N1E1NzUgNjE2IDU1NCA2MjZUNTA4IDYzN0g1MDNWNjgzSDUxMlE1MjcgNjgwIDYyNyA2ODBRNzE4IDY4MCA3MjQgNjgzSDczMFY2MzdINzIzUTY0OCA2MzcgNjI3IDU5NlE2MjcgNTk1IDUxNSAyOTFUNDAxIC0xNFEzOTYgLTIyIDM4MiAtMjJIMzc0SDM2N1EzNTMgLTIyIDM0OCAtMTRRMzQ2IC0xMiAyMzEgMzAzUTExNCA2MTcgMTE0IDYyMFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTYxIiBkPSJNMTM3IDMwNVQxMTUgMzA1VDc4IDMyMFQ2MyAzNTlRNjMgMzk0IDk3IDQyMVQyMTggNDQ4UTI5MSA0NDggMzM2IDQxNlQzOTYgMzQwUTQwMSAzMjYgNDAxIDMwOVQ0MDIgMTk0VjEyNFE0MDIgNzYgNDA3IDU4VDQyOCA0MFE0NDMgNDAgNDQ4IDU2VDQ1MyAxMDlWMTQ1SDQ5M1YxMDZRNDkyIDY2IDQ5MCA1OVE0ODEgMjkgNDU1IDEyVDQwMCAtNlQzNTMgMTJUMzI5IDU0VjU4TDMyNyA1NVEzMjUgNTIgMzIyIDQ5VDMxNCA0MFQzMDIgMjlUMjg3IDE3VDI2OSA2VDI0NyAtMlQyMjEgLThUMTkwIC0xMVExMzAgLTExIDgyIDIwVDM0IDEwN1EzNCAxMjggNDEgMTQ3VDY4IDE4OFQxMTYgMjI1VDE5NCAyNTNUMzA0IDI2OEgzMThWMjkwUTMxOCAzMjQgMzEyIDM0MFEyOTAgNDExIDIxNSA0MTFRMTk3IDQxMSAxODEgNDEwVDE1NiA0MDZUMTQ4IDQwM1ExNzAgMzg4IDE3MCAzNTlRMTcwIDMzNCAxNTQgMzIwWk0xMjYgMTA2UTEyNiA3NSAxNTAgNTFUMjA5IDI2UTI0NyAyNiAyNzYgNDlUMzE1IDEwOVEzMTcgMTE2IDMxOCAxNzVRMzE4IDIzMyAzMTcgMjMzUTMwOSAyMzMgMjk2IDIzMlQyNTEgMjIzVDE5MyAyMDNUMTQ3IDE2NlQxMjYgMTA2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNzIiIGQ9Ik0zNiA0Nkg1MFE4OSA0NiA5NyA2MFY2OFE5NyA3NyA5NyA5MVQ5OCAxMjJUOTggMTYxVDk4IDIwM1E5OCAyMzQgOTggMjY5VDk4IDMyOEw5NyAzNTFROTQgMzcwIDgzIDM3NlQzOCAzODVIMjBWNDA4UTIwIDQzMSAyMiA0MzFMMzIgNDMyUTQyIDQzMyA2MCA0MzRUOTYgNDM2UTExMiA0MzcgMTMxIDQzOFQxNjAgNDQxVDE3MSA0NDJIMTc0VjM3M1EyMTMgNDQxIDI3MSA0NDFIMjc3UTMyMiA0NDEgMzQzIDQxOVQzNjQgMzczUTM2NCAzNTIgMzUxIDMzN1QzMTMgMzIyUTI4OCAzMjIgMjc2IDMzOFQyNjMgMzcyUTI2MyAzODEgMjY1IDM4OFQyNzAgNDAwVDI3MyA0MDVRMjcxIDQwNyAyNTAgNDAxUTIzNCAzOTMgMjI2IDM4NlExNzkgMzQxIDE3OSAyMDdWMTU0UTE3OSAxNDEgMTc5IDEyN1QxNzkgMTAxVDE4MCA4MVQxODAgNjZWNjFRMTgxIDU5IDE4MyA1N1QxODggNTRUMTkzIDUxVDIwMCA0OVQyMDcgNDhUMjE2IDQ3VDIyNSA0N1QyMzUgNDZUMjQ1IDQ2SDI3NlYwSDI2N1EyNDkgMyAxNDAgM1EzNyAzIDI4IDBIMjBWNDZIMzZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDUiIGQ9Ik00OTIgMjEzUTQ3MiAyMTMgNDcyIDIyNlE0NzIgMjMwIDQ3NyAyNTBUNDgyIDI4NVE0ODIgMzE2IDQ2MSAzMjNUMzY0IDMzMEgzMTJRMzExIDMyOCAyNzcgMTkyVDI0MyA1MlEyNDMgNDggMjU0IDQ4VDMzNCA0NlE0MjggNDYgNDU4IDQ4VDUxOCA2MVE1NjcgNzcgNTk5IDExN1Q2NzAgMjQ4UTY4MCAyNzAgNjgzIDI3MlE2OTAgMjc0IDY5OCAyNzRRNzE4IDI3NCA3MTggMjYxUTYxMyA3IDYwOCAyUTYwNSAwIDMyMiAwSDEzM1EzMSAwIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc1N1E3NjQgNjc2IDc2NCA2NjlRNzY0IDY2NCA3NTEgNTU3VDczNyA0NDdRNzM1IDQ0MCA3MTcgNDQwSDcwNVE2OTggNDQ1IDY5OCA0NTNMNzAxIDQ3NlE3MDQgNTAwIDcwNCA1MjhRNzA0IDU1OCA2OTcgNTc4VDY3OCA2MDlUNjQzIDYyNVQ1OTYgNjMyVDUzMiA2MzRINDg1UTM5NyA2MzMgMzkyIDYzMVEzODggNjI5IDM4NiA2MjJRMzg1IDYxOSAzNTUgNDk5VDMyNCAzNzdRMzQ3IDM3NiAzNzIgMzc2SDM5OFE0NjQgMzc2IDQ4OSAzOTFUNTM0IDQ3MlE1MzggNDg4IDU0MCA0OTBUNTU3IDQ5M1E1NjIgNDkzIDU2NSA0OTNUNTcwIDQ5MlQ1NzIgNDkxVDU3NCA0ODdUNTc3IDQ4M0w1NDQgMzUxUTUxMSAyMTggNTA4IDIxNlE1MDUgMjEzIDQ5MiAyMTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkUiIGQ9Ik0yMSAyODdRMjIgMjkzIDI0IDMwM1QzNiAzNDFUNTYgMzg4VDg5IDQyNVQxMzUgNDQyUTE3MSA0NDIgMTk1IDQyNFQyMjUgMzkwVDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzA0IDQ0MiAzODIgNDQyUTQzNiA0NDIgNDY5IDQxNVQ1MDMgMzM2VDQ2NSAxNzlUNDI3IDUyUTQyNyAyNiA0NDQgMjZRNDUwIDI2IDQ1MyAyN1E0ODIgMzIgNTA1IDY1VDU0MCAxNDVRNTQyIDE1MyA1NjAgMTUzUTU4MCAxNTMgNTgwIDE0NVE1ODAgMTQ0IDU3NiAxMzBRNTY4IDEwMSA1NTQgNzNUNTA4IDE3VDQzOSAtMTBRMzkyIC0xMCAzNzEgMTdUMzUwIDczUTM1MCA5MiAzODYgMTkzVDQyMyAzNDVRNDIzIDQwNCAzNzkgNDA0SDM3NFEyODggNDA0IDIyOSAzMDNMMjIyIDI5MUwxODkgMTU3UTE1NiAyNiAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExMiAxODBUMTUyIDM0M1ExNTMgMzQ4IDE1MyAzNjZRMTUzIDQwNSAxMjkgNDA1UTkxIDQwNSA2NiAzMDVRNjAgMjg1IDYwIDI4NFE1OCAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY2IiBkPSJNMTE4IC0xNjJRMTIwIC0xNjIgMTI0IC0xNjRUMTM1IC0xNjdUMTQ3IC0xNjhRMTYwIC0xNjggMTcxIC0xNTVUMTg3IC0xMjZRMTk3IC05OSAyMjEgMjdUMjY3IDI2N1QyODkgMzgyVjM4NUgyNDJRMTk1IDM4NSAxOTIgMzg3UTE4OCAzOTAgMTg4IDM5N0wxOTUgNDI1UTE5NyA0MzAgMjAzIDQzMFQyNTAgNDMxUTI5OCA0MzEgMjk4IDQzMlEyOTggNDM0IDMwNyA0ODJUMzE5IDU0MFEzNTYgNzA1IDQ2NSA3MDVRNTAyIDcwMyA1MjYgNjgzVDU1MCA2MzBRNTUwIDU5NCA1MjkgNTc4VDQ4NyA1NjFRNDQzIDU2MSA0NDMgNjAzUTQ0MyA2MjIgNDU0IDYzNlQ0NzggNjU3TDQ4NyA2NjJRNDcxIDY2OCA0NTcgNjY4UTQ0NSA2NjggNDM0IDY1OFQ0MTkgNjMwUTQxMiA2MDEgNDAzIDU1MlQzODcgNDY5VDM4MCA0MzNRMzgwIDQzMSA0MzUgNDMxUTQ4MCA0MzEgNDg3IDQzMFQ0OTggNDI0UTQ5OSA0MjAgNDk2IDQwN1Q0OTEgMzkxUTQ4OSAzODYgNDgyIDM4NlQ0MjggMzg1SDM3MkwzNDkgMjYzUTMwMSAxNSAyODIgLTQ3UTI1NSAtMTMyIDIxMiAtMTczUTE3NSAtMjA1IDEzOSAtMjA1UTEwNyAtMjA1IDgxIC0xODZUNTUgLTEzMlE1NSAtOTUgNzYgLTc4VDExOCAtNjFRMTYyIC02MSAxNjIgLTEwM1ExNjIgLTEyMiAxNTEgLTEzNlQxMjcgLTE1N0wxMTggLTE2MloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMCIgZD0iTTk2IDU4NVExNTIgNjY2IDI0OSA2NjZRMjk3IDY2NiAzNDUgNjQwVDQyMyA1NDhRNDYwIDQ2NSA0NjAgMzIwUTQ2MCAxNjUgNDE3IDgzUTM5NyA0MSAzNjIgMTZUMzAxIC0xNVQyNTAgLTIyUTIyNCAtMjIgMTk4IC0xNlQxMzcgMTZUODIgODNRMzkgMTY1IDM5IDMyMFEzOSA0OTQgOTYgNTg1Wk0zMjEgNTk3UTI5MSA2MjkgMjUwIDYyOVEyMDggNjI5IDE3OCA1OTdRMTUzIDU3MSAxNDUgNTI1VDEzNyAzMzNRMTM3IDE3NSAxNDUgMTI1VDE4MSA0NlEyMDkgMTYgMjUwIDE2UTI5MCAxNiAzMTggNDZRMzQ3IDc2IDM1NCAxMzBUMzYyIDMzM1EzNjIgNDc4IDM1NCA1MjRUMzIxIDU5N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJCIiBkPSJNNTYgMjM3VDU2IDI1MFQ3MCAyNzBIMzY5VjQyMEwzNzAgNTcwUTM4MCA1ODMgMzg5IDU4M1E0MDIgNTgzIDQwOSA1NjhWMjcwSDcwN1E3MjIgMjYyIDcyMiAyNTBUNzA3IDIzMEg0MDlWLTY4UTQwMSAtODIgMzkxIC04MkgzODlIMzg3UTM3NSAtODIgMzY5IC02OFYyMzBINzBRNTYgMjM3IDU2IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMUEiIGQ9Ik05NSAxNzhRODkgMTc4IDgxIDE4NlQ3MiAyMDBUMTAzIDIzMFQxNjkgMjgwVDIwNyAzMDlRMjA5IDMxMSAyMTIgMzExSDIxM1EyMTkgMzExIDIyNyAyOTRUMjgxIDE3N1EzMDAgMTM0IDMxMiAxMDhMMzk3IC03N1EzOTggLTc3IDUwMSAxMzZUNzA3IDU2NVQ4MTQgNzg2UTgyMCA4MDAgODM0IDgwMFE4NDEgODAwIDg0NiA3OTRUODUzIDc4MlY3NzZMNjIwIDI5M0wzODUgLTE5M1EzODEgLTIwMCAzNjYgLTIwMFEzNTcgLTIwMCAzNTQgLTE5N1EzNTIgLTE5NSAyNTYgMTVMMTYwIDIyNUwxNDQgMjE0UTEyOSAyMDIgMTEzIDE5MFQ5NSAxNzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjAyIiBkPSJNMjAyIDUwOFExNzkgNTA4IDE2OSA1MjBUMTU4IDU0N1ExNTggNTU3IDE2NCA1NzdUMTg1IDYyNFQyMzAgNjc1VDMwMSA3MTBMMzMzIDcxNUgzNDVRMzc4IDcxNSAzODQgNzE0UTQ0NyA3MDMgNDg5IDY2MVQ1NDkgNTY4VDU2NiA0NTdRNTY2IDM2MiA1MTkgMjQwVDQwMiA1M1EzMjEgLTIyIDIyMyAtMjJRMTIzIC0yMiA3MyA1NlE0MiAxMDIgNDIgMTQ4VjE1OVE0MiAyNzYgMTI5IDM3MFQzMjIgNDY1UTM4MyA0NjUgNDE0IDQzNFQ0NTUgMzY3TDQ1OCAzNzhRNDc4IDQ2MSA0NzggNTE1UTQ3OCA2MDMgNDM3IDYzOVQzNDQgNjc2UTI2NiA2NzYgMjIzIDYxMlEyNjQgNjA2IDI2NCA1NzJRMjY0IDU0NyAyNDYgNTI4VDIwMiA1MDhaTTQzMCAzMDZRNDMwIDM3MiA0MDEgNDAwVDMzMyA0MjhRMjcwIDQyOCAyMjIgMzgyUTE5NyAzNTQgMTgzIDMyM1QxNTAgMjIxUTEzMiAxNDkgMTMyIDExNlExMzIgMjEgMjMyIDIxUTI0NCAyMSAyNTAgMjJRMzI3IDM1IDM3NCAxMTJRMzg5IDEzNyA0MDkgMTk2VDQzMCAzMDZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktM0I0IiBkPSJNMTk1IDYwOVExOTUgNjU2IDIyNyA2ODZUMzAyIDcxN1EzMTkgNzE2IDM1MSA3MDlUNDA3IDY5N1Q0MzMgNjkwUTQ1MSA2ODIgNDUxIDY2MlE0NTEgNjQ0IDQzOCA2MjhUNDAzIDYxMlEzODIgNjEyIDM0OCA2NDFUMjg4IDY3MVQyNDkgNjU3VDIzNSA2MjhRMjM1IDU4NCAzMzQgNDYzUTQwMSAzNzkgNDAxIDI5MlE0MDEgMTY5IDM0MCA4MFQyMDUgLTEwSDE5OFExMjcgLTEwIDgzIDM2VDM2IDE1M1EzNiAyODYgMTUxIDM4MlExOTEgNDEzIDI1MiA0MzRRMjUyIDQzNSAyNDUgNDQ5VDIzMCA0ODFUMjE0IDUyMVQyMDEgNTY2VDE5NSA2MDlaTTExMiAxMzBRMTEyIDgzIDEzNiA1NVQyMDQgMjdRMjMzIDI3IDI1NiA1MVQyOTEgMTExVDMwOSAxNzhUMzE2IDIzMlEzMTYgMjY3IDMwOSAyOThUMjk1IDM0NFQyNjkgNDAwTDI1OSAzOTZRMjE1IDM4MSAxODMgMzQyVDEzNyAyNTZUMTE4IDE3OVQxMTIgMTMwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0MiIGQ9Ik0xMzkgLTI0OUgxMzdRMTI1IC0yNDkgMTE5IC0yMzVWMjUxTDEyMCA3MzdRMTMwIDc1MCAxMzkgNzUwUTE1MiA3NTAgMTU5IDczNVYtMjM1UTE1MSAtMjQ5IDE0MSAtMjQ5SDEzOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIxIiBkPSJNNzggNjYxUTc4IDY4MiA5NiA2OTlUMTM4IDcxNlQxODAgNzAwVDE5OSA2NjFRMTk5IDY1NCAxNzkgNDMyVDE1OCAyMDZRMTU2IDE5OCAxMzkgMTk4UTEyMSAxOTggMTE5IDIwNlExMTggMjA5IDk4IDQzMVQ3OCA2NjFaTTc5IDYxUTc5IDg5IDk3IDEwNVQxNDEgMTIxUTE2NCAxMTkgMTgxIDEwNFQxOTggNjFRMTk4IDMxIDE4MSAxNlQxMzkgMVExMTQgMSA5NyAxNlQ3OSA2MVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdEIiBkPSJNNjUgNzMxUTY1IDc0NSA2OCA3NDdUODggNzUwUTE3MSA3NTAgMjE2IDcyNVQyNzkgNjcwUTI4OCA2NDkgMjg5IDYzNVQyOTEgNTAxUTI5MiAzNjIgMjkzIDM1N1EzMDYgMzEyIDM0NSAyOTFUNDE3IDI2OVE0MjggMjY5IDQzMSAyNjZUNDM0IDI1MFQ0MzEgMjM0VDQxNyAyMzFRMzgwIDIzMSAzNDUgMjEwVDI5OCAxNTdRMjkzIDE0MyAyOTIgMTIxVDI5MSAtMjhWLTc5UTI5MSAtMTM0IDI4NSAtMTU2VDI1NiAtMTk4UTIwMiAtMjUwIDg5IC0yNTBRNzEgLTI1MCA2OCAtMjQ3VDY1IC0yMzBRNjUgLTIyNCA2NSAtMjIzVDY2IC0yMThUNjkgLTIxNFQ3NyAtMjEzUTkxIC0yMTMgMTA4IC0yMTBUMTQ2IC0yMDBUMTgzIC0xNzdUMjA3IC0xMzlRMjA4IC0xMzQgMjA5IDNMMjEwIDEzOVEyMjMgMTk2IDI4MCAyMzBRMzE1IDI0NyAzMzAgMjUwUTMwNSAyNTcgMjgwIDI3MFEyMjUgMzA0IDIxMiAzNTJMMjEwIDM2MkwyMDkgNDk4UTIwOCA2MzUgMjA3IDY0MFExOTUgNjgwIDE1NCA2OTZUNzcgNzEzUTY4IDcxMyA2NyA3MTZUNjUgNzMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMy03QiIgZD0iTTYxOCAtOTQzTDYxMiAtOTQ5SDU4Mkw1NjggLTk0M1E0NzIgLTkwMyA0MTEgLTg0MVQzMzIgLTcwM1EzMjcgLTY4MiAzMjcgLTY1M1QzMjUgLTM1MFEzMjQgLTI4IDMyMyAtMThRMzE3IDI0IDMwMSA2MVQyNjQgMTI0VDIyMSAxNzFUMTc5IDIwNVQxNDcgMjI1VDEzMiAyMzRRMTMwIDIzOCAxMzAgMjUwUTEzMCAyNTUgMTMwIDI1OFQxMzEgMjY0VDEzMiAyNjdUMTM0IDI2OVQxMzkgMjcyVDE0NCAyNzVRMjA3IDMwOCAyNTYgMzY3UTMxMCA0MzYgMzIzIDUxOVEzMjQgNTI5IDMyNSA4NTFRMzI2IDExMjQgMzI2IDExNTRUMzMyIDEyMDVRMzY5IDEzNTggNTY2IDE0NDNMNTgyIDE0NTBINjEyTDYxOCAxNDQ0VjE0MjlRNjE4IDE0MTMgNjE2IDE0MTFMNjA4IDE0MDZRNTk5IDE0MDIgNTg1IDEzOTNUNTUyIDEzNzJUNTE1IDEzNDNUNDc5IDEzMDVUNDQ5IDEyNTdUNDI5IDEyMDBRNDI1IDExODAgNDI1IDExNTJUNDIzIDg1MVE0MjIgNTc5IDQyMiA1NDlUNDE2IDQ5OFE0MDcgNDU5IDM4OCA0MjRUMzQ2IDM2NFQyOTcgMzE4VDI1MCAyODRUMjE0IDI2NFQxOTcgMjU0TDE4OCAyNTFMMjA1IDI0MlEyOTAgMjAwIDM0NSAxMzhUNDE2IDNRNDIxIC0xOCA0MjEgLTQ4VDQyMyAtMzQ5UTQyMyAtMzk3IDQyMyAtNDcyUTQyNCAtNjc3IDQyOCAtNjk0UTQyOSAtNjk3IDQyOSAtNjk5UTQzNCAtNzIyIDQ0MyAtNzQzVDQ2NSAtNzgyVDQ5MSAtODE2VDUxOSAtODQ1VDU0OCAtODY4VDU3NCAtODg2VDU5NSAtODk5VDYxMCAtOTA4TDYxNiAtOTEwUTYxOCAtOTEyIDYxOCAtOTI4Vi05NDNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1ozLTdEIiBkPSJNMTMxIDE0MTRUMTMxIDE0MjlUMTMzIDE0NDdUMTQ4IDE0NTBIMTUzSDE2N0wxODIgMTQ0NFEyNzYgMTQwNCAzMzYgMTM0M1Q0MTUgMTIwN1E0MjEgMTE4NCA0MjEgMTE1NFQ0MjMgODUxTDQyNCA1MzFMNDI2IDUxN1E0MzQgNDYyIDQ2MCA0MTVUNTE4IDMzOVQ1NzEgMjk2VDYwOCAyNzRRNjE1IDI3MCA2MTYgMjY3VDYxOCAyNTFRNjE4IDI0MSA2MTggMjM4VDYxNSAyMzJUNjA4IDIyN1E1NDIgMTk0IDQ5MSAxMzJUNDI2IC0xNUw0MjQgLTI5TDQyMyAtMzUwUTQyMiAtNjIyIDQyMiAtNjUyVDQxNSAtNzA2UTM5NyAtNzgwIDMzNyAtODQxVDE4MiAtOTQzTDE2NyAtOTQ5SDE1M1ExMzcgLTk0OSAxMzQgLTk0NlQxMzEgLTkyOFExMzEgLTkxNCAxMzIgLTkxMVQxNDQgLTkwNFExNDYgLTkwMyAxNDggLTkwMlEyOTkgLTgyMCAzMjMgLTY4MFEzMjQgLTY2MyAzMjUgLTM0OVQzMjcgLTE5UTM1NSAxNDUgNTQxIDI0MUw1NjEgMjUwTDU0MSAyNjBRMzU2IDM1NSAzMjcgNTIwUTMyNiA1MzcgMzI1IDg1MFQzMjMgMTE4MVEzMTUgMTIyNyAyOTMgMTI2N1QyNDQgMTMzMlQxOTMgMTM3NFQxNTEgMTQwMVQxMzIgMTQxM1ExMzEgMTQxNCAxMzEgMTQyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTM2IiBkPSJNNDIgMzEzUTQyIDQ3NiAxMjMgNTcxVDMwMyA2NjZRMzcyIDY2NiA0MDIgNjMwVDQzMiA1NTBRNDMyIDUyNSA0MTggNTEwVDM3OSA0OTVRMzU2IDQ5NSAzNDEgNTA5VDMyNiA1NDhRMzI2IDU5MiAzNzMgNjAxUTM1MSA2MjMgMzExIDYyNlEyNDAgNjI2IDE5NCA1NjZRMTQ3IDUwMCAxNDcgMzY0TDE0OCAzNjBRMTUzIDM2NiAxNTYgMzczUTE5NyA0MzMgMjYzIDQzM0gyNjdRMzEzIDQzMyAzNDggNDE0UTM3MiA0MDAgMzk2IDM3NFQ0MzUgMzE3UTQ1NiAyNjggNDU2IDIxMFYxOTJRNDU2IDE2OSA0NTEgMTQ5UTQ0MCA5MCAzODcgMzRUMjUzIC0yMlEyMjUgLTIyIDE5OSAtMTRUMTQzIDE2VDkyIDc1VDU2IDE3MlQ0MiAzMTNaTTI1NyAzOTdRMjI3IDM5NyAyMDUgMzgwVDE3MSAzMzVUMTU0IDI3OFQxNDggMjE2UTE0OCAxMzMgMTYwIDk3VDE5OCAzOVEyMjIgMjEgMjUxIDIxUTMwMiAyMSAzMjkgNTlRMzQyIDc3IDM0NyAxMDRUMzUyIDIwOVEzNTIgMjg5IDM0NyAzMTZUMzI5IDM2MVEzMDIgMzk3IDI1NyAzOTdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMyIgZD0iTTEyNyA0NjNRMTAwIDQ2MyA4NSA0ODBUNjkgNTI0UTY5IDU3OSAxMTcgNjIyVDIzMyA2NjVRMjY4IDY2NSAyNzcgNjY0UTM1MSA2NTIgMzkwIDYxMVQ0MzAgNTIyUTQzMCA0NzAgMzk2IDQyMVQzMDIgMzUwTDI5OSAzNDhRMjk5IDM0NyAzMDggMzQ1VDMzNyAzMzZUMzc1IDMxNVE0NTcgMjYyIDQ1NyAxNzVRNDU3IDk2IDM5NSAzN1QyMzggLTIyUTE1OCAtMjIgMTAwIDIxVDQyIDEzMFE0MiAxNTggNjAgMTc1VDEwNSAxOTNRMTMzIDE5MyAxNTEgMTc1VDE2OSAxMzBRMTY5IDExOSAxNjYgMTEwVDE1OSA5NFQxNDggODJUMTM2IDc0VDEyNiA3MFQxMTggNjdMMTE0IDY2UTE2NSAyMSAyMzggMjFRMjkzIDIxIDMyMSA3NFEzMzggMTA3IDMzOCAxNzVWMTk1UTMzOCAyOTAgMjc0IDMyMlEyNTkgMzI4IDIxMyAzMjlMMTcxIDMzMEwxNjggMzMyUTE2NiAzMzUgMTY2IDM0OFExNjYgMzY2IDE3NCAzNjZRMjAyIDM2NiAyMzIgMzcxUTI2NiAzNzYgMjk0IDQxM1QzMjIgNTI1VjUzM1EzMjIgNTkwIDI4NyA2MTJRMjY1IDYyNiAyNDAgNjI2UTIwOCA2MjYgMTgxIDYxNVQxNDMgNTkyVDEzMiA1ODBIMTM1UTEzOCA1NzkgMTQzIDU3OFQxNTMgNTczVDE2NSA1NjZUMTc1IDU1NVQxODMgNTQwVDE4NiA1MjBRMTg2IDQ5OCAxNzIgNDgxVDEyNyA0NjNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yRSIgZD0iTTc4IDYwUTc4IDg0IDk1IDEwMlQxMzggMTIwUTE2MiAxMjAgMTgwIDEwNFQxOTkgNjFRMTk5IDM2IDE4MiAxOFQxMzkgMFQ5NiAxN1Q3OCA2MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjQtN0IiIGQ9Ik02NjEgLTEyNDNMNjU1IC0xMjQ5SDYyMkw2MDQgLTEyNDBRNTAzIC0xMTkwIDQzNCAtMTEwN1QzNDggLTkwOVEzNDYgLTg5NyAzNDYgLTQ5OUwzNDUgLTk4TDM0MyAtODJRMzM1IDMgMjg3IDg3VDE1NyAyMjNRMTQ2IDIzMiAxNDUgMjM2UTE0NCAyNDAgMTQ0IDI1MFExNDQgMjY1IDE0NSAyNjhUMTU3IDI3OFEyNDIgMzMzIDI4OCA0MTdUMzQzIDU4M0wzNDUgNjAwTDM0NiAxMDAxUTM0NiAxMzk4IDM0OCAxNDEwUTM3OSAxNjIyIDYwMCAxNzM5TDYyMiAxNzUwSDY1NUw2NjEgMTc0NFYxNzI3VjE3MjFRNjYxIDE3MTIgNjYxIDE3MTBUNjU3IDE3MDVUNjQ4IDE3MDBUNjMwIDE2OTBUNjAyIDE2NjhRNTg5IDE2NTkgNTc0IDE2NDNUNTMxIDE1OTNUNDg0IDE1MDhUNDU5IDEzOThRNDU4IDEzODkgNDU4IDEwMDFRNDU4IDYxNCA0NTcgNjA1UTQ0MSA0MzUgMzAxIDMxNlEyNTQgMjc3IDIwMiAyNTFMMjUwIDIyMlEyNjAgMjE2IDMwMSAxODVRNDQzIDY2IDQ1NyAtMTA0UTQ1OCAtMTEzIDQ1OCAtNTAxUTQ1OCAtODg4IDQ1OSAtODk3UTQ2MyAtOTQ0IDQ3OCAtOTg4VDUwOSAtMTA2MFQ1NDggLTExMTRUNTgwIC0xMTQ5VDYwMiAtMTE2N1E2MjAgLTExODMgNjM0IC0xMTkyVDY1MyAtMTIwMlQ2NTkgLTEyMDdUNjYxIC0xMjIwVi0xMjI2Vi0xMjQzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaNC03RCIgZD0iTTE0NCAxNzI3UTE0NCAxNzQzIDE0NiAxNzQ2VDE2MiAxNzUwSDE2N0gxODNMMjAzIDE3NDBRMjc0IDE3MDUgMzI1IDE2NThUNDAzIDE1NjJUNDQwIDE0NzhUNDU2IDE0MTBRNDU4IDEzOTggNDU4IDEwMDFRNDU5IDY2MSA0NTkgNjI0VDQ2NSA1NThRNDcwIDUyNiA0ODAgNDk2VDUwMiA0NDFUNTI5IDM5NVQ1NTkgMzU2VDU4OCAzMjVUNjE1IDMwMVQ2MzcgMjg0VDY1NCAyNzNMNjYwIDI2OVYyNjZRNjYwIDI2MyA2NjAgMjU5VDY2MSAyNTBWMjM5UTY2MSAyMzYgNjYxIDIzNFQ2NjAgMjMyVDY1NiAyMjlUNjQ5IDIyNFE1NzcgMTc5IDUyOCAxMDVUNDY1IC01N1E0NjAgLTg2IDQ2MCAtMTIzVDQ1OCAtNDk5Vi02NjFRNDU4IC04NTcgNDU3IC04OTNUNDQ3IC05NTVRNDI1IC0xMDQ4IDM1OSAtMTEyMFQyMDMgLTEyMzlMMTgzIC0xMjQ5SDE2OFExNTAgLTEyNDkgMTQ3IC0xMjQ2VDE0NCAtMTIyNlExNDQgLTEyMTMgMTQ1IC0xMjEwVDE1MyAtMTIwMlExNjkgLTExOTMgMTg2IC0xMTgxVDIzMiAtMTE0MFQyODIgLTEwODFUMzIyIC0xMDAwVDM0NSAtODk3UTM0NiAtODg4IDM0NiAtNTAxUTM0NiAtMTEzIDM0NyAtMTA0UTM1OSA1OCA1MDMgMTg0UTU1NCAyMjYgNjAzIDI1MFE1MDQgMjk5IDQzMCAzOTNUMzQ3IDYwNVEzNDYgNjE0IDM0NiAxMDAyUTM0NiAxMzg5IDM0NSAxMzk4UTMzOCAxNDkzIDI4OCAxNTczVDE1MyAxNzAzUTE0NiAxNzA3IDE0NSAxNzEwVDE0NCAxNzI3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjIxMiIgZD0iTTg0IDIzN1Q4NCAyNTBUOTggMjcwSDY3OVE2OTQgMjYyIDY5NCAyNTBUNjc5IDIzMEg5OFE4NCAyMzcgODQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU2IiBkPSJNNTIgNjQ4UTUyIDY3MCA2NSA2ODNINzZRMTE4IDY4MCAxODEgNjgwUTI5OSA2ODAgMzIwIDY4M0gzMzBRMzM2IDY3NyAzMzYgNjc0VDMzNCA2NTZRMzI5IDY0MSAzMjUgNjM3SDMwNFEyODIgNjM1IDI3NCA2MzVRMjQ1IDYzMCAyNDIgNjIwUTI0MiA2MTggMjcxIDM2OVQzMDEgMTE4TDM3NCAyMzVRNDQ3IDM1MiA1MjAgNDcxVDU5NSA1OTRRNTk5IDYwMSA1OTkgNjA5UTU5OSA2MzMgNTU1IDYzN1E1MzcgNjM3IDUzNyA2NDhRNTM3IDY0OSA1MzkgNjYxUTU0MiA2NzUgNTQ1IDY3OVQ1NTggNjgzUTU2MCA2ODMgNTcwIDY4M1Q2MDQgNjgyVDY2OCA2ODFRNzM3IDY4MSA3NTUgNjgzSDc2MlE3NjkgNjc2IDc2OSA2NzJRNzY5IDY1NSA3NjAgNjQwUTc1NyA2MzcgNzQzIDYzN1E3MzAgNjM2IDcxOSA2MzVUNjk4IDYzMFQ2ODIgNjIzVDY3MCA2MTVUNjYwIDYwOFQ2NTIgNTk5VDY0NSA1OTJMNDUyIDI4MlEyNzIgLTkgMjY2IC0xNlEyNjMgLTE4IDI1OSAtMjFMMjQxIC0yMkgyMzRRMjE2IC0yMiAyMTYgLTE1UTIxMyAtOSAxNzcgMzA1UTEzOSA2MjMgMTM4IDYyNlExMzMgNjM3IDc2IDYzN0g1OVE1MiA2NDIgNTIgNjQ4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMS03QiIgZD0iTTQ3NyAtMzQzTDQ3MSAtMzQ5SDQ1OFE0MzIgLTM0OSAzNjcgLTMyNVQyNzMgLTI2M1EyNTggLTI0NSAyNTAgLTIxMkwyNDkgLTUxUTI0OSAtMjcgMjQ5IDEyUTI0OCAxMTggMjQ0IDEyOFEyNDMgMTI5IDI0MyAxMzBRMjIwIDE4OSAxMjEgMjI4UTEwOSAyMzIgMTA3IDIzNVQxMDUgMjUwUTEwNSAyNTYgMTA1IDI1N1QxMDUgMjYxVDEwNyAyNjVUMTExIDI2OFQxMTggMjcyVDEyOCAyNzZUMTQyIDI4M1QxNjIgMjkxUTIyNCAzMjQgMjQzIDM3MVEyNDMgMzcyIDI0NCAzNzNRMjQ4IDM4NCAyNDkgNDY5UTI0OSA0NzUgMjQ5IDQ4OVEyNDkgNTI4IDI0OSA1NTJMMjUwIDcxNFEyNTMgNzI4IDI1NiA3MzZUMjcxIDc2MVQyOTkgNzg5VDM0NyA4MTZUNDIyIDg0M1E0NDAgODQ5IDQ0MSA4NDlINDQzUTQ0NSA4NDkgNDQ3IDg0OVQ0NTIgODUwVDQ1NyA4NTBINDcxTDQ3NyA4NDRWODMwUTQ3NyA4MjAgNDc2IDgxN1Q0NzAgODExVDQ1OSA4MDdUNDM3IDgwMVQ0MDQgNzg1UTM1MyA3NjAgMzM4IDcyNFEzMzMgNzEwIDMzMyA1NTBRMzMzIDUyNiAzMzMgNDkyVDMzNCA0NDdRMzM0IDM5MyAzMjcgMzY4VDI5NSAzMThRMjU3IDI4MCAxODEgMjU1TDE2OSAyNTFMMTg0IDI0NVEzMTggMTk4IDMzMiAxMTJRMzMzIDEwNiAzMzMgLTQ5UTMzMyAtMjA5IDMzOCAtMjIzUTM1MSAtMjU1IDM5MSAtMjc3VDQ2OSAtMzA5UTQ3NyAtMzExIDQ3NyAtMzI5Vi0zNDNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oxLTdEIiBkPSJNMTEwIDg0OUwxMTUgODUwUTEyMCA4NTAgMTI1IDg1MFExNTEgODUwIDIxNSA4MjZUMzA5IDc2NFEzMjQgNzQ3IDMzMiA3MTRMMzMzIDU1MlEzMzMgNTI4IDMzMyA0ODlRMzM0IDM4MyAzMzggMzczUTMzOSAzNzIgMzM5IDM3MVEzNTMgMzM2IDM5MSAzMTBUNDY5IDI3MVE0NzcgMjY4IDQ3NyAyNTFRNDc3IDI0MSA0NzYgMjM3VDQ3MiAyMzJUNDU2IDIyNVQ0MjggMjE0UTM1NyAxNzkgMzM5IDEzMFEzMzkgMTI5IDMzOCAxMjhRMzM0IDExNyAzMzMgMzJRMzMzIDI2IDMzMyAxMlEzMzMgLTI3IDMzMyAtNTFMMzMyIC0yMTJRMzI4IC0yMjggMzIzIC0yNDBUMzAyIC0yNzFUMjU1IC0zMDdUMTc1IC0zMzhRMTM5IC0zNDkgMTI1IC0zNDlUMTA4IC0zNDZUMTA1IC0zMjlRMTA1IC0zMTQgMTA3IC0zMTJUMTMwIC0zMDRRMjMzIC0yNzEgMjQ4IC0yMDlRMjQ5IC0yMDMgMjQ5IC00OVY1N1EyNDkgMTA2IDI1MyAxMjVUMjczIDE2N1EzMDcgMjEzIDM5OCAyNDVMNDEzIDI1MUw0MDEgMjU1UTI2NSAzMDAgMjUwIDM4OVEyNDkgMzk1IDI0OSA1NTBRMjQ5IDcxMCAyNDQgNzI0UTIyNCA3NzQgMTEyIDgxMVExMDUgODEzIDEwNSA4MzBRMTA1IDg0NSAxMTAgODQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMS0yOCIgZD0iTTE1MiAyNTFRMTUyIDY0NiAzODggODUwSDQxNlE0MjIgODQ0IDQyMiA4NDFRNDIyIDgzNyA0MDMgODE2VDM1NyA3NTNUMzAyIDY0OVQyNTUgNDgyVDIzNiAyNTBRMjM2IDEyNCAyNTUgMTlUMzAxIC0xNDdUMzU2IC0yNTFUNDAzIC0zMTVUNDIyIC0zNDBRNDIyIC0zNDMgNDE2IC0zNDlIMzg4UTM1OSAtMzI1IDMzMiAtMjk2VDI3MSAtMjEzVDIxMiAtOTdUMTcwIDU2VDE1MiAyNTFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oxLTI5IiBkPSJNMzA1IDI1MVEzMDUgLTE0NSA2OSAtMzQ5SDU2UTQzIC0zNDkgMzkgLTM0N1QzNSAtMzM4UTM3IC0zMzMgNjAgLTMwN1QxMDggLTIzOVQxNjAgLTEzNlQyMDQgMjdUMjIxIDI1MFQyMDQgNDczVDE2MCA2MzZUMTA4IDc0MFQ2MCA4MDdUMzUgODM5UTM1IDg1MCA1MCA4NTBINTZINjlRMTk3IDc0MyAyNTYgNTY2UTMwNSA0MjUgMzA1IDI1MVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMzkzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9IjIzMjQiIHk9IjU4MSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMjMyNCIgeT0iLTM1MCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI0NTAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMzk3NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSI1MDMzIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTk2NCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMy03QiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDc1MCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjgwNCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI2OTMiIHk9Ii0yMTIiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMTg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzAiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg5MCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMjY5MCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0NjksMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxNTU0IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iNTI2IiB5PSI2NzYiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtODAzKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxQSIgeD0iMCIgeT0iLTc4Ij48L3VzZT4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNjAwIiBoZWlnaHQ9IjYwIiB4PSI4MzMiIHk9IjY2MyI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iODMzIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTQ4NSwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjExMzkiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMDIiIHg9IjI4NSIgeT0iNjc2Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTczOCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMDIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS0zQjQiIHg9IjU2NyIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDY4NjQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI4MDQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iNjkzIiB5PSItMjEyIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4MDUzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTNCNCIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODQxIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5NDUwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QyIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI3OCwtMjg2KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS0zQjQiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iNDUxIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzAiIHg9IjEyMzAiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTEyNzUiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjA1MywwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjE0OTkiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSI0OTkiIHk9IjY3NiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03MzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI2MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIxIiB4PSIxMTAxIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQwMTUsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxNTk1IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjgxLDY3NikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMDIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iODE3IiB5PSI1MTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03ODApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjAyIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTY3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktM0I0IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjY0MSIgeT0iNDA4Ij48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNTg1MCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjgwNCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI2OTMiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE3MDM5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTNCNCIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODQxIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODQzNiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0MiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNzgsLTI4NikiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktM0I0IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjQ1MSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMwIiB4PSIxMjMwIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1ozLTdEIiB4PSIyMDc4OSIgeT0iLTEiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTQxMywtMzI2MykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9IjEwMDAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxOTMxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTdCIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODA2LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTk2OCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjczMyIgeT0iNjc2Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTEyOTYpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zNiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAwLDUwOCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI0MDciIGhlaWdodD0iNjAiIHg9IjAiIHk9IjE0NiI+PC9yZWN0PgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNTc0KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMyIgeD0iMTA0IiB5PSI2NjkiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNTc0KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA0IiB5PSItNjk4Ij48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIyMDgsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxNTk1IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjgxLDY3NikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMDIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMyIgeD0iODE3IiB5PSI1MTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03ODApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjAyIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTY3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktM0I0IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzMiIHg9IjY0MSIgeT0iNDA4Ij48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0MDQzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjYiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iODA0IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjY5MyIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTIzMiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS0zQjQiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg0MSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjYyOSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0MiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNzgsLTI4NikiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktM0I0IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjQ1MSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMwIiB4PSIxMjMwIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjgyMzEiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSI5MDEwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iOTQ1NSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9Ijk5MDAiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaNC03RCIgeD0iMTExNTIiIHk9Ii0xIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjE0MTEyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTUxMTMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjEtMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NTgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkzMSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMS03QiIgeD0iMCIgeT0iLTEiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1ODMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iMTE2NyIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI4MjUiIHk9Ii0yMTIiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjMyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTdEIiB4PSIzNDY0IiB5PSItMSI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjEtMjkiIHg9IjU0MzciIHk9Ii0xIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjgzMzgiIHk9IjgxNyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+Cjwvc3ZnPg==)
我们将在下面证明, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjI5LjkzOGV4IiBoZWlnaHQ9IjcuNjc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4zMzhleDsiIHZpZXdCb3g9IjAgLTE4NjcuNyAxMjg5MCAzMzA0LjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDUiIGQ9Ik00OTIgMjEzUTQ3MiAyMTMgNDcyIDIyNlE0NzIgMjMwIDQ3NyAyNTBUNDgyIDI4NVE0ODIgMzE2IDQ2MSAzMjNUMzY0IDMzMEgzMTJRMzExIDMyOCAyNzcgMTkyVDI0MyA1MlEyNDMgNDggMjU0IDQ4VDMzNCA0NlE0MjggNDYgNDU4IDQ4VDUxOCA2MVE1NjcgNzcgNTk5IDExN1Q2NzAgMjQ4UTY4MCAyNzAgNjgzIDI3MlE2OTAgMjc0IDY5OCAyNzRRNzE4IDI3NCA3MTggMjYxUTYxMyA3IDYwOCAyUTYwNSAwIDMyMiAwSDEzM1EzMSAwIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc1N1E3NjQgNjc2IDc2NCA2NjlRNzY0IDY2NCA3NTEgNTU3VDczNyA0NDdRNzM1IDQ0MCA3MTcgNDQwSDcwNVE2OTggNDQ1IDY5OCA0NTNMNzAxIDQ3NlE3MDQgNTAwIDcwNCA1MjhRNzA0IDU1OCA2OTcgNTc4VDY3OCA2MDlUNjQzIDYyNVQ1OTYgNjMyVDUzMiA2MzRINDg1UTM5NyA2MzMgMzkyIDYzMVEzODggNjI5IDM4NiA2MjJRMzg1IDYxOSAzNTUgNDk5VDMyNCAzNzdRMzQ3IDM3NiAzNzIgMzc2SDM5OFE0NjQgMzc2IDQ4OSAzOTFUNTM0IDQ3MlE1MzggNDg4IDU0MCA0OTBUNTU3IDQ5M1E1NjIgNDkzIDU2NSA0OTNUNTcwIDQ5MlQ1NzIgNDkxVDU3NCA0ODdUNTc3IDQ4M0w1NDQgMzUxUTUxMSAyMTggNTA4IDIxNlE1MDUgMjEzIDQ5MiAyMTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03QiIgZD0iTTQzNCAtMjMxUTQzNCAtMjQ0IDQyOCAtMjUwSDQxMFEyODEgLTI1MCAyMzAgLTE4NFEyMjUgLTE3NyAyMjIgLTE3MlQyMTcgLTE2MVQyMTMgLTE0OFQyMTEgLTEzM1QyMTAgLTExMVQyMDkgLTg0VDIwOSAtNDdUMjA5IDBRMjA5IDIxIDIwOSA1M1EyMDggMTQyIDIwNCAxNTNRMjAzIDE1NCAyMDMgMTU1UTE4OSAxOTEgMTUzIDIxMVQ4MiAyMzFRNzEgMjMxIDY4IDIzNFQ2NSAyNTBUNjggMjY2VDgyIDI2OVExMTYgMjY5IDE1MiAyODlUMjAzIDM0NVEyMDggMzU2IDIwOCAzNzdUMjA5IDUyOVY1NzlRMjA5IDYzNCAyMTUgNjU2VDI0NCA2OThRMjcwIDcyNCAzMjQgNzQwUTM2MSA3NDggMzc3IDc0OVEzNzkgNzQ5IDM5MCA3NDlUNDA4IDc1MEg0MjhRNDM0IDc0NCA0MzQgNzMyUTQzNCA3MTkgNDMxIDcxNlE0MjkgNzEzIDQxNSA3MTNRMzYyIDcxMCAzMzIgNjg5VDI5NiA2NDdRMjkxIDYzNCAyOTEgNDk5VjQxN1EyOTEgMzcwIDI4OCAzNTNUMjcxIDMxNFEyNDAgMjcxIDE4NCAyNTVMMTcwIDI1MEwxODQgMjQ1UTIwMiAyMzkgMjIwIDIzMFQyNjIgMTk2VDI5MCAxMzdRMjkxIDEzMSAyOTEgMVEyOTEgLTEzNCAyOTYgLTE0N1EzMDYgLTE3NCAzMzkgLTE5MlQ0MTUgLTIxM1E0MjkgLTIxMyA0MzEgLTIxNlE0MzQgLTIxOSA0MzQgLTIzMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTM2IiBkPSJNNDIgMzEzUTQyIDQ3NiAxMjMgNTcxVDMwMyA2NjZRMzcyIDY2NiA0MDIgNjMwVDQzMiA1NTBRNDMyIDUyNSA0MTggNTEwVDM3OSA0OTVRMzU2IDQ5NSAzNDEgNTA5VDMyNiA1NDhRMzI2IDU5MiAzNzMgNjAxUTM1MSA2MjMgMzExIDYyNlEyNDAgNjI2IDE5NCA1NjZRMTQ3IDUwMCAxNDcgMzY0TDE0OCAzNjBRMTUzIDM2NiAxNTYgMzczUTE5NyA0MzMgMjYzIDQzM0gyNjdRMzEzIDQzMyAzNDggNDE0UTM3MiA0MDAgMzk2IDM3NFQ0MzUgMzE3UTQ1NiAyNjggNDU2IDIxMFYxOTJRNDU2IDE2OSA0NTEgMTQ5UTQ0MCA5MCAzODcgMzRUMjUzIC0yMlEyMjUgLTIyIDE5OSAtMTRUMTQzIDE2VDkyIDc1VDU2IDE3MlQ0MiAzMTNaTTI1NyAzOTdRMjI3IDM5NyAyMDUgMzgwVDE3MSAzMzVUMTU0IDI3OFQxNDggMjE2UTE0OCAxMzMgMTYwIDk3VDE5OCAzOVEyMjIgMjEgMjUxIDIxUTMwMiAyMSAzMjkgNTlRMzQyIDc3IDM0NyAxMDRUMzUyIDIwOVEzNTIgMjg5IDM0NyAzMTZUMzI5IDM2MVEzMDIgMzk3IDI1NyAzOTdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkUiIGQ9Ik0yMSAyODdRMjIgMjkzIDI0IDMwM1QzNiAzNDFUNTYgMzg4VDg5IDQyNVQxMzUgNDQyUTE3MSA0NDIgMTk1IDQyNFQyMjUgMzkwVDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzA0IDQ0MiAzODIgNDQyUTQzNiA0NDIgNDY5IDQxNVQ1MDMgMzM2VDQ2NSAxNzlUNDI3IDUyUTQyNyAyNiA0NDQgMjZRNDUwIDI2IDQ1MyAyN1E0ODIgMzIgNTA1IDY1VDU0MCAxNDVRNTQyIDE1MyA1NjAgMTUzUTU4MCAxNTMgNTgwIDE0NVE1ODAgMTQ0IDU3NiAxMzBRNTY4IDEwMSA1NTQgNzNUNTA4IDE3VDQzOSAtMTBRMzkyIC0xMCAzNzEgMTdUMzUwIDczUTM1MCA5MiAzODYgMTkzVDQyMyAzNDVRNDIzIDQwNCAzNzkgNDA0SDM3NFEyODggNDA0IDIyOSAzMDNMMjIyIDI5MUwxODkgMTU3UTE1NiAyNiAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExMiAxODBUMTUyIDM0M1ExNTMgMzQ4IDE1MyAzNjZRMTUzIDQwNSAxMjkgNDA1UTkxIDQwNSA2NiAzMDVRNjAgMjg1IDYwIDI4NFE1OCAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMyIgZD0iTTEyNyA0NjNRMTAwIDQ2MyA4NSA0ODBUNjkgNTI0UTY5IDU3OSAxMTcgNjIyVDIzMyA2NjVRMjY4IDY2NSAyNzcgNjY0UTM1MSA2NTIgMzkwIDYxMVQ0MzAgNTIyUTQzMCA0NzAgMzk2IDQyMVQzMDIgMzUwTDI5OSAzNDhRMjk5IDM0NyAzMDggMzQ1VDMzNyAzMzZUMzc1IDMxNVE0NTcgMjYyIDQ1NyAxNzVRNDU3IDk2IDM5NSAzN1QyMzggLTIyUTE1OCAtMjIgMTAwIDIxVDQyIDEzMFE0MiAxNTggNjAgMTc1VDEwNSAxOTNRMTMzIDE5MyAxNTEgMTc1VDE2OSAxMzBRMTY5IDExOSAxNjYgMTEwVDE1OSA5NFQxNDggODJUMTM2IDc0VDEyNiA3MFQxMTggNjdMMTE0IDY2UTE2NSAyMSAyMzggMjFRMjkzIDIxIDMyMSA3NFEzMzggMTA3IDMzOCAxNzVWMTk1UTMzOCAyOTAgMjc0IDMyMlEyNTkgMzI4IDIxMyAzMjlMMTcxIDMzMEwxNjggMzMyUTE2NiAzMzUgMTY2IDM0OFExNjYgMzY2IDE3NCAzNjZRMjAyIDM2NiAyMzIgMzcxUTI2NiAzNzYgMjk0IDQxM1QzMjIgNTI1VjUzM1EzMjIgNTkwIDI4NyA2MTJRMjY1IDYyNiAyNDAgNjI2UTIwOCA2MjYgMTgxIDYxNVQxNDMgNTkyVDEzMiA1ODBIMTM1UTEzOCA1NzkgMTQzIDU3OFQxNTMgNTczVDE2NSA1NjZUMTc1IDU1NVQxODMgNTQwVDE4NiA1MjBRMTg2IDQ5OCAxNzIgNDgxVDEyNyA0NjNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMiIgZD0iTTEwOSA0MjlRODIgNDI5IDY2IDQ0N1Q1MCA0OTFRNTAgNTYyIDEwMyA2MTRUMjM1IDY2NlEzMjYgNjY2IDM4NyA2MTBUNDQ5IDQ2NVE0NDkgNDIyIDQyOSAzODNUMzgxIDMxNVQzMDEgMjQxUTI2NSAyMTAgMjAxIDE0OUwxNDIgOTNMMjE4IDkyUTM3NSA5MiAzODUgOTdRMzkyIDk5IDQwOSAxODZWMTg5SDQ0OVYxODZRNDQ4IDE4MyA0MzYgOTVUNDIxIDNWMEg1MFYxOVYzMVE1MCAzOCA1NiA0NlQ4NiA4MVExMTUgMTEzIDEzNiAxMzdRMTQ1IDE0NyAxNzAgMTc0VDIwNCAyMTFUMjMzIDI0NFQyNjEgMjc4VDI4NCAzMDhUMzA1IDM0MFQzMjAgMzY5VDMzMyA0MDFUMzQwIDQzMVQzNDMgNDY0UTM0MyA1MjcgMzA5IDU3M1QyMTIgNjE5UTE3OSA2MTkgMTU0IDYwMlQxMTkgNTY5VDEwOSA1NTBRMTA5IDU0OSAxMTQgNTQ5UTEzMiA1NDkgMTUxIDUzNVQxNzAgNDg5UTE3MCA0NjQgMTU0IDQ0N1QxMDkgNDI5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjIwMiIgZD0iTTIwMiA1MDhRMTc5IDUwOCAxNjkgNTIwVDE1OCA1NDdRMTU4IDU1NyAxNjQgNTc3VDE4NSA2MjRUMjMwIDY3NVQzMDEgNzEwTDMzMyA3MTVIMzQ1UTM3OCA3MTUgMzg0IDcxNFE0NDcgNzAzIDQ4OSA2NjFUNTQ5IDU2OFQ1NjYgNDU3UTU2NiAzNjIgNTE5IDI0MFQ0MDIgNTNRMzIxIC0yMiAyMjMgLTIyUTEyMyAtMjIgNzMgNTZRNDIgMTAyIDQyIDE0OFYxNTlRNDIgMjc2IDEyOSAzNzBUMzIyIDQ2NVEzODMgNDY1IDQxNCA0MzRUNDU1IDM2N0w0NTggMzc4UTQ3OCA0NjEgNDc4IDUxNVE0NzggNjAzIDQzNyA2MzlUMzQ0IDY3NlEyNjYgNjc2IDIyMyA2MTJRMjY0IDYwNiAyNjQgNTcyUTI2NCA1NDcgMjQ2IDUyOFQyMDIgNTA4Wk00MzAgMzA2UTQzMCAzNzIgNDAxIDQwMFQzMzMgNDI4UTI3MCA0MjggMjIyIDM4MlExOTcgMzU0IDE4MyAzMjNUMTUwIDIyMVExMzIgMTQ5IDEzMiAxMTZRMTMyIDIxIDIzMiAyMVEyNDQgMjEgMjUwIDIyUTMyNyAzNSAzNzQgMTEyUTM4OSAxMzcgNDA5IDE5NlQ0MzAgMzA2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTNCNCIgZD0iTTE5NSA2MDlRMTk1IDY1NiAyMjcgNjg2VDMwMiA3MTdRMzE5IDcxNiAzNTEgNzA5VDQwNyA2OTdUNDMzIDY5MFE0NTEgNjgyIDQ1MSA2NjJRNDUxIDY0NCA0MzggNjI4VDQwMyA2MTJRMzgyIDYxMiAzNDggNjQxVDI4OCA2NzFUMjQ5IDY1N1QyMzUgNjI4UTIzNSA1ODQgMzM0IDQ2M1E0MDEgMzc5IDQwMSAyOTJRNDAxIDE2OSAzNDAgODBUMjA1IC0xMEgxOThRMTI3IC0xMCA4MyAzNlQzNiAxNTNRMzYgMjg2IDE1MSAzODJRMTkxIDQxMyAyNTIgNDM0UTI1MiA0MzUgMjQ1IDQ0OVQyMzAgNDgxVDIxNCA1MjFUMjAxIDU2NlQxOTUgNjA5Wk0xMTIgMTMwUTExMiA4MyAxMzYgNTVUMjA0IDI3UTIzMyAyNyAyNTYgNTFUMjkxIDExMVQzMDkgMTc4VDMxNiAyMzJRMzE2IDI2NyAzMDkgMjk4VDI5NSAzNDRUMjY5IDQwMEwyNTkgMzk2UTIxNSAzODEgMTgzIDM0MlQxMzcgMjU2VDExOCAxNzlUMTEyIDEzMFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02NiIgZD0iTTExOCAtMTYyUTEyMCAtMTYyIDEyNCAtMTY0VDEzNSAtMTY3VDE0NyAtMTY4UTE2MCAtMTY4IDE3MSAtMTU1VDE4NyAtMTI2UTE5NyAtOTkgMjIxIDI3VDI2NyAyNjdUMjg5IDM4MlYzODVIMjQyUTE5NSAzODUgMTkyIDM4N1ExODggMzkwIDE4OCAzOTdMMTk1IDQyNVExOTcgNDMwIDIwMyA0MzBUMjUwIDQzMVEyOTggNDMxIDI5OCA0MzJRMjk4IDQzNCAzMDcgNDgyVDMxOSA1NDBRMzU2IDcwNSA0NjUgNzA1UTUwMiA3MDMgNTI2IDY4M1Q1NTAgNjMwUTU1MCA1OTQgNTI5IDU3OFQ0ODcgNTYxUTQ0MyA1NjEgNDQzIDYwM1E0NDMgNjIyIDQ1NCA2MzZUNDc4IDY1N0w0ODcgNjYyUTQ3MSA2NjggNDU3IDY2OFE0NDUgNjY4IDQzNCA2NThUNDE5IDYzMFE0MTIgNjAxIDQwMyA1NTJUMzg3IDQ2OVQzODAgNDMzUTM4MCA0MzEgNDM1IDQzMVE0ODAgNDMxIDQ4NyA0MzBUNDk4IDQyNFE0OTkgNDIwIDQ5NiA0MDdUNDkxIDM5MVE0ODkgMzg2IDQ4MiAzODZUNDI4IDM4NUgzNzJMMzQ5IDI2M1EzMDEgMTUgMjgyIC00N1EyNTUgLTEzMiAyMTIgLTE3M1ExNzUgLTIwNSAxMzkgLTIwNVExMDcgLTIwNSA4MSAtMTg2VDU1IC0xMzJRNTUgLTk1IDc2IC03OFQxMTggLTYxUTE2MiAtNjEgMTYyIC0xMDNRMTYyIC0xMjIgMTUxIC0xMzZUMTI3IC0xNTdMMTE4IC0xNjJaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03QyIgZD0iTTEzOSAtMjQ5SDEzN1ExMjUgLTI0OSAxMTkgLTIzNVYyNTFMMTIwIDczN1ExMzAgNzUwIDEzOSA3NTBRMTUyIDc1MCAxNTkgNzM1Vi0yMzVRMTUxIC0yNDkgMTQxIC0yNDlIMTM5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMCIgZD0iTTk2IDU4NVExNTIgNjY2IDI0OSA2NjZRMjk3IDY2NiAzNDUgNjQwVDQyMyA1NDhRNDYwIDQ2NSA0NjAgMzIwUTQ2MCAxNjUgNDE3IDgzUTM5NyA0MSAzNjIgMTZUMzAxIC0xNVQyNTAgLTIyUTIyNCAtMjIgMTk4IC0xNlQxMzcgMTZUODIgODNRMzkgMTY1IDM5IDMyMFEzOSA0OTQgOTYgNTg1Wk0zMjEgNTk3UTI5MSA2MjkgMjUwIDYyOVEyMDggNjI5IDE3OCA1OTdRMTUzIDU3MSAxNDUgNTI1VDEzNyAzMzNRMTM3IDE3NSAxNDUgMTI1VDE4MSA0NlEyMDkgMTYgMjUwIDE2UTI5MCAxNiAzMTggNDZRMzQ3IDc2IDM1NCAxMzBUMzYyIDMzM1EzNjIgNDc4IDM1NCA1MjRUMzIxIDU5N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJCIiBkPSJNNTYgMjM3VDU2IDI1MFQ3MCAyNzBIMzY5VjQyMEwzNzAgNTcwUTM4MCA1ODMgMzg5IDU4M1E0MDIgNTgzIDQwOSA1NjhWMjcwSDcwN1E3MjIgMjYyIDcyMiAyNTBUNzA3IDIzMEg0MDlWLTY4UTQwMSAtODIgMzkxIC04MkgzODlIMzg3UTM3NSAtODIgMzY5IC02OFYyMzBINzBRNTYgMjM3IDU2IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJFIiBkPSJNNzggNjBRNzggODQgOTUgMTAyVDEzOCAxMjBRMTYyIDEyMCAxODAgMTA0VDE5OSA2MVExOTkgMzYgMTgyIDE4VDEzOSAwVDk2IDE3VDc4IDYwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1o0LTdCIiBkPSJNNjYxIC0xMjQzTDY1NSAtMTI0OUg2MjJMNjA0IC0xMjQwUTUwMyAtMTE5MCA0MzQgLTExMDdUMzQ4IC05MDlRMzQ2IC04OTcgMzQ2IC00OTlMMzQ1IC05OEwzNDMgLTgyUTMzNSAzIDI4NyA4N1QxNTcgMjIzUTE0NiAyMzIgMTQ1IDIzNlExNDQgMjQwIDE0NCAyNTBRMTQ0IDI2NSAxNDUgMjY4VDE1NyAyNzhRMjQyIDMzMyAyODggNDE3VDM0MyA1ODNMMzQ1IDYwMEwzNDYgMTAwMVEzNDYgMTM5OCAzNDggMTQxMFEzNzkgMTYyMiA2MDAgMTczOUw2MjIgMTc1MEg2NTVMNjYxIDE3NDRWMTcyN1YxNzIxUTY2MSAxNzEyIDY2MSAxNzEwVDY1NyAxNzA1VDY0OCAxNzAwVDYzMCAxNjkwVDYwMiAxNjY4UTU4OSAxNjU5IDU3NCAxNjQzVDUzMSAxNTkzVDQ4NCAxNTA4VDQ1OSAxMzk4UTQ1OCAxMzg5IDQ1OCAxMDAxUTQ1OCA2MTQgNDU3IDYwNVE0NDEgNDM1IDMwMSAzMTZRMjU0IDI3NyAyMDIgMjUxTDI1MCAyMjJRMjYwIDIxNiAzMDEgMTg1UTQ0MyA2NiA0NTcgLTEwNFE0NTggLTExMyA0NTggLTUwMVE0NTggLTg4OCA0NTkgLTg5N1E0NjMgLTk0NCA0NzggLTk4OFQ1MDkgLTEwNjBUNTQ4IC0xMTE0VDU4MCAtMTE0OVQ2MDIgLTExNjdRNjIwIC0xMTgzIDYzNCAtMTE5MlQ2NTMgLTEyMDJUNjU5IC0xMjA3VDY2MSAtMTIyMFYtMTIyNlYtMTI0M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjQtN0QiIGQ9Ik0xNDQgMTcyN1ExNDQgMTc0MyAxNDYgMTc0NlQxNjIgMTc1MEgxNjdIMTgzTDIwMyAxNzQwUTI3NCAxNzA1IDMyNSAxNjU4VDQwMyAxNTYyVDQ0MCAxNDc4VDQ1NiAxNDEwUTQ1OCAxMzk4IDQ1OCAxMDAxUTQ1OSA2NjEgNDU5IDYyNFQ0NjUgNTU4UTQ3MCA1MjYgNDgwIDQ5NlQ1MDIgNDQxVDUyOSAzOTVUNTU5IDM1NlQ1ODggMzI1VDYxNSAzMDFUNjM3IDI4NFQ2NTQgMjczTDY2MCAyNjlWMjY2UTY2MCAyNjMgNjYwIDI1OVQ2NjEgMjUwVjIzOVE2NjEgMjM2IDY2MSAyMzRUNjYwIDIzMlQ2NTYgMjI5VDY0OSAyMjRRNTc3IDE3OSA1MjggMTA1VDQ2NSAtNTdRNDYwIC04NiA0NjAgLTEyM1Q0NTggLTQ5OVYtNjYxUTQ1OCAtODU3IDQ1NyAtODkzVDQ0NyAtOTU1UTQyNSAtMTA0OCAzNTkgLTExMjBUMjAzIC0xMjM5TDE4MyAtMTI0OUgxNjhRMTUwIC0xMjQ5IDE0NyAtMTI0NlQxNDQgLTEyMjZRMTQ0IC0xMjEzIDE0NSAtMTIxMFQxNTMgLTEyMDJRMTY5IC0xMTkzIDE4NiAtMTE4MVQyMzIgLTExNDBUMjgyIC0xMDgxVDMyMiAtMTAwMFQzNDUgLTg5N1EzNDYgLTg4OCAzNDYgLTUwMVEzNDYgLTExMyAzNDcgLTEwNFEzNTkgNTggNTAzIDE4NFE1NTQgMjI2IDYwMyAyNTBRNTA0IDI5OSA0MzAgMzkzVDM0NyA2MDVRMzQ2IDYxNCAzNDYgMTAwMlEzNDYgMTM4OSAzNDUgMTM5OFEzMzggMTQ5MyAyODggMTU3M1QxNTMgMTcwM1ExNDYgMTcwNyAxNDUgMTcxMFQxNDQgMTcyN1oiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkzMSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaNC03QiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDgwNiwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjE5NjgiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSI3MzMiIHk9IjY3NiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC0xMjk2KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzYiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwMCw1MDgpIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNDA3IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIxNDYiPjwvcmVjdD4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjU3NCkiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzMiIHg9IjEwNCIgeT0iNjY5Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjU3NCkiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwNCIgeT0iLTY5OCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMjA4LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTU5NSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI4MSw2NzYpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjAyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzMiIHg9IjgxNyIgeT0iNTEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzgwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIwMiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU2NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTNCNCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMzIiB4PSI2NDEiIHk9IjQwOCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDA0MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjgwNCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI2OTMiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUyMzIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktM0I0IiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NDEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDY2MjksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdDIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjc4LC0yODYpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTNCNCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI0NTEiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMCIgeD0iMTIzMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI4MjMxIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yRSIgeD0iOTAxMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkUiIHg9Ijk0NTUiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJFIiB4PSI5OTAwIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtN0QiIHg9IjExMTUyIiB5PSItMSI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=) 是
是 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjkuODg1ZXgiIGhlaWdodD0iNy42NzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0zLjMzOGV4OyIgdmlld0JveD0iMCAtMTg2Ny43IDQyNTYgMzMwNC45IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSkNBTC00RiIgZD0iTTMwOCA0MjhRMjg5IDQyOCAyODkgNDM4UTI4OSA0NTcgMzE4IDUwOFQzNzggNTkzUTQxNyA2MzggNDc1IDY3MVQ1OTkgNzA1UTY4OCA3MDUgNzMyIDY0M1Q3NzcgNDgzUTc3NyAzODAgNzMzIDI4NVQ2MjAgMTIzVDQ2NCAxOFQyOTMgLTIyUTE4OCAtMjIgMTIzIDUxVDU4IDI0NVE1OCAzMjcgODcgNDAzVDE1OSA1MzNUMjQ5IDYyNlQzMzMgNjg1VDM4OCA3MDVRNDA0IDcwNSA0MDQgNjkzUTQwNCA2NzQgMzYzIDY0OVEzMzMgNjMyIDMwNCA2MDZUMjM5IDUzN1QxODEgNDI5VDE1OCAyOTBRMTU4IDE3OSAyMTQgMTE0VDM2NCA0OFE0ODkgNDggNTgzIDE2NVQ2NzcgNDM4UTY3NyA0NzMgNjcwIDUwNVQ2NDggNTY4VDYwMSA2MTdUNTI4IDYzNlE1MTggNjM2IDUxMyA2MzVRNDg2IDYyOSA0NjAgNjAwVDQxOSA1NDRUMzkyIDQ5MFEzODMgNDcwIDM3MiA0NTlRMzQxIDQzMCAzMDggNDI4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMzIiBkPSJNMTI3IDQ2M1ExMDAgNDYzIDg1IDQ4MFQ2OSA1MjRRNjkgNTc5IDExNyA2MjJUMjMzIDY2NVEyNjggNjY1IDI3NyA2NjRRMzUxIDY1MiAzOTAgNjExVDQzMCA1MjJRNDMwIDQ3MCAzOTYgNDIxVDMwMiAzNTBMMjk5IDM0OFEyOTkgMzQ3IDMwOCAzNDVUMzM3IDMzNlQzNzUgMzE1UTQ1NyAyNjIgNDU3IDE3NVE0NTcgOTYgMzk1IDM3VDIzOCAtMjJRMTU4IC0yMiAxMDAgMjFUNDIgMTMwUTQyIDE1OCA2MCAxNzVUMTA1IDE5M1ExMzMgMTkzIDE1MSAxNzVUMTY5IDEzMFExNjkgMTE5IDE2NiAxMTBUMTU5IDk0VDE0OCA4MlQxMzYgNzRUMTI2IDcwVDExOCA2N0wxMTQgNjZRMTY1IDIxIDIzOCAyMVEyOTMgMjEgMzIxIDc0UTMzOCAxMDcgMzM4IDE3NVYxOTVRMzM4IDI5MCAyNzQgMzIyUTI1OSAzMjggMjEzIDMyOUwxNzEgMzMwTDE2OCAzMzJRMTY2IDMzNSAxNjYgMzQ4UTE2NiAzNjYgMTc0IDM2NlEyMDIgMzY2IDIzMiAzNzFRMjY2IDM3NiAyOTQgNDEzVDMyMiA1MjVWNTMzUTMyMiA1OTAgMjg3IDYxMlEyNjUgNjI2IDI0MCA2MjZRMjA4IDYyNiAxODEgNjE1VDE0MyA1OTJUMTMyIDU4MEgxMzVRMTM4IDU3OSAxNDMgNTc4VDE1MyA1NzNUMTY1IDU2NlQxNzUgNTU1VDE4MyA1NDBUMTg2IDUyMFExODYgNDk4IDE3MiA0ODFUMTI3IDQ2M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjQtMjgiIGQ9Ik03NTggLTEyMzdUNzU4IC0xMjQwVDc1MiAtMTI0OUg3MzZRNzE4IC0xMjQ5IDcxNyAtMTI0OFE3MTEgLTEyNDUgNjcyIC0xMTk5UTIzNyAtNzA2IDIzNyAyNTFUNjcyIDE3MDBRNjk3IDE3MzAgNzE2IDE3NDlRNzE4IDE3NTAgNzM1IDE3NTBINzUyUTc1OCAxNzQ0IDc1OCAxNzQxUTc1OCAxNzM3IDc0MCAxNzEzVDY4OSAxNjQ0VDYxOSAxNTM3VDU0MCAxMzgwVDQ2MyAxMTc2UTM0OCA4MDIgMzQ4IDI1MVEzNDggLTI0MiA0NDEgLTU5OVQ3NDQgLTEyMThRNzU4IC0xMjM3IDc1OCAtMTI0MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjQtMjkiIGQ9Ik0zMyAxNzQxUTMzIDE3NTAgNTEgMTc1MEg2MEg2NVE3MyAxNzUwIDgxIDE3NDNUMTE5IDE3MDBRNTU0IDEyMDcgNTU0IDI1MVE1NTQgLTcwNyAxMTkgLTExOTlRNzYgLTEyNTAgNjYgLTEyNTBRNjUgLTEyNTAgNjIgLTEyNTBUNTYgLTEyNDlRNTUgLTEyNDkgNTMgLTEyNDlUNDkgLTEyNTBRMzMgLTEyNTAgMzMgLTEyMzlRMzMgLTEyMzYgNTAgLTEyMTRUOTggLTExNTBUMTYzIC0xMDUyVDIzOCAtOTEwVDMxMSAtNzI3UTQ0MyAtMzM1IDQ0MyAyNTFRNDQzIDQwMiA0MzYgNTMyVDQwNSA4MzFUMzM5IDExNDJUMjI0IDE0MzhUNTAgMTcxNlEzMyAxNzM3IDMzIDE3NDFaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KQ0FMLTRGIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTYzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzkyLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTQ2NyIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjQ4MyIgeT0iNjc2Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTEyOTYpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MDAsNTA4KSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjQwNyIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMTQ2Ij48L3JlY3Q+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMzIiB4PSIxMDQiIHk9IjY2OSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC41NzQpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMDQiIHk9Ii02OTgiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTI5IiB4PSIyNTAwIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==)
对于所有的 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjUuMDYzZXgiIGhlaWdodD0iMi4zNDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjUwNWV4OyIgdmlld0JveD0iMCAtNzkxLjMgMjE4MC4xIDEwMDguNiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02OSIgZD0iTTE4NCA2MDBRMTg0IDYyNCAyMDMgNjQyVDI0NyA2NjFRMjY1IDY2MSAyNzcgNjQ5VDI5MCA2MTlRMjkwIDU5NiAyNzAgNTc3VDIyNiA1NTdRMjExIDU1NyAxOTggNTY3VDE4NCA2MDBaTTIxIDI4N1EyMSAyOTUgMzAgMzE4VDU0IDM2OVQ5OCA0MjBUMTU4IDQ0MlExOTcgNDQyIDIyMyA0MTlUMjUwIDM1N1EyNTAgMzQwIDIzNiAzMDFUMTk2IDE5NlQxNTQgODNRMTQ5IDYxIDE0OSA1MVExNDkgMjYgMTY2IDI2UTE3NSAyNiAxODUgMjlUMjA4IDQzVDIzNSA3OFQyNjAgMTM3UTI2MyAxNDkgMjY1IDE1MVQyODIgMTUzUTMwMiAxNTMgMzAyIDE0M1EzMDIgMTM1IDI5MyAxMTJUMjY4IDYxVDIyMyAxMVQxNjEgLTExUTEyOSAtMTEgMTAyIDEwVDc0IDc0UTc0IDkxIDc5IDEwNlQxMjIgMjIwUTE2MCAzMjEgMTY2IDM0MVQxNzMgMzgwUTE3MyA0MDQgMTU2IDQwNEgxNTRRMTI0IDQwNCA5OSAzNzFUNjEgMjg3UTYwIDI4NiA1OSAyODRUNTggMjgxVDU2IDI3OVQ1MyAyNzhUNDkgMjc4VDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjI2NSIgZD0iTTgzIDYxNlE4MyA2MjQgODkgNjMwVDk5IDYzNlExMDcgNjM2IDI1MyA1NjhUNTQzIDQzMVQ2ODcgMzYxUTY5NCAzNTYgNjk0IDM0NlQ2ODcgMzMxUTY4NSAzMjkgMzk1IDE5MkwxMDcgNTZIMTAxUTgzIDU4IDgzIDc2UTgzIDc3IDgzIDc5UTgyIDg2IDk4IDk1UTExNyAxMDUgMjQ4IDE2N1EzMjYgMjA0IDM3OCAyMjhMNjI2IDM0NkwzNjAgNDcyUTI5MSA1MDUgMjAwIDU0OFExMTIgNTg5IDk4IDU5N1Q4MyA2MTZaTTg0IC0xMThRODQgLTEwOCA5OSAtOThINjc4UTY5NCAtMTA0IDY5NCAtMTE4UTY5NCAtMTMwIDY3OSAtMTM4SDk4UTg0IC0xMzEgODQgLTExOFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjkiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyNjUiIHg9IjYyMyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjE2NzkiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) ,
, ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjE5LjU3NGV4IiBoZWlnaHQ9IjYuMzQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMi41MDVleDsiIHZpZXdCb3g9IjAgLTE2NTIuNSA4NDI3LjcgMjczMC44IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQ1IiBkPSJNNDkyIDIxM1E0NzIgMjEzIDQ3MiAyMjZRNDcyIDIzMCA0NzcgMjUwVDQ4MiAyODVRNDgyIDMxNiA0NjEgMzIzVDM2NCAzMzBIMzEyUTMxMSAzMjggMjc3IDE5MlQyNDMgNTJRMjQzIDQ4IDI1NCA0OFQzMzQgNDZRNDI4IDQ2IDQ1OCA0OFQ1MTggNjFRNTY3IDc3IDU5OSAxMTdUNjcwIDI0OFE2ODAgMjcwIDY4MyAyNzJRNjkwIDI3NCA2OTggMjc0UTcxOCAyNzQgNzE4IDI2MVE2MTMgNyA2MDggMlE2MDUgMCAzMjIgMEgxMzNRMzEgMCAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDYgNjYgMjE1IDM0MlQyODUgNjIyUTI4NSA2MjkgMjgxIDYyOVEyNzMgNjMyIDIyOCA2MzRIMTk3UTE5MSA2NDAgMTkxIDY0MlQxOTMgNjU5UTE5NyA2NzYgMjAzIDY4MEg3NTdRNzY0IDY3NiA3NjQgNjY5UTc2NCA2NjQgNzUxIDU1N1Q3MzcgNDQ3UTczNSA0NDAgNzE3IDQ0MEg3MDVRNjk4IDQ0NSA2OTggNDUzTDcwMSA0NzZRNzA0IDUwMCA3MDQgNTI4UTcwNCA1NTggNjk3IDU3OFQ2NzggNjA5VDY0MyA2MjVUNTk2IDYzMlQ1MzIgNjM0SDQ4NVEzOTcgNjMzIDM5MiA2MzFRMzg4IDYyOSAzODYgNjIyUTM4NSA2MTkgMzU1IDQ5OVQzMjQgMzc3UTM0NyAzNzYgMzcyIDM3NkgzOThRNDY0IDM3NiA0ODkgMzkxVDUzNCA0NzJRNTM4IDQ4OCA1NDAgNDkwVDU1NyA0OTNRNTYyIDQ5MyA1NjUgNDkzVDU3MCA0OTJUNTcyIDQ5MVQ1NzQgNDg3VDU3NyA0ODNMNTQ0IDM1MVE1MTEgMjE4IDUwOCAyMTZRNTA1IDIxMyA0OTIgMjEzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMDIiIGQ9Ik0yMDIgNTA4UTE3OSA1MDggMTY5IDUyMFQxNTggNTQ3UTE1OCA1NTcgMTY0IDU3N1QxODUgNjI0VDIzMCA2NzVUMzAxIDcxMEwzMzMgNzE1SDM0NVEzNzggNzE1IDM4NCA3MTRRNDQ3IDcwMyA0ODkgNjYxVDU0OSA1NjhUNTY2IDQ1N1E1NjYgMzYyIDUxOSAyNDBUNDAyIDUzUTMyMSAtMjIgMjIzIC0yMlExMjMgLTIyIDczIDU2UTQyIDEwMiA0MiAxNDhWMTU5UTQyIDI3NiAxMjkgMzcwVDMyMiA0NjVRMzgzIDQ2NSA0MTQgNDM0VDQ1NSAzNjdMNDU4IDM3OFE0NzggNDYxIDQ3OCA1MTVRNDc4IDYwMyA0MzcgNjM5VDM0NCA2NzZRMjY2IDY3NiAyMjMgNjEyUTI2NCA2MDYgMjY0IDU3MlEyNjQgNTQ3IDI0NiA1MjhUMjAyIDUwOFpNNDMwIDMwNlE0MzAgMzcyIDQwMSA0MDBUMzMzIDQyOFEyNzAgNDI4IDIyMiAzODJRMTk3IDM1NCAxODMgMzIzVDE1MCAyMjFRMTMyIDE0OSAxMzIgMTE2UTEzMiAyMSAyMzIgMjFRMjQ0IDIxIDI1MCAyMlEzMjcgMzUgMzc0IDExMlEzODkgMTM3IDQwOSAxOTZUNDMwIDMwNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktM0I0IiBkPSJNMTk1IDYwOVExOTUgNjU2IDIyNyA2ODZUMzAyIDcxN1EzMTkgNzE2IDM1MSA3MDlUNDA3IDY5N1Q0MzMgNjkwUTQ1MSA2ODIgNDUxIDY2MlE0NTEgNjQ0IDQzOCA2MjhUNDAzIDYxMlEzODIgNjEyIDM0OCA2NDFUMjg4IDY3MVQyNDkgNjU3VDIzNSA2MjhRMjM1IDU4NCAzMzQgNDYzUTQwMSAzNzkgNDAxIDI5MlE0MDEgMTY5IDM0MCA4MFQyMDUgLTEwSDE5OFExMjcgLTEwIDgzIDM2VDM2IDE1M1EzNiAyODYgMTUxIDM4MlExOTEgNDEzIDI1MiA0MzRRMjUyIDQzNSAyNDUgNDQ5VDIzMCA0ODFUMjE0IDUyMVQyMDEgNTY2VDE5NSA2MDlaTTExMiAxMzBRMTEyIDgzIDEzNiA1NVQyMDQgMjdRMjMzIDI3IDI1NiA1MVQyOTEgMTExVDMwOSAxNzhUMzE2IDIzMlEzMTYgMjY3IDMwOSAyOThUMjk1IDM0NFQyNjkgNDAwTDI1OSAzOTZRMjE1IDM4MSAxODMgMzQyVDEzNyAyNTZUMTE4IDE3OVQxMTIgMTMwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY2IiBkPSJNMTE4IC0xNjJRMTIwIC0xNjIgMTI0IC0xNjRUMTM1IC0xNjdUMTQ3IC0xNjhRMTYwIC0xNjggMTcxIC0xNTVUMTg3IC0xMjZRMTk3IC05OSAyMjEgMjdUMjY3IDI2N1QyODkgMzgyVjM4NUgyNDJRMTk1IDM4NSAxOTIgMzg3UTE4OCAzOTAgMTg4IDM5N0wxOTUgNDI1UTE5NyA0MzAgMjAzIDQzMFQyNTAgNDMxUTI5OCA0MzEgMjk4IDQzMlEyOTggNDM0IDMwNyA0ODJUMzE5IDU0MFEzNTYgNzA1IDQ2NSA3MDVRNTAyIDcwMyA1MjYgNjgzVDU1MCA2MzBRNTUwIDU5NCA1MjkgNTc4VDQ4NyA1NjFRNDQzIDU2MSA0NDMgNjAzUTQ0MyA2MjIgNDU0IDYzNlQ0NzggNjU3TDQ4NyA2NjJRNDcxIDY2OCA0NTcgNjY4UTQ0NSA2NjggNDM0IDY1OFQ0MTkgNjMwUTQxMiA2MDEgNDAzIDU1MlQzODcgNDY5VDM4MCA0MzNRMzgwIDQzMSA0MzUgNDMxUTQ4MCA0MzEgNDg3IDQzMFQ0OTggNDI0UTQ5OSA0MjAgNDk2IDQwN1Q0OTEgMzkxUTQ4OSAzODYgNDgyIDM4NlQ0MjggMzg1SDM3MkwzNDkgMjYzUTMwMSAxNSAyODIgLTQ3UTI1NSAtMTMyIDIxMiAtMTczUTE3NSAtMjA1IDEzOSAtMjA1UTEwNyAtMjA1IDgxIC0xODZUNTUgLTEzMlE1NSAtOTUgNzYgLTc4VDExOCAtNjFRMTYyIC02MSAxNjIgLTEwM1ExNjIgLTEyMiAxNTEgLTEzNlQxMjcgLTE1N0wxMTggLTE2MloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0MiIGQ9Ik0xMzkgLTI0OUgxMzdRMTI1IC0yNDkgMTE5IC0yMzVWMjUxTDEyMCA3MzdRMTMwIDc1MCAxMzkgNzUwUTE1MiA3NTAgMTU5IDczNVYtMjM1UTE1MSAtMjQ5IDE0MSAtMjQ5SDEzOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzAiIGQ9Ik05NiA1ODVRMTUyIDY2NiAyNDkgNjY2UTI5NyA2NjYgMzQ1IDY0MFQ0MjMgNTQ4UTQ2MCA0NjUgNDYwIDMyMFE0NjAgMTY1IDQxNyA4M1EzOTcgNDEgMzYyIDE2VDMwMSAtMTVUMjUwIC0yMlEyMjQgLTIyIDE5OCAtMTZUMTM3IDE2VDgyIDgzUTM5IDE2NSAzOSAzMjBRMzkgNDk0IDk2IDU4NVpNMzIxIDU5N1EyOTEgNjI5IDI1MCA2MjlRMjA4IDYyOSAxNzggNTk3UTE1MyA1NzEgMTQ1IDUyNVQxMzcgMzMzUTEzNyAxNzUgMTQ1IDEyNVQxODEgNDZRMjA5IDE2IDI1MCAxNlEyOTAgMTYgMzE4IDQ2UTM0NyA3NiAzNTQgMTMwVDM2MiAzMzNRMzYyIDQ3OCAzNTQgNTI0VDMyMSA1OTdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1ozLTI4IiBkPSJNNzAxIC05NDBRNzAxIC05NDMgNjk1IC05NDlINjY0UTY2MiAtOTQ3IDYzNiAtOTIyVDU5MSAtODc5VDUzNyAtODE4VDQ3NSAtNzM3VDQxMiAtNjM2VDM1MCAtNTExVDI5NSAtMzYyVDI1MCAtMTg2VDIyMSAxN1QyMDkgMjUxUTIwOSA5NjIgNTczIDEzNjFRNTk2IDEzODYgNjE2IDE0MDVUNjQ5IDE0MzdUNjY0IDE0NTBINjk1UTcwMSAxNDQ0IDcwMSAxNDQxUTcwMSAxNDM2IDY4MSAxNDE1VDYyOSAxMzU2VDU1NyAxMjYxVDQ3NiAxMTE4VDQwMCA5MjdUMzQwIDY3NVQzMDggMzU5UTMwNiAzMjEgMzA2IDI1MFEzMDYgLTEzOSA0MDAgLTQzMFQ2OTAgLTkyNFE3MDEgLTkzNiA3MDEgLTk0MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjMtMjkiIGQ9Ik0zNCAxNDM4UTM0IDE0NDYgMzcgMTQ0OFQ1MCAxNDUwSDU2SDcxUTczIDE0NDggOTkgMTQyM1QxNDQgMTM4MFQxOTggMTMxOVQyNjAgMTIzOFQzMjMgMTEzN1QzODUgMTAxM1Q0NDAgODY0VDQ4NSA2ODhUNTE0IDQ4NVQ1MjYgMjUxUTUyNiAxMzQgNTE5IDUzUTQ3MiAtNTE5IDE2MiAtODYwUTEzOSAtODg1IDExOSAtOTA0VDg2IC05MzZUNzEgLTk0OUg1NlE0MyAtOTQ5IDM5IC05NDdUMzQgLTkzN1E4OCAtODgzIDE0MCAtODEzUTQyOCAtNDMwIDQyOCAyNTFRNDI4IDQ1MyA0MDIgNjI4VDMzOCA5MjJUMjQ1IDExNDZUMTQ1IDEzMDlUNDYgMTQyNVE0NCAxNDI3IDQyIDE0MjlUMzkgMTQzM1QzNiAxNDM2TDM0IDE0MzhaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5MzEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjMtMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MzYsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxNTk1IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjgxLDY3NikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMDIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iODE3IiB5PSI1MTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03ODApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjAyIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTY3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktM0I0IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjY0MSIgeT0iNDA4Ij48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTgzNSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjgwNCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI2OTMiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDMwMjQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktM0I0IiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NDEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ0MjEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdDIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjc4LC0yODYpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTNCNCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI0NTEiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMCIgeD0iMTIzMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMy0yOSIgeD0iNjc1OSIgeT0iLTEiPjwvdXNlPgo8L2c+CjwvZz4KPC9zdmc+) 是
是 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjUuMjA5ZXgiIGhlaWdodD0iMi44NDNleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjgzOGV4OyIgdmlld0JveD0iMCAtODYzLjEgMjI0Mi43IDEyMjMuOSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpDQUwtNEYiIGQ9Ik0zMDggNDI4UTI4OSA0MjggMjg5IDQzOFEyODkgNDU3IDMxOCA1MDhUMzc4IDU5M1E0MTcgNjM4IDQ3NSA2NzFUNTk5IDcwNVE2ODggNzA1IDczMiA2NDNUNzc3IDQ4M1E3NzcgMzgwIDczMyAyODVUNjIwIDEyM1Q0NjQgMThUMjkzIC0yMlExODggLTIyIDEyMyA1MVQ1OCAyNDVRNTggMzI3IDg3IDQwM1QxNTkgNTMzVDI0OSA2MjZUMzMzIDY4NVQzODggNzA1UTQwNCA3MDUgNDA0IDY5M1E0MDQgNjc0IDM2MyA2NDlRMzMzIDYzMiAzMDQgNjA2VDIzOSA1MzdUMTgxIDQyOVQxNTggMjkwUTE1OCAxNzkgMjE0IDExNFQzNjQgNDhRNDg5IDQ4IDU4MyAxNjVUNjc3IDQzOFE2NzcgNDczIDY3MCA1MDVUNjQ4IDU2OFQ2MDEgNjE3VDUyOCA2MzZRNTE4IDYzNiA1MTMgNjM1UTQ4NiA2MjkgNDYwIDYwMFQ0MTkgNTQ0VDM5MiA0OTBRMzgzIDQ3MCAzNzIgNDU5UTM0MSA0MzAgMzA4IDQyOFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMSIgZD0iTTIxMyA1NzhMMjAwIDU3M1ExODYgNTY4IDE2MCA1NjNUMTAyIDU1Nkg4M1Y2MDJIMTAyUTE0OSA2MDQgMTg5IDYxN1QyNDUgNjQxVDI3MyA2NjNRMjc1IDY2NiAyODUgNjY2UTI5NCA2NjYgMzAyIDY2MFYzNjFMMzAzIDYxUTMxMCA1NCAzMTUgNTJUMzM5IDQ4VDQwMSA0Nkg0MjdWMEg0MTZRMzk1IDMgMjU3IDNRMTIxIDMgMTAwIDBIODhWNDZIMTE0UTEzNiA0NiAxNTIgNDZUMTc3IDQ3VDE5MyA1MFQyMDEgNTJUMjA3IDU3VDIxMyA2MVY1NzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpDQUwtNEYiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5NjMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODkwIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==)
的部分即可省略,因为 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjguNTY3ZXgiIGhlaWdodD0iMy4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjgzOGV4OyIgdmlld0JveD0iMCAtMTAwNi42IDM2ODguNiAxMzY3LjQiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi01NiIgZD0iTTExNCA2MjBRMTEzIDYyMSAxMTAgNjI0VDEwNyA2MjdUMTAzIDYzMFQ5OCA2MzJUOTEgNjM0VDgwIDYzNVQ2NyA2MzZUNDggNjM3SDE5VjY4M0gyOFE0NiA2ODAgMTUyIDY4MFEyNzMgNjgwIDI5NCA2ODNIMzA1VjYzN0gyODRRMjIzIDYzNCAyMjMgNjIwUTIyMyA2MTggMzEzIDM3MlQ0MDQgMTI2TDQ5MCAzNThRNTc1IDU4OCA1NzUgNTk3UTU3NSA2MTYgNTU0IDYyNlQ1MDggNjM3SDUwM1Y2ODNINTEyUTUyNyA2ODAgNjI3IDY4MFE3MTggNjgwIDcyNCA2ODNINzMwVjYzN0g3MjNRNjQ4IDYzNyA2MjcgNTk2UTYyNyA1OTUgNTE1IDI5MVQ0MDEgLTE0UTM5NiAtMjIgMzgyIC0yMkgzNzRIMzY3UTM1MyAtMjIgMzQ4IC0xNFEzNDYgLTEyIDIzMSAzMDNRMTE0IDYxNyAxMTQgNjIwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNjEiIGQ9Ik0xMzcgMzA1VDExNSAzMDVUNzggMzIwVDYzIDM1OVE2MyAzOTQgOTcgNDIxVDIxOCA0NDhRMjkxIDQ0OCAzMzYgNDE2VDM5NiAzNDBRNDAxIDMyNiA0MDEgMzA5VDQwMiAxOTRWMTI0UTQwMiA3NiA0MDcgNThUNDI4IDQwUTQ0MyA0MCA0NDggNTZUNDUzIDEwOVYxNDVINDkzVjEwNlE0OTIgNjYgNDkwIDU5UTQ4MSAyOSA0NTUgMTJUNDAwIC02VDM1MyAxMlQzMjkgNTRWNThMMzI3IDU1UTMyNSA1MiAzMjIgNDlUMzE0IDQwVDMwMiAyOVQyODcgMTdUMjY5IDZUMjQ3IC0yVDIyMSAtOFQxOTAgLTExUTEzMCAtMTEgODIgMjBUMzQgMTA3UTM0IDEyOCA0MSAxNDdUNjggMTg4VDExNiAyMjVUMTk0IDI1M1QzMDQgMjY4SDMxOFYyOTBRMzE4IDMyNCAzMTIgMzQwUTI5MCA0MTEgMjE1IDQxMVExOTcgNDExIDE4MSA0MTBUMTU2IDQwNlQxNDggNDAzUTE3MCAzODggMTcwIDM1OVExNzAgMzM0IDE1NCAzMjBaTTEyNiAxMDZRMTI2IDc1IDE1MCA1MVQyMDkgMjZRMjQ3IDI2IDI3NiA0OVQzMTUgMTA5UTMxNyAxMTYgMzE4IDE3NVEzMTggMjMzIDMxNyAyMzNRMzA5IDIzMyAyOTYgMjMyVDI1MSAyMjNUMTkzIDIwM1QxNDcgMTY2VDEyNiAxMDZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03MiIgZD0iTTM2IDQ2SDUwUTg5IDQ2IDk3IDYwVjY4UTk3IDc3IDk3IDkxVDk4IDEyMlQ5OCAxNjFUOTggMjAzUTk4IDIzNCA5OCAyNjlUOTggMzI4TDk3IDM1MVE5NCAzNzAgODMgMzc2VDM4IDM4NUgyMFY0MDhRMjAgNDMxIDIyIDQzMUwzMiA0MzJRNDIgNDMzIDYwIDQzNFQ5NiA0MzZRMTEyIDQzNyAxMzEgNDM4VDE2MCA0NDFUMTcxIDQ0MkgxNzRWMzczUTIxMyA0NDEgMjcxIDQ0MUgyNzdRMzIyIDQ0MSAzNDMgNDE5VDM2NCAzNzNRMzY0IDM1MiAzNTEgMzM3VDMxMyAzMjJRMjg4IDMyMiAyNzYgMzM4VDI2MyAzNzJRMjYzIDM4MSAyNjUgMzg4VDI3MCA0MDBUMjczIDQwNVEyNzEgNDA3IDI1MCA0MDFRMjM0IDM5MyAyMjYgMzg2UTE3OSAzNDEgMTc5IDIwN1YxNTRRMTc5IDE0MSAxNzkgMTI3VDE3OSAxMDFUMTgwIDgxVDE4MCA2NlY2MVExODEgNTkgMTgzIDU3VDE4OCA1NFQxOTMgNTFUMjAwIDQ5VDIwNyA0OFQyMTYgNDdUMjI1IDQ3VDIzNSA0NlQyNDUgNDZIMjc2VjBIMjY3UTI0OSAzIDE0MCAzUTM3IDMgMjggMEgyMFY0NkgzNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NiIgZD0iTTQ4IDFRMzEgMSAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDYgNjYgMjE1IDM0MlQyODUgNjIyUTI4NSA2MjkgMjgxIDYyOVEyNzMgNjMyIDIyOCA2MzRIMTk3UTE5MSA2NDAgMTkxIDY0MlQxOTMgNjU5UTE5NyA2NzYgMjAzIDY4MEg3NDJRNzQ5IDY3NiA3NDkgNjY5UTc0OSA2NjQgNzM2IDU1N1Q3MjIgNDQ3UTcyMCA0NDAgNzAyIDQ0MEg2OTBRNjgzIDQ0NSA2ODMgNDUzUTY4MyA0NTQgNjg2IDQ3N1Q2ODkgNTMwUTY4OSA1NjAgNjgyIDU3OVQ2NjMgNjEwVDYyNiA2MjZUNTc1IDYzM1Q1MDMgNjM0SDQ4MFEzOTggNjMzIDM5MyA2MzFRMzg4IDYyOSAzODYgNjIzUTM4NSA2MjIgMzUyIDQ5MkwzMjAgMzYzSDM3NVEzNzggMzYzIDM5OCAzNjNUNDI2IDM2NFQ0NDggMzY3VDQ3MiAzNzRUNDg5IDM4NlE1MDIgMzk4IDUxMSA0MTlUNTI0IDQ1N1Q1MjkgNDc1UTUzMiA0ODAgNTQ4IDQ4MEg1NjBRNTY3IDQ3NSA1NjcgNDcwUTU2NyA0NjcgNTM2IDMzOVQ1MDIgMjA3UTUwMCAyMDAgNDgyIDIwMEg0NzBRNDYzIDIwNiA0NjMgMjEyUTQ2MyAyMTUgNDY4IDIzNFQ0NzMgMjc0UTQ3MyAzMDMgNDUzIDMxMFQzNjQgMzE3SDMwOUwyNzcgMTkwUTI0NSA2NiAyNDUgNjBRMjQ1IDQ2IDMzNCA0NkgzNTlRMzY1IDQwIDM2NSAzOVQzNjMgMTlRMzU5IDYgMzUzIDBIMzM2UTI5NSAyIDE4NSAyUTEyMCAyIDg2IDJUNDggMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NiIgeD0iMjMyNCIgeT0iNTgxIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIyMzI0IiB5PSItMzUwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjQ0MCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==) 衰减为
衰减为 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIuMjMxZXgiIGhlaWdodD0iNS4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0xLjgzOGV4OyIgdmlld0JveD0iMCAtMTQzNy4yIDk2MC41IDIyMjguNSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI3MjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxMTAiIHk9IjY3NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI2MCIgeT0iLTY4NiI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=) ,所以对于一个较大的
,所以对于一个较大的 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIuMDY0ZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgODg4LjUgOTM2LjkiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNEUiIGQ9Ik0yMzQgNjM3UTIzMSA2MzcgMjI2IDYzN1EyMDEgNjM3IDE5NiA2MzhUMTkxIDY0OVExOTEgNjc2IDIwMiA2ODJRMjA0IDY4MyAyOTkgNjgzUTM3NiA2ODMgMzg3IDY4M1Q0MDEgNjc3UTYxMiAxODEgNjE2IDE2OEw2NzAgMzgxUTcyMyA1OTIgNzIzIDYwNlE3MjMgNjMzIDY1OSA2MzdRNjM1IDYzNyA2MzUgNjQ4UTYzNSA2NTAgNjM3IDY2MFE2NDEgNjc2IDY0MyA2NzlUNjUzIDY4M1E2NTYgNjgzIDY4NCA2ODJUNzY3IDY4MFE4MTcgNjgwIDg0MyA2ODFUODczIDY4MlE4ODggNjgyIDg4OCA2NzJRODg4IDY1MCA4ODAgNjQyUTg3OCA2MzcgODU4IDYzN1E3ODcgNjMzIDc2OSA1OTdMNjIwIDdRNjE4IDAgNTk5IDBRNTg1IDAgNTgyIDJRNTc5IDUgNDUzIDMwNUwzMjYgNjA0TDI2MSAzNDRRMTk2IDg4IDE5NiA3OVEyMDEgNDYgMjY4IDQ2SDI3OFEyODQgNDEgMjg0IDM4VDI4MiAxOVEyNzggNiAyNzIgMEgyNTlRMjI4IDIgMTUxIDJRMTIzIDIgMTAwIDJUNjMgMlQ0NiAxUTMxIDEgMzEgMTBRMzEgMTQgMzQgMjZUMzkgNDBRNDEgNDYgNjIgNDZRMTMwIDQ5IDE1MCA4NVExNTQgOTEgMjIxIDM2MkwyODkgNjM0UTI4NyA2MzUgMjM0IDYzN1oiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00RSIgeD0iMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9zdmc+) 而言,对于所有的
而言,对于所有的 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjYuNTU3ZXgiIGhlaWdodD0iMi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0wLjMzOGV4OyIgdmlld0JveD0iMCAtNzkxLjMgMjgyMy4xIDkzNi45IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZFIiBkPSJNMjEgMjg3UTIyIDI5MyAyNCAzMDNUMzYgMzQxVDU2IDM4OFQ4OSA0MjVUMTM1IDQ0MlExNzEgNDQyIDE5NSA0MjRUMjI1IDM5MFQyMzEgMzY5UTIzMSAzNjcgMjMyIDM2N0wyNDMgMzc4UTMwNCA0NDIgMzgyIDQ0MlE0MzYgNDQyIDQ2OSA0MTVUNTAzIDMzNlQ0NjUgMTc5VDQyNyA1MlE0MjcgMjYgNDQ0IDI2UTQ1MCAyNiA0NTMgMjdRNDgyIDMyIDUwNSA2NVQ1NDAgMTQ1UTU0MiAxNTMgNTYwIDE1M1E1ODAgMTUzIDU4MCAxNDVRNTgwIDE0NCA1NzYgMTMwUTU2OCAxMDEgNTU0IDczVDUwOCAxN1Q0MzkgLTEwUTM5MiAtMTAgMzcxIDE3VDM1MCA3M1EzNTAgOTIgMzg2IDE5M1Q0MjMgMzQ1UTQyMyA0MDQgMzc5IDQwNEgzNzRRMjg4IDQwNCAyMjkgMzAzTDIyMiAyOTFMMTg5IDE1N1ExNTYgMjYgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTIgMTgwVDE1MiAzNDNRMTUzIDM0OCAxNTMgMzY2UTE1MyA0MDUgMTI5IDQwNVE5MSA0MDUgNjYgMzA1UTYwIDI4NSA2MCAyODRRNTggMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0UiIGQ9Ik04NCA1MjBRODQgNTI4IDg4IDUzM1Q5NiA1MzlMOTkgNTQwUTEwNiA1NDAgMjUzIDQ3MVQ1NDQgMzM0TDY4NyAyNjVRNjk0IDI2MCA2OTQgMjUwVDY4NyAyMzVRNjg1IDIzMyAzOTUgOTZMMTA3IC00MEgxMDFRODMgLTM4IDgzIC0yMFE4MyAtMTkgODMgLTE3UTgyIC0xMCA5OCAtMVExMTcgOSAyNDggNzFRMzI2IDEwOCAzNzggMTMyTDYyNiAyNTBMMzc4IDM2OFE5MCA1MDQgODYgNTA5UTg0IDUxMyA4NCA1MjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNEUiIGQ9Ik0yMzQgNjM3UTIzMSA2MzcgMjI2IDYzN1EyMDEgNjM3IDE5NiA2MzhUMTkxIDY0OVExOTEgNjc2IDIwMiA2ODJRMjA0IDY4MyAyOTkgNjgzUTM3NiA2ODMgMzg3IDY4M1Q0MDEgNjc3UTYxMiAxODEgNjE2IDE2OEw2NzAgMzgxUTcyMyA1OTIgNzIzIDYwNlE3MjMgNjMzIDY1OSA2MzdRNjM1IDYzNyA2MzUgNjQ4UTYzNSA2NTAgNjM3IDY2MFE2NDEgNjc2IDY0MyA2NzlUNjUzIDY4M1E2NTYgNjgzIDY4NCA2ODJUNzY3IDY4MFE4MTcgNjgwIDg0MyA2ODFUODczIDY4MlE4ODggNjgyIDg4OCA2NzJRODg4IDY1MCA4ODAgNjQyUTg3OCA2MzcgODU4IDYzN1E3ODcgNjMzIDc2OSA1OTdMNjIwIDdRNjE4IDAgNTk5IDBRNTg1IDAgNTgyIDJRNTc5IDUgNDUzIDMwNUwzMjYgNjA0TDI2MSAzNDRRMTk2IDg4IDE5NiA3OVEyMDEgNDYgMjY4IDQ2SDI3OFEyODQgNDEgMjg0IDM4VDI4MiAxOVEyNzggNiAyNzIgMEgyNTlRMjI4IDIgMTUxIDJRMTIzIDIgMTAwIDJUNjMgMlQ0NiAxUTMxIDEgMzEgMTBRMzEgMTQgMzQgMjZUMzkgNDBRNDEgNDYgNjIgNDZRMTMwIDQ5IDE1MCA4NVExNTQgOTEgMjIxIDM2MkwyODkgNjM0UTI4NyA2MzUgMjM0IDYzN1oiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0UiIHg9Ijg3OCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTRFIiB4PSIxOTM0IiB5PSIwIj48L3VzZT4KPC9nPgo8L3N2Zz4=) ,
,
我们将利用以下的事实,除fact 12外不给出证明
fact 5 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjE5Ljk2M2V4IiBoZWlnaHQ9IjMuMzQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMS4wMDVleDsiIHZpZXdCb3g9IjAgLTEwMDYuNiA4NTk1LjMgMTQzOS4yIiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQ1IiBkPSJNNDkyIDIxM1E0NzIgMjEzIDQ3MiAyMjZRNDcyIDIzMCA0NzcgMjUwVDQ4MiAyODVRNDgyIDMxNiA0NjEgMzIzVDM2NCAzMzBIMzEyUTMxMSAzMjggMjc3IDE5MlQyNDMgNTJRMjQzIDQ4IDI1NCA0OFQzMzQgNDZRNDI4IDQ2IDQ1OCA0OFQ1MTggNjFRNTY3IDc3IDU5OSAxMTdUNjcwIDI0OFE2ODAgMjcwIDY4MyAyNzJRNjkwIDI3NCA2OTggMjc0UTcxOCAyNzQgNzE4IDI2MVE2MTMgNyA2MDggMlE2MDUgMCAzMjIgMEgxMzNRMzEgMCAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDYgNjYgMjE1IDM0MlQyODUgNjIyUTI4NSA2MjkgMjgxIDYyOVEyNzMgNjMyIDIyOCA2MzRIMTk3UTE5MSA2NDAgMTkxIDY0MlQxOTMgNjU5UTE5NyA2NzYgMjAzIDY4MEg3NTdRNzY0IDY3NiA3NjQgNjY5UTc2NCA2NjQgNzUxIDU1N1Q3MzcgNDQ3UTczNSA0NDAgNzE3IDQ0MEg3MDVRNjk4IDQ0NSA2OTggNDUzTDcwMSA0NzZRNzA0IDUwMCA3MDQgNTI4UTcwNCA1NTggNjk3IDU3OFQ2NzggNjA5VDY0MyA2MjVUNTk2IDYzMlQ1MzIgNjM0SDQ4NVEzOTcgNjMzIDM5MiA2MzFRMzg4IDYyOSAzODYgNjIyUTM4NSA2MTkgMzU1IDQ5OVQzMjQgMzc3UTM0NyAzNzYgMzcyIDM3NkgzOThRNDY0IDM3NiA0ODkgMzkxVDUzNCA0NzJRNTM4IDQ4OCA1NDAgNDkwVDU1NyA0OTNRNTYyIDQ5MyA1NjUgNDkzVDU3MCA0OTJUNTcyIDQ5MVQ1NzQgNDg3VDU3NyA0ODNMNTQ0IDM1MVE1MTEgMjE4IDUwOCAyMTZRNTA1IDIxMyA0OTIgMjEzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0IiIGQ9Ik00MzQgLTIzMVE0MzQgLTI0NCA0MjggLTI1MEg0MTBRMjgxIC0yNTAgMjMwIC0xODRRMjI1IC0xNzcgMjIyIC0xNzJUMjE3IC0xNjFUMjEzIC0xNDhUMjExIC0xMzNUMjEwIC0xMTFUMjA5IC04NFQyMDkgLTQ3VDIwOSAwUTIwOSAyMSAyMDkgNTNRMjA4IDE0MiAyMDQgMTUzUTIwMyAxNTQgMjAzIDE1NVExODkgMTkxIDE1MyAyMTFUODIgMjMxUTcxIDIzMSA2OCAyMzRUNjUgMjUwVDY4IDI2NlQ4MiAyNjlRMTE2IDI2OSAxNTIgMjg5VDIwMyAzNDVRMjA4IDM1NiAyMDggMzc3VDIwOSA1MjlWNTc5UTIwOSA2MzQgMjE1IDY1NlQyNDQgNjk4UTI3MCA3MjQgMzI0IDc0MFEzNjEgNzQ4IDM3NyA3NDlRMzc5IDc0OSAzOTAgNzQ5VDQwOCA3NTBINDI4UTQzNCA3NDQgNDM0IDczMlE0MzQgNzE5IDQzMSA3MTZRNDI5IDcxMyA0MTUgNzEzUTM2MiA3MTAgMzMyIDY4OVQyOTYgNjQ3UTI5MSA2MzQgMjkxIDQ5OVY0MTdRMjkxIDM3MCAyODggMzUzVDI3MSAzMTRRMjQwIDI3MSAxODQgMjU1TDE3MCAyNTBMMTg0IDI0NVEyMDIgMjM5IDIyMCAyMzBUMjYyIDE5NlQyOTAgMTM3UTI5MSAxMzEgMjkxIDFRMjkxIC0xMzQgMjk2IC0xNDdRMzA2IC0xNzQgMzM5IC0xOTJUNDE1IC0yMTNRNDI5IC0yMTMgNDMxIC0yMTZRNDM0IC0yMTkgNDM0IC0yMzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNjYiIGQ9Ik0xMTggLTE2MlExMjAgLTE2MiAxMjQgLTE2NFQxMzUgLTE2N1QxNDcgLTE2OFExNjAgLTE2OCAxNzEgLTE1NVQxODcgLTEyNlExOTcgLTk5IDIyMSAyN1QyNjcgMjY3VDI4OSAzODJWMzg1SDI0MlExOTUgMzg1IDE5MiAzODdRMTg4IDM5MCAxODggMzk3TDE5NSA0MjVRMTk3IDQzMCAyMDMgNDMwVDI1MCA0MzFRMjk4IDQzMSAyOTggNDMyUTI5OCA0MzQgMzA3IDQ4MlQzMTkgNTQwUTM1NiA3MDUgNDY1IDcwNVE1MDIgNzAzIDUyNiA2ODNUNTUwIDYzMFE1NTAgNTk0IDUyOSA1NzhUNDg3IDU2MVE0NDMgNTYxIDQ0MyA2MDNRNDQzIDYyMiA0NTQgNjM2VDQ3OCA2NTdMNDg3IDY2MlE0NzEgNjY4IDQ1NyA2NjhRNDQ1IDY2OCA0MzQgNjU4VDQxOSA2MzBRNDEyIDYwMSA0MDMgNTUyVDM4NyA0NjlUMzgwIDQzM1EzODAgNDMxIDQzNSA0MzFRNDgwIDQzMSA0ODcgNDMwVDQ5OCA0MjRRNDk5IDQyMCA0OTYgNDA3VDQ5MSAzOTFRNDg5IDM4NiA0ODIgMzg2VDQyOCAzODVIMzcyTDM0OSAyNjNRMzAxIDE1IDI4MiAtNDdRMjU1IC0xMzIgMjEyIC0xNzNRMTc1IC0yMDUgMTM5IC0yMDVRMTA3IC0yMDUgODEgLTE4NlQ1NSAtMTMyUTU1IC05NSA3NiAtNzhUMTE4IC02MVExNjIgLTYxIDE2MiAtMTAzUTE2MiAtMTIyIDE1MSAtMTM2VDEyNyAtMTU3TDExOCAtMTYyWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzIiIGQ9Ik0xMDkgNDI5UTgyIDQyOSA2NiA0NDdUNTAgNDkxUTUwIDU2MiAxMDMgNjE0VDIzNSA2NjZRMzI2IDY2NiAzODcgNjEwVDQ0OSA0NjVRNDQ5IDQyMiA0MjkgMzgzVDM4MSAzMTVUMzAxIDI0MVEyNjUgMjEwIDIwMSAxNDlMMTQyIDkzTDIxOCA5MlEzNzUgOTIgMzg1IDk3UTM5MiA5OSA0MDkgMTg2VjE4OUg0NDlWMTg2UTQ0OCAxODMgNDM2IDk1VDQyMSAzVjBINTBWMTlWMzFRNTAgMzggNTYgNDZUODYgODFRMTE1IDExMyAxMzYgMTM3UTE0NSAxNDcgMTcwIDE3NFQyMDQgMjExVDIzMyAyNDRUMjYxIDI3OFQyODQgMzA4VDMwNSAzNDBUMzIwIDM2OVQzMzMgNDAxVDM0MCA0MzFUMzQzIDQ2NFEzNDMgNTI3IDMwOSA1NzNUMjEyIDYxOVExNzkgNjE5IDE1NCA2MDJUMTE5IDU2OVQxMDkgNTUwUTEwOSA1NDkgMTE0IDU0OVExMzIgNTQ5IDE1MSA1MzVUMTcwIDQ4OVExNzAgNDY0IDE1NCA0NDdUMTA5IDQyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMCIgZD0iTTk2IDU4NVExNTIgNjY2IDI0OSA2NjZRMjk3IDY2NiAzNDUgNjQwVDQyMyA1NDhRNDYwIDQ2NSA0NjAgMzIwUTQ2MCAxNjUgNDE3IDgzUTM5NyA0MSAzNjIgMTZUMzAxIC0xNVQyNTAgLTIyUTIyNCAtMjIgMTk4IC0xNlQxMzcgMTZUODIgODNRMzkgMTY1IDM5IDMyMFEzOSA0OTQgOTYgNTg1Wk0zMjEgNTk3UTI5MSA2MjkgMjUwIDYyOVEyMDggNjI5IDE3OCA1OTdRMTUzIDU3MSAxNDUgNTI1VDEzNyAzMzNRMTM3IDE3NSAxNDUgMTI1VDE4MSA0NlEyMDkgMTYgMjUwIDE2UTI5MCAxNiAzMTggNDZRMzQ3IDc2IDM1NCAxMzBUMzYyIDMzM1EzNjIgNDc4IDM1NCA1MjRUMzIxIDU5N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oxLTdCIiBkPSJNNDc3IC0zNDNMNDcxIC0zNDlINDU4UTQzMiAtMzQ5IDM2NyAtMzI1VDI3MyAtMjYzUTI1OCAtMjQ1IDI1MCAtMjEyTDI0OSAtNTFRMjQ5IC0yNyAyNDkgMTJRMjQ4IDExOCAyNDQgMTI4UTI0MyAxMjkgMjQzIDEzMFEyMjAgMTg5IDEyMSAyMjhRMTA5IDIzMiAxMDcgMjM1VDEwNSAyNTBRMTA1IDI1NiAxMDUgMjU3VDEwNSAyNjFUMTA3IDI2NVQxMTEgMjY4VDExOCAyNzJUMTI4IDI3NlQxNDIgMjgzVDE2MiAyOTFRMjI0IDMyNCAyNDMgMzcxUTI0MyAzNzIgMjQ0IDM3M1EyNDggMzg0IDI0OSA0NjlRMjQ5IDQ3NSAyNDkgNDg5UTI0OSA1MjggMjQ5IDU1MkwyNTAgNzE0UTI1MyA3MjggMjU2IDczNlQyNzEgNzYxVDI5OSA3ODlUMzQ3IDgxNlQ0MjIgODQzUTQ0MCA4NDkgNDQxIDg0OUg0NDNRNDQ1IDg0OSA0NDcgODQ5VDQ1MiA4NTBUNDU3IDg1MEg0NzFMNDc3IDg0NFY4MzBRNDc3IDgyMCA0NzYgODE3VDQ3MCA4MTFUNDU5IDgwN1Q0MzcgODAxVDQwNCA3ODVRMzUzIDc2MCAzMzggNzI0UTMzMyA3MTAgMzMzIDU1MFEzMzMgNTI2IDMzMyA0OTJUMzM0IDQ0N1EzMzQgMzkzIDMyNyAzNjhUMjk1IDMxOFEyNTcgMjgwIDE4MSAyNTVMMTY5IDI1MUwxODQgMjQ1UTMxOCAxOTggMzMyIDExMlEzMzMgMTA2IDMzMyAtNDlRMzMzIC0yMDkgMzM4IC0yMjNRMzUxIC0yNTUgMzkxIC0yNzdUNDY5IC0zMDlRNDc3IC0zMTEgNDc3IC0zMjlWLTM0M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjEtN0QiIGQ9Ik0xMTAgODQ5TDExNSA4NTBRMTIwIDg1MCAxMjUgODUwUTE1MSA4NTAgMjE1IDgyNlQzMDkgNzY0UTMyNCA3NDcgMzMyIDcxNEwzMzMgNTUyUTMzMyA1MjggMzMzIDQ4OVEzMzQgMzgzIDMzOCAzNzNRMzM5IDM3MiAzMzkgMzcxUTM1MyAzMzYgMzkxIDMxMFQ0NjkgMjcxUTQ3NyAyNjggNDc3IDI1MVE0NzcgMjQxIDQ3NiAyMzdUNDcyIDIzMlQ0NTYgMjI1VDQyOCAyMTRRMzU3IDE3OSAzMzkgMTMwUTMzOSAxMjkgMzM4IDEyOFEzMzQgMTE3IDMzMyAzMlEzMzMgMjYgMzMzIDEyUTMzMyAtMjcgMzMzIC01MUwzMzIgLTIxMlEzMjggLTIyOCAzMjMgLTI0MFQzMDIgLTI3MVQyNTUgLTMwN1QxNzUgLTMzOFExMzkgLTM0OSAxMjUgLTM0OVQxMDggLTM0NlQxMDUgLTMyOVExMDUgLTMxNCAxMDcgLTMxMlQxMzAgLTMwNFEyMzMgLTI3MSAyNDggLTIwOVEyNDkgLTIwMyAyNDkgLTQ5VjU3UTI0OSAxMDYgMjUzIDEyNVQyNzMgMTY3UTMwNyAyMTMgMzk4IDI0NUw0MTMgMjUxTDQwMSAyNTVRMjY1IDMwMCAyNTAgMzg5UTI0OSAzOTUgMjQ5IDU1MFEyNDkgNzEwIDI0NCA3MjRRMjI0IDc3NCAxMTIgODExUTEwNSA4MTMgMTA1IDgzMFExMDUgODQ1IDExMCA4NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NiIgZD0iTTUyIDY0OFE1MiA2NzAgNjUgNjgzSDc2UTExOCA2ODAgMTgxIDY4MFEyOTkgNjgwIDMyMCA2ODNIMzMwUTMzNiA2NzcgMzM2IDY3NFQzMzQgNjU2UTMyOSA2NDEgMzI1IDYzN0gzMDRRMjgyIDYzNSAyNzQgNjM1UTI0NSA2MzAgMjQyIDYyMFEyNDIgNjE4IDI3MSAzNjlUMzAxIDExOEwzNzQgMjM1UTQ0NyAzNTIgNTIwIDQ3MVQ1OTUgNTk0UTU5OSA2MDEgNTk5IDYwOVE1OTkgNjMzIDU1NSA2MzdRNTM3IDYzNyA1MzcgNjQ4UTUzNyA2NDkgNTM5IDY2MVE1NDIgNjc1IDU0NSA2NzlUNTU4IDY4M1E1NjAgNjgzIDU3MCA2ODNUNjA0IDY4MlQ2NjggNjgxUTczNyA2ODEgNzU1IDY4M0g3NjJRNzY5IDY3NiA3NjkgNjcyUTc2OSA2NTUgNzYwIDY0MFE3NTcgNjM3IDc0MyA2MzdRNzMwIDYzNiA3MTkgNjM1VDY5OCA2MzBUNjgyIDYyM1Q2NzAgNjE1VDY2MCA2MDhUNjUyIDU5OVQ2NDUgNTkyTDQ1MiAyODJRMjcyIC05IDI2NiAtMTZRMjYzIC0xOCAyNTkgLTIxTDI0MSAtMjJIMjM0UTIxNiAtMjIgMjE2IC0xNVEyMTMgLTkgMTc3IDMwNVExMzkgNjIzIDEzOCA2MjZRMTMzIDYzNyA3NiA2MzdINTlRNTIgNjQyIDUyIDY0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkzMSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMS03QiIgeD0iMCIgeT0iLTEiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1ODMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI4MDQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iNjkzIiB5PSItMjEyIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTE4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMwIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4OTAiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTdEIiB4PSIzMDUyIiB5PSItMSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iNDg0NCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU5MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTY3IiB5PSI1ODMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDczNDYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=)
fact 6 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjIyLjg0MWV4IiBoZWlnaHQ9IjYuMTc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMi41MDVleDsiIHZpZXdCb3g9IjAgLTE1ODAuNyA5ODM0LjIgMjY1OS4xIiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQ1IiBkPSJNNDkyIDIxM1E0NzIgMjEzIDQ3MiAyMjZRNDcyIDIzMCA0NzcgMjUwVDQ4MiAyODVRNDgyIDMxNiA0NjEgMzIzVDM2NCAzMzBIMzEyUTMxMSAzMjggMjc3IDE5MlQyNDMgNTJRMjQzIDQ4IDI1NCA0OFQzMzQgNDZRNDI4IDQ2IDQ1OCA0OFQ1MTggNjFRNTY3IDc3IDU5OSAxMTdUNjcwIDI0OFE2ODAgMjcwIDY4MyAyNzJRNjkwIDI3NCA2OTggMjc0UTcxOCAyNzQgNzE4IDI2MVE2MTMgNyA2MDggMlE2MDUgMCAzMjIgMEgxMzNRMzEgMCAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDYgNjYgMjE1IDM0MlQyODUgNjIyUTI4NSA2MjkgMjgxIDYyOVEyNzMgNjMyIDIyOCA2MzRIMTk3UTE5MSA2NDAgMTkxIDY0MlQxOTMgNjU5UTE5NyA2NzYgMjAzIDY4MEg3NTdRNzY0IDY3NiA3NjQgNjY5UTc2NCA2NjQgNzUxIDU1N1Q3MzcgNDQ3UTczNSA0NDAgNzE3IDQ0MEg3MDVRNjk4IDQ0NSA2OTggNDUzTDcwMSA0NzZRNzA0IDUwMCA3MDQgNTI4UTcwNCA1NTggNjk3IDU3OFQ2NzggNjA5VDY0MyA2MjVUNTk2IDYzMlQ1MzIgNjM0SDQ4NVEzOTcgNjMzIDM5MiA2MzFRMzg4IDYyOSAzODYgNjIyUTM4NSA2MTkgMzU1IDQ5OVQzMjQgMzc3UTM0NyAzNzYgMzcyIDM3NkgzOThRNDY0IDM3NiA0ODkgMzkxVDUzNCA0NzJRNTM4IDQ4OCA1NDAgNDkwVDU1NyA0OTNRNTYyIDQ5MyA1NjUgNDkzVDU3MCA0OTJUNTcyIDQ5MVQ1NzQgNDg3VDU3NyA0ODNMNTQ0IDM1MVE1MTEgMjE4IDUwOCAyMTZRNTA1IDIxMyA0OTIgMjEzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0IiIGQ9Ik00MzQgLTIzMVE0MzQgLTI0NCA0MjggLTI1MEg0MTBRMjgxIC0yNTAgMjMwIC0xODRRMjI1IC0xNzcgMjIyIC0xNzJUMjE3IC0xNjFUMjEzIC0xNDhUMjExIC0xMzNUMjEwIC0xMTFUMjA5IC04NFQyMDkgLTQ3VDIwOSAwUTIwOSAyMSAyMDkgNTNRMjA4IDE0MiAyMDQgMTUzUTIwMyAxNTQgMjAzIDE1NVExODkgMTkxIDE1MyAyMTFUODIgMjMxUTcxIDIzMSA2OCAyMzRUNjUgMjUwVDY4IDI2NlQ4MiAyNjlRMTE2IDI2OSAxNTIgMjg5VDIwMyAzNDVRMjA4IDM1NiAyMDggMzc3VDIwOSA1MjlWNTc5UTIwOSA2MzQgMjE1IDY1NlQyNDQgNjk4UTI3MCA3MjQgMzI0IDc0MFEzNjEgNzQ4IDM3NyA3NDlRMzc5IDc0OSAzOTAgNzQ5VDQwOCA3NTBINDI4UTQzNCA3NDQgNDM0IDczMlE0MzQgNzE5IDQzMSA3MTZRNDI5IDcxMyA0MTUgNzEzUTM2MiA3MTAgMzMyIDY4OVQyOTYgNjQ3UTI5MSA2MzQgMjkxIDQ5OVY0MTdRMjkxIDM3MCAyODggMzUzVDI3MSAzMTRRMjQwIDI3MSAxODQgMjU1TDE3MCAyNTBMMTg0IDI0NVEyMDIgMjM5IDIyMCAyMzBUMjYyIDE5NlQyOTAgMTM3UTI5MSAxMzEgMjkxIDFRMjkxIC0xMzQgMjk2IC0xNDdRMzA2IC0xNzQgMzM5IC0xOTJUNDE1IC0yMTNRNDI5IC0yMTMgNDMxIC0yMTZRNDM0IC0yMTkgNDM0IC0yMzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjAyIiBkPSJNMjAyIDUwOFExNzkgNTA4IDE2OSA1MjBUMTU4IDU0N1ExNTggNTU3IDE2NCA1NzdUMTg1IDYyNFQyMzAgNjc1VDMwMSA3MTBMMzMzIDcxNUgzNDVRMzc4IDcxNSAzODQgNzE0UTQ0NyA3MDMgNDg5IDY2MVQ1NDkgNTY4VDU2NiA0NTdRNTY2IDM2MiA1MTkgMjQwVDQwMiA1M1EzMjEgLTIyIDIyMyAtMjJRMTIzIC0yMiA3MyA1NlE0MiAxMDIgNDIgMTQ4VjE1OVE0MiAyNzYgMTI5IDM3MFQzMjIgNDY1UTM4MyA0NjUgNDE0IDQzNFQ0NTUgMzY3TDQ1OCAzNzhRNDc4IDQ2MSA0NzggNTE1UTQ3OCA2MDMgNDM3IDYzOVQzNDQgNjc2UTI2NiA2NzYgMjIzIDYxMlEyNjQgNjA2IDI2NCA1NzJRMjY0IDU0NyAyNDYgNTI4VDIwMiA1MDhaTTQzMCAzMDZRNDMwIDM3MiA0MDEgNDAwVDMzMyA0MjhRMjcwIDQyOCAyMjIgMzgyUTE5NyAzNTQgMTgzIDMyM1QxNTAgMjIxUTEzMiAxNDkgMTMyIDExNlExMzIgMjEgMjMyIDIxUTI0NCAyMSAyNTAgMjJRMzI3IDM1IDM3NCAxMTJRMzg5IDEzNyA0MDkgMTk2VDQzMCAzMDZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktM0I0IiBkPSJNMTk1IDYwOVExOTUgNjU2IDIyNyA2ODZUMzAyIDcxN1EzMTkgNzE2IDM1MSA3MDlUNDA3IDY5N1Q0MzMgNjkwUTQ1MSA2ODIgNDUxIDY2MlE0NTEgNjQ0IDQzOCA2MjhUNDAzIDYxMlEzODIgNjEyIDM0OCA2NDFUMjg4IDY3MVQyNDkgNjU3VDIzNSA2MjhRMjM1IDU4NCAzMzQgNDYzUTQwMSAzNzkgNDAxIDI5MlE0MDEgMTY5IDM0MCA4MFQyMDUgLTEwSDE5OFExMjcgLTEwIDgzIDM2VDM2IDE1M1EzNiAyODYgMTUxIDM4MlExOTEgNDEzIDI1MiA0MzRRMjUyIDQzNSAyNDUgNDQ5VDIzMCA0ODFUMjE0IDUyMVQyMDEgNTY2VDE5NSA2MDlaTTExMiAxMzBRMTEyIDgzIDEzNiA1NVQyMDQgMjdRMjMzIDI3IDI1NiA1MVQyOTEgMTExVDMwOSAxNzhUMzE2IDIzMlEzMTYgMjY3IDMwOSAyOThUMjk1IDM0NFQyNjkgNDAwTDI1OSAzOTZRMjE1IDM4MSAxODMgMzQyVDEzNyAyNTZUMTE4IDE3OVQxMTIgMTMwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY2IiBkPSJNMTE4IC0xNjJRMTIwIC0xNjIgMTI0IC0xNjRUMTM1IC0xNjdUMTQ3IC0xNjhRMTYwIC0xNjggMTcxIC0xNTVUMTg3IC0xMjZRMTk3IC05OSAyMjEgMjdUMjY3IDI2N1QyODkgMzgyVjM4NUgyNDJRMTk1IDM4NSAxOTIgMzg3UTE4OCAzOTAgMTg4IDM5N0wxOTUgNDI1UTE5NyA0MzAgMjAzIDQzMFQyNTAgNDMxUTI5OCA0MzEgMjk4IDQzMlEyOTggNDM0IDMwNyA0ODJUMzE5IDU0MFEzNTYgNzA1IDQ2NSA3MDVRNTAyIDcwMyA1MjYgNjgzVDU1MCA2MzBRNTUwIDU5NCA1MjkgNTc4VDQ4NyA1NjFRNDQzIDU2MSA0NDMgNjAzUTQ0MyA2MjIgNDU0IDYzNlQ0NzggNjU3TDQ4NyA2NjJRNDcxIDY2OCA0NTcgNjY4UTQ0NSA2NjggNDM0IDY1OFQ0MTkgNjMwUTQxMiA2MDEgNDAzIDU1MlQzODcgNDY5VDM4MCA0MzNRMzgwIDQzMSA0MzUgNDMxUTQ4MCA0MzEgNDg3IDQzMFQ0OTggNDI0UTQ5OSA0MjAgNDk2IDQwN1Q0OTEgMzkxUTQ4OSAzODYgNDgyIDM4NlQ0MjggMzg1SDM3MkwzNDkgMjYzUTMwMSAxNSAyODIgLTQ3UTI1NSAtMTMyIDIxMiAtMTczUTE3NSAtMjA1IDEzOSAtMjA1UTEwNyAtMjA1IDgxIC0xODZUNTUgLTEzMlE1NSAtOTUgNzYgLTc4VDExOCAtNjFRMTYyIC02MSAxNjIgLTEwM1ExNjIgLTEyMiAxNTEgLTEzNlQxMjcgLTE1N0wxMTggLTE2MloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkUiIGQ9Ik0yMSAyODdRMjIgMjkzIDI0IDMwM1QzNiAzNDFUNTYgMzg4VDg5IDQyNVQxMzUgNDQyUTE3MSA0NDIgMTk1IDQyNFQyMjUgMzkwVDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzA0IDQ0MiAzODIgNDQyUTQzNiA0NDIgNDY5IDQxNVQ1MDMgMzM2VDQ2NSAxNzlUNDI3IDUyUTQyNyAyNiA0NDQgMjZRNDUwIDI2IDQ1MyAyN1E0ODIgMzIgNTA1IDY1VDU0MCAxNDVRNTQyIDE1MyA1NjAgMTUzUTU4MCAxNTMgNTgwIDE0NVE1ODAgMTQ0IDU3NiAxMzBRNTY4IDEwMSA1NTQgNzNUNTA4IDE3VDQzOSAtMTBRMzkyIC0xMCAzNzEgMTdUMzUwIDczUTM1MCA5MiAzODYgMTkzVDQyMyAzNDVRNDIzIDQwNCAzNzkgNDA0SDM3NFEyODggNDA0IDIyOSAzMDNMMjIyIDI5MUwxODkgMTU3UTE1NiAyNiAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExMiAxODBUMTUyIDM0M1ExNTMgMzQ4IDE1MyAzNjZRMTUzIDQwNSAxMjkgNDA1UTkxIDQwNSA2NiAzMDVRNjAgMjg1IDYwIDI4NFE1OCAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03QyIgZD0iTTEzOSAtMjQ5SDEzN1ExMjUgLTI0OSAxMTkgLTIzNVYyNTFMMTIwIDczN1ExMzAgNzUwIDEzOSA3NTBRMTUyIDc1MCAxNTkgNzM1Vi0yMzVRMTUxIC0yNDkgMTQxIC0yNDlIMTM5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMCIgZD0iTTk2IDU4NVExNTIgNjY2IDI0OSA2NjZRMjk3IDY2NiAzNDUgNjQwVDQyMyA1NDhRNDYwIDQ2NSA0NjAgMzIwUTQ2MCAxNjUgNDE3IDgzUTM5NyA0MSAzNjIgMTZUMzAxIC0xNVQyNTAgLTIyUTIyNCAtMjIgMTk4IC0xNlQxMzcgMTZUODIgODNRMzkgMTY1IDM5IDMyMFEzOSA0OTQgOTYgNTg1Wk0zMjEgNTk3UTI5MSA2MjkgMjUwIDYyOVEyMDggNjI5IDE3OCA1OTdRMTUzIDU3MSAxNDUgNTI1VDEzNyAzMzNRMTM3IDE3NSAxNDUgMTI1VDE4MSA0NlEyMDkgMTYgMjUwIDE2UTI5MCAxNiAzMTggNDZRMzQ3IDc2IDM1NCAxMzBUMzYyIDMzM1EzNjIgNDc4IDM1NCA1MjRUMzIxIDU5N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdEIiBkPSJNNjUgNzMxUTY1IDc0NSA2OCA3NDdUODggNzUwUTE3MSA3NTAgMjE2IDcyNVQyNzkgNjcwUTI4OCA2NDkgMjg5IDYzNVQyOTEgNTAxUTI5MiAzNjIgMjkzIDM1N1EzMDYgMzEyIDM0NSAyOTFUNDE3IDI2OVE0MjggMjY5IDQzMSAyNjZUNDM0IDI1MFQ0MzEgMjM0VDQxNyAyMzFRMzgwIDIzMSAzNDUgMjEwVDI5OCAxNTdRMjkzIDE0MyAyOTIgMTIxVDI5MSAtMjhWLTc5UTI5MSAtMTM0IDI4NSAtMTU2VDI1NiAtMTk4UTIwMiAtMjUwIDg5IC0yNTBRNzEgLTI1MCA2OCAtMjQ3VDY1IC0yMzBRNjUgLTIyNCA2NSAtMjIzVDY2IC0yMThUNjkgLTIxNFQ3NyAtMjEzUTkxIC0yMTMgMTA4IC0yMTBUMTQ2IC0yMDBUMTgzIC0xNzdUMjA3IC0xMzlRMjA4IC0xMzQgMjA5IDNMMjEwIDEzOVEyMjMgMTk2IDI4MCAyMzBRMzE1IDI0NyAzMzAgMjUwUTMwNSAyNTcgMjgwIDI3MFEyMjUgMzA0IDIxMiAzNTJMMjEwIDM2MkwyMDkgNDk4UTIwOCA2MzUgMjA3IDY0MFExOTUgNjgwIDE1NCA2OTZUNzcgNzEzUTY4IDcxMyA2NyA3MTZUNjUgNzMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMy03QiIgZD0iTTYxOCAtOTQzTDYxMiAtOTQ5SDU4Mkw1NjggLTk0M1E0NzIgLTkwMyA0MTEgLTg0MVQzMzIgLTcwM1EzMjcgLTY4MiAzMjcgLTY1M1QzMjUgLTM1MFEzMjQgLTI4IDMyMyAtMThRMzE3IDI0IDMwMSA2MVQyNjQgMTI0VDIyMSAxNzFUMTc5IDIwNVQxNDcgMjI1VDEzMiAyMzRRMTMwIDIzOCAxMzAgMjUwUTEzMCAyNTUgMTMwIDI1OFQxMzEgMjY0VDEzMiAyNjdUMTM0IDI2OVQxMzkgMjcyVDE0NCAyNzVRMjA3IDMwOCAyNTYgMzY3UTMxMCA0MzYgMzIzIDUxOVEzMjQgNTI5IDMyNSA4NTFRMzI2IDExMjQgMzI2IDExNTRUMzMyIDEyMDVRMzY5IDEzNTggNTY2IDE0NDNMNTgyIDE0NTBINjEyTDYxOCAxNDQ0VjE0MjlRNjE4IDE0MTMgNjE2IDE0MTFMNjA4IDE0MDZRNTk5IDE0MDIgNTg1IDEzOTNUNTUyIDEzNzJUNTE1IDEzNDNUNDc5IDEzMDVUNDQ5IDEyNTdUNDI5IDEyMDBRNDI1IDExODAgNDI1IDExNTJUNDIzIDg1MVE0MjIgNTc5IDQyMiA1NDlUNDE2IDQ5OFE0MDcgNDU5IDM4OCA0MjRUMzQ2IDM2NFQyOTcgMzE4VDI1MCAyODRUMjE0IDI2NFQxOTcgMjU0TDE4OCAyNTFMMjA1IDI0MlEyOTAgMjAwIDM0NSAxMzhUNDE2IDNRNDIxIC0xOCA0MjEgLTQ4VDQyMyAtMzQ5UTQyMyAtMzk3IDQyMyAtNDcyUTQyNCAtNjc3IDQyOCAtNjk0UTQyOSAtNjk3IDQyOSAtNjk5UTQzNCAtNzIyIDQ0MyAtNzQzVDQ2NSAtNzgyVDQ5MSAtODE2VDUxOSAtODQ1VDU0OCAtODY4VDU3NCAtODg2VDU5NSAtODk5VDYxMCAtOTA4TDYxNiAtOTEwUTYxOCAtOTEyIDYxOCAtOTI4Vi05NDNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1ozLTdEIiBkPSJNMTMxIDE0MTRUMTMxIDE0MjlUMTMzIDE0NDdUMTQ4IDE0NTBIMTUzSDE2N0wxODIgMTQ0NFEyNzYgMTQwNCAzMzYgMTM0M1Q0MTUgMTIwN1E0MjEgMTE4NCA0MjEgMTE1NFQ0MjMgODUxTDQyNCA1MzFMNDI2IDUxN1E0MzQgNDYyIDQ2MCA0MTVUNTE4IDMzOVQ1NzEgMjk2VDYwOCAyNzRRNjE1IDI3MCA2MTYgMjY3VDYxOCAyNTFRNjE4IDI0MSA2MTggMjM4VDYxNSAyMzJUNjA4IDIyN1E1NDIgMTk0IDQ5MSAxMzJUNDI2IC0xNUw0MjQgLTI5TDQyMyAtMzUwUTQyMiAtNjIyIDQyMiAtNjUyVDQxNSAtNzA2UTM5NyAtNzgwIDMzNyAtODQxVDE4MiAtOTQzTDE2NyAtOTQ5SDE1M1ExMzcgLTk0OSAxMzQgLTk0NlQxMzEgLTkyOFExMzEgLTkxNCAxMzIgLTkxMVQxNDQgLTkwNFExNDYgLTkwMyAxNDggLTkwMlEyOTkgLTgyMCAzMjMgLTY4MFEzMjQgLTY2MyAzMjUgLTM0OVQzMjcgLTE5UTM1NSAxNDUgNTQxIDI0MUw1NjEgMjUwTDU0MSAyNjBRMzU2IDM1NSAzMjcgNTIwUTMyNiA1MzcgMzI1IDg1MFQzMjMgMTE4MVEzMTUgMTIyNyAyOTMgMTI2N1QyNDQgMTMzMlQxOTMgMTM3NFQxNTEgMTQwMVQxMzIgMTQxM1ExMzEgMTQxNCAxMzEgMTQyOVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkzMSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMy03QiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDc1MCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjExMzkiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMDIiIHg9IjI4NSIgeT0iNjc2Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTczOCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMDIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS0zQjQiIHg9IjU2NyIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzc5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjYiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iODA0IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjY5MyIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjU2OCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS0zQjQiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg0MSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzk2NSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0MiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNzgsLTI4NikiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktM0I0IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjQ1MSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMwIiB4PSIxMjMwIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1ozLTdEIiB4PSI2MzE3IiB5PSItMSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iODI3NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzAiIHg9IjkzMzMiIHk9IjAiPjwvdXNlPgo8L2c+Cjwvc3ZnPg==) 因为
因为 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQwLjM0MWV4IiBoZWlnaHQ9IjUuNTA5ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMi4wMDVleDsiIHZpZXdCb3g9IjAgLTE1MDguOSAxNzM2OC45IDIzNzIiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjAyIiBkPSJNMjAyIDUwOFExNzkgNTA4IDE2OSA1MjBUMTU4IDU0N1ExNTggNTU3IDE2NCA1NzdUMTg1IDYyNFQyMzAgNjc1VDMwMSA3MTBMMzMzIDcxNUgzNDVRMzc4IDcxNSAzODQgNzE0UTQ0NyA3MDMgNDg5IDY2MVQ1NDkgNTY4VDU2NiA0NTdRNTY2IDM2MiA1MTkgMjQwVDQwMiA1M1EzMjEgLTIyIDIyMyAtMjJRMTIzIC0yMiA3MyA1NlE0MiAxMDIgNDIgMTQ4VjE1OVE0MiAyNzYgMTI5IDM3MFQzMjIgNDY1UTM4MyA0NjUgNDE0IDQzNFQ0NTUgMzY3TDQ1OCAzNzhRNDc4IDQ2MSA0NzggNTE1UTQ3OCA2MDMgNDM3IDYzOVQzNDQgNjc2UTI2NiA2NzYgMjIzIDYxMlEyNjQgNjA2IDI2NCA1NzJRMjY0IDU0NyAyNDYgNTI4VDIwMiA1MDhaTTQzMCAzMDZRNDMwIDM3MiA0MDEgNDAwVDMzMyA0MjhRMjcwIDQyOCAyMjIgMzgyUTE5NyAzNTQgMTgzIDMyM1QxNTAgMjIxUTEzMiAxNDkgMTMyIDExNlExMzIgMjEgMjMyIDIxUTI0NCAyMSAyNTAgMjJRMzI3IDM1IDM3NCAxMTJRMzg5IDEzNyA0MDkgMTk2VDQzMCAzMDZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktM0I0IiBkPSJNMTk1IDYwOVExOTUgNjU2IDIyNyA2ODZUMzAyIDcxN1EzMTkgNzE2IDM1MSA3MDlUNDA3IDY5N1Q0MzMgNjkwUTQ1MSA2ODIgNDUxIDY2MlE0NTEgNjQ0IDQzOCA2MjhUNDAzIDYxMlEzODIgNjEyIDM0OCA2NDFUMjg4IDY3MVQyNDkgNjU3VDIzNSA2MjhRMjM1IDU4NCAzMzQgNDYzUTQwMSAzNzkgNDAxIDI5MlE0MDEgMTY5IDM0MCA4MFQyMDUgLTEwSDE5OFExMjcgLTEwIDgzIDM2VDM2IDE1M1EzNiAyODYgMTUxIDM4MlExOTEgNDEzIDI1MiA0MzRRMjUyIDQzNSAyNDUgNDQ5VDIzMCA0ODFUMjE0IDUyMVQyMDEgNTY2VDE5NSA2MDlaTTExMiAxMzBRMTEyIDgzIDEzNiA1NVQyMDQgMjdRMjMzIDI3IDI1NiA1MVQyOTEgMTExVDMwOSAxNzhUMzE2IDIzMlEzMTYgMjY3IDMwOSAyOThUMjk1IDM0NFQyNjkgNDAwTDI1OSAzOTZRMjE1IDM4MSAxODMgMzQyVDEzNyAyNTZUMTE4IDE3OVQxMTIgMTMwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY2IiBkPSJNMTE4IC0xNjJRMTIwIC0xNjIgMTI0IC0xNjRUMTM1IC0xNjdUMTQ3IC0xNjhRMTYwIC0xNjggMTcxIC0xNTVUMTg3IC0xMjZRMTk3IC05OSAyMjEgMjdUMjY3IDI2N1QyODkgMzgyVjM4NUgyNDJRMTk1IDM4NSAxOTIgMzg3UTE4OCAzOTAgMTg4IDM5N0wxOTUgNDI1UTE5NyA0MzAgMjAzIDQzMFQyNTAgNDMxUTI5OCA0MzEgMjk4IDQzMlEyOTggNDM0IDMwNyA0ODJUMzE5IDU0MFEzNTYgNzA1IDQ2NSA3MDVRNTAyIDcwMyA1MjYgNjgzVDU1MCA2MzBRNTUwIDU5NCA1MjkgNTc4VDQ4NyA1NjFRNDQzIDU2MSA0NDMgNjAzUTQ0MyA2MjIgNDU0IDYzNlQ0NzggNjU3TDQ4NyA2NjJRNDcxIDY2OCA0NTcgNjY4UTQ0NSA2NjggNDM0IDY1OFQ0MTkgNjMwUTQxMiA2MDEgNDAzIDU1MlQzODcgNDY5VDM4MCA0MzNRMzgwIDQzMSA0MzUgNDMxUTQ4MCA0MzEgNDg3IDQzMFQ0OTggNDI0UTQ5OSA0MjAgNDk2IDQwN1Q0OTEgMzkxUTQ4OSAzODYgNDgyIDM4NlQ0MjggMzg1SDM3MkwzNDkgMjYzUTMwMSAxNSAyODIgLTQ3UTI1NSAtMTMyIDIxMiAtMTczUTE3NSAtMjA1IDEzOSAtMjA1UTEwNyAtMjA1IDgxIC0xODZUNTUgLTEzMlE1NSAtOTUgNzYgLTc4VDExOCAtNjFRMTYyIC02MSAxNjIgLTEwM1ExNjIgLTEyMiAxNTEgLTEzNlQxMjcgLTE1N0wxMTggLTE2MloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkUiIGQ9Ik0yMSAyODdRMjIgMjkzIDI0IDMwM1QzNiAzNDFUNTYgMzg4VDg5IDQyNVQxMzUgNDQyUTE3MSA0NDIgMTk1IDQyNFQyMjUgMzkwVDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzA0IDQ0MiAzODIgNDQyUTQzNiA0NDIgNDY5IDQxNVQ1MDMgMzM2VDQ2NSAxNzlUNDI3IDUyUTQyNyAyNiA0NDQgMjZRNDUwIDI2IDQ1MyAyN1E0ODIgMzIgNTA1IDY1VDU0MCAxNDVRNTQyIDE1MyA1NjAgMTUzUTU4MCAxNTMgNTgwIDE0NVE1ODAgMTQ0IDU3NiAxMzBRNTY4IDEwMSA1NTQgNzNUNTA4IDE3VDQzOSAtMTBRMzkyIC0xMCAzNzEgMTdUMzUwIDczUTM1MCA5MiAzODYgMTkzVDQyMyAzNDVRNDIzIDQwNCAzNzkgNDA0SDM3NFEyODggNDA0IDIyOSAzMDNMMjIyIDI5MUwxODkgMTU3UTE1NiAyNiAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExMiAxODBUMTUyIDM0M1ExNTMgMzQ4IDE1MyAzNjZRMTUzIDQwNSAxMjkgNDA1UTkxIDQwNSA2NiAzMDVRNjAgMjg1IDYwIDI4NFE1OCAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03QyIgZD0iTTEzOSAtMjQ5SDEzN1ExMjUgLTI0OSAxMTkgLTIzNVYyNTFMMTIwIDczN1ExMzAgNzUwIDEzOSA3NTBRMTUyIDc1MCAxNTkgNzM1Vi0yMzVRMTUxIC0yNDkgMTQxIC0yNDlIMTM5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMCIgZD0iTTk2IDU4NVExNTIgNjY2IDI0OSA2NjZRMjk3IDY2NiAzNDUgNjQwVDQyMyA1NDhRNDYwIDQ2NSA0NjAgMzIwUTQ2MCAxNjUgNDE3IDgzUTM5NyA0MSAzNjIgMTZUMzAxIC0xNVQyNTAgLTIyUTIyNCAtMjIgMTk4IC0xNlQxMzcgMTZUODIgODNRMzkgMTY1IDM5IDMyMFEzOSA0OTQgOTYgNTg1Wk0zMjEgNTk3UTI5MSA2MjkgMjUwIDYyOVEyMDggNjI5IDE3OCA1OTdRMTUzIDU3MSAxNDUgNTI1VDEzNyAzMzNRMTM3IDE3NSAxNDUgMTI1VDE4MSA0NlEyMDkgMTYgMjUwIDE2UTI5MCAxNiAzMTggNDZRMzQ3IDc2IDM1NCAxMzBUMzYyIDMzM1EzNjIgNDc4IDM1NCA1MjRUMzIxIDU5N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NiIgZD0iTTUyIDY0OFE1MiA2NzAgNjUgNjgzSDc2UTExOCA2ODAgMTgxIDY4MFEyOTkgNjgwIDMyMCA2ODNIMzMwUTMzNiA2NzcgMzM2IDY3NFQzMzQgNjU2UTMyOSA2NDEgMzI1IDYzN0gzMDRRMjgyIDYzNSAyNzQgNjM1UTI0NSA2MzAgMjQyIDYyMFEyNDIgNjE4IDI3MSAzNjlUMzAxIDExOEwzNzQgMjM1UTQ0NyAzNTIgNTIwIDQ3MVQ1OTUgNTk0UTU5OSA2MDEgNTk5IDYwOVE1OTkgNjMzIDU1NSA2MzdRNTM3IDYzNyA1MzcgNjQ4UTUzNyA2NDkgNTM5IDY2MVE1NDIgNjc1IDU0NSA2NzlUNTU4IDY4M1E1NjAgNjgzIDU3MCA2ODNUNjA0IDY4MlQ2NjggNjgxUTczNyA2ODEgNzU1IDY4M0g3NjJRNzY5IDY3NiA3NjkgNjcyUTc2OSA2NTUgNzYwIDY0MFE3NTcgNjM3IDc0MyA2MzdRNzMwIDYzNiA3MTkgNjM1VDY5OCA2MzBUNjgyIDYyM1Q2NzAgNjE1VDY2MCA2MDhUNjUyIDU5OVQ2NDUgNTkyTDQ1MiAyODJRMjcyIC05IDI2NiAtMTZRMjYzIC0xOCAyNTkgLTIxTDI0MSAtMjJIMjM0UTIxNiAtMjIgMjE2IC0xNVEyMTMgLTkgMTc3IDMwNVExMzkgNjIzIDEzOCA2MjZRMTMzIDYzNyA3NiA2MzdINTlRNTIgNjQyIDUyIDY0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tQUYiIGQ9Ik02OSA1NDRWNTkwSDQzMFY1NDRINjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjEyIiBkPSJNODQgMjM3VDg0IDI1MFQ5OCAyNzBINjc5UTY5NCAyNjIgNjk0IDI1MFQ2NzkgMjMwSDk4UTg0IDIzNyA4NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNEIiIGQ9Ik0yODUgNjI4UTI4NSA2MzUgMjI4IDYzN1EyMDUgNjM3IDE5OCA2MzhUMTkxIDY0N1ExOTEgNjQ5IDE5MyA2NjFRMTk5IDY4MSAyMDMgNjgyUTIwNSA2ODMgMjE0IDY4M0gyMTlRMjYwIDY4MSAzNTUgNjgxUTM4OSA2ODEgNDE4IDY4MVQ0NjMgNjgyVDQ4MyA2ODJRNTAwIDY4MiA1MDAgNjc0UTUwMCA2NjkgNDk3IDY2MFE0OTYgNjU4IDQ5NiA2NTRUNDk1IDY0OFQ0OTMgNjQ0VDQ5MCA2NDFUNDg2IDYzOVQ0NzkgNjM4VDQ3MCA2MzdUNDU2IDYzN1E0MTYgNjM2IDQwNSA2MzRUMzg3IDYyM0wzMDYgMzA1UTMwNyAzMDUgNDkwIDQ0OVQ2NzggNTk3UTY5MiA2MTEgNjkyIDYyMFE2OTIgNjM1IDY2NyA2MzdRNjUxIDYzNyA2NTEgNjQ4UTY1MSA2NTAgNjU0IDY2MlQ2NTkgNjc3UTY2MiA2ODIgNjc2IDY4MlE2ODAgNjgyIDcxMSA2ODFUNzkxIDY4MFE4MTQgNjgwIDgzOSA2ODFUODY5IDY4MlE4ODkgNjgyIDg4OSA2NzJRODg5IDY1MCA4ODEgNjQyUTg3OCA2MzcgODYyIDYzN1E3ODcgNjMyIDcyNiA1ODZRNzEwIDU3NiA2NTYgNTM0VDU1NiA0NTVMNTA5IDQxOEw1MTggMzk2UTUyNyAzNzQgNTQ2IDMyOVQ1ODEgMjQ0UTY1NiA2NyA2NjEgNjFRNjYzIDU5IDY2NiA1N1E2ODAgNDcgNzE3IDQ2SDczOFE3NDQgMzggNzQ0IDM3VDc0MSAxOVE3MzcgNiA3MzEgMEg3MjBRNjgwIDMgNjI1IDNRNTAzIDMgNDg4IDBINDc4UTQ3MiA2IDQ3MiA5VDQ3NCAyN1E0NzggNDAgNDgwIDQzVDQ5MSA0Nkg0OTRRNTQ0IDQ2IDU0NCA3MVE1NDQgNzUgNTE3IDE0MVQ0ODUgMjE2TDQyNyAzNTRMMzU5IDMwMUwyOTEgMjQ4TDI2OCAxNTVRMjQ1IDYzIDI0NSA1OFEyNDUgNTEgMjUzIDQ5VDMwMyA0NkgzMzRRMzQwIDM3IDM0MCAzNVEzNDAgMTkgMzMzIDVRMzI4IDAgMzE3IDBRMzE0IDAgMjgwIDFUMTgwIDJRMTE4IDIgODUgMlQ0OSAxUTMxIDEgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ3IDY1IDIxNiAzMzlUMjg1IDYyOFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItMjgiIGQ9Ik0xODAgOTZUMTgwIDI1MFQyMDUgNTQxVDI2NiA3NzBUMzUzIDk0NFQ0NDQgMTA2OVQ1MjcgMTE1MEg1NTVRNTYxIDExNDQgNTYxIDExNDFRNTYxIDExMzcgNTQ1IDExMjBUNTA0IDEwNzJUNDQ3IDk5NVQzODYgODc4VDMzMCA3MjFUMjg4IDUxM1QyNzIgMjUxUTI3MiAxMzMgMjgwIDU2UTI5MyAtODcgMzI2IC0yMDlUMzk5IC00MDVUNDc1IC01MzFUNTM2IC02MDlUNTYxIC02NDBRNTYxIC02NDMgNTU1IC02NDlINTI3UTQ4MyAtNjEyIDQ0MyAtNTY4VDM1MyAtNDQzVDI2NiAtMjcwVDIwNSAtNDFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oyLTI5IiBkPSJNMzUgMTEzOFEzNSAxMTUwIDUxIDExNTBINTZINjlRMTEzIDExMTMgMTUzIDEwNjlUMjQzIDk0NFQzMzAgNzcxVDM5MSA1NDFUNDE2IDI1MFQzOTEgLTQwVDMzMCAtMjcwVDI0MyAtNDQzVDE1MiAtNTY4VDY5IC02NDlINTZRNDMgLTY0OSAzOSAtNjQ3VDM1IC02MzdRNjUgLTYwNyAxMTAgLTU0OFEyODMgLTMxNiAzMTYgNTZRMzI0IDEzMyAzMjQgMjUxUTMyNCAzNjggMzE2IDQ0NVEyNzggODc3IDQ4IDExMjNRMzYgMTEzNyAzNSAxMTM4WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjExMzkiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMDIiIHg9IjI4NSIgeT0iNjc2Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTczOCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMDIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS0zQjQiIHg9IjU2NyIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzc5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNjYiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iODA0IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjY5MyIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjU2OCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS0zQjQiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg0MSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzk2NSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tN0MiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNzgsLTI4NikiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktM0I0IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjQ1MSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMwIiB4PSIxMjMwIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjU4NDUiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI2OTAxIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9Ijc0MDEiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4MzM4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDk3NTMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1OTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMjQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3OCw0OTQpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiIHg9Ii03MCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIxNy45MjI1MDQxNjY2ODEsMCkgc2NhbGUoMC43NTk4NzEwNjU2MjgzODA2LDEpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSI1NjUiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTE3NiIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMTU3OCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIyNTc5IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzUxNSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0OTMwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNEIiIHg9IjI0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjYsNTAwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSItNzAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODIuMzA2MTYwNjc2Mzc2MjcsMCkgc2NhbGUoMS40ODQ2MDY1NDc3MzA5MzYzLDEpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSI4MjciIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTM2NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItMjkiIHg9IjcwMTgiIHk9Ii0xIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==)
fact 7 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjUxLjU4NWV4IiBoZWlnaHQ9IjYuMDA5ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMi4xNzFleDsiIHZpZXdCb3g9IjAgLTE2NTIuNSAyMjIwOS45IDI1ODcuMyIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMDIiIGQ9Ik0yMDIgNTA4UTE3OSA1MDggMTY5IDUyMFQxNTggNTQ3UTE1OCA1NTcgMTY0IDU3N1QxODUgNjI0VDIzMCA2NzVUMzAxIDcxMEwzMzMgNzE1SDM0NVEzNzggNzE1IDM4NCA3MTRRNDQ3IDcwMyA0ODkgNjYxVDU0OSA1NjhUNTY2IDQ1N1E1NjYgMzYyIDUxOSAyNDBUNDAyIDUzUTMyMSAtMjIgMjIzIC0yMlExMjMgLTIyIDczIDU2UTQyIDEwMiA0MiAxNDhWMTU5UTQyIDI3NiAxMjkgMzcwVDMyMiA0NjVRMzgzIDQ2NSA0MTQgNDM0VDQ1NSAzNjdMNDU4IDM3OFE0NzggNDYxIDQ3OCA1MTVRNDc4IDYwMyA0MzcgNjM5VDM0NCA2NzZRMjY2IDY3NiAyMjMgNjEyUTI2NCA2MDYgMjY0IDU3MlEyNjQgNTQ3IDI0NiA1MjhUMjAyIDUwOFpNNDMwIDMwNlE0MzAgMzcyIDQwMSA0MDBUMzMzIDQyOFEyNzAgNDI4IDIyMiAzODJRMTk3IDM1NCAxODMgMzIzVDE1MCAyMjFRMTMyIDE0OSAxMzIgMTE2UTEzMiAyMSAyMzIgMjFRMjQ0IDIxIDI1MCAyMlEzMjcgMzUgMzc0IDExMlEzODkgMTM3IDQwOSAxOTZUNDMwIDMwNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktM0I0IiBkPSJNMTk1IDYwOVExOTUgNjU2IDIyNyA2ODZUMzAyIDcxN1EzMTkgNzE2IDM1MSA3MDlUNDA3IDY5N1Q0MzMgNjkwUTQ1MSA2ODIgNDUxIDY2MlE0NTEgNjQ0IDQzOCA2MjhUNDAzIDYxMlEzODIgNjEyIDM0OCA2NDFUMjg4IDY3MVQyNDkgNjU3VDIzNSA2MjhRMjM1IDU4NCAzMzQgNDYzUTQwMSAzNzkgNDAxIDI5MlE0MDEgMTY5IDM0MCA4MFQyMDUgLTEwSDE5OFExMjcgLTEwIDgzIDM2VDM2IDE1M1EzNiAyODYgMTUxIDM4MlExOTEgNDEzIDI1MiA0MzRRMjUyIDQzNSAyNDUgNDQ5VDIzMCA0ODFUMjE0IDUyMVQyMDEgNTY2VDE5NSA2MDlaTTExMiAxMzBRMTEyIDgzIDEzNiA1NVQyMDQgMjdRMjMzIDI3IDI1NiA1MVQyOTEgMTExVDMwOSAxNzhUMzE2IDIzMlEzMTYgMjY3IDMwOSAyOThUMjk1IDM0NFQyNjkgNDAwTDI1OSAzOTZRMjE1IDM4MSAxODMgMzQyVDEzNyAyNTZUMTE4IDE3OVQxMTIgMTMwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY2IiBkPSJNMTE4IC0xNjJRMTIwIC0xNjIgMTI0IC0xNjRUMTM1IC0xNjdUMTQ3IC0xNjhRMTYwIC0xNjggMTcxIC0xNTVUMTg3IC0xMjZRMTk3IC05OSAyMjEgMjdUMjY3IDI2N1QyODkgMzgyVjM4NUgyNDJRMTk1IDM4NSAxOTIgMzg3UTE4OCAzOTAgMTg4IDM5N0wxOTUgNDI1UTE5NyA0MzAgMjAzIDQzMFQyNTAgNDMxUTI5OCA0MzEgMjk4IDQzMlEyOTggNDM0IDMwNyA0ODJUMzE5IDU0MFEzNTYgNzA1IDQ2NSA3MDVRNTAyIDcwMyA1MjYgNjgzVDU1MCA2MzBRNTUwIDU5NCA1MjkgNTc4VDQ4NyA1NjFRNDQzIDU2MSA0NDMgNjAzUTQ0MyA2MjIgNDU0IDYzNlQ0NzggNjU3TDQ4NyA2NjJRNDcxIDY2OCA0NTcgNjY4UTQ0NSA2NjggNDM0IDY1OFQ0MTkgNjMwUTQxMiA2MDEgNDAzIDU1MlQzODcgNDY5VDM4MCA0MzNRMzgwIDQzMSA0MzUgNDMxUTQ4MCA0MzEgNDg3IDQzMFQ0OTggNDI0UTQ5OSA0MjAgNDk2IDQwN1Q0OTEgMzkxUTQ4OSAzODYgNDgyIDM4NlQ0MjggMzg1SDM3MkwzNDkgMjYzUTMwMSAxNSAyODIgLTQ3UTI1NSAtMTMyIDIxMiAtMTczUTE3NSAtMjA1IDEzOSAtMjA1UTEwNyAtMjA1IDgxIC0xODZUNTUgLTEzMlE1NSAtOTUgNzYgLTc4VDExOCAtNjFRMTYyIC02MSAxNjIgLTEwM1ExNjIgLTEyMiAxNTEgLTEzNlQxMjcgLTE1N0wxMTggLTE2MloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdDIiBkPSJNMTM5IC0yNDlIMTM3UTEyNSAtMjQ5IDExOSAtMjM1VjI1MUwxMjAgNzM3UTEzMCA3NTAgMTM5IDc1MFExNTIgNzUwIDE1OSA3MzVWLTIzNVExNTEgLTI0OSAxNDEgLTI0OUgxMzlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMwIiBkPSJNOTYgNTg1UTE1MiA2NjYgMjQ5IDY2NlEyOTcgNjY2IDM0NSA2NDBUNDIzIDU0OFE0NjAgNDY1IDQ2MCAzMjBRNDYwIDE2NSA0MTcgODNRMzk3IDQxIDM2MiAxNlQzMDEgLTE1VDI1MCAtMjJRMjI0IC0yMiAxOTggLTE2VDEzNyAxNlQ4MiA4M1EzOSAxNjUgMzkgMzIwUTM5IDQ5NCA5NiA1ODVaTTMyMSA1OTdRMjkxIDYyOSAyNTAgNjI5UTIwOCA2MjkgMTc4IDU5N1ExNTMgNTcxIDE0NSA1MjVUMTM3IDMzM1ExMzcgMTc1IDE0NSAxMjVUMTgxIDQ2UTIwOSAxNiAyNTAgMTZRMjkwIDE2IDMxOCA0NlEzNDcgNzYgMzU0IDEzMFQzNjIgMzMzUTM2MiA0NzggMzU0IDUyNFQzMjEgNTk3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU0IiBkPSJNNDAgNDM3UTIxIDQzNyAyMSA0NDVRMjEgNDUwIDM3IDUwMVQ3MSA2MDJMODggNjUxUTkzIDY2OSAxMDEgNjc3SDU2OUg2NTlRNjkxIDY3NyA2OTcgNjc2VDcwNCA2NjdRNzA0IDY2MSA2ODcgNTUzVDY2OCA0NDRRNjY4IDQzNyA2NDkgNDM3UTY0MCA0MzcgNjM3IDQzN1Q2MzEgNDQyTDYyOSA0NDVRNjI5IDQ1MSA2MzUgNDkwVDY0MSA1NTFRNjQxIDU4NiA2MjggNjA0VDU3MyA2MjlRNTY4IDYzMCA1MTUgNjMxUTQ2OSA2MzEgNDU3IDYzMFQ0MzkgNjIyUTQzOCA2MjEgMzY4IDM0M1QyOTggNjBRMjk4IDQ4IDM4NiA0NlE0MTggNDYgNDI3IDQ1VDQzNiAzNlE0MzYgMzEgNDMzIDIyUTQyOSA0IDQyNCAxTDQyMiAwUTQxOSAwIDQxNSAwUTQxMCAwIDM2MyAxVDIyOCAyUTk5IDIgNjQgMEg0OVE0MyA2IDQzIDlUNDUgMjdRNDkgNDAgNTUgNDZIODNIOTRRMTc0IDQ2IDE4OSA1NVExOTAgNTYgMTkxIDU2UTE5NiA1OSAyMDEgNzZUMjQxIDIzM1EyNTggMzAxIDI2OSAzNDRRMzM5IDYxOSAzMzkgNjI1UTMzOSA2MzAgMzEwIDYzMEgyNzlRMjEyIDYzMCAxOTEgNjI0UTE0NiA2MTQgMTIxIDU4M1Q2NyA0NjdRNjAgNDQ1IDU3IDQ0MVQ0MyA0MzdINDBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi1BRiIgZD0iTTY5IDU0NFY1OTBINDMwVjU0NEg2OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMTIiIGQ9Ik04NCAyMzdUODQgMjUwVDk4IDI3MEg2NzlRNjk0IDI2MiA2OTQgMjUwVDY3OSAyMzBIOThRODQgMjM3IDg0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTM4IiBkPSJNNzAgNDE3VDcwIDQ5NFQxMjQgNjE4VDI0OCA2NjZRMzE5IDY2NiAzNzQgNjI0VDQyOSA1MTVRNDI5IDQ4NSA0MTggNDU5VDM5MiA0MTdUMzYxIDM4OVQzMzUgMzcxVDMyNCAzNjNMMzM4IDM1NFEzNTIgMzQ0IDM2NiAzMzRUMzgyIDMyM1E0NTcgMjY0IDQ1NyAxNzRRNDU3IDk1IDM5OSAzN1QyNDkgLTIyUTE1OSAtMjIgMTAxIDI5VDQzIDE1NVE0MyAyNjMgMTcyIDMzNUwxNTQgMzQ4UTEzMyAzNjEgMTI3IDM2OFE3MCA0MTcgNzAgNDk0Wk0yODYgMzg2TDI5MiAzOTBRMjk4IDM5NCAzMDEgMzk2VDMxMSA0MDNUMzIzIDQxM1QzMzQgNDI1VDM0NSA0MzhUMzU1IDQ1NFQzNjQgNDcxVDM2OSA0OTFUMzcxIDUxM1EzNzEgNTU2IDM0MiA1ODZUMjc1IDYyNFEyNjggNjI1IDI0MiA2MjVRMjAxIDYyNSAxNjUgNTk5VDEyOCA1MzRRMTI4IDUxMSAxNDEgNDkyVDE2NyA0NjNUMjE3IDQzMVEyMjQgNDI2IDIyOCA0MjRMMjg2IDM4NlpNMjUwIDIxUTMwOCAyMSAzNTAgNTVUMzkyIDEzN1EzOTIgMTU0IDM4NyAxNjlUMzc1IDE5NFQzNTMgMjE2VDMzMCAyMzRUMzAxIDI1M1QyNzQgMjcwUTI2MCAyNzkgMjQ0IDI4OVQyMTggMzA2TDIxMCAzMTFRMjA0IDMxMSAxODEgMjk0VDEzMyAyMzlUMTA3IDE1N1ExMDcgOTggMTUwIDYwVDI1MCAyMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NiIgZD0iTTUyIDY0OFE1MiA2NzAgNjUgNjgzSDc2UTExOCA2ODAgMTgxIDY4MFEyOTkgNjgwIDMyMCA2ODNIMzMwUTMzNiA2NzcgMzM2IDY3NFQzMzQgNjU2UTMyOSA2NDEgMzI1IDYzN0gzMDRRMjgyIDYzNSAyNzQgNjM1UTI0NSA2MzAgMjQyIDYyMFEyNDIgNjE4IDI3MSAzNjlUMzAxIDExOEwzNzQgMjM1UTQ0NyAzNTIgNTIwIDQ3MVQ1OTUgNTk0UTU5OSA2MDEgNTk5IDYwOVE1OTkgNjMzIDU1NSA2MzdRNTM3IDYzNyA1MzcgNjQ4UTUzNyA2NDkgNTM5IDY2MVE1NDIgNjc1IDU0NSA2NzlUNTU4IDY4M1E1NjAgNjgzIDU3MCA2ODNUNjA0IDY4MlQ2NjggNjgxUTczNyA2ODEgNzU1IDY4M0g3NjJRNzY5IDY3NiA3NjkgNjcyUTc2OSA2NTUgNzYwIDY0MFE3NTcgNjM3IDc0MyA2MzdRNzMwIDYzNiA3MTkgNjM1VDY5OCA2MzBUNjgyIDYyM1Q2NzAgNjE1VDY2MCA2MDhUNjUyIDU5OVQ2NDUgNTkyTDQ1MiAyODJRMjcyIC05IDI2NiAtMTZRMjYzIC0xOCAyNTkgLTIxTDI0MSAtMjJIMjM0UTIxNiAtMjIgMjE2IC0xNVEyMTMgLTkgMTc3IDMwNVExMzkgNjIzIDEzOCA2MjZRMTMzIDYzNyA3NiA2MzdINTlRNTIgNjQyIDUyIDY0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00QiIgZD0iTTI4NSA2MjhRMjg1IDYzNSAyMjggNjM3UTIwNSA2MzcgMTk4IDYzOFQxOTEgNjQ3UTE5MSA2NDkgMTkzIDY2MVExOTkgNjgxIDIwMyA2ODJRMjA1IDY4MyAyMTQgNjgzSDIxOVEyNjAgNjgxIDM1NSA2ODFRMzg5IDY4MSA0MTggNjgxVDQ2MyA2ODJUNDgzIDY4MlE1MDAgNjgyIDUwMCA2NzRRNTAwIDY2OSA0OTcgNjYwUTQ5NiA2NTggNDk2IDY1NFQ0OTUgNjQ4VDQ5MyA2NDRUNDkwIDY0MVQ0ODYgNjM5VDQ3OSA2MzhUNDcwIDYzN1Q0NTYgNjM3UTQxNiA2MzYgNDA1IDYzNFQzODcgNjIzTDMwNiAzMDVRMzA3IDMwNSA0OTAgNDQ5VDY3OCA1OTdRNjkyIDYxMSA2OTIgNjIwUTY5MiA2MzUgNjY3IDYzN1E2NTEgNjM3IDY1MSA2NDhRNjUxIDY1MCA2NTQgNjYyVDY1OSA2NzdRNjYyIDY4MiA2NzYgNjgyUTY4MCA2ODIgNzExIDY4MVQ3OTEgNjgwUTgxNCA2ODAgODM5IDY4MVQ4NjkgNjgyUTg4OSA2ODIgODg5IDY3MlE4ODkgNjUwIDg4MSA2NDJRODc4IDYzNyA4NjIgNjM3UTc4NyA2MzIgNzI2IDU4NlE3MTAgNTc2IDY1NiA1MzRUNTU2IDQ1NUw1MDkgNDE4TDUxOCAzOTZRNTI3IDM3NCA1NDYgMzI5VDU4MSAyNDRRNjU2IDY3IDY2MSA2MVE2NjMgNTkgNjY2IDU3UTY4MCA0NyA3MTcgNDZINzM4UTc0NCAzOCA3NDQgMzdUNzQxIDE5UTczNyA2IDczMSAwSDcyMFE2ODAgMyA2MjUgM1E1MDMgMyA0ODggMEg0NzhRNDcyIDYgNDcyIDlUNDc0IDI3UTQ3OCA0MCA0ODAgNDNUNDkxIDQ2SDQ5NFE1NDQgNDYgNTQ0IDcxUTU0NCA3NSA1MTcgMTQxVDQ4NSAyMTZMNDI3IDM1NEwzNTkgMzAxTDI5MSAyNDhMMjY4IDE1NVEyNDUgNjMgMjQ1IDU4UTI0NSA1MSAyNTMgNDlUMzAzIDQ2SDMzNFEzNDAgMzcgMzQwIDM1UTM0MCAxOSAzMzMgNVEzMjggMCAzMTcgMFEzMTQgMCAyODAgMVQxODAgMlExMTggMiA4NSAyVDQ5IDFRMzEgMSAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDcgNjUgMjE2IDMzOVQyODUgNjI4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzYiIGQ9Ik00MiAzMTNRNDIgNDc2IDEyMyA1NzFUMzAzIDY2NlEzNzIgNjY2IDQwMiA2MzBUNDMyIDU1MFE0MzIgNTI1IDQxOCA1MTBUMzc5IDQ5NVEzNTYgNDk1IDM0MSA1MDlUMzI2IDU0OFEzMjYgNTkyIDM3MyA2MDFRMzUxIDYyMyAzMTEgNjI2UTI0MCA2MjYgMTk0IDU2NlExNDcgNTAwIDE0NyAzNjRMMTQ4IDM2MFExNTMgMzY2IDE1NiAzNzNRMTk3IDQzMyAyNjMgNDMzSDI2N1EzMTMgNDMzIDM0OCA0MTRRMzcyIDQwMCAzOTYgMzc0VDQzNSAzMTdRNDU2IDI2OCA0NTYgMjEwVjE5MlE0NTYgMTY5IDQ1MSAxNDlRNDQwIDkwIDM4NyAzNFQyNTMgLTIyUTIyNSAtMjIgMTk5IC0xNFQxNDMgMTZUOTIgNzVUNTYgMTcyVDQyIDMxM1pNMjU3IDM5N1EyMjcgMzk3IDIwNSAzODBUMTcxIDMzNVQxNTQgMjc4VDE0OCAyMTZRMTQ4IDEzMyAxNjAgOTdUMTk4IDM5UTIyMiAyMSAyNTEgMjFRMzAyIDIxIDMyOSA1OVEzNDIgNzcgMzQ3IDEwNFQzNTIgMjA5UTM1MiAyODkgMzQ3IDMxNlQzMjkgMzYxUTMwMiAzOTcgMjU3IDM5N1oiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxNTk1IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjgxLDY3NikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMDIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iODE3IiB5PSI1MTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03ODApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjAyIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTY3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktM0I0IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjY0MSIgeT0iNDA4Ij48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTgzNSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjgwNCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI2OTMiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDMwMjQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktM0I0IiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NDEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ0MjEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdDIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjc4LC0yODYpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTNCNCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI0NTEiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMCIgeD0iMTIzMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI2MzAxIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iNzM1NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDc4NTgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMjQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3OCw0OTQpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiIHg9Ii03MCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIxNy45MjI1MDQxNjY2ODEsMCkgc2NhbGUoMC43NTk4NzEwNjU2MjgzODA2LDEpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSI1NjUiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTc2IiB5PSIxMDQ0Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIxMTc2IiB5PSItMzUwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9Ijk0MzYiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTM4IiB4PSIxMDQzNyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIxMDkzOCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDExODc0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzMjg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjI0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzgsNDk0KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSItNzAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMTcuOTIyNTA0MTY2NjgxLDApIHNjYWxlKDAuNzU5ODcxMDY1NjI4MzgwNiwxKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiIgeD0iNTY1IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjExNzYiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0NjQ2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNEIiIHg9IjI0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjYsNTAwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSItNzAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODIuMzA2MTYwNjc2Mzc2MjcsMCkgc2NhbGUoMS40ODQ2MDY1NDc3MzA5MzYzLDEpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSI4MjciIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTM2NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTYzNTciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTM2IiB4PSIxNzM1OCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE3ODU5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTE2NyIgeT0iNTgzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxOTMwNSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMDcyMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTRCIiB4PSIyNCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI2LDUwMCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiIgeD0iLTcwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTgyLjMwNjE2MDY3NjM3NjI3LDApIHNjYWxlKDEuNDg0NjA2NTQ3NzMwOTM2MywxKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiIgeD0iODI3IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTM2NCIgeT0iMTA1MyI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTM2NCIgeT0iLTM1MCI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=)
fact 8 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjE0LjMxN2V4IiBoZWlnaHQ9IjQuODQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMS44MzhleDsiIHZpZXdCb3g9IjAgLTEyOTMuNyA2MTY0LjMgMjA4NSIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NSIgZD0iTTQ5MiAyMTNRNDcyIDIxMyA0NzIgMjI2UTQ3MiAyMzAgNDc3IDI1MFQ0ODIgMjg1UTQ4MiAzMTYgNDYxIDMyM1QzNjQgMzMwSDMxMlEzMTEgMzI4IDI3NyAxOTJUMjQzIDUyUTI0MyA0OCAyNTQgNDhUMzM0IDQ2UTQyOCA0NiA0NTggNDhUNTE4IDYxUTU2NyA3NyA1OTkgMTE3VDY3MCAyNDhRNjgwIDI3MCA2ODMgMjcyUTY5MCAyNzQgNjk4IDI3NFE3MTggMjc0IDcxOCAyNjFRNjEzIDcgNjA4IDJRNjA1IDAgMzIyIDBIMTMzUTMxIDAgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ2IDY2IDIxNSAzNDJUMjg1IDYyMlEyODUgNjI5IDI4MSA2MjlRMjczIDYzMiAyMjggNjM0SDE5N1ExOTEgNjQwIDE5MSA2NDJUMTkzIDY1OVExOTcgNjc2IDIwMyA2ODBINzU3UTc2NCA2NzYgNzY0IDY2OVE3NjQgNjY0IDc1MSA1NTdUNzM3IDQ0N1E3MzUgNDQwIDcxNyA0NDBINzA1UTY5OCA0NDUgNjk4IDQ1M0w3MDEgNDc2UTcwNCA1MDAgNzA0IDUyOFE3MDQgNTU4IDY5NyA1NzhUNjc4IDYwOVQ2NDMgNjI1VDU5NiA2MzJUNTMyIDYzNEg0ODVRMzk3IDYzMyAzOTIgNjMxUTM4OCA2MjkgMzg2IDYyMlEzODUgNjE5IDM1NSA0OTlUMzI0IDM3N1EzNDcgMzc2IDM3MiAzNzZIMzk4UTQ2NCAzNzYgNDg5IDM5MVQ1MzQgNDcyUTUzOCA0ODggNTQwIDQ5MFQ1NTcgNDkzUTU2MiA0OTMgNTY1IDQ5M1Q1NzAgNDkyVDU3MiA0OTFUNTc0IDQ4N1Q1NzcgNDgzTDU0NCAzNTFRNTExIDIxOCA1MDggMjE2UTUwNSAyMTMgNDkyIDIxM1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTRCIiBkPSJNMjg1IDYyOFEyODUgNjM1IDIyOCA2MzdRMjA1IDYzNyAxOTggNjM4VDE5MSA2NDdRMTkxIDY0OSAxOTMgNjYxUTE5OSA2ODEgMjAzIDY4MlEyMDUgNjgzIDIxNCA2ODNIMjE5UTI2MCA2ODEgMzU1IDY4MVEzODkgNjgxIDQxOCA2ODFUNDYzIDY4MlQ0ODMgNjgyUTUwMCA2ODIgNTAwIDY3NFE1MDAgNjY5IDQ5NyA2NjBRNDk2IDY1OCA0OTYgNjU0VDQ5NSA2NDhUNDkzIDY0NFQ0OTAgNjQxVDQ4NiA2MzlUNDc5IDYzOFQ0NzAgNjM3VDQ1NiA2MzdRNDE2IDYzNiA0MDUgNjM0VDM4NyA2MjNMMzA2IDMwNVEzMDcgMzA1IDQ5MCA0NDlUNjc4IDU5N1E2OTIgNjExIDY5MiA2MjBRNjkyIDYzNSA2NjcgNjM3UTY1MSA2MzcgNjUxIDY0OFE2NTEgNjUwIDY1NCA2NjJUNjU5IDY3N1E2NjIgNjgyIDY3NiA2ODJRNjgwIDY4MiA3MTEgNjgxVDc5MSA2ODBRODE0IDY4MCA4MzkgNjgxVDg2OSA2ODJRODg5IDY4MiA4ODkgNjcyUTg4OSA2NTAgODgxIDY0MlE4NzggNjM3IDg2MiA2MzdRNzg3IDYzMiA3MjYgNTg2UTcxMCA1NzYgNjU2IDUzNFQ1NTYgNDU1TDUwOSA0MThMNTE4IDM5NlE1MjcgMzc0IDU0NiAzMjlUNTgxIDI0NFE2NTYgNjcgNjYxIDYxUTY2MyA1OSA2NjYgNTdRNjgwIDQ3IDcxNyA0Nkg3MzhRNzQ0IDM4IDc0NCAzN1Q3NDEgMTlRNzM3IDYgNzMxIDBINzIwUTY4MCAzIDYyNSAzUTUwMyAzIDQ4OCAwSDQ3OFE0NzIgNiA0NzIgOVQ0NzQgMjdRNDc4IDQwIDQ4MCA0M1Q0OTEgNDZINDk0UTU0NCA0NiA1NDQgNzFRNTQ0IDc1IDUxNyAxNDFUNDg1IDIxNkw0MjcgMzU0TDM1OSAzMDFMMjkxIDI0OEwyNjggMTU1UTI0NSA2MyAyNDUgNThRMjQ1IDUxIDI1MyA0OVQzMDMgNDZIMzM0UTM0MCAzNyAzNDAgMzVRMzQwIDE5IDMzMyA1UTMyOCAwIDMxNyAwUTMxNCAwIDI4MCAxVDE4MCAyUTExOCAyIDg1IDJUNDkgMVEzMSAxIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NyA2NSAyMTYgMzM5VDI4NSA2MjhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi1BRiIgZD0iTTY5IDU0NFY1OTBINDMwVjU0NEg2OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkUiIGQ9Ik0yMSAyODdRMjIgMjkzIDI0IDMwM1QzNiAzNDFUNTYgMzg4VDg5IDQyNVQxMzUgNDQyUTE3MSA0NDIgMTk1IDQyNFQyMjUgMzkwVDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzA0IDQ0MiAzODIgNDQyUTQzNiA0NDIgNDY5IDQxNVQ1MDMgMzM2VDQ2NSAxNzlUNDI3IDUyUTQyNyAyNiA0NDQgMjZRNDUwIDI2IDQ1MyAyN1E0ODIgMzIgNTA1IDY1VDU0MCAxNDVRNTQyIDE1MyA1NjAgMTUzUTU4MCAxNTMgNTgwIDE0NVE1ODAgMTQ0IDU3NiAxMzBRNTY4IDEwMSA1NTQgNzNUNTA4IDE3VDQzOSAtMTBRMzkyIC0xMCAzNzEgMTdUMzUwIDczUTM1MCA5MiAzODYgMTkzVDQyMyAzNDVRNDIzIDQwNCAzNzkgNDA0SDM3NFEyODggNDA0IDIyOSAzMDNMMjIyIDI5MUwxODkgMTU3UTE1NiAyNiAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExMiAxODBUMTUyIDM0M1ExNTMgMzQ4IDE1MyAzNjZRMTUzIDQwNSAxMjkgNDA1UTkxIDQwNSA2NiAzMDVRNjAgMjg1IDYwIDI4NFE1OCAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03RCIgZD0iTTY1IDczMVE2NSA3NDUgNjggNzQ3VDg4IDc1MFExNzEgNzUwIDIxNiA3MjVUMjc5IDY3MFEyODggNjQ5IDI4OSA2MzVUMjkxIDUwMVEyOTIgMzYyIDI5MyAzNTdRMzA2IDMxMiAzNDUgMjkxVDQxNyAyNjlRNDI4IDI2OSA0MzEgMjY2VDQzNCAyNTBUNDMxIDIzNFQ0MTcgMjMxUTM4MCAyMzEgMzQ1IDIxMFQyOTggMTU3UTI5MyAxNDMgMjkyIDEyMVQyOTEgLTI4Vi03OVEyOTEgLTEzNCAyODUgLTE1NlQyNTYgLTE5OFEyMDIgLTI1MCA4OSAtMjUwUTcxIC0yNTAgNjggLTI0N1Q2NSAtMjMwUTY1IC0yMjQgNjUgLTIyM1Q2NiAtMjE4VDY5IC0yMTRUNzcgLTIxM1E5MSAtMjEzIDEwOCAtMjEwVDE0NiAtMjAwVDE4MyAtMTc3VDIwNyAtMTM5UTIwOCAtMTM0IDIwOSAzTDIxMCAxMzlRMjIzIDE5NiAyODAgMjMwUTMxNSAyNDcgMzMwIDI1MFEzMDUgMjU3IDI4MCAyNzBRMjI1IDMwNCAyMTIgMzUyTDIxMCAzNjJMMjA5IDQ5OFEyMDggNjM1IDIwNyA2NDBRMTk1IDY4MCAxNTQgNjk2VDc3IDcxM1E2OCA3MTMgNjcgNzE2VDY1IDczMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItN0IiIGQ9Ik01NDcgLTY0M0w1NDEgLTY0OUg1MjhRNTE1IC02NDkgNTAzIC02NDVRMzI0IC01ODIgMjkzIC00NjZRMjg5IC00NDkgMjg5IC00MjhUMjg3IC0yMDBMMjg2IDQyTDI4NCA1M1EyNzQgOTggMjQ4IDEzNVQxOTYgMTkwVDE0NiAyMjJMMTIxIDIzNVExMTkgMjM5IDExOSAyNTBRMTE5IDI2MiAxMjEgMjY2VDEzMyAyNzNRMjYyIDMzNiAyODQgNDQ5TDI4NiA0NjBMMjg3IDcwMVEyODcgNzM3IDI4NyA3OTRRMjg4IDk0OSAyOTIgOTYzUTI5MyA5NjYgMjkzIDk2N1EzMjUgMTA4MCA1MDggMTE0OFE1MTYgMTE1MCA1MjcgMTE1MEg1NDFMNTQ3IDExNDRWMTEzMFE1NDcgMTExNyA1NDYgMTExNVQ1MzYgMTEwOVE0ODAgMTA4NiA0MzcgMTA0NlQzODEgOTUwTDM3OSA5NDBMMzc4IDY5OVEzNzggNjU3IDM3OCA1OTRRMzc3IDQ1MiAzNzQgNDM4UTM3MyA0MzcgMzczIDQzNlEzNTAgMzQ4IDI0MyAyODJRMTkyIDI1NyAxODYgMjU0TDE3NiAyNTFMMTg4IDI0NVEyMTEgMjM2IDIzNCAyMjNUMjg3IDE4OVQzNDAgMTM1VDM3MyA2NVEzNzMgNjQgMzc0IDYzUTM3NyA0OSAzNzggLTkzUTM3OCAtMTU2IDM3OCAtMTk4TDM3OSAtNDM4TDM4MSAtNDQ5UTM5MyAtNTA0IDQzNiAtNTQ0VDUzNiAtNjA4UTU0NCAtNjExIDU0NSAtNjEzVDU0NyAtNjI5Vi02NDNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oyLTdEIiBkPSJNMTE5IDExMzBRMTE5IDExNDQgMTIxIDExNDdUMTM1IDExNTBIMTM5UTE1MSAxMTUwIDE4MiAxMTM4VDI1MiAxMTA1VDMyNiAxMDQ2VDM3MyA5NjRRMzc4IDk0MiAzNzggNzAyUTM3OCA0NjkgMzc5IDQ2MlEzODYgMzk0IDQzOSAzMzlRNDgyIDI5NiA1MzUgMjcyUTU0NCAyNjggNTQ1IDI2NlQ1NDcgMjUxUTU0NyAyNDEgNTQ3IDIzOFQ1NDIgMjMxVDUzMSAyMjdUNTEwIDIxN1Q0NzcgMTk0UTM5MCAxMjkgMzc5IDM5UTM3OCAzMiAzNzggLTIwMVEzNzggLTQ0MSAzNzMgLTQ2M1EzNDIgLTU4MCAxNjUgLTY0NFExNTIgLTY0OSAxMzkgLTY0OVExMjUgLTY0OSAxMjIgLTY0NlQxMTkgLTYyOVExMTkgLTYyMiAxMTkgLTYxOVQxMjEgLTYxNFQxMjQgLTYxMFQxMzIgLTYwN1QxNDMgLTYwMlExOTUgLTU3OSAyMzUgLTUzOVQyODUgLTQ0N1EyODYgLTQzNSAyODcgLTE5OVQyODkgNTFRMjk0IDc0IDMwMCA5MVQzMjkgMTM4VDM5MCAxOTdRNDEyIDIxMyA0MzYgMjI2VDQ3NSAyNDRMNDg5IDI1MEw0NzIgMjU4UTQ1NSAyNjUgNDMwIDI3OVQzNzcgMzEzVDMyNyAzNjZUMjkzIDQzNFEyODkgNDUxIDI4OSA0NzJUMjg3IDY5OVEyODYgOTQxIDI4NSA5NDhRMjc5IDk3OCAyNjIgMTAwNVQyMjcgMTA0OFQxODQgMTA4MFQxNTEgMTEwMFQxMjkgMTEwOUwxMjcgMTExMFExMTkgMTExMyAxMTkgMTEzMFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUwIiBkPSJNMjg3IDYyOFEyODcgNjM1IDIzMCA2MzdRMjA2IDYzNyAxOTkgNjM4VDE5MiA2NDhRMTkyIDY0OSAxOTQgNjU5UTIwMCA2NzkgMjAzIDY4MVQzOTcgNjgzUTU4NyA2ODIgNjAwIDY4MFE2NjQgNjY5IDcwNyA2MzFUNzUxIDUzMFE3NTEgNDUzIDY4NSAzODlRNjE2IDMyMSA1MDcgMzAzUTUwMCAzMDIgNDAyIDMwMUgzMDdMMjc3IDE4MlEyNDcgNjYgMjQ3IDU5UTI0NyA1NSAyNDggNTRUMjU1IDUwVDI3MiA0OFQzMDUgNDZIMzM2UTM0MiAzNyAzNDIgMzVRMzQyIDE5IDMzNSA1UTMzMCAwIDMxOSAwUTMxNiAwIDI4MiAxVDE4MiAyUTEyMCAyIDg3IDJUNTEgMVEzMyAxIDMzIDExUTMzIDEzIDM2IDI1UTQwIDQxIDQ0IDQzVDY3IDQ2UTk0IDQ2IDEyNyA0OVExNDEgNTIgMTQ2IDYxUTE0OSA2NSAyMTggMzM5VDI4NyA2MjhaTTY0NSA1NTRRNjQ1IDU2NyA2NDMgNTc1VDYzNCA1OTdUNjA5IDYxOVQ1NjAgNjM1UTU1MyA2MzYgNDgwIDYzN1E0NjMgNjM3IDQ0NSA2MzdUNDE2IDYzNlQ0MDQgNjM2UTM5MSA2MzUgMzg2IDYyN1EzODQgNjIxIDM2NyA1NTBUMzMyIDQxMlQzMTQgMzQ0UTMxNCAzNDIgMzk1IDM0Mkg0MDdINDMwUTU0MiAzNDIgNTkwIDM5MlE2MTcgNDE5IDYzMSA0NzFUNjQ1IDU1NFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkzMSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi03QiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDY2NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTRCIiB4PSIyNCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI2LDUwMCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiIgeD0iLTcwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTgyLjMwNjE2MDY3NjM3NjI3LDApIHNjYWxlKDEuNDg0NjA2NTQ3NzMwOTM2MywxKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiIgeD0iODI3IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTM2NCIgeT0iMTA1MyI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTM2NCIgeT0iLTM1MCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTdEIiB4PSIyMTU3IiB5PSItMSI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iNDAzMyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==)
fact 9 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjUwLjU1M2V4IiBoZWlnaHQ9IjUuODQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMi4xNzFleDsiIHZpZXdCb3g9IjAgLTE1ODAuNyAyMTc2NS45IDI1MTUuNiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NSIgZD0iTTQ5MiAyMTNRNDcyIDIxMyA0NzIgMjI2UTQ3MiAyMzAgNDc3IDI1MFQ0ODIgMjg1UTQ4MiAzMTYgNDYxIDMyM1QzNjQgMzMwSDMxMlEzMTEgMzI4IDI3NyAxOTJUMjQzIDUyUTI0MyA0OCAyNTQgNDhUMzM0IDQ2UTQyOCA0NiA0NTggNDhUNTE4IDYxUTU2NyA3NyA1OTkgMTE3VDY3MCAyNDhRNjgwIDI3MCA2ODMgMjcyUTY5MCAyNzQgNjk4IDI3NFE3MTggMjc0IDcxOCAyNjFRNjEzIDcgNjA4IDJRNjA1IDAgMzIyIDBIMTMzUTMxIDAgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ2IDY2IDIxNSAzNDJUMjg1IDYyMlEyODUgNjI5IDI4MSA2MjlRMjczIDYzMiAyMjggNjM0SDE5N1ExOTEgNjQwIDE5MSA2NDJUMTkzIDY1OVExOTcgNjc2IDIwMyA2ODBINzU3UTc2NCA2NzYgNzY0IDY2OVE3NjQgNjY0IDc1MSA1NTdUNzM3IDQ0N1E3MzUgNDQwIDcxNyA0NDBINzA1UTY5OCA0NDUgNjk4IDQ1M0w3MDEgNDc2UTcwNCA1MDAgNzA0IDUyOFE3MDQgNTU4IDY5NyA1NzhUNjc4IDYwOVQ2NDMgNjI1VDU5NiA2MzJUNTMyIDYzNEg0ODVRMzk3IDYzMyAzOTIgNjMxUTM4OCA2MjkgMzg2IDYyMlEzODUgNjE5IDM1NSA0OTlUMzI0IDM3N1EzNDcgMzc2IDM3MiAzNzZIMzk4UTQ2NCAzNzYgNDg5IDM5MVQ1MzQgNDcyUTUzOCA0ODggNTQwIDQ5MFQ1NTcgNDkzUTU2MiA0OTMgNTY1IDQ5M1Q1NzAgNDkyVDU3MiA0OTFUNTc0IDQ4N1Q1NzcgNDgzTDU0NCAzNTFRNTExIDIxOCA1MDggMjE2UTUwNSAyMTMgNDkyIDIxM1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTRCIiBkPSJNMjg1IDYyOFEyODUgNjM1IDIyOCA2MzdRMjA1IDYzNyAxOTggNjM4VDE5MSA2NDdRMTkxIDY0OSAxOTMgNjYxUTE5OSA2ODEgMjAzIDY4MlEyMDUgNjgzIDIxNCA2ODNIMjE5UTI2MCA2ODEgMzU1IDY4MVEzODkgNjgxIDQxOCA2ODFUNDYzIDY4MlQ0ODMgNjgyUTUwMCA2ODIgNTAwIDY3NFE1MDAgNjY5IDQ5NyA2NjBRNDk2IDY1OCA0OTYgNjU0VDQ5NSA2NDhUNDkzIDY0NFQ0OTAgNjQxVDQ4NiA2MzlUNDc5IDYzOFQ0NzAgNjM3VDQ1NiA2MzdRNDE2IDYzNiA0MDUgNjM0VDM4NyA2MjNMMzA2IDMwNVEzMDcgMzA1IDQ5MCA0NDlUNjc4IDU5N1E2OTIgNjExIDY5MiA2MjBRNjkyIDYzNSA2NjcgNjM3UTY1MSA2MzcgNjUxIDY0OFE2NTEgNjUwIDY1NCA2NjJUNjU5IDY3N1E2NjIgNjgyIDY3NiA2ODJRNjgwIDY4MiA3MTEgNjgxVDc5MSA2ODBRODE0IDY4MCA4MzkgNjgxVDg2OSA2ODJRODg5IDY4MiA4ODkgNjcyUTg4OSA2NTAgODgxIDY0MlE4NzggNjM3IDg2MiA2MzdRNzg3IDYzMiA3MjYgNTg2UTcxMCA1NzYgNjU2IDUzNFQ1NTYgNDU1TDUwOSA0MThMNTE4IDM5NlE1MjcgMzc0IDU0NiAzMjlUNTgxIDI0NFE2NTYgNjcgNjYxIDYxUTY2MyA1OSA2NjYgNTdRNjgwIDQ3IDcxNyA0Nkg3MzhRNzQ0IDM4IDc0NCAzN1Q3NDEgMTlRNzM3IDYgNzMxIDBINzIwUTY4MCAzIDYyNSAzUTUwMyAzIDQ4OCAwSDQ3OFE0NzIgNiA0NzIgOVQ0NzQgMjdRNDc4IDQwIDQ4MCA0M1Q0OTEgNDZINDk0UTU0NCA0NiA1NDQgNzFRNTQ0IDc1IDUxNyAxNDFUNDg1IDIxNkw0MjcgMzU0TDM1OSAzMDFMMjkxIDI0OEwyNjggMTU1UTI0NSA2MyAyNDUgNThRMjQ1IDUxIDI1MyA0OVQzMDMgNDZIMzM0UTM0MCAzNyAzNDAgMzVRMzQwIDE5IDMzMyA1UTMyOCAwIDMxNyAwUTMxNCAwIDI4MCAxVDE4MCAyUTExOCAyIDg1IDJUNDkgMVEzMSAxIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NyA2NSAyMTYgMzM5VDI4NSA2MjhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi1BRiIgZD0iTTY5IDU0NFY1OTBINDMwVjU0NEg2OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oyLTdCIiBkPSJNNTQ3IC02NDNMNTQxIC02NDlINTI4UTUxNSAtNjQ5IDUwMyAtNjQ1UTMyNCAtNTgyIDI5MyAtNDY2UTI4OSAtNDQ5IDI4OSAtNDI4VDI4NyAtMjAwTDI4NiA0MkwyODQgNTNRMjc0IDk4IDI0OCAxMzVUMTk2IDE5MFQxNDYgMjIyTDEyMSAyMzVRMTE5IDIzOSAxMTkgMjUwUTExOSAyNjIgMTIxIDI2NlQxMzMgMjczUTI2MiAzMzYgMjg0IDQ0OUwyODYgNDYwTDI4NyA3MDFRMjg3IDczNyAyODcgNzk0UTI4OCA5NDkgMjkyIDk2M1EyOTMgOTY2IDI5MyA5NjdRMzI1IDEwODAgNTA4IDExNDhRNTE2IDExNTAgNTI3IDExNTBINTQxTDU0NyAxMTQ0VjExMzBRNTQ3IDExMTcgNTQ2IDExMTVUNTM2IDExMDlRNDgwIDEwODYgNDM3IDEwNDZUMzgxIDk1MEwzNzkgOTQwTDM3OCA2OTlRMzc4IDY1NyAzNzggNTk0UTM3NyA0NTIgMzc0IDQzOFEzNzMgNDM3IDM3MyA0MzZRMzUwIDM0OCAyNDMgMjgyUTE5MiAyNTcgMTg2IDI1NEwxNzYgMjUxTDE4OCAyNDVRMjExIDIzNiAyMzQgMjIzVDI4NyAxODlUMzQwIDEzNVQzNzMgNjVRMzczIDY0IDM3NCA2M1EzNzcgNDkgMzc4IC05M1EzNzggLTE1NiAzNzggLTE5OEwzNzkgLTQzOEwzODEgLTQ0OVEzOTMgLTUwNCA0MzYgLTU0NFQ1MzYgLTYwOFE1NDQgLTYxMSA1NDUgLTYxM1Q1NDcgLTYyOVYtNjQzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMi03RCIgZD0iTTExOSAxMTMwUTExOSAxMTQ0IDEyMSAxMTQ3VDEzNSAxMTUwSDEzOVExNTEgMTE1MCAxODIgMTEzOFQyNTIgMTEwNVQzMjYgMTA0NlQzNzMgOTY0UTM3OCA5NDIgMzc4IDcwMlEzNzggNDY5IDM3OSA0NjJRMzg2IDM5NCA0MzkgMzM5UTQ4MiAyOTYgNTM1IDI3MlE1NDQgMjY4IDU0NSAyNjZUNTQ3IDI1MVE1NDcgMjQxIDU0NyAyMzhUNTQyIDIzMVQ1MzEgMjI3VDUxMCAyMTdUNDc3IDE5NFEzOTAgMTI5IDM3OSAzOVEzNzggMzIgMzc4IC0yMDFRMzc4IC00NDEgMzczIC00NjNRMzQyIC01ODAgMTY1IC02NDRRMTUyIC02NDkgMTM5IC02NDlRMTI1IC02NDkgMTIyIC02NDZUMTE5IC02MjlRMTE5IC02MjIgMTE5IC02MTlUMTIxIC02MTRUMTI0IC02MTBUMTMyIC02MDdUMTQzIC02MDJRMTk1IC01NzkgMjM1IC01MzlUMjg1IC00NDdRMjg2IC00MzUgMjg3IC0xOTlUMjg5IDUxUTI5NCA3NCAzMDAgOTFUMzI5IDEzOFQzOTAgMTk3UTQxMiAyMTMgNDM2IDIyNlQ0NzUgMjQ0TDQ4OSAyNTBMNDcyIDI1OFE0NTUgMjY1IDQzMCAyNzlUMzc3IDMxM1QzMjcgMzY2VDI5MyA0MzRRMjg5IDQ1MSAyODkgNDcyVDI4NyA2OTlRMjg2IDk0MSAyODUgOTQ4UTI3OSA5NzggMjYyIDEwMDVUMjI3IDEwNDhUMTg0IDEwODBUMTUxIDExMDBUMTI5IDExMDlMMTI3IDExMTBRMTE5IDExMTMgMTE5IDExMzBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTAiIGQ9Ik0yODcgNjI4UTI4NyA2MzUgMjMwIDYzN1EyMDYgNjM3IDE5OSA2MzhUMTkyIDY0OFExOTIgNjQ5IDE5NCA2NTlRMjAwIDY3OSAyMDMgNjgxVDM5NyA2ODNRNTg3IDY4MiA2MDAgNjgwUTY2NCA2NjkgNzA3IDYzMVQ3NTEgNTMwUTc1MSA0NTMgNjg1IDM4OVE2MTYgMzIxIDUwNyAzMDNRNTAwIDMwMiA0MDIgMzAxSDMwN0wyNzcgMTgyUTI0NyA2NiAyNDcgNTlRMjQ3IDU1IDI0OCA1NFQyNTUgNTBUMjcyIDQ4VDMwNSA0NkgzMzZRMzQyIDM3IDM0MiAzNVEzNDIgMTkgMzM1IDVRMzMwIDAgMzE5IDBRMzE2IDAgMjgyIDFUMTgyIDJRMTIwIDIgODcgMlQ1MSAxUTMzIDEgMzMgMTFRMzMgMTMgMzYgMjVRNDAgNDEgNDQgNDNUNjcgNDZROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFpNNjQ1IDU1NFE2NDUgNTY3IDY0MyA1NzVUNjM0IDU5N1Q2MDkgNjE5VDU2MCA2MzVRNTUzIDYzNiA0ODAgNjM3UTQ2MyA2MzcgNDQ1IDYzN1Q0MTYgNjM2VDQwNCA2MzZRMzkxIDYzNSAzODYgNjI3UTM4NCA2MjEgMzY3IDU1MFQzMzIgNDEyVDMxNCAzNDRRMzE0IDM0MiAzOTUgMzQySDQwN0g0MzBRNTQyIDM0MiA1OTAgMzkyUTYxNyA0MTkgNjMxIDQ3MVQ2NDUgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUyIiBkPSJNMjMwIDYzN1EyMDMgNjM3IDE5OCA2MzhUMTkzIDY0OVExOTMgNjc2IDIwNCA2ODJRMjA2IDY4MyAzNzggNjgzUTU1MCA2ODIgNTY0IDY4MFE2MjAgNjcyIDY1OCA2NTJUNzEyIDYwNlQ3MzMgNTYzVDczOSA1MjlRNzM5IDQ4NCA3MTAgNDQ1VDY0MyAzODVUNTc2IDM1MVQ1MzggMzM4TDU0NSAzMzNRNjEyIDI5NSA2MTIgMjIzUTYxMiAyMTIgNjA3IDE2MlQ2MDIgODBWNzFRNjAyIDUzIDYwMyA0M1Q2MTQgMjVUNjQwIDE2UTY2OCAxNiA2ODYgMzhUNzEyIDg1UTcxNyA5OSA3MjAgMTAyVDczNSAxMDVRNzU1IDEwNSA3NTUgOTNRNzU1IDc1IDczMSAzNlE2OTMgLTIxIDY0MSAtMjFINjMyUTU3MSAtMjEgNTMxIDRUNDg3IDgyUTQ4NyAxMDkgNTAyIDE2NlQ1MTcgMjM5UTUxNyAyOTAgNDc0IDMxM1E0NTkgMzIwIDQ0OSAzMjFUMzc4IDMyM0gzMDlMMjc3IDE5M1EyNDQgNjEgMjQ0IDU5UTI0NCA1NSAyNDUgNTRUMjUyIDUwVDI2OSA0OFQzMDIgNDZIMzMzUTMzOSAzOCAzMzkgMzdUMzM2IDE5UTMzMiA2IDMyNiAwSDMxMVEyNzUgMiAxODAgMlExNDYgMiAxMTcgMlQ3MSAyVDUwIDFRMzMgMSAzMyAxMFEzMyAxMiAzNiAyNFE0MSA0MyA0NiA0NVE1MCA0NiA2MSA0Nkg2N1E5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4UTI4NyA2MzUgMjMwIDYzN1pNNjMwIDU1NFE2MzAgNTg2IDYwOSA2MDhUNTIzIDYzNlE1MjEgNjM2IDUwMCA2MzZUNDYyIDYzN0g0NDBRMzkzIDYzNyAzODYgNjI3UTM4NSA2MjQgMzUyIDQ5NFQzMTkgMzYxUTMxOSAzNjAgMzg4IDM2MFE0NjYgMzYxIDQ5MiAzNjdRNTU2IDM3NyA1OTIgNDI2UTYwOCA0NDkgNjE5IDQ4NlQ2MzAgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjIxMiIgZD0iTTg0IDIzN1Q4NCAyNTBUOTggMjcwSDY3OVE2OTQgMjYyIDY5NCAyNTBUNjc5IDIzMEg5OFE4NCAyMzcgODQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU2IiBkPSJNNTIgNjQ4UTUyIDY3MCA2NSA2ODNINzZRMTE4IDY4MCAxODEgNjgwUTI5OSA2ODAgMzIwIDY4M0gzMzBRMzM2IDY3NyAzMzYgNjc0VDMzNCA2NTZRMzI5IDY0MSAzMjUgNjM3SDMwNFEyODIgNjM1IDI3NCA2MzVRMjQ1IDYzMCAyNDIgNjIwUTI0MiA2MTggMjcxIDM2OVQzMDEgMTE4TDM3NCAyMzVRNDQ3IDM1MiA1MjAgNDcxVDU5NSA1OTRRNTk5IDYwMSA1OTkgNjA5UTU5OSA2MzMgNTU1IDYzN1E1MzcgNjM3IDUzNyA2NDhRNTM3IDY0OSA1MzkgNjYxUTU0MiA2NzUgNTQ1IDY3OVQ1NTggNjgzUTU2MCA2ODMgNTcwIDY4M1Q2MDQgNjgyVDY2OCA2ODFRNzM3IDY4MSA3NTUgNjgzSDc2MlE3NjkgNjc2IDc2OSA2NzJRNzY5IDY1NSA3NjAgNjQwUTc1NyA2MzcgNzQzIDYzN1E3MzAgNjM2IDcxOSA2MzVUNjk4IDYzMFQ2ODIgNjIzVDY3MCA2MTVUNjYwIDYwOFQ2NTIgNTk5VDY0NSA1OTJMNDUyIDI4MlEyNzIgLTkgMjY2IC0xNlEyNjMgLTE4IDI1OSAtMjFMMjQxIC0yMkgyMzRRMjE2IC0yMiAyMTYgLTE1UTIxMyAtOSAxNzcgMzA1UTEzOSA2MjMgMTM4IDYyNlExMzMgNjM3IDc2IDYzN0g1OVE1MiA2NDIgNTIgNjQ4WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTMxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTdCIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjY3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNEIiIHg9IjI0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjYsNTAwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSItNzAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODIuMzA2MTYwNjc2Mzc2MjcsMCkgc2NhbGUoMS40ODQ2MDY1NDc3MzA5MzYzLDEpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSI4MjciIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTM2NCIgeT0iLTIxMyI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0ODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMjQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3OCw0OTQpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiIHg9Ii03MCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIxNy45MjI1MDQxNjY2ODEsMCkgc2NhbGUoMC43NTk4NzEwNjU2MjgzODA2LDEpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSI1NjUiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTE3NiIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItN0QiIHg9IjM1MTMiIHk9Ii0xIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI1MzkwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjE2OCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM5NywwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjQxNTYiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjE3OTciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNzk3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQ1NywtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDg0MiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMjI1NiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzMjU3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0NzgxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMjk2IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMjI5NyIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMzE4NyIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIxODU4MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIxOTU4MSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIwNTE3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9zdmc+)
fact 10 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjY1LjU3M2V4IiBoZWlnaHQ9IjEyLjg0M2V4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTUuODM4ZXg7IiB2aWV3Qm94PSIwIC0zMDE1LjkgMjgyMzIuOCA1NTI5LjQiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDUiIGQ9Ik00OTIgMjEzUTQ3MiAyMTMgNDcyIDIyNlE0NzIgMjMwIDQ3NyAyNTBUNDgyIDI4NVE0ODIgMzE2IDQ2MSAzMjNUMzY0IDMzMEgzMTJRMzExIDMyOCAyNzcgMTkyVDI0MyA1MlEyNDMgNDggMjU0IDQ4VDMzNCA0NlE0MjggNDYgNDU4IDQ4VDUxOCA2MVE1NjcgNzcgNTk5IDExN1Q2NzAgMjQ4UTY4MCAyNzAgNjgzIDI3MlE2OTAgMjc0IDY5OCAyNzRRNzE4IDI3NCA3MTggMjYxUTYxMyA3IDYwOCAyUTYwNSAwIDMyMiAwSDEzM1EzMSAwIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc1N1E3NjQgNjc2IDc2NCA2NjlRNzY0IDY2NCA3NTEgNTU3VDczNyA0NDdRNzM1IDQ0MCA3MTcgNDQwSDcwNVE2OTggNDQ1IDY5OCA0NTNMNzAxIDQ3NlE3MDQgNTAwIDcwNCA1MjhRNzA0IDU1OCA2OTcgNTc4VDY3OCA2MDlUNjQzIDYyNVQ1OTYgNjMyVDUzMiA2MzRINDg1UTM5NyA2MzMgMzkyIDYzMVEzODggNjI5IDM4NiA2MjJRMzg1IDYxOSAzNTUgNDk5VDMyNCAzNzdRMzQ3IDM3NiAzNzIgMzc2SDM5OFE0NjQgMzc2IDQ4OSAzOTFUNTM0IDQ3MlE1MzggNDg4IDU0MCA0OTBUNTU3IDQ5M1E1NjIgNDkzIDU2NSA0OTNUNTcwIDQ5MlQ1NzIgNDkxVDU3NCA0ODdUNTc3IDQ4M0w1NDQgMzUxUTUxMSAyMTggNTA4IDIxNlE1MDUgMjEzIDQ5MiAyMTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03QiIgZD0iTTQzNCAtMjMxUTQzNCAtMjQ0IDQyOCAtMjUwSDQxMFEyODEgLTI1MCAyMzAgLTE4NFEyMjUgLTE3NyAyMjIgLTE3MlQyMTcgLTE2MVQyMTMgLTE0OFQyMTEgLTEzM1QyMTAgLTExMVQyMDkgLTg0VDIwOSAtNDdUMjA5IDBRMjA5IDIxIDIwOSA1M1EyMDggMTQyIDIwNCAxNTNRMjAzIDE1NCAyMDMgMTU1UTE4OSAxOTEgMTUzIDIxMVQ4MiAyMzFRNzEgMjMxIDY4IDIzNFQ2NSAyNTBUNjggMjY2VDgyIDI2OVExMTYgMjY5IDE1MiAyODlUMjAzIDM0NVEyMDggMzU2IDIwOCAzNzdUMjA5IDUyOVY1NzlRMjA5IDYzNCAyMTUgNjU2VDI0NCA2OThRMjcwIDcyNCAzMjQgNzQwUTM2MSA3NDggMzc3IDc0OVEzNzkgNzQ5IDM5MCA3NDlUNDA4IDc1MEg0MjhRNDM0IDc0NCA0MzQgNzMyUTQzNCA3MTkgNDMxIDcxNlE0MjkgNzEzIDQxNSA3MTNRMzYyIDcxMCAzMzIgNjg5VDI5NiA2NDdRMjkxIDYzNCAyOTEgNDk5VjQxN1EyOTEgMzcwIDI4OCAzNTNUMjcxIDMxNFEyNDAgMjcxIDE4NCAyNTVMMTcwIDI1MEwxODQgMjQ1UTIwMiAyMzkgMjIwIDIzMFQyNjIgMTk2VDI5MCAxMzdRMjkxIDEzMSAyOTEgMVEyOTEgLTEzNCAyOTYgLTE0N1EzMDYgLTE3NCAzMzkgLTE5MlQ0MTUgLTIxM1E0MjkgLTIxMyA0MzEgLTIxNlE0MzQgLTIxOSA0MzQgLTIzMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tQUYiIGQ9Ik02OSA1NDRWNTkwSDQzMFY1NDRINjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMiIgZD0iTTEwOSA0MjlRODIgNDI5IDY2IDQ0N1Q1MCA0OTFRNTAgNTYyIDEwMyA2MTRUMjM1IDY2NlEzMjYgNjY2IDM4NyA2MTBUNDQ5IDQ2NVE0NDkgNDIyIDQyOSAzODNUMzgxIDMxNVQzMDEgMjQxUTI2NSAyMTAgMjAxIDE0OUwxNDIgOTNMMjE4IDkyUTM3NSA5MiAzODUgOTdRMzkyIDk5IDQwOSAxODZWMTg5SDQ0OVYxODZRNDQ4IDE4MyA0MzYgOTVUNDIxIDNWMEg1MFYxOVYzMVE1MCAzOCA1NiA0NlQ4NiA4MVExMTUgMTEzIDEzNiAxMzdRMTQ1IDE0NyAxNzAgMTc0VDIwNCAyMTFUMjMzIDI0NFQyNjEgMjc4VDI4NCAzMDhUMzA1IDM0MFQzMjAgMzY5VDMzMyA0MDFUMzQwIDQzMVQzNDMgNDY0UTM0MyA1MjcgMzA5IDU3M1QyMTIgNjE5UTE3OSA2MTkgMTU0IDYwMlQxMTkgNTY5VDEwOSA1NTBRMTA5IDU0OSAxMTQgNTQ5UTEzMiA1NDkgMTUxIDUzNVQxNzAgNDg5UTE3MCA0NjQgMTU0IDQ0N1QxMDkgNDI5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZFIiBkPSJNMjEgMjg3UTIyIDI5MyAyNCAzMDNUMzYgMzQxVDU2IDM4OFQ4OSA0MjVUMTM1IDQ0MlExNzEgNDQyIDE5NSA0MjRUMjI1IDM5MFQyMzEgMzY5UTIzMSAzNjcgMjMyIDM2N0wyNDMgMzc4UTMwNCA0NDIgMzgyIDQ0MlE0MzYgNDQyIDQ2OSA0MTVUNTAzIDMzNlQ0NjUgMTc5VDQyNyA1MlE0MjcgMjYgNDQ0IDI2UTQ1MCAyNiA0NTMgMjdRNDgyIDMyIDUwNSA2NVQ1NDAgMTQ1UTU0MiAxNTMgNTYwIDE1M1E1ODAgMTUzIDU4MCAxNDVRNTgwIDE0NCA1NzYgMTMwUTU2OCAxMDEgNTU0IDczVDUwOCAxN1Q0MzkgLTEwUTM5MiAtMTAgMzcxIDE3VDM1MCA3M1EzNTAgOTIgMzg2IDE5M1Q0MjMgMzQ1UTQyMyA0MDQgMzc5IDQwNEgzNzRRMjg4IDQwNCAyMjkgMzAzTDIyMiAyOTFMMTg5IDE1N1ExNTYgMjYgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTIgMTgwVDE1MiAzNDNRMTUzIDM0OCAxNTMgMzY2UTE1MyA0MDUgMTI5IDQwNVE5MSA0MDUgNjYgMzA1UTYwIDI4NSA2MCAyODRRNTggMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oyLTdCIiBkPSJNNTQ3IC02NDNMNTQxIC02NDlINTI4UTUxNSAtNjQ5IDUwMyAtNjQ1UTMyNCAtNTgyIDI5MyAtNDY2UTI4OSAtNDQ5IDI4OSAtNDI4VDI4NyAtMjAwTDI4NiA0MkwyODQgNTNRMjc0IDk4IDI0OCAxMzVUMTk2IDE5MFQxNDYgMjIyTDEyMSAyMzVRMTE5IDIzOSAxMTkgMjUwUTExOSAyNjIgMTIxIDI2NlQxMzMgMjczUTI2MiAzMzYgMjg0IDQ0OUwyODYgNDYwTDI4NyA3MDFRMjg3IDczNyAyODcgNzk0UTI4OCA5NDkgMjkyIDk2M1EyOTMgOTY2IDI5MyA5NjdRMzI1IDEwODAgNTA4IDExNDhRNTE2IDExNTAgNTI3IDExNTBINTQxTDU0NyAxMTQ0VjExMzBRNTQ3IDExMTcgNTQ2IDExMTVUNTM2IDExMDlRNDgwIDEwODYgNDM3IDEwNDZUMzgxIDk1MEwzNzkgOTQwTDM3OCA2OTlRMzc4IDY1NyAzNzggNTk0UTM3NyA0NTIgMzc0IDQzOFEzNzMgNDM3IDM3MyA0MzZRMzUwIDM0OCAyNDMgMjgyUTE5MiAyNTcgMTg2IDI1NEwxNzYgMjUxTDE4OCAyNDVRMjExIDIzNiAyMzQgMjIzVDI4NyAxODlUMzQwIDEzNVQzNzMgNjVRMzczIDY0IDM3NCA2M1EzNzcgNDkgMzc4IC05M1EzNzggLTE1NiAzNzggLTE5OEwzNzkgLTQzOEwzODEgLTQ0OVEzOTMgLTUwNCA0MzYgLTU0NFQ1MzYgLTYwOFE1NDQgLTYxMSA1NDUgLTYxM1Q1NDcgLTYyOVYtNjQzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMi03RCIgZD0iTTExOSAxMTMwUTExOSAxMTQ0IDEyMSAxMTQ3VDEzNSAxMTUwSDEzOVExNTEgMTE1MCAxODIgMTEzOFQyNTIgMTEwNVQzMjYgMTA0NlQzNzMgOTY0UTM3OCA5NDIgMzc4IDcwMlEzNzggNDY5IDM3OSA0NjJRMzg2IDM5NCA0MzkgMzM5UTQ4MiAyOTYgNTM1IDI3MlE1NDQgMjY4IDU0NSAyNjZUNTQ3IDI1MVE1NDcgMjQxIDU0NyAyMzhUNTQyIDIzMVQ1MzEgMjI3VDUxMCAyMTdUNDc3IDE5NFEzOTAgMTI5IDM3OSAzOVEzNzggMzIgMzc4IC0yMDFRMzc4IC00NDEgMzczIC00NjNRMzQyIC01ODAgMTY1IC02NDRRMTUyIC02NDkgMTM5IC02NDlRMTI1IC02NDkgMTIyIC02NDZUMTE5IC02MjlRMTE5IC02MjIgMTE5IC02MTlUMTIxIC02MTRUMTI0IC02MTBUMTMyIC02MDdUMTQzIC02MDJRMTk1IC01NzkgMjM1IC01MzlUMjg1IC00NDdRMjg2IC00MzUgMjg3IC0xOTlUMjg5IDUxUTI5NCA3NCAzMDAgOTFUMzI5IDEzOFQzOTAgMTk3UTQxMiAyMTMgNDM2IDIyNlQ0NzUgMjQ0TDQ4OSAyNTBMNDcyIDI1OFE0NTUgMjY1IDQzMCAyNzlUMzc3IDMxM1QzMjcgMzY2VDI5MyA0MzRRMjg5IDQ1MSAyODkgNDcyVDI4NyA2OTlRMjg2IDk0MSAyODUgOTQ4UTI3OSA5NzggMjYyIDEwMDVUMjI3IDEwNDhUMTg0IDEwODBUMTUxIDExMDBUMTI5IDExMDlMMTI3IDExMTBRMTE5IDExMTMgMTE5IDExMzBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MCIgZD0iTTI4NyA2MjhRMjg3IDYzNSAyMzAgNjM3UTIwNiA2MzcgMTk5IDYzOFQxOTIgNjQ4UTE5MiA2NDkgMTk0IDY1OVEyMDAgNjc5IDIwMyA2ODFUMzk3IDY4M1E1ODcgNjgyIDYwMCA2ODBRNjY0IDY2OSA3MDcgNjMxVDc1MSA1MzBRNzUxIDQ1MyA2ODUgMzg5UTYxNiAzMjEgNTA3IDMwM1E1MDAgMzAyIDQwMiAzMDFIMzA3TDI3NyAxODJRMjQ3IDY2IDI0NyA1OVEyNDcgNTUgMjQ4IDU0VDI1NSA1MFQyNzIgNDhUMzA1IDQ2SDMzNlEzNDIgMzcgMzQyIDM1UTM0MiAxOSAzMzUgNVEzMzAgMCAzMTkgMFEzMTYgMCAyODIgMVQxODIgMlExMjAgMiA4NyAyVDUxIDFRMzMgMSAzMyAxMVEzMyAxMyAzNiAyNVE0MCA0MSA0NCA0M1Q2NyA0NlE5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4Wk02NDUgNTU0UTY0NSA1NjcgNjQzIDU3NVQ2MzQgNTk3VDYwOSA2MTlUNTYwIDYzNVE1NTMgNjM2IDQ4MCA2MzdRNDYzIDYzNyA0NDUgNjM3VDQxNiA2MzZUNDA0IDYzNlEzOTEgNjM1IDM4NiA2MjdRMzg0IDYyMSAzNjcgNTUwVDMzMiA0MTJUMzE0IDM0NFEzMTQgMzQyIDM5NSAzNDJINDA3SDQzMFE1NDIgMzQyIDU5MCAzOTJRNjE3IDQxOSA2MzEgNDcxVDY0NSA1NTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzMiIGQ9Ik0xMzEgMjg5UTEzMSAzMjEgMTQ3IDM1NFQyMDMgNDE1VDMwMCA0NDJRMzYyIDQ0MiAzOTAgNDE1VDQxOSAzNTVRNDE5IDMyMyA0MDIgMzA4VDM2NCAyOTJRMzUxIDI5MiAzNDAgMzAwVDMyOCAzMjZRMzI4IDM0MiAzMzcgMzU0VDM1NCAzNzJUMzY3IDM3OFEzNjggMzc4IDM2OCAzNzlRMzY4IDM4MiAzNjEgMzg4VDMzNiAzOTlUMjk3IDQwNVEyNDkgNDA1IDIyNyAzNzlUMjA0IDMyNlEyMDQgMzAxIDIyMyAyOTFUMjc4IDI3NFQzMzAgMjU5UTM5NiAyMzAgMzk2IDE2M1EzOTYgMTM1IDM4NSAxMDdUMzUyIDUxVDI4OSA3VDE5NSAtMTBRMTE4IC0xMCA4NiAxOVQ1MyA4N1E1MyAxMjYgNzQgMTQzVDExOCAxNjBRMTMzIDE2MCAxNDYgMTUxVDE2MCAxMjBRMTYwIDk0IDE0MiA3NlQxMTEgNThRMTA5IDU3IDEwOCA1N1QxMDcgNTVRMTA4IDUyIDExNSA0N1QxNDYgMzRUMjAxIDI3UTIzNyAyNyAyNjMgMzhUMzAxIDY2VDMxOCA5N1QzMjMgMTIyUTMyMyAxNTAgMzAyIDE2NFQyNTQgMTgxVDE5NSAxOTZUMTQ4IDIzMVExMzEgMjU2IDEzMSAyODlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yQiIgZD0iTTU2IDIzN1Q1NiAyNTBUNzAgMjcwSDM2OVY0MjBMMzcwIDU3MFEzODAgNTgzIDM4OSA1ODNRNDAyIDU4MyA0MDkgNTY4VjI3MEg3MDdRNzIyIDI2MiA3MjIgMjUwVDcwNyAyMzBINDA5Vi02OFE0MDEgLTgyIDM5MSAtODJIMzg5SDM4N1EzNzUgLTgyIDM2OSAtNjhWMjMwSDcwUTU2IDIzNyA1NiAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi01NiIgZD0iTTExNCA2MjBRMTEzIDYyMSAxMTAgNjI0VDEwNyA2MjdUMTAzIDYzMFQ5OCA2MzJUOTEgNjM0VDgwIDYzNVQ2NyA2MzZUNDggNjM3SDE5VjY4M0gyOFE0NiA2ODAgMTUyIDY4MFEyNzMgNjgwIDI5NCA2ODNIMzA1VjYzN0gyODRRMjIzIDYzNCAyMjMgNjIwUTIyMyA2MTggMzEzIDM3MlQ0MDQgMTI2TDQ5MCAzNThRNTc1IDU4OCA1NzUgNTk3UTU3NSA2MTYgNTU0IDYyNlQ1MDggNjM3SDUwM1Y2ODNINTEyUTUyNyA2ODAgNjI3IDY4MFE3MTggNjgwIDcyNCA2ODNINzMwVjYzN0g3MjNRNjQ4IDYzNyA2MjcgNTk2UTYyNyA1OTUgNTE1IDI5MVQ0MDEgLTE0UTM5NiAtMjIgMzgyIC0yMkgzNzRIMzY3UTM1MyAtMjIgMzQ4IC0xNFEzNDYgLTEyIDIzMSAzMDNRMTE0IDYxNyAxMTQgNjIwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNjEiIGQ9Ik0xMzcgMzA1VDExNSAzMDVUNzggMzIwVDYzIDM1OVE2MyAzOTQgOTcgNDIxVDIxOCA0NDhRMjkxIDQ0OCAzMzYgNDE2VDM5NiAzNDBRNDAxIDMyNiA0MDEgMzA5VDQwMiAxOTRWMTI0UTQwMiA3NiA0MDcgNThUNDI4IDQwUTQ0MyA0MCA0NDggNTZUNDUzIDEwOVYxNDVINDkzVjEwNlE0OTIgNjYgNDkwIDU5UTQ4MSAyOSA0NTUgMTJUNDAwIC02VDM1MyAxMlQzMjkgNTRWNThMMzI3IDU1UTMyNSA1MiAzMjIgNDlUMzE0IDQwVDMwMiAyOVQyODcgMTdUMjY5IDZUMjQ3IC0yVDIyMSAtOFQxOTAgLTExUTEzMCAtMTEgODIgMjBUMzQgMTA3UTM0IDEyOCA0MSAxNDdUNjggMTg4VDExNiAyMjVUMTk0IDI1M1QzMDQgMjY4SDMxOFYyOTBRMzE4IDMyNCAzMTIgMzQwUTI5MCA0MTEgMjE1IDQxMVExOTcgNDExIDE4MSA0MTBUMTU2IDQwNlQxNDggNDAzUTE3MCAzODggMTcwIDM1OVExNzAgMzM0IDE1NCAzMjBaTTEyNiAxMDZRMTI2IDc1IDE1MCA1MVQyMDkgMjZRMjQ3IDI2IDI3NiA0OVQzMTUgMTA5UTMxNyAxMTYgMzE4IDE3NVEzMTggMjMzIDMxNyAyMzNRMzA5IDIzMyAyOTYgMjMyVDI1MSAyMjNUMTkzIDIwM1QxNDcgMTY2VDEyNiAxMDZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03MiIgZD0iTTM2IDQ2SDUwUTg5IDQ2IDk3IDYwVjY4UTk3IDc3IDk3IDkxVDk4IDEyMlQ5OCAxNjFUOTggMjAzUTk4IDIzNCA5OCAyNjlUOTggMzI4TDk3IDM1MVE5NCAzNzAgODMgMzc2VDM4IDM4NUgyMFY0MDhRMjAgNDMxIDIyIDQzMUwzMiA0MzJRNDIgNDMzIDYwIDQzNFQ5NiA0MzZRMTEyIDQzNyAxMzEgNDM4VDE2MCA0NDFUMTcxIDQ0MkgxNzRWMzczUTIxMyA0NDEgMjcxIDQ0MUgyNzdRMzIyIDQ0MSAzNDMgNDE5VDM2NCAzNzNRMzY0IDM1MiAzNTEgMzM3VDMxMyAzMjJRMjg4IDMyMiAyNzYgMzM4VDI2MyAzNzJRMjYzIDM4MSAyNjUgMzg4VDI3MCA0MDBUMjczIDQwNVEyNzEgNDA3IDI1MCA0MDFRMjM0IDM5MyAyMjYgMzg2UTE3OSAzNDEgMTc5IDIwN1YxNTRRMTc5IDE0MSAxNzkgMTI3VDE3OSAxMDFUMTgwIDgxVDE4MCA2NlY2MVExODEgNTkgMTgzIDU3VDE4OCA1NFQxOTMgNTFUMjAwIDQ5VDIwNyA0OFQyMTYgNDdUMjI1IDQ3VDIzNSA0NlQyNDUgNDZIMjc2VjBIMjY3UTI0OSAzIDE0MCAzUTM3IDMgMjggMEgyMFY0NkgzNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzIiIGQ9Ik0yMSAyODdRMjIgMjkwIDIzIDI5NVQyOCAzMTdUMzggMzQ4VDUzIDM4MVQ3MyA0MTFUOTkgNDMzVDEzMiA0NDJRMTYxIDQ0MiAxODMgNDMwVDIxNCA0MDhUMjI1IDM4OFEyMjcgMzgyIDIyOCAzODJUMjM2IDM4OVEyODQgNDQxIDM0NyA0NDFIMzUwUTM5OCA0NDEgNDIyIDQwMFE0MzAgMzgxIDQzMCAzNjNRNDMwIDMzMyA0MTcgMzE1VDM5MSAyOTJUMzY2IDI4OFEzNDYgMjg4IDMzNCAyOTlUMzIyIDMyOFEzMjIgMzc2IDM3OCAzOTJRMzU2IDQwNSAzNDIgNDA1UTI4NiA0MDUgMjM5IDMzMVEyMjkgMzE1IDIyNCAyOThUMTkwIDE2NVExNTYgMjUgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTQgMTg5VDE1NCAzNjZRMTU0IDQwNSAxMjggNDA1UTEwNyA0MDUgOTIgMzc3VDY4IDMxNlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMSIgZD0iTTIxMyA1NzhMMjAwIDU3M1ExODYgNTY4IDE2MCA1NjNUMTAyIDU1Nkg4M1Y2MDJIMTAyUTE0OSA2MDQgMTg5IDYxN1QyNDUgNjQxVDI3MyA2NjNRMjc1IDY2NiAyODUgNjY2UTI5NCA2NjYgMzAyIDY2MFYzNjFMMzAzIDYxUTMxMCA1NCAzMTUgNTJUMzM5IDQ4VDQwMSA0Nkg0MjdWMEg0MTZRMzk1IDMgMjU3IDNRMTIxIDMgMTAwIDBIODhWNDZIMTE0UTEzNiA0NiAxNTIgNDZUMTc3IDQ3VDE5MyA1MFQyMDEgNTJUMjA3IDU3VDIxMyA2MVY1NzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjEyIiBkPSJNODQgMjM3VDg0IDI1MFQ5OCAyNzBINjc5UTY5NCAyNjIgNjk0IDI1MFQ2NzkgMjMwSDk4UTg0IDIzNyA4NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTYiIGQ9Ik01MiA2NDhRNTIgNjcwIDY1IDY4M0g3NlExMTggNjgwIDE4MSA2ODBRMjk5IDY4MCAzMjAgNjgzSDMzMFEzMzYgNjc3IDMzNiA2NzRUMzM0IDY1NlEzMjkgNjQxIDMyNSA2MzdIMzA0UTI4MiA2MzUgMjc0IDYzNVEyNDUgNjMwIDI0MiA2MjBRMjQyIDYxOCAyNzEgMzY5VDMwMSAxMThMMzc0IDIzNVE0NDcgMzUyIDUyMCA0NzFUNTk1IDU5NFE1OTkgNjAxIDU5OSA2MDlRNTk5IDYzMyA1NTUgNjM3UTUzNyA2MzcgNTM3IDY0OFE1MzcgNjQ5IDUzOSA2NjFRNTQyIDY3NSA1NDUgNjc5VDU1OCA2ODNRNTYwIDY4MyA1NzAgNjgzVDYwNCA2ODJUNjY4IDY4MVE3MzcgNjgxIDc1NSA2ODNINzYyUTc2OSA2NzYgNzY5IDY3MlE3NjkgNjU1IDc2MCA2NDBRNzU3IDYzNyA3NDMgNjM3UTczMCA2MzYgNzE5IDYzNVQ2OTggNjMwVDY4MiA2MjNUNjcwIDYxNVQ2NjAgNjA4VDY1MiA1OTlUNjQ1IDU5Mkw0NTIgMjgyUTI3MiAtOSAyNjYgLTE2UTI2MyAtMTggMjU5IC0yMUwyNDEgLTIySDIzNFEyMTYgLTIyIDIxNiAtMTVRMjEzIC05IDE3NyAzMDVRMTM5IDYyMyAxMzggNjI2UTEzMyA2MzcgNzYgNjM3SDU5UTUyIDY0MiA1MiA2NDhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTIiIGQ9Ik0yMzAgNjM3UTIwMyA2MzcgMTk4IDYzOFQxOTMgNjQ5UTE5MyA2NzYgMjA0IDY4MlEyMDYgNjgzIDM3OCA2ODNRNTUwIDY4MiA1NjQgNjgwUTYyMCA2NzIgNjU4IDY1MlQ3MTIgNjA2VDczMyA1NjNUNzM5IDUyOVE3MzkgNDg0IDcxMCA0NDVUNjQzIDM4NVQ1NzYgMzUxVDUzOCAzMzhMNTQ1IDMzM1E2MTIgMjk1IDYxMiAyMjNRNjEyIDIxMiA2MDcgMTYyVDYwMiA4MFY3MVE2MDIgNTMgNjAzIDQzVDYxNCAyNVQ2NDAgMTZRNjY4IDE2IDY4NiAzOFQ3MTIgODVRNzE3IDk5IDcyMCAxMDJUNzM1IDEwNVE3NTUgMTA1IDc1NSA5M1E3NTUgNzUgNzMxIDM2UTY5MyAtMjEgNjQxIC0yMUg2MzJRNTcxIC0yMSA1MzEgNFQ0ODcgODJRNDg3IDEwOSA1MDIgMTY2VDUxNyAyMzlRNTE3IDI5MCA0NzQgMzEzUTQ1OSAzMjAgNDQ5IDMyMVQzNzggMzIzSDMwOUwyNzcgMTkzUTI0NCA2MSAyNDQgNTlRMjQ0IDU1IDI0NSA1NFQyNTIgNTBUMjY5IDQ4VDMwMiA0NkgzMzNRMzM5IDM4IDMzOSAzN1QzMzYgMTlRMzMyIDYgMzI2IDBIMzExUTI3NSAyIDE4MCAyUTE0NiAyIDExNyAyVDcxIDJUNTAgMVEzMyAxIDMzIDEwUTMzIDEyIDM2IDI0UTQxIDQzIDQ2IDQ1UTUwIDQ2IDYxIDQ2SDY3UTk0IDQ2IDEyNyA0OVExNDEgNTIgMTQ2IDYxUTE0OSA2NSAyMTggMzM5VDI4NyA2MjhRMjg3IDYzNSAyMzAgNjM3Wk02MzAgNTU0UTYzMCA1ODYgNjA5IDYwOFQ1MjMgNjM2UTUyMSA2MzYgNTAwIDYzNlQ0NjIgNjM3SDQ0MFEzOTMgNjM3IDM4NiA2MjdRMzg1IDYyNCAzNTIgNDk0VDMxOSAzNjFRMzE5IDM2MCAzODggMzYwUTQ2NiAzNjEgNDkyIDM2N1E1NTYgMzc3IDU5MiA0MjZRNjA4IDQ0OSA2MTkgNDg2VDYzMCA1NTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zNCIgZD0iTTQ2MiAwUTQ0NCAzIDMzMyAzUTIxNyAzIDE5OSAwSDE5MFY0NkgyMjFRMjQxIDQ2IDI0OCA0NlQyNjUgNDhUMjc5IDUzVDI4NiA2MVEyODcgNjMgMjg3IDExNVYxNjVIMjhWMjExTDE3OSA0NDJRMzMyIDY3NCAzMzQgNjc1UTMzNiA2NzcgMzU1IDY3N0gzNzNMMzc5IDY3MVYyMTFINDcxVjE2NUgzNzlWMTE0UTM3OSA3MyAzNzkgNjZUMzg1IDU0UTM5MyA0NyA0NDIgNDZINDcxVjBINDYyWk0yOTMgMjExVjU0NUw3NCAyMTJMMTgzIDIxMUgyOTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMyIgZD0iTTEyNyA0NjNRMTAwIDQ2MyA4NSA0ODBUNjkgNTI0UTY5IDU3OSAxMTcgNjIyVDIzMyA2NjVRMjY4IDY2NSAyNzcgNjY0UTM1MSA2NTIgMzkwIDYxMVQ0MzAgNTIyUTQzMCA0NzAgMzk2IDQyMVQzMDIgMzUwTDI5OSAzNDhRMjk5IDM0NyAzMDggMzQ1VDMzNyAzMzZUMzc1IDMxNVE0NTcgMjYyIDQ1NyAxNzVRNDU3IDk2IDM5NSAzN1QyMzggLTIyUTE1OCAtMjIgMTAwIDIxVDQyIDEzMFE0MiAxNTggNjAgMTc1VDEwNSAxOTNRMTMzIDE5MyAxNTEgMTc1VDE2OSAxMzBRMTY5IDExOSAxNjYgMTEwVDE1OSA5NFQxNDggODJUMTM2IDc0VDEyNiA3MFQxMTggNjdMMTE0IDY2UTE2NSAyMSAyMzggMjFRMjkzIDIxIDMyMSA3NFEzMzggMTA3IDMzOCAxNzVWMTk1UTMzOCAyOTAgMjc0IDMyMlEyNTkgMzI4IDIxMyAzMjlMMTcxIDMzMEwxNjggMzMyUTE2NiAzMzUgMTY2IDM0OFExNjYgMzY2IDE3NCAzNjZRMjAyIDM2NiAyMzIgMzcxUTI2NiAzNzYgMjk0IDQxM1QzMjIgNTI1VjUzM1EzMjIgNTkwIDI4NyA2MTJRMjY1IDYyNiAyNDAgNjI2UTIwOCA2MjYgMTgxIDYxNVQxNDMgNTkyVDEzMiA1ODBIMTM1UTEzOCA1NzkgMTQzIDU3OFQxNTMgNTczVDE2NSA1NjZUMTc1IDU1NVQxODMgNTQwVDE4NiA1MjBRMTg2IDQ5OCAxNzIgNDgxVDEyNyA0NjNaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTY3LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoLTExLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwxNDEwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTMxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTdCIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjY3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjI0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzgsNDk0KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSItNzAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMTcuOTIyNTA0MTY2NjgxLDApIHNjYWxlKDAuNzU5ODcxMDY1NjI4MzgwNiwxKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiIgeD0iNTY1IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTE3NiIgeT0iMTA0NCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTE3NiIgeT0iLTM1MCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTdEIiB4PSIyMDI0IiB5PSItMSI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM2MTIsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDE0MTApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjc3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTA1NiwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM5NywwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjM2NTUiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEyOTYiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMjk3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwNywtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MjI5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDcwMzksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTI3MiIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iODkyNCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDk5MjUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEyOTYiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIyMjk3IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIzMTg3IiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzY2OCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNTYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI3NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNTQ3OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxNDM5IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjE3NTI5IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTg1MzAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTY3IiB5PSI1ODMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE5OTc2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwtMTI1MykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIyMjIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjIyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMjk2IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMjI5NyIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMzE4NyIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDk2NiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwNzQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTQ0NiI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNjU0NiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDczMjQsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI0NjU2IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzQiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxNzk3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMjc5NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDMyOTgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNzA3LC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyNDQzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzNjM1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjE1MjE1IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTU5OTMsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI2NjE3IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMjk2IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zNCIgeD0iMjI5NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI3OTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNDI1OCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUyNTksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMzIiB4PSIxMTA5IiB5PSI1MTAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNjg4LC04MzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii00NDYiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMzA3MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwNzQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8L3N2Zz4=)
fact 11 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjYyLjMwNWV4IiBoZWlnaHQ9IjcuMTc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4xNzFleDsiIHZpZXdCb3g9IjAgLTE3MjQuMiAyNjgyNS42IDMwODkuNiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NiIgZD0iTTUyIDY0OFE1MiA2NzAgNjUgNjgzSDc2UTExOCA2ODAgMTgxIDY4MFEyOTkgNjgwIDMyMCA2ODNIMzMwUTMzNiA2NzcgMzM2IDY3NFQzMzQgNjU2UTMyOSA2NDEgMzI1IDYzN0gzMDRRMjgyIDYzNSAyNzQgNjM1UTI0NSA2MzAgMjQyIDYyMFEyNDIgNjE4IDI3MSAzNjlUMzAxIDExOEwzNzQgMjM1UTQ0NyAzNTIgNTIwIDQ3MVQ1OTUgNTk0UTU5OSA2MDEgNTk5IDYwOVE1OTkgNjMzIDU1NSA2MzdRNTM3IDYzNyA1MzcgNjQ4UTUzNyA2NDkgNTM5IDY2MVE1NDIgNjc1IDU0NSA2NzlUNTU4IDY4M1E1NjAgNjgzIDU3MCA2ODNUNjA0IDY4MlQ2NjggNjgxUTczNyA2ODEgNzU1IDY4M0g3NjJRNzY5IDY3NiA3NjkgNjcyUTc2OSA2NTUgNzYwIDY0MFE3NTcgNjM3IDc0MyA2MzdRNzMwIDYzNiA3MTkgNjM1VDY5OCA2MzBUNjgyIDYyM1Q2NzAgNjE1VDY2MCA2MDhUNjUyIDU5OVQ2NDUgNTkyTDQ1MiAyODJRMjcyIC05IDI2NiAtMTZRMjYzIC0xOCAyNTkgLTIxTDI0MSAtMjJIMjM0UTIxNiAtMjIgMjE2IC0xNVEyMTMgLTkgMTc3IDMwNVExMzkgNjIzIDEzOCA2MjZRMTMzIDYzNyA3NiA2MzdINTlRNTIgNjQyIDUyIDY0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjEyIiBkPSJNODQgMjM3VDg0IDI1MFQ5OCAyNzBINjc5UTY5NCAyNjIgNjk0IDI1MFQ2NzkgMjMwSDk4UTg0IDIzNyA4NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDUiIGQ9Ik00OTIgMjEzUTQ3MiAyMTMgNDcyIDIyNlE0NzIgMjMwIDQ3NyAyNTBUNDgyIDI4NVE0ODIgMzE2IDQ2MSAzMjNUMzY0IDMzMEgzMTJRMzExIDMyOCAyNzcgMTkyVDI0MyA1MlEyNDMgNDggMjU0IDQ4VDMzNCA0NlE0MjggNDYgNDU4IDQ4VDUxOCA2MVE1NjcgNzcgNTk5IDExN1Q2NzAgMjQ4UTY4MCAyNzAgNjgzIDI3MlE2OTAgMjc0IDY5OCAyNzRRNzE4IDI3NCA3MTggMjYxUTYxMyA3IDYwOCAyUTYwNSAwIDMyMiAwSDEzM1EzMSAwIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc1N1E3NjQgNjc2IDc2NCA2NjlRNzY0IDY2NCA3NTEgNTU3VDczNyA0NDdRNzM1IDQ0MCA3MTcgNDQwSDcwNVE2OTggNDQ1IDY5OCA0NTNMNzAxIDQ3NlE3MDQgNTAwIDcwNCA1MjhRNzA0IDU1OCA2OTcgNTc4VDY3OCA2MDlUNjQzIDYyNVQ1OTYgNjMyVDUzMiA2MzRINDg1UTM5NyA2MzMgMzkyIDYzMVEzODggNjI5IDM4NiA2MjJRMzg1IDYxOSAzNTUgNDk5VDMyNCAzNzdRMzQ3IDM3NiAzNzIgMzc2SDM5OFE0NjQgMzc2IDQ4OSAzOTFUNTM0IDQ3MlE1MzggNDg4IDU0MCA0OTBUNTU3IDQ5M1E1NjIgNDkzIDU2NSA0OTNUNTcwIDQ5MlQ1NzIgNDkxVDU3NCA0ODdUNTc3IDQ4M0w1NDQgMzUxUTUxMSAyMTggNTA4IDIxNlE1MDUgMjEzIDQ5MiAyMTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03QiIgZD0iTTQzNCAtMjMxUTQzNCAtMjQ0IDQyOCAtMjUwSDQxMFEyODEgLTI1MCAyMzAgLTE4NFEyMjUgLTE3NyAyMjIgLTE3MlQyMTcgLTE2MVQyMTMgLTE0OFQyMTEgLTEzM1QyMTAgLTExMVQyMDkgLTg0VDIwOSAtNDdUMjA5IDBRMjA5IDIxIDIwOSA1M1EyMDggMTQyIDIwNCAxNTNRMjAzIDE1NCAyMDMgMTU1UTE4OSAxOTEgMTUzIDIxMVQ4MiAyMzFRNzEgMjMxIDY4IDIzNFQ2NSAyNTBUNjggMjY2VDgyIDI2OVExMTYgMjY5IDE1MiAyODlUMjAzIDM0NVEyMDggMzU2IDIwOCAzNzdUMjA5IDUyOVY1NzlRMjA5IDYzNCAyMTUgNjU2VDI0NCA2OThRMjcwIDcyNCAzMjQgNzQwUTM2MSA3NDggMzc3IDc0OVEzNzkgNzQ5IDM5MCA3NDlUNDA4IDc1MEg0MjhRNDM0IDc0NCA0MzQgNzMyUTQzNCA3MTkgNDMxIDcxNlE0MjkgNzEzIDQxNSA3MTNRMzYyIDcxMCAzMzIgNjg5VDI5NiA2NDdRMjkxIDYzNCAyOTEgNDk5VjQxN1EyOTEgMzcwIDI4OCAzNTNUMjcxIDMxNFEyNDAgMjcxIDE4NCAyNTVMMTcwIDI1MEwxODQgMjQ1UTIwMiAyMzkgMjIwIDIzMFQyNjIgMTk2VDI5MCAxMzdRMjkxIDEzMSAyOTEgMVEyOTEgLTEzNCAyOTYgLTE0N1EzMDYgLTE3NCAzMzkgLTE5MlQ0MTUgLTIxM1E0MjkgLTIxMyA0MzEgLTIxNlE0MzQgLTIxOSA0MzQgLTIzMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdEIiBkPSJNNjUgNzMxUTY1IDc0NSA2OCA3NDdUODggNzUwUTE3MSA3NTAgMjE2IDcyNVQyNzkgNjcwUTI4OCA2NDkgMjg5IDYzNVQyOTEgNTAxUTI5MiAzNjIgMjkzIDM1N1EzMDYgMzEyIDM0NSAyOTFUNDE3IDI2OVE0MjggMjY5IDQzMSAyNjZUNDM0IDI1MFQ0MzEgMjM0VDQxNyAyMzFRMzgwIDIzMSAzNDUgMjEwVDI5OCAxNTdRMjkzIDE0MyAyOTIgMTIxVDI5MSAtMjhWLTc5UTI5MSAtMTM0IDI4NSAtMTU2VDI1NiAtMTk4UTIwMiAtMjUwIDg5IC0yNTBRNzEgLTI1MCA2OCAtMjQ3VDY1IC0yMzBRNjUgLTIyNCA2NSAtMjIzVDY2IC0yMThUNjkgLTIxNFQ3NyAtMjEzUTkxIC0yMTMgMTA4IC0yMTBUMTQ2IC0yMDBUMTgzIC0xNzdUMjA3IC0xMzlRMjA4IC0xMzQgMjA5IDNMMjEwIDEzOVEyMjMgMTk2IDI4MCAyMzBRMzE1IDI0NyAzMzAgMjUwUTMwNSAyNTcgMjgwIDI3MFEyMjUgMzA0IDIxMiAzNTJMMjEwIDM2MkwyMDkgNDk4UTIwOCA2MzUgMjA3IDY0MFExOTUgNjgwIDE1NCA2OTZUNzcgNzEzUTY4IDcxMyA2NyA3MTZUNjUgNzMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMS03QiIgZD0iTTQ3NyAtMzQzTDQ3MSAtMzQ5SDQ1OFE0MzIgLTM0OSAzNjcgLTMyNVQyNzMgLTI2M1EyNTggLTI0NSAyNTAgLTIxMkwyNDkgLTUxUTI0OSAtMjcgMjQ5IDEyUTI0OCAxMTggMjQ0IDEyOFEyNDMgMTI5IDI0MyAxMzBRMjIwIDE4OSAxMjEgMjI4UTEwOSAyMzIgMTA3IDIzNVQxMDUgMjUwUTEwNSAyNTYgMTA1IDI1N1QxMDUgMjYxVDEwNyAyNjVUMTExIDI2OFQxMTggMjcyVDEyOCAyNzZUMTQyIDI4M1QxNjIgMjkxUTIyNCAzMjQgMjQzIDM3MVEyNDMgMzcyIDI0NCAzNzNRMjQ4IDM4NCAyNDkgNDY5UTI0OSA0NzUgMjQ5IDQ4OVEyNDkgNTI4IDI0OSA1NTJMMjUwIDcxNFEyNTMgNzI4IDI1NiA3MzZUMjcxIDc2MVQyOTkgNzg5VDM0NyA4MTZUNDIyIDg0M1E0NDAgODQ5IDQ0MSA4NDlINDQzUTQ0NSA4NDkgNDQ3IDg0OVQ0NTIgODUwVDQ1NyA4NTBINDcxTDQ3NyA4NDRWODMwUTQ3NyA4MjAgNDc2IDgxN1Q0NzAgODExVDQ1OSA4MDdUNDM3IDgwMVQ0MDQgNzg1UTM1MyA3NjAgMzM4IDcyNFEzMzMgNzEwIDMzMyA1NTBRMzMzIDUyNiAzMzMgNDkyVDMzNCA0NDdRMzM0IDM5MyAzMjcgMzY4VDI5NSAzMThRMjU3IDI4MCAxODEgMjU1TDE2OSAyNTFMMTg0IDI0NVEzMTggMTk4IDMzMiAxMTJRMzMzIDEwNiAzMzMgLTQ5UTMzMyAtMjA5IDMzOCAtMjIzUTM1MSAtMjU1IDM5MSAtMjc3VDQ2OSAtMzA5UTQ3NyAtMzExIDQ3NyAtMzI5Vi0zNDNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oxLTdEIiBkPSJNMTEwIDg0OUwxMTUgODUwUTEyMCA4NTAgMTI1IDg1MFExNTEgODUwIDIxNSA4MjZUMzA5IDc2NFEzMjQgNzQ3IDMzMiA3MTRMMzMzIDU1MlEzMzMgNTI4IDMzMyA0ODlRMzM0IDM4MyAzMzggMzczUTMzOSAzNzIgMzM5IDM3MVEzNTMgMzM2IDM5MSAzMTBUNDY5IDI3MVE0NzcgMjY4IDQ3NyAyNTFRNDc3IDI0MSA0NzYgMjM3VDQ3MiAyMzJUNDU2IDIyNVQ0MjggMjE0UTM1NyAxNzkgMzM5IDEzMFEzMzkgMTI5IDMzOCAxMjhRMzM0IDExNyAzMzMgMzJRMzMzIDI2IDMzMyAxMlEzMzMgLTI3IDMzMyAtNTFMMzMyIC0yMTJRMzI4IC0yMjggMzIzIC0yNDBUMzAyIC0yNzFUMjU1IC0zMDdUMTc1IC0zMzhRMTM5IC0zNDkgMTI1IC0zNDlUMTA4IC0zNDZUMTA1IC0zMjlRMTA1IC0zMTQgMTA3IC0zMTJUMTMwIC0zMDRRMjMzIC0yNzEgMjQ4IC0yMDlRMjQ5IC0yMDMgMjQ5IC00OVY1N1EyNDkgMTA2IDI1MyAxMjVUMjczIDE2N1EzMDcgMjEzIDM5OCAyNDVMNDEzIDI1MUw0MDEgMjU1UTI2NSAzMDAgMjUwIDM4OVEyNDkgMzk1IDI0OSA1NTBRMjQ5IDcxMCAyNDQgNzI0UTIyNCA3NzQgMTEyIDgxMVExMDUgODEzIDEwNSA4MzBRMTA1IDg0NSAxMTAgODQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMS0yOCIgZD0iTTE1MiAyNTFRMTUyIDY0NiAzODggODUwSDQxNlE0MjIgODQ0IDQyMiA4NDFRNDIyIDgzNyA0MDMgODE2VDM1NyA3NTNUMzAyIDY0OVQyNTUgNDgyVDIzNiAyNTBRMjM2IDEyNCAyNTUgMTlUMzAxIC0xNDdUMzU2IC0yNTFUNDAzIC0zMTVUNDIyIC0zNDBRNDIyIC0zNDMgNDE2IC0zNDlIMzg4UTM1OSAtMzI1IDMzMiAtMjk2VDI3MSAtMjEzVDIxMiAtOTdUMTcwIDU2VDE1MiAyNTFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oxLTI5IiBkPSJNMzA1IDI1MVEzMDUgLTE0NSA2OSAtMzQ5SDU2UTQzIC0zNDkgMzkgLTM0N1QzNSAtMzM4UTM3IC0zMzMgNjAgLTMwN1QxMDggLTIzOVQxNjAgLTEzNlQyMDQgMjdUMjIxIDI1MFQyMDQgNDczVDE2MCA2MzZUMTA4IDc0MFQ2MCA4MDdUMzUgODM5UTM1IDg1MCA1MCA4NTBINTZINjlRMTk3IDc0MyAyNTYgNTY2UTMwNSA0MjUgMzA1IDI1MVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUwIiBkPSJNMjg3IDYyOFEyODcgNjM1IDIzMCA2MzdRMjA2IDYzNyAxOTkgNjM4VDE5MiA2NDhRMTkyIDY0OSAxOTQgNjU5UTIwMCA2NzkgMjAzIDY4MVQzOTcgNjgzUTU4NyA2ODIgNjAwIDY4MFE2NjQgNjY5IDcwNyA2MzFUNzUxIDUzMFE3NTEgNDUzIDY4NSAzODlRNjE2IDMyMSA1MDcgMzAzUTUwMCAzMDIgNDAyIDMwMUgzMDdMMjc3IDE4MlEyNDcgNjYgMjQ3IDU5UTI0NyA1NSAyNDggNTRUMjU1IDUwVDI3MiA0OFQzMDUgNDZIMzM2UTM0MiAzNyAzNDIgMzVRMzQyIDE5IDMzNSA1UTMzMCAwIDMxOSAwUTMxNiAwIDI4MiAxVDE4MiAyUTEyMCAyIDg3IDJUNTEgMVEzMyAxIDMzIDExUTMzIDEzIDM2IDI1UTQwIDQxIDQ0IDQzVDY3IDQ2UTk0IDQ2IDEyNyA0OVExNDEgNTIgMTQ2IDYxUTE0OSA2NSAyMTggMzM5VDI4NyA2MjhaTTY0NSA1NTRRNjQ1IDU2NyA2NDMgNTc1VDYzNCA1OTdUNjA5IDYxOVQ1NjAgNjM1UTU1MyA2MzYgNDgwIDYzN1E0NjMgNjM3IDQ0NSA2MzdUNDE2IDYzNlQ0MDQgNjM2UTM5MSA2MzUgMzg2IDYyN1EzODQgNjIxIDM2NyA1NTBUMzMyIDQxMlQzMTQgMzQ0UTMxNCAzNDIgMzk1IDM0Mkg0MDdINDMwUTU0MiAzNDIgNTkwIDM5MlE2MTcgNDE5IDYzMSA0NzFUNjQ1IDU1NFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUyIiBkPSJNMjMwIDYzN1EyMDMgNjM3IDE5OCA2MzhUMTkzIDY0OVExOTMgNjc2IDIwNCA2ODJRMjA2IDY4MyAzNzggNjgzUTU1MCA2ODIgNTY0IDY4MFE2MjAgNjcyIDY1OCA2NTJUNzEyIDYwNlQ3MzMgNTYzVDczOSA1MjlRNzM5IDQ4NCA3MTAgNDQ1VDY0MyAzODVUNTc2IDM1MVQ1MzggMzM4TDU0NSAzMzNRNjEyIDI5NSA2MTIgMjIzUTYxMiAyMTIgNjA3IDE2MlQ2MDIgODBWNzFRNjAyIDUzIDYwMyA0M1Q2MTQgMjVUNjQwIDE2UTY2OCAxNiA2ODYgMzhUNzEyIDg1UTcxNyA5OSA3MjAgMTAyVDczNSAxMDVRNzU1IDEwNSA3NTUgOTNRNzU1IDc1IDczMSAzNlE2OTMgLTIxIDY0MSAtMjFINjMyUTU3MSAtMjEgNTMxIDRUNDg3IDgyUTQ4NyAxMDkgNTAyIDE2NlQ1MTcgMjM5UTUxNyAyOTAgNDc0IDMxM1E0NTkgMzIwIDQ0OSAzMjFUMzc4IDMyM0gzMDlMMjc3IDE5M1EyNDQgNjEgMjQ0IDU5UTI0NCA1NSAyNDUgNTRUMjUyIDUwVDI2OSA0OFQzMDIgNDZIMzMzUTMzOSAzOCAzMzkgMzdUMzM2IDE5UTMzMiA2IDMyNiAwSDMxMVEyNzUgMiAxODAgMlExNDYgMiAxMTcgMlQ3MSAyVDUwIDFRMzMgMSAzMyAxMFEzMyAxMiAzNiAyNFE0MSA0MyA0NiA0NVE1MCA0NiA2MSA0Nkg2N1E5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4UTI4NyA2MzUgMjMwIDYzN1pNNjMwIDU1NFE2MzAgNTg2IDYwOSA2MDhUNTIzIDYzNlE1MjEgNjM2IDUwMCA2MzZUNDYyIDYzN0g0NDBRMzkzIDYzNyAzODYgNjI3UTM4NSA2MjQgMzUyIDQ5NFQzMTkgMzYxUTMxOSAzNjAgMzg4IDM2MFE0NjYgMzYxIDQ5MiAzNjdRNTU2IDM3NyA1OTIgNDI2UTYwOCA0NDkgNjE5IDQ4NlQ2MzAgNTU0WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExNjciIHk9IjU4MyI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0NDUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIyOTE2IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzkxNywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMS0yOCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ1OCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTMxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTdCIiB4PSIwIiB5PSItMSI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU4MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIxMTY3IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjgyNSIgeT0iLTIxMiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2MzIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjEtN0QiIHg9IjM0NjQiIHk9Ii0xIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMS0yOSIgeD0iNTQzNyIgeT0iLTEiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iODMzOCIgeT0iODE3Ij48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIxMDU0NSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDExMzIzLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzk3LDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNTEyOCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDc3MCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI1MDAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMzIzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMjMyMyIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMzIxMyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM3NzAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjUsLTk3MCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI4MjIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxODIzIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIyNzEzIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjQzODgiIHk9IjY3NSI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM1NTYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTQ0NiI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTY5NjksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMDc0IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjE4NDA1IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTkxODMsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI0NjMwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTUyNyw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTc3MSkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI4MjIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxODIzIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIyNzEzIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzI2OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI0Mjc2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI1NDY3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9zdmc+)
fact 12 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjY0LjQzMWV4IiBoZWlnaHQ9IjEzLjE3NmV4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTUuNzExZXg7IG1hcmdpbi1ib3R0b206IC0wLjI5NGV4OyIgdmlld0JveD0iMCAtMzA4Ny42IDI3NzQxLjIgNTY3MyIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NSIgZD0iTTQ5MiAyMTNRNDcyIDIxMyA0NzIgMjI2UTQ3MiAyMzAgNDc3IDI1MFQ0ODIgMjg1UTQ4MiAzMTYgNDYxIDMyM1QzNjQgMzMwSDMxMlEzMTEgMzI4IDI3NyAxOTJUMjQzIDUyUTI0MyA0OCAyNTQgNDhUMzM0IDQ2UTQyOCA0NiA0NTggNDhUNTE4IDYxUTU2NyA3NyA1OTkgMTE3VDY3MCAyNDhRNjgwIDI3MCA2ODMgMjcyUTY5MCAyNzQgNjk4IDI3NFE3MTggMjc0IDcxOCAyNjFRNjEzIDcgNjA4IDJRNjA1IDAgMzIyIDBIMTMzUTMxIDAgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ2IDY2IDIxNSAzNDJUMjg1IDYyMlEyODUgNjI5IDI4MSA2MjlRMjczIDYzMiAyMjggNjM0SDE5N1ExOTEgNjQwIDE5MSA2NDJUMTkzIDY1OVExOTcgNjc2IDIwMyA2ODBINzU3UTc2NCA2NzYgNzY0IDY2OVE3NjQgNjY0IDc1MSA1NTdUNzM3IDQ0N1E3MzUgNDQwIDcxNyA0NDBINzA1UTY5OCA0NDUgNjk4IDQ1M0w3MDEgNDc2UTcwNCA1MDAgNzA0IDUyOFE3MDQgNTU4IDY5NyA1NzhUNjc4IDYwOVQ2NDMgNjI1VDU5NiA2MzJUNTMyIDYzNEg0ODVRMzk3IDYzMyAzOTIgNjMxUTM4OCA2MjkgMzg2IDYyMlEzODUgNjE5IDM1NSA0OTlUMzI0IDM3N1EzNDcgMzc2IDM3MiAzNzZIMzk4UTQ2NCAzNzYgNDg5IDM5MVQ1MzQgNDcyUTUzOCA0ODggNTQwIDQ5MFQ1NTcgNDkzUTU2MiA0OTMgNTY1IDQ5M1Q1NzAgNDkyVDU3MiA0OTFUNTc0IDQ4N1Q1NzcgNDgzTDU0NCAzNTFRNTExIDIxOCA1MDggMjE2UTUwNSAyMTMgNDkyIDIxM1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzIiIGQ9Ik0xMDkgNDI5UTgyIDQyOSA2NiA0NDdUNTAgNDkxUTUwIDU2MiAxMDMgNjE0VDIzNSA2NjZRMzI2IDY2NiAzODcgNjEwVDQ0OSA0NjVRNDQ5IDQyMiA0MjkgMzgzVDM4MSAzMTVUMzAxIDI0MVEyNjUgMjEwIDIwMSAxNDlMMTQyIDkzTDIxOCA5MlEzNzUgOTIgMzg1IDk3UTM5MiA5OSA0MDkgMTg2VjE4OUg0NDlWMTg2UTQ0OCAxODMgNDM2IDk1VDQyMSAzVjBINTBWMTlWMzFRNTAgMzggNTYgNDZUODYgODFRMTE1IDExMyAxMzYgMTM3UTE0NSAxNDcgMTcwIDE3NFQyMDQgMjExVDIzMyAyNDRUMjYxIDI3OFQyODQgMzA4VDMwNSAzNDBUMzIwIDM2OVQzMzMgNDAxVDM0MCA0MzFUMzQzIDQ2NFEzNDMgNTI3IDMwOSA1NzNUMjEyIDYxOVExNzkgNjE5IDE1NCA2MDJUMTE5IDU2OVQxMDkgNTUwUTEwOSA1NDkgMTE0IDU0OVExMzIgNTQ5IDE1MSA1MzVUMTcwIDQ4OVExNzAgNDY0IDE1NCA0NDdUMTA5IDQyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMDIiIGQ9Ik0yMDIgNTA4UTE3OSA1MDggMTY5IDUyMFQxNTggNTQ3UTE1OCA1NTcgMTY0IDU3N1QxODUgNjI0VDIzMCA2NzVUMzAxIDcxMEwzMzMgNzE1SDM0NVEzNzggNzE1IDM4NCA3MTRRNDQ3IDcwMyA0ODkgNjYxVDU0OSA1NjhUNTY2IDQ1N1E1NjYgMzYyIDUxOSAyNDBUNDAyIDUzUTMyMSAtMjIgMjIzIC0yMlExMjMgLTIyIDczIDU2UTQyIDEwMiA0MiAxNDhWMTU5UTQyIDI3NiAxMjkgMzcwVDMyMiA0NjVRMzgzIDQ2NSA0MTQgNDM0VDQ1NSAzNjdMNDU4IDM3OFE0NzggNDYxIDQ3OCA1MTVRNDc4IDYwMyA0MzcgNjM5VDM0NCA2NzZRMjY2IDY3NiAyMjMgNjEyUTI2NCA2MDYgMjY0IDU3MlEyNjQgNTQ3IDI0NiA1MjhUMjAyIDUwOFpNNDMwIDMwNlE0MzAgMzcyIDQwMSA0MDBUMzMzIDQyOFEyNzAgNDI4IDIyMiAzODJRMTk3IDM1NCAxODMgMzIzVDE1MCAyMjFRMTMyIDE0OSAxMzIgMTE2UTEzMiAyMSAyMzIgMjFRMjQ0IDIxIDI1MCAyMlEzMjcgMzUgMzc0IDExMlEzODkgMTM3IDQwOSAxOTZUNDMwIDMwNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS0zQjQiIGQ9Ik0xOTUgNjA5UTE5NSA2NTYgMjI3IDY4NlQzMDIgNzE3UTMxOSA3MTYgMzUxIDcwOVQ0MDcgNjk3VDQzMyA2OTBRNDUxIDY4MiA0NTEgNjYyUTQ1MSA2NDQgNDM4IDYyOFQ0MDMgNjEyUTM4MiA2MTIgMzQ4IDY0MVQyODggNjcxVDI0OSA2NTdUMjM1IDYyOFEyMzUgNTg0IDMzNCA0NjNRNDAxIDM3OSA0MDEgMjkyUTQwMSAxNjkgMzQwIDgwVDIwNSAtMTBIMTk4UTEyNyAtMTAgODMgMzZUMzYgMTUzUTM2IDI4NiAxNTEgMzgyUTE5MSA0MTMgMjUyIDQzNFEyNTIgNDM1IDI0NSA0NDlUMjMwIDQ4MVQyMTQgNTIxVDIwMSA1NjZUMTk1IDYwOVpNMTEyIDEzMFExMTIgODMgMTM2IDU1VDIwNCAyN1EyMzMgMjcgMjU2IDUxVDI5MSAxMTFUMzA5IDE3OFQzMTYgMjMyUTMxNiAyNjcgMzA5IDI5OFQyOTUgMzQ0VDI2OSA0MDBMMjU5IDM5NlEyMTUgMzgxIDE4MyAzNDJUMTM3IDI1NlQxMTggMTc5VDExMiAxMzBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNjYiIGQ9Ik0xMTggLTE2MlExMjAgLTE2MiAxMjQgLTE2NFQxMzUgLTE2N1QxNDcgLTE2OFExNjAgLTE2OCAxNzEgLTE1NVQxODcgLTEyNlExOTcgLTk5IDIyMSAyN1QyNjcgMjY3VDI4OSAzODJWMzg1SDI0MlExOTUgMzg1IDE5MiAzODdRMTg4IDM5MCAxODggMzk3TDE5NSA0MjVRMTk3IDQzMCAyMDMgNDMwVDI1MCA0MzFRMjk4IDQzMSAyOTggNDMyUTI5OCA0MzQgMzA3IDQ4MlQzMTkgNTQwUTM1NiA3MDUgNDY1IDcwNVE1MDIgNzAzIDUyNiA2ODNUNTUwIDYzMFE1NTAgNTk0IDUyOSA1NzhUNDg3IDU2MVE0NDMgNTYxIDQ0MyA2MDNRNDQzIDYyMiA0NTQgNjM2VDQ3OCA2NTdMNDg3IDY2MlE0NzEgNjY4IDQ1NyA2NjhRNDQ1IDY2OCA0MzQgNjU4VDQxOSA2MzBRNDEyIDYwMSA0MDMgNTUyVDM4NyA0NjlUMzgwIDQzM1EzODAgNDMxIDQzNSA0MzFRNDgwIDQzMSA0ODcgNDMwVDQ5OCA0MjRRNDk5IDQyMCA0OTYgNDA3VDQ5MSAzOTFRNDg5IDM4NiA0ODIgMzg2VDQyOCAzODVIMzcyTDM0OSAyNjNRMzAxIDE1IDI4MiAtNDdRMjU1IC0xMzIgMjEyIC0xNzNRMTc1IC0yMDUgMTM5IC0yMDVRMTA3IC0yMDUgODEgLTE4NlQ1NSAtMTMyUTU1IC05NSA3NiAtNzhUMTE4IC02MVExNjIgLTYxIDE2MiAtMTAzUTE2MiAtMTIyIDE1MSAtMTM2VDEyNyAtMTU3TDExOCAtMTYyWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0MiIGQ9Ik0xMzkgLTI0OUgxMzdRMTI1IC0yNDkgMTE5IC0yMzVWMjUxTDEyMCA3MzdRMTMwIDc1MCAxMzkgNzUwUTE1MiA3NTAgMTU5IDczNVYtMjM1UTE1MSAtMjQ5IDE0MSAtMjQ5SDEzOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzAiIGQ9Ik05NiA1ODVRMTUyIDY2NiAyNDkgNjY2UTI5NyA2NjYgMzQ1IDY0MFQ0MjMgNTQ4UTQ2MCA0NjUgNDYwIDMyMFE0NjAgMTY1IDQxNyA4M1EzOTcgNDEgMzYyIDE2VDMwMSAtMTVUMjUwIC0yMlEyMjQgLTIyIDE5OCAtMTZUMTM3IDE2VDgyIDgzUTM5IDE2NSAzOSAzMjBRMzkgNDk0IDk2IDU4NVpNMzIxIDU5N1EyOTEgNjI5IDI1MCA2MjlRMjA4IDYyOSAxNzggNTk3UTE1MyA1NzEgMTQ1IDUyNVQxMzcgMzMzUTEzNyAxNzUgMTQ1IDEyNVQxODEgNDZRMjA5IDE2IDI1MCAxNlEyOTAgMTYgMzE4IDQ2UTM0NyA3NiAzNTQgMTMwVDM2MiAzMzNRMzYyIDQ3OCAzNTQgNTI0VDMyMSA1OTdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03RCIgZD0iTTY1IDczMVE2NSA3NDUgNjggNzQ3VDg4IDc1MFExNzEgNzUwIDIxNiA3MjVUMjc5IDY3MFEyODggNjQ5IDI4OSA2MzVUMjkxIDUwMVEyOTIgMzYyIDI5MyAzNTdRMzA2IDMxMiAzNDUgMjkxVDQxNyAyNjlRNDI4IDI2OSA0MzEgMjY2VDQzNCAyNTBUNDMxIDIzNFQ0MTcgMjMxUTM4MCAyMzEgMzQ1IDIxMFQyOTggMTU3UTI5MyAxNDMgMjkyIDEyMVQyOTEgLTI4Vi03OVEyOTEgLTEzNCAyODUgLTE1NlQyNTYgLTE5OFEyMDIgLTI1MCA4OSAtMjUwUTcxIC0yNTAgNjggLTI0N1Q2NSAtMjMwUTY1IC0yMjQgNjUgLTIyM1Q2NiAtMjE4VDY5IC0yMTRUNzcgLTIxM1E5MSAtMjEzIDEwOCAtMjEwVDE0NiAtMjAwVDE4MyAtMTc3VDIwNyAtMTM5UTIwOCAtMTM0IDIwOSAzTDIxMCAxMzlRMjIzIDE5NiAyODAgMjMwUTMxNSAyNDcgMzMwIDI1MFEzMDUgMjU3IDI4MCAyNzBRMjI1IDMwNCAyMTIgMzUyTDIxMCAzNjJMMjA5IDQ5OFEyMDggNjM1IDIwNyA2NDBRMTk1IDY4MCAxNTQgNjk2VDc3IDcxM1E2OCA3MTMgNjcgNzE2VDY1IDczMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjMtN0IiIGQ9Ik02MTggLTk0M0w2MTIgLTk0OUg1ODJMNTY4IC05NDNRNDcyIC05MDMgNDExIC04NDFUMzMyIC03MDNRMzI3IC02ODIgMzI3IC02NTNUMzI1IC0zNTBRMzI0IC0yOCAzMjMgLTE4UTMxNyAyNCAzMDEgNjFUMjY0IDEyNFQyMjEgMTcxVDE3OSAyMDVUMTQ3IDIyNVQxMzIgMjM0UTEzMCAyMzggMTMwIDI1MFExMzAgMjU1IDEzMCAyNThUMTMxIDI2NFQxMzIgMjY3VDEzNCAyNjlUMTM5IDI3MlQxNDQgMjc1UTIwNyAzMDggMjU2IDM2N1EzMTAgNDM2IDMyMyA1MTlRMzI0IDUyOSAzMjUgODUxUTMyNiAxMTI0IDMyNiAxMTU0VDMzMiAxMjA1UTM2OSAxMzU4IDU2NiAxNDQzTDU4MiAxNDUwSDYxMkw2MTggMTQ0NFYxNDI5UTYxOCAxNDEzIDYxNiAxNDExTDYwOCAxNDA2UTU5OSAxNDAyIDU4NSAxMzkzVDU1MiAxMzcyVDUxNSAxMzQzVDQ3OSAxMzA1VDQ0OSAxMjU3VDQyOSAxMjAwUTQyNSAxMTgwIDQyNSAxMTUyVDQyMyA4NTFRNDIyIDU3OSA0MjIgNTQ5VDQxNiA0OThRNDA3IDQ1OSAzODggNDI0VDM0NiAzNjRUMjk3IDMxOFQyNTAgMjg0VDIxNCAyNjRUMTk3IDI1NEwxODggMjUxTDIwNSAyNDJRMjkwIDIwMCAzNDUgMTM4VDQxNiAzUTQyMSAtMTggNDIxIC00OFQ0MjMgLTM0OVE0MjMgLTM5NyA0MjMgLTQ3MlE0MjQgLTY3NyA0MjggLTY5NFE0MjkgLTY5NyA0MjkgLTY5OVE0MzQgLTcyMiA0NDMgLTc0M1Q0NjUgLTc4MlQ0OTEgLTgxNlQ1MTkgLTg0NVQ1NDggLTg2OFQ1NzQgLTg4NlQ1OTUgLTg5OVQ2MTAgLTkwOEw2MTYgLTkxMFE2MTggLTkxMiA2MTggLTkyOFYtOTQzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMy03RCIgZD0iTTEzMSAxNDE0VDEzMSAxNDI5VDEzMyAxNDQ3VDE0OCAxNDUwSDE1M0gxNjdMMTgyIDE0NDRRMjc2IDE0MDQgMzM2IDEzNDNUNDE1IDEyMDdRNDIxIDExODQgNDIxIDExNTRUNDIzIDg1MUw0MjQgNTMxTDQyNiA1MTdRNDM0IDQ2MiA0NjAgNDE1VDUxOCAzMzlUNTcxIDI5NlQ2MDggMjc0UTYxNSAyNzAgNjE2IDI2N1Q2MTggMjUxUTYxOCAyNDEgNjE4IDIzOFQ2MTUgMjMyVDYwOCAyMjdRNTQyIDE5NCA0OTEgMTMyVDQyNiAtMTVMNDI0IC0yOUw0MjMgLTM1MFE0MjIgLTYyMiA0MjIgLTY1MlQ0MTUgLTcwNlEzOTcgLTc4MCAzMzcgLTg0MVQxODIgLTk0M0wxNjcgLTk0OUgxNTNRMTM3IC05NDkgMTM0IC05NDZUMTMxIC05MjhRMTMxIC05MTQgMTMyIC05MTFUMTQ0IC05MDRRMTQ2IC05MDMgMTQ4IC05MDJRMjk5IC04MjAgMzIzIC02ODBRMzI0IC02NjMgMzI1IC0zNDlUMzI3IC0xOVEzNTUgMTQ1IDU0MSAyNDFMNTYxIDI1MEw1NDEgMjYwUTM1NiAzNTUgMzI3IDUyMFEzMjYgNTM3IDMyNSA4NTBUMzIzIDExODFRMzE1IDEyMjcgMjkzIDEyNjdUMjQ0IDEzMzJUMTkzIDEzNzRUMTUxIDE0MDFUMTMyIDE0MTNRMTMxIDE0MTQgMTMxIDE0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTAiIGQ9Ik0yODcgNjI4UTI4NyA2MzUgMjMwIDYzN1EyMDYgNjM3IDE5OSA2MzhUMTkyIDY0OFExOTIgNjQ5IDE5NCA2NTlRMjAwIDY3OSAyMDMgNjgxVDM5NyA2ODNRNTg3IDY4MiA2MDAgNjgwUTY2NCA2NjkgNzA3IDYzMVQ3NTEgNTMwUTc1MSA0NTMgNjg1IDM4OVE2MTYgMzIxIDUwNyAzMDNRNTAwIDMwMiA0MDIgMzAxSDMwN0wyNzcgMTgyUTI0NyA2NiAyNDcgNTlRMjQ3IDU1IDI0OCA1NFQyNTUgNTBUMjcyIDQ4VDMwNSA0NkgzMzZRMzQyIDM3IDM0MiAzNVEzNDIgMTkgMzM1IDVRMzMwIDAgMzE5IDBRMzE2IDAgMjgyIDFUMTgyIDJRMTIwIDIgODcgMlQ1MSAxUTMzIDEgMzMgMTFRMzMgMTMgMzYgMjVRNDAgNDEgNDQgNDNUNjcgNDZROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFpNNjQ1IDU1NFE2NDUgNTY3IDY0MyA1NzVUNjM0IDU5N1Q2MDkgNjE5VDU2MCA2MzVRNTUzIDYzNiA0ODAgNjM3UTQ2MyA2MzcgNDQ1IDYzN1Q0MTYgNjM2VDQwNCA2MzZRMzkxIDYzNSAzODYgNjI3UTM4NCA2MjEgMzY3IDU1MFQzMzIgNDEyVDMxNCAzNDRRMzE0IDM0MiAzOTUgMzQySDQwN0g0MzBRNTQyIDM0MiA1OTAgMzkyUTYxNyA0MTkgNjMxIDQ3MVQ2NDUgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU0IiBkPSJNNDAgNDM3UTIxIDQzNyAyMSA0NDVRMjEgNDUwIDM3IDUwMVQ3MSA2MDJMODggNjUxUTkzIDY2OSAxMDEgNjc3SDU2OUg2NTlRNjkxIDY3NyA2OTcgNjc2VDcwNCA2NjdRNzA0IDY2MSA2ODcgNTUzVDY2OCA0NDRRNjY4IDQzNyA2NDkgNDM3UTY0MCA0MzcgNjM3IDQzN1Q2MzEgNDQyTDYyOSA0NDVRNjI5IDQ1MSA2MzUgNDkwVDY0MSA1NTFRNjQxIDU4NiA2MjggNjA0VDU3MyA2MjlRNTY4IDYzMCA1MTUgNjMxUTQ2OSA2MzEgNDU3IDYzMFQ0MzkgNjIyUTQzOCA2MjEgMzY4IDM0M1QyOTggNjBRMjk4IDQ4IDM4NiA0NlE0MTggNDYgNDI3IDQ1VDQzNiAzNlE0MzYgMzEgNDMzIDIyUTQyOSA0IDQyNCAxTDQyMiAwUTQxOSAwIDQxNSAwUTQxMCAwIDM2MyAxVDIyOCAyUTk5IDIgNjQgMEg0OVE0MyA2IDQzIDlUNDUgMjdRNDkgNDAgNTUgNDZIODNIOTRRMTc0IDQ2IDE4OSA1NVExOTAgNTYgMTkxIDU2UTE5NiA1OSAyMDEgNzZUMjQxIDIzM1EyNTggMzAxIDI2OSAzNDRRMzM5IDYxOSAzMzkgNjI1UTMzOSA2MzAgMzEwIDYzMEgyNzlRMjEyIDYzMCAxOTEgNjI0UTE0NiA2MTQgMTIxIDU4M1Q2NyA0NjdRNjAgNDQ1IDU3IDQ0MVQ0MyA0MzdINDBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi01NiIgZD0iTTExNCA2MjBRMTEzIDYyMSAxMTAgNjI0VDEwNyA2MjdUMTAzIDYzMFQ5OCA2MzJUOTEgNjM0VDgwIDYzNVQ2NyA2MzZUNDggNjM3SDE5VjY4M0gyOFE0NiA2ODAgMTUyIDY4MFEyNzMgNjgwIDI5NCA2ODNIMzA1VjYzN0gyODRRMjIzIDYzNCAyMjMgNjIwUTIyMyA2MTggMzEzIDM3MlQ0MDQgMTI2TDQ5MCAzNThRNTc1IDU4OCA1NzUgNTk3UTU3NSA2MTYgNTU0IDYyNlQ1MDggNjM3SDUwM1Y2ODNINTEyUTUyNyA2ODAgNjI3IDY4MFE3MTggNjgwIDcyNCA2ODNINzMwVjYzN0g3MjNRNjQ4IDYzNyA2MjcgNTk2UTYyNyA1OTUgNTE1IDI5MVQ0MDEgLTE0UTM5NiAtMjIgMzgyIC0yMkgzNzRIMzY3UTM1MyAtMjIgMzQ4IC0xNFEzNDYgLTEyIDIzMSAzMDNRMTE0IDYxNyAxMTQgNjIwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNjEiIGQ9Ik0xMzcgMzA1VDExNSAzMDVUNzggMzIwVDYzIDM1OVE2MyAzOTQgOTcgNDIxVDIxOCA0NDhRMjkxIDQ0OCAzMzYgNDE2VDM5NiAzNDBRNDAxIDMyNiA0MDEgMzA5VDQwMiAxOTRWMTI0UTQwMiA3NiA0MDcgNThUNDI4IDQwUTQ0MyA0MCA0NDggNTZUNDUzIDEwOVYxNDVINDkzVjEwNlE0OTIgNjYgNDkwIDU5UTQ4MSAyOSA0NTUgMTJUNDAwIC02VDM1MyAxMlQzMjkgNTRWNThMMzI3IDU1UTMyNSA1MiAzMjIgNDlUMzE0IDQwVDMwMiAyOVQyODcgMTdUMjY5IDZUMjQ3IC0yVDIyMSAtOFQxOTAgLTExUTEzMCAtMTEgODIgMjBUMzQgMTA3UTM0IDEyOCA0MSAxNDdUNjggMTg4VDExNiAyMjVUMTk0IDI1M1QzMDQgMjY4SDMxOFYyOTBRMzE4IDMyNCAzMTIgMzQwUTI5MCA0MTEgMjE1IDQxMVExOTcgNDExIDE4MSA0MTBUMTU2IDQwNlQxNDggNDAzUTE3MCAzODggMTcwIDM1OVExNzAgMzM0IDE1NCAzMjBaTTEyNiAxMDZRMTI2IDc1IDE1MCA1MVQyMDkgMjZRMjQ3IDI2IDI3NiA0OVQzMTUgMTA5UTMxNyAxMTYgMzE4IDE3NVEzMTggMjMzIDMxNyAyMzNRMzA5IDIzMyAyOTYgMjMyVDI1MSAyMjNUMTkzIDIwM1QxNDcgMTY2VDEyNiAxMDZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03MiIgZD0iTTM2IDQ2SDUwUTg5IDQ2IDk3IDYwVjY4UTk3IDc3IDk3IDkxVDk4IDEyMlQ5OCAxNjFUOTggMjAzUTk4IDIzNCA5OCAyNjlUOTggMzI4TDk3IDM1MVE5NCAzNzAgODMgMzc2VDM4IDM4NUgyMFY0MDhRMjAgNDMxIDIyIDQzMUwzMiA0MzJRNDIgNDMzIDYwIDQzNFQ5NiA0MzZRMTEyIDQzNyAxMzEgNDM4VDE2MCA0NDFUMTcxIDQ0MkgxNzRWMzczUTIxMyA0NDEgMjcxIDQ0MUgyNzdRMzIyIDQ0MSAzNDMgNDE5VDM2NCAzNzNRMzY0IDM1MiAzNTEgMzM3VDMxMyAzMjJRMjg4IDMyMiAyNzYgMzM4VDI2MyAzNzJRMjYzIDM4MSAyNjUgMzg4VDI3MCA0MDBUMjczIDQwNVEyNzEgNDA3IDI1MCA0MDFRMjM0IDM5MyAyMjYgMzg2UTE3OSAzNDEgMTc5IDIwN1YxNTRRMTc5IDE0MSAxNzkgMTI3VDE3OSAxMDFUMTgwIDgxVDE4MCA2NlY2MVExODEgNTkgMTgzIDU3VDE4OCA1NFQxOTMgNTFUMjAwIDQ5VDIwNyA0OFQyMTYgNDdUMjI1IDQ3VDIzNSA0NlQyNDUgNDZIMjc2VjBIMjY3UTI0OSAzIDE0MCAzUTM3IDMgMjggMEgyMFY0NkgzNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MiIgZD0iTTIxIDI4N1EyMiAyOTAgMjMgMjk1VDI4IDMxN1QzOCAzNDhUNTMgMzgxVDczIDQxMVQ5OSA0MzNUMTMyIDQ0MlExNjEgNDQyIDE4MyA0MzBUMjE0IDQwOFQyMjUgMzg4UTIyNyAzODIgMjI4IDM4MlQyMzYgMzg5UTI4NCA0NDEgMzQ3IDQ0MUgzNTBRMzk4IDQ0MSA0MjIgNDAwUTQzMCAzODEgNDMwIDM2M1E0MzAgMzMzIDQxNyAzMTVUMzkxIDI5MlQzNjYgMjg4UTM0NiAyODggMzM0IDI5OVQzMjIgMzI4UTMyMiAzNzYgMzc4IDM5MlEzNTYgNDA1IDM0MiA0MDVRMjg2IDQwNSAyMzkgMzMxUTIyOSAzMTUgMjI0IDI5OFQxOTAgMTY1UTE1NiAyNSAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExNCAxODlUMTU0IDM2NlExNTQgNDA1IDEyOCA0MDVRMTA3IDQwNSA5MiAzNzdUNjggMzE2VDU3IDI4MFE1NSAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjEyIiBkPSJNODQgMjM3VDg0IDI1MFQ5OCAyNzBINjc5UTY5NCAyNjIgNjk0IDI1MFQ2NzkgMjMwSDk4UTg0IDIzNyA4NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTIiIGQ9Ik0yMzAgNjM3UTIwMyA2MzcgMTk4IDYzOFQxOTMgNjQ5UTE5MyA2NzYgMjA0IDY4MlEyMDYgNjgzIDM3OCA2ODNRNTUwIDY4MiA1NjQgNjgwUTYyMCA2NzIgNjU4IDY1MlQ3MTIgNjA2VDczMyA1NjNUNzM5IDUyOVE3MzkgNDg0IDcxMCA0NDVUNjQzIDM4NVQ1NzYgMzUxVDUzOCAzMzhMNTQ1IDMzM1E2MTIgMjk1IDYxMiAyMjNRNjEyIDIxMiA2MDcgMTYyVDYwMiA4MFY3MVE2MDIgNTMgNjAzIDQzVDYxNCAyNVQ2NDAgMTZRNjY4IDE2IDY4NiAzOFQ3MTIgODVRNzE3IDk5IDcyMCAxMDJUNzM1IDEwNVE3NTUgMTA1IDc1NSA5M1E3NTUgNzUgNzMxIDM2UTY5MyAtMjEgNjQxIC0yMUg2MzJRNTcxIC0yMSA1MzEgNFQ0ODcgODJRNDg3IDEwOSA1MDIgMTY2VDUxNyAyMzlRNTE3IDI5MCA0NzQgMzEzUTQ1OSAzMjAgNDQ5IDMyMVQzNzggMzIzSDMwOUwyNzcgMTkzUTI0NCA2MSAyNDQgNTlRMjQ0IDU1IDI0NSA1NFQyNTIgNTBUMjY5IDQ4VDMwMiA0NkgzMzNRMzM5IDM4IDMzOSAzN1QzMzYgMTlRMzMyIDYgMzI2IDBIMzExUTI3NSAyIDE4MCAyUTE0NiAyIDExNyAyVDcxIDJUNTAgMVEzMyAxIDMzIDEwUTMzIDEyIDM2IDI0UTQxIDQzIDQ2IDQ1UTUwIDQ2IDYxIDQ2SDY3UTk0IDQ2IDEyNyA0OVExNDEgNTIgMTQ2IDYxUTE0OSA2NSAyMTggMzM5VDI4NyA2MjhRMjg3IDYzNSAyMzAgNjM3Wk02MzAgNTU0UTYzMCA1ODYgNjA5IDYwOFQ1MjMgNjM2UTUyMSA2MzYgNTAwIDYzNlQ0NjIgNjM3SDQ0MFEzOTMgNjM3IDM4NiA2MjdRMzg1IDYyNCAzNTIgNDk0VDMxOSAzNjFRMzE5IDM2MCAzODggMzYwUTQ2NiAzNjEgNDkyIDM2N1E1NTYgMzc3IDU5MiA0MjZRNjA4IDQ0OSA2MTkgNDg2VDYzMCA1NTRaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTY3LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoLTExLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwxNDM3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTMxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1ozLTdCIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzUwLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTIyMSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjM2MCIgeT0iNjc2Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTY4NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjUwMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDYxLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTU5NSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI4MSw2NzYpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjAyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjgxNyIgeT0iNTEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzgwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIwMiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU2NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTNCNCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI2NDEiIHk9IjQwOCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzI5NiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjgwNCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI2OTMiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ0ODUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktM0I0IiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NDEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU4ODIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdDIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjc4LC0yODYpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTNCNCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI0NTEiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMCIgeD0iMTIzMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMy03RCIgeD0iODIzNCIgeT0iLTEiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5OTA2LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwxNDM3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwNTYsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIzNjU1IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMjk2IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjI5NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExMDkiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEyIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkwNywtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTIyOSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNTYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI3NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MDM5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI2MzgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjEyNzIiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9Ijg5MjQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5NzAzLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQyLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMzY5NiIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDc3MCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEyOTYiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIyMjk3IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIzMTg3IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTU0OCIgeT0iLTY4NiI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzg2MiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNTYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI3NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNTY3MiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxNDM5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTEzMDcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMjIyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTAwMCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjM2NTUiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMTI5NiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIyOTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5MDcsLTgzNykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExMDkiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItNDQ2Ij48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MTE4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA3NCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEyIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjY1NTQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MzMyLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQyLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTk2MSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE5Myw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDk3NTYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTA5NDcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8L3N2Zz4=)
因此,每次访问MC估计的方差的行为是 ![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjcuODg5ZXgiIGhlaWdodD0iNi4xNzZleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0yLjUwNWV4OyIgdmlld0JveD0iMCAtMTU4MC43IDMzOTYuNyAyNjU5LjEiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KQ0FMLTRGIiBkPSJNMzA4IDQyOFEyODkgNDI4IDI4OSA0MzhRMjg5IDQ1NyAzMTggNTA4VDM3OCA1OTNRNDE3IDYzOCA0NzUgNjcxVDU5OSA3MDVRNjg4IDcwNSA3MzIgNjQzVDc3NyA0ODNRNzc3IDM4MCA3MzMgMjg1VDYyMCAxMjNUNDY0IDE4VDI5MyAtMjJRMTg4IC0yMiAxMjMgNTFUNTggMjQ1UTU4IDMyNyA4NyA0MDNUMTU5IDUzM1QyNDkgNjI2VDMzMyA2ODVUMzg4IDcwNVE0MDQgNzA1IDQwNCA2OTNRNDA0IDY3NCAzNjMgNjQ5UTMzMyA2MzIgMzA0IDYwNlQyMzkgNTM3VDE4MSA0MjlUMTU4IDI5MFExNTggMTc5IDIxNCAxMTRUMzY0IDQ4UTQ4OSA0OCA1ODMgMTY1VDY3NyA0MzhRNjc3IDQ3MyA2NzAgNTA1VDY0OCA1NjhUNjAxIDYxN1Q1MjggNjM2UTUxOCA2MzYgNTEzIDYzNVE0ODYgNjI5IDQ2MCA2MDBUNDE5IDU0NFQzOTIgNDkwUTM4MyA0NzAgMzcyIDQ1OVEzNDEgNDMwIDMwOCA0MjhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZFIiBkPSJNMjEgMjg3UTIyIDI5MyAyNCAzMDNUMzYgMzQxVDU2IDM4OFQ4OSA0MjVUMTM1IDQ0MlExNzEgNDQyIDE5NSA0MjRUMjI1IDM5MFQyMzEgMzY5UTIzMSAzNjcgMjMyIDM2N0wyNDMgMzc4UTMwNCA0NDIgMzgyIDQ0MlE0MzYgNDQyIDQ2OSA0MTVUNTAzIDMzNlQ0NjUgMTc5VDQyNyA1MlE0MjcgMjYgNDQ0IDI2UTQ1MCAyNiA0NTMgMjdRNDgyIDMyIDUwNSA2NVQ1NDAgMTQ1UTU0MiAxNTMgNTYwIDE1M1E1ODAgMTUzIDU4MCAxNDVRNTgwIDE0NCA1NzYgMTMwUTU2OCAxMDEgNTU0IDczVDUwOCAxN1Q0MzkgLTEwUTM5MiAtMTAgMzcxIDE3VDM1MCA3M1EzNTAgOTIgMzg2IDE5M1Q0MjMgMzQ1UTQyMyA0MDQgMzc5IDQwNEgzNzRRMjg4IDQwNCAyMjkgMzAzTDIyMiAyOTFMMTg5IDE1N1ExNTYgMjYgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTIgMTgwVDE1MiAzNDNRMTUzIDM0OCAxNTMgMzY2UTE1MyA0MDUgMTI5IDQwNVE5MSA0MDUgNjYgMzA1UTYwIDI4NSA2MCAyODRRNTggMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1ozLTI4IiBkPSJNNzAxIC05NDBRNzAxIC05NDMgNjk1IC05NDlINjY0UTY2MiAtOTQ3IDYzNiAtOTIyVDU5MSAtODc5VDUzNyAtODE4VDQ3NSAtNzM3VDQxMiAtNjM2VDM1MCAtNTExVDI5NSAtMzYyVDI1MCAtMTg2VDIyMSAxN1QyMDkgMjUxUTIwOSA5NjIgNTczIDEzNjFRNTk2IDEzODYgNjE2IDE0MDVUNjQ5IDE0MzdUNjY0IDE0NTBINjk1UTcwMSAxNDQ0IDcwMSAxNDQxUTcwMSAxNDM2IDY4MSAxNDE1VDYyOSAxMzU2VDU1NyAxMjYxVDQ3NiAxMTE4VDQwMCA5MjdUMzQwIDY3NVQzMDggMzU5UTMwNiAzMjEgMzA2IDI1MFEzMDYgLTEzOSA0MDAgLTQzMFQ2OTAgLTkyNFE3MDEgLTkzNiA3MDEgLTk0MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjMtMjkiIGQ9Ik0zNCAxNDM4UTM0IDE0NDYgMzcgMTQ0OFQ1MCAxNDUwSDU2SDcxUTczIDE0NDggOTkgMTQyM1QxNDQgMTM4MFQxOTggMTMxOVQyNjAgMTIzOFQzMjMgMTEzN1QzODUgMTAxM1Q0NDAgODY0VDQ4NSA2ODhUNTE0IDQ4NVQ1MjYgMjUxUTUyNiAxMzQgNTE5IDUzUTQ3MiAtNTE5IDE2MiAtODYwUTEzOSAtODg1IDExOSAtOTA0VDg2IC05MzZUNzEgLTk0OUg1NlE0MyAtOTQ5IDM5IC05NDdUMzQgLTkzN1E4OCAtODgzIDE0MCAtODEzUTQyOCAtNDMwIDQyOCAyNTFRNDI4IDQ1MyA0MDIgNjI4VDMzOCA5MjJUMjQ1IDExNDZUMTQ1IDEzMDlUNDYgMTQyNVE0NCAxNDI3IDQyIDE0MjlUMzkgMTQzM1QzNiAxNDM2TDM0IDE0MzhaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KQ0FMLTRGIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTYzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1ozLTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzM2LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNzIwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMTEwIiB5PSI2NzYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iNjAiIHk9Ii02ODYiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1ozLTI5IiB4PSIxNjk3IiB5PSItMSI+PC91c2U+CjwvZz4KPC9nPgo8L3N2Zz4=)
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjgwLjkxZXgiIGhlaWdodD0iNy4wMDlleCIgc3R5bGU9ImZvbnQtc2l6ZTogMTVweDsgdmVydGljYWwtYWxpZ246IC0zLjE3MWV4OyIgdmlld0JveD0iMCAtMTY1Mi41IDM0ODM2LjEgMzAxNy45IiByb2xlPSJpbWciIGZvY3VzYWJsZT0iZmFsc2UiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+CjxkZWZzPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNTYiIGQ9Ik0xMTQgNjIwUTExMyA2MjEgMTEwIDYyNFQxMDcgNjI3VDEwMyA2MzBUOTggNjMyVDkxIDYzNFQ4MCA2MzVUNjcgNjM2VDQ4IDYzN0gxOVY2ODNIMjhRNDYgNjgwIDE1MiA2ODBRMjczIDY4MCAyOTQgNjgzSDMwNVY2MzdIMjg0UTIyMyA2MzQgMjIzIDYyMFEyMjMgNjE4IDMxMyAzNzJUNDA0IDEyNkw0OTAgMzU4UTU3NSA1ODggNTc1IDU5N1E1NzUgNjE2IDU1NCA2MjZUNTA4IDYzN0g1MDNWNjgzSDUxMlE1MjcgNjgwIDYyNyA2ODBRNzE4IDY4MCA3MjQgNjgzSDczMFY2MzdINzIzUTY0OCA2MzcgNjI3IDU5NlE2MjcgNTk1IDUxNSAyOTFUNDAxIC0xNFEzOTYgLTIyIDM4MiAtMjJIMzc0SDM2N1EzNTMgLTIyIDM0OCAtMTRRMzQ2IC0xMiAyMzEgMzAzUTExNCA2MTcgMTE0IDYyMFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTYxIiBkPSJNMTM3IDMwNVQxMTUgMzA1VDc4IDMyMFQ2MyAzNTlRNjMgMzk0IDk3IDQyMVQyMTggNDQ4UTI5MSA0NDggMzM2IDQxNlQzOTYgMzQwUTQwMSAzMjYgNDAxIDMwOVQ0MDIgMTk0VjEyNFE0MDIgNzYgNDA3IDU4VDQyOCA0MFE0NDMgNDAgNDQ4IDU2VDQ1MyAxMDlWMTQ1SDQ5M1YxMDZRNDkyIDY2IDQ5MCA1OVE0ODEgMjkgNDU1IDEyVDQwMCAtNlQzNTMgMTJUMzI5IDU0VjU4TDMyNyA1NVEzMjUgNTIgMzIyIDQ5VDMxNCA0MFQzMDIgMjlUMjg3IDE3VDI2OSA2VDI0NyAtMlQyMjEgLThUMTkwIC0xMVExMzAgLTExIDgyIDIwVDM0IDEwN1EzNCAxMjggNDEgMTQ3VDY4IDE4OFQxMTYgMjI1VDE5NCAyNTNUMzA0IDI2OEgzMThWMjkwUTMxOCAzMjQgMzEyIDM0MFEyOTAgNDExIDIxNSA0MTFRMTk3IDQxMSAxODEgNDEwVDE1NiA0MDZUMTQ4IDQwM1ExNzAgMzg4IDE3MCAzNTlRMTcwIDMzNCAxNTQgMzIwWk0xMjYgMTA2UTEyNiA3NSAxNTAgNTFUMjA5IDI2UTI0NyAyNiAyNzYgNDlUMzE1IDEwOVEzMTcgMTE2IDMxOCAxNzVRMzE4IDIzMyAzMTcgMjMzUTMwOSAyMzMgMjk2IDIzMlQyNTEgMjIzVDE5MyAyMDNUMTQ3IDE2NlQxMjYgMTA2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNzIiIGQ9Ik0zNiA0Nkg1MFE4OSA0NiA5NyA2MFY2OFE5NyA3NyA5NyA5MVQ5OCAxMjJUOTggMTYxVDk4IDIwM1E5OCAyMzQgOTggMjY5VDk4IDMyOEw5NyAzNTFROTQgMzcwIDgzIDM3NlQzOCAzODVIMjBWNDA4UTIwIDQzMSAyMiA0MzFMMzIgNDMyUTQyIDQzMyA2MCA0MzRUOTYgNDM2UTExMiA0MzcgMTMxIDQzOFQxNjAgNDQxVDE3MSA0NDJIMTc0VjM3M1EyMTMgNDQxIDI3MSA0NDFIMjc3UTMyMiA0NDEgMzQzIDQxOVQzNjQgMzczUTM2NCAzNTIgMzUxIDMzN1QzMTMgMzIyUTI4OCAzMjIgMjc2IDMzOFQyNjMgMzcyUTI2MyAzODEgMjY1IDM4OFQyNzAgNDAwVDI3MyA0MDVRMjcxIDQwNyAyNTAgNDAxUTIzNCAzOTMgMjI2IDM4NlExNzkgMzQxIDE3OSAyMDdWMTU0UTE3OSAxNDEgMTc5IDEyN1QxNzkgMTAxVDE4MCA4MVQxODAgNjZWNjFRMTgxIDU5IDE4MyA1N1QxODggNTRUMTkzIDUxVDIwMCA0OVQyMDcgNDhUMjE2IDQ3VDIyNSA0N1QyMzUgNDZUMjQ1IDQ2SDI3NlYwSDI2N1EyNDkgMyAxNDAgM1EzNyAzIDI4IDBIMjBWNDZIMzZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDUiIGQ9Ik00OTIgMjEzUTQ3MiAyMTMgNDcyIDIyNlE0NzIgMjMwIDQ3NyAyNTBUNDgyIDI4NVE0ODIgMzE2IDQ2MSAzMjNUMzY0IDMzMEgzMTJRMzExIDMyOCAyNzcgMTkyVDI0MyA1MlEyNDMgNDggMjU0IDQ4VDMzNCA0NlE0MjggNDYgNDU4IDQ4VDUxOCA2MVE1NjcgNzcgNTk5IDExN1Q2NzAgMjQ4UTY4MCAyNzAgNjgzIDI3MlE2OTAgMjc0IDY5OCAyNzRRNzE4IDI3NCA3MTggMjYxUTYxMyA3IDYwOCAyUTYwNSAwIDMyMiAwSDEzM1EzMSAwIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc1N1E3NjQgNjc2IDc2NCA2NjlRNzY0IDY2NCA3NTEgNTU3VDczNyA0NDdRNzM1IDQ0MCA3MTcgNDQwSDcwNVE2OTggNDQ1IDY5OCA0NTNMNzAxIDQ3NlE3MDQgNTAwIDcwNCA1MjhRNzA0IDU1OCA2OTcgNTc4VDY3OCA2MDlUNjQzIDYyNVQ1OTYgNjMyVDUzMiA2MzRINDg1UTM5NyA2MzMgMzkyIDYzMVEzODggNjI5IDM4NiA2MjJRMzg1IDYxOSAzNTUgNDk5VDMyNCAzNzdRMzQ3IDM3NiAzNzIgMzc2SDM5OFE0NjQgMzc2IDQ4OSAzOTFUNTM0IDQ3MlE1MzggNDg4IDU0MCA0OTBUNTU3IDQ5M1E1NjIgNDkzIDU2NSA0OTNUNTcwIDQ5MlQ1NzIgNDkxVDU3NCA0ODdUNTc3IDQ4M0w1NDQgMzUxUTUxMSAyMTggNTA4IDIxNlE1MDUgMjEzIDQ5MiAyMTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkUiIGQ9Ik0yMSAyODdRMjIgMjkzIDI0IDMwM1QzNiAzNDFUNTYgMzg4VDg5IDQyNVQxMzUgNDQyUTE3MSA0NDIgMTk1IDQyNFQyMjUgMzkwVDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzA0IDQ0MiAzODIgNDQyUTQzNiA0NDIgNDY5IDQxNVQ1MDMgMzM2VDQ2NSAxNzlUNDI3IDUyUTQyNyAyNiA0NDQgMjZRNDUwIDI2IDQ1MyAyN1E0ODIgMzIgNTA1IDY1VDU0MCAxNDVRNTQyIDE1MyA1NjAgMTUzUTU4MCAxNTMgNTgwIDE0NVE1ODAgMTQ0IDU3NiAxMzBRNTY4IDEwMSA1NTQgNzNUNTA4IDE3VDQzOSAtMTBRMzkyIC0xMCAzNzEgMTdUMzUwIDczUTM1MCA5MiAzODYgMTkzVDQyMyAzNDVRNDIzIDQwNCAzNzkgNDA0SDM3NFEyODggNDA0IDIyOSAzMDNMMjIyIDI5MUwxODkgMTU3UTE1NiAyNiAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExMiAxODBUMTUyIDM0M1ExNTMgMzQ4IDE1MyAzNjZRMTUzIDQwNSAxMjkgNDA1UTkxIDQwNSA2NiAzMDVRNjAgMjg1IDYwIDI4NFE1OCAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOCIgZD0iTTk0IDI1MFE5NCAzMTkgMTA0IDM4MVQxMjcgNDg4VDE2NCA1NzZUMjAyIDY0M1QyNDQgNjk1VDI3NyA3MjlUMzAyIDc1MEgzMTVIMzE5UTMzMyA3NTAgMzMzIDc0MVEzMzMgNzM4IDMxNiA3MjBUMjc1IDY2N1QyMjYgNTgxVDE4NCA0NDNUMTY3IDI1MFQxODQgNThUMjI1IC04MVQyNzQgLTE2N1QzMTYgLTIyMFQzMzMgLTI0MVEzMzMgLTI1MCAzMTggLTI1MEgzMTVIMzAyTDI3NCAtMjI2UTE4MCAtMTQxIDEzNyAtMTRUOTQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjkiIGQ9Ik02MCA3NDlMNjQgNzUwUTY5IDc1MCA3NCA3NTBIODZMMTE0IDcyNlEyMDggNjQxIDI1MSA1MTRUMjk0IDI1MFEyOTQgMTgyIDI4NCAxMTlUMjYxIDEyVDIyNCAtNzZUMTg2IC0xNDNUMTQ1IC0xOTRUMTEzIC0yMjdUOTAgLTI0NlE4NyAtMjQ5IDg2IC0yNTBINzRRNjYgLTI1MCA2MyAtMjUwVDU4IC0yNDdUNTUgLTIzOFE1NiAtMjM3IDY2IC0yMjVRMjIxIC02NCAyMjEgMjUwVDY2IDcyNVE1NiA3MzcgNTUgNzM4UTU1IDc0NiA2MCA3NDlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjQ4IiBkPSJNNTUgMzE5UTU1IDM2MCA3MiAzOTNUMTE0IDQ0NFQxNjMgNDcyVDIwNSA0ODJRMjA3IDQ4MiAyMTMgNDgyVDIyMyA0ODNRMjYyIDQ4MyAyOTYgNDY4VDM5MyA0MTNMNDQzIDM4MVE1MDIgMzQ2IDU1MyAzNDZRNjA5IDM0NiA2NDkgMzc1VDY5NCA0NTRRNjk0IDQ2NSA2OTggNDc0VDcwOCA0ODNRNzIyIDQ4MyA3MjIgNDUyUTcyMiAzODYgNjc1IDMzOFQ1NTUgMjg5UTUxNCAyODkgNDY4IDMxMFQzODggMzU3VDMwOCA0MDRUMjI0IDQyNlExNjQgNDI2IDEyNSAzOTNUODMgMzE4UTgxIDI4OSA2OSAyODlRNTUgMjg5IDU1IDMxOVpNNTUgODVRNTUgMTI2IDcyIDE1OVQxMTQgMjEwVDE2MyAyMzhUMjA1IDI0OFEyMDcgMjQ4IDIxMyAyNDhUMjIzIDI0OVEyNjIgMjQ5IDI5NiAyMzRUMzkzIDE3OUw0NDMgMTQ3UTUwMiAxMTIgNTUzIDExMlE2MDkgMTEyIDY0OSAxNDFUNjk0IDIyMFE2OTQgMjQ5IDcwOCAyNDlUNzIyIDIxN1E3MjIgMTUzIDY3NSAxMDRUNTU1IDU1UTUxNCA1NSA0NjggNzZUMzg4IDEyM1QzMDggMTcwVDIyNCAxOTJRMTY0IDE5MiAxMjUgMTU5VDgzIDg0UTgwIDU1IDY5IDU1UTU1IDU1IDU1IDg1WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUwIiBkPSJNMjg3IDYyOFEyODcgNjM1IDIzMCA2MzdRMjA2IDYzNyAxOTkgNjM4VDE5MiA2NDhRMTkyIDY0OSAxOTQgNjU5UTIwMCA2NzkgMjAzIDY4MVQzOTcgNjgzUTU4NyA2ODIgNjAwIDY4MFE2NjQgNjY5IDcwNyA2MzFUNzUxIDUzMFE3NTEgNDUzIDY4NSAzODlRNjE2IDMyMSA1MDcgMzAzUTUwMCAzMDIgNDAyIDMwMUgzMDdMMjc3IDE4MlEyNDcgNjYgMjQ3IDU5UTI0NyA1NSAyNDggNTRUMjU1IDUwVDI3MiA0OFQzMDUgNDZIMzM2UTM0MiAzNyAzNDIgMzVRMzQyIDE5IDMzNSA1UTMzMCAwIDMxOSAwUTMxNiAwIDI4MiAxVDE4MiAyUTEyMCAyIDg3IDJUNTEgMVEzMyAxIDMzIDExUTMzIDEzIDM2IDI1UTQwIDQxIDQ0IDQzVDY3IDQ2UTk0IDQ2IDEyNyA0OVExNDEgNTIgMTQ2IDYxUTE0OSA2NSAyMTggMzM5VDI4NyA2MjhaTTY0NSA1NTRRNjQ1IDU2NyA2NDMgNTc1VDYzNCA1OTdUNjA5IDYxOVQ1NjAgNjM1UTU1MyA2MzYgNDgwIDYzN1E0NjMgNjM3IDQ0NSA2MzdUNDE2IDYzNlQ0MDQgNjM2UTM5MSA2MzUgMzg2IDYyN1EzODQgNjIxIDM2NyA1NTBUMzMyIDQxMlQzMTQgMzQ0UTMxNCAzNDIgMzk1IDM0Mkg0MDdINDMwUTU0MiAzNDIgNTkwIDM5MlE2MTcgNDE5IDYzMSA0NzFUNjQ1IDU1NFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJCIiBkPSJNNTYgMjM3VDU2IDI1MFQ3MCAyNzBIMzY5VjQyMEwzNzAgNTcwUTM4MCA1ODMgMzg5IDU4M1E0MDIgNTgzIDQwOSA1NjhWMjcwSDcwN1E3MjIgMjYyIDcyMiAyNTBUNzA3IDIzMEg0MDlWLTY4UTQwMSAtODIgMzkxIC04MkgzODlIMzg3UTM3NSAtODIgMzY5IC02OFYyMzBINzBRNTYgMjM3IDU2IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTQiIGQ9Ik00MCA0MzdRMjEgNDM3IDIxIDQ0NVEyMSA0NTAgMzcgNTAxVDcxIDYwMkw4OCA2NTFROTMgNjY5IDEwMSA2NzdINTY5SDY1OVE2OTEgNjc3IDY5NyA2NzZUNzA0IDY2N1E3MDQgNjYxIDY4NyA1NTNUNjY4IDQ0NFE2NjggNDM3IDY0OSA0MzdRNjQwIDQzNyA2MzcgNDM3VDYzMSA0NDJMNjI5IDQ0NVE2MjkgNDUxIDYzNSA0OTBUNjQxIDU1MVE2NDEgNTg2IDYyOCA2MDRUNTczIDYyOVE1NjggNjMwIDUxNSA2MzFRNDY5IDYzMSA0NTcgNjMwVDQzOSA2MjJRNDM4IDYyMSAzNjggMzQzVDI5OCA2MFEyOTggNDggMzg2IDQ2UTQxOCA0NiA0MjcgNDVUNDM2IDM2UTQzNiAzMSA0MzMgMjJRNDI5IDQgNDI0IDFMNDIyIDBRNDE5IDAgNDE1IDBRNDEwIDAgMzYzIDFUMjI4IDJROTkgMiA2NCAwSDQ5UTQzIDYgNDMgOVQ0NSAyN1E0OSA0MCA1NSA0Nkg4M0g5NFExNzQgNDYgMTg5IDU1UTE5MCA1NiAxOTEgNTZRMTk2IDU5IDIwMSA3NlQyNDEgMjMzUTI1OCAzMDEgMjY5IDM0NFEzMzkgNjE5IDMzOSA2MjVRMzM5IDYzMCAzMTAgNjMwSDI3OVEyMTIgNjMwIDE5MSA2MjRRMTQ2IDYxNCAxMjEgNTgzVDY3IDQ2N1E2MCA0NDUgNTcgNDQxVDQzIDQzN0g0MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MiIgZD0iTTIxIDI4N1EyMiAyOTAgMjMgMjk1VDI4IDMxN1QzOCAzNDhUNTMgMzgxVDczIDQxMVQ5OSA0MzNUMTMyIDQ0MlExNjEgNDQyIDE4MyA0MzBUMjE0IDQwOFQyMjUgMzg4UTIyNyAzODIgMjI4IDM4MlQyMzYgMzg5UTI4NCA0NDEgMzQ3IDQ0MUgzNTBRMzk4IDQ0MSA0MjIgNDAwUTQzMCAzODEgNDMwIDM2M1E0MzAgMzMzIDQxNyAzMTVUMzkxIDI5MlQzNjYgMjg4UTM0NiAyODggMzM0IDI5OVQzMjIgMzI4UTMyMiAzNzYgMzc4IDM5MlEzNTYgNDA1IDM0MiA0MDVRMjg2IDQwNSAyMzkgMzMxUTIyOSAzMTUgMjI0IDI5OFQxOTAgMTY1UTE1NiAyNSAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExNCAxODlUMTU0IDM2NlExNTQgNDA1IDEyOCA0MDVRMTA3IDQwNSA5MiAzNzdUNjggMzE2VDU3IDI4MFE1NSAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMSIgZD0iTTIxMyA1NzhMMjAwIDU3M1ExODYgNTY4IDE2MCA1NjNUMTAyIDU1Nkg4M1Y2MDJIMTAyUTE0OSA2MDQgMTg5IDYxN1QyNDUgNjQxVDI3MyA2NjNRMjc1IDY2NiAyODUgNjY2UTI5NCA2NjYgMzAyIDY2MFYzNjFMMzAzIDYxUTMxMCA1NCAzMTUgNTJUMzM5IDQ4VDQwMSA0Nkg0MjdWMEg0MTZRMzk1IDMgMjU3IDNRMTIxIDMgMTAwIDBIODhWNDZIMTE0UTEzNiA0NiAxNTIgNDZUMTc3IDQ3VDE5MyA1MFQyMDEgNTJUMjA3IDU3VDIxMyA2MVY1NzhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTIiIGQ9Ik0yMzAgNjM3UTIwMyA2MzcgMTk4IDYzOFQxOTMgNjQ5UTE5MyA2NzYgMjA0IDY4MlEyMDYgNjgzIDM3OCA2ODNRNTUwIDY4MiA1NjQgNjgwUTYyMCA2NzIgNjU4IDY1MlQ3MTIgNjA2VDczMyA1NjNUNzM5IDUyOVE3MzkgNDg0IDcxMCA0NDVUNjQzIDM4NVQ1NzYgMzUxVDUzOCAzMzhMNTQ1IDMzM1E2MTIgMjk1IDYxMiAyMjNRNjEyIDIxMiA2MDcgMTYyVDYwMiA4MFY3MVE2MDIgNTMgNjAzIDQzVDYxNCAyNVQ2NDAgMTZRNjY4IDE2IDY4NiAzOFQ3MTIgODVRNzE3IDk5IDcyMCAxMDJUNzM1IDEwNVE3NTUgMTA1IDc1NSA5M1E3NTUgNzUgNzMxIDM2UTY5MyAtMjEgNjQxIC0yMUg2MzJRNTcxIC0yMSA1MzEgNFQ0ODcgODJRNDg3IDEwOSA1MDIgMTY2VDUxNyAyMzlRNTE3IDI5MCA0NzQgMzEzUTQ1OSAzMjAgNDQ5IDMyMVQzNzggMzIzSDMwOUwyNzcgMTkzUTI0NCA2MSAyNDQgNTlRMjQ0IDU1IDI0NSA1NFQyNTIgNTBUMjY5IDQ4VDMwMiA0NkgzMzNRMzM5IDM4IDMzOSAzN1QzMzYgMTlRMzMyIDYgMzI2IDBIMzExUTI3NSAyIDE4MCAyUTE0NiAyIDExNyAyVDcxIDJUNTAgMVEzMyAxIDMzIDEwUTMzIDEyIDM2IDI0UTQxIDQzIDQ2IDQ1UTUwIDQ2IDYxIDQ2SDY3UTk0IDQ2IDEyNyA0OVExNDEgNTIgMTQ2IDYxUTE0OSA2NSAyMTggMzM5VDI4NyA2MjhRMjg3IDYzNSAyMzAgNjM3Wk02MzAgNTU0UTYzMCA1ODYgNjA5IDYwOFQ1MjMgNjM2UTUyMSA2MzYgNTAwIDYzNlQ0NjIgNjM3SDQ0MFEzOTMgNjM3IDM4NiA2MjdRMzg1IDYyNCAzNTIgNDk0VDMxOSAzNjFRMzE5IDM2MCAzODggMzYwUTQ2NiAzNjEgNDkyIDM2N1E1NTYgMzc3IDU5MiA0MjZRNjA4IDQ0OSA2MTkgNDg2VDYzMCA1NTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjEyIiBkPSJNODQgMjM3VDg0IDI1MFQ5OCAyNzBINjc5UTY5NCAyNjIgNjk0IDI1MFQ2NzkgMjMwSDk4UTg0IDIzNyA4NCAyNTBaIj48L3BhdGg+CjwvZGVmcz4KPGcgc3Ryb2tlPSJjdXJyZW50Q29sb3IiIGZpbGw9ImN1cnJlbnRDb2xvciIgc3Ryb2tlLXdpZHRoPSIwIiB0cmFuc2Zvcm09Im1hdHJpeCgxIDAgMCAtMSAwIDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9IjIzMjQiIHk9IjU4MSI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMjMyNCIgeT0iLTM1MCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI0NTAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjQ4IiB4PSIzOTc3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDc1NSwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM5NywwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjM2NTUiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEyOTYiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMjk3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTA3LC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4OTI4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwNzM5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI2MzgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjEyNzIiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEyNjIzIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTM0MDIsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIzNjk2IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsNzcwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTI5NiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjIyOTciIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjMxODciIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIxNTQ4IiB5PSItNjg2Ij48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE3NTYxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE5MzcxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI2MzgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjE0MzkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjIxNDIyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjIyMDAsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxOTYxIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDQzLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtODM3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii00NDYiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI0NjI0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA3NCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEyIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIyNjA1OSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI2ODM4LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQyLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNDcyMSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDY3NikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI4NDkiIHk9IjUxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMTI3NiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIyMjc3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIzMTAwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iNDEwMCIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjgxLC05NzApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI4MjIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIxODIzIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIyNzEzIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjQzODgiIHk9IjY3NSI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzIwMjEsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMzYwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjEsNjc2KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExMDkiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEyIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtODM3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExMDkiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItNDQ2Ij48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzM2MjIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMDc0IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjwvZz4KPC9zdmc+)
对比,
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjQ5LjEzN2V4IiBoZWlnaHQ9IjYuMzQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy4wMDVleDsiIHZpZXdCb3g9IjAgLTE0MzcuMiAyMTE1Ni4zIDI3MzAuOCIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTU2IiBkPSJNMTE0IDYyMFExMTMgNjIxIDExMCA2MjRUMTA3IDYyN1QxMDMgNjMwVDk4IDYzMlQ5MSA2MzRUODAgNjM1VDY3IDYzNlQ0OCA2MzdIMTlWNjgzSDI4UTQ2IDY4MCAxNTIgNjgwUTI3MyA2ODAgMjk0IDY4M0gzMDVWNjM3SDI4NFEyMjMgNjM0IDIyMyA2MjBRMjIzIDYxOCAzMTMgMzcyVDQwNCAxMjZMNDkwIDM1OFE1NzUgNTg4IDU3NSA1OTdRNTc1IDYxNiA1NTQgNjI2VDUwOCA2MzdINTAzVjY4M0g1MTJRNTI3IDY4MCA2MjcgNjgwUTcxOCA2ODAgNzI0IDY4M0g3MzBWNjM3SDcyM1E2NDggNjM3IDYyNyA1OTZRNjI3IDU5NSA1MTUgMjkxVDQwMSAtMTRRMzk2IC0yMiAzODIgLTIySDM3NEgzNjdRMzUzIC0yMiAzNDggLTE0UTM0NiAtMTIgMjMxIDMwM1ExMTQgNjE3IDExNCA2MjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi02MSIgZD0iTTEzNyAzMDVUMTE1IDMwNVQ3OCAzMjBUNjMgMzU5UTYzIDM5NCA5NyA0MjFUMjE4IDQ0OFEyOTEgNDQ4IDMzNiA0MTZUMzk2IDM0MFE0MDEgMzI2IDQwMSAzMDlUNDAyIDE5NFYxMjRRNDAyIDc2IDQwNyA1OFQ0MjggNDBRNDQzIDQwIDQ0OCA1NlQ0NTMgMTA5VjE0NUg0OTNWMTA2UTQ5MiA2NiA0OTAgNTlRNDgxIDI5IDQ1NSAxMlQ0MDAgLTZUMzUzIDEyVDMyOSA1NFY1OEwzMjcgNTVRMzI1IDUyIDMyMiA0OVQzMTQgNDBUMzAyIDI5VDI4NyAxN1QyNjkgNlQyNDcgLTJUMjIxIC04VDE5MCAtMTFRMTMwIC0xMSA4MiAyMFQzNCAxMDdRMzQgMTI4IDQxIDE0N1Q2OCAxODhUMTE2IDIyNVQxOTQgMjUzVDMwNCAyNjhIMzE4VjI5MFEzMTggMzI0IDMxMiAzNDBRMjkwIDQxMSAyMTUgNDExUTE5NyA0MTEgMTgxIDQxMFQxNTYgNDA2VDE0OCA0MDNRMTcwIDM4OCAxNzAgMzU5UTE3MCAzMzQgMTU0IDMyMFpNMTI2IDEwNlExMjYgNzUgMTUwIDUxVDIwOSAyNlEyNDcgMjYgMjc2IDQ5VDMxNSAxMDlRMzE3IDExNiAzMTggMTc1UTMxOCAyMzMgMzE3IDIzM1EzMDkgMjMzIDI5NiAyMzJUMjUxIDIyM1QxOTMgMjAzVDE0NyAxNjZUMTI2IDEwNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTcyIiBkPSJNMzYgNDZINTBRODkgNDYgOTcgNjBWNjhROTcgNzcgOTcgOTFUOTggMTIyVDk4IDE2MVQ5OCAyMDNROTggMjM0IDk4IDI2OVQ5OCAzMjhMOTcgMzUxUTk0IDM3MCA4MyAzNzZUMzggMzg1SDIwVjQwOFEyMCA0MzEgMjIgNDMxTDMyIDQzMlE0MiA0MzMgNjAgNDM0VDk2IDQzNlExMTIgNDM3IDEzMSA0MzhUMTYwIDQ0MVQxNzEgNDQySDE3NFYzNzNRMjEzIDQ0MSAyNzEgNDQxSDI3N1EzMjIgNDQxIDM0MyA0MTlUMzY0IDM3M1EzNjQgMzUyIDM1MSAzMzdUMzEzIDMyMlEyODggMzIyIDI3NiAzMzhUMjYzIDM3MlEyNjMgMzgxIDI2NSAzODhUMjcwIDQwMFQyNzMgNDA1UTI3MSA0MDcgMjUwIDQwMVEyMzQgMzkzIDIyNiAzODZRMTc5IDM0MSAxNzkgMjA3VjE1NFExNzkgMTQxIDE3OSAxMjdUMTc5IDEwMVQxODAgODFUMTgwIDY2VjYxUTE4MSA1OSAxODMgNTdUMTg4IDU0VDE5MyA1MVQyMDAgNDlUMjA3IDQ4VDIxNiA0N1QyMjUgNDdUMjM1IDQ2VDI0NSA0NkgyNzZWMEgyNjdRMjQ5IDMgMTQwIDNRMzcgMyAyOCAwSDIwVjQ2SDM2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTQ2IiBkPSJNNDggMVEzMSAxIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc0MlE3NDkgNjc2IDc0OSA2NjlRNzQ5IDY2NCA3MzYgNTU3VDcyMiA0NDdRNzIwIDQ0MCA3MDIgNDQwSDY5MFE2ODMgNDQ1IDY4MyA0NTNRNjgzIDQ1NCA2ODYgNDc3VDY4OSA1MzBRNjg5IDU2MCA2ODIgNTc5VDY2MyA2MTBUNjI2IDYyNlQ1NzUgNjMzVDUwMyA2MzRINDgwUTM5OCA2MzMgMzkzIDYzMVEzODggNjI5IDM4NiA2MjNRMzg1IDYyMiAzNTIgNDkyTDMyMCAzNjNIMzc1UTM3OCAzNjMgMzk4IDM2M1Q0MjYgMzY0VDQ0OCAzNjdUNDcyIDM3NFQ0ODkgMzg2UTUwMiAzOTggNTExIDQxOVQ1MjQgNDU3VDUyOSA0NzVRNTMyIDQ4MCA1NDggNDgwSDU2MFE1NjcgNDc1IDU2NyA0NzBRNTY3IDQ2NyA1MzYgMzM5VDUwMiAyMDdRNTAwIDIwMCA0ODIgMjAwSDQ3MFE0NjMgMjA2IDQ2MyAyMTJRNDYzIDIxNSA0NjggMjM0VDQ3MyAyNzRRNDczIDMwMyA0NTMgMzEwVDM2NCAzMTdIMzA5TDI3NyAxOTBRMjQ1IDY2IDI0NSA2MFEyNDUgNDYgMzM0IDQ2SDM1OVEzNjUgNDAgMzY1IDM5VDM2MyAxOVEzNTkgNiAzNTMgMEgzMzZRMjk1IDIgMTg1IDJRMTIwIDIgODYgMlQ0OCAxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTZFIiBkPSJNMjEgMjg3UTIyIDI5MyAyNCAzMDNUMzYgMzQxVDU2IDM4OFQ4OSA0MjVUMTM1IDQ0MlExNzEgNDQyIDE5NSA0MjRUMjI1IDM5MFQyMzEgMzY5UTIzMSAzNjcgMjMyIDM2N0wyNDMgMzc4UTMwNCA0NDIgMzgyIDQ0MlE0MzYgNDQyIDQ2OSA0MTVUNTAzIDMzNlQ0NjUgMTc5VDQyNyA1MlE0MjcgMjYgNDQ0IDI2UTQ1MCAyNiA0NTMgMjdRNDgyIDMyIDUwNSA2NVQ1NDAgMTQ1UTU0MiAxNTMgNTYwIDE1M1E1ODAgMTUzIDU4MCAxNDVRNTgwIDE0NCA1NzYgMTMwUTU2OCAxMDEgNTU0IDczVDUwOCAxN1Q0MzkgLTEwUTM5MiAtMTAgMzcxIDE3VDM1MCA3M1EzNTAgOTIgMzg2IDE5M1Q0MjMgMzQ1UTQyMyA0MDQgMzc5IDQwNEgzNzRRMjg4IDQwNCAyMjkgMzAzTDIyMiAyOTFMMTg5IDE1N1ExNTYgMjYgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTIgMTgwVDE1MiAzNDNRMTUzIDM0OCAxNTMgMzY2UTE1MyA0MDUgMTI5IDQwNVE5MSA0MDUgNjYgMzA1UTYwIDI4NSA2MCAyODRRNTggMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTAiIGQ9Ik0yODcgNjI4UTI4NyA2MzUgMjMwIDYzN1EyMDYgNjM3IDE5OSA2MzhUMTkyIDY0OFExOTIgNjQ5IDE5NCA2NTlRMjAwIDY3OSAyMDMgNjgxVDM5NyA2ODNRNTg3IDY4MiA2MDAgNjgwUTY2NCA2NjkgNzA3IDYzMVQ3NTEgNTMwUTc1MSA0NTMgNjg1IDM4OVE2MTYgMzIxIDUwNyAzMDNRNTAwIDMwMiA0MDIgMzAxSDMwN0wyNzcgMTgyUTI0NyA2NiAyNDcgNTlRMjQ3IDU1IDI0OCA1NFQyNTUgNTBUMjcyIDQ4VDMwNSA0NkgzMzZRMzQyIDM3IDM0MiAzNVEzNDIgMTkgMzM1IDVRMzMwIDAgMzE5IDBRMzE2IDAgMjgyIDFUMTgyIDJRMTIwIDIgODcgMlQ1MSAxUTMzIDEgMzMgMTFRMzMgMTMgMzYgMjVRNDAgNDEgNDQgNDNUNjcgNDZROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFpNNjQ1IDU1NFE2NDUgNTY3IDY0MyA1NzVUNjM0IDU5N1Q2MDkgNjE5VDU2MCA2MzVRNTUzIDYzNiA0ODAgNjM3UTQ2MyA2MzcgNDQ1IDYzN1Q0MTYgNjM2VDQwNCA2MzZRMzkxIDYzNSAzODYgNjI3UTM4NCA2MjEgMzY3IDU1MFQzMzIgNDEyVDMxNCAzNDRRMzE0IDM0MiAzOTUgMzQySDQwN0g0MzBRNTQyIDM0MiA1OTAgMzkyUTYxNyA0MTkgNjMxIDQ3MVQ2NDUgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU0IiBkPSJNNDAgNDM3UTIxIDQzNyAyMSA0NDVRMjEgNDUwIDM3IDUwMVQ3MSA2MDJMODggNjUxUTkzIDY2OSAxMDEgNjc3SDU2OUg2NTlRNjkxIDY3NyA2OTcgNjc2VDcwNCA2NjdRNzA0IDY2MSA2ODcgNTUzVDY2OCA0NDRRNjY4IDQzNyA2NDkgNDM3UTY0MCA0MzcgNjM3IDQzN1Q2MzEgNDQyTDYyOSA0NDVRNjI5IDQ1MSA2MzUgNDkwVDY0MSA1NTFRNjQxIDU4NiA2MjggNjA0VDU3MyA2MjlRNTY4IDYzMCA1MTUgNjMxUTQ2OSA2MzEgNDU3IDYzMFQ0MzkgNjIyUTQzOCA2MjEgMzY4IDM0M1QyOTggNjBRMjk4IDQ4IDM4NiA0NlE0MTggNDYgNDI3IDQ1VDQzNiAzNlE0MzYgMzEgNDMzIDIyUTQyOSA0IDQyNCAxTDQyMiAwUTQxOSAwIDQxNSAwUTQxMCAwIDM2MyAxVDIyOCAyUTk5IDIgNjQgMEg0OVE0MyA2IDQzIDlUNDUgMjdRNDkgNDAgNTUgNDZIODNIOTRRMTc0IDQ2IDE4OSA1NVExOTAgNTYgMTkxIDU2UTE5NiA1OSAyMDEgNzZUMjQxIDIzM1EyNTggMzAxIDI2OSAzNDRRMzM5IDYxOSAzMzkgNjI1UTMzOSA2MzAgMzEwIDYzMEgyNzlRMjEyIDYzMCAxOTEgNjI0UTE0NiA2MTQgMTIxIDU4M1Q2NyA0NjdRNjAgNDQ1IDU3IDQ0MVQ0MyA0MzdINDBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNzIiIGQ9Ik0yMSAyODdRMjIgMjkwIDIzIDI5NVQyOCAzMTdUMzggMzQ4VDUzIDM4MVQ3MyA0MTFUOTkgNDMzVDEzMiA0NDJRMTYxIDQ0MiAxODMgNDMwVDIxNCA0MDhUMjI1IDM4OFEyMjcgMzgyIDIyOCAzODJUMjM2IDM4OVEyODQgNDQxIDM0NyA0NDFIMzUwUTM5OCA0NDEgNDIyIDQwMFE0MzAgMzgxIDQzMCAzNjNRNDMwIDMzMyA0MTcgMzE1VDM5MSAyOTJUMzY2IDI4OFEzNDYgMjg4IDMzNCAyOTlUMzIyIDMyOFEzMjIgMzc2IDM3OCAzOTJRMzU2IDQwNSAzNDIgNDA1UTI4NiA0MDUgMjM5IDMzMVEyMjkgMzE1IDIyNCAyOThUMTkwIDE2NVExNTYgMjUgMTUxIDE2UTEzOCAtMTEgMTA4IC0xMVE5NSAtMTEgODcgLTVUNzYgN1Q3NCAxN1E3NCAzMCAxMTQgMTg5VDE1NCAzNjZRMTU0IDQwNSAxMjggNDA1UTEwNyA0MDUgOTIgMzc3VDY4IDMxNlQ1NyAyODBRNTUgMjc4IDQxIDI3OEgyN1EyMSAyODQgMjEgMjg3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzIiIGQ9Ik0xMDkgNDI5UTgyIDQyOSA2NiA0NDdUNTAgNDkxUTUwIDU2MiAxMDMgNjE0VDIzNSA2NjZRMzI2IDY2NiAzODcgNjEwVDQ0OSA0NjVRNDQ5IDQyMiA0MjkgMzgzVDM4MSAzMTVUMzAxIDI0MVEyNjUgMjEwIDIwMSAxNDlMMTQyIDkzTDIxOCA5MlEzNzUgOTIgMzg1IDk3UTM5MiA5OSA0MDkgMTg2VjE4OUg0NDlWMTg2UTQ0OCAxODMgNDM2IDk1VDQyMSAzVjBINTBWMTlWMzFRNTAgMzggNTYgNDZUODYgODFRMTE1IDExMyAxMzYgMTM3UTE0NSAxNDcgMTcwIDE3NFQyMDQgMjExVDIzMyAyNDRUMjYxIDI3OFQyODQgMzA4VDMwNSAzNDBUMzIwIDM2OVQzMzMgNDAxVDM0MCA0MzFUMzQzIDQ2NFEzNDMgNTI3IDMwOSA1NzNUMjEyIDYxOVExNzkgNjE5IDE1NCA2MDJUMTE5IDU2OVQxMDkgNTUwUTEwOSA1NDkgMTE0IDU0OVExMzIgNTQ5IDE1MSA1MzVUMTcwIDQ4OVExNzAgNDY0IDE1NCA0NDdUMTA5IDQyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MiIgZD0iTTIzMCA2MzdRMjAzIDYzNyAxOTggNjM4VDE5MyA2NDlRMTkzIDY3NiAyMDQgNjgyUTIwNiA2ODMgMzc4IDY4M1E1NTAgNjgyIDU2NCA2ODBRNjIwIDY3MiA2NTggNjUyVDcxMiA2MDZUNzMzIDU2M1Q3MzkgNTI5UTczOSA0ODQgNzEwIDQ0NVQ2NDMgMzg1VDU3NiAzNTFUNTM4IDMzOEw1NDUgMzMzUTYxMiAyOTUgNjEyIDIyM1E2MTIgMjEyIDYwNyAxNjJUNjAyIDgwVjcxUTYwMiA1MyA2MDMgNDNUNjE0IDI1VDY0MCAxNlE2NjggMTYgNjg2IDM4VDcxMiA4NVE3MTcgOTkgNzIwIDEwMlQ3MzUgMTA1UTc1NSAxMDUgNzU1IDkzUTc1NSA3NSA3MzEgMzZRNjkzIC0yMSA2NDEgLTIxSDYzMlE1NzEgLTIxIDUzMSA0VDQ4NyA4MlE0ODcgMTA5IDUwMiAxNjZUNTE3IDIzOVE1MTcgMjkwIDQ3NCAzMTNRNDU5IDMyMCA0NDkgMzIxVDM3OCAzMjNIMzA5TDI3NyAxOTNRMjQ0IDYxIDI0NCA1OVEyNDQgNTUgMjQ1IDU0VDI1MiA1MFQyNjkgNDhUMzAyIDQ2SDMzM1EzMzkgMzggMzM5IDM3VDMzNiAxOVEzMzIgNiAzMjYgMEgzMTFRMjc1IDIgMTgwIDJRMTQ2IDIgMTE3IDJUNzEgMlQ1MCAxUTMzIDEgMzMgMTBRMzMgMTIgMzYgMjRRNDEgNDMgNDYgNDVRNTAgNDYgNjEgNDZINjdROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFEyODcgNjM1IDIzMCA2MzdaTTYzMCA1NTRRNjMwIDU4NiA2MDkgNjA4VDUyMyA2MzZRNTIxIDYzNiA1MDAgNjM2VDQ2MiA2MzdINDQwUTM5MyA2MzcgMzg2IDYyN1EzODUgNjI0IDM1MiA0OTRUMzE5IDM2MVEzMTkgMzYwIDM4OCAzNjBRNDY2IDM2MSA0OTIgMzY3UTU1NiAzNzcgNTkyIDQyNlE2MDggNDQ5IDYxOSA0ODZUNjMwIDU1NFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NiIgeD0iMjMyNCIgeT0iNTgxIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIyMzI0IiB5PSItMzUwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjQ0MCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIzOTY2IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDc0NCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM5NywwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjE5NjEiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NDMsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MjIzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkwMzQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTI3MiIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTA5MTgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMTY5NywwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjcyMCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjExMCIgeT0iNjc2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjYwIiB5PSItNjg2Ij48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyODc5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0NjkwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI2MzgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjE0MzkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjE2NzQwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTc1MTksMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxOTYxIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDQzLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtODM3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii00NDYiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE5OTQyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA3NCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEyIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==)
给出fact 12的证明:
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjY3LjQ3OGV4IiBoZWlnaHQ9IjguMTc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMy41MDVleDsiIHZpZXdCb3g9IjAgLTIwMTEuMyAyOTA1Mi44IDM1MjAuMiIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NSIgZD0iTTQ5MiAyMTNRNDcyIDIxMyA0NzIgMjI2UTQ3MiAyMzAgNDc3IDI1MFQ0ODIgMjg1UTQ4MiAzMTYgNDYxIDMyM1QzNjQgMzMwSDMxMlEzMTEgMzI4IDI3NyAxOTJUMjQzIDUyUTI0MyA0OCAyNTQgNDhUMzM0IDQ2UTQyOCA0NiA0NTggNDhUNTE4IDYxUTU2NyA3NyA1OTkgMTE3VDY3MCAyNDhRNjgwIDI3MCA2ODMgMjcyUTY5MCAyNzQgNjk4IDI3NFE3MTggMjc0IDcxOCAyNjFRNjEzIDcgNjA4IDJRNjA1IDAgMzIyIDBIMTMzUTMxIDAgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ2IDY2IDIxNSAzNDJUMjg1IDYyMlEyODUgNjI5IDI4MSA2MjlRMjczIDYzMiAyMjggNjM0SDE5N1ExOTEgNjQwIDE5MSA2NDJUMTkzIDY1OVExOTcgNjc2IDIwMyA2ODBINzU3UTc2NCA2NzYgNzY0IDY2OVE3NjQgNjY0IDc1MSA1NTdUNzM3IDQ0N1E3MzUgNDQwIDcxNyA0NDBINzA1UTY5OCA0NDUgNjk4IDQ1M0w3MDEgNDc2UTcwNCA1MDAgNzA0IDUyOFE3MDQgNTU4IDY5NyA1NzhUNjc4IDYwOVQ2NDMgNjI1VDU5NiA2MzJUNTMyIDYzNEg0ODVRMzk3IDYzMyAzOTIgNjMxUTM4OCA2MjkgMzg2IDYyMlEzODUgNjE5IDM1NSA0OTlUMzI0IDM3N1EzNDcgMzc2IDM3MiAzNzZIMzk4UTQ2NCAzNzYgNDg5IDM5MVQ1MzQgNDcyUTUzOCA0ODggNTQwIDQ5MFQ1NTcgNDkzUTU2MiA0OTMgNTY1IDQ5M1Q1NzAgNDkyVDU3MiA0OTFUNTc0IDQ4N1Q1NzcgNDgzTDU0NCAzNTFRNTExIDIxOCA1MDggMjE2UTUwNSAyMTMgNDkyIDIxM1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzIiIGQ9Ik0xMDkgNDI5UTgyIDQyOSA2NiA0NDdUNTAgNDkxUTUwIDU2MiAxMDMgNjE0VDIzNSA2NjZRMzI2IDY2NiAzODcgNjEwVDQ0OSA0NjVRNDQ5IDQyMiA0MjkgMzgzVDM4MSAzMTVUMzAxIDI0MVEyNjUgMjEwIDIwMSAxNDlMMTQyIDkzTDIxOCA5MlEzNzUgOTIgMzg1IDk3UTM5MiA5OSA0MDkgMTg2VjE4OUg0NDlWMTg2UTQ0OCAxODMgNDM2IDk1VDQyMSAzVjBINTBWMTlWMzFRNTAgMzggNTYgNDZUODYgODFRMTE1IDExMyAxMzYgMTM3UTE0NSAxNDcgMTcwIDE3NFQyMDQgMjExVDIzMyAyNDRUMjYxIDI3OFQyODQgMzA4VDMwNSAzNDBUMzIwIDM2OVQzMzMgNDAxVDM0MCA0MzFUMzQzIDQ2NFEzNDMgNTI3IDMwOSA1NzNUMjEyIDYxOVExNzkgNjE5IDE1NCA2MDJUMTE5IDU2OVQxMDkgNTUwUTEwOSA1NDkgMTE0IDU0OVExMzIgNTQ5IDE1MSA1MzVUMTcwIDQ4OVExNzAgNDY0IDE1NCA0NDdUMTA5IDQyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMDIiIGQ9Ik0yMDIgNTA4UTE3OSA1MDggMTY5IDUyMFQxNTggNTQ3UTE1OCA1NTcgMTY0IDU3N1QxODUgNjI0VDIzMCA2NzVUMzAxIDcxMEwzMzMgNzE1SDM0NVEzNzggNzE1IDM4NCA3MTRRNDQ3IDcwMyA0ODkgNjYxVDU0OSA1NjhUNTY2IDQ1N1E1NjYgMzYyIDUxOSAyNDBUNDAyIDUzUTMyMSAtMjIgMjIzIC0yMlExMjMgLTIyIDczIDU2UTQyIDEwMiA0MiAxNDhWMTU5UTQyIDI3NiAxMjkgMzcwVDMyMiA0NjVRMzgzIDQ2NSA0MTQgNDM0VDQ1NSAzNjdMNDU4IDM3OFE0NzggNDYxIDQ3OCA1MTVRNDc4IDYwMyA0MzcgNjM5VDM0NCA2NzZRMjY2IDY3NiAyMjMgNjEyUTI2NCA2MDYgMjY0IDU3MlEyNjQgNTQ3IDI0NiA1MjhUMjAyIDUwOFpNNDMwIDMwNlE0MzAgMzcyIDQwMSA0MDBUMzMzIDQyOFEyNzAgNDI4IDIyMiAzODJRMTk3IDM1NCAxODMgMzIzVDE1MCAyMjFRMTMyIDE0OSAxMzIgMTE2UTEzMiAyMSAyMzIgMjFRMjQ0IDIxIDI1MCAyMlEzMjcgMzUgMzc0IDExMlEzODkgMTM3IDQwOSAxOTZUNDMwIDMwNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS0zQjQiIGQ9Ik0xOTUgNjA5UTE5NSA2NTYgMjI3IDY4NlQzMDIgNzE3UTMxOSA3MTYgMzUxIDcwOVQ0MDcgNjk3VDQzMyA2OTBRNDUxIDY4MiA0NTEgNjYyUTQ1MSA2NDQgNDM4IDYyOFQ0MDMgNjEyUTM4MiA2MTIgMzQ4IDY0MVQyODggNjcxVDI0OSA2NTdUMjM1IDYyOFEyMzUgNTg0IDMzNCA0NjNRNDAxIDM3OSA0MDEgMjkyUTQwMSAxNjkgMzQwIDgwVDIwNSAtMTBIMTk4UTEyNyAtMTAgODMgMzZUMzYgMTUzUTM2IDI4NiAxNTEgMzgyUTE5MSA0MTMgMjUyIDQzNFEyNTIgNDM1IDI0NSA0NDlUMjMwIDQ4MVQyMTQgNTIxVDIwMSA1NjZUMTk1IDYwOVpNMTEyIDEzMFExMTIgODMgMTM2IDU1VDIwNCAyN1EyMzMgMjcgMjU2IDUxVDI5MSAxMTFUMzA5IDE3OFQzMTYgMjMyUTMxNiAyNjcgMzA5IDI5OFQyOTUgMzQ0VDI2OSA0MDBMMjU5IDM5NlEyMTUgMzgxIDE4MyAzNDJUMTM3IDI1NlQxMTggMTc5VDExMiAxMzBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNjYiIGQ9Ik0xMTggLTE2MlExMjAgLTE2MiAxMjQgLTE2NFQxMzUgLTE2N1QxNDcgLTE2OFExNjAgLTE2OCAxNzEgLTE1NVQxODcgLTEyNlExOTcgLTk5IDIyMSAyN1QyNjcgMjY3VDI4OSAzODJWMzg1SDI0MlExOTUgMzg1IDE5MiAzODdRMTg4IDM5MCAxODggMzk3TDE5NSA0MjVRMTk3IDQzMCAyMDMgNDMwVDI1MCA0MzFRMjk4IDQzMSAyOTggNDMyUTI5OCA0MzQgMzA3IDQ4MlQzMTkgNTQwUTM1NiA3MDUgNDY1IDcwNVE1MDIgNzAzIDUyNiA2ODNUNTUwIDYzMFE1NTAgNTk0IDUyOSA1NzhUNDg3IDU2MVE0NDMgNTYxIDQ0MyA2MDNRNDQzIDYyMiA0NTQgNjM2VDQ3OCA2NTdMNDg3IDY2MlE0NzEgNjY4IDQ1NyA2NjhRNDQ1IDY2OCA0MzQgNjU4VDQxOSA2MzBRNDEyIDYwMSA0MDMgNTUyVDM4NyA0NjlUMzgwIDQzM1EzODAgNDMxIDQzNSA0MzFRNDgwIDQzMSA0ODcgNDMwVDQ5OCA0MjRRNDk5IDQyMCA0OTYgNDA3VDQ5MSAzOTFRNDg5IDM4NiA0ODIgMzg2VDQyOCAzODVIMzcyTDM0OSAyNjNRMzAxIDE1IDI4MiAtNDdRMjU1IC0xMzIgMjEyIC0xNzNRMTc1IC0yMDUgMTM5IC0yMDVRMTA3IC0yMDUgODEgLTE4NlQ1NSAtMTMyUTU1IC05NSA3NiAtNzhUMTE4IC02MVExNjIgLTYxIDE2MiAtMTAzUTE2MiAtMTIyIDE1MSAtMTM2VDEyNyAtMTU3TDExOCAtMTYyWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0MiIGQ9Ik0xMzkgLTI0OUgxMzdRMTI1IC0yNDkgMTE5IC0yMzVWMjUxTDEyMCA3MzdRMTMwIDc1MCAxMzkgNzUwUTE1MiA3NTAgMTU5IDczNVYtMjM1UTE1MSAtMjQ5IDE0MSAtMjQ5SDEzOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzAiIGQ9Ik05NiA1ODVRMTUyIDY2NiAyNDkgNjY2UTI5NyA2NjYgMzQ1IDY0MFQ0MjMgNTQ4UTQ2MCA0NjUgNDYwIDMyMFE0NjAgMTY1IDQxNyA4M1EzOTcgNDEgMzYyIDE2VDMwMSAtMTVUMjUwIC0yMlEyMjQgLTIyIDE5OCAtMTZUMTM3IDE2VDgyIDgzUTM5IDE2NSAzOSAzMjBRMzkgNDk0IDk2IDU4NVpNMzIxIDU5N1EyOTEgNjI5IDI1MCA2MjlRMjA4IDYyOSAxNzggNTk3UTE1MyA1NzEgMTQ1IDUyNVQxMzcgMzMzUTEzNyAxNzUgMTQ1IDEyNVQxODEgNDZRMjA5IDE2IDI1MCAxNlEyOTAgMTYgMzE4IDQ2UTM0NyA3NiAzNTQgMTMwVDM2MiAzMzNRMzYyIDQ3OCAzNTQgNTI0VDMyMSA1OTdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03RCIgZD0iTTY1IDczMVE2NSA3NDUgNjggNzQ3VDg4IDc1MFExNzEgNzUwIDIxNiA3MjVUMjc5IDY3MFEyODggNjQ5IDI4OSA2MzVUMjkxIDUwMVEyOTIgMzYyIDI5MyAzNTdRMzA2IDMxMiAzNDUgMjkxVDQxNyAyNjlRNDI4IDI2OSA0MzEgMjY2VDQzNCAyNTBUNDMxIDIzNFQ0MTcgMjMxUTM4MCAyMzEgMzQ1IDIxMFQyOTggMTU3UTI5MyAxNDMgMjkyIDEyMVQyOTEgLTI4Vi03OVEyOTEgLTEzNCAyODUgLTE1NlQyNTYgLTE5OFEyMDIgLTI1MCA4OSAtMjUwUTcxIC0yNTAgNjggLTI0N1Q2NSAtMjMwUTY1IC0yMjQgNjUgLTIyM1Q2NiAtMjE4VDY5IC0yMTRUNzcgLTIxM1E5MSAtMjEzIDEwOCAtMjEwVDE0NiAtMjAwVDE4MyAtMTc3VDIwNyAtMTM5UTIwOCAtMTM0IDIwOSAzTDIxMCAxMzlRMjIzIDE5NiAyODAgMjMwUTMxNSAyNDcgMzMwIDI1MFEzMDUgMjU3IDI4MCAyNzBRMjI1IDMwNCAyMTIgMzUyTDIxMCAzNjJMMjA5IDQ5OFEyMDggNjM1IDIwNyA2NDBRMTk1IDY4MCAxNTQgNjk2VDc3IDcxM1E2OCA3MTMgNjcgNzE2VDY1IDczMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjMtN0IiIGQ9Ik02MTggLTk0M0w2MTIgLTk0OUg1ODJMNTY4IC05NDNRNDcyIC05MDMgNDExIC04NDFUMzMyIC03MDNRMzI3IC02ODIgMzI3IC02NTNUMzI1IC0zNTBRMzI0IC0yOCAzMjMgLTE4UTMxNyAyNCAzMDEgNjFUMjY0IDEyNFQyMjEgMTcxVDE3OSAyMDVUMTQ3IDIyNVQxMzIgMjM0UTEzMCAyMzggMTMwIDI1MFExMzAgMjU1IDEzMCAyNThUMTMxIDI2NFQxMzIgMjY3VDEzNCAyNjlUMTM5IDI3MlQxNDQgMjc1UTIwNyAzMDggMjU2IDM2N1EzMTAgNDM2IDMyMyA1MTlRMzI0IDUyOSAzMjUgODUxUTMyNiAxMTI0IDMyNiAxMTU0VDMzMiAxMjA1UTM2OSAxMzU4IDU2NiAxNDQzTDU4MiAxNDUwSDYxMkw2MTggMTQ0NFYxNDI5UTYxOCAxNDEzIDYxNiAxNDExTDYwOCAxNDA2UTU5OSAxNDAyIDU4NSAxMzkzVDU1MiAxMzcyVDUxNSAxMzQzVDQ3OSAxMzA1VDQ0OSAxMjU3VDQyOSAxMjAwUTQyNSAxMTgwIDQyNSAxMTUyVDQyMyA4NTFRNDIyIDU3OSA0MjIgNTQ5VDQxNiA0OThRNDA3IDQ1OSAzODggNDI0VDM0NiAzNjRUMjk3IDMxOFQyNTAgMjg0VDIxNCAyNjRUMTk3IDI1NEwxODggMjUxTDIwNSAyNDJRMjkwIDIwMCAzNDUgMTM4VDQxNiAzUTQyMSAtMTggNDIxIC00OFQ0MjMgLTM0OVE0MjMgLTM5NyA0MjMgLTQ3MlE0MjQgLTY3NyA0MjggLTY5NFE0MjkgLTY5NyA0MjkgLTY5OVE0MzQgLTcyMiA0NDMgLTc0M1Q0NjUgLTc4MlQ0OTEgLTgxNlQ1MTkgLTg0NVQ1NDggLTg2OFQ1NzQgLTg4NlQ1OTUgLTg5OVQ2MTAgLTkwOEw2MTYgLTkxMFE2MTggLTkxMiA2MTggLTkyOFYtOTQzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMy03RCIgZD0iTTEzMSAxNDE0VDEzMSAxNDI5VDEzMyAxNDQ3VDE0OCAxNDUwSDE1M0gxNjdMMTgyIDE0NDRRMjc2IDE0MDQgMzM2IDEzNDNUNDE1IDEyMDdRNDIxIDExODQgNDIxIDExNTRUNDIzIDg1MUw0MjQgNTMxTDQyNiA1MTdRNDM0IDQ2MiA0NjAgNDE1VDUxOCAzMzlUNTcxIDI5NlQ2MDggMjc0UTYxNSAyNzAgNjE2IDI2N1Q2MTggMjUxUTYxOCAyNDEgNjE4IDIzOFQ2MTUgMjMyVDYwOCAyMjdRNTQyIDE5NCA0OTEgMTMyVDQyNiAtMTVMNDI0IC0yOUw0MjMgLTM1MFE0MjIgLTYyMiA0MjIgLTY1MlQ0MTUgLTcwNlEzOTcgLTc4MCAzMzcgLTg0MVQxODIgLTk0M0wxNjcgLTk0OUgxNTNRMTM3IC05NDkgMTM0IC05NDZUMTMxIC05MjhRMTMxIC05MTQgMTMyIC05MTFUMTQ0IC05MDRRMTQ2IC05MDMgMTQ4IC05MDJRMjk5IC04MjAgMzIzIC02ODBRMzI0IC02NjMgMzI1IC0zNDlUMzI3IC0xOVEzNTUgMTQ1IDU0MSAyNDFMNTYxIDI1MEw1NDEgMjYwUTM1NiAzNTUgMzI3IDUyMFEzMjYgNTM3IDMyNSA4NTBUMzIzIDExODFRMzE1IDEyMjcgMjkzIDEyNjdUMjQ0IDEzMzJUMTkzIDEzNzRUMTUxIDE0MDFUMTMyIDE0MTNRMTMxIDE0MTQgMTMxIDE0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTQiIGQ9Ik00MCA0MzdRMjEgNDM3IDIxIDQ0NVEyMSA0NTAgMzcgNTAxVDcxIDYwMkw4OCA2NTFROTMgNjY5IDEwMSA2NzdINTY5SDY1OVE2OTEgNjc3IDY5NyA2NzZUNzA0IDY2N1E3MDQgNjYxIDY4NyA1NTNUNjY4IDQ0NFE2NjggNDM3IDY0OSA0MzdRNjQwIDQzNyA2MzcgNDM3VDYzMSA0NDJMNjI5IDQ0NVE2MjkgNDUxIDYzNSA0OTBUNjQxIDU1MVE2NDEgNTg2IDYyOCA2MDRUNTczIDYyOVE1NjggNjMwIDUxNSA2MzFRNDY5IDYzMSA0NTcgNjMwVDQzOSA2MjJRNDM4IDYyMSAzNjggMzQzVDI5OCA2MFEyOTggNDggMzg2IDQ2UTQxOCA0NiA0MjcgNDVUNDM2IDM2UTQzNiAzMSA0MzMgMjJRNDI5IDQgNDI0IDFMNDIyIDBRNDE5IDAgNDE1IDBRNDEwIDAgMzYzIDFUMjI4IDJROTkgMiA2NCAwSDQ5UTQzIDYgNDMgOVQ0NSAyN1E0OSA0MCA1NSA0Nkg4M0g5NFExNzQgNDYgMTg5IDU1UTE5MCA1NiAxOTEgNTZRMTk2IDU5IDIwMSA3NlQyNDEgMjMzUTI1OCAzMDEgMjY5IDM0NFEzMzkgNjE5IDMzOSA2MjVRMzM5IDYzMCAzMTAgNjMwSDI3OVEyMTIgNjMwIDE5MSA2MjRRMTQ2IDYxNCAxMjEgNTgzVDY3IDQ2N1E2MCA0NDUgNTcgNDQxVDQzIDQzN0g0MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLUFGIiBkPSJNNjkgNTQ0VjU5MEg0MzBWNTQ0SDY5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjIxMiIgZD0iTTg0IDIzN1Q4NCAyNTBUOTggMjcwSDY3OVE2OTQgMjYyIDY5NCAyNTBUNjc5IDIzMEg5OFE4NCAyMzcgODQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzgiIGQ9Ik03MCA0MTdUNzAgNDk0VDEyNCA2MThUMjQ4IDY2NlEzMTkgNjY2IDM3NCA2MjRUNDI5IDUxNVE0MjkgNDg1IDQxOCA0NTlUMzkyIDQxN1QzNjEgMzg5VDMzNSAzNzFUMzI0IDM2M0wzMzggMzU0UTM1MiAzNDQgMzY2IDMzNFQzODIgMzIzUTQ1NyAyNjQgNDU3IDE3NFE0NTcgOTUgMzk5IDM3VDI0OSAtMjJRMTU5IC0yMiAxMDEgMjlUNDMgMTU1UTQzIDI2MyAxNzIgMzM1TDE1NCAzNDhRMTMzIDM2MSAxMjcgMzY4UTcwIDQxNyA3MCA0OTRaTTI4NiAzODZMMjkyIDM5MFEyOTggMzk0IDMwMSAzOTZUMzExIDQwM1QzMjMgNDEzVDMzNCA0MjVUMzQ1IDQzOFQzNTUgNDU0VDM2NCA0NzFUMzY5IDQ5MVQzNzEgNTEzUTM3MSA1NTYgMzQyIDU4NlQyNzUgNjI0UTI2OCA2MjUgMjQyIDYyNVEyMDEgNjI1IDE2NSA1OTlUMTI4IDUzNFExMjggNTExIDE0MSA0OTJUMTY3IDQ2M1QyMTcgNDMxUTIyNCA0MjYgMjI4IDQyNEwyODYgMzg2Wk0yNTAgMjFRMzA4IDIxIDM1MCA1NVQzOTIgMTM3UTM5MiAxNTQgMzg3IDE2OVQzNzUgMTk0VDM1MyAyMTZUMzMwIDIzNFQzMDEgMjUzVDI3NCAyNzBRMjYwIDI3OSAyNDQgMjg5VDIxOCAzMDZMMjEwIDMxMVEyMDQgMzExIDE4MSAyOTRUMTMzIDIzOVQxMDcgMTU3UTEwNyA5OCAxNTAgNjBUMjUwIDIxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU2IiBkPSJNNTIgNjQ4UTUyIDY3MCA2NSA2ODNINzZRMTE4IDY4MCAxODEgNjgwUTI5OSA2ODAgMzIwIDY4M0gzMzBRMzM2IDY3NyAzMzYgNjc0VDMzNCA2NTZRMzI5IDY0MSAzMjUgNjM3SDMwNFEyODIgNjM1IDI3NCA2MzVRMjQ1IDYzMCAyNDIgNjIwUTI0MiA2MTggMjcxIDM2OVQzMDEgMTE4TDM3NCAyMzVRNDQ3IDM1MiA1MjAgNDcxVDU5NSA1OTRRNTk5IDYwMSA1OTkgNjA5UTU5OSA2MzMgNTU1IDYzN1E1MzcgNjM3IDUzNyA2NDhRNTM3IDY0OSA1MzkgNjYxUTU0MiA2NzUgNTQ1IDY3OVQ1NTggNjgzUTU2MCA2ODMgNTcwIDY4M1Q2MDQgNjgyVDY2OCA2ODFRNzM3IDY4MSA3NTUgNjgzSDc2MlE3NjkgNjc2IDc2OSA2NzJRNzY5IDY1NSA3NjAgNjQwUTc1NyA2MzcgNzQzIDYzN1E3MzAgNjM2IDcxOSA2MzVUNjk4IDYzMFQ2ODIgNjIzVDY3MCA2MTVUNjYwIDYwOFQ2NTIgNTk5VDY0NSA1OTJMNDUyIDI4MlEyNzIgLTkgMjY2IC0xNlEyNjMgLTE4IDI1OSAtMjFMMjQxIC0yMkgyMzRRMjE2IC0yMiAyMTYgLTE1UTIxMyAtOSAxNzcgMzA1UTEzOSA2MjMgMTM4IDYyNlExMzMgNjM3IDc2IDYzN0g1OVE1MiA2NDIgNTIgNjQ4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTczIiBkPSJNMTMxIDI4OVExMzEgMzIxIDE0NyAzNTRUMjAzIDQxNVQzMDAgNDQyUTM2MiA0NDIgMzkwIDQxNVQ0MTkgMzU1UTQxOSAzMjMgNDAyIDMwOFQzNjQgMjkyUTM1MSAyOTIgMzQwIDMwMFQzMjggMzI2UTMyOCAzNDIgMzM3IDM1NFQzNTQgMzcyVDM2NyAzNzhRMzY4IDM3OCAzNjggMzc5UTM2OCAzODIgMzYxIDM4OFQzMzYgMzk5VDI5NyA0MDVRMjQ5IDQwNSAyMjcgMzc5VDIwNCAzMjZRMjA0IDMwMSAyMjMgMjkxVDI3OCAyNzRUMzMwIDI1OVEzOTYgMjMwIDM5NiAxNjNRMzk2IDEzNSAzODUgMTA3VDM1MiA1MVQyODkgN1QxOTUgLTEwUTExOCAtMTAgODYgMTlUNTMgODdRNTMgMTI2IDc0IDE0M1QxMTggMTYwUTEzMyAxNjAgMTQ2IDE1MVQxNjAgMTIwUTE2MCA5NCAxNDIgNzZUMTExIDU4UTEwOSA1NyAxMDggNTdUMTA3IDU1UTEwOCA1MiAxMTUgNDdUMTQ2IDM0VDIwMSAyN1EyMzcgMjcgMjYzIDM4VDMwMSA2NlQzMTggOTdUMzIzIDEyMlEzMjMgMTUwIDMwMiAxNjRUMjU0IDE4MVQxOTUgMTk2VDE0OCAyMzFRMTMxIDI1NiAxMzEgMjg5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTRCIiBkPSJNMjg1IDYyOFEyODUgNjM1IDIyOCA2MzdRMjA1IDYzNyAxOTggNjM4VDE5MSA2NDdRMTkxIDY0OSAxOTMgNjYxUTE5OSA2ODEgMjAzIDY4MlEyMDUgNjgzIDIxNCA2ODNIMjE5UTI2MCA2ODEgMzU1IDY4MVEzODkgNjgxIDQxOCA2ODFUNDYzIDY4MlQ0ODMgNjgyUTUwMCA2ODIgNTAwIDY3NFE1MDAgNjY5IDQ5NyA2NjBRNDk2IDY1OCA0OTYgNjU0VDQ5NSA2NDhUNDkzIDY0NFQ0OTAgNjQxVDQ4NiA2MzlUNDc5IDYzOFQ0NzAgNjM3VDQ1NiA2MzdRNDE2IDYzNiA0MDUgNjM0VDM4NyA2MjNMMzA2IDMwNVEzMDcgMzA1IDQ5MCA0NDlUNjc4IDU5N1E2OTIgNjExIDY5MiA2MjBRNjkyIDYzNSA2NjcgNjM3UTY1MSA2MzcgNjUxIDY0OFE2NTEgNjUwIDY1NCA2NjJUNjU5IDY3N1E2NjIgNjgyIDY3NiA2ODJRNjgwIDY4MiA3MTEgNjgxVDc5MSA2ODBRODE0IDY4MCA4MzkgNjgxVDg2OSA2ODJRODg5IDY4MiA4ODkgNjcyUTg4OSA2NTAgODgxIDY0MlE4NzggNjM3IDg2MiA2MzdRNzg3IDYzMiA3MjYgNTg2UTcxMCA1NzYgNjU2IDUzNFQ1NTYgNDU1TDUwOSA0MThMNTE4IDM5NlE1MjcgMzc0IDU0NiAzMjlUNTgxIDI0NFE2NTYgNjcgNjYxIDYxUTY2MyA1OSA2NjYgNTdRNjgwIDQ3IDcxNyA0Nkg3MzhRNzQ0IDM4IDc0NCAzN1Q3NDEgMTlRNzM3IDYgNzMxIDBINzIwUTY4MCAzIDYyNSAzUTUwMyAzIDQ4OCAwSDQ3OFE0NzIgNiA0NzIgOVQ0NzQgMjdRNDc4IDQwIDQ4MCA0M1Q0OTEgNDZINDk0UTU0NCA0NiA1NDQgNzFRNTQ0IDc1IDUxNyAxNDFUNDg1IDIxNkw0MjcgMzU0TDM1OSAzMDFMMjkxIDI0OEwyNjggMTU1UTI0NSA2MyAyNDUgNThRMjQ1IDUxIDI1MyA0OVQzMDMgNDZIMzM0UTM0MCAzNyAzNDAgMzVRMzQwIDE5IDMzMyA1UTMyOCAwIDMxNyAwUTMxNCAwIDI4MCAxVDE4MCAyUTExOCAyIDg1IDJUNDkgMVEzMSAxIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NyA2NSAyMTYgMzM5VDI4NSA2MjhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yQiIgZD0iTTU2IDIzN1Q1NiAyNTBUNzAgMjcwSDM2OVY0MjBMMzcwIDU3MFEzODAgNTgzIDM4OSA1ODNRNDAyIDU4MyA0MDkgNTY4VjI3MEg3MDdRNzIyIDI2MiA3MjIgMjUwVDcwNyAyMzBINDA5Vi02OFE0MDEgLTgyIDM5MSAtODJIMzg5SDM4N1EzNzUgLTgyIDM2OSAtNjhWMjMwSDcwUTU2IDIzNyA1NiAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zNiIgZD0iTTQyIDMxM1E0MiA0NzYgMTIzIDU3MVQzMDMgNjY2UTM3MiA2NjYgNDAyIDYzMFQ0MzIgNTUwUTQzMiA1MjUgNDE4IDUxMFQzNzkgNDk1UTM1NiA0OTUgMzQxIDUwOVQzMjYgNTQ4UTMyNiA1OTIgMzczIDYwMVEzNTEgNjIzIDMxMSA2MjZRMjQwIDYyNiAxOTQgNTY2UTE0NyA1MDAgMTQ3IDM2NEwxNDggMzYwUTE1MyAzNjYgMTU2IDM3M1ExOTcgNDMzIDI2MyA0MzNIMjY3UTMxMyA0MzMgMzQ4IDQxNFEzNzIgNDAwIDM5NiAzNzRUNDM1IDMxN1E0NTYgMjY4IDQ1NiAyMTBWMTkyUTQ1NiAxNjkgNDUxIDE0OVE0NDAgOTAgMzg3IDM0VDI1MyAtMjJRMjI1IC0yMiAxOTkgLTE0VDE0MyAxNlQ5MiA3NVQ1NiAxNzJUNDIgMzEzWk0yNTcgMzk3UTIyNyAzOTcgMjA1IDM4MFQxNzEgMzM1VDE1NCAyNzhUMTQ4IDIxNlExNDggMTMzIDE2MCA5N1QxOTggMzlRMjIyIDIxIDI1MSAyMVEzMDIgMjEgMzI5IDU5UTM0MiA3NyAzNDcgMTA0VDM1MiAyMDlRMzUyIDI4OSAzNDcgMzE2VDMyOSAzNjFRMzAyIDM5NyAyNTcgMzk3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMi03QiIgZD0iTTU0NyAtNjQzTDU0MSAtNjQ5SDUyOFE1MTUgLTY0OSA1MDMgLTY0NVEzMjQgLTU4MiAyOTMgLTQ2NlEyODkgLTQ0OSAyODkgLTQyOFQyODcgLTIwMEwyODYgNDJMMjg0IDUzUTI3NCA5OCAyNDggMTM1VDE5NiAxOTBUMTQ2IDIyMkwxMjEgMjM1UTExOSAyMzkgMTE5IDI1MFExMTkgMjYyIDEyMSAyNjZUMTMzIDI3M1EyNjIgMzM2IDI4NCA0NDlMMjg2IDQ2MEwyODcgNzAxUTI4NyA3MzcgMjg3IDc5NFEyODggOTQ5IDI5MiA5NjNRMjkzIDk2NiAyOTMgOTY3UTMyNSAxMDgwIDUwOCAxMTQ4UTUxNiAxMTUwIDUyNyAxMTUwSDU0MUw1NDcgMTE0NFYxMTMwUTU0NyAxMTE3IDU0NiAxMTE1VDUzNiAxMTA5UTQ4MCAxMDg2IDQzNyAxMDQ2VDM4MSA5NTBMMzc5IDk0MEwzNzggNjk5UTM3OCA2NTcgMzc4IDU5NFEzNzcgNDUyIDM3NCA0MzhRMzczIDQzNyAzNzMgNDM2UTM1MCAzNDggMjQzIDI4MlExOTIgMjU3IDE4NiAyNTRMMTc2IDI1MUwxODggMjQ1UTIxMSAyMzYgMjM0IDIyM1QyODcgMTg5VDM0MCAxMzVUMzczIDY1UTM3MyA2NCAzNzQgNjNRMzc3IDQ5IDM3OCAtOTNRMzc4IC0xNTYgMzc4IC0xOThMMzc5IC00MzhMMzgxIC00NDlRMzkzIC01MDQgNDM2IC01NDRUNTM2IC02MDhRNTQ0IC02MTEgNTQ1IC02MTNUNTQ3IC02MjlWLTY0M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItN0QiIGQ9Ik0xMTkgMTEzMFExMTkgMTE0NCAxMjEgMTE0N1QxMzUgMTE1MEgxMzlRMTUxIDExNTAgMTgyIDExMzhUMjUyIDExMDVUMzI2IDEwNDZUMzczIDk2NFEzNzggOTQyIDM3OCA3MDJRMzc4IDQ2OSAzNzkgNDYyUTM4NiAzOTQgNDM5IDMzOVE0ODIgMjk2IDUzNSAyNzJRNTQ0IDI2OCA1NDUgMjY2VDU0NyAyNTFRNTQ3IDI0MSA1NDcgMjM4VDU0MiAyMzFUNTMxIDIyN1Q1MTAgMjE3VDQ3NyAxOTRRMzkwIDEyOSAzNzkgMzlRMzc4IDMyIDM3OCAtMjAxUTM3OCAtNDQxIDM3MyAtNDYzUTM0MiAtNTgwIDE2NSAtNjQ0UTE1MiAtNjQ5IDEzOSAtNjQ5UTEyNSAtNjQ5IDEyMiAtNjQ2VDExOSAtNjI5UTExOSAtNjIyIDExOSAtNjE5VDEyMSAtNjE0VDEyNCAtNjEwVDEzMiAtNjA3VDE0MyAtNjAyUTE5NSAtNTc5IDIzNSAtNTM5VDI4NSAtNDQ3UTI4NiAtNDM1IDI4NyAtMTk5VDI4OSA1MVEyOTQgNzQgMzAwIDkxVDMyOSAxMzhUMzkwIDE5N1E0MTIgMjEzIDQzNiAyMjZUNDc1IDI0NEw0ODkgMjUwTDQ3MiAyNThRNDU1IDI2NSA0MzAgMjc5VDM3NyAzMTNUMzI3IDM2NlQyOTMgNDM0UTI4OSA0NTEgMjg5IDQ3MlQyODcgNjk5UTI4NiA5NDEgMjg1IDk0OFEyNzkgOTc4IDI2MiAxMDA1VDIyNyAxMDQ4VDE4NCAxMDgwVDE1MSAxMTAwVDEyOSAxMTA5TDEyNyAxMTEwUTExOSAxMTEzIDExOSAxMTMwWiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2NywwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKC0xMSwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTQ2OCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS00NSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkzMSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMy03QiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDc1MCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEyMjEiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIzNjAiIHk9IjY3NiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC02ODcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI1MDAiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQ2MSwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjE1OTUiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyODEsNjc2KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIwMiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI4MTciIHk9IjUxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTc4MCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMDIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1NjcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS0zQjQiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iNjQxIiB5PSI0MDgiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDMyOTYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI4MDQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iNjkzIiB5PSItMjEyIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NDg1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTNCNCIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODQxIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1ODgyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03QyIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI3OCwtMjg2KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS0zQjQiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iNDUxIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzAiIHg9IjEyMzAiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjMtN0QiIHg9IjgyMzQiIHk9Ii0xIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIxMDE5NCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwOTcyLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzk3LDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTcyMzgiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwxMTY5KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTMxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTdCIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjY3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIyNCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDc4LDQ5NCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiIgeD0iLTcwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjE3LjkyMjUwNDE2NjY4MSwwKSBzY2FsZSgwLjc1OTg3MTA2NTYyODM4MDYsMSkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiIHg9IjU2NSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExNzYiIHk9IjEwNDQiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjExNzYiIHk9Ii0zNTAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMjA3OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzgiIHg9IjMwODAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMzU4MCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ1MTYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTkzMSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIyNCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDc4LDQ5NCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiIgeD0iLTcwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjE3LjkyMjUwNDE2NjY4MSwwKSBzY2FsZSgwLjc1OTg3MTA2NTYyODM4MDYsMSkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiIHg9IjU2NSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIxMTc2IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3Mjg4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNEIiIHg9IjI0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjYsNTAwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSItNzAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODIuMzA2MTYwNjc2Mzc2MjcsMCkgc2NhbGUoMS40ODQ2MDY1NDc3MzA5MzYzLDEpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSI4MjciIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTM2NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iOTAwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzYiIHg9IjEwMDAxIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTA1MDEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTY3IiB5PSI1MTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDExOTQ3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzMzYyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNEIiIHg9IjI0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjYsNTAwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSItNzAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODIuMzA2MTYwNjc2Mzc2MjcsMCkgc2NhbGUoMS40ODQ2MDY1NDc3MzA5MzYzLDEpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSI4MjciIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMzY0IiB5PSIxMDUzIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIxMzY0IiB5PSItMzUwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi03RCIgeD0iMTU1MTkiIHk9Ii0xIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDgwNjgsLTY4NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjUwMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9zdmc+)
由fact 10得到,
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjgwLjUxOWV4IiBoZWlnaHQ9Ijk3LjUwOWV4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTQ3Ljk4OWV4OyBtYXJnaW4tYm90dG9tOiAtMC4xODJleDsiIHZpZXdCb3g9IjAgLTIxMjQyLjcgMzQ2NjcuNiA0MTk4MyIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NSIgZD0iTTQ5MiAyMTNRNDcyIDIxMyA0NzIgMjI2UTQ3MiAyMzAgNDc3IDI1MFQ0ODIgMjg1UTQ4MiAzMTYgNDYxIDMyM1QzNjQgMzMwSDMxMlEzMTEgMzI4IDI3NyAxOTJUMjQzIDUyUTI0MyA0OCAyNTQgNDhUMzM0IDQ2UTQyOCA0NiA0NTggNDhUNTE4IDYxUTU2NyA3NyA1OTkgMTE3VDY3MCAyNDhRNjgwIDI3MCA2ODMgMjcyUTY5MCAyNzQgNjk4IDI3NFE3MTggMjc0IDcxOCAyNjFRNjEzIDcgNjA4IDJRNjA1IDAgMzIyIDBIMTMzUTMxIDAgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ2IDY2IDIxNSAzNDJUMjg1IDYyMlEyODUgNjI5IDI4MSA2MjlRMjczIDYzMiAyMjggNjM0SDE5N1ExOTEgNjQwIDE5MSA2NDJUMTkzIDY1OVExOTcgNjc2IDIwMyA2ODBINzU3UTc2NCA2NzYgNzY0IDY2OVE3NjQgNjY0IDc1MSA1NTdUNzM3IDQ0N1E3MzUgNDQwIDcxNyA0NDBINzA1UTY5OCA0NDUgNjk4IDQ1M0w3MDEgNDc2UTcwNCA1MDAgNzA0IDUyOFE3MDQgNTU4IDY5NyA1NzhUNjc4IDYwOVQ2NDMgNjI1VDU5NiA2MzJUNTMyIDYzNEg0ODVRMzk3IDYzMyAzOTIgNjMxUTM4OCA2MjkgMzg2IDYyMlEzODUgNjE5IDM1NSA0OTlUMzI0IDM3N1EzNDcgMzc2IDM3MiAzNzZIMzk4UTQ2NCAzNzYgNDg5IDM5MVQ1MzQgNDcyUTUzOCA0ODggNTQwIDQ5MFQ1NTcgNDkzUTU2MiA0OTMgNTY1IDQ5M1Q1NzAgNDkyVDU3MiA0OTFUNTc0IDQ4N1Q1NzcgNDgzTDU0NCAzNTFRNTExIDIxOCA1MDggMjE2UTUwNSAyMTMgNDkyIDIxM1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzIiIGQ9Ik0xMDkgNDI5UTgyIDQyOSA2NiA0NDdUNTAgNDkxUTUwIDU2MiAxMDMgNjE0VDIzNSA2NjZRMzI2IDY2NiAzODcgNjEwVDQ0OSA0NjVRNDQ5IDQyMiA0MjkgMzgzVDM4MSAzMTVUMzAxIDI0MVEyNjUgMjEwIDIwMSAxNDlMMTQyIDkzTDIxOCA5MlEzNzUgOTIgMzg1IDk3UTM5MiA5OSA0MDkgMTg2VjE4OUg0NDlWMTg2UTQ0OCAxODMgNDM2IDk1VDQyMSAzVjBINTBWMTlWMzFRNTAgMzggNTYgNDZUODYgODFRMTE1IDExMyAxMzYgMTM3UTE0NSAxNDcgMTcwIDE3NFQyMDQgMjExVDIzMyAyNDRUMjYxIDI3OFQyODQgMzA4VDMwNSAzNDBUMzIwIDM2OVQzMzMgNDAxVDM0MCA0MzFUMzQzIDQ2NFEzNDMgNTI3IDMwOSA1NzNUMjEyIDYxOVExNzkgNjE5IDE1NCA2MDJUMTE5IDU2OVQxMDkgNTUwUTEwOSA1NDkgMTE0IDU0OVExMzIgNTQ5IDE1MSA1MzVUMTcwIDQ4OVExNzAgNDY0IDE1NCA0NDdUMTA5IDQyOVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tQUYiIGQ9Ik02OSA1NDRWNTkwSDQzMFY1NDRINjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkUiIGQ9Ik0yMSAyODdRMjIgMjkzIDI0IDMwM1QzNiAzNDFUNTYgMzg4VDg5IDQyNVQxMzUgNDQyUTE3MSA0NDIgMTk1IDQyNFQyMjUgMzkwVDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzA0IDQ0MiAzODIgNDQyUTQzNiA0NDIgNDY5IDQxNVQ1MDMgMzM2VDQ2NSAxNzlUNDI3IDUyUTQyNyAyNiA0NDQgMjZRNDUwIDI2IDQ1MyAyN1E0ODIgMzIgNTA1IDY1VDU0MCAxNDVRNTQyIDE1MyA1NjAgMTUzUTU4MCAxNTMgNTgwIDE0NVE1ODAgMTQ0IDU3NiAxMzBRNTY4IDEwMSA1NTQgNzNUNTA4IDE3VDQzOSAtMTBRMzkyIC0xMCAzNzEgMTdUMzUwIDczUTM1MCA5MiAzODYgMTkzVDQyMyAzNDVRNDIzIDQwNCAzNzkgNDA0SDM3NFEyODggNDA0IDIyOSAzMDNMMjIyIDI5MUwxODkgMTU3UTE1NiAyNiAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExMiAxODBUMTUyIDM0M1ExNTMgMzQ4IDE1MyAzNjZRMTUzIDQwNSAxMjkgNDA1UTkxIDQwNSA2NiAzMDVRNjAgMjg1IDYwIDI4NFE1OCAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03RCIgZD0iTTY1IDczMVE2NSA3NDUgNjggNzQ3VDg4IDc1MFExNzEgNzUwIDIxNiA3MjVUMjc5IDY3MFEyODggNjQ5IDI4OSA2MzVUMjkxIDUwMVEyOTIgMzYyIDI5MyAzNTdRMzA2IDMxMiAzNDUgMjkxVDQxNyAyNjlRNDI4IDI2OSA0MzEgMjY2VDQzNCAyNTBUNDMxIDIzNFQ0MTcgMjMxUTM4MCAyMzEgMzQ1IDIxMFQyOTggMTU3UTI5MyAxNDMgMjkyIDEyMVQyOTEgLTI4Vi03OVEyOTEgLTEzNCAyODUgLTE1NlQyNTYgLTE5OFEyMDIgLTI1MCA4OSAtMjUwUTcxIC0yNTAgNjggLTI0N1Q2NSAtMjMwUTY1IC0yMjQgNjUgLTIyM1Q2NiAtMjE4VDY5IC0yMTRUNzcgLTIxM1E5MSAtMjEzIDEwOCAtMjEwVDE0NiAtMjAwVDE4MyAtMTc3VDIwNyAtMTM5UTIwOCAtMTM0IDIwOSAzTDIxMCAxMzlRMjIzIDE5NiAyODAgMjMwUTMxNSAyNDcgMzMwIDI1MFEzMDUgMjU3IDI4MCAyNzBRMjI1IDMwNCAyMTIgMzUyTDIxMCAzNjJMMjA5IDQ5OFEyMDggNjM1IDIwNyA2NDBRMTk1IDY4MCAxNTQgNjk2VDc3IDcxM1E2OCA3MTMgNjcgNzE2VDY1IDczMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItN0IiIGQ9Ik01NDcgLTY0M0w1NDEgLTY0OUg1MjhRNTE1IC02NDkgNTAzIC02NDVRMzI0IC01ODIgMjkzIC00NjZRMjg5IC00NDkgMjg5IC00MjhUMjg3IC0yMDBMMjg2IDQyTDI4NCA1M1EyNzQgOTggMjQ4IDEzNVQxOTYgMTkwVDE0NiAyMjJMMTIxIDIzNVExMTkgMjM5IDExOSAyNTBRMTE5IDI2MiAxMjEgMjY2VDEzMyAyNzNRMjYyIDMzNiAyODQgNDQ5TDI4NiA0NjBMMjg3IDcwMVEyODcgNzM3IDI4NyA3OTRRMjg4IDk0OSAyOTIgOTYzUTI5MyA5NjYgMjkzIDk2N1EzMjUgMTA4MCA1MDggMTE0OFE1MTYgMTE1MCA1MjcgMTE1MEg1NDFMNTQ3IDExNDRWMTEzMFE1NDcgMTExNyA1NDYgMTExNVQ1MzYgMTEwOVE0ODAgMTA4NiA0MzcgMTA0NlQzODEgOTUwTDM3OSA5NDBMMzc4IDY5OVEzNzggNjU3IDM3OCA1OTRRMzc3IDQ1MiAzNzQgNDM4UTM3MyA0MzcgMzczIDQzNlEzNTAgMzQ4IDI0MyAyODJRMTkyIDI1NyAxODYgMjU0TDE3NiAyNTFMMTg4IDI0NVEyMTEgMjM2IDIzNCAyMjNUMjg3IDE4OVQzNDAgMTM1VDM3MyA2NVEzNzMgNjQgMzc0IDYzUTM3NyA0OSAzNzggLTkzUTM3OCAtMTU2IDM3OCAtMTk4TDM3OSAtNDM4TDM4MSAtNDQ5UTM5MyAtNTA0IDQzNiAtNTQ0VDUzNiAtNjA4UTU0NCAtNjExIDU0NSAtNjEzVDU0NyAtNjI5Vi02NDNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oyLTdEIiBkPSJNMTE5IDExMzBRMTE5IDExNDQgMTIxIDExNDdUMTM1IDExNTBIMTM5UTE1MSAxMTUwIDE4MiAxMTM4VDI1MiAxMTA1VDMyNiAxMDQ2VDM3MyA5NjRRMzc4IDk0MiAzNzggNzAyUTM3OCA0NjkgMzc5IDQ2MlEzODYgMzk0IDQzOSAzMzlRNDgyIDI5NiA1MzUgMjcyUTU0NCAyNjggNTQ1IDI2NlQ1NDcgMjUxUTU0NyAyNDEgNTQ3IDIzOFQ1NDIgMjMxVDUzMSAyMjdUNTEwIDIxN1Q0NzcgMTk0UTM5MCAxMjkgMzc5IDM5UTM3OCAzMiAzNzggLTIwMVEzNzggLTQ0MSAzNzMgLTQ2M1EzNDIgLTU4MCAxNjUgLTY0NFExNTIgLTY0OSAxMzkgLTY0OVExMjUgLTY0OSAxMjIgLTY0NlQxMTkgLTYyOVExMTkgLTYyMiAxMTkgLTYxOVQxMjEgLTYxNFQxMjQgLTYxMFQxMzIgLTYwN1QxNDMgLTYwMlExOTUgLTU3OSAyMzUgLTUzOVQyODUgLTQ0N1EyODYgLTQzNSAyODcgLTE5OVQyODkgNTFRMjk0IDc0IDMwMCA5MVQzMjkgMTM4VDM5MCAxOTdRNDEyIDIxMyA0MzYgMjI2VDQ3NSAyNDRMNDg5IDI1MEw0NzIgMjU4UTQ1NSAyNjUgNDMwIDI3OVQzNzcgMzEzVDMyNyAzNjZUMjkzIDQzNFEyODkgNDUxIDI4OSA0NzJUMjg3IDY5OVEyODYgOTQxIDI4NSA5NDhRMjc5IDk3OCAyNjIgMTAwNVQyMjcgMTA0OFQxODQgMTA4MFQxNTEgMTEwMFQxMjkgMTEwOUwxMjcgMTExMFExMTkgMTExMyAxMTkgMTEzMFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTNEIiBkPSJNNTYgMzQ3UTU2IDM2MCA3MCAzNjdINzA3UTcyMiAzNTkgNzIyIDM0N1E3MjIgMzM2IDcwOCAzMjhMMzkwIDMyN0g3MlE1NiAzMzIgNTYgMzQ3Wk01NiAxNTNRNTYgMTY4IDcyIDE3M0g3MDhRNzIyIDE2MyA3MjIgMTUzUTcyMiAxNDAgNzA3IDEzM0g3MFE1NiAxNDAgNTYgMTUzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUwIiBkPSJNMjg3IDYyOFEyODcgNjM1IDIzMCA2MzdRMjA2IDYzNyAxOTkgNjM4VDE5MiA2NDhRMTkyIDY0OSAxOTQgNjU5UTIwMCA2NzkgMjAzIDY4MVQzOTcgNjgzUTU4NyA2ODIgNjAwIDY4MFE2NjQgNjY5IDcwNyA2MzFUNzUxIDUzMFE3NTEgNDUzIDY4NSAzODlRNjE2IDMyMSA1MDcgMzAzUTUwMCAzMDIgNDAyIDMwMUgzMDdMMjc3IDE4MlEyNDcgNjYgMjQ3IDU5UTI0NyA1NSAyNDggNTRUMjU1IDUwVDI3MiA0OFQzMDUgNDZIMzM2UTM0MiAzNyAzNDIgMzVRMzQyIDE5IDMzNSA1UTMzMCAwIDMxOSAwUTMxNiAwIDI4MiAxVDE4MiAyUTEyMCAyIDg3IDJUNTEgMVEzMyAxIDMzIDExUTMzIDEzIDM2IDI1UTQwIDQxIDQ0IDQzVDY3IDQ2UTk0IDQ2IDEyNyA0OVExNDEgNTIgMTQ2IDYxUTE0OSA2NSAyMTggMzM5VDI4NyA2MjhaTTY0NSA1NTRRNjQ1IDU2NyA2NDMgNTc1VDYzNCA1OTdUNjA5IDYxOVQ1NjAgNjM1UTU1MyA2MzYgNDgwIDYzN1E0NjMgNjM3IDQ0NSA2MzdUNDE2IDYzNlQ0MDQgNjM2UTM5MSA2MzUgMzg2IDYyN1EzODQgNjIxIDM2NyA1NTBUMzMyIDQxMlQzMTQgMzQ0UTMxNCAzNDIgMzk1IDM0Mkg0MDdINDMwUTU0MiAzNDIgNTkwIDM5MlE2MTcgNDE5IDYzMSA0NzFUNjQ1IDU1NFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTJCIiBkPSJNNTYgMjM3VDU2IDI1MFQ3MCAyNzBIMzY5VjQyMEwzNzAgNTcwUTM4MCA1ODMgMzg5IDU4M1E0MDIgNTgzIDQwOSA1NjhWMjcwSDcwN1E3MjIgMjYyIDcyMiAyNTBUNzA3IDIzMEg0MDlWLTY4UTQwMSAtODIgMzkxIC04MkgzODlIMzg3UTM3NSAtODIgMzY5IC02OFYyMzBINzBRNTYgMjM3IDU2IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTU2IiBkPSJNMTE0IDYyMFExMTMgNjIxIDExMCA2MjRUMTA3IDYyN1QxMDMgNjMwVDk4IDYzMlQ5MSA2MzRUODAgNjM1VDY3IDYzNlQ0OCA2MzdIMTlWNjgzSDI4UTQ2IDY4MCAxNTIgNjgwUTI3MyA2ODAgMjk0IDY4M0gzMDVWNjM3SDI4NFEyMjMgNjM0IDIyMyA2MjBRMjIzIDYxOCAzMTMgMzcyVDQwNCAxMjZMNDkwIDM1OFE1NzUgNTg4IDU3NSA1OTdRNTc1IDYxNiA1NTQgNjI2VDUwOCA2MzdINTAzVjY4M0g1MTJRNTI3IDY4MCA2MjcgNjgwUTcxOCA2ODAgNzI0IDY4M0g3MzBWNjM3SDcyM1E2NDggNjM3IDYyNyA1OTZRNjI3IDU5NSA1MTUgMjkxVDQwMSAtMTRRMzk2IC0yMiAzODIgLTIySDM3NEgzNjdRMzUzIC0yMiAzNDggLTE0UTM0NiAtMTIgMjMxIDMwM1ExMTQgNjE3IDExNCA2MjBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi02MSIgZD0iTTEzNyAzMDVUMTE1IDMwNVQ3OCAzMjBUNjMgMzU5UTYzIDM5NCA5NyA0MjFUMjE4IDQ0OFEyOTEgNDQ4IDMzNiA0MTZUMzk2IDM0MFE0MDEgMzI2IDQwMSAzMDlUNDAyIDE5NFYxMjRRNDAyIDc2IDQwNyA1OFQ0MjggNDBRNDQzIDQwIDQ0OCA1NlQ0NTMgMTA5VjE0NUg0OTNWMTA2UTQ5MiA2NiA0OTAgNTlRNDgxIDI5IDQ1NSAxMlQ0MDAgLTZUMzUzIDEyVDMyOSA1NFY1OEwzMjcgNTVRMzI1IDUyIDMyMiA0OVQzMTQgNDBUMzAyIDI5VDI4NyAxN1QyNjkgNlQyNDcgLTJUMjIxIC04VDE5MCAtMTFRMTMwIC0xMSA4MiAyMFQzNCAxMDdRMzQgMTI4IDQxIDE0N1Q2OCAxODhUMTE2IDIyNVQxOTQgMjUzVDMwNCAyNjhIMzE4VjI5MFEzMTggMzI0IDMxMiAzNDBRMjkwIDQxMSAyMTUgNDExUTE5NyA0MTEgMTgxIDQxMFQxNTYgNDA2VDE0OCA0MDNRMTcwIDM4OCAxNzAgMzU5UTE3MCAzMzQgMTU0IDMyMFpNMTI2IDEwNlExMjYgNzUgMTUwIDUxVDIwOSAyNlEyNDcgMjYgMjc2IDQ5VDMxNSAxMDlRMzE3IDExNiAzMTggMTc1UTMxOCAyMzMgMzE3IDIzM1EzMDkgMjMzIDI5NiAyMzJUMjUxIDIyM1QxOTMgMjAzVDE0NyAxNjZUMTI2IDEwNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTcyIiBkPSJNMzYgNDZINTBRODkgNDYgOTcgNjBWNjhROTcgNzcgOTcgOTFUOTggMTIyVDk4IDE2MVQ5OCAyMDNROTggMjM0IDk4IDI2OVQ5OCAzMjhMOTcgMzUxUTk0IDM3MCA4MyAzNzZUMzggMzg1SDIwVjQwOFEyMCA0MzEgMjIgNDMxTDMyIDQzMlE0MiA0MzMgNjAgNDM0VDk2IDQzNlExMTIgNDM3IDEzMSA0MzhUMTYwIDQ0MVQxNzEgNDQySDE3NFYzNzNRMjEzIDQ0MSAyNzEgNDQxSDI3N1EzMjIgNDQxIDM0MyA0MTlUMzY0IDM3M1EzNjQgMzUyIDM1MSAzMzdUMzEzIDMyMlEyODggMzIyIDI3NiAzMzhUMjYzIDM3MlEyNjMgMzgxIDI2NSAzODhUMjcwIDQwMFQyNzMgNDA1UTI3MSA0MDcgMjUwIDQwMVEyMzQgMzkzIDIyNiAzODZRMTc5IDM0MSAxNzkgMjA3VjE1NFExNzkgMTQxIDE3OSAxMjdUMTc5IDEwMVQxODAgODFUMTgwIDY2VjYxUTE4MSA1OSAxODMgNTdUMTg4IDU0VDE5MyA1MVQyMDAgNDlUMjA3IDQ4VDIxNiA0N1QyMjUgNDdUMjM1IDQ2VDI0NSA0NkgyNzZWMEgyNjdRMjQ5IDMgMTQwIDNRMzcgMyAyOCAwSDIwVjQ2SDM2WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MiIgZD0iTTIxIDI4N1EyMiAyOTAgMjMgMjk1VDI4IDMxN1QzOCAzNDhUNTMgMzgxVDczIDQxMVQ5OSA0MzNUMTMyIDQ0MlExNjEgNDQyIDE4MyA0MzBUMjE0IDQwOFQyMjUgMzg4UTIyNyAzODIgMjI4IDM4MlQyMzYgMzg5UTI4NCA0NDEgMzQ3IDQ0MUgzNTBRMzk4IDQ0MSA0MjIgNDAwUTQzMCAzODEgNDMwIDM2M1E0MzAgMzMzIDQxNyAzMTVUMzkxIDI5MlQzNjYgMjg4UTM0NiAyODggMzM0IDI5OVQzMjIgMzI4UTMyMiAzNzYgMzc4IDM5MlEzNTYgNDA1IDM0MiA0MDVRMjg2IDQwNSAyMzkgMzMxUTIyOSAzMTUgMjI0IDI5OFQxOTAgMTY1UTE1NiAyNSAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExNCAxODlUMTU0IDM2NlExNTQgNDA1IDEyOCA0MDVRMTA3IDQwNSA5MiAzNzdUNjggMzE2VDU3IDI4MFE1NSAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMTIiIGQ9Ik04NCAyMzdUODQgMjUwVDk4IDI3MEg2NzlRNjk0IDI2MiA2OTQgMjUwVDY3OSAyMzBIOThRODQgMjM3IDg0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NiIgZD0iTTUyIDY0OFE1MiA2NzAgNjUgNjgzSDc2UTExOCA2ODAgMTgxIDY4MFEyOTkgNjgwIDMyMCA2ODNIMzMwUTMzNiA2NzcgMzM2IDY3NFQzMzQgNjU2UTMyOSA2NDEgMzI1IDYzN0gzMDRRMjgyIDYzNSAyNzQgNjM1UTI0NSA2MzAgMjQyIDYyMFEyNDIgNjE4IDI3MSAzNjlUMzAxIDExOEwzNzQgMjM1UTQ0NyAzNTIgNTIwIDQ3MVQ1OTUgNTk0UTU5OSA2MDEgNTk5IDYwOVE1OTkgNjMzIDU1NSA2MzdRNTM3IDYzNyA1MzcgNjQ4UTUzNyA2NDkgNTM5IDY2MVE1NDIgNjc1IDU0NSA2NzlUNTU4IDY4M1E1NjAgNjgzIDU3MCA2ODNUNjA0IDY4MlQ2NjggNjgxUTczNyA2ODEgNzU1IDY4M0g3NjJRNzY5IDY3NiA3NjkgNjcyUTc2OSA2NTUgNzYwIDY0MFE3NTcgNjM3IDc0MyA2MzdRNzMwIDYzNiA3MTkgNjM1VDY5OCA2MzBUNjgyIDYyM1Q2NzAgNjE1VDY2MCA2MDhUNjUyIDU5OVQ2NDUgNTkyTDQ1MiAyODJRMjcyIC05IDI2NiAtMTZRMjYzIC0xOCAyNTkgLTIxTDI0MSAtMjJIMjM0UTIxNiAtMjIgMjE2IC0xNVEyMTMgLTkgMTc3IDMwNVExMzkgNjIzIDEzOCA2MjZRMTMzIDYzNyA3NiA2MzdINTlRNTIgNjQyIDUyIDY0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MiIgZD0iTTIzMCA2MzdRMjAzIDYzNyAxOTggNjM4VDE5MyA2NDlRMTkzIDY3NiAyMDQgNjgyUTIwNiA2ODMgMzc4IDY4M1E1NTAgNjgyIDU2NCA2ODBRNjIwIDY3MiA2NTggNjUyVDcxMiA2MDZUNzMzIDU2M1Q3MzkgNTI5UTczOSA0ODQgNzEwIDQ0NVQ2NDMgMzg1VDU3NiAzNTFUNTM4IDMzOEw1NDUgMzMzUTYxMiAyOTUgNjEyIDIyM1E2MTIgMjEyIDYwNyAxNjJUNjAyIDgwVjcxUTYwMiA1MyA2MDMgNDNUNjE0IDI1VDY0MCAxNlE2NjggMTYgNjg2IDM4VDcxMiA4NVE3MTcgOTkgNzIwIDEwMlQ3MzUgMTA1UTc1NSAxMDUgNzU1IDkzUTc1NSA3NSA3MzEgMzZRNjkzIC0yMSA2NDEgLTIxSDYzMlE1NzEgLTIxIDUzMSA0VDQ4NyA4MlE0ODcgMTA5IDUwMiAxNjZUNTE3IDIzOVE1MTcgMjkwIDQ3NCAzMTNRNDU5IDMyMCA0NDkgMzIxVDM3OCAzMjNIMzA5TDI3NyAxOTNRMjQ0IDYxIDI0NCA1OVEyNDQgNTUgMjQ1IDU0VDI1MiA1MFQyNjkgNDhUMzAyIDQ2SDMzM1EzMzkgMzggMzM5IDM3VDMzNiAxOVEzMzIgNiAzMjYgMEgzMTFRMjc1IDIgMTgwIDJRMTQ2IDIgMTE3IDJUNzEgMlQ1MCAxUTMzIDEgMzMgMTBRMzMgMTIgMzYgMjRRNDEgNDMgNDYgNDVRNTAgNDYgNjEgNDZINjdROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFEyODcgNjM1IDIzMCA2MzdaTTYzMCA1NTRRNjMwIDU4NiA2MDkgNjA4VDUyMyA2MzZRNTIxIDYzNiA1MDAgNjM2VDQ2MiA2MzdINDQwUTM5MyA2MzcgMzg2IDYyN1EzODUgNjI0IDM1MiA0OTRUMzE5IDM2MVEzMTkgMzYwIDM4OCAzNjBRNDY2IDM2MSA0OTIgMzY3UTU1NiAzNzcgNTkyIDQyNlE2MDggNDQ5IDYxOSA0ODZUNjMwIDU1NFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTM0IiBkPSJNNDYyIDBRNDQ0IDMgMzMzIDNRMjE3IDMgMTk5IDBIMTkwVjQ2SDIyMVEyNDEgNDYgMjQ4IDQ2VDI2NSA0OFQyNzkgNTNUMjg2IDYxUTI4NyA2MyAyODcgMTE1VjE2NUgyOFYyMTFMMTc5IDQ0MlEzMzIgNjc0IDMzNCA2NzVRMzM2IDY3NyAzNTUgNjc3SDM3M0wzNzkgNjcxVjIxMUg0NzFWMTY1SDM3OVYxMTRRMzc5IDczIDM3OSA2NlQzODUgNTRRMzkzIDQ3IDQ0MiA0Nkg0NzFWMEg0NjJaTTI5MyAyMTFWNTQ1TDc0IDIxMkwxODMgMjExSDI5M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMzIiBkPSJNMTI3IDQ2M1ExMDAgNDYzIDg1IDQ4MFQ2OSA1MjRRNjkgNTc5IDExNyA2MjJUMjMzIDY2NVEyNjggNjY1IDI3NyA2NjRRMzUxIDY1MiAzOTAgNjExVDQzMCA1MjJRNDMwIDQ3MCAzOTYgNDIxVDMwMiAzNTBMMjk5IDM0OFEyOTkgMzQ3IDMwOCAzNDVUMzM3IDMzNlQzNzUgMzE1UTQ1NyAyNjIgNDU3IDE3NVE0NTcgOTYgMzk1IDM3VDIzOCAtMjJRMTU4IC0yMiAxMDAgMjFUNDIgMTMwUTQyIDE1OCA2MCAxNzVUMTA1IDE5M1ExMzMgMTkzIDE1MSAxNzVUMTY5IDEzMFExNjkgMTE5IDE2NiAxMTBUMTU5IDk0VDE0OCA4MlQxMzYgNzRUMTI2IDcwVDExOCA2N0wxMTQgNjZRMTY1IDIxIDIzOCAyMVEyOTMgMjEgMzIxIDc0UTMzOCAxMDcgMzM4IDE3NVYxOTVRMzM4IDI5MCAyNzQgMzIyUTI1OSAzMjggMjEzIDMyOUwxNzEgMzMwTDE2OCAzMzJRMTY2IDMzNSAxNjYgMzQ4UTE2NiAzNjYgMTc0IDM2NlEyMDIgMzY2IDIzMiAzNzFRMjY2IDM3NiAyOTQgNDEzVDMyMiA1MjVWNTMzUTMyMiA1OTAgMjg3IDYxMlEyNjUgNjI2IDI0MCA2MjZRMjA4IDYyNiAxODEgNjE1VDE0MyA1OTJUMTMyIDU4MEgxMzVRMTM4IDU3OSAxNDMgNTc4VDE1MyA1NzNUMTY1IDU2NlQxNzUgNTU1VDE4MyA1NDBUMTg2IDUyMFExODYgNDk4IDE3MiA0ODFUMTI3IDQ2M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTM4IiBkPSJNNzAgNDE3VDcwIDQ5NFQxMjQgNjE4VDI0OCA2NjZRMzE5IDY2NiAzNzQgNjI0VDQyOSA1MTVRNDI5IDQ4NSA0MTggNDU5VDM5MiA0MTdUMzYxIDM4OVQzMzUgMzcxVDMyNCAzNjNMMzM4IDM1NFEzNTIgMzQ0IDM2NiAzMzRUMzgyIDMyM1E0NTcgMjY0IDQ1NyAxNzRRNDU3IDk1IDM5OSAzN1QyNDkgLTIyUTE1OSAtMjIgMTAxIDI5VDQzIDE1NVE0MyAyNjMgMTcyIDMzNUwxNTQgMzQ4UTEzMyAzNjEgMTI3IDM2OFE3MCA0MTcgNzAgNDk0Wk0yODYgMzg2TDI5MiAzOTBRMjk4IDM5NCAzMDEgMzk2VDMxMSA0MDNUMzIzIDQxM1QzMzQgNDI1VDM0NSA0MzhUMzU1IDQ1NFQzNjQgNDcxVDM2OSA0OTFUMzcxIDUxM1EzNzEgNTU2IDM0MiA1ODZUMjc1IDYyNFEyNjggNjI1IDI0MiA2MjVRMjAxIDYyNSAxNjUgNTk5VDEyOCA1MzRRMTI4IDUxMSAxNDEgNDkyVDE2NyA0NjNUMjE3IDQzMVEyMjQgNDI2IDIyOCA0MjRMMjg2IDM4NlpNMjUwIDIxUTMwOCAyMSAzNTAgNTVUMzkyIDEzN1EzOTIgMTU0IDM4NyAxNjlUMzc1IDE5NFQzNTMgMjE2VDMzMCAyMzRUMzAxIDI1M1QyNzQgMjcwUTI2MCAyNzkgMjQ0IDI4OVQyMTggMzA2TDIxMCAzMTFRMjA0IDMxMSAxODEgMjk0VDEzMyAyMzlUMTA3IDE1N1ExMDcgOTggMTUwIDYwVDI1MCAyMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjMtMjgiIGQ9Ik03MDEgLTk0MFE3MDEgLTk0MyA2OTUgLTk0OUg2NjRRNjYyIC05NDcgNjM2IC05MjJUNTkxIC04NzlUNTM3IC04MThUNDc1IC03MzdUNDEyIC02MzZUMzUwIC01MTFUMjk1IC0zNjJUMjUwIC0xODZUMjIxIDE3VDIwOSAyNTFRMjA5IDk2MiA1NzMgMTM2MVE1OTYgMTM4NiA2MTYgMTQwNVQ2NDkgMTQzN1Q2NjQgMTQ1MEg2OTVRNzAxIDE0NDQgNzAxIDE0NDFRNzAxIDE0MzYgNjgxIDE0MTVUNjI5IDEzNTZUNTU3IDEyNjFUNDc2IDExMThUNDAwIDkyN1QzNDAgNjc1VDMwOCAzNTlRMzA2IDMyMSAzMDYgMjUwUTMwNiAtMTM5IDQwMCAtNDMwVDY5MCAtOTI0UTcwMSAtOTM2IDcwMSAtOTQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMy0yOSIgZD0iTTM0IDE0MzhRMzQgMTQ0NiAzNyAxNDQ4VDUwIDE0NTBINTZINzFRNzMgMTQ0OCA5OSAxNDIzVDE0NCAxMzgwVDE5OCAxMzE5VDI2MCAxMjM4VDMyMyAxMTM3VDM4NSAxMDEzVDQ0MCA4NjRUNDg1IDY4OFQ1MTQgNDg1VDUyNiAyNTFRNTI2IDEzNCA1MTkgNTNRNDcyIC01MTkgMTYyIC04NjBRMTM5IC04ODUgMTE5IC05MDRUODYgLTkzNlQ3MSAtOTQ5SDU2UTQzIC05NDkgMzkgLTk0N1QzNCAtOTM3UTg4IC04ODMgMTQwIC04MTNRNDI4IC00MzAgNDI4IDI1MVE0MjggNDUzIDQwMiA2MjhUMzM4IDkyMlQyNDUgMTE0NlQxNDUgMTMwOVQ0NiAxNDI1UTQ0IDE0MjcgNDIgMTQyOVQzOSAxNDMzVDM2IDE0MzZMMzQgMTQzOFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjQtMjgiIGQ9Ik03NTggLTEyMzdUNzU4IC0xMjQwVDc1MiAtMTI0OUg3MzZRNzE4IC0xMjQ5IDcxNyAtMTI0OFE3MTEgLTEyNDUgNjcyIC0xMTk5UTIzNyAtNzA2IDIzNyAyNTFUNjcyIDE3MDBRNjk3IDE3MzAgNzE2IDE3NDlRNzE4IDE3NTAgNzM1IDE3NTBINzUyUTc1OCAxNzQ0IDc1OCAxNzQxUTc1OCAxNzM3IDc0MCAxNzEzVDY4OSAxNjQ0VDYxOSAxNTM3VDU0MCAxMzgwVDQ2MyAxMTc2UTM0OCA4MDIgMzQ4IDI1MVEzNDggLTI0MiA0NDEgLTU5OVQ3NDQgLTEyMThRNzU4IC0xMjM3IDc1OCAtMTI0MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjQtMjkiIGQ9Ik0zMyAxNzQxUTMzIDE3NTAgNTEgMTc1MEg2MEg2NVE3MyAxNzUwIDgxIDE3NDNUMTE5IDE3MDBRNTU0IDEyMDcgNTU0IDI1MVE1NTQgLTcwNyAxMTkgLTExOTlRNzYgLTEyNTAgNjYgLTEyNTBRNjUgLTEyNTAgNjIgLTEyNTBUNTYgLTEyNDlRNTUgLTEyNDkgNTMgLTEyNDlUNDkgLTEyNTBRMzMgLTEyNTAgMzMgLTEyMzlRMzMgLTEyMzYgNTAgLTEyMTRUOTggLTExNTBUMTYzIC0xMDUyVDIzOCAtOTEwVDMxMSAtNzI3UTQ0MyAtMzM1IDQ0MyAyNTFRNDQzIDQwMiA0MzYgNTMyVDQwNSA4MzFUMzM5IDExNDJUMjI0IDE0MzhUNTAgMTcxNlEzMyAxNzM3IDMzIDE3NDFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zNiIgZD0iTTQyIDMxM1E0MiA0NzYgMTIzIDU3MVQzMDMgNjY2UTM3MiA2NjYgNDAyIDYzMFQ0MzIgNTUwUTQzMiA1MjUgNDE4IDUxMFQzNzkgNDk1UTM1NiA0OTUgMzQxIDUwOVQzMjYgNTQ4UTMyNiA1OTIgMzczIDYwMVEzNTEgNjIzIDMxMSA2MjZRMjQwIDYyNiAxOTQgNTY2UTE0NyA1MDAgMTQ3IDM2NEwxNDggMzYwUTE1MyAzNjYgMTU2IDM3M1ExOTcgNDMzIDI2MyA0MzNIMjY3UTMxMyA0MzMgMzQ4IDQxNFEzNzIgNDAwIDM5NiAzNzRUNDM1IDMxN1E0NTYgMjY4IDQ1NiAyMTBWMTkyUTQ1NiAxNjkgNDUxIDE0OVE0NDAgOTAgMzg3IDM0VDI1MyAtMjJRMjI1IC0yMiAxOTkgLTE0VDE0MyAxNlQ5MiA3NVQ1NiAxNzJUNDIgMzEzWk0yNTcgMzk3UTIyNyAzOTcgMjA1IDM4MFQxNzEgMzM1VDE1NCAyNzhUMTQ4IDIxNlExNDggMTMzIDE2MCA5N1QxOTggMzlRMjIyIDIxIDI1MSAyMVEzMDIgMjEgMzI5IDU5UTM0MiA3NyAzNDcgMTA0VDM1MiAyMDlRMzUyIDI4OSAzNDcgMzE2VDMyOSAzNjFRMzAyIDM5NyAyNTcgMzk3WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2NywwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKC0xMSwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsMTk2NjcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5MzEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItN0IiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2NjcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjI0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzgsNDk0KSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSItNzAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMTcuOTIyNTA0MTY2NjgxLDApIHNjYWxlKDAuNzU5ODcxMDY1NjI4MzgwNiwxKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiIgeD0iNTY1IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTE3NiIgeT0iMTA0NCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTE3NiIgeT0iLTM1MCI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItN0QiIHg9IjI1MjQiIHk9Ii0xIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDExMiwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsMTk2NjcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjc3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTMzNCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE4MzQsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIzNjU1IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMjk2IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjI5NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExMDkiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEyIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMDcsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTczMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNTYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI3NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3NTQwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI2MzgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjEyNzIiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9Ijk0MjUiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMDQyNSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDExMDkyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMjk2IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMjI5NyIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMzE4NyIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQ4MzYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTY2NDYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTQzOSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIxODY5NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjE5Njk4IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjAxOTgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTY3IiB5PSI1ODMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIxNjQ0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwxNzAwNSkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIyMjIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMjIyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTg5MCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTI5NiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjIyOTciIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjMxODciIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU2MzMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMDc0IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii00NDYiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjcyMTMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI4MjE0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODcxNCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjQ2NTYiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zNCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjE3OTciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIyNzk3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzI5OCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExMDkiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEyIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE3MDcsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTM2MTEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQ4MDIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTYzODIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxNzM4MyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE3ODgzLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iNjYxNyIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTI5NiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzQiIHg9IjIyOTciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNzk3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjQyNTgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MjU5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMyIgeD0iMTEwOSIgeT0iNTEwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjY4OCwtODM3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExMDkiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItNDQ2Ij48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjQ3NDEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMDc0IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwxNDA1OSkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIyNzciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMzM0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTgzNCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjM2NTUiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEyOTYiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMjk3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwNywtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1NzMwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDc1NDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTI3MiIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iOTQyNSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwNDI1IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTEwOTIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEyOTYiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIyMjk3IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIzMTg3IiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDgzNiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNTYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI3NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjY0NiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxNDM5IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjE4Njk3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTk2OTgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMDE5OCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExNjciIHk9IjU4MyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjE2NDQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDExMzk2KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjIyMiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEyMjIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODkwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI3MjIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNzIzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIzMTg3IiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1NjMzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA3NCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDc0IiB5PSItNDQ2Ij48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI3MjEzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zNCIgeD0iODIxNCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDg3MTQsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMzYwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQzLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDMxNSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNzIyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTcyMywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMzE4NyIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQwNTksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTUyNTAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTY4MzAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxNzgzMSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE4MzMxLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTM2MCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0Myw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTgzNykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTQ0NiI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE5OTMyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA3NCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEyIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIyMTM2NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzgiIHg9IjIyMzY4IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjI4NjksMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMzYwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjEsNjc2KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExMDkiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEyIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtODM3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExMDkiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItNDQ2Ij48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjQ0NjksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMDc0IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjI1OTA1IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMjY5MDYiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNzQwNiwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEzNjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MSw2NzYpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMyIgeD0iMTEwOSIgeT0iNTEwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC04MzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii00NDYiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyOTAwNywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwNzQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDg0NTApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjc3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTMzNCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE4MzQsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIzNjU1IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMjk2IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjI5NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExMDkiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEyIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMDcsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTczMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNTYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI3NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3NTQwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI2MzgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjEyNzIiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9Ijk0MjUiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMDQyNSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDExMDkyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMjk2IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMjI5NyIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMzE4NyIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQ4MzYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTY2NDYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTQzOSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIxODY5NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjE5Njk4IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjAxOTgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTY3IiB5PSI1ODMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIxNjQ0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCw1OTM1KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjIyMiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEyMjIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODkwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI3MjIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNzIzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIzMTg3IiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1NjMzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA3NCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDc0IiB5PSItNDQ2Ij48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI3MjEzIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zNCIgeD0iODIxNCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDg3MTQsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMzYwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQzLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDMxNSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNzIyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTcyMywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMzE4NyIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQwNTksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTUyNTAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDMyNzMpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMjIyIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zNCIgeD0iMTIyMiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE3MjMsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMzYwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQzLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzMzI0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ1MTUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNjA5NSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjcwOTYiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3NTk2LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTM2MCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0Myw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTgzNykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTQ0NiI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkxOTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMDc0IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEwNjMyIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zOCIgeD0iMTE2MzMiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjEzNCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEzNjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MSw2NzYpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC04MzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii00NDYiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzczNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwNzQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTUxNzAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxNjE3MSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2NjcxLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTM2MCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYxLDY3NikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMzIiB4PSIxMTA5IiB5PSI1MTAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTgzNykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTQ0NiI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE4MjcyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA3NCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEyIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsMzI3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEzMzQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODM0LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMzY1NSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTI5NiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIyOTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjA3LC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU3MzAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzU0MCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxMjcyIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI5NDI1IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA0MjUiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMTA5MiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTI5NiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjIyOTciIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjMxODciIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0ODM2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2NjQ2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI2MzgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjE0MzkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMTg2OTciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxOTY5OCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIwMTk4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTE2NyIgeT0iNTgzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMTY0NCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTIyNzgpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMjIyIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTIyMiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE4OTAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjcyMiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE3MjMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjMxODciIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU2MzMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjMtMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MzYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMDc0IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii00NDYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxNTc5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMjU4MCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDMwODEsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMzYwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQzLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NjgxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU4NzMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjMtMjkiIHg9Ijc5NjciIHk9Ii0xIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTUwMjIpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMjIyIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zNCIgeD0iMTIyMiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE3MjMsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMzYwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQzLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzMzI0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ1MTUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNjA5NSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjcwOTYiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3NTk2LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTM2MCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0Myw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTgzNykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTQ0NiI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkxOTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMDc0IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEwNjMyIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTE2MzMiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjEzNCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEzNjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MSw2NzYpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC04MzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii00NDYiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzczNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwNzQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTUxMTQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMyIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjcyMiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjE3MjMiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIyNDQ2IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQ0NiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iNDkxMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC03OTY4KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEzMzQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODM0LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMzY1NSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTI5NiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIyOTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjA3LC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU3MzAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzU0MCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxMjcyIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI5NDI1IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA0MjUiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMTA5MiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTI5NiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjIyOTciIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjMxODciIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0ODM2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2NjQ2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI2MzgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjE0MzkiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMTg2OTciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxOTY5OCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIwMTk4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTE2NyIgeT0iNTgzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMTY0NCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTEwODczKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjIyMiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEyMjIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODkwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI3MjIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNzIzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIzMTg3IiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1NjMzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzkyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA3NCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDc0IiB5PSItNDQ2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTU3OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjI1ODAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzMDgxLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTM2MCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0Myw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDY4MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1ODczLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9Ijc0NTMiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4MjMxLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQyLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTM2MCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYxLDY3NikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTgzNykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTQ0NiI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwMDU0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA3NCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEyIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaNC0yOSIgeD0iMTIwNjAiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwtMTM5MTcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMjIyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTAwMCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjE2OTQiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zNCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjI3LC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDMxNTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDM0OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI1OTI5IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjcwNywwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjE2OTQiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjI3LC04MzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii00NDYiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4ODY1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA3NCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEyIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMDMwMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDExMDc5LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQyLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTg1OCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDY3NikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTM2IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzA5LC04MzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii00NDYiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzQwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwNzQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC0xNjg2MykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIyNzciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMzM0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTgzNCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjM2NTUiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEyOTYiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMjk3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwNywtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1NzMwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDc1NDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTI3MiIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iOTQyNSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwNDI1IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTEwOTIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEyOTYiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIyMjk3IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIzMTg3IiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDgzNiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNTYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI3NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjY0NiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxNDM5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTE5NTExKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjIyMiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEyMjIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNzIzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjc5NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExNjciIHk9IjU4MyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDI0MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI1NzE0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjQ5MywwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjE2OTQiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zNCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjI3LC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDg2NTAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTg0MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMTQyMSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMjAwLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQyLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTY5NCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMjcsLTgzNykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTQ0NiI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0MzU3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA3NCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEyIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxNTc5MiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2NTcxLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQyLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTg1OCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDY3NikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTM2IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzA5LC04MzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii00NDYiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODg5MiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwNzQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8L3N2Zz4=)
由fact 9得到,
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9Ijg4LjY1ZXgiIGhlaWdodD0iNDcuMTc2ZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMjMuMDA1ZXg7IiB2aWV3Qm94PSIwIC0xMDQwNy4xIDM4MTY4LjggMjAzMTEuOCIgcm9sZT0iaW1nIiBmb2N1c2FibGU9ImZhbHNlIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciPgo8ZGVmcz4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00NSIgZD0iTTQ5MiAyMTNRNDcyIDIxMyA0NzIgMjI2UTQ3MiAyMzAgNDc3IDI1MFQ0ODIgMjg1UTQ4MiAzMTYgNDYxIDMyM1QzNjQgMzMwSDMxMlEzMTEgMzI4IDI3NyAxOTJUMjQzIDUyUTI0MyA0OCAyNTQgNDhUMzM0IDQ2UTQyOCA0NiA0NTggNDhUNTE4IDYxUTU2NyA3NyA1OTkgMTE3VDY3MCAyNDhRNjgwIDI3MCA2ODMgMjcyUTY5MCAyNzQgNjk4IDI3NFE3MTggMjc0IDcxOCAyNjFRNjEzIDcgNjA4IDJRNjA1IDAgMzIyIDBIMTMzUTMxIDAgMzEgMTFRMzEgMTMgMzQgMjVRMzggNDEgNDIgNDNUNjUgNDZROTIgNDYgMTI1IDQ5UTEzOSA1MiAxNDQgNjFRMTQ2IDY2IDIxNSAzNDJUMjg1IDYyMlEyODUgNjI5IDI4MSA2MjlRMjczIDYzMiAyMjggNjM0SDE5N1ExOTEgNjQwIDE5MSA2NDJUMTkzIDY1OVExOTcgNjc2IDIwMyA2ODBINzU3UTc2NCA2NzYgNzY0IDY2OVE3NjQgNjY0IDc1MSA1NTdUNzM3IDQ0N1E3MzUgNDQwIDcxNyA0NDBINzA1UTY5OCA0NDUgNjk4IDQ1M0w3MDEgNDc2UTcwNCA1MDAgNzA0IDUyOFE3MDQgNTU4IDY5NyA1NzhUNjc4IDYwOVQ2NDMgNjI1VDU5NiA2MzJUNTMyIDYzNEg0ODVRMzk3IDYzMyAzOTIgNjMxUTM4OCA2MjkgMzg2IDYyMlEzODUgNjE5IDM1NSA0OTlUMzI0IDM3N1EzNDcgMzc2IDM3MiAzNzZIMzk4UTQ2NCAzNzYgNDg5IDM5MVQ1MzQgNDcyUTUzOCA0ODggNTQwIDQ5MFQ1NTcgNDkzUTU2MiA0OTMgNTY1IDQ5M1Q1NzAgNDkyVDU3MiA0OTFUNTc0IDQ4N1Q1NzcgNDgzTDU0NCAzNTFRNTExIDIxOCA1MDggMjE2UTUwNSAyMTMgNDkyIDIxM1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdCIiBkPSJNNDM0IC0yMzFRNDM0IC0yNDQgNDI4IC0yNTBINDEwUTI4MSAtMjUwIDIzMCAtMTg0UTIyNSAtMTc3IDIyMiAtMTcyVDIxNyAtMTYxVDIxMyAtMTQ4VDIxMSAtMTMzVDIxMCAtMTExVDIwOSAtODRUMjA5IC00N1QyMDkgMFEyMDkgMjEgMjA5IDUzUTIwOCAxNDIgMjA0IDE1M1EyMDMgMTU0IDIwMyAxNTVRMTg5IDE5MSAxNTMgMjExVDgyIDIzMVE3MSAyMzEgNjggMjM0VDY1IDI1MFQ2OCAyNjZUODIgMjY5UTExNiAyNjkgMTUyIDI4OVQyMDMgMzQ1UTIwOCAzNTYgMjA4IDM3N1QyMDkgNTI5VjU3OVEyMDkgNjM0IDIxNSA2NTZUMjQ0IDY5OFEyNzAgNzI0IDMyNCA3NDBRMzYxIDc0OCAzNzcgNzQ5UTM3OSA3NDkgMzkwIDc0OVQ0MDggNzUwSDQyOFE0MzQgNzQ0IDQzNCA3MzJRNDM0IDcxOSA0MzEgNzE2UTQyOSA3MTMgNDE1IDcxM1EzNjIgNzEwIDMzMiA2ODlUMjk2IDY0N1EyOTEgNjM0IDI5MSA0OTlWNDE3UTI5MSAzNzAgMjg4IDM1M1QyNzEgMzE0UTI0MCAyNzEgMTg0IDI1NUwxNzAgMjUwTDE4NCAyNDVRMjAyIDIzOSAyMjAgMjMwVDI2MiAxOTZUMjkwIDEzN1EyOTEgMTMxIDI5MSAxUTI5MSAtMTM0IDI5NiAtMTQ3UTMwNiAtMTc0IDMzOSAtMTkyVDQxNSAtMjEzUTQyOSAtMjEzIDQzMSAtMjE2UTQzNCAtMjE5IDQzNCAtMjMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjIxMiIgZD0iTTg0IDIzN1Q4NCAyNTBUOTggMjcwSDY3OVE2OTQgMjYyIDY5NCAyNTBUNjc5IDIzMEg5OFE4NCAyMzcgODQgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzgiIGQ9Ik03MCA0MTdUNzAgNDk0VDEyNCA2MThUMjQ4IDY2NlEzMTkgNjY2IDM3NCA2MjRUNDI5IDUxNVE0MjkgNDg1IDQxOCA0NTlUMzkyIDQxN1QzNjEgMzg5VDMzNSAzNzFUMzI0IDM2M0wzMzggMzU0UTM1MiAzNDQgMzY2IDMzNFQzODIgMzIzUTQ1NyAyNjQgNDU3IDE3NFE0NTcgOTUgMzk5IDM3VDI0OSAtMjJRMTU5IC0yMiAxMDEgMjlUNDMgMTU1UTQzIDI2MyAxNzIgMzM1TDE1NCAzNDhRMTMzIDM2MSAxMjcgMzY4UTcwIDQxNyA3MCA0OTRaTTI4NiAzODZMMjkyIDM5MFEyOTggMzk0IDMwMSAzOTZUMzExIDQwM1QzMjMgNDEzVDMzNCA0MjVUMzQ1IDQzOFQzNTUgNDU0VDM2NCA0NzFUMzY5IDQ5MVQzNzEgNTEzUTM3MSA1NTYgMzQyIDU4NlQyNzUgNjI0UTI2OCA2MjUgMjQyIDYyNVEyMDEgNjI1IDE2NSA1OTlUMTI4IDUzNFExMjggNTExIDE0MSA0OTJUMTY3IDQ2M1QyMTcgNDMxUTIyNCA0MjYgMjI4IDQyNEwyODYgMzg2Wk0yNTAgMjFRMzA4IDIxIDM1MCA1NVQzOTIgMTM3UTM5MiAxNTQgMzg3IDE2OVQzNzUgMTk0VDM1MyAyMTZUMzMwIDIzNFQzMDEgMjUzVDI3NCAyNzBRMjYwIDI3OSAyNDQgMjg5VDIxOCAzMDZMMjEwIDMxMVEyMDQgMzExIDE4MSAyOTRUMTMzIDIzOVQxMDcgMTU3UTEwNyA5OCAxNTAgNjBUMjUwIDIxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU2IiBkPSJNNTIgNjQ4UTUyIDY3MCA2NSA2ODNINzZRMTE4IDY4MCAxODEgNjgwUTI5OSA2ODAgMzIwIDY4M0gzMzBRMzM2IDY3NyAzMzYgNjc0VDMzNCA2NTZRMzI5IDY0MSAzMjUgNjM3SDMwNFEyODIgNjM1IDI3NCA2MzVRMjQ1IDYzMCAyNDIgNjIwUTI0MiA2MTggMjcxIDM2OVQzMDEgMTE4TDM3NCAyMzVRNDQ3IDM1MiA1MjAgNDcxVDU5NSA1OTRRNTk5IDYwMSA1OTkgNjA5UTU5OSA2MzMgNTU1IDYzN1E1MzcgNjM3IDUzNyA2NDhRNTM3IDY0OSA1MzkgNjYxUTU0MiA2NzUgNTQ1IDY3OVQ1NTggNjgzUTU2MCA2ODMgNTcwIDY4M1Q2MDQgNjgyVDY2OCA2ODFRNzM3IDY4MSA3NTUgNjgzSDc2MlE3NjkgNjc2IDc2OSA2NzJRNzY5IDY1NSA3NjAgNjQwUTc1NyA2MzcgNzQzIDYzN1E3MzAgNjM2IDcxOSA2MzVUNjk4IDYzMFQ2ODIgNjIzVDY3MCA2MTVUNjYwIDYwOFQ2NTIgNTk5VDY0NSA1OTJMNDUyIDI4MlEyNzIgLTkgMjY2IC0xNlEyNjMgLTE4IDI1OSAtMjFMMjQxIC0yMkgyMzRRMjE2IC0yMiAyMTYgLTE1UTIxMyAtOSAxNzcgMzA1UTEzOSA2MjMgMTM4IDYyNlExMzMgNjM3IDc2IDYzN0g1OVE1MiA2NDIgNTIgNjQ4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTRCIiBkPSJNMjg1IDYyOFEyODUgNjM1IDIyOCA2MzdRMjA1IDYzNyAxOTggNjM4VDE5MSA2NDdRMTkxIDY0OSAxOTMgNjYxUTE5OSA2ODEgMjAzIDY4MlEyMDUgNjgzIDIxNCA2ODNIMjE5UTI2MCA2ODEgMzU1IDY4MVEzODkgNjgxIDQxOCA2ODFUNDYzIDY4MlQ0ODMgNjgyUTUwMCA2ODIgNTAwIDY3NFE1MDAgNjY5IDQ5NyA2NjBRNDk2IDY1OCA0OTYgNjU0VDQ5NSA2NDhUNDkzIDY0NFQ0OTAgNjQxVDQ4NiA2MzlUNDc5IDYzOFQ0NzAgNjM3VDQ1NiA2MzdRNDE2IDYzNiA0MDUgNjM0VDM4NyA2MjNMMzA2IDMwNVEzMDcgMzA1IDQ5MCA0NDlUNjc4IDU5N1E2OTIgNjExIDY5MiA2MjBRNjkyIDYzNSA2NjcgNjM3UTY1MSA2MzcgNjUxIDY0OFE2NTEgNjUwIDY1NCA2NjJUNjU5IDY3N1E2NjIgNjgyIDY3NiA2ODJRNjgwIDY4MiA3MTEgNjgxVDc5MSA2ODBRODE0IDY4MCA4MzkgNjgxVDg2OSA2ODJRODg5IDY4MiA4ODkgNjcyUTg4OSA2NTAgODgxIDY0MlE4NzggNjM3IDg2MiA2MzdRNzg3IDYzMiA3MjYgNTg2UTcxMCA1NzYgNjU2IDUzNFQ1NTYgNDU1TDUwOSA0MThMNTE4IDM5NlE1MjcgMzc0IDU0NiAzMjlUNTgxIDI0NFE2NTYgNjcgNjYxIDYxUTY2MyA1OSA2NjYgNTdRNjgwIDQ3IDcxNyA0Nkg3MzhRNzQ0IDM4IDc0NCAzN1Q3NDEgMTlRNzM3IDYgNzMxIDBINzIwUTY4MCAzIDYyNSAzUTUwMyAzIDQ4OCAwSDQ3OFE0NzIgNiA0NzIgOVQ0NzQgMjdRNDc4IDQwIDQ4MCA0M1Q0OTEgNDZINDk0UTU0NCA0NiA1NDQgNzFRNTQ0IDc1IDUxNyAxNDFUNDg1IDIxNkw0MjcgMzU0TDM1OSAzMDFMMjkxIDI0OEwyNjggMTU1UTI0NSA2MyAyNDUgNThRMjQ1IDUxIDI1MyA0OVQzMDMgNDZIMzM0UTM0MCAzNyAzNDAgMzVRMzQwIDE5IDMzMyA1UTMyOCAwIDMxNyAwUTMxNCAwIDI4MCAxVDE4MCAyUTExOCAyIDg1IDJUNDkgMVEzMSAxIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NyA2NSAyMTYgMzM5VDI4NSA2MjhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi1BRiIgZD0iTTY5IDU0NFY1OTBINDMwVjU0NEg2OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NCIgZD0iTTQwIDQzN1EyMSA0MzcgMjEgNDQ1UTIxIDQ1MCAzNyA1MDFUNzEgNjAyTDg4IDY1MVE5MyA2NjkgMTAxIDY3N0g1NjlINjU5UTY5MSA2NzcgNjk3IDY3NlQ3MDQgNjY3UTcwNCA2NjEgNjg3IDU1M1Q2NjggNDQ0UTY2OCA0MzcgNjQ5IDQzN1E2NDAgNDM3IDYzNyA0MzdUNjMxIDQ0Mkw2MjkgNDQ1UTYyOSA0NTEgNjM1IDQ5MFQ2NDEgNTUxUTY0MSA1ODYgNjI4IDYwNFQ1NzMgNjI5UTU2OCA2MzAgNTE1IDYzMVE0NjkgNjMxIDQ1NyA2MzBUNDM5IDYyMlE0MzggNjIxIDM2OCAzNDNUMjk4IDYwUTI5OCA0OCAzODYgNDZRNDE4IDQ2IDQyNyA0NVQ0MzYgMzZRNDM2IDMxIDQzMyAyMlE0MjkgNCA0MjQgMUw0MjIgMFE0MTkgMCA0MTUgMFE0MTAgMCAzNjMgMVQyMjggMlE5OSAyIDY0IDBINDlRNDMgNiA0MyA5VDQ1IDI3UTQ5IDQwIDU1IDQ2SDgzSDk0UTE3NCA0NiAxODkgNTVRMTkwIDU2IDE5MSA1NlExOTYgNTkgMjAxIDc2VDI0MSAyMzNRMjU4IDMwMSAyNjkgMzQ0UTMzOSA2MTkgMzM5IDYyNVEzMzkgNjMwIDMxMCA2MzBIMjc5UTIxMiA2MzAgMTkxIDYyNFExNDYgNjE0IDEyMSA1ODNUNjcgNDY3UTYwIDQ0NSA1NyA0NDFUNDMgNDM3SDQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oyLTdCIiBkPSJNNTQ3IC02NDNMNTQxIC02NDlINTI4UTUxNSAtNjQ5IDUwMyAtNjQ1UTMyNCAtNTgyIDI5MyAtNDY2UTI4OSAtNDQ5IDI4OSAtNDI4VDI4NyAtMjAwTDI4NiA0MkwyODQgNTNRMjc0IDk4IDI0OCAxMzVUMTk2IDE5MFQxNDYgMjIyTDEyMSAyMzVRMTE5IDIzOSAxMTkgMjUwUTExOSAyNjIgMTIxIDI2NlQxMzMgMjczUTI2MiAzMzYgMjg0IDQ0OUwyODYgNDYwTDI4NyA3MDFRMjg3IDczNyAyODcgNzk0UTI4OCA5NDkgMjkyIDk2M1EyOTMgOTY2IDI5MyA5NjdRMzI1IDEwODAgNTA4IDExNDhRNTE2IDExNTAgNTI3IDExNTBINTQxTDU0NyAxMTQ0VjExMzBRNTQ3IDExMTcgNTQ2IDExMTVUNTM2IDExMDlRNDgwIDEwODYgNDM3IDEwNDZUMzgxIDk1MEwzNzkgOTQwTDM3OCA2OTlRMzc4IDY1NyAzNzggNTk0UTM3NyA0NTIgMzc0IDQzOFEzNzMgNDM3IDM3MyA0MzZRMzUwIDM0OCAyNDMgMjgyUTE5MiAyNTcgMTg2IDI1NEwxNzYgMjUxTDE4OCAyNDVRMjExIDIzNiAyMzQgMjIzVDI4NyAxODlUMzQwIDEzNVQzNzMgNjVRMzczIDY0IDM3NCA2M1EzNzcgNDkgMzc4IC05M1EzNzggLTE1NiAzNzggLTE5OEwzNzkgLTQzOEwzODEgLTQ0OVEzOTMgLTUwNCA0MzYgLTU0NFQ1MzYgLTYwOFE1NDQgLTYxMSA1NDUgLTYxM1Q1NDcgLTYyOVYtNjQzWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMi03RCIgZD0iTTExOSAxMTMwUTExOSAxMTQ0IDEyMSAxMTQ3VDEzNSAxMTUwSDEzOVExNTEgMTE1MCAxODIgMTEzOFQyNTIgMTEwNVQzMjYgMTA0NlQzNzMgOTY0UTM3OCA5NDIgMzc4IDcwMlEzNzggNDY5IDM3OSA0NjJRMzg2IDM5NCA0MzkgMzM5UTQ4MiAyOTYgNTM1IDI3MlE1NDQgMjY4IDU0NSAyNjZUNTQ3IDI1MVE1NDcgMjQxIDU0NyAyMzhUNTQyIDIzMVQ1MzEgMjI3VDUxMCAyMTdUNDc3IDE5NFEzOTAgMTI5IDM3OSAzOVEzNzggMzIgMzc4IC0yMDFRMzc4IC00NDEgMzczIC00NjNRMzQyIC01ODAgMTY1IC02NDRRMTUyIC02NDkgMTM5IC02NDlRMTI1IC02NDkgMTIyIC02NDZUMTE5IC02MjlRMTE5IC02MjIgMTE5IC02MTlUMTIxIC02MTRUMTI0IC02MTBUMTMyIC02MDdUMTQzIC02MDJRMTk1IC01NzkgMjM1IC01MzlUMjg1IC00NDdRMjg2IC00MzUgMjg3IC0xOTlUMjg5IDUxUTI5NCA3NCAzMDAgOTFUMzI5IDEzOFQzOTAgMTk3UTQxMiAyMTMgNDM2IDIyNlQ0NzUgMjQ0TDQ4OSAyNTBMNDcyIDI1OFE0NTUgMjY1IDQzMCAyNzlUMzc3IDMxM1QzMjcgMzY2VDI5MyA0MzRRMjg5IDQ1MSAyODkgNDcyVDI4NyA2OTlRMjg2IDk0MSAyODUgOTQ4UTI3OSA5NzggMjYyIDEwMDVUMjI3IDEwNDhUMTg0IDEwODBUMTUxIDExMDBUMTI5IDExMDlMMTI3IDExMTBRMTE5IDExMTMgMTE5IDExMzBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTAiIGQ9Ik0yODcgNjI4UTI4NyA2MzUgMjMwIDYzN1EyMDYgNjM3IDE5OSA2MzhUMTkyIDY0OFExOTIgNjQ5IDE5NCA2NTlRMjAwIDY3OSAyMDMgNjgxVDM5NyA2ODNRNTg3IDY4MiA2MDAgNjgwUTY2NCA2NjkgNzA3IDYzMVQ3NTEgNTMwUTc1MSA0NTMgNjg1IDM4OVE2MTYgMzIxIDUwNyAzMDNRNTAwIDMwMiA0MDIgMzAxSDMwN0wyNzcgMTgyUTI0NyA2NiAyNDcgNTlRMjQ3IDU1IDI0OCA1NFQyNTUgNTBUMjcyIDQ4VDMwNSA0NkgzMzZRMzQyIDM3IDM0MiAzNVEzNDIgMTkgMzM1IDVRMzMwIDAgMzE5IDBRMzE2IDAgMjgyIDFUMTgyIDJRMTIwIDIgODcgMlQ1MSAxUTMzIDEgMzMgMTFRMzMgMTMgMzYgMjVRNDAgNDEgNDQgNDNUNjcgNDZROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFpNNjQ1IDU1NFE2NDUgNTY3IDY0MyA1NzVUNjM0IDU5N1Q2MDkgNjE5VDU2MCA2MzVRNTUzIDYzNiA0ODAgNjM3UTQ2MyA2MzcgNDQ1IDYzN1Q0MTYgNjM2VDQwNCA2MzZRMzkxIDYzNSAzODYgNjI3UTM4NCA2MjEgMzY3IDU1MFQzMzIgNDEyVDMxNCAzNDRRMzE0IDM0MiAzOTUgMzQySDQwN0g0MzBRNTQyIDM0MiA1OTAgMzkyUTYxNyA0MTkgNjMxIDQ3MVQ2NDUgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTUyIiBkPSJNMjMwIDYzN1EyMDMgNjM3IDE5OCA2MzhUMTkzIDY0OVExOTMgNjc2IDIwNCA2ODJRMjA2IDY4MyAzNzggNjgzUTU1MCA2ODIgNTY0IDY4MFE2MjAgNjcyIDY1OCA2NTJUNzEyIDYwNlQ3MzMgNTYzVDczOSA1MjlRNzM5IDQ4NCA3MTAgNDQ1VDY0MyAzODVUNTc2IDM1MVQ1MzggMzM4TDU0NSAzMzNRNjEyIDI5NSA2MTIgMjIzUTYxMiAyMTIgNjA3IDE2MlQ2MDIgODBWNzFRNjAyIDUzIDYwMyA0M1Q2MTQgMjVUNjQwIDE2UTY2OCAxNiA2ODYgMzhUNzEyIDg1UTcxNyA5OSA3MjAgMTAyVDczNSAxMDVRNzU1IDEwNSA3NTUgOTNRNzU1IDc1IDczMSAzNlE2OTMgLTIxIDY0MSAtMjFINjMyUTU3MSAtMjEgNTMxIDRUNDg3IDgyUTQ4NyAxMDkgNTAyIDE2NlQ1MTcgMjM5UTUxNyAyOTAgNDc0IDMxM1E0NTkgMzIwIDQ0OSAzMjFUMzc4IDMyM0gzMDlMMjc3IDE5M1EyNDQgNjEgMjQ0IDU5UTI0NCA1NSAyNDUgNTRUMjUyIDUwVDI2OSA0OFQzMDIgNDZIMzMzUTMzOSAzOCAzMzkgMzdUMzM2IDE5UTMzMiA2IDMyNiAwSDMxMVEyNzUgMiAxODAgMlExNDYgMiAxMTcgMlQ3MSAyVDUwIDFRMzMgMSAzMyAxMFEzMyAxMiAzNiAyNFE0MSA0MyA0NiA0NVE1MCA0NiA2MSA0Nkg2N1E5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4UTI4NyA2MzUgMjMwIDYzN1pNNjMwIDU1NFE2MzAgNTg2IDYwOSA2MDhUNTIzIDYzNlE1MjEgNjM2IDUwMCA2MzZUNDYyIDYzN0g0NDBRMzkzIDYzNyAzODYgNjI3UTM4NSA2MjQgMzUyIDQ5NFQzMTkgMzYxUTMxOSAzNjAgMzg4IDM2MFE0NjYgMzYxIDQ5MiAzNjdRNTU2IDM3NyA1OTIgNDI2UTYwOCA0NDkgNjE5IDQ4NlQ2MzAgNTU0WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzEiIGQ9Ik0yMTMgNTc4TDIwMCA1NzNRMTg2IDU2OCAxNjAgNTYzVDEwMiA1NTZIODNWNjAySDEwMlExNDkgNjA0IDE4OSA2MTdUMjQ1IDY0MVQyNzMgNjYzUTI3NSA2NjYgMjg1IDY2NlEyOTQgNjY2IDMwMiA2NjBWMzYxTDMwMyA2MVEzMTAgNTQgMzE1IDUyVDMzOSA0OFQ0MDEgNDZINDI3VjBINDE2UTM5NSAzIDI1NyAzUTEyMSAzIDEwMCAwSDg4VjQ2SDExNFExMzYgNDYgMTUyIDQ2VDE3NyA0N1QxOTMgNTBUMjAxIDUyVDIwNyA1N1QyMTMgNjFWNTc4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzYiIGQ9Ik00MiAzMTNRNDIgNDc2IDEyMyA1NzFUMzAzIDY2NlEzNzIgNjY2IDQwMiA2MzBUNDMyIDU1MFE0MzIgNTI1IDQxOCA1MTBUMzc5IDQ5NVEzNTYgNDk1IDM0MSA1MDlUMzI2IDU0OFEzMjYgNTkyIDM3MyA2MDFRMzUxIDYyMyAzMTEgNjI2UTI0MCA2MjYgMTk0IDU2NlExNDcgNTAwIDE0NyAzNjRMMTQ4IDM2MFExNTMgMzY2IDE1NiAzNzNRMTk3IDQzMyAyNjMgNDMzSDI2N1EzMTMgNDMzIDM0OCA0MTRRMzcyIDQwMCAzOTYgMzc0VDQzNSAzMTdRNDU2IDI2OCA0NTYgMjEwVjE5MlE0NTYgMTY5IDQ1MSAxNDlRNDQwIDkwIDM4NyAzNFQyNTMgLTIyUTIyNSAtMjIgMTk5IC0xNFQxNDMgMTZUOTIgNzVUNTYgMTcyVDQyIDMxM1pNMjU3IDM5N1EyMjcgMzk3IDIwNSAzODBUMTcxIDMzNVQxNTQgMjc4VDE0OCAyMTZRMTQ4IDEzMyAxNjAgOTdUMTk4IDM5UTIyMiAyMSAyNTEgMjFRMzAyIDIxIDMyOSA1OVEzNDIgNzcgMzQ3IDEwNFQzNTIgMjA5UTM1MiAyODkgMzQ3IDMxNlQzMjkgMzYxUTMwMiAzOTcgMjU3IDM5N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjMtMjgiIGQ9Ik03MDEgLTk0MFE3MDEgLTk0MyA2OTUgLTk0OUg2NjRRNjYyIC05NDcgNjM2IC05MjJUNTkxIC04NzlUNTM3IC04MThUNDc1IC03MzdUNDEyIC02MzZUMzUwIC01MTFUMjk1IC0zNjJUMjUwIC0xODZUMjIxIDE3VDIwOSAyNTFRMjA5IDk2MiA1NzMgMTM2MVE1OTYgMTM4NiA2MTYgMTQwNVQ2NDkgMTQzN1Q2NjQgMTQ1MEg2OTVRNzAxIDE0NDQgNzAxIDE0NDFRNzAxIDE0MzYgNjgxIDE0MTVUNjI5IDEzNTZUNTU3IDEyNjFUNDc2IDExMThUNDAwIDkyN1QzNDAgNjc1VDMwOCAzNTlRMzA2IDMyMSAzMDYgMjUwUTMwNiAtMTM5IDQwMCAtNDMwVDY5MCAtOTI0UTcwMSAtOTM2IDcwMSAtOTQwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMy0yOSIgZD0iTTM0IDE0MzhRMzQgMTQ0NiAzNyAxNDQ4VDUwIDE0NTBINTZINzFRNzMgMTQ0OCA5OSAxNDIzVDE0NCAxMzgwVDE5OCAxMzE5VDI2MCAxMjM4VDMyMyAxMTM3VDM4NSAxMDEzVDQ0MCA4NjRUNDg1IDY4OFQ1MTQgNDg1VDUyNiAyNTFRNTI2IDEzNCA1MTkgNTNRNDcyIC01MTkgMTYyIC04NjBRMTM5IC04ODUgMTE5IC05MDRUODYgLTkzNlQ3MSAtOTQ5SDU2UTQzIC05NDkgMzkgLTk0N1QzNCAtOTM3UTg4IC04ODMgMTQwIC04MTNRNDI4IC00MzAgNDI4IDI1MVE0MjggNDUzIDQwMiA2MjhUMzM4IDkyMlQyNDUgMTE0NlQxNDUgMTMwOVQ0NiAxNDI1UTQ0IDE0MjcgNDIgMTQyOVQzOSAxNDMzVDM2IDE0MzZMMzQgMTQzOFoiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjcsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgtMTEsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDg3NzQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNDUiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5MzEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItN0IiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2NjcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTM4IiB4PSI3NzgiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMTI3OSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIyMTUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzYzMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTRCIiB4PSIyNCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI2LDUwMCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiIgeD0iLTcwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTgyLjMwNjE2MDY3NjM3NjI3LDApIHNjYWxlKDEuNDg0NjA2NTQ3NzMwOTM2MywxKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiIgeD0iODI3IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjEzNjQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUxMTksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMjQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3OCw0OTQpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiIHg9Ii03MCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIxNy45MjI1MDQxNjY2ODEsMCkgc2NhbGUoMC43NTk4NzEwNjU2MjgzODA2LDEpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSI1NjUiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTE3NiIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItN0QiIHg9IjcxNDQiIHk9Ii0xIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODczMiwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsODc3NCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIyNzciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjEzMzQiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTM4IiB4PSIyMTEyIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjI2MTMiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNTQ5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ3OTcsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyODYsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSI0MTU2IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxNzk3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjc5NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExMDkiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEyIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0NTcsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTM2MCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMDc3NCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDExNzc0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzgiIHg9Ijc3OCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIxMjc5IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjIxNSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjM4NTMiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2MTg0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE3NzA4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMjk2IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMjI5NyIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMzE4NyIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIyMTUwNyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIyNTA4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzgiIHg9Ijc3OCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIxMjc5IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjIxNSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjM4NTMiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIyNjkxNyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI3ODUzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCw2MjU5KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMTMzNCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzgiIHg9IjIxMTIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMjYxMyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM1NDksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDc5NywwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI4NiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEzNjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDMsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDY1NjUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjcyMiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE3MjMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjMxODciIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwMzA4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMTE3MjIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTM4IiB4PSIxMjcyMyIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIxMzIyMyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0MTU5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE1NTc0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2OTMyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIxODIyOSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzgiIHg9IjE5MjI5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjE5NzMwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjA2NjYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjIwODEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMjM2NjEiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTM4IiB4PSIyNDY2MiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI1MTYyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTE2NyIgeT0iNTgzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNjYwOCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsMzYxMikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIyNzciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjEzMzQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMTEyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzYiIHg9IjUwMCIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjMxMTMiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0MDQ5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUyOTgsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyODYsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMzYwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQzLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MDY1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iODQ3OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzgiIHg9Ijk0NzkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iOTk4MCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwOTE2LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMTY1LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjg2LDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTM2MCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYxLDY3NikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTM5MzIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDE1NzMpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIyMjIiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTM4IiB4PSIxMjIyIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjE3MjMiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNjU5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQwNzQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTQzMiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iNjcyOSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzgiIHg9Ijc3MjkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iODIzMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkxNjYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTA1ODEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTIxNjEiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTM4IiB4PSIxMzE2MiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzNjYyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTE2NyIgeT0iNTgzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNTEwOCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTQ3MikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIyNzciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjEzMzQiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTM4IiB4PSIyMTEyIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjI2MTMiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNTQ5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ5NjQsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjMtMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MzYsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMzYwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQzLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTYwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIzMDE0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzc5MiwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEzNjAiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDMsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU2MTUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNzAyOSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDc4MDcsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMzYwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjEsNjc2KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExMDkiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEyIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5NjMwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjExMDQ0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwNDUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTM0MDIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxNDY5OSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE1NzAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMTcyODAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMTgyODAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxOTIxNywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMy0yOSIgeD0iMjEyMDIiIHk9Ii0xIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTMxNzMpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjc3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIxMzM0IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zOCIgeD0iMjExMiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIyNjEzIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzU0OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0OTY0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1ozLTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzM2LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTM2MCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0Myw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMzAxNCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM3OTIsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMzYwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQzLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1NjE1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDY5NzMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjcyMiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE3MjMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjMxODciIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEwNzczIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTE3NzMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTMyOTgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjcyMiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE3MjMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjMxODciIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMTcwOTciIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMTgwOTciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxOTAzNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMy0yOSIgeD0iMjEwMTkiIHk9Ii0xIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTU4NzQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjc3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIxMzM0IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zOCIgeD0iMjExMiIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIyNjEzIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzU0OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0OTY0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1ozLTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzM2LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTM2MCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0Myw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMzAxNCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQwMTUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjcyMiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE3MjMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjMxODciIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDc3NTgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjMtMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MzYsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMzYwIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQzLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTYwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIzMDE0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDAxNSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMy0yOSIgeD0iNjEwOSIgeT0iLTEiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMTQ4MjYiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMTU4MjciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjc2MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMy0yOSIgeD0iMTg3NDgiIHk9Ii0xIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTg2MTgpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjc3IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIxMzM0IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zOCIgeD0iMjExMiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI2MTMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTY3IiB5PSI1ODMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQwNTgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTQ3NCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iNjc3MCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDc1NDksMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxODU4IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsNjc2KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzMDksLTgzNykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTQ0NiI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDk4NzAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMDc0IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMTEzMDUiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjA4NCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjE2OTQiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjI3LC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0MjQxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE1NDMzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjEwNzQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9zdmc+)
由fact 8得到,
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjI5LjkzMmV4IiBoZWlnaHQ9IjQuODQzZXgiIHN0eWxlPSJmb250LXNpemU6IDE1cHg7IHZlcnRpY2FsLWFsaWduOiAtMS44MzhleDsiIHZpZXdCb3g9IjAgLTEyOTMuNyAxMjg4Ny41IDIwODUiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDUiIGQ9Ik00OTIgMjEzUTQ3MiAyMTMgNDcyIDIyNlE0NzIgMjMwIDQ3NyAyNTBUNDgyIDI4NVE0ODIgMzE2IDQ2MSAzMjNUMzY0IDMzMEgzMTJRMzExIDMyOCAyNzcgMTkyVDI0MyA1MlEyNDMgNDggMjU0IDQ4VDMzNCA0NlE0MjggNDYgNDU4IDQ4VDUxOCA2MVE1NjcgNzcgNTk5IDExN1Q2NzAgMjQ4UTY4MCAyNzAgNjgzIDI3MlE2OTAgMjc0IDY5OCAyNzRRNzE4IDI3NCA3MTggMjYxUTYxMyA3IDYwOCAyUTYwNSAwIDMyMiAwSDEzM1EzMSAwIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc1N1E3NjQgNjc2IDc2NCA2NjlRNzY0IDY2NCA3NTEgNTU3VDczNyA0NDdRNzM1IDQ0MCA3MTcgNDQwSDcwNVE2OTggNDQ1IDY5OCA0NTNMNzAxIDQ3NlE3MDQgNTAwIDcwNCA1MjhRNzA0IDU1OCA2OTcgNTc4VDY3OCA2MDlUNjQzIDYyNVQ1OTYgNjMyVDUzMiA2MzRINDg1UTM5NyA2MzMgMzkyIDYzMVEzODggNjI5IDM4NiA2MjJRMzg1IDYxOSAzNTUgNDk5VDMyNCAzNzdRMzQ3IDM3NiAzNzIgMzc2SDM5OFE0NjQgMzc2IDQ4OSAzOTFUNTM0IDQ3MlE1MzggNDg4IDU0MCA0OTBUNTU3IDQ5M1E1NjIgNDkzIDU2NSA0OTNUNTcwIDQ5MlQ1NzIgNDkxVDU3NCA0ODdUNTc3IDQ4M0w1NDQgMzUxUTUxMSAyMTggNTA4IDIxNlE1MDUgMjEzIDQ5MiAyMTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03QiIgZD0iTTQzNCAtMjMxUTQzNCAtMjQ0IDQyOCAtMjUwSDQxMFEyODEgLTI1MCAyMzAgLTE4NFEyMjUgLTE3NyAyMjIgLTE3MlQyMTcgLTE2MVQyMTMgLTE0OFQyMTEgLTEzM1QyMTAgLTExMVQyMDkgLTg0VDIwOSAtNDdUMjA5IDBRMjA5IDIxIDIwOSA1M1EyMDggMTQyIDIwNCAxNTNRMjAzIDE1NCAyMDMgMTU1UTE4OSAxOTEgMTUzIDIxMVQ4MiAyMzFRNzEgMjMxIDY4IDIzNFQ2NSAyNTBUNjggMjY2VDgyIDI2OVExMTYgMjY5IDE1MiAyODlUMjAzIDM0NVEyMDggMzU2IDIwOCAzNzdUMjA5IDUyOVY1NzlRMjA5IDYzNCAyMTUgNjU2VDI0NCA2OThRMjcwIDcyNCAzMjQgNzQwUTM2MSA3NDggMzc3IDc0OVEzNzkgNzQ5IDM5MCA3NDlUNDA4IDc1MEg0MjhRNDM0IDc0NCA0MzQgNzMyUTQzNCA3MTkgNDMxIDcxNlE0MjkgNzEzIDQxNSA3MTNRMzYyIDcxMCAzMzIgNjg5VDI5NiA2NDdRMjkxIDYzNCAyOTEgNDk5VjQxN1EyOTEgMzcwIDI4OCAzNTNUMjcxIDMxNFEyNDAgMjcxIDE4NCAyNTVMMTcwIDI1MEwxODQgMjQ1UTIwMiAyMzkgMjIwIDIzMFQyNjIgMTk2VDI5MCAxMzdRMjkxIDEzMSAyOTEgMVEyOTEgLTEzNCAyOTYgLTE0N1EzMDYgLTE3NCAzMzkgLTE5MlQ0MTUgLTIxM1E0MjkgLTIxMyA0MzEgLTIxNlE0MzQgLTIxOSA0MzQgLTIzMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTM2IiBkPSJNNDIgMzEzUTQyIDQ3NiAxMjMgNTcxVDMwMyA2NjZRMzcyIDY2NiA0MDIgNjMwVDQzMiA1NTBRNDMyIDUyNSA0MTggNTEwVDM3OSA0OTVRMzU2IDQ5NSAzNDEgNTA5VDMyNiA1NDhRMzI2IDU5MiAzNzMgNjAxUTM1MSA2MjMgMzExIDYyNlEyNDAgNjI2IDE5NCA1NjZRMTQ3IDUwMCAxNDcgMzY0TDE0OCAzNjBRMTUzIDM2NiAxNTYgMzczUTE5NyA0MzMgMjYzIDQzM0gyNjdRMzEzIDQzMyAzNDggNDE0UTM3MiA0MDAgMzk2IDM3NFQ0MzUgMzE3UTQ1NiAyNjggNDU2IDIxMFYxOTJRNDU2IDE2OSA0NTEgMTQ5UTQ0MCA5MCAzODcgMzRUMjUzIC0yMlEyMjUgLTIyIDE5OSAtMTRUMTQzIDE2VDkyIDc1VDU2IDE3MlQ0MiAzMTNaTTI1NyAzOTdRMjI3IDM5NyAyMDUgMzgwVDE3MSAzMzVUMTU0IDI3OFQxNDggMjE2UTE0OCAxMzMgMTYwIDk3VDE5OCAzOVEyMjIgMjEgMjUxIDIxUTMwMiAyMSAzMjkgNTlRMzQyIDc3IDM0NyAxMDRUMzUyIDIwOVEzNTIgMjg5IDM0NyAzMTZUMzI5IDM2MVEzMDIgMzk3IDI1NyAzOTdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTYiIGQ9Ik01MiA2NDhRNTIgNjcwIDY1IDY4M0g3NlExMTggNjgwIDE4MSA2ODBRMjk5IDY4MCAzMjAgNjgzSDMzMFEzMzYgNjc3IDMzNiA2NzRUMzM0IDY1NlEzMjkgNjQxIDMyNSA2MzdIMzA0UTI4MiA2MzUgMjc0IDYzNVEyNDUgNjMwIDI0MiA2MjBRMjQyIDYxOCAyNzEgMzY5VDMwMSAxMThMMzc0IDIzNVE0NDcgMzUyIDUyMCA0NzFUNTk1IDU5NFE1OTkgNjAxIDU5OSA2MDlRNTk5IDYzMyA1NTUgNjM3UTUzNyA2MzcgNTM3IDY0OFE1MzcgNjQ5IDUzOSA2NjFRNTQyIDY3NSA1NDUgNjc5VDU1OCA2ODNRNTYwIDY4MyA1NzAgNjgzVDYwNCA2ODJUNjY4IDY4MVE3MzcgNjgxIDc1NSA2ODNINzYyUTc2OSA2NzYgNzY5IDY3MlE3NjkgNjU1IDc2MCA2NDBRNzU3IDYzNyA3NDMgNjM3UTczMCA2MzYgNzE5IDYzNVQ2OTggNjMwVDY4MiA2MjNUNjcwIDYxNVQ2NjAgNjA4VDY1MiA1OTlUNjQ1IDU5Mkw0NTIgMjgyUTI3MiAtOSAyNjYgLTE2UTI2MyAtMTggMjU5IC0yMUwyNDEgLTIySDIzNFEyMTYgLTIyIDIxNiAtMTVRMjEzIC05IDE3NyAzMDVRMTM5IDYyMyAxMzggNjI2UTEzMyA2MzcgNzYgNjM3SDU5UTUyIDY0MiA1MiA2NDhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zMiIgZD0iTTEwOSA0MjlRODIgNDI5IDY2IDQ0N1Q1MCA0OTFRNTAgNTYyIDEwMyA2MTRUMjM1IDY2NlEzMjYgNjY2IDM4NyA2MTBUNDQ5IDQ2NVE0NDkgNDIyIDQyOSAzODNUMzgxIDMxNVQzMDEgMjQxUTI2NSAyMTAgMjAxIDE0OUwxNDIgOTNMMjE4IDkyUTM3NSA5MiAzODUgOTdRMzkyIDk5IDQwOSAxODZWMTg5SDQ0OVYxODZRNDQ4IDE4MyA0MzYgOTVUNDIxIDNWMEg1MFYxOVYzMVE1MCAzOCA1NiA0NlQ4NiA4MVExMTUgMTEzIDEzNiAxMzdRMTQ1IDE0NyAxNzAgMTc0VDIwNCAyMTFUMjMzIDI0NFQyNjEgMjc4VDI4NCAzMDhUMzA1IDM0MFQzMjAgMzY5VDMzMyA0MDFUMzQwIDQzMVQzNDMgNDY0UTM0MyA1MjcgMzA5IDU3M1QyMTIgNjE5UTE3OSA2MTkgMTU0IDYwMlQxMTkgNTY5VDEwOSA1NTBRMTA5IDU0OSAxMTQgNTQ5UTEzMiA1NDkgMTUxIDUzNVQxNzAgNDg5UTE3MCA0NjQgMTU0IDQ0N1QxMDkgNDI5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMjgiIGQ9Ik05NCAyNTBROTQgMzE5IDEwNCAzODFUMTI3IDQ4OFQxNjQgNTc2VDIwMiA2NDNUMjQ0IDY5NVQyNzcgNzI5VDMwMiA3NTBIMzE1SDMxOVEzMzMgNzUwIDMzMyA3NDFRMzMzIDczOCAzMTYgNzIwVDI3NSA2NjdUMjI2IDU4MVQxODQgNDQzVDE2NyAyNTBUMTg0IDU4VDIyNSAtODFUMjc0IC0xNjdUMzE2IC0yMjBUMzMzIC0yNDFRMzMzIC0yNTAgMzE4IC0yNTBIMzE1SDMwMkwyNzQgLTIyNlExODAgLTE0MSAxMzcgLTE0VDk0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI5IiBkPSJNNjAgNzQ5TDY0IDc1MFE2OSA3NTAgNzQgNzUwSDg2TDExNCA3MjZRMjA4IDY0MSAyNTEgNTE0VDI5NCAyNTBRMjk0IDE4MiAyODQgMTE5VDI2MSAxMlQyMjQgLTc2VDE4NiAtMTQzVDE0NSAtMTk0VDExMyAtMjI3VDkwIC0yNDZRODcgLTI0OSA4NiAtMjUwSDc0UTY2IC0yNTAgNjMgLTI1MFQ1OCAtMjQ3VDU1IC0yMzhRNTYgLTIzNyA2NiAtMjI1UTIyMSAtNjQgMjIxIDI1MFQ2NiA3MjVRNTYgNzM3IDU1IDczOFE1NSA3NDYgNjAgNzQ5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTRCIiBkPSJNMjg1IDYyOFEyODUgNjM1IDIyOCA2MzdRMjA1IDYzNyAxOTggNjM4VDE5MSA2NDdRMTkxIDY0OSAxOTMgNjYxUTE5OSA2ODEgMjAzIDY4MlEyMDUgNjgzIDIxNCA2ODNIMjE5UTI2MCA2ODEgMzU1IDY4MVEzODkgNjgxIDQxOCA2ODFUNDYzIDY4MlQ0ODMgNjgyUTUwMCA2ODIgNTAwIDY3NFE1MDAgNjY5IDQ5NyA2NjBRNDk2IDY1OCA0OTYgNjU0VDQ5NSA2NDhUNDkzIDY0NFQ0OTAgNjQxVDQ4NiA2MzlUNDc5IDYzOFQ0NzAgNjM3VDQ1NiA2MzdRNDE2IDYzNiA0MDUgNjM0VDM4NyA2MjNMMzA2IDMwNVEzMDcgMzA1IDQ5MCA0NDlUNjc4IDU5N1E2OTIgNjExIDY5MiA2MjBRNjkyIDYzNSA2NjcgNjM3UTY1MSA2MzcgNjUxIDY0OFE2NTEgNjUwIDY1NCA2NjJUNjU5IDY3N1E2NjIgNjgyIDY3NiA2ODJRNjgwIDY4MiA3MTEgNjgxVDc5MSA2ODBRODE0IDY4MCA4MzkgNjgxVDg2OSA2ODJRODg5IDY4MiA4ODkgNjcyUTg4OSA2NTAgODgxIDY0MlE4NzggNjM3IDg2MiA2MzdRNzg3IDYzMiA3MjYgNTg2UTcxMCA1NzYgNjU2IDUzNFQ1NTYgNDU1TDUwOSA0MThMNTE4IDM5NlE1MjcgMzc0IDU0NiAzMjlUNTgxIDI0NFE2NTYgNjcgNjYxIDYxUTY2MyA1OSA2NjYgNTdRNjgwIDQ3IDcxNyA0Nkg3MzhRNzQ0IDM4IDc0NCAzN1Q3NDEgMTlRNzM3IDYgNzMxIDBINzIwUTY4MCAzIDYyNSAzUTUwMyAzIDQ4OCAwSDQ3OFE0NzIgNiA0NzIgOVQ0NzQgMjdRNDc4IDQwIDQ4MCA0M1Q0OTEgNDZINDk0UTU0NCA0NiA1NDQgNzFRNTQ0IDc1IDUxNyAxNDFUNDg1IDIxNkw0MjcgMzU0TDM1OSAzMDFMMjkxIDI0OEwyNjggMTU1UTI0NSA2MyAyNDUgNThRMjQ1IDUxIDI1MyA0OVQzMDMgNDZIMzM0UTM0MCAzNyAzNDAgMzVRMzQwIDE5IDMzMyA1UTMyOCAwIDMxNyAwUTMxNCAwIDI4MCAxVDE4MCAyUTExOCAyIDg1IDJUNDkgMVEzMSAxIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NyA2NSAyMTYgMzM5VDI4NSA2MjhaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi1BRiIgZD0iTTY5IDU0NFY1OTBINDMwVjU0NEg2OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS02RSIgZD0iTTIxIDI4N1EyMiAyOTMgMjQgMzAzVDM2IDM0MVQ1NiAzODhUODkgNDI1VDEzNSA0NDJRMTcxIDQ0MiAxOTUgNDI0VDIyNSAzOTBUMjMxIDM2OVEyMzEgMzY3IDIzMiAzNjdMMjQzIDM3OFEzMDQgNDQyIDM4MiA0NDJRNDM2IDQ0MiA0NjkgNDE1VDUwMyAzMzZUNDY1IDE3OVQ0MjcgNTJRNDI3IDI2IDQ0NCAyNlE0NTAgMjYgNDUzIDI3UTQ4MiAzMiA1MDUgNjVUNTQwIDE0NVE1NDIgMTUzIDU2MCAxNTNRNTgwIDE1MyA1ODAgMTQ1UTU4MCAxNDQgNTc2IDEzMFE1NjggMTAxIDU1NCA3M1Q1MDggMTdUNDM5IC0xMFEzOTIgLTEwIDM3MSAxN1QzNTAgNzNRMzUwIDkyIDM4NiAxOTNUNDIzIDM0NVE0MjMgNDA0IDM3OSA0MDRIMzc0UTI4OCA0MDQgMjI5IDMwM0wyMjIgMjkxTDE4OSAxNTdRMTU2IDI2IDE1MSAxNlExMzggLTExIDEwOCAtMTFROTUgLTExIDg3IC01VDc2IDdUNzQgMTdRNzQgMzAgMTEyIDE4MFQxNTIgMzQzUTE1MyAzNDggMTUzIDM2NlExNTMgNDA1IDEyOSA0MDVROTEgNDA1IDY2IDMwNVE2MCAyODUgNjAgMjg0UTU4IDI3OCA0MSAyNzhIMjdRMjEgMjg0IDIxIDI4N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdEIiBkPSJNNjUgNzMxUTY1IDc0NSA2OCA3NDdUODggNzUwUTE3MSA3NTAgMjE2IDcyNVQyNzkgNjcwUTI4OCA2NDkgMjg5IDYzNVQyOTEgNTAxUTI5MiAzNjIgMjkzIDM1N1EzMDYgMzEyIDM0NSAyOTFUNDE3IDI2OVE0MjggMjY5IDQzMSAyNjZUNDM0IDI1MFQ0MzEgMjM0VDQxNyAyMzFRMzgwIDIzMSAzNDUgMjEwVDI5OCAxNTdRMjkzIDE0MyAyOTIgMTIxVDI5MSAtMjhWLTc5UTI5MSAtMTM0IDI4NSAtMTU2VDI1NiAtMTk4UTIwMiAtMjUwIDg5IC0yNTBRNzEgLTI1MCA2OCAtMjQ3VDY1IC0yMzBRNjUgLTIyNCA2NSAtMjIzVDY2IC0yMThUNjkgLTIxNFQ3NyAtMjEzUTkxIC0yMTMgMTA4IC0yMTBUMTQ2IC0yMDBUMTgzIC0xNzdUMjA3IC0xMzlRMjA4IC0xMzQgMjA5IDNMMjEwIDEzOVEyMjMgMTk2IDI4MCAyMzBRMzE1IDI0NyAzMzAgMjUwUTMwNSAyNTcgMjgwIDI3MFEyMjUgMzA0IDIxMiAzNTJMMjEwIDM2MkwyMDkgNDk4UTIwOCA2MzUgMjA3IDY0MFExOTUgNjgwIDE1NCA2OTZUNzcgNzEzUTY4IDcxMyA2NyA3MTZUNjUgNzMxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMi03QiIgZD0iTTU0NyAtNjQzTDU0MSAtNjQ5SDUyOFE1MTUgLTY0OSA1MDMgLTY0NVEzMjQgLTU4MiAyOTMgLTQ2NlEyODkgLTQ0OSAyODkgLTQyOFQyODcgLTIwMEwyODYgNDJMMjg0IDUzUTI3NCA5OCAyNDggMTM1VDE5NiAxOTBUMTQ2IDIyMkwxMjEgMjM1UTExOSAyMzkgMTE5IDI1MFExMTkgMjYyIDEyMSAyNjZUMTMzIDI3M1EyNjIgMzM2IDI4NCA0NDlMMjg2IDQ2MEwyODcgNzAxUTI4NyA3MzcgMjg3IDc5NFEyODggOTQ5IDI5MiA5NjNRMjkzIDk2NiAyOTMgOTY3UTMyNSAxMDgwIDUwOCAxMTQ4UTUxNiAxMTUwIDUyNyAxMTUwSDU0MUw1NDcgMTE0NFYxMTMwUTU0NyAxMTE3IDU0NiAxMTE1VDUzNiAxMTA5UTQ4MCAxMDg2IDQzNyAxMDQ2VDM4MSA5NTBMMzc5IDk0MEwzNzggNjk5UTM3OCA2NTcgMzc4IDU5NFEzNzcgNDUyIDM3NCA0MzhRMzczIDQzNyAzNzMgNDM2UTM1MCAzNDggMjQzIDI4MlExOTIgMjU3IDE4NiAyNTRMMTc2IDI1MUwxODggMjQ1UTIxMSAyMzYgMjM0IDIyM1QyODcgMTg5VDM0MCAxMzVUMzczIDY1UTM3MyA2NCAzNzQgNjNRMzc3IDQ5IDM3OCAtOTNRMzc4IC0xNTYgMzc4IC0xOThMMzc5IC00MzhMMzgxIC00NDlRMzkzIC01MDQgNDM2IC01NDRUNTM2IC02MDhRNTQ0IC02MTEgNTQ1IC02MTNUNTQ3IC02MjlWLTY0M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItN0QiIGQ9Ik0xMTkgMTEzMFExMTkgMTE0NCAxMjEgMTE0N1QxMzUgMTE1MEgxMzlRMTUxIDExNTAgMTgyIDExMzhUMjUyIDExMDVUMzI2IDEwNDZUMzczIDk2NFEzNzggOTQyIDM3OCA3MDJRMzc4IDQ2OSAzNzkgNDYyUTM4NiAzOTQgNDM5IDMzOVE0ODIgMjk2IDUzNSAyNzJRNTQ0IDI2OCA1NDUgMjY2VDU0NyAyNTFRNTQ3IDI0MSA1NDcgMjM4VDU0MiAyMzFUNTMxIDIyN1Q1MTAgMjE3VDQ3NyAxOTRRMzkwIDEyOSAzNzkgMzlRMzc4IDMyIDM3OCAtMjAxUTM3OCAtNDQxIDM3MyAtNDYzUTM0MiAtNTgwIDE2NSAtNjQ0UTE1MiAtNjQ5IDEzOSAtNjQ5UTEyNSAtNjQ5IDEyMiAtNjQ2VDExOSAtNjI5UTExOSAtNjIyIDExOSAtNjE5VDEyMSAtNjE0VDEyNCAtNjEwVDEzMiAtNjA3VDE0MyAtNjAyUTE5NSAtNTc5IDIzNSAtNTM5VDI4NSAtNDQ3UTI4NiAtNDM1IDI4NyAtMTk5VDI4OSA1MVEyOTQgNzQgMzAwIDkxVDMyOSAxMzhUMzkwIDE5N1E0MTIgMjEzIDQzNiAyMjZUNDc1IDI0NEw0ODkgMjUwTDQ3MiAyNThRNDU1IDI2NSA0MzAgMjc5VDM3NyAzMTNUMzI3IDM2NlQyOTMgNDM0UTI4OSA0NTEgMjg5IDQ3MlQyODcgNjk5UTI4NiA5NDEgMjg1IDk0OFEyNzkgOTc4IDI2MiAxMDA1VDIyNyAxMDQ4VDE4NCAxMDgwVDE1MSAxMTAwVDEyOSAxMTA5TDEyNyAxMTEwUTExOSAxMTEzIDExOSAxMTMwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tM0QiIGQ9Ik01NiAzNDdRNTYgMzYwIDcwIDM2N0g3MDdRNzIyIDM1OSA3MjIgMzQ3UTcyMiAzMzYgNzA4IDMyOEwzOTAgMzI3SDcyUTU2IDMzMiA1NiAzNDdaTTU2IDE1M1E1NiAxNjggNzIgMTczSDcwOFE3MjIgMTYzIDcyMiAxNTNRNzIyIDE0MCA3MDcgMTMzSDcwUTU2IDE0MCA1NiAxNTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTAiIGQ9Ik0yODcgNjI4UTI4NyA2MzUgMjMwIDYzN1EyMDYgNjM3IDE5OSA2MzhUMTkyIDY0OFExOTIgNjQ5IDE5NCA2NTlRMjAwIDY3OSAyMDMgNjgxVDM5NyA2ODNRNTg3IDY4MiA2MDAgNjgwUTY2NCA2NjkgNzA3IDYzMVQ3NTEgNTMwUTc1MSA0NTMgNjg1IDM4OVE2MTYgMzIxIDUwNyAzMDNRNTAwIDMwMiA0MDIgMzAxSDMwN0wyNzcgMTgyUTI0NyA2NiAyNDcgNTlRMjQ3IDU1IDI0OCA1NFQyNTUgNTBUMjcyIDQ4VDMwNSA0NkgzMzZRMzQyIDM3IDM0MiAzNVEzNDIgMTkgMzM1IDVRMzMwIDAgMzE5IDBRMzE2IDAgMjgyIDFUMTgyIDJRMTIwIDIgODcgMlQ1MSAxUTMzIDEgMzMgMTFRMzMgMTMgMzYgMjVRNDAgNDEgNDQgNDNUNjcgNDZROTQgNDYgMTI3IDQ5UTE0MSA1MiAxNDYgNjFRMTQ5IDY1IDIxOCAzMzlUMjg3IDYyOFpNNjQ1IDU1NFE2NDUgNTY3IDY0MyA1NzVUNjM0IDU5N1Q2MDkgNjE5VDU2MCA2MzVRNTUzIDYzNiA0ODAgNjM3UTQ2MyA2MzcgNDQ1IDYzN1Q0MTYgNjM2VDQwNCA2MzZRMzkxIDYzNSAzODYgNjI3UTM4NCA2MjEgMzY3IDU1MFQzMzIgNDEyVDMxNCAzNDRRMzE0IDM0MiAzOTUgMzQySDQwN0g0MzBRNTQyIDM0MiA1OTAgMzkyUTYxNyA0MTkgNjMxIDQ3MVQ2NDUgNTU0WiI+PC9wYXRoPgo8L2RlZnM+CjxnIHN0cm9rZT0iY3VycmVudENvbG9yIiBmaWxsPSJjdXJyZW50Q29sb3IiIHN0cm9rZS13aWR0aD0iMCIgdHJhbnNmb3JtPSJtYXRyaXgoMSAwIDAgLTEgMCAwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTMxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTdCIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjY3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zNiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExNjciIHk9IjU4MyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTk0NiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzMzYxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNEIiIHg9IjI0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjYsNTAwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSItNzAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODIuMzA2MTYwNjc2Mzc2MjcsMCkgc2NhbGUoMS40ODQ2MDY1NDc3MzA5MzYzLDEpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSI4MjciIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMzY0IiB5PSIxMDUzIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIxMzY0IiB5PSItMzUwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi03RCIgeD0iNTUxOCIgeT0iLTEiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjczOTUiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTM2IiB4PSI4NDUxIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODk1MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExNjciIHk9IjU4MyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTAzOTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTE4MTMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+Cjwvc3ZnPg==)
因此,
![[公式]](data:image/svg+xml;base64,PHN2ZyB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgd2lkdGg9IjkwLjcxOWV4IiBoZWlnaHQ9Ijg5LjUwOWV4IiBzdHlsZT0iZm9udC1zaXplOiAxNXB4OyB2ZXJ0aWNhbC1hbGlnbjogLTQ0LjE3MWV4OyIgdmlld0JveD0iMCAtMTk1MjAuNCAzOTA1OS41IDM4NTM4LjYiIHJvbGU9ImltZyIgZm9jdXNhYmxlPSJmYWxzZSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KPGRlZnM+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNDUiIGQ9Ik00OTIgMjEzUTQ3MiAyMTMgNDcyIDIyNlE0NzIgMjMwIDQ3NyAyNTBUNDgyIDI4NVE0ODIgMzE2IDQ2MSAzMjNUMzY0IDMzMEgzMTJRMzExIDMyOCAyNzcgMTkyVDI0MyA1MlEyNDMgNDggMjU0IDQ4VDMzNCA0NlE0MjggNDYgNDU4IDQ4VDUxOCA2MVE1NjcgNzcgNTk5IDExN1Q2NzAgMjQ4UTY4MCAyNzAgNjgzIDI3MlE2OTAgMjc0IDY5OCAyNzRRNzE4IDI3NCA3MTggMjYxUTYxMyA3IDYwOCAyUTYwNSAwIDMyMiAwSDEzM1EzMSAwIDMxIDExUTMxIDEzIDM0IDI1UTM4IDQxIDQyIDQzVDY1IDQ2UTkyIDQ2IDEyNSA0OVExMzkgNTIgMTQ0IDYxUTE0NiA2NiAyMTUgMzQyVDI4NSA2MjJRMjg1IDYyOSAyODEgNjI5UTI3MyA2MzIgMjI4IDYzNEgxOTdRMTkxIDY0MCAxOTEgNjQyVDE5MyA2NTlRMTk3IDY3NiAyMDMgNjgwSDc1N1E3NjQgNjc2IDc2NCA2NjlRNzY0IDY2NCA3NTEgNTU3VDczNyA0NDdRNzM1IDQ0MCA3MTcgNDQwSDcwNVE2OTggNDQ1IDY5OCA0NTNMNzAxIDQ3NlE3MDQgNTAwIDcwNCA1MjhRNzA0IDU1OCA2OTcgNTc4VDY3OCA2MDlUNjQzIDYyNVQ1OTYgNjMyVDUzMiA2MzRINDg1UTM5NyA2MzMgMzkyIDYzMVEzODggNjI5IDM4NiA2MjJRMzg1IDYxOSAzNTUgNDk5VDMyNCAzNzdRMzQ3IDM3NiAzNzIgMzc2SDM5OFE0NjQgMzc2IDQ4OSAzOTFUNTM0IDQ3MlE1MzggNDg4IDU0MCA0OTBUNTU3IDQ5M1E1NjIgNDkzIDU2NSA0OTNUNTcwIDQ5MlQ1NzIgNDkxVDU3NCA0ODdUNTc3IDQ4M0w1NDQgMzUxUTUxMSAyMTggNTA4IDIxNlE1MDUgMjEzIDQ5MiAyMTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03QiIgZD0iTTQzNCAtMjMxUTQzNCAtMjQ0IDQyOCAtMjUwSDQxMFEyODEgLTI1MCAyMzAgLTE4NFEyMjUgLTE3NyAyMjIgLTE3MlQyMTcgLTE2MVQyMTMgLTE0OFQyMTEgLTEzM1QyMTAgLTExMVQyMDkgLTg0VDIwOSAtNDdUMjA5IDBRMjA5IDIxIDIwOSA1M1EyMDggMTQyIDIwNCAxNTNRMjAzIDE1NCAyMDMgMTU1UTE4OSAxOTEgMTUzIDIxMVQ4MiAyMzFRNzEgMjMxIDY4IDIzNFQ2NSAyNTBUNjggMjY2VDgyIDI2OVExMTYgMjY5IDE1MiAyODlUMjAzIDM0NVEyMDggMzU2IDIwOCAzNzdUMjA5IDUyOVY1NzlRMjA5IDYzNCAyMTUgNjU2VDI0NCA2OThRMjcwIDcyNCAzMjQgNzQwUTM2MSA3NDggMzc3IDc0OVEzNzkgNzQ5IDM5MCA3NDlUNDA4IDc1MEg0MjhRNDM0IDc0NCA0MzQgNzMyUTQzNCA3MTkgNDMxIDcxNlE0MjkgNzEzIDQxNSA3MTNRMzYyIDcxMCAzMzIgNjg5VDI5NiA2NDdRMjkxIDYzNCAyOTEgNDk5VjQxN1EyOTEgMzcwIDI4OCAzNTNUMjcxIDMxNFEyNDAgMjcxIDE4NCAyNTVMMTcwIDI1MEwxODQgMjQ1UTIwMiAyMzkgMjIwIDIzMFQyNjIgMTk2VDI5MCAxMzdRMjkxIDEzMSAyOTEgMVEyOTEgLTEzNCAyOTYgLTE0N1EzMDYgLTE3NCAzMzkgLTE5MlQ0MTUgLTIxM1E0MjkgLTIxMyA0MzEgLTIxNlE0MzQgLTIxOSA0MzQgLTIzMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMxIiBkPSJNMjEzIDU3OEwyMDAgNTczUTE4NiA1NjggMTYwIDU2M1QxMDIgNTU2SDgzVjYwMkgxMDJRMTQ5IDYwNCAxODkgNjE3VDI0NSA2NDFUMjczIDY2M1EyNzUgNjY2IDI4NSA2NjZRMjk0IDY2NiAzMDIgNjYwVjM2MUwzMDMgNjFRMzEwIDU0IDMxNSA1MlQzMzkgNDhUNDAxIDQ2SDQyN1YwSDQxNlEzOTUgMyAyNTcgM1ExMjEgMyAxMDAgMEg4OFY0NkgxMTRRMTM2IDQ2IDE1MiA0NlQxNzcgNDdUMTkzIDUwVDIwMSA1MlQyMDcgNTdUMjEzIDYxVjU3OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMyIiBkPSJNMTA5IDQyOVE4MiA0MjkgNjYgNDQ3VDUwIDQ5MVE1MCA1NjIgMTAzIDYxNFQyMzUgNjY2UTMyNiA2NjYgMzg3IDYxMFQ0NDkgNDY1UTQ0OSA0MjIgNDI5IDM4M1QzODEgMzE1VDMwMSAyNDFRMjY1IDIxMCAyMDEgMTQ5TDE0MiA5M0wyMTggOTJRMzc1IDkyIDM4NSA5N1EzOTIgOTkgNDA5IDE4NlYxODlINDQ5VjE4NlE0NDggMTgzIDQzNiA5NVQ0MjEgM1YwSDUwVjE5VjMxUTUwIDM4IDU2IDQ2VDg2IDgxUTExNSAxMTMgMTM2IDEzN1ExNDUgMTQ3IDE3MCAxNzRUMjA0IDIxMVQyMzMgMjQ0VDI2MSAyNzhUMjg0IDMwOFQzMDUgMzQwVDMyMCAzNjlUMzMzIDQwMVQzNDAgNDMxVDM0MyA0NjRRMzQzIDUyNyAzMDkgNTczVDIxMiA2MTlRMTc5IDYxOSAxNTQgNjAyVDExOSA1NjlUMTA5IDU1MFExMDkgNTQ5IDExNCA1NDlRMTMyIDU0OSAxNTEgNTM1VDE3MCA0ODlRMTcwIDQ2NCAxNTQgNDQ3VDEwOSA0MjlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNkUiIGQ9Ik0yMSAyODdRMjIgMjkzIDI0IDMwM1QzNiAzNDFUNTYgMzg4VDg5IDQyNVQxMzUgNDQyUTE3MSA0NDIgMTk1IDQyNFQyMjUgMzkwVDIzMSAzNjlRMjMxIDM2NyAyMzIgMzY3TDI0MyAzNzhRMzA0IDQ0MiAzODIgNDQyUTQzNiA0NDIgNDY5IDQxNVQ1MDMgMzM2VDQ2NSAxNzlUNDI3IDUyUTQyNyAyNiA0NDQgMjZRNDUwIDI2IDQ1MyAyN1E0ODIgMzIgNTA1IDY1VDU0MCAxNDVRNTQyIDE1MyA1NjAgMTUzUTU4MCAxNTMgNTgwIDE0NVE1ODAgMTQ0IDU3NiAxMzBRNTY4IDEwMSA1NTQgNzNUNTA4IDE3VDQzOSAtMTBRMzkyIC0xMCAzNzEgMTdUMzUwIDczUTM1MCA5MiAzODYgMTkzVDQyMyAzNDVRNDIzIDQwNCAzNzkgNDA0SDM3NFEyODggNDA0IDIyOSAzMDNMMjIyIDI5MUwxODkgMTU3UTE1NiAyNiAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExMiAxODBUMTUyIDM0M1ExNTMgMzQ4IDE1MyAzNjZRMTUzIDQwNSAxMjkgNDA1UTkxIDQwNSA2NiAzMDVRNjAgMjg1IDYwIDI4NFE1OCAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yMjAyIiBkPSJNMjAyIDUwOFExNzkgNTA4IDE2OSA1MjBUMTU4IDU0N1ExNTggNTU3IDE2NCA1NzdUMTg1IDYyNFQyMzAgNjc1VDMwMSA3MTBMMzMzIDcxNUgzNDVRMzc4IDcxNSAzODQgNzE0UTQ0NyA3MDMgNDg5IDY2MVQ1NDkgNTY4VDU2NiA0NTdRNTY2IDM2MiA1MTkgMjQwVDQwMiA1M1EzMjEgLTIyIDIyMyAtMjJRMTIzIC0yMiA3MyA1NlE0MiAxMDIgNDIgMTQ4VjE1OVE0MiAyNzYgMTI5IDM3MFQzMjIgNDY1UTM4MyA0NjUgNDE0IDQzNFQ0NTUgMzY3TDQ1OCAzNzhRNDc4IDQ2MSA0NzggNTE1UTQ3OCA2MDMgNDM3IDYzOVQzNDQgNjc2UTI2NiA2NzYgMjIzIDYxMlEyNjQgNjA2IDI2NCA1NzJRMjY0IDU0NyAyNDYgNTI4VDIwMiA1MDhaTTQzMCAzMDZRNDMwIDM3MiA0MDEgNDAwVDMzMyA0MjhRMjcwIDQyOCAyMjIgMzgyUTE5NyAzNTQgMTgzIDMyM1QxNTAgMjIxUTEzMiAxNDkgMTMyIDExNlExMzIgMjEgMjMyIDIxUTI0NCAyMSAyNTAgMjJRMzI3IDM1IDM3NCAxMTJRMzg5IDEzNyA0MDkgMTk2VDQzMCAzMDZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktM0I0IiBkPSJNMTk1IDYwOVExOTUgNjU2IDIyNyA2ODZUMzAyIDcxN1EzMTkgNzE2IDM1MSA3MDlUNDA3IDY5N1Q0MzMgNjkwUTQ1MSA2ODIgNDUxIDY2MlE0NTEgNjQ0IDQzOCA2MjhUNDAzIDYxMlEzODIgNjEyIDM0OCA2NDFUMjg4IDY3MVQyNDkgNjU3VDIzNSA2MjhRMjM1IDU4NCAzMzQgNDYzUTQwMSAzNzkgNDAxIDI5MlE0MDEgMTY5IDM0MCA4MFQyMDUgLTEwSDE5OFExMjcgLTEwIDgzIDM2VDM2IDE1M1EzNiAyODYgMTUxIDM4MlExOTEgNDEzIDI1MiA0MzRRMjUyIDQzNSAyNDUgNDQ5VDIzMCA0ODFUMjE0IDUyMVQyMDEgNTY2VDE5NSA2MDlaTTExMiAxMzBRMTEyIDgzIDEzNiA1NVQyMDQgMjdRMjMzIDI3IDI1NiA1MVQyOTEgMTExVDMwOSAxNzhUMzE2IDIzMlEzMTYgMjY3IDMwOSAyOThUMjk1IDM0NFQyNjkgNDAwTDI1OSAzOTZRMjE1IDM4MSAxODMgMzQyVDEzNyAyNTZUMTE4IDE3OVQxMTIgMTMwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTY2IiBkPSJNMTE4IC0xNjJRMTIwIC0xNjIgMTI0IC0xNjRUMTM1IC0xNjdUMTQ3IC0xNjhRMTYwIC0xNjggMTcxIC0xNTVUMTg3IC0xMjZRMTk3IC05OSAyMjEgMjdUMjY3IDI2N1QyODkgMzgyVjM4NUgyNDJRMTk1IDM4NSAxOTIgMzg3UTE4OCAzOTAgMTg4IDM5N0wxOTUgNDI1UTE5NyA0MzAgMjAzIDQzMFQyNTAgNDMxUTI5OCA0MzEgMjk4IDQzMlEyOTggNDM0IDMwNyA0ODJUMzE5IDU0MFEzNTYgNzA1IDQ2NSA3MDVRNTAyIDcwMyA1MjYgNjgzVDU1MCA2MzBRNTUwIDU5NCA1MjkgNTc4VDQ4NyA1NjFRNDQzIDU2MSA0NDMgNjAzUTQ0MyA2MjIgNDU0IDYzNlQ0NzggNjU3TDQ4NyA2NjJRNDcxIDY2OCA0NTcgNjY4UTQ0NSA2NjggNDM0IDY1OFQ0MTkgNjMwUTQxMiA2MDEgNDAzIDU1MlQzODcgNDY5VDM4MCA0MzNRMzgwIDQzMSA0MzUgNDMxUTQ4MCA0MzEgNDg3IDQzMFQ0OTggNDI0UTQ5OSA0MjAgNDk2IDQwN1Q0OTEgMzkxUTQ4OSAzODYgNDgyIDM4NlQ0MjggMzg1SDM3MkwzNDkgMjYzUTMwMSAxNSAyODIgLTQ3UTI1NSAtMTMyIDIxMiAtMTczUTE3NSAtMjA1IDEzOSAtMjA1UTEwNyAtMjA1IDgxIC0xODZUNTUgLTEzMlE1NSAtOTUgNzYgLTc4VDExOCAtNjFRMTYyIC02MSAxNjIgLTEwM1ExNjIgLTEyMiAxNTEgLTEzNlQxMjcgLTE1N0wxMTggLTE2MloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTI4IiBkPSJNOTQgMjUwUTk0IDMxOSAxMDQgMzgxVDEyNyA0ODhUMTY0IDU3NlQyMDIgNjQzVDI0NCA2OTVUMjc3IDcyOVQzMDIgNzUwSDMxNUgzMTlRMzMzIDc1MCAzMzMgNzQxUTMzMyA3MzggMzE2IDcyMFQyNzUgNjY3VDIyNiA1ODFUMTg0IDQ0M1QxNjcgMjUwVDE4NCA1OFQyMjUgLTgxVDI3NCAtMTY3VDMxNiAtMjIwVDMzMyAtMjQxUTMzMyAtMjUwIDMxOCAtMjUwSDMxNUgzMDJMMjc0IC0yMjZRMTgwIC0xNDEgMTM3IC0xNFQ5NCAyNTBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0yOSIgZD0iTTYwIDc0OUw2NCA3NTBRNjkgNzUwIDc0IDc1MEg4NkwxMTQgNzI2UTIwOCA2NDEgMjUxIDUxNFQyOTQgMjUwUTI5NCAxODIgMjg0IDExOVQyNjEgMTJUMjI0IC03NlQxODYgLTE0M1QxNDUgLTE5NFQxMTMgLTIyN1Q5MCAtMjQ2UTg3IC0yNDkgODYgLTI1MEg3NFE2NiAtMjUwIDYzIC0yNTBUNTggLTI0N1Q1NSAtMjM4UTU2IC0yMzcgNjYgLTIyNVEyMjEgLTY0IDIyMSAyNTBUNjYgNzI1UTU2IDczNyA1NSA3MzhRNTUgNzQ2IDYwIDc0OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTdDIiBkPSJNMTM5IC0yNDlIMTM3UTEyNSAtMjQ5IDExOSAtMjM1VjI1MUwxMjAgNzM3UTEzMCA3NTAgMTM5IDc1MFExNTIgNzUwIDE1OSA3MzVWLTIzNVExNTEgLTI0OSAxNDEgLTI0OUgxMzlaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zRCIgZD0iTTU2IDM0N1E1NiAzNjAgNzAgMzY3SDcwN1E3MjIgMzU5IDcyMiAzNDdRNzIyIDMzNiA3MDggMzI4TDM5MCAzMjdINzJRNTYgMzMyIDU2IDM0N1pNNTYgMTUzUTU2IDE2OCA3MiAxNzNINzA4UTcyMiAxNjMgNzIyIDE1M1E3MjIgMTQwIDcwNyAxMzNINzBRNTYgMTQwIDU2IDE1M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMwIiBkPSJNOTYgNTg1UTE1MiA2NjYgMjQ5IDY2NlEyOTcgNjY2IDM0NSA2NDBUNDIzIDU0OFE0NjAgNDY1IDQ2MCAzMjBRNDYwIDE2NSA0MTcgODNRMzk3IDQxIDM2MiAxNlQzMDEgLTE1VDI1MCAtMjJRMjI0IC0yMiAxOTggLTE2VDEzNyAxNlQ4MiA4M1EzOSAxNjUgMzkgMzIwUTM5IDQ5NCA5NiA1ODVaTTMyMSA1OTdRMjkxIDYyOSAyNTAgNjI5UTIwOCA2MjkgMTc4IDU5N1ExNTMgNTcxIDE0NSA1MjVUMTM3IDMzM1ExMzcgMTc1IDE0NSAxMjVUMTgxIDQ2UTIwOSAxNiAyNTAgMTZRMjkwIDE2IDMxOCA0NlEzNDcgNzYgMzU0IDEzMFQzNjIgMzMzUTM2MiA0NzggMzU0IDUyNFQzMjEgNTk3WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tN0QiIGQ9Ik02NSA3MzFRNjUgNzQ1IDY4IDc0N1Q4OCA3NTBRMTcxIDc1MCAyMTYgNzI1VDI3OSA2NzBRMjg4IDY0OSAyODkgNjM1VDI5MSA1MDFRMjkyIDM2MiAyOTMgMzU3UTMwNiAzMTIgMzQ1IDI5MVQ0MTcgMjY5UTQyOCAyNjkgNDMxIDI2NlQ0MzQgMjUwVDQzMSAyMzRUNDE3IDIzMVEzODAgMjMxIDM0NSAyMTBUMjk4IDE1N1EyOTMgMTQzIDI5MiAxMjFUMjkxIC0yOFYtNzlRMjkxIC0xMzQgMjg1IC0xNTZUMjU2IC0xOThRMjAyIC0yNTAgODkgLTI1MFE3MSAtMjUwIDY4IC0yNDdUNjUgLTIzMFE2NSAtMjI0IDY1IC0yMjNUNjYgLTIxOFQ2OSAtMjE0VDc3IC0yMTNROTEgLTIxMyAxMDggLTIxMFQxNDYgLTIwMFQxODMgLTE3N1QyMDcgLTEzOVEyMDggLTEzNCAyMDkgM0wyMTAgMTM5UTIyMyAxOTYgMjgwIDIzMFEzMTUgMjQ3IDMzMCAyNTBRMzA1IDI1NyAyODAgMjcwUTIyNSAzMDQgMjEyIDM1MkwyMTAgMzYyTDIwOSA0OThRMjA4IDYzNSAyMDcgNjQwUTE5NSA2ODAgMTU0IDY5NlQ3NyA3MTNRNjggNzEzIDY3IDcxNlQ2NSA3MzFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1ozLTdCIiBkPSJNNjE4IC05NDNMNjEyIC05NDlINTgyTDU2OCAtOTQzUTQ3MiAtOTAzIDQxMSAtODQxVDMzMiAtNzAzUTMyNyAtNjgyIDMyNyAtNjUzVDMyNSAtMzUwUTMyNCAtMjggMzIzIC0xOFEzMTcgMjQgMzAxIDYxVDI2NCAxMjRUMjIxIDE3MVQxNzkgMjA1VDE0NyAyMjVUMTMyIDIzNFExMzAgMjM4IDEzMCAyNTBRMTMwIDI1NSAxMzAgMjU4VDEzMSAyNjRUMTMyIDI2N1QxMzQgMjY5VDEzOSAyNzJUMTQ0IDI3NVEyMDcgMzA4IDI1NiAzNjdRMzEwIDQzNiAzMjMgNTE5UTMyNCA1MjkgMzI1IDg1MVEzMjYgMTEyNCAzMjYgMTE1NFQzMzIgMTIwNVEzNjkgMTM1OCA1NjYgMTQ0M0w1ODIgMTQ1MEg2MTJMNjE4IDE0NDRWMTQyOVE2MTggMTQxMyA2MTYgMTQxMUw2MDggMTQwNlE1OTkgMTQwMiA1ODUgMTM5M1Q1NTIgMTM3MlQ1MTUgMTM0M1Q0NzkgMTMwNVQ0NDkgMTI1N1Q0MjkgMTIwMFE0MjUgMTE4MCA0MjUgMTE1MlQ0MjMgODUxUTQyMiA1NzkgNDIyIDU0OVQ0MTYgNDk4UTQwNyA0NTkgMzg4IDQyNFQzNDYgMzY0VDI5NyAzMThUMjUwIDI4NFQyMTQgMjY0VDE5NyAyNTRMMTg4IDI1MUwyMDUgMjQyUTI5MCAyMDAgMzQ1IDEzOFQ0MTYgM1E0MjEgLTE4IDQyMSAtNDhUNDIzIC0zNDlRNDIzIC0zOTcgNDIzIC00NzJRNDI0IC02NzcgNDI4IC02OTRRNDI5IC02OTcgNDI5IC02OTlRNDM0IC03MjIgNDQzIC03NDNUNDY1IC03ODJUNDkxIC04MTZUNTE5IC04NDVUNTQ4IC04NjhUNTc0IC04ODZUNTk1IC04OTlUNjEwIC05MDhMNjE2IC05MTBRNjE4IC05MTIgNjE4IC05MjhWLTk0M1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjMtN0QiIGQ9Ik0xMzEgMTQxNFQxMzEgMTQyOVQxMzMgMTQ0N1QxNDggMTQ1MEgxNTNIMTY3TDE4MiAxNDQ0UTI3NiAxNDA0IDMzNiAxMzQzVDQxNSAxMjA3UTQyMSAxMTg0IDQyMSAxMTU0VDQyMyA4NTFMNDI0IDUzMUw0MjYgNTE3UTQzNCA0NjIgNDYwIDQxNVQ1MTggMzM5VDU3MSAyOTZUNjA4IDI3NFE2MTUgMjcwIDYxNiAyNjdUNjE4IDI1MVE2MTggMjQxIDYxOCAyMzhUNjE1IDIzMlQ2MDggMjI3UTU0MiAxOTQgNDkxIDEzMlQ0MjYgLTE1TDQyNCAtMjlMNDIzIC0zNTBRNDIyIC02MjIgNDIyIC02NTJUNDE1IC03MDZRMzk3IC03ODAgMzM3IC04NDFUMTgyIC05NDNMMTY3IC05NDlIMTUzUTEzNyAtOTQ5IDEzNCAtOTQ2VDEzMSAtOTI4UTEzMSAtOTE0IDEzMiAtOTExVDE0NCAtOTA0UTE0NiAtOTAzIDE0OCAtOTAyUTI5OSAtODIwIDMyMyAtNjgwUTMyNCAtNjYzIDMyNSAtMzQ5VDMyNyAtMTlRMzU1IDE0NSA1NDEgMjQxTDU2MSAyNTBMNTQxIDI2MFEzNTYgMzU1IDMyNyA1MjBRMzI2IDUzNyAzMjUgODUwVDMyMyAxMTgxUTMxNSAxMjI3IDI5MyAxMjY3VDI0NCAxMzMyVDE5MyAxMzc0VDE1MSAxNDAxVDEzMiAxNDEzUTEzMSAxNDE0IDEzMSAxNDI5WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BVEhJLTU0IiBkPSJNNDAgNDM3UTIxIDQzNyAyMSA0NDVRMjEgNDUwIDM3IDUwMVQ3MSA2MDJMODggNjUxUTkzIDY2OSAxMDEgNjc3SDU2OUg2NTlRNjkxIDY3NyA2OTcgNjc2VDcwNCA2NjdRNzA0IDY2MSA2ODcgNTUzVDY2OCA0NDRRNjY4IDQzNyA2NDkgNDM3UTY0MCA0MzcgNjM3IDQzN1Q2MzEgNDQyTDYyOSA0NDVRNjI5IDQ1MSA2MzUgNDkwVDY0MSA1NTFRNjQxIDU4NiA2MjggNjA0VDU3MyA2MjlRNTY4IDYzMCA1MTUgNjMxUTQ2OSA2MzEgNDU3IDYzMFQ0MzkgNjIyUTQzOCA2MjEgMzY4IDM0M1QyOTggNjBRMjk4IDQ4IDM4NiA0NlE0MTggNDYgNDI3IDQ1VDQzNiAzNlE0MzYgMzEgNDMzIDIyUTQyOSA0IDQyNCAxTDQyMiAwUTQxOSAwIDQxNSAwUTQxMCAwIDM2MyAxVDIyOCAyUTk5IDIgNjQgMEg0OVE0MyA2IDQzIDlUNDUgMjdRNDkgNDAgNTUgNDZIODNIOTRRMTc0IDQ2IDE4OSA1NVExOTAgNTYgMTkxIDU2UTE5NiA1OSAyMDEgNzZUMjQxIDIzM1EyNTggMzAxIDI2OSAzNDRRMzM5IDYxOSAzMzkgNjI1UTMzOSA2MzAgMzEwIDYzMEgyNzlRMjEyIDYzMCAxOTEgNjI0UTE0NiA2MTQgMTIxIDU4M1Q2NyA0NjdRNjAgNDQ1IDU3IDQ0MVQ0MyA0MzdINDBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi1BRiIgZD0iTTY5IDU0NFY1OTBINDMwVjU0NEg2OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTIyMTIiIGQ9Ik04NCAyMzdUODQgMjUwVDk4IDI3MEg2NzlRNjk0IDI2MiA2OTQgMjUwVDY3OSAyMzBIOThRODQgMjM3IDg0IDI1MFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTM4IiBkPSJNNzAgNDE3VDcwIDQ5NFQxMjQgNjE4VDI0OCA2NjZRMzE5IDY2NiAzNzQgNjI0VDQyOSA1MTVRNDI5IDQ4NSA0MTggNDU5VDM5MiA0MTdUMzYxIDM4OVQzMzUgMzcxVDMyNCAzNjNMMzM4IDM1NFEzNTIgMzQ0IDM2NiAzMzRUMzgyIDMyM1E0NTcgMjY0IDQ1NyAxNzRRNDU3IDk1IDM5OSAzN1QyNDkgLTIyUTE1OSAtMjIgMTAxIDI5VDQzIDE1NVE0MyAyNjMgMTcyIDMzNUwxNTQgMzQ4UTEzMyAzNjEgMTI3IDM2OFE3MCA0MTcgNzAgNDk0Wk0yODYgMzg2TDI5MiAzOTBRMjk4IDM5NCAzMDEgMzk2VDMxMSA0MDNUMzIzIDQxM1QzMzQgNDI1VDM0NSA0MzhUMzU1IDQ1NFQzNjQgNDcxVDM2OSA0OTFUMzcxIDUxM1EzNzEgNTU2IDM0MiA1ODZUMjc1IDYyNFEyNjggNjI1IDI0MiA2MjVRMjAxIDYyNSAxNjUgNTk5VDEyOCA1MzRRMTI4IDUxMSAxNDEgNDkyVDE2NyA0NjNUMjE3IDQzMVEyMjQgNDI2IDIyOCA0MjRMMjg2IDM4NlpNMjUwIDIxUTMwOCAyMSAzNTAgNTVUMzkyIDEzN1EzOTIgMTU0IDM4NyAxNjlUMzc1IDE5NFQzNTMgMjE2VDMzMCAyMzRUMzAxIDI1M1QyNzQgMjcwUTI2MCAyNzkgMjQ0IDI4OVQyMTggMzA2TDIxMCAzMTFRMjA0IDMxMSAxODEgMjk0VDEzMyAyMzlUMTA3IDE1N1ExMDcgOTggMTUwIDYwVDI1MCAyMVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01NiIgZD0iTTUyIDY0OFE1MiA2NzAgNjUgNjgzSDc2UTExOCA2ODAgMTgxIDY4MFEyOTkgNjgwIDMyMCA2ODNIMzMwUTMzNiA2NzcgMzM2IDY3NFQzMzQgNjU2UTMyOSA2NDEgMzI1IDYzN0gzMDRRMjgyIDYzNSAyNzQgNjM1UTI0NSA2MzAgMjQyIDYyMFEyNDIgNjE4IDI3MSAzNjlUMzAxIDExOEwzNzQgMjM1UTQ0NyAzNTIgNTIwIDQ3MVQ1OTUgNTk0UTU5OSA2MDEgNTk5IDYwOVE1OTkgNjMzIDU1NSA2MzdRNTM3IDYzNyA1MzcgNjQ4UTUzNyA2NDkgNTM5IDY2MVE1NDIgNjc1IDU0NSA2NzlUNTU4IDY4M1E1NjAgNjgzIDU3MCA2ODNUNjA0IDY4MlQ2NjggNjgxUTczNyA2ODEgNzU1IDY4M0g3NjJRNzY5IDY3NiA3NjkgNjcyUTc2OSA2NTUgNzYwIDY0MFE3NTcgNjM3IDc0MyA2MzdRNzMwIDYzNiA3MTkgNjM1VDY5OCA2MzBUNjgyIDYyM1Q2NzAgNjE1VDY2MCA2MDhUNjUyIDU5OVQ2NDUgNTkyTDQ1MiAyODJRMjcyIC05IDI2NiAtMTZRMjYzIC0xOCAyNTkgLTIxTDI0MSAtMjJIMjM0UTIxNiAtMjIgMjE2IC0xNVEyMTMgLTkgMTc3IDMwNVExMzkgNjIzIDEzOCA2MjZRMTMzIDYzNyA3NiA2MzdINTlRNTIgNjQyIDUyIDY0OFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MyIgZD0iTTEzMSAyODlRMTMxIDMyMSAxNDcgMzU0VDIwMyA0MTVUMzAwIDQ0MlEzNjIgNDQyIDM5MCA0MTVUNDE5IDM1NVE0MTkgMzIzIDQwMiAzMDhUMzY0IDI5MlEzNTEgMjkyIDM0MCAzMDBUMzI4IDMyNlEzMjggMzQyIDMzNyAzNTRUMzU0IDM3MlQzNjcgMzc4UTM2OCAzNzggMzY4IDM3OVEzNjggMzgyIDM2MSAzODhUMzM2IDM5OVQyOTcgNDA1UTI0OSA0MDUgMjI3IDM3OVQyMDQgMzI2UTIwNCAzMDEgMjIzIDI5MVQyNzggMjc0VDMzMCAyNTlRMzk2IDIzMCAzOTYgMTYzUTM5NiAxMzUgMzg1IDEwN1QzNTIgNTFUMjg5IDdUMTk1IC0xMFExMTggLTEwIDg2IDE5VDUzIDg3UTUzIDEyNiA3NCAxNDNUMTE4IDE2MFExMzMgMTYwIDE0NiAxNTFUMTYwIDEyMFExNjAgOTQgMTQyIDc2VDExMSA1OFExMDkgNTcgMTA4IDU3VDEwNyA1NVExMDggNTIgMTE1IDQ3VDE0NiAzNFQyMDEgMjdRMjM3IDI3IDI2MyAzOFQzMDEgNjZUMzE4IDk3VDMyMyAxMjJRMzIzIDE1MCAzMDIgMTY0VDI1NCAxODFUMTk1IDE5NlQxNDggMjMxUTEzMSAyNTYgMTMxIDI4OVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS00QiIgZD0iTTI4NSA2MjhRMjg1IDYzNSAyMjggNjM3UTIwNSA2MzcgMTk4IDYzOFQxOTEgNjQ3UTE5MSA2NDkgMTkzIDY2MVExOTkgNjgxIDIwMyA2ODJRMjA1IDY4MyAyMTQgNjgzSDIxOVEyNjAgNjgxIDM1NSA2ODFRMzg5IDY4MSA0MTggNjgxVDQ2MyA2ODJUNDgzIDY4MlE1MDAgNjgyIDUwMCA2NzRRNTAwIDY2OSA0OTcgNjYwUTQ5NiA2NTggNDk2IDY1NFQ0OTUgNjQ4VDQ5MyA2NDRUNDkwIDY0MVQ0ODYgNjM5VDQ3OSA2MzhUNDcwIDYzN1Q0NTYgNjM3UTQxNiA2MzYgNDA1IDYzNFQzODcgNjIzTDMwNiAzMDVRMzA3IDMwNSA0OTAgNDQ5VDY3OCA1OTdRNjkyIDYxMSA2OTIgNjIwUTY5MiA2MzUgNjY3IDYzN1E2NTEgNjM3IDY1MSA2NDhRNjUxIDY1MCA2NTQgNjYyVDY1OSA2NzdRNjYyIDY4MiA2NzYgNjgyUTY4MCA2ODIgNzExIDY4MVQ3OTEgNjgwUTgxNCA2ODAgODM5IDY4MVQ4NjkgNjgyUTg4OSA2ODIgODg5IDY3MlE4ODkgNjUwIDg4MSA2NDJRODc4IDYzNyA4NjIgNjM3UTc4NyA2MzIgNzI2IDU4NlE3MTAgNTc2IDY1NiA1MzRUNTU2IDQ1NUw1MDkgNDE4TDUxOCAzOTZRNTI3IDM3NCA1NDYgMzI5VDU4MSAyNDRRNjU2IDY3IDY2MSA2MVE2NjMgNTkgNjY2IDU3UTY4MCA0NyA3MTcgNDZINzM4UTc0NCAzOCA3NDQgMzdUNzQxIDE5UTczNyA2IDczMSAwSDcyMFE2ODAgMyA2MjUgM1E1MDMgMyA0ODggMEg0NzhRNDcyIDYgNDcyIDlUNDc0IDI3UTQ3OCA0MCA0ODAgNDNUNDkxIDQ2SDQ5NFE1NDQgNDYgNTQ0IDcxUTU0NCA3NSA1MTcgMTQxVDQ4NSAyMTZMNDI3IDM1NEwzNTkgMzAxTDI5MSAyNDhMMjY4IDE1NVEyNDUgNjMgMjQ1IDU4UTI0NSA1MSAyNTMgNDlUMzAzIDQ2SDMzNFEzNDAgMzcgMzQwIDM1UTM0MCAxOSAzMzMgNVEzMjggMCAzMTcgMFEzMTQgMCAyODAgMVQxODAgMlExMTggMiA4NSAyVDQ5IDFRMzEgMSAzMSAxMVEzMSAxMyAzNCAyNVEzOCA0MSA0MiA0M1Q2NSA0NlE5MiA0NiAxMjUgNDlRMTM5IDUyIDE0NCA2MVExNDcgNjUgMjE2IDMzOVQyODUgNjI4WiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMkIiIGQ9Ik01NiAyMzdUNTYgMjUwVDcwIDI3MEgzNjlWNDIwTDM3MCA1NzBRMzgwIDU4MyAzODkgNTgzUTQwMiA1ODMgNDA5IDU2OFYyNzBINzA3UTcyMiAyNjIgNzIyIDI1MFQ3MDcgMjMwSDQwOVYtNjhRNDAxIC04MiAzOTEgLTgySDM4OUgzODdRMzc1IC04MiAzNjkgLTY4VjIzMEg3MFE1NiAyMzcgNTYgMjUwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tMzYiIGQ9Ik00MiAzMTNRNDIgNDc2IDEyMyA1NzFUMzAzIDY2NlEzNzIgNjY2IDQwMiA2MzBUNDMyIDU1MFE0MzIgNTI1IDQxOCA1MTBUMzc5IDQ5NVEzNTYgNDk1IDM0MSA1MDlUMzI2IDU0OFEzMjYgNTkyIDM3MyA2MDFRMzUxIDYyMyAzMTEgNjI2UTI0MCA2MjYgMTk0IDU2NlExNDcgNTAwIDE0NyAzNjRMMTQ4IDM2MFExNTMgMzY2IDE1NiAzNzNRMTk3IDQzMyAyNjMgNDMzSDI2N1EzMTMgNDMzIDM0OCA0MTRRMzcyIDQwMCAzOTYgMzc0VDQzNSAzMTdRNDU2IDI2OCA0NTYgMjEwVjE5MlE0NTYgMTY5IDQ1MSAxNDlRNDQwIDkwIDM4NyAzNFQyNTMgLTIyUTIyNSAtMjIgMTk5IC0xNFQxNDMgMTZUOTIgNzVUNTYgMTcyVDQyIDMxM1pNMjU3IDM5N1EyMjcgMzk3IDIwNSAzODBUMTcxIDMzNVQxNTQgMjc4VDE0OCAyMTZRMTQ4IDEzMyAxNjAgOTdUMTk4IDM5UTIyMiAyMSAyNTEgMjFRMzAyIDIxIDMyOSA1OVEzNDIgNzcgMzQ3IDEwNFQzNTIgMjA5UTM1MiAyODkgMzQ3IDMxNlQzMjkgMzYxUTMwMiAzOTcgMjU3IDM5N1oiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpTWjItN0IiIGQ9Ik01NDcgLTY0M0w1NDEgLTY0OUg1MjhRNTE1IC02NDkgNTAzIC02NDVRMzI0IC01ODIgMjkzIC00NjZRMjg5IC00NDkgMjg5IC00MjhUMjg3IC0yMDBMMjg2IDQyTDI4NCA1M1EyNzQgOTggMjQ4IDEzNVQxOTYgMTkwVDE0NiAyMjJMMTIxIDIzNVExMTkgMjM5IDExOSAyNTBRMTE5IDI2MiAxMjEgMjY2VDEzMyAyNzNRMjYyIDMzNiAyODQgNDQ5TDI4NiA0NjBMMjg3IDcwMVEyODcgNzM3IDI4NyA3OTRRMjg4IDk0OSAyOTIgOTYzUTI5MyA5NjYgMjkzIDk2N1EzMjUgMTA4MCA1MDggMTE0OFE1MTYgMTE1MCA1MjcgMTE1MEg1NDFMNTQ3IDExNDRWMTEzMFE1NDcgMTExNyA1NDYgMTExNVQ1MzYgMTEwOVE0ODAgMTA4NiA0MzcgMTA0NlQzODEgOTUwTDM3OSA5NDBMMzc4IDY5OVEzNzggNjU3IDM3OCA1OTRRMzc3IDQ1MiAzNzQgNDM4UTM3MyA0MzcgMzczIDQzNlEzNTAgMzQ4IDI0MyAyODJRMTkyIDI1NyAxODYgMjU0TDE3NiAyNTFMMTg4IDI0NVEyMTEgMjM2IDIzNCAyMjNUMjg3IDE4OVQzNDAgMTM1VDM3MyA2NVEzNzMgNjQgMzc0IDYzUTM3NyA0OSAzNzggLTkzUTM3OCAtMTU2IDM3OCAtMTk4TDM3OSAtNDM4TDM4MSAtNDQ5UTM5MyAtNTA0IDQzNiAtNTQ0VDUzNiAtNjA4UTU0NCAtNjExIDU0NSAtNjEzVDU0NyAtNjI5Vi02NDNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oyLTdEIiBkPSJNMTE5IDExMzBRMTE5IDExNDQgMTIxIDExNDdUMTM1IDExNTBIMTM5UTE1MSAxMTUwIDE4MiAxMTM4VDI1MiAxMTA1VDMyNiAxMDQ2VDM3MyA5NjRRMzc4IDk0MiAzNzggNzAyUTM3OCA0NjkgMzc5IDQ2MlEzODYgMzk0IDQzOSAzMzlRNDgyIDI5NiA1MzUgMjcyUTU0NCAyNjggNTQ1IDI2NlQ1NDcgMjUxUTU0NyAyNDEgNTQ3IDIzOFQ1NDIgMjMxVDUzMSAyMjdUNTEwIDIxN1Q0NzcgMTk0UTM5MCAxMjkgMzc5IDM5UTM3OCAzMiAzNzggLTIwMVEzNzggLTQ0MSAzNzMgLTQ2M1EzNDIgLTU4MCAxNjUgLTY0NFExNTIgLTY0OSAxMzkgLTY0OVExMjUgLTY0OSAxMjIgLTY0NlQxMTkgLTYyOVExMTkgLTYyMiAxMTkgLTYxOVQxMjEgLTYxNFQxMjQgLTYxMFQxMzIgLTYwN1QxNDMgLTYwMlExOTUgLTU3OSAyMzUgLTUzOVQyODUgLTQ0N1EyODYgLTQzNSAyODcgLTE5OVQyODkgNTFRMjk0IDc0IDMwMCA5MVQzMjkgMTM4VDM5MCAxOTdRNDEyIDIxMyA0MzYgMjI2VDQ3NSAyNDRMNDg5IDI1MEw0NzIgMjU4UTQ1NSAyNjUgNDMwIDI3OVQzNzcgMzEzVDMyNyAzNjZUMjkzIDQzNFEyODkgNDUxIDI4OSA0NzJUMjg3IDY5OVEyODYgOTQxIDI4NSA5NDhRMjc5IDk3OCAyNjIgMTAwNVQyMjcgMTA0OFQxODQgMTA4MFQxNTEgMTEwMFQxMjkgMTEwOUwxMjcgMTExMFExMTkgMTExMyAxMTkgMTEzMFoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS01MCIgZD0iTTI4NyA2MjhRMjg3IDYzNSAyMzAgNjM3UTIwNiA2MzcgMTk5IDYzOFQxOTIgNjQ4UTE5MiA2NDkgMTk0IDY1OVEyMDAgNjc5IDIwMyA2ODFUMzk3IDY4M1E1ODcgNjgyIDYwMCA2ODBRNjY0IDY2OSA3MDcgNjMxVDc1MSA1MzBRNzUxIDQ1MyA2ODUgMzg5UTYxNiAzMjEgNTA3IDMwM1E1MDAgMzAyIDQwMiAzMDFIMzA3TDI3NyAxODJRMjQ3IDY2IDI0NyA1OVEyNDcgNTUgMjQ4IDU0VDI1NSA1MFQyNzIgNDhUMzA1IDQ2SDMzNlEzNDIgMzcgMzQyIDM1UTM0MiAxOSAzMzUgNVEzMzAgMCAzMTkgMFEzMTYgMCAyODIgMVQxODIgMlExMjAgMiA4NyAyVDUxIDFRMzMgMSAzMyAxMVEzMyAxMyAzNiAyNVE0MCA0MSA0NCA0M1Q2NyA0NlE5NCA0NiAxMjcgNDlRMTQxIDUyIDE0NiA2MVExNDkgNjUgMjE4IDMzOVQyODcgNjI4Wk02NDUgNTU0UTY0NSA1NjcgNjQzIDU3NVQ2MzQgNTk3VDYwOSA2MTlUNTYwIDYzNVE1NTMgNjM2IDQ4MCA2MzdRNDYzIDYzNyA0NDUgNjM3VDQxNiA2MzZUNDA0IDYzNlEzOTEgNjM1IDM4NiA2MjdRMzg0IDYyMSAzNjcgNTUwVDMzMiA0MTJUMzE0IDM0NFEzMTQgMzQyIDM5NSAzNDJINDA3SDQzMFE1NDIgMzQyIDU5MCAzOTJRNjE3IDQxOSA2MzEgNDcxVDY0NSA1NTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi01NiIgZD0iTTExNCA2MjBRMTEzIDYyMSAxMTAgNjI0VDEwNyA2MjdUMTAzIDYzMFQ5OCA2MzJUOTEgNjM0VDgwIDYzNVQ2NyA2MzZUNDggNjM3SDE5VjY4M0gyOFE0NiA2ODAgMTUyIDY4MFEyNzMgNjgwIDI5NCA2ODNIMzA1VjYzN0gyODRRMjIzIDYzNCAyMjMgNjIwUTIyMyA2MTggMzEzIDM3MlQ0MDQgMTI2TDQ5MCAzNThRNTc1IDU4OCA1NzUgNTk3UTU3NSA2MTYgNTU0IDYyNlQ1MDggNjM3SDUwM1Y2ODNINTEyUTUyNyA2ODAgNjI3IDY4MFE3MTggNjgwIDcyNCA2ODNINzMwVjYzN0g3MjNRNjQ4IDYzNyA2MjcgNTk2UTYyNyA1OTUgNTE1IDI5MVQ0MDEgLTE0UTM5NiAtMjIgMzgyIC0yMkgzNzRIMzY3UTM1MyAtMjIgMzQ4IC0xNFEzNDYgLTEyIDIzMSAzMDNRMTE0IDYxNyAxMTQgNjIwWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSk1BSU4tNjEiIGQ9Ik0xMzcgMzA1VDExNSAzMDVUNzggMzIwVDYzIDM1OVE2MyAzOTQgOTcgNDIxVDIxOCA0NDhRMjkxIDQ0OCAzMzYgNDE2VDM5NiAzNDBRNDAxIDMyNiA0MDEgMzA5VDQwMiAxOTRWMTI0UTQwMiA3NiA0MDcgNThUNDI4IDQwUTQ0MyA0MCA0NDggNTZUNDUzIDEwOVYxNDVINDkzVjEwNlE0OTIgNjYgNDkwIDU5UTQ4MSAyOSA0NTUgMTJUNDAwIC02VDM1MyAxMlQzMjkgNTRWNThMMzI3IDU1UTMyNSA1MiAzMjIgNDlUMzE0IDQwVDMwMiAyOVQyODcgMTdUMjY5IDZUMjQ3IC0yVDIyMSAtOFQxOTAgLTExUTEzMCAtMTEgODIgMjBUMzQgMTA3UTM0IDEyOCA0MSAxNDdUNjggMTg4VDExNiAyMjVUMTk0IDI1M1QzMDQgMjY4SDMxOFYyOTBRMzE4IDMyNCAzMTIgMzQwUTI5MCA0MTEgMjE1IDQxMVExOTcgNDExIDE4MSA0MTBUMTU2IDQwNlQxNDggNDAzUTE3MCAzODggMTcwIDM1OVExNzAgMzM0IDE1NCAzMjBaTTEyNiAxMDZRMTI2IDc1IDE1MCA1MVQyMDkgMjZRMjQ3IDI2IDI3NiA0OVQzMTUgMTA5UTMxNyAxMTYgMzE4IDE3NVEzMTggMjMzIDMxNyAyMzNRMzA5IDIzMyAyOTYgMjMyVDI1MSAyMjNUMTkzIDIwM1QxNDcgMTY2VDEyNiAxMDZaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi03MiIgZD0iTTM2IDQ2SDUwUTg5IDQ2IDk3IDYwVjY4UTk3IDc3IDk3IDkxVDk4IDEyMlQ5OCAxNjFUOTggMjAzUTk4IDIzNCA5OCAyNjlUOTggMzI4TDk3IDM1MVE5NCAzNzAgODMgMzc2VDM4IDM4NUgyMFY0MDhRMjAgNDMxIDIyIDQzMUwzMiA0MzJRNDIgNDMzIDYwIDQzNFQ5NiA0MzZRMTEyIDQzNyAxMzEgNDM4VDE2MCA0NDFUMTcxIDQ0MkgxNzRWMzczUTIxMyA0NDEgMjcxIDQ0MUgyNzdRMzIyIDQ0MSAzNDMgNDE5VDM2NCAzNzNRMzY0IDM1MiAzNTEgMzM3VDMxMyAzMjJRMjg4IDMyMiAyNzYgMzM4VDI2MyAzNzJRMjYzIDM4MSAyNjUgMzg4VDI3MCA0MDBUMjczIDQwNVEyNzEgNDA3IDI1MCA0MDFRMjM0IDM5MyAyMjYgMzg2UTE3OSAzNDEgMTc5IDIwN1YxNTRRMTc5IDE0MSAxNzkgMTI3VDE3OSAxMDFUMTgwIDgxVDE4MCA2NlY2MVExODEgNTkgMTgzIDU3VDE4OCA1NFQxOTMgNTFUMjAwIDQ5VDIwNyA0OFQyMTYgNDdUMjI1IDQ3VDIzNSA0NlQyNDUgNDZIMjc2VjBIMjY3UTI0OSAzIDE0MCAzUTM3IDMgMjggMEgyMFY0NkgzNloiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQVRISS03MiIgZD0iTTIxIDI4N1EyMiAyOTAgMjMgMjk1VDI4IDMxN1QzOCAzNDhUNTMgMzgxVDczIDQxMVQ5OSA0MzNUMTMyIDQ0MlExNjEgNDQyIDE4MyA0MzBUMjE0IDQwOFQyMjUgMzg4UTIyNyAzODIgMjI4IDM4MlQyMzYgMzg5UTI4NCA0NDEgMzQ3IDQ0MUgzNTBRMzk4IDQ0MSA0MjIgNDAwUTQzMCAzODEgNDMwIDM2M1E0MzAgMzMzIDQxNyAzMTVUMzkxIDI5MlQzNjYgMjg4UTM0NiAyODggMzM0IDI5OVQzMjIgMzI4UTMyMiAzNzYgMzc4IDM5MlEzNTYgNDA1IDM0MiA0MDVRMjg2IDQwNSAyMzkgMzMxUTIyOSAzMTUgMjI0IDI5OFQxOTAgMTY1UTE1NiAyNSAxNTEgMTZRMTM4IC0xMSAxMDggLTExUTk1IC0xMSA4NyAtNVQ3NiA3VDc0IDE3UTc0IDMwIDExNCAxODlUMTU0IDM2NlExNTQgNDA1IDEyOCA0MDVRMTA3IDQwNSA5MiAzNzdUNjggMzE2VDU3IDI4MFE1NSAyNzggNDEgMjc4SDI3UTIxIDI4NCAyMSAyODdaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFJTi0zNCIgZD0iTTQ2MiAwUTQ0NCAzIDMzMyAzUTIxNyAzIDE5OSAwSDE5MFY0NkgyMjFRMjQxIDQ2IDI0OCA0NlQyNjUgNDhUMjc5IDUzVDI4NiA2MVEyODcgNjMgMjg3IDExNVYxNjVIMjhWMjExTDE3OSA0NDJRMzMyIDY3NCAzMzQgNjc1UTMzNiA2NzcgMzU1IDY3N0gzNzNMMzc5IDY3MVYyMTFINDcxVjE2NUgzNzlWMTE0UTM3OSA3MyAzNzkgNjZUMzg1IDU0UTM5MyA0NyA0NDIgNDZINDcxVjBINDYyWk0yOTMgMjExVjU0NUw3NCAyMTJMMTgzIDIxMUgyOTNaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KTUFUSEktNTIiIGQ9Ik0yMzAgNjM3UTIwMyA2MzcgMTk4IDYzOFQxOTMgNjQ5UTE5MyA2NzYgMjA0IDY4MlEyMDYgNjgzIDM3OCA2ODNRNTUwIDY4MiA1NjQgNjgwUTYyMCA2NzIgNjU4IDY1MlQ3MTIgNjA2VDczMyA1NjNUNzM5IDUyOVE3MzkgNDg0IDcxMCA0NDVUNjQzIDM4NVQ1NzYgMzUxVDUzOCAzMzhMNTQ1IDMzM1E2MTIgMjk1IDYxMiAyMjNRNjEyIDIxMiA2MDcgMTYyVDYwMiA4MFY3MVE2MDIgNTMgNjAzIDQzVDYxNCAyNVQ2NDAgMTZRNjY4IDE2IDY4NiAzOFQ3MTIgODVRNzE3IDk5IDcyMCAxMDJUNzM1IDEwNVE3NTUgMTA1IDc1NSA5M1E3NTUgNzUgNzMxIDM2UTY5MyAtMjEgNjQxIC0yMUg2MzJRNTcxIC0yMSA1MzEgNFQ0ODcgODJRNDg3IDEwOSA1MDIgMTY2VDUxNyAyMzlRNTE3IDI5MCA0NzQgMzEzUTQ1OSAzMjAgNDQ5IDMyMVQzNzggMzIzSDMwOUwyNzcgMTkzUTI0NCA2MSAyNDQgNTlRMjQ0IDU1IDI0NSA1NFQyNTIgNTBUMjY5IDQ4VDMwMiA0NkgzMzNRMzM5IDM4IDMzOSAzN1QzMzYgMTlRMzMyIDYgMzI2IDBIMzExUTI3NSAyIDE4MCAyUTE0NiAyIDExNyAyVDcxIDJUNTAgMVEzMyAxIDMzIDEwUTMzIDEyIDM2IDI0UTQxIDQzIDQ2IDQ1UTUwIDQ2IDYxIDQ2SDY3UTk0IDQ2IDEyNyA0OVExNDEgNTIgMTQ2IDYxUTE0OSA2NSAyMTggMzM5VDI4NyA2MjhRMjg3IDYzNSAyMzAgNjM3Wk02MzAgNTU0UTYzMCA1ODYgNjA5IDYwOFQ1MjMgNjM2UTUyMSA2MzYgNTAwIDYzNlQ0NjIgNjM3SDQ0MFEzOTMgNjM3IDM4NiA2MjdRMzg1IDYyNCAzNTIgNDk0VDMxOSAzNjFRMzE5IDM2MCAzODggMzYwUTQ2NiAzNjEgNDkyIDM2N1E1NTYgMzc3IDU5MiA0MjZRNjA4IDQ0OSA2MTkgNDg2VDYzMCA1NTRaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1o0LTI4IiBkPSJNNzU4IC0xMjM3VDc1OCAtMTI0MFQ3NTIgLTEyNDlINzM2UTcxOCAtMTI0OSA3MTcgLTEyNDhRNzExIC0xMjQ1IDY3MiAtMTE5OVEyMzcgLTcwNiAyMzcgMjUxVDY3MiAxNzAwUTY5NyAxNzMwIDcxNiAxNzQ5UTcxOCAxNzUwIDczNSAxNzUwSDc1MlE3NTggMTc0NCA3NTggMTc0MVE3NTggMTczNyA3NDAgMTcxM1Q2ODkgMTY0NFQ2MTkgMTUzN1Q1NDAgMTM4MFQ0NjMgMTE3NlEzNDggODAyIDM0OCAyNTFRMzQ4IC0yNDIgNDQxIC01OTlUNzQ0IC0xMjE4UTc1OCAtMTIzNyA3NTggLTEyNDBaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1o0LTI5IiBkPSJNMzMgMTc0MVEzMyAxNzUwIDUxIDE3NTBINjBINjVRNzMgMTc1MCA4MSAxNzQzVDExOSAxNzAwUTU1NCAxMjA3IDU1NCAyNTFRNTU0IC03MDcgMTE5IC0xMTk5UTc2IC0xMjUwIDY2IC0xMjUwUTY1IC0xMjUwIDYyIC0xMjUwVDU2IC0xMjQ5UTU1IC0xMjQ5IDUzIC0xMjQ5VDQ5IC0xMjUwUTMzIC0xMjUwIDMzIC0xMjM5UTMzIC0xMjM2IDUwIC0xMjE0VDk4IC0xMTUwVDE2MyAtMTA1MlQyMzggLTkxMFQzMTEgLTcyN1E0NDMgLTMzNSA0NDMgMjUxUTQ0MyA0MDIgNDM2IDUzMlQ0MDUgODMxVDMzOSAxMTQyVDIyNCAxNDM4VDUwIDE3MTZRMzMgMTczNyAzMyAxNzQxWiI+PC9wYXRoPgo8cGF0aCBzdHJva2Utd2lkdGg9IjEiIGlkPSJFMS1NSlNaMS0yOCIgZD0iTTE1MiAyNTFRMTUyIDY0NiAzODggODUwSDQxNlE0MjIgODQ0IDQyMiA4NDFRNDIyIDgzNyA0MDMgODE2VDM1NyA3NTNUMzAyIDY0OVQyNTUgNDgyVDIzNiAyNTBRMjM2IDEyNCAyNTUgMTlUMzAxIC0xNDdUMzU2IC0yNTFUNDAzIC0zMTVUNDIyIC0zNDBRNDIyIC0zNDMgNDE2IC0zNDlIMzg4UTM1OSAtMzI1IDMzMiAtMjk2VDI3MSAtMjEzVDIxMiAtOTdUMTcwIDU2VDE1MiAyNTFaIj48L3BhdGg+CjxwYXRoIHN0cm9rZS13aWR0aD0iMSIgaWQ9IkUxLU1KU1oxLTI5IiBkPSJNMzA1IDI1MVEzMDUgLTE0NSA2OSAtMzQ5SDU2UTQzIC0zNDkgMzkgLTM0N1QzNSAtMzM4UTM3IC0zMzMgNjAgLTMwN1QxMDggLTIzOVQxNjAgLTEzNlQyMDQgMjdUMjIxIDI1MFQyMDQgNDczVDE2MCA2MzZUMTA4IDc0MFQ2MCA4MDdUMzUgODM5UTM1IDg1MCA1MCA4NTBINTZINjlRMTk3IDc0MyAyNTYgNTY2UTMwNSA0MjUgMzA1IDI1MVoiPjwvcGF0aD4KPHBhdGggc3Ryb2tlLXdpZHRoPSIxIiBpZD0iRTEtTUpNQUlOLTMzIiBkPSJNMTI3IDQ2M1ExMDAgNDYzIDg1IDQ4MFQ2OSA1MjRRNjkgNTc5IDExNyA2MjJUMjMzIDY2NVEyNjggNjY1IDI3NyA2NjRRMzUxIDY1MiAzOTAgNjExVDQzMCA1MjJRNDMwIDQ3MCAzOTYgNDIxVDMwMiAzNTBMMjk5IDM0OFEyOTkgMzQ3IDMwOCAzNDVUMzM3IDMzNlQzNzUgMzE1UTQ1NyAyNjIgNDU3IDE3NVE0NTcgOTYgMzk1IDM3VDIzOCAtMjJRMTU4IC0yMiAxMDAgMjFUNDIgMTMwUTQyIDE1OCA2MCAxNzVUMTA1IDE5M1ExMzMgMTkzIDE1MSAxNzVUMTY5IDEzMFExNjkgMTE5IDE2NiAxMTBUMTU5IDk0VDE0OCA4MlQxMzYgNzRUMTI2IDcwVDExOCA2N0wxMTQgNjZRMTY1IDIxIDIzOCAyMVEyOTMgMjEgMzIxIDc0UTMzOCAxMDcgMzM4IDE3NVYxOTVRMzM4IDI5MCAyNzQgMzIyUTI1OSAzMjggMjEzIDMyOUwxNzEgMzMwTDE2OCAzMzJRMTY2IDMzNSAxNjYgMzQ4UTE2NiAzNjYgMTc0IDM2NlEyMDIgMzY2IDIzMiAzNzFRMjY2IDM3NiAyOTQgNDEzVDMyMiA1MjVWNTMzUTMyMiA1OTAgMjg3IDYxMlEyNjUgNjI2IDI0MCA2MjZRMjA4IDYyNiAxODEgNjE1VDE0MyA1OTJUMTMyIDU4MEgxMzVRMTM4IDU3OSAxNDMgNTc4VDE1MyA1NzNUMTY1IDU2NlQxNzUgNTU1VDE4MyA1NDBUMTg2IDUyMFExODYgNDk4IDE3MiA0ODFUMTI3IDQ2M1oiPjwvcGF0aD4KPC9kZWZzPgo8ZyBzdHJva2U9ImN1cnJlbnRDb2xvciIgZmlsbD0iY3VycmVudENvbG9yIiBzdHJva2Utd2lkdGg9IjAiIHRyYW5zZm9ybT0ibWF0cml4KDEgMCAwIC0xIDAgMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjcsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgtMTEsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDE3MDI3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTMxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1ozLTdCIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzUwLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTIyMSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjM2MCIgeT0iNjc2Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTY4NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjUwMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDYxLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTU5NSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI4MSw2NzYpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjAyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjgxNyIgeT0iNTEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzgwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIwMiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU2NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTNCNCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSI2NDEiIHk9IjQwOCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzI5NiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTY2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjgwNCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI2OTMiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ0ODUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktM0I0IiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NDEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU4ODIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTdDIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjc4LC0yODYpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTNCNCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSI0NTEiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMCIgeD0iMTIzMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMy03RCIgeD0iODIzNCIgeT0iLTEiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5OTA2LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwxNzAyNykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIyNzciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDU2LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzk3LDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTcyMzgiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwxMTY5KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTMxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTdCIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjY3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIyNCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDc4LDQ5NCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiIgeD0iLTcwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjE3LjkyMjUwNDE2NjY4MSwwKSBzY2FsZSgwLjc1OTg3MTA2NTYyODM4MDYsMSkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiIHg9IjU2NSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExNzYiIHk9IjEwNDQiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjExNzYiIHk9Ii0zNTAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMjA3OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzgiIHg9IjMwODAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMzU4MCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ1MTYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTkzMSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIyNCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDc4LDQ5NCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiIgeD0iLTcwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjE3LjkyMjUwNDE2NjY4MSwwKSBzY2FsZSgwLjc1OTg3MTA2NTYyODM4MDYsMSkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiIHg9IjU2NSIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIxMTc2IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3Mjg4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNEIiIHg9IjI0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjYsNTAwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSItNzAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODIuMzA2MTYwNjc2Mzc2MjcsMCkgc2NhbGUoMS40ODQ2MDY1NDc3MzA5MzYzLDEpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSI4MjciIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTM2NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iOTAwMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzYiIHg9IjEwMDAxIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTA1MDEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTY3IiB5PSI1MTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDExOTQ3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzMzYyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNEIiIHg9IjI0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjYsNTAwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSItNzAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODIuMzA2MTYwNjc2Mzc2MjcsMCkgc2NhbGUoMS40ODQ2MDY1NDc3MzA5MzYzLDEpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSI4MjciIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMzY0IiB5PSIxMDUzIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIxMzY0IiB5PSItMzUwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi03RCIgeD0iMTU1MTkiIHk9Ii0xIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDgwNjgsLTY4NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjUwMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwxNDQzMykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIyNzciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzM0LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTIyMSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjM2MCIgeT0iNjc2Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTY4NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjUwMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIyNzk1IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzcyNiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi03QiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDY2NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMjQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3OCw0OTQpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiIHg9Ii03MCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIxNy45MjI1MDQxNjY2ODEsMCkgc2NhbGUoMC43NTk4NzEwNjU2MjgzODA2LDEpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSI1NjUiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTc2IiB5PSIxMDQ0Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIxMTc2IiB5PSItMzUwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi03RCIgeD0iMjUyNCIgeT0iLTEiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjcxNDAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4MTQxLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTIyMSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjM2MCIgeT0iNjc2Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTY4NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjUwMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSI5NjAyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTA1MzMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItN0IiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2NjcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTM4IiB4PSI3NzgiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMTI3OSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIyMTUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzYzMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTRCIiB4PSIyNCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI2LDUwMCkiPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiIgeD0iLTcwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTgyLjMwNjE2MDY3NjM3NjI3LDApIHNjYWxlKDEuNDg0NjA2NTQ3NzMwOTM2MywxKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi1BRiIgeD0iODI3IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjEzNjQiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUxMTksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMjQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3OCw0OTQpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiIHg9Ii03MCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIxNy45MjI1MDQxNjY2ODEsMCkgc2NhbGUoMC43NTk4NzEwNjU2MjgzODA2LDEpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSI1NjUiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTE3NiIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjItN0QiIHg9IjcxNDQiIHk9Ii0xIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxODU2NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE5NTY4LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTIyMSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjM2MCIgeT0iNjc2Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTY4NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjUwMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTQ1IiB4PSIyMTAyOSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIxOTYwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oyLTdCIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjY3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zNiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExNjciIHk9IjU4MyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTk0NiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzMzYxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNEIiIHg9IjI0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjYsNTAwKSI+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSItNzAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODIuMzA2MTYwNjc2Mzc2MjcsMCkgc2NhbGUoMS40ODQ2MDY1NDc3MzA5MzYzLDEpIj4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tQUYiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLUFGIiB4PSI4MjciIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMzY0IiB5PSIxMDUzIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIxMzY0IiB5PSItMzUwIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMi03RCIgeD0iNTUxOCIgeT0iLTEiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwxMTY4NSkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIyNzciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzM0LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTIyMSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjM2MCIgeT0iNjc2Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTY4NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjUwMCIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI3OTUsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpTWjQtMjgiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3OTIsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTAwLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMzY1NSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTI5NiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIyOTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjA3LC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQzOTYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjIwNiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxMjcyIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI4MDkwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iOTA5MSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDk3NTgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEyOTYiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIyMjk3IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIzMTg3IiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzUwMiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNTYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI3NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNTMxMiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxNDM5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjYsLTM0MzMpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwMDAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNTAxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjU3NSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExNjciIHk9IjU4MyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNDAyMSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI1NDkyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjI3MCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjE2OTQiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zNCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjI3LC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDg0MjgsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTYxOSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMTE5OSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDExOTc3LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQyLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTY5NCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMjcsLTgzNykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTQ0NiI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0MTM1LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA3NCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEyIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxNTU3MCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2MzQ5LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQyLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTg1OCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDY3NikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTM2IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzA5LC04MzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii00NDYiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxODY3MCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwNzQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTI5IiB4PSIxOTg4MyIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLDQ5NTEpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMjIyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIyMiwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjEyMjEiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0PgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIzNjAiIHk9IjY3NiI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC02ODcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSI1MDAiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyODUwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1o0LTI4Ij48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzkyLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zOCIgeD0iNzc4IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTI3OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExNjciIHk9IjU4MyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjcyNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0MTQwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSI1NDM2IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjIxNSwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjE4NTgiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw2NzYpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExMDkiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEyIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDMwOSwtODM3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExMDkiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItNDQ2Ij48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODUzNiwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwNzQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSI5OTcxIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTA3NTAsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxNjk0IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIyNywtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjkwNywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDA5OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaNC0yOSIgeD0iMTYyNDkiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwyMDU2KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjIyMiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMjIsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxMjIxIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMzYwIiB5PSI2NzYiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNjg3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iNTAwIiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjg1MCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSlNaMS0yOCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ1OCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzYiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTY3IiB5PSI1ODMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE5NDYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjM4OSIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9Ijg1OSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzM2MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KU1oxLTI5IiB4PSI0ODk0IiB5PSItMSI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC01NzkpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zRCIgeD0iMjc3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTA1NiwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM5NywwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjM2NTUiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjEyOTYiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMjk3LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTA3LC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MjI5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDcwMzksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTI3MiIgeT0iMCI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iODkyNCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDk3MDMsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIyOTE3IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzEiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI3MjIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNzIzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMTE1OCIgeT0iLTY4NiI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMzA4MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNTYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI3NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDg5MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxNDM5IiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxNjk0NCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE4MTY3LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjc1LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTE5NCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMjk2IiB5PSItNjg2Ij48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNDM0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTE2NyIgeT0iNTgzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyODgwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGxpbmUgZmlsbD0ibm9uZSIgc3Ryb2tlLXdpZHRoPSI3NSIgeDE9IjM3IiB5MT0iLTkzNiIgeDI9IjQ2NDEiIHkyPSIxNTk4Ij48L2xpbmU+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMjMwNjgiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyMzg0NiwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjE5NjEiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxOTMsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC03MDQpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNjI3MCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgyNzQ2MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAsLTM0ODgpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMjIyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTAwMCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjE5NjEiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg0NDMsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC04MzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTQ0NiI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQyNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwNzQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNDg1OSIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDU2MzgsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxOTYxIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTExLDY3NikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMzIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTgzNykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExMDkiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItNDQ2Ij48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg4MDYxLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA3NCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEyIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9Ijk0OTciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDcyMCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDI3NSwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMCwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjE2OTQiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zNCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjU0NyIgeT0iLTY4NiI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTkzNCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU2IiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExNjciIHk9IjU4MyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzM4MCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMzg5IiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iODU5IiB5PSIwIj48L3VzZT4KPC9nPgo8L2c+CjxsaW5lIGZpbGw9Im5vbmUiIHN0cm9rZS13aWR0aD0iNzUiIHgxPSIzNyIgeTE9Ii05MzYiIHgyPSI1MTQxIiB5Mj0iMTU5OCI+PC9saW5lPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwtNjU3NikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjIyMiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwMDAsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxOTYxIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTExLDY3NikiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTM0IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTgzNykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExMDkiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItNDQ2Ij48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDI0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA3NCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEyIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjQ4NTkiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1NjM4LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQyLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTk2MSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE5Myw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zNCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDgwNjEsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTI1MywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSIxMDc0IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMDgzMiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEyMDU1LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjc1LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTIwLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTY5NCIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMzIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iNTQ3IiB5PSItNjg2Ij48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxOTM0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTYiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTE2NyIgeT0iNTgzIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzMzgwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIzODkiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSI4NTkiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGxpbmUgZmlsbD0ibm9uZSIgc3Ryb2tlLXdpZHRoPSI3NSIgeDE9IjM3IiB5MT0iLTkzNiIgeDI9IjUxNDEiIHkyPSIxNTk4Ij48L2xpbmU+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC05NTIyKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tM0QiIHg9IjI3NyIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEwNTYsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTcsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIzNjU1IiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsNjc3KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIxMjk2IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMjI5NywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExMDkiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEyIj48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkwNywtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTIyOSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNTYiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTYxIiB4PSI3NTAiIHk9IjAiPjwvdXNlPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTcyIiB4PSIxMjUxIiB5PSIwIj48L3VzZT4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MDM5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI2MzgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjEyNzIiIHk9IjAiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9Ijg5MjQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5NzAzLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQyLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMjkxNyIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMxIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iNzIyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTcyMywwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjExNTgiIHk9Ii02ODYiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTMwODMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTQ4OTMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI4IiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzg5LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjYzOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOSIgeD0iMTQzOSIgeT0iMCI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC0xMjE2OSkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSIyMjIiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDAwLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQyLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTk2MSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ0Myw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTgzNykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExMDkiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItNDQ2Ij48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDI0LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA3NCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEyIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjQ4NTkiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1NjM4LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQyLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTk2MSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM2MSw2NzYpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTEwOSIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTIiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLC04MzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNkUiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MDAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTQ0NiI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODA2MSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjEwNzQiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yMjEyIiB4PSI5NDk3IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTAyNzUsMCkiPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzNDIsMCkiPgo8cmVjdCBzdHJva2U9Im5vbmUiIHdpZHRoPSIxOTYxIiBoZWlnaHQ9IjYwIiB4PSIwIiB5PSIyMjAiPjwvcmVjdD4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTkzLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNTAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCwtNzA0KSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIwIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAwLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTQiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTI2OTksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTM4OTAsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLC0xNTExNSkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTNEIiB4PSIyNzciIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMDU2LDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzk3LDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMzY1NSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwLDY3NykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMTI5NiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIyOTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5MDcsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUyMjksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTU2Ij48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi02MSIgeD0iNzUwIiB5PSIwIj48L3VzZT4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi03MiIgeD0iMTI1MSIgeT0iMCI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNzAzOSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjgiIHg9IjAiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzODksMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iNjM4IiB5PSItMjEzIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTI5IiB4PSIxMjcyIiB5PSIwIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTJCIiB4PSI4OTI0IiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTcwMywwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjI5MTciIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMSIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMkIiIHg9IjcyMiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE3MjMsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iOTA4IiB5PSItMjEzIj48L3VzZT4KPC9nPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTZFIiB4PSIxMTU4IiB5PSItNjg2Ij48L3VzZT4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEzMDgzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi01NiI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNjEiIHg9Ijc1MCIgeT0iMCI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tNzIiIHg9IjEyNTEiIHk9IjAiPjwvdXNlPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE0ODkzLDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yOCIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM4OSwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTcyIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI2MzgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjkiIHg9IjE0MzkiIHk9IjAiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMCwtMTc3NjMpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0yQiIgeD0iMjIyIiB5PSIwIj48L3VzZT4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTAwMCwwKSI+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDM0MiwwKSI+CjxyZWN0IHN0cm9rZT0ibm9uZSIgd2lkdGg9IjM2NTUiIGhlaWdodD0iNjAiIHg9IjAiIHk9IjIyMCI+PC9yZWN0Pgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MCw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTAiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMyI+PC91c2U+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMjIxMiIgeD0iMTI5NiIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIyOTcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MCIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQUlOLTMyIiB4PSIxMTA5IiB5PSI0ODgiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNzMiIHg9IjkwOCIgeT0iLTIxMiI+PC91c2U+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg5MDcsLTgzNykiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BSU4tMzIiIHg9IjExMDkiIHk9IjQ4OCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iOTA4IiB5PSItNDQ2Ij48L3VzZT4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg1MTE4LDApIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFUSEktNTIiIHg9IjAiIHk9IjAiPjwvdXNlPgogPHVzZSB0cmFuc2Zvcm09InNjYWxlKDAuNzA3KSIgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMTA3NCIgeT0iNDg4Ij48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSIxMDc0IiB5PSItMjEyIj48L3VzZT4KPC9nPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQUlOLTIyMTIiIHg9IjY1NTQiIHk9IjAiPjwvdXNlPgo8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg3MzMyLDApIj4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMzQyLDApIj4KPHJlY3Qgc3Ryb2tlPSJub25lIiB3aWR0aD0iMTk2MSIgaGVpZ2h0PSI2MCIgeD0iMCIgeT0iMjIwIj48L3JlY3Q+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE5Myw2NzcpIj4KIDx1c2UgeGxpbms6aHJlZj0iI0UxLU1KTUFJTi0zMiIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDUwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTczIiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoNjAsLTcwNCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS02RSIgeD0iMCIgeT0iMCI+PC91c2U+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDYwMCwwKSI+CiA8dXNlIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTUwIiB4PSIwIiB5PSIwIj48L3VzZT4KIDx1c2UgdHJhbnNmb3JtPSJzY2FsZSgwLjcwNykiIHhsaW5rOmhyZWY9IiNFMS1NSk1BVEhJLTU0IiB4PSI5MDgiIHk9Ii0yMTMiPjwvdXNlPgo8L2c+CjwvZz4KPC9nPgo8L2c+CjxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDk3NTYsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS03MyIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTA5NDcsMCkiPgogPHVzZSB4bGluazpocmVmPSIjRTEtTUpNQVRISS01MiIgeD0iMCIgeT0iMCI+PC91c2U+CiA8dXNlIHRyYW5zZm9ybT0ic2NhbGUoMC43MDcpIiB4bGluazpocmVmPSIjRTEtTUpNQVRISS01NCIgeD0iMTA3NCIgeT0iLTIxMyI+PC91c2U+CjwvZz4KPC9nPgo8L2c+CjwvZz4KPC9nPgo8L3N2Zz4=)
小结


参考文献:
【1】Reinforcement Learning with Replacing Eligibility Traces
请大家批评指正,谢谢 ~



4 条评论
您好博主,请问ml估计中的kr是什么呢,没看懂那个ml估计的公式。。。
这么多证明。。。我眼睛已经花了 小姐姐厉害了
博主真厉害!我要消化好久才能懂,学的高工都忘完了